machine learning for body sensor networks
DESCRIPTION
Slides from the tutorial on "Machine Learning for Body Sensor Networks" at the BSN Conference in Zürich, Switzerland, June 2014. It covers mainly reinforcement learning, neural networks and decision trees and their applications in body sensor networking.TRANSCRIPT

Machine Learning for BSN Dr. Anna Förster, Alessandro Puia4 BSN Tutorial, June 17th 2014 Zürich, Switzerland
Copyrig
ht A.Förster, A
.Puia4
2014
1

Presenters Dr. Anna Förster
Researcher at SUPSI [email protected]
Alessandro Puia< Senior researcher at SUPSI alessandro.puia<@supsi.ch
2
Copyrig
ht A.Förster, A
.Puia4
2014

Schedule and outlook • Data in Body Sensor Networks • What is Machine Learning? • Decision Trees and their applicaNons • Discussion
• Break
• Neural networks and their applicaNons • Reinforcement Learning and its applicaNons • Other Machine Learning techniques • Comparison of ML for BSNs • Open discussion! 3
Copyrig
ht A.Förster, A
.Puia4
2014

BSN: The Challenges Dr. Anna Förster, Alessandro Puia4 BSN Tutorial, June 17th 2014 Zürich, Switzerland
Copyrig
ht A.Förster, A
.Puia4
2014
4

BSN vs WSN
DC-DC
Sensors ADC MCU
Memory
Wireless
Battery
Node Architecture
Network Architecture
DC-DC
Sensors ADC MCU
Memory
Wireless
Battery
DC-DC
Sensors ADC MCU
Memory
Wireless
Battery
DC-DC
Sensors ADC MCU
Memory
Wireless
Battery
SINK
5
Copyrig
ht A.Förster, A
.Puia4
2014

BSN vs WSN: Number of Nodes
WSN
BSN 6
Copyrig
ht A.Förster, A
.Puia4
2014

BSN vs WSN: Parameters WSN
BSN
Almost homogeneous: same sensors in every node
Extremely heterogeneous: different sensor for each node
Temperature Humidity Light
Body Temperature EEG EMG SPO2
7
Copyrig
ht A.Förster, A
.Puia4
2014

BSN vs WSN: Other requirements
8
Requirements WSN BSN
Babery life Years App. dependent
Network topology Mostly Mesh Star
Mobility StaNc Mobile
ComputaNon Low Low, Medium, High
Frequency Low High
Form factor Almost indifferent Hidden, Invisible
“Wearability” -‐-‐ Mandatory
Copyrig
ht A.Förster, A
.Puia4
2014

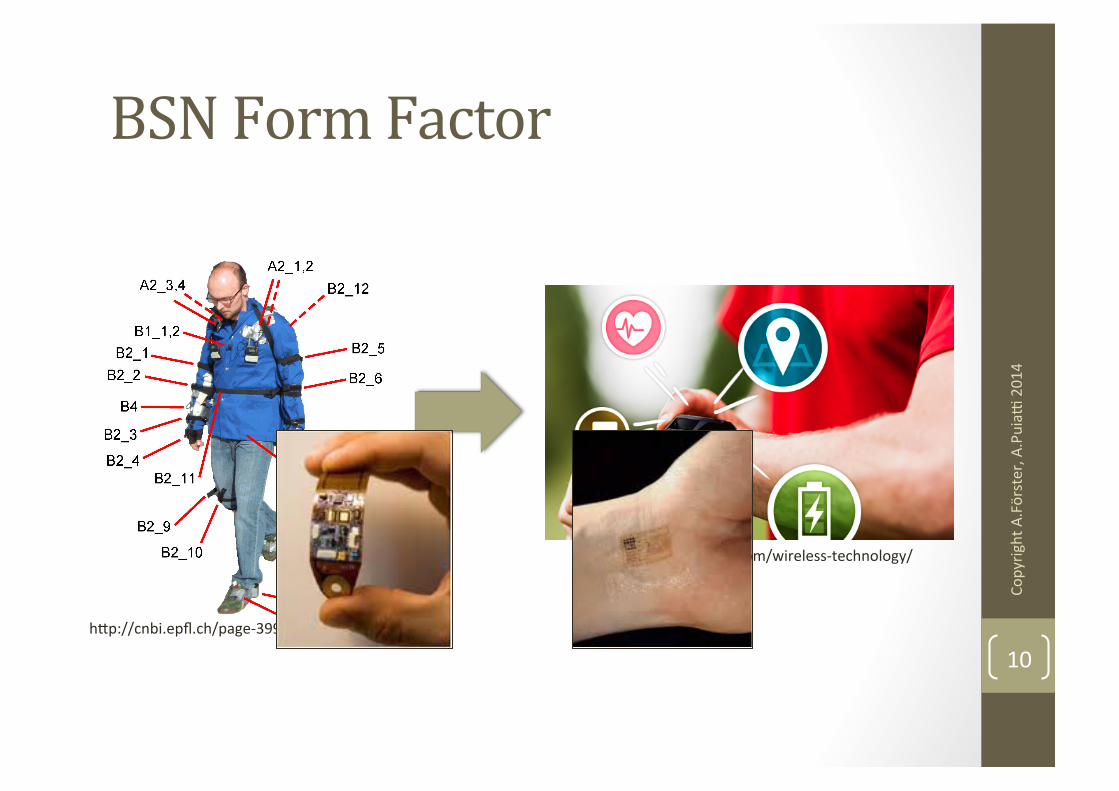
BSN Form Factor
9 hbp://cnbi.epfl.ch/page-‐39979-‐en.html
hbp://blog.broadcom.com/wireless-‐technology/
Copyrig
ht A.Förster, A
.Puia4
2014
BSN Form Factor
10 hbp://cnbi.epfl.ch/page-‐39979-‐en.html
hbp://blog.broadcom.com/wireless-‐technology/
Copyrig
ht A.Förster, A
.Puia4
2014

BSN Form Factor
11 hbp://cnbi.epfl.ch/page-‐39979-‐en.html
hbp://blog.broadcom.com/wireless-‐technology/
Copyrig
ht A.Förster, A
.Puia4
2014

BSN Devices
12
Copyrig
ht A.Förster, A
.Puia4
2014
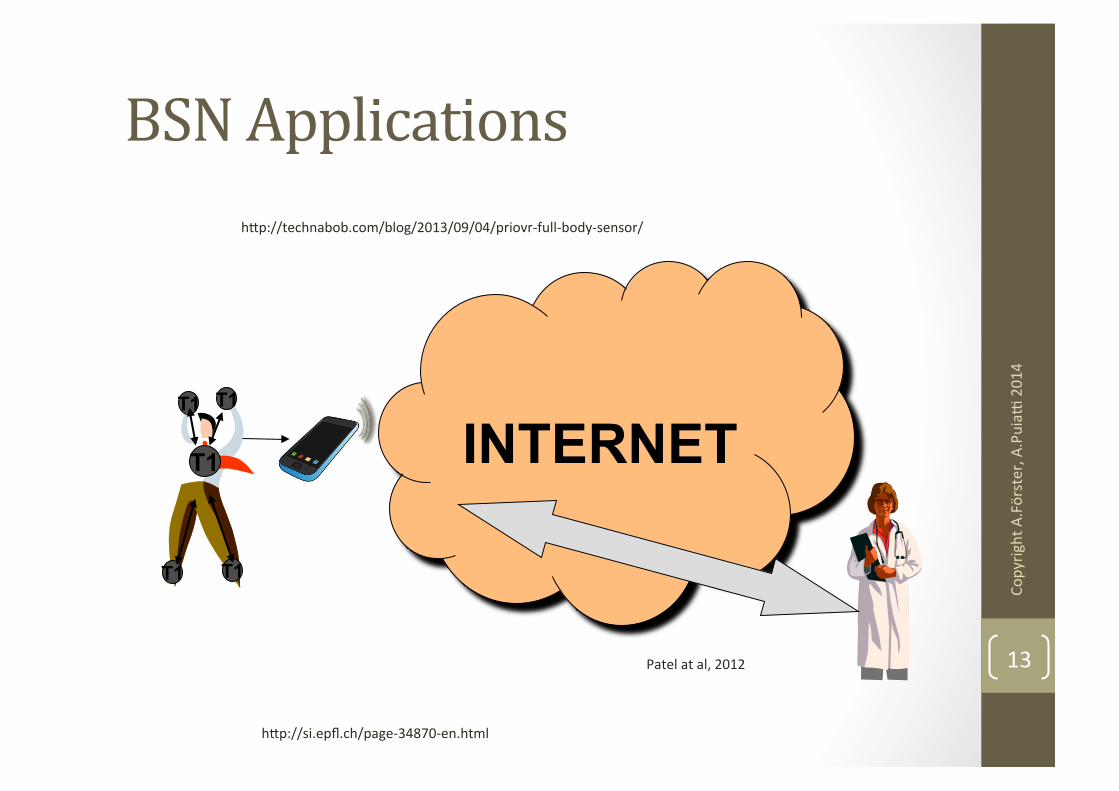
BSN Applications
13
INTERNET T1
T1 T1
T1 T1
hbp://si.epfl.ch/page-‐34870-‐en.html
Patel at al, 2012
hbp://technabob.com/blog/2013/09/04/priovr-‐full-‐body-‐sensor/
Copyrig
ht A.Förster, A
.Puia4
2014

BSN Applications
14
INTERNET T1
T1 T1
T1 T1
hbp://si.epfl.ch/page-‐34870-‐en.html
Patel at al, 2012
hbp://technabob.com/blog/2013/09/04/priovr-‐full-‐body-‐sensor/
Copyrig
ht A.Förster, A
.Puia4
2014

