macromolecular structure refinement garib n murshudov york structural biology laboratory chemistry...
Post on 20-Dec-2015
214 views
TRANSCRIPT

Macromolecular structure refinement
Garib N Murshudov
York Structural Biology Laboratory
Chemistry Department
University of York

Contents
• Purpose of and considerations for refinement
• Prior information: Dictionary of ligands
• Prior information: B value – How to deal with them
• Conclusions and future developments

Purpose
• Optimal fit of the model to the experimental data while retaining its chemical integrity
• Estimation of errors for the refined parameters
• Improvement of phases to facilitate model building (automatic e.g. ARP/wARP or manual)
• Give deviation from chemistry and experiment to aid analysis of the model

Considerations
• Function to optimise– Should use experimental data– Should be able to handle chemical information
• Parameters– Depends on the stage of analysis– Depends on amount and quality of the experimental data
• Methods to optimise– Depends on stage of analysis: simulated annealing, tunneling,
conjugate gradient, second order (normal matrix, information matrix, second derivatives)
– Some methods can give error estimate as a by-product. Second order methods give error estimate.

Function
Probabilistic viewChemical information – prior knowledge
Fit to experiment - likelihood
Total function - posterior
View from physicsInternal energy
External energy
Total energy = internal + external
Gibbs distribution: Probability of the state of the system is:
externalinernal EEE
kTxEKxP
))/()(exp()(
Bayes’s theorem: Probability of the system (x) given experiment(x0)
));(ln)(exp(ln );()( );( 000 xxPxPNxxPxPNxxP

System describing treatment of the experiment
Internal energy orPrior probability
External energy or likelihood

