lowering next gen sequencing dna input requirements · pdf file lowering next gen sequencing...
TRANSCRIPT

www.lucigen.com
Lowering Next Gen Sequencing DNA Input Requirements and Gaining Access to More Samples
Rob Brazas, Ph.D.Sr. Product Manager, LucigenNovember, 2017

AgendaBuilding High Quality PCR Amplified DNA Fragment Libraries
• Review DNA fragment library prep workflow
• Examine effects of poor library construction
• Investigate duplicates and effects of read number, sequencer, and sample
• Review current problems faced by DNA NGS researchers
• Introduce NxSeq® UltraLow DNA Library Kit, 12 Reactions and NxSeq® Single Indexing Kits
o Features and benefits
o How does it work?
o Applications
o Supporting data
• Summary
• Contact information
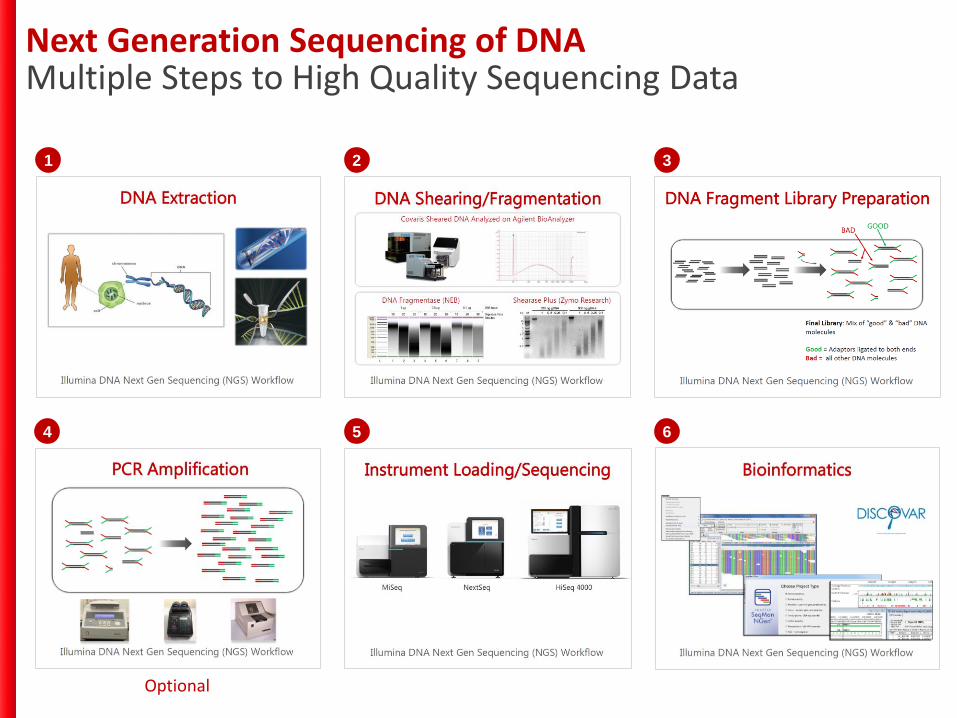
Next Generation Sequencing of DNAMultiple Steps to High Quality Sequencing Data
1 2 3
4 5 6
Optional

NextSeq 500HiSeq 2500, 4000
MiSeq
SequencingIllumina
HiSeq X Ten
End-repair, A-tailing
Adaptor Ligation
AA
AA
AA
AA
AA
AA
AA
AA
AA
T
+ PCR
T
Library Construction (Preparation)aka: Sample PrepFragment (sonication, enzymatic)
DNA Fragment Library Prep for Illumina SequencersA Critical Step in Producing High Quality Sequencing Data
Genomic DNA Sample
PCR-free
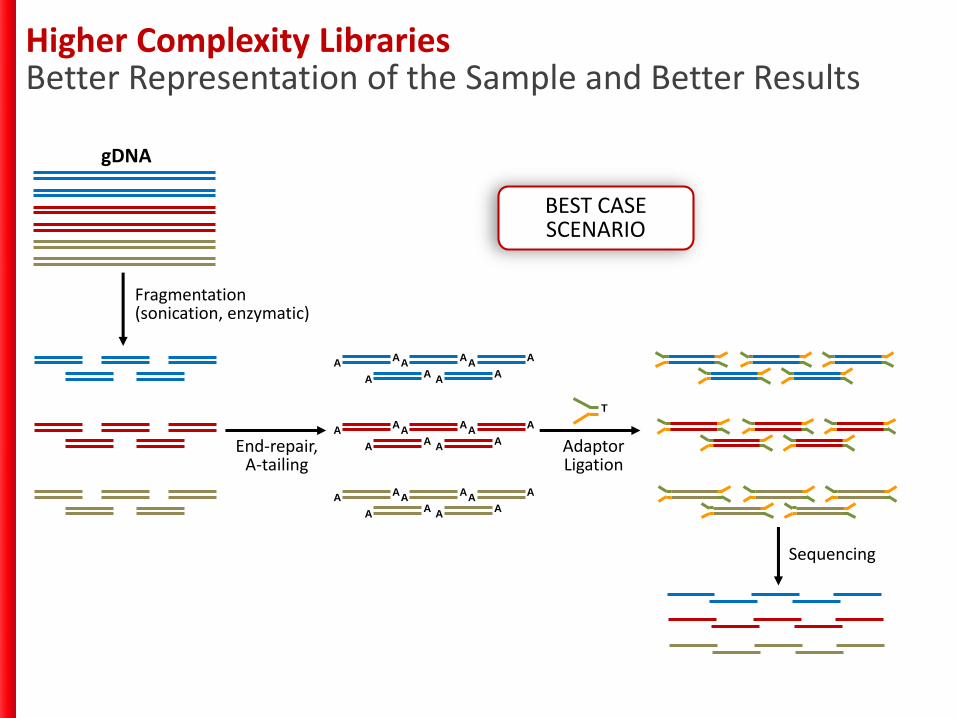
Higher Complexity LibrariesBetter Representation of the Sample and Better Results
gDNA
Fragmentation(sonication, enzymatic)
End-repair, A-tailing
Adaptor Ligation
AA
AA
AA
AA
AA
AA
AA
AA
AA
AA
AA
AA
AA
AA
AA
T
Sequencing
BEST CASE SCENARIO

Lower Complexity LibrariesPoor Representation of the Sample
gDNA
Fragmentation(sonication, enzymatic)
End-repair, A-tailing
Adaptor Ligation
AA
AA
AA
A
AA
AA
AA
A
AA
A
A
AA
AA
AA
AA
T
Sequencing
AA
AA
Poor Ligation
Poor A-tailing
DECREASED COMPLEXITY

Duplicates are Sequencing Reads or Inserts with Identical Starts
Sequencing reads
R1, R2
No Duplicates(no reads with same start points or same mapped inserts)
Sequencing reads
R1, R2
with Duplicates(reads with same start points and same mapped inserts)
Mapped Inserts
Mapped Inserts
Reference Genome
Duplicate Analysis Program Examples• FASTQC: analyzes one read file (R1 or R2) and determines duplicates based on the identical read starts• Picard: Uses both read files to determine duplicates, insert ends determine duplicates (more accurate)

Sequencing Duplicates Arise from Multiple Sources
Biological Duplicates• Generated by random chance• Two identical fragments produced from two
genome equivalents
PCR Duplicates• PCR creates duplicate sequenceable fragments• Duplicates are loaded on sequencer & sequenced
Optical Duplicates• One sequencing cluster is interpreted as two• Leads to duplicate sequencing reads from
“different clusters”
ExAmp Duplicates• Occurs on Illumina sequencers with patterned
flow cells (HiSeq X, HiSeq 3000/4000, NovaSeq• Seeding of neighboring nanowells with identical
fragments during amplification on the flow cell
Clusters in flow cell
Interpreted as two clusters & two sequences
Genome Copy 1Genome Copy 2
Shearing/fragmentation
Identical fragments by chance
PCR amplification
Fragment Library
Amplified Library
PCR Duplicates
12 13 14
9 10 11
1 2 3
4 5
6 7 8
ExAmp
12 2 13 2 14
2 9 2 2 11
1 2 2 2 3
2 4 2 5 2
6 2 7 8
Cluster generation

Duplication Rates Increase as the Sequencing Depth/Number of Reads Increases
All Mapped Inserts• 1 unique• 9 dupes for each
mapped insert• 90% duplicates
Reference Genome
50% Sampling• 1 unique• 4 dupes for each
mapped insert• 80% duplicates
20% Sampling• 1 unique• 1 dupes for each
mapped insert• 50% duplicates How are depth and reads controlled or varied?
• Sampling to a specific number of reads analyzed per library• Differential sample loading (more total reads from one library vs another)• Sample multiplexing
Same library, sampled different numbers of reads per experiment

Demonstrating the Effect of Sampling/Analyzing Different Numbers of Reads per Library on Duplication Rates
0%
1%
2%
3%
4%
5%
6%
7%
100 300 900 1800 2700 100 300 900 1800 2700 3600 4500 5400 100 300 900 1800
50 pg 500 pg 75 ng
Du
plic
atio
n R
ate
Sampled Reads X 1000
4
E. coli DNA Library Input Amount
Number of PCR Cycles1316
Duplication Rates Increase as the Number of Reads/Sample Analyzed Increases
Take Homes
• When testing/comparing library prep kits, use: One sheared DNA sample for all libraries Identical DNA input amounts when possible Use manufacturer recommended protocols Analyze the same number of reads with the same software packages Use same instrument type and sequence on the same day if possible

The Complexity of the Sample Also Impacts the Number of Duplicates Observed
Theoretical Analysis of the Number of Unique Fragments in a 50 pg Human LibraryPCR Duplicates Must be Loaded on HiSeq to Fill All Clusters = High Duplication Rate
Genome Human
Diploid Genome Size (bp) 6,000,000,000
No. of Unique 300 bp fragments from 1 Genome Equivalent 20,000,000
1 Genome (pg) 6
No. of Genome Equivalents in 50 pg 8.33
Number of Unique Fragments in 50 pg 166,666,667
Number of HiSeq Clusters 450,000,000
Duplication Factor Needed to Fill HiSeq Flowcell 2.7
Too few unique fragments to fill HiSeq
~63% Duplication Rate Expected

Major Impact of ExAmp Duplication on SequencingHigh Numbers of Duplicates from HiSeq X Sequencers
High Initial Duplication Rates for All 10 ng Libraries on HiSeq X Ten
NxSeq® UltraLow Kit Kapa Hyper Prep KitNEB NEBNext
Ultra II Kit
Total PF Sampled Reads 200,000,000 200,000,000 200,000,000
Duplicates (Proper Read Pairs) 29.59% 23.04% 24.83%
12 13 14
9 10 11
1 2 3
4 5
6 7 8
Initial Seeding of Patterned Flow Cell
12 2 13 2 14
2 9 2 2 11
1 2 2 2 3
2 4 2 5 2
6 2 7 8
Initial Seeding of Patterned Flow Cell
ExAmp
Amplifying fragments in each cluster
Instrument generated duplicates
• ExAmp duplicates or optical Duplicates
• Not library/PCR generated duplicates!
Bioinformatically remove ExAmp duplicates with “Clumpify” program
12 13 14
9 2 11
1 3
4 5
6 2 7 8
Significantly Reduced Duplication Rates After Removal of ExAmp Duplicates with Clumpify
NxSeq® UltraLow Kit Kapa Hyper Prep KitNEB NEBNext
Ultra II Kit
Total PF Sampled Reads 200,000,000 200,000,000 200,000,000
Duplicates (Proper Read Pairs) 11.30% 9.88% 10.10%

DNA Fragment Library Prep Challenges Pushing the Limits of Current Library Prep Kits
Large DNA input requirements and limiting DNA samples• Limiting DNA sample amounts even when performing library amplification by
PCR (FFPE, cfDNA, etc.)
PCR bias• Some fragments amplify better while others amplify worse• Leads to uneven coverage across the genome or target regions
Inefficient library construction• Generates libraries with low percentage of fragments with adaptors at both ends• Decreases library complexity (decreases coverage, depth uniformity)• Decreases confidence in data, makes interpretation more difficult
Complicated library prep workflows• Decreases workflow efficiency and complicates automation• Increases risk of errors• No access to a Covaris instrument for mechanical shearing of DNA samples
High library prep costs• Stresses lab budgets and may inhibit some labs from attempting NGS

NxSeq® UltraLow DNA Library & Single Indexing KitsSolving Many of the Challenges Associated with Library Prep
• High Quality Data: Produces more complex libraries with more uniform sequencing depth and better coverage due to high efficiency adaptor ligation
• Sensitive: Works with as little as 50 pg to as much 75 ng of fragmented DNA input
• Minimal Bias: Robust, uniform PCR amplification improves coverage uniformity when working with low input amounts of genomic DNA
• Flexible: Extensively tested for whole genome sequencing, but also compatible with exome-seq, ChIP-seq, and FFPE and cell free DNA samples
• Fast: 3 hour protocol gets samples on the sequencer quicker
• High Value: Cost-effective library and indexing kits without sacrificing sequencingdata quality
A PCR-amplified DNA fragment library prep and indexing system

Library Construction Mechanics of the NxSeq® UltraLow KitPart A: Ligation of a the Universal Adaptor to Fragments
Part A: Creation of Adaptor-ligated Library Fragments
Ligation/Universal Adaptor Notes:
• Incomplete, not sequenceable
• Improves ligation efficiency due to small size

Library Construction Mechanics of the NxSeq® UltraLow KitPart B: PCR Amp with Addition of P5/P7/Index Sequences
Part B: PCR Amplification and P5/P7/Index Addition
PCR Amplification Notes:
• Amplifies library
• Adds P5, P7 and single index sequences
• Produces complete, sequenceable library fragments
• Requires at least 2 cycles to produce a complete sequenceable fragment

Standard Application of NxSeq® UltraLow DNA Library KitWhole Genome Sequencing and Resequencing
NextSeq 500HiSeq 2500, 4000
MiSeq
Fragmented Whole Genome DNA sample
Sequencing
Illumina
HiSeq X Ten
End-repair, A-tailing
Adaptor Ligation
AA
AA
AA
AA
AA
AA
AA
AA
AA
T
PCR
T
Suggested WGS Input Amounts:• Human, deep sequencing: ≥1 ng• Bacterial genomes, MiSeq: ≥50 pg• Ultra-low input with human samples are
possible, but recommend high multiplexing or willingness to accept high duplicate rates
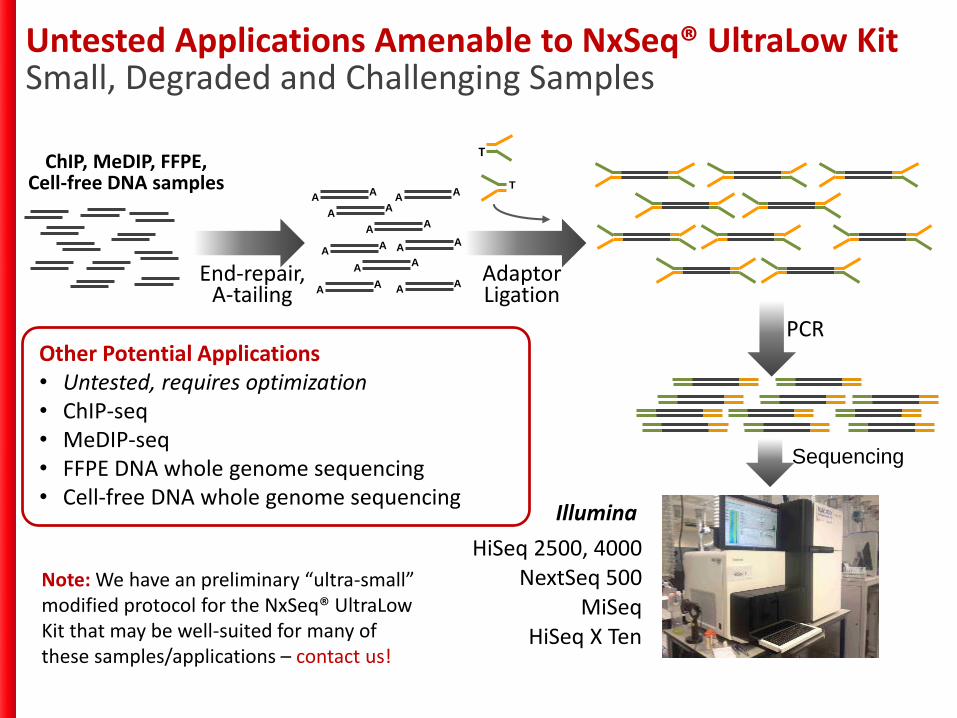
Untested Applications Amenable to NxSeq® UltraLow KitSmall, Degraded and Challenging Samples
NextSeq 500HiSeq 2500, 4000
MiSeq
ChIP, MeDIP, FFPE, Cell-free DNA samples
Sequencing
Illumina
HiSeq X Ten
Other Potential Applications• Untested, requires optimization• ChIP-seq• MeDIP-seq• FFPE DNA whole genome sequencing• Cell-free DNA whole genome sequencing
End-repair, A-tailing
Adaptor Ligation
AA
AA
AA
AA
AA
AA
AA
AA
AA
T
PCR
T
Note: We have an preliminary “ultra-small” modified protocol for the NxSeq® UltraLow Kit that may be well-suited for many of these samples/applications – contact us!

Untested Applications Amenable to NxSeq® UltraLow KitExome-sequencing and Custom Capture Library Sequencing
NextSeq 500HiSeq 2500, 4000
MiSeq
Fragmented gDNA Sample
Sequencing
Illumina
HiSeq X Ten
Other Possible Applications• Untested, requires optimization• Exome-sequencing• Custom target capture-sequencing (e.g.
cancer panels)
Library Prep w/ PCR
Library capture/ enrichment
PCR
= Target DNA regions of interest

The NxSeq® UltraLow DNA Library and Indexing KitsAffordable, High Quality Library Prep and Indexing Kits
Product Cat. No. Size (Rxn)U.S. List
Price
NxSeq® UltraLow DNA Library Kit, 12 Reactions 15012-1 12 $264
NxSeq® Single Indexing Kit, Set A 15100-1 48 (12 x 4 rxn) $190
NxSeq® Single Indexing Kit, Set B 15200-1 48 (12 x 4 rxn) $190
NxSeq UltraLow DNA Library Kit, 12 Reactions contains:Enzyme Mix (EM)2X Buffer (2XB)Ligase (LIG)2X PCR Master Mix (MM)Elution Buffer (EB)
Each NxSeq Single Indexing Kit contains:Universal Adaptor(12) different Primer Indexing Mixes
Set A contains Primer Indexing Mixes 1-12 and Set B contains Primer Indexing Mixes 13-16, 18-23, 25, and 27. Each NxSeq® Single Index equals the TruSeq® LT Index with the same number.
Coming Soon!A 96 reaction library kit and dual indexing
primers with 96 unique combinations
Primer Indexing
Mixes
NxSeq® Single Indexing Kits

NxSeq® Single Index SequencesIdentical to TruSeq® LT Indexes of the Same Number
Set A, Indexing Primer Mixes
Index Sequence
Set B, Indexing Primer Mixes
Index Sequence
Primer Mix 1 ATCACG Primer Mix 13 AGTCAA
Primer Mix 2 CGATGT Primer Mix 14 AGTTCC
Primer Mix 3 TTAGGC Primer Mix 15 ATGTCA
Primer Mix 4 TGACCA Primer Mix 16 CCGTCC
Primer Mix 5 ACAGTG Primer Mix 18 GTCCGC
Primer Mix 6 GCCAAT Primer Mix 19 GTGAAA
Primer Mix 7 CAGATC Primer Mix 20 GTGGCC
Primer Mix 8 ACTTGA Primer Mix 21 GTTTCG
Primer Mix 9 GATCAG Primer Mix 22 CGTACG
Primer Mix 10 TAGCTT Primer Mix 23 GAGTGG
Primer Mix 11 GGCTAC Primer Mix 25 ACTGAT
Primer Mix 12 CTTGTA Primer Mix 27 ATTCCT
NxSeq® Single Indexing Kit, Set A(Cat. No. 15100-1)
NxSeq® Single Indexing Kit, Set B(Cat. No. 15200-1)

NxSeq® UltraLow DNA Library Kit WorkflowEasy and Fast
Sheared DNA or
Enz. Fragmented DNA
• Fast: 3 hours
• Easy: Only 1 hr and 27 min of hands-on time, minimal components
• Flexible: Both mechanical shearing and enzymatic (Shearase Plus, Zymo Research) fragmentation protocols are provided in the User Manual
• Automation-friendly: Simple protocol, low number of reagents makes automation easy

Comparison of WorkflowsFast with Similar Workflow to Kapa Hyper Prep Kit
Lucigen: NxSeq® UltraLow DNA Library Kit
Illumina: TruSeq Nano DNA LT Library Pre Kit
Kapa: Hyper Prep Kit w/ Library Amp Primer Mix
NEB: NEBNext Ultra II DNA Library Prep Kit for Illumina

Determining Library EfficiencyMeasuring Frequency of Adaptors at Both Ends of Fragments
Examples of Possible DNA Structures in a Library
Method Basics:
• Used qPCR to measure amount of sequenceable fragments in library (before PCR amplification)
• Measure total double-stranded DNA in the library by fluorescent dye DNA quantitation (e.g. Qubit)
• Divide qPCR quantity (sequenceable) by fluorescence quantity (total DNA) x 100 (Percent efficiency)
• Efficiency determination required a Lucigen designed “universal qPCR primer set”

Maximizing Universal Adaptor Ligation Efficiency with the Goal of Improving Library Quality and Sequencing Data
Important Notes:
• Measuring adaptor ligation efficiency required use of a Lucigen designed “universal qPCR primer set”
• Adaptor ligation efficiency was measured before PCR amplification

Improved Adaptor Ligation Efficiency Enables Generation of High Quality Libraries from as Little as 50 pg of Input DNA
Methods:
• Duplicate E. coli 300 bp fragment DNA libraries using the NxSeq® UltraLow DNA Library Kit
• Normalized each library to 2 nM using a combination of Bioanalyzer (size) and Qubit Fluorometer (amount) analyses
• Multiplexed equimolar amounts of each library and ran on a MiSeq using 2 x 150 bp chemistry
• Analyzed the results and presented the average of each set of duplicates

More Uniform PCR Amplification Indicated by Lower Standard Deviations in Coverage Depth
Methods:
• Triplicate E. coli 300 bp fragment DNA libraries
• Normalized each library to 2 nM using a combination of Bioanalyzer (size) and Qubit Fluorometer (amount) analyses
• Multiplexed equimolar amounts of each library and ran on a MiSeq using 2 x 150 bp chemistry
• Analyzed the results and presented the average of each set of duplicates
E. coli R. sphaeroides S. aureus
Lucigen NxSeq
UltraLow
Kapa Hyper Prep
NEB Ultra IILucigen NxSeq
UltraLow
Kapa Hyper Prep
NEB Ultra IILucigen NxSeq
UltraLow
Kapa Hyper Prep
NEB Ultra II
Ave. Coverage Depth 10.05 10.09 9.73 9.64 9.51 9.36 10.16 10.04 9.76
Depth Std Dev 3.73 3.82 3.87 3.84 3.87 3.98 3.88 3.92 3.97
%CV 37.1% 37.9% 39.8% 39.8% 40.7% 42.5% 38.1% 39.0% 40.7%
Increased Average Coverage Depth (X) with Decreased Variability

Similar or Improved GC- and AT-bias Performance with the NxSeq® UltraLow DNA Library Kit
Methods:
• Triplicate 300 bp fragment DNA libraries starting with 1 ng of input DNA using these kits and protocols
• Multiplexed equimolar amounts of each library and ran on a MiSeq using 2 x 150 bp chemistry
• Calculated results and presented averaged data
Normalized Coverage = Average coverage of all windows with X% GC contentOverall average coverage
Perfect Results – No Bias

Better Libraries Leads to Better Whole Genome Seq DataBeating Kapa by All Metrics in a HiSeq 2500 Run
Methods:
• Triplicate human DNA fragment libraries were constructed using either the Lucigen NxSeq® UltraLow DNA Library Kit or the Kapa Hyper Prep Kit with 10 ng DNA inputs of mechanically sheared gDNA (300 bp peak size)
• Eight cycles of PCR were used to amplify each library, and the amplified libraries where cleaned/size selected as recommended
• Final libraries were sent to Hudson Alpha and were sequenced on a HiSeq 2500 using 2 x 100 bp chemistry
• Results from each set of triplicate libraries were averaged and presented

Better Libraries Lead to Better Whole Genome Seq DataImproved Results on a HiSeq X Ten Instrument
Methods:
• Duplicate human DNA fragment libraries were constructed with the Lucigen NxSeq® UltraLow DNA Library Kit, Kapa Hyper Prep Kit or NEB NEBNext Ultra II Kits using 10 ng DNA inputs of mechanically sheared gDNA (300 bp peak size)
• Eight cycles of PCR were used to amplify the Lucigen and Kapa libraries, while 7 cycles were used for the NEB libraries
• Amplified libraries were cleaned/size selected as recommended and sent to Hudson Alpha for sequencing on the HiSeq X Ten using 2 x 150 bp chemistry
• Clumpify was used to remove instrument generated optical/ExAmp duplicates from each set of reads, and then 200 million reads were sampled and analyzed. Results from each set of duplicates were averaged and presented

Higher Ligation Efficiency Increases Library Size/Complexity
KitEstimated Library Size
(Picard’s Estimate)
NxSeq® UltraLow Kit 4.548 x 109
Kapa Hyper Prep Kit 2.499 x 109
NEB NEBNext Ultra II Kit 3.200 x 109
Higher Estimated Number of Unique Fragments per Library
0.0E+00
5.0E+08
1.0E+09
1.5E+09
2.0E+09
2.5E+09
3.0E+09
3.5E+09
4.0E+09
4.5E+09
5.0E+09
NxSeq®UltraLow Kit
Kapa Hyper PrepKit
NEB NEBNextUltra II Kit
Est.
Lib
rary
Siz
e (P
icar
d's
Est
imat
e)
Methods:
• Same duplicate libraries as previous slide
• ~200M reads per library were analyzed on DNAnexus using Picard to determine library size/complexity
• Clumpify was not used to remove optical duplicates
• Results from each set of duplicates were averaged and presented

Significant Cost Savings Without Sacrificing PerformancePerformance of the NxSeq® UltraLow Kit is Actually Better!

SummaryUltra-low Input, High Efficiency Kit Enables Sequencing of More Samples with Limiting DNA
Highest efficiency PCR+ kit enables use of very small amounts of input DNA (50 pg) and produces more high quality sequencing data from each library
Current best fit for this kit is whole genome sequencing applications but it can also be used with other applications that require PCR-amplified libraries
• Contact our Tech Support team for guidance with non-WGS applications
Lower price decreases your costs and extends your budgets
Easy-to-use protocol and minimal reagents simplifies library prep reducing the chance of errors and simplifying automation
http://www.lucigen.com/ultralow-dna-library-prep-kit/

Questions?Please Do Not Hesitate to Contact Me or Tech Support
Contact me.Rob Brazas, Ph.D.Sr. Product [email protected]
Lucigen Tech [email protected](608) 831-90118 am – 5 pm central time
Thank You for Listening-in Today!
http://www.lucigen.com/ultralow-dna-library-prep-kit/