BSN Applications
15
INTERNET T1
T1 T1
T1 T1
hbp://si.epfl.ch/page-‐34870-‐en.html
Patel at al, 2012
hbp://technabob.com/blog/2013/09/04/priovr-‐full-‐body-‐sensor/
Copyrig
ht A.Förster, A
.Puia4
2014
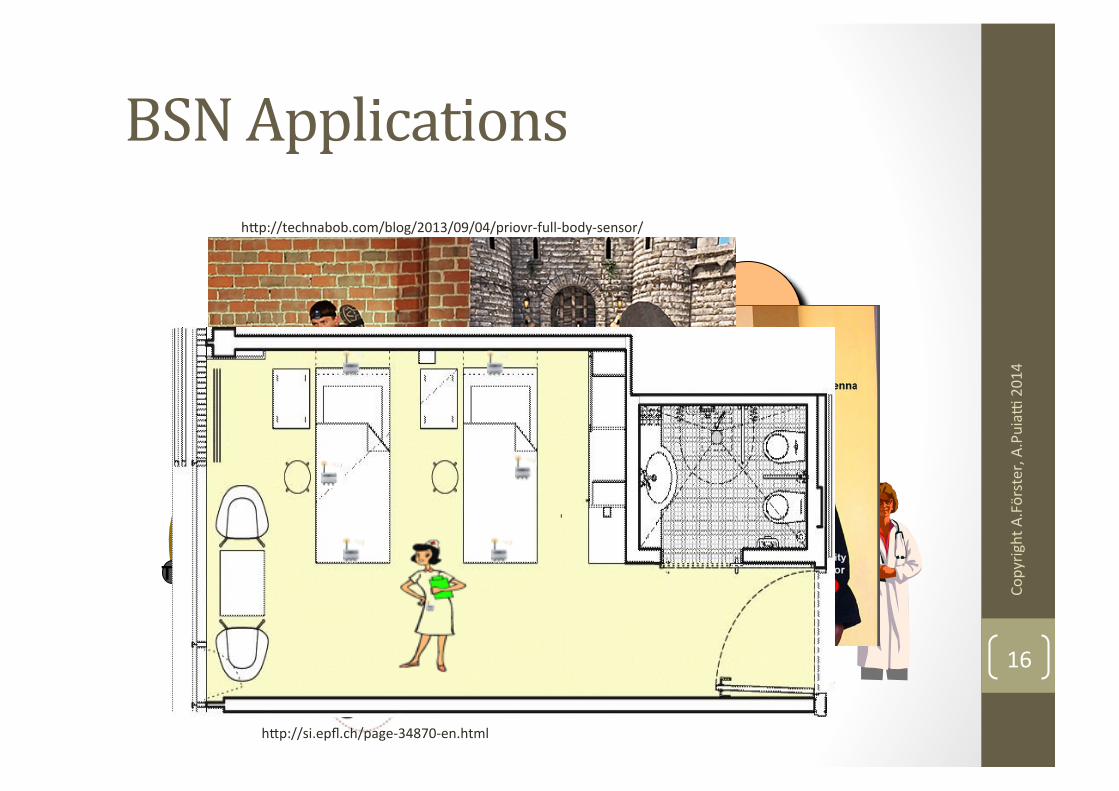
BSN Applications
16
INTERNET T1
T1 T1
T1 T1
hbp://si.epfl.ch/page-‐34870-‐en.html
Patel at al, 2012
hbp://technabob.com/blog/2013/09/04/priovr-‐full-‐body-‐sensor/
Copyrig
ht A.Förster, A
.Puia4
2014

BSN: In Summary • High heterogeneous data
• High sampling/sending frequency
• Small number of nodes (even only one)
• Many applicaNons: not only e-‐health
Copyrig
ht A.Förster, A
.Puia4
2014
17

Introduction to Machine Learning Dr. Anna Förster, Alessandro Puia4 BSN Tutorial, June 17th 2014 Zürich, Switzerland
Copyrig
ht A.Förster, A
.Puia4
2014
18

Major goal Produce models (rules,
paberns) from data
ProperGes
Robust and flexible Global models from local data No environmental model
Machine Learning
…
Neural Networks
Reinforcement Learning
GeneNc Algorithms
Decision Trees
?
?
? ?
?
Swarm Intelligence
Copyrig
ht A.Förster, A
.Puia4
2014
Clustering
19

Classes of Machine Learning Algorithms
Copyrig
ht A.Förster, A
.Puia4
2014
Pre-‐labeled Training Dataset
TesNng Dataset (Usage)
Supervised learning
Model
Unsupervised learning Model
Non-‐labeled data item
Reinforcement learning
Agent /Model
Environment
20
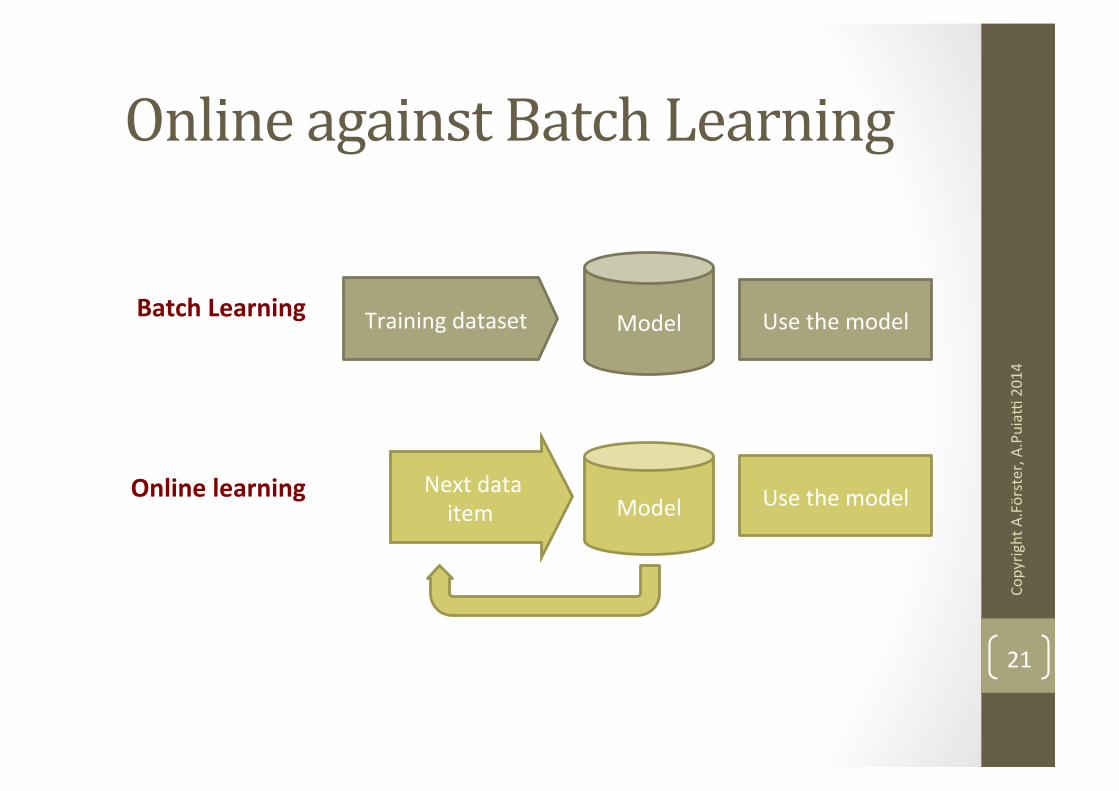
Online against Batch Learning
Training dataset Use the model Batch Learning Model
Use the model Online learning Model
Next data item
Copyrig
ht A.Förster, A
.Puia4
2014
21

Introduction to Decision Trees Dr. Anna Förster, Alessandro Puia4 BSN Tutorial, June 17th 2014 Zürich, Switzerland
Copyrig
ht A.Förster, A
.Puia4
2014
22

Decision Based Learning • Classifying objects into groups based on abribute pairs
form = round color = orange taste = sour
form = round color = red, orange, green taste = sweet
apple orange
? 23
Copyrig
ht A.Förster, A
.Puia4
2014

Decision Based Learning • Classifying objects into groups based on abribute pairs
form = round color = orange taste = sour
form = round color = red, orange, green taste = sweet
apple orange
form = ? color = ? taste = ?
24
Copyrig
ht A.Förster, A
.Puia4
2014

Decision Based Learning • Classifying objects into groups based on abribute pairs
form = round color = orange taste = sour
form = round color = red, orange, green taste = sweet
apple orange
form = round color = ? taste = ?
??? 25
Copyrig
ht A.Förster, A
.Puia4
2014

Decision Based Learning • Classifying objects into groups based on abribute pairs
form = round color = orange taste = sour
apple orange
form = round color = orange taste = ?
???
form = round color = red, orange, green taste = sweet
26
Copyrig
ht A.Förster, A
.Puia4
2014

Decision Based Learning • Classifying objects into groups based on abribute pairs
form = round color = orange taste = sour
apple orange
form = round color = orange taste = sweet
apple!
form = round color = red, orange, green taste = sweet
27
Copyrig
ht A.Förster, A
.Puia4
2014

Decision Based Learning • Classifying objects into groups based on abribute pairs
form = round color = orange taste = sour
apple orange
form = round color = orange taste = sweet
apple!
form = round color = red, orange, green taste = sweet
3 quesNons! 28
Copyrig
ht A.Förster, A
.Puia4
2014

Decision Based Learning • Classifying objects into groups based on abribute pairs
form = round color = orange taste = sour
apple orange
taste = sweet color = ? form = ?
apple!
form = round color = red, orange, green taste = sweet
29
Copyrig
ht A.Förster, A
.Puia4
2014
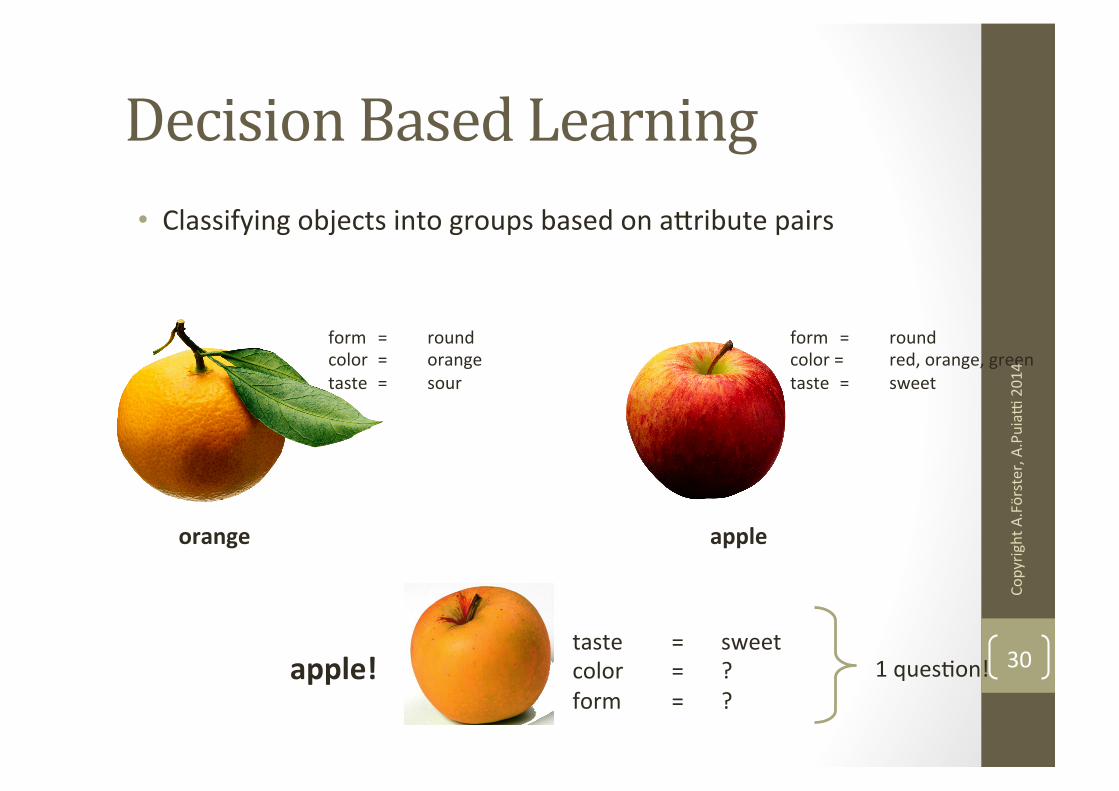
Decision Based Learning • Classifying objects into groups based on abribute pairs
form = round color = orange taste = sour
apple orange
taste = sweet color = ? form = ?
apple!
form = round color = red, orange, green taste = sweet
1 quesNon! 30
Copyrig
ht A.Förster, A
.Puia4
2014

Decision Tree Learning • Supervised learning approach (use pre-‐labeled dataset) • Maps observaNons (features, abributes) into classes (decisions) • Very powerful and efficient technique to analyze large and fuzzy datasets
Is male?
Is age < 9.5?
Family on board > 2.5?
survived
survived died
died
0.73 : 36%
0.89 : 2% 0.05 : 2%
0.17 : 61%
Probability of survival on the Titanic : %observa@ons
31
Copyrig
ht A.Förster, A
.Puia4
2014

Decision Based Learning • Classifying objects into groups based on abribute pairs
• Which quesNons to ask first, which next? • Compute informaNon gain of abributes
• How well does an abribute separates the tesNng set?
32
Copyrig
ht A.Förster, A
.Puia4
2014

C4.5 algorithm Goal: construct a decision tree with aVribute at each node 1. Start at root 2. Find the abribute with maximal informaNon gain, which is
not an ancestor of the node 3. Put a child node for each value of this abribute 4. Add all examples from the training set to the
corresponding child 5. If all examples of a child belong to the same class, put the
class there and go back up in the tree 6. If not, conNnue with step 2 while abributes are let 7. When no more abributes are let, put the classificaNon of
the majority of the examples to this node 33
Copyrig
ht A.Förster, A
.Puia4
2014

C4.5 algorithm: Example
example form color class
1 round red apple
2 round orange apple
3 round orange orange
4 round green apple
5 round yellow apple
6 round orange orange
¡ InformaNon gain of FORM: zero ¡ InformaNon gain of COLOR: more
34
Copyrig
ht A.Förster, A
.Puia4
2014

C4.5 algorithm: Example
example form color class
1 round red apple
2 round orange apple
3 round orange orange
4 round green apple
5 round yellow apple
6 round orange orange
¡ InformaNon gain of FORM: zero ¡ InformaNon gain of COLOR: more
color
red green orange yellow
35
Copyrig
ht A.Förster, A
.Puia4
2014
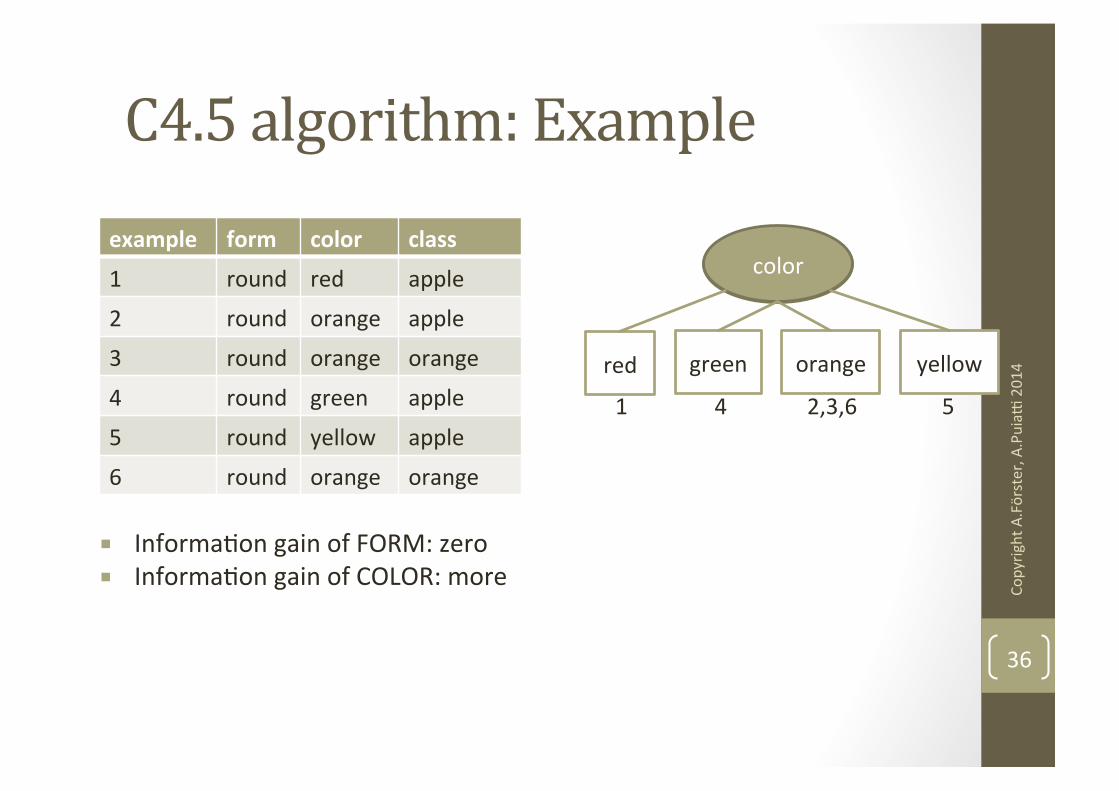
C4.5 algorithm: Example
example form color class
1 round red apple
2 round orange apple
3 round orange orange
4 round green apple
5 round yellow apple
6 round orange orange
¡ InformaNon gain of FORM: zero ¡ InformaNon gain of COLOR: more
color
red green orange yellow
1 4 2,3,6 5
36
Copyrig
ht A.Förster, A
.Puia4
2014

C4.5 algorithm: Example
example form color class
1 round red apple
2 round orange apple
3 round orange orange
4 round green apple
5 round yellow apple
6 round orange orange
¡ InformaNon gain of FORM: zero ¡ InformaNon gain of COLOR: more
color
red green orange yellow
1 4 2,3,6 5
apple apple apple ?
37
Copyrig
ht A.Förster, A
.Puia4
2014

C4.5 algorithm: Example
example form color class
1 round red apple
2 round orange apple
3 round orange orange
4 round green apple
5 round yellow apple
6 round orange orange
¡ InformaNon gain of FORM: zero ¡ InformaNon gain of COLOR: more
¡ Only let abribute: FORM
color
red green orange yellow
1 4 2,3,6 5
apple apple apple
form
round
2,3,6
orange
38
Copyrig
ht A.Förster, A
.Puia4
2014

C4.5 algorithm: Problems
example form color class
1 round red apple
2 round orange apple
3 round orange orange
4 round green apple
5 round yellow apple
6 round orange orange
¡ All orange apples will be classified as oranges ¡ Leaf node FORM unnecessary
¡ DECISION TREE DEPENDS ON TRAINING SET
color
red green orange yellow
1 4 2,3,6 5
apple apple apple
form
round
2,3,6
orange
39
Copyrig
ht A.Förster, A
.Puia4
2014

Information Gain • Input are T tuples (classified samples with K features):
• The informaNon gain of feature a is defined in terms of the entropy as follows:
x,Y( ) = x1, x2, x3,..., xk,Y( )xa ∈ vals a( ),Y = class
IG T,a( ) = H T( )−x ∈ T xa = v{ }
T⋅H x ∈ T xa = v{ }( )∑
H (T ) = − pi log2i=1
Y
∑ (pi )Entropy of the full dataset Entropies of the sub-‐
datasets “MALE” and “FEMALE”
40
Copyrig
ht A.Förster, A
.Puia4
2014

Properties of Decision Based Learning
• Good for fast classificaNon of fuzzy, overlapping groups • Tree generated only once • Well-‐suited for staNc, but error-‐prone environments
• Needs a good large training set • Moderate processing and large memory requirements (to hold the training set)
41
Copyrig
ht A.Förster, A
.Puia4
2014

Incremental Decision Trees • Hoeffding tree algorithm • Hoeffding bound guarantees that if Xa is indeed the best feature with some small probability
Copyrig
ht A.Förster, A
.Puia4
2014
Pre
DT
+/-‐
WSN
IDT
Disc
Classify the new sample
Save the sample at the leaf
Compute IG for each feature X
All samples belong to same
class?
IG(Xa )− IG(Xb )< ε
Split the node according to feature Xa
true
false
IG(Xa )− IG(Xb )< ε
[Domingos:2000] P. Domingos and G. Hulten: Mining High-‐speed Data Streams, in Proceedings of the 6th ACM Interna@onal Conference on Knowledge Discovery and Data Mining (SIGKDD)
42

Neural Networks – Introduction and Applications Dr. Anna Förster, Alessandro Puia4 BSN Tutorial, June 17th 2014 Zürich, Switzerland
Copyrig
ht A.Förster, A
.Puia4
2014
43

Background • Simplified (extremely!) model of the human brain and its neurons
44
Copyrig
ht A.Förster, A
.Puia4
2014

Fundamentals
45
Copyrig
ht A.Förster, A
.Puia4
2014

Perceptron • Simplest form of neural network • Computes linear funcNons only • AcNvaNon funcNon is simple threshold
• Where do the weights come from?
46
Copyrig
ht A.Förster, A
.Puia4
2014

Perceptron Learning 1. Present the network with an input 2. Calculate its current output 3. Compare with real output (supervised learning!) 4. Correct the weights to minimize the error between the
computer output and the desired one
wnew = wold – α*(desired-‐output)*input, α – learning constant
47
Copyrig
ht A.Förster, A
.Puia4
2014

Multi-‐Layer Networks
48
• Generalizes all possible funcNons
• Uses the logisNc funcNon (sigmoid) for acNvaNon
• Back propagaNon is the most oten used weight learning method
Copyrig
ht A.Förster, A
.Puia4
2014

Applications • Very well suited for
• Pabern recogniNon, image recogniNon • Noise cancelling • PredicNon (based on extrapolated data)
• ProperNes: • Supervised learning, requires a large training set • Memory and processing intensive training • TesNng is also processing intensive
• Examples from BSN: • Paberns recogniNon based on mulN-‐modal data
• Cardio-‐vascular problems, heart abacks
• Falls • AcNviNes
49
Zhanpeng Jin, Yuwen Sun, and Allen C. Cheng: PredicNng Cardiovascular Disease from Real-‐Time Electrocardiographic Monitoring: An AdapNve Machine Learning Approach on a Cell Phone, IEEE EMBS 2009.
Copyrig
ht A.Förster, A
.Puia4
2014

Introduction to Reinforcement Learning Dr. Anna Förster, Alessandro Puia4 BSN Tutorial, June 17th 2014 Zürich, Switzerland
Copyrig
ht A.Förster, A
.Puia4
2014
50

Reinforcement Learning
• A learning agent • A pool of possible acNons • Goodness of acNons • A reward funcNon
• Select one acNon • Execute the acNon • Observe the reward • Correct the goodness of the executed acNon 51
Copyrig
ht A.Förster, A
.Puia4
2014

Introduction to Q-‐Learning
52
Copyrig
ht A.Förster, A
.Puia4
2014

Introduction to Q-‐Learning ¤ Learning agent
53
Copyrig
ht A.Förster, A
.Puia4
2014

D
B
A
E
F
C
START
Introduction to Q-‐Learning ¤ Learning agent ¤ Internal current state st
54
Copyrig
ht A.Förster, A
.Puia4
2014

D
B
A
E
F
C
START
Introduction to Q-‐Learning ¤ Learning agent ¤ Internal current state st ¤ Pool of possible acNons
At(st)
55
Copyrig
ht A.Förster, A
.Puia4
2014

Introduction to Q-‐Learning
D
B
A
E
F
C
START
¤ Learning agent ¤ Internal current state st ¤ Pool of possible acNons
At(st) ¤ Associated Q-‐value to each
acNon in each state
56
Copyrig
ht A.Förster, A
.Puia4
2014
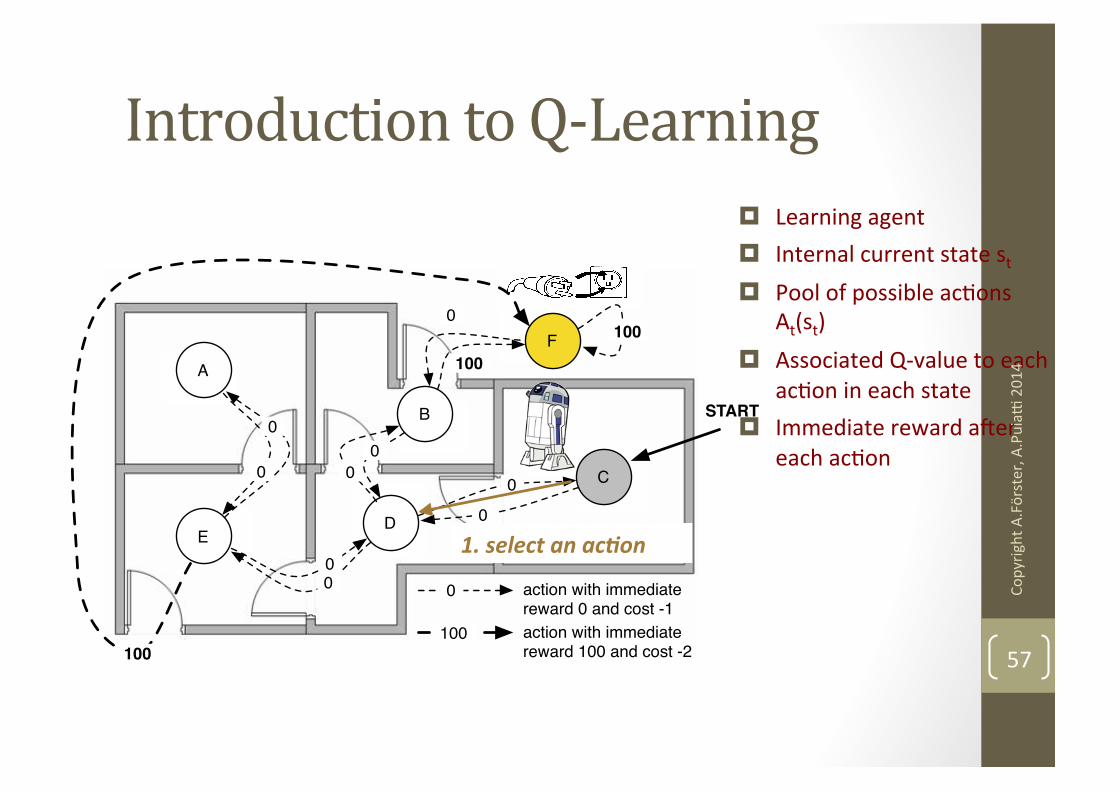
D
B
A
E
F
C
START
0
0
0
0
100
0
0
0
100
0
0
action with immediate
reward 0 and cost -1
action with immediate
reward 100 and cost -2
0
100
100
Introduction to Q-‐Learning ¤ Learning agent ¤ Internal current state st ¤ Pool of possible acNons
At(st) ¤ Associated Q-‐value to each
acNon in each state ¤ Immediate reward ater
each acNon
1. select an ac+on
57
Copyrig
ht A.Förster, A
.Puia4
2014
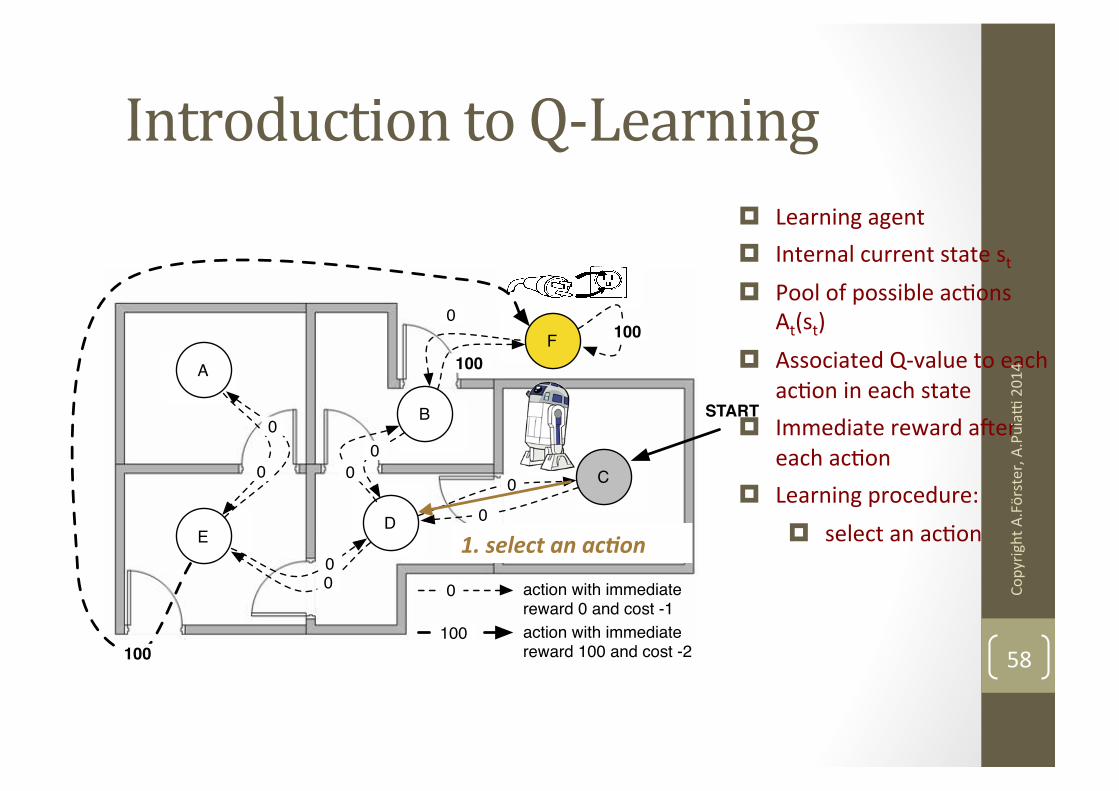
D
B
A
E
F
C
START
0
0
0
0
100
0
0
0
100
0
0
action with immediate
reward 0 and cost -1
action with immediate
reward 100 and cost -2
0
100
100
Introduction to Q-‐Learning ¤ Learning agent ¤ Internal current state st ¤ Pool of possible acNons
At(st) ¤ Associated Q-‐value to each
acNon in each state ¤ Immediate reward ater
each acNon ¤ Learning procedure:
¤ select an acNon 1. select an ac+on
58
Copyrig
ht A.Förster, A
.Puia4
2014

D
B
A
E
F
C
START
00
00
100
0
0
0
100
0
0
action with immediate reward 0 and cost -1action with immediate reward 100 and cost -2
0
100100
Introduction to Q-‐Learning ¤ Learning agent ¤ Internal current state st ¤ Pool of possible acNons
At(st) ¤ Associated Q-‐value to each
acNon in each state ¤ Immediate reward ater
each acNon ¤ Learning procedure:
¤ select an acNon ¤ execute the acNon
1. select an ac+on
2. execute the ac+on
59
Copyrig
ht A.Förster, A
.Puia4
2014

D
B
A
E
F
C
START
00
00
100
0
0
0
100
0
0
action with immediate reward 0 and cost -1action with immediate reward 100 and cost -2
0
100100
Introduction to Q-‐Learning ¤ Learning agent ¤ Internal current state st ¤ Pool of possible acNons
At(st) ¤ Associated Q-‐value to each
acNon in each state ¤ Immediate reward ater
each acNon ¤ Learning procedure:
¤ select an acNon ¤ execute the acNon ¤ observe reward
1. select an ac+on 2. execute the ac+on
3. receive reward 60
Copyrig
ht A.Förster, A
.Puia4
2014

D
B
A
E
F
C
START
00
00
100
0
0
0
100
0
0
action with immediate reward 0 and cost -1action with immediate reward 100 and cost -2
0
100100
Introduction to Q-‐Learning ¤ Learning agent ¤ Internal current state st ¤ Pool of possible acNons
At(st) ¤ Associated Q-‐value to each
acNon in each state ¤ Immediate reward ater
each acNon ¤ Learning procedure:
¤ select an acNon ¤ execute the acNon ¤ observe reward ¤ update state and Q-‐
values
1. select an ac+on 2. execute the ac+on
3. receive reward
4. st = D, Q(aD, C)
61
Copyrig
ht A.Förster, A
.Puia4
2014

D
B
A
E
F
C
START
00
00
100
0
0
0
100
0
0
action with immediate reward 0 and cost -1action with immediate reward 100 and cost -2
0
100100
Introduction to Q-‐Learning ¤ Learning agent ¤ Internal current state st ¤ Pool of possible acNons
At(st) ¤ Associated Q-‐value to each
acNon in each state ¤ Immediate reward ater
each acNon ¤ Learning procedure:
¤ select an acNon ¤ execute the acNon ¤ observe reward ¤ update state and Q-‐
values
1. select an ac+on 2. execute the ac+on
3. receive reward
4. st = D, Q(aD, C)
62
Copyrig
ht A.Förster, A
.Puia4
2014
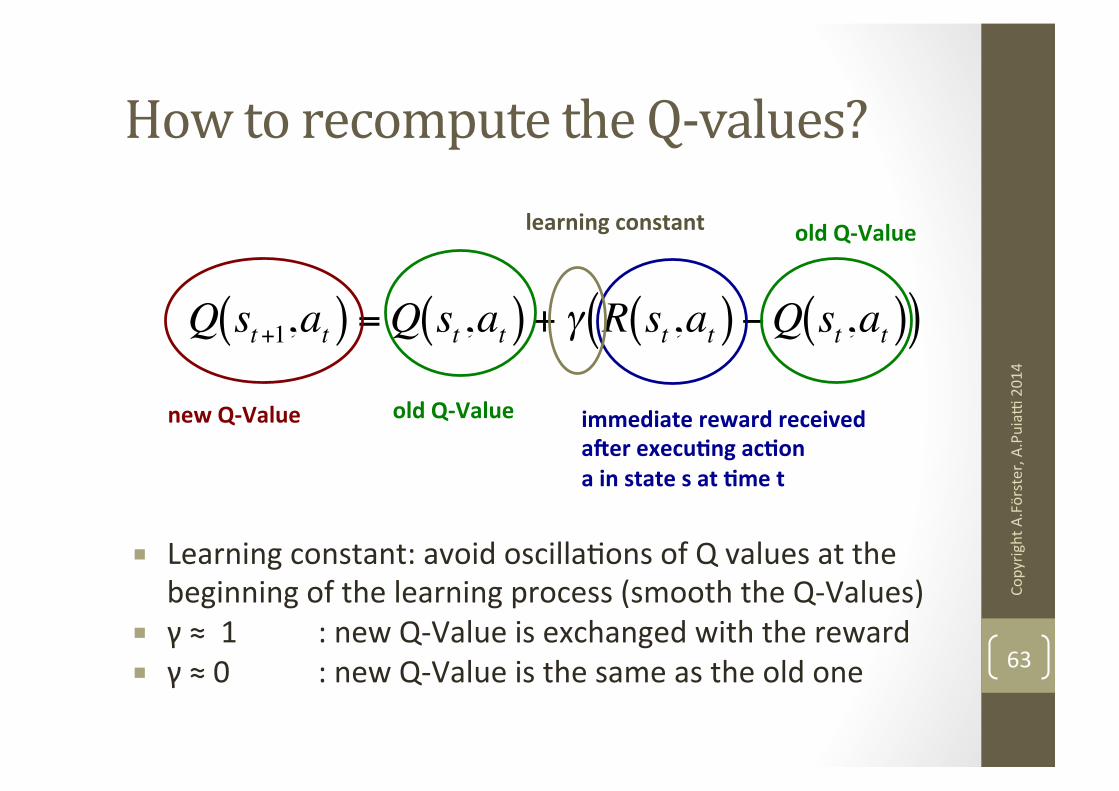
How to recompute the Q-‐values?
€
Q st+1,at( ) =Q st ,at( ) + γ R st ,at( ) −Q st ,at( )( )new Q-‐Value old Q-‐Value immediate reward received
a`er execuGng acGon a in state s at Gme t
old Q-‐Value learning constant
¡ Learning constant: avoid oscillaNons of Q values at the beginning of the learning process (smooth the Q-‐Values)
¡ γ ≈ 1 : new Q-‐Value is exchanged with the reward ¡ γ ≈ 0 : new Q-‐Value is the same as the old one 63
Copyrig
ht A.Förster, A
.Puia4
2014

How to deTine the reward function? • Two main types:
• Pre-‐defined • Computed ater each acNon
• Oten used : • zero awards for acNons leading directly to the goal • negaNve for all others (e.g. -‐1)
• Also used: • Manhaban distance to the goal • Geographic distance to the goal • Currently best available Q value at the state (!!)
64
Copyrig
ht A.Förster, A
.Puia4
2014

How to decide which action to take? • ExploraGon strategy (acGon selecGon policy) • Cannot be random, need to use accumulated knowledge • Cannot be greedy, need to explore all possibiliNes • Oten used: ε-‐greedy
• select a random acNon with probability ε • select the best available one (best Q-‐value) with probability (1-‐ε)
65
Copyrig
ht A.Förster, A
.Puia4
2014

Properties of Reinforcement Learning
• Simple, flexible model • Adapts to changing environments, re-‐learns quickly • Copes successfully with mobile or unreliable environments • Simple to design and implement • Small to moderate processing and memory needs • Can be implemented fully distributed
66
Copyrig
ht A.Förster, A
.Puia4
2014

Reinforcement Learning for BSNs?
• All distributed problems: • RouNng protocols • Clustering protocols • Neighborhood management protocols • Medium Access protocols
• Further • Parameter opNmizaNon and learning • ApplicaNon-‐level cooperaNon among nodes
67
Copyrig
ht A.Förster, A
.Puia4
2014

Applications of Reinforcement Learning Dr. Anna Förster, Alessandro Puia4 BSN Tutorial, June 17th 2014 Zürich, Switzerland
Copyrig
ht A.Förster, A
.Puia4
2014
68

Q-‐Learning in WSN Routing • Agents: the packets • States: the nodes • AcGons: next hops • q-‐values: esNmaNons of rouNng costs • IniGal q-‐values: some first guess about rouNng costs • Reward funcNon: the best cost esNmaNon of the next hop
• ExploraGon strategy: simple, e.g. ε-‐greedy
69
Copyrig
ht A.Förster, A
.Puia4
2014

Unicast routing with RL
Sending a packet from A to D Init all q values to 10 (guess)
A
B
C
D
Rewards:""r = qbest, if not sink""r = 0, if sink"
Send rewards to all neighbors (broadcast)"
70
Copyrig
ht A.Förster, A
.Puia4
2014

Sending a packet from A to D Init all q values to 10 (guess)
A
B
C
D
QB = 10 (initial)"
QC = 10 (initial)"
Action selection policy"(Exploration strategy)""ε-greedy"
Balance exploration/exploitation"
Unicast routing with RL
state Q
B 10
C 10
state Q
A 10
C 10
D 10
state Q
B 10
A 10
D 10
71
Copyrig
ht A.Förster, A
.Puia4
2014

A
B
C
D
QB = 10 (initial)"
Sending a packet from A to D Select next hop (state) B
Unicast routing with RL
state Q
B 10
C 10
72
Copyrig
ht A.Förster, A
.Puia4
2014

A
B
C
D
QA = 10 (initial)"
Sending a packet from A to D B has 3 possible next hops, with qbest = 10
QC = 10 (initial)"
QD = 10 (initial)"
Unicast routing with RL state Q
A 10
C 10
D 10
73
Copyrig
ht A.Förster, A
.Puia4
2014
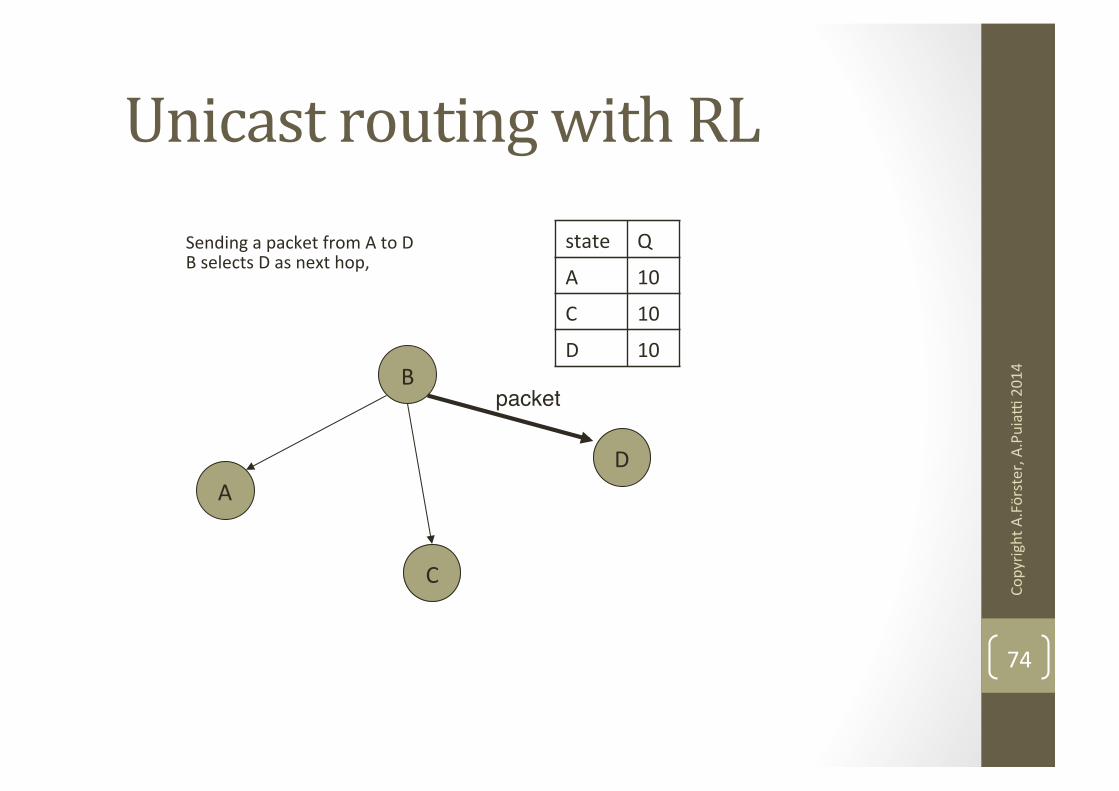
A
B
C
D
Sending a packet from A to D B selects D as next hop,
packet"
Unicast routing with RL state Q
A 10
C 10
D 10
74
Copyrig
ht A.Förster, A
.Puia4
2014

A
B
C
D
Sending a packet from A to D B selects D as next hop,
reward = qbest = 10
packet"reward"
reward"
Unicast routing with RL state Q
A 10
C 10
D 10
75
Copyrig
ht A.Förster, A
.Puia4
2014

A
B
C
D
Sending a packet from A to D B selects D as next hop,
reward = qbest = 10
packet"reward"
QB = cB + rB = 11"QC = 10"
reward"
QA = 10"QB = cB + rB = 11"QD = 10"
Unicast routing with RL state Q
A 10
C 10
D 10
76
Copyrig
ht A.Förster, A
.Puia4
2014

A
B
C
D
Sending a packet from A to D B selects D as next hop,
reward = qbest = 10
packet"reward"
QB = cB + rB = 11"
reward"
QB = cB + rB = 11"
Unicast routing with RL state Q
A 10
C 10
D 10
state Q
B 11
C 10
state Q
B 11
A 10
D 10
77
Copyrig
ht A.Förster, A
.Puia4
2014
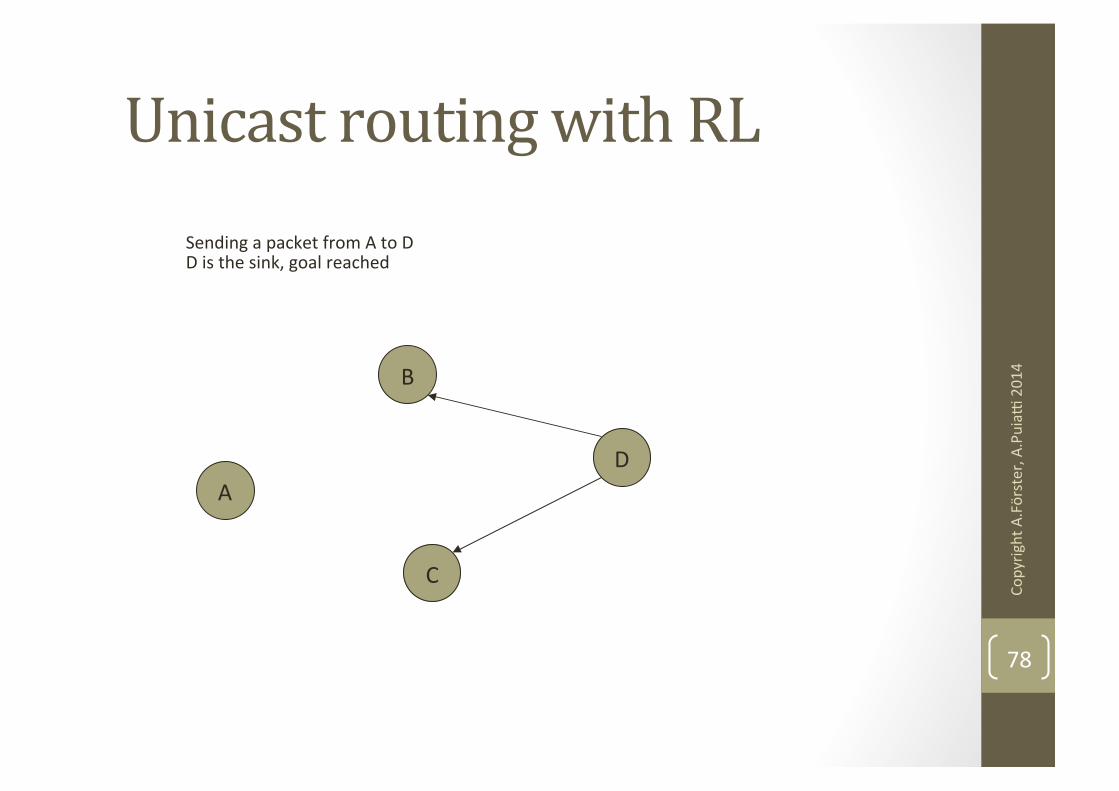
A
B
C
D
Sending a packet from A to D D is the sink, goal reached
Unicast routing with RL
78
Copyrig
ht A.Förster, A
.Puia4
2014

A
B
C
D
Sending a packet from A to D D is the sink, goal reached
reward = 0 (real costs)
reward"
reward"
Unicast routing with RL
79
Copyrig
ht A.Förster, A
.Puia4
2014

A
B
C
D
Sending a packet from A to D D is the sink, goal reached
reward = 0 (real costs)
reward"
QD = cB + rB = 1"
QD = cB + rB = 1"
reward"
Unicast routing with RL state Q
A 10
C 10
D 1
state Q
B 11
A 10
D 1
80
Copyrig
ht A.Förster, A
.Puia4
2014

A
B
C
D
Sending a packet from A to D State of the network ater first packet
Unicast routing with RL
state Q
B 11
C 10
state Q
A 10
C 10
D 1
state Q
B 11
A 10
D 1
81
Copyrig
ht A.Förster, A
.Puia4
2014

A
B
C
D
Sending a packet from A to D State of the network ater many packets
Unicast routing with RL
state Q
B 2
C 2
state Q
A 3
C 2
D 1
state Q
B 2
A 3
D 1
How to go faster?!Make better guesses!!
82
Copyrig
ht A.Förster, A
.Puia4
2014

Unicast routing with RL Bene3its • Simple and powerful • Reacts immediately to changes:
• New rewards propagate quickly • New routes are learnt • Only necessary changes in the immediate neighborhood of failure
• Route iniNalizaNon is sink/source driven • Low memory and processing overhead
83
Copyrig
ht A.Förster, A
.Puia4
2014

Unicast Routing with RL • Hops: too trivial to deserve a publicaNon… • Maximum aggregaNon rate: P. Beyens, M. Peeters, K. Steenhaut, and A. Nowe. RouGng with compression in wireless sensor networks: A Q-‐learning approach. In Proceedings of the 5th European Workshop on AdapNve Agents and MulN-‐Agent Systems (AAMAS), page 12pp., Paris, France, 2005.
• Combined with geographic rouNng: R. Arroyo-‐Valles, R. Alaiz-‐Rodrigues, A. Guerrero-‐Curieses, and J. Cid-‐ Suiero. Q-‐probabilisGc rouGng in wireless sensor networks. In Proceedings of the 3rd InternaNonal Conference on Intelligent Sensors, Sensor Networks and InformaNon Processing (ISSNIP), pages 1–6, Melbourne, Australia, 2007.
• Minimum delay: J. A. Boyan and M. L. Libman. Packet rouGng in dynamically changing networks: A reinforcement learning approach. Advances in Neural InformaNon Processing Systems, 6:671–678, 1994.
84
Copyrig
ht A.Förster, A
.Puia4
2014

• Challenges: • AcNons need to reflect not the next hop, but HOPS
• Reward funcNon is distributed among several neighbors
• Set of acNons very large – needs a lot of exploraNon!
• SoluNon steps: • Separate acNons into sub-‐acNons • Smart iniNal Q values
Multicast Routing with RL
A
B
C
D
A. Förster and A. L. Murphy. FROMS: A Failure Tolerant and Mobility Enabled MulGcast RouGng Paradigm with Reinforcement Learning. Elsevier Ad Hoc Networks, 2011
85
Copyrig
ht A.Förster, A
.Puia4
2014

FROMS: Multicast routing with Q-‐Learning
§ Localized view ater sink announcement
§ The minimum esNmated is not the opNmal: § best esNmate for (A,B): 3 + 3 -‐ 1 = 5 hops § opNmal for (A,B): 4 hops
A -‐ 5 hops B -‐ 3 hops
A -‐ 3 hops B -‐ 5 hops
2 1 3
A B
A -‐ 4 hops B -‐ 4 hops
st+1, Qt+1 environment agent
rt(st,at)
at
st, At, Qt
86
Copyrig
ht A.Förster, A
.Puia4
2014

FROMS: Multicast routing with Q-‐Learning
agent
st+1, Qt+1 environment agent
rt(st,at)
at
st, At, Qt
§ Agent: each node in the network
87
Copyrig
ht A.Förster, A
.Puia4
2014
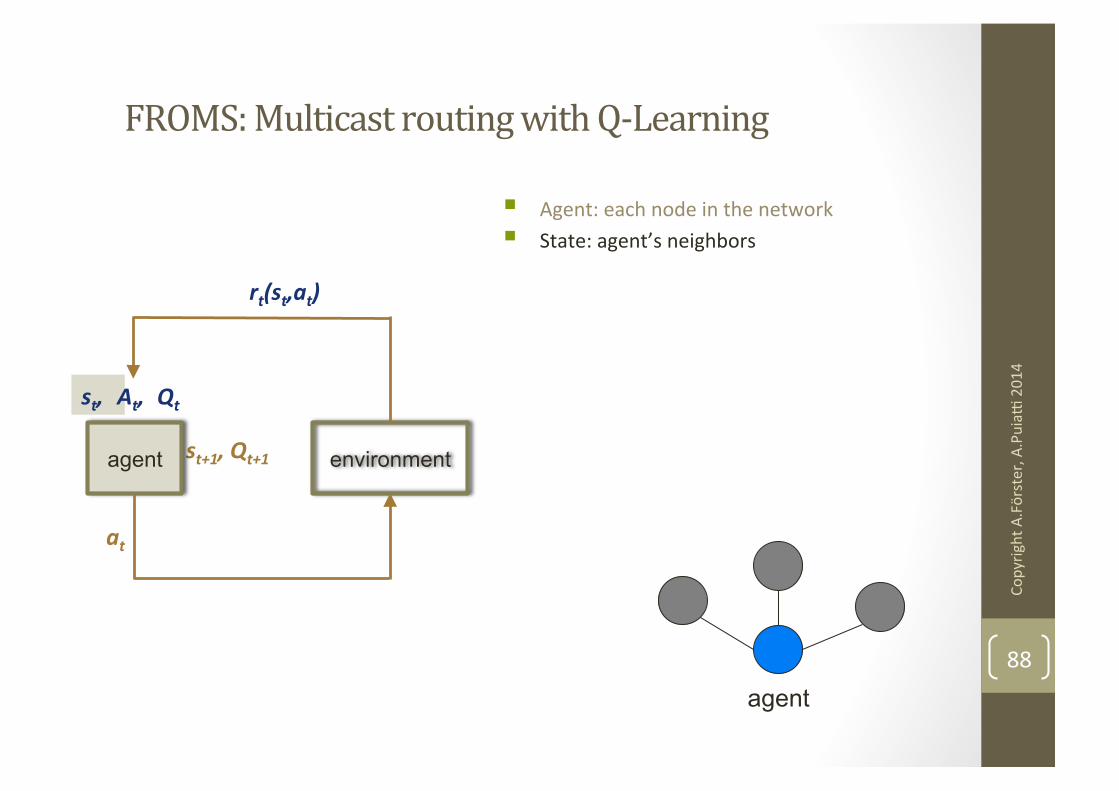
FROMS: Multicast routing with Q-‐Learning
agent
st+1, Qt+1 environment agent
rt(st,at)
at
st,
At, Qt
§ Agent: each node in the network § State: agent’s neighbors
88
Copyrig
ht A.Förster, A
.Puia4
2014

FROMS: Multicast routing with Q-‐Learning
2 1 3
agent for sink A
for sink B
ai = {n1 for A}, {n3 for B} !Actions:!
aj = {n2 for A,B} !
for sinks A, B
sub-actions
st+1, Qt+1 environment agent
rt(st,at)
at
st, At, Qt
§ Agent: each node in the network § State: agent’s neighbors § Possible acNons: combinaNon of neighbors to reach
all sinks
89
Copyrig
ht A.Förster, A
.Puia4
2014
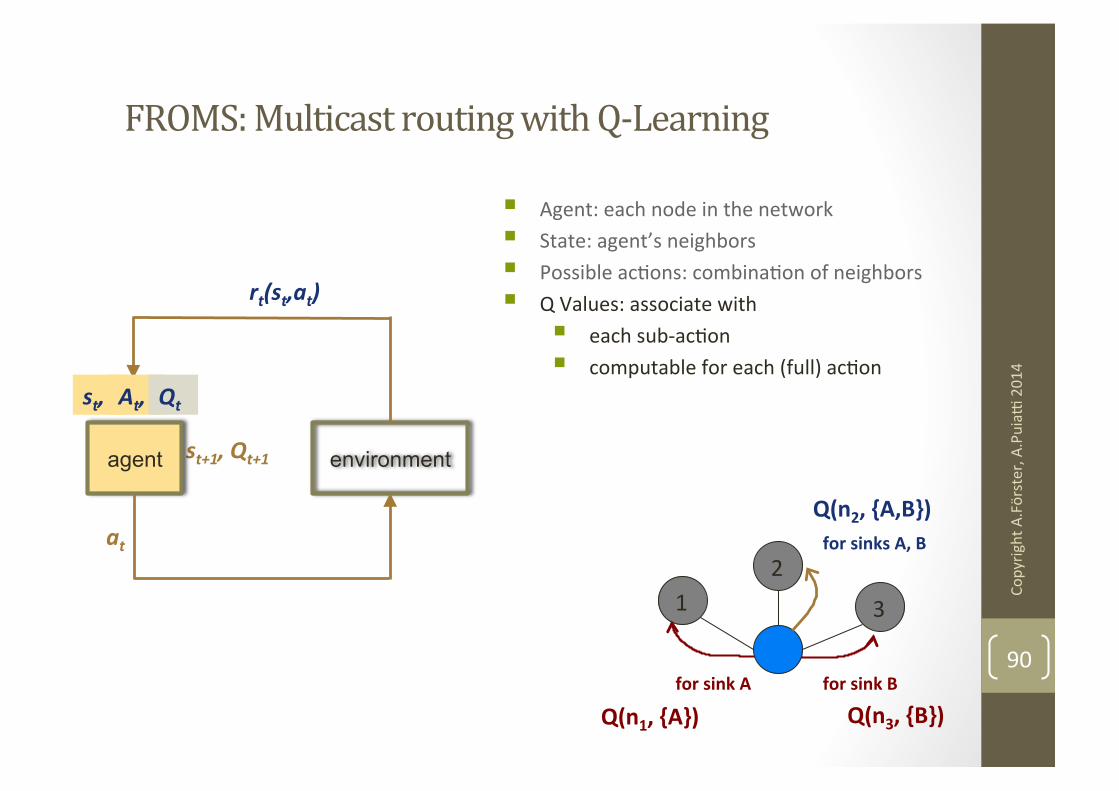
FROMS: Multicast routing with Q-‐Learning
2 1 3
for sink A
for sink B
for sinks A, B
Q(n2, {A,B})
Q(n3, {B}) Q(n1, {A})
st+1, Qt+1 environment agent
rt(st,at)
at
st, At, Qt
§ Agent: each node in the network § State: agent’s neighbors § Possible acNons: combinaNon of neighbors § Q Values: associate with
§ each sub-‐acNon § computable for each (full) acNon
90
Copyrig
ht A.Förster, A
.Puia4
2014

FROMS: Multicast routing with Q-‐Learning
2 1 3
for sinks A (4 hops) B (4 hops)
Q(n2, {A,B}) = 4+4-‐1
st+1, Qt+1 environment agent
rt(st,at)
at
st, At, Qt
§ Agent: each node in the network § State: agent’s neighbors § Possible acNons: combinaNon of neighbors § Q Values: associate with sub-‐acNons,
compute for acNons § IniNalize Q Values with number of esNmated hops
91
Copyrig
ht A.Förster, A
.Puia4
2014

FROMS: Multicast routing with Q-‐Learning
2 1 3
st+1, Qt+1 environment agent
rt(st,at)
at
st,
At, Qt
§ Agent: each node in the network § State: agent’s neighbors § Possible acNons: combinaNon of neighbors § Q Values: associate with sub-‐acNons,
compute for acNons § IniNalize Q Values with number of esNmated hops § Environment: all other nodes
92
Copyrig
ht A.Förster, A
.Puia4
2014

FROMS: Multicast routing with Q-‐Learning
2 1 3
for sinks A,B
st+1, Qt+1 environment agent
rt(st,at)
at
st,
At, Qt
§ Agent: each node in the network § State: agent’s neighbors § Possible acNons: combinaNon of § Q Values: associate with sub-‐acNons,
compute for acNons § IniNalize Q Values with number of esNmated hops § Environment: all other nodes
93
Copyrig
ht A.Förster, A
.Puia4
2014

FROMS: Multicast routing with Q-‐Learning
2 1 3
§ Agent: each node in the network § State: agent’s neighbors § Possible acNons: combinaNon of § Q Values: associate with sub-‐acNons,
compute for acNons § IniNalize Q Values with number of esNmated hops § Environment: all other nodes § Reward: the best available Q value + 1 hop
for sinks A,B
i
st+1, Qt+1 environment agent
rt(st,at)
at
st,
At, Qt
94
Copyrig
ht A.Förster, A
.Puia4
2014

environment agent
FROMS: Multicast routing with Q-‐Learning
2 1 3
§ Agent: each node in the network § State: agent’s neighbors § Possible acNons: combinaNon of § Q Values: associate with sub-‐acNons,
compute for acNons § IniNalize Q Values with number of esNmated hops § Environment: all other nodes § Reward: the best available Q value + 1 hop § Update at neighboring nodes (learn)
for sinks A,B
i
st+1, Qt+1
rt(st,at)
at
st,
At, Qt
exploraNon strategy
update rules
reward computaNon
95
Copyrig
ht A.Förster, A
.Puia4
2014

Parameters of FROMS • Possible cost funcNons:
• Any cost funcNon defined over the edges or nodes of the communicaNon graph
• Here: minimum hops to desGnaGons • Further: minimum delay to the sinks; minimum geographic progress; minimum transmission power; maximum remaining energy on the nodes; combinaNons; …
• ExploraNon strategy • Balance exploraNon against exploitaNon • Depend on the used cost funcNon
• Memory management • HeurisNcs for pruning the available acNons and sub-‐acNons
st+1, Qt+1 environment agent
rt(st,at)
at
st,
At, Qt
96
Copyrig
ht A.Förster, A
.Puia4
2014

Further Applications of RL to WSNs • Clustering for WSNs: Anna Förster and Amy L. Murphy, Clique: Role-‐free Clustering with Q-‐Learning for Wireless Sensor Networks, in Proceedings of the 29th InternaNonal Conference on Distributed CompuNng Systems (ICDCS) 2009, 9pp., Canada, June 2009
• MAC protocols: Z. Liu and I. Elahanany. RL-‐MAC: A reinforcement learning based MAC protocol for wireless sensor networks. InternaNonal Journal on Sensor Networks, 1(3/4):117–124, 2006.
• Best coverage: M.W.M. Seah, C.K. Tham, K. Srinivasan, and A. Xin. Achieving coverage through distributed reinforcement learning in wireless sensor networks. In Proceedings of the 3rd InternaNonal Conference on Intelligent Sensors, Sensor Networks and InformaNon Processing (ISSNIP), 2007. 97
Copyrig
ht A.Förster, A
.Puia4
2014

Discussion Dr. Anna Förster, Alessandro Puia4 BSN Tutorial, June 17th 2014 Zürich, Switzerland
Copyrig
ht A.Förster, A
.Puia4
2014
98

ML Techniques! Memory! ComputaGon! Tolerance to topology changes!
OpGmality! Init.costs! Add. costs!
Reinforcement Learning!
low" low" high" high" medium" low"
Swarm Intelligence!
medium" low" high" high" high" medium"
HeurisGcs! low" low" low/medium" medium" high" low"
Mobile Agents! low" low" medium" low" low" medium/high"
Neural networks!
medium" medium" low" high" high" low"
GeneGc algorithms!
high" medium" low" high" high" low"
Comparison of properties
required memory for on-‐node storage
required processing on the node or base
staNon
flexibility of the found soluNon to environmental
changes
opNmality of derived soluNon compared
to a centrally computed opNmal
soluNon
required communicaNon or processing costs before starNng normal work
addiNonal communicaNon or processing costs during runNme
99
Copyrig
ht A.Förster, A
.Puia4
2014

ML Techniques! Memory! ComputaGon! Tolerance to topology changes!
OpGmality! Init.costs! Add. costs!
Reinforcement Learning!
low" low" high" high" medium" low"
Swarm Intelligence!
medium" low" high" high" high" medium"
HeurisGcs! low" low" low/medium" medium" high" low"
Mobile Agents! low" low" medium" low" low" medium/high"
Neural networks!
medium" medium" low" high" high" low"
GeneGc algorithms!
high" medium" low" high" high" low"
Comparison of properties
100
Copyrig
ht A.Förster, A
.Puia4
2014

ML Techniques! Memory! ComputaGon! Tolerance to topology changes!
OpGmality! Init.costs! Add. costs!
Reinforcement Learning!
low" low" high" high" medium" low"
Swarm Intelligence!
medium" low" high" high" high" medium"
HeurisGcs! low" low" low/medium" medium" high" low"
Mobile Agents! low" low" medium" low" low" medium/high"
Neural networks!
medium" medium" low" high" high" low"
GeneGc algorithms!
high" medium" low" high" high" low"
Comparison of properties
101
Copyrig
ht A.Förster, A
.Puia4
2014

ML Techniques! Memory! ComputaGon! Tolerance to topology changes!
OpGmality! Init.costs! Add. costs!
Reinforcement Learning!
low" low" high" high" medium" low"
Swarm Intelligence!
medium" low" high" high" high" medium"
HeurisGcs! low" low" low/medium" medium" high" low"
Mobile Agents! low" low" medium" low" low" medium/high"
Neural networks!
medium" medium" low" high" high" low"
GeneGc algorithms!
high" medium" low" high" high" low"
Comparison of properties
102
Copyrig
ht A.Förster, A
.Puia4
2014
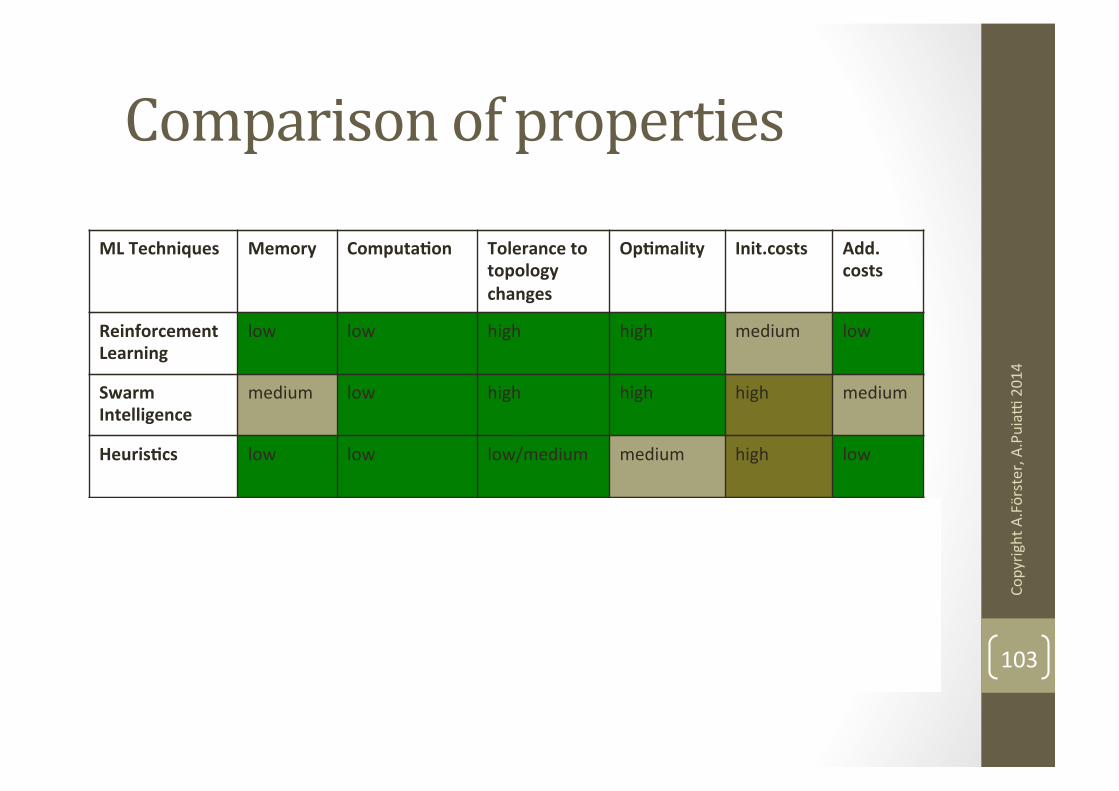
ML Techniques! Memory! ComputaGon! Tolerance to topology changes!
OpGmality! Init.costs! Add. costs!
Reinforcement Learning!
low" low" high" high" medium" low"
Swarm Intelligence!
medium" low" high" high" high" medium"
HeurisGcs! low" low" low/medium" medium" high" low"
Mobile Agents! low" low" medium" low" low" medium/high"
Neural networks!
medium" medium" low" high" high" low"
GeneGc algorithms!
high" medium" low" high" high" low"
Comparison of properties
103
Copyrig
ht A.Förster, A
.Puia4
2014

ML Techniques! Memory! ComputaGon! Tolerance to topology changes!
OpGmality! Init.costs! Add. costs!
Reinforcement Learning!
low" low" high" high" medium" low"
Swarm Intelligence!
medium" low" high" high" high" medium"
HeurisGcs! low" low" low/medium" medium" high" low"
Mobile Agents! low" low" medium" low" low" medium/high"
Neural networks!
medium" medium" low" high" high" low"
GeneGc algorithms!
high" medium" low" high" high" low"
Comparison of properties
104
Copyrig
ht A.Förster, A
.Puia4
2014

ML Techniques! Memory! ComputaGon! Tolerance to topology changes!
OpGmality! Init.costs! Add. costs!
Reinforcement Learning!
low" low" high" high" medium" low"
Swarm Intelligence!
medium" low" high" high" high" medium"
HeurisGcs! low" low" low/medium" medium" high" low"
Mobile Agents! low" low" medium" low" low" medium/high"
Neural networks!
medium" medium" low" high" high" low"
GeneGc algorithms!
high" medium" low" high" high" low"
Comparison of properties
105
Copyrig
ht A.Förster, A
.Puia4
2014

Comparison of properties
ML Techniques! Memory! ComputaGon! Tolerance to topology changes!
OpGmality! Init.costs! Add. costs!
Reinforcement Learning!
low" low" high" high" medium" low"
Swarm Intelligence!
medium" low" high" high" high" medium"
HeurisGcs! low" low" low/medium" medium" high" low"
Mobile Agents! low" low" medium" low" low" medium/high"
Neural networks!
medium" medium" low" high" high" low"
GeneGc algorithms!
high" medium" low" high" high" low"106
Copyrig
ht A.Förster, A
.Puia4
2014

Comparison of properties
ML Techniques! Memory! ComputaGon! Tolerance to topology changes!
OpGmality! Init.costs! Add. costs!
Reinforcement Learning!
low" low" high" high" medium" low"
Swarm Intelligence!
medium" low" high" high" high" medium"
HeurisGcs! low" low" low/medium" medium" high" low"
Mobile Agents! low" low" medium" low" low" medium/high"
Neural networks!
medium" medium" low" high" high" low"
GeneGc algorithms!
high" medium" low" high" high" Low "
Decision Trees medium medium low high high low
107
Copyrig
ht A.Förster, A
.Puia4
2014

Comparison of properties
ML Techniques! Memory! ComputaGon! Tolerance to topology changes!
OpGmality! Init.costs! Add. costs!
Reinforcement Learning!
low" low" high" high" medium" low"
Swarm Intelligence!
medium" low" high" high" high" medium"
HeurisGcs! low" low" low/medium" medium" high" low"
Mobile Agents! low" low" medium" low" low" medium/high"
Neural networks!
medium" medium" low" high" high" low"
GeneGc algorithms!
high" medium" low" high" high" low"
Decision Trees!
high" medium" low" high" high" low"
Distributed problems
Centralized and localized problems
Optimization
108
Copyrig
ht A.Förster, A
.Puia4
2014

Further readings M. Dorigo and T. Stuetzle. Ant Colony OpGmizaGon. MIT Press, 2004.
J. Kennedy and R.C. Eberhart. Swarm Intelligence. Morgan Kaufmann, 2001.
T.M. Mitchell. Machine Learning. McGraw-‐Hill, 1997.
A. Förster. Teaching Networks How to Learn SVH Verlag, 2009
S.J. Russell and P. Norvig. ArGficial Intelligence: A Modern Approach. PrenNce Hall InternaNonal, 2003.
R. S. Subon and A. G. Barto. Reinforcement Learning: An IntroducGon. The MIT Press, March 1998.
109
Copyrig
ht A.Förster, A
.Puia4
2014

Copyrig
ht A.Förster, A
.Puia4
2014
110

OPEN DISCUSSION
111
Copyrig
ht A.Förster, A
.Puia4
2014