manaŽerskÁ informatika - files.vsrr.webnode.czfiles.vsrr.webnode.cz/200000019-d2a71d3a11/so -...
TRANSCRIPT

1
Evropský sociální fond
Praha & EU: Investujeme do vaší budoucnosti
VYSOKÁ ŠKOLA REGIONÁLNÍHO ROZVOJE PRAHA
MANAŽERSKÁ INFORMATIKA
Ing. Josef Brzák, CSc
PRAHA 2012

2
Název: Manažerská informatika
Autor: Ing. Josef Brzák, CSc
Počet stran: 148
Studijní opory určené pro studenty kombinované formy studia
Studijní program Regionální rozvoj, obor Management a regionální rozvoj
Studijní opory byly zpracovány v rámci Inovace bakalářského studijního programu v kontextu
Boloňského procesu s důrazem na výsledky učení
OPERAČNÍ PROGRAM Praha Adaptabilita registrační číslo CZ.2.17/3.1.00/32599
Tato publikace neprošla redakční jazykovou úpravou
Vydala v elektronické podobě Vysoká škola regionálního rozvoje Praha
Žalanského 68/54
16300 Praha 17
e-mail: [email protected]
Praha 2012

3
Obsah
Titulní strana .....................................................................................................................................................11
1. Úvod do předmětu ........................................................................................................................................... 8
1.1. Informatika ........................................................................................................................................... 8
1.2. Informační systémy .............................................................................................................................. 9
1.3. Informatika a Manažerská informatika ...............................................................................................10
2. Základní pojmy teorie informace ..................................................................................................................15
2.1. Podstata a pojem informace ...............................................................................................................15
2.2. Charakteristické znaky informace .......................................................................................................16
2.3. Sémiotické pojetí informace ................................................................................................................16
2.4. Pojem entropie ....................................................................................................................................18
2.5. Omezení kvantitativního přístupu k informacím .................................................................................20
2.6. Kvalitativní pojetí informace ..............................................................................................................21
3. Počítačové sítě .................................................................................................................................................27
3.1. Pojem počítačová síť, typologie počítačových sítí ..............................................................................27
3.2. Základní druhy přenosů ......................................................................................................................31
3.3. Zabezpečení dat ..................................................................................................................................32
3.4. Protokol ..............................................................................................................................................32
3.5. IP adresa .............................................................................................................................................34
3.6. Adresa v síti Internet ...........................................................................................................................35
4. Informační systémy, charakteristiky, projektování provoz a údržba........................................................40
4.1. Charakteristika informačního systému ...............................................................................................40
4.2. Druhy informačních systémů ..............................................................................................................41
4.3. Význam a způsoby budování informačních systémů............................................................................42
4.4. Projektování, provoz a údržba informačních systémů ........................................................................43
4.5. Etapy životního cyklu informačního systému ......................................................................................43
4.6. Typy životních cyklů vývoje systému ...................................................................................................44
4.7. Obecné, správní a policejní informační systémy .................................................................................45
5. Databáze ..........................................................................................................................................................52

4
5.1. Typy databází ......................................................................................................................................52
5.1.1. Souborové databáze........................................................................................................................52
5.1.2. Hierarchické databáze ....................................................................................................................53
5.1.3. Databáze objektové ........................................................................................................................53
5.1.4. Síťové databáze ..............................................................................................................................53
5.1.5. Relační databáze .............................................................................................................................53
5.2. Tabulkové vyjádření relace a její vlastnosti. .......................................................................................54
5.3. Indexování dat .....................................................................................................................................55
5.4. Redundance dat ...................................................................................................................................55
5.5. Systémy řízení báze dat .......................................................................................................................56
5.5.1. Centralizované databáze .................................................................................................................57
5.5.2. Systémy na sítích osobních počítačů. .............................................................................................58
5.5.3. Databáze v lokální síti PC (File server). .........................................................................................59
5.5.4. Databázové systémy klient/server ..................................................................................................60
5.5.5. Systémy distribuovaného zpracování .............................................................................................61
5.6. Sdílený přístup k datům. ......................................................................................................................62
6. Datové sklady – budování a způsoby práce ..................................................................................................69
6.1. Data v datovém skladu ........................................................................................................................69
6.2. Budování datového skladu ..................................................................................................................70
6.3. Datové sklady a OLAP ........................................................................................................................72
6.4. Struktura datového skladu ..................................................................................................................73
6.5. Funkce datového skladu ......................................................................................................................76
6.6. Plnění datového skladu .......................................................................................................................77
6.7. Datové kostky ......................................................................................................................................77
6.8. Datové sklady nejen pro vrcholový management ................................................................................78
7. Dobývání dat z databází (data mining) .........................................................................................................83
7.1. Data mining ........................................................................................................................................83
7.2. Datová pumpa jako nástroj pro Data mining .....................................................................................84
7.3. Postup při dolování dat .......................................................................................................................85
7.4. Metody dobývání dat ...........................................................................................................................88
7.5. Informační analýza .............................................................................................................................90
7.6. Použití technik dobývání dat ...............................................................................................................91

5
7.7. Softwarové produkty pro dobývání dat ...............................................................................................93
7.8. Dolování dat a datové sklady ..............................................................................................................94
7.9. Potenciální nebezpečí DM ..................................................................................................................95
8. Zálohování a archivace dat v IS ..................................................................................................................101
8.1. Zálohování dat v IS ...........................................................................................................................101
8.2. Zálohování dat ..................................................................................................................................102
8.3. Způsoby zálohování dat ....................................................................................................................103
8.4. Strategie zálohování dat....................................................................................................................105
8.5. Archivace dat v informačních systémech ..........................................................................................110
8.5.1. Dlouhodobá archivace dat ............................................................................................................111
8.5.2. Kriteria pro archivování dat .........................................................................................................112
8.5.3. Životnost archivovaných dat ........................................................................................................113
8.5.4. Přístup k archivovaným datům .....................................................................................................114
9. Bezpečnost IS a počítačová kriminalita ......................................................................................................122
9.1. Úvod ..................................................................................................................................................122
9.2. Druhy škod a jejich ohodnocování ....................................................................................................124
9.3. Základní pojmy ochrany dat a informací ..........................................................................................125
9.3.1. Informační rizika ..........................................................................................................................125
9.3.2. Bezpečnostní incident ..................................................................................................................126
9.3.3. Klasifikace rizik ...........................................................................................................................127
9.3.4. Cesty k minimalizaci rizika a výskytu incidentů ..........................................................................128
9.4. Způsoby ztrát, úniků důležitých informací a jejich získávání pachateli ...........................................128
9.4.1. Cesty a způsoby úniku informací .................................................................................................129
9.4.2. Využití technických prostředků k získávání informací ................................................................130
9.4.3. Úniky a ztráty v automatizovaných informačních systémech ......................................................131
9.5. Počítačová kriminalita ......................................................................................................................133
9.6. Rozdělení počítačové kriminality ......................................................................................................134
9.7. Software (počítačové programy) .......................................................................................................136
9.8. Typy pachatelů ..................................................................................................................................136
9.9. Boj proti počítačové kriminalitě........................................................................................................137
10. Informace a právo v současné Evropě ........................................................................................................142
11. Literatura. .....................................................................................................................................................146

6
PRŮVODCE STUDIJNÍ OPOROU
Studijní opora Manažerská informatika je určena studentům studijního oboru
Management a regionální rozvoj, kteří studují v kombinované formě studia. Kombinovaná
forma studia předpokládá zvládnutí části předmětu formou samostudia. Z těchto důvodů tato
forma studia vyžaduje přípravu speciálních studijních textů a dalších studijních pomůcek.
Předložená opora nahrazuje přímou výuku vybraných častí kurzu. Obsahuje kontrolní
otázky, klíčová slova k zapamatování, kontrolní otázky za každou kapitolou a stručné shrnutí
textu jednotlivých částí studijních opor. Otázky v závěru kapitol mají kontrolní funkci
vzhledem k pochopení textu a jsou zároveň přípravou na zkoušku. Oporu si lze průběžně
doplňovat na základě vlastního studia doporučené literatury, osvojených znalostí z
předchozího studia, stáží, studijních pobytů, neformálního studia, pracovních zkušeností s
cílem vytvořit si vlastní studijní materiál.
Studijní texty jsou členěny do 9 kapitol, které pokrývají oblasti vztahující se
k základům Manažerské informatiky. Cílem textů je osvojit si základní informace
k hlubšímu studiu. Předmět seznamuje studenty se základními pojmy v interdisciplinárním
oboru informatika a její úlohou v managementu, učí je teorii i praxi uplatnění moderních
informačních technologií při budování a provozu informačních systémů.
V úvodní kapitole jsou stručně popsány základní terminologické pojmy, Informatika,
Informační systémy, Manažerská informatika a Výpočetní technika
Druhá kapitola se zabývá základními pojmy z teorie informace jako jsou Podstata a
pojem informace, Charakteristické znaky informace, Sémiotické pojetí informace,
Kvantitativní a kvalitativní pojetí informace, Sociální informace.
Třetí kapitola je věnována problematice počítačových sítí, kde jsou stručně popsány
základní pojmy a rozdělení počítačových sítí, základní formy přenosů, zabezpečení dat,.
hardware počítačových sítí a aktivní prvky počítačových sítí, síťové technologie, protokoly,
internetovské služby
Čtvrtá kapitola se zabývá širší problematikou Informačních systémů a jejich vztahem
ke struktuře a procesu managementu. Tvorba a budování struktury informačních systémů za
využívání moderních informačních technologií. Životní cyklus informačních systémů,
efektivnost inovací. Zdroje informací, přenosové kanály, uživatelé veřejné správy s důrazem

7
na vyšší management. Informační proces s důrazem na analyzování informací pro
rozhodování managementu státní správy, měst a významných obcí.
V páté kapitole jsou stručně popsány Databázové systémy, Historie vývoje databází,
Datové modely od souborových architektur až po současné nejrozšířenější relační a dále
Systémy řízení báze dat od centralizovaného zpracování po distribuované systémy na sítích
počítačů
Šestá kapitola se zabývá rozsáhlou problematikou datových skladů, popisuje jejich
typickou strukturu a její návrh,Analýzu požadovaných funkcí, Přístupová práva, Budování
datového skladu, popisuje vztah analytického procesu vzhledem k obsahu skladu, Formu
uspořádání dat, a vazbu skladu na management
Sedmá kapitola je věnována nejvýznamnější funkci datového skladu dolování dat,
Formalizovaným postupům, metodám a informační analýze používaných při dolování dat.
Dále jsou stručně popsány dva softwarové produkty nejčastěji užívané dolování dat.
Osmá kapitola je věnována základům velmi důležité činnosti zálohování a archivace
dat v IS, jsou popsány nejčastější příčiny ztráty dat, způsoby zálohování a strategie
zálohování. V druhé části je vysvětlen pojem archivace dat a rozdíly mezi archivací a
zálohováním.
Devátá kapitola je věnována Informační bezpečnosti a kybernetické kriminalitě. Jsou
popsány základní pojmy ochrany dat a informací, jaká jsou informační rizika, nejčastější
bezpečnostní incidenty s krátkou klasifikací rizik a možnými cestami k jejich minimalizaci.
Způsoby ztrát, úniků informací a jejich získávání pachateli,Využití technických prostředků
k získávání informací z automatizovaných IS. Poslední část se zabývá Počítačovou
kriminalitou, její historií a důvody vzniku.
V desáté kapitole jsou uvedeny základní právní předpisy a nařízení platné v současné
době týkající se práce s informacemi.
Obsah opory je do jisté míry kompilací názorů různých autorů, včetně jejich
sestavitele, text je třeba přijímat jako souhrn poznatků a doplňovat si jejich tvrzení
aktuálními názory. Snahou autora bylo dosažení pokud možno stručné úrovně této rozsáhlé
problematiky a přizpůsobení skutečnosti, že většina studentů kombinované formy studia má
vlastní zkušenosti z pracovního či služebního zařazení.
Leden 2012 Ing Josef Brzák, CSc

8
1. Úvod do předmětu
1.1. Informatika
Vědní obor zabývající se strukturou, vlastnostmi (ne obsahem) technologií zpracování
informací, které podporují lidské znalosti (vědění) a komunikaci.
Předmětem informatiky je nalézání obecných zákonitostí vytváření informace, její
transformace, přenos a využívání v příslušných činnostech člověka. Studuje zákonitosti,
teorie, metody a organizace práce s informacemi. Zajímá ji významová stránka a nehodnotí
informace kvalitativně na rozdíl od teorie informace. Využívá se jí v počítačové vědě (ta se
zabývá zpracováním dat), což často vede k tomu, že je mylně chápána či dokonce
ztotožňována jako pouhé počítačové zpracovávání dat.
Cílem informatiky je propracovat optimální způsoby a prostředky pro zobrazení,
shromažďování, analytické a syntetické zpracování, ukládání, vyhledávání a rozšiřování
informací. Proto jsou základním nástrojem v informatice počítače, přenosová technika a
počítači řízená technika (informační a komunikační technologie). Informatika navazuje na
kybernetiku, dříve mnohem populárnější
Obecně se informatika dělí na:
teoretickou - sem patří teorie informace, teorie automatů, numerická
analýza, metodologie zpracování dat, organizace informačních procesů
systémovou - architektura počítačů, informačních systémů, sítí apod.,
technologickou - zabývá se naukou o materiálech, využitelných pro výrobu
součástí počítačů (paměti, polovodiče apod.),
aplikovanou - zahrnuje všechny oblasti praktického využití ICT a
automatizovaného zpracování informací. a využívání dat
Počátky informatiky sahají do r. 1966, kdy dostala své jméno ve Francii (informace +
automatika), ale svůj zrod má v USA. Formulovala se jako protipól k empirickému přístupu
řešení přechodu od mechanizace k automatizaci při zpracovávání informací. Je tedy vědou
interdisciplinární. Lze říci že Informatika je věda, zkoumající zpracovávání a komunikaci
informací ve společnosti, operace s informacemi pomocí soudobé výpočetní a přenosové
techniky a odpovídající metody.
Pojem informace je však nejobecnější kategorií vědy a k jejímu zkoumání přistupuje každý
vědní obor svým zvláštním způsobem. Stejně tak existují různé definice informace,

9
v závislosti na jejím odlišném pojetí. Z laického pohledu je informace sdělením či zprávou.
Z filozofického hlediska je vlastností hmotné reality být uspořádán a její schopnost
uspořádávat. Často uváděnou je definice z pohledu kybernetiky, od jejího zakladatele N.
Wienera: “Informace je obsah toho, co se vymění s vnějším světem, když se mu
přizpůsobujeme a působíme na něj svým přizpůsobováním“. Výkladový slovník výpočetní
techniky uvádí velmi stručnou definici :“Informace je význam, který člověk přisuzuje
údajům.“ (ČSN 36 9001/I-1987).
„Informace je poznatek týkající se jakýchkoli objektů, např. fakt, událostí, věcí,
procesů nebo myšlenek, včetně pojmů, který má v daném kontextu smysl“. (ČSN ISO/IEC
2382-1). Podle P. F. Druckera : „Informace jsou data, obohacená o relevantnost a účelnost,
přeměna dat v informace tudíž vyžaduje znalost“.
Tak by bylo možno uvést ještě řadu dalších definic, jak již z výše uvedených hledisek,
tak např. z oblasti lingvistiky, matematiky, estetiky, teorie poznání či komunikace.
Správná informace by měla být:
• levná
• integrovaná – soustředit informace do jednoho místa
• dostupná – hierarchické třídění a full-textové vyhledávání
• zabezpečení – proti zneužití a poškození
• intuitivní – přizpůsobení uživatelům
• efektivní a pružná
1.2. Informační systémy
IS jsou - účelové uspořádání vztahů mezi lidmi, datovými zdroji a procedurami jejich
zpracování (včetně technologických prostředků).
IS slouží - ke sběru, přenosu, uchování, transformaci, aktualizaci a poskytování dat pro jejich
informační využití lidmi.
V 70. letech došlo ke vzniku prvních systémů řízení bází dat a datových modelů, které
umožnili vzájemné sdílení dat. Postupně se pro soubor aplikací sdílejících data, včetně jich
samých, vžil termín „informační systém“. Snad každý se již s tímto pojmem setkal, avšak jen
málokdo přesně ví, co tento pojem znamená, jaké různé typy informačních systémů existují.
Většina z nás si pod pojmem informační systém představí nějaký program, např. pro

10
zpracování účetnictví. Tato představa je však velmi nepřesná. Pod informačním systémem
musíme chápat celou soustavu zdrojů, prostředků a lidí.
Informační systém = celek zabezpečující systematické shromaždování, zpracovávání,
uchovávání a zpřístupňování informací. Zahrnuje informační základnu, technické a
programové prostředky, postupy, technologie a pracovníky (Encyklopedický slovník, 12).
Jak vyplývá z výše uvedené definice, účelem informačního systému je sběr, přenos,
aktualizace, uskladnění, zpracovávání a prezentace informací s cílem zajistit co nejvyšší
efektivitu práce organizace a jejích zaměstnanců.
Informační systém můžeme chápat v širším a užším smyslu. V širším smyslu zahrnuje
vytváření, zprostředkování a využívání informací. V užším smyslu zahrnuje pouze systém
zprostředkování informací.
Pokud jde o klasifikaci informačních systému, existuje zde řada hledisek, podle nichž je
možno ji provést, od komplexnosti, přes účel až po vztah k systému řízení. Podle posledního
hlediska, které je nejčastěji zmiňováno, je možno informační systémy klasifikovat za pomoci
informační pyramidy, která posuzuje informační systémy na základě růstu informační
neurčitosti na straně výstupu systému. Podrobněji o informačních systémech viz kap. 4.
1.3. Informatika a Manažerská informatika
I. Etapa – 70. léta zpracování technických informací, hromadné evidenční zpracování dat
II. Etapa – 80. léta soustava manažersky založených doporučení pro postupy aplikace IS/IT
III. Etapa – 90. léta využití prostředků VT a IT k zabezpečení kvality manažerské práce
IV. Etapa – Současnost – propojení poznatků moderního managementu, informatiky a
systémových přístupů (viz obr č.1)
V osmdesátých letech byl používán především odborníky v USA z oblastí informačních
technologií a využití výpočetní techniky pojem „informační management“. Interpretovali ho
v širším kontextu především jako racionální manažerské přístupy, metody a postupy pro
zabezpečování hospodárných postupů přípravy, zpracování a využití údajů. Spojení
informatiky a managementu se v manažerské literatuře se používá v různých interpretacích.
Především se zdůrazňuje využití prostředků výpočetní techniky a informačních technologií
k zabezpečení kvalitní manažerské práce v různých funkčních oblastech firmy. Základní cíle
informačního managementu jsou tedy odvozeny z potřeby manažerů správně a včas stanovit a
návazně zabezpečit dosažení cílů firmy resp. jejich organizační části.

11
Obr. č . 1 Propojení manažerské informatiky na okolí
Pojetí využití informatiky může být různorodé:
• samostatné, jen jako zkoumání uvnitř informačních problémů,
• se vztahem k jiným vědním disciplínám, zejména ve vztahu k procesům řízení
společnosti (managementu či společenských procesů), pro důležitou úlohu
informací v tomto procesu.
Nové možnosti informačních technologií jsou spojovány s významem informací, které
mají nejenom v managementu, ale vůbec v organizaci jako přirozeném systému. V této
souvislosti se pak stále více prosazuje názor, že tvůrčí a zároveň významově rozhodující
manažerská práce je založená na individuálních schopnostech zpracovat i interpretovat
informace. Jen manažer je schopen identifikovat svoji individuální informační potřebu a
svými myšlenkovými pochody zpracování informací zvládnout takové nestandardní procesy
jako je tvorba a implementace podnikatelské strategie, pružných organizačních struktur apod.
Základní teze o poslání informačního managementu je tedy odvozena z potřeby
manažerů správně a včas stanovit a návazně zabezpečit dosažení cílů firmy resp. jejich
organizační části. Z terminologického hlediska to lze vystihnout nejen již zmíněným pojmem
„dělat správné věci“ (effectiveness), ale dělat je i hospodárně („efficiency“). Jde přitom i o
správné pořadí. Nejprve umět správně rozhodnout a pak toto rozhodnutí umět hospodárně
SYSTÉMOVÉ PŘÍSTUPY
MANAŽERSKÁ INFORMATIKA
INFORMATIKA MANAGEMENT

12
realizovat. Pro manažery nejsou přitom přirozeně moderní informační systémy cílem, nýbrž
efektivním prostředkem, který jim má pomáhat umožnit, usnadnit, zhospodárnit a především
zkvalitnit jejich jednání.
Základní myšlenka informačního managementu jako odborné disciplíny spočívá
v současné době v účelném interdisciplinárním propojení manažersky relevantních,
samostatně pojímaných oblastí. Tj. managementu, informatiky a systémových přístupů.
Nezbytnou složkou Manažerské informatiky je její systémový přístup k řešení problémů.
Tento systémový přístup zamezuje jejich prosté aglomeraci, ale vytváří tvůrčí syntézu
k zabezpečení informačních procesů manažerské práce.
Jak teorie, tak praxe stále zřetelněji prokazují význam neformalizovaných a
neformálních aspektů informačních systémů a na rostoucí význam znalostí manažerů i dalších
pracovníků podniku. Úloha informačního manažera není omezována na pouhé technologické
aspekty a rozšiřuje se o poznávací aktivity včetně široké podpory informačních procesů uvnitř
organizace. Existuje celá řada definic managementu (I.Látal). Management lze vysvětlovat ve
třech rovinách:1. jako vedení lidí
2. specifická funkce manažerů
3. odborná disciplína
Pro účely tohoto kurzu může být vhodná následující : Management je proces
systematického provádění manažerských funkcí a efektivního využití všech zdrojů instituce
ke stanovení a dosažení jejích cílů. Nebo jinak vyjádřeno : Managament
- je disciplinou, návodem, který je třeba zvládnout (P.F.Drucker),
- je účinné řízení, tj. dělání věcí správným způsobem,
- je ucelený soubor ověřených přístupů, názorů, zkušeností, doporučení a metod, jež
jsou nezbytné k dosažení podnikatelských cílů organizace.
Komponenty systémového přístupu :
Systém – účelově definovaná množina prvků a vazeb nimi, jež vykazují určité vlastnosti
Prvek – nedělitelná část celku
Vazba – spojení mezi prvky nebo množinami
Struktura – způsob uspořádání vazeb mezi prvky systému
Okolí systému – množina prvků, které nejsou zahrnuty do systému
Vstup/Výstup – množina vazeb, jejichž prostřednictvím prvek nebo systém je ovlivňován,
nebo projevuje své vnější působení

13
SHRNUTÍ KAPITOLY
Stručný popis základních terminologických pojmů: Informatika, Informační systémy,
Manažerská informatika a Výpočetní technika
Informatika - věda o vlastnostech informace, metodách její tvorby, zpracování a využívání.
Vývoj informatiky od hromadného zpracování dat do současného systémového pohledu.
Informace - každá zpráva, sdělení, které zmenšuje neurčitost (entropii) o daném problému
(systému).
Manažerská informatika - spojení informatiky a managementu
Výpočetní technika – technické zabezpečení automatizovaného informačního systému
Komponenty systémového přístupu :
Systém, Prvek, Vazba, Struktura, Okolí systému, Vstup, Výstup
Pohledy na informatiku z hlediska :
- Teoretická disciplína
- Aplikační disciplína
- Informace
- Data
Pojem data a informace

14
SEZNAM KLÍČOVÝCH SLOV K ZAPAMATOVÁNÍ
Informatika, Informace, Číselné soustavy, Bit, Byte, Hexadecimální soustava, ASCI, Počítač,
Hardware, Software, Operační systém, Directory (adresář), Data, Program, Překladač,
Strojový kód, Device
KONTROLNÍ OTÁZKY
1. Co je informatika
2. K čemu slouží z hlediska managementu informační technologie.
3. Jaké jsou složky manažerské informatiky
KONTROLNÍ TEST
Vysvětlete rozdíl mezi pojmy data a informace.
Co rozumíte pod pojmem informační systém.
Vysvětlete rozdíl mezi Informatikou, Výpočetní technikou, Informačním managementem a
Manažerskou informatikou

15
VÝSTUPY Z UČENÍ
Po prostudování textu a vypracování úkolů v rámci této kapitoly
BUDETE UMĚT
Definovat co to je informatika a její základní pojmy
Definovat pojem informační systém
ZNALOSTI
BUDETE SCHOPNI
se orientovat v typech informačních systémů,
mít přehled o vývoji informatických disciplin ve 20. stol
identifikovat, popsat a porozumět vztahu Informatika a Manažerská
informatika.
SCHOPNOSTI
ZÍSKÁTE
Pohled na vztah informatiky a informačních systémů,
Strukturované informace a úvod do vzniku Manažerské informatiky
DOVEDNOSTI

- 15 -
2. Základní pojmy teorie informace
2.1. Podstata a pojem informace
Informace obsahuje výsledky lidské poznávací činnosti. Dosažený stupeň poznání a jeho
realizace v praxi charakterizuje, do jaké míry člověk ovládá přírodu, techniku, hospodářství,
společenské procesy a sebe sama. Rozvoj vědy a techniky, rozvoj společnosti vcelku, úroveň
vztahů mezi systémy i rostoucí složitost všech oblastí společenského života jsou
neoddělitelně spjaty s růstem objemu informací a informačních toků. Čím složitější je
systém, čím různorodější jsou vazby mezi jeho prvky, tím větší objem informací musí
zpracovat a tím početnější jsou toky informací mezi prvky a okolím systému.
V soudobém chápání je informace adekvátním libovolným sdělením, přičemž zdroji i
příjemci informace mohou být jak živé organismy, tak i technická zařízení. Informace vzniká
zpravidla na jednom místě, ale využívá se na jiném. Proto je pojem informace spjat s pojmem
jejího přenosu. Pro přenos informace od zdroje k příjemci je třeba mít materiálně
energetického nositele. Tímto nositelem je signál, který představuje určitý fyzikální proces,
probíhající v prostoru a čase.
Aby mohl vzniknout informační systém, musí existovat:
soustava znaků a pravidel jejich použití
soubor objektů a jevů s jejich označením (jmény)
množina komunikujících subjektů (příjemci,odesilatelé), kteří komunikují pomocí
znakové soustavy
množina pojmů, úsudků,obrazů v paměti příjemců a odesilatelů.
Tato zásoba významů (tezaurus) je podmínkou vzájemné výměny informací.
Přesná a jednoznačná definice pojmu informace není dosud vypracovaná. Existuje mnoho
přístupů a definic, které spolu souvisejí a které se zabývají teorií informace z různých
hledisek. Z hlediska potřeb praxe a důkladného pochopení pojmu informace je možné
definovat informaci takto:
Informace je ta část zprávy (sdělení), resp. taková zpráva, která směřuje od zdroje
k příjemci a ten ji potřebuje pro plnění svých úkolů; obsahuje něco nového - originálního, o

16
čem příjemce nevěděl, čím se rozšiřují jeho vědomosti a znalosti, týkající se zobrazované
reality a zároveň se odstraňuje nebo alespoň snižuje stupen neurčitosti jeho chování.
Je příznačné, že informace není jakoukoliv vědomostí, ale vědomostí obsaženou ve
zprávě. Představuje sdělení, zprávu, tj. takovou znalost, pro kterou existuje příjemce, který ji
může využít, tj. stává se informací. Informace je tvořena tou částí znalosti, která je využívána
k orientaci, k aktivnímu jednání, k řízení s cílem zachování, zdokonalování a rozvoje
systému.
2.2. Charakteristické znaky informace
informace není totožná s hmotou ani energií
může uchovávat svou životnost (existenci) nezávisle na trvání jevu, jehož se týká
(může se např. týkat jevu, který již neexistuje nebo který teprve nastane)
může být přenášena v čase a prostoru pomocí nositele informace a uchovává se;
jedna a tatáž informace může mít mnoho nositelů
informace plní svou praktickou funkci tehdy, když je směrována od zdroje
k příjemci a příjemce ji obdrží.
Informace cirkuluje v uzavřeném řetězci řízení. Řídící cyklus je realizovatelný jen
pomocí informačního procesu, který umožňuje postupný přechod mezi jednotlivými stadii
řídícího
cyklu.
V orgánech státní správy má informace rozhodující význam. Bez organizovaného
informačního systému nemůže žádná ze složek státní správy úspěšně řešit své úkoly. Na
kvalitě informací závisí správnost zhodnocení operativní situace, optimálnost přijímaných
rozhodnutí, plánování opatření, srozumitelné přenesení úkolů vykonavatelům, úspěšné
organizování i operativní řízení bezpečnostních akcí, efektivnost kontroly.
2.3. Sémiotické pojetí informace
Teorie informace je exaktní vědní disciplína, jejímž předmětem zkoumání jsou podstata a
formy informace a obecné zákonitosti procesů přenosu a zpracování informací. Obecně lze
informace a informační procesy zkoumat ze dvou hlavních hledisek:

17
a) z obecně teoretického hlediska, které se zabývá těmi zákonitostmi informace, jež platí
pro jakýkoliv informační proces,
b) se zřetelem ke konkrétním informačním systémům, neboť každá informace je
informací jen vzhledem k určitým systémům, tedy každý systém specifikuje své informace a
své informační procesy.
Každá informace zahrnuje dvě stránky:
a) kvantitativní — tato stránka informace vyjadřuje množství informace obsažené ve
zprávě. V tomto smyslu je informace veličinou, která vyjadřuje hodnotu snížení neurčitosti
chování u příjemce, tj. hodnotu rozdílu mezi neurčitostí před přijetím a zbytkem neurčitosti
po přijetí informace.
b) kvalitativní - tato stránka informace vyjadřuje smysl, obsah a význam informace
z hlediska potřeb a zájmů příjemce.
Teorie informace vznikla jako kvantitativní matematická teorie, jejímž tvůrcem je
C. E. Shannon. Vychází z teorie pravděpodobnosti a využívá statistické a matematické
metody k popisu jevu a procesů. Její matematické vyjádření umožnilo určit jednotku pro
měření množství informace a číselně vyjádřit míru uspořádanosti nebo stupeň
organizovanosti procesů a systémů. Shannon chápal informaci jako snížení míry neurčitosti.
Matematicko-statistická teorie studuje množství informace v mezích vnitřní struktury
systému, používaných znaků a vzájemných statistických vztahů, přičemž nebere v úvahu
jejich funkční a obsahovou stránku.
Uvnitř matematické teorie informace se začaly postupně rozvíjet sémantické a
pragmatické koncepce, které zkoumají nejen formální pravidla ale i pojmovou, obsahovou a
významovou stránku informace, neboli jde o kvalitativní chápání informace.
Za moderní východisko zkoumání informace lze označit její tzv. sémiotické pojetí.
(Sémiotika je vědní obor, zabývající se studiem znakových systémů).
Dělí se na:
syntax - zabývá se vnitřní strukturou soustavy znaků nezávisle na jejich funkci;
sémantiku - zabývá se systémem znaků. jakožto prostředkem vyjadřování smyslu;
pragmatiku - zabývá se vztahy systémů znaků k těm, kdo jich používají. Z tohoto
hlediska lze členit teorii informace na následující základní speciální oblasti :

18
Syntaktická teorie informace se zabývá vzájemnými vazbami mezi znaky v informaci,
tj. jejich spojením, skladbou slov a vět ve smyslu formálních jazykových pravidel. Exaktně
zkoumá informační procesy na syntaktické úrovni, tj. zkoumá především elementy zpráv a
jejich vztahy navzájem. Jde o pojetí podle pravidel skladby vět a slov příslušného jazyka. Lze
sem zařadit i zkoumání přenosových kanálů, jejich kapacity, spolehlivosti atd.
Sémantická teorie informace se zabývá významem, obsahem informace. Vychází
z obsahové a pojmové stránky slov (symbolů, znaků) vzhledem k zobrazované realitě.
Analyzuje vztahy mezi elementy zpráv a tím, co je jimi označováno, resp. zabývá se mírou
smyslu - významu, který má informace pro odesilatele i příjemce.
Pragmatická teorie informace se zabývá účelem informace, vyjadřuje její hodnotu se
zřetelem na vyvolaný účinek u uživatele resp. příjemce informace. Zkoumá závislosti mezi
informací, jejím příjemcem a cílem, který si vytkl. Pragmatičnost čili užitečnost zprávy je
v tomto pojetí kritériem hodnoty informace.
Pokud jde o sémantické a pragmatické pojetí informace, jedná se o méně propracovanou
oblast teorie informace. Je to způsobeno obtížností měřit a vyjádřit kvalitativní hodnotu
informace z hlediska jejího obsahu, významu a vyvolaného účinku příjemce. Tyto nesnáze
plynou z rozmanitosti sémantické a pragmatické interpretace jednotlivých jazykových
elementů a z obtížnosti exaktně vyjádřit vztahy mezi znaky v informaci a jejich pojmovým
obsahem.
2.4. Pojem entropie
K dalšímu kvantitativnímu měření množství informace podle statistické teorie
C. E. Shannona potřebujeme znát pojem entropie.
Entropie je matematická funkce, jejíž hodnota souvisí s hodnotou pravděpodobnosti
dané soustavy tak, že maximum entropie odpovídá nejpravděpodobnějšímu stavu. Vyjadřuje
tendenci soustavy přecházet z méně pravděpodobných stavů (uspořádaných) do stavů
pravděpodobnějších (méně uspořádaných). Všechny samovolné děje probíhají ve směru růstu
entropie až po dosažení její maximální hodnoty. Entropie tedy dosahuje svého maxima, když
všechny stavy prvků systému jsou stejné pravděpodobné.
U každá soustavy lze mluvit o její uspořádanosti, která může být malá nebo velká.
Soustava, která je neuspořádaná, se skládá z volné seskupených prvků, jež lze libovolně

19
přeskupit, aniž by se tím změnila uspořádanost soustavy. Není to vlastně již systém, ale
pouhý konglomerát - seskupení prvků. Všechny prvky takového seskupení mohou mít vcelku
stejnou funkci a jejich vzájemné vztahy (vazby) nejsou pevné ani složité.
Entropie je množství, resp. míra neurčitosti, neuspořádanosti soustavy. Je mírou
nedostatečné (chybějící) informace o stavu nebo chování systému.
V uzavřených soustavách, tj. v těch, ve kterých neprobíhá výměna hmoty, energie ani
informace s okolím, probíhá nevratně růst entropie, soustavy snižují svou uspořádanost a
dosahují trvalé - statické rovnováhy. Otevřené soustavy uchovávají stupeň své uspořádanosti
pomocí vratných procesů výměny hmoty, energie a informace s okolím a dosahují neustále
dynamické rovnováhy.
Soustava uchovává svou organizovanost “odsáváním“ pořádku z okolí. Informace je
(podle Ashbyho) to, co odstraňuje entropii a měří se množstvím odstraněné entropie.
Podle Shannona je entropie H číselně rovna záporně vzatému součtu součinů
pravděpodobností i-tého jevu a jejího příslušného dvojkového logaritmu:
H = -∑pi * log2 pi.
kde i je pravděpodobnost i-tého jevu. Množství informace je číselně rovno rozdílu entropie
soustavy před a po obdržení zprávy, což lze vyjádřit vztahem :
I = H0 – H1 kde
I - je množství informace získané přijetím zprávy
H0 - je neurčitost před přijetím zprávy
H1 - je zbytek neurčitostí, čili množství neodstraněné entropie po přijetí zprávy
V teorii informace je množství informace I zkoumáno jako číselná veličina vyjádřená
v binárních jednotkách (bitech).
Obdobně jako v desítkové soustavě máme k dispozici 10 číslic (0 — 9) a pak dochází
přenosu do vyššího řádu, máme v binární (dvojkové) soustavě k dispozici 2 číslice, tj, 0 a 1.
V podstatě představuje soustava dvouhodnotovou logiku : odpověď ANO - NE.
Jednotkou množství informace a tedy i entropie je 1 bit. Množství informace 1 bitu si
lze představit jako zprávu o události, která má pouze dva stejně pravděpodobné stavy

20
(výsledky), což znamená, že za měrnou jednotku bylo vzato množství informace ve zprávě o
události, jež má pravděpodobnost rovnu 0,5.
1 bit je takové množství informace, které odstraňuje neurčitost při dvou různých, ale
stejně pravděpodobných možnostech, jde tedy o množství informace obsažené v odpovědi na
otázku, která má jen dva možné a stejně pravděpodobné stavy : ANO nebo NE.
I = log2N log22 = 1
N = počet stejně pravděpodobných jevů
2.5. Omezení kvantitativního přístupu k informacím
Omezení se na čisté kvantitativní, formální teorii informace, abstrahování od její
sémantiky, pragmatiky a konečně i emocionálního významu vede k určitému omezení obsahu
i rozsahu informace. V oblasti řízení jsme nuceni analyzovat a řešit složité problémy, kdy
obíhají informace různých kvalit, jmenovitě společenské informace, což předpokládá nejen
kvantitativní‚ logické ale i emocionální a volní aspekty.
Zatím není dostatečné rozvinut matematický aparát teorie informace, aby bylo možno
zkoumat podstatu informace, její význam, hodnověrnost, aktuálnost a jiné charakteristiky,
které se stanoví subjektivně a které tvoří její „lidské“ ocenění. To má souvislost
s algoritmizovatelností procesů. V praktické činnosti orgánů řízení se často používají různé
metody hodnocení hodnověrnosti a aktuálnosti informace. Používají se různé grafy, které
umožňují stanovit stárnutí informace. Všechny tyto metody mají empirický charakter a
nejsou zbaveny subjektivismu.
Subjekt v závislosti na stupni poznání dostává z okolí různé množství sdělení. Záleží na
jeho kvalifikaci, zkušenostech popř. dalších okolnostech, jak velké množství informace je
v té či oné zprávě pro něj obsaženo. Zlepšení připravenosti může množství informace ve
zprávě nejen zvyšovat, ale i snižovat.
Jestliže je zdrojem informací konečná struktura, která se v daném časovém úseku nemění,
pak množství informace obsažené ve zprávě bude nepřímo úměrné kvalifikaci příjemce, tj. na
množství dříve nashromážděné a zpracované informace.

21
2.6. Kvalitativní pojetí informace
Kvalita informace je obecně dána těmito kriterii:
účelností, úplností, hodnověrností, srozumitelností, přesností a včasností.
Účelnost je daná tím, do jaké míry je informace způsobilá k využití v rámci
rozhodovacího procesu, ke kontrole plnění úkolů, v plánování, organizování, operativním
řízení apod.
Úplnost informace vyjadřuje do jaké hloubky a šířky zobrazuje objektivní realitu (určitý
jev, proces, systém apod.). Tento požadavek je důležitý pro vlastní rozhodovací proces,
protože neúplnost snižuje hodnotu informace a zvyšuje entropii u příjemce.
Hodnověrnost informace je zvláště důležitá. Rozhodnutí přijímaná na základě málo
hodnověrných informací jsou často nesprávná a mají negativní dopady. Z této skutečnosti
plyne potřeba prověřování informací.
Srozumitelnost má též své opodstatnění z hlediska její kvality. Závisí na vyjadřovacích
schopnostech a na používání jasných pojmů a také na logické a konkrétní formulaci ze strany
zdroje informace. Malá srozumitelnost a nejasnost informace ji může znehodnotit a způsobit
její nepoužitelnost.
Přesnost informace se týká především údajů v ní uvedených ať už jde o čísla, rozměry,
polohu, množství apod. Přesnost těchto údajů má velký význam v procesu rozhodování a při
zpracování podkladů pro řídící činnost.
Včasnost informace je jednou z nejdůležitějších vlastností z hlediska její kvality. Týká se
to zejména bezpečnostních a vojenských informací. Při opožděném obdržení se často ztrácí
aktuálnost informace a snižuje se možnost operativního provedení účinných opatření, což je
zejména v oblasti boje s trestnou činností velmi nežádoucím jevem.
Hodnota a užitečnost informace je z hlediska potřeb řízení zabezpečena jen v případě
kdy:
1. informační systém je úzce propojen s řídícím systémem,
2. výběr informací je optimalizován, což znamená, že řídící systém není přesycen
nadměrným množstvím a vysokou frekvencí informací a že budou vybírány a
zpracovávány obsahově nejvýhodnější soubory a struktury informací,
3. informační tok je nepřetržitý, plynulý a bezporuchový, nevyskytují se informační
mezery (informační vakuum) a je minimalizován informační “šum“, tj. zkreslení,
zkomolení a deformace informaci.

22
Sémantický a pragmatický obsah informace je dán tím, jak informace jednoznačně a
konkrétně zobrazuje určitý děj, jev, proces, událost, systém apod. Čím je tento obsah
objektivnější, hlubší a obsažnější, tím je informace kvalitnější a vhodnější pro využití
v procesu rozhodování.
Zajímavý je názor vyjadřovat kvalitu informace mírou, v jaké slouží ke splnění daného
cíle. Informace je hodnotná pokud napomáhá dosažení vytčeného cíle. Jedna a tatáž
informace může mít různou hodnotu, zkoumáme-li ji z hlediska využití k různým cílům.
Hodnota informace se vyjadřuje pomocí rozdílu pravděpodobností dosažení cíle před jejím
získáním a po něm. Je zřejmé, že hodnota informace může být měřena pomocí přírůstku míry
dosažení cíle pouze v tom případě, že sám cíl je přesně určen.
Existují i jiné pokusy o hodnocení kvality informace, ve všech případech je však vždy snaha
o takovou formalizaci, aby logicko-matematická forma, v níž je informace vyjádřena, co
nejvíce odpovídala obsahu samotných objektů informace. Zde však zatím nebylo dosaženo
úspěchů, protože hodnota informace vystupuje jako kvalitativní jev, který je, jak již bylo
řečeno v části o sémantické a pragmatické teorii informace, obtížně formalizovatelný a
algoritmizovatelný. Tatáž informace má pro různé subjekty různou hodnotu. Hodnota totiž
nese subjektivní stopy cílů, zájmů a potřeb subjektu, který informace využívá.

23
SHRNUTÍ KAPITOLY
Podstata a pojem informace
Informace obsahuje výsledky lidské poznávací činnosti. Dosažený stupeň poznání a jeho
realizace v praxi charakterizuje, do jaké míry člověk ovládá přírodu, techniku, hospodářství,
společenské procesy a sebe sama.
V soudobém chápání je informace adekvátním libovolným sdělením, přičemž zdroji i
příjemci informace mohou být jak živé organismy, tak i technická zařízení.
Z hlediska potřeb praxe a důkladného pochopení pojmu informace je možné definovat
informaci takto:
Informace je ta část zprávy (sdělení), resp. taková zpráva, která směřuje od zdroje
k příjemci a ten ji potřebuje pro plnění svých úkolů; obsahuje něco nového - originálního o
čem příjemce nevěděl, čím se rozšiřují jeho vědomosti a znalosti, týkající se zobrazované
reality a zároveň se odstraňuje nebo alespoň snižuje stupen neurčitosti jeho chování.
Charakteristické znaky informace :
informace není totožná s hmotou ani energií
může uchovávat svou životnost (existenci) nezávisle na trvání jevu, jehož se týká
(může se např. týkat jevu, který již neexistuje nebo který teprve nastane)
může být přenášena v čase a prostoru pomocí nositele informace a uchovává se;
jedna a tatáž informace může mít mnoho nositelů
informace plní svou praktickou funkci tehdy, když je směrována od zdroje
k příjemci a příjemce ji obdrží.
Sémiotické pojetí informace
Teorie informace je exaktní vědní disciplína, jejímž předmětem zkoumání jsou podstata a
formy informace a obecné zákonitosti procesů přenosu a zpracování informací. Obecně lze
informace a informační procesy zkoumat ze dvou hlavních hledisek:
1) z obecně teoretického hlediska,
2) se zřetelem ke konkrétním informačním systémům

24
Každá informace zahrnuje dvě stránky:
a) kvantitativní.
b) kvalitativní.
a) Kvantitativní pojetí informace
Množství informace ve zprávě je závislé jednak na pravděpodobnosti výskytu jevu
(události), jednak na pravděpodobnosti jejího doručení příjemci bez zkomolení
(znehodnocení).
Pojem entropie - entropie je matematická funkce, jejíž hodnota souvisí s hodnotou
pravděpodobnosti dané soustavy tak, že maximum entropie odpovídá
nejpravděpodobnějšímu stavu.
Entropie je množství, resp. míra neurčitosti, neuspořádanosti soustavy. Je mírou
nedostatečné (chybějící) informace o stavu nebo chování systému.
b) Kvalitativní pojetí informace
Kvalita informace je obecně dána těmito kriterii:
účelností, úplností, hodnověrností, srozumitelností, přesností a včasností.
Přesnost informací.
Včasnost a operativnost informací.
Optimalizace nákladů na získání informací.
Stručnost a logičnost vyjádření informací.
Užitečnost informaci.

25
SEZNAM KLÍČOVÝCH SLOV K ZAPAMATOVÁNÍ
Podstata a pojem informace, Charakteristické znaky informace, Sémiotické pojetí informace,
Kvantitativní pojetí informace, Kvalitativní pojetí informace, Pojem sociální informace,
Druhy sociální informace, Úloha informací v řízení společnosti, Požadavky na sociální
informace
KONTROLNÍ OTÁZKY
1. Co je podstatou informace
2. Jak se měří množství informace
3. Co jsou sociální informace
4. Úloha informací v řízení společnosti
KONTROLNÍ TEST
Jak se číselně vyjádří množství informace obsažené ve zprávě

26
VÝSTUPY Z UČENÍ
Po prostudování textu a vypracování úkolů v rámci této kapitoly
BUDETE UMĚT
Rozlišit pojmy Syntaktická teorie informace, Sémantická teorie informace,
Pragmatická teorie informace
Rozlišit různé druhy a pojetí informace a jejich úlohu v řízení společnosti
Seznámíte se se způsobem kvantitativního měření informace
ZNALOSTI
BUDETE SCHOPNI
Pochopit význam informace v řízení společnosti a její úlohu v managementu
SCHOPNOSTI
ZÍSKÁTE
Představu o podstatě a pojmu informace která obsahuje výsledky lidské
poznávací činnosti. A jejího vlivu na dosažený stupeň poznání a jeho realizace
v praxi.
DOVEDNOSTI

- 27 -
3. Počítačové sítě
3.1. Pojem počítačová síť, typologie počítačových sítí
Zejména v posledních letech stále roste potřeba a význam komunikačních
prostředků a služeb. Využívání sítí je důležitým předpokladem pro úspěšnou činnost podniků.
Ve vývoji výpočetní techniky došlo k mnoha mezníkům, jedním z nich byl právě vznik
počítačových sítí.
Síť = komunikace mezi dvěma či více stranami, která má stanoveny určitá pravidla
pro dorozumívání se, mluvíme tzv. o standardech a protokolech sítí.
Např. u počítačových sítí jsou těmito stranami počítače a další fyzická příslušenství, u
lidské komunikace člověk apod.
Skupina počítačů a dalších zařízení (například tiskárny a skenery) propojená
komunikačními linkami umožňujícími vzájemnou interakci jednotlivých zařízení v síti. Sítě
mohou být malé i rozsáhlé, trvale propojené dráty nebo kabely anebo dočasně připojené
prostřednictvím telefonních linek nebo bezdrátového přenosu. Nejrozsáhlejší je síť Internet,
která představuje skupinu sítí na celém světě.
Podstatou komunikace v rámci počítačových sítí je výměna informací mezi dvěma nebo
více účastníky. Přenášenou informací může být zvuk, obraz nebo textová data. Informace
nemusí být pouze přenášeny, ale také sdíleny.
Počítačovou síť lze obecně definovat jako soustavu vzájemně propojených počítačů.
V počítačové síti můžeme rozlišit dva typy stanic:
pracovní stanice – zpracování dat může uživatel provádět podobně jako na osobním
počítači a navíc může využívat služby poskytované sítí.
servery – oproti pracovní stanici server poskytuje uživatelům vlastní prostředky
(tiskárny, atd.).
Základní součásti sítě
Nejdůležitějšími součástmi sítě jsou:
hardware sítě – všechny technické prostředky, které síť využívá (tiskárny,
scannery,…) a dále sem můžeme zařadit i technické prostředky, díky kterým dochází ke
spojení jednotlivých počítačů (síťové adaptéry).

28
síťový software – jedná se o programové vybavení, může mít různou podobu –
v některých operačních systémech jsou síťové služby přímo jejich součástí, u jiných OS
jde o dodatečné programové vybavení.
Software sítě - LINUX, Windows server, Novell
Počítače pro práci v síti - specializované servery
organizační zajištění činnosti – mezi toto zajištění můžeme zařadit například opatření,
která zajišťují správu sítě nebo soubor pravidel chování uživatelů.
Mezi nejvýznamnější výhody počítačových sítí patří:
sdílení dat – neboli společné užívání dat, umožňuje zpracování dat na více počítačích
současně, data mohou být umístěna na servery a ostatní uživatelé k nim mají přístup
prostřednictvím sítě.
sdílení prostředků – nejčastěji se jedná o diskové jednotky nebo tiskárny, ale v úvahu
přichází i sdílení procesoru nebo programů.
zvýšení spolehlivosti systému.
Počítačové sítě je možné rozlišit podle mnoha kritérií:
1. podle rozsahu
Podle rozsahu můžeme rozdělit sítě na LAN (Local Area Network), MAN (Metropolitan
Area Network), WAN (Wide Area Network). Jedná se o vůbec nejznámější dělení. Přesné
vymezení těchto pojmů ovšem neexistuje. Jako rozlišující kritérium se používá zejména
geografická oblast, ve které jsou počítače rozmístěny.
LAN je síť, která se rozprostírá v jedné nebo několika místnostech nebo v jedné či
několika sousedních budovách. Vzdálenost mezi počítači je v desítkách, maximálně
stovkách metrů. Ke spojení se využívají UTP (kroucený dvoupár) kabely a optické kabely.
MAN je označení pro síť většího rozsahu, která pokrývá území podniku nebo města.
WAN je tvořena určitým počtem sítí LAN, které jsou spojeny datovými okruhy. Touto sítí
mohou být propojeny celé kontinenty.
Dalším rozdílem mezi výše uvedenými typy sítí je druh uzlových počítačů. U sítě LAN
se využívají zejména osobní počítače. Naproti tomu u sítí WAN se jedná o tzv.
střediskové počítače, tedy počítače se sítí terminálů. Zpráva je doručena do uzlového
počítače a uschována do doby, než si ji adresát vyzvedne.
Další odlišností je účel, ke kterému je síť využívána. V případě LAN se jedná o možnost
sdílení souborů a databází. U WAN je hlavním cílem přenos zpráv a dat na větší
vzdálenost.
29
2. podle topologie
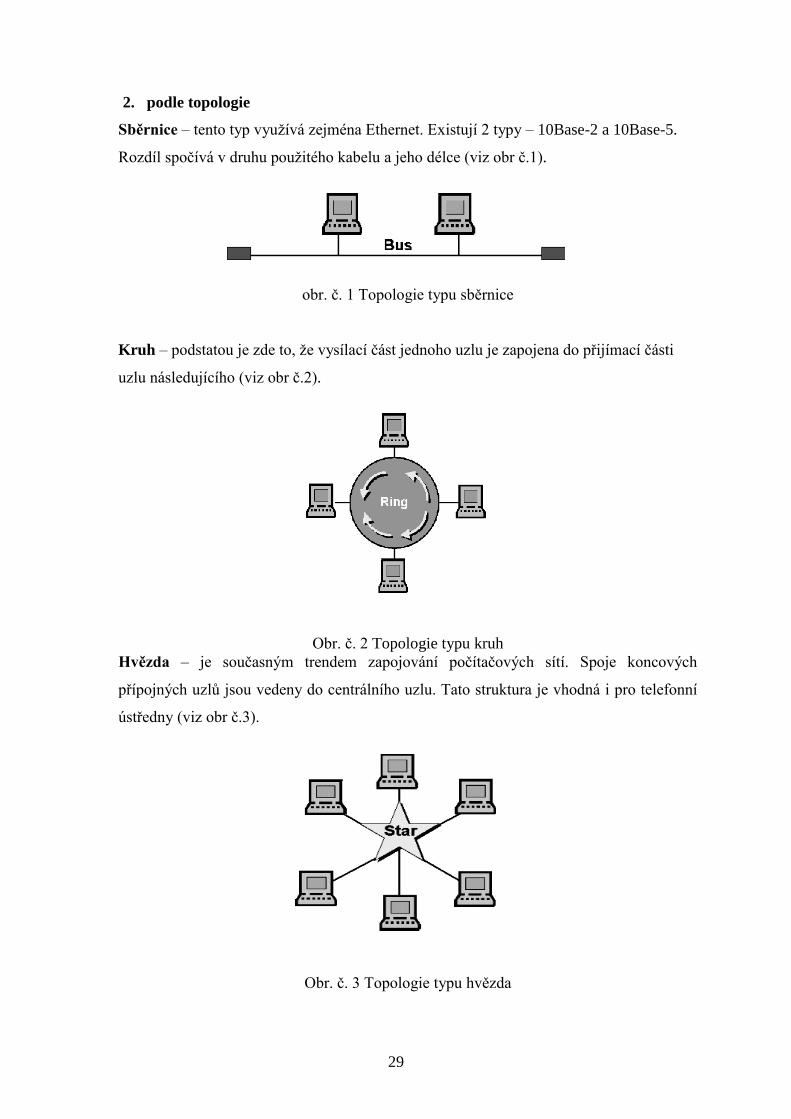
Sběrnice – tento typ využívá zejména Ethernet. Existují 2 typy – 10Base-2 a 10Base-5.
Rozdíl spočívá v druhu použitého kabelu a jeho délce (viz obr č.1).
obr. č. 1 Topologie typu sběrnice
Kruh – podstatou je zde to, že vysílací část jednoho uzlu je zapojena do přijímací části
uzlu následujícího (viz obr č.2).
Obr. č. 2 Topologie typu kruh
Hvězda – je současným trendem zapojování počítačových sítí. Spoje koncových
přípojných uzlů jsou vedeny do centrálního uzlu. Tato struktura je vhodná i pro telefonní
ústředny (viz obr č.3).
Obr. č. 3 Topologie typu hvězda

30
3. podle charakteru komunikace
Podle tohoto kritéria můžeme sítě rozdělit na spojové a nespojové. Resp. sítě
s navazováním spojení nebo bez navazování spojení.
Nespojové – Příkladem jsou technologie založené na broadcastu = všesměrovém
vysílání (viz obr č.4).
Obr. č. 4 Všesměrové vysílání
Spojové – zde je příkladem technologie ATM. Před zahájením komunikace musí dojít
vytvoření trvalého nebo dočasného spojení (viz obr č.5).
Obr. č. 5 Přepínané (komutované) vysílání
4. podle principu komunikace
Stochastické metody – jsou založeny na náhodném přístupu k médiu. Příkladem je
Ethernet. Jednotlivé uzly se pokoušejí komunikovat bez jakéhokoli pořadí.
Deterministické metody – jsou založeny na řízení přístupu k médiu. Po síti je
přenášen paket (tzv.token). Uzel, který chce komunikovat musí počkat, až k němu
token dorazí. Paket je přenosová jednotka síťových vrstev OSI (Open Systems
Interconnection) skládající se z binárních informací reprezentujících data a záhlaví
obsahující identifikační číslo, zdrojovou a cílovou adresu a data pro řízení chyb.

31
5. podle použitého přenosového média
V současnosti je nejpoužívanějším médiem v sítích LAN kroucený dvoupár (UTP).
Dále se využívá strukturovaná kabeláž. Před nedávnem byl nejvyužívanějším
médiem koaxiální kabel. Jeho nevýhodami je náchylnost k poruchovosti a
technologická omezení (rychlost). Na větší vzdálenosti se využívají optické kabely.
Používají se zejména tam, kde je třeba vést spojení venkovním prostředím.
3.2. Základní druhy přenosů
Můžeme se setkat s různými formami přenosů signálů, které mohou být modulovány a
kódovány.
Paralelní a sériový přenos
Data jsou přenášena po více bitech najednou. Používají se k tomu souběžné (paralelní)
vodiče. Nejčastějším příkladem je přenos mezi počítačem a tiskárnou.
V počítačových sítích se využívá zejména sériový přenos. Data jsou přenášena postupně bit
po bitu.
Sériový asynchronní přenos
Při asynchronním sériovém přenosu mohou být jednotlivé znaky přenášeny s libovolnými
časovými odstupy mezi sebou, příjemce pak ovšem nemůže předem vědět, kdy začíná další
znak a proto musí být schopen jeho příchod podle vhodného příznaku rozpoznat. Tímto
příznakem je tzv. start bit, kterým začíná každý asynchronní přenášený znak. Za vlastními
datovými bity může následovat jeden tzv. paritní bit, a konečně tzv. stop bit (závěrný prvek).
Asynchronnímu způsobu přenosu se někdy říká také start-stop přenos.
Sériový synchronní přenos
Při tomto přenosu jsou přenášeny celé bloky znaků a to bez jakýchkoli časových odstupů.
Tento přenos je rychlejší než přenos asynchronní.
Parita
Při sériovém i paralelním přenosu může dojít k chybám. V těchto případech se využije
způsob, při kterém se datové bity doplní dalším bitem tak, aby celkový počet jedniček byl
lichý (tzv. lichá parita) nebo naopak sudý (sudá parita). Příjemce ale musí vědět, zda mu
odesilatel posílá data se sudou nebo lichou paritou.

32
3.3. Zabezpečení dat
Nejčastěji se k tomu využívají tzv. bezpečnostní kódy. Původní znaky se podle
určitých pravidel transformují na znaky jiného typu. Tyto transformované znaky se pak
přenesou a příjemce je převede zpět do původního stavu.
Rozlišujeme 2 typy bezpečnostních kódů:
1. detekční kódy – umožňují rozpoznat, že přijatý znak je chybný,
2. samoopravné kódy – kromě toho, že rozpoznají chybu, ji umí i opravit.
Nejjednodušší detekční kód (zabezpečení sudou nebo lichou paritou) přidává k
datovým bitům jeden další bit a dokáže detekovat chybu v jednom bytu. Samoopravný kód
přidává ke každému 8-bitovému bytu navíc pět bitů. V praxi je výhodnější nezabezpečovat
proti chybám jednotlivé znaky, ale celé postoupnosti znaků resp. celé přenášené bloky dat.
K tomu se využívá tzv. podélná parita nebo kontrolní součet. Nejúčinnější formou je ovšem
použití tzv. cyklických kódů –CRC. Princip spočívá v tom, že se průběžně vypočítává
zabezpečovací údaj, který se porovnává s údajem, který takto vypočítal i odesilatel. Pokud se
oba údaje shodují, jsou data správná.
3.4. Protokol
Sada pravidel a konvencí pro posílání informací v rámci sítě. Tato pravidla určují obsah,
formát, čas a způsob zpracování a řízení chyb zpráv vyměňovaných mezi síťovými
zařízeními.
Počítače připojené k Internetu mezi sebou komunikují na základě sady protokolů a tyto
protokoly jsou definovány v referenčním modelu OSI (Open System Interconnection). Na
základě referenčního modelu ISO OSI byl ve zjednodušené míře použit tento model na
protokol TCP a IP. Jeho sloučením vznikl známý protokol TCP/IP, který právě pro svoji
univerzálnost a spolehlivost používají dnes sítě typu policejního Intranetu nebo globálního
Internetu.
Model OSI má 7 vrstev (fyzickou, linkovou, síťovou, transportní, relační, prezentační,
aplikační). Jde o 7vrstvý referenční model ISO OSI, slouží k popisu komunikačních systémů.
Počítače v Internetu komunikují na základě TCP/IP protokolů (Transmission Control
Protocol/Internet Protocol).

33
TCP = protokol transportní vrstvy modelu OSI převádí zprávy do sekvence paketů na
zdrojovém uzlu a pak je znovu sestavuje do původních zpráv na cílovém uzlu sítě. TCP / IP
Transmission Control Protocol / Internet Protocol. Sada síťových protokolů používaných v
síti Internet, která poskytuje komunikaci v rámci vzájemně propojených sítí tvořených
počítači s různou hardwarovou architekturou a různými operačními systémy. Protokol TCP/IP
zahrnuje standardy pro komunikaci počítačů a konvence propojování sítí a směrování
provozu. TCP (Transmission Control Protocol) - realizace virtuálního spojení mezi uzly sítě
IP = protokol síťové vrstvy modelu OSI obhospodařuje adresování, pakety jsou
směrovány nejen přes uzly, ale i přes řadu sítí s různými komunikačními protokoly (NCP,
Ethernet, FDDI, X.25 apod.). IP protokol (Internet Protocol). Směrovatelný protokol ze sady
protokolů TCP/IP, který slouží k adresování, směrování a fragmentaci a opětovnému složení
paketů IP v síti.
IPX / SPX Internet Packet eXchange / Sequenced Packet eXchange
TCP/IP protokoly zvoleny jako nejuniverzálnější prostředek k propojení počítačů na různých
HW platformách a s různými OS. Pro UNIX TCP/IP znamená začlenění do heterogenního
síťového prostředí.
ICMP (Internet Control Message Protocol) - řešení chybových stavů při doručování. Protokol
údržby sady protokolů TCP/IP, který slouží k hlášení chyb a umožňuje jednoduchá propojení.
Protokol ICMP je používán nástrojem ping při řešení potíží s protokolem TCP/IP.
ARP (Adress Resolution Protocol) protokol pro mapování IP adres (logické adresy) 4 byty na
HW adresy síťových adaptérů (fyzické adresy) 6 byte. Protokol, který v rámci protokolu
TCP/IP používá všesměrové vysílání v místní síti k překladu logicky přiřazených adres IP na
jejich adresu fyzického hardwaru nebo vrstvy pro řízení přístupu k médiím.
RARP (Reverz Adress Resolution Protocol) - reverzní ARP (bezdiskové pracovní stanice)
UDP (User Datagram Protocol) - zajišťuje přenos paketů s daty
TELNET - Protokol terminálové emulace často používaný v síti Internet pro vzdálené
přihlášení k síťovým počítačům navozuje iluzi práce na lokálním terminálu v interaktivním
režimu. Protokol Telnet také odkazuje na aplikace, které používají tento protokol pro
uživatele, kteří se přihlašují ze vzdáleného umístění.
FTP (File Transfer Protocol) - člen sady protokolů TCP/IP používaný ke kopírování souborů
mezi dvěma počítači (i na různých platformách) v síti Internet. Oba počítače musí podporovat
příslušné role protokolu FTP: jeden musí být klientem a druhý serverem

34
HTTP (HyperText Transfer Protokol). Protokol používaný k přenosu informací na webu.
Adresa HTTP (jde o typ adresy URL – Uniform Resource Locator) má následující formát:
http://www.microsoft.com.
Jazyk HTML (Hypertext Markup Language).
Jednoduchý kódový jazyk sloužící k vytváření hypertextových dokumentů, které lze přenášet
mezi platformami. Soubory HTML jsou jednoduché textové soubory ASCII, v nichž jsou
vloženy kódy určující formátování a hypertextové odkazy.
Hypertextový odkaz.
Barevně označený a podtržený text nebo obrázek, na který lze klepnout a přejít tak k souboru,
do určitého umístění v souboru nebo umístění na stránce ve formátu HTML v síti Internet či
intranet. Hypertextové odkazy lze používat také v diskusních skupinách, v rámci nástrojů
Gopher, Telnet nebo na serverech FTP.
Ve složkách systému Windows jsou hypertextové odkazy textové odkazy, které jsou
zobrazeny v levém podokně složky. Klepnutím na tyto odkazy můžete provádět určité
činnosti, například přesunout nebo kopírovat soubory nebo přejít na jiné umístění v počítači,
například do složky Dokumenty nebo do Ovládacích panelů.
3.5. IP adresa
Adresování v TCP / IP
IP adresy
IPv4 xxx.xxx.xxx.xxx
IPv6 xxx.xxx.xxx.xxx.xxx.xxx
Každý počítač (ethernetové zařízení) má v síti Internet přidělenou IP adresu. IP adresa je 32-
bitové číslo, které se zapisuje jako čtveřice čísel, např. 212.71.161.78.
IP adres je 232
, tedy něco přes 4 miliardy.
IP adresa : jednoznačná identifikace síťového rozhraní v Internetu. Je to 32bitová adresa
sloužící k identifikaci uzlu v rámci propojení sítí IP. Každému uzlu v propojení sítí IP musí
být přidělena jedinečná adresa IP, která je tvořena identifikátorem sítě a identifikátorem
hostitele. Adresa je obvykle reprezentována desítkovými hodnotami jednotlivých oktetů
(velikost 4 byte) oddělených tečkou (tzv. Tečková notace ), například 192.168.7.27. V XP
verzi systému Windows lze adresy IP konfigurovat staticky nebo dynamicky prostřednictvím
protokolu DHCP.

35
IP adresa se skládá ze 2 částí:
1) adresa lokální sítě;
2) adresa počítače v lokální síti.
3.6. Adresa v síti Internet
Adresa URL (Uniform Resource Locator)
Adresa, která jednoznačně identifikuje umístění v síti Internet. Adrese URL na webu
předchází označení http://, jako například ve fiktivní adrese URL
http://www.example.microsoft.com/. Adresa URL může obsahovat podrobnější údaje,
například název hypertextové stránky, obvykle identifikovaný příponou HTML nebo HTM.
Adresa prostředku v síti Internet, která je webovými prohlížeči používána k vyhledání
prostředku v síti Internet. Internetová adresa obvykle začíná názvem protokolu, za ním je
uveden název organizace, která server spravuje a přípona určuje, o jaký typ organizace se
jedná. Z adresy http://www.yale.edu/ lze například zjistit následující informace:
http: Tento webový server používá protokol HTTP (Hypertext Transfer
Protocol).
www: Tento server je umístěn na webu.
edu: Jedná se o vzdělávací instituci.

36
SHRNUTÍ KAPITOLY
Pojem síť
Skupina počítačů a dalších zařízení (například tiskárny a skenery) propojená komunikačními
linkami umožňujícími vzájemnou interakci jednotlivých zařízení v síti. Sítě mohou být malé i
rozsáhlé, trvale propojené dráty nebo kabely anebo dočasně připojené prostřednictvím
telefonních linek nebo bezdrátového přenosu.
Důvody pro návrh a realizaci sítí počítačů :
sdílení dat a jejich snadný přenos
sdílení prostředků
zvýšení funkčnosti organizace - e-mail
dokonalejší ochrana dat
Druhy počítačových sítí
Podle rozlohy:
lokální sítě - Local Area Network
globální sítě - Wide Area Network
metropolitní sítě - Metropolitan Area Network
Topologie počítačových sítí
sběrnicové uspořádání bus topology
hvězdicové uspořádání star topology
kruhové uspořádání ring topology
páteřní uspořádání backbone
Software sítě - LINUX, Windows server, Novell
Počítače pro práci v síti - specializované servery
Navzájem propojené počítače s centrálním počítačem (server) – tzv. topologie klient - server.
Tento centrální počítač je vybaven speciálním softwarem (LINUX, Windows server, Novell).
Výhody internetu
• Celosvětová dostupnost;
• Snadno nalezitelné přes katalogy a vyhledávače,
• Interaktivnost - webové stránky reagují přesně na požadavky a podněty,
• Snadné a rychlé aktualizace umožňují udržovat webové stránky stále aktuální,
• Snadné ovládání i pro slabší uživatele,
• Rychlá komunikace - především prostřednictvím elektronické pošty, E-mailu,

37
• Snadná navigace pomocí odkazů,
• Přímý prodej přes internet, tzv. E-shop,
• Nízká cena vytvoření stránek a jejich provozu.
Nevýhody internetu
• Nedostatečná rychlost (velký počet uživatelů, nedostatečný hardware),
• Drogy, výbušniny,
• Chování uživatelů (nedododržování nepsaných pravidel "NetEthics"),
• Bezpečnost obchodu (možnosti podvodů).
Využití internetu a management
Největší potenciál pro management mají WWW stránky a elektronická pošta. Střední využití
je u diskusních skupin, elektronických konferencí a IRC (Internet Relay Chat
Jako příklady komerčního využití internetu je možné uvést:
firemní prezentace na trhu,
elektronická pošta (freemails),
specializované servery – odborné servery s nejrůznějšími informacemi,
E-commerce servery – nákup, prodej a platby přes internet.

38
SEZNAM KLÍČOVÝCH SLOV K ZAPAMATOVÁNÍ
Lokální sítě , globální sítě, metropolitní sítě, topologie sběrnicová, hvězdicová, kruhová,
páteřní, software sítě , protokol, server, Internet, IP adresa
KONTROLNÍ OTÁZKY
1. Základní druhy sítí
2. Síťové protokoly
3. Vznik a důvody vzniku Internetu
4. Úloha serveru v síti
KONTROLNÍ TEST
Co to je topologie počítačových sítí a jaké rozeznáváte druhy sítí

39
VÝSTUPY Z UČENÍ
Po prostudování textu a vypracování úkolů v rámci této kapitoly
BUDETE UMĚT
Popsat pojem počítačová síť, její základní součásti, funkce a typologii.
Se orientovat v pojmech software sítě , protokol, server, Internet, IP adresa
ZNALOSTI
BUDETE SCHOPNI
Budete schopni definovat pojem počítačová síť.
Uvědomíte si výhody internetu, nevýhody internetu a využití internetu v
managementu
SCHOPNOSTI
ZÍSKÁTE
Přehled o důvodech vzniku počítačových sítí, a jejich základní funkcích a způsobech
práce.
DOVEDNOSTI

- 40 -
4. Informační systémy, charakteristiky, projektování provoz a
údržba
4.1. Charakteristika informačního systému
Informační systém je soubor lidí, technických prostředků a metod, zabezpečujících sběr,
přenos, uchování a zpracování dat za účelem tvorby a prezentace informací pro potřeby
uživatelů.
Norma ČSN/ISO IEC 23821:
„Informační systém je systém zpracování informací spolu s návaznými organizačními
prostředky (personálem, technickými prostředky). Takový systém získává a distribuuje
informace.“
Zákon č. 256/1992 Sb., o ochraně osobních údajů:
„Informační systémem se rozumí funkční celek, který zabezpečuje cílevědomé a
systematické shromažďování, zpracování, uchovávání a opětovné zpřístupňování informací.“
Informační systém by měl obsahovat:
tvorbu základní databáze na systémové úrovni, kdy soubory mají přesně definované
struktury, chráněné před nahlížením do jejich obsahu a především pak před neoprávněnou
změnou jejich obsahu, systém chránící integritu údajů a souborů, zaručující dokončení každé
transakce i při poruše počítače nebo výpadku elektřiny, jednotný systém výběru informací,
který pozná strukturu souborů a vazbu v nich uložených dat (systém přístupu k údajům a
výstupu požadovaných informací), současný přístup, který je sdílený k údajům v souborech
pro více uživatelů, kteří právě potřebují systém využívat ve stejnou dobu, prostředky pro
jednotnou, centralizovanou správu dat v souborech, které jsou jádrem, základem
informačního systému,
možnost vytváření složitých hierarchických datových struktur, propojujících údaje
z více souborů, kdy se odstraňuje redundance, ukrytí struktur souborů i mechanismu vybírání
údajů z nich podle požadavků, prostředky pro popis dat v jednotlivých souborech a vazeb
mezi nimi, což je relační systém.

41
4.2. Druhy informačních systémů
V rámci struktury členíme informační systémy podle různých hledisek:
Podle zdrojů informací
informace vnější
informace vnitřní
Podle vztahu k procesu řízení
direktivní
metodické
sdělovací
Ve vztahu k místu uložení
banky dat systému
vlastní vnitřní paměť pracovníků
Podle nositele dat
noviny, časopisy, patenty
elektronické banky dat počítačů
Podle věcného obsahu
bibliografické
referenční
faktografické
Podle příjemce informací
zpracovatelé přepracovávají informace do podoby využitelné zejména řídícími
subjekty v podobě direktivní či metodické informace sdělené manažerem
uživatelé, vykonavatelé využívají informací ke konkrétnímu účelu
EIS – Executive Information system
úlohy orientované na podporu vrcholového řízení organizace
podpora globálních a strategických rozhodnutí
zajišťuje výběr a zpracování nejdůležitějších dat ze všech podstatných oblastí
v organizaci
MIS – Management Information system
úlohy podporující zejména taktickou úroveň řízení a částečně i operativní úroveň
slouží středním řídícím vrstvám
řeší zejména logistické a personální činnosti

42
TPS – Transaction Processing System
úlohy spojené bezprostředně s informační podporou výrobních činností a služeb
slouží pro podporu operativního řízení
DSS – Decision Support System
úlohy podporující obvykle taktické rozhodování a opírající se o optimalizační a
simulační programy
používání tabulkových programů (spreadsheets)
Expertní systémy
založeny na systému pravidel, které pomáhají méně zkušeným pracovníkům při
řešení úloh diagnostického charakteru
využívání technologie umělé inteligence - AI
OIS – Office Information System
úlohy pro podporu individuální práce uživatele
podpora typických kancelářských činností
EDI – Electronic Data Interchange
úlohy zajišťující elektronickou výměnu dat
CIS – Customer Information System
informační podpora styku se zákazníky
RIS – Reservation Information System
úlohy podporující různé rezervace
4.3. Význam a způsoby budování informačních systémů
Dva důvody budování IS:
efektivnost informačního systému
okamžitá přístupnost veškerých potřebných informací
Postup budování informačního systému:
plánování (specifikace)
identifikace problémů, možností a cílů
definování informačních potřeb
analýza systémových potřeb
návrh doporučeného systému

43
vývoj a dokumentace softwaru
zavádění a testování
provoz a údržba
Způsoby budování informačního systému
nákupem hotového aplikačního programu
jeho vybudováním vlastními silami
zadáním projektu a jeho realizaci odborné firmě
nájem programového vybavení
4.4. Projektování, provoz a údržba informačních systémů
Strategie projektování IS:
Souběžná strategie
činnost starého systému pokračuje s novým několik týdnů či měsíců, dokud nový
systém nepracuje zcela spolehlivě
náročnost na pracovní kapacity
Pilotní strategie
systém se zavede jen v jednom oddělení a teprve po ověření se zavede naráz v celé
instituci
průběžné odstraňování problémů
Postupná strategie
použití u rozsáhlejších systémů se složitými vzájemnými vazbami
časově náročná
Nárazová strategie
starý systém ukončí činnost v pátek, sobota a neděle se věnuje přeměně a v
pondělí zahájí činnost systém nový
4.5. Etapy životního cyklu informačního systému
I. Předanalytická fáze
zadání požadavku

44
studie proveditelnosti
specifikace požadavků
II. Analýza (system analysis)
jedná se o modelování budoucího systému na konceptuální úrovni
III. Návrh (system design)
realizuje se modelování budoucího systému na technologické úrovni
IV. Vývoj systému (system development)
psaní a testování počítačového software
vývoj vstupních a výstupních formulářů a konvencí
V. Implementace systému
uvedení systému (hardware i software) do provozu
jeho instalace, školení operátorů a uživatelů
VI. Správa systému
další vývoj funkcí a struktury systému
dolaďování jeho výkonu
VII. Údržba systému
úprava systému při jeho provozování podle nově vzniklých požadavků uživatele
4.6. Typy životních cyklů vývoje systému
A. Vývojový cyklus „vodopád“
Analýza---návrh---vývoj---testování---instalace---provoz
přehlednost, jednoduchost, jasná posloupnost etap projektu
B. Fontánový typ
analýza---návrh---vývoj---testování---instalace---provoz
po dosažení vyšší etapy se vracíme k předchozí etapě řešení projektu -
minimalizace chyb v průběhu řešení
C. Přírůstkový vývojový cyklus
analýza---definice---specifikace---vývoj---instalace---provoz
architektury přírůstku přírůstku přírůstku

45
existuje zde zpětná vazba od uživatele
D. Síťový typ
dosahuje časových úspor umožněním současného řešení některých etap projektu
E. Spirálový typ
postupné zdokonalování systému dalšími verzemi
kombinace vodopádového modelu s přírůstkovým vývojem
Lidský faktor v informačních systémech
lidský činitel je rozhodující prvek informačního systému
na vzdělávání je nutné počítat nejméně s 10 % pracovní doby
je nutné se zabývat výchovou lidí, nejen jejich školením
4.7. Obecné, správní a policejní informační systémy
Obecné informační systémy – pomocí jich lze získat faktografické údaje pro práci
bezpečnostní resortu, hledat a ověřovat fakta pro vyšetřování a dokazování trestného činu,
nalezení a usvědčení pachatele. Mají různý charakter, formu uchovávání a zpracování
informací s různými věcnými a provozními gestory a možnostmi zpřístupnění.
Jedná se např. o informační systémy bank, pojišťoven, leasingových společností,
resortu sociální, zdravotního finančního, registr katastrů a nemovitostí, obchodní rejstřík,
informační systém právní podpory (ASPI, JURIX, atd.), elektronické knihovny, „otevřené
zdroje – tisk, knihy, jízdní řády, seznamy, Internet a další.
Civilně správní informační systémy – tyto systémy vedou orgány státu jako základní
informační zdroje pro výkon státní správy. Jedná se především o referenční databáze, které
obsahují základní identifikační údaje o osobách, dokladech, vozidlech, zbraních a atd.,
Patří sem: registr obyvatel, registr vozidel, evidence občanských průkazů, cestovních a
diplomatických pasů, řidičských oprávnění, zbrojních průkazů.
Údaje z těchto evidencí nejsou přístupné veřejnosti, jsou ale často sdíleny institucemi
státní správy. Jsou základem, určitým jádrem dalších informačních systémů, včetně systému
policejních a zpravodajských. Z těchto evidencí jsou pro potřeby ostatních informačních
systémů přebírány garantované identifikační údaje o osobách, dokladech, vozidlech a jiné.
Cílem je zjednodušení a zefektivnění základních informačních toků, zaručení vysoké kvality

46
dat, vyloučení duplicit, minimalizace nákladů na provoz informačních systému, úspora času
úřední, ale i občanů.
Policejní a zpravodajské informační systémy
Tyto systémy provozuje Policie ČR a další bezpečnostní služby při provádění
specifických činností, ke kterým jsou ze zákona příslušné.
Informační systému této kategorie jsou až na nepatrné výjimky mimo bezpečnostní
resort běžně nepřístupné. Toto je garantovány např. využitím jen v rámci vnitřní sítě, např. u
Policie ČR sítě „INTRANET“, kde je zabezpečeno přihlášení pouze registrovaného
pracovníka na základě jeho „loginu“ a hesla do systému.
Komponenty tvoří:
Evidence – tvoří je databázová struktura, je nutné znát předem jejich předmět, rozsah
a především účel, tedy možnost jejich následného využití. Jedná se např. o pátrací systémy
(po hledaných, pohřešovaných osobách, hledaných nebo odcizených věcech, uměleckých
předmětech, vozidlech atd.), evidence spáchaných trestných činů, událostí, nežádoucích
(cizinců), rozpracovaných nebo sledovaných osob, odcizených nebo ztracených zbraní,
dokladů, atd.. Předpokladem pro evidenční činnost je jednoznačná identifikace evidovaných
objektů (např. pomocí rodného čísla osoba).
Poznatkové fondy – cílený i náhodný sběr projevů trestných činů (např. stop), dat a
informací z různých šetření, operativního rozpracování nebo prověřování za pomoci policistů,
svědků, nestranných i nezúčastěných osob, informátorů, agenturní sítě atd.. Data a informace,
které jsou takto získány, nemusejí mít v okamžiku získání přesně definovanou, formátovanou
strukturu a nemusí být momentálně znám způsob jejich využití. Informace, které jsou
bezprostředně získány, mohou mít i subjektivní charakter, nemusí být prověřované (jsou
prověřovány následně pomocí specializované činnosti. Mnohé z poznatkových fondů je
možné zpracovávat s využitím moderních informačních technologií.
Specializované, laboratorní a expertní informační systémy – mají význam při
specifické činnosti, jejich charakter je převážně identifikační a analytický, vědecko-technický.
Patří sem např. informační technologie pro zpracování a analýzu obrazových, textových,
zvukových a dalších informací, pro identifikaci na základě otisků prstů, DNA, hlasu, portrétu
osoby, dále elektronické systémy biologické a chemické analýzy, systému na podporu
zpracování poznatků z trasologie, mechanoskopie, informační systémy, které umožňují
matematické, fyzikálně-technické modelování, soudní lékařství a inženýrství, analýzu

47
dopravních nehod apod.. Tyto informační systémy jsou provozovány vysoce
specializovanými pracovišti Kriminalistického ústavu, OKTE apod..
Podpůrné a manažerské IS
Podpůrné a manažerské informační systémy – pomocí jich dochází k zajištění
efektivity a automatizace výkonných, řídících a komunikačních činností policie a
bezpečnostních služeb. Patří sem systémy pro podporu rozhodování a velení, manažerské
informační systému, dále systému pro týlové, ekonomické a sociální zabezpečení (mzdy,
personální sféra, pojištění) – jedná se např. o systém EKIS (Ekonomický informační systém
MV ČR), elektronická pošta (e-mail), kancelářské systémy (MS Office, T602, WinText602
atd.). Uvádí se zde i Integrovaný záchranný systém, který spojuje a koordinuje činnost
policie, záchranné služby, hasičského sboru, civilní obrany atd.. K podpůrným systémům se
řadí i statistické nadstavby různých informačních systémů (evidencí, poznatkových fondů,
specializovaných, laboratorních nebo expertních systémů atd.). Tyto nadstavby pomáhají
vyhodnocovat a efektivně, ekonomicky řídit svěřenou profesní oblast, realizovat nejrůznější
prevence – např. Evidenčně statistický systém kriminality (ESSK), Evidence dopravních
nehod (EDN) atd.

48
SHRNUTÍ KAPITOLY
Informační systém - definice
je soubor lidí, technických prostředků a metod, zabezpečujících sběr, přenos, uchování
a zpracování dat za účelem tvorby a prezentace informací pro potřeby uživatelů.
Informační systém by měl obsahovat:
a) Tvorbu základní databáze na systémové úrovni
b) Systém chránící integritu údajů a souborů
c) Jednotný systém výběru informací
d) Současný sdílený přístup k údajům v souborech
e) Prostředky pro jednotnou, centralizovanou správu dat
f) Možnost vytváření složitých hierarchických datových struktur
g) Ukrytí struktur souborů i mechanismu vybírání údajů z nich
h) Prostředky pro popis dat v jednotlivých souborech
Typy informačních systémů :
EIS – Executive Information system
MIS – Management Information system
TPS – Transaction Processing System
DSS – Decision Support System
Expertní systémy
OIS – Office Information System
EDI – Electronic Data Interchange
CIS – Customer Information System
RIS – Reservation Information Systém
Etapy životního cyklu informačního systému:
Předanalytická fáze
Analýza (system analysis)
Návrh (system design)
Vývoj systému (system development)

49
Implementace systému
Správa systému
Údržba systému
Obecné, správní a policejní informační systémy
Obecné informační systémy
Civilně správní informační systémy
Policejní informační systémy

50
SEZNAM KLÍČOVÝCH SLOV K ZAPAMATOVÁNÍ
Informační systém, Předanalytická fáze, Analýza (system analysis), Návrh (system design),
Vývoj systému, (system development), Implementace systému, Správa systému, Údržba
systému
KONTROLNÍ OTÁZKY
1. Definujte Informační systém
2. Co obsahuje Informační systém
3. Jaké jsou etapy životního cyklu informačního systému
KONTROLNÍ TEST
Vyjmenujte a stručně charakterizujte druhy IS podle příjemce informací
Který prvek informačního systému bývá rozhodující

51
VÝSTUPY Z UČENÍ
Po prostudování textu a vypracování úkolů v rámci této kapitoly
BUDETE UMĚT
Definovat Informační systém
Obsah Informačního systému
Etapy životního cyklu informačního systému
ZNALOSTI
BUDETE SCHOPNI
Rozlišit informační systémy podle vztahu k managementu.
Pochopit základní problematiku bezpečnosti Informačních systémů
Definovat jednotlivé stupně tvorby, zavádění a realizace Informačního systému
SCHOPNOSTI
ZÍSKÁTE
Informace o základních druzích obecných, správních a policejních informačních
systémech. Získáte představu o postupu realizace informačního systému.
DOVEDNOSTI

52
5. Databáze
S rozvojem lidského poznání roste prudce množství informací, které tento proces vyžaduje a
také produkuje. Pro efektivní práci s informacemi začaly vznikat specializované informační
systémy. Můžeme je definovat např. jako : "systémy pro sběr, uchovávání, vyhledávání a
zpracovávání informací (údajů, dat) za účelem jejich poskytování". Tvorbou informačních
systémů se zabývá vědní obor Informatika, vydělený v nedávné době z oboru Kybernetika.
Rozvoj informačních systémů je úzce spjat s rozvojem výpočetní techniky, zejména počítačů.
Od svých počátků byla využívána na zpracování velkých informačních objemů na jednom
počítači. Takové systémy obvykle nazýváme systémy hromadného zpracování dat nebo
agendové zpracování.
Pojem databáze dnes není zcela jistě nikomu cizí. Lidé mají potřebu evidovat a
shromažďovat informace už odpradávna. Celá dnešní moderní společnost je postavena na
databázových systémech, od evidence občanů, přes zdravotnictví, hospodářství, školství až po
letectví, výzkum, nebo síť mobilních telefonů.
Databanka (banka dat), (neboli Datová základna) je určitá uspořádaná množina informací
(dat) uložená na paměťovém médiu. Data uložená v bance dat se označují jako báze dat či
databáze. Souhrn pravidel pro reprezentaci logické organizace dat v databázi je model dat.
Rozeznáváme tři základní modely dat - hierarchický, síťový a relační. Nejnovější a zároveň
nejpoužívanější je relační model, který odstraňuje některé nedostatky ostatních modelů.
Z hlediska způsobu ukládání dat a vazeb mezi nimi můžeme rozdělit databáze do
základních typů:
5.1. Typy databází
5.1.1. Souborové databáze
Způsob ukládání údajů lze provádět různým způsobem. Nejjednodušší je ten, jak ho
známe z běžného používání počítače. Jednotlivé soubory se ukládají do složek a tyto se
ukládají případně do dalších složek až do počtu vrstev, které považujeme za dostatečné,
abychom jednoznačně rozlišili zařazení příslušného souboru na to místo, kam dle našeho

53
uvážení patří. Tvoření souborové struktury je jednoduché a pro uživatele, který má smysl pro
pořádek je i dostatečné.
5.1.2. Hierarchické databáze
Historicky nejstarším modelem organizování báze dat je model hierarchický. V tomto modelu
jsou data organizována ve formě stromu. Každá entita umístěná v tomto stromu je
charakterizována svými specifickými atributy a dále atributy, které zdědila od své nadřízené
entity. Hierarchický model se dobře hodí pro popis systémů, které mají jasné definovanou
hierarchickou strukturu. V ostatních případech je ale dosti nepružný a těžkopádný.
5.1.3. Databáze objektové
– data sdružena spolu s funkcemi, nejsou zde tabulky, záznam je naprosto oddělený element,
nese všechny atributy, predikáty, funkce
- existuje zde hierarchie prvků – rodič – potomek
abstrakce = třída, konkrétní instrukce = objekt
- pohyb pomocí traverzování – nějak si zaměříme objekt a pomocí struktury * * se dostáváme
k jinému objektu
5.1.4. Síťové databáze
Síťový model dat je v podstatě zobecněním hierarchického modelu dat, který doplňuje
o mnohonásobné vztahy. Tyto vztahy jsou označovány jako C-množiny neboli Sets (dále
budeme používat pojem set, pro který neexistuje ekvivalentní český výraz). Tyto sety
propojují záznamy různého či stejného typu, přičemž spojení může být realizováno na jeden
nebo více záznamů.
Síťový model báze dat odstraňuje většinu nedostatků modelu hierarchického, ovšem za cenu
podstatně větších nároků na údržbu databáze.
5.1.5. Relační databáze
Nejmladším databázovým modelem je model relační, který byl popsán v roce 1970 Dr.
Coddem. V současnosti je tento model nejčastěji využíván u komerčních SŘBD. Relační
databázový model má jednoduchou strukturu (E-R model, entita-relace). Data jsou
organizována v tabulkách, které se skládají z řádků a sloupců.
Mezi tabulkami pak lze definovat různé vztahy - relace a provádět s nimi rozmanité operace.
Množina tabulek a vztahů pak vytvoří celou bázi dat.

54
5.2. Tabulkové vyjádření relace a její vlastnosti.
Na osobních počítačích se dnes provozují prakticky výhradně SŘBD s relační architekturou,
proto jí budeme věnovat větší pozornost. Základním pojmem je relace. Relaci, bez zavádění
jakékoliv matematické definice, si lze představit jako tabulku, která se skládá ze sloupců a
řádků.
Tabulka je základním stavebním kamenem pro budování celé databáze. Je nezbytné, aby
každá tabulka v databázi měla své jedinečné jméno.
Relační tabulka je definována jako relace. Množiny atributů jsou konečné a označují
jednotlivé charakteristické vlastnosti entit. Každá entita je přitom jednoznačně určena
hodnotami svých atributů. Nejpraktičtějším způsobem zápisu takovéto relace je tabulka.
Každý řádek tabulky odpovídá jedné entitě a každý sloupec jednomu atributu. Řádky tabulky
se někdy nazývají též věty, či záznamy (anglicky records), sloupce se nazývají atributy, pole,
či položky (anglicky fields).
Každý sloupec tabulky má své jednoznačné označení a má přiřazen typ, tedy množinu údajů,
které se v něm mohou vyskytovat. Je vhodné, aby každý řádek tabulky byl jednoznačně
identifikován hodnotou některého svého atributu. Takový atribut nazýváme klíčem relační
tabulky. S relačními tabulkami lze dělat některé základní operace a je možné používat
dotazovací jazyky pro dotazy na jejich obsah. Mezi operace s relačními tabulkami patří
filtrování (na základě logického dotazu), faktorizace (výsledná relační tabulka obsahuje jen ty
sloupce, které byly uvedeny v seznamu vstupních atributů), spojování tabulek (na základě
stejného atributu - položky), rozložení tabulky na několik menších. Soubor tabulek (relací)
pak tvoří celou databázi (relační schéma).
Primární klíč je taková podmnožina položek, která má nezávisle na čase tu vlastnost,
že jednoznačně identifikuje každý záznam relace. Z toho je zřejmé, že primární klíč relace je
neredundandní. V tabulce vždy existuje alespoň jeden primární klíč, který je v nejhorším
případě tvořen všemi položkami dané tabulky. Řada SŘBD umožňuje vytvořit zvláštní
položku, která nabývá hodnot pořadových čísel záznamů, v některých případech je tato
položka vhodná jako primární klíč.

55
5.3. Indexování dat
Klíčem, či klíčovou položkou nazýváme atribut relační tabulky, který jednoznačně určuje
entity v ní obsažené. V příkladě relační tabulky je takovou položkou položka ID (identifikační
číslo). Klíčovou položku lze často s výhodou využít při operacích s relačními tabulkami,
především při jejich spojování. Klíčová položka je často v databázi redundantní, je proto
vhodné, aby byla co nejjednodušší.
Rychlost a efektivita SŘBD do značné míry závisí právě na vhodně vyřešeném indexování
relačních tabulek.
5.4. Redundance dat
Pokud se v bázi dat objevují některé údaje vícekrát, říkáme jim údaje redundantní.
Redundance dat je obvykle nevítaný jev. Jejími negativními důsledky jsou zejména:
Nárůst objemu dat a tím i vetší požadavky na prostředky pro jejich údržbu
Hrozba porušení referenční identity (provázanosti a vztahů dat -> rozpory mezi daty)
Občas je však redundance do dat zavedena záměrně. Důvody mohou být například tyto:
Zabezpečení dat proti náhodné chybě
Zrychlení a zjednodušení přístupu k datům
Odkazy na data uložená v jiných tabulkách
Z popisu tabulkového vyjádření relace vyplývají tyto vlastnosti:
Homogenita sloupců - v každém sloupci jsou všechny položky stejného typu.
V relaci neexistují dva stejné řádky
Pořadí řádků je nevýznamné, protože jednotlivé řádky jsou identifikovatelné pomocí
primárního klíče
Pořadí sloupců (položek) je nevýznamné, protože sloupce jsou označeny názvem
položky
Nevýhody relačních DB :
nejsou schopny pracovat na úrovni jednotlivého prvku, protože výsledkem je vždy
tabulka,
nejlépe pracují s jednoduchými daty. Typy skalárního typu (čísla, řetězce znaků),
skalární typy by měly být pevně formátované,

56
problémem jsou složitá data, data, která mají proměnlivou délku – relace. Databáze
tato data rozloží do mnoha tabulek – definice pak vznikne spojením tabulek,
udržování konzistence dat – tím, že data jsou separovaná, rozbitá, je problém udržovat
konzistenci,
problémy RDB se řeší od 70. let způsobem řešení jsou postrelační databáze,
vznikly postupným vývojem RDB, kdy byly odstraněny nedostatky .
5.5. Systémy řízení báze dat
SŘBD je programový produkt, který slouží pro manipulaci s bází dat. SŘBD může být
prázdný, tedy použitelný pro libovolnou bázi dat, nebo přizpůsobený známé konkrétní
struktuře báze dat.
Prázdné SŘBD obsahují obvykle vývojové prostředí, tedy prostředky (programovací
jazyky) pro vytváření specializovaných SŘBD. SŘBD často obsahují prostředky pro snadnou
údržbu údajů v bázi dat, pro jejich vstup pomocí uživatelských obrazovek a výstup pomocí
výstupních sestav.
Mezi nejrozšířenější SŘBD pro osobní počítače s operačními systémy MS-DOS a Windows
patřili systémy dBASE, FoxBase, FoxPro (americké produkty) a Paradox. Pro správu
rozsáhlejších bázi dat se používají obvykle SŘBD pracující na vyšších platformách, obvykle
pod operačním systémem UNIX. Sem patří například SŘBD Informix, Progress a Oracle
Tento systém byl původně určen pro velké počítače, později byl přenesen na počítače osobní.
První SŘBD, které vznikaly na konci 60. let, se vyznačovaly úzkou provázaností fyzického
a logického formátu dat. U novějších SŘBD pak dochází k hierarchickému rozvrstvení dat do
těchto úrovní, přičemž jednotlivé úrovně jsou relativně nezávislé. Nejdůležitější je zejména
nezávislost logického schématu báze dat od interního a fyzického schématu.
Fyzické schéma - úzce souvisí s použitým operačním systémem (konkrétní organizace
souborů na disku, jejich rozložení na sektory a clustry určité délky atd.).
Interní schéma - data jsou uložena v typových souborech, přístup k jednotlivým větám
souborů je organizován vhodným mechanismem (primární a sekundární indexy, Bayerovy
stromy atd.).
Logické schéma - vzniká implementací konceptuálního modelu do konkrétního SŘBD (návrh
struktury datových vět). Struktura tohoto schématu je určena použitým datovým modelem v
daném SŘBD (hierarchický, síťový, relační).

57
Externí schéma - je rozdílné pro každou skupinu uživatelů. Umožňuje virtuální pohledy
na zvolenou část báze dat (pomocí konkrétních formulářů, výstupních sestav, ale také
přístupových práv k datům).
Počítačové systémy, na kterých jsou provozovány databáze lze rozdělit do následujících
základních kategorií, čili platforem:
Centralizované databáze.
Systémy na sítích osobních počítačů.
Databáze v lokální síti PC (File server).
Databázové systémy klient/server.
Databáze naWEBu.
Systémy distribuovaného zpracování.
Sama architektura SŘBD nemusí rozhodovat, ve které kategorii se bude databázový systém
provozovat.
Některé architektury jsou pro některé platformy vhodnější nebo obvyklejší.
5.5.1. Centralizované databáze
V centralizovaném systému se na hlavním hostitelském počítači zpracovávají všechny
programy: SŘBD, databázovou aplikaci i komunikační software (data mezi počítačem a uživ.
terminály). V této architektuře jsou data i SŘBD v centrálním počítači. Tato architektura je
typická pro terminálovou síť, kdy se po síti přenáší vstupní údaje z terminálu na centrální
počítač do příslušné aplikace, výstupy z této aplikace se přenáší na terminál. Protože aplikační
program i vlastní zpracování probíhá na centrálním počítači, který může zpracovávat více
úloh, mají odezvy na dotazy určité zpoždění (viz obr č.1).
Obr. č. 1 Architektura centralizovaného zpracování

58
Základní výhody centralizovaných systémů:
Centrální zabezpečení dat.
Schopnost uložení obrovského množství dat na vnějších pamětech.
Podpora současné práce velkého množství uživatelů (až 1000).
Nevýhody:
Vysoké náklady na pořízení a údržbu (klimatizace, …) i provozní náklady (vyžadují
vysoce kvalifikované operátory a systémové programátory).
V poslední době stále častější přechod na minipočítače nebo výkonné servery na bázi
PC – levnější pořizovací i provozní náklady a přechod na systémy distribuované.
SŘBD, který běží na hostitelském systému, může být založen na kterémkoliv ze čtyř
modelů, nejčastěji hierarchický a relační.
5.5.2. Systémy na sítích osobních počítačů.
Běží-li SŘBD na PC, pracuje PC současně jako hostitelský počítač i jako terminál
(funkce SŘBD a databázových aplikací spojeny do jednoho programu).
Databázové aplikace na PC zpracovávají
vstup od uživatele
výstup na obrazovku
přístup k datům na disku
SŘBD tím získá značnou mohutnost, flexibilitu a rychlost za cenu snížení bezpečnosti
integrity dat.
PC se propojují do lokálních sítí (LAN – Local Area Network).
V LAN jsou data uložena na serveru souborů (File server).
PC pracují pod speciálním operačním systémem NOS (Network Operating System),
např. Novell NetWare, Microsft LAN Manager.
Server zajišťuje uživatelům lokální sítě sdílený přístup k datům (viz příslušnou
kapitolu těchto přednášek) na jeho pevných discích, popřípadě i sdílený přístup k periferním
zařízením (tiskárny).

59
5.5.3. Databáze v lokální síti PC (File server).
Tato metoda souvisí zejména s rozšířením osobních počítačů a sítí LAN. SŘBD a příslušné
databázové aplikace jsou provozovány na jednotlivých počítačích, data jsou umístěna na file-
serveru a mohou být sdílena. Aby nedocházelo ke kolizím při přístupu více uživatelů k
jedněm datům, musí SŘBD používat vhodný systém zamykání (položek nebo celých tabulek).
Komunikace uživatele se systémem probíhá následujícím způsobem:
uživatel zadá dotaz,
SŘBD přijme dotaz, zasílá požadavky na data file-serveru,
file-server posílá bloky dat na lokální počítač, kde jsou data zpracovávána podle
zadaného dotazu (vyhledávání, setřídění atd.),
výsledek dotazu se zobrazí se na obrazovce osobního počítače (viz obr č.2).
Obr. č. 2 Architektura systému file server
Činnost systému File server.
Veškeré vlastní zpracování dat se provádí na PC, kde běží databázová aplikace.
Server souborů vyhledává na discích data, žádaná uživatelem a posílá je po síťovém
médiu (např. Koaxiálním kabelu) na uživatelovo PC. Data jsou zpracovávána SŘBD na tomto
PC.
Každá změna v databázi vyžaduje, aby PC poslalo celý soubor zpět na server.
Hlavní nevýhody systému File server:
Bez ohledu na rychlost serveru je výkonnost systému limitována výkonem PC, na
němž běží vlastní SŘBD.
Pracuje-li s databází více uživatelů, musí server poslat tytéž soubory na každé PC,
které je používá. Tento zvýšený provoz může práci sítě zpomalit.
Víceuživatelský SŘBD musí mít schopnost vypořádat se se současnými změnami dat,
prováděnými více uživateli.

60
Většina dnešních SŘBD jsou prostě víceuživatelské verze běžných databázových
systémů většinou relačního modelu.
5.5.4. Databázové systémy klient/server
V podstatě je založena na lokální síti (LAN), personálních počítačích a databázovém serveru.
Na personálních počítačích běží program podporující např. vstup dat, formulaci dotazu atd.
Dotaz se dále předává pomocí jazyka SQL (Structured Query Language) na databázový
server, který jej vykoná a vrátí výsledky zpět na personální počítač. Databázový server je tedy
nejvíce zatíženým prvkem systému a musí být tvořen dostatečně výkonným počítačem. Celá
komunikace probíhá tímto způsobem:
uživatel zadává dotaz (buď přímo v SQL, nebo musí být do tohoto jazyka
přeložen),
dotaz je odeslán na databázový server,
databázový server vykoná dotaz,
výsledek dotazu je poslán zpět na vysílací počítač, kde je zobrazen.
Architektura klient-server redukuje přenos dat po síti, protože dotazy jsou prováděny přímo
na databázovém serveru a na personální počítač jsou posílány pouze výsledky. Např. pokud je
mezi 10 000 záznamy pouze 100 záznamů, které splňují podmínku dotazu, pak na personální
počítač putuje pouze těchto 100 záznamů. V případě architektury file-server je však nutné
poslat všech 10 000 záznamů na personální počítač, tam se teprve provede dotaz a zpracuje
nalezených 100 záznamů.
Architektura klient-server vyhovuje i náročným aplikacím a je využívána většinou
renomovaných databázových firem (viz obr č.3).
Obr. č. 3 Architektura client-server

61
Kromě jazyka SQL, který představuje standardní dotazovací jazyk, existují ještě další
standardy pro navazování komunikace mezi aplikacemi ještě před vlastním zahájením
komunikace v SQL
Databáze pracující s SQL jsou založeny na modelu klient - server. Na server lze pohlížet ze
dvou úhlů. Server je vybraný stroj v naší firmě, na kterém je nainstalovaný databázový systém
a na jeho discích jsou uložena naše data. Na druhou stranu je server proces (program), který
běží na zvoleném počítači a který obsluhuje jednotlivé požadavky klientů. Klienti zadávají
SQL příkazy a server tyto příkazy nad databází vykonává. Klientem pak může být konkrétní
databázová aplikace, nebo také řádkový terminál, ve kterém můžeme SQL příkazy zadávat
přímo.
5.5.5. Systémy distribuovaného zpracování
Velmi rozsáhlé databáze se občas nachází na několika různých počítačích. Uživateli se však
jeví jako jedna velká databáze. Takovým databázím se říká databáze distribuované.
Distribuovanou databázi je možno využívat prostřednictvím počítačové sítě. V celosvětové
počítačové síti Internet existuje celá řada distribuovaných databází. Pro práci s distribuovanou
databází je potřeba použít zvláštní metody a specializované systémy pro řízení báze dat.
Příkladem takového systému může být Gupta SQL.
Distribuovanou databázi charakterizujeme třemi vlastnostmi:
1. Transparentnost - z pohledu klienta se zdá, že všechna data jsou zpracovávána na
jednom serveru v lokální databázi. Uživatel používá syntakticky shodné příkazy
pro lokální i vzdálená data, nespecifikuje místo uložení dat, o to se stará distribuovaný
SŘBD.
2. Autonomnost - s každou lokální bází dat zapojenou do distribuované databáze je
možno pracovat nezávisle na ostatních databázích. Lokální databáze je funkčně
samostatná, propojení do jiné části distribuované databáze se v případě potřeby
zřizují dynamicky. V distribuované databázi neexistuje žádný centrální uzel nebo
proces odpovědný za vrcholové řízení funkcí celého systému, což výrazně zvyšuje
odolnost systému proti výpadkům jeho částí.
3. Nezávislost na počítačové síti - jsou podporovány různé typy architektur lokálních i
globálních počítačových sítí (LAN, WAN). V jedné distribuované databázi tedy
mohou být zapojeny počítače i počítačové sítě různých architektur, pro komunikaci
se používá jazyk SQL.

62
Požadavek, aby data byla uložena na jediném počítači může vyvolat problémy, jsou-li
podporovaní uživatelé rozptýleni po velkém území. Je nutno najít nějaký způsob rozdělení dat
mezi různými počítači nebo lokalitami - distribuované zpracování.
Pojem distribuované databázové systémy – relativně nový.
Jejich rozvoj umožněn dynamickým rozvojem sítí v poslední době. Názvosloví není
zcela ustálené. Hlavní součást je SŘDBD. Umožňuje transparentní přístup k datům, která jsou
distribuována na množství mnohdy značně vzdálených lokálních databázových serverů.
Typický postup v SŘDBD:
Uživatel požádá o data hostitelský lokální počítač.
Zjistí-li se, že požadovaná data na tomto počítači nejsou, pošle se po síti požadavek na
počítač, kde data jsou. V případě, že se najdou jsou uživateli zaslána, aniž by se uživatel
dozvěděl odkud jsou.
5.6. Sdílený přístup k datům.
Ve víceuživatelském prostředí, v aplikaci, která bude pracovat na více počítačích v síťovém
prostředí bude několik uživatelů nezávisle na sobě pracovat se stejnými daty (databází),
přičemž každý z nich může data nejen číst, ale i je měnit, zavádět, případně i rušit.
Ve víceprocesovém prostředí (multiprocessing). Aplikaci bude využívat sice jen jeden
uživatel, ale implementace aplikace mu dovolí, aby v jejím rámci spouštěl současně různé
úlohy, které mohou (např. v uživatelském interfejsu používat konstrukty (objekty, např.
formuláře), které budou pracovat nad stejnými daty.
Tyto požadavky je možno splnit řadou opatření, která jsou vykonávána většinou až na nejnižší
úrovně implementace aplikace, při nedokonalém nebo neodborném provedení však mohou
způsobit totální selhání aplikace v praktickém provozu.
Techniky, které požadavky na sdílený přístup k datům mohou splnit je např:
Selektivní otevírání souborů.
Jde o starší způsob, kterého využívaly hlavně systémy ovládání souborů, hostující
v programovacích jazycích třetí generace.
Většinou se postupuje takto:
Uživatelé se roztřídí na ty, kteří mohou data pouze číst, ti pak mohou příslušné soubory
otevírat pouze pro čtení, a na ty, kteří je mohou i měnit. Ti pak mohou otevřít příslušný
soubor pro čtení i zápis. U takových uživatelů, se použije následující pravidlo:

63
Každý soubor může být v jednom okamžiku otevřen libovolným počtem uživatelů pro čtení,
ale pro zápis pouze jedním z nich (s příslušným právem). Eventuální požadavek na další
otevření pro zápis je systémem odmítnut.
Výhody:
Jednoduchý a přehledný způsob, vhodný pro jednoduché aplikace, případně pro různé
informační systémy, jejichž úkolem je poskytovat informace velkému počtu uživatelů,
přičemž změny se provádějí občas z jednoho místa.
Nevýhody:
Vyžaduje striktní organizační provozní pravidla. U složitějších aplikací je málo efektivní.
Je závislý na kázni uživatelů, kteří musí soubory po ukončení změn v datech uzavírat, jinak
žádný uživatel se ke změnám nedostane.
Z toho důvodu je systém náchylný k “zamrzání”.

64
SHRNUTÍ KAPITOLY
Z hlediska způsobu ukládání dat a vazeb mezi nimi rozdělujeme databáze do tří
základních typů podle organizace dat, neboli modelů dat v nich uložených. Datový model je
souhrn pravidel pro reprezentaci logické organizace dat v databázi. Rozeznáváme tři
základní modely dat - hierarchický, síťový a relační. Nejnovější a zároveň nejpoužívanější
je relační model, který odstraňuje některé nedostatky ostatních modelů.
Databáze jako pojem je slovo poměrně lehce zavádějící, ale zde jím budeme rozumět skupinu
informací uspořádaných podle určitých pravidel tak, aby následná práce s nimi byla co
nejdokonalejší.
Z hlediska způsobu ukládání dat a vazeb mezi nimi můžeme rozdělit databáze do
základních typů:
Souborové databáze
Způsob ukládání údajů lze provádět různým způsobem. Nejjednodušší je ten, jak ho známe z
běžného používání počítače. Jednotlivé soubory se ukládají do složek a tyto se ukládají
případně do dalších složek až do počtu vrstev, které považujeme za dostatečné, abychom
jednoznačně rozlišili zařazení příslušného souboru na to místo, kam dle našeho uvážení patří.
Tvoření souborové struktury je jednoduché a pro uživatele, který má smysl pro pořádek je i
dostatečné.
Hierarchické databáze
Historicky nejstarším modelem organizování báze dat je model hierarchický. V tomto modelu
jsou data organizována ve formě stromu. Každá entita umístěná v tomto stromu je
charakterizována svými specifickými atributy a dále atributy, které zdědila od své nadřízené
entity. Hierarchický model se dobře hodí pro popis systémů, které mají jasné definovanou
hierarchickou strukturu. V ostatních případech je ale dosti nepružný a těžkopádný.
Síťové databáze
Síťový model dat je v podstatě zobecněním hierarchického modelu dat, který doplňuje
o mnohonásobné vztahy. Tyto vztahy jsou označovány jako C-množiny neboli Sets (dále
budeme používat pojem set, pro který neexistuje ekvivalentní český výraz). Tyto sety
propojují záznamy různého či stejného typu, přičemž spojení může být realizováno na jeden
nebo více záznamů.

65
Relační databáze
Nejmladším databázovým modelem je model relační, který byl popsán v roce 1970
Dr. Coddem. V současnosti je tento model nejčastěji využíván u komerčních SŘBD. Relační
databázový model má jednoduchou strukturu (E-R model, entita-relace). Data jsou
organizována v tabulkách, které se skládají z řádků a sloupců. Všechny databázové operace
jsou prováděny na těchto tabulkách.
Systémy řízení báze dat
SŘBD je programový produkt, který slouží pro manipulaci s bází dat. SŘBD může být
prázdný, tedy použitelný pro libovolnou bázi dat, nebo přizpůsobený známé konkrétní
struktuře báze dat.
Prázdné SŘBD obsahují obvykle vývojové prostředí, tedy prostředky (programovací
jazyky) pro vytváření specializovaných SŘBD. SŘBD často obsahují prostředky pro snadnou
údržbu údajů v bázi dat, pro jejich vstup pomocí uživatelských obrazovek a výstup pomocí
výstupních sestav.
Výhody a nevýhody jednotlivých modelů dat
Historicky se vyvinuly tři hlavní databázové modely, a to síťový, hierarchický a
relační. Nejstarší z uvedených je hierarchické modelování databází. Toto pojetí pochází z
reálného uspořádání světa. Jako příklad si můžeme vzít třeba model organizace moci, rozklad
výrobků na součástky, strom adresářů aj. Pro hierarchické modelování je typická práce se
stromy, kdy ve stromu jsou realizovány vztahy 1:N.
Variací hierarchického modelu je síťový model databáze. V síťovém modelování je
možné vyjadřovat vedle vztahů 1:N i vztahy M:N. Fyzická realizace síťového modelu je ale
náročná a aktualizace obvykle komplikovaná.
Základní výhodou hierarchického a síťového modelu je efektivnost zpracování, tj.
rychlost přístupu k datovým záznamům. Na druhé straně mezi nevýhody patří to, že je
nesnadné jednou nadefinované stromy a vazby mezi nimi měnit. Nejsou uzpůsobeny pro
dotazy.
Z teoretického hlediska je nejpropracovanější relační model databáze, který byl
vyvinut doktorem E. F. Coddem už v šedesátých letech minulého století.
Relační model definuje způsob, jakým je možné reprezentovat strukturu dat, způsoby
jejich ochrany a operace, které můžeme nad daty provádět. Relační databáze je sestavená z
řady tabulek, jejichž sloupce jsou vázány na sloupce v jiných tabulkách. Takto propojená

66
datová pole jsou na sobě určitým způsobem závislá. Jejich vztahy jsou založeny na klíčových
hodnotách uložených v příslušných sloupcích.
U relačních databází je základní výhodou relativně snadná modifikace a propojování
tabulek a s nimi spojená možnost dotazů. Slabým místem je nízká efektivnost zpracování, což
se projevuje v tom, že řada příkazů vyžaduje velké množství přístupů na disk a tím se
zpomaluje zpracování.

67
SEZNAM KLÍČOVÝCH SLOV K ZAPAMATOVÁNÍ
Datový model, hierarchický, síťový a relační, Databáze, Systémy řízení báze dat, normalizace
dat, Distribuovaná databáze, Entita, Atribut entity, Indexování dat, Redundance dat
KONTROLNÍ OTÁZKY
1. Co to je databáze
2. Na kterých základních typech počítačových systémů jsou provozovány databáze
3. Co to je normalizace dat
KONTROLNÍ TEST
Uveďte základní typy vazeb mezi entitami

68
VÝSTUPY Z UČENÍ
Po prostudování textu a vypracování úkolů v rámci této kapitoly
BUDETE UMĚT
Znát základní typy databází a jejich postupný vývoj. Rozeznáte základní
modely dat v databázi. Budete informováni o úloze systému řízení báze dat,
distribuovaném zpracování a základech jazyků pro popis dat.
Budete znát pojmy Indexování dat a Redundance dat
ZNALOSTI
BUDETE SCHOPNI
Orientovat se v problematice ukládání dat v databázích, v problematice
nástrojů umožňujících zpracování dat v databázi uložených.
SCHOPNOSTI
ZÍSKÁTE
Přehled o systémech používaných pro uložení a práci s daty v databázích
uložených
DOVEDNOSTI

69
6. Datové sklady – budování a způsoby práce
Pojem datový sklad (DW – Data Warehouse) se během posledních několika let
nesmazatelně zabydlel v povědomí uživatelů informačních systémů (IS). Datový sklad je
správně chápán jako nezbytná nadstavba provozních IS, pomocí které pracovníci
managementu snadno a rychle získávají ve velmi přehledné podobě informace pro sumární
analýzu dat, odhalování skrytých souvislostí, sledování trendů v různých oblastech apod.
Pod pojmem „datový sklad“ můžeme chápat „Komplexní data uložená ve
struktuře, která umožňuje efektivní analýzu a dotazování.
Data do datového skladu jsou čerpána z primárních informačních systémů a dalších
zdrojů.
Využití dobře navrženého datového skladu není jen záležitost pro pracovníky
vrcholového managementu. Je naléhavě potřeba přiblížit možnosti využití datových skladů i
uživatelům mimo vrcholový management a to zcela obecně v různých podnicích a na různých
úrovních.
V rámci provozních IS jsou v současné době ve většině podniků spravovány více či
méně rozsáhlé databáze. Pro tyto databáze lze, v podstatě bez ohledu na typ firmy, najít
některé společné rysy:
databáze bývají často velmi rozsáhlé
struktura je optimalizována na transakční způsob zpracování v reálném čase
historická data bývají archivována odděleně od dat provozních
historická data jsou často "on line" nedostupná
- v podnicích často existují různorodá data z období provozování různých IS
Pro prezentaci takto spravovaných prvotních dat jsou v různých IS k dispozici různé
prostředky v podobě výstupních sestav či reportovacích nástrojů. Jejich společným rysem je
to, že požadované údaje získávají z provozní databáze. To způsobuje, že vstupní údaje pro
požadované výstupy mohou být obtížně dostupné a jejich získání ve formě různých reportů se
stává problematickou záležitostí.
6.1. Data v datovém skladu
Uložení dat v datovém skladu se v porovnání s ukládáním dat v provozních IS řídí
poněkud odlišnými pravidly. Hlavním důvodem je, že v datovém skladu je třeba mít

70
k dispozici data vyčištěná a také co do struktury uložená jinak než v provozním IS.
Zdánlivým paradoxem je, že objem dat, uložených v datovém skladu, může být i podstatně
větší než v prostředí provozního IS. Díky stavu na poli HW se tato skutečnost postupně stává
méně závažnou a do popředí vystupují přínosy, které toto navýšení poskytuje.
6.2. Budování datového skladu
Na úrovni datového skladu je výhodné mít k dispozici primární databázi. Údaje v této
primární databázi jsou do značné míry shodné s daty v databázi provozních IS. Pro vytvoření
primární databáze vede několik závažných důvodů:
do primární databáze jsou ukládána data vyčištěná a plně verifikovaná
ukládaná data mohou pocházet z různých IS (sjednocení zdrojů)
do primární databáze mohou být ukládána i historická data
vytvořením primární databáze je v prostředí datových skladů k dispozici potřebná
detailní úroveň informace
primární databáze může být provozována v odlišném prostředí (server, databázový
stroj) než databáze provozního IS
převážná většina činností nad primární databází v datovém skladu nezatěžuje databázi
provozního IS
aktualizace primární databáze se provádí v době minimálního zatížení provozního IS
aktualizace primární databáze se provádí s minimální účastí uživatele (řešení
nejednoznačných či chybových stavů)
Vytvořením primární databáze tak získáme v datovém skladu jednotnou datovou
základnu pro další využití.
Data jsou v datovém skladu obvykle udržována v historické podobě, nikoliv pouze v
aktuálním stavu.
U běžné relační databáze je obvyklá snaha o co nejmenší redundanci (nadbytek)
uložení dat, které je dosahováno jejich normalizací do 3NF a vnitřním provázáním
jednotlivých logických funkčních celků. V datovém skladu je naproti tomu řešení vždy
vedeno snahou o jasnou vnitřní separaci jednotlivých funkčních celků – výsledkem je
struktura, která je čitelnější pro uživatele (manažera, business analytika) za cenu zvýšených
nároků na paměťový prostor.

71
Běžná provozní aplikace (program) nad relační databází řeší určitý specifický okruh
úloh nad „svými“ specifickými daty. V datovém skladu je třeba naproti tomu shromáždit
informace z mnoha různých zdrojů a seskupit je nikoliv podle původu, ale podle logického
významu (úzce souvisí s orientací na subjekt – všechna data týkající se určité funkční oblasti
potřebuji mít „na jedné hromadě“ bez ohledu na to, odkud pocházejí).
Data jsou do datového skladu obvykle nahrávána ve větších dávkách (například v
denních nebo týdenních intervalech) a pak již nejsou nijak modifikována. To má za následek
nízkou proměnlivost.
Data jsou v datovém skladu obvykle udržována v historické podobě, nikoliv pouze v
aktuálním stavu. To je dáno nutností provádění analýz zaměřených na vývoj v čase. V běžné
relační databázi je z pohledu uživatelů obvykle zajímavý pouze aktuální stav datových
objektů.
Do datového skladu se většinou nepřebírají všechna data provozního informačního
systému, ale pouze určité podoblasti, které mají být předmětem dalšího zkoumání. V primární
databázi datového skladu jsou data stále ještě uložena relačním způsobem a jde vlastně o
jakýsi obraz vybrané části provozního systému s tím rozdílem, že se zde uchovávají data
včetně historie.
Realizace datového skladu není jednoduchou záležitostí. Informace pro rozhodování na
nejvyšší úrovni jsou často čerpány z různých navzájem neprovázaných informačních systémů.
Úkolem datového skladu je tyto systémy zkonsolidovat, doplnit chybějící data, přepsat nebo
vyloučit chybné údaje a vyřešit údržbu dat v čase. Přesto, že dnes je již oblast datových
skladů poměrně dobře prozkoumána a je definována metodika řešení nejčastěji se
vyskytujících problémů, zůstává budování datového skladu pro firmu závažným rozhodnutím,
které ji spojí s dodavatelem řešení datového skladu v mnoha případech na několik let, kdy se
postupně sklad rozšiřuje a doplňuje o další a další oblasti.
Oblastí, ve které se při implementaci datového skladu stráví nejvíce času, je vytváření
datových pump, neboli ETL skriptů (Extraction, Transformation and Loading), které
přesouvají data z primárních informačních systémů do datového skladu. Z několika důvodů
nelze pro tvorbu těchto skriptů využít pouze jazyka SQL:
dotazovaná data se často nacházejí v různých databázích, dokonce na různých
platformách.

72
transformace potřebné pro výpočty obchodních ukazatelů jsou často natolik složité, že
konstrukty SQL na ně nestačí a je nutné použít procedurálního jazyka s proměnnými,
cykly a rozhodovacími příkazy.
je nutné dohledávat cizí klíče v číselníkových tabulkách, generovat umělé klíče
tabulek a zpracovávat chybějící a nesprávná data.
Všechny výše uvedené důvody a mnohé další vedly k vytvoření specializovaných
nástrojů pro extrakci, transformaci a ukládání dat – datových pump ETL.
6.3. Datové sklady a OLAP
V literatuře bývá někdy synonymem pro datové sklady zkratka OLAP, která pochází ze
slov „on-line analytical processing“ a znamená okamžité zpracování dat. Spíše bychom pod
tím měli rozumět pružné (rychlé) zpracování dotazů a analýz.
Celý systém datového hospodaření lze obecně rozdělit na dvě základní části. První z nich je
OLAP, což je analytické zpracování dat.Na druhé straně stojí klasické databázové systémy,
které se označují jako OLTP, což je zkratka „on-line transaction processing“ neboli „okamžité
zpracování transakcí“. Hlavním účelem provozních informačních systémů je podpora
každodenních elementárních operací a činností v daném podniku a zajištění informační
provázanosti a integrace jednotlivých částí nebo oblastí činnosti.
Rozdílnost mezi OLAP a OLTP spočívá v tom, že OLTP systémy uchovávají záznamy
o jednotlivých uskutečněných transakcích a jsou obvykle realizovány pomocí dnes
nejběžnější – relační – databázové technologie. Data uchovávaná v OLTP databázovém
systému jsou (zpravidla periodicky) agregována (typicky sumarizována) a poté ukládána do
datového skladu, nad nímž se posléze podle potřeb provádí okamžité zpracování analýz
pomocí vrstvy OLAP.
Ve architektuře DW rozlišujeme následující vrstvy:
a) spodní – do této vrstvy patří server skladu, na kterém jsou uloženy relační databáze.
Této vrstvě odpovídá položka „Datový sklad“.
b) prostřední – tato vrstva zahrnuje OLAP server, který obvykle implementuje buď
relační OLAP model (ROLAP), což je rozšířený relační DBMS, který převádí operace nad
multidimenzionálními daty na standardní relační operace. Druhou možností je
multidimenzionální OLAP (MOLAP), který přímo umí pracovat s multidimenzionálními daty
a operacemi. Tato vrstva koresponduje s „Aplikační vrstvou“ ve schématu (viz obr. č. 1).
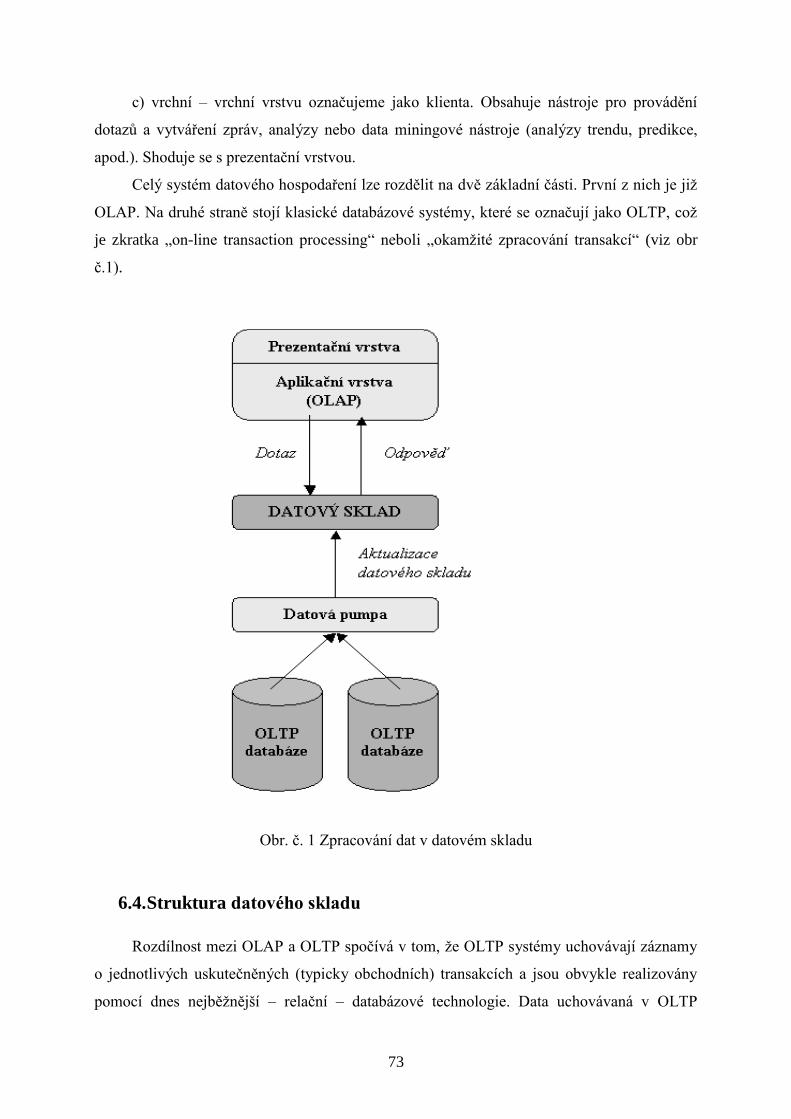
73
c) vrchní – vrchní vrstvu označujeme jako klienta. Obsahuje nástroje pro provádění
dotazů a vytváření zpráv, analýzy nebo data miningové nástroje (analýzy trendu, predikce,
apod.). Shoduje se s prezentační vrstvou.
Celý systém datového hospodaření lze rozdělit na dvě základní části. První z nich je již
OLAP. Na druhé straně stojí klasické databázové systémy, které se označují jako OLTP, což
je zkratka „on-line transaction processing“ neboli „okamžité zpracování transakcí“ (viz obr
č.1).
Obr. č. 1 Zpracování dat v datovém skladu
6.4. Struktura datového skladu
Rozdílnost mezi OLAP a OLTP spočívá v tom, že OLTP systémy uchovávají záznamy
o jednotlivých uskutečněných (typicky obchodních) transakcích a jsou obvykle realizovány
pomocí dnes nejběžnější – relační – databázové technologie. Data uchovávaná v OLTP

74
databázovém systému jsou (zpravidla periodicky) agregována (typicky sumarizována) a poté
ukládána do datového skladu, nad nímž se posléze podle potřeb provádí okamžité zpracování
analýz pomocí vrstvy OLAP.
Datový sklad je na rozdíl od OLTP databáze určen výhradně ke čtení dat pro potřeby
nejrůznějších analýz. Jedinou výjimkou jsou (obvykle periodické) aktualizace datového
skladu, tj. přidávání nových datových agregátů či odstraňování již neaktuálních datových
agregátů, které probíhají obvykle periodicky každý týden, měsíc, atp.
Tyto akce je ovšem možno chápat za součást údržby datového skladu, která probíhá ve
speciálním režimu při momentálním vyloučení zpracování OLAP požadavků uživatelů
datového skladu. V běžném režimu práce (tzn. při provádění dotazů a analýz) není obsah
datového skladu modifikován. Tento zásadní rozdíl mezi OLTP systémy a datovými sklady
má rozsáhlé důsledky pro způsob jeho implementace, návrhu a tvorby konceptuálního
modelu, který je orientován na dosažení co nejrychlejšího zpracování dotazů kladených
datovému skladu vrstvou OLAP.
Data v datovém skladu jsou z logického (uživatelského) pohledu členěna do schéma
(topologické uspořádání). Každé schéma odpovídá jedné analyzované funkční oblasti.
Schéma obsahuje dva typy tabulek – faktové a dimenzionální. Jádro každého schématu tvoří
jedna nebo několik faktových tabulek. V nich jsou uložena vlastní analyzovaná data -
veličiny, které sledujeme (hodnoty,které jsou použity k analytickým výpočtům - agregacím,
třídění apod.). Většina paměťového místa v datovém skladu zabírají faktové tabulky, které
obsahují detailní údaje ze všech zdrojů, tedy řádově více údajů než ostatní tabulky.
S faktovou tabulkou je spojena granularita. Faktové tabulky jsou pomocí cizích klíčů
spojeny s dimenzemi. Dimenze jsou tabulky, které obsahují seznamy hodnot sloužících ke
kategorizaci a třídění dat ve faktových tabulkách (atributy, prostřednictvím kterých se
„díváme“ na data). Je to vlastně číselník, podle kterého chceme data analyzovat.
Vlastnosti dimenzí:
a) Dimenze určují úhel pohledu – čas, produkt, zákazník…
b) Dimenze udržují hierarchie (vztah 1:N)
c) Vztah mezi faktovou tabulkou a dimenzemi je 1:N
Datový sklad je založen na multidimenzionálním datovém modelu. S takto uloženými
daty lze následně pracovat jako s tzv. datovou kostkou (cube). Datová kostka může mít větší
množství rozměrů (dimenzí). Dimenze kostky reprezentují rozdílné kategorie pro analýzu dat.
Kategorie jako například čas, geografické umístění nebo různé výrobkové řady jsou

75
typickými dimenzemi v datových kostkách. Kostky nejsou omezeny na tři dimenze. Např.
kostky vytvořené v MS OLAP services mohou obsahovat až 64 dimenzí.
Dimenze jsou obvykle uspořádány do hierarchií tak, že mapují sloupce v relačních
databázích. Hierarchie dimenzí jsou seskupovány do úrovní obsahujících hodnoty dané
dimenze. Každá úroveň v dimenzi může být sumarizována, aby vytvořila hodnoty pro vyšší
úroveň. Např. v dimenzi času sumarizací hodnot v úrovni den získáme hodnoty pro vyšší
úroveň měsíc.
Podle napojení dimenzí na faktovou tabulku rozlišujeme schéma typu hvězda (star) a
schéma typu sněhová vločka (snowflake). U schématu typu sněhová vločka jsou tabulky
dimenzí normalizovány. Faktová tabulka obsahuje cizí klíče do tabulek dimenzí.
Nejčastějším způsobem jak převést relační data na multidimenzionální je využít tzv.
star schéma (hvězda). Hvězdicové schéma se skládá z rozsáhlé centrální tabulky s hodnotami
(tzv. tabulka faktů) a řadou malých doprovodných tabulek pro každou dimenzi. Grafické
vyjádření schématu připomíná hvězdu, s tabulkami dimenzí zobrazenými v paprskovité
struktuře okolo centrální tabulky faktů. Ve hvězdicovém schématu je každá dimenze
reprezentována právě jednou tabulkou. A každá tabulka obsahuje několik atributů. Např.
dimenze „čas“ může mít tyto atributy: den, měsíc, kvartál, rok.
Snowflake (sněhová vločka) je určitým druhem hvězdicového schéma, ve kterém jsou
tabulky dimenzí normalizovány, čímž se data rozdělují do dalších tabulek. Výsledné grafické
schéma pak vytváří tvar podobný sněhové vločce. Hlavní rozdíl mezi těmito dvěma modely
spočívá v tom, že tabulky dimenzí jsou normalizované, aby snížili redundance v uložených
datech. Takováto tabulka je snadno udržovatelná a šetří diskový prostor. Ovšem tato úspora je
zanedbatelná ve srovnání s typickou velikostí tabulky faktů. Navíc toto schéma může snižovat
efektivnost analýz dat, neboť je zapotřebí provést více spojení tabulek, aby mohl být dotaz
proveden. Proto může být výkon systému nepříznivě ovlivněn. Z tohoto důvodu není schéma
sněhové vločky tak časté při návrhu datového skladu jako hvězdicové schéma.
Některé aplikace mohou vyžadovat více tabulek faktů, aby mohly sdílet tabulky
dimenzí. Toto schéma může být zobrazeno jako soubor hvězd a proto se nazývá
„Constellation“ (galaxie nebo souhvězdí).

76
6.5. Funkce datového skladu
Mezi klasickým informačním systémem a datovým skladem existuje zcela zásadní
rozdíl. Klasický informační systém slouží k momentálnímu zpracování a vyhodnocení
jednotlivých transakcí a k základnímu sběru dat a tím pádem i k vytváření momentálního
obrazu sledované reality. Datový sklad je naopak dlouhodobým úložištěm, kam data
shromážděná klasickými informačními systémy přibývají periodicky po jednotlivých
dávkách. Datovém skladu se připouští i vícenásobné uložení stejných dat a také nižší detail
uchovávaných dat. Důležité vlastnosti datového skladu jsou různorodost zdroje a
nesmazatelnost dat. Je běžné, že vznikne požadavek na sjednocení a vytěžování informací
z řady datových zdrojů, ale tyto zdroje jsou naprosto nekonzistentní, tzn., jsou uloženy ve
zcela odlišných strukturách, formátech, některé mohou být i zcela nestrukturované, mají
odlišnou filozofii záznamu, jsou uloženy na různých médiích atd. V souvislosti s touto
problematikou se objevuje termín ETL (extraction, transformation, load).
Extraction (extrakce) je prvním a zároveň nejkritičtějším krokem ke správnému a
informační hodnotu přinášejícímu využití datového skladu. Jedná se o schopnost převzít data
z co nejširšího spektra datových zdrojů nejrůznějšího charakteru s periodicitou (textové
soubory, standardy elektronické pošty, databázové standardy, webovské logovací soubory a
protokoly). Jedná se tedy o pracovní etapu, kdy usilujeme o přesné, rychlé, bezpečné, lehce
kontrolovatelné a dobře řiditelné načtení dat z co nejvíce externích datových zdrojů. Po jejím
skončení budou potřebná data načtena přímo do připravených zdrojových struktur pro
extrahovaná data.
Transformation (Transformace) je postupná řada operací, které extrahovaná data
připraví pro vlastní načtení do datového skladu (důvodem je zejména nesoulad mezi daty
z jednotlivých zdrojů a jejich neúplnost). Základem transformace je vytvoření programové
logiky, která provede převod mezi zdrojovými strukturami naplněnými syrovými daty a
cílovými strukturami, které jsou zdrojem pro pozdější vytěžování dat. Dalším nedílnou
součástí je validace (ověření správnosti extrahovaných dat, případně odhalení rozporů
v těchto datech). Transformace je tedy chápána jako proces získání co nejkvalitnějších dat.
Load (natažení) je poslední část celého procesu, kdy jsou transformovaná data načtena
do vlastního fyzického prostoru datového skladu a jsou přístupná pro vytěžování – pokládání
dotazů. Data mohou být kopírována ve stejném tvaru, jaký mají cílové struktury, nebo mohou

77
být načtena v předzpracovaném tvaru do tzv. multidimenzionálních tabulek (kostek), které
obsahují předpřipravené podklady pro rychlé odezvy na dotazy zpracované podle jednotlivých
dimenzí (hran kostky). Load je také periodický.
6.6. Plnění datového skladu
Proces plnění datového skladu je někdy označován jako proces ETL (extraction-
transformation- load). Tato zkratka vystihuje složitost plnění datového skladu. Data je třeba
nejprve extrahovat z primárních datových zdrojů. Vzhledem k tomu, že jednotlivé primární
datové zdroje nepracují s týmž datovým modelem, mnohdy nepoužívají ani tytéž datové typy,
některé údaje jsou v datových zdrojích obsaženy pouze implicitně a je třeba je odvozovat
z jiných údajů, následuje krok transformace, který převede data získaná z jednotlivých
datových zdrojů do unifikovaného datového modelu, nad nímž je možné vytvářet agregace a
získaná agregovaná data pak uložit do datového skladu (fáze load).
Smyslem OLAP systémů je co nejrychleji poskytnout uživateli požadované agregace
dat, popřípadě výsledky analýz provedených právě nad těmito agregacemi. Zatímco v případě
návrhu OLTP systému je jakákoliv redundance údajů nežádoucí, neboť je právem považována
za potenciální zdroj vzniku nekonzistencí, v případě OLAP systémů se redundance připouštějí
a dokonce se jich hojně využívá k dosažení rychlejší odezvy na OLAP dotazy.
6.7. Datové kostky
Datové sklady a OLAP nástroje jsou založeny na multidimenzionálním datovém
modelu. Tento model zobrazuje data ve formě datové kostky (viz obr č.2).
Dimenze kostky reprezentují rozdílné kategorie pro analýzu dat. Kategorie jako
například čas, geografické umístění nebo různé výrobkové řady jsou typickými dimenzemi
v datových kostkách. Kostky nejsou omezeny na tři dimenze. Dimenze jsou obvykle
uspořádány do hierarchií tak, že mapují sloupce v relačních databázích. Hierarchie dimenzí
jsou seskupovány do úrovní obsahujících hodnoty dané dimenze. Každá úroveň v dimenzi

78
může být sumarizována, aby vytvořila hodnoty pro vyšší úroveň. Např. v dimenzi času
sumarizací hodnot v úrovni den získáme hodnoty pro vyšší úroveň měsíc.
Míry jsou kvantitativní hodnoty v databázi, které mají být analyzovány. Typickými
mírami bývají prodeje, náklady a rozpočty. Míry jsou analyzovány oproti různým kategoriím
dimenzí datové kostky. Např. analýza prodejů (míra) určitého výrobku (dimenze) v různých
zemích (konkrétní úroveň dimenze geografická poloha) během dvou určitých roků (úroveň
dimenze čas).
Obr. č. 2
Multidimenzionální
datový model
6.8. Datové sklady nejen pro vrcholový management
V dalším jsou uvedeny přínosy, které řešení formou datového skladu přinese uživatelům
mimo vrcholový management. Jde zejména o tu část uživatelů, pro které byly ve stávajících
IS určeny rozličné výstupní sestavy a přehledy. Při rozšířeném využití datových skladů budou
mít tito uživatelé možnost ocenit zejména následující skutečnosti:
Snadná a rychlá dostupnost informace
Ve srovnání se standardními výstupy v prostředí provozního IS dostane uživatel u
kritických výstupů požadovanou informaci ve zlomkovém čase. Navíc u takto získané
informace má možnost využít dalších funkcí (drill down, drill up, drill across,
porovnávání apod.), které by při standardním způsobu zpracování byly uskutečnitelné
pouze obtížně, částečně anebo vůbec.