Function: likelihood and prior
• Likelihood describes fit of model parameters into experiment. There are few papers describing various aspects. E.g.
Murshudov, Vagin, (1997) Acta Cryst. D53, 240-255
Pannu, Murshudov, , Read (1998) Acta Cryst D5, 1285-1294
• Prior: Should include our knowledge about chemistry, biology and physics of the system: Bond lengths, angles, B values, overall organisations
Dodson
Dodson
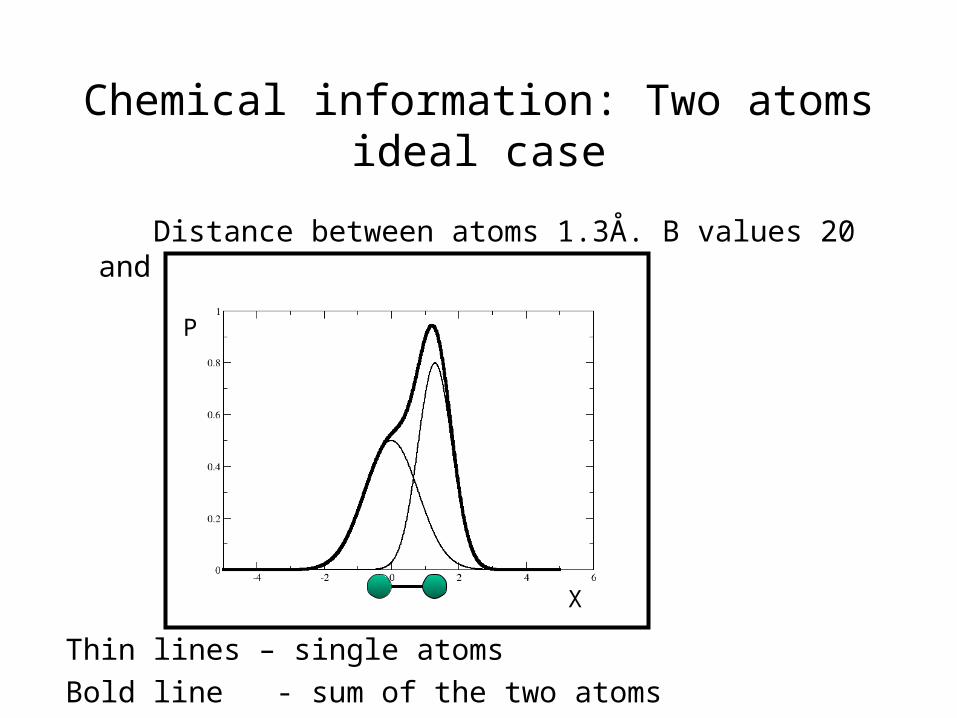
Chemical information: Two atoms ideal case
Distance between atoms 1.3Å. B values 20 and 50
Thin lines – single atoms
Bold line - sum of the two atoms
P
X
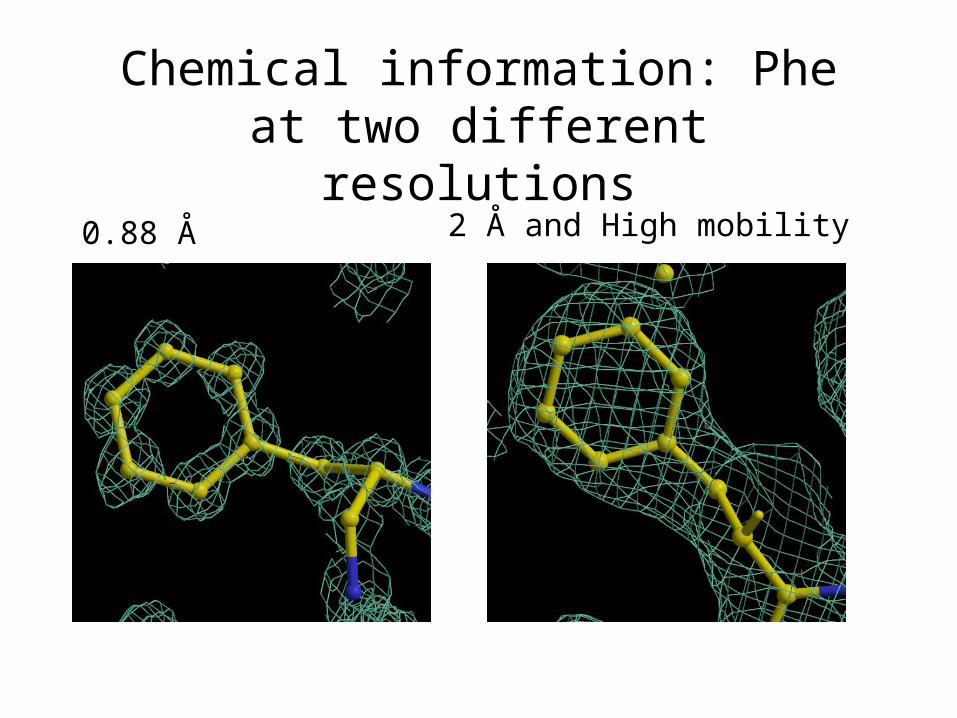
Chemical information: Phe at two different resolutions
2 Å and High mobility0.88 Å
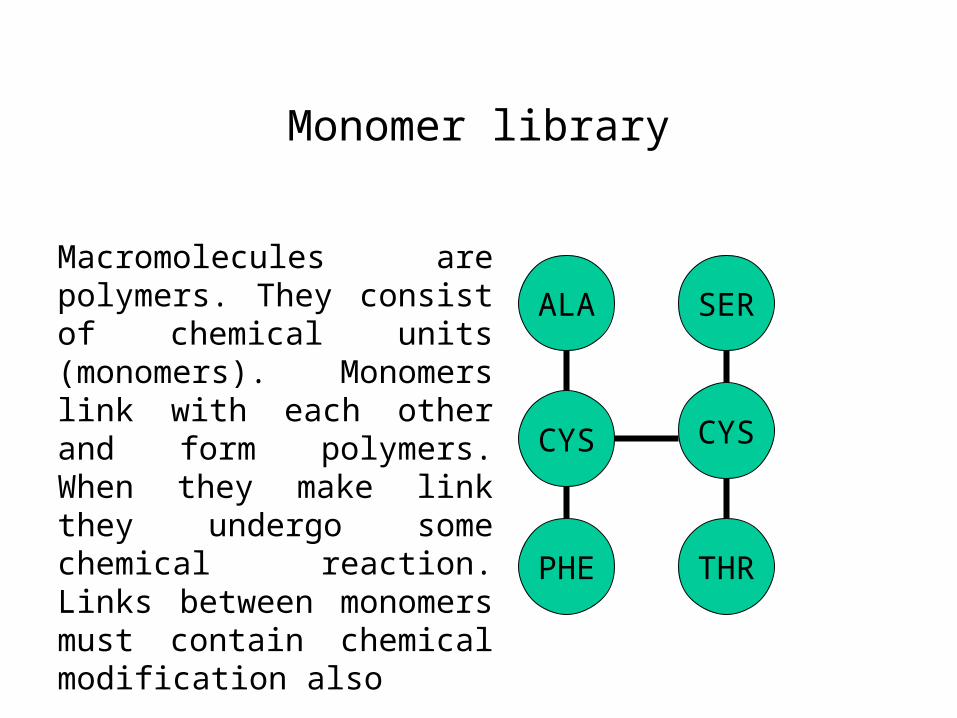
Monomer library
ALA
CYS
PHE
SER
CYS
THR
Macromolecules are polymers. They consist of chemical units (monomers). Monomers link with each other and form polymers. When they make link they undergo some chemical reaction. Links between monomers must contain chemical modification also
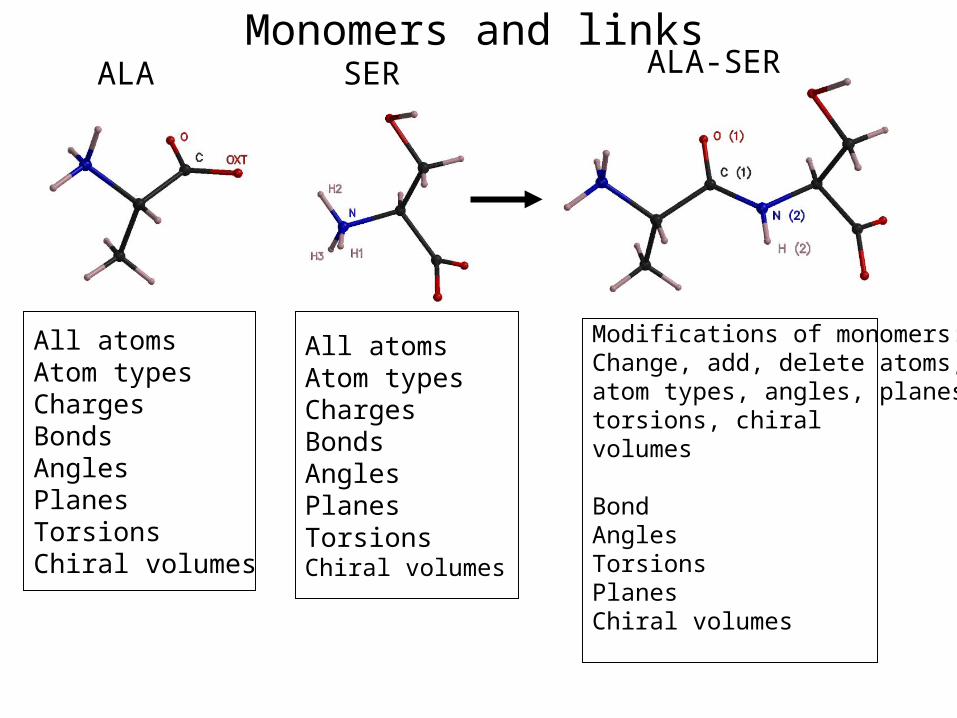
Monomers and linksALA SER ALA-SER
All atomsAtom typesChargesBondsAnglesPlanesTorsionsChiral volumes
All atomsAtom typesChargesBondsAnglesPlanesTorsionsChiral volumes
Modifications of monomers:Change, add, delete atoms, atom types, angles, planes, torsions, chiralvolumes
BondAnglesTorsionsPlanesChiral volumes
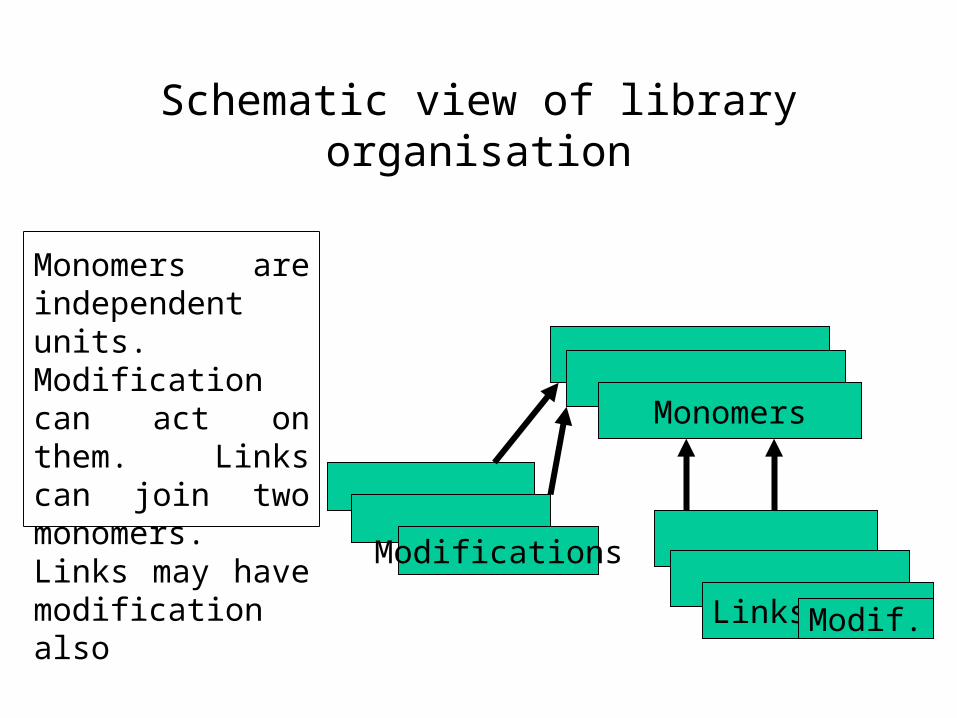
Schematic view of library organisation
Monomers
Modifications
Links Modif.
Monomers are independent units. Modification can act on them. Links can join two monomers. Links may have modification also

