machine translation & automated speech recognition jaime carbonell with richard stern and alex...
TRANSCRIPT

Machine Translation & Automated Speech Recognition
Jaime CarbonellWith Richard Stern and Alex Rudnicky
Language Technologies InstituteCarnegie Mellon University
Telephone: +1 412 268 7279Fax: +1 412 268 6298
For Samsung, February 20, 2008

CarnegieMellon Slide 2 Languge Technologies Insitute
Outline of Presentation
Machine Translation (MT):
– Three major paradigms for MT (transfer, example-based, statistical)
– New method: Context-Based MT
Automated Speech Recognition (ASR):
– The Sphinx family of recognizers
Environmental Robustness for ASR
Intelligent Tutoring for English
– Native Accent: Pronunciation product
– Grammar, Vocabulary & other tutotring
Components for Virtual English Village

CarnegieMellon Slide 3 Languge Technologies Insitute
Language Technologies BILL OF RIGHTS TECHNOLGY (e.g.)
“…right information”
“…right people”
“…right time”
“…right medium”
“…right language”
“…right level of detail”
IR (search engines)
Routing, personalization
Anticipatory analysis
Speech: ASR, TTS
Machine translation
Summarization, Drill down

CarnegieMellon Slide 4 Languge Technologies Insitute
Machine Translation:Context is Needed to Resolve Ambiguity
Example: English Japanese Power line – densen ( 電線 ) Subway line – chikatetsu ( 地下鉄 )
(Be) on line – onrain ( オンライン ) (Be) on the line – denwachuu ( 電話中 ) Line up – narabu ( 並ぶ ) Line one’s pockets – kanemochi ni naru ( 金持ちになる ) Line one’s jacket – uwagi o nijuu ni suru ( 上着を二重にする ) Actor’s line – serifu ( セリフ ) Get a line on – joho o eru ( 情報を得る )
Sometimes local context suffices (as above) . . . but sometimes not

CarnegieMellon Slide 5 Languge Technologies Insitute
CONTEXT: More is Better
Examples requiring longer-range context:– “The line for the new play extended for 3 blocks.”
– “The line for the new play was changed by the scriptwriter.”
– “The line for the new play got tangled with the other props.”
– “The line for the new play better protected the quarterback.”
Better MT requires better context sensitivity
– Syntax-rule based MT little or no context
– EBMT potentially long context on exact substring matches
– SMT short context with proper probabilistic optimization
– CBMT long context with optimization (but still experimental)

CarnegieMellon Slide 6 Languge Technologies Insitute
Types of Machine Translation
Text Generation
Syntactic Parsing
Semantic Analysis
Sentence Planning
Source (Arabic)
Target(English)
Transfer Rules
Direct: SMT, EBMT
Interlingua

CarnegieMellon Slide 7 Languge Technologies Insitute
Example-Based Machine Translation Example
English: I would like to meet her.Mapudungun: Ayükefun trawüael fey engu.
English: The tallest man is my father.Mapudungun: Chi doy fütra chi wentru fey ta inche ñi chaw.
English: I would like to meet the tallest man Mapudungun (new): Ayükefun trawüael Chi doy fütra chi wentru Mapudungun (correct): Ayüken ñi trawüael chi doy fütra wentruengu.

CarnegieMellon Slide 8 Languge Technologies Insitute
Statistical Machine Translation: The Three Ingredients
English Language Model
English-KoreanTranslation
Model
Decoder
E K
p(E) p(K|E)
E* K
E*=arg max p(E|K)= argmax p(E) p(K|E)

AlignmentsThe
proposal
Will
Not
Now
Be
Implemented
Les
Propositions
ne
seront
Pas
mises
En
Application
maintenant
Translation models built in terms of hidden alignmentsp(F|E)= )|,( EAFp
A
Each English word “generates” zero or more French words.

CarnegieMellon Slide 10 Languge Technologies Insitute
Conditioning Joint Probabilities
),,,|(
),,,|(
|)(()|,(
111
11
11
1
Emfafp
Emfaap
EFlengthmpEAFp
jjj
jjm
jj
The modeling problem is how to approximate these terms to achieve:
Statistically robust estimates
Computationally efficient training
An effective and accurate model

CarnegieMellon Slide 11 Languge Technologies Insitute
The Gang of Five IBM++ Models
A series of five models is sequentially trained to “bootstrap a detailed translation model from parallel corpora:
1. Word-byword translation. Parameters p(f|e) between pairs of words.
2. Local alignments. Adds alignment probabilities
3. Fertilities and distortions. Allow a source word to generate zero or more target words, then place words in position with p(j|i,sentence lengths).
4. Tablets. Groups words into phrases
• Primary idea of Example-Based MT incorporated into SMT
• Currently seeking meaningful (vs arbitrary phrases), e.g. NPs. PPs.
5. Non-deficient alignments. Don’t ask. . .
lengths) sentence,|( jap j
)|)(( eeφp

CarnegieMellon Slide 12 Languge Technologies Insitute
Multi-Engine Machine Transaltion
MT Systems have different strengths– Rapidly adaptable: Statistical, example-based
– Good grammar: Rule-Based (linguisitic) MT
– High precision in narrow domains: KBMT
– Minority Language MT: Learnable from informant
Combine results of parallel-invoked MT– Select best of multiple translations
– Selection based on optimizing combination of:
» Target language joint-exponential model
» Confidence scores of individual MT engines

CarnegieMellon Slide 13 Languge Technologies Insitute
Illustration of Multi-Engine MT
El punto de descarge
The drop-off point
se cumplirá en
will comply with
el puente Agua Fria
The cold Bridgewater
El punto de descarge
The discharge point
se cumplirá en
will self comply in
el puente Agua Fria
the “Agua Fria” bridge
El punto de descarge
Unload of the point
se cumplirá en
will take place at
el puente Agua Fria
the cold water of bridge

CarnegieMellon Slide 14 Languge Technologies Insitute
Key Challenges for Corpus-Based MT
Long-Range Context
– More is better
– How to incorporate it?
– How to do so tractably?
– “I conjecture that MT is AI complete” – H. Simon
State-of-the-Art
– Trigrams 4 or 5-grams in LM only (e.g., Google)
– SMT SMT+EBMT (phrase tables, etc.)
Parallel Corpora
– More is better
– Where to find enough of it?
– What about rare languages?
– “There’s no data like more data” – IBM SMT circa 1992
State-of-the-Art
– Avoids rare languages (GALE only does Arabic & Chinese)
– Symbolic rule-learning from minimalist parallel corpus (AVENUE project at CMU)

CarnegieMellon Slide 15 Languge Technologies Insitute
Parallel Text: Requiring Less is Better (Requiring None is Best )
Challenge– There is just not enough to approach human-quality MT for most major
language pairs (we need ~100X more)
– Much parallel text is not on-point (not on domain)
– Rare languages and some distant pairs have virtually no parallel text
Context-Based (CBMT) Approach
– Invented and patented by Meaningful Machines (in New York)
– Requires no parallel text, no transfer rules . . .
– Instead, CBMT needs
» A fully-inflected bilingual dictionary
» A (very large) target-language-only corpus
» A (modest) source-language-only corpus [optional, but preferred]

CMBT System
Parser
Target Language
Source Language
ParserN-gram Segmenter
Overlap-based Decoder
Bilingual Dictionary
INDEXED RESOURCES
Target Corpora
[Source Corpora]
N-GRAM BUILDERS(Translation Model)
Flooder(non-parallel text method)
Cross-LanguageN-gram Database
CACHE DATABASE
N-GRAM CONNECTOR
N-gram Candidates
Approved N-gram
Pairs
Stored N-gram
PairsGazetteers
Edge Locker
TTR
Substitution Request

Step 1: Source Sentence Chunking Segment source sentence into overlapping n-grams via sliding window Typical n-gram length 4 to 9 terms Each term is a word or a known phrase Any sentence length (for BLEU test: ave-27; shortest-8; longest-66 words)
S1 S2 S3 S4 S5 S6 S7 S8 S9
S1 S2 S3 S4 S5
S2 S3 S4 S5 S6
S3 S4 S5 S6 S7
S4 S5 S6 S7 S8
S5 S6 S7 S8 S9

Flooding Set
Step 2: Dictionary Lookup
T3-aT3-bT3-c
T4-aT4-bT4-cT4-dT4-e
T5-a T6-aT6-bT6-c
Using bilingual dictionary, list all possible target translations for each source word or phrase
Source Word-String
T2-aT2-bT2-cT2-d
Target Word Lists
S2 S3 S4 S5 S6
Inflected Bilingual Dictionary

Step 3: Search Target Text
Using the Flooding Set, search target text for word-strings containing one
word from each group
Find maximum number of words from Flooding Set in minimum length word-string
– Words or phrases can be in any order
– Ignore function words in initial step (T5 is a function word in this example)
T2-aT2-bT2-cT2-d
T3-aT3-bT3-c
T4-aT4-bT4-cT4-dT4-e
T5-a T6-aT6-bT6-cFlooding Set

T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T3-b T(x) T2-d T(x) T(x) T6-cT(x) T(x) T(x) T(x) T(x) T(x) T(x)T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x)T(x) T(x) T(x) T(x) T(x) T(x) T(x)
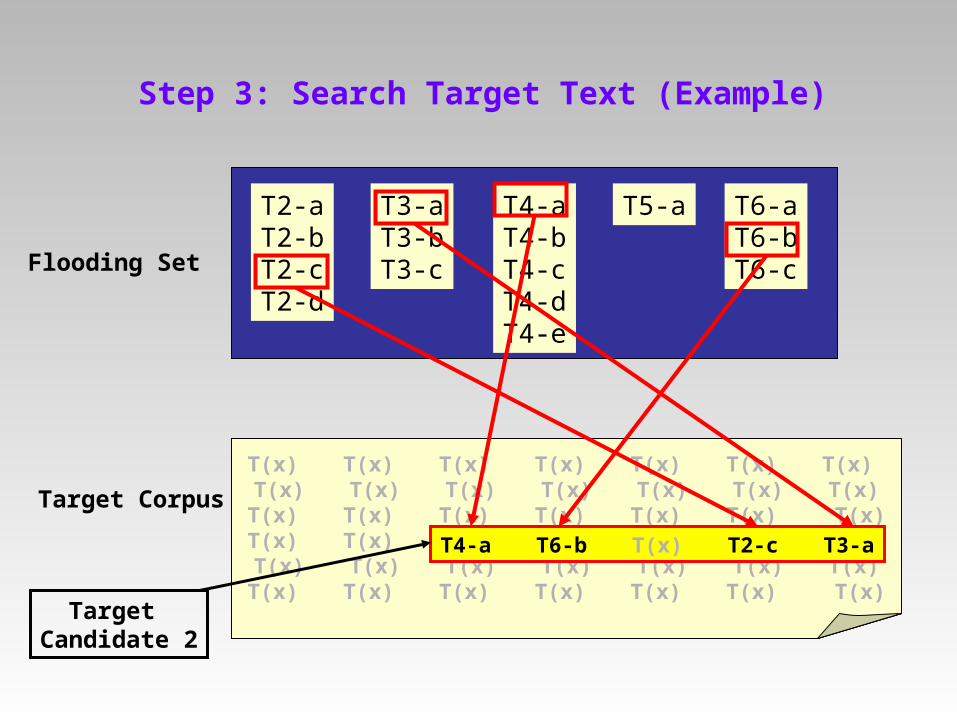
Step 3: Search Target Text (Example)
T2-aT2-bT2-cT2-d
T3-aT3-bT3-c
T4-aT4-bT4-cT4-dT4-e
T5-a T6-aT6-bT6-cFlooding Set
Target Corpus
T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T3-b T(x) T2-d T(x) T(x) T6-cT(x) T(x) T(x) T(x) T(x) T(x) T(x)T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x)T(x) T(x) T(x) T(x) T(x) T(x) T(x)
T3-b T(x) T2-d T(x) T(x) T6-c
Target Candidate 1
T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x)T(x) T(x) T(x) T(x) T(x) T(x) T(x)T(x) T(x) T(x) T(x) T(x) T(x) T(x)T(x) T(x) T(x) T(x) T(x) T(x) T(x)T(x) T(x) T(x) T(x) T(x) T(x) T(x)
Step 3: Search Target Text (Example)
T2-aT2-bT2-cT2-d
T3-aT3-bT3-c
T4-aT4-bT4-cT4-dT4-e
T5-a T6-aT6-bT6-cFlooding Set
Target Corpus
T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x)T(x) T(x) T(x) T(x) T(x) T(x) T(x)T(x) T(x) T4-a T6-b T(x) T2-c T3-a T(x) T(x) T(x) T(x) T(x) T(x) T(x)T(x) T(x) T(x) T(x) T(x) T(x) T(x)
T4-a T6-b T(x) T2-c T3-a
Target Candidate 2