79
Podpora grafického výstupu
Uživatel má k dispozici požadovanou informaci jak v podobě číselné tabulky, tak i ve
vybrané grafické podobě. Grafickou podobu má k dispozici přímo v prostředí
prezentačního nástroje bez nutnosti přenášení údajů do prostředí, které zobrazení
formou grafů podporuje.
Samostatné provádění úprav v existujících přehledech
V předem připravených přehledech má uživatel možnost provádět celou řadu úprav jak
ve smyslu uspořádání získané informace, tak ve smyslu změn výběrových kriterií. Díky
odlišnému způsobu uložení dat v datovém skladu se u podstatné části takovýchto úprav
nemusí provádět opakované vyhledávání údajů. Avšak i při opakovaném vyhledávání je
požadovaná informace k dispozici neporovnatelně rychleji.
Samostatné vytváření nových přehledů
Na základě existujících přehledů nebo s využitím možností prezentačního nástroje si
může uživatel velice snadno a rychle definovat výstupy podle svých představ. Není přitom
omezen časově zdlouhavým definováním svých požadavků a čekáním na to, až budou jeho
požadavky někým jiným zrealizovány. Interaktivní formou má možnost v podstatě modelovat
formu a obsah požadovaných výstupů a vytvořené produkty si uložit pro další použití.
Otevřenost řešení
Otevřenost řešení s použitím datového skladu je jednou z nejdůležitějších vlastností
nového přístupu. Otevřenost je možno chápat z více hledisek. Například otevřenost ve smyslu
volné přístupnosti údajů ze všech úhlů pohledu v souladu s navrženou datovou strukturou
datového skladu nebo otevřenost z hlediska disponibilních dat (provozní, historická, z jiných
IS) v souladu s tím, jak jsou do navržených datových struktur naplněna.
Přístupnost z prostředí Internetu
Vybrané údaje je možno snadno uložit ve formátu přístupném pro prohlížení z prostředí
internetu. Toto uložení je vesměs podporováno v rámci použitých prezentačních nástrojů. V
závislosti na typu či konfiguraci prezentačního nástroje je možno mít uloženu jak pasivní, tak
i aktivní aplikaci (podporující provádění řady úprav i v prostředí internetu).
Shrnutí
Datový sklad je samozřejmě i nadále v první řadě určen pro potřeby managementu a
podporu rozhodování ve firmě. Návrh a realizaci modelu datového skladu lze velmi výhodně
využít i pro pokrytí těch funkcí, kde to v nedávné minulosti z různých důvodů (kapacitní,
cenové, neexistence potřebných produktů atd.) bylo prakticky nemožné.

80
SHRNUTÍ KAPITOLY
Datový sklad (anglicky Data Warehouse, případně DWH) je zvláštní typ relační databáze,
která umožňuje řešit úlohy zaměřené převážně na analytické dotazování nad rozsáhlými
soubory dat.
Definice datového skladu: K definici rozdílu mezi „běžnou“ relační databází a datovým
skladem se obvykle používá následujících charakteristik :
1. Orientace na subjekt
výsledkem je struktura, která je čitelnější pro uživatele (manažera, business analytika) za cenu
zvýšených nároků na paměťový prostor.
2. Integrovanost
úzce souvisí s orientací na subjekt – všechna data týkající se určité funkční oblasti potřebuji
mít „na jedné hromadě“ bez ohledu na to, odkud pocházejí.
3. Nízká proměnlivost
Data jsou do datového skladu obvykle nahrávána ve větších dávkách (například v denních
nebo týdenních intervalech) a pak již nejsou nijak modifikována.
4. Historizace
Data jsou v datovém skladu obvykle udržována v historické podobě, nikoliv pouze v
aktuálním stavu.
Celý systém datového hospodaření lze rozdělit na dvě základní části. První z nich je OLAP,
což je analytické zpracování dat.Na druhé straně stojí klasické databázové systémy, které se
označují jako OLTP, což je zkratka „on-line transaction processing“ neboli „okamžité
zpracování transakcí.
Struktura datového skladu
Data v datovém skladu jsou z logického (uživatelského) pohledu členěna do schéma
(topologické uspořádání). Každé schéma odpovídá jedné analyzované funkční oblasti.
Schéma obsahuje dva typy tabulek – faktové a dimenzionální.
Funkce datového skladu
Mezi klasickým informačním systémem a datovým skladem existuje zcela zásadní rozdíl.
Klasický informační systém slouží k momentálnímu zpracování a vyhodnocení jednotlivých
transakcí a k základnímu sběru dat a tím pádem i k vytváření momentálního obrazu sledované
reality. Datový sklad je naopak dlouhodobým úložištěm, kam data shromážděná klasickými
informačními systémy přibývají periodicky po jednotlivých dávkách.

81
SEZNAM KLÍČOVÝCH SLOV K ZAPAMATOVÁNÍ
Datový sklad, Podnikový sklad, Datové tržiště, Virtuální sklad, Datová pumpa, OLAP,
OLTP, Datová kostka,
.
KONTROLNÍ OTÁZKY
1. Rozdíl mezi databází a datovým skladem
2. Co je OLAP a OLTP
3. Popište strukturu a funkci datového skladu
KONTROLNÍ TEST
Navrhněte jednoduchou tabulku (v Excelu) prodejů zboží s uvedením ceny, množství a
prodejců v jednotlivých měsících roku. Zobrazte prodeje zboží vyjádřené v penězích podle
prodejců a měsíců pomocí nástroje kontingenční tabulka.

82
VÝSTUPY Z UČENÍ
Po prostudování textu a vypracování úkolů v rámci této kapitoly
BUDETE UMĚT
Definovat strukturu a funkci datového skladu. Budete znát rozdíl mezi
databází a datovým skladem. Budete vědět co je to OLAP jeho význam a
použití a rozdíl od OLTP.
ZNALOSTI
BUDETE SCHOPNI
Se orientovat v základní problematice týkající se práce a používání datových
skladů, jejich struktury a způsobu ukládání dat.
SCHOPNOSTI
ZÍSKÁTE
Můžete se orientovat v pojmech OLAP a OLTP a struktuře odpovídající
datovému skladu.
DOVEDNOSTI

83
7. Dobývání dat z databází (data mining)
V posledních asi pěti letech vznikla a rozvinula se nová profese, která se označuje
anglickým výrazem “data mining“ - dolování v datech (DM). Tento směr činnosti v oboru
zpracování informací byl rozvíjen na základě objektivních potřeb manažerů v situacích, kde
jsou pro rozhodování nedostatečné podklady, ale jsou k dispozici datové zdroje.
Ve světě je taková profese považována za jednu z nejperspektivnějších a to vzhledem
k tomu, že moderní technologie umožňují stálé a průběžné kumulování velmi obsáhlých
datových zdrojů, které k takovým účelům mohou být využity. DM je nový směr v oboru
procesu vytváření informací, který je založen na metodách matematické statistiky, vizuální
analýzy, matematiky, matematické logiky a umělé inteligence.
Vyžaduje nový metodologický aparát a schopnosti ovládat nově vzniklý typ softwaru.
Jeho cílem je nalézt skryté vztahy a zákonitosti v datových souborech, především ve velkých,
a přinést novou znalost a to jak na úrovni poznání, tak na úrovni rozhodování.
7.1. Data mining
(angl. dolování z dat, vytěžování dat, DM ).
Pojem byl definován jako řada automatizovaných postupů používaných k nalezení dosud
neznámých vzorů a vztahů v datech. Jedná se o pojem z oblasti Business Intelligence, kde
tyto vzory a vztahy mohou být použity, aby dokázaly předpovědět chování zákazníka. Definic
DM je velmi mnoho. V poslední době převládá názor, že DM je součástí procesu aplikace
vybraných analytických metod pro vyhledávání zajímavých vztahů v datech a spadá do
širšího pojmu KDD (Knowledge Discovery in Databases – dobývání znalostí z databází).
První náznaky aktivit, které dnes označujeme jako DM, se objevily v 60. letech 20. století s
rozvojem počítačové techniky. Šlo například o využívání regresní analýzy s automatickým
výběrem proměnných a prvních rozhodovacích stromů. Většinou však šlo jen o ojedinělé
nebo akademické záležitosti.
Databázové technologie představují osvědčený prostředek jak uchovávat rozsáhlá data a
vyhledávat v nich informace, statistika představuje osvědčený prostředek jak modelovat a
analyzovat závislosti v datech. Po léta se tyto disciplíny vyvíjely nezávisle, až přišla ta chvíle,
kdy rozsah automaticky sbíraných dat začínal uživatelům přerůstat přes hlavu. Současně s tím
také vznikla potřeba tato data používat pro podporu (strategického) rozhodování ve firmách.

84
Zájem finančně silných uživatelů o aplikace pak stimuloval ono propojení a dal vzniknout
dobývání znalostí z databází.
Některé databáze se rozrostly do takových rozměrů, že ani systémový administrátor
vždy neví, jaká data databáze obsahují či jak relevantní jsou data pro zodpovězení aktuální
otázky. Pro organizaci by bylo přínosné, pokud by dokázala z těchto rozsáhlých databází
„vytěžit“ důležité informace nebo struktury chování. Tyto skutečnosti vedly k tomu, že byl
DM, tak jak jej dnes chápeme, vytvořen.
7.2. Datová pumpa jako nástroj pro Data mining
Úkolem datové pumpy není jen vybrat specifikovanou část dat z provozního systému a
tuto část překopírovat do primární databáze datového skladu. Proces převodu většinou
představuje částečnou nebo i značnou změnu struktury ukládaných dat a hlavně jejich
"čištění". V provozních systémech (zvláště těch hůře navržených) mohou být data většinou
globálně a někdy i lokálně nekonzistentní.
Proces čištění má za úkol zjistit a odstranit nekonzistence ve vstupních datech a může
sloužit i jako opravná zpětná vazba pro provozní informační systém.
Datová pumpa je v praxi tvořena několika programy, které musí být přímo
přizpůsobeny cílové aplikační doméně na jedné straně a struktuře primární databáze na straně
druhé. Primární databáze datového skladu je ovšem v podstatě obrazem aplikační domény.
Datová pumpa je tudíž závislá na cílové aplikační doméně nasazovaného datového skladu. Na
rozdíl od většiny dalších součástí datového skladu je datová pumpa obvykle pro každou
instalaci datového skladu unikátní.
Úkolem datové pumpy je vybrat specifikovanou část dat z provozního systému (např.
z databáze ERP či CRM) a tuto část překopírovat do databáze samotného data warehouse.
Proces převodu občas představuje změnu struktury ukládaných dat a hlavně jejich "čištění".
Základem datové pumpy jsou tzv. ETL nástroje. ETL nástroje zabezpečují tři důležité kroky v
plnění datového skladu daty pomocí datové pumpy: Extraction (extrakce, vylití)
Transformation (transformace, kontrola dat) Loading (plnění).
Datová pumpa je prvním potenciálně slabým místem datového skladu a tudíž i prvním
adeptem na případnou optimalizaci. Vyladění datové pumpy obvykle spočívá v práci návrhářů
a programátorů a provádí se v podstatě jednorázově při jejím vytváření a ladění.
Z teoretického hlediska datová pumpa opravdu nepřináší mnoho zajímavých nebo nových

85
problémů, ale její konkrétní realizace bývá často z hlediska výkonu velice kritickým místem
celého skladu. Aby datová pumpa fungovala nejen na školních případech s malým množstvím
jednoduchým dat, je třeba ji věnovat pozornost a v žádném případě ji nepodceňovat.
7.3. Postup při dolování dat
Dvěma primárními cíly DM v praxi jsou predikce a deskripce.
• Predikce (Prediction) – umožňuje předvídat budoucí hodnoty atributů na základě
nalezených vzorů v datech
• Deskripce (Description) – popisuje nalezené vzory a vztahy v datech, které mohou ovlivnit
rozhodování
Cílů predikce a deskripce je dosaženo pomocí následujících úkolů:
• Klasifikace (Classification) – podstatou klasifikace je rozdělit objekty s určitými
charakteristickými rysy do jednotlivých tříd na základě modelu vybudovaného podle
tréninkové množiny dat (třídy jsou dány předem a každý objekt je možné zařadit).
• Regrese (Regression) – řada již dříve zjištěných hodnot, která slouží k předpovědi toho,
jaké další hodnoty budou následovat
• Shlukování (Clustering) – rozdělení datového souboru do určitých skupin (počet skupin je
většinou zjišťován v průběhu analýzy dat), čímž jsou vytvářeny shluky objektů. Užívanými
metodami pro tento úkol jsou rozhodovací stromy, neuronové sítě, logistická regrese,
diskriminační analýza.
• Sumarizace (Summarization) – zahrnuje metody pro hledání uceleného popisu
podmnožiny dat
• Modelování závislostí (Dependency Modeling) – spočívá v nalezení modelu, který
popisuje podstatné závislosti mezi proměnnými
• Detekce změn a odchylek (Change and Deviation Detection) – se zaměřuje na objevení
nejpodstatnějších změn v datech od původně naměřených nebo normativních hodnot
Společnou podstatou všech metodologií je následnost několika kroků:
Obchodní/praktický – formulace úlohy a porozumění problému. Ani automatické
vyhledávání znalostí nelze provádět zcela naslepo.
Datový – vyhledání a příprava dat pro analýzu. Statistické algoritmy většinou potřebují
data připravená v určité podobě, a proto není možné použít přímo surových dat z
obchodních databází.
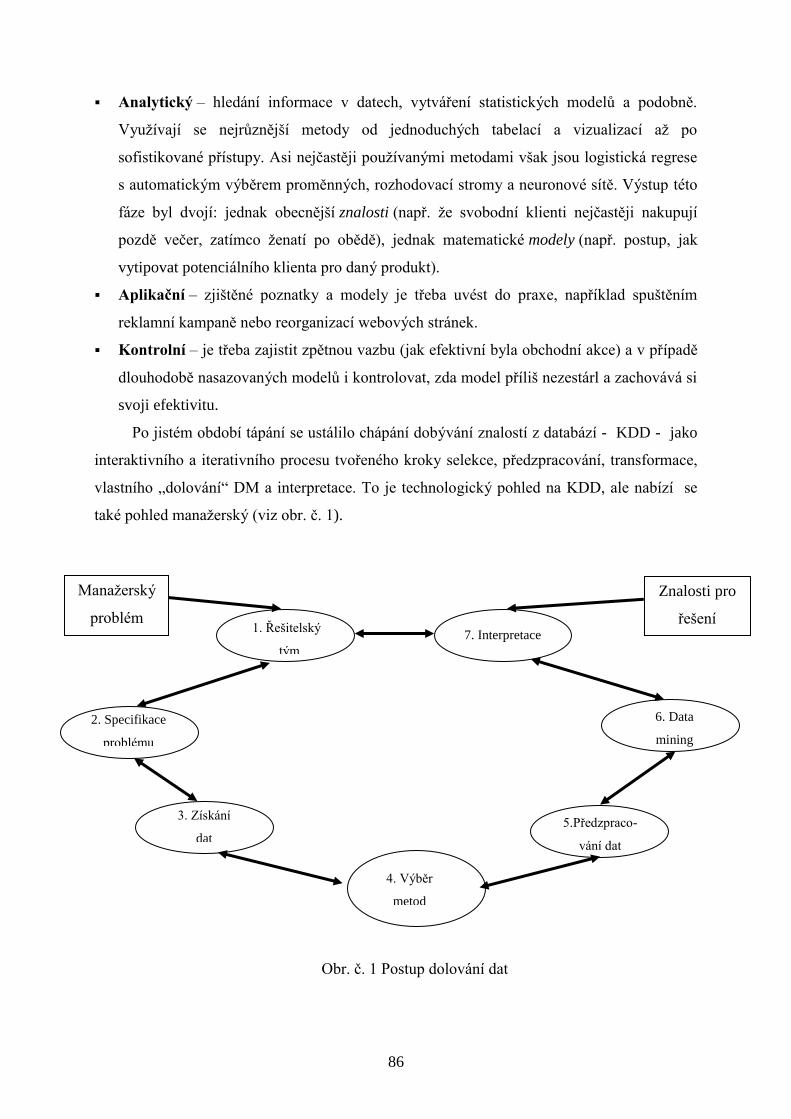
86
Analytický – hledání informace v datech, vytváření statistických modelů a podobně.
Využívají se nejrůznější metody od jednoduchých tabelací a vizualizací až po
sofistikované přístupy. Asi nejčastěji používanými metodami však jsou logistická regrese
s automatickým výběrem proměnných, rozhodovací stromy a neuronové sítě. Výstup této
fáze byl dvojí: jednak obecnější znalosti (např. že svobodní klienti nejčastěji nakupují
pozdě večer, zatímco ženatí po obědě), jednak matematické modely (např. postup, jak
vytipovat potenciálního klienta pro daný produkt).
Aplikační – zjištěné poznatky a modely je třeba uvést do praxe, například spuštěním
reklamní kampaně nebo reorganizací webových stránek.
Kontrolní – je třeba zajistit zpětnou vazbu (jak efektivní byla obchodní akce) a v případě
dlouhodobě nasazovaných modelů i kontrolovat, zda model příliš nezestárl a zachovává si
svoji efektivitu.
Po jistém období tápání se ustálilo chápání dobývání znalostí z databází - KDD - jako
interaktivního a iterativního procesu tvořeného kroky selekce, předzpracování, transformace,
vlastního „dolování“ DM a interpretace. To je technologický pohled na KDD, ale nabízí se
také pohled manažerský (viz obr. č. 1).
Obr. č. 1 Postup dolování dat
7. Interpretace
3. Získání
dat
4. Výběr
metod
5.Předzpraco-
vání dat
6. Data
mining
Manažerský
problém
Znalosti pro
řešení 1. Řešitelský
tým
2. Specifikace
problému

87
Impulsem pro zahájení procesu dobývání znalostí je nějaký reálný problém. Cílem
procesu dobývání znalostí je získat co nejvíce relevantních informací vhodných k řešení
daného problému.
Prvním krokem při řešení problému je vytvořit řešitelský tým.
Jeho členy musí být:
expert na řešenou problematiku,
expert na data — jak v organizaci, tak popřípadě i na externí data
expert na metody KDD,
V případě rozsáhlejších problémů je obvyklé, že jednotliví experti mají k dispozici
vlastní tým, nebo alespoň využívají konzultací s dalšími experty.
Prvním úkolem sestaveného týmu je specifikace problému, který je třeba řešit
v souvislostech dobývání znalostí.
Po specifikaci problému je třeba získat všechna dostupná data, která mohou být
použita pro řešení problému. Znamená to posoudit všechna dostupná data a zvážit, zda
odpovídají danému problému. Tento proces může vyvolat menší či větší přeformulování
problému. V některých případech je třeba pracovat i s daty, která jsou archivována po delší
dobu ve formě datových souborů a ne v databázi, data jsou někdy dokonce uložena v několika
různých systémech. Náročnost získání dat je nepřímo úměrná úrovni datové základny, která je
k dispozici.
V mnohých případech je vhodné uvažovat i externí data popisující prostředí, ve kterém
se analyzované děje odehrávají.
Zpracování dat z rozsáhlých databází a datových skladů má nejrůznější formy.
Tradiční přístupy analyzující data prostřednictvím sestav a výkazů jsou dnes většinou
založený na dotazovacích nástrojích (SQL) pracujících nad relačními databázemi, případně na
technikách označovaných jako OLAP (On-Line Analytical Processing), které často využívají
uložení dat v multidimenzionálních databázích k rychlé prezentaci dat ve formě tabulek,
sumarizovaných přes různé hierarchicky uspořádané dimense (např. rok, čtvrtletí, měsíc
versus kraje, okresy, obce). Tyto techniky umožňují udržovat přehled o okamžité pozici
podniku v rozsáhlých organizacích a během doby, která by se před několika lety zdála
nesplnitelná.

88
Z hlediska komerčního využití je přijatá následující definice dobývání dat.
Dobývání dat je proces výběru, prohledávání a modelování ve velkých objemech dat
sloužící k odhalení dříve neznámých vztahů mezi daty za účelem získání obchodní
výhody.
Obchodní výhoda označuje cíl dobývání dat, jež by vždy mělo mít za cíl řešení
konkrétního obchodního problému či nalezení cesty k vylepšení procesu. Cíl by měl
být předem definován a jen na jeho základě by se měla připravovat data. Pojem velký
objem dat samozřejmě může znamenat různé objemy v různě velkých organizacích,
ale zdůrazňuje nutnost podpory managementu a IT při zpřístupňování rozsáhlých dat
z různých částí organizace.
Data pro dobývání by ideálně měla být brána z datového skladu zahrnujícího
historické hodnoty z různých podnikových systémů. Příprava dat je úzce svázána s
pojmem proces. Ten znamená, že dobývání není jednorázová analýza, ale, že nasazení
technologie dobývání dat předpokládá přípravu podnikových procesů umožňujících
kontinuální využívání analýz a podporujících zpětné vazby od uživatelů. Ty pak
mohou ovlivňovat jak proces sběru data, tak definice nových cílů.
7.4. Metody dobývání dat
Dobývání dat je označením třídy úloh, které řeší mnohdy zdánlivě nesouvisející
problémy z nejrůznějších oborů. Je pozoruhodné, kolik praktických aplikací má několik
obecných metod analýzy dat. Výběr metody, která bude použita pro řešení daného problému,
je jen jedním z kroků procesu dobývání dat. Je třeba mít na zřeteli cíl, pro jehož splnění lze
použít více metod. Pak je dobré znát jejich výhody a mít možnost porovnat jejich výsledky.
Prediktivní modelování
je postupem, kdy se, na základě známé množiny vstupních a známých jim
odpovídajících výstupních hodnot, hledá nejpravděpodobnější hodnota výstupu pro předem
neznámé kombinace vstupních hodnot. Elementárním příkladem prediktivního modelování je
např. hodnocení rizika úvěru v bankovnictví.
Používanými technikami pro prediktivní modelování jsou různé typy regrese,
neuronové sítě a rozhodovací stromy.

89
Regrese je standardní statistická metoda schopná popsat stupeň důležitosti vstupních
proměnných na výstup. Její síla tkví s teoretické propracovanosti odhadu chyb modelu a
možnosti hledat i závislost na kombinaci vstupních proměnných. (Praktický příklad)
Neuronové sítě jsou novou moderní technikou prediktivního modelování vynikající
velkou variabilitou možných modelů a snadností modifikace jejich návrhu. Z pohledu regrese
jsou neuronové sítě elegantní technikou pro hledání parametrů modelu založeného na velice
flexibilním systému vnořených funkcí. Na druhé straně model založený na neuronové síti
nemá srozumitelnou interpretaci.
Rozhodovací stromy naopak získaly popularitu díky své snadné interpretaci. Popis
modelu pomocí rozhodovacího stromu je řadou jednoduchých rozhodovacích pravidel často
presentovaných ve formě grafu. Tyto grafy mohou být snadno bez hlubokých znalostí
statistických metod interpretovány řídícími pracovníky.
Při použití všech technik modelování je nutno řešit problémy s volbou počtu parametrů
modelu, jejich konvergence a odhadu chyb.
Klasifikace je obecně metodou pro rozdělování dat do skupin dle jistých kriterií. Pokud
jsou tato kriteria předem známa, alespoň pro vzorek dat, lze pomocí metod prediktivního
modelování vyvinout model jehož výstupem je klasifikační proměnná. Mnohem častější
případ je neřízená klasifikace, kdy výsledná kriteria nejsou předem známa a úlohou
klasifikace je jejich nalezení. Používanou technikou v takovýchto případech je shluková
analýza (Cluster Analysis). Elementárním příkladem shlukové analýzy je např. nalezení
skupin obchodů na základě jejich obratu, sortimentů a typu zákazníků. Nalezené skupiny lze
pak použít např. pro specifikaci reklamní kampaně zaměřené na jednotlivé skupiny prodejen.
Analýza asociací se zabývá hledáním kombinací produktů, které se ve vstupních datech
vyskytují významně častěji spolu. Nejčastějším použitím analýzy asociací, a zároveň jejím
ilustrativním příkladem, je tzv. analýza nákupního košíku. Cílem je odhalit pravidla typu: při
nákupu zboží A a C spotřebitele výrazně častěji nakupují zboží D a B. Odhalení takovýchto
kombinací pomáhá marketingovým odborníkům v organizování nabídky či společných
balíčků produktů.
Vzorkování je výběr omezené množiny dat ze základního souboru. Není to algoritmus
řešící přímo nějaký zadaný úkol dobývání dat, ale je to jedna ze základních technik dobývání
dat umožňující a získat výsledek v rozumném čase. Nejjednodušším způsobem vzorkování je
náhodný výběr, který slouží jen ke zmenšení objemu zpracovávaných dat a tím k zrychlení
výpočtů.

90
Vizualizace Datové sklady a nástroj pro jejich využívání existují na různých úrovních.
Těžbu dat lze provádět od jednoduchého dotazu do databáze přes tvorbu tabulky z uložených
dat až po vizuální zobrazení analýz z dat pocházejících z několika databází. První stupeň -
jednoduché dotazy, krátké výpisy, malé tabulky nebo nepříliš složité analýzy zvládne každý
trochu fundovanější člověk téměř "on-line", ihned. O stupeň výše je "typicky počítačové"
zobrazení ve formě např. tabulky nebo 3D grafu spolu s jednoduchou analýzou. Nejvyšší
stupeň představuje 2D nebo 3D vizualizace uložených dat.
Vizualizace vznikla proto, že grafická podoba dat je pro člověka intuitivní, více přijatelná,
rychleji se chápe a lépe se pamatuje.
Výpočetní a komunikační technika umožňují shromažďovat a zpracovávat obrovské
množství dat. Růst výkonnosti počítačů a kapacity elektronických médií (magnetických,
optických disků, diskových polí, pásek atd.) dovolují uchovávat stále větší a větší objemy dat,
které jsou pak výchozí surovinou pro získávání informací pro zainteresované a problematiky
znalé subjekty (osoby, organizace, firmy, instituce, atd.).
7.5. Informační analýza
Problém dneška tedy nespočívá ani tak v technologickém hromadění neustále
přibývajících dat, ale v účinném, rychlém a lidsky blízkém hledání jejich vztahů, souvislostí,
závislostí, podřízenosti, nadřazenosti, podmíněnosti atd. V praxi hovoříme o datové,
informační analýze. Z dat, jejich vzájemných vazeb a vztahů vznikají v procesu analýzy
informace, které mají pro konečného uživatele svůj cenný, často strategický význam.
Výpočetní technika, informatika jako taková, dnes dokáže kromě pouhého hromadění
obrovského objemu dat a zabezpečení rychlého přístupu k nim pomoci i při jejich
komplexním zkoumání, interpretaci a zobrazování. Speciální vizualizační techniky umožňují
názornější představu o skutečné realitě a podstatně urychlují poznání zkoumaného objektu.
Počítačové analytické nástroje dovolují automatickou analýzu velkých datových souborů
způsobem, který je nám velice blízký a příjemný, lidsky pochopitelný. Pomáhají nám
orientovat se v rozsáhlých a složitých vztazích a rychle nalézat společné nebo klíčové
informace. Výpočetní technika zapojená do sítě zpřístupňuje informace širokému okruhu
oprávněných uživatelů a nabízí jim možnost pracovat paralelně na daném problému z míst,
která jsou vzdálená i stovky kilometrů a tím si navzájem vyměňovat aktuální poznatky
v reálném čase. Podpora e-mailu dovoluje posílat produkty analýzy ve formě grafů, textů,
obrázků apod. kolegům z ostatních součástí.

91
Ve skutečném světě konečnou informaci získáváme ze zdrojů širokého spektra:
z mluveného slova, psaných textů, fotografií, zvukových a obrazových záznamů, textových a
tabulkových procesorů, mailů, telefonátů, firemních nebo interních databází, osobních
zkušeností apod. Moderní analytické nástroje podporované výpočetní technikou dokážou
integrovat a organizovat multimediální data ze všech případných informačních zdrojů a
zároveň je zobrazovat, analyzovat a sumarizovat v grafické podobě.
Informační analýzou (a zpravodajstvím) se profesně zabývá řada státních i nestátních
institucí. Jsou to banky, pojišťovací a další finanční instituce, telekomunikační, poštovní,
obchodní nebo výrobní společnosti, organizace spojené s dopravou, službami apod.
Analýza informací je používána v masově sdělovacích prostředcích (tisk, rozhlas, TV,
Internet atd.), ve vládních i nevládních institucích, v soudnictví, při výběru a správě daní, při
ekonomickém auditu atd.
7.6. Použití technik dobývání dat
Následující výčet popisuje současné nejčastější použití technologie dobývání dat
v různých oborech. Při jejich čtení je nutno si uvědomit, že některé oblasti aplikace dobývání
dat zůstávají důvěrným firemním tajemstvím. To samé platí i pro většinu získaných výsledků.
Analýza úvěrového rizika - výběr a ověřování kandidátů žádajících o úvěr, lze opět
popsat prediktivním modelem, založeném na známém chování stávajících klientů
Výhodou je v tomto případě znalost mnoha dat o klientech.
Vyhodnocování marketingových kampaní - tvorbou prediktivního modelu odezvy,
získaného na základě dat ze vzorku zákazníků, lze provést výběr z rozsáhlé databáze
zákazníků, který garantuje s největší pravděpodobností odezvy.
Analýza odchodu zákazníků (churn) - prediktivní model získaný analýzou dat o
zákaznících lze použít pro plánování akcí, jenž mohou zabránit odchodu stávajících,
nejrizikovějších, zákazníků. V telekomunikacích je používán pojem churn pro změnu
poskytovatele služeb.
Segmentace zákazníků - rozdělení zákazníků do skupin pro marketingové účely.
Segmenty pak mohou definovat různé cílové skupiny.
Detekce podvodů - pomocí prediktivního modelování (nejčastěji neuronové sítě), či
shlukové analýzy, lze odhalit podezřelé chování či platebního styku.

92
Analýza produktů - přímá aplikace analýzy asociací - umožňuje definovat
komplementární produkty pro dané segmenty zákazníků. Lze pak cíleně oslovovat
zákazníky, kterým chybí část portfolia produktů či sestavovat požadované balíčky
služeb.
Analýza chování zákazníků - predikce např. vývoje poptávky na základě historických
dat.
Analýza sekvencí - výběr nejčastěji se vyskytující posloupnosti, či hledání stavů
předcházejících nějaké události (poškození iniciované více vlivy)
Zdroje dat:
Dnešní svět je charakterizován explozí objemu dat sbíraných a ukládaných do databází.
Připomeňme si některé oblasti a data v nich získávaná:
Služby (objednávky zásilkových služeb či cestovních kanceláří, reservace
jízdenek/letenek)
Bankovnictví (bankovní transakce, žádosti o úvěr, historie splátek)
Telekomunikace (informace o telefonním provozu a platbách za něj, v případě
mobilních telefonů obsahuje záznam i informace o poloze atd.)
Státní správa (daňová přiznání, celní deklarace, žádosti o sociální podporu,
geografické informační systémy)
Koncový prodej (data z registračních pokladen a zákaznických karet)
Pojišťovnictví (registrace pojistek a plnění)
Zdravotnictví (zdravotní záznamy, informace pro zdravotní pojišťovny)
Jestliže u nás ještě nejsou některé, výše popisované, zdroje dat běžné v elektronické
podobě, pak ve vyspělých státech, pokud v elektronické formě přímo nevznikají, tak v ní
určitě končí, uloženy v databázích. Tato záplava dat je obhospodařována transakčními
systémy, které většinou zpracovávají aktuální transakce, popřípadě je postupována do
systémů navržených pro analýzy (systémy na dodávání informací - Information Delivery),
jejichž úkolem je poskytovat přehledné informace pro rozhodování. Základem moderních
systémů na dodávání informací je datový sklad (Data Warehouse) DW - centrální úložiště
sjednocující sběr informací z celého podniku a ukládání historických dat, to vše
optimalizované pro analýzy a výkaznictví.