Dictionary: Plans
• Finish mutual test of Fei’s program and dictionary
• Improve values using CSD and quantum chemical calculations
• Input formats: SMILE, MDL MOLFILE
• More automation of links and modifications
• More chemical assumptions
• Better links to other web resources (e.g. sweet, disacharide data base, corina, prodrg, msd/ebi)
• More monomers and links???
• Adding more knowledge like frequently occurring fragment, most probable rotamers
• etc

B values
• B values are important component of atomic models
• They model molecular mobility as well as errors in atoms
• Distribution of B values is important for proper maximum likelihood estimation
• If estimated accurately their analysis can give some insight into biology of the molecule
Note: Protein data bank is very rich source of prior information. But one must be careful in extracting them

Modeling of B values: TLS
• TLS model of atomic B values assumes that they depend on position of atoms (as implemented in REFMAC):
U = Uind + T + r x L x rT + rT x S – ST x rT = A(r) • Effect of this on electron density:
• This linear equations must be solved to calculate electron density without TLS
)(),()(
parameters withplayingafter space reciprocal In
)(),()(
0
0
hFhkhTkF
ydyxyxTy
R

B values: Intuition and Bayesian
• B values are variances of Gaussians
• B values cannot be negative!!!!!
• Larger mean B larger variation of B
• Inverse gamma is natural prior of variances (It is used in microarray data analysis and can be used in X-ray data processing)
• Assumption: B values of macromolecules have inverse Gamma distribution.