T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x)T(x) T(x) T(x) T(x) T(x) T(x) T(x)T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x)T(x) T(x) T(x) T(x) T(x) T(x) T(x)
Step 3: Search Target Text (Example)
T2-aT2-bT2-cT2-d
T3-aT3-bT3-c
T4-aT4-bT4-cT4-dT4-e
T5-a T6-aT6-bT6-cFlooding Set
Target Corpus
T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x) T(x)T(x) T(x) T(x) T(x) T(x) T(x) T(x)T(x) T(x) T(x) T(x) T(x) T(x) T(x) T3-c T2-b T4-e T5-a T6-a T(x) T(x)T(x) T(x) T(x) T(x) T(x) T(x) T(x)T3-c T2-b T4-e T5-a T6-a
Target Candidate 3
Reintroduce function words after initial match (e.g. T5)
Scoring
---
---
---
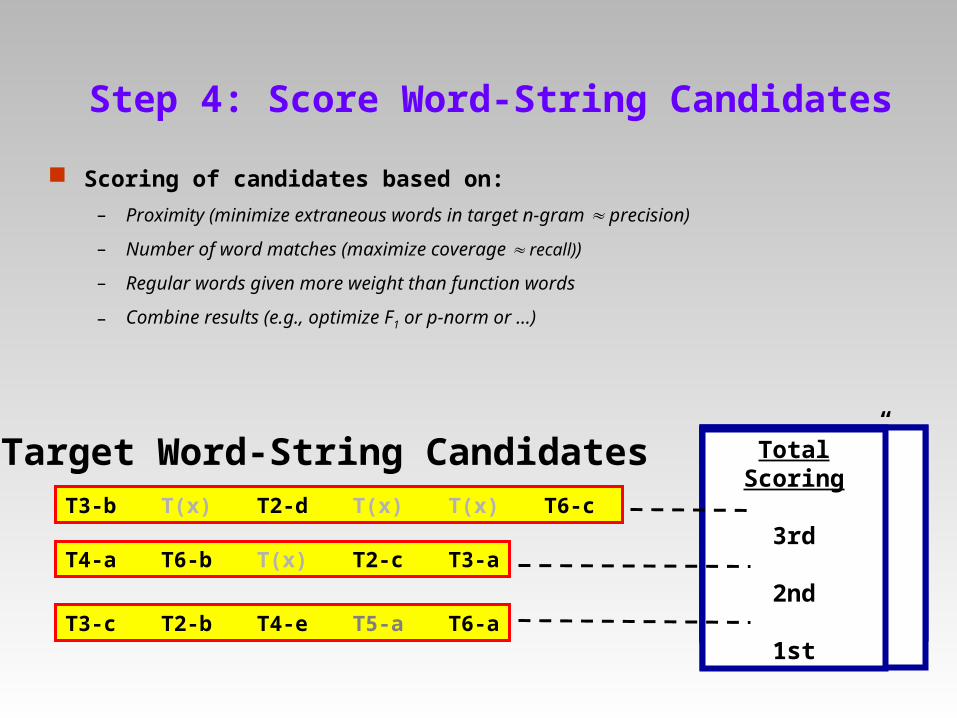
Step 4: Score Word-String Candidates
Scoring of candidates based on:
– Proximity (minimize extraneous words in target n-gram precision)
– Number of word matches (maximize coverage recall))
– Regular words given more weight than function words
– Combine results (e.g., optimize F1 or p-norm or …)
T3-b T(x) T2-d T(x) T(x) T6-c
T4-a T6-b T(x) T2-c T3-a
T3-c T2-b T4-e T5-a T6-a
Proximity
3rd
1st
1st
Word Matches
3rd
2st
1st
“Regular” Words
3rd
1st
1st
Total Scoring
3rd
2nd
1st
Target Word-String Candidates

T3-b T(x3) T2-d T(x5) T(x6) T6-c
T4-a T6-b T(x3) T2-c T3-a
T3-c T2-b T4-e T5-a T6-a
T(x2) T4-a T6-b T(x3) T2-c
T(x1) T2-d T3-c T(x2) T4-b
T(x1) T3-c T2-b T4-e
T6-b T(x11) T2-c T3-a T(x9)
T2-b T4-e T5-a T6-a T(x8)
T6-b T(x3) T2-c T3-a T(x8)
Step 5: Select Candidates Using Overlap(Propagate context over entire sentence)
Word-String 1Candidates
Word-String 2Candidates
Word-String 3Candidates
T(x2) T4-a T6-b T(x3) T2-c
T4-a T6-b T(x3) T2-c T3-a
T6-b T(x3) T2-c T3-a T(x8)
T3-c T2-b T4-e T5-a T6-a
T3-b T(x3) T2-d T(x5) T(x6) T6-cT3-b T(x3) T2-d T(x5) T(x6) T6-c
T4-a T6-b T(x3) T2-c T3-a
T(x1) T3-c T2-b T4-e
T3-c T2-b T4-e T5-a T6-a
T2-b T4-e T5-a T6-a T(x8)

CarnegieMellon Slide 25 Languge Technologies Insitute
Step 5: Select Candidates Using Overlap
T(x1) T3-c T2-b T4-e
T3-c T2-b T4-e T5-a T6-a
T2-b T4-e T5-a T6-a T(x8)
T(x2) T4-a T6-b T(x3) T2-c
T4-a T6-b T(x3) T2-c T3-a
T6-b T(x3) T2-c T3-a T(x8)
T(x2) T4-a T6-b T(x3) T2-c T3-a T(x8)
T(x1) T3-c T2-b T4-e T5-a T6-a T(x8)
Best translations selected via maximal overlap
Alternative 1
Alternative 2