93
7.7. Softwarové produkty pro dobývání dat
Techniky dobývání dat dnes vstupují do běžné obchodní praxe. Nástroje pro dobývání
dat a jejich využití jsou asi ve stejné situaci jako byla relační databázová technologie ke konci
osmdesátých let. Komerční uživatelé z nejprogresivnějších společností již léta používají
vlastní speciálně vyvinuté programy např. pro modelování marketingových kampaní či
analýzu úvěrového risku.
Další společnosti přivádí k zavádění technik dobývání dat zostřená konkurence na trhu,
zvyšující se počty cílových zákazníků, ale i klesající náklady na tuto technologii. Obě tyto
skupiny dnes hledají standardizovaná řešení, která pokrývají nejrůznější typy úloh a poskytují
výstupy snadno srozumitelné managementu.
S postupem doby začaly vznikat metodiky, které si kladou za cíl poskytnout uživatelům
jednotný rámec pro řešení různých úloh z oblasti dobývání znalostí. Tyto metodiky umožňují
sdílet a přenášet zkušenosti z úspěšných projektů. Za některými metodikami stojí producenti
programových systémů (např. metodika 5A firmy SPSS), jiné vznikají ve spolupráci
výzkumných a komerčních institucí jako „softwarově nezávislé“.
V rámci výzkumného projektu Evropské komise vznikla během 90. let souhrnná DM
metodologie CRISP-DM (CRoss-Industry Standard Proces for Data Mining) vyvinutá
konsorciem firem, popisující v hrubých rysech jednotlivé etapy: Její model nabízí návody
krok po kroku, úkoly a cíle pro každou část celého procesu. CRISP-DM umožňuje provádět
rozsáhlé DM projekty rychleji, efektivněji a méně nákladně prostřednictví osvědčených
postupů. Model pomáhá vyhnout se běžných chybám.
Metodologie CRISP-DM rozděluje celý proces DM projektu do šesti základních etap, v
rámci nichž dále rozlišuje další kroky.
Těmito etapami jsou:
1. Definování cílů
2. Porozumění datům
3. Příprava dat
4. Modelování
5. Hodnocení výsledků
6. Implementace vytvořeného modelu

94
Tři zdroje KDD (Knowledge Discovery in Databases – dobývání znalostí z databází).
Relační databáze
EIS (Executive Information System) – to byl první pokus, jak přiblížit
dotazování do databáze manažerům. Systém byl sice uživatelsky „přátelský“, ale
málo flexibilní. Vyžadoval i účast systémového programátora.
OLAP (On-line Analytical Processing) – nabízí uživatelům flexibilitu a rychlost,
jakož i příjemné intuitivní ovládání. Typické jsou možnosti vizualizace.
Datové sklady a datová tržiště
Dotazovací jazyky pro DM (výroková logika)
Statistika
kontingenční tabulky (námět pro cvičení)
regresní analýza (námět pro cvičení)
diskriminační analýza
shluková analýza
Strojové učení
učení znalostem
učení dovednostem
7.8. Dolování dat a datové sklady
Existuje mnoho důvodů pro úzkou návaznost datového skladu a dolování dat.
Nejdůležitějším důvodem je kvalita vstupních dat pro dolování. Sebedokonalejší modelovací
technika či analýza nepřinesou očekávaný výsledek, pokud nejsou vstupní data očištěna od
chyb, zkontrolována úplnost všech požadovaných údajů a sjednoceny formáty z různých
systémů. Procesní charakter dolování dat vyžaduje, aby se jako vstup dolování dat používala
průběžně aktualizována data. Všem těmto požadavkům vyhovuje datový sklad. Rozšíření
datových skladů je naopak jedním z hybných prvků bouřlivého rozvoje technologii dolování
dat.
Obecné zkušenosti
Zkušenosti z reálných komerčních aplikací patří k žárlivě střeženým tajemstvím
příslušných firem. Aby měli i odborníci zabývající se vývojem celého oboru KDD možnost
„nakouknout pod pokličku“ reálných úloh, bývají zpřístupňována (reálná nebo simulovaná)
data z řady aplikačních oblastí pro provádění analýz na nekomerční bázi. V posledních letech
se analýzy takovýchto dat prezentují v řadě mezinárodních konferencí věnovaných dobývání

95
znalostí z databází. Společně řešené úlohy a následné diskuze ukazují, jaké jsou klíčové
předpoklady úspěchu použití metod dobývání znalostí z databází v praxi (Berka, 2001):
Spolupráce s experty z dané aplikační oblasti
Podobně jako v případě expertních systémů, i při dobývání znalostí má expert z dané
aplikační oblasti (a expert na data) důležitou roli. Jeho spolupráce je klíčová jak v úvodních
krocích (porozumění dané problematice a porozumění datům), tak pro ocenění a využití
znalostí.
Dokonalejší metody předzpracování
Algoritmy pro předzpracování a transformace dat (diskretizace a seskupování hodnot,
ošetření chybějících hodnot, vytváření nových atributů) obvykle pracují nezávisle na
aplikační oblasti. Zdá se, že využití doménových znalostí může výrazně zvýšit efektivnost
těchto metod.
Algoritmy schopné zpracovávat složitější data
Většina algoritmů používaných pro modelování pracuje s jedinou datovou tabulkou
tvořenou záznamy s pevnou strukturou. V reálných aplikacích se ale setkáváme s podstatně
složitějšími typy dat: vzájemně provázanými relacemi, časovými daty, prostorovými daty,
texty, strukturovanými daty. Řada činností v kroku předzpracování jde tedy na vrub
„nedokonalým“ nástrojům pro modelování.
Interpretace výsledků srozumitelná expertovi
Rozhodujícím kritériem pro úspěch nějaké reálné aplikace KDD je akceptování
výsledků experty a potenciálními uživateli. To nejlepší řešení je bezcenné, pokud nebude
používáno. Experti nejsou ochotni probírat se stovkami a stovkami pravidel, ani je nezajímají
tabulky ukazující zlepšení jednoho klasifikátoru vůči jinému o zlomky procent. Co je zajímá,
je vhled do nalezených znalostí nebo silná a slabá místa naučeného klasifikátoru. Jako
důležité se tedy jeví následné zpracování výsledků a jejich vizualizace.
7.9. Potenciální nebezpečí DM
Protože komerční DM představuje často masivní a inteligentní zpracování osobních údajů,
vznikají často obavy ze zneužití těchto informací.
Kromě obvyklých negativ spojených se shromažďováním osobních údajů, jako je záměrný i
nezáměrný únik dat a jejich využití k různým nečestným aktivitám od spamu až po vydírání,
zde teoreticky hrozí i specifické zneužití statistických technik. Lze si například představit
zločince, který si pomocí analýzy dat vytipovává své oběti.

96
Zdá se však, že toto nebezpečí je – alespoň v současném stavu DM – nepatrné. I kdyby se
náhodou zločinci dostali k využitelným osobním datům, pravděpodobně by jim použití
sofistikovaných statistických metod příliš nepomohlo, už proto, že by jim chyběla databáze
„pozitivních příkladů“ úspěšných zločinů, na níž by mohli své modely postavit.
Za větší potenciální nebezpečí lze považovat technologie, k jejichž vzniku DM přispívá v
akademické sféře. Například dekódování genomu může být použito k nehumánním selekcím
osob, ale postaveným na vědeckém základě. Anebo pokročilé metody identifikace osob
mohou být spolu s kamerovými systémy používány ke špehování pohybu občanů.
Dobývání musí být založeno na správných datech. Z nesmyslných dat dostaneme nesmyslné
výsledky, Smetí dovnitř, smetí ven (angl. Garbage In, Garbage Out - GIGO).

97
SHRNUTÍ KAPITOLY
Dolování dat a datové sklady
Existuje mnoho důvodů pro úzkou návaznost datového skladu a dolování dat. Nejdůležitějším
důvodem je kvalita vstupních dat pro dolování. Sebedokonalejší modelovací technika či
analýza nepřinesou očekávaný výsledek pokud nejsou vstupní data očištěna od chyb,
zkontrolována úplnost všech požadovaných údajů a sjednoceny formáty z různých systémů.
Procesní charakter dolování dat vyžaduje, aby se jako vstup dolování dat používala průběžně
aktualizovaná data. Všem těmto požadavkům vyhovuje datový sklad. Rozšíření datových
skladů je naopak jedním z hybných prvků bouřlivého rozvoje technologii
Dolování dat je proces výběru, prohledávání a modelování velkého objemu dat za
účelem odhalení dříve neznámých vztahů mezi daty a za účelem získání obchodní
výhody.
Vyžaduje spolupráci IT oddělení, obchodních uživatelů a analytiků.
Dolování dat je analytická metodologie získávání netriviálních skrytých a potenciálně
užitečných informací dat. Někdy se chápe jako analytická součást dobývání znalostí z
databází (Knowledge Discovery in Databases, KDD).
Data Mining je proces, který používá různé analytické nástroje pro odhalení ukrytých
vzorů a závislostí v datech. Výsledkem je predikční model, který je podkladem pro
rozhodování (definice firmy Two Crows Corporation).
Dobývání dat je proces výběru, prohledávání a modelování ve velkých objemech dat
sloužící k odhalení dříve neznámých vztahů mezi daty za účelem získání obchodní
výhody.
Data mining je způsob přeměny dat na informace.
Jedná se o proces získávání znalostí vztahů dříve neznámých informací z rozsáhlých
firemních databází.

98
Fáze dataminingu :
1. Nasazení vhodného zdroje
2. Úprava dat
3. Výběr a transformace vhodných proměnných
4. Zpracování a vyhodnocení modelu
5. Ověření modelu
6. Implementace a údržba výsledného modelu
Předpoklady úspěchu dolování dat :
Zkušenosti firem plánujících podobným způsobem i několik kampaní týdně lze shrnout do
následujících podmínek úspěšného nasazení technologie dolování dat:
Kvalitní vstupní data
Spolupráce IT a uživatelů
Softwarové nástroje urychlující vývoj modelů a porovnání více technik dolování dat
Propracovaná metodologie implementace procesů dolování dat a řízení projektů
dolování dat

99
SEZNAM KLÍČOVÝCH SLOV K ZAPAMATOVÁNÍ
Dobývání dat, Datový sklad, Dobývání znalostí z databází
KONTROLNÍ OTÁZKY
1. Co to je dobývání dat
2. Základní fáze dobývání dat
3. Jaké softwarové produkty používané pro dobývání dat znáte
KONTROLNÍ TEST
Navrhněte jednoduchou tabulku (v Excelu) prodejů zboží s uvedením ceny, množství a
prodejců v jednotlivých měsících roku. Zobrazte prodeje zboží vyjádřené v penězích podle
prodejců a měsíců pomocí nástroje kontingenční tabulka.
100
VÝSTUPY Z UČENÍ
Po prostudování textu a vypracování úkolů v rámci této kapitoly
BUDETE UMĚT
Seznámíte se s postupem při dolování dat a jednotlivými metodami při tom
používanými. Poznáte pojem Informační analýza a její možné použití při
dolování dat. Poznáte úlohu datové pumpa jako nástroj pro Data mining.
ZNALOSTI
BUDETE SCHOPNI
Se orientovat v základní problematice týkající se práce a funkce datových
pump, některých softwarových produktů vyvinutých pro jejich použití.
SCHOPNOSTI
ZÍSKÁTE
Seznámíte se s postupem při navrhování řešitelského týmu pro dolování dat.
Se základními metodami modelování dat používanými při informační analýze.
Informace o dvou softwarových produktech používaných při dolování dat.
DOVEDNOSTI

101
8. Zálohování a archivace dat v IS
8.1. Zálohování dat v IS
V poslední době dochází k výrazným změnám, především na poli technologickém. Velká
část osobních či firemních dat je shromažďována v elektronické podobě a jejich případná
ztráta může mít vážné následky, a proto je potřeba data zálohovat. Problematika zálohování
dat je součástí řešení bezpečnostní politiky informačních systémů.
V případě osobních dat je ztráta velmi nepříjemná, ale přesto často nahraditelná. Jiná situace
je u dat firemních, kdy ztráta může vést až k likvidaci firmy, neboť mohou být ztraceny nejen
kontakty na partnery, ale i data účetní. Naprosto nepřípustná ztráta dat je v oblasti
bankovního, důchodového, zdravotního systému a v dalších životně důležitých oblastech. V
každém případě včasné zálohování/archivace uživatelských dat je bezesporu nejlevnější
způsob, jak předcházet především finančním ztrátám.
Příčiny ztráty dat je možné rozdělit do několika skupin:
porucha hardwaru (je nepředvídatelná). Poškodit se mohou části počítače, jako
např. základní deska, paměti, procesor, napájení, počítačová síť. Za nejzávažnější
typ výpadku se považuje porucha pevných disků počítače.
lidský faktor, kdy uživatel nebo administrátor informačního systému může
omylem smazat důležitá data. Významným faktorem poškození dat může být
záměrně způsoben interními (nebo externími) narušiteli, kteří mohou zneužít práv
pro přístup k cizím datům.
softwarové selhání je dalším významným faktorem. Konkrétně se jedná
o smazání dat důsledkem chyb v aplikacích a existencí bezpečnostních dír, které
mohou způsobit zhroucení systému (resp. ztrátu důležitých dat).
počítačové viry, jejichž působením může dojít k modifikaci, příp. k smazání
důležitých dat v informačním systému.
přírodní katastrofy – zahrnujeme zde požáry, povodně, zemětřesení, výbuchy
apod. Některým katastrofám můžeme předcházet, některé jsou u nás
nepravděpodobné (zemětřesení) a některé časté a nepředvídatelné (zásah bleskem).

102
8.2. Zálohování dat
Cílem zálohování je rychle obnovit plně funkční stav informačního systému takový, jaký byl
těsně před katastrofou. Zálohování (backup) je možné popsat jako vytváření bezpečnostní
kopie dat nebo celého operačního systému tak, abychom mohli v případě havárie obnovit
(restore) stav, který existoval těsně před vznikem poruchy. Zálohování je prostředkem pro
udržení dostupnosti informací na předem určené úrovni ve vztahu k jejich ceně. Slouží ke
krátkodobému ukládání aktuálních dat za účelem jejich obnovení při výpadku systému, jejich
porušení či zničení. Kritickým faktorem při obnově stavu před havárií je její rychlost.
Zálohování se provádí jak na magnetická, tak i na optická média, s možností jejich přepisu.
Provádí se každý den, týden nebo měsíc na to samé médium. Data jsou vždy přemazána a
nahrazena novými.
Proces zálohování dat se liší od archivace dat. Za archivaci lze považovat data uložená
na bezpečném místě, která jsou určena k pozdějšímu použití. Její životnost se počítá na
desítky let, zatímco zálohování je využitelné buď ze dne na den, maximálně s odstupem
několika měsíců. Z toho tedy vyplývají rozdílné požadavky na média pro archivaci nebo pro
zálohování.
Anglická terminologie rozlišuje několik pojmů pro zálohování dat, a to :
Backup – zálohování dat (systému a jeho nastavení, aplikací a databází) pro potřebu obnovy,
Cold Backup – záloha s časovou posunem (distorzí),
Hot Backup – záloha v reálném čase (tzv. on-line záloha),
Full backup - jedná se o zálohu, kdy není zjišťováno, zda byla data od poslední zálohy nějak
modifikována a je provedena jejich záloha,
Offline backup - znamená to, že záloha je prováděna při zastavených procesech
informačního systému,
Online backup – je záloha, která se provádí při běžících procesech informačního systému,
Incremental backup - jedná se o přírůstkovou zálohu, při které je zjišťováno, zda data byla
od poslední zálohy modifikována. Pokud byla modifikována, data se nově zálohují, v
opačném případě se jejich záloha neprovede.
Restore – obnova dat po logické chybě (závada způsobená lidskou chybou) nebo technické
chybě (závada technického vybavení).
Zálohování zahrnuje následující funkce:
záchrana dat po havárii,
ochrana provozuschopnosti informačního systému,

103
záchrana operačního systému a databází, zejména
- konfigurace,
- uživatelských účtů, jejich profilů, práv a omezení,
rychlost obnovy stavu před havárií.
8.3. Způsoby zálohování dat
Mezi základní způsoby zálohování patří:
výchozí – je to kopie původního systému. Provádí se po první instalaci, zálohuje všechny
soubory a programy.
kompletní - při každém zálohování jsou vždy zálohována všechna data najednou.
Kompletní zálohování patří mezi nejznámější a nejjednodušší způsob zálohování. Za
výhodu je považována jednoduchost obnovy v případě potřeby. Mezi nevýhody
kompletního zálohování patří skutečnost, že je náročnější na výpočetní prostředky a zabírá
výrazně větší množství úložného prostoru.
inkrementální (přírůstkové) - při prvním spuštění se provede kompletní záloha, ale při
dalších se již provádí záloha těch dat, která byla od posledního spuštění modifikována. Po
nějakém časovém intervalu, resp. po určitém počtu spuštění zálohování, se celý postup
opakuje. Výhodou této metody je časová a objemová (co se týče přírůstků) nenáročnost.
Nevýhodou inkrementálního zálohování je, že v případě potřeby obnovení dat ze zálohy je
potřeba poskládat všechny zálohy od posledního spuštění kompletní zálohy, což může
znamenat potřebu obnovy dat z několika po sobě jdoucích zálohovacích médií.
diferenční (rozdílové) - jde o obdobu inkrementálního zálohování s tím rozdílem, že při
každém dalším spuštění nezálohují změny pouze od posledního spuštění, ale od poslední
kompletní zálohy. Diferenční zálohování představuje zálohu pro všechna data od poslední
úplné zálohy. Tím pádem odpadá potřeba obnovy dat z více záloh. Cenou za to je mírně
větší potřeba úložného prostoru.
Každá z uvedených metod zálohování může být vhodná pro jiný typ dat. Například data,
která se téměř zcela mění velmi často se nevyplatí zálohovat inkrementálně nebo
diferenčně. Naopak data, kde se mění pouze malá část celkového objemu, se vyplatí
zálohovat inkrementálně. Diferenční zálohování se vyplatí v případě nutnosti rychlé
obnovy dat.

104
Podle způsobu vytváření záloh se rozlišuje
decentralizované zálohování – patří mezi starší způsoby zálohování dat v informačních
systémech. Bylo založeno na individuální péči uživatele o data. Každý uživatel si
zajišťoval zálohování tím, že si data nahrával na jiná média (ve víceméně nepravidelných
intervalech), nepravidelnost a ruční přístup však často vedl ke ztrátě dat (omylem došlo k
přepsání aktivní dat, uživatel zapomněl udělat zálohu, ...) a z pohledu organizace se jednalo
o velmi neefektivní činnost – bylo zapotřebí zakoupit zálohovací zařízení téměř ke
každému počítači, cena médií pro tato malá zálohovací zařízení je poměrně vysoká, velké
množství lidí v organizaci dělá stejnou činnost (často na úkor původní pracovní náplně)
a nakonec míra zajištění není příliš vysoká. Problémy nastávaly v případech, kde bylo
nutno zálohovat větší objemy dat – velké objemy dat již nelze jednoduše zálohovat tímto
způsobem. Navíc, v případě komplexní obnovy informačního systému bylo zapotřebí
fyzicky sjednotit všechny zálohy, což mnohokrát způsobovalo potíže.
centralizované zálohování – je založeno na využití velkokapacitního zálohování z centra
(prostřednictvím vysokorychlostních sítí snadno dostupné i z koncových stanic). Je
nejefektivněji realizováno diskovými systémy připojenými na obslužný počítač a jeho
prostřednictvím na počítačovou síť (nebo existují i zálohovací zařízení přímo připojená na
síť). Výměna záložních medií se realizuje automaticky robotem, který je rovněž ovládán
zmíněným řídícím počítačem. Vyšší počet zálohovacích zařízení a velký počet použitých
zálohovacích medií vytváří spolehlivé prostředí s možnostmi velmi rychlého zápisu
a obnovování dat.
Centralizované zálohování využívá automatickou úschovu dat (automatické
zálohování). Automatické zálohování se vyznačuje následujícími vlastnostmi:
odstraňuje nespolehlivý lidský faktor, zabezpečuje správnou výměnu zálohovacích
médií,
pravidelně provádí naplánované akce,
podrobně dokumentuje všechny činnosti,
hlídá technický stav zálohovacích médií a zálohovacích mechanik, stará se o
čištění zálohovacích mechanik,
pravidelně informuje správce systému o výsledku práce.

105
Zařízení pro automatizované zálohování je kombinací robotiky, slotů a příslušné
zálohovací mechaniky. Systémy automatického zálohování umožňují vkládání, vyjímání a
výměnu médií bez zásahu obsluhy. Tato zařízení můžeme rozdělit do dvou základních skupin:
Autoloader - jsou automatizované systémy vybavené pouze jednou mechanikou, ale mají
možnost výměny médii ze slotů podle požadavků zálohovacího systému. Konstrukce
zařízení, ale především malý počet médií (8, max. 12) předurčují autoloadery, pro
zálohování a obnovu dat v rámci malých síťových konfigurací.
Knihovny - mají podobnou funkci jako autoloadery. Mohou však být vybaveny větším
počtem mechanik a umožňují i uložení většího počtu médií. Jsou určeny pro zálohování
velkého objemu dat a pro rozsáhlá síťová řešení.
Součástí dobrých systémů pro automatizované zálohování je podpora páskových a optických
knihoven. Robotická knihovna představuje sadu záložních médií, která jsou uložena
v zásobnících. V systémech pro automatizované zálohování je robot sám vyjímá a vkládá do
jedné nebo i více záznamových mechanik. Pro snížení pravděpodobnosti zničení zdroje i
úložiště dat se přijímají nezbytná organizační opatření (umístění knihovny mimo běžné
kancelářské prostředí, např. do místnosti serverů, u velkých organizací s vysoce cennými daty
umístění centrálních výpočetních prostředků mimo hlavní budovu, atd.). Pro další zvýšení
bezpečnosti je možné pracovat s několika identickými sadami médií, jejichž kopie jsou po
určitou dobu umístěny na bezpečném místě (ve vzdálenějších lokalitách) s využitím
moderních technologií SAN (Storage Area Networks) a rychlými periferními komunikacemi
FC (Fibre Channel).
Filosofie zálohování určuje, co se má v informačních systémech zálohovat:
zálohovat by se mělo to, co je v systému jedinečné, např. uživatelské adresáře
a systémové databáze.
zálohovat by se mělo úplně všechno, tedy celý systém, protože pak je obnova
systému jednodušší.
8.4. Strategie zálohování dat
Vlastní strategie zálohování dat v informačních systémech (viz obr č.1) spočívá ve
vytvoření záloh – jedná se o vytváření datových záloh na fyzická zálohová media a v
ochraně záloh – ochrana záloh se realizuje např. vytvořením tzv. tandemových záloh, která
vytvoří zálohu před selháním zálohovacího média, protože každý soubor je zálohovaný

106
dvakrát. Je to vlastně „záloha zálohy dat“. Po každém zálohování by se mělo zkusit obnovit
pár zálohovaných souborů, aby se verifikovala funkčnost provedeného zálohování,
Uchovávání záloh - zálohy je nutné nějaký čas uchovávat. Roční zálohy se doporučují
uchovávat trvale (archivace dat). Je důležité chránit zálohy před nebezpečím jako je požár,
krádež a jiné. Proto by se měly uchovávat odděleně od počítačového systému. Po vyjmutí
zálohovacího média ze zálohovací mechaniky je dobré přepnout ochranu proti zápisu. Takto
je totiž nebude možné omylem přemazat. Důležité je také uchovávat data na záložních
mediích. Bezpečnost se podstatně zvýší pomocí šifrování.
Z pohledu systémových prostředků, na kterých jsou zálohy uskutečňovány, se rozlišuje:
zálohování individuálních pracovních stanic - celý systém se zálohuje jednou za měsíc nebo
po instalaci většího softwarového produktu. Tato strategie většinou nevyužívá inkrementální
zálohy. Každý další den se provádí inkrementální záloha, střídavě na dvě záložní média.
Každý soubor je tak zálohovaný na dvou záložních médiích. zálohování malých sítí - malá síť
je zde představována jedním serverem a několika pracovními stanicemi. Zde se doporučuje
provádět měsíční zálohy celého systému, týdenní zálohy standardních systémových souborů a
denní zálohy uživatelských souborů. Je doporučeno měsíční zálohy uchovávat po celý rok,
týdenní zálohy uchovávat měsíc, denní zálohy uchovávat pouze jeden den.
zálohování velkých sítí – jsou dána především požadavky větších firem (např. bank) na
minimalizaci času odstavení v případě havárie. Proto jsou zde nutné aktuální a úplné zálohy,
které je možno okamžitě použít. Zde se používá síťové zálohování na speciální disky. Zápisy
na každý disk by se tedy měly zrcadlit, tak aby havárie jednoho disku neměla dopad na
uživatele. Každý večer by se měl obsah celého disku zrcadlit na vzdálené disky na jiném
místě. Kdyby došlo k výpadku hlavního systému může naběhnout systém vzdálený.

107
Obr.č. 1 Strategie zálohování dat
Pro efektivní zálohování je nutno vytvořit zálohovací strategii (viz obr č.1). Ta spočívá
v určení „chráněných“ aktiv, jejich ocenění, stanovení zálohovacího plánu a plánu obnovy.
Samotný zálohovací plán říká, jak často a jakou metodou bude záloha prováděna, jak budou
data chráněna a na jaké datové úložiště bude záloha směrována. Zálohovací strategie
obsahuje:
plánování zálohování - každá činnost, aby měla nějaký smysl, musí mít svůj vnitřní řád.
Nejhorší je samozřejmě nedělat zálohy vůbec žádné. Stejného výsledku můžeme ale
dosáhnout zálohováním, které se děje nepravidelně a nekontrolovaně. Nakonec uchovávaná
data bývají natolik neaktuální, že jsou prakticky nepoužitelná. Plán obnovy je vlastně jakýmsi
krizovým plánem, ve kterém bychom měli pamatovat na souslednost jednotlivých úkonů,
které je potřeba postupně vykonat, abychom provedli rekonstrukci dat s úspěchem. Plán
obnovy musí být pravidelně aktualizován, aby odrážel pokud možno stále skutečný stav
informačního systému.
Proces vlastního zálohování dat se skládá ze dvou fází, a to:
vlastní zálohování dat (backup),
zpětná obnova dat (restore) při obnově systému (plán obnovy).
vlastní zálohování dat (backup) – stanovuje tzv. Backup Management. Backup Management
lze chápat jako stanovení strategie ukládání dat, stanovení objemu zálohovaných dat a toho,

108
jaká data a z jakých systémů budou v daném okamžiku zálohována. Výsledkem tohoto
procesu je stanovení konceptu, kam a jak budou data v informačním systému zálohována.
Prvním krokem při tvorbě zálohovacího (backup) konceptu je rozdělení zálohovaných dat
podle stupně důležitosti. Rozlišují se tři stupně důležitosti dat:
nekritická data (non critical data) – jsou to data, jejichž ztráta nepřinese větší
problémy a s určitým úsilím se nám je podaří nahradit, i kdybychom neměli
vytvořenou zálohu. Do této skupiny dat řadíme veškeré instalace, jak operačního
systému a databázových systémů, tak i dalších programů a aplikací. Bude to sice trvat
určitý čas, ale lze je z instalačních médií vrátit do původního stavu. Tato data se
doporučuje zálohovat maximálně jednou týdně, minimálně alespoň jednou měsíčně.
nízko-kritická data (low critical data) – jsou to taková data, která se jen velmi málo
mění a změny se dají s určitou námahou dohledat a obnovit. Anebo se jedná o data,
která v průběhu činnosti určitého systému nejsou aktuálně zapotřebí, ale z hlediska
bezpečnosti celého řešení je možno je v kritických případech použít. Tato data se
doporučuje zálohovat maximálně jedenkrát denně, minimálně alespoň jednou týdně je
potřeba vytvořit zálohu.
kritická data (critical data) – jsou to skutečně kritická data, která jsou neustále
vytvářena a jsou nutná pro bezproblémový provoz systému. Jejich ztráta by pak mohla
způsobit nestabilitu celého systému. Tato data se vždy doporučují zálohovat i
několikrát denně a ještě na různá media. Za ideální řešení se považuje vytvoření dvou
stejných záloh současně.
Druhým krokem při tvorbě zálohovacího (backup) konceptu je stanovení časové
periodicity tvorby záloh (tzv. časový navigační plán). Správně zvolená strategie
zálohování (backupu) se provádí jednou týdně (např. v neděli) full backup celého systému
a následující dny v týdnu se pak provádí pouze inkrementální backup (z důvodu menší
časové náročnosti přírůstkového zálohování). Periodicita záleží na několika faktorech:
cena chráněných aktiv,
povaha dat z hlediska rychlosti zastarávání,
objem dat - velké množství dat je velmi nákladné zálohovat často z důvodů ceny
datových úložišť,
použitelné metody zálohování – jestliže není možné kvůli povaze dat použít
například inkrementální zálohování, tak se zvyšuje nákladnost zálohování a není
ekonomické je provádět často.

109
Zpětná obnova dat (restore) - je tedy nutné mít data nejen zálohovaná, ale systém musí být
schopen je obnovit. Plán obnovy představuje krizový plán, ve kterém bychom měli pamatovat
na souslednost jednotlivých úkonů, které je potřeba postupně vykonat, abychom provedli
rekonstrukci dat s úspěchem. Plán obnovy musí být pravidelně aktualizován, aby odrážel
pokud možno stále skutečný stav informačního systému. V krizovém plánu je obnova dat sice
podstatnou, ale nikoliv jedinou nutnou činností. Je například dobré znát umístění médií s
poslední zálohou, znát případná hesla, kterými bývá záloha chráněna. Významným krokem v
procesu obnovy dat je použití tzv. časové navigace. Během zálohovacího procesu jsou
veškeré informace o prováděných operacích ukládány do databáze. Databáze obsahuje
veškeré informace o souborech, jeho atributech, jeho modifikacích, ale hlavně na jaké
médium jsou uloženy. Všechny tyto informace jsou vždy svázány s časem realizace. Při
obnově pak nemusíme pracně prohledávat jednotlivá média, ale stačí si pouze vzpomenout,
kdy naposledy byl daný soubor používán. Pomocí uživatelského prostředí je pak simulován
stav, který byl na serveru v dané době a hledaný soubor je možné obnovit. Zálohovací systém,
pak sám oznámí, jaké médium potřebuje pro obnovu hledaného souboru. Plán obnovy by měl
řešit především následující otázky:
kde je možné nalézt zálohy,
jakým způsobem jsou značeny,
jaká technologie (hardware, software) je potřeba k jejich obnovení a jak se s ní
pracuje,
kdo zodpovídá za provedení obnovy dat a kdo jej zastupuje v případě
nepřítomnosti,
kde je možné získat přístupová hesla k chráněným zálohám.
V rámci zpětné obnovy dat je nutné sestavení tzv. krizového plánu (ve formě dokumentu),
aby obnova systému po havárii mohla úspěšně a korektně proběhnout podle stanovených
postupů. Krizový plán by měl být aktualizován a modifikován v souladu se změnami, které
v informačním systému probíhají. Součástí krizového plánu je i plán obnovy sestavený
podle logické časové posloupnosti zhruba podle následujících kroků:
oprava závady,
instalace operačního systému,
rekonstrukce účtů uživatelů,
instalace aplikací,
rekonstrukce dat,

110
zajištění kontinuity a navazujících činností,
vyvarovat se provizorií i za cenu pomalejšího návratu k normálnímu stavu,
obnovení zálohování.
Ztráta dat v informačních systémech je i v případě havarijních stavů informačního
systému mnohokrát pro organizace nepřípustná. Technickým řešením, aby ke ztrátě dat
nedocházelo, je zálohování dat. Toto umožňuje obnovu stavu informačního systému do
identické podoby, jaká existovala těsně před vznikem poruchy. Problematika zálohování dat
je součástí bezpečnostní politiky informačních systémů.
8.5. Archivace dat v informačních systémech
Vytváření trvalých záloh dat v informačních systémech je jednou ze součástí bezpečnostní
politiky informačních systémů. Na rozdíl od zálohování dat, archivace dat zabezpečuje trvalé
uložení dat bez možnosti jejích dalších změn.
Archivace dat v informačních systémech představuje především shromažďování informací
pro případné pozdější použití a znamená trvalé uložení dat, bez možnosti dalších změn.
Archivovaná data nejsou přemazávaná. Při archivaci dat se počítá i s nasazením technologií
pro rychlé vyhledávání a třídění výsledků. Pro práci s archivem pak bude nejdůležitější jeho
uspořádání, dlouhodobá spolehlivost a vysoká trvanlivost.
Digitální data se vyznačují několika vlastnostmi, se kterými se u jinak reprezentovaných dat (
tj. psané, tištěné dokumenty a fotografie, dokumenty s analogovým záznamem zvuku a videa)
nesetkáme vůbec nebo jen v omezené míře. Tyto vlastnosti jsou:
distribuovanost - umožňující vzdálený a paralelní přístup neomezeného počtu
uživatelů k datům,
hypertextová struktura elektronických dokumentů,
multimedialita – možnost vjímání digitálních dat nejmíň dvěma formami percepce,
interaktivita – možnost aktivního přístupu k datům v reálném čase,
přidaná hodnota – zahrnující např. bezprostřední vazbu metadata-primární data,
vyhledávání ve strukturovaných datech nebo v plném textu v reálném čase,
automatická konverze, generování dokumentu z databáze na základě uživatelského
požadavku atd.)
bezztrátová reprodukovatelnost – kopie dat je identická jejich originálu (v
důsledku toho přestává být patrný rozdíl mezi originálem a kopií)
aktuálnost – možnosti rychlé modifikace a aktualizace dat.

111
8.5.1. Dlouhodobá archivace dat
V souvislosti s dlouhodobou archivací digitálních dat však musíme brát v úvahu jako
podstatnější tyto specifické znaky:
závislost na tzv. digitálním prostředí – digitální data jsou na jedné straně flexibilní a snadno
transformovatelná a modifikovatelná, na druhé straně mohou během poměrně krátké doby
pozbýt svou funkčnost, a tedy i informační hodnotu, protože digitální prostředí, v němž byly
vytvořeny, rychle morálně zastarávají. Digitálním prostředím se rozumí soubor technických
prostředků (hardwarová platforma, operační systém a aplikační software) nezbytných pro
správné (či dostatečné) dekódování digitálních dokumentů, resp. pro provedení zpětné
konverze do takové formy, která zajišťuje, aby mohly být vnímány lidskými smysly (např.
tisk na papír, zobrazení na monitoru, zvukový výstup pomocí reproduktoru). Je složité
odhadnout, kudy se bude další vývoj ubírat. Hrozí tak reálné nebezpečí, že se nepodaří
některá digitální data uchovat do budoucnosti, protože nebudou k dispozici technologie, které
umožní jeho čitelnost, ačkoliv jako artefakty budou nadále existovat.
nezávislost na nosiči - ochranné metody, které se uplatňují u tradičních dat, jsou primárně
podmíněny skutečností, že v jejich případě představují hmotný nosič a informace, které jsou
na něm (nebo v něm) fixovány, dva neoddělitelné prvky jednoho homogenního objektu.
Jelikož v tomto smyslu uchovat data čitelná, a tak umožnit jich zpřístupnění, znamená totéž
co zabezpečit fyzickou celistvost nosiče, soustřeďuje se pozornost (preventivní ochrana dat)
na klimatické parametry prostředí, v němž jsou data deponována (teplota, relativní vlhkost a
intenzita světla). U digitálních dat se díky tomu, že k záznamu se používá jeden univerzální
kódovací systém (binární soustava) bez ohledu na to, jakou formu nebo obsah mají, ruší
dosavadní pevná svázanost nosiče a informací (dat), které tak mohou být podle potřeby po
dobu jejích existence uloženy na libovolném nosiči, kterého jediným praktickým limitujícím
faktorem je jeho paměťová kapacita. Pro takto reprezentovaná data je jejích nosič irelevantní,
rozhodující je dlouhodobá (ideálně trvalá) čitelnost digitálního záznamu, na druhé straně pro
jejich dekódování nestačí archivovat samotný dokument, je nutná rovněž specifická
konfigurace digitálního prostředí, ve kterém bude interpretován.