B distribution: Inverse gamma
Inverse gamma distribution:
We can assume that to some degree is constant for all proteins.
2/ ))2()1(/(1 )),1(/(1
or
//1 / ,//1
properties with
)) /(1exp(),;(
2B
222
21/B
2221/B
1
BB
BB
BBBIG
B
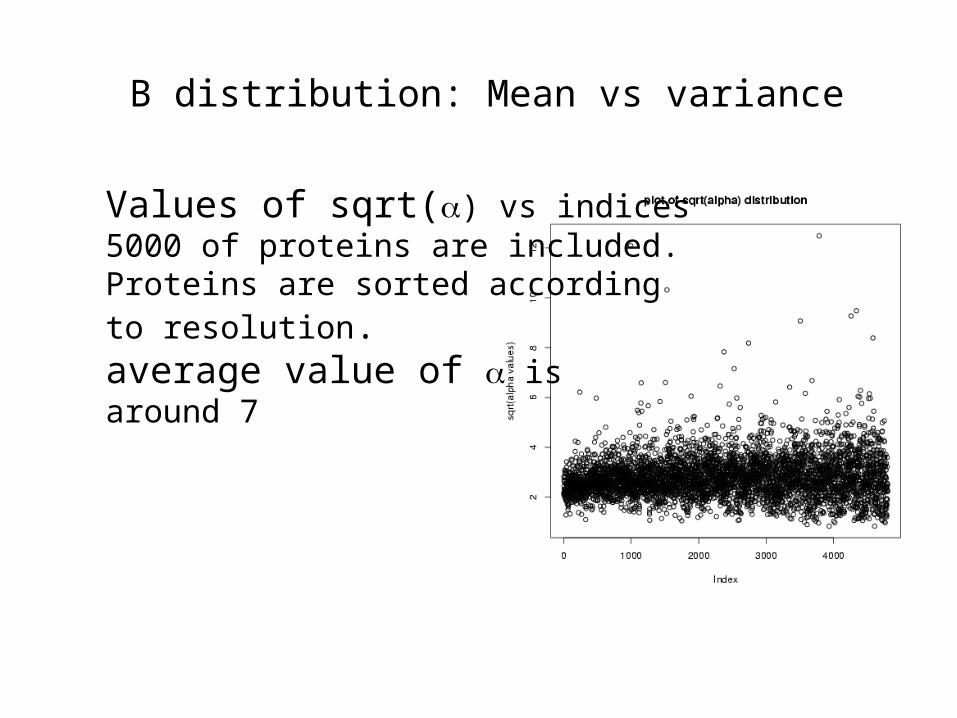
B distribution: Mean vs variance
Values of sqrt() vs indices5000 of proteins are included.Proteins are sorted accordingto resolution.average value of isaround 7
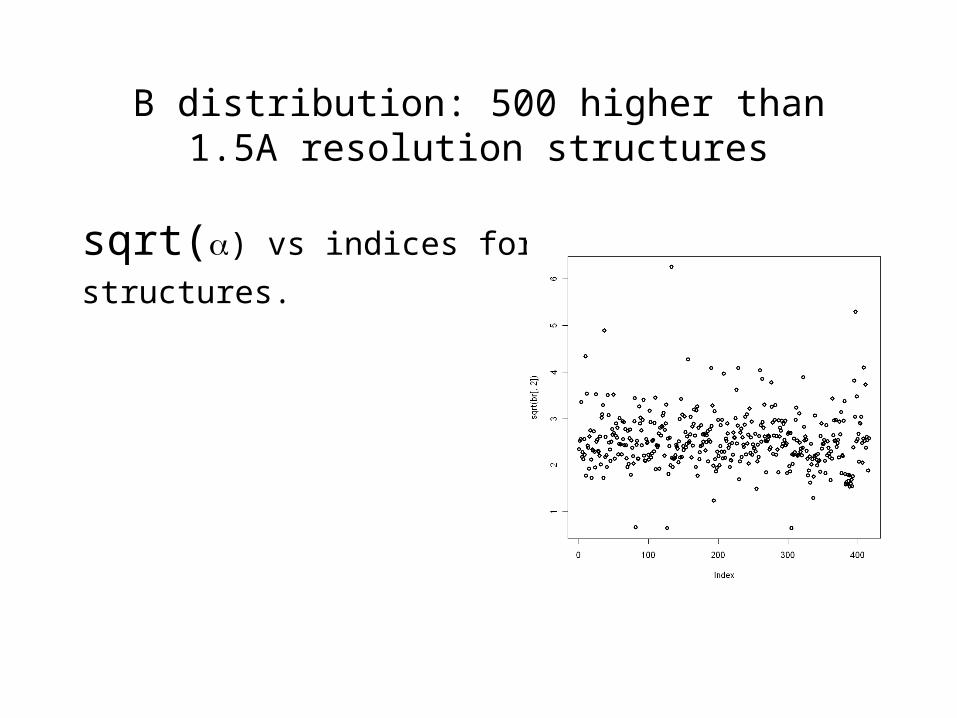
B distribution: 500 higher than 1.5A resolution structures
sqrt() vs indices for 400
structures.
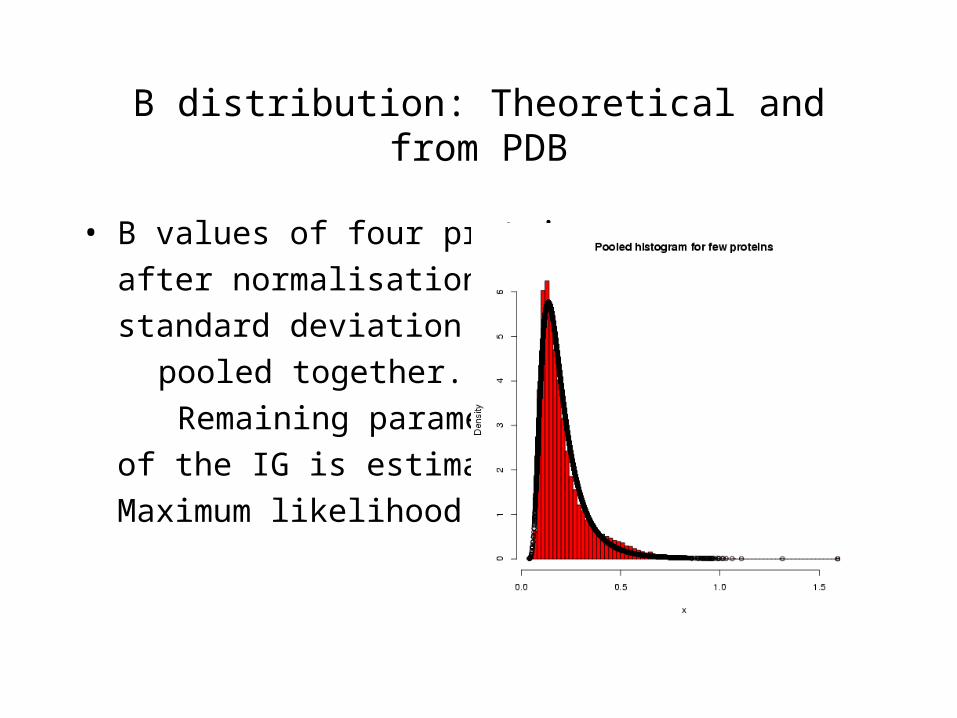
B distribution: Theoretical and from PDB
• B values of four proteins
after normalisation by
standard deviation are
pooled together.
Remaining parameter
of the IG is estimated using
Maximum likelihood
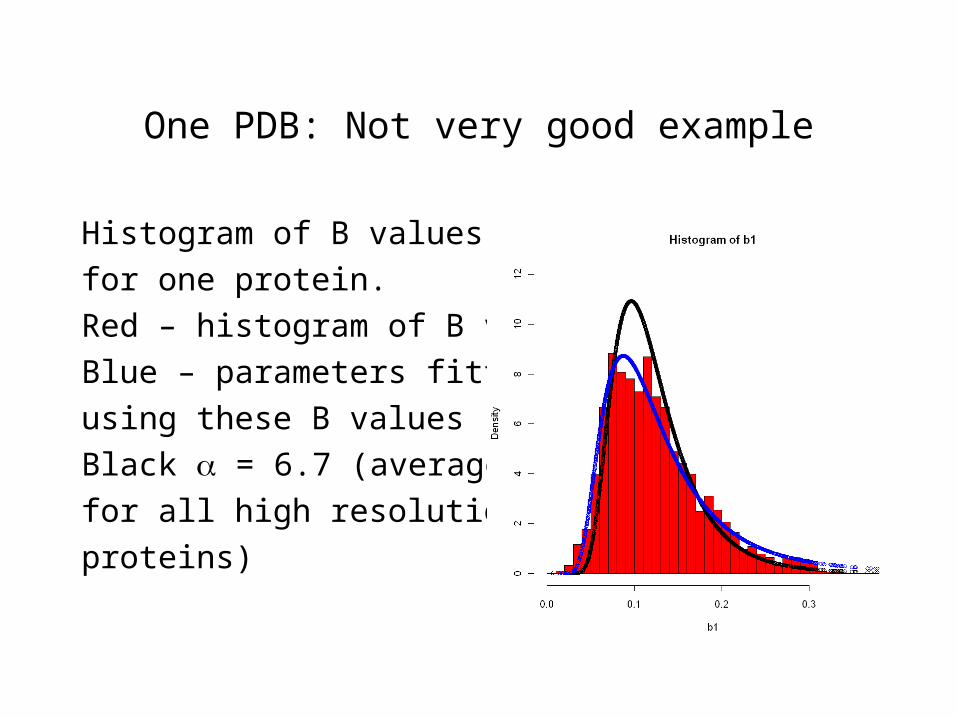
One PDB: Not very good example
Histogram of B values
for one protein.
Red – histogram of B values
Blue – parameters fitted
using these B values
Black = 6.7 (average
for all high resolution
proteins)

Use of B distributions
• Restraints on individual B values. It will allow refinement of B values reliable at medium and low resolutions
• Better restraints on differences between B values of close atoms.
• Detection of outliers (low B value – potential metal, high B value – potentially wrong)
• For normalisation of structure factor
• For improved Maximum likelihood estimation
• For map improvement

Conclusion and future perspectives
• Dictionary of monomers and links have been developed and implemented
• B value distributions look like IG. • Analysis of B value distribution for solvent is needed
Future
• “Proper” B value restraints• Global and local improvement of dictionary• Restraints to external information (small fragments)• Twin, psuedotranslational (etc) refinement• Inversion of sparse and full (Fisher information) matrix to estimate
reliability of the parmaters

Acknowledgements
• Alexey Vagin• Andrey Lebedev• Roberto Steiner• Fei Long• Dan Zhou• Najida Begum• Mark Dunning• Gleb Bourinkov• Alexander Popov• YSBL research environment• Users• CCP4• Wellcome Trust, BBSRC, EU BIOXHIT project

And of course!!!!