machine learning techniques for computer vision
TRANSCRIPT

Part 2: Unsupervised Learning
Machine Learning Techniques for Computer Vision
Microsoft Research Cambridge
ECCV 2004, Prague
Christopher M. Bishop
0 0.5 1
0
0.5
1
0.5 0.3
0.2
x1
x1
x3
x3
x2
x2

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Overview of Part 2• Mixture models• EM• Variational Inference• Bayesian model complexity• Continuous latent variables

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
The Gaussian Distribution• Multivariate Gaussian
• Maximum likelihood
meancovariance

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Gaussian Mixtures• Linear super-position of Gaussians
• Normalization and positivity require

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Example: Mixture of 3 Gaussians
0 0.5 10
0.5
1
(a)0 0.5 1
0
0.5
1
(b)

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Maximum Likelihood for the GMM• Log likelihood function
• Sum over components appears inside the log– no closed form ML solution

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
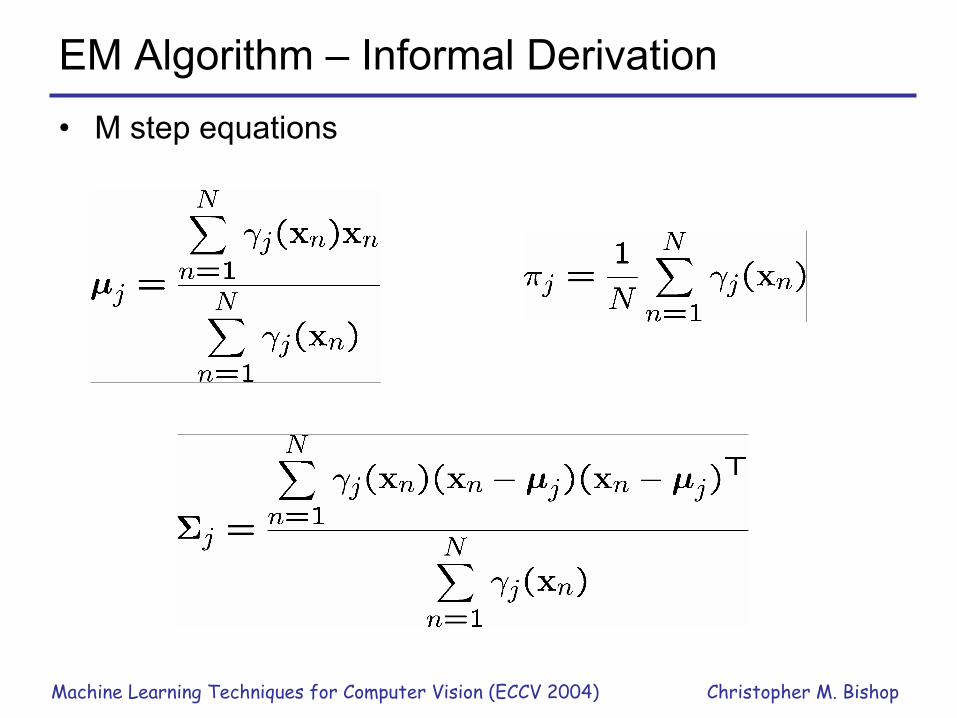
EM Algorithm – Informal Derivation
Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
EM Algorithm – Informal Derivation• M step equations

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
EM Algorithm – Informal Derivation• E step equation

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
EM Algorithm – Informal Derivation• Can interpret the mixing coefficients as prior probabilities
• Corresponding posterior probabilities (responsibilities)