112
8.5.2. Kriteria pro archivování dat
Z hlediska budoucího použití digitálních dat je nutné klasifikovat podstatné objekty těchto dat
– tj. určit kritéria, na jejichž základě bude možné posoudit, zda daná data (v původní nebo
konvertované podobě) si uchovávají svou integritu (tj. validitu, kompletnost) a autenticitu
(použitelnost dat pro ty účely, pro které byly vytvořeny). Jde v podstatě o klasifikaci objektů,
z nichž jsou digitální data složeny (objekty, které nesou informační hodnotu). Z tohoto
pohledu jsou u archivovaných dat významné:
obsah,
forma (formální struktura dat),
funkčnost ,
kontext – představuje dodatečnou informaci o identifikaci dat, často ve formě tzv.
metadat (Metadata jsou odvozená strukturovaná data o jiných, primárních datech.).
V procesu archivování dat se využívá jejich funkce integritní – metadata jsou
jedním z prostředků nutných ke správnému dekódování digitálních dat, ke kterým se
vztahují (bez metadat jsou nesrozumitelné).
Archivace dat plní následující cíle:
dlouhodobá úschova informací,
uvolnění primárních prostředků pro aktuální projekty,
dislokace strategických dat,
rychlost vyhledání,
možnost paralelního využití (publikace v intranetu, Internetu).
Za základní důvody provádění archivace jsou považovány:
uchování dat pro budoucí použití,
ochrana před zničením dat,
nutnost uchování dokladů o provedených pracích.
Vzdálenost archivu (zvyšováním vzdálenosti roste i bezpečnost uchování):
příruční – na stejném disku,
odkládací – na stejném počítači, ale jiném disku,
bezpečnostní – mimo počítač (archivní média).

113
8.5.3. Životnost archivovaných dat
Významným aspektem v procesu archivování digitálních dat je jejích životnost. V rámci
životnosti archivovaných digitálních dat rozlišujeme (viz obr č.2)
Obr.č. 2 Vliv životnosti na archivovaná data
softwarovou životnost – která představuje životnost digitálního prostředí, ve kterém byla
data vytvořena. Aby byla archivovaná data použitelná používají se pro eliminaci vlivu
životnosti digitálního prostředí dvě metody, a to:
Migrace - metoda migrace představuje v současnosti hlavní strategii archivace
digitálních dat (především digitálních dokumentů). Cílem metody je čelit morálnímu
stárnutí informačních technologií, který ovlivňuje čitelnost dat. Metoda migrace
spočívá v periodicky probíhajícím procesu konverze dat z jednoho digitálního
prostředí do druhého. Problémem metody migrace je tzv.“hledání vhodného
standardu”. Nekompatibilita je totiž nástrojem konkurenčního soupeření producentů
aplikačního softwaru. Podle J. Rothenberga je principiálně nemožné realizovat
bezztrátovou konverzi mezi dvěma logickými formáty (tj. způsoby, jakým jsou data
uspořádána). Migrace může mít negativní dopad na integritu digitálních dat jako
celku, nebo jeho dílčích objektů proto, že původní a cílové digitální prostředí se
zpravidla liší v některých svých vlastnostech (např. jiná konfigurace platformy, jiný
nosič apod.). V reálných podmínkách archivování dat se používá tzv. částečná
migrace, která zahrnuje konverze:
softwarová aplikace 1 → softwarová aplikace 2 (resp. formát 1 → formát 2),
operační systém 1 → operační systém 2 (např. Linux → Windows 98),

114
hardwarová platforma 1 → hardwarová platforma 2 (např. PC IBM → Apple
Macintosh).
Emulace - označuje proces, jehož smyslem je co možná nejvěrněji modelovat funkční
vlastnosti digitálního prostředí (morálně zastaralého) či jeho komponentů na jiném
počítači, než pro který bylo (byly) určeny.
fyzickou životnost – která představuje fyzickou trvanlivost nosičů digitálního záznamu.
Zvýšení fyzické životnosti se zabezpečuje :
několikanásobnou archivací dat (na různých typech archivačních medií),
vhodným umístěním archivovaných dat.
8.5.4. Přístup k archivovaným datům
Z pohledu rychlosti přístupu k archivovaným datům se rozlišuje:
rychlý on-line přístup – využívá se při kritických požadavcích na rychlost přístupu
k archivovaných datům – řádově milisekundy. Používá ho velmi malá skupina
uživatelů.
near-on-line přístup - se vyznačuje průměrným přístupem k datům v trvání 10-15 s.
Near-on-line přístup k archivovaným datům je kompromisem rychlostí zápisu
a přístupu k archivovaným datům mezi on-line a off-line přístupem (i kompromisem
mezi finančními náklady těchto archivačních přístupů).
off-line přístup, které jsou z hlediska správy podstatně levnější – používají se běžná
archivační zařízení, u nichž trvají přístupy k datům průměrně 30 sekund. Využití
tohoto přístupu výrazně snižuje náklady na ukládání dat.
Pro archivní účely jsou používána obdobná média jako pro zálohování dat. Základním
požadavkem na archivační média je dlouhodobá spolehlivost a vysoká trvanlivost.
Představuje především shromažďování informací pro případné pozdější použití. Protože při
práci s archivem je důležité rychlé vyhledávání a třídění výsledků, významným prvkem při
archivace dat je jejích uspořádání. Periferie a média vhodná pro archivaci jsou
charakterizována vysokou rychlostí vyhledání informace a dlouhou trvanlivostí, řádově
mnoho desítek let. Značná je jejich odolnost proti vnějším vlivům prostředí.
Periferie vhodné pro archivaci:
jednotky magneto-optických disků,
jednotky optických disků CD nebo DVD,

115
jednotky pro média s jedním možným zápisem (WORM - Write Once Read Many).
Mezi jednotlivými technologiemi existuje řada rozdílů, ale společnou vlastností je rychlý
náhodný přístup k požadovaným informacím, snadná manipulovatelnost a skladovatelnost.
Trvanlivost záznamu může dosahovat i 100 let, a důležitá je i kompatibilita, popřípadě
možnost budoucí automatické konverze na jiný, modernější formát.
Periferie a média vhodná pro archivaci jsou charakterizována vysokou rychlostí vyhledání
informace a dlouhou trvanlivostí, řádově mnoho desítek let. Značná je jejich odolnost proti
vnějším vlivům prostředí. U optických disků se udává životnost 15 až 20 let, u některých
druhů CD-R až 200 let. Životnost pásek v závislosti na druhu je až 30 let.
V současnosti se v archivních systémech nejvíce uplatňují optické systémy ukládání. Je
pravdou, že jejich kapacita dnes již není příliš adekvátní, ale nenahraditelná je jejich životnost
a odolnost proti vnějším vlivům. Moderní technologií je magneto-optický záznam s nedávno
dostupnou kapacitou 9.1 GB na jednu kazetu a 12" WORM s kapacitou 30 GB na jedno
médium a garantovanou životností pro čtení 100 let. Velmi populární optické technologie CD
a DVD by mohly dosahovat také trvanlivosti v řádech desítek let, ale pouze v lisované
podobě. Média zapisovatelná a zejména přepisovatelná se nepovažují za vhodné pro
dlouhodobou úschovu informací. Médium skutečně vhodné pro dlouhodobou archivaci je
vždy chráněno pevným obalem a samotný nosič má velmi robustní konstrukci. Uživatel za
běžných okolností aktivní povrch média nikdy neuvidí.
Mezi jednotlivými technologiemi existuje samozřejmě řada rozdílů, ale společným
jmenovatelem pro jejich fungování je:
rychlý náhodný přístup k požadovaným informacím,
snadná manipulovatelnost a skladovatelnost.
Vytváření archivních souborů se provádí většinou vhodným komprimačním programem nebo
specializovanými programy.
Základním předpokladem fungování archívu je jeho automatizace. Velké množství souborů a
velké objemy dat již nelze z praktických důvodů zvládat ruční manipulací. Navíc, obnova dat
po havárii je velmi stresující chvíle pro všechny zainteresované a všechny chyby, které se
v průběhu obnovy dat uskuteční, jenom oddálí opětovné spuštění informačního systému.
Proto se snažíme tyto kroky automatizovat, jejich činnost musíme ale pravidelně kontrolovat.

116
Automatizace úschovy dat se vyznačuje těmito vlastnostmi:
odstraňuje nespolehlivý lidský faktor, zabezpečuje správné výměny archivních
médií,
pravidelně provádí naplánované akce,
dopodrobna dokumentuje všechny činnosti,
hlídá technický stav archivních médií a mechanik, stará se o čištění mechanik,
pravidelně informuje správce systému o výsledku práce,
Významným prvkem v rámci řešení bezpečnostní politiky organizací je přijetí tzv. strategie
dlouhodobé archivace digitálních dat (digital preservation strategy), která má komplexní
povahu, a obsahuje technické, organizační (např. řízení toku dat a stanovení způsobu a
intervalu kontroly kvality digitálního záznamu na použitých nosičích), knihovnickou (např.
definování kritérií výběru dokumentů a sady identifikačních údajů-metadat) a autorskoprávní
aspekty archivování dat.

117
SHRNUTÍ KAPITOLY
Hlavní příčiny ztráty dat :
porucha hardwaru,
lidský faktor,.
softwarové počítačové viry,
přírodní
Cílem zálohování (backup) je rychle obnovit plně funkční stav informačního systému takový,
jaký byl těsně před katastrofou. Zálohování je prostředkem pro udržení dostupnosti informací
na předem určené úrovni ve vztahu k jejich ceně. Slouží ke krátkodobému ukládání aktuálních
dat za účelem jejich obnovení při výpadku systému, jejich porušení či zničení. Kritickým
faktorem při obnově stavu před havárií je její rychlost. Zálohování se provádí jak na
magnetická, tak i na optická média, s možností jejich přepisu. Provádí se každý den, týden
nebo měsíc na to samé médium. Data jsou vždy přemazána a nahrazena novými.
Proces zálohování dat se liší od archivace dat. Cílem archivace je uložení dat na
bezpečném místě, připravená k pozdějšímu použití. Její životnost se počítá na desítky let,
zatímco zálohování je využitelné buď ze dne na den, maximálně s odstupem několika měsíců.
Z toho tedy vyplývají rozdílné požadavky na média pro archivaci nebo pro zálohování.
Mezi základní způsoby zálohování patří:
výchozí – je to kopie původního systému.
kompletní - při každém zálohování jsou vždy zálohována všechna data najednou.
inkrementální (přírůstkové) - při prvním spuštění se provede kompletní záloha, ale
při dalších se již provádí záloha těch dat, která byla od posledního spuštění
modifikována
diferenční (rozdílové) - jde o obdobu inkrementálního zálohování s tím rozdílem, že
při každém dalším spuštění nezálohují změny pouze od posledního spuštění, ale od
poslední kompletní zálohy..
Podle způsobu vytváření záloh se rozlišuje
decentralizované zálohování – patří mezi starší způsoby zálohování dat
v informačních systémech. Bylo založeno na individuální péči uživatele o data.

118
centralizované zálohování – je založeno na využití velkokapacitního zálohování
z centra prostřednictvím vysokorychlostních sítí snadno dostupné i z koncových
stanic.
Vlastní strategie zálohování dat v informačních systémech spočívá ve:
vytvoření záloh – jedná se o vytváření datových záloh na fyzická zálohová media,
ochraně záloh – ochrana záloh se realizuje např. vytvořením tzv. tandemových záloh,
která vytvoří zálohu před selháním zálohovacího média, protože každý soubor je zálohovaný
dvakrát. Je to vlastně „záloha zálohy dat“. uchovávání záloh - zálohy je nutné nějaký čas
uchovávat. Roční zálohy se doporučují uchovávat trvale (archivace dat).
Vytváření trvalých záloh dat tedy archivace v informačních systémech je jednou ze součástí
bezpečnostní politiky informačních systémů. Na rozdíl od zálohování dat, archivace dat
zabezpečuje trvalé uložení dat bez možnosti jejích dalších změn.
Archivace dat v informačních systémech představuje především shromažďování informací
pro případné pozdější použití a znamená trvalé uložení dat, bez možnosti dalších změn.
Archivovaná data nejsou přemazávaná. Při archivaci dat se počítá i s nasazením technologií
pro rychlé vyhledávání a třídění výsledků. Pro práci s archivem pak bude nejdůležitější jeho
uspořádání, dlouhodobá spolehlivost a vysoká trvanlivost
Archivace dat plní následující cíle:
dlouhodobá úschova informací,
uvolnění primárních prostředků pro aktuální projekty,
dislokace strategických dat,
rychlost vyhledání,
možnost paralelního využití (publikace v intranetu, Internetu).
Za základní důvody provádění archivace jsou považovány:
uchování dat pro budoucí použití,
ochrana před zničením dat,
nutnost uchování dokladů o provedených pracích

119
Významným aspektem v procesu archivování digitálních dat je jejích životnost. V rámci
životnosti archivovaných digitálních dat rozlišujeme :
softwarovou životnost – která představuje životnost digitálního prostředí, ve kterém
byla data vytvořena
fyzickou životnost – která představuje fyzickou trvanlivost nosičů digitálního
záznamu.
Z pohledu rychlosti přístupu k archivovaným datům se rozlišuje:
rychlý on-line přístup – využívá se při kritických požadavcích na rychlost přístupu
k archivovaných datům – řádově milisekundy. Používá ho velmi malá skupina uživatelů.
near-on-line přístup - se vyznačuje průměrným přístupem k datům v trvání 10-15 s.
Near-on-line přístup k archivovaným datům je kompromisem rychlostí zápisu a přístupu
k archivovaným datům mezi on-line a off-line přístupem (i kompromisem mezi finančními
náklady těchto archivačních přístupů).
off-line přístup, které jsou z hlediska správy podstatně levnější – používají se běžná
archivační zařízení, u nichž trvají přístupy k datům průměrně 30 sekund. Využití tohoto
přístupu výrazně snižuje náklady na ukládání dat.

120
SEZNAM KLÍČOVÝCH SLOV K ZAPAMATOVÁNÍ
Zálohování dat, Archivace dat, Backup, Nekritická data, Nízko-kritická data, Kritická data,
Zpětná obnova dat, (Restore), Migrace, Emulace, Softwarovou životnost, Fyzická životnost,
distribuovanost, hypertextová struktura, multimedialita, interaktivita, přidaná hodnota,
bezztrátová reprodukovatelnost, aktuálnost
KONTROLNÍ OTÁZKY
1. Rozdíl mezi zálohováním a archivací
2. Typy zálohování
3. Co je zálohovací strategie
4. Jak se liší migrace a emulace
5. Jak se archivuje v informačních systémech
KONTROLNÍ TEST
Navrhněte způsob zabezpečení dat ve zvoleném ekonomickém informačním systému
vzhledem k charakteru jednotlivých typů dat v něm zpracovávaných.

121
VÝSTUPY Z UČENÍ
Po prostudování textu a vypracování úkolů v rámci této kapitoly
BUDETE UMĚT
Rozlišit pojmy zálohování a archivace.
Seznámíte se se základními způsoby zálohování
ZNALOSTI
BUDETE SCHOPNI
Specifikovat hlavní příčiny ztráty dat:
Pochopit cíl, úlohu a význam zálohování (backup) a archivace dat
v počítačových informačních systémech
SCHOPNOSTI
ZÍSKÁTE
Znalosti o:
1. Způsobech zálohování dat
2. Strategii zálohování dat
Archivaci dat v informačních systémech
3. Životnosti archivovaných dat
4. Přístupu k archivovaným datům
DOVEDNOSTI

122
9. Bezpečnost IS a počítačová kriminalita
9.1. Úvod
Řešení bezpečnosti informační soustavy je proces, který začíná záměrem budování
informačního systému a probíhá po celou dobu jeho životnosti.
Ochraně informačního systému je tedy nutné věnovat stálou pozornost ve všech fázích
realizace budování i provozu systému (při zpracovávání dat, jejich archivaci a zvláště
přenosu). Z hlediska životnosti existence informačního systému procesu půjde zejména o
etapy při:
zadání úlohy,
volbě technického vybavení, systému a aplikačního prostředí,
změně citlivosti dat z hlediska jejich, hodnoty, ceny nebo významu pro organizaci,
zjištění a identifikaci nových, dosud neexistujících hrozeb,
zásadních organizačních a personálních změnách.
Příčiny vedoucí k narušení narušení ochrany informačních systémů :
náhodné příčiny,
chyby technického a programového vybavení,
lidská nevšímavost (lajdáctví),
úmyslné poškození, včetně projevů kriminality.
Důsledky jsou velmi rozmanité, a to od bezprostředních, poškozujících existenci a
provoz informačních systémů a tím i vlastní organizaci, až po následné, projevující se třeba
po delší době a v jiných souvislostech (narušení strategických cílů organizace).
Bezpečnost IS se skládá z :
Komunikační bezpečnosti (ochrana informací přenášených počítači)
Fyzické bezpečnosti (ochrana před přírodními hrozbami a fyzickými útočníky)
Personální bezpečnosti (ochrana před vnitřními útočníky)
Bezpečný IS je takový IS, který je zajištěn
fyzicky
administrativně
logicky
technicky

123
Bezpečnost IS je dána zajištěním:
důvěrnosti – k archivům mají přístup pouze autorizované subjekty
integrity a autenticity – data, software, hardware smí modifikovat jen autorizované
subjekty
dostupnosti – data, služby jsou autorizovaným subjektům dostupná
Celková bezpečnostní politika IS.
Uvádí specifikaci cílů zabezpečení, definici citlivých dat a definici ostatních citlivých aktiv IS
a definici odpovědností za ně.
Systémová bezpečnostní politika IS.
Definuje způsob implementace celkové bezpečnostní politiky IS v konkrétním informačně
technologickém prostředí
V současné době se 95 % zpravodajských informací získává technickými prostředky,
zejména pomocí satelitů, pozemních odposlouchávacích či pozorovacích stanovišť, až po užití
této techniky jednotlivci. Zbytek je doplňován klasickými formami získávání informací, tj.
prostřednictvím osob, jejich prací uvnitř zájmových objektů (zcizování informací opisem,
kopírováním, vlastním odposlechem atd.).
Z hlediska způsobu ohrožení informačního systému rozlišujeme dva druhy:
a) úmyslné - sem patří zejména vyzvídání, odposlouchávání, tzv. počítačové pirátství
(pronikání do informačního systému s cílem data získat nebo je změnit, eventuálně
je zničit), ohrožení systémů počítačovými viry aj. V rámci trestné činnosti na
informačních systémech automatizovaných hovoříme o počítačové kriminalitě.
b) nedbalostní - způsobené rovněž lidským faktorem (např. chybami operátorů),
chybnými vstupními daty, chybami programového vybavení, selháním hardware,
prostředím (výpadek proudu, přírodní katastrofa aj.).
Další rozvoj a rozšiřování užití výpočetní techniky, které vede k vytváření a užívání
počítačových sítí obzvláště nese sebou nutnost ochrany informací. V zemích, jako je USA,
kde počítačové sítě jsou již bohatě rozvinuty, jsou osobní počítače chápány čím dál více jako
prostředky všestranné komunikace. A to nejen uvnitř státu, ale i na mezinárodní úrovni.
Prakticky kdokoli, kdo má osobní počítač se může zapojit do sítě a účastnit se „elektronické“
diskuse po komunikačních kanálech. Vytvářejí se tak vlastně jakési diskusní kluby na
nejrůznější témata.

124
Výše uvedené prvky systému činnosti, nebo z jiného pohledu informačního systému,
mohou být napadány různými způsoby. Ty lze dělit na dva základní:
1) fyzicky - působením silou, jehož následkem je poranění či smrt osoby, poškození
nebo ztráta věci, zařízení, produktů, informací
2) intelektuálně - slovním napadáním, protiprávní činností, (např. poškozováním
obchodního jména, pomluvou, apod.), získáváním informací k vlastnímu
prospěchu aj
To je útok pachatele z vnějšku. Existuje také útok z vnitřku organizace. Ten bude
uskutečňovat vždy osoba-zaměstnanec v podobě vyzrazování. Hlavním činitelem, který
ohrozí nebo napadne informační systém nebo jeho produkt je člověk
uskutečňuje produktivní (materiální i nemateriální) činnost,
daný systém napadá fyzicky nebo intelektuálně,
využívá nebo zneužívá jeho výsledků opět v podobě materiální nebo informační.
Jeho motivace je ovšem problémem samým o sobě, který je třeba vykládat i z
psychologického hlediska.
9.2. Druhy škod a jejich ohodnocování
V jakémkoli podniku mohou vznikat následující druhy škod:
1) přímé ztráty - vyzrazení obchodních záměrů, výsledku výzkumu či možnosti
uplatnění výsledku, důsledky nelegálních finančních transakcí, zvýšené náklady
na obnovení ztracených informací či obnovení výroby v důsledku nuceného
přerušení výroby či expedice zboží aj. Tedy škody nejen v materiální, ale i v
duchovní podobě.
2) nepřímé ztráty - ztráta dobrého jména podniku, protože nebyly dodrženy dohodnut
podmínky a tím finanční ztráty aj.
V rámci ochrany informačního systému je třeba dbát na ochranu nejen dat, ale i
programů, které zpracování dat, řízení výroby či celého podniku ovlivňují. Proto ochraně
veškerého vlastnictví je třeba věnovat pozornost již v období projekce informačního systému
a samozřejmě v době jeho běžného užívání. Je žel pravdou, že ochranná opatření jednak
poněkud ztěžují činnost provozovatelů a jednak zvyšují náklady. Ty by tedy měly být úměrné
škodám, které by mohly vzniknout a proto se obecně považuje za rozumné věnovat 10-20 %
celkových nákladů na informační systém k zabezpečení jeho ochrany.

125
Problémem je ovšem stanovení hodnoty a ceny informací a dat uložených nebo
obíhajících v informačním systému. Fyzická a softwarová aktiva se nejčastěji oceňují podle
jejich ceny, přesněji řečeno, ceny jejich náhrady v případě poškození nebo zničení.
Data však tímto způsobem oceňovat nelze. Připusťme sice, že je možné ocenit
například nějakou databázi tak, že vyčíslíme náklady na její rekonstrukci v případě zničení.
To je sice možné a dokonce potřebné udělat, v žádném případě to však neodráží všechna
hlediska jejich hodnoty. Jedná se především o požadovanou dostupnost, věrohodnost a
důvěrnost dat. Uvedené hodnoty je nutno ocenit jinak.
Nejlépe je to možné udělat s využitím hodnocení následků různých hledisek hrozeb.
Těmito následky může být například ztráta dobrého jména, ohrožení bezpečnosti osob,
porušení právních norem, porušení důvěrnosti osobních údajů, vyzrazení obchodního
tajemství, přímé finanční ztráty a v neposlední řadě i přerušení aktivit organizace tím, že
služby informačního systému nebudou dostupné.
9.3. Základní pojmy ochrany dat a informací
9.3.1. Informační rizika
Při budování a provozu informačního systému v konkrétní organizaci je třeba vyjádřit
riziko narušení informačního systému tzv. rizikovým faktorem. Pod pojmem riziko chápeme
možnou událost v budoucnosti, možné ohrožení, kdy se zatím nic nestalo, ale stát se může. Až
se stane, pak hovoříme o bezpečnostním incidentu. Snižování rizikového faktoru lze
dosáhnout uplatněním konkrétních bezpečnostních opatření, jak bude popsáno dále.
Při ochraně informací, dat a informačního systému lze posuzovat následující rizika:
úroveň fyzické a technické spolehlivosti prostředí, v němž funguje informační
systém,
stav technické spolehlivosti prvků informačního systému,
náhodné působení přírodních sil v daném prostoru dislokace objektu s
informačním systémem (působení vyšší moci),
neúmyslné působení lidského faktoru,
úmyslné působení osob, a to z vnějšku i zevnitř.

126
9.3.2. Bezpečnostní incident
Poškození datových souborů, delší vyřazení systému z provozu, rozšíření
počítačových virů v LAN nebo průnik do informačního systému je třeba považovat za
bezpečnostní incident. Tato událost je vždy provázena informačními ztrátami, jak je popsáno
níže. Po zjištění bezpečnostního incidentu je třeba vyšetřit jeho příčinu, podrobně analyzovat
situaci s cílem zjištění zdrojů infiltrace a uvedení informačního systému do důvěryhodného
stavu. Současně s odstraněním důsledků je třeba uskutečnit i opatření zamezující možnosti
opakování tohoto jevu. Obecně by se při šetření bezpečnostního incidentu mělo postupovat
následovně:
a) zjistit zdroj,
b) zajistit důkazy podrobným šetřením,
c) zjistit možnosti fyzického přístupu ke zdroji a osobní odpovědnost pracovníků,
d) zpracovat protokol s osobami, které byly, mohly nebo neměly být účastníky
incidentu,
e) po důkladném prošetření vyvodit disciplinární nebo kázeňská opatření s viníky,
eventuálně ocenit přístup osob, které zabránily větším ztrátám apod.,
f) přijmout technická, režimová a jiná preventivní opatření v informačním systému a
na příslušných pracovištích.
V souvislosti s bezpečnostními incidenty v rozsáhlých sítích je nutné varovat před
dosti častou tendencí některých pracovníků nebo pracovišť utajovat vzniklé bezpečnostní
incidenty, neanalyzovat a nepřijímat následná opatření. Bez potřebné loajality a vědomí
osobní odpovědnosti uživatelů a správců za bezpečnost informačního systému nelze
důvěryhodný informační systém dále spravovat.
V důsledku nedostatků v analýzách, návrhu, implementaci nebo provozu systému
vznikají slabá místa v informačním systému, která charakterizují jeho zranitelnost. Jedná se
vlastně o akce nebo události představující nebezpečí pro informace, jako je ztráta
dostupnosti, porušení integrity a ztráta důvěrnosti. Svůj původ mohou mít v úmyslném nebo
neúmyslném konání osob, selhání technických či programových prostředků a působení
vnějších vlivů, např. přírodních sil. Původcem největšího nebezpečí, hrozeb, rizik pro
informace je však člověk.

127
9.3.3. Klasifikace rizik
Zpracování informací ve výpočetním systému je zásadním způsobem závislé na
použitém technickém i programovém vybavení. Jedná se o tak složitý problém, že mnoho
autorů vůbec odmítá hovořit o "bezpečném" informačním systému prostě proto, že takový
neexistuje. Místo toho se někdy používá pojmu "důvěryhodný", jak jsme již vyjádřili výše.
Míru důvěryhodnosti je však třeba ocenit. Pokusy o klasifikaci důvěryhodnosti existují. Jsou
vyjádřeny v tzv. Orange book z r. 1983 "Kriteria hodnocení důvěryhodných počítačových
systémů", zpracovanou min. obrany USA.
Dalším významným počinem bylo vydání prozatímních harmonizovaných kriterií
Evropských společenství pod názvem "Kriteria hodnocení bezpečnosti informačních
systémů", známých pod zkratkou ITSEC (Information Technology Security Evaluation
Criteria). Jde o důležitý dokument metodického charakteru, definující požadavky na
funkčnost (třídy funkčnosti),
správnost (úrovně důvěry ve správnost konstrukce a provozuschopnosti) produktů
a systémů informačních technologií,
základní předpoklady výstavby „důvěryhodného“ informačního systému, tj.
specifikaci bezpečnostních cílů a obsahu bezpečnostní politiky.
Většinou se předpokládá, že o úspěchu zajištění ochrany informací při jejich
zpracování rozhoduje především dodavatel technického a programového vybavení. Se
zpracováním úzce souvisí i ukládání informací (dat) zpravidla na média. V tomto případě je
třeba zamezit přístupu neautorizovaným osobám k uloženým datům a tím eliminovat výše
uvedené hrozby ztrát. A dále správně zorganizovat pořizování bezpečnostních kopií a jejich
ukládání a tím zabránit hrozbě ztráty dostupnosti informací v případě havárie systému.
Největší škody při provozu informačního systému souvisejí právě s nevhodnou strategií
zálohování dat a jeho nedůsledné provádění. O úspěchu ochrany informací při jejich ukládání
rozhoduje většinou uživatel.
Přenosy informací, zejména uskutečňované veřejnými telekomunikacemi, jsou
nejslabším článkem všech informačních systémů. Na rozdíl od výpočetního střediska nebo
míst, kde jsou informace zpracovávány, nelze telekomunikační kanál uzavřít do
nepřístupného objektu. Je jen technickou otázkou, jak takový kanál napadnout a ohrozit
důvěrnost, integritu i dostupnost přenášených informací, včetně možnosti uplatnit
neautorizovaný přístup k uloženým datům. Přitom bez dálkových přenosů se neobejdeme,
naopak trend na podstatný nárůst potřeb propojování počítačů i výpočetních systémů je dnes

128
dominující. O úspěchu ochrany informací při jejich přenosech rozhoduje opět většinou
uživatel a to jak volbou vhodných prostředků tak jejich správným používáním.
9.3.4. Cesty k minimalizaci rizika a výskytu incidentů
Zdroje informačního systému podniku obsahují rozsáhlé soubory personálních,
ekonomických a technických dat, jejichž únik by společnost mohl ekonomicky poškodit. Ta je
proto povinna data chránit, v mnohých případech i ze zákona. Jedná se např. o soubory
osobních dat zaměstnanců, mzdové soubory, údaje spořitelny, akcionářů, soubory výrobních,
ekonomických a technických dat. K úniku může dojít zkopírováním dat nebo tiskem sestav z
osobního počítače, sítě LAN nebo odcizením zdroje informací (viz dále). Bránit se lze
identifikací, kdy se posuzuje prokazatelnost konkrétního zdroje informace a kteréhokoli prvku
informačního systému (včetně osob), který s informací přišel do styku. U lidského činitele se
posuzuje i prokazatelnost kontaktu s informačním systémem a informačním prostředím.
Pro splnění výše uvedených rizik je třeba, aby informační systém plnil řadu
podpůrných služeb, funkcí podporujících bezpečnost, jakou je např. účtovatelnost všech
důležitých akcí. Je třeba, aby bylo možno prokázat přístup jednotlivých subjektů ke
konkrétním informacím a zdrojům informačního systému, tj. k jeho objektům.
Nepochybně máme zájem maximálně omezit vznik bezpečnostního incidentu nebo
výskyt informačního rizika. Ještě raději musíme zajistit, aby incident vůbec nevznikl. Mohou
k tomu vést tři způsoby:
1) minimalizace pravděpodobnosti vzniku kalamitní situace komplexním
preventivním působením,
2) minimalizace škod v případě, že kalamitní situace již nastala a to zabráněním
dalšího šíření, omezením rozsahu škod
3) návrhem a užitím vhodné metody obnovy po odeznění kalamitní situace
9.4. Způsoby ztrát, úniků důležitých informací a jejich získávání
pachateli
Při hodnocení jakýchkoli úniků nebo zneužití informací se ukazuje, že nejslabším
článkem v celém systému ochrany je lidský faktor. Ještě navíc, nejrizikovějším faktorem
úniku informací se jeví vlastní, interní zaměstnanci. Odhaduje se, že např. 80 - 90 % případů
porušení ochrany informací je způsobeno právě jimi. Pokud se přidá jejich nespokojenost,

129
zloba nebo pomstychtivost, riziko se ještě zvyšuje. To rovněž narůstá s koncentrováním
pravomocí. Např. jestliže je správce informačního systému současně bezpečnostním
manažerem. Jiným faktorem jsou bývalí zaměstnanci, jejichž funkce souvisela s provozem
informačního systému.
Někdy mají možnost seznamovat s řadou skutečností i externí pracovníci, protože jsou
za určitých okolností bráni jako „vlastní lidé“. Všeho toho lze využít k prolomení bezpečnosti
informačního systému. Tak např. zaměstnanec ve výpovědi nebo nespokojený, který má zlost
na svého zaměstnavatele, může udělat podniku hodně škody. Stává se často „velmi sdílným“
a nebo dokonce vstupuje „do služeb“ konkurence. Dokonce v některých případech vznikne
zárodek pozdější systematické špionáže jen pouhým náhodným „uniknutím“ informací,
kterého se pracovník neúmyslně dopustil.
Nepochybně nejjednodušší je přímá krádež tajemství a to zejména v tom případě, kdy
je příliš snadné vloupat se do kanceláří, laboratoří či dílen v noci, kdy místnosti jsou prázdné.
Ovšem je to možné také ve dne, před očima zaměstnanců. Souběžně s tím přispívá určitě k
velkým úspěchům průmyslové špionáže rozsáhlá škála speciálních metod a technických
prostředků (odposlouchávacích, fotografických, snímacích) od „hračiček“ až k instalacím,
jejichž komplexnost ruší jakoukoli diskrétnost.
9.4.1. Cesty a způsoby úniku informací
Kdykoli podnik přijímá nového zaměstnance na citlivé místo, vždy vyvstávají dvě
otázky:
- nepracoval nový zaměstnanec už u konkurence,
- a nemá v konkurenčním podniku nějakého příbuzného.
Někteří lidé se specializují na to, že mění zaměstnání a přitom z podniku odnášejí
spoustu důvěrných informací.
Velmi dobře informované služby v podniku jsou zpravidla pracoviště marketingu či
reklamní oddělení. Tato by měla velmi pozorně sledovat vše, co má být zveřejněno
prostředky masové komunikace (tisk, foto, film, televize, video apod.), aby neunikly důležité
informace..
Všeobecně je důležité, aby se zaměstnanci nechlubili příliš úspěchy svého podniku,
nevydávali žádné významné dokumenty a nikdy nediskutovali o důvěrných otázkách na
veřejných místech, např. na různých tiskových konferencích, trzích, veletrzích, výstavách
apod. Jde zejména o to, aby tiskové konference byly připraveny a neodbočovaly od daného

130
tématu. Důležitá sdělení tisku, rozhlasu a televize by měl prověřit právník, eventuálně
bezpečnostní manažer, pracující pro podnik. Většina úspěšných firem získává bohatství
informací např. z odborných časopisů, majetkových analýz a i z výročních zpráv konkurence,
protože malé společnosti nebo vývojově organizovaná oddělení odhalují více ze své
technologie, protože potřebují publicitu.
Konkurenční společnosti mohou také sdílet informace shromážděné „třetí stranou“.
Proto je nutno vedle ochrany vlastních zaměstnanců, střežit případné „špióny“, odhalovat je
nějakým způsobem v jejich působišti, zabránit jim v činnosti a dohnat je k tomu, aby se
dopustili nějakého činu, který bude mít za následek policejní zásah a zadržení.
Jinými zdroji jsou např. tiskové výstupy. Ty zejména proto, že obsahují informace
přístupné bez dalších technických prostředků. Praxe bývá taková, že použité výstupní,
podkladové dokumenty) často slouží pro psaní dalších poznámek a to nejen vlastním
zaměstnancům, ale často i jejich rodinám.
Ochrana zálohovacích disket, pásek, a jiných médií, ač obsahují cenné informace, je
značně podceňována. A to nejen z hlediska důvěrnosti nebo integrity, ale i z hlediska
dostupnosti. Často je záložní, magnetické médium nečitelné, a tudíž i nepoužitelné, nebo je
uloženo na nevhodném místě, takže naopak dojde k jeho zničení či zneužití. „Vadné disky“ se
vyhazují, aniž se je někdo pokusí opravit. A přitom data jsou na nich po určitou dobu
zachována a tedy i dosti čitelná..
9.4.2. Využití technických prostředků k získávání informací
Telefon je stále nejpoužívanějším prostředkem komunikace mezi lidmi. Není nic
snazšího, než získat informace napojením na příslušnou linku. Rovněž faxu se používá ke
sdělování skutečností, které zcela jistě někdy tvoří součást obchodního tajemství firmy.
Zpráva např. může dojít na nesprávnou adresu. Diskety, pásky, přenášené fyzicky k příjemci
jsou vlastně také komunikační cestou (nepoužijeme-li modemu).
Sítě LAN a WAN jsou obzvlášť zranitelným místem informačního systému. Je spíše
pravidlem, že data jsou přenášena v otevřené formě, podobě, přihlašovací heslo často také.
Nic nebrání nepovolané osobě získat potřebné údaje, aniž by musela překonávat značné
bariéry.
Samozřejmě, že se jedná o protizákonnou činnost, ale velké obchody se v rámci tvrdé
konkurence neponechávají náhodě. Tehdy je každý způsob dobrý, jen když vede k úspěchu.

131
Proto se může část podnikatelských aktivit i pohybovat na hranici zákona nebo za ní. Patří k
tomu hon za ekonomickými informacemi.
9.4.3. Úniky a ztráty v automatizovaných informačních systémech
Při využívání výpočetní techniky jsou samozřejmě způsoby získávání informací,
respektive jejich úniky specifické. Problém nedovoleného získávání informací se dostal až k
naplňování ustanovení trestního zákoníku, tedy k páchání trestné činnosti tak, že mluvíme již
speciálně o počítačové kriminalitě.
Do této oblasti na př. patří:
a) Napadání technického nebo programového vybavení, dat nebo komunikačních
zařízení, tj. nejen fyzické odcizení nebo poškození technického prostředku, ale
zejména na něm uloženého programu a dat (informací). Mohli bychom sem zahrnout
i tzv. logické bomby, aktivující se za určitých podmínek, viry, dálková mazání dat
apod.
b) Neoprávněné užívání počítače či komunikačního zařízení, tj. zneužívání cizího
počítače nebo počítačové technologie kompetentní obsluhou, ale v neprospěch jejího
majitele, zpracováváním zcela jiných úloh za úplatu pro jiného odběratele
c) Neoprávněný (nelegální) přístup k datům s cílem získat utajované informace. V tomto
případě však asi musíme odlišit profesionální počítačovou špionáž (vojenskou,
hospodářskou, politickou apod.) od působení tzv. hackerů (průnikářů). Cílem těchto je
prokázání vlastních schopností k prolomení ochrany a většinou nikoli materiální zisk,
spočívající v získání obsahu utajovaných informací. To je zájmem profesionálů.
Nevylučujeme však, že činnost hackerů může být spojena s jinou trestnou činností,
nebo využita jinými subjekty.
d) Krádež technických prostředků, tj. počítače, jeho příslušenství, programového
vybavení, komunikačního zařízení i vlastních dat. Prostá krádež je jasná, motiv a cíl
můžeme odhadnout a zjistit. Složitější je to s okopírováním programů nebo dat. Jedná
se spíše o počítačové pirátství, mimochodem u nás značně rozšířené zejména mezi
amatéry, ale i v profesionální sféře.
e) Úmyslná změna v programech a datech (eventuálně i v technickém zapojení), vložení
virů, jiných programů, počítačová defraudace apod.
f) Zneužití počítačových prostředků k páchání jiné trestné činnosti, tzn. neoprávněná a
úmyslná manipulace s daty, např. stavy ve skladu, tržby, nemocenské pojištění,

132
úprava dokladů apod. Tohoto způsobu se využívá snadněji než při úpravě dokladů
papírových.
g) Jiné podvody páchané v souvislosti s výpočetní technikou,
kdy např. programátor vytvoří v rámci pracovního poměru v kolektivu program a po
okopírování ho prodá pod vlastním jménem.
Útočníky mohou být:
amatéři, kteří se do informačního systému dostanou přes náhodně objevená zranitelná
místa,
hackeři, usilující prokázat své mimořádné schopnosti úmyslným prolomením ochrany
systému,
profesionální zločinci, kteří vedou útok v podstatě „neomezenými prostředky“. Např.
může jít o zájem cizí mocnosti (špionáž, zejména průmyslová nebo obchodní),
silného konkurenčního podniku, teroristy, mafii apod.
Důsledkem útoků na informace a informační systém může být:
znehodnocení částečné nebo úplné,
pozměnění částečné nebo úplné ( a tím znehodnocení),
znehodnocení či zneužití krádeží,
zneužití neoprávněným využíváním,
zneužití podsunutím falešné informace,
dočasná nebo trvalá ztráta informace.
Rozvoj a rozšiřování uplatnění výpočetní technologie které vede k vytváření a užívání
počítačových sítí, sebou přináší další důvod k ochraně informací. Jak již bylo řečeno, v
zemích, jako je USA, kde počítačové sítě jsou již bohatě rozvinuty, jsou osobní počítače
chápány čím dál více jako prostředky osobní komunikace. A to nejen uvnitř státu, ale i na
mezinárodní úrovni. Zneužití pro zcela jiné účely, než studijní, vzdělávací nebo prostě jen
komunikační je jistě přinejmenším hodně přitažlivé.

133
9.5. Počítačová kriminalita
V současné době nemá pojem počítačová kriminalita žádný oficiálně definovaný obsah,
ale existuje více různorodých pojetí, podle toho, z jakého hlediska se autoři na problém dívají.
„Počítačovou kriminalitu je třeba chápat jako specifickou trestnou činnost, kterou je možné
spáchat pouze s pomocí výpočetní techniky, a kde je výpočetní technika předmětem trestného
činu nebo pachatelovým nástrojem ke spáchání trestného činu.
Aby bylo možno hovořit o počítačové kriminalitě, musí pachatel ke svému jednání užít
nejen výpočetní techniku, ale jeho jednání musí také naplňovat znaky skutkové podstaty
některého trestného činu uvedeného v trestním zákoně a nebezpečnost takového jednání musí
dosahovat požadovaného stupně nebezpečnosti činu pro společnost.
Důvody vzniku počítačové kriminality
1) Složitost informačních technologií
Pro většinu lidí (uživatelů) je svět počítačů absolutně nepochopitelný a neproniknutelný
a z toho také pramení vnímání informační technologie jako velmi podezřelé.
2) Důvěra uživatelů
Málokoho napadne kontrolovat např. účet v supermarketu, kde máme desítky položek,
jestli nám náhodou pokladna nenamarkovala o nějaký rohlík navíc.
3) Objem dat
V prostředí kde se pachatelé pohybují (např. Internet) je obrovské množství dat a je
nemožné všechny efektivně kontrolovat.
4) Snadnější podmínky
Vyloupit banku tzv. od obrazovky počítače stisknutím nějaké klávesy je mnohem snazší,
než si opatřit zbraň, neprůstřelnou vetu, kuklu a vydat se do banky reálně.
5) Nízké právní vědomí populace
6) Nedokonalost legislativy vzhledem k dynamickému vývoji v IT

134
9.6. Rozdělení počítačové kriminality
Podle postavení počítače při páchání trestné činnosti:
1) Protiprávní jednání směřující proti počítači – počítač je zde přímo terčem útoku
(krádeže dat, průmyslové špionáže, bankovní podvody, zneužití osobních údajů…)
Tradiční jednání :
Průmyslová špionáž - Jde o zločin, který existoval dávno před tím, než vznikl
první počítač. Dnes je však získání informací ze systému konkurence
mnohem jednoduší. Jde o tzv. hackerský útok.
Krádež - O trestný čin krádeže se jedná především, dojde- li k odcizení
počítače nebo nějaké z jeho částí (záznamová média, příslušenství…).
Loupež
Zpronevěra - Například když zaměstnanec po ukončení pracovního poměru
nevrátí zapůjčený přístroj (počítač, notebook).
Nová jednání :
Hacking – pronikání do systému
Carding – zneužívání platebních karet
Zneužití osobních údajů -Stále více údajů je uloženo na magnetických
médiích. Tím roste zájem zločinců o jejich obsah, především o osobní data
občanů a hospodářsky využitelné údaje.
2) Protiprávní jednání spáchaná s využitím počítače – počítač slouží pouze jako
nástroj trestné činnosti (porušování autorského práva…)“.Velmi často může docházet
k prolínání. Jeden počítač se stane nástrojem a druhý je cílem spáchání trestné
činnosti. Protože bez počítače se do počítače proniknout nedá.
Tradiční jednání :
Podvody, zpronevěry
Nové technologie vytvořily živnou půdu pro podvodníky, kteří začali využívat
počítačů pro klasickou trestnou činnost. Na rozdíl od klasických manipulací s
papírovými doklady má manipulace s počítačovými daty pro pachatele výhody:
vymazání či přemazání údaje na magnetickém médiu je podstatně
snazší a nezanechává žádné stopy,
člověk z psychologického hlediska považuje výsledky z počítače za
správné a více jim důvěřuje. Tento druhý aspekt počítačové kriminality

135
má za následek vysokou úspěšnost trestných činů páchaných za využití
výpočetní techniky.
Padělání a penězokazectví
V praxi zločinců se například velmi osvědčily grafické počítačové systémy pro
elektronickou sazbu a grafickou úpravu publikací, tzv. Desk Top Publishing. S jejich
pomocí jdou zhotovit falešné technické průkazy a jiné doklady, falešné cenné papíry,
platební karty a jiné bankovní dokumenty.
Útoky na čest a pověst
Vydírání, elektronické výpalné
Šíření pornografie
Extremismus na Internetu
Nová jednání :
Spamming - zasílání nevyžádané pošty
Warez – moderní počítačové pirátství
Phreaking – zneužívání telekomunikačních služeb
Cracking – prolomování ochrany systému
Porušování autorského práva - „Autorský zákon je zkrácený název zákona číslo
121/2000 Sb., o právu autorském, právech souvisejících s právem autorským a o
změně některých zákonů, který Parlament České republiky přijal 7. dubna 2000, a
který vstoupil v platnost 1. prosince roku 2000.
Z § 1 je patrné, že cílem zákona je chránit především práva autora a ostatních
zúčastněných osob. Zároveň je zde řešena ochrana autorských práv a jejich kolektivní správa.
Druhou, neméně důležitou věcí je určení, koho se tento zákon týká, což je ošetřeno § 107. Ten
říká, že se tento zákon vztahuje na všechna díla a umělecké výkony výkonných umělců
uveřejněná občany České republiky, ať byla uveřejněna kdekoli.
U občanů jiných států je toto řízeno mezinárodními smlouvami. Zákon se dále vztahuje
na díla prvně uveřejněná v ČR, případně pokud má autor či právnická osoba v ČR bydliště,
resp. sídlo. Díla cizích státních příslušníků nemohou mít delší ochranu než je tomu v zemi
původu díla, to vychází z Bernské úmluvy (čl. 5 odst. 4). Jediným způsobem zániku
autorských práv je jejich vypršení, tzn. práv se nelze vzdát. Vypršením práv se dílo stává
dílem volným (§ 28).
Přestupku se může dopustit pouze osoba fyzická. Pokud dojde k porušení povinnosti
uložené právnické osobě, odpovídá podle zákona o přestupcích ten, kdo za právnickou osobu

136
jednal, nebo měl jednat, a jde-li o jednání na příkaz, ten kdo dal k jednání příkaz (§ 6
přestupkového zákona).
9.7. Software (počítačové programy)
Nelegální užívání software prošlo intenzívním nárůstem, kdy se hovořilo až o 80%
nelegálně užívaného programového vybavení. Současná situace není tak dramatická, ale podle
odhadů (byť ze strany výrobců a distributorů software) je každý druhý počítačový program
užíván v ČR nelegálně.
„V České republice bylo loni nelegálně nainstalováno 39% počítačových programů, což
podle studie společnosti IDC pro Business Software Alliance (BSA) výrobcům software
způsobilo ztráty za 147 milionů dolarů (2,5 miliardy korun).
Míra softwarového pirátství loni opět klesla, a to o jeden procentní bod. Nejvíce se v
Česku nelegálně šíří kancelářské softwarové balíky, grafické programy, antiviry, operační
systém Windows a počítačové hry. Nejnovější verze Windows Vista se v nabídkách pirátů
objevila dokonce ještě před jejím oficiálním uvedením na český trh. Mezi nejvíce
poškozované výrobce softwaru patří firmy Microsoft, Adobe, Autodesk či Symantec.
Co do množství případů softwarového pirátství se podle statistiky BSA na prvním místě
umístila Praha (25 procent), následovaly Jihomoravský (13 procent) a Ústecký kraj (12
procent). Na tyto tři regiony tak připadá polovina všech případů porušování autorského práva
k softwaru a třetina způsobené škody.
Nejméně se nelegální software v rámci Evropy užívá v Dánsku (25 procent), ve
skandinávských státech (26 procent) a rovněž v Rakousku (26 procent). Nejhůře jsou na tom
v EU nováčci Rumunsko a Bulharsko (69 procent) a rovněž některé baltské státy včetně
Polska (57 procent).
9.8. Typy pachatelů
Pachatele můžeme rozdělit na cílevědomé osobnosti a příležitostné typy.
„Z rozboru vybraných trestných činů počítačové kriminality vyplývá zatím, že se
převážně jedná o typy příležitostné, využívající dané situace nebo dosavadní vlastní sociální
zkušenosti. Ty pak můžeme podrobněji rozdělit na typy:
kořistnicky zaměřené

137
plánovité (zaměřené převážně na překonání překážek ochrany systémů),
situační (využívajících příhodných podmínek k uskutečnění jakékoli motivace).
Pachateli trestných činů bývají obvykle osoby:
se středoškolským, jiným vyšším nebo vysokoškolským vzděláním, zejména v
technických oborech, speciálně v oboru informačních technologií,
často nadprůměrně inteligentní, vynalézavé, zejména ve specifické programátorské
oblasti,
zneužívající svého vyššího výsadního postavení v zaměstnání s tomu odpovídající
pravomocí,
ve svém pracovním zařazení nebo ohodnocení neuspokojení,
jejich protiprávní jednání je vzdáleno tradičním hrubým formám delikvence,
neobsahuje prvky násilí.
Pokud se jedná o motiv jejich jednání, u nás zatím zcela jednoznačně převažuje touha po
zisku. Statistiky ukazují, že např. počítačová bankovní kriminalita je jednou z
nejvýnosnějších. Existují však i jiné motivy, např. získat domnělou převahu nad
zaměstnavatelem, pocit beztrestnosti, touha po uplatňování rizika nebo dobrodružství.
9.9. Boj proti počítačové kriminalitě
Prevence
1) psychologická – jedná se o taková opatření, která se snaží vytvářet povědomí, že
kopírování, padělání a další trestné činy jsou nemorální a společensky nepřijatelné.
2) technologická – jedná se zejména o zabezpečení. Administrátoři a tvůrci ochran proti
kopírování se snaží vymýšlet stále nová a nová zabezpečení. Bohužel, dokonalá
ochrana počítače neexistuje a po nějaké době se vždy hackrům podaří do systému
dostat.
Represe
„Represi v oblasti počítačové kriminality provádí, tak jako u ostatních protiprávních
činů, státní orgány – policie, soudy aj. Jde o vyšetřování správních deliktů, přestupků a
trestných činů a ukládání sankcí, které jsou za ně stanoveny zákonem.

138
SHRNUTÍ KAPITOLY
Projevy počítačové kriminality
• Podvody (§ 250 tr. Z.)
• Padělky (např. platební karty),
• Bankovní a počítačové podvody,
• Finanční hry „letadla“, „pyramidy“,
• porušování autorských práv,
• Infikování počítačovými viry,
• Zneužívání osobních dat a počítačová špionáž,
• Šíření informací,
• shromažďování citlivých informací
• Internetovská trestná činnost různého charakteru
Pachatelé trestné činnosti
Podle výzkumu se trestné činnosti dopouštějí:
• Zaměstnanci ………………….82 %
• Hackeři ……………………….17 %
• Ostatní uživatelé mimo (klienti odhalující přístupová hesla) organizovaný zločin
(snaží se vyžít systémů k legalizaci kriminální činnosti)…………….1 %
Příčiny kriminality
Kriminologické:
• Nežádoucí fungování systémů společenských, právních, politických atd.
• Rozpornost, různé deformace informací.
• Přemíra informací („vymývání mozků“).
• Přílišní frekvence nevhodných informací (masové sdělovací prostředky).
Sociologické:
• Pozice, role jedince ve společnosti.
• Charakter formálních a neformálních společenských skupin.
• Charakter a kvalita vůdců (autorita).
Ekonomické:
• Neuspokojování materiálních potřeb a zájmů jednotlivců i kolektivů.
• Neujasněný vztah k vlastnictví, lhostejnost.

139
• Nízká ekonomická zainteresovanost.
• Existence podplácení, přeplácení, padělků, nekvalitních výrobků.
• Porušování pravidel hospodářské soutěže.
Vyšší formy počítačové kriminality
Prudký rozvoj ICT, odstraňování geografických bariér, trendy zostřování a opětné zmírňování
společenských, zejména mezinárodních vztahů, mohou vést či již vedou k novým, vyšším
formám počítačové kriminality. Jsou jimi:
• Informační válka
• Válka vedená v oblasti informací, zejména o ně.
• Válka, v níž se bojuje informacemi.
V podstatě nic nového, vždy ve válkách měly důležité postavení informace všeho druhu
(oficiální, zpravodajské, politické, diplomatické, ekonomické a další druhy). Nyní
nabývají na významu moderní ICT – zvyšující rychlost, komplexnost, působnost
• Dříve se politický terorismus zaměřoval na vybrané individuální cíle – představitele
státní a hospodářské moci.
• Dnes lze během několika milisekund napadnout rozsáhlé komunikační sítě a narušit
jejich funkci.
• Charakteristikou je pak značná plošnost působení a rovněž i brutalita a rozsah
následných škod.
• Kyberterorismus
Zneužití počítačových technologií proti osobám, či majetku za účelem vyvolání strachu nebo
vydírání a vymáhání ústupků, zaměřené proti vládním institucím nebo civilnímu obyvatelstvu,
případně proti jejich částem, pro podporu politických, sociálních, ekonomických, eventuálně
jiných cílů, zaměřené na IS používané cílovým objektem.
Účelem je:
• Zlikvidovat co nejvíce lidí, způsobit rozsáhlé materiální škody a hospodářské ztráty.
• Vyvolat strach, hrůzu a paniku širokých vrstev obyvatelstva na rozsáhlém prostoru.
• Otřást psychikou společnosti, zviklat víru lidí ve schopnost své vlády je ochránit.
Praktický vývoj jevů a činů v oblasti ochrany informací a dat vede k nutnosti uplatňovat buď
stávající právní normy, nebo k jejich úpravě, eventuálně k tvorbě nových. Problematika je
živá a je třeba ji systematicky a neustále věnovat pozornost

140
SEZNAM KLÍČOVÝCH SLOV K ZAPAMATOVÁNÍ
Komunikační bezpečnost, Fyzická bezpečnost, Personální bezpečnost, Spamming, Warez ,
Phreaking , Cracking, Carding
KONTROLNÍ OTÁZKY
1. Jaké jsou základní typy počítačové kriminality
2. Důvody vzniku nových a vyšších forem počítačové kriminality
KONTROLNÍ TEST
Podle vlastních zkušeností navrhněte opatření vedoucí ke zvýšení informační bezpečnosti
počítačového informačního systému v prostředí sítě.

141
VÝSTUPY Z UČENÍ
Po prostudování textu a vypracování úkolů v rámci této kapitoly
BUDETE UMĚT
Seznámíte se s pojmem a některými aspekty počítačového pirátství.
Klasifikovat základní projevy a příčiny počítačové kriminality jako jsou :
Informační rizika, Bezpečnostní incident, Klasifikace rizik,
Cesty vedoucí k minimalizaci rizika a výskytu incidentů
ZNALOSTI
BUDETE SCHOPNI
Určit příčiny a způsoby ochrany informačních systémů z hlediska počítačové
kriminality.
Rozlišit protiprávní jednání směřující proti počítači a protiprávní jednání
spáchaná s využitím počítače
SCHOPNOSTI
ZÍSKÁTE
Přehled o základní problematice v této oblasti.
Přehled o nejčastějších možnostech úniku a ztrát dat v automatizovaných
informačních systémech
Představu o zabezpečení Informačních systémů
DOVEDNOSTI

142
10. Informace a právo v současné Evropě
Přehled základních zákonů a nařízení týkajících se práce s informacemi.
Zákon č. 121/2000 Sb
Autorský zákon , o právu autorském, právech souvisejících s ním.
Zákonem je chráněn počítačový program i zdrojový kód, včetně přípravných a koncepčních
materiálů, nikoli však myšlenky, principy ani technická řešení (ta lze ochránit uplatněním
obchodního zákoníku).
Zákon č. 527/1990
Zákon patří do skupiny norem týkajících se patentového práva. Patentem je možné chránit
pouze programy, jež jsou nedílnou součástí patentové technologie, vynálezu.
Program není vynálezem, neřeší technický problém.
Zákon č. 413/1991
Obchodní zákon upravuje postavení podnikatelů, obchodní závazkové vztahy, jakož i některé
jiné vztahy s podnikáním související.
Předmětem práv náležejících k podniku je i obchodní tajemství, tvořící veškeré skutečnosti
obchodní, výrobní či technické povahy související s podnikem, které mají skutečnou nebo
alespoň potenciální materiální či nemateriální hodnotu, nejsou v příslušných obchodních
kruzích běžně dostupné, mají být podle vůle podnikatele utajeny a podnikatel odpovídajícím
způsobem jejich utajení zajišťuje
Zákon č. 412/2005
O ohraně utajovaných informací a o bezpečnostní způsobilosti. Obsahuje zásady pro
stanovení informací jako utajovaných, podmínky pro přístup k nim a další požadavky na
jejich ochranu, zásady pro stanovení citlivých činností a podmínky pro jejich výkon.
Zákon č. 176/2006
O svobodném přístupu k informacím. Upravuje pravidla pro poskytování informací a
podmínky práva přístupu k těmto informacím.
Zákon č. 151/2000
Zákon o telekomunikacích, určující podmínky pro zřizování a provozování
telekomunikačních zařízení a sítí, pro poskytování služeb a výkonu státní správy včetně
regulace.

143
Zákon č. 227/2000
Zákon o používání elektronického podpisu, poskytování souvisejících služeb, kontrole
povinností stanovených zákonem a sankcích za jejich porušení.
Zákon č. 101/2000, změna č. 227/2000 – 1. část
Zákon o ochraně osobních údajů, upravuje ochranu osobních údajů o fyzických osobách,
práva a povinnosti při zpracovávání těchto údajů a stanoví podmínky, za nichž se uskutečňuje
jejich předávání do jiných států.
• Zákonem se zřizuje Úřad pro ochranu osobních údajů se sídlem v Praze.
• Zákon se vztahuje na osobní údaje zpracovávané státními orgány, orgány územní
samosprávy, jiné orgány veřejné moci, jakož i fyzické a právnické osoby, pokud není
stanoveno jinak.
• Vztahuje se na veškeré zpracovávání osobních údajů, ať k němu dochází
automatizovaně nebo jinými prostředky.
• Zákon se nevztahuje na zpracování osobních údajů, prováděných výlučně pro osobní
potřebu, na nahodilé shromažďování osobních údajů, pokud nejsou dále
zpracovávány.
• Zvláštní zákony stanoví zpracovávání údajů pro účely statistické a archivnictví,
zpravodajských služeb, Policie ČR, Interpolu, NBÚ, min. financí a min. vnitra
Zákon č. 89/1995
Zákon o státní statistické službě
§16 Povinnost mlčenlivosti a ochrana důvěrných statistických údajů
(1) Zaměstnanci orgánů vykonávajících státní statistickou službu nebo fyzické osoby, které
zajišťují zpracování statistických zjišťování nebo sběr údajů, jsou povinni zachovávat
mlčenlivost o důvěrných statistických údajích, se kterými se seznámí. Za tímto účelem jsou
povinni složit slib mlčenlivosti.
Nařízení vlády 522/2005, vyhlášky č. 523-529/2005
• Nařízení vlády, kterým se stanoví seznam utajovaných informací.
• Vyhláška č. 523 o bezpečnosti informací a komunikačních systémů a dalších
elektronických zařízení nakládajících s utajovanými informacemi.
• Vyhláška č. 524 o zajištění kryptografické ochrany utajovaných informací.
• Vyhláška č. 525 o provádění certifikace při zabezpečování kryptografické ochrany.
• Vyhláška č. 526 o průmyslové bezpečnosti.
• Vyhláška č. 527 o personální bezpečnosti.

144
• Vyhláška č. 528 o fyzické bezpečnosti a certifikaci technických prostředků.
• Vyhláška č. 529 administrativní bezpečnosti a o registrech utajovaných informací.
Nekomerčně šířené zákony
• Public domain – nejsou chráněny autorským právem, lze je, užívat i šířit bez omezení.
• Freeware – autorské právo se na ně vztahuje, lze je kopírovat i šířit, ale ne bez upírání
autorství.
• Shareware – lze legálně kopírovat, před koupí bezplatně vyzkoušet, očekává se určitá
finanční odměna (nepříliš vysoká).
Listina základních práv a svobod
Poskytuje:
• fyzickým osobám ochranu osobnosti podle čl. 10 LZPS před neoprávněným
shromažďováním, zveřejňováním nebo jiným zneužíváním údajů o své osobě (ochrana
databází),
• právnickým osobám ochrana dobré pověsti a názvu (opírá o urážku na cti a ochranu
proti nekalé soutěži).
Národní bezpečnostní úřad
Úřad vykonávající státní správu v oblasti utajovaných informací a bezpečnostní způsobilosti.
Rozhoduje o žádosti fyzické osoby, podnikatele o doklad a o zrušení platnosti osvědčení,
zabezpečuje ochranu utajovaných informací v souladu se závazky z členství v EU, NATO a z
mezinárodních smluv, vede ústřední registr, povoluje poskytování utajovaných informací v
mezinárodním styku, zajišťuje kryptografickou činnost, měření elektromagnetického
vyzařování aj.
Evropský inspektor ochrany údajů
Svoji činnost zahájil počátkem r. 2004 a jeho úkolem je zajišťovat, aby instituce EU
respektovaly právo na soukromí, a v případě potřeby poskytovaly poradenskou službu s
následným vyřešením problému.
Orgány a instituce EU nesmějí zpracovávat údaje odhalující rasový či etnický původ,
politické názory, náboženské či filozofické přesvědčení, odborovou příslušnost, údaje o
zdraví a sexuálním životě (pokud neslouží zdravotní péči).
Vybrané právní normy mezinárodní (evropské)
• Pařížská úmluva na ochranu průmyslové vlastnictví - vyhláška č. 64/1975
• Pařížská úmluva o autorském právu – vyhláška č. 134/1980

145
Uplatnění trestního práva
• Páchání trestné činnosti, v níž figuruje určitým způsobem počítač jako souhrn
technického a programového vybavení včetně dat je nazýváno počítačovou
kriminalitou.
• Vztahují se na ně ustanovení zák. č. 140/1961
• Počítač může být předmětem, ale i nástrojem (prostředkem) páchání trestné činnosti.

146
11. Literatura.
Základní:
BARTOŚOVÁ, H.: Management II, Základy , Vybrané metody a techniky, PAČR,
Praha: 2005
HORZINKOVÁ, E., Čechmánek, B.: Zákon o Policii České republiky a související
předpisy, Eurounion, Praha:2001
CHMELÍK, J. a kolektiv: Rukověť kriminalistiky, Vydavatelství a nakladatelství
Čeněk, Plzeň: 2006
KOCAN, M., Učíme se orientovat v IS – computer 1/99
MATES, P., MATOUŠOVÁ, M. Evidence, informace, systémy. Právní úprava. Praha:
Codex Bohemia, 1999.
MOLNÁR, Z. Moderní metody řízení informačních systémů. Praha: Grada, 1992.
POŹAR J., Informační bezpečnost, Vydavatelství a nakladatelství Aleš ČENĚK s.r.o.,
2005
POŽÁR, J. Manažerská informatika. Praha : PA ČR, 2003.
RAK, R. A KOL. Informatika v kriminalistické a bezpečnostní praxi. Praha: Policejní
prezidium MV ČR, 2000.
www.mvcr.cz
Doporučená:
BERKA, Petr. Aplikace systémů dobývání znalostí pro analýzu medicínských
dat [online]. 2001, poslední revize 30.5.2003 [cit. 2010-06-09]. Dostupné z:
<http://euromise.vse.cz/kdd>.
BERKA, Petr. Dobývání znalostí z databází. 1.vyd. Praha: Academia, 2003. 366
s. ISBN 80-200-1062-9.
BREJCHA, A Právo na informace a povinnost mlčenlivosti v českém právním řádu.
Praha: Codex Bohemia, 1998.
Bulletin AFOI. Praha: Asociace firem pro ochranu informací, 1998.
ČADA, O. Operační systémy. Praha : Grada a.s., 1994. 377 s. ISBN 80-85623-44-7
CVRČEK, F., NOVÁK, F. Základy právní informatiky. Brno: Masarykova univerzita,
1992.
ČERVEŃ, P. Cracking a jak se proti němu bránit. Praha, 2001
DLOUHÝ, M. Úmluva o počítačové kriminalitě. In Kriminalistický sborník 2/2004.
Praha : Kriminalistický ústav Praha, 2004, s. 37-38
DOSEDĚL, T. Počítačová bezpečnost a ochrana dat. Brno : Computer Press, 2004.
190 s. ISBN 80-251-0106-1
DYSON, E. Release 2.1 Vize života v digitálním věku. Praha: Management Press,
2001
HAUGTON et al. 'S 2003 Revize dat softwarové balíčky dolování v americké
Statistice.
FAYYAD, Usama M.: Data Mining and Knowledge Discovery. An International
Journal. [online]. [1996]. vol. 1. is. 1 [cit. 2010-06-09]. Dostupné z:
<http://www.kdnuggets.com/gpspubs/aimag-kdd-overview-1996-Fayyad.pdf>.

147
HEJNA, L. Lokální počítačové sítě. Praha: Grada, 1994.
KNAPP, V. A KOL. Právo a informace. Praha: Academia, 1988.
KOUBA Z. - Datové sklady, Dobývání znalostí z databází 2000, Sborník přednášek,
FIS VŠE Praha
LÁTAL, I. aj. Ochrana informací, dat a počítačových systémů. Praha: Eurounion,
1996
MATĚJKA,M., Počítačová kriminalita, Praha:Computer Press, 2002, ISBN 80-7226-
419-2
MATES, P. - MATOUŚOVÁ, M. Evidence, informace, systémy. (Právní úprava).
Praha: Codex Bohemia, 1997.
MOLNÁR, Z. Efektivnost informačních systémů. Praha: Grada Publishing, 2001
NISBET Robert z roku 2006 tři části série článků "dolování dat Nástroje: Jedním z
nich je nejlepší pro CRM? Které"
ODEHNAL, P., ZAHRADNÍČEK, P., Praktická sebeobrana proti virům. Praha :
Grada Publishing, spol. s r.o., 1996. 115 s. ISBN 80-7169-363-4
PC WORLD edition, Viry a počítače. Brno : UNIS Publishing s.r.o., 2001. 80 s.
ISBN 80-86593-02-9
PŔIBYL, J. Ochrana dat v informatice. Praha: ČVUT, 1996.
REISCHL, G. Sběratelé elektronických dat pod lupou. Praha: Euromedia Group, 2001
SMEJKAL, V. Internet a §§§. Praha: Grada Publishing, 2001
SMEJKAL, Vladimír.; SOKOL, Tomáš; VLČEK, Martin. Počítačové právo. Praha :
C. H. Beck/SEFT, 1995. 264 s. ISBN 80-7179-009-5
SVOBODA, S. Informační systémy podnikatelských subjektů. Praha: VŠE, 1995
SKLENÁ, Vilém. Data, informace, znalosti a internet. Praha : C. H. Beck, 2001.
ISBN 80-7179-409-0
TIETZE, P. Strukturální analýza, úvod do projektu řízení. Praha: Grada, 1992.
TVRDÍKOVÁ, M. Zavádění a inovace IS ve firmách. Praha: Grada Publishing, 2001
TVRDÍKOVÁ, Milena. Aplikace moderních informačních technologií v řízení firmy.
Praha: Grada Publishing, a. s., 2008. s. 176. ISBN 978-80-247-2728-8
VÁŇA, J. Informácie a ich ochrana. Bratislava: Akadémia Policajného zboru, 1999
VODÁČEK, Leo; VODÁČKOVÁ, Olga. Moderní management v teorii a
praxi.,1.vyd. Praha: Management Press, 2006, 295 s. ISBN: 80-7261-143-7
VODÁČEK, Leo., ROSICKÝ, Antonín. Manažerská informatika. Praha :
Management Press, 1997.
WANG, John. Data mining : opportunities and challenges. Hershey : IRM Press,
2003. xiii, 468 s. ISBN 1-931777-83-7
ŽID, N. A KOL. Orientace ve světě informatiky. Praha: Management Press, 1998.
www.wikipedia.org
www.denik.cz/ekonomika
www.itbiz.cz/schengensky-informacni-system
www.mvcr.cz/archiv2008/eunie/policejni.html
www.mzv.cz/servis/soubor.asp?id=30503
www.policie.cz/clanek/rok-sis-v-ceske-republice.aspx
Časopisecké články časopisů Chip, ComputerWorld, Softwarové noviny 1996-2010
aj.
Wikipedia, Autorský zákon, (citace říjen, 5., 2007)
CRoss Industry Standard Process for Data Mining [online]. [cit. 2010-06-09].

148
Právní předpisy
Zákon č. 101/2000 Sb., o ochraně osobních údajů v platném znění
Zákon č. 106/1999 Sb., o svobodném přístupu k informacím v platném znění
Zákon č. 365/2000 Sb. o informačních systémech veřejné spávy
Zákon č. 412/2005 Sb., o ochraně utajovaných informací v platném znění