A (Simple) Real Example of Overlap
a United States soldier died and two others were injured Monday
a United States soldier
United States soldier died
soldier died and two others
died and two others were injured
two others were injured Monday
A soldier of the wounded United States died and other two were east Monday
N-grams generated
from Flooding
Systran
Flooding N-gram fidelity
Overlap Long range fidelity
N-grams connected via Overlap

Comparative System Scores
Based on same Spanish test set
0.4
0.5
0.6
0.7
0.8
BL
EU
SC
OR
ES
SystranSpanish
GoogleChinese
(‘06 NIST)
MMSpanish
0.3GoogleArabic
(‘05 NIST)
0.3859
0.5137
0.5551 0.5610
SDLSpanish
0.7533
0.85
0.7447
MMSpanish
(Non-blind)
GoogleSpanish
’08 top lang
0.7209
Human Scoring Range

0.4
0.5
0.6
0.7
0.8
BL
EU
SC
OR
ES
0.3
Human Scoring Range
Apr 04 Aug 04 Dec 04 Apr 05 Aug 05 Dec 05 Apr 06 Aug 06 Dec 06 Apr 07 Aug 07 Dec 07
0.85
.3743
.5670
.6144.6165
.6456
.6950
.5953.6129
Non-Blind
.6374.6393
.6267
.7059
.6694 .6929
Blind
Historical CBMT Scoring
.7354
.6645
.7365
.7276
.7447
.7533

Illustrative Translation Examples
Un coche bomba estalla junto a una comisaría de policía en Bagdad
MM: A car bomb explodes next to a police station in Baghdad
Systran: A car pump explodes next to a police station of police in bagdad
Hamas anunció este jueves el fin de su cese del fuego con Israel
MM: Hamas announced Thursday the end of the cease fire with israel
Systran: Hamas announced east Thursday the aim of its cease-fire with Israel
Testigos dijeron haber visto seis jeeps y dos vehículos blindados
MM: Witnesses said they have seen six jeeps and two armored vehicles
Systran: Six witnesses said to have seen jeeps and two armored vehicles

A More Complex Example
Un soldado de Estados Unidos murió y otros dos resultaron heridos este lunes
por el estallido de un artefacto explosivo improvisado en el centro de Bagdad,
dijeron funcionarios militares estadounidenses.
MM: A United States soldier died and two others were injured monday by the
explosion of an improvised explosive device in the heart of Baghdad, American
military officials said.
Systran: A soldier of the wounded United States died and other two were east
Monday by the outbreak from an improvised explosive device in the center of
Bagdad, said American military civil employees.

Summing up CBMT
What if a source word or phrase is not in the bilingual dictionary?
– Automatically Find near synonyms in source,
– Replace and retranslate
Current Status
– Developing a Chinese-to-English CBMT system (no results yet)
– Pre-commercial (field-testing)
– CMU participating in improving CBMT technology
Advantages
– Most accurate MT method in existance
– Does not require parallel text
Disadvantages
– Run time speed: 20s/w (7/07) 1.5s/w (2/08) 0.1s/w(12/08)
– Requires heavy-duty servers (not yet miniturizable)

CarnegieMellon Slide 32 Languge Technologies Insitute
Compositionality
Adjust rule toreflect compositionality
NP rule can be used to translate part of the
sentence; keep / add context constraints,
eliminate unnecessary ones
Flat Seed Generation
The highly qualified applicant visits the company.Der äußerst qualifizierte Bewerber besucht die Firma.
((1,1),(2,2),(3,3),(4,4),(5,5),(6,6))
S::S [det adv adj n v det n] [det adv adj n v det n]
((x1::y1) (x2::y2)….((x4 agr) = *3-sing) …((y3 case) = *nom)…)
Goal: Syntactic Transfer Rules1) Flat Seed Generation: produce rules from word-aligned sentence pairs, abstracted only to POS level; no syntactic structure2) Add compositional structure to Seed Rule by exploiting previously learned rules3) Seeded Version Space Learning group seed rules by constituent sequences and alignments, seed rules form s-boundary of VS; generalize with validation
Seeded Version Space LearningGroup seed rules into version spaces:
… …
NP v det n …
Notes:1) Partial order ofrules in VS2) Generalization
via merging
S::S [NP v det n] [NP n v det n]
((x1::y1) (x2::y2)….…
((y1 case) = *nom)…)
NP::NP [det adv adj n][det adv adj n]
((x1::y1)…((y4 agr) = (x4 agr)
….)Merge two rules:
1) Deletion of constraint2) Raising of two value to one
Agreement constraint, e.g.((x1 num) = *pl), ((x3 num) = *pl)
((x1 num) = (x3 num)3) Use merged rule to translate

CarnegieMellon Slide 33 Languge Technologies Insitute
Version Spaces (Mitchell, 1980)
G boundary
S boundary
“Target” concept N
Specific Instances
Anything
b

CarnegieMellon Slide 34 Languge Technologies Insitute
Original & Seeded Version Spaces
Version-spaces (Mitchell, 1980)
– Symbolic multivariate learning
– S & G sets define lattice boundaries
– Exponential worst-case: O(bN)
Seeded Version Spaces (Carbonell, 2002)
– Generality level hypothesis seed
S & G subsets effective lattice
– Polynomial worst case: O(bk/2), k=3,4