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
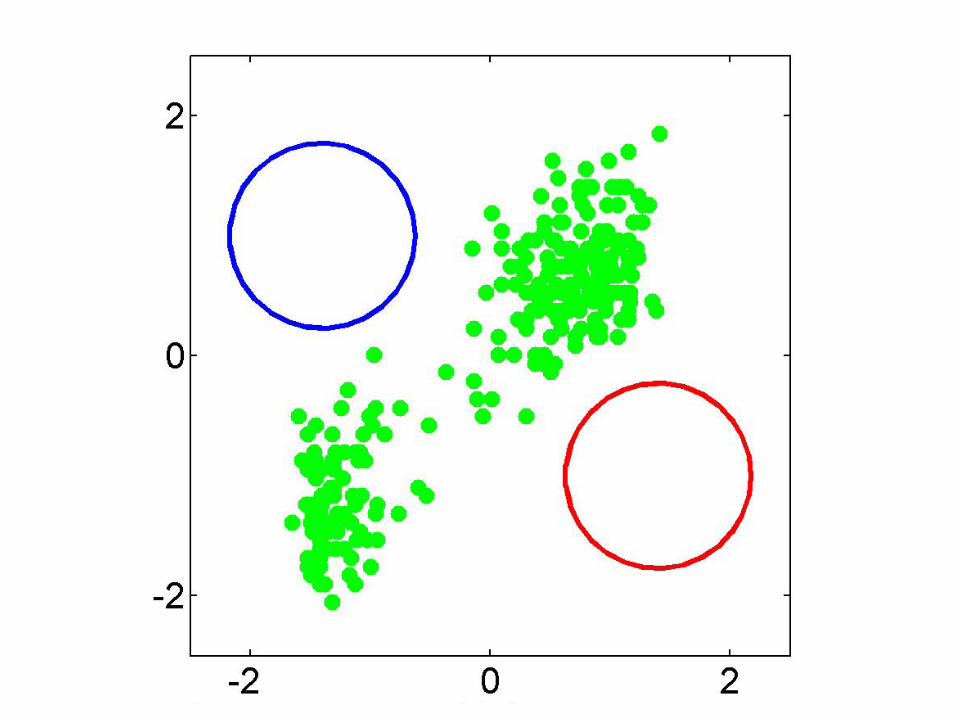
Old Faithful Data Set
Duration of eruption (minutes)
Time betweeneruptions (minutes)
Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Latent Variable View of EM• To sample from a Gaussian mixture:
– first pick one of the components with probability – then draw a sample from that component– repeat these two steps for each new data point
0 0.5 10
0.5
1
(a)

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Latent Variable View of EM• Goal: given a data set, find • Suppose we knew the colours
– maximum likelihood would involve fitting each component to the corresponding cluster
• Problem: the colours are latent (hidden) variables

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Incomplete and Complete Data
complete
0 0.5 10
0.5
1
(a)0 0.5 1
0
0.5
1
(b)
incomplete

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Latent Variable Viewpoint

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Latent Variable Viewpoint • Binary latent variables describing which
component generated each data point • Conditional distribution of observed variable
• Prior distribution of latent variables
• Marginalizing over the latent variables we obtain
X
Z

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Graphical Representation of GMM
�z
nz
n
xn
xn
��N

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Latent Variable View of EM• Suppose we knew the values for the latent variables
– maximize the complete-data log likelihood
– trivial closed-form solution: fit each component to the corresponding set of data points
• We don’t know the values of the latent variables– however, for given parameter values we can compute
the expected values of the latent variables

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Posterior Probabilities (colour coded)
0 0.5 10
0.5
1
(a)0 0.5 1
0
0.5
1
(b)

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Over-fitting in Gaussian Mixture Models• Infinities in likelihood function when a component
‘collapses’ onto a data point:
with
• Also, maximum likelihood cannot determine the number K of components

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Cross Validation• Can select model complexity using an independent
validation data set• If data is scarce use cross-validation:
– partition data into S subsets– train on S−1 subsets – test on remainder– repeat and average
• Disadvantages– computationally expensive – can only determine one or
two complexity parameters
Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
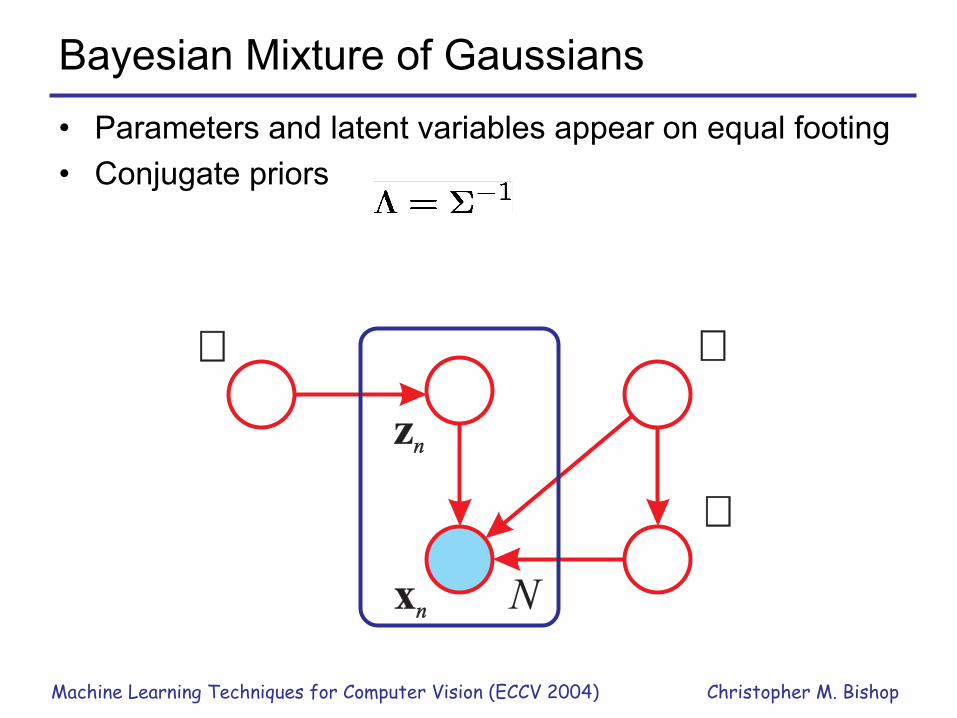
Bayesian Mixture of Gaussians• Parameters and latent variables appear on equal footing• Conjugate priors
�
zn
zn
xn
xn
�
�
N

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Data Set Size• Problem 1: learn the function
for from 100 (slightly) noisy examples– data set is computationally small but statistically large
• Problem 2: learn to recognize 1,000 everyday objects from 5,000,000 natural images– data set is computationally large but statistically small
• Bayesian inference – computationally more demanding than ML or MAP
(but see discussion of Gaussian mixtures later)– significant benefit for statistically small data sets

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Variational Inference• Exact Bayesian inference intractable• Markov chain Monte Carlo
– computationally expensive– issues of convergence
• Variational Inference– broadly applicable deterministic approximation– let denote all latent variables and parameters– approximate true posterior using a simpler
distribution – minimize Kullback-Leibler divergence

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
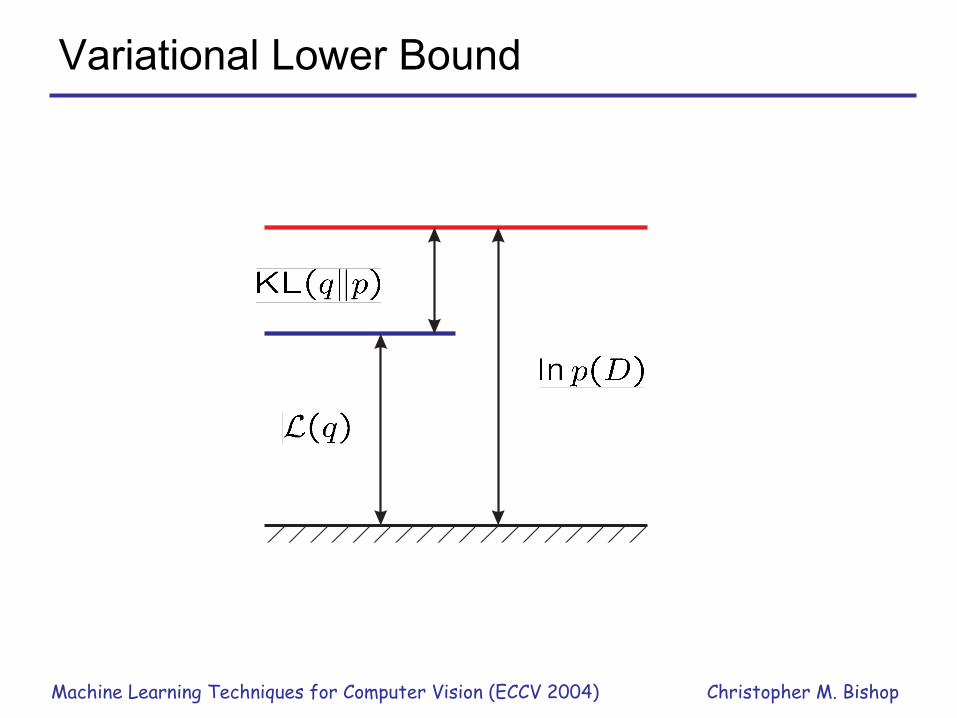
General View of Variational Inference• For arbitrary
where
• Maximizing over would give the true posterior– this is intractable by definition
Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Variational Lower Bound

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Factorized Approximation• Goal: choose a family of q distributions which are:
– sufficiently flexible to give good approximation– sufficiently simple to remain tractable
• Here we consider factorized distributions
• No further assumptions are required!• Optimal solution for one factor, keeping the remainder fixed
– coupled solutions so initialize then cyclically update– message passing view (Winn and Bishop, 2004)

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
0 0.5 10
0.5
1
x1
x2
(a)

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Lower Bound• Can also be evaluated• Useful for maths/code verification• Also useful for model comparison:

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
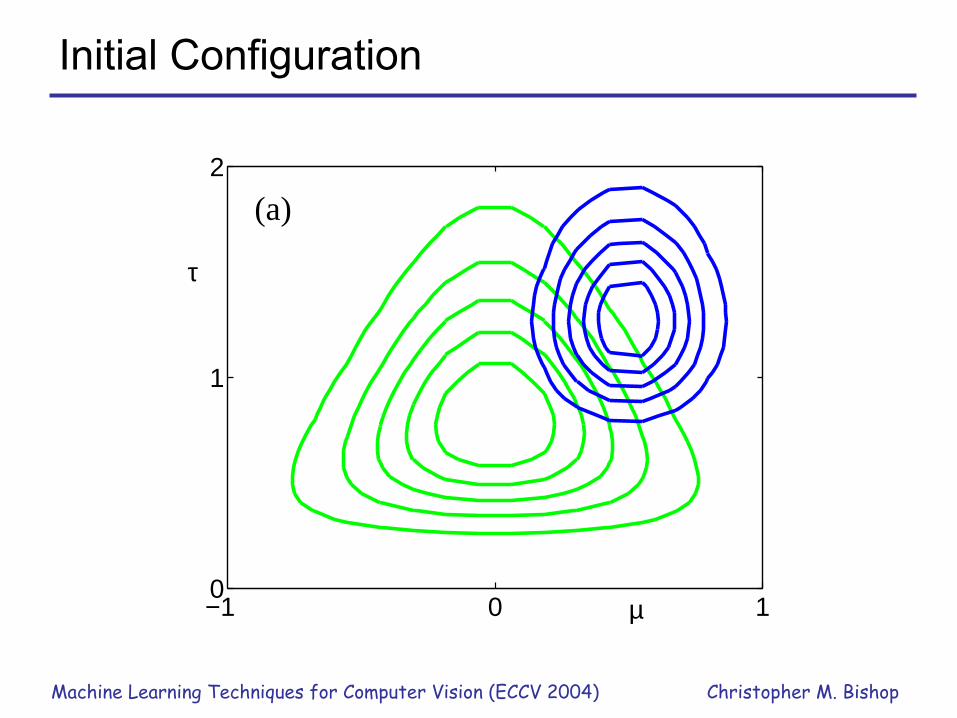
Illustration: Univariate Gaussian• Likelihood function
• Conjugate prior • Factorized variational distribution
Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Initial Configuration
−1 0 10
1
2
µ
τ
(a)

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
After Updating
−1 0 10
1
2
µ
τ
(b)

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
After Updating
−1 0 10
1
2
µ
τ
(c)

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Converged Solution
−1 0 10
1
2
µ
τ
(d)

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Variational Mixture of Gaussians• Assume factorized posterior distribution
• No other approximations needed!

