magic: a multi-activity graph index for activity detection
DESCRIPTION
MAGIC: A Multi-Activity Graph Index for Activity Detection. Massimiliano Albanese 1 Andrea Pugliese 2 V.S. Subrahmanian 1 Octavian Udrea 1 1 University of Maryland Institute for Advanced Computer Studies, College Park, Maryland, USA 2 University of Calabria - DEIS department, Rende, Italy. - PowerPoint PPT PresentationTRANSCRIPT

IRI 2007 1
MAGIC: A Multi-Activity Graph Index for Activity Detection
Massimiliano Albanese1
Andrea Pugliese2
V.S. Subrahmanian1
Octavian Udrea1
1 University of Maryland Institute for Advanced Computer Studies, College Park, Maryland, USA 2 University of Calabria - DEIS department, Rende, Italy

IRI 2007 2
Introduction
Many applications require to monitor large volumes of observation data for the occurrence of certain activities E.g. web servers maintain large server logs
Early detecting what action a user is trying to perform may allow to prefetch or customize data
Activity detection is a non trivial task Real world activities tend to be high level and can
often be executed in many different ways Observations may be the result of interleaved
activities

IRI 2007 3
Key contributions
The main contributions of this work are The definition of a Multi-Activity Graph Index
(MAGIC), which can index very large numbers of observations from interleaved activities
Algorithms to build such index Algorithms to answer two types of queries
Evidence problem: find all sequences of observations that validate the occurrence of an activity with a minimum probability threshold
Identification problem: identify the most probable activity occurring in an observation sequence

IRI 2007 4
Stochastic Activity
A Stochastic Activity is a labeled graph (V,E,δ) where V is a finite set of action symbols E is a subset of (V×V) vV s.t. v'∄ V s.t. (v',v)E, i.e., there exists at least
one start node in V vV s.t. v'∄ V s.t. (v,v')E, i.e., there exists at least
one end node in V δ :E[0,1] is a function that associates a probability
distribution with the outgoing edges of each node vV Σ{v' V | (v,v') E} δ(v,v') = 1

IRI 2007 5
Example of Stochastic Activity
Online purchase stochastic activity
V = {catalog, itemDetails, cart, shippingMethod, paymentMethod, review, confirm}
start node end node(V, E, δ)

IRI 2007 6
Activity Instance and Occurrence
Assumptions Each node in an activity is an observable event The probability of taking an action at any time only depends on the last action All observations are stored in a single relational database table
An instance of a stochastic activity (V,E,δ) is a path (sequence of nodes) from a start node to an end node The probability of an activity instance is the product of the edge probabilities
along the path An occurrence of a stochastic activity (V,E,δ) in an observation table O with
probability p is a sequence of observations corresponding to the nodes of an activity instance The probability of an occurrence is the probability of the instance The span of an occurrence is the time interval including all the observations

IRI 2007 7
Example of Activity Occurrence
The “online purchase stochastic activity” occurs in the web server log shown in the table The sequence of observations with identifiers
{1, 4, 7, 10, 13, 14} corresponds to the activity instance {catalog, cart, shippingMethod, paymentMethod, review, confirm}
The span of this activity occurrence is [1,10]
id ts action
1 1 catalog
2 2 catalog
3 2 itemDetails
4 3 cart
5 4 itemDetails
6 5 itemDetails
7 5 shippingMethod
8 6 cart
9 7 shippingMethod
10 7 paymentMethod
11 8 itemDetails
12 9 cart
13 9 review
14 10 confirm
15 11 shippingMethod
16 11 paymentMethod
17 11 review
18 12 confirm

IRI 2007 8
Complexity
Given an observation table O and a stochastic activity A, the problem of finding all occurrences of A in O takes exponential time, w.r.t. the size of O It is not feasible to try to find all possible occurrences
We propose restrictions on what constitutes a valid occurrence in order to greatly reduce the number of possible occurrences
Due to the size of the search space, it is important to have a data structure that enables very fast searches for activity occurrences
We propose the MAGIC index structure that allows to answer the Evidence and Identification problems efficiently monitor activity occurrences as new observations are collected

IRI 2007 9
Minimal Span (MS) restriction
If two occurrences O1 and O2 are found in the observation sequence and the span of O2 is contained within the span of O1, O1 is discarded from the result set The two sequences of
observations with identifiers {1, 4, 7, 10, 13, 14} and {1, 4, 7, 10, 17, 18} respectively, are both activity occurrences corresponding to the instance {catalog, cart, shippingMethod, paymentMethod, review, confirm}
The second one is discarded under this restriction
id ts action
1 1 catalog
2 2 catalog
3 2 itemDetails
4 3 cart
5 4 itemDetails
6 5 itemDetails
7 5 shippingMethod
8 6 cart
9 7 shippingMethod
10
7 paymentMethod
11
8 itemDetails
12
9 cart
13
9 review
14
10
confirm
15
11
shippingMethod
16
11
paymentMethod
17
11
review
18
12
confirm
id ts action
1 1 catalog
2 2 catalog
3 2 itemDetails
4 3 cart
5 4 itemDetails
6 5 itemDetails
7 5 shippingMethod
8 6 cart
9 7 shippingMethod
10
7 paymentMethod
11
8 itemDetails
12
9 cart
13
9 review
14
10
confirm
15
11
shippingMethod
16
11
paymentMethod
17
11
review
18
12
confirm

IRI 2007 10
Earliest Action (EA) restriction
When looking for the next action symbol in an activity occurrence, the first possible successor in the sequence is chosen. The two sequences of
observations with identifiers {1, 4, 7, 10, 13, 14} and {1, 4, 9, 10, 13, 14} respectively, are both activity occurrences corresponding to the instance {catalog, cart, shippingMethod, paymentMethod, review, confirm}
The second one is discarded under this restriction
id ts action
1 1 catalog
2 2 catalog
3 2 itemDetails
4 3 cart
5 4 itemDetails
6 5 itemDetails
7 5 shippingMethod
8 6 cart
9 7 shippingMethod
10
7 paymentMethod
11
8 itemDetails
12
9 cart
13
9 review
14
10
confirm
15
11
shippingMethod
16
11
paymentMethod
17
11
review
18
12
confirm
id ts action
1 1 catalog
2 2 catalog
3 2 itemDetails
4 3 cart
5 4 itemDetails
6 5 itemDetails
7 5 shippingMethod
8 6 cart
9 7 shippingMethod
10
7 paymentMethod
11
8 itemDetails
12
9 cart
13
9 review
14
10
confirm
15
11
shippingMethod
16
11
paymentMethod
17
11
review
18
12
confirm

IRI 2007 11
Multi-Activity Graph
In order to efficiently monitor observations for occurrences of multiple activities, we first merge all activity definitions from A = {A1,…, Ak} into a single
graph A Multi-Activity Graph is a triple G = (VG, IA, δG) where
VG=∪i=1,…,kVi is a set of action symbols
IA={id(A1),…,id(Ak)} is a set of unique identifiers for activities in A
δG: VG×VG×IA[0,1] is a function that associates a triple
(v,v',id(Ai)) with δi(v,v'), if (v,v') Ei and 0 otherwise.

IRI 2007 12
Example of Multi-Activity Graph
b
a d
A1(0.4)
A1(0.6)e
c
A2
A1,A2
A1
A2(0.3)A2(0.7)
b
a de
A1
0.4
0.6
a d
e
c
A2
0.7
0.3Merged graph

IRI 2007 13
Multi-Activity Graph Index
Given a Multi-Activity Graph G = (VG, IA, δG) built over A = {A1,…, Ak}, a Multi-Activity Graph Index is a 6-tuple IG = (G,startG,endG,maxG,tablesG,completedG), where startG and endG are functions that associate each node vVG with the set
of activities for which v is a start or end node respectively maxG is a function that associates a pair (v,id(Ai)) with the maximum
product of probabilities on any path in Ai between v and an end node for each vVG, tablesG(v) is a set of tuples of the form (current, activityID,
t0, probability, previous, next), where current is a pointer to an observation, activityID IA, previous and next are pointers to tuples in tablesG
completedG is a function that associates an activity with a set of references to tuples in tablesG corresponding to completed instances of the activity

IRI 2007 14
MAGIC insertion algorithm
Complexity: algorithm insert runs in time O(|A|∙ max(V,E,δ)A(|V |) ∙ |O|), where O is the
set of observations indexed so far.
Check whether the newly observed action is the start node for any activity
For intermediate nodes, explore entries in the index tables associated with predecessor nodes

IRI 2007 15
Evolution of a MAGIC index (1/6)
… ts Action
… 1 a
b
a d
A1(0.4)
A1(0.6)e
c
A2
A1,A2
A1
A2(0.3)A2(0.7)
Index tables tablesGObservation table O
Both activities A1 and A2 have a as their start node
a
curr actID t0 prob prev next
A1 1 1
A2 1 1

IRI 2007 16
Evolution of a MAGIC index (2/6)b
a d
A1(0.4)
A1(0.6)e
c
A2
A1,A2
A1
A2(0.3)A2(0.7)
Index tables tablesGObservation table O
To apply the Minimal Span restriction, the tuples in tablesG(a) are updated to
point to the new observation
… ts Action
… 1 a
… 2 a
a
curr actID t0 prob prev next
A1 1 1
A2 1 1

IRI 2007 17
Evolution of a MAGIC index (3/6)b
a d
A1(0.4)
A1(0.6)e
c
A2
A1,A2
A1
A2(0.3)A2(0.7)
Index tables tablesGObservation table O
a is the only predecessor of b in the multi-activity graph
… ts Action
… 1 a
… 2 a
… 3 b
a
curr actID t0 prob prev next
A1 1 1
A2 1 1
b
curr actID t0 prob prev next
A1 1 0.4
The probability is equal to the product of the probability of the tuple in tablesG(a) and
the probability on the edge from a to b

IRI 2007 18
Evolution of a MAGIC index (4/6)b
a d
A1(0.4)
A1(0.6)e
c
A2
A1,A2
A1
A2(0.3)A2(0.7)
Index tables tablesGObservation table O
… ts Action
… 1 a
… 2 a
… 3 b
… 4 b
a
curr actID t0 prob prev next
A1 1 1
A2 1 1
b
curr actID t0 prob prev next
A1 1 0.4
To apply the Earliest Action restriction the fourth observation is not linked to the first tuple
in tablesG(a) that already has a successor

IRI 2007 19
Evolution of a MAGIC index (5/6)b
a d
A1(0.4)
A1(0.6)e
c
A2
A1,A2
A1
A2(0.3)A2(0.7)
Index tables tablesGObservation table O
a is the only predecessor of c in the multi-activity graph
… ts Action
… 1 a
… 2 a
… 3 b
… 4 b
… 5 c
a
curr actID t0 prob prev next
A1 1 1
A2 1 1
b
curr actID t0 prob prev next
A1 1 0.4
c
curr actID t0 prob prev next
A2 1 1

IRI 2007 20
Evolution of a MAGIC index (6/6)b
a d
A1(0.4)
A1(0.6)e
c
A2
A1,A2
A1
A2(0.3)A2(0.7)
Index tables tablesGObservation table O
b, c, and e are predecessors of d in the multi-activity graph
… ts Action
… 1 a
… 2 a
… 3 b
… 4 b
… 5 c
… 6 d
d is an end node for both activities A1 and A2: two completed occurrences are thus identified
a
curr actID t0 prob prev next
A1 1 1
A2 1 1
b
curr actID t0 prob prev next
A1 1 0.4
c
curr actID t0 prob prev next
A2 1 1
d
curr actID t0 prob prev next
A1 1 0.4
A2 1 0.3

IRI 2007 21
MAGIC-evidence and MAGIC-id
The MAGIC-evidence algorithm finds all minimal sets of observations that validate the occurrence of activities in A with a probability exceeding a given threshold
The MAGIC-id algorithm identifies those tuples in completedG (and hence the set of associated activity IDs) that have maximum probability and are within the required time span

IRI 2007 22
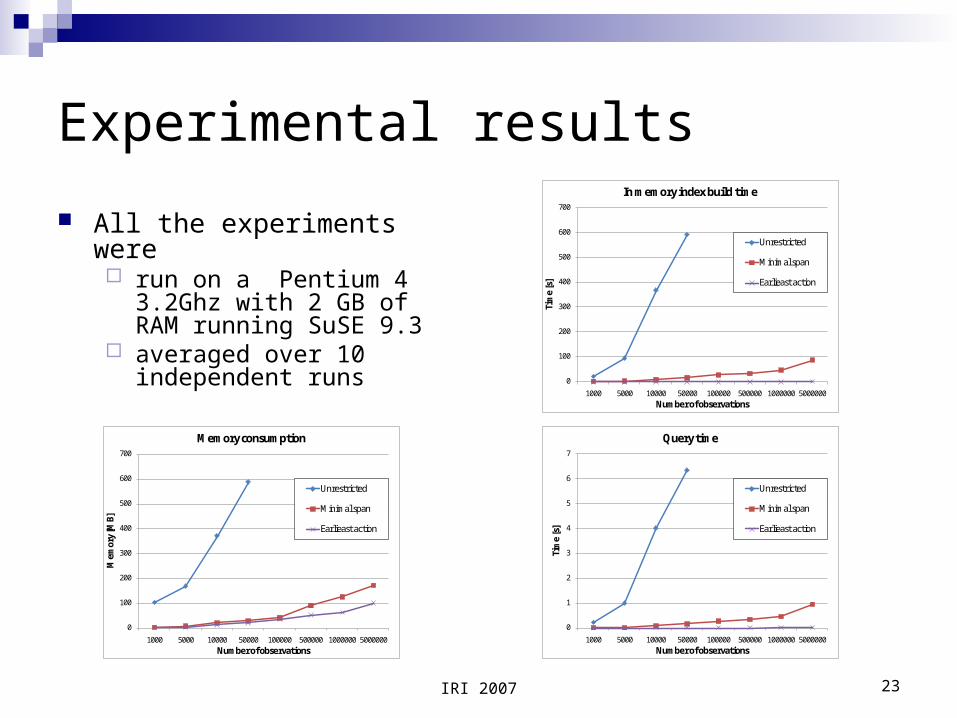
Experimental results
Experiments were conducted on two data sets A third party depersonalized dataset consisting of travel
information and containing approximately 7.5 million observations
30 manually generated activity definitions were used in this experiment
A synthetic dataset of 5 million observations randomly generated randomly generated activity definitions were used in this experiment
We measured The time to build the index The consumption of memory The time to answer queries
IRI 2007 23
Experimental results
0
100
200
300
400
500
600
700
1000 5000 10000 50000 100000 500000 1000000 5000000
Tim
e [s
]
Number of observations
In memory index build time
Unrestricted
Minimal span
Earlieast action
0
100
200
300
400
500
600
700
1000 5000 10000 50000 100000 500000 1000000 5000000
Mem
ory
[MB]
Number of observations
Memory consumption
Unrestricted
Minimal span
Earlieast action
0
1
2
3
4
5
6
7
1000 5000 10000 50000 100000 500000 1000000 5000000
Tim
e [s
]
Number of observations
Query time
Unrestricted
Minimal span
Earlieast action
All the experiments were run on a Pentium 4 3.2Ghz
with 2 GB of RAM running SuSE 9.3
averaged over 10 independent runs

IRI 2007 24
Conclusions
We showed that finding all the occurrences of multiple interleaved activities in observation data is a computationally complex problem We proposed an effective data structure to index large numbers of
observations and concurrently monitor occurrences of multiple activities as new observations are collected
A key point in our approach is the introduction of two reasonable restrictions – but other restrictions can be defined as well – that reduce the overall complexity of the activity recognition problem to a manageable level
The experiments on both a synthetic and a third-party dataset show that MAGIC is fast and has reasonable memory consumption, and allows to solve the Evidence and Identification problems effectively
Further efforts will be devoted to The definition of an on-disk version of the index The application of our approach to index video surveillance data