CarnegieMellon Slide 35 Languge Technologies Insitute
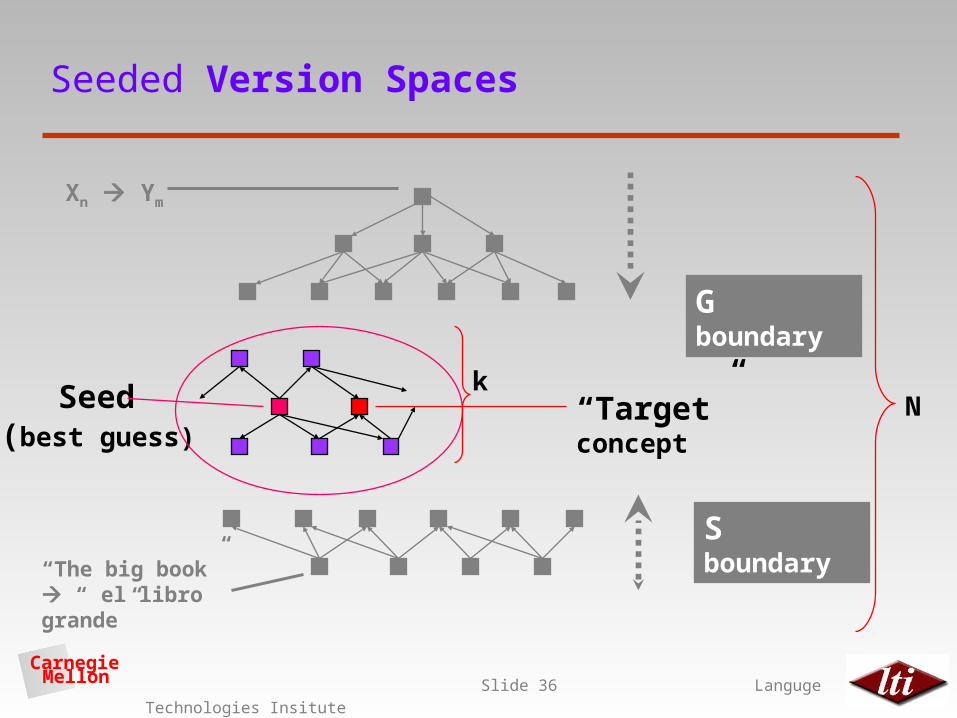
Seeded Version Spaces (Carbonell, 2002)
G boundary
S boundary
“Target” concept N
Xn Ym
“The big book” “ el libro grande”
Det Adj N Det N Adj(Y2 num) = (Y3 num)(Y2 gen) = (Y3 gen)(X3 num) = (Y2 num)
CarnegieMellon Slide 36 Languge Technologies Insitute
Seeded Version Spaces
S boundary
“Target” concept Seed(best guess)
kN
G boundary
Xn Ym
“The big book” “ el libro grande”

CarnegieMellon Slide 37 Languge Technologies Insitute
Transfer Rule Learning
One SVS per transfer rule
– Alignment + generalization level = seed
– Apply SVS(seed,k) learning method
» High confidence seed small k [k too small increases prob(failure)]
» Low confidence seed larger k [k too large increases computation & elicitation]
For translation use SVS f-centroid
– If success % > threshold, halt SVS
– If no rule found, k := K+1 & redo (to max K)

CarnegieMellon Slide 38 Languge Technologies Insitute
Sample learned Rule

Compositionality
;;L2: h &niin h rxb b h bxirwt
;;L1: the widespread interest in the election
NP::NP
[Det N Det Adj PP] -> [Det Adj N PP]
((X1::Y1)(X2::Y3)
(X3::Y1)(X4::Y2)
(X5::Y4)
((Y3 num) = (X2 num))
((X2 num) = sg)
((X2 gen) = m)
((Y1 def) = +) )
Training example
Rule type
Component sequences
Component alignments
Agreement constraints
Value constraints

CarnegieMellon Slide 40 Languge Technologies Insitute
Automated Speech Recognition at CMU:Sphinx and related technologies
Sphinx is the name for a family of speech recognition engines – developed by Reddy, Lee & Rudnicky
– First continuous-speech, speaker-independent large vocabulary system
– Standard continuous HMM technology
– Multiple languages
– Open source code base
– Miniaturized and integrated with MT, dialog, and TTS
– Basis for Native Accent & Carnegies Speech prouducts
Janus system developed–by Waibel and Schultz – Started as Neural-Net Approach
– Now standard continuous HMM system
– Multiple languages
– NOT open source code base
– Held WER advantage over Sphinx till recently (now both are equal)

CarnegieMellon Slide 41 Languge Technologies Insitute
Sphinx ASR at Carnegie Mellon
Sphinx systems have evolved along two parallel batch
Technology innovation occurs in the Research branch, then transitions to the Live branch
The Live branch focuses on the additional requirements of interactive real-time recognition and on the integration with higher-level components such as spoken language understanding and dialog management
Sphinx
Sphinx-2
Sphinx-3.x
Sphinx-3.7
PocketSphinx
Live ASR Research ASR
Sphinx-2L
SphinxL
1986
1992
1999
2006

CarnegieMellon Slide 42 Languge Technologies Insitute
Some features of Sphinx
Level Features
Acoustic Modeling CHMM-based representationsFeature-space reduction (LDA/MLLT)Adaptive training (based on VTLN)Speaker adaptation (MLLR)Discriminative Training
Real-Time Decoding GMM selection (4 level)Lexical trees; fixed-sized tree copyingParameter quantization
Live interaction support End-point detectionDynamic lass-based language modelsDynamic language modelsPartial hypothesesConfidence annotationDynamic noise processing

CarnegieMellon Slide 43 Languge Technologies InsituteApril 19, 2023 Speech Group 43
Spoken language processing
speech
text
meaning
action
recognition dialogue discourse understanding
generation synthesis
task & domain knowledge

CarnegieMellon Slide 44 Languge Technologies InsituteApril 19, 2023 Speech Group 44
A generic speech system
human speech
SignalProcessing
DialogManager
Decoder
Parser LanguageGenerator
SpeechSynthesizer
postParser Domain
agent
Domainagent
DomainAgent
display
machine speech
effector

CarnegieMellon Slide 45 Languge Technologies InsituteApril 19, 2023 Speech Group 45
Decoding speech
Signalprocessing
Decoder
Reduce dimensionality of signal
noise conditioning
Transcribe speech to words
Acousticmodels
Languagemodels
Corpus-base statistical models
Lexicalmodels

CarnegieMellon Slide 46 Languge Technologies InsituteApril 19, 2023 Speech Group 46
A model for speech recognition
Speech recognition as an estimation problem– A = sequence of acoustic observations– W = string of words
)|(maxargˆ AWPWW