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Variational Equations for GMM

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Lower Bound for GMM

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
VIBES
Bishop, Spiegelhalter and Winn (2002)

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
ML Limit• If instead we choose
we recover the maximum likelihood EM algorithm
Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Bound vs. K for Old Faithful Data

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Bayesian Model Complexity

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Sparse Bayes for Gaussian Mixture• Corduneanu and Bishop (2001)• Start with large value of K
– treat mixing coefficients as parameters– maximize marginal likelihood– prunes out excess components

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Summary: Variational Gaussian Mixtures• Simple modification of maximum likelihood EM code• Small computational overhead compared to EM• No singularities• Automatic model order selection

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Continuous Latent Variables• Conventional PCA
– data covariance matrix
– eigenvector decomposition
• Minimizes sum-of-squares projection– not a probabilistic model– how should we choose L ?
x1
x1
x2
x2
xn
xn
~x
n
~x
n
u1
u1

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Probabilistic PCA• Tipping and Bishop (1998)• L dimensional continuous latent space
• D dimensional data space
x1
x1
x2
x2
z
�
w
{
PCAfactor analysis

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Probabilistic PCA• Marginal distribution
• Advantages– exact ML solution– computationally efficient EM algorithm– captures dominant correlations with few parameters– mixtures of PPCA– Bayesian PCA– building block for more complex models
� �� �
�N
W
zn
zn
xn
xn

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
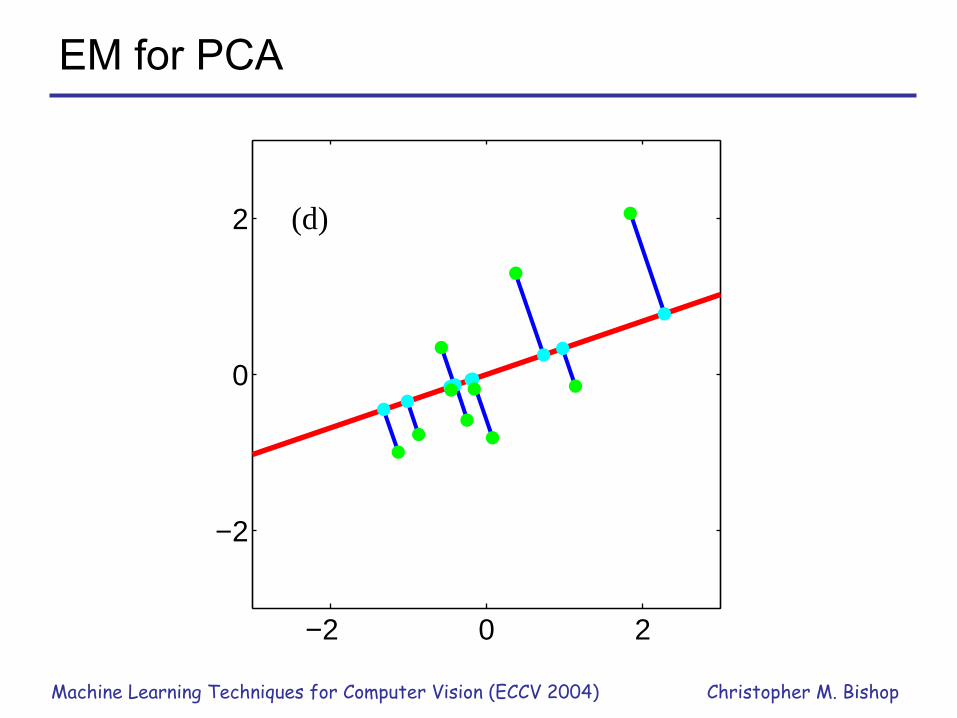
EM for PCA
−2 0 2
−2
0
2 (a)

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
EM for PCA
−2 0 2
−2
0
2 (b)

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
EM for PCA
−2 0 2
−2
0
2 (c)
Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
EM for PCA
−2 0 2
−2
0
2 (d)

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
EM for PCA
−2 0 2
−2
0
2 (e)
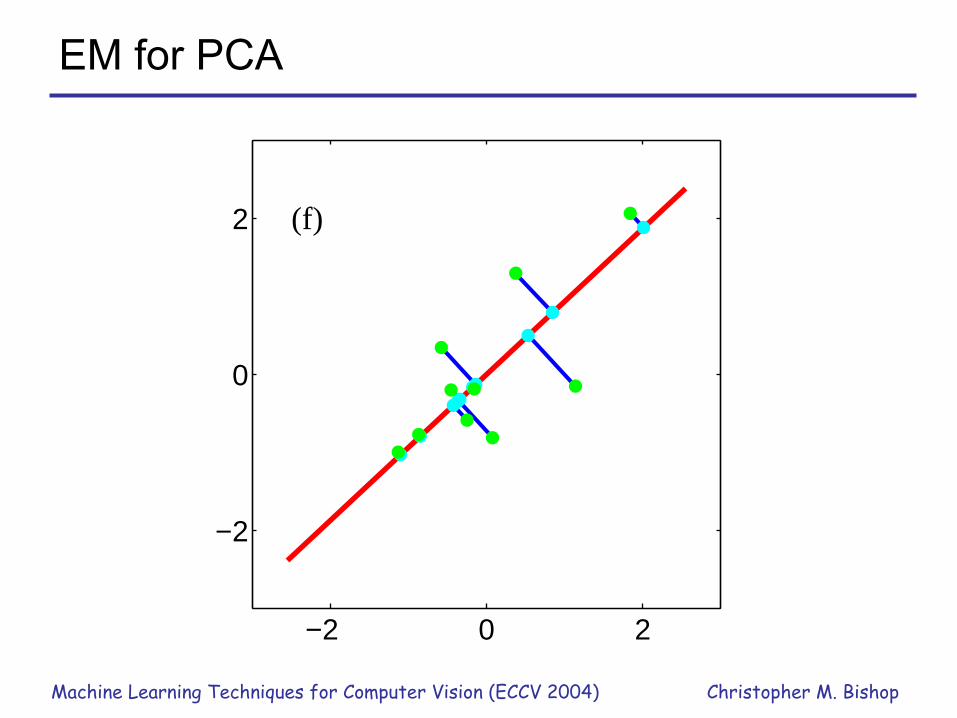
Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
EM for PCA
−2 0 2
−2
0
2 (f)

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
−2 0 2
−2
0
2 (g)
EM for PCA

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Bayesian PCA• Bishop (1998)• Gaussian prior over columns of
• Automatic relevance determination (ARD)
ML PCA Bayesian PCA
� �� �
�N
W
zn
zn
xn
xn
��

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
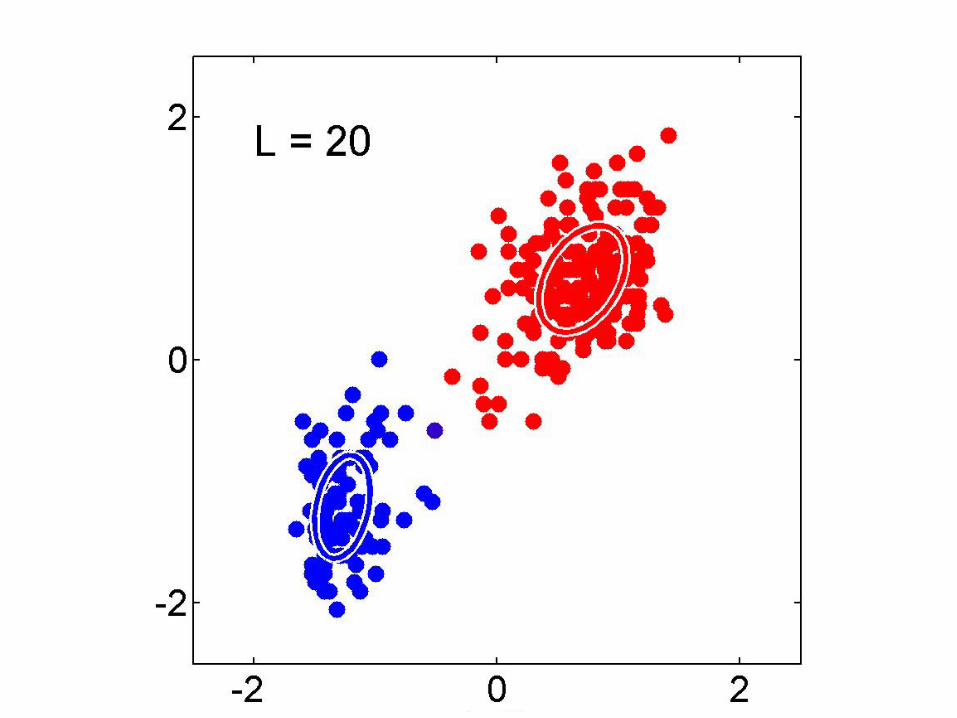
Non-linear Manifolds• Example: images of a rigid object
x1
x1
x3
x3
x2
x2
Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
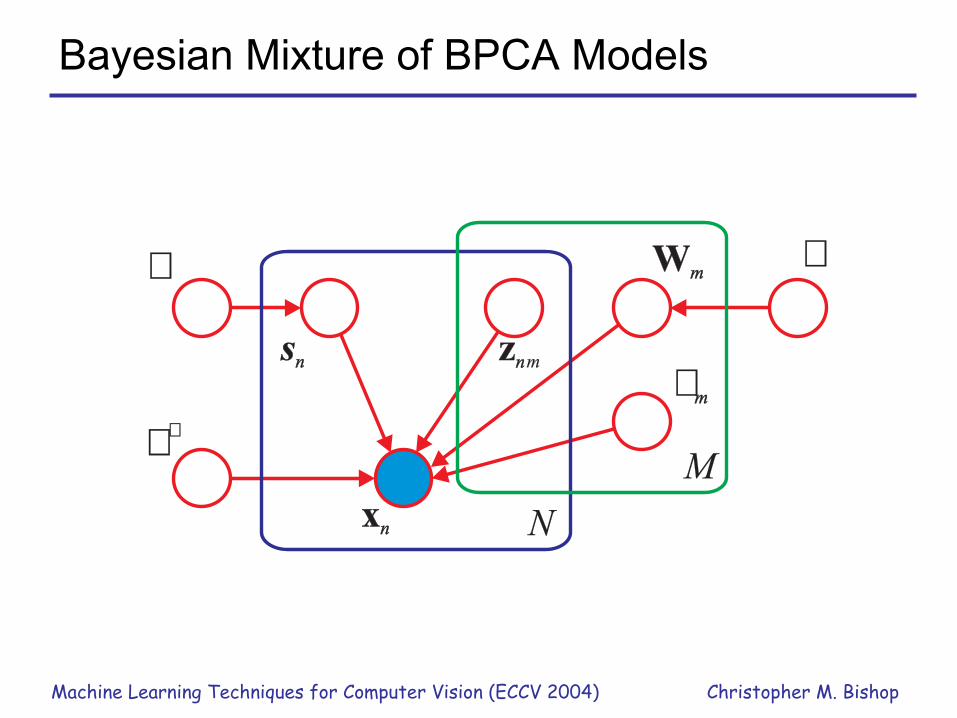
Bayesian Mixture of BPCA Models
�
sn
sn
zn
znm
xn
xn
�m
�m
N
M
Wm
Wm
�
� �� �
Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Flexible Sprites• Jojic and Frey (2001)• Automatic decomposition of video sequence into
– background model– ordered set of masks (one per object per frame)– foreground model (one per object per frame)

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Transformed Component Analysis• Generative model
• Now include transformations (translations)
• Extend to L layers• Inference intractable so
use variational framework
�s
ls
l ml
ml
Tn l
Tn l
xn
xn N
L

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Bayesian Constellation Model• Li, Fergus and Perona (2003)• Object recognition from small training sets• Variational treatment of fully Bayesian model

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Bayesian Constellation Model

Machine Learning Techniques for Computer Vision (ECCV 2004) Christopher M. Bishop
Summary of Part 2• Discrete and continuous latent variables
– EM algorithm• Build complex models from simple components
– represented graphically– incorporates prior knowledge
• Variational inference– Bayesian model comparison