manual de epidemiologia y salud publica veterinaria · veterinaria, existen diversidad de sistemas...
TRANSCRIPT

MANUAL DE EPIDEMIOLOGIA Y SALUD PUBLICA VETERINARIA
Med Vet Edmundo Larrieu
Cátedra de Epidemiología y Salud Pública
Facultad Ciencias Veterinarias
U.N. La Pampa
2003 PRIMERA PARTE :
Capítulo I: Introducción a la epidemiología 3

Usos de la epidemiología. 3
El método epidemiológico 4
Observación sobre los cálculos estadísticos 5
Capítulo II: Ocurrencia de la enfermedad 6
1. Epidemia y endemia 6
2. Como mediar la ocurrencia de la enfermedad 7
2.1. Colección de los hechos 7
2.2. Uso de cifras en epidemiología 9
2.2.1. Tasas crudas, específicas y ajustadas 10
2.2.2. Tasas de morbilidad y mortalidad 11
2.3. Medidas de resumen de datos 14
3. Estudios epidemiológicos descriptivos 20
3.1. Cadena epidemiológica 21
3.2. Diseño de estudios descriptivos 22
3.2.1. Estimación del tamaño de la muestra 23
4. Interpretación de pruebas diagnósticas 25
4.1. Intervalo de confianza 25
4.2. Sensibilidad y especificidad 26
Capítulo III: Explicación de los hechos 30

1. Verificación de hipótesis epidemiológicas 30
2. Estudios epidemiológicos longitudinales 31
2.1. Asociación Causal 32
2.2. Multicausalidad 33
2.3. Determinación de asociación estadística 33
2.3.1. Estimación del riesgo 34
3. Diseño de estudios de casos y controles 42
Capítulo IV
Un estudio descriptivo (Historia natural) 45
Un estudio descriptivo (Bases para el control) 49
Un estudio de casos y controles (Evaluar programa de control) 51
CAPITULO I: INTRODUCCION A LA EPIDEMIOLOGIA

USOS DE LA EPIDEMIOLOGIA
Epidemiología significa desde un punto de vista etimológico "estudio de lo que acontece por sobre el pueblo" (EPI: sobre, DEMOS: pueblo, LOGOS: estudio)
Históricamente se la ha asociado al estudio de las epidemias. Modernamente, sin embargo, es definida como el "estudio de la distribución de las enfermedades y de las causas determinantes de su ocurrencia".
De esta forma la epidemiología excede el marco de situaciones epidémicas para definir principios generales que permitan, por una parte, explicar eventos ocurridos y, por la otra, predecir y prevenir la ocurrencia de enfermedades en la población.
Diferentes grupos de poblaciones humanas y animales tienen características específicas determinadas por factores del ambiente biológico, físico, social, cultural y económico, determinando condiciones de vida, niveles de bienestar y grados variables de exposición a diferentes riesgos. Esta situación genera, por consecuencia, disímiles perfiles de salud en cada uno de los grupos poblacionales considerados.
En este esquema, podemos definir los principales Usos de la epidemiología:
Descripción de la distribución de la enfermedad en términos de tiempo, lugar de ocurrencia de los eventos y personas afectadas y susceptibles.
Explicación de las mecanismos causales que permitieron la ocurrencia de enfermedad en un momento determinado
Descripción de la historia natural de la enfermedad y de las causas locales de su ocurrencia
Evaluación de los programas de lucha contra las enfermedades, identificando estrategias adecuadas para cortar el ciclo de transmisión, midiendo el impacto de los programas e identificando factores de persistencia que limiten los resultados previstos
Planeamiento de la asistencia sanitaria con selección de tecnologías apropiadas sustentables por los sistemas locales de salud.
La epidemiología, tal cual ha sido definido por Urquijo en 1969, se encuentra relacionada estrechamente con la estadística (para medir con precisión a los fenómenos observados) y con la clínica y la patología (para el ajuste diagnóstico de las observaciones efectuadas)
En el trabajo clínico, el diagnóstico de la enfermedad en un individuo, se basa en general en identificar al agente etiológico o a una causa simple como desencadenante DE LA

enfermedad, que, en función del diagnóstico, posibilitará la implantación de un tratamiento específico y eficaz al paciente.
En epidemiología, por el contrario, la enfermedad es estudiada en función de la interacción de agentes patógenos, huéspedes susceptibles y ambiente, interacción que limita o favorece la ocurrencia de la enfermedad en una parte de la población. Por ello, la tarea prioritaria es determinar los factores de riesgo que produjeron o producirán una determinada ocurrencia de enfermedad y, en función de ello, aplicar medidas de prevención o control eficaces para limitar el número de casos, aún en ausencia de un diagnóstico exacto del agente causal.
Por ejemplo, el padre de la investigación epidemiológica, Jhon Snow en 1849 demuestra en Londres, la propagación del cólera por la contaminación fecal del agua potable, determinando grados de exposición al riesgo según la compañía proveedora del agua y define medidas de prevención basadas en la clausura de la fuente de agua contaminada, poniendo fin a la epidemia que azotaba a esa ciudad, aún en ausencia de mínimos conocimientos de bacteriología y, menos aún, de la existencia de Vibrio cholerae. en la naturaleza
EL METODO EPIDEMIOLOGICO
La epidemiología de campo requiere de una organización metodológica que no es otra cosa que la utilización sistemática del método científico.
El Método Científico trata un conjunto de problemas para arribar a un resultado con el mínimo de esfuerzos y tiempo, máximo de eficacia y menor margen de error. Supone contar con un conocimiento amplio del tema objeto de estudio, el cual se consigue a través de la investigación documental (análisis bibliográfico, publicaciones científicas, de documentos etc.) y de la investigación de campo (por medio de observaciones, entrevistas, encuestas, etc.).
El Método Epidemiológico, por lo tanto, ha sido definido como "metodología científica aplicada al estudio de la enfermedad en las poblaciones".
La secuencia característica del método incluye:
observación y descripción de los hechos
elaboración de hipótesis tentativas que traten de explicar lo ocurrido
verificación de las hipótesis
conclusiones

Desde un punto de vista didáctico (pues en la práctica epidemiológica resulta en ocasiones difícil encasillar los procesos tan claramente) podemos dividir la actividad epidemiológica, por un lado, en la observación, registro y descripción de los hechos (presentado en detalle en el Capítulo 2) y por el otro, en la verificación de las hipótesis y la explicación de los hechos ocurridos, incluyendo en este sentido a los estudios epidemiológicos analíticos y experimentales (presentado en detalle en el Capítulo 3).
CALCULOS ESTADISTICOS
Como se ha señalado, los cálculos estadísticos están estrechamente relacionados con la epidemiología. En el presente Manual, se presentan las estimaciones estadísticas mas habitualmente utilizadas en los estudios epidemiológicos de campo, presentándose su definición e interpretación y las fórmulas de calculo manual más elementales.
En la práctica epidemiológica actual, todas las estimaciones estadísticas son efectuadas en softwares específicos. De hecho, los más sencillos y habituales se encuentran disponibles gratuitamente en Internet, tal como EPIDAT (desarrollado por la Xunta de Galicia, España) y EPIINFO (desarrollado por OPS) y permiten resolver la totalidad de las estimaciones estadísticas abordadas en este Manual.
CAPITULO II: OCURRENCIA DE LA ENFERMEDAD
1. EPIDEMIA Y ENDEMIA
Constituyen dos definiciones de uso habitual para el epidemiólogo en la descripción de la ocurrencia de una enfermedad.
En muchos casos, la existencia de una epidemia es obvia: por ejemplo cuando afecta a una gran proporción de personas o animales, produce evidencias claras de enfermedad y se presenta en un corto período de tiempo (encefalitis equina, hantavirus). Por el contrario no resulta tan sencillo caracterizar como epidémica la ocurrencia de una enfermedad crónica, por ejemplo echinococcosis quística, al presentarse en un lapso de tiempo prolongado.
Rouquayrol clasificó en 1988 a la enfermedad de acuerdo a su ocurrencia en:
Presente en nivel epidémico

Presente en nivel endémico
Presente con casos esporádicos
Inexistente
Así, definimos a la Epidemia como la "aparición en una comunidad de un número de casos de una enfermedad claramente en exceso sobre su expectación normal" ("prevalencia excesiva")
Este concepto es aplicable tanto a enfermedades infecciosas como no infecciosas. La determinación que un número de casos implica una prevalencia excesiva implica conocer la frecuencia de la enfermedad a lo largo de un período de tiempo prolongado o, asumiendo un mayor margen de error, comprar muestra frecuencia de casos con la frecuencia en otros lugares. Un valor absoluto (número de casos) por sí solo no permite clasificar una ocurrencia como epidémica.
Así, por ejemplo, la ocurrencia de 3 casos de encefalitis equina en trabajadores rurales de la Provincia de Río Negro (Argentina) en 1983 constituye una epidemia en tanto la ocurrencia habitual durante los cinco años anteriores era de 0 caso.
Un caso especial de epidemia está asociado al concepto de brote, término que expresa con mayor precisión episodios que ocurren en cortos períodos de tiempo, iniciado por casos primarios a fuente única de infección. Son ejemplos típicos de esta situación las intoxicaciones alimentarias.
Endemia, por su parte, es definida como la "situación normal esperada de una enfermedad". Es la condición por la cual una enfermedad se mantiene en una ocurrencia más o menos estable, con una regularidad previsible y afectando sistemáticamente a grupos humanos distribuidos en espacios delimitados. Por ejemplo Echinococcosis quística en la Patagonia Argentina y Hantavirus en Orán (Argentina).
La Presentación Esporádica, por el contrario, es una situación en la cual la enfermedad presenta una "ocurrencia rara y sin regularidad en el tiempo", resultando botulismo uno de los mejores ejemplos de esta situación.
Finalmente, una enfermedad es considerada Inexistente en un área dada, en "ausencia de notificación de casos", aunque no necesariamente implique la inexistencia del agente en el ambiente. Un ejemplo de ello, es la ausencia de notificaciones de casos de rabia canina y humana en la región patagónica argentina, status de zona libre alterado a partir de 1997 por el hallazgo de virus rábico en murciélagos de diversas localidades de la región.
2. COMO MEDIR LA OCURRENCIA DE UNA ENFERMEDAD

2.1. COLECCION DE LOS HECHOS
En el campo de la Salud Pública, incluido el ámbito correspondiente a la Salud Pública Veterinaria, existen diversidad de sistemas de registro y notificación de datos: historias clínicas, anotaciones de laboratorio, certificados de defunción, libros de guardia en hospitales, registro de actividades en programas específicos, planillas de decomisos en mataderos, etc. obtenidos de la población.
Población será el "conjunto de objetos o individuos pasibles de ser estudiados, considerando a cada uno de ellos como Unidades de Observación". Siendo a menudo imposible examinar a la totalidad de los individuos u objetos que componen el universo, la información corresponderá a solo una parte del mismo, la que es denominada Muestra. Si esta ha sido adecuadamente obtenida las conclusiones que podamos extraer de ella podrán extenderse a la población total o universo.
Los objetos o individuos que componen la Población poseen Variables, definidas como "características que pueden ser registradas para su consideración en un estudio". Por ende pueden asumir distintos valores. Por ejemplo, si recopilamos información sobre dinámica de poblaciones caninas, "perro" será la unidad de observación, siendo "edad" y "sexo" algunas de las variables de interés para el estudio.
Estas variables pueden presentar distintas modalidades: la edad de los canes puede ser de 1, 2 o 5 años, constituyendo una característica Cuantitativa o Magnitud (es expresada en forma numérica). Por el contrario, la característica sexo en tanto puede presentar una modalidad masculina o femenina, es considerada una característica Cualitativa o Atributo (no puede ser expresada en forma numérica).
Las variables cuantitativas pueden ser clasificadas como Discretas (se cuentan o miden como números enteros, ejemplo número de perros) o Continuas (se cuentan o miden por cualquier valor o fracción, ejemplo altura).
Las variables pueden ser también clasificadas en Dependiente (es causada o modificada por otra) e Independiente (variable que modifica o produce la otra). por ejemplo podemos relacionar en un estudio la variable temperatura, que sería dependiente, con la variable estado de salud, que sería independiente.
Finalmente, Frecuencia es el número de veces que se repite la característica en un estudio. Por ejemplo, en nuestro estudio de dinámica de poblaciones, una encuesta domiciliaria nos arroja la existencia de 1700 canes, siendo 750 la frecuencia de hembras y 950 la de machos.
A partir de estas definiciones podemos ingresar a la recolección de datos acerca de la distribución de la enfermedad en la población.

La información puede obtenerse de distintas fuentes de datos, que pueden ser clasificados en:
Primarias y Secundarias: si quien ha publicado los datos es el mismo que los ha recogido o supervisado se considera fuente primaria. (ejemplo censos de población). Si por el contrario, la información es extraída de una publicación que contiene resultados extraídos de una fuente primaria, estaremos frente a una fuente secundaria. Las fuentes primarias tienen como ventaja evitar errores de transcripción, ofrecer más detalles e incluir aclaraciones del procedimiento de recolección de datos.
Oficiales y Privadas: son fuentes oficiales los organismos gubernamentales, siendo por ende todo organismo no gubernamental una fuente privada.
Ocasionales (encuestas o censos) y Continuas (Registros): Si son ocasionales, la información se recoge en un momento (o periodo) determinado. Por ende constituyen un corte de la población; por ejemplo, una encuesta seroepidemiológica de hidatidosis en una población rural nos indicará la prevalencia de la enfermedad en un momento dado Las continuas, por su parte, son la anotación de los hechos de los cuales se requiere información a medida que estos se van produciendo; por ejemplo registros de hospitalización, notificación de enfermedades transmisibles, registro de hechos vitales como nacimientos y defunciones, registro de decomisos en mataderos.
Un aspecto a considerarse es la comparabilidad de las fuentes.
Cuando se trabaja con datos de dos o más fuentes, se tendrá en cuenta la confianza que merezca cada una en cuanto a su veracidad y calidad de recolección y que se hayan utilizados las mismas definiciones, términos, períodos y procedimientos en la toma de datos.
De tratarse de Muestras habrá que considerar su representatividad en relación al Universo. Si la información es de varios años, asimismo, estudiaremos las posibles variaciones ocurridas en dichos años en los procedimientos de recolección o definición de términos.
2.2. USO DE CIFRAS EN EPIDEMIOLOGIA
En todos los casos, nuestras fuentes de datos nos proporcionarán Cifras Absolutas (casos) que adquieren importancia administrativa, pues al permitir conocer volúmenes de tareas y necesidad de prestaciones establecerán, por ejemplo, requerimientos de drogas y vacunas para un servicio, antiparasitarios para un programa o camas para un hospital; aunque, su utilidad en epidemiología se verá limitada, pues no están relacionadas con la población que les dio origen. Así, 50 casos de brucelosis en una comunidad pueden implicar una situación

epidemiológica mucho más grave que 100 casos en otra comunidad, si la primer población es de 1000 personas y la otra de 1000000.
Más conveniente en términos epidemiológicos, pues permite su uso comparativo, es el manejo de Cifras Relativas construidas relacionado a las cifras absolutas (casos) con la población de la que provienen, expresándolas en término de frecuencia (tasas).
Las Tasas, así, constituyen uno de los instrumentos epidemiológicos de mayor uso. Se construyen como un cociente en el cual el denominador queda constituido por la población y el numerador por la cantidad de individuos que han sido afectados por cierta "causa" (usualmente enfermedad o muerte). Es decir que las tasas "relacionan un evento (enfermedad) con la población que la ha sufrido".
Al indicar enfermedad o muerte, las tasas están expresando el "riesgo" que un miembro de la población tiene de enfermar o morir por la "causa" productora del evento por el solo hecho de pertenecer a esa población.
Toda tasa incluye la descripción precisa de los límites de tiempo (hora, mes, año) y de lugar (escuela, región, país) en que ha ocurrido el evento descripto. Asimismo, dado que el resultado del cociente es siempre menor a uno, se aplica en todos los casos un factor de multiplicación (100, 1000, 100000) generalmente estandarizado de acuerdo al tipo de tasa que se desee expresar.
Por ejemplo: la tasa de incidencia de Hidatidosis humana (Causa) en la Provincia de Río Negro (Límite de lugar) en el año 1983 (Límite de tiempo) fue de 26 x 100000 (Factor de multiplicación), siendo 26 el cociente entre 131 casos nuevos y 485633 habitantes expuestos al riesgo.
Expresado en términos de riesgo, esta tasa significa que cualquier habitante de la Provincia de Río Negro tuvo en 1983 una posibilidad del 26 x 100000 de enfermar de hidatidosis.
2.2.1. TASAS CRUDAS, ESPECIFICAS Y AJUSTADAS
Existen diversos tipos de tasas.
Tasas Crudas o Brutas son aquellas que se elaboran relacionando la totalidad de los casos (morbilidad o mortalidad) ocurridos por una o varias causas en un período y lugar determinado con la población total del país. (por ejemplo, tasa de mortalidad por tétanos en la República Argentina en 1988)

Este tipo de tasas, cuya información está casi siempre disponible, son de valor epidemiológico limitado, pues están muy influenciadas por la estructura de edades de la población.
Por ejemplo, países con altas tasas de enfermedades degenerativas en adultos, pueden enmascarar la tasa cruda si tienen una alta proporción de jóvenes en su población.
Para superar esta limitación se han desarrollado métodos estadísticos para eliminar las diferencias en las proporciones de edades entre las poblaciones que queremos comparar, métodos a partir de los cuales pueden construirse Tasas Ajustadas..
Las Tasas Específicas, por su parte, se elaboran circunscribiendo el fenómeno a un sector de la población determinado por alguna característica como edad o sexo, lo que les confiere alto valor epidemiológico, dado que algunas características de las personas, tales como edad, sexo, ocupación o domicilio, pueden tener alta influencia en el riesgo de enfermar o morir. Por ejemplo, Tasa de morbilidad por Larva migrans en la República Argentina en 1988 en niños de 5/10 años de edad.
Las ventajas y limitaciones de cada tipo de tasa se expresan en el cuadro siguiente
2.2.2. TASAS DE MORBILIDAD Y DE MORTALIDAD
Las tasas, crudas o específicas, pueden expresar enfermedad (tasas de morbilidad) o muerte (tasas de mortalidad). Así, las tasas de morbilidad expresan la proporción de sujetos enfermos de una comunidad, mientras que las tasas de mortalidad expresan la proporción de sujetos que mueren.
En ambos casos, las tasas quedan limitadas como expresión del estado sanitario de una población en cuanto el numerador solo recoge información oficialmente registrada, quedando excluidos los no notificados, los no asistidos y los incorrectamente diagnosticados.
De tal forma, las tasas usualmente expresan valores inferiores a los existentes en la realidad.
Sin embargo, en tanto la subnotificación es un elemento que podría ser considerado estable (mientras no se instrumenten programas específicos que puedan modificar esa situación) a lo largo de los años, las series históricas de las tasas de morbilidad y mortalidad expresan con bastante justeza la historia natural de una enfermedad en una población.
En relación al denominador, la población expresada será siempre la que es definida como expuesta al riesgo. Podrá estar representada por la totalidad de la población de una

comunidad, por una parte de ella (por ejemplo en cáncer de próstata se considerarán solamente los individuos de sexo masculino) o por el número de sujetos sometidos a un estudio.
Dentro de las tasas de morbilidad, incidencia y prevalencia representan dos conceptos claves.
Tasa de Incidencia: expresa el número de casos "nuevos" ocurridos en el período considerado (día, mes, año) en relación a la población expuesta al riesgo. Mide la aparición de la enfermedad.
Se calcula como el cociente entre el número de casos nuevos de una enfermedad (casos diagnosticados en el año considerado) y la población expuesta al riesgo (a la mitad del período considerado)
Ejemplo: Tasa de incidencia de Triquinosis en Argentina en el año 1982: 154 casos / 26735000 de habitantes x 100000 (factor de multiplicación) = 0.58
Tasa de Prevalencia: expresa el "total" de casos existentes en una comunidad en el período considerado. Mide la existencia de enfermedad.
Se calcula como el cociente entre el número total de casos de una enfermedad (casos diagnosticados en el período considerado más los casos preexistentes) y la población expuesta al riesgo (a la mitad del período considerado)
Ejemplo: Tasa de prevalencia para TBC: Total de Casos (diagnosticados en 1988 + diagnosticados en años anteriores y no curados al 1/1/88)/ población 0-20 años, x 100.000, Buenos Aires, 1988
La tasa de prevalencia puede ser de período (1 año) o de punto (un momento dado).
Las tasas de incidencia y prevalencia expresan usualmente la ocurrencia de una enfermedad en una población en función de los casos diagnosticados y notificados a los sistemas de salud. Por ello, normalmente, el factor de multiplicación es 100000.
Los resultados de encuestas en población no sintomática para detectar portadores de una determinada enfermedad, por su parte, son expresados en términos de prevalencia (por ejemplo, tasa de prevalencia de brucelosis en trabajadores del matadero municipal: total de casos positivos a Huddlesson / total de trabajadores estudiados). En estos casos, el factor de multiplicación usualmente utilizado es 100.
Tasa de Ataque: es una tasa de incidencia que se utiliza en casos de brotes. Relaciona, por lo tanto, una población acotada y definida expuesta al riesgo en un período de tiempo también acotado, correspondiente al momento de exposición al riesgo.

Por ejemplo: Tasa de Ataque en un brote de triquinosis, Viedma, agosto, 1982: 28 enfermos de triquinosis / 49 expuestos al riesgo por consumir embutidos frescos contaminados x 100: 57.14 x 100.
Factor de multiplicación en brotes: siempre es usado el valor 100.
Tasa de Ataque Secundario: es una tasa de incidencia de aplicación exclusiva en enfermedades transmisibles por cuanto mide el riesgo que corre un grupo delimitado de adquirir determinada enfermedad por estar en contacto con la fuente original de infección o con el caso primario.
Es decir que el numerador expresará el número de casos secundarios (contactos del caso primario) y el denominador el total de contactos.
Por ejemplo: Tasa de Ataque Secundario en Hepatitis: número de casos en hermanos menores de niños concurrentes a una escuela en donde se desarrolló un brote de Hepatitis / Total de hermanos menores.
Incidencia Acumulada: Es un indicador utilizado en situaciones especiales.
Define la proporción de individuos que estando libres de una enfermedad al comienzo del período considerado enferman a lo largo del mismo.
La Incidencia Acumulada es expresada como producto del cociente entre el número de individuos que presentan la enfermedad y el número de individuos de la población considerada en el período, siendo por lo tanto un valor numérico que se encontrará siempre en el rango entre 0 y 1.
Por ejemplo: En una población minera de Río Negro compuesta por 4800 trabajadores entre 20 y 65 años de edad se produjeron 24 casos de silicosis en el período 1970/1980. Incidencia acumulada 24 / 4800 = 0.005
Por su parte, tres son las tasas de mortalidad más utilizadas.
Tasa de Mortalidad Propiamente Dicha: expresa la cantidad de individuos que mueren en una población, ya sea por todas las causas (mortalidad general) o por una patología específica (mortalidad por causa).
Mide la proporción de población que muere cada año en relación a la población expuesta.
Ejemplo: Tasa de Mortalidad por Rabia, El Salvador, 1987: 0.06 x 100.000
Es decir que se construye como producto de: número de muertos (por una o todas las causas) / población expuesta al riesgo (a la mitad del período considerado) x factor de corrección (usualmente 1000000, a excepción de las tasas de mortalidad infantil que se expresan x 1000).

Tasa de Letalidad: expresa la probabilidad que existe de morir en relación a la ocurrencia de casos de una enfermedad.
Mide la gravedad o potencial mortal de una enfermedad. Se construye como producto de: número de muertos por una causa / total de enfermos por esa causa x factor de corrección (usualmente 100).
Ejemplo: Tasa de Letalidad por Hidatidosis, Rio Negro, 1987: 1.8 x 100 (2 muertos por hidatidosis / 111 enfermos de hidatidosis x 100)
Tasa de Mortalidad Proporcional: expresa la proporción de las muertes por una causa específica en relación a la mortalidad global. (número de muertos por una causa / todos los muertos)
Es decir que al no establecer relaciones con la población total este tipo de tasa no expresa el riesgo de que los miembros de la población mueran por la causa estudiada.
Ejemplo: en la Provincia de Río Negro hubo en 1981 10 casos de muerte por Hidatidosis, siendo 2442 los muertos por todas las causas. T.M.P: 10 / 2.442 x 100: 0.40
2.3. MEDIDAS DE RESUMEN DE DATOS
Hemos desarrollado los mecanismos para la obtención de datos, y sus fuentes.
Sabemos que la primer y más común aplicación de los datos obtenidos es la descripción de la situación en término de tiempo, lugar y persona. También sabemos que, parte de esa descripción es efectuada mediante la utilización de indicadores o tasas.
Normalmente, sin embargo, al terminar los pasos correspondientes a la producción de datos queda disponible una cantidad de información que no puede ser utilizada con fines descriptivos y de comparación, a menos que sea resumida en forma tal que sea posible entender su significado en términos prácticos y sencillos.
Es necesario para ello recurrir a la utilización de valores que sean representativos del total de datos acumulados. Estos valores pueden ser divididos en dos grandes grupos: Medidas de Tendencia Central y Medidas de Dispersión.
Para su mejor comprensión primero debemos definir a la Distribución de Frecuencias como la "representación gráfica de una serie de observaciones según la frecuencia con que ellas ocurren". Si el número de observaciones es suficiente y ellas se han efectuado al azar, la

distribución de frecuencias se agrupará alrededor de un punto central y formará una curva en forma de campana conocida como curva normal o de Gauss.
Las Medidas de Tendencia Central se ubican en la parte central de la distribución y pueden ser definidas como promedios. Son Media, Mediana y Modo.
Las tres nos permiten, así, expresar con una sola cifra el valor central de una serie de datos (observaciones). Por ejemplo: valor medio de la eosinofilia en parasitosis intestinales, edad media de los afectados por fiebre tifoidea en una localidad, mediana de los valores de fosfatasa alcalina en pacientes con hidatidosis, media o mediana del número de casos de triquinosis en el período 1970/80, etc.
Media: o media aritmética en una serie de datos no agrupados es la suma de los valores de las observaciones / el total de las observaciones realizadas:
Σ ( x)
x = ────
n
Ejemplo: una serie de análisis de agua arrojan los siguientes tenores de flúor (en mg/l): 0.2 / 0.7 / 0.7 / 0.7 / 0.8 / 1.0 / 1.0 / 1.2/ 1.5 / 1.5 / 1.8 / 2.2 / 2.8 / 3.3 / 3.4 / 3.4/ 3.9 / 4.2 / 4.5 / 4.8
Media x = 2.18
La media es una medida de resumen de elección cuando se aplica a una serie de datos cuya distribución es aritmética, no tiene valores aberrantes en los extremos ( por ejemplo, si en la situación anterior hubiera un análisis que presentara un tenor de flúor de 45 mg/l la media sería 4.2 no siendo ya representativa de los valores reales de flúor)
Mediana (Mna): En una serie de datos no agrupados, ordenados en forma correlativa (de menor a mayor) la mediana deja igual número de observaciones por arriba y por debajo. Si la serie es impar la Mna será el valor central y sí, por el contrario, es par se promedian los dos valores centrales.
En el ejemplo anterior, los valores que dejan igual número de observaciones por arriba y por abajo son 1.5 y 1.8.

Mna = 1.5 + 1.8 = 1.65
─────
2
La Mna es una medida de resumen que describe correctamente serie de datos tanto simétricos como asimétricos, puede ser utilizada en presencia de valores aberrantes (en el ejemplo anterior, la presencia de un resultado 45 en un análisis no modificaría el valor de la mediana) y si existen clases abiertas.
Modo (Mo): Es la forma más sencilla y menos eficiente de obtener una medida de tendencia central. Es el valor que se presenta con mayor frecuencia. El Modo puede no ser único y, aún, puede no existir.
En el ejemplo anterior es 0.7 pues se presenta en 3 ocasiones.
Se lo usa para determinar el tipo de fuente de contagio en investigaciones epidemiológicas. Así una distribución unimodal de casos de, por ejemplo, hepatitis infecciosa, indicará una sola fuente de infección, bimodal indicará propagación secundaria y multimodal indicará la existencia de múltiples fuentes de infección o transmisión persona/persona.
Para describir una determinada situación epidemiológica, por ejemplo características etáreas de un grupo de pobladores rurales afectados de brucelosis, no es suficiente el cálculo de las medidas de tendencia central, ya que las mismas solo expresan las características medias de los individuos, pero no aportan información de su variabilidad. Es decir, como se distribuye la muestra o el universo alrededor de la media, o sea hacia los costados de nuestra distribución de frecuencias.
Si, por ejemplo, dos poblaciones (A y B) presentan distintas tasas de prevalencia de Larva migrans, teniendo ambas una edad promedio 30 años, no podremos explicar las distintas prevalencias a partir del factor edad. Sin embargo, si la población A presenta una alta proporción de personas entre 25 y 35 años y la B una alta proporción de niños y ancianos (ambas por ende con similar edad media) podremos realizar inferencias sobre el efecto de la edad en la prevalencia de la enfermedad en ambas poblaciones.
Para que eso sea posible, precisamos Medidas de Dispersión que definan la población en base a otros valores, aparte de los de tendencia central, y que expresen la variabilidad.
Así, nos encontramos con medidas utilizadas usualmente para describir como se alejan las observaciones en relación al eje central de la distribución: Desvío Estándar, Error Estándar, Cuartiles y Rango.

Desvío Estándar (DE): Es una medida de dispersión que describe la variabilidad existente entre los individuos de una muestra. Una de sus características es que sus valores no están influenciados por el tamaño de la muestra sino solo por la variabilidad que ella presenta.
Es decir que, volviendo al ejemplo anterior, la muestra A de una población que presenta alta proporción de individuos de entre 25 y 35 años de edad tendrá un DE pequeño en comparación con la muestra B que tenía alta proporción de niños y ancianos en su composición. Podremos así, hacer inferencias sobre las causas de la mayor prevalencia en la población B, al ser los niños los más expuestos al riesgo.
El Desvío Estándar, en este caso, es una medida que describe las características de una muestra y permite realizar comparaciones con otras.
Desde un punto de vista estadístico:
Desvío estándar: σ = Raíz cuadrada de √ siendo que √ (Varianza)
√ = (x - x)² : promedio de los desvíos cuadráticos
─── alrededor de la media.
n
Así, la fórmula nos está indicando que, lo que en definitiva medimos es la distancia o desviación de cada observación con respecto al valor medio. Cuanto más dispersos estén los datos, mayor será el desvío (σ) y, a la inversa, cuanto más agrupados estén alrededor de la media, menor será el desvío (σ).
Hemos expresado que la curva normal o de gauss es simétrica respecto al valor central de máxima frecuencia relativa (media). En ella coinciden los valores de Media, Mediana y Modo, siendo el área total bajo la curva igual a 1. La curva se encuentra dividida en dos mitades por la media y subdividida en 6 por el Desvío Estándar (tres a cada lado de la medida central). El área encerrada en 1 σ será el 68.3% del área total, en 2 σ será el 95.5% y en 3 σ 99.7% del área total.
Es decir que los valores de la Media trasladan la gráfica a lo largo del eje de las X y diferentes valores del σ determinan la altura que la misma alcanza. En el ejemplo anterior, las muestras A y B se ubican en el mismo punto del eje de las X (valor 30) mientras que la muestra A presentará mayor altura que la B.

Por ejemplo, en nuestra serie de análisis de agua para determinar concentración de flúor, puede ser descripta mediante los siguientes valores:
Promedio: x = 2.18
Variabilidad: σ = 1.43
Error Estándar (ES): Es una medida de dispersión que permite estimar la distancia existente entre la media de la muestra y la media del universo del cual procede la muestra (por ende no es una medida descriptiva de la muestra, aspecto reservado al desvío estándar).
Sabemos que, salvo en raras ocasiones (por ejemplo censos), no es posible conocer los valores que describen la totalidad del Universo. Por el contrario, normalmente, solo podemos manejarnos con datos parciales obtenidos de una parte o fracción de la realidad (Muestra).
En una distribución normal o de Gauss, a una distancia de 2 ES de la media del universo se ubican el 95.5% de las medias de las muestras posibles y a 3 ES de la media del universo se ubican el 99.7% de las medias posibles a obtenerse de ese universo (siempre que se respeten las normas estadísticas de muestreo). Esto es así en tanto siempre los valores de la media de una muestra, por más representativa que sea, presentarán alguna diferencia con los valores medios del universo.
Las razones de las diferencias entre la muestra y el universo se deben al tamaño de la muestra (a mayor tamaño de la muestra menor error estándar por mayor aproximación al valor del universo) y a la variabilidad del universo del cual se extrae la muestra (cuanto más varíen los individuos entre sí mas variarán los valores establecidos a partir de una muestra).
En la práctica, solo conocemos el valor de una muestra. Casi nunca conocemos al total de los individuos que componen el universo. Por lo tanto, en realidad, el ES estimado a partir del valor de la media de la muestra nos expresa entre que valor mínimo y que valor máximo se ubica la media del universo. De hecho, ante la imposibilidad de medir a todos los valores del universo por medio de un censo, lo estimamos a partir del ES.
Desde un punto de vista estadístico:
ES : σ

────
√ n
En nuestro estudio de flúor, el Error Estándar es 0.32. Podemos ahora construir un Intervalo de Confianza para determinar los límites mínimos y máximos del tenor de flúor en agua, sumando y restando el valor del error estándar a la media. Si es un IC95% incluiremos el coeficiente 1.96 y si es un IC90% lo reemplazamos por el coeficiente 1.67. Así, en nuestro caso, el verdadero valor del tenor de flúor en agua se encontrará entre
1.96 x σ
IC 95%: ──── +/- x :
√ n
IC 95% = 1.56 / 2.8
Rango: Es la diferencia entre el valor más alto y el más bajo de la serie de observaciones. Mide la homogeneidad de los datos, aunque su valor como medida de dispersión es limitada pues solo intervienen 2 valores en su determinación.
En el ejemplo de tenor de flúor en agua, el rango será:
R = 4.8 - 0.2 = 4.6
Cuartiles: A diferencia de las anteriores medidas de dispersión, donde se usaba la media como medida de tendencia central, se debe usar en este caso, la Mediana.
Son tres valores de la variable que separan la serie de datos en cuatro grupos constituidos cada uno por la misma cantidad de observaciones.
1º Cuartil (Q1): es el valor por debajo del cual hay un 25% de las observaciones.
2º Cuartil (Q2): coincide con el valor de la mediana.
3º Cuartil (Q3): es el valor debajo del cual queda el 75% de los datos y por encima el 25%.

Entre el 1º y 3º Cuartil están incluidos el 50% de las observaciones (Intervalo Intercuartilar).
Para su determinación nos basamos en la misma técnica que aplicamos en el cálculo de la Mediana.
De esta forma, nuestra serie de análisis de agua para determinar tenor de flúor, puede ser descripta mediante los siguientes datos:
Promedio: Mna = 1.65
Variabilidad: Q3/Q1 = 3.40/0.90 = 2.50
Es decir que el tenor de flúor en agua variará entre 0.90 y 3.40.
Cubriendo el intervalo intercuartilar el 50% de las observaciones, podremos esperar que el 50% de las muestras que obtengamos fluctúen entre esos dos valores.
3. ESTUDIOS EPIDEMIOLOGICOS DESCRIPTIVOS
La descripción de eventos de enfermedad o muerte comprende determinar la ocurrencia, las características del lugar donde ocurrieron los hechos (país, localidad, urbano/rural) y las características de las personas o animales afectadas (sexo, edad, raza, especie).
Por ejemplo, cuantificaremos y describiremos una intoxicación alimentaria como un episodio ocurrido entre los asistentes a una cena, que afectó más seriamente a niños que a adultos, mediando 36 hs. entre la cena y la aparición de síntomas en la mayor parte de los afectados, con una tasa de ataque para los que consumieron pastel de papas y carnes del 76 x 100.
La sola cuantificación y descripción de los hechos no permite arribar a conclusiones definitivas sobre las razones para que el fenómeno se haya producido, pero da fundamento a la elaboración de hipótesis que intenten explicarla.
Por ejemplo, en función del período de incubación, síntomas predominantes, tasa de ataque del alimento y características de las personas afectadas se establece la hipótesis de una contaminación por Salmonella sp. de la carne utilizada en el pastel. Estudios epidemiológicos analíticos y el apoyo de laboratorio permitirán confirmar o rechazar esta hipótesis.

3.1. CADENA EPIDEMIOLOGICA
La descripción por parte del epidemiólogo, de la ocurrencia de una enfermedad y de los factores determinantes de dicha ocurrencia incluye necesariamente el análisis de la cadena epidemiológica. Esta es definida como la "sucesión de eslabones que componen los mecanismos de transmisión en una enfermedad y que son susceptibles de ser atacados en eventuales medidas de control". Son ellos:
Fuente de Infección »»» Vía de Eliminación »»» Mecanismo de Transmisión »»» Puerta de Entrada »»» Huésped Susceptible.
La fuente de infección es el animal (huésped), objeto o substancia de la cual el agente infecciosos pasa a un huésped susceptible.
Las vías de eliminación o puertas de salida y las de entrada pueden estar constituidas por las vías respiratorias, digestivo, vías urinarias, piel y mucosas y aparato sexual.
Los mecanismos de transmisión, por su parte, pueden ser clasificados en:
Transmisión directa: por contacto (Ej enfermedades venéreas, rabia)
Transmisión indirecta: por vehículos, objetos o substancias inanimadas, que pueden transportar al agente patógeno (transmisión por aire, agua o alimentos)
Transmisión por vectores: un animal invertebrado es responsable de la transmisión del agente infeccioso, ya sea por transmisión mecánica en la que el artrópodo es portador por accidente y no se produce desarrollo del parásito en el vector (Por ejemplo ciertas enfermedades entéricas transmitidas por la mosca de la basura) o por transmisión biológica en la que el agente cambia de forma y se multiplica en el vector resultando paso obligado en el ciclo del agente infeccioso. Por ejemplo: Tripanosoma cruzi
El Huésped constituye toda persona o animal vivo que alberga y permite la subsistencia de un agente infecciosos, resultando huésped susceptible toda persona o animal vivo pasible de ser infectado.
En la cadena epidemiológica cumplirá funciones de Reservóreo toda persona, animal, artrópodo, planta o suelo donde normalmente vive y se multiplica un agente infeccioso y del cual depende para su supervivencia, reproduciéndose de manera que pueda ser transmitido a un huésped susceptible. Vector, por su parte, implica la participación de un invertebrado que propaga la enfermedad entre dos vertebrados.

Portador será considerado toda persona o animal infectado que alberga un agente infeccioso sin presentar síntomas clínicos de enfermedad. Es fuente potencial de infección para otros animales o personas. Puede serlo en fase de incubación, como convaleciente o crónico.
3.2. DISEÑO DE ESTUDIOS DESCRIPTIVOS
Las investigaciones epidemiológicas efectuadas con fines de descripción constituyen Estudios Epidemiológicos Transversales (o verticales). Este tipo de estudio, no considera el factor tiempo sino que solo analizan la situación de los grupos bajo estudio en un momento dado.
Normalmente la técnica empleada para su ejecución es el tamizaje de un grupo de población aparentemente sana (encuesta de campo), por ejemplo por medio de métodos serológicos o de imágenes, pudiendo estar acompañado por cuestionarios o observaciones de campo que permitan completar la información sobre factores de riesgo presente o ausente.
Son estudios de diseño sencillos y baratos. Al radiografiar una situación permiten obtener información sobre la presencia de los factores de riesgo en la población y sobre el daño a la salud que estos puedan haber provocado (permiten estimar la prevalencia, aunque no la incidencia).
Sin embargo, al ser obtenidos ambos simultáneamente no es posible probar que exista relación temporal o asociación causal entre ellos, por lo que, apoyados por el conocimiento científico, solo podemos plantear hipótesis sobre su existencia o ausencia a los efectos de explicar la situación descripta.
Por ejemplo, ante la aparición de casos humanos de Trichinella spiralis se diseña un estudio epidemiológico transversal para determinar la prevalencia de Trichinella sp en cerdos y roedores en una región geográfica determinada, para lo cual se toman muestras de sangre a una determinada proporción de animales de un determinado número de criaderos, procesándose las muestras mediante la técnica de ELISA y se capturan roedores con trampas tipo sherman en los mismos criaderos y en basural, procediéndose a estudios mediante la técnica de digestión de larvas. Paralelamente se procede a la recolección de información sobre tipo de alimentación de los animales, tipo de instalación y nivel socioeconómico.
El diseño y ejecución de estudios poblacionales transversales requiere de algunas precauciones elementales que aseguren la confiabilidad y validez del resultado:

Deben ser llevados a cabo en un corto período de tiempo para evitar variaciones en la situación epidemiológica estudiada (por ejemplo por la ocurrencia de brotes). Este aspecto sería de menor importancia si el estudio estuviera referido a una enfermedad crónica.
La muestra debe ser rigurosamente diseñada en términos estadísticos y de eliminación de sesgos.
3.2.1. ESTIMACION Y SELECCIÓN DE LA MUESTRA
Existen tres elementos que deben ser considerados para determinar el Tamaño de una muestra en una encuesta, por ejemplo serológica:
Nivel de Confianza: decisión arbitraria a ser tomada por el investigador: normalmente se ubicará en 90%, 95% o 99%. Un mayor nivel de confianza significará un mayor tamaño de la muestra
Margen de Error: (o precisión absoluta) decisión arbitraria a ser tomada por el investigador: normalmente será del 10%, 5% o 1%. Un menor margen de error significará un mayor tamaño de la muestra.
Prevalencia esperada: la estimación del tamaño de la muestra requiere de un cierto conocimiento de la prevalencia que esperamos hallar, pues no es lo mismo buscar algo que es habitual en la naturaleza, por ejemplo anticuerpos contra Toxoplasma gondi, que identificar portadores de una enfermedad ocasional, por ejemplo síndrome pulmonar por hantavirus. Cuanto menor sea la prevalencia de la enfermedad mayor tamaño de la muestra se requerirá.
Con estos parámetros definidos, el tamaño de la muestra puede extraerse de tablas (Thrusfield, 1990) u obtenerse de un software para epidemiología (Epidat, Epiinfo). En cualquier caso deberá evitarse considerar el tamaño de la muestra como un porcentaje fijo del número de individuos de la población.
Por ejemplo, si queremos efectuar una encuesta para determinar prevalencia de brucelosis, definimos un nivel de confianza del 95% y aceptamos un margen de error absoluto del 1% con una prevalencia esperada del 10% (significa que aceptamos hallar una prevalencia fluctuante de 10-1 a 10 +1: 9-11) nuestro tamaño de muestra (n) será de 3457 individuos. Si por el contrario, y para la misma prevalencia, definimos un nivel de confianza del 10% y aceptamos un margen de error absoluto del 10% (significa que aceptamos hallar una prevalencia fluctuante entre 10-10 y 10+10: 0-20) el tamaño de la muestra ("n") se reduce a 24 (valor de "n": extraído de tabla)
El segundo aspecto a considerar, es la Selección de los individuos que entraran en la muestra. La mejor forma de evitar sesgos es aplicar criterios de muestreo probabilístico, o sea mediante un proceso aleatorio que asegure a todos los individuos la misma posibilidad

de ser incluidos en el estudio. Por ejemplo, asignando un número a cada individuo los cuales serán escritos en un papel, seleccionándose los individuos a muestrearse extrayendo "n" números de una caja en donde se habrán colocados los mismos (muestreo simple). Si el tamaño del universo es grande podemos dividir el total de individuos del universo por "n", obteniéndose una cifra base de muestreo (por ejemplo 100) a partir de lo cual elegiremos 1 individuo de cada 100, seleccionándose en forma aleatoria uno de los primeros 100 (muestreo sistemático), presupone contar con listados correlativos de la totalidad de los individuos.
Estimación en software EPIDAT: opción MUESTRAS – Situación con una muestra
4. INTERPRETACION DE PRUEBAS DIAGNOSTICAS
4.1. INTERVALO DE CONFIANZA
Según Jenicek (1987), dado que toda estimación se basa en el azar y lleva consigo cierta variabilidad los resultados que hallemos en nuestra encuesta se modificarán ligeramente de un estudio al otro. Por ejemplo, en nuestra investigación de Trichinelosis, la tasa de prevalencia en cerdos encontrada es del 18%. Si repetimos varias veces el estudio, aún con un correcto diseño, difícilmente presentará siempre exactamente la misma cifra.
Por ello, mejora enormemente la interpretación epidemiológica del dato la determinación del Intervalo de Confianza, o sea la determinación de los límites inferior y superior entre los que debería ubicarse el valor real de la tasa de prevalencia si pudiéramos estudiar a todo el universo. Si lo estimamos al 95%, significa que 95 de cada 100 veces que efectuemos el mismo estudio, el valor de la tasa quedará comprendido dentro de esos límites.
Un intervalo de confianza amplio será producto de un tamaño de muestra pequeño y/o de una baja prevalencia del factor estudiado. Un intervalo de confianza pequeño le dará mayor confiabilidad a nuestro resultado. Por ejemplo, si en nuestro estudio el IC 95% resulta de 2-44, significa que nuestra prevalencia del 18% en realidad puede ser de solo el 2% o hasta del 44%. Si por el contrario nuestro IC95% se ubica en 16-22 tendremos mayor seguridad de la prevalencia real de trichinelosis en cerdos pues no se aleja demasiado de nuestro 18%.
Para el cálculo del IC se establece primero el grado de confianza que se desea (99%, 95%, 90%), porque a cada uno de ellos corresponde un factor (aproximadamente 2.6, 2, 1.6) por

el que hay que multiplicar al Error Estándar de la proporción. Esos múltiplos del E.S.p. se suman y se restan al valor de la prevalencia obteniéndose de esa manera los límites del intervalo.
Estimación en software EPIDAT: opción INFERENCIAS – Inferencias para proporción
4.2. SENSIBILIDAD Y ESPECIFICIDAD
Hay dos parámetros empleados para medir la capacidad de una prueba de selección o de tamiz para diferenciar entre los individuos que tienen la enfermedad y los que no la tienen.
Sensibilidad: capacidad para identificar de manera exacta a los sujetos que tienen la enfermedad.
personas con la enfermedad clasificadas como + por la prueba de selección
S: ──────────────────────────────────────────────
total de personas con la enfermedad
Especificidad: capacidad para identificar con exactitud a quienes no tienen la enfermedad.
personas sin la enfermedad clasificadas como - por la prueba de selección
E: ─────────────────────────────────────────
total de personas sin la enfermedad
Para estimar la Sensibilidad y la Especificidad se comparan los resultados obtenidos con nuestra prueba con los obtenidos por algún medio diagnóstico de certeza, reconocido por la ciencia y concluyente, conocido como Prueba Patrón o Gold Stándar (del inglés, prueba de oro. El porcentaje en que nuestra prueba de selección concuerde con el obtenido por estos métodos concluyentes proporciona la medida de ambos parámetros.

Por lo general, las pruebas que arrojan resultados concluyentes son más invasoras (por ejemplo se puede confirmar un diagnóstico de hidatidosis mediante cirugía) o más caros (por ejemplo tomografía computada).
Otro indicador para evaluar la efectividad de nuestra prueba es el:
Valor Predictivo (de una prueba positiva): proporción de pruebas positivas que son efectivamente positivas, pudiéndose también estimar el Valor Predictivo de una Prueba negativa, siendo este un parámetro mucho menos utilizado.
personas con la enfermedad clasificadas como + por la prueba de selección
VP: ──────────────────────────────────────────────
total de personas que resultaron + a la prueba de selección.
Así, el Valor Predictivo (+) define cual es la probabilidad que un sujeto clasificado como positivo por la prueba de selección sea realmente positivo.
La sensibilidad y la especificidad son inherentes a la técnica y no se modifican de acuerdo a la prevalencia de la enfermedad. El Valor Predictivo, por su parte, depende de la sensibilidad, la especificidad y la prevalencia de la enfermedad. Cuanto menor sea la prevalencia, menor será el valor predictivo positivo, en tanto es mayor la probabilidad de detectar falsos positivos.
De acuerdo a lo expuesto, la prevalencia de una enfermedad obtenida por medio de una encuesta serológica no refleja con exactitud la real prevalencia de la enfermedad en la población.
Aún en el caso de una enfermedad inexistente en un territorio dado, si nuestra prueba arroja falsos positivos siempre habrá una Prevalencia Serológica (PS) que no se corresponde con la Prevalencia Real (P). Esta situación es estimada mediante el Valor Predictivo.
Así, podemos ajustar el cálculo del Valor Predictivo a la prevalecia mediante la siguiente fórmula:
Prevalencia real + especificidad - 1

VP (+): _____________________________________________________________
Prevalencia real x sensibilidad + (1 – Prevalencia real) x (1 – especificidad
Asimismo, conociendo el resultado de nuestra encuesta serológica, podemos estimar la Prevalencia real de la enfermedad en la población, mediante la siguiente fórmula:
Prevalencia serológica + especificidad
P real: _______________________________
Sensibilidad + especificidad – 1
Si volcamos los datos en una tabla tetracórica tenemos:
Resultado de la prueba
Diagnóstico verdadero
Enfermos Sanos Total
Positiva a b a + b
Negativa c d c + d
Total a + c b + d a+b+c+d: n
En donde: Sensibilidad: a/a+c x 100
Especificidad: d/b+d x 100
Valor Predictivo +: b/a+b x 100
Prevalencia real: a+c/n x 100
Prevalencia serológica: a+b/n x 100

Por ejemplo se efectúa un estudio para determinar la Sensibilidad y la Especificidad de Elisa y DD5 en el diagnóstico de la Hidatidosis Humana.
Para ello se estudian serológicamente 499 habitantes de un área rural endémica, procesándose el material con ambas técnicas. 47 personas que presentaron Elisa reaccionante (título superior a 0 DE) fueron trasladados a un centro de alta complejidad, siendo estudiados mediante radiología de tórax, ecografía de abdomen y tomografía computarizada, lo cual implicaba una buena seguridad de detectar todo quiste hidatídico existente. Todos los casos DD5 + presentaban título de Elisa =/> 8 DE.
Se seleccionó como grupo control un conjunto de 47 pobladores con Elisa no reactiva, tomándose el criterio de muestras pareadas por domicilio, edad y sexo. Este grupo también fue derivado para ser sometido a estudios por imágenes.
Concurren a la consulta 43 casos y 44 testigos, resultando
============================================
PARAMETRO DD5 Elisa (>8 DE)
============================================
Sensibilidad (%) 31 63
Especificidad (%) 100 97
Valor Predictivo + (%) 100 85
=============================================
Sin embargo, para nuestro estudio de hidatidosis, a una prevalencia esperada del 1% el Valor Predictivo positivo de Elisa resultará del 17.5%, mientras que a una Prevalencia esperada del 5% será del 52.5%.
Estos hallazgos permiten estimar las ventajas y limitaciones de cada prueba, como asimismo permiten interpretar con mejor criterio los resultados. Así, y en nuestro ejemplo:
Todo caso dd5 + necesariamente es portador de un quiste (especificidad 100%).
Un resultado dd5 - no tiene utilidad clínica para descartar la presencia de un quiste (sensibilidad 31%)
Un resultado Elisa reactivo > 8 DE indica alta probabilidad de hidatidosis (especificidad 97%).

Dicho de otro modo, una prueba muy sensible tiene pocos resultados falsos negativos, una prueba muy específica tiene pocos resultados falsos positivos. En donde es necesario determinar título diagnóstico, si es fijado en un valor elevado se aumenta la Especificidad pero con pérdida de Sensibilidad. Por el contrario, si bajamos el título, aumentaremos la Sensibilidad pero a costa de pérdida de Especificidad.
Las decisiones a este respecto dependen de los objetivos de la técnica. Por ejemplo, en un Banco de Sangre será importante aplicar técnicas o títulos muy Sensibles para evitar se transfunda sangre con Chagas o Sida. Por el contrario, si deseamos confirmar un diagnóstico clínico de esas enfermedades precisamos pruebas muy Específicas. Cuando se aplican pruebas para determinar prevalencia de la enfermedad en una población, se utiliza como prueba tamiz una prueba de alta sensibilidad, con confirmación posterior de los positivos mediante el uso de una prueba de alta especificidad.
Estimación en software EPIDAT: opción PRUEBAS DX – Pruebas simples
CAPITULO 3: EXPLICACION DE LOS HECHOS
1. VERIFICACION DE HIPOTESIS EPIDEMIOLOGICAS
La elaboración de hipótesis constituye un proceso que incluye el análisis de la información recolectada, su comparación con situaciones análogas obtenidas de la literatura científica o del conocimiento existente, a los efectos de tratar de explicar los hechos con criterio racional y científico.
Una vez establecida la hipótesis explicativa debemos tratar de verificarla o rechazarla. Para ello, existe la posibilidad de diseñar estudios epidemiológicos analíticos, definidos tradicionalmente como "estudios de observación diseñados especialmente para examinar la validez de las hipótesis".
Estos estudios no incluyen la introducción o supresión artificial de los factores de riesgo bajo estudio sino que simplemente incorporan una selección rigurosa de grupos a ser comparados en base a su mayor o menor exposición al riesgo. Es decir que se establece como elemento distintivo la existencia de un grupo control o testigo que permitirá construir análisis estadísticos concluyentes sobre los factores de riesgo que sean estudiados.
Los estudios epidemiológicos experimentales, por su parte, incluyen la introducción o supresión deliberada de la causa presuntiva (manipulación por parte del investigador de alguna de las variables bajo estudio) para observar la subsiguiente aparición o ausencia del efecto.

Es un proceso de investigación muy limitado por razones éticas en el campo médico (riesgo de producir un efecto indeseable) y de costos. Son, sin embargo necesarios en ciertas etapas de, por ejemplo, el desarrollo de vacunas o medicamentos (y en los cuales el proceso experimental se efectúa en la medida de lo posible en animales) o para comprobar la efectividad de medidas de control de enfermedades (que requieren de la selección de un área piloto donde instrumentar las técnicas de control y de un área testigo de similares características y en la cual estas medidas no serán aplicadas).
Son ejemplo de este tipo de estudios los ensayos de fluoración de aguas para consumo (factor artificial introducido por el investigador en una población) efectuados para determinar su impacto en la prevención de la carie dental (en comparación a una población con agua no fluorada).
2. ESTUDIOS EPIDEMIOLOGICOS LONGITUDINALES
Los estudios epidemiológicos analíticos son básicamente longitudinales, en tanto la presencia de la "causa/factor de riesgo" y la aparición del "efecto/enfermedad" se presentan en dos puntos diferentes en el tiempo.
Así, los Estudios Longitudinales toman en cuenta el tiempo transcurrido entre la actuación de un agente etiológico y la aparición de síntomas.
Si iniciamos nuestro estudio a partir de la aparición de síntomas y, hacia atrás en el tiempo, tratamos de determinar el momento de acción del factor causal, nos encontraremos en presencia de estudios Retrospectivos o de Casos y Controles. Son estudios de diseño sencillo, baratos de ejecutar y en donde pueden obtenerse conclusiones en forma rápida. Su limitación es que no permiten determinar incidencia y los factores de riesgo son estimados en forma aproximada.
Por el contrario, si partimos de la actuación del factor causal y seguimos al grupo bajo estudio hasta la aparición de los síntomas pertinentes estaremos en presencia de estudios de Prospectivos o de Cohorte. Este tipo de estudios permiten con un mínimo de sesgos, determinar incidencia y estimar el riesgo relativo.
Este tipo de estudio consiste en escoger dos poblaciones compuestas por individuos sin síntomas de la enfermedad a estudiar. Uno de los grupos (Cohorte) estará expuesto al factor de riesgo (por ejemplo estudiantes de veterinaria) y el otro (Cohorte de control) no (por ejemplo estudiantes de arquitectura). Se controlan ambos grupos en espera de la aparición de casos de enfermedad (por ejemplo aparición de síntomas de brucelosis).

El epidemiólogo comparará la proporción de enfermos que aparecen en los no expuestos y en los expuestos, a los efectos de determinar si, efectivamente, la presencia del factor de riesgo produce mayor número de enfermos que su ausencia.
Sin embargo son estudios caros que requieren habitualmente de mucho tiempo y muchos individuos para la obtención de conclusiones, en particular si la incidencia de la enfermedad es baja. Así, Mac Mahon (1975) señala que parece razonable primero desarrollar estudios de Casos y Controles y, si se comprueba asociación causal, pasar al diseño de un estudio de Cohorte.
Por su parte Rothman (1986) señala con precisión que un elemento común a todos los estudios es la necesidad de formular los objetivos con la mayor precisión posible, en forma clara y cuantitativa, dejando sentado el parámetro que se quiere medir, pues de lo contrario cualquier estudio poblacional que tenga objetivos deficientemente conceptualizados será de calidad endeble.
2.1. ASOCIACION CAUSAL
Siguiendo a Mac Mahon (1975) vemos que ciertos eventos o circunstancias tienden a aparecer cronológicamente luego de la ocurrencia de otro evento o circunstancia (relación temporal). Estas asociaciones cronológicas son consideradas como asociación entre causa y efecto, tomándose al evento producido en primera instancia como causa (presencia de un factor de riesgo) y a su consecuencia como efecto (enfermedad o muerte)
Los estudios epidemiológicos longitudinales tienden a establecer con precisión si la relación temporal incluye:
Asociación estadística entre la presencia de un factor de riesgo y la presencia o ausencia de enfermedad, determinada mediante la estimación del odd ratio o del riesgo relativo, con sus pertinentes intervalos de confianza y con estimación del valor de "p"
Plausibilidad biológica dada por el conocimiento científico existente.
Ausencia de Factores de Confusión, definidos por Guerrero (1981) como "variables introducidas sistemáticamente en el estudio de una asociación y que deben ser consideradas para no incurrir en errores de apreciación".
Por ejemplo, si relacionamos desnutrición infantil con nivel de ingresos (probable asociación estadística positiva) debemos considerar y probar otras variables como nivel educativo de la madre antes de aceptar la existencia de una asociación causal.

2.2. MULTICAUSALIDAD
La existencia de una gran cantidad de acontecimientos (enfermedades) no puede ser explicada en forma completa en virtud de la ausencia o presencia de un solo factor causal. (Urquijo, 1969)
Así, podemos definir que la ocurrencia de un gran número de hechos depende de redes de causalidad en los que los factores intervinientes se interconectan en forma sucesiva y recíproca.
Esto, sin embargo, no es limitante para la puesta en marcha de medidas de control, dado que, a partir del conocimiento de solo alguno de los eslabones que componen esta red de causalidad es posible incidir limitando el daño por la implementación de medidas de prevención o control (siendo esto posible aunque no sea conocido el factor causal mas importante e incluso siendo desconocido el agente etiológico productor de la enfermedad).
Por ejemplo, la Fiebre Hemorrágica Argentina es causado por virus Junín (Causa Necesaria) que circula en una población de roedores (Calomys) que proliferan en función del tipo de actividad agropecuaria, favorecido por la eliminación de sus predatores naturales, posibilitando el contacto agente – huésped susceptible la actividad agropecuaria y la falta de ropa adecuada. (Causas Contribuyentes)
2.3. DETERMINACION DE ASOCIACION ESTADISTICA
Desde un punto de vista práctico, la mayor parte de los estudios epidemiológicos destinados a la verificación de Hipótesis, pueden ser planteados dentro de una tabla tetracórica (o de cuatro casillas):

Variable Independiente
(causa)
Variable Dependiente (efecto)
Enfermos Sanos Total
Exposición a un Factor A b a + b
No Exposición a un Factor C d c + d
Total a + c b + d a+b+c+d
Es decir que la población estudiada (a+b+c+d) es separada de acuerdo a la presencia o ausencia de la Variable Independiente (exposición a un factor) y la presencia o ausencia de la Variable Dependiente (enfermedad). El tema ha resolver es si la proporción de enfermos expuestos a un factor es más alta que en los no expuestos.
Para ello, en los estudios de Casos y Controles se compara la frecuencia de la exposición en enfermos y no enfermos (o sea a/a+c versus b/b+d) mientras que en los estudios de Cohorte se compara la presencia de enfermedad en expuestos y no expuestos (o sea a/a+b versus c/c+d).
2.3.1. ESTIMACION DEL RIESGO
Hemos definido el concepto de "incidencia" como sinónimo conceptual de "riesgo". Así, la tasa de incidencia mide el "Riesgo Absoluto" que tiene un individuo de una comunidad de sufrir una determinada enfermedad (o morir de determinada causa). Es decir que expresa la probabilidad que una enfermedad o muerte ocurra en un lapso de tiempo.
El riesgo absoluto es la cifra básica a partir de la cual se obtienen el Riesgo Relativo y el Riesgo Atribuible, mediante los cuales estimamos la asociación entre la exposición a un factor de riesgo y la presencia de enfermedad.
Riesgo Relativo: Expresa el cociente entre la tasa de incidencia del grupo expuesto al riesgo y la tasa de incidencia del grupo no expuesto a dicho factor (o, en estudios de población, el cociente entre incidencia en población expuesta y población general).
Mide, así, la fuerza de la asociación entre el factor de riesgo y la ocurrencia de enfermedad.

tasa de incidencia población expuesta
R.R. = ────────────────────
tasa de incidencia población no expuesta
Así, El Riesgo Relativo no es una tasa sino solamente un cociente. Expresa en que medida está aumentado el riesgo de enfermar en alguien (por ejemplo un trabajador de la carne) expuesto a un factor (brucelosis) en comparación a alguien que no desarrolla esta actividad.
Por ejemplo, si el resultado del cociente es 120, significa que el riesgo de contraer brucelosis es 120 veces mayor en trabajadores de la carne que para alguien no relacionado a dicha actividad.
Al medir fuerza de una relación, el Riesgo Relativo sugiere etiología o causalidad, también expresará el beneficio que se podría obtener para el paciente si se eliminara el factor.
Riesgo Atribuible: Mide la proporción de incidencia de enfermedad (riesgo) que puede ser atribuida a la exposición específica a un factor.
Se calcula restando a la tasa de incidencia del grupo expuesto al factor la tasa de incidencia del grupo no expuesto (o, en estudios de población, la resta entre la tasa de incidencia en población expuesta y población general.
R.A.= tasa de incidencia población expuesta - tasa de incidencia población no expuesta.
La cifra resultante expresa el exceso de enfermedad que experimentan, por ejemplo los trabajadores de la carne, por su actividad en relación a los no expuestos, es decir plantea la incidencia que es atribuible exclusivamente a la exposición a la causa.
El Riesgo Atribuible tiene importancia para los administradores de salud pues mide el beneficio potencial que generaría en la salud de la comunidad la eliminación de los factores de riesgo. Así, cuanto mayor sea el Riesgo Atribuible, mayor será la justificación para la instrumentación de medidas.
En términos prácticos puede utilizarse la tabla tetracórica para la estimación del riesgo de la siguiente forma:

Variable Independiente
(causa)
Variable Dependiente (efecto)
Enfermos Sanos Total
Exposición a un Factor a b a + b
No Exposición a un Factor c d c + d
Total a + c b + d a+b+c+d
a\(a+b)
RR: --------
c\(c+d)
RA: a\(a+b) - c\(c+d)
Esta formulación es válida para estudios de Cohortes, en que es posible la determinación de la tasa de incidencia.
En estudios de Casos y Controles, dado que no puede estimarse la tasa de incidencia pues no se conoce la población expuesta al riesgo, no es posible la estimación del Riesgo Relativo.
En estos casos se utiliza la Desigualdad Relativa u Odds Ratio (OR), de acuerdo a la siguiente fórmula extraída de la tabla tetracórica:
OR: (a * d) \ (b * c)
Tanto para el riesgo atribuible como para el riesgo relativo o el odds ratio corresponde incorporar el cálculo del Intervalo de Confianza.
Por ejemplo, en un estudio de Casos y Testigos, el riesgo de enfermar de hidatidosis por consumir agua no potable resulta de OR: 8. Si estimamos el IC 95%, significa que 95 de

cada 100 veces que efectuemos el mismo estudio, el valor de OR quedará comprendido dentro de esos límites.
Un Intervalo de Confianza amplio implicará la posible existencia de sesgos en la investigación o que el tamaño de la muestra es insuficiente o una combinación de estos factores (en nuestro ejemplo de hidatidosis, para un OR: 8, los límites podrían ubicarse en 1.8 y 172, lo que se interpreta que consumir agua no potable produce un riesgo de enfermar de hidatidosis 8 veces mayor que tomar agua potable, pudiendo variar entre 1.7 veces mas y 172 veces mas).
Un Intervalo de Confianza estrecho será indicativo de un tamaño de la muestra adecuado y/o de una fuerte asociación (en nuestro ejemplo de hidatidosis podría ubicarse entre 4 y 12).
Un Intervalo de Confianza en que el límite inferior resulte una cifra menor a 1 (en presencia de un límite superior mayor a 1) es indicación estadística de débil asociación causal y/o de tamaño insuficiente de muestra, aún cuando el valor central del OR sea elevado (en nuestro ejemplo, 0.7 y 172, lo que se interpreta como que el consumo de agua no potable puede aumentar o disminuir el riesgo de enfermar de hidatidosis).
Puede estimarse el IC para el riesgo atribuible mediante la siguiente fórmula:
IC(RA) = RA +/- Z x ES
En donde Z es el valor correspondiente al Nivel de Confianza seleccionado y ES el Error Estándar.
O, para un Intervalo de Confianza del 95%:
IC(RA) = RA +/- (1.96/chi)
También podemos estimar el IC para el riesgo relativo, mediante la siguiente fórmula:
IC(RR) = RR +/- Z x ES.
O, para un Intervalo de Confianza del 95%:
IC(RR) = RR +/- (1.96/chi)
Finalmente, podemos incorporar a nuestro análisis Pruebas de Significación Estadística para determinar si un estudio poblacional es concluyente en indicar la existencia de asociación causal entre la exposición al riesgo y la presencia de enfermedad (o entre la exposición a un tratamiento y la desaparición de la enfermedad).
Debe entenderse, que las pruebas de significación no son más que fórmulas estadísticas que incluyen la definición de límites impuestos arbitrariamente para la aceptación o el rechazo

de las hipótesis de trabajo. No siendo capaces tampoco de analizar la plausibilidad biológica o la verosimilitud de las conclusiones a las que hemos arribado.
Para una interpretación adecuada de los conceptos de significación debemos recordar los conceptos referidos sobre Error Estandar (ES).
Así, se planteó que, a una distancia de 2ES de la media del universo se ubican el 95.45% de las medias de todas las muestras posibles que se obtengan de dicho universo; y a 3 ES el 99.73%. De tal forma, y tomando un límite en forma arbitraria (por ejemplo 95%) diremos que el objetivo de nuestra prueba de significación es comparar "las medias de dos muestras" (una de población expuesta al riesgo y otra de población no expuesta al riesgo).
Si ambas medias caen dentro de los límites establecidos por 2ES pertenecerán al mismo universo no existiendo, por ende, diferencias significativas entre ellas. En este caso se descartaría la importancia del Factor de Riesgo (inexistencia de Asociación Causal).
Por el contrario, si la media de los expuestos al riesgo cae más allá de 2ES diremos que pertenece a un Universo distinto al de no expuestos, por ende habrá diferencias significativas entre las dos muestras, existiendo Asociación Causal entre el Factor de Riesgo y el daño a la salud.
El punto de 2ES (95%) representa el límite arbitrario usualmente definido como límite de significación y es igual a una probabilidad del 5% que la diferencia entre las dos muestras se deban al azar (p = 0.05). El punto correspondiente al 99%, por su parte, representa una probabilidad del 1% (p = 0.01). El punto de 3ES (99.7%) representa el límite arbitrario usualmente definido como límite superior de la significación (p = 0.001).
De hecho, de acuerdo a la seguridad que busquemos en nuestro estudio, fijaremos el límite de significación en uno u otro punto.
Esta idea aparece asociada al concepto de Hipótesis Nula utilizado cuando se trabaja en la comparación de dos grupos. La hipótesis nula enuncia que no hay diferencias entre los grupos de expuestos y de no expuestos al riesgo, esto es que las diferencias se deben al azar. Para decidir si se debe aceptar o rechazar esta hipótesis se efectúa una prueba estadística comparándose este resultado con un valor crítico o límite arbitrario preestablecido, extraído de una tabla estadística. Si excede dicho valor se rechaza la hipótesis nula y se declara a la diferencia como estadísticamente significativa.
Toda decisión de rechazar la hipótesis nula entraña cierto riesgo de equivocarse. Por ejemplo:
===========================================================================
Situación real
indica que la

Hipótesis Nula es:
VERDADERA FALSA
============================================================================
Prueba estadística ACEPTADA DESICION CORRECTA ERROR TIPO II
indica que
Hipótesis Nula es RECHAZADA ERROR TIPO I DESICION CORRECTA
============================================================================
Así, el nivel de significación del 5% restringe la posibilidad que se dé un error de tipo I (aceptar una asociación cuando no existe). Si usamos por el contrario, valores del 10% o 20% restringimos la posibilidad que se dé un error de tipo II (rechazar una asociación que existe).
Por ejemplo, si en un consultorio de pequeños animales han utilizado dos tipos de tratamiento en cachorros con parvovirus, si el profesional estima que uno de ellos, en general, ha tenido mayor respuesta, su interrogante será si la diferencia observada es real o sencillamente se trata de un error de muestreo. Esta valoración se puede hacer con una prueba estadística en donde un nivel de significación del 5% implicará asumir un 5% de probabilidad de rechazar la hipótesis nula aunque sea verdadera.
Existen muchas pruebas estadísticas para efectuar este análisis, siendo la mas empleada la Prueba de Chi Cuadrado.
Desde un punto de vista estadístico, la formula del Chi2 es:
Observado - Esperado D
x2 = Σ -(----------------------)2 : ( --- )2
Esperado ES
Sin embargo, puede utilizarse un método simplificado para su cálculo:

Para ello volcamos los datos en la tabla tetracórica, calculamos los totales, estimamos las tasas y calculamos las diferencias entre las tasas:
Variable
Independiente (causa)
Variable
Enfermos
Depend.
Sanos
(efect
Total
o)
Tasas de
Incidencia
Diferencia
Exposicion
a un factor
a b a + b a \ (a+b) a\(a+b)-c\(c+d)
No Exposicion a un factor
c d c + d c \ (c+d)
Total a + c b + d a+b+
c+d
Tasas de
Exposic.
a\ (a+c) b\ (b+d)
Diferencia a\(a+c) -
b\(b+d)
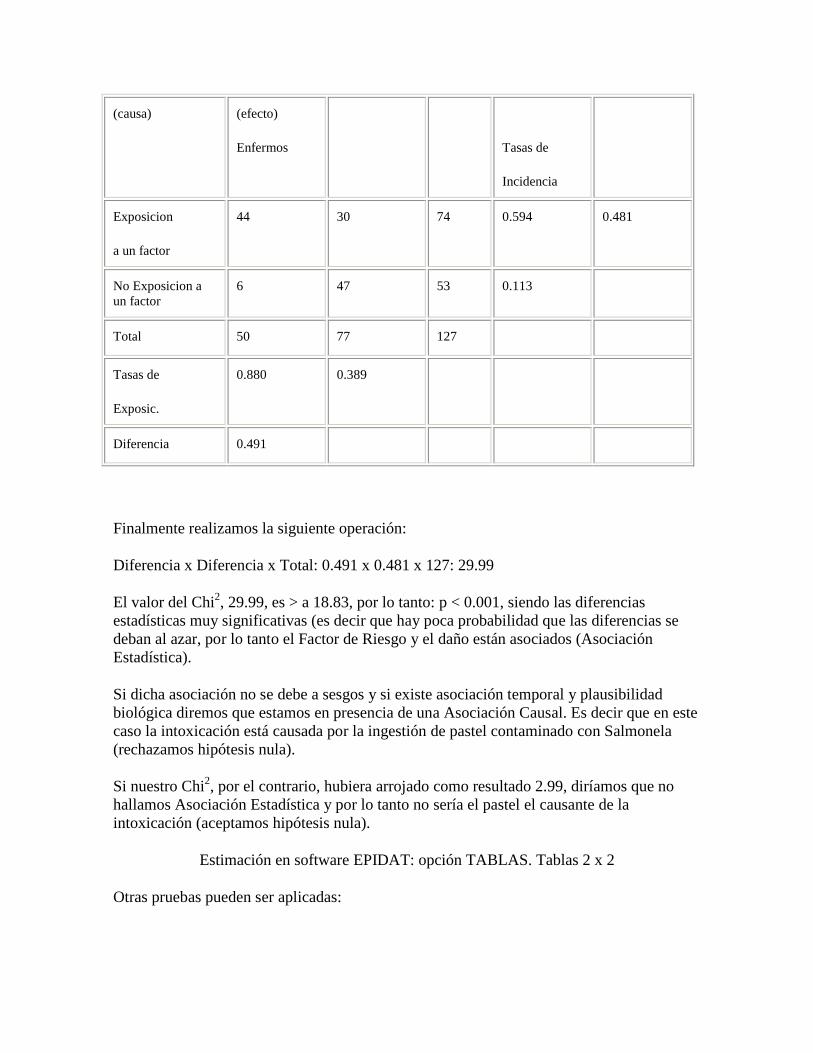
Finalmente realizamos la siguiente operación:
Diferencia x Diferencia x Total, lo cual nos dará el valor del Chi2.
Comparamos el valor hallado con la siguiente tabla de interpretación:

========================================================
VALOR DEL CHI PROBABILIDAD INTERPRETACION DE LAS
CUADRADO (1) DEL AZAR DIFERENCIAS (2)
========================================================
> 10.83 p < 0.001 muy significativas
= 10.83 p = 0.001 muy significativas
< 10.83 p < 0.01 significativas
= 6.6 p = 0.01 significativas
> 3.8 p < 0.05 significativas
= 3.8 p = 0.05 no significativas
< 3.8 p > 0.05 no significativas
=========================================================
1: obtenido de la tabla de chi2.
2: el nivel de significación es definido arbitrariamente y puede ser modificado
Por ejemplo: un grupo de personas sufre una intoxicación alimentaria, supuestamente por ingestión de pastel de carne contaminado con salmonela:
Variable
Independiente
Variable Depend.
Sanos
Total
Diferencia
(causa) (efecto)
Enfermos
Tasas de
Incidencia
Exposicion
a un factor
44 30 74 0.594 0.481
No Exposicion a un factor
6 47 53 0.113
Total 50 77 127
Tasas de
Exposic.
0.880 0.389
Diferencia 0.491
Finalmente realizamos la siguiente operación:
Diferencia x Diferencia x Total: 0.491 x 0.481 x 127: 29.99
El valor del Chi2, 29.99, es > a 18.83, por lo tanto: p < 0.001, siendo las diferencias estadísticas muy significativas (es decir que hay poca probabilidad que las diferencias se deban al azar, por lo tanto el Factor de Riesgo y el daño están asociados (Asociación Estadística).
Si dicha asociación no se debe a sesgos y si existe asociación temporal y plausibilidad biológica diremos que estamos en presencia de una Asociación Causal. Es decir que en este caso la intoxicación está causada por la ingestión de pastel contaminado con Salmonela (rechazamos hipótesis nula).
Si nuestro Chi2, por el contrario, hubiera arrojado como resultado 2.99, diríamos que no hallamos Asociación Estadística y por lo tanto no sería el pastel el causante de la intoxicación (aceptamos hipótesis nula).
Estimación en software EPIDAT: opción TABLAS. Tablas 2 x 2
Otras pruebas pueden ser aplicadas:

Prueba de contraste de hipótesis: se usa para determinar la probabilidad que una diferencia sea atribuible a un error de muestreo y no a diferencias poblacionales reales.
También puede ser utilizada para comparar los resultados hallados en un estudio transversal con una prevalencia poblacional conocida.
La fórmula utilizada es:
Z: ( x 1 – x 2) / (σ de x 2 / raíz cuadrada de n)
Estimación en software EPIDAT: opción MUESTRAS – Situación con una muestra
Pruebas t: especialmente aplicadas cuando las muestras son pequeñas.
Se construyen en forma similar a las pruebas Z, pero en este caso no conocemos el desvío estándar del universo, pero sí de la muestra.
La fórmula utilizada es:
t: ( x 1 – x 2) / (σ de x 1 x (raíz cuadrada de la suma de 1/ n 1 y 1/n 2)
Análisis multivariado
En los estudios de Casos y Controles, el proceso de análisis incluye una gran cantidad de tablas tetracóricas pues cada factor de riesgo es analizado en forma individual, además, si el análisis es efectuado en forma apareada pueden construirse muchas tablas para distintas combinaciones de variables. En cualquier caso, si la enfermedad es poco frecuente, los intervalos de confianza pueden resultar muy amplios y el valor de "p" poco significativo. Para superar estos problemas, como asimismo para ajustar los análisis a una visión de multicausalidad, se puede apelar a técnicas multivariadas que incluyen el análisis simultáneo de una gran cantidad de factores de riesgo.
Este tipo de análisis se ha generalizado con la disponibilidad de software estadísticos necesarios para su estimación. Los métodos incluyen modelos logísticos para variables discretas continuas y modelos logarítmicos lineales para variables discretas agrupadas.
3. DISEÑO DE ESTUDIOS DE CASOS Y CONTROLES
La estructura básica del diseño consiste en escoger un grupo de individuos que han presentan la enfermedad, a los que denominamos Casos (por ejemplo enfermos de

hidatidosis) y otro constituido por individuos que no presentan la enfermedad, a los que denominamos Controles y que serán utilizado como elemento de comparación.
Mediante el uso de cuestionarios, entrevista personal, análisis de historias clínicas u otra documentación escrita se establece la proporción de casos y de controles que estuvieron en contacto con cada uno de los Factores de Riesgo que suponemos (hipótesis de multicausalidad) favorecen la aparición de la enfermedad. Por ejemplo suponemos que la ocurrencia de casos de hidatidosis se ve favorecida por: tener alto número de perros, consumir agua no potable, consumir verduras crudas y tener nivel socioeconómico bajo.
El principal elemento a considerar para seleccionar los Casos es un criterio diagnóstico preciso para la definición de la enfermedad. Los criterios para la definición de Caso deben ser claros, específicos, reproducibles y deben minimizar errores diagnósticos (para evitar incluir como Caso a quien no lo es). Por ejemplo, para un estudio de Casos y Controles vinculado a Brucelosis humana, la definición de Caso puede ser exclusivamente "sintomatología clínica presente (definiendo con claridad los síntomas que se admitirán como necesarios para ser Caso)" o "sintomatología clínica presente con diagnóstico serológico positivo" o "sintomatología clínica presente con serología positiva y bacteriología positiva". De tal forma, a mayor especificidad del diagnóstico menor posibilidad de categorizar erróneamente al Caso, aunque esto tendrá como consecuencia una cierta pérdida de sensibilidad por lo que algunos Casos reales quedarán fuera de nuestro estudio (lo cual constituiría un problema si tenemos pocos Casos para nuestro estudio).
Los Casos pueden ser seleccionados de historias clínicas u otro sistema de registro o mediante encuestas en población aparentemente sana para detectar portadores no sintomáticos.
El principal elemento a considerar para la selección de los Controles, por su parte, es que a excepción de estar libres de la enfermedad tengan características similares a los Casos. Así, deben ser preferentemente equiparados en edad y sexo y en cualesquier otra característica que, de una forma u otra, pueda incidir en los resultados (nivel socioeconómico, hábitat, costumbres, etc). Es vital en el estudio la seguridad en que nuestros Controles estén efectivamente libres de la enfermedad.
Los Controles pueden ser extraídos de muy diversa manera, respetando el concepto de aleatorización.. Por ejemplo de un área geográfica determinada (vecinos de los Casos), de historias clínicas (consultantes por otra causa), etc.
Lo ideal es que el grupo de Controles constituya una muestra apareada, de forma tal de eliminar el mayor número posible de sesgos y asegurándose la comparabilidad de los resultados. Normalmente se seleccionan entre 1 y 4 Controles por Caso. Si la Asociación Causal es fuerte bastarán 1 o 2 Controles, pero si la Asociación Causal no es tan fuerte o el número de Casos es pequeño, podrían requerirse 3 o 4 Controles para que logremos una expresión estadística de la Asociación.

El tamaño óptimo de la muestra de un estudio de Casos y Controles implicará definir el nivel de significación (error de Tipo I aceptado), la potencia del test (error de Tipo II aceptado) y el valor del riesgo hipotético que esperamos sea capaz de detectar nuestro estudio.
Estimación en software EPIDAT: opción MUESTRAS – Estudio Casos y controles
Si se utilizan cuestionarios para determinar Factores de Riesgo estos deben ser de preguntas precisas, preferentemente cerrados y aplicados por la menor cantidad posible de entrevistadores, para evitar inducir respuestas al entrevistado.
Así, el diseño de estudios analíticos debe comprender un análisis detallado que posibilite disminuir sesgos de selección, sesgos de clasificación ("misclassification") y de la interferencia dada por la existencia de variables de confusión ("confounding").
Sesgo de selección: incluye la posibilidad que existan diferencias entre nuestra muestra de casos y controles y la población de la que se han extraído. Se cotrola mediante una correcta aleatorización en la selección de los individuos que participarán del estudio
Sesgo de clasificación: Ocurre cuando individuos sanos son clasificados como enfermos o cuando individuos enfermos son clasificados como sanos. Se controla utilizando pruebas diagnósticas sensibles y especificas.
Variables de confusión: son variables que está correlacionada con la enfermedad y con el factor de riesgo bajo estudio y que por ende pueden llevar a errores de interpretación, particularmente si su frecuencia es distinta en cada grupo. Por ejemplo, si se analiza para hidatidosis humana la variable no contar con agua potable, la misma está asociada a vivir en un medio rural, lo cual también es un factor de riesgo para hidatidosis. Se controlan mediante un procesamiento de datos apareados o mediante un análisis estratificado, o sea midiendo la fuerza de las asociaciones en categorías bien definidas de la variable de confusión.
Finalmente trasladaremos la información a la tabla tetracórica para estimar los OR, los IC95% y los valores de "p" para cada Factor de Riesgo a los efectos de determinar si, efectivamente, la exposición a cada factor genera mayor número de enfermos que la no exposición.
EJEMPLO 1: ESTUDIO DESCRIPTIVO PARA DETERMINAR LA HISTORIA NATURAL DE UNA ENFERMEDAD

Triquinosis: Historia natural en la localidad de Sierra Grande, Río Negro, Argentina
En el año 1984, la detección por parte del servicio veterinario de la Secretaría de Estado de Salud de la Provincia de canales de cerdo parasitadas y la identificación de criaderos locales de cerdos con fuerte proporción de animales portadores promovió la Resolución 2839/84 que declaró a la localidad de Sierra Grande como área de infección triquinósica grave y promovió la intervención del Servicio Nacional de Sanidad Animal para la adopción de medidas sanitarias para la erradicación de la enfermedad. Mas de 600 cerdos (100% de la población) fueron sacrificados en consecuencia, determinándose mediante triquinoscopía una tasa de prevalencia del 22%.
A partir de esa fecha se produce el paulatino repoblamiento de la población de cerdos.
En el año 2000, el hospital local notifica la ocurrencia de dos casos humanos, identificándose dos criaderos de cerdos involucrados en el brote. Autoridades del Servicio Nacional de Sanidad Animal proceden a la faena compulsiva de la totalidad de los cerdos de ambos propietarios, determinándose mediante la técnica de digestión de larvas una tasa de prevalencia del 10 %.
A partir de este hecho se diseña el presente estudio conjunto entre la Secretaría de Estado de Salud de la Provincia de Río Negro y el Instituto Nacional de Microbiología "Carlos Malbrán" para conocer la historia natural de la triquinosis en un área endémica con producción porcina en condiciones de economía de subsistencia, durante el período 2000-2002.
Se diseñó una encuesta para el relevamiento inicial del stock porcino y de las características de los criaderos de la localidad, procediéndose a la identificación de los animales mayores de 6 meses de edad con caravanas numeradas colocadas en la oreja izquierda. Posteriormente se mantuvo un sistema de monitoreo para la actualización de la información y la identificación de los animales ingresados o egresados del sistema
Inmunodiagnóstico en cerdos vivos:
Se obtuvieron muestras de sangre de cerdos vivos mayores de seis meses mediante corte en la vena caudal central; se separó el suero mediante centrifugación y se mantuvo en heladera hasta su remisión al laboratorio de parasitología ANLIS Malbrán.
Las muestras fueron procesadas mediante enzimoinmunoenzayo (EIE), Todo suero con un título menor a 3 D.E. (desvío estándar) fue considerado no reactivo, lo que presentaron títulos superiores a 4 D.E. fueron clasificados como reactivo a trichinella sp. Finalmente, los sueros con títulos entre 3 y 4 D.E. fueron confirmados mediante westerblot (WB).

En el año 2002 se efectúa el control serológico de los cerdos originalmente no reactivos que permanecían en condiciones de producción y de 2 cerdos reactivos mantenidos inmovilizados en poder de sus propietarios.
Estudios parasitológicos en cerdos faenados:
Todo cerdo faenado para consumo se analizó mediante la técnica de digestión de larvas, procesándose 10 grs de muestra obtenida de la porción muscular del diafragma. Los análisis fueron efectuados en el Hospital local, remitiéndose a partir del 2001 muestras de casos positivos al Laboratorio de Parasitología ANLIS MALBRAN para confirmación diagnóstica y tipificación de cepas.
Determinación de la densidad poblacional de roedores y estimación de la carga parasitaria
Se procedió a la captura de roedores mediante la colocación de trampas de captura viva tipo Sherman. Se colocaron en total 1102 trampas/noche distribuidas en líneas representativas de distintos estratos herbáceos e instalaciones de criaderos. 661 trampas/noche se colocaron en criaderos de cerdos y 441 trampas/noche en el basurero municipal.
Los animales capturados fueron procesados mediante la técnica de digestión de larvas, procediéndose al procesado de la carcasa completa del animal.
Los resultados incluyeron:
Relevamiento de la población porcina:
El primer relevamiento, efectuado en consonancia con el hallazgo de cerdos con triquinosis, mostró 27 criaderos con un total de 287 animales, de los cuales 182 (63.4%) eran lechones y 105 (36.6) eran animales de mas de 6 meses de edad (promedio 3.2 madres por criadero).
Luego del primer relevamiento se establecieron 5 nuevos criaderos, mientras que 6 abandonaron la producción de cerdos.
De los 32 criaderos, 2 (6.2%) se ubicaban en el radio urbano, 26 (81.3%) en la periferia de la ciudad a una distancia de entre 100 y 1000 mts del área urbana y 4 (12.5%) en establecimientos ganaderos dedicados a la producción extensiva de lanares o bovinos a una distancia de entre 5 y 20 kms del área urbana.
Determinación de la prevalencia de infección en cerdos:
Se evaluaron inicialmente 95 (90.5%) animales vivos mayores de seis meses presentando 27 (28.4% IC95% 19.8-38.7) anticuerpos contra trichinella sp, de los cuales 18 (66.7%) fueron reactivos a EIE mientras que 9 (33.4%) presentaron a la EIE títulos entre 3 y 4 DE y fueron confirmados por WB.

En el año 2001 se evaluaron 44 animales ingresados a producción presentando 4 (9.1% IC95% 2.9-22.5) anticuerpos anti-trichinella sp a la prueba de EIE. En el año 2002, finalmente, se evaluaron 42 animales ingresados a producción presentando 5 (11.9% IC 95% 4.4-26.4) anticuerpos anti-trichinella sp de los cuales 3 (60%) fueron reactivos a la prueba de EIE y 2 (40%) presentaron a la EIE títulos entre 3 y 4 DE y fueron confirmados por WB.
En total se evaluaron 181 cerdos presentando 36 (19.9% IC 95% 14.4-26.6) anticuerpos contra trichinella sp .
En función de la edad, resultaron reactivos el 16.1% de los animales de hasta 1 año de edad, el 18.4% de los animales de 2 a 3 años y el 27.3% de los animales mayores de 3 años de edad, resultando las diferencias estadísticamente significativas (Chi de tendencia p < 0.01); mientras que en relación al sexo, no se observaron diferencias significativas (chi de mantel p < 0.05) entre hembras (21.8% de reactivos) y machos (22.2% de reactivos)
En el año 2002 se efectuaron, asimismo, 35 controles serológicos a cerdos originalmente no reactivos, de los cuales 32 (91.4%) se mantuvieron no reactivos, mientras que 3 (8.6%) pasaron a ser reactivos a EIE o WB. Se controlaron asimismo 2 cerdos originalmente reactivos, los cuales mantuvieron títulos anti-Trichinella sp durante 18 y 23 meses respectivamente
De los 32 criaderos en 15 (46.9%) se detectaron animales reactivos, de los cuales 14 correspondieron a los criaderos ubicados en el área urbana o periurbana (50% de los criaderos existentes) y 1 a los ubicados en el área rural (25% de los existentes), resultando las diferencias. (chi de mantel p < 0.05).
Estudios parasitológicos en cerdos faenados
Durante el año 2000, antes del inicio de los estudios serológicos, se estudiaron por digestión de larvas 55 animales, encontrándose en 4 (7.3%) larvas de Trichinella sp.
Durante el año 2001, por su parte, se efectuaron 105 análisis, hallándose larvas de Trichinella sp en 5 (4.8%). De estos, 23 correspondían a cerdos mayores de seis meses previamente controlados por serología, encontrándose en 3 (13%) larvas de Trichinella sp y 82 a lechones menores de 6 meses, encontrándose en 2 (2.4%) larvas de Trichinella sp.
Los 3 cerdos adultos positivos a digestión de larvas eran reactivos a EIE, mientras que los 20 negativos a la digestión de larvas eran no reactivos. La sensibilidad, especificidad y valor predictivo de EIE resultó del 100%.
Determinación de la prevalencia de infección en roedores:
Se capturaron un total de 26 roedores con 1102 trampas/noche (éxito de trampeo 2.7%). En el basurero municipal el éxito de trampeo resultó del 1.6%, mientras que en criaderos de cerdos el éxito de trampeo alcanzó al 2.9%.

En los dos criaderos erradicados por SENASA por estar asociados a casos de triquinosis humana, el éxito de trampeo resultó del 5.7%, mientras que en los restantes criaderos resultó del 2.3%
De los 26 roedores capturados, 4 resultaron positivos a la digestión de larvas (15.4% IC95% 5.0-35.7), de los cuales 3 de 4 (42.8%) correspondieron a las capturadas en el basural y 1 de 4 (5.3%) a los capturadas en criaderos de cerdos.
EJEMPLO 2: ESTUDIO EPIDEMIOLOGICO DESCRIPTIVO PARA ESTABLECER UNA LINEA BASE PARA UN PROGRAMA DE CONTROL
En la Argentina, la Echinococcosis quística se extiende sobre casi todo el territorio configurando la característica epidemiológica de endemia. Las mayores frecuencias de parasitación se presentan en patagonia.
Para los programas vigentes la identificación de los peros parasitados es una actividad sustantiva sobre la que descansa la estrategia actual de control y vigilancia. La identificación de la infección en el ovino, por su parte, define la evolución de la infección en el tiempo.
Hasta los últimos años, la técnica para la identificación de perros parasitados con Echinococcus granulosus era el uso del tenífugo bromhidrato de arecolina, prueba de sensibilidad limitada (70%, Schantz P. 1973), riesgosa en términos de bioseguridad, y costosa en términos de cantidad de personal necesario para su ejecución.
En el año 1993 Allan y col emplearon un método inmunológico capaz de revelar perros infectados con Eg aplicando un test de ELISA de captura para detectar antígenos género específicos en las heces de perros recién emitidas.
Guarnera y col plantearon en el año 2000 que el reemplazo de heces recién emitidas por heces antiguas como substrato no disminuye la sensibilidad de las pruebas diagnósticas, pudiéndose trasladar la unidad de observación perro a unidades de observación catastrales de mayor valor de interpretación epidemiológica, resultando la técnica con una sensibilidad del 80% y una especificidad del 95%.
Así, se planteó como objetivo conocer la prevalencia y distribución de la infección en perros de las Provincias Patagónicas mediante la evaluación de antígenos de cepas locales de Echinococcus granulosus del ciclo perro-ovino-perro mediante el uso de una prueba tamiz (elisa-coproantígenos) y una pruebas de confirmación (westernblot) en heces antiguas caninas.

Los resultados hallados constituirían la línea base (Unidad de observación perro: porcentaje de muestras positivas; Unidad de observación catastral: porcentaje de establecimientos ganaderos infectados) sobre los cuales medir la evolución de la infección en los años siguientes.
El tamaño de la muestra se estimó con una prevalencia esperada del 10%, un nivel de confianza del 95% y un margen de error del 20%, resultando un "n" de 775 establecimientos ganaderos a muestrearse.
Para la selección de los establecimientos, se estratificó un "n" por Provincia, asignando una proporción de campos similar a la proporción sobre los establecimientos totales existentes (por ejemplo, existiendo un total de 7534 establecimientos en la patagonia, según la base de datos del Servicio Nacional de Sanidad Animal, a la Provincia de Neuquen corresponden 821 (10.9%). En función de ello se asignan a Neuquen el 10.9% de los 775 Establecimientos: 77.5 establecimientos..
Para la selección individual, se obtuvieron mapas catastrales numerándose en el mapa los establecimientos ganaderos. Todos los números fueron introducidos en una caja sorteándose aleatoriamente 76 establecimientos ganaderos. Se estableció, dadas las dificultades geográficas y costos de traslado, que ante la imposibilidad de acceder a un establecimiento ganadero se procediera a muestrear el inmediato a la derecha.
Para determinar el número de muestras se estandarizó su obtención: 1 a 3 muestras de materia fecal del piso del "Centro de manejo del Establecimiento" y, para establecimientos que corresponda por tamaño, 1 pool extra cada 4 Puestos del Establecimiento ganadero (entendiendo por Puesto al que tiene personal fijo con vivienda).
Se elaboró un cuestionario cerrado para obtener información de ciertas variables, tal como número de ovinos en el predio, número de perros y superficie.
Finalmente se estandarizó el sistema de recolección: Por ejemplo muestras de materia fecal de perros recién emitidas o secas (pero emitidas lo más recientemente posible), tomada cada muestra se tomará individual, es decir, en cada frasco colocar sólo una deposición, Colocando cada muestra en un frasco de plástico, de boca ancha y con cierre hermético (tipo recolector de muestras biológicas, capacidad 120 cc), etc.
Por ejemplo para la Provincia de Río Negro se detactaron un 6% de muestras positivas y un 10% de establecimientos ganaderos infectados, cifras que para Tierra del Fuego resultaron del 1% de muestras positivas y del 4% de establecimientos ganaderos.
EJEMPLO 3: DISEÑO DE UN ESTUDIO DE CASOS Y CONTROLES

La Provincia de Río Negro, Argentina presenta niveles de hidatidosis humana, sumamente elevados, por ejemplo la tasa de casos humanos sintomáticos alcanzaba valores de 77 x 100000 en población general y del 50 x 100000 en población de 0 a 10 años. Sin embargo las tasas de prevalencia en niños de 7 a 13 años de edad, no sintomáticos, alcanzaban el 5.6 x 100, determinado mediante encuestas poblacionales con ultrasonografía, transformando a las actividades de diagnóstico, tratamiento y control de esta enfermedad en una de las prioridades de su sistema oficial de salud.
En función de ello, en el período 1980/1998 se desarrollaron actividades sistemáticas de control basadas en la desparasitación de perros con Praziquantel.
Para 1998, las encuestas ultrasonográficas mostraban en niños de 7 a 13 años de edad una tasa de prevalencia de1.1 x 100 resultando las diferencias al comienzo y al final del programa estadísticamente significativas (p = 0.0004)
Se llevó a cabo un estudio de casos y controles a fin de investigar y evaluar en la Provincia de Río Negro los factores de riesgo asociados a la transmisión de la hidatidosis que aún generan presencia de portadores de quistes hidatídicos en el hombre, en particular en jóvenes de edad escolar, y determinar posibles fallas en las estrategias de control desarrolladas a los efectos de ajustar las actividades del programa.
Definición y selección de casos:
Se efectuó una encuesta poblacional con ultrasonografía abdominal que abarcó la totalidad de la población escolar concurrente a las 12 escuelas urbanas y rurales ubicadas en el área de trabajo, previo consentimiento de los padres.
Se consideraron como criterios de positividad para hidatidosis a las siguientes imágenes ultrasonográficas: vesículas aisladas, vesículas hijas múltiples, observación del "nevado" dado por la movilización de la arenilla hidatídica al movilizar bruscamente al paciente 180 grados, aparición de membranas desprendidas, espesor de la pared del quiste.
Los portadores de imágenes ultrasonográficas compatibles con hidatidosis, fueron clasificados como casos presuntivos y trasladados a un centro especializado de diagnóstico por imágenes, siendo examinados por ultrasonografía abdominal, radiografía de pulmón y tomografía axial computarizada. Se incluyó, asimismo, un control serológico mediante enzmoinmunoensayo. Fueron clasificados como "caso" todos los portadores de imágenes compatibles con hidatidosis confirmados mediante la segunda ultrasonografía y la tomografía..
Definición y selección de controles:
Fueron elegidos aleatoriamente entre los que resultaron negativos a la encuesta ultrasonografica, siendo seleccionados consecutivamente de los listados oficiales de

alumnos del Ministerio de Educación, de forma tal de mantener similar proporción que los "casos" para las variables edad, sexo y escuela de procedencia. Se seleccionaron tres controles por cada caso. Para asegurar su condición de control sano (no hidatídico) fueron derivados al mismo centro especializado de diagnóstico por imágenes para ser examinados por ultrasonografía abdominal y radiología de pulmón y, en casos de duda, por tomografía axial computarizada. Se incluyó, asimismo, un control serológico mediante enizoinmunoensayo. Fueron considerado como "control" los que resultaron negativos a todas las pruebas diagnósticas efectuadas.
Tanto los casos como los controles carecían de sintomatología clínica compatible con hidatidosis.
Recolección de datos:
Los casos y los controles seleccionados fueron visitados por un único agente encuestador entrenado. En todos los casos se procedió a determinar un informante clave (madre, madre de crianza, abuela, etc.) en condiciones de responder un cuestionario estandarizado que incluyó la evaluación de factores de riesgo vinculados a:
El núcleo familiar:
Antecedentes familiares de hidatidosis (casos de hidatidosis ocurridos en la familia); condición socioeconómica (clasificándose como condición socioeconómica baja a las familias que reciben asistencia social y alimentaria del Estado); nivel educativo paterno; prácticas vinculadas al trabajo paterno (asociación con producción ovina) y a la costumbre de faenar ovejas para consumo familiar.
Relación del niño y del núcleo familiar con el huésped definitivo (perro):
Prácticas vinculadas a la tenencia del perro (accesibilidad del perro al domicilio); alimentación del perro (uso y destino de vísceras ovinas en la matanza domiciliaria) y forma de vinculación con el perro (juegos del niño con su perro o con perros de terceras personas), incluyendo el tipo de relación del perro con el medio rural (medido en promedio de días en los que el perro es trasladado a ámbitos rurales).
Relación del niño y del núcleo familiar con el ambiente:
Relación del niño con el medio rural (medido en términos de períodos de tiempo en que el niño vive o concurre al medio rural); prácticas relacionadas al consumo de verduras (verduras provenientes de huerta personal); higiene personal y características del abastecimiento de agua.
Relación del núcleo familiar con el programa de control:
Vinculación con el programa de control (medido en términos de recepción de la asistencia brindada por los agentes sanitarios del Estado responsables de la desparasitación del perro)

y cumplimiento de sus actividades (incluyendo aspectos de la forma de desparasitación del perro y a la dosis de antiparasitario aplicada al perro en función de su tamaño o peso).
Se procuró, asimismo, obtener información sobre infección por Echinococcus granulosus en perros del domicilio del niño o de los parajes rurales visitados regularmente por el niño, definidos como áreas de riesgo de infección. Se determinó mediante visualización de parásitos adultos mediante el uso de bromidrato de arecolina (4) ó mediante la detección de antígenos en materia fecal canina.
Analisis de datos:
Se inició el análisis utilizando métodos estadísticos descriptivos (frecuencias, media, mediana, histogramas. Para las variables continuas y categóricas también se calculo Chi cuadrado de tendencias. Posteriormente se realizó la estimación de odds ratio, riesgo atribuible poblacional y análisis por el método de Manzel-Haenzel para Chi cuadrado. Todas aquellas variables que arrojaron en el análisis univariado un OR > 3 o tuvieron un p > 0.25 fueron incluidas en un análisis multivariado, mientras que aquellas variables con p >/= 0.1 fueron removidas.
Resultados:
Se evaluaron mediante ultrasonografía abdominal 1070 (100%) de los escolares de 7 a 14 años concurrentes a escuelas urbanas y rurales de Ingeniero Jacobacci, 28 escolares fueron clasificados como "caso presuntivo" y derivados para su reexaminación. 24 (85.7%) fueron confirmados como "caso".
Se seleccionaron 72 probables controles, de los cuales 66 (91.6%), fueron reexaminados y confirmados como control
El 40% de la población seleccionada correspondió al sexo femenino y el 60% al sexo masculino. En relación a la edad, el 6% pertenecía al grupo 5-7 años, el 31% al grupo 8-10 años, el 31% al grupo 11 a 13 años y el 32% al grupo 14-16 años. En relación al desarrollo físico de los niños estudiados, no se hallaron diferencias entre la talla y el peso de los casos y los controles (P: 0.16 para talla y P: 0.29 para peso)
El promedio del numero de habitantes del domicilio entre los casos fue 5.7 y 5.9 en el grupo control, siendo esta diferencias no significativas (P: 0.35).
El número de animales en la familia, por su parte, mostró en los controles un promedio de 1.5 perros en el domicilio 10 años atrás, 1.2 perros actuales y 122.6 ovinos propiedad del padre, mientras en los controles los promedios resultaron de 2.8, 2.7 y 204.1 respectivamente, resultando en todos los casos las diferencias estadísticamente significativas (P: 0.001, P: 0.00, P: 0.02).
El 13% de las muestras de materia fecal canina analizadas resultaron positivas a Echinococcus granulosus.

Los resultados del análisis univariado muestran como principales factores de riesgo para contraer hidatidosis a:
El núcleo familiar: trabajo paterno vinculado al medio rural (OR: 3.4) y ser propietario de ovinos (OR: 3.8) o de caprinos (OR:3). En ambos casos las diferencias entre casos y controles son estadísticamente significativas (p < 0.05). No se pudieron demostrar como factores de riesgo condición social y educación paterna. Tener familiares con hidatidosis, presentó un OR de 2.5 con un valor de "p" cercano al valor de corte (P:0.055) y un límite inferior del intervalo de confianza menor a 1.
El perro: tenencia actual de un número elevado de perros. (OR: 12.8) incluyendo una tendencia signbificativa al aumento del riesgo en función del aumento del número de perros (p < 0.05), tenencia en los primeros años de vida de un elevado número de perros (OR: 20.8), tenencia de perros que van al campo (OR: 7.1), tenencia de perros alimentados con vísceras ovinas (OR: 3.5). En los cuatro casos con una p < 0.05. El contacto actual con perros portadores de Echinococcus granulosus
El ambiente: vivir en el medio rural desde el nacimiento hasta los 5 años de edad (OR: 4) o desde los 5 a los 10 años (OR: 2.8). En ambos casos con una p < 0.05. No se pudo demostrar como factor de riesgo el consumo de verduras. La faena de ovinos en el domicilio, presentó un OR elevado (3.2) resultando las diferencias entre casos y controles muy cercanas al valor de corte (P: 0.051) aunque presenta el IC inferior por debajo de 1. Como factor de protección se determinó la presencia domiciliaria de agua potable (OR: 0.1), resultando la diferencia entre casos y controles estadísticamente significativa (P: 0.00)
presentó un OR elevado (OR: 12, p < 0.05), aunque con el límite inferior del intervalo de confianza menor a 1, probablemente por el pequeño número de perros evaluados ante la imposibilidad de obtener mayor número de muestras. No se pudo demostrar como factor de riesgo los hábitos de tenencia del perro (a excepción de permitir al perro dormir en la cama con el niño, que presenta un OR de 3.5 pero con una p > a 0.05)
El programa de control: En relación a la evaluación del impacto y de las fallas del programa de control, la desparasitación de perros con dosis menores a la indicada en función del peso del animal presenta características especiales: OR elevado (2.6), un valor de "p" cercano al límite de significación (P: 0.08) pero un límite inferior del IC menor a 1. La organización del programa de control y de los servicios de salud (visita domiciliaria de agentes sanitarios), demostraron que la presencia de estos y la desparasitación por ellos efectuada actúa como factor de protección (OR < 1). Debe señalarse la existencia de una baja proporción de agentes sanitarios (13%) en los domicilios de los casos.
La determinación del riesgo atribuible presentó como valores mas elevados a contacto con perros con echinococcosis (0.77), presencia de los perros en el medio rural (0.54) y fuente de agua no potable (0.50).
El análisis multivariado en el modelo de regresión logística condicional confirmó al número de perros en los primeros años de vida del niño como uno de los principales factores de riesgo (OR: 2.6), incorporando a tener familiares con hidatidosis como un factor de riesgo

primordial (OR:4.7). La fuente de agua potable, asimismo, se confirma como factor absoluto de protección (OR:0.17)