CarnegieMellon Slide 47 Languge Technologies InsituteApril 19, 2023 Speech Group 47
Recognition
A Bayesian formulation of the recognition problem
– the “fundamental equation” of speech recognition
)(/)|()()|( ApWApWpAWp
posterior prior
The “model”
conditional
event evidence

CarnegieMellon Slide 48 Languge Technologies InsituteApril 19, 2023 Speech Group 48
Understanding speech
Parser
Postparser
Extract semantic content from utterance
Introduce context and world knowledge into interpretation
Grammar
Context DomainAgents
Grounding, knowledge engineering
Ontology design, language acquisition

CarnegieMellon Slide 49 Languge Technologies InsituteApril 19, 2023 Speech Group 49
Interacting with the user
Dialogmanager
Domainagent
Domainagent
Domainagent
Guide interaction through task
Map user inputs and system state into actions
Interact with back-end(s)
Interpret information using domain knowledge
Taskschemas
Database Live data (e.g. Web)
Domainexpert
Context
Task analysis
Knowledge engineering

CarnegieMellon Slide 50 Languge Technologies InsituteApril 19, 2023 Speech Group 50
Communicating with the user
LanguageGenerator
Speechsynthesizer
DisplayGenerator
ActionGenerator
Decide what to say to user (and how to phrase it)
RulesDatabase
RulesDatabase
Construct sounds and intonation

CarnegieMellon Slide 51 Languge Technologies Insitute
Environmental robustness for the STS
Expected types of disturbance:
– White/broadband noise
– Speech babble
– Single competing speakers
– Other background music
Comments:
– State-of-the art technologies have been applied mostly to applications where time and computation is unlimited
– Samsung expects reverberation will not be a factor; if reverb actually is in environment, compensation becomes more difficult

CarnegieMellon Slide 52 Languge Technologies Insitute
Speech recognition as pattern classification
Major functional components:
– Signal processing to extract features from speech waveforms
– Comparison of features to pre-stored representations
Important design choices:
– Choice of features
– Specific method of comparing features to stored representations
Feature extractionDecision making
procedure
Speech features
Wordhypotheses

CarnegieMellon Slide 53 Languge Technologies Insitute
Multistage environmental compensationfor Samsung STC
Compensation is a combination of:
– ZCAE separates speech from noise based on direction of arrival
– ANC cancels noise
– CDCN, VTS, DCN provide static and dynamic noise removal, channel compensation, feature normalization
– CBMF restores missing features that are lost due to transient noise

CarnegieMellon Slide 54 Languge Technologies Insitute
Short-time Fourier analysis separates speech in time and frequency
Separate time-frequency components according to direction of arrival based on time delay comparisons (ITD)
Reconstruct signal from only the components that are believed to arise from desired source
Missing feature restoration can smooth reconstruction
Binaural processing for selective reconstruction (the ZCAE algorithm)

CarnegieMellon Slide 55 Languge Technologies Insitute
Sample results with 45-degree arrival angle difference:
Original Separated
– With no reverberation:
– With 300-ms reverb time: ZCAE provides excellent separation in “dry” rooms but fails in
reverberation
Performance of zero-crossing-based amplitude estimation (ZCAE)
CarnegieMellon Slide 56 Languge Technologies Insitute
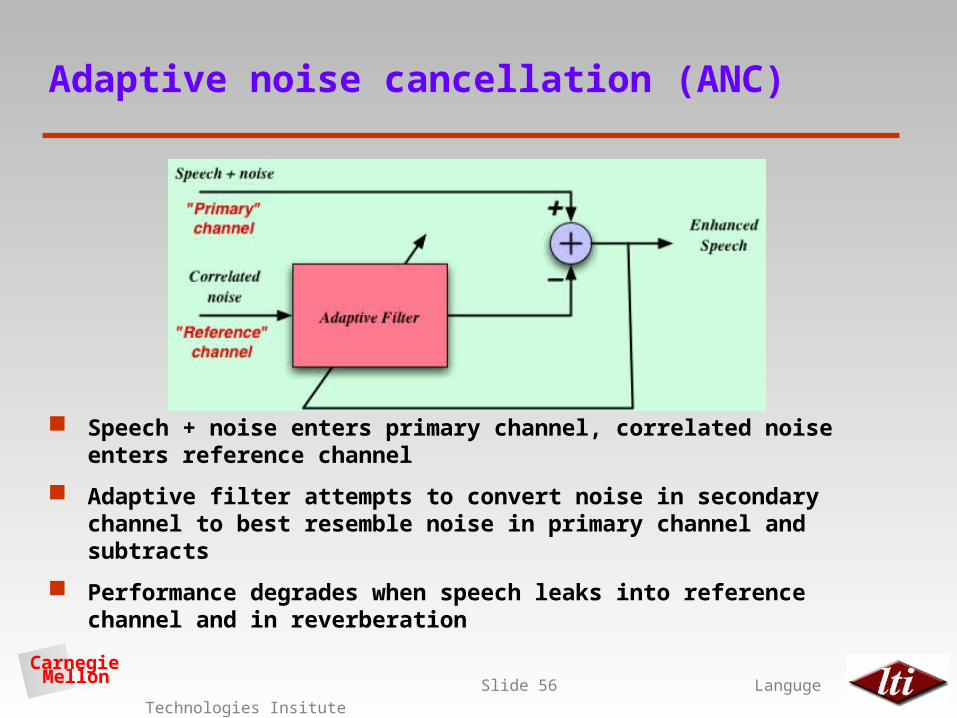
Adaptive noise cancellation (ANC)
Speech + noise enters primary channel, correlated noise enters reference channel
Adaptive filter attempts to convert noise in secondary channel to best resemble noise in primary channel and subtracts
Performance degrades when speech leaks into reference channel and in reverberation

CarnegieMellon Slide 57 Languge Technologies Insitute
Possible placement of mics for ZCAE and ANC
One possible arrangement:
– Two omni mics for ZCAE processing
– One uni mic (notch toward speaker) for ANC reference
Another option is to have reference mic on back, away from speaker

CarnegieMellon Slide 58 Languge Technologies Insitute
“Classic” compensation for noise and filtering
Model of Signal Degradation:
Compensation procedures attempt to estimate characteristics of filter and additive noise, and then apply inverse operations
Algorithms include CDCN, VTS, DCN
Compensation applied at cepstral level (not to waveforms)
Supersedes Wiener filtering
CarnegieMellon Slide 59 Languge Technologies Insitute
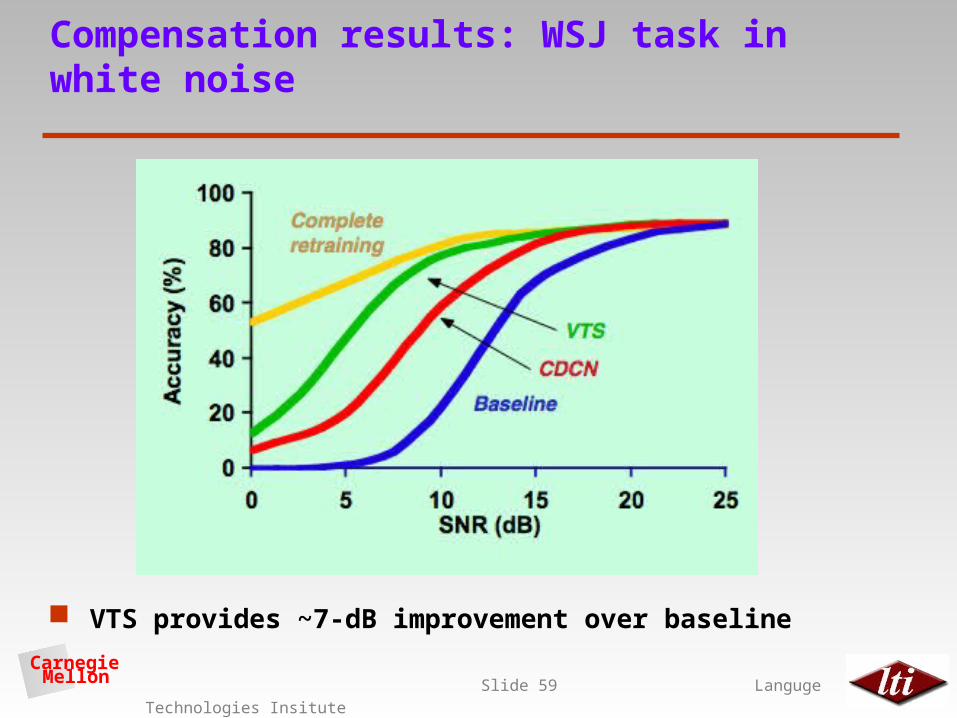
Compensation results: WSJ task in white noise
VTS provides ~7-dB improvement over baseline
CarnegieMellon Slide 60 Languge Technologies Insitute
What does compensated speech “sound” like?
Speech reconstructed after CDCN processing:
Signals that sound “better” do not produce lower error rates
0 dB 20 dB Clean
Original“Recovered”

CarnegieMellon Slide 61 Languge Technologies Insitute
Missing-feature recognition
General approach:
– Determine which cells of a spectrogram-like display are unreliable (or “missing”)
– Ignore missing features or make best guess about their values based on data that are present
Comment:
– Used in the STS for transient compensation and as a supporting technology for ZCAE
CarnegieMellon Slide 62 Languge Technologies Insitute
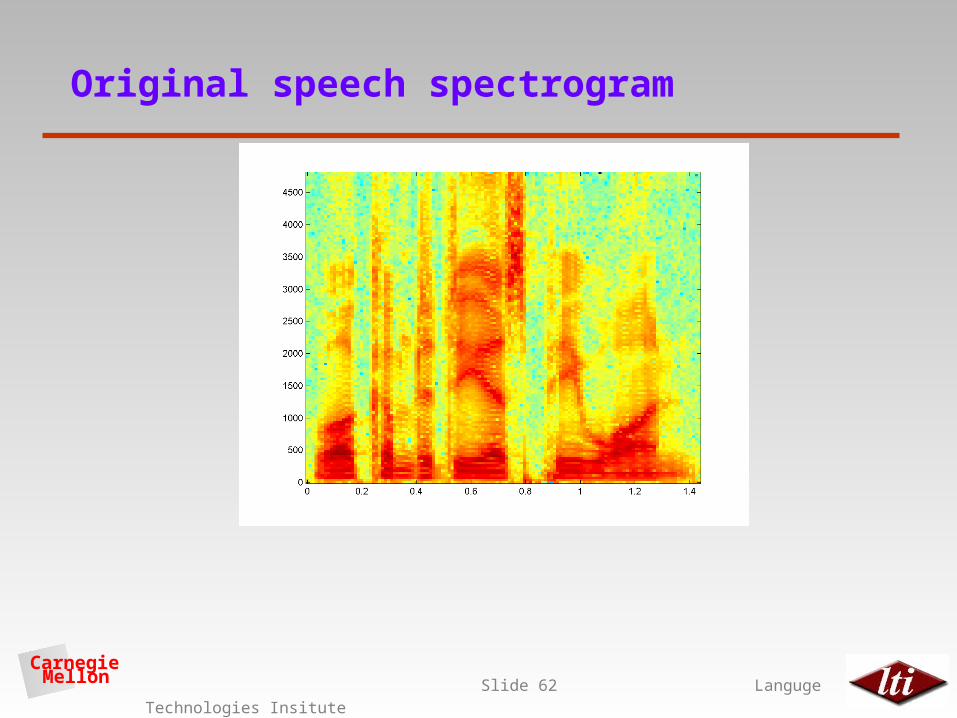
Original speech spectrogram

CarnegieMellon Slide 63 Languge Technologies Insitute
Spectrogram corrupted by noise at SNR 15 dB
Some regions are affected far more than others

CarnegieMellon Slide 64 Languge Technologies Insitute
Ignoring regions in the spectrogram that are corrupted by noise
All regions with SNR less than 0 dB deemed missing (dark blue)
Recognition performed based on colored regions alone

CarnegieMellon Slide 65 Languge Technologies Insitute
Robustness Summary
The CMU Robust Group will implement an ensemble of complementary technologies for the Samsung STS:
– ZCAE for speech separation by arrival angle
– Adaptive noise compensation to reduce background interference
– CDCN, VTS, DCN to reduce stationary residual noise and provide channel compensation
– Cluster-based missing-feature compensation to protect against transient interference and to improve ZCAE performance
Most compensation procedures are based on a tight integration of environmental compensation with the core speech recognition engine.

Virtual English Village (VEV) [SAMSUNG SLIDE]
Service Overview– An online 3D virtual world providing language students with an opportunity to practice and
develop conversational skills for pre-defined domains/scenarios.– Provide students with a fun, safe environment to develop conversational skills.– Improve students:-
» Grammar by correcting student input or suggesting other appropriate variations» Vocabulary by suggesting other words» Pronunciation through clear, synthesized speech and correcting students input
– Service requires student to have access to a microphone.– A complement to existing English language services in Korea.
Target Market– Initially targeting Korean Elementary to High-School Students (~8 to 16 year olds) with some
familiarity of the English language.

CarnegieMellon Slide 67 Languge Technologies Insitute
Potential Carnegie Contributions to VEG
ASR: Sphinx speech recognition (CMU)
TTS: Festival/Festbox text-to-speech (CMU)
Let’s Go & Olympus dialog systems (CMU)
Native Accent pronunciation tutor (Carnegie Speech)
Grammar & lexicon tutors (Carnegie Speech)
– Story Friends, Story Librarian, …
– Intelligent tutoring architecture
Language parsing/generation (CMU & CS)

CarnegieMellon Slide 68 Languge Technologies Insitute
Let’s Go Performance
Automated bus schedule/routes for Port Authority of Pittsburgh
Answers phone every evening and on weekends since March 5, 2005
Presently over 52,000 calls from real users
– Variety of noise and transmission conditions
– Variety of dialects and other variants
Estimated Task Success = about 75%
Average number of turns = 12-14
Dialogue characteristics:
– Mixed initiative after first turn
– Open-ended first turn (“What can I do for you?”)
– Change of topic upon comprehension problem (e.g. “what neighborhood are you in?”)
CarnegieMellon Slide 69 Languge Technologies Insitute
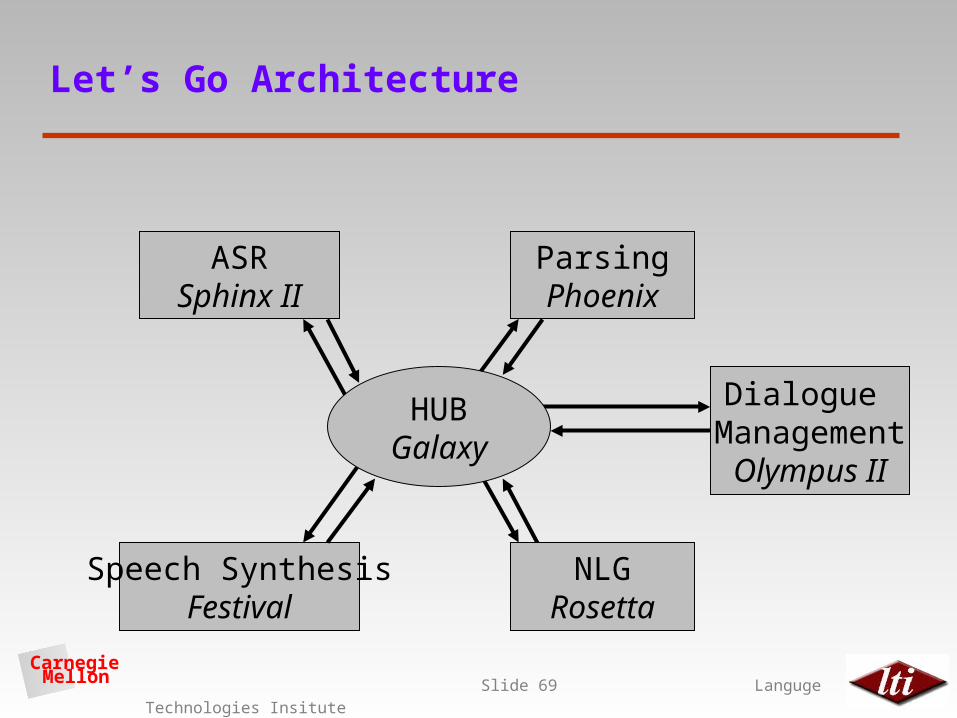
Let’s Go Architecture
ASRSphinx II
ParsingPhoenix
Dialogue ManagementOlympus II
Speech SynthesisFestival
HUBGalaxy
NLGRosetta

CarnegieMellon Slide 70 Languge Technologies Insitute
Olympus II dialogue architecture
Improves timing awareness – separates DM decision making and awareness into separate modules– Improves turntaking
– Higher success after barge-in
– Reduces system cut-ins
International spoken dialogue community uses OlympusII for different systems– About 10 different applications
» Bus, air reservations, room reservations, movie line, personal minder, etc.
Open Source with Documentation

CarnegieMellon Slide 71 Languge Technologies Insitute
Olympus II architecture

CarnegieMellon Slide 72 Languge Technologies Insitute
Speech synthesis
Recognizer = Sphinx-II (enhanced, customized)
Synthesizer = Festival
– Well-known, open source
– Provides very high quality limited domain synthesis
» Some people calling Let’s Go think they are talking to a person
Rosetta Spoken Language Generation
– Generate natural language sentences using templates

CarnegieMellon Slide 73 Languge Technologies Insitute
Spoken Dialogue and Language Learning
Correction of any of several levels of language within a dialogue while keeping the dialogue on track
– “I want to go the airport”
– “Going to the airport, at what time?”
Adaptation to non-native speech
Uses F0 unit selection (Raux, Black ASRU 2003) for emphasis in synthesis
Lexical entrainment for rapid correction
– Implicit strategy, no break in dialogue

CarnegieMellon Slide 74 Languge Technologies Insitute
Spoken Dialogue and Language Learning
Lexical entrainment for rapid correction
Collect speech in WOZ setup
Model expected error
Find closest user utterance
TargetPrompts
ASR Hypothesis
DP-basedAlignment
PromptSelection
EmphasisConfirmation
Prompt