lógica nebulosa (fuzzy logic) - unesp: câmpus de … · lógica nebulosa: resumo • lotfi zadeh...
TRANSCRIPT

Universidade Estadual Paulista – UNESP Campus de Ilha Solteira Departamento de Engenharia Elétrica
Programa de Pós-Graduação em Engenharia Elétrica
Carlos R. Minussi
Anna Diva Plasencia Lotufo
Ilha Solteira-SP, junho-2011.
Lógica Nebulosa (Fuzzy Logic)
(Introdução)

Lógica Nebulosa: Resumo
• Lotfi Zadeh (1965) desenvolveu o conceito de conjunto
nebuloso (fuzzy set) baseado em pesquisas
desenvolvidas por Lukasiewisz;
• O cérebro humano consegue resolver questões que
envolvem imprecisões:
• Fuzzy set: modelagem matemática destes eventos;
• Mais recentemente surgiu o conceito de Rough Set (FL
é um caso particular de RS)
Lógica Binária
Lógica Nebulosa
Rough Sets
Conjuntos Rústicos (Lógica Rústica)
• Projetos: - entrada / saída;
- facilmente implementados (sistemas não
lineares;
- utilização de declarações if – then
- variáveis lingüísticas.
2

• Grau (função) de Pertinência: m ˛ [0, 1]
Pertinência nula Pertinência completa
• Exemplo: Variável “Temperatura pode ter vários estados:
Fria, fresca, moderada, morna, quente, muito quente
Variáveis lingüísticas
• A mudança de um estado para outro não precisa ser rigorosamente definida;
• A idéia de : que é muito frio que é morno
ou que é quente
está sujeita a diferentes interpretações.
• Regras: se <proposição nebulosa>, então, <proposição nebulosa> if then
• Exemplo: “X é Y”ou “X não é Y”, X sendo uma variáveis escalar e Y sendo um conjunto nebuloso associado com a variável X.
3
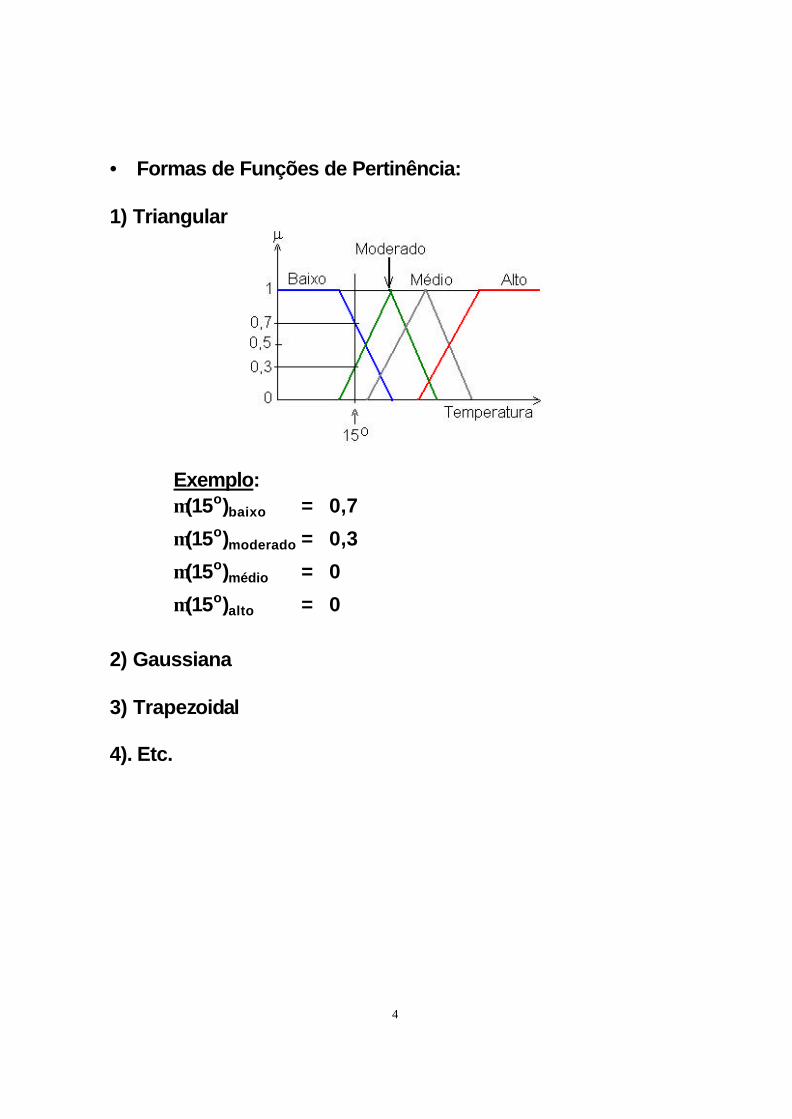
• Formas de Funções de Pertinência:
1) Triangular
Exemplo: m(15o)baixo =
m(15o)moderado =
m(15o)médio =
m(15o)alto =
0,7
0,3
0
0
2) Gaussiana
3) Trapezoidal
4). Etc.
4
5
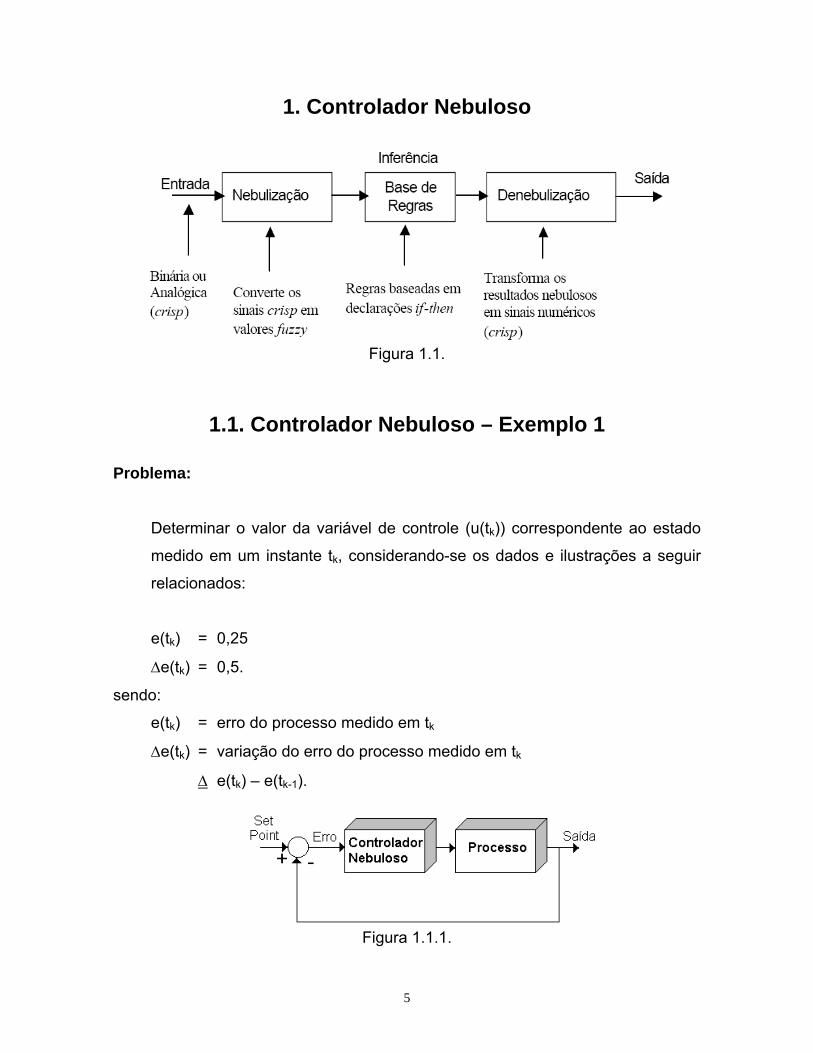
1. Controlador Nebuloso
Figura 1.1.
1.1. Controlador Nebuloso – Exemplo 1
Problema:
Determinar o valor da variável de controle (u(tk)) correspondente ao estado
medido em um instante tk, considerando-se os dados e ilustrações a seguir
relacionados:
e(tk) = 0,25
Δe(tk) = 0,5.
sendo:
e(tk) = erro do processo medido em tk
Δe(tk) = variação do erro do processo medido em tk
Δ e(tk) – e(tk-1).
Figura 1.1.1.
6
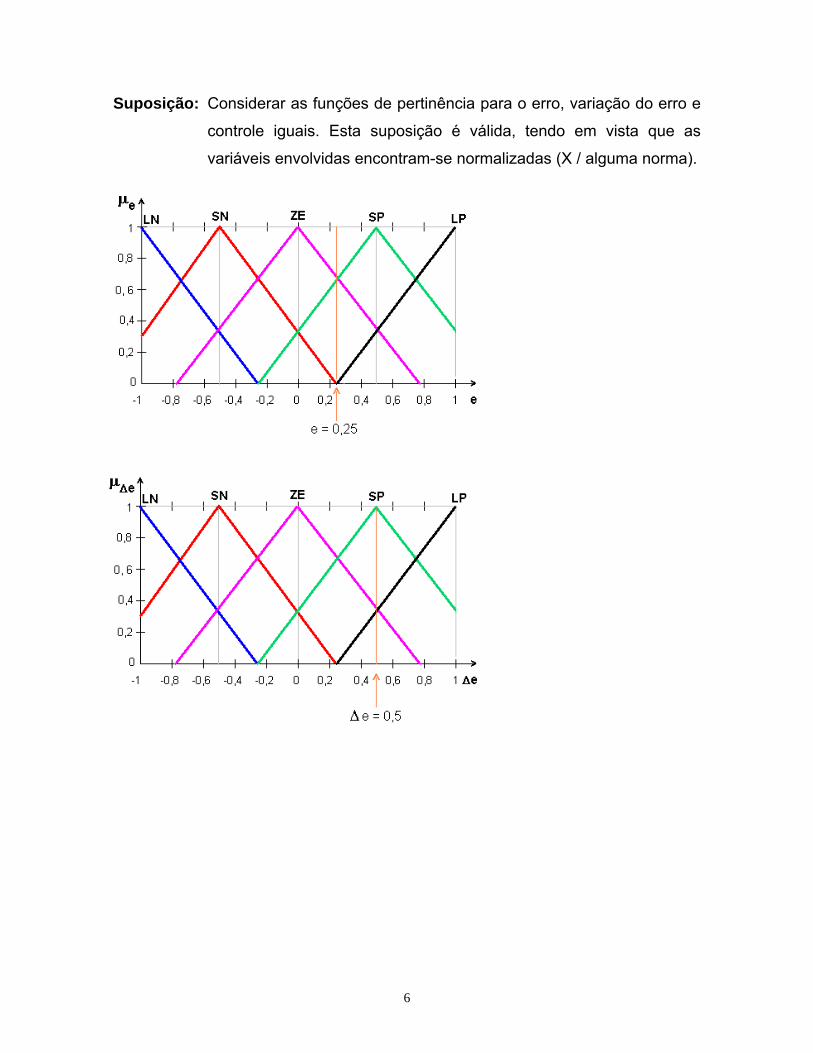
Suposição: Considerar as funções de pertinência para o erro, variação do erro e
controle iguais. Esta suposição é válida, tendo em vista que as
variáveis envolvidas encontram-se normalizadas (X / alguma norma).
7
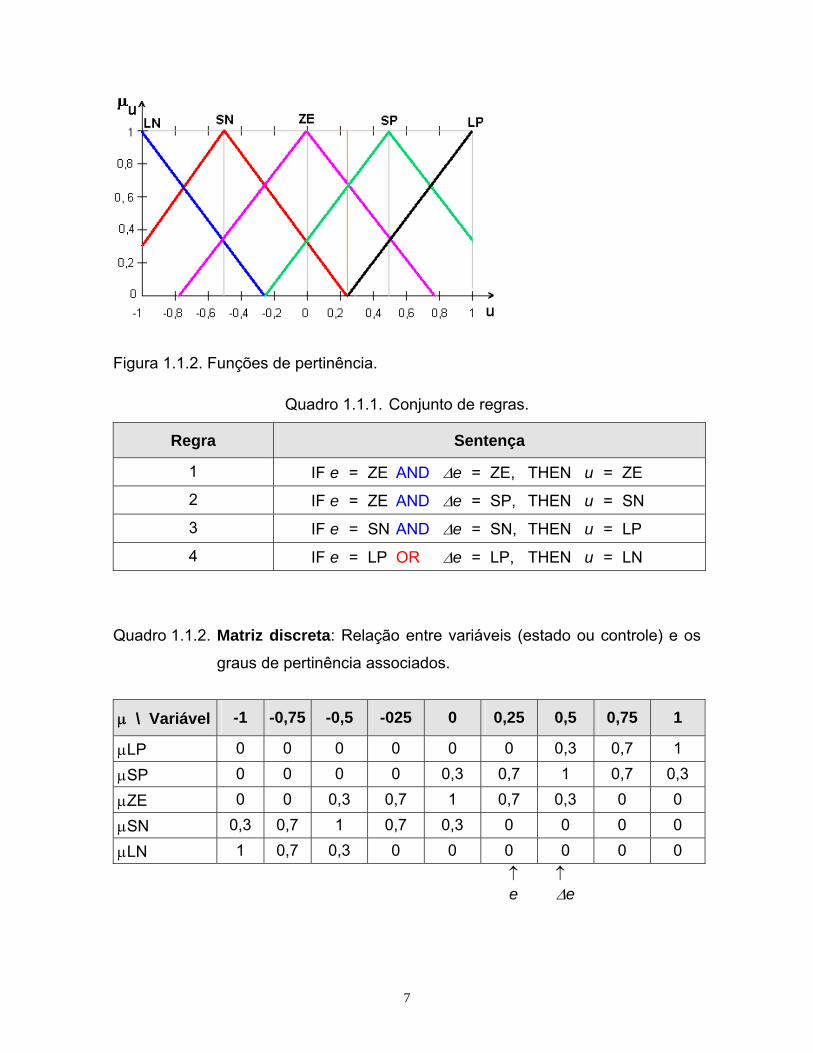
Figura 1.1.2. Funções de pertinência.
Quadro 1.1.1. Conjunto de regras.
Regra Sentença
1 IF e = ZE AND Δe = ZE, THEN u = ZE
2 IF e = ZE AND Δe = SP, THEN u = SN
3 IF e = SN AND Δe = SN, THEN u = LP
4 IF e = LP OR Δe = LP, THEN u = LN
Quadro 1.1.2. Matriz discreta: Relação entre variáveis (estado ou controle) e os
graus de pertinência associados.
μ \ Variável -1 -0,75 -0,5 -025 0 0,25 0,5 0,75 1
μLP 0 0 0 0 0 0 0,3 0,7 1
μSP 0 0 0 0 0,3 0,7 1 0,7 0,3
μZE 0 0 0,3 0,7 1 0,7 0,3 0 0
μSN 0,3 0,7 1 0,7 0,3 0 0 0 0
μLN 1 0,7 0,3 0 0 0 0 0 0 ↑ ↑
e Δe
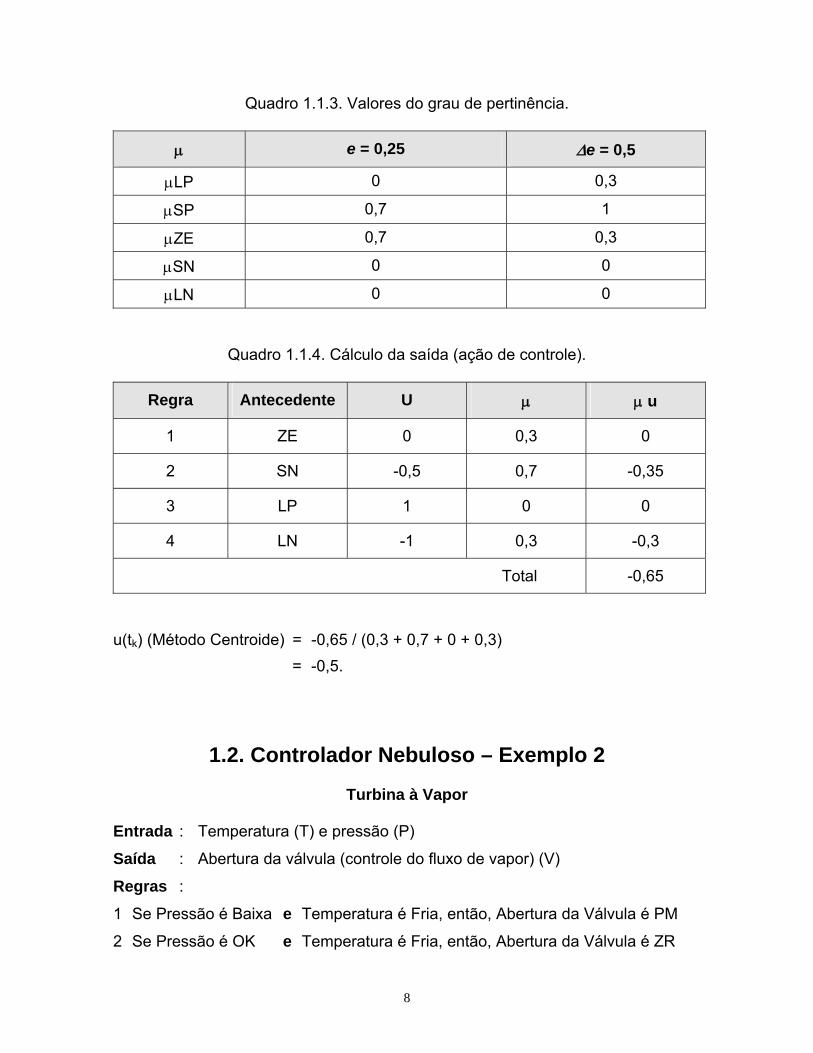
8
Quadro 1.1.3. Valores do grau de pertinência.
μ e = 0,25 Δe = 0,5
μLP 0 0,3
μSP 0,7 1
μZE 0,7 0,3
μSN 0 0
μLN 0 0
Quadro 1.1.4. Cálculo da saída (ação de controle).
Regra Antecedente U μ μ u
1 ZE 0 0,3 0
2 SN -0,5 0,7 -0,35
3 LP 1 0 0
4 LN -1 0,3 -0,3
Total -0,65
u(tk) (Método Centroide) = -0,65 / (0,3 + 0,7 + 0 + 0,3) = -0,5.
1.2. Controlador Nebuloso – Exemplo 2
Turbina à Vapor Entrada : Temperatura (T) e pressão (P)
Saída : Abertura da válvula (controle do fluxo de vapor) (V)
Regras :
1 Se Pressão é Baixa e Temperatura é Fria, então, Abertura da Válvula é PM
2 Se Pressão é OK e Temperatura é Fria, então, Abertura da Válvula é ZR
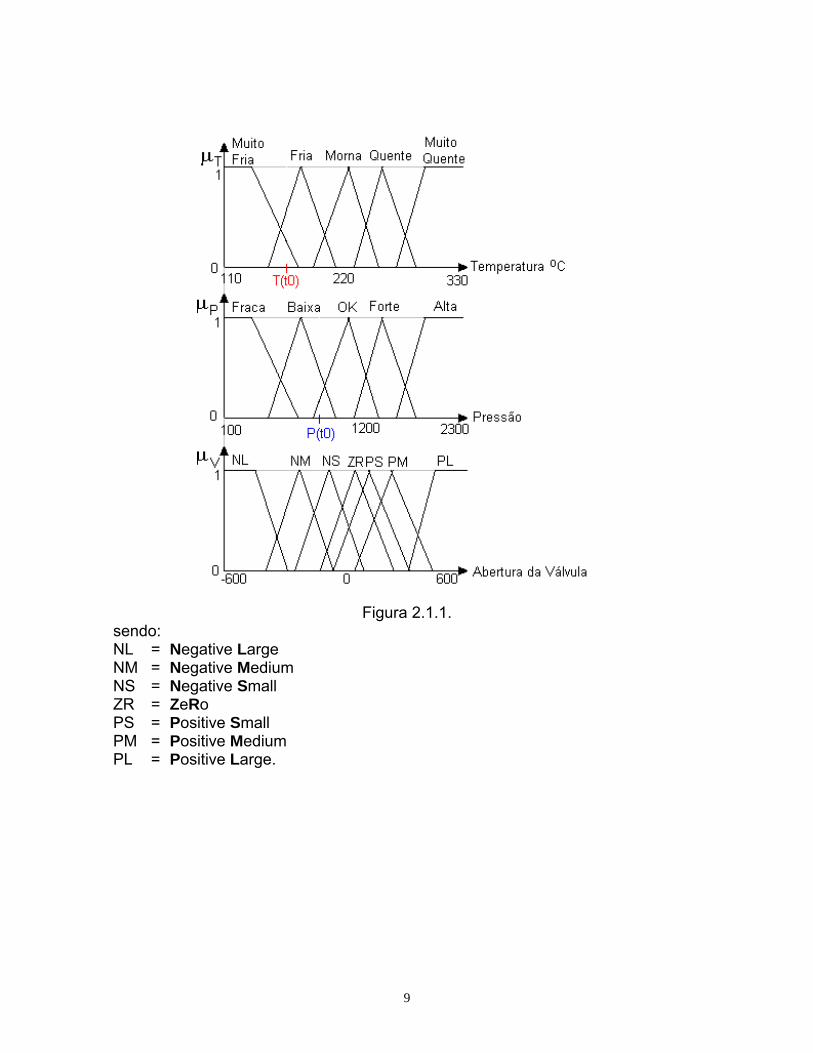
9
Figura 2.1.1.
sendo: NL = Negative Large NM = Negative Medium NS = Negative Small ZR = ZeRo PS = Positive Small PM = Positive Medium PL = Positive Large.
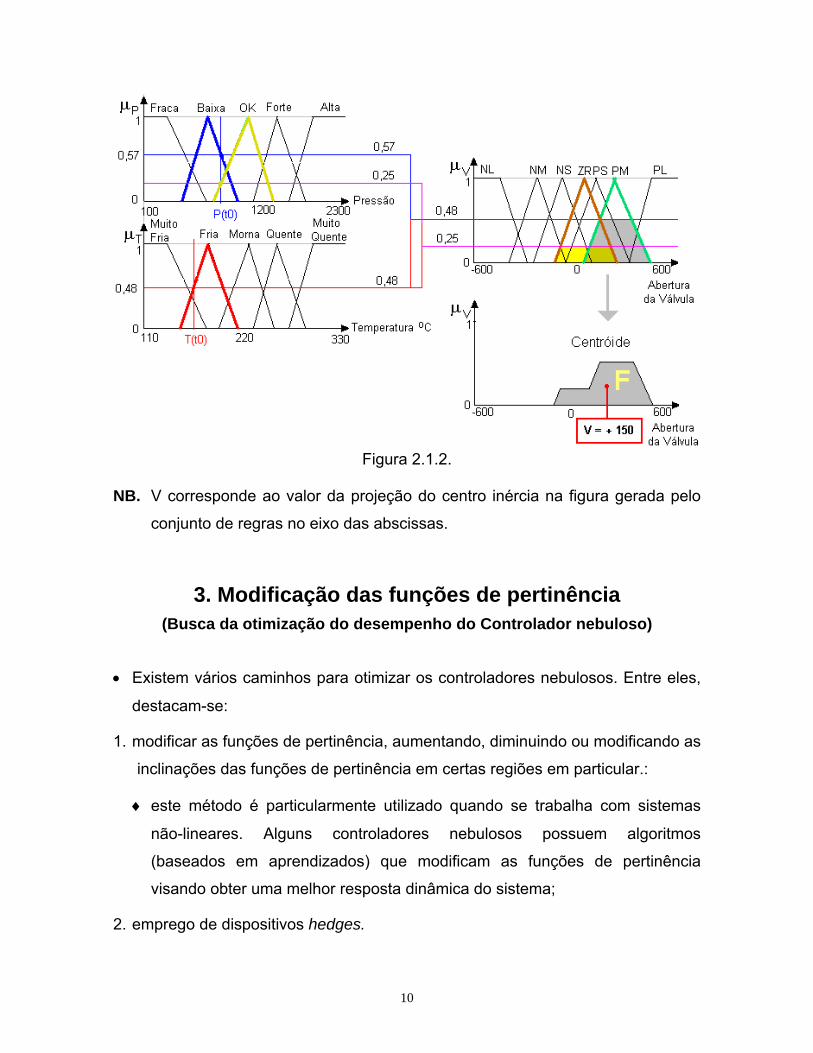
10
Figura 2.1.2. NB. V corresponde ao valor da projeção do centro inércia na figura gerada pelo
conjunto de regras no eixo das abscissas.
3. Modificação das funções de pertinência
(Busca da otimização do desempenho do Controlador nebuloso)
• Existem vários caminhos para otimizar os controladores nebulosos. Entre eles,
destacam-se:
1. modificar as funções de pertinência, aumentando, diminuindo ou modificando as
inclinações das funções de pertinência em certas regiões em particular.:
♦ este método é particularmente utilizado quando se trabalha com sistemas
não-lineares. Alguns controladores nebulosos possuem algoritmos
(baseados em aprendizados) que modificam as funções de pertinência
visando obter uma melhor resposta dinâmica do sistema;
2. emprego de dispositivos hedges.
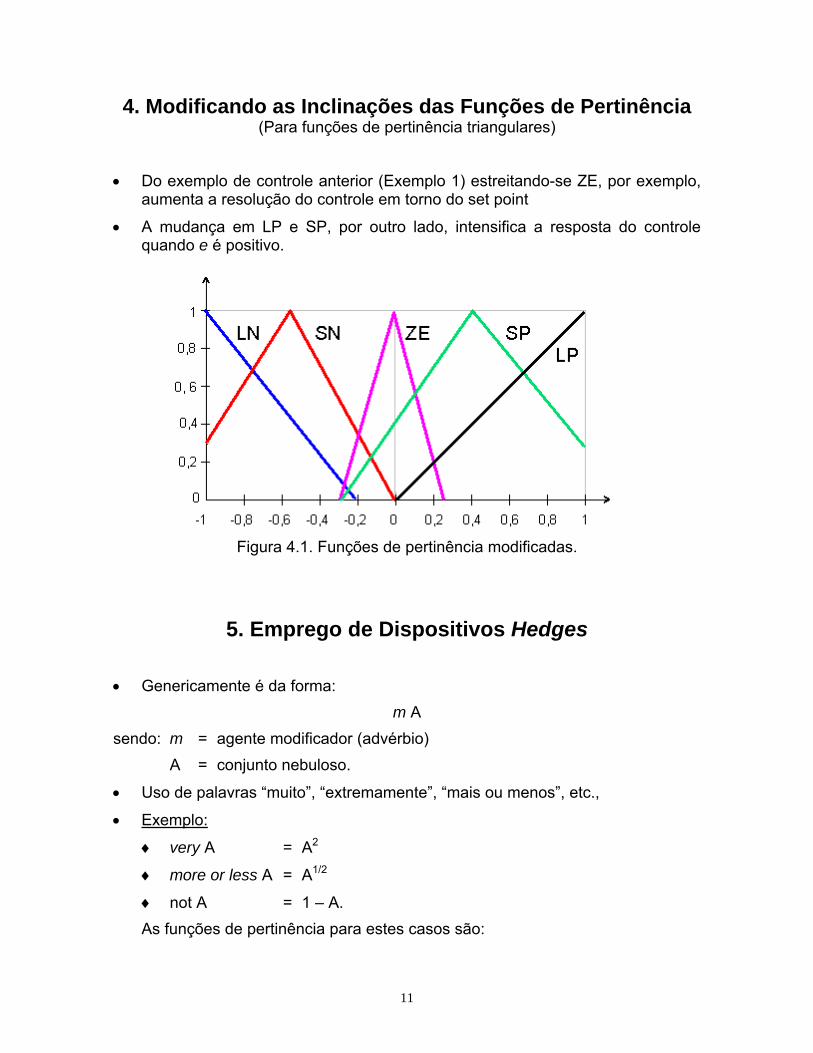
11
4. Modificando as Inclinações das Funções de Pertinência (Para funções de pertinência triangulares)
• Do exemplo de controle anterior (Exemplo 1) estreitando-se ZE, por exemplo, aumenta a resolução do controle em torno do set point
• A mudança em LP e SP, por outro lado, intensifica a resposta do controle quando e é positivo.
Figura 4.1. Funções de pertinência modificadas.
5. Emprego de Dispositivos Hedges
• Genericamente é da forma: m A
sendo: m = agente modificador (advérbio) A = conjunto nebuloso.
• Uso de palavras “muito”, “extremamente”, “mais ou menos”, etc.,
• Exemplo:
♦ very A = A2
♦ more or less A = A1/2
♦ not A = 1 – A. As funções de pertinência para estes casos são:

12
♦ μ A2 (X) = {μ A(x)} 2
♦ μ A1/2 (X) = {μ A(x)} 1/2
♦ μ A - 1(X) = 1 - μ A(x).
Figura 5.1.
NB: na regra IF e = SP THEN u = LP, usando-se um hedge: IF e = very SP
THEN u = LP (very é um operador quadrático da função de pertinência
sobre SP) proporciona variações (relativas):
- pequenas para valores de μ próximos de 1
- grandes para valores de μ pequenos.
Vantagens: 1. ao invés de modificar o conjunto de regras, o hedge modifica somente uma
regra, enquanto que a modificação da inclinação da função de pertinência afeta todas as regras.
6. Sistemas Nebulosos Adaptativos
• Sistemas capazes de se adaptarem em consequência das mudanças
ambientais.
• No caso do controle, são dispositivos capazes de se adaptarem em função de
mudanças como parâmetros e condições operativas, e.g.:

13
♦ envelhecimento de componentes (mecânicos, elétricos, eletrônicos)
♦ em sistemas de energia elétrica (modelos não-lineares), o ponto de
operação é alterado, ao longo do tempo, visando atender a demanda
(consumo de energia);
♦ Exemplo: Durante o governo de Carter (Estados Unidos), por ocasião da
tentativa de libertar americanos seqüestrados (em um avião) no Irã, um
helicóptero caiu no deserto por motivo de que dispositivos de navegação e
de controle falharam causados por condições ambientais adversas
(mudança intensa de temperatura, umidade, etc.).
• Sistemas nebulosos convencionais apresentam desempenho semelhante aos
controladores PID (Proporcional + Integral + Derivativo). Neste caso, podem
não se adaptarem às mudanças graduais em seus ambientes de trabalho;
• Deste modo, surge a necessidade de desenvolver controladores adaptativos.
No caso de controladores nebulosos adaptativos.
• O controlador nebuloso adaptativo, contém a mesma estrutura do controlador
nebuloso convencional, acrescido de um mecanismo que permite implementar
e gerenciar as modificações no conjunto de regras (mudança na inclinação
das funções de pertinência (triangulares) e dispositivos hedges).
7. Problemas no Processo de Desnebulização Quando se Utiliza o Método Baricentro (Centro de Gravidade)
Figura 7.1.

14
Problemas: 1. tratamento de regras redundantes (cotas g1, g3, g4 e g7) 2. interseções entre conjuntos consequentes (áreas na cor cinza escuro).
• Considere o seguinte conjunto de regras nebulosas: X------------------------ Antecedente ----------------------X X- Consequente-X Regra 0: If x0 = A0 and X1 = A1 and x2 = A2, then y = P0
Regra 1: If x0 = B0 and x2 = B2, then y = P0 Regra 2: If X1 = C1 and x2 = C2, then y = P1 Regra 3: If x0 = D0 and X1 = D1 then y = P2 Regra 4: If x0 = E0 and x2 = E2, then y = P2 Regra 5: If x0 = F0 and X1 = F1 and x2 = F2, then y = P2
Regra 6: If X1 = G1 and x2 = G2, then y = P3
Regra 7: If x0 = H0 then y = P3 • a figura gerada pelo conjunto de regras corresponde a figura em com cinza,
cuja projeção do baricentro sobre o eixo das abscissas é valor da ação de
controle “recomendada”;
• as cotas (alturas) (g0, g2, etc.) correspondem aos graus de pertinência,
respectivamente das regras 0, 1, 2, etc.;
• observa-se que somente g0, g2, g5 e g6 afetam a inferência que são as maiores
cotas sobre cada conjunto nebuloso (P0, P1, P2 e P3).
Solução: Empregar, por exemplo, o método Centroide Min-Max. Este método
não será tratado aqui, visto que ele é habitalmente abordado na
literatura especializada.

15
Abordagem Alternativa • o centroide pode ser estimado da seguinte forma:
Centroide = = =
n
1i
n
1iiμ/)uiiμ(
sendo:
n = número de regras
μi = grau de pertinência da regra i
ui = ação de controle recomendada referente à regra i.
NB: A ação recomendada (ui) aqui é considerada como sendo o valor da
projeção sobre a abscissa, correspondente ao valor máximo do conjunto
nebuloso (μ = 1):
Figura 7.1.
NB.: 1. Os controladores via métodos de desnebulização baseados no centro de
gravidade possuem comportamento semelhante ao controladores PI
(Proporcional+Integral).
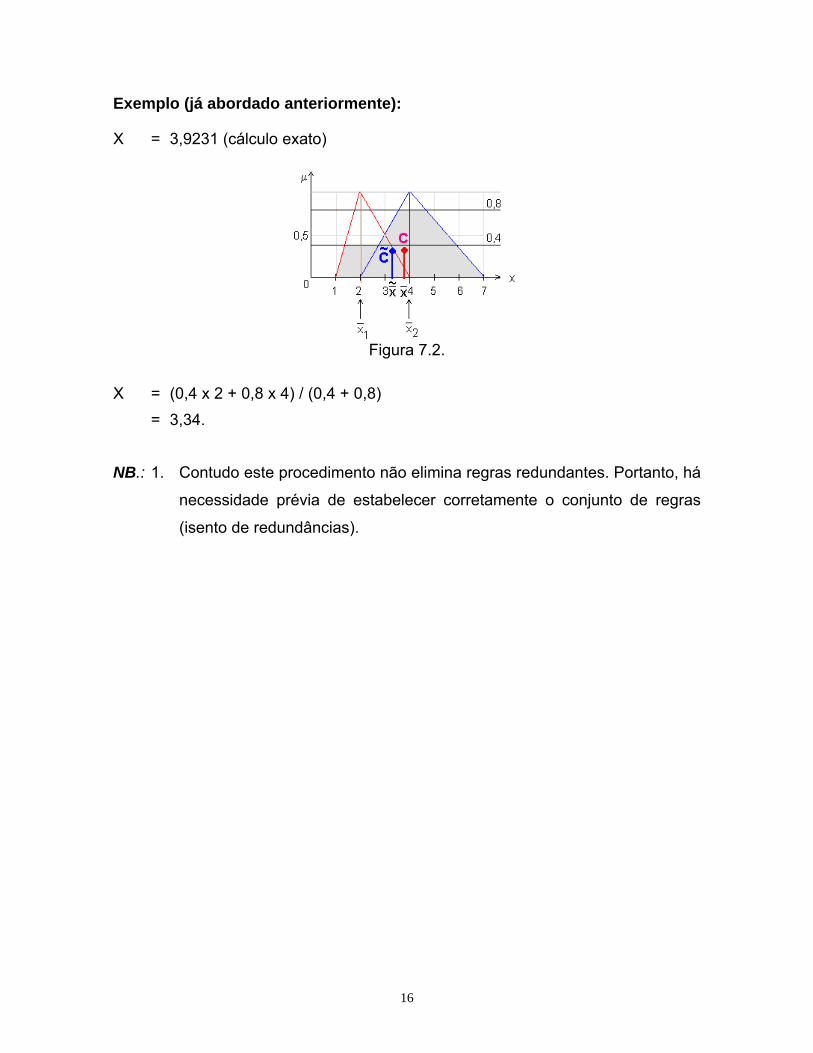
16
Exemplo (já abordado anteriormente):
X = 3,9231 (cálculo exato)
Figura 7.2.
X = (0,4 x 2 + 0,8 x 4) / (0,4 + 0,8) = 3,34. NB.: 1. Contudo este procedimento não elimina regras redundantes. Portanto, há
necessidade prévia de estabelecer corretamente o conjunto de regras
(isento de redundâncias).

17
8. Granulação
• Como já abordado anteriormente, o uso das palavras pode ser visto como
uma forma de quantização nebulosa ou, mais genericamente, como
granulação.
• Basicamente, a granulação envolve a substituição de uma restrição da forma:
X = a
por uma restrição da forma:
X é A
sendo:
A = um subconjunto de U (conjunto universo de X)
Exemplo: X = 2 pode ser substituído por: X é pequeno. • Na lógica nebulosa, a declaração X é A é interpretada como a caracterização
de possíveis valores de X, em que A representa a distribuição de
possibilidades. Assim, a possibilidade que X pode possuir um valor u é dada
por:
poss{X = u} = μ A(u).
• Isto é, no senso em que X é μ A(u), com possibilidade sendo interpretada uma
fácil realização, podendo, também, ser interpretada como sendo uma restrição
elástica sobre X.
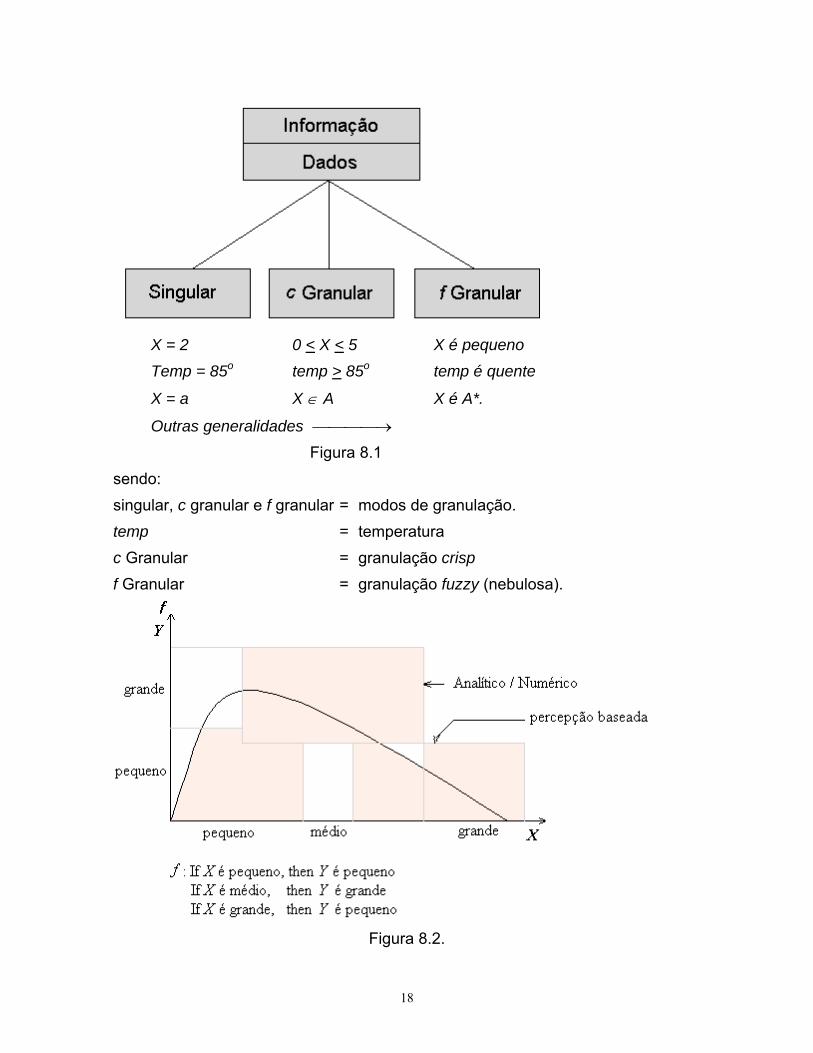
18
X = 2 0 < X < 5 X é pequeno Temp = 85o temp > 85o temp é quente
X = a X ∈ A X é A*.
Outras generalidades ⎯⎯⎯⎯→ Figura 8.1 sendo: singular, c granular e f granular = modos de granulação. temp = temperatura c Granular = granulação crisp f Granular = granulação fuzzy (nebulosa).
Figura 8.2.

19
9. Principais Conceitos
9.1. União μA∪B(x) = μA(x) ∨ μB(x) 9.2. Interseção μA∩B(x) = μA(x) ∧ μB(x) 9.3. Complemento μ A (x) = 1 − μA(x) 9.4. Relação de Equivalência
A = B ↔ μA(x) = μB(x) 9.5. Relação de Inclusão
A ⊂ B ↔ μA(x) < μB(x)
9.6. Lei de Negação Dupla
=A = A
20
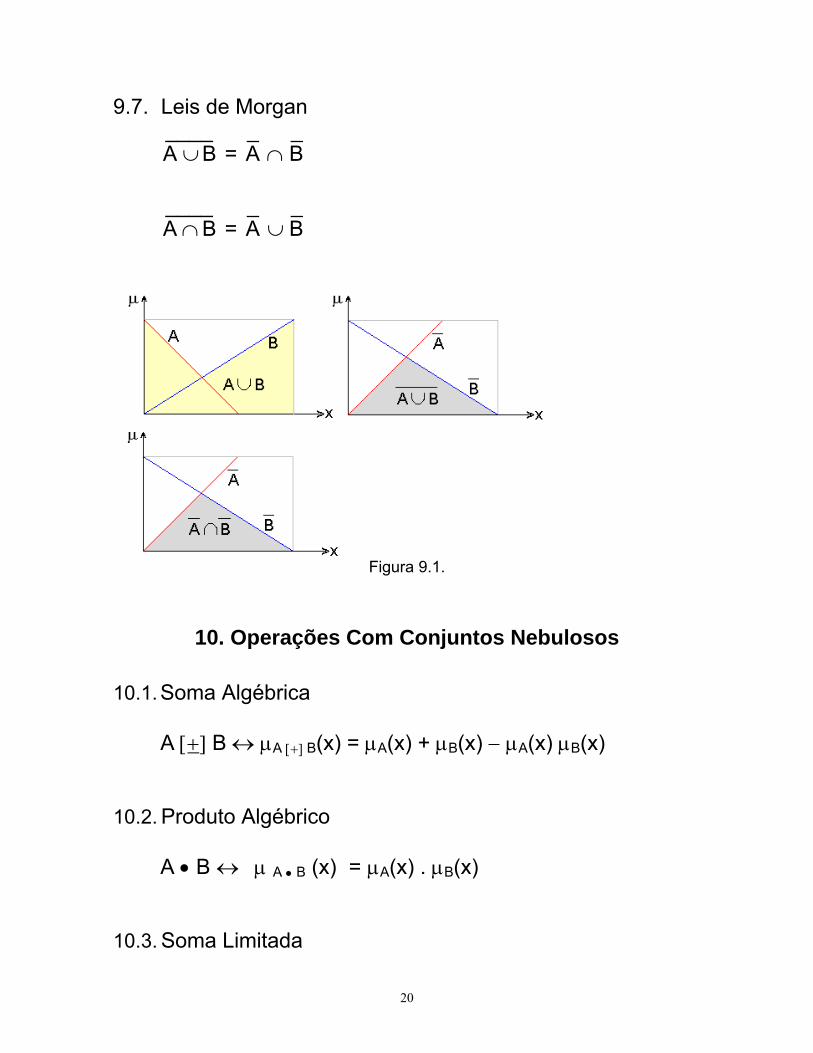
9.7. Leis de Morgan
____
BA ∪ = _B
_A ∩
____
BA ∩ = _B
_A ∪
Figura 9.1.
10. Operações Com Conjuntos Nebulosos
10.1. Soma Algébrica A [+] B ↔ μA [ +] B(x) = μA(x) + μB(x) − μA(x) μB(x) 10.2. Produto Algébrico A • B ↔ μ A • B (x) = μA(x) . μB(x) 10.3. Soma Limitada

21
A ⊕ B ↔ μ A ⊕ B (x) = (μA(x) + μB(x)) ∧ 1 10.4. Diferença Limitada A Θ B ↔ μ A Θ B (x) = (μA(x) - μB(x)) ∨ 0 10.5. λ-Complemento
_A λ ↔ μ
_A
λ (x) = (1 - μA(x)) / ( 1+ λ μA(x)) 10.6. As leis de Morgan aplicam-se à soma algébrica,
diferença algébrica e complemento:
_____ _ _ A [+] B = A • B
____ _ _ A • B = A [+] B
10.7. No caso de λ-complemento, as leis de Morgan são: ____ _ _ (A ∪ B)λ = Aλ ∩ Bλ
____ _ _ (A ∩ B)λ = Aλ ∪ Bλ

22
10.8. Lei de Morgan referente à dupla negação: ____ __
(Aλ)λ = A . 10.9. Quando o conjunto suporte é um conjunto finito, torna-se
conveniente utilizar as seguintes expressões: Considere: X = { x1, x2, x3, ..., xn}. O subconjunto A de X pode, então, ser expresso por:
A = ix/)ix(n
1iAμ∑
=
= μA(x1) / x1 + μA(x2) / x2 + ... + μA(xn) / xn
10.10. Os termos de grau zero são eliminados. O símbolo (+) significa or, por exemplo: a / x1+ b /x1 = a ∨ b / x1 ↑ Associado ao operador max. 10.11. Assim, a união de dois conjuntos é encontrada através
da conexão com um símbolo (+). Exemplo: Considere um conjunto que pode ser chamado
de grande composto por graus de pertinência em uma variação de números inteiros compreendidos entre 1 e 10:

23
grande = 0,2/5 + 0,4/6 + 0,7/7 + 0,9/8 + 1/9 + 1/10 e o conjunto em torno do valor médio é expresso por:
em torno do valor médio = 0,4/3 + 0,8/4 + 1/5 + 0,8/6 + 0,4/7
então: grande ∪ em torno do valor médio = (0,2/5 + 0,4/6 + 0,7/7 + 0,9/8 + 1/9 + 1/10) + (0,4/3 + 0,8/4 + 1/5 + 0,8/6 + 0,4/7) = 0,4/3 + 0,8/4 + (0,2 ∨ 1)/5 + (0,4 ∨ 0,8)/6 + (0,7 ∨ 0,4)/7
+ 0,9/8 + 1/9 + 1/10
= 0,4/3 + 0,8/4 + 1/5 + 0,8/6 + 0,7/7 + 0,9/8 + 1/9 + 1/10.
11. Regras Básicas de Inferência
1. x é A A ⊂ B ⎯⎯⎯ x é B
2. Usualmente (x é A) A ⊂ B ⎯⎯⎯⎯⎯⎯ usualmente (x é B)
3. Idade (Maria) é Jovem

24
sendo: Jovem é interpretada como sendo um conjunto
nebuloso ou, equivalentemente, como um predicativo
nebuloso. Portanto, podendo ser interpretado como:
“Maria não é velha”,
Jovem é um subconjunto do complemento de velho, que é: μjovem(u) ⊂ (1 - μvelho(u)), u ∈, e.g., [0, 100]. sendo: μjovem(u) e μvelho(u) são, respectivamente, funções de
pertinência de Jovem e de Velho considerando-se o
universo de abrangência o intervalo [0,100].
4. Regra Conjuntiva
x é A x é B ⎯⎯⎯ x é A ∩ B

25
5. Produto Cartesiano x é A y é B ⎯⎯⎯⎯⎯⎯⎯⎯⎯ (x, y) é A x B sendo: (x, y) é uma variável binária e A x B é definida por: μ A x B(u,v) = μA(u) ∧ μB(v) u ∈ U , v ∈ V
6. Regra de Projeção (x, y) é R ⎯⎯⎯⎯ x é xR sendo: xR a projeção da relação binária R no domínio de x
e definida por:
μxR (u) = supv μR (u,v)
u ∈ U e v ∈ V
em que:
μR (u,v) = função de pertinência de R
sup = supremo sobre v ∈ V.

26
7. Regra Composicional
X é A (x,y) é R ⎯⎯⎯⎯ y é A ο R sendo: A ο R = composição da relação binária A com a relação
binária R defina por:
μA ο R (v) 0 supu (μA(u) ∧ (μB(u))
8. Modus Ponens Proposição 1. Se x é A, então, y é B
Proposição 2. x é A’
Conclusão: y é B’
(A e A’), (B e B´) não são necessariamente iguais.
9. Modus Ponens Generalizado
Proposição 1. x é A
Proposição 2. Se (x for A), então, (y será B)

27
Conclusão: y é B
Exemplo: Se tomate é vermelho, então, tomate é maduro
Se tomate for muito vermelho, então, tomate
será muito maduro.
12. Matrizes e Grafos Nebulosos • Matriz nebulosa: A relação nebulosa R definidade sobre o espaço X x Y,
sendo: X = { x1, x2, ..., xn} Y = { y1, y2, ..., yn} pode ser expressa na forma matricial:
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
)nx,nx(R...)2x,nx(R)2x,nx(R
............)nx,2x(R...)2x,2x(R)2y,2x(R
)nn,1x(R...)2y,1x(Rμ)1y,1x(Rμ
μμμ
μμμμ
Exemplo 1: A relação nebulosa “x possui forma
semelhante a y” pode ser expressa pela
matriz:

28
Pera Banana Maçã Bola
Pera 1 0,2 0,6 0,6 Banana 0,2 1 0,1 0,1 Maçã 0,6 0,1 1 0,8 Bola 0,6 0,1 0,8 1
Exemplo 2: Quando a relação nebulosa sobre X = {a, b, c}
é: R = 0,2/(a,a) + 1/(a,b) + 0,4/(a,c) + 0,6/(b,b) + 0,3/(b,c) + 1/(c,b) + 0,8/(c,c)
a b c a 0,2 1 0,4 b 0 0,6 0,3 c 0 1 0,8
(Matriz nebulosa)
(Grafo nebuloso)

29
13. Operações com Relações Nebulosas
• Se R for uma relação em X x Y e S uma relação em Y x Z,
a composição de R e S, R, R ο S, é a relação em X x Z definida por:
R ο S ↔ μR ο S(x,z) = ∨ {μR (x,y) ∧ μS (y,z)} y
(Composição max-min)
• Exemplo: Considere X = {x1, x2}, Y = {y1, y2, y3}, Z = {z1, z2}.
Se as relações nebulosas R e S são expressa
pelas seguintes matrizes, a composição R ο S
pode ser determinada como segue:
R = ⎥⎦
⎤⎢⎣
⎡1,019,0
06,04,0, S =
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
6,0011,08,05,0
R Ο S = ⎥⎦
⎤⎢⎣
⎡1,019,0
06,04,0Ο
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
6,0011,08,05,0
= ⎥⎦
⎤⎢⎣
⎡∧∨∧∨∧∧∨∧∨∧∧∨∧∨∧∧∨∧∨∧
)6,01,0()11()8,09,0()01,0()1,01()5,09,0()6,00()16,0()8,04,0()00()1,06,0()5,04,0(
= ⎥⎦
⎤⎢⎣
⎡∨∨∨∨
∨∨∨∨)1,0()1()8,0()0()1,0()5,0()0()6,0()4,0()0()1,0()4,0(
= ⎥⎦
⎤⎢⎣
⎡15,06,04,0 .

30
NB.: Outros tipos de composições podem ser considerados, por exemplo:
• Composição min-max R S ↔ μR S(x,z) = ∧ {μR (x,y) ∨ μS (y,z)} Y ____ _ _ R S = R Ο S

31
14. Conjunto Nebuloso Normal
• Um conjunto nebuloso, cuja função de pertinência possui
grau 1, é chamada normal, ou seja:
A é chamado conjunto “normal” ↔ max μA(x) = 1
x ∈ X
Figura 14.1 Conjuntos nebulosos normal e não-normal.
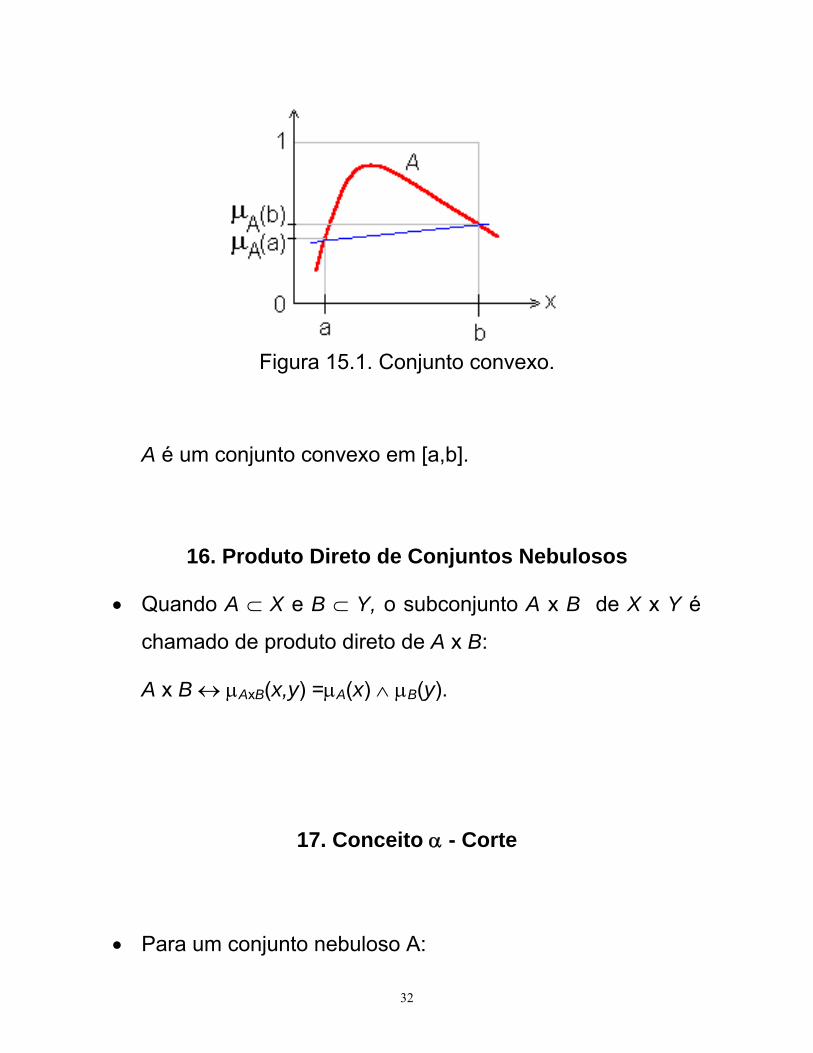
15. Conjunto nebuloso Convexo
• Quando o conjunto suporte é um conjunto de números
reais e a seguinte propriedade para todo x ∈ [a,b]:
μA(x) > μA(a) ∧ μA(b), então,
A é chamado conjunto convexo.
32
Figura 15.1. Conjunto convexo.
A é um conjunto convexo em [a,b].
16. Produto Direto de Conjuntos Nebulosos
• Quando A ⊂ X e B ⊂ Y, o subconjunto A x B de X x Y é
chamado de produto direto de A x B:
A x B ↔ μAxB(x,y) =μA(x) ∧ μB(y).
17. Conceito α - Corte
• Para um conjunto nebuloso A:
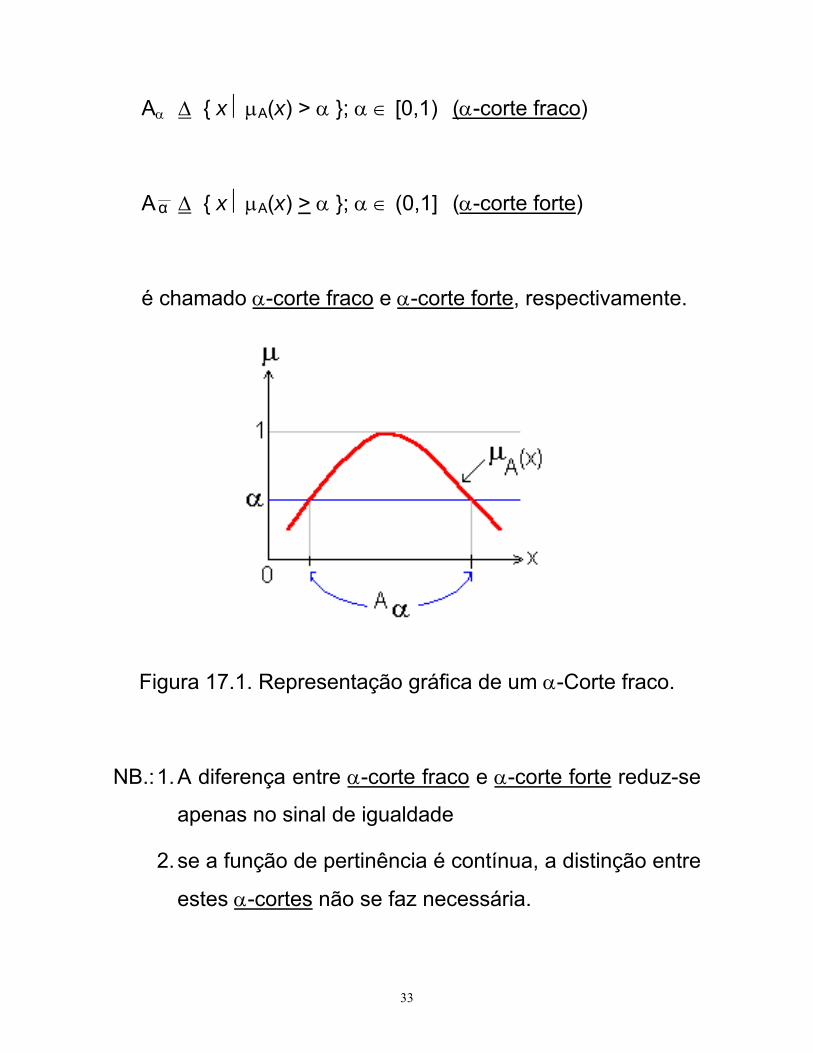
33
Aα Δ { x ⏐μA(x) > α }; α ∈ [0,1) (α-corte fraco)
Aα Δ { x ⏐μA(x) > α }; α ∈ (0,1] (α-corte forte)
é chamado α-corte fraco e α-corte forte, respectivamente.
Figura 17.1. Representação gráfica de um α-Corte fraco.
NB.: 1. A diferença entre α-corte fraco e α-corte forte reduz-se
apenas no sinal de igualdade
2. se a função de pertinência é contínua, a distinção entre
estes α-cortes não se faz necessária.

34
18. Princípio da Resolução
• Necessidade: 1. conjunto nebuloso normal
2. conjunto nebuloso convexo.
• O princípio da resolução é definido como:
μA(x) = sup [α ∧ χAα(x)]
α ∈ [0,1)
= sup [α ∧ χAα (x)]
α ∈ (0,1].
sendo:
sup = supremo
χE(x) = função característica de E
Δ 1, se x ∈ E
0, se x ∉ E.
• Usando-se o princípio da resolução, a função de
pertinência pode ser expressa via uso do conceito α-corte;

35
• considera-se que χAα (x) é a função característica de
Aα , então, tem-se:
para x ∈ Aα , ↔ μA(χ) > α (χA(x) = 1)
para x ∉ Aα , ↔ μA(χ) < α (χA(x) = 0).
• portanto, tem-se:
sup [α ∧ χAα(x)] = sup [α ∧ χAα (x)]
α ∈ [0,1) α ∈ (0,1]
= sup [α ∧ χAα (x)]
α ∈ (0, μ A (x)]
∨
sup [α ∧ χAα (x)]
α ∈ (μ A(x),1]
= sup [α ∧ 1] ∨ sup [α ∧ 0]
α ∈ (0,μ A(x)] α ∈ (μ A(x),1]
= sup α
α ∈ (0,μ A(x)]
= μ A(x).

36
• Se definirmos o conjunto α Aα como sendo:
αAα ↔ μαAα = α ∧ χAα (x),
então, o princípio da resolução pode ser expresso por:
A = ( ]U
1,0α∈ αAα .
• Ou seja, um conjunto nebulosos A é decomposto em
αAα , α ∈ (0,1] e é expresso como uma união destes
(αAα ). Este é o significado do princípio da resolução.
Figura 18.1. Decomposição de um conjunto nebuloso.
• A partir da Figura 18.1, se α1 < α2, então, Aα1 ⊃ Aα2.

37
• Dado os conjuntos nebulosos na forma de Aα1 e Aα2, pode-
se recuperar a função de pertinência original do conjunto
nebuloso A:
μA(x) ↔ Aα , α ∈ (0,1],
ou seja, um conjunto nebuloso pode ser expresso em
termos do conceito de α-cortes sem recorrer a função de
pertinência.
19. Números Nebulosos
• Para um conjunto nebuloso normal e convexo, se um α-
corte fraco é um intervalo fechado, ele (α-corte fraco) é
chamado de número nebuloso;
• números nebulosos possuem funções de pertinência
semelhantes às mostradas na Figura 19.1;
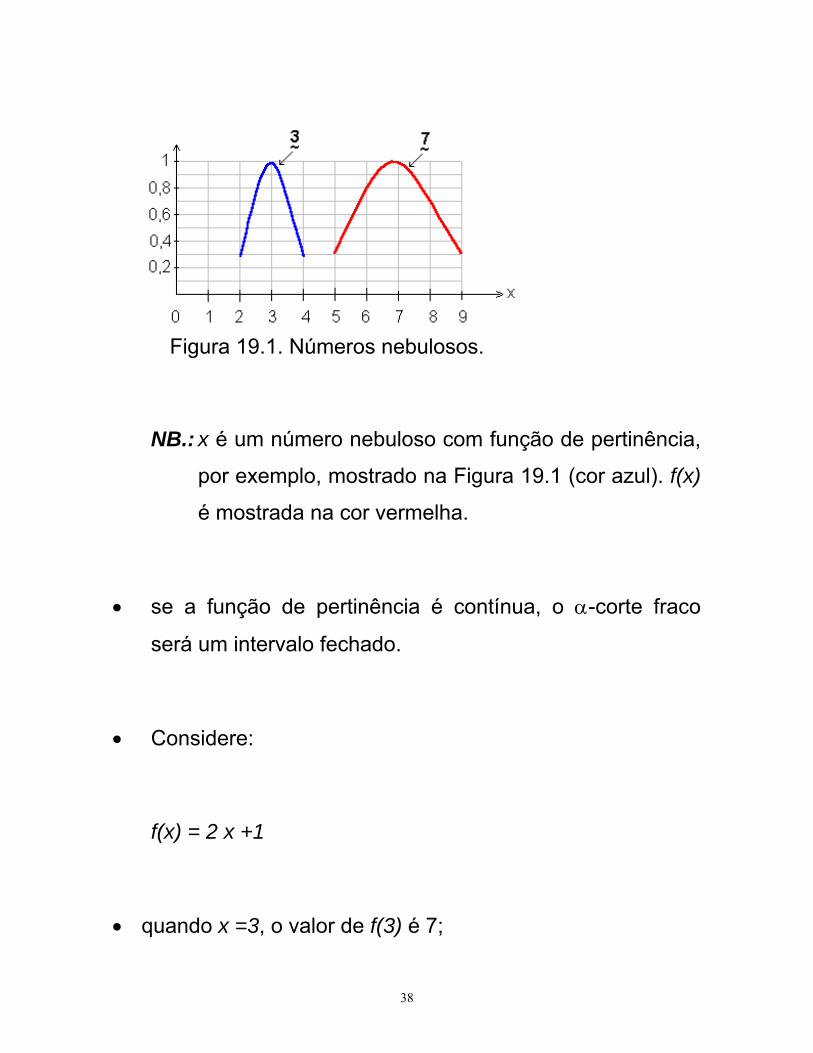
38
Figura 19.1. Números nebulosos.
NB.: x é um número nebuloso com função de pertinência,
por exemplo, mostrado na Figura 19.1 (cor azul). f(x)
é mostrada na cor vermelha.
• se a função de pertinência é contínua, o α-corte fraco
será um intervalo fechado.
• Considere:
f(x) = 2 x +1
• quando x =3, o valor de f(3) é 7;

39
• agora, se x não é um valor único, mas sim que varia entre
2 e 4, o valor de f(x) de 5 até 9:
f([2,4]) = 2 . [2,4] +1
= [2 . 2, 2. 4] +1
= [4+1,8+1]
= [5,9]
• o que acontece com os valores de f(x) se os valores de x
são ambíguos, e.g., “em torno de 3” ao invés do intervalo
[2,4]?
• os números do tipo “em torno de 3” em “em torno de 5”
são chamados números nebulosos, com grafia ~3 e
~5,
respectivamente.
• expressar “em torno de 3”: substituir x em f(x) com ~3,
obtém-se:
f(~3) = 2 .
~3 +1
= ~7

40
• se calcularmos f(~3) usando o princípio de extensão (a
partir da Figura 19.1), obtém-se:
~3 α = 3, para α = 1
= [2,5, 3,5], para α = 0,8
= [2,4] para α = 0,3.
f(~3)α = 7, para α = 1
= [6, 8], para α = 0,8
= [5,9], para α = 0,3.
• Se desenharmos a função de pertinência de f(3) usando-
se estes resultados, obtém-se o número nebuloso 7 como
mostrado na curva vermelha (Figura 19.1);
• Neste sentido, calculam-se as extensões de funções
simples usando o conceito de α-cortes;
• quando o conjunto suporte do conjunto nebuloso é finito,
os cálculos são sempre mais simples se realizados
diretamente pelo uso da definição de função estabelecida
pelo princípio da resolução.

41
20. Operações com Números Nebulosos
• Considere uma função com duas variáveis:
g: X x Y → Z
sendo:
x ∈ X e y ∈ Y em g(x,y) são substituídos por conjuntos
nebulosos A ⊂ X e B ⊂ Y, assim:
μg(A,B)(z) = sup [μA(x) ∧ μB(y)]
z = g(x,y)
• isto expressa o produto direto de A e B (operação entre
parênteses);
• o operador sup é efetivo em relação a x e y de z = g(x,y)
para um dado valor z;
• o conjunto nebulosos g(A,B) de Z é representado por:
g(A,B) = ∫z
[μA(x) ∧ μA(y)] / g(x,y)
• usando-se o conceito de α-corte, torna-se:
g(A,B)α = g(Aα,Bα).

42
Exemplo. Supondo-se:
g(x,y) = x+ y
sendo: x e y são números reais que correspondem à
obtenção da soma de números nebulosos A e B. Por
exemplo, pode-se usuar:
g(~2,
~3) =
~2 +
~3
= ~5
isto confirma que o resultado refere-se “em torno de 5”.
• Para x e y, g é uma função contínua, assim usando-se o
conceito de α-corte fraco, tem-se:
(~2 +
~3)α =
~2 α +
~3 α .
• desde que o α-corte de números nebulosos está em um
intervalo, o cálculo corresponde à soma de 2 intervalos
[a,b] e [c,d]:
[a,b] + [c,d] = {ω⏐ω = u + v; u ∈ [a,b]; v ∈ [c,d]}.

43
• ou seja, se u e v são números que podem variar dentro
dos intervalos [a,b] e [c,d], respectivamente, suas somas
é, então:
[a,b] + [c,d] =[a+ c, b + d].
• O α-corte de 3, como anteriormente abordado, será:
~3 α = 3, para α = 1
= [2,5, 3,5], para α = 0,8
= [2,4] para α = 0,3.
e o α-corte de 2 será:
~2 α = 2, para α = 1
= [1,5, 2,5], para α = 0,8
= [1,3] para α = 0,3.
(~2 α +
~3 α ) = 5, para α = 1
= [4,6], para α = 0,8
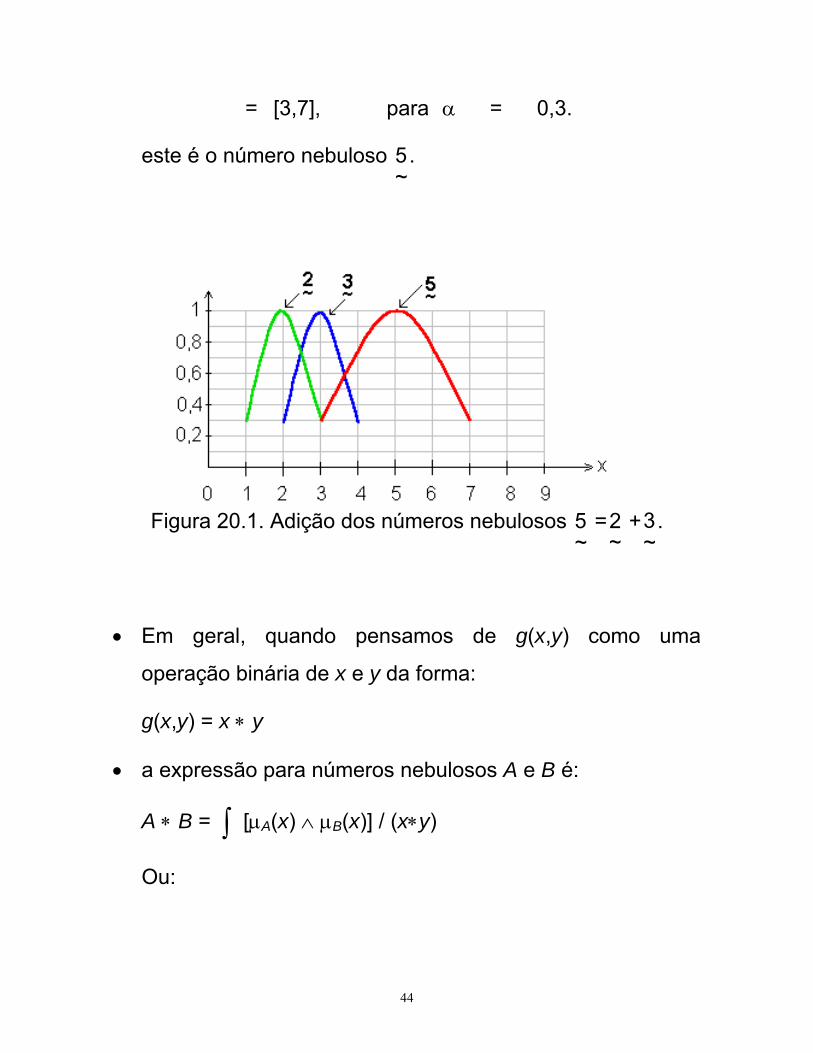
44
= [3,7], para α = 0,3.
este é o número nebuloso ~5.
Figura 20.1. Adição dos números nebulosos ~5 =
~2 +
~3.
• Em geral, quando pensamos de g(x,y) como uma
operação binária de x e y da forma:
g(x,y) = x ∗ y
• a expressão para números nebulosos A e B é:
A ∗ B = ∫ [μA(x) ∧ μB(x)] / (x∗y)
Ou:
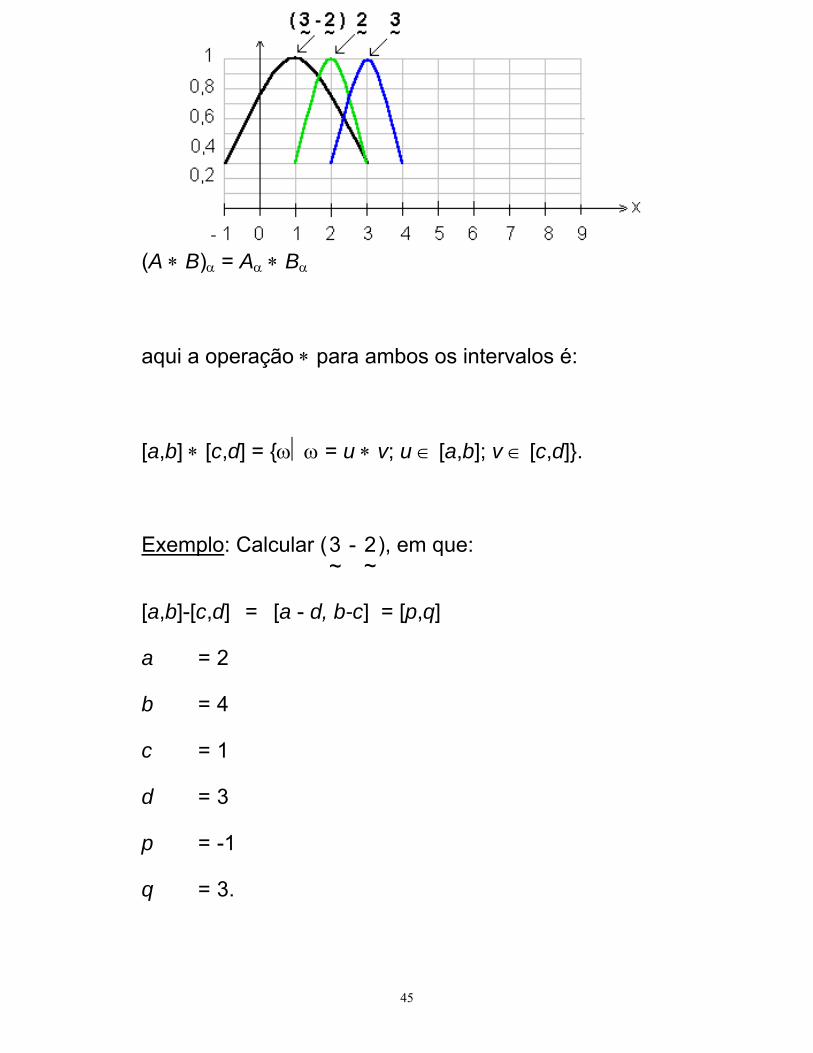
45
(A ∗ B)α = Aα ∗ Bα
aqui a operação ∗ para ambos os intervalos é:
[a,b] ∗ [c,d] = {ω⏐ω = u ∗ v; u ∈ [a,b]; v ∈ [c,d]}.
Exemplo: Calcular (~3 -
~2), em que:
[a,b]-[c,d] = [a - d, b-c] = [p,q]
a = 2
b = 4
c = 1
d = 3
p = -1
q = 3.

46
Figura 20.2. Número nebuloso ~2,
~3 e (
~3 -
~2).
(~3 −
~2)α = 1, para α = 1
= [0,2], para α = 0,8
= [-1,3], para α = 0,3.
NB.: A operação com números nebulosos de subtração
não é uma operação reversa de adição. Ou seja:
(3 – 2) + 2 = 3 é uma relação verdadeira, porém:
((~3 -
~2) +
~2)α = 3, para α = 1
= [1,5;4,5], para α = 0,8
= [0;6], para α = 0,3.
• Contudo:

47
~3 α = 3, para α = 1
= [2,5, 3,5], para α = 0,8
= [2,4] para α = 0,3.
• Portanto:
~3 α ≠ {(
~3 -
~2) +
~2}α .
p = -1
q = 3. (intervalos de (~3 -
~2))
c = 1
d = 3 (intervalos de ~2)
Intervalos de {(~3 -
~2)) +
~2 } = [p+c, q+d]
= [-1+1,3+3]
= [0,6]
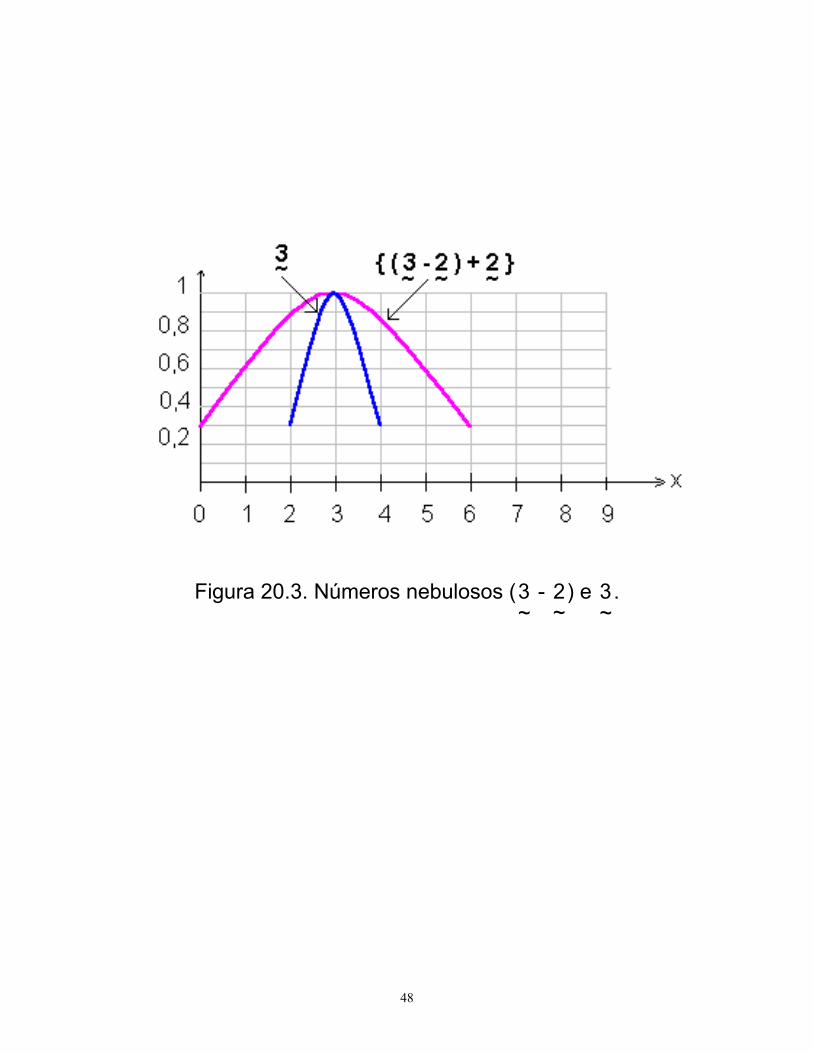
48
Figura 20.3. Números nebulosos (~3 -
~2) e
~3.

Universidade Estadual Paulista – UNESP Campus de Ilha Solteira Departamento de Engenharia Elétrica
Programa de Pós-Graduação em Engenharia Elétrica
Disciplina: Lógica Nebulosa
Carlos R. Minussi
Ilha Solteira-SP, junho-2010.
Aritmética de Intervalos Fuzzy

2
21. ARITMÉTICA DE INTERVALOS FUZZY
A aritmética de intervalos tenta obter um intervalo resultante de uma
operação fuzzy, de tal forma que nele contenha todas as possíveis soluções. Neste caso,
estas regras operacionais são definidas num sentido conservativo, no senso em que se
obtêm intervalos maiores do que o necessário, evitando, deste modo, perdas de
informações em relação às soluções verdadeiras. Por exemplo:
[1, 2] [0, 1] = [0, 2] significa que, para parâmetros a [1, 2] e b [0, 1], garante-se
que a b [0, 2].
Figura 21.1.
Notação de intervalo fuzzy:
[s, s ] s s s ,
sendo:
s = limite inferior;
s = limite superior.
21.1. Aritmética de Intervalos As operações com intervalos fuzzy mais usuais são: z = x y, sendo x e y dois conjuntos
fuzzy e () (+ , , . , /, min, max), ou seja:
(1) Adição
[s1, 1s ] + [s2, 2s ] = [s1, + s2, 1s + 2s ].
(2) Subtração
[s1, 1s ] [s2, 2s ] = [s1, 2s , 1s s2].
(3) Reciprocidade
Se 0 [s, s ], então, [s, s ]1 = [1/ s , 1/s];

3
Se 0 [s, s ], então, [s, s ]1 é indefinido.
(4) Multiplicação
[s1, 1s ] . [s2, 2s ] = [p, p ].
sendo:
p = min { s1 s2, s1 2s , 1s s2, 1s 2s }
p = max{ s1 s2, s1 2s , 1s s2, 1s 2s }.
(5) Divisão
[s1, 1s ] / [s2, 2s ] = [s1, 1s ] . [s2, 2s ]1
desde que 0 [s2, 2s ].
(6) Máximo
max{ [s1, 1s ], [s2, 2s ]} = [p, p ]
sendo:
p = max{ s1, s2 }
p = max{ 1s , 2s }.
(7) Mínimo
mim{ [s1, 1s ], [s2, 2s ]} = [p, p ]
sendo:
p = min{ s1, s2 }
p = min{ 1s , 2s }.
22. Exercícios Ilustrativos: Notação de -Corte e Princípio da Resolução Exercício 1 (Adição). Considerando-se x e y dois conjuntos fuzzy (vide Figura 22.1), tais que:
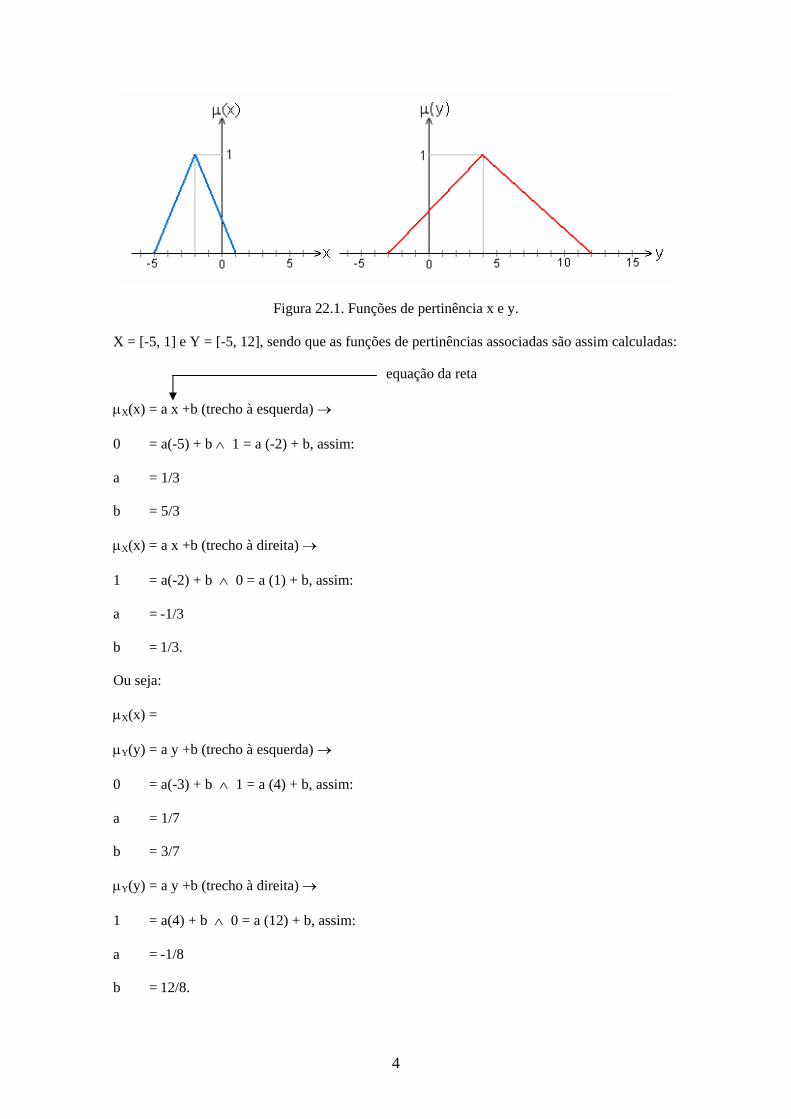
4
Figura 22.1. Funções de pertinência x e y.
X = [-5, 1] e Y = [-5, 12], sendo que as funções de pertinências associadas são assim calculadas:
X(x) = a x +b (trecho à esquerda)
0 = a(-5) + b 1 = a (-2) + b, assim:
a = 1/3
b = 5/3
X(x) = a x +b (trecho à direita)
1 = a(-2) + b 0 = a (1) + b, assim:
a = -1/3
b = 1/3.
Ou seja:
X(x) =
Y(y) = a y +b (trecho à esquerda)
0 = a(-3) + b 1 = a (4) + b, assim:
a = 1/7
b = 3/7
Y(y) = a y +b (trecho à direita)
1 = a(4) + b 0 = a (12) + b, assim:
a = -1/8
b = 12/8.
equação da reta
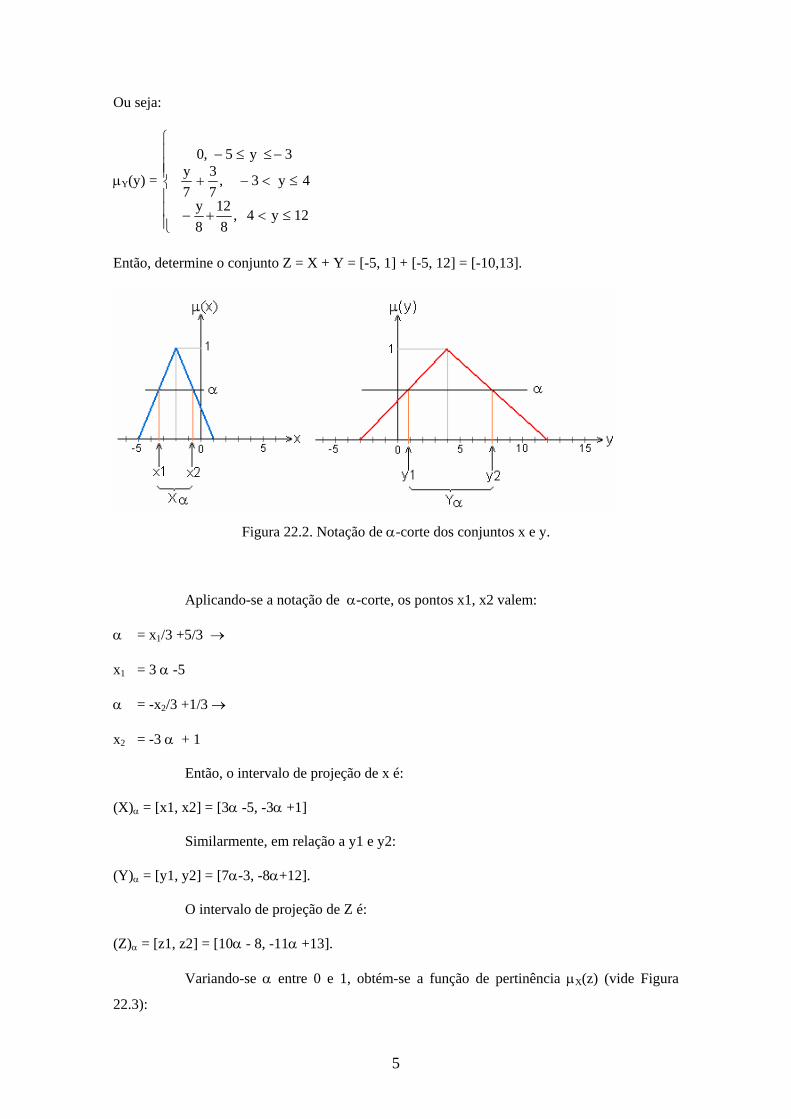
5
Ou seja:
Y(y) =
12y4,8
12
8
y
4y3,7
3
7
y3y5,0
Então, determine o conjunto Z = X + Y = [-5, 1] + [-5, 12] = [-10,13].
Figura 22.2. Notação de -corte dos conjuntos x e y.
Aplicando-se a notação de -corte, os pontos x1, x2 valem:
= x1/3 +5/3
x1 = 3 -5
= -x2/3 +1/3
x2 = -3 + 1
Então, o intervalo de projeção de x é:
(X) = [x1, x2] = [3 -5, -3 +1]
Similarmente, em relação a y1 e y2:
(Y) = [y1, y2] = [7-3, -8+12].
O intervalo de projeção de Z é:
(Z) = [z1, z2] = [10 - 8, -11 +13].
Variando-se entre 0 e 1, obtém-se a função de pertinência X(z) (vide Figura
22.3):
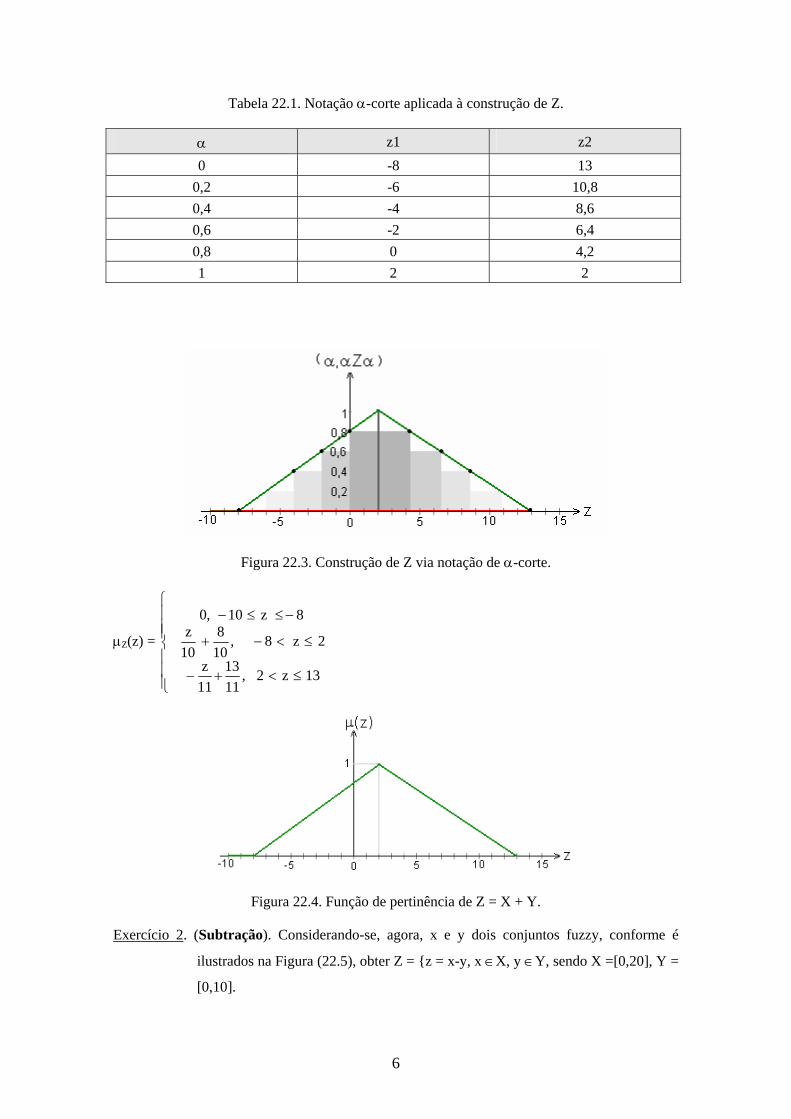
6
Tabela 22.1. Notação -corte aplicada à construção de Z.
z1 z2
0 -8 13
0,2 -6 10,8
0,4 -4 8,6
0,6 -2 6,4
0,8 0 4,2
1 2 2
Figura 22.3. Construção de Z via notação de -corte.
Z(z) =
13z2,11
13
11
z
2z8,10
8
10
z8z10,0
Figura 22.4. Função de pertinência de Z = X + Y.
Exercício 2. (Subtração). Considerando-se, agora, x e y dois conjuntos fuzzy, conforme é
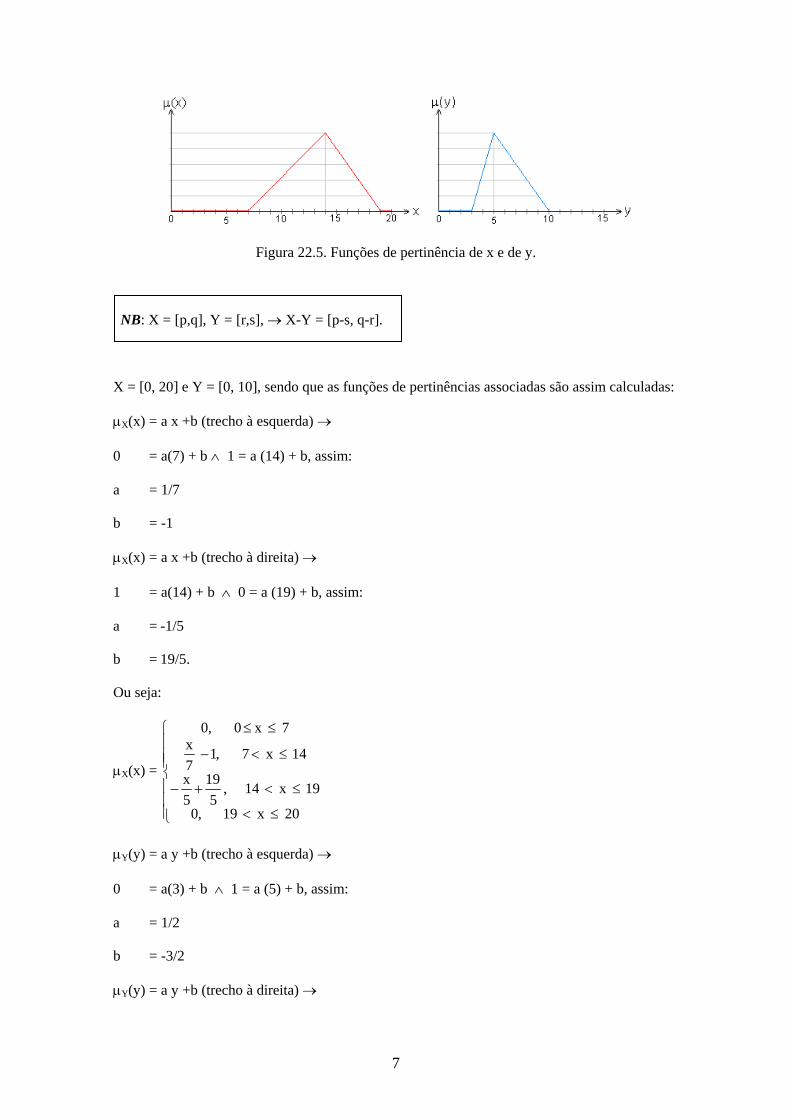
ilustrados na Figura (22.5), obter Z = {z = x-y, x X, y Y, sendo X =[0,20], Y =
[0,10].
7
Figura 22.5. Funções de pertinência de x e de y.
NB: X = [p,q], Y = [r,s], X-Y = [p-s, q-r].
X = [0, 20] e Y = [0, 10], sendo que as funções de pertinências associadas são assim calculadas:
X(x) = a x +b (trecho à esquerda)
0 = a(7) + b 1 = a (14) + b, assim:
a = 1/7
b = -1
X(x) = a x +b (trecho à direita)
1 = a(14) + b 0 = a (19) + b, assim:
a = -1/5
b = 19/5.
Ou seja:
X(x) =
20x19,0
19x14,5
19
5
x
14x7,17
x7x0,0
Y(y) = a y +b (trecho à esquerda)
0 = a(3) + b 1 = a (5) + b, assim:
a = 1/2
b = -3/2
Y(y) = a y +b (trecho à direita)
8
1 = a(5) + b 0 = a (10) + b, assim:
a = -1/5
b = 2.
Ou seja:
Y(y) =
10y5,25
y
5y3,2
3
2
y3y0,0
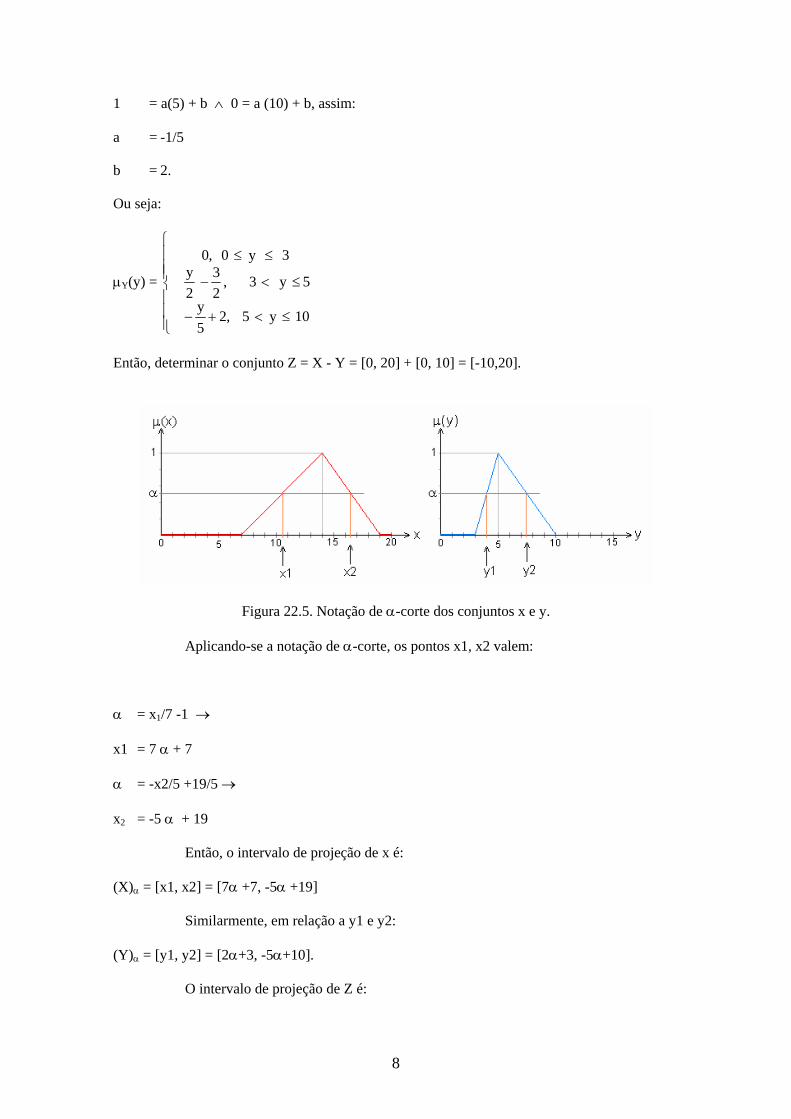
Então, determinar o conjunto Z = X - Y = [0, 20] + [0, 10] = [-10,20].
Figura 22.5. Notação de -corte dos conjuntos x e y.
Aplicando-se a notação de -corte, os pontos x1, x2 valem:
= x1/7 -1
x1 = 7 + 7
= -x2/5 +19/5
x2 = -5 + 19
Então, o intervalo de projeção de x é:
(X) = [x1, x2] = [7 +7, -5 +19]
Similarmente, em relação a y1 e y2:
(Y) = [y1, y2] = [2+3, -5+10].
O intervalo de projeção de Z é:
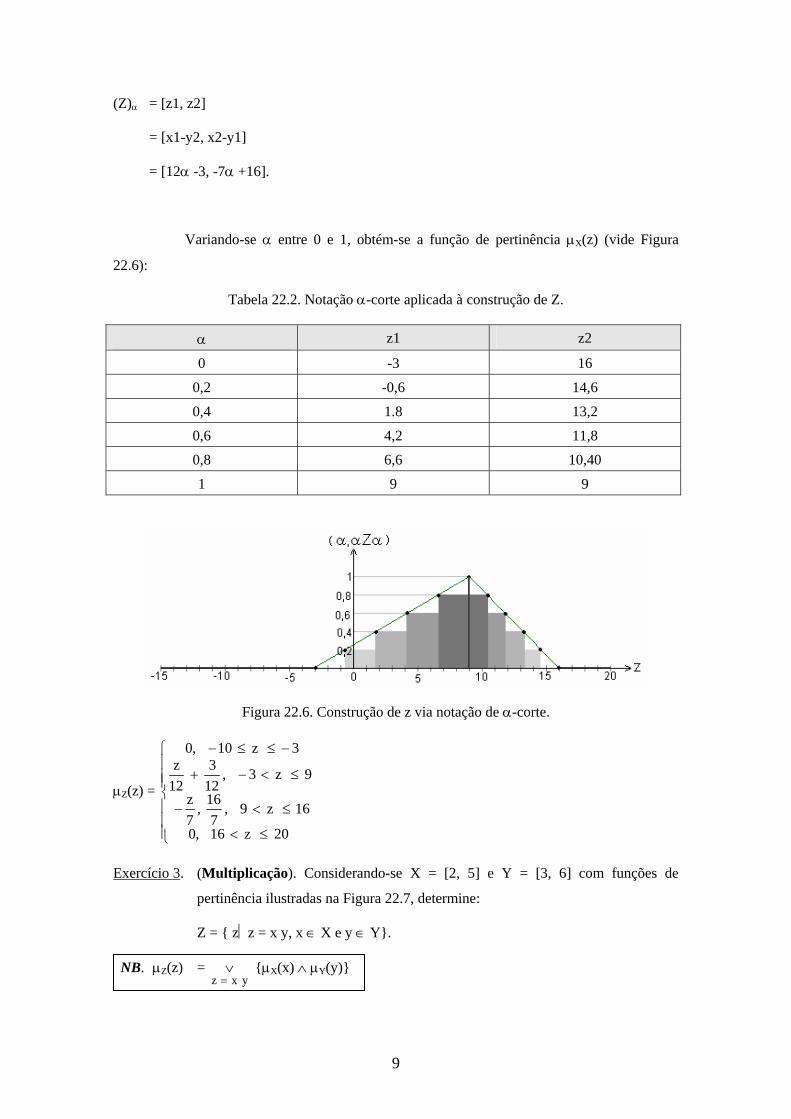
9
(Z) = [z1, z2]
= [x1-y2, x2-y1]
= [12 -3, -7 +16].
Variando-se entre 0 e 1, obtém-se a função de pertinência X(z) (vide Figura
22.6):
Tabela 22.2. Notação -corte aplicada à construção de Z.
z1 z2
0 -3 16
0,2 -0,6 14,6
0,4 1.8 13,2
0,6 4,2 11,8
0,8 6,6 10,40
1 9 9
Figura 22.6. Construção de z via notação de -corte.
Z(z) =
20z16,0
16z9,7
16,
7
z
9z3,12
3
12
z3z10,0
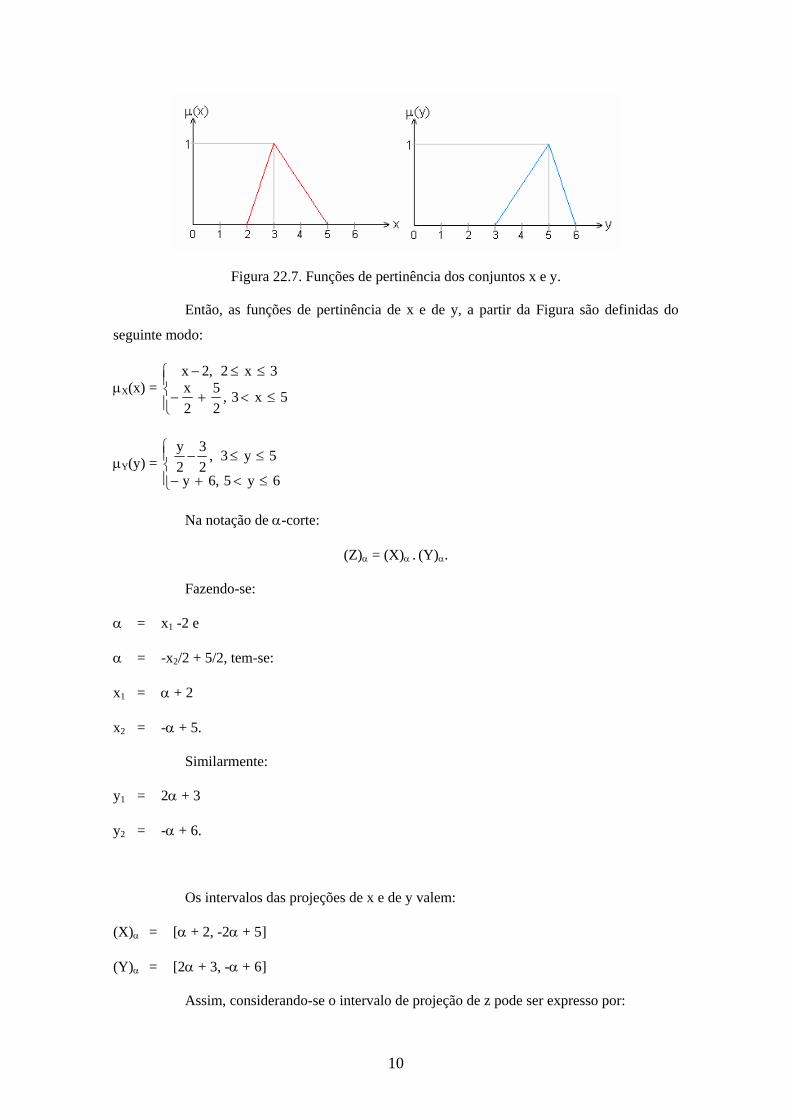
Exercício 3. (Multiplicação). Considerando-se X = [2, 5] e Y = [3, 6] com funções de
pertinência ilustradas na Figura 22.7, determine:
Z = { z z = x y, x X e y Y}.
NB. Z(z) = yxz
{X(x) Y(y)}
10
Figura 22.7. Funções de pertinência dos conjuntos x e y.
Então, as funções de pertinência de x e de y, a partir da Figura são definidas do
seguinte modo:
X(x) =
5x3,2
5
2
x3x2,2x
Y(y) =
6y5,6y
5y3,2
3
2
y
Na notação de -corte:
(Z) = (X) . (Y).
Fazendo-se:
= x1 -2 e
= -x2/2 + 5/2, tem-se:
x1 = + 2
x2 = - + 5.
Similarmente:
y1 = 2 + 3
y2 = - + 6.
Os intervalos das projeções de x e de y valem:
(X) = [ + 2, -2 + 5]
(Y) = [2 + 3, - + 6]
Assim, considerando-se o intervalo de projeção de z pode ser expresso por:
11
(Z) = [ + 2, -2 + 5] . [2 + 3, - + 6]
= yxz
{X(x) Y(y)}
= [p(), )(p ]
sendo:
p() = min[c, d, e, f]
)(p = max[c, d, e, f]
c = ( + 2) (2 + 3) = 22 +7 +6
d = ( + 2) (- + 6) = -2 + 4 +12
e = (-2 + 5) (2 + 3) = -42 + 4 +15
f = (-2 + 5) (- + 6) = 22 - 17 +30.
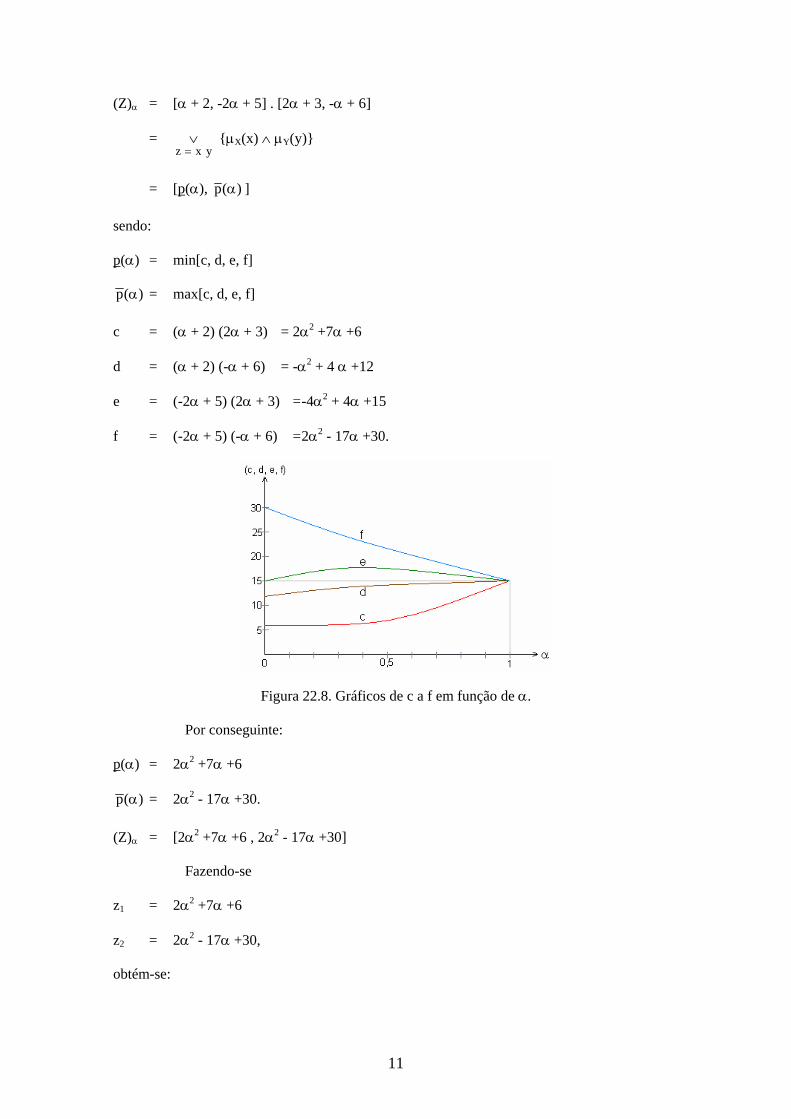
Figura 22.8. Gráficos de c a f em função de .
Por conseguinte:
p() = 22 +7 +6
)(p = 22 - 17 +30.
(Z) = [22 +7 +6 , 22 - 17 +30]
Fazendo-se
z1 = 22 +7 +6
z2 = 22 - 17 +30,
obtém-se:
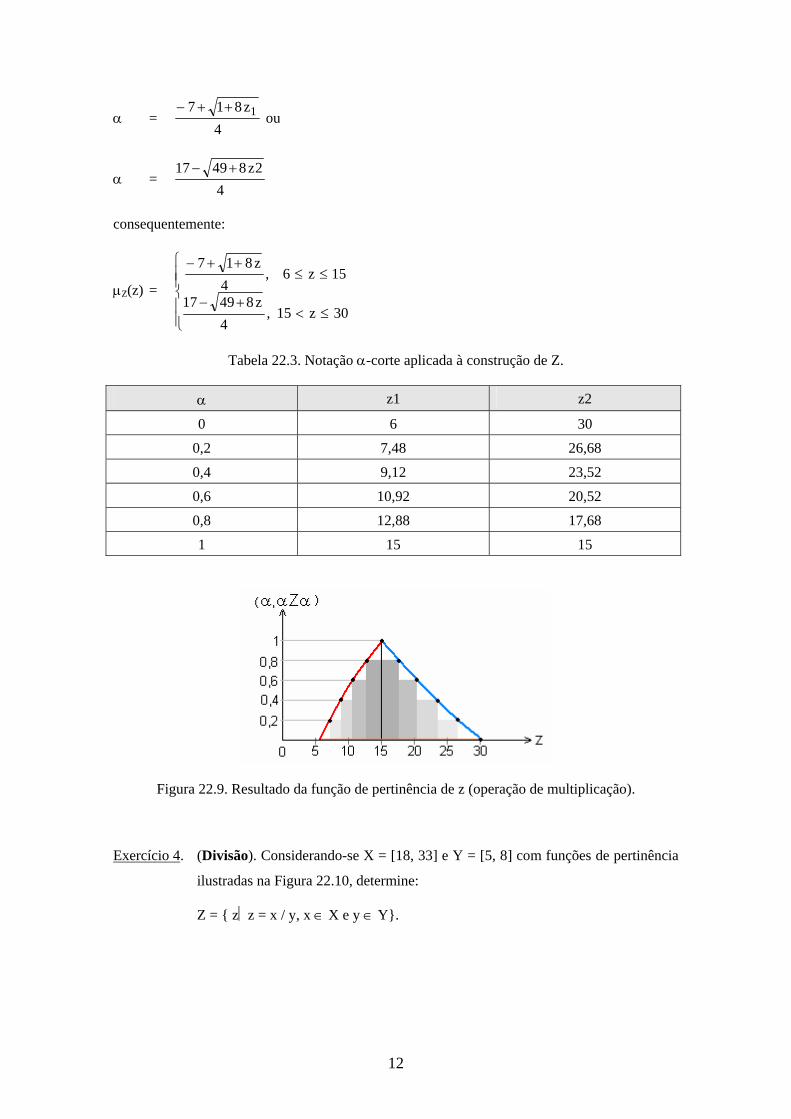
12
= 4
z817 1 ou
= 4
2z84917
consequentemente:
Z(z) =
30z15,4
z84917
15z6,4
z817
Tabela 22.3. Notação -corte aplicada à construção de Z.
z1 z2
0 6 30
0,2 7,48 26,68
0,4 9,12 23,52
0,6 10,92 20,52
0,8 12,88 17,68
1 15 15
Figura 22.9. Resultado da função de pertinência de z (operação de multiplicação).
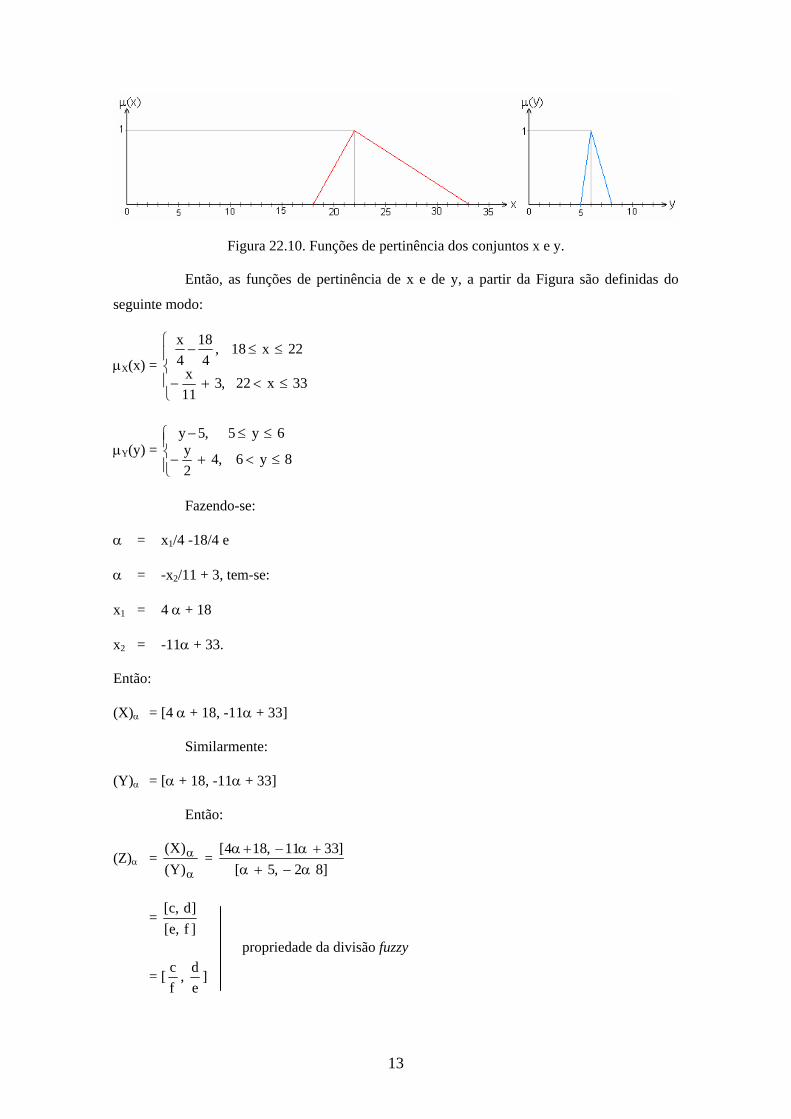
Exercício 4. (Divisão). Considerando-se X = [18, 33] e Y = [5, 8] com funções de pertinência
ilustradas na Figura 22.10, determine:
Z = { z z = x / y, x X e y Y}.
13
Figura 22.10. Funções de pertinência dos conjuntos x e y.
Então, as funções de pertinência de x e de y, a partir da Figura são definidas do
seguinte modo:
X(x) =
33x22,311
x
22x18,4
18
4
x
Y(y) =
8y6,42
y6y5,5y
Fazendo-se:
= x1/4 -18/4 e
= -x2/11 + 3, tem-se:
x1 = 4 + 18
x2 = -11 + 33.
Então:
(X) = [4 + 18, -11 + 33]
Similarmente:
(Y) = [ + 18, -11 + 33]
Então:
(Z) =
)Y(
)X( =
]82,5[
]3311,184[
= ]f,e[
]d,c[
= [f
c,
e
d]
propriedade da divisão fuzzy
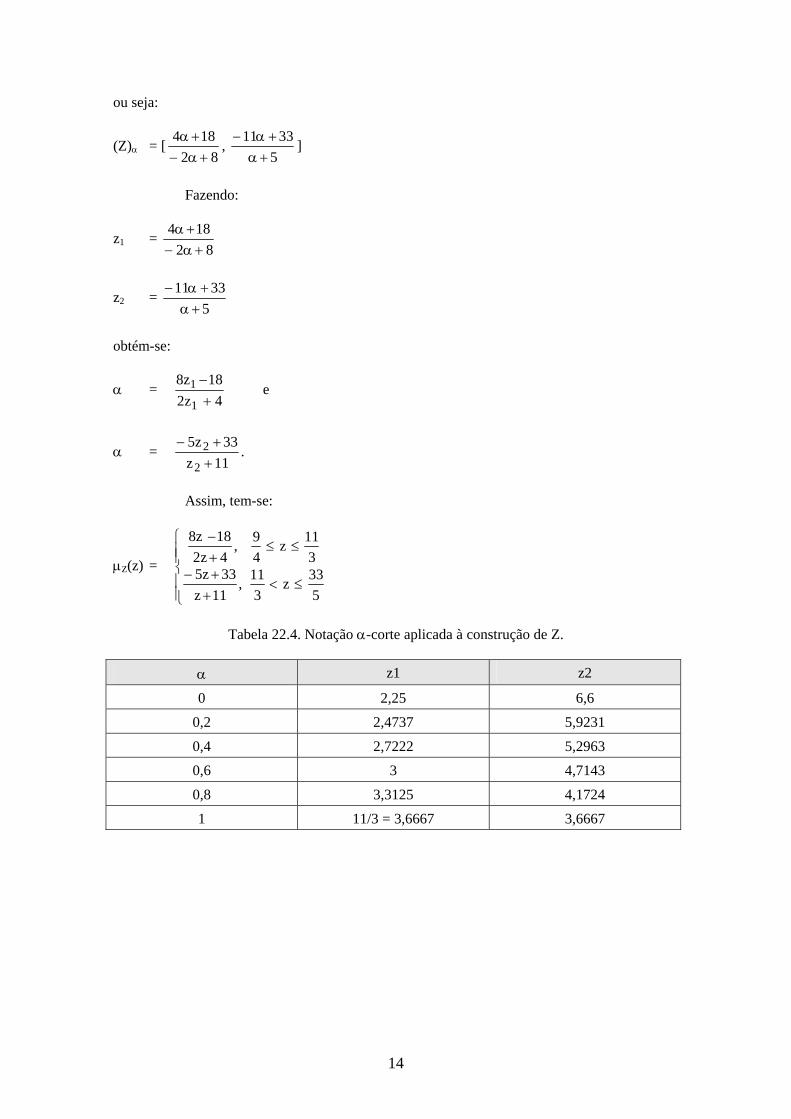
14
ou seja:
(Z) = [82
184
, 5
3311
]
Fazendo:
z1 = 82
184
z2 = 5
3311
obtém-se:
= 4z2
18z8
1
1
e
= 11z
33z5
2
2
.
Assim, tem-se:
Z(z) =
5
33z
3
11,
11z
33z53
11z
4
9,
4z2
18z8
Tabela 22.4. Notação -corte aplicada à construção de Z.
z1 z2
0 2,25 6,6
0,2 2,4737 5,9231
0,4 2,7222 5,2963
0,6 3 4,7143
0,8 3,3125 4,1724
1 11/3 = 3,6667 3,6667
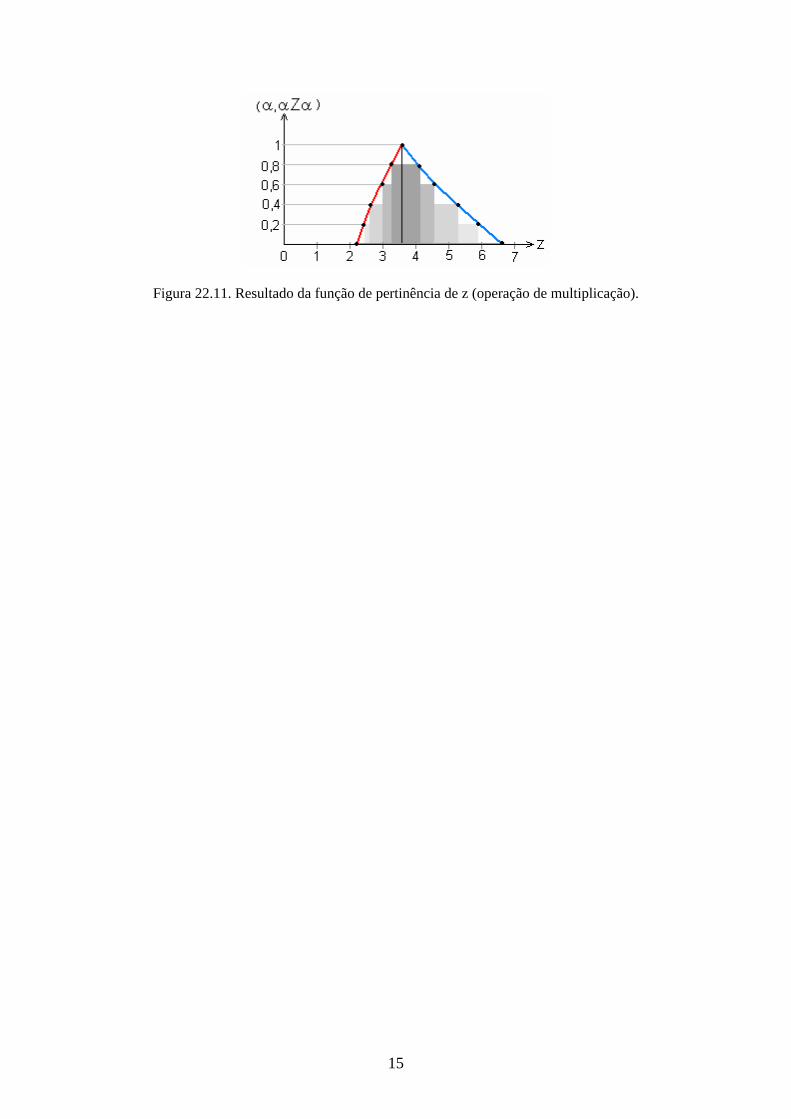
15
Figura 22.11. Resultado da função de pertinência de z (operação de multiplicação).

Universidade estadual Paulista – UNESP Campus de Ilha Solteira
Programa de Pós-Graduação em Engenharia Elétrica
Disciplina: Lógica Nebulosa
Carlos Roberto Minussi
Ilha Solteira-SP, agosto-2009.
Programação Matemática Fuzzy

1
PROGRAMAÇÃO MATEMÁTICA NEBULOSA
Problema: Min (max) FO = f(x) s.a. restrições com ambigüidade. sendo: max = maximização min = minimização FO = função objetivo s.a. = sujeito a f(x) = função objetivo (linear ou não-linear)
ou seja, determinação de solução ótima (maximização ou
minimização) de um problema com restrições. • Funções objetivos e restrições são flexíveis.
Conceitos Básicos e Formulação Geral • Funções objetivos e restrições podem ser expressas pelos
conjuntos nebulosos G e C, respectivamente. • Funções de pertinência: µG(x) ← Função objetivo µC(x) ← Restrições. • neste caso, o conjunto de decisão nebuloso D pode ser definido
por: D = C ∩ G µD(x) = µC(x) ∧ µG(x). sendo: ∧ = operador min.
D =

2
• Isto significa que deve satisfazer tanto as restrições, assim como as funções objetivos.
• A função de pertinência do conjunto de decisão nebulosa D, µD(x),
expressa o grau (ou margem) que a solução se encontra em D. • Se µD(x) < µD(x’) (sentido maximização), então, x’ é uma melhor
decisão de x. • Deste modo, pode-se selecionar x* tal que: max µD(x) = max µC(x) ∧ µG(x) = µC(x*) ∧ µG(x*) (1) x x sendo: x* = solução ótima (maximização). • A decisão maximizada é definida por operações max e min. • Assume-se que existem dois conjuntos nebulosos µ1(x) e µ2(x), e
funções f e g que combinam µ1 e µ2 com AND e OR definidas como f e g:
[0,1] x [0,1] → [0,1], mais especificamente: (µ1 AND µ2) (x) = f(µ1(x), µ2(x)) (associada ao operador min) (µ1 OR µ2) (x) = g(µ1(x), µ2(x)) (associada ao operador max) • Por simplicidade de notação, fazem-se µ1(x) = α e µ2(x) = β. Por
conseguinte, as funções f e g são expressas como f(α,β) e g(α,β).
Axiomas para f e g (Axioma = Premissa imediatamente evidente que se admite como
universalmente verdadeira sem exigência de demonstração).
(1) f e g são funções contínuas e não-descendentes (2) f e g são simétricas para α e β: f(α,β) = f(β, α) e

3
g(α,β) = g(β, α) (3) f(α,α) e g(β,β) são funções estritamente crescentes (4) f(α,β) < min[α,β] e g(α,β) > max [α,β] (5) f(1,1) = 1 e g(0,0) = 0
(6) {µ1 AND (µ2 OR µ3)}(x) = {(µ1 AND µ2) OR (µ1 AND µ3)}(x).
Teorema. As funções f e g que satisfazem os Axiomas (1) − (6) são limitadas para: f(µ1,µ2) =µ1 ∧ µ2, e g(µ1,µ2) = µ1 ∨ µ2, • O problema de maximização (1) pode ser transformado no seguinte
problema de maximização, através do uso de conjuntos α-cortes: sup µD(x) = sup [ α ∧ sup µG(x)] (2) x α ∈ [0,1] x ∈ Cα sendo: Cα = {x µC(x) > α} • Se α1 < α2, tem-se: sup µG(x) > sup µG(x) x ∈ Cα1 x ∈ Cα2
isto porque: Cα1 ⊃ Cα2. • Fazendo-se: sup µG(x) = φ(α) x ∈ Cα
se a função φ(α) for contínua para α, a função α* é obtida de: α* = φ(α*).

4
se φ(α) é contínua, então, tem-se o seguinte problema de
otimização: sup µG(x), µC(x) > µG(x) (3) x para o problema (2). Reduz-se, portanto, a um problema standard
de programação matemática que não inclui o operador lógico ∧. • O conjunto nebulosos C é um conjunto nebulosos fortemente
convexo, se e somente se a seguinte relação for observada: µC(λ x + (1 - λ) y) > µC(x) ∧ µC(y); ∀ λ ∈ [0,1]. • Se a função φ(α) é contínua, o problema de programação
matemática nebulosa pode ser resolvido através da obtenção de α* tal que:
α = sup µG(x) x ∈ Cα.
Algoritmo
(1) ∀ ∂k é estabelecido para k = 1 (2) calcule
µG
k(x*) = max µG(x) x ∈ Cαk .
(3) se εk = αk - µGk(x*) > ε, vá para o passo (4), e se εk < ε,
vá para o passo (5). (4) faça:
αk+1 = a k - rk εk e k = k +1 e vá para o passo (2),
sendo: rk é escolhido (arbitrado) tal que:

5
0 < αk+1 < 1 seja observado. (5) faça:
α* = αk, encontre x* tal que:
max µG(x) = µG(x*) x ∈ Cαk
e finalize o processo.
• No algoritmo anterior, Passo (2), a solução é encontrada através de programação matemática convencional.
Programação Linear Nebulosa • PL (Programação Linear) nebulosa usando desigualdades
nebulosas. • Um problema de PL pode ser expresso por: min ou max FO = < c, x > s.a: A x < b X > 0 sendo: <. , . > = produto interno. • Em termos da lógica nebulosa, este problema pode ser formulado
do seguinte modo: < c, x > = cT x
~< z, A x
~< b, x > 0,
sendo:
~< = é uma desigualdade nebulosa;
Exemplos: A x é uma expressão em torno de b ou menor e cT x é uma expressão em torno de z ou menor.

6
Programação Linear Nebulosa
Problemas de PL nebulosa usando desigualdades • O problema: Funções objetivos / restrições são dadas pelo
seguinte sistema: min z = cT x s.a A x < b x > 0. ↑ ↓ cT x
~< z
s.a A x ~< b
x > 0.
PL nebuloso
sendo: cT x ↔ “em torno de z ou menor (about z or less)” A x ↔ “em torno de b ou menor (about b or less)”. • As funções objetivos e restrições são expressas por inequações da
seguinte forma: B x < b B = matriz A aumentada (inclusão das linhas das funções
objetivos). A i-ésima inequação “em torno de b i ou menor” é definida através
das seguintes funções de pertinência:

7
µi([Bx]i) = 1, para [Bx] i < bi 0 < µi([Bx]i) < 1, para bi < [Bx]i < bi + di µi([Bx]i) = 0, para [Bx] i > bi + di sendo: µi = função de pertinência da i-ésima inequação di = valor máximo possível do lado direito da desigualdade
(constante escolhida considerando-se as violações admissíveis).
• O problema de decisão maximizada:
max µD(x) = max µC(x) ∧ µG(x) = µC(x*) ∧ µG(x*)
x x
|_________| associado ao min {µCG(x)} ↔ min{[Bx]} consiste em encontrar x tal que: max min { µi ([Bx]i) } (4) x > 0 i sendo: µi([Bx]i) = 1, para [Bx] i < bi µi([Bx]i) = ri [Bx]i + si = 1 – ([Bx]i - bi ) / di , bi < [Bx]i < bi + di µi([Bx]i) = 0, para [Bx] i > bi + di NB.: fazendo-se: ri (bi) + si = 1 ri (bi+di) + si = 0 ri (bi) + si = 1 -ri (bi+di) - si = 0 _____________ (+) ri (bi - bi - di) = 1

8
ri = - 1/ di si = 1 - ri bi si = 1 + bi / di então: ri [Bx]i + si = - [Bx]i / di + 1 + bi / di = 1 – ([Bx]i – bi) / di • Fazendo-se a normalização das equações: bi’ = bi / di , [B’]ij = [B]ij / di e considerando-se que as restrições são lineares, o problema (4)
torna-se: max min {bi’ – [B’ x]i} (5) x > 0 i • Este problema (equação (5)) é equivalente ao seguinte problema
de PL padrão (standard): max λ (6) λ < bi’- [B’x]i para i = 1,2,3, ..., m.

9
NB.: fazendo-se: µ = r [Bx] + s r (b) + s = 0 r (b+d) + s = 1 -r (b) - s = 0 r (b + d) + s = 1 _____________ (+) r (b + d - b) = 1 r = 1/ d s = - r b s = - b / d então: µ = ([Bx] – b) / d µi([Bx]i) = 0, para [Bx] i < bi µi([Bx]i) = ri [Bx]i + si = ([Bx]i - bi ) / di , bi < [Bx] i < bi + di µi([Bx]i) = 1, para [Bx] i > bi + di

10
max min { µi ([Bx]i) } x > 0 i sendo: µi([Bx]i) = 1, para [Bx] i < bi µi([Bx]i) = ri [Bx]i + si = 1 – ([Bx]i - bi ) / di , bi < [Bx]i < bi + di µi([Bx]i) = 0, para [Bx] i > bi + di max λ (6) λ < bi’- [B’x]i para i = 1,2,3, ..., m.

11
max min { µi ([Bx]i) } x > 0 i sendo: µi([Bx]i) = 0, para [Bx] i < bi µi([Bx]i) = ri [Bx]i + si = ([Bx]i - bi ) / di , bi < [Bx] i < bi + di µi([Bx]i) = 1, para [Bx] i > bi + di max λ (6) λ < − bi’+ [B’x]i para i = 1,2,3, ..., m.

12
Exemplo: PL standard (Problema de transporte: 4 caminhões trucks) Min z = 41400 x1 + 44300 x2 + 48100 x3 + 49100 x4 x sa: 0,84 x1 + 1, 44 x2 + 2,16 x3 + 2,4 x4 > 170 16 x1 + 16 x2 + 16 x3 + 16 x4 > 1300 x1 > 6 • Solução via PL convencional: x1* = 6 x2* = 17,85 x3* = 0 x4* = 58,64 z* = 3918850 (função objetivo). • Considerando-se, agora, a ambigüidade das restrições e os dados
apresentados na seguinte tabela:
Restrição nebulosa
Item Restrição não-nebulosa
µ = 0 µ = 1
d
FO − 4.200.000 3.700.000 +500.000 1ª restrição 170 170 180 10 2ª restrição 1300 1300 1400 100 3ª restrição 6 6 12 6

13
1a restrição: “about 170 or more”, µ1(170) = 0 2a restrição: “about 1300 or more”, µ1(1300) = 0 3a restrição: “about 6 or more”, µ1(6) = 0 λ < − bi’+ [B’x]i ( para ss restrições 1, 2 e 3) 1a restrição: b1 = 170, d1 =10 → b1’ =170 / 10 = 17 λ < -17 + (0,84 x1 + 1,44 x2 + 2,16 x3 + 2,40 x4) / 10 λ < -17 + 0,084 x1 + 0,144 x2 +0,216 x3 + 0,240 x4 2a restrição: b2 = 1300, d2 = 100 →b2’ = 1300 / 100 = 13 λ < -13 + 0,16 x1 + 0,16 x2 +0,16 x3 + 0,16 x4 3a restrição: b3 = 6, d3 = 6 → b3’ = 6 / 6 = 1 λ < -1 + 0,167 x1 Função objetivo: b0 = 4.200.000, d0 = 500.000 → b0’ = 4200.000/500.000 = 8,4 λ < b0’- [B’x]0 (para a função objetivo) λ < 8,4 – 0,083 x1 - 0,0886 x2 - 0,096 x3 – 0,098 x4 x > 0.

14
Solução do Problema PL
Solução convencional Solução nebulosa
X1 = 6 X1 = 17,41 X2 = 17,85 X2 = 0 X3 = 0 X3 = 0 X4 = 58,65 X4 = 66,54
Valor para as restrições Valor para as restrições
1. 171,5 1. 174,2 2. 1300 2. 1342,4 3. 6 3. 17,4 FO = 3.918.850 FO = 3.988.257
↑ 1,7% maior do que a solução
standard.

Universidade estadual Paulista – UNESP Campus de Ilha Solteira
Programa de Pós-Graduação em Engenharia Elétrica
Disciplina: Lógica Nebulosa
Carlos Roberto Minussi
Ilha Solteira-SP, agosto-2009.
Representação do Conjunto de Regras via Matriz Fuzzy
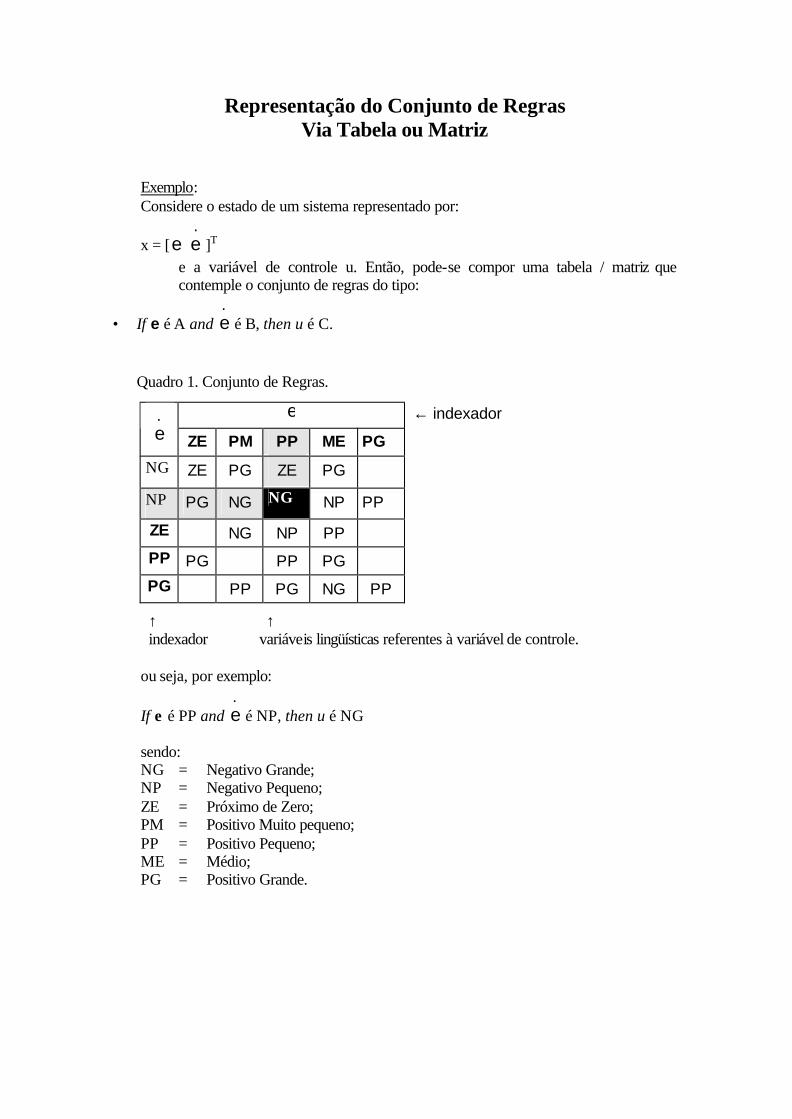
Representação do Conjunto de Regras Via Tabela ou Matriz
Exemplo: Considere o estado de um sistema representado por:
x = [.ee ]T
e a variável de controle u. Então, pode-se compor uma tabela / matriz que contemple o conjunto de regras do tipo:
• If e é A and .e é B, then u é C.
Quadro 1. Conjunto de Regras.
e ← indexador .e ZE PM PP ME PG
NG ZE PG ZE PG
NP PG NG NG NP PP
ZE NG NP PP
PP PG PP PG
PG PP PG NG PP
↑ ↑ indexador variáveis lingüísticas referentes à variável de controle. ou seja, por exemplo:
If ε é PP and .e é NP, then u é NG
sendo: NG = Negativo Grande; NP = Negativo Pequeno; ZE = Próximo de Zero; PM = Positivo Muito pequeno; PP = Positivo Pequeno; ME = Médio; PG = Positivo Grande.
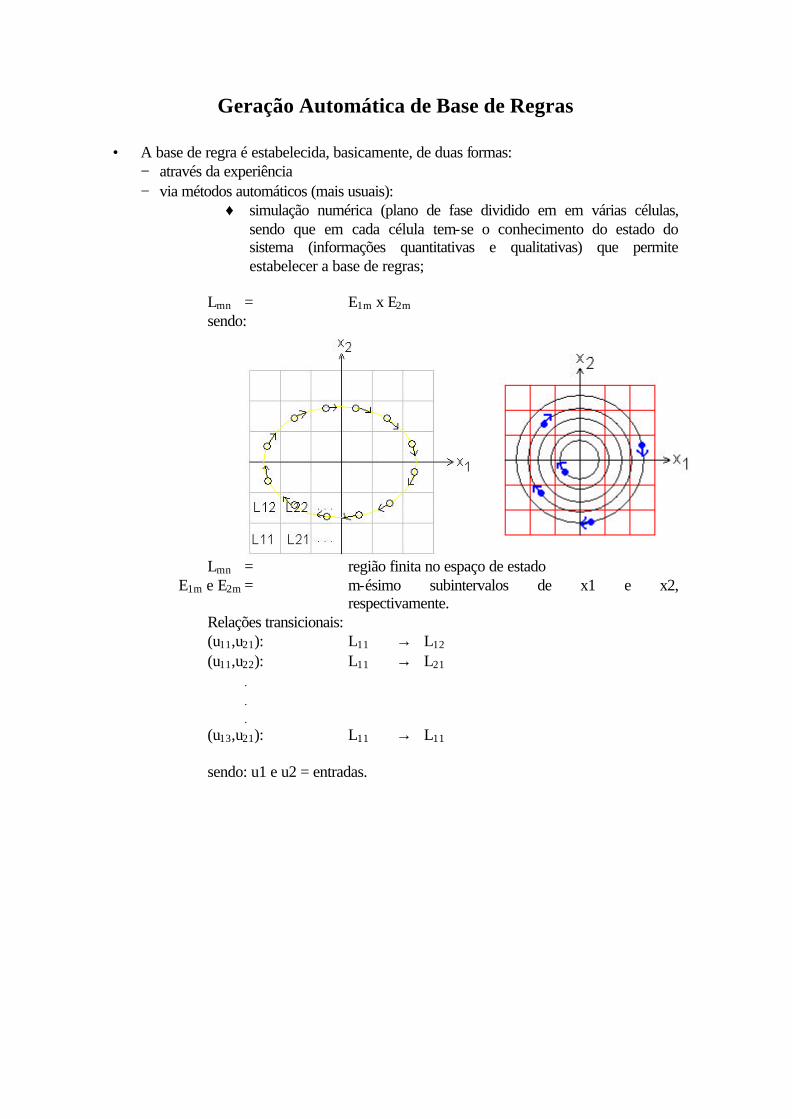
Geração Automática de Base de Regras
• A base de regra é estabelecida, basicamente, de duas formas: − através da experiência − via métodos automáticos (mais usuais):
♦ simulação numérica (plano de fase dividido em em várias células, sendo que em cada célula tem-se o conhecimento do estado do sistema (informações quantitativas e qualitativas) que permite estabelecer a base de regras;
Lmn = E1m x E2m
sendo:
Lmn = região finita no espaço de estado E1m e E2m = m-ésimo subintervalos de x1 e x2,
respectivamente. Relações transicionais: (u11,u21): L11 → L12 (u11,u22): L11 → L21
.
.
.
(u13,u21): L11 → L11
sendo: u1 e u2 = entradas.
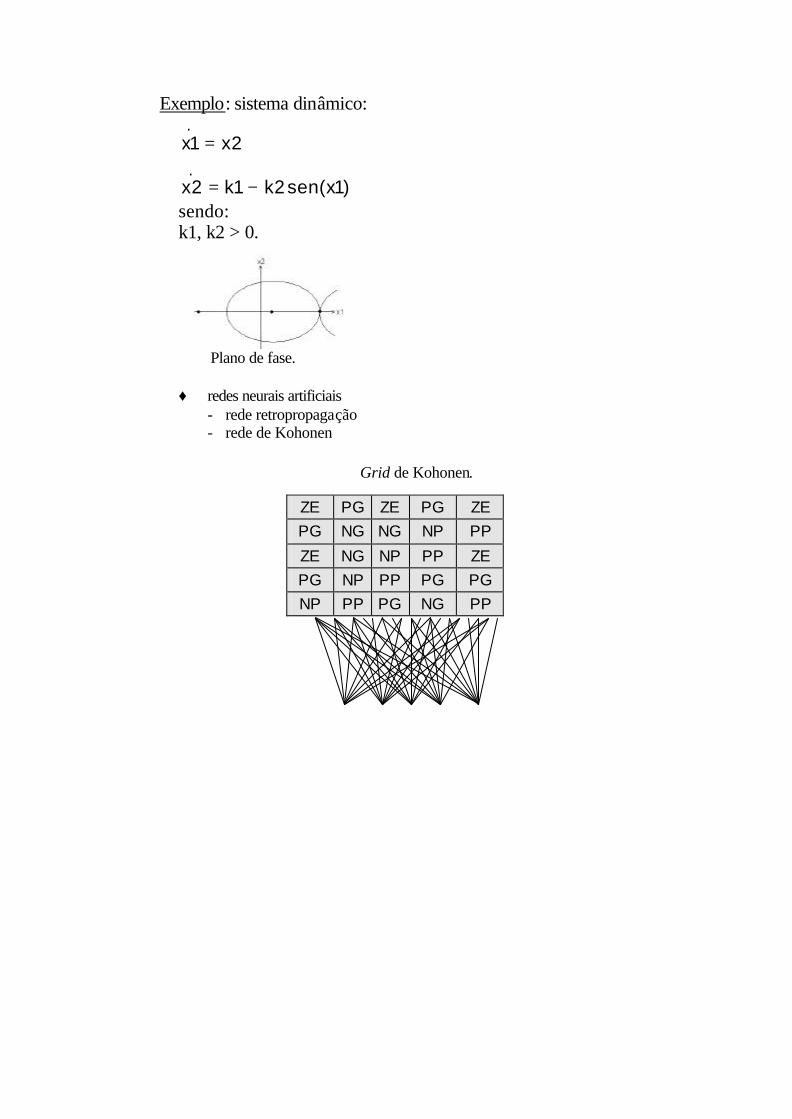
Exemplo: sistema dinâmico:
)1x(sen2k1k2x
2x1x.
.
−=
=
sendo: k1, k2 > 0.
Plano de fase.
♦ redes neurais artificiais - rede retropropagação
- rede de Kohonen
Grid de Kohonen.
ZE PG ZE PG ZE PG NG NG NP PP
ZE NG NP PP ZE PG NP PP PG PG NP PP PG NG PP

Rede Neural de Kohonen
A rede de Kohonen é uma rede neural não-supervisionada de mapeamentos
auto-organizável, conforme mostrada na Figura 1. É composta por um reticulado
(grade) bi-dimensional e um conjunto de vetores pesos, fixado inicialmente
considerando-se valores aleatórios compreendidos entre 0 e 1, wj = [ w1j w2j . . . wnj]T ,
1 = 1, . . . , nn, e x = [ x1 x2 . . . xn]T um vetor de entrada, sendo nn o número de
neurônios sobre a grade da rede neural. Trata-se, portanto, de um mapeamento de ℜn em
ℜ2.
Figura 1. Estrutura da rede neural de Kohonen.
Cada neurônio sobre a grade está conectado a entrada da rede, através do
vetor de entrada, conforme é mostrado na Figura 2.
Figura 2. Conexão do vetor padrão de entrada x com o j-ésimo neurônio da rede de
Kohonen.

Deste modo, a saída yj (atividade do j-ésimo neurônio) pode ser calculado
da seguinte forma:
yj = < wj, x> (1)
sendo:
yj = atividade (saída) do j-ésimo neurônio sobre a grade de Kohonen;
wj = [ w1j w2j . . . wnj]T
x = [x1 x2 . . . xn]T
NB:
• Kohonen propôs esta rede baseada na regra de aprendizado de Hebb (Donald
Hebb). Propôs, por conseguinte, um procedimento sistemático e simplificado do
método de Hebb;
• o aprendizado é similar ao que ocorre no cérebro (neo-cortex cerebral).
O treinamento (ou aprendizagem) é um processo através do qual os
parâmetros de uma rede neural artificial são ajustados utilizando uma forma contínua de
estímulos. No caso do treinamento por competição, dado um estímulo à rede (vetor de
entrada), as unidades de saída disputam entre si para serem ativadas. O neurônio
vencedor terá seus pesos atualizados no treinamento. A forma mais extrema de
competição entre neurônios é chamada o vencedor leva tudo (winner take all). Como o
próprio nome sugere, apenas um neurônio terá sua saída ativada. Já o mapeamento auto-
organizável, proposto por Kohonen, que organiza os dados de entrada em agrupamentos
(clusters), corresponde a um tipo de treinamento competitiva e não-supervisionada.
Nesta forma de treinamento, as unidades que atualizam seus pesos, o fazem formando
um novo vetor peso que é uma combinação linear dos pesos antigos e o atual vetor de
entrada. O método consiste na adaptação de pesos da rede neural como mostrado na
Figura 3 em que os vetores x e w encontram-se normalizados (comprimentos unitários).
Considera-se um determinado vetor de pesos w(h) correspondente ao tempo discreto h.
O novo valor w(h+1) pode ser encontrado da seguinte forma:
w(h+1) = w(h) + α (x – w(h) ). (2) sendo:
α = taxa de treinamento (0 < α < 1);
h = índice de atualização.

A taxa de treinamento α pode ser um valor constante ou uma função
decrescente.
Figura 3. Regra de adaptação de pesos da rede de Kohonen.
O comprimento do vetor w, em cada atualização, será menor do que 1.
Portanto, após cada adaptação de pesos, há necessidade de uma nova normalização do
vetor de pesos.
O neurônio vencedor é escolhido como sendo aquele que apresentar maior
atividade (y) sobre a grade de Kohonen, ou seja:
NV = i
max {<wi, x>} (3)
ou: = i
min { || x – wi ||} (4)
sendo:
NV = neurônio vencedor;
|| . || = norma Euclidiana.
Ao neurônio vencedor (Equação 3), atribui-se índice k. Deve-se observar
que, quando os vetores wi e x encontram-se normalizados (comprimentos unitários), as
indicações do neurônio vencedor, através do máximo produto interno (Equação 3), ou
através da mínima distância (Equação 4), são rigorosamente as mesmas, ou seja, estes
dois procedimentos são equivalentes. Usando-se, então, a regra de adaptação, Kohonen

propôs que o ajuste da rede neural em que os pesos são ajustados considerando-se
vizinhanças em torno do neurônio vencedor, como mostrado na Figura 4, sendo:
NCk(Si) = vizinhança do neurônio vencedor k, referente à região Si, em que
S1 ⊂ (contido) S2 ⊂ S3.
Figura 4. Vizinhanças (quadradas) do neurônio vencedor.
Na Figura 5 são mostrados alguns tipos mais freqüentes de vizinhanças
encontrados na literatura especializada.
Figura 5. Tipos de vizinhanças mais utilizadas.
Algoritmo (conceitual) Básico
Passo 1. Iniciar os pesos da rede de Kohonen entre a entrada e a grade de Kohonen.
Estes pesos podem ser gerados randomicamente com valores compreendidos
entre 0 e 1.

Passo 2. Normalizar os vetores de pesos.
Passo 3. Normalizar todos os vetores padrões de entrada.
Passo 4. Apresentar um novo vetor padrão de entrada. O conjunto de vetores padrões
contém M vetores).
Passo 5. Calcular a distância ou o produto interno para todos os neurônios sobre a
grade de Kohonen.
Passo 6. Encontrar o neurônio vencedor (Equação 3 ou 4). Designe o neurônio
vencedor pelo índice k.
Passo 7. Adaptar os vetores pesos do neurônio vencedor e dos demais neurônios
contidos na vizinhança escolhida (vide Figura 4).
wi (h+1) = wi(h)+ α (x – wi (h)), para i ∈ NCk. (5)
wi (h+1) = wi(h), para i ∉ NCk.
Passo 8. Renormalisar todos os vetores de pesos adaptados no passo 7. Este
procedimento se faz necessário tendo em vista que o vetor peso, após a
adaptação, não possui comprimento unitário, sendo portanto, necessário
torná-lo (com comprimento unitário).
Passo 9. Retornar ao Passo 2. Este procedimento deve ser repetido, considerando-se
um número fixo de ciclos de adaptação, ou até que as variações (módulos)
dos pesos sejam inferiores a uma certa tolerância preestabelecida.
NB:
• No algoritmo anterior, um ciclo de adaptação é concluído após ter sido apresentado
todos os vetores padrões ()p(
x , p = 1, 2, . . ., M, sendo M = número de vetores
padrões).

• A ordem de entrada dos vetores pode ser natural (ordem em que são fornecidos para
a leitura) ou aleatória. Ressalta-se que a ordem aleatória proporciona melhores
resultados, se comparada à ordem natural.
• A auto-organização se dá à medida que aumente o número de ciclos de adaptação.
• Treinamento lento.
• Aumento da velocidade de treinamento:
− Uso do conceito de consciência ([1]);
− Uso de lógica nebulosa ([4]).
Referências Bibliográficas
[1] DeSieno, D. “Adding a Conscience to Competitive Learning”, IEEE International
Conference Neural Networks, San Diego, CA, 1987, vol. 1, pp. 117-124.
[2] Kohonen, T. “Self-organization and Associative Memory”, Springer-Verlag, 2nd
Edition, Berling, Germany, 1989.
[3] Kohonen, T. “Self-organizing Map”, Proceedings of IEEE, 1990, pp. 1464 – 1480,
vol 78, no. 09.
[4] Terano, T.; Asai, K. and Sugeno, M. Fuzzy Systems Theory and its Application,
Academic Press, New York, USA, 1987.
1
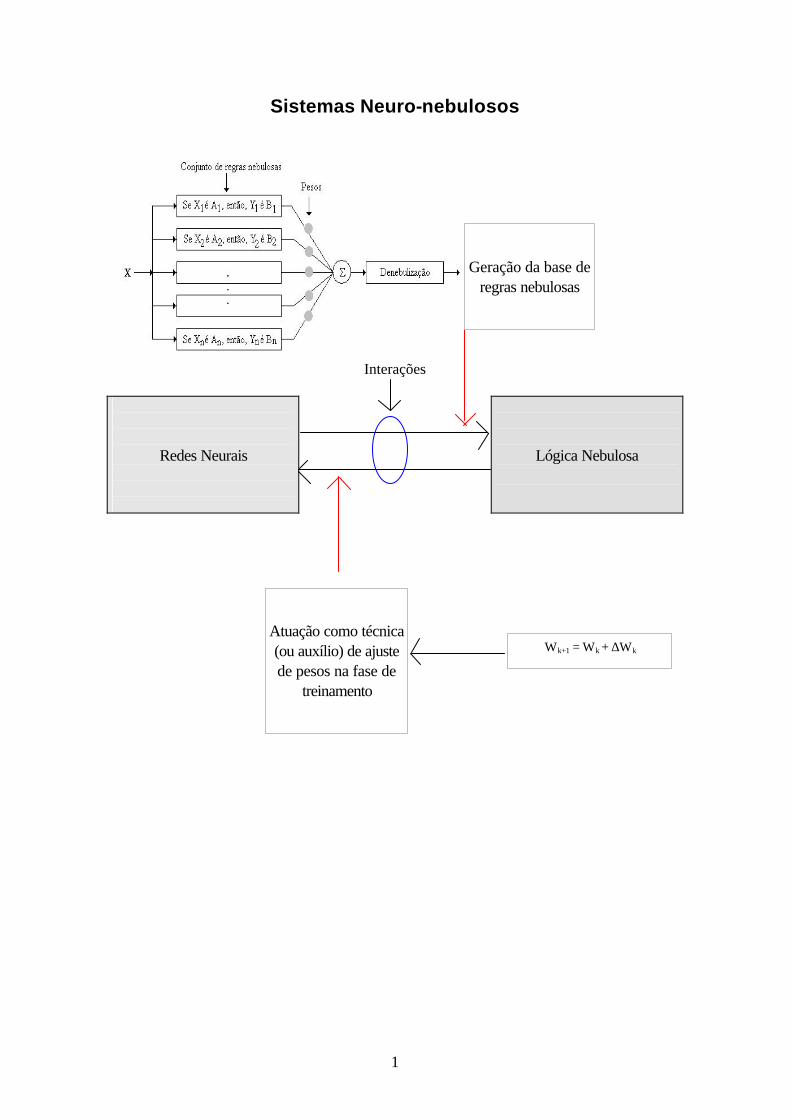
Sistemas Neuro-nebulosos
Interações
Redes Neurais
Lógica Nebulosa
Geração da base de
regras nebulosas
Atuação como técnica (ou auxílio) de ajuste de pesos na fase de
treinamento
Wk+1 = Wk + ∆Wk
2
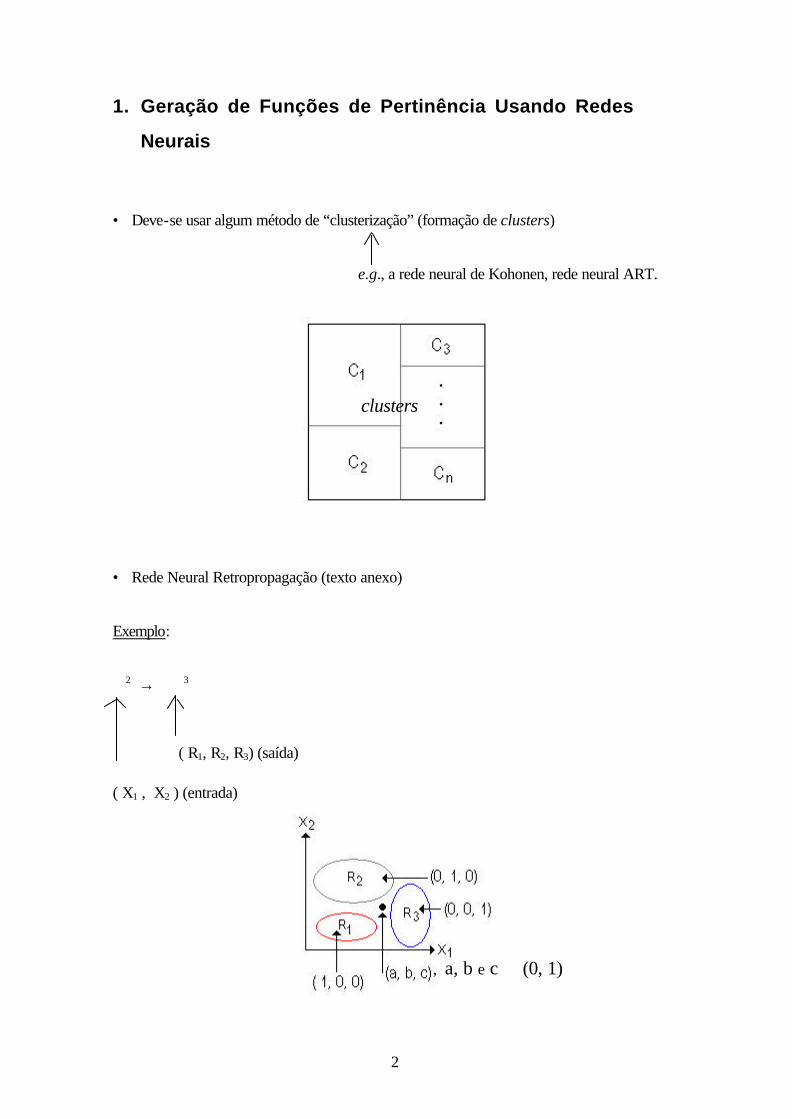
1. Geração de Funções de Pertinência Usando Redes
Neurais
• Deve-se usar algum método de “clusterização” (formação de clusters)
e.g., a rede neural de Kohonen, rede neural ART.
• Rede Neural Retropropagação (texto anexo)
Exemplo:
ℜ2 → ℜ3
( R1, R2, R3) (saída) ( X1 , X2 ) (entrada)
clusters
, a, b e c ∈ (0, 1)
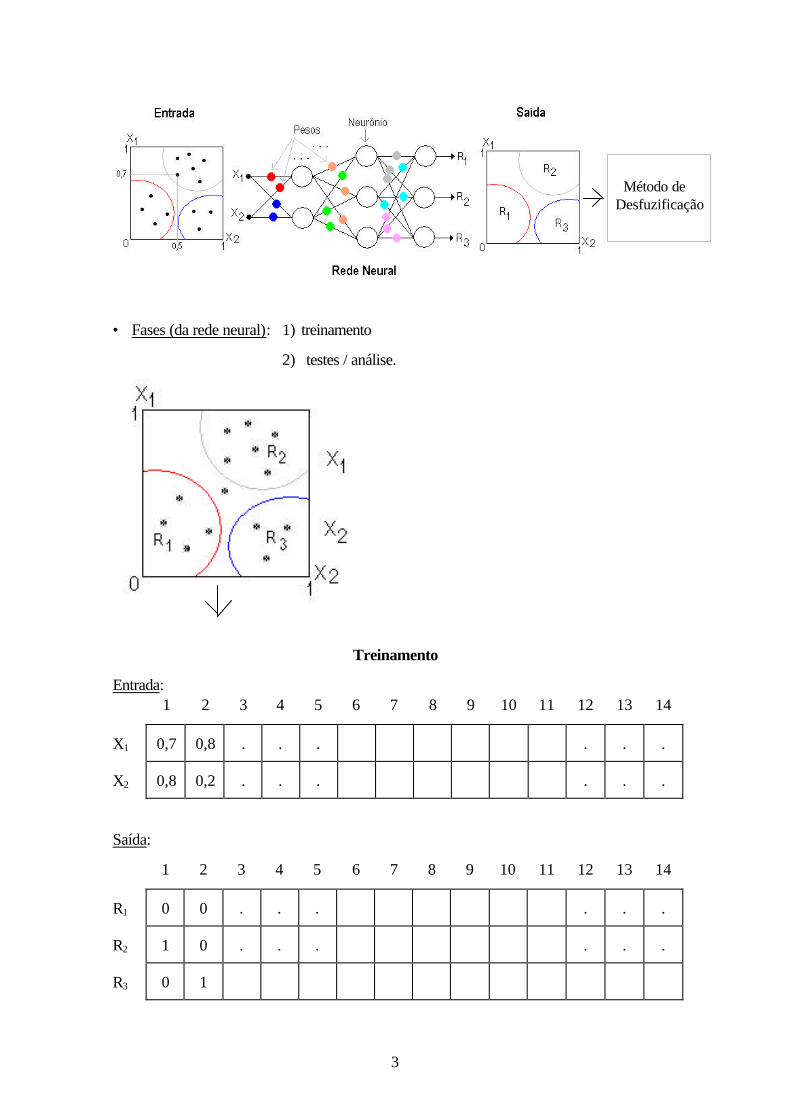
3
• Fases (da rede neural): 1) treinamento
2) testes / análise.
Treinamento
Entrada: 1 2 3 4 5 6 7 8 9 10 11 12 13 14
X1 0,7 0,8 . . . . . .
X2 0,8 0,2 . . . . . .
Saída:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
R1 0 0 . . . . . .
R2 1 0 . . . . . .
R3 0 1
Método de Desfuzificação
4
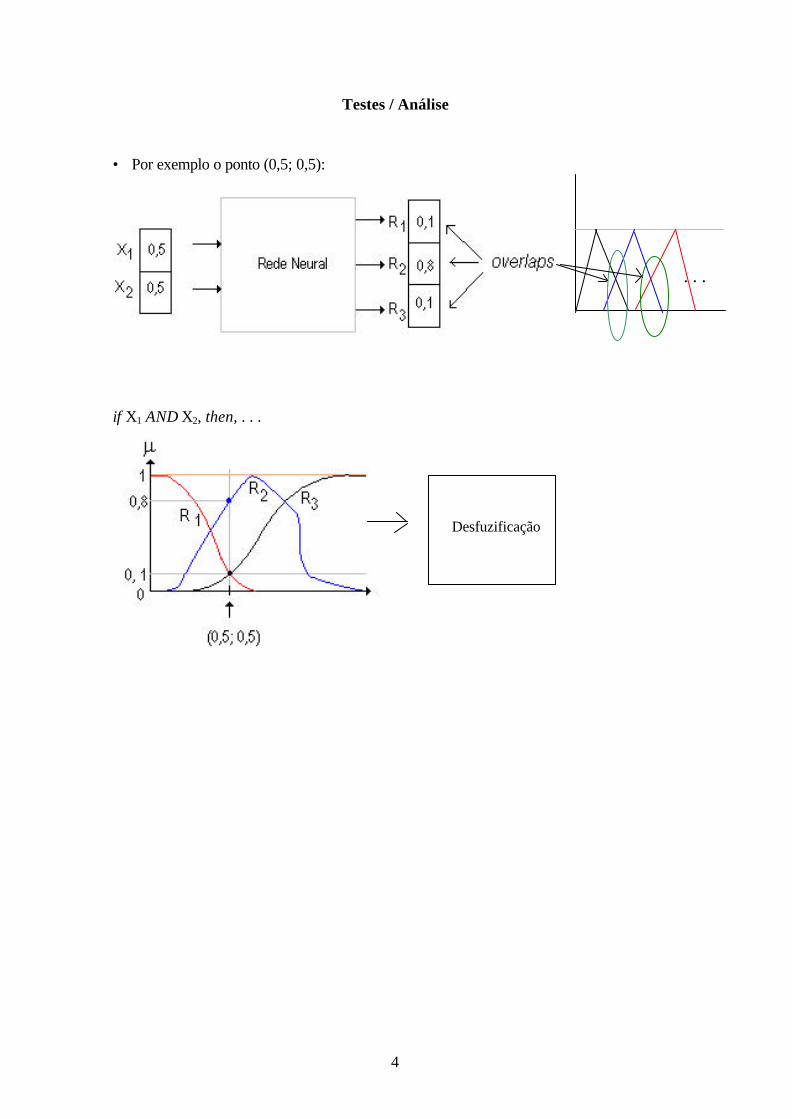
Testes / Análise
• Por exemplo o ponto (0,5; 0,5):
if X1 AND X2, then, . . .
Desfuzificação
. . .
5
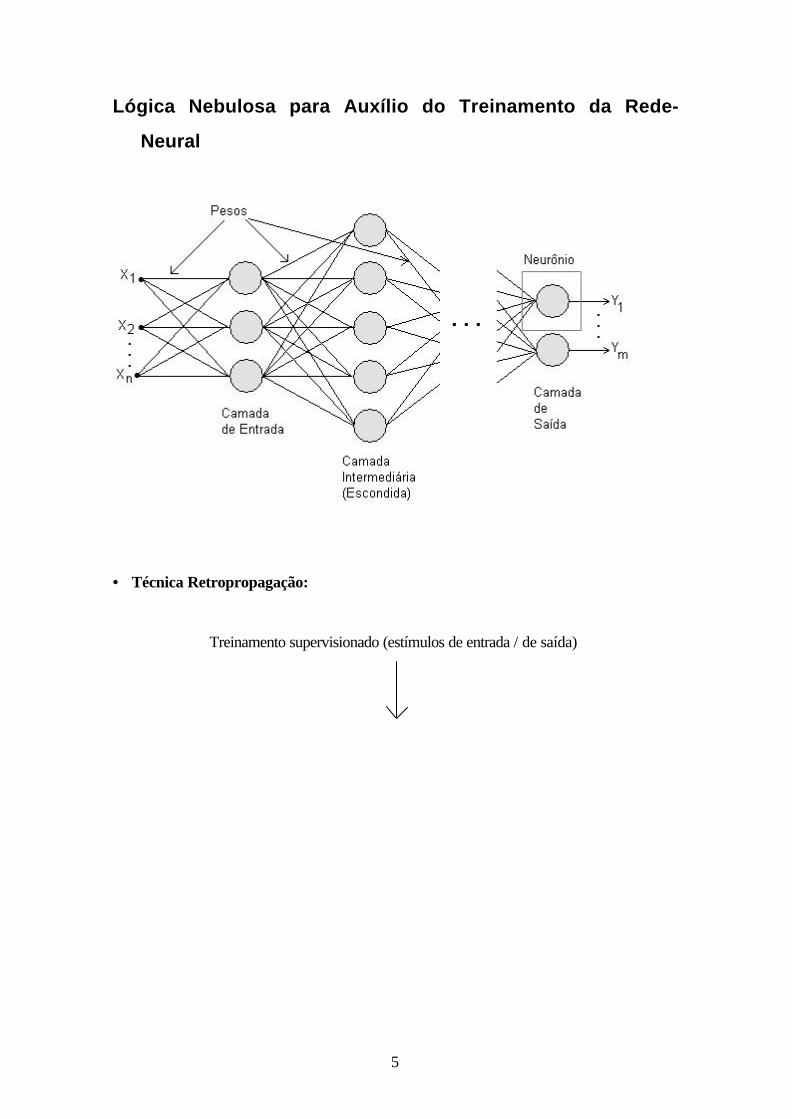
Lógica Nebulosa para Auxílio do Treinamento da Rede-
Neural
• Técnica Retropropagação:
Treinamento supervisionado (estímulos de entrada / de saída)
6
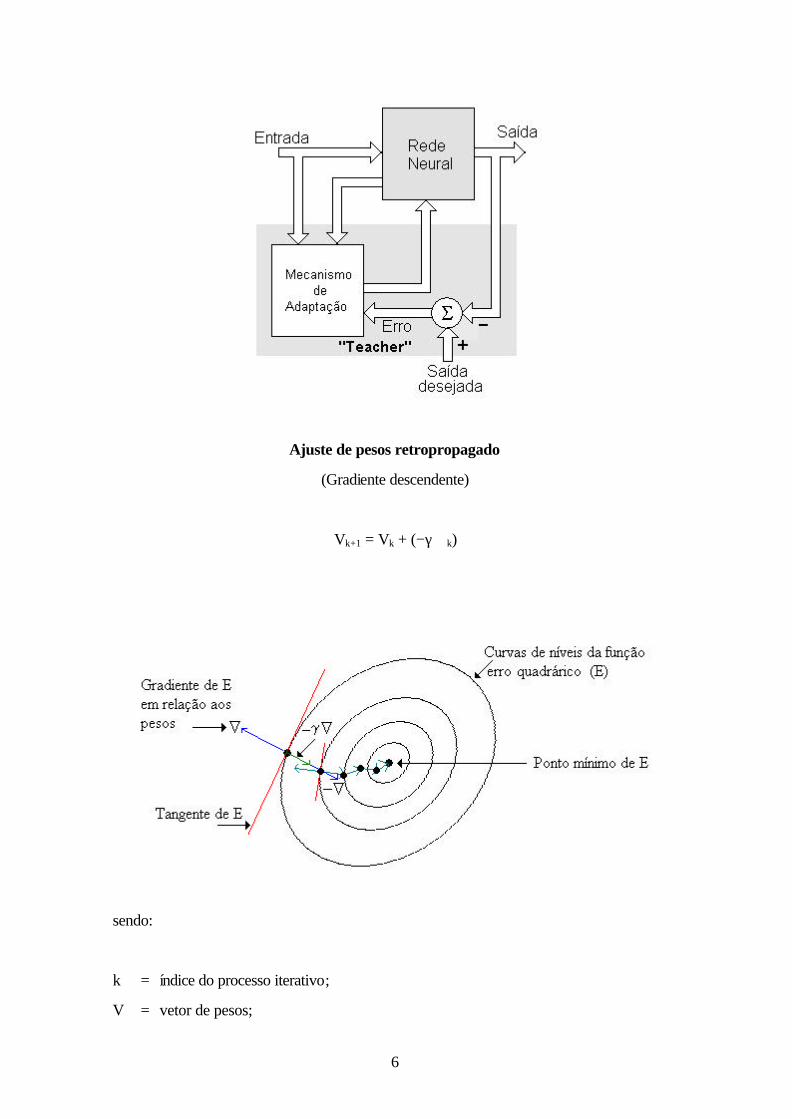
Ajuste de pesos retropropagado
(Gradiente descendente)
Vk+1 = Vk + (−γ ∇k)
sendo:
k = índice do processo iterativo;
V = vetor de pesos;

7
∇ = função gradiente;
γ = taxa de treinamento.
O algoritmo Retropropagação (RP) consiste na adaptação de pesos, tal que, é
minimizado o erro quadrático da rede. A soma do erro quadrático instantâneo de cada
neurônio alocado na última camada (saída da rede) é dada por:
∑ ε=ε=
ns
1i
2i
2 (1)
sendo:
ε i = di − yi ;
di = saída desejada do i-ésimo elemento da última camada da rede;
y i = saída do i-ésimo elemento da última camada da rede;
ns = número de neurônios da última camada da rede.
Considerando-se o neurônio de índice i da rede, e utilizando-se o método do
gradiente descendente, o ajuste de pesos pode ser formulado como:
Vi (h+1) = Vi
(h) + θ i (h) (2)
sendo:
θ i (h) = − γ [∇i (h)] (3)
γ = parâmetro de controle da estabilidade ou taxa de treinamento;
h = representa o índice de iteração;
∇i (h) = gradiente do erro quadrático com relação aos pesos do neurônio i avaliado em h;
Vi = vetor contendo os pesos do neurônio i
= [ w0i w1i w2i . . . wni ] T .

8
Na equação (3) a direção adotada para minimizar a função objetivo do erro
quadrático corresponde à direção contrária ao gradiente. O parâmetro γ determina o
comprimento do vetor [θi(h)].
A função sigmóide é definida por:
yi = {1 − exp (− λ si )} / {1 + exp (− λ si )} (4)
ou
yi = 1 / {1 + exp (− λ si )} (5)
sendo:
λ = constante que determina a inclinação da curva yi
O algoritmo RP é abordado na literatura sob várias formas com o propósito de
torná-lo mais rápido computacionalmente. Uma formulação bastante interessante é o
algoritmo RP com momento.
Então, efetuando-se o cálculo do gradiente como indicado na equação (3),
considerando-se a função sigmóide definida pela equação (4) ou (5) e o termo momento,
obtém-se o seguinte esquema de adaptação de pesos:
v ij (h+1) = v ij (h) + ∆v ij (h) (6)
sendo:
∆v ij (h) = 2 γ (1 − η) β j x i + η ∆v ij (h-1); (7)
v ij = peso correspondente à interligação entre o i-ésimo e j-ésimo neurônio;
γ = taxa de treinamento;

9
η = constante momento (0 ≤ η < 1).
Se o elemento j encontrar-se na última camada, então:
β j = σj ε j (8)
em que:
σj = derivada da função sigmóide dada pela equação (4) ou (5), respectivamente, com
relação a sj
= 0,5 λ (1 − yj 2 ) (9)
= λ yj (1 − yj ). (10)
Se o elemento j encontrar-se nas demais camadas, tem-se:
β j = σj ∑∈ )j(Rk
wjk βk (11)
sendo:
R(j) = conjunto dos índices dos elementos que se encontram na fileira seguinte à fileira do
elemento j e que estão interligados ao elemento j.
O parâmetro γ serve como controle de estabilidade do processo iterativo.
Os pesos da rede são iniciados randomicamente considerando-se o intervalo
{0,1}.
O treinamento, via RP, pode ser efetuado, basicamente, de duas formas:
• Procedimento 1. Consiste em ajustar os pesos da rede (considerando-
se todas as camadas), fazendo-se com que haja convergência para cada padrão, até que se
complete o conjunto de padrões de entrada. O processo deverá ser repetido até a total

10
convergência, i.e., o erro quadrático seja inferior a uma tolerância preestabelecida para os
padrões considerados.
• Procedimento 2. Este procedimento é idêntico ao primeiro, porém,
fazendo-se somente uma iteração (ajuste de pesos) por padrão.
O algoritmo retropropagação é considerado, na literatura especializada, um referencial
em termos de precisão. Contudo, a sua convergência é bastante lenta. Deste modo, a
proposta deste trabalho é o ajuste da taxa de treinamento γ durante o processo de
convergência, visando a redução do tempo de execução do treinamento. O ajuste de γ é
efetuado via procedimento baseado em um controlador nebuloso.
A idéia básica da metodologia consiste na determinação do estado do sistema definido
como sendo o erro global εg e a variação do erro global ∆εg, cujo objetivo é a obtenção de
uma estrutura de controle que consiga com que o erro tenda para zero em um número
reduzido de iterações, se comparado ao RP convencional. O controle, neste trabalho, é
formulado usando os conceitos de lógica nebulosa. O erro global εg e sua variação ∆εg são
os componentes do estado do sistema, e ∆γ é a ação de controle que deve ser exercida no
sistema. Inicialmente, define-se o erro global:
∑ ε∑=ε==
ns
1i
2i
np
1jg (12)
sendo:
εg = erro global da rede neural;
np = número de vetores padrões da rede.
O erro global corresponde ao cálculo de erros de todas as saídas (neurônios de saída),
considerando-se todos os vetores padrões da rede. O treinamento deve ser executado
utilizando o procedimento 2 (uma iteração por padrão). O erro global é calculado em cada
iteração e ajustado o parâmetro γ, através de um acréscimo ∆γ determinado via lógica
nebulosa. Este parâmetro será utilizado para ajustar o conjunto de pesos da rede referente à
iteração subseqüente. O estado do sistema e a ação de controle são assim definidos:

11
Ek = [εgk ∆εgk ] T (13)
uk = ∆γ (14)
sendo:
k = o índice que indica a iteração corrente.
O processo deverá, então, ser repetido até que o treinamento seja concluído. Trata-se de
um procedimento bastante simples cujo sistema de controle requer um esforço adicional
bastante reduzido, tendo em vista que o controlador possui duas variáveis de entrada e uma
única de saída. Esta abordagem é uma versão da proposta apresentada na referência
Arabshahi et al. (1996), ou seja, utilizando-se as mesmas variáveis εg e ∆εg para efetuar o
controle. Contudo, a proposta do controlador nebuloso é original.
Lógica Nebulosa
Lógica nebulosa é uma forma matemática para representação de definições
vagas. Conjuntos nebulosos são generalizações da teoria de conjunto convencional. Contém
objetos que contemplam imprecisão no referido conjunto. O grau de pertinência é definido
por um valor da função de pertinência a qual tem valores compreendidos entre 0 e +1. Deste
modo, a seguir são apresentados os principais conceitos sobre lógica nebulosa.
Definição 1. Considere uma coleção de objetos Z. Então, um conjunto nebuloso A em Z é
definido como sendo o conjunto de pares ordenados:
A = {(z,µA (z))| z ∈ Z} (15)
sendo:
µA (z) = valor da função de pertinência do conjunto nebuloso A correspondente ao
elemento z.

12
Operações semelhantes a AND, OR e NOT são alguns dos mais importantes operadores
de conjuntos nebulosos. Supondo-se que A e B são dois conjuntos nebulosos com funções de
pertinências designadas por µA (z) e µB (z), respectivamente, então, tem-se
Operador AND ou interseção de dois conjuntos. A função de pertinência da interseção
destes dois conjuntos nebulosos (C = A ∩ B) é definida por:
µC (z) = min {µA (z), µB (z)}, z ∈ Z (16)
b) Operador OR ou união entre dois conjuntos. A função de pertinência da união destes
conjuntos nebulosos (D = A ∪ B) é definida por:
µD (z) = max{µA (z), µB (z)}, z ∈ Z (17)
c) Operador NOT ou o complemento de um conjunto nebuloso. A função de pertinência
do complemento de A, A’ é definida por:
d)
µA’ (z) = 1 − µA (z), z ∈ Z (18)

13
d) Relação Nebulosa. A função nebulosa R de A em B pode ser considerada como um grafo
nebuloso e é caracterizada pela função de pertinência µR (z,y), a qual satisfaz a seguinte
regra de composição:
µB (z) = Zz
max∈
{ min [µR (z,y), µA (z)]} (19)
O controle nebuloso é um mecanismo constituído, basicamente, de três partes:
nebulização que converte variáveis reais em variáveis lingüísticas; inferência que consiste em
manipulação de base de regras utilizando declarações if-then e, ainda, operações nebulosas,
como definidas anteriormente (equações (15)−(19)) e desnebulização que converte o
resultado obtido (variáveis lingüísticas) em variáveis reais, as quais constituem a ação de
controle.
As funções de pertinência nebulosas podem ter diferentes formas, tais como triangular,
trapezoidal e gaussiana, de acordo com a preferência / experiência do projetista.
O método mais comum de desnebulização é o método de centro de área (centróide)
que encontra o centro da gravidade da solução dos conjuntos nebulosos. Para um conjunto
nebuloso discreto tem-se (Arabshahi et al., 1996; Terano et al., 1991):
u = { ∑=
n
1iµi δ i} / { ∑
=
n
1iµi} (20)
sendo:
δ i = valor do conjunto que possui um valor de pertinência µi;

14
n = número de regras nebulosas.
O valor u calculado pela equação (20) corresponde a projeção do centro de inércia da
figura definida pelo conjunto de regras sobre o eixo da variável de controle.
Cada variável de estado deverá ser representada entre 3 e 7 conjuntos nebulosos. A
variável de controle também deverá ser representada com o mesmo número de conjuntos
nebulosos. A variável εg deverá ser normalizada, considerando-se como fator de escala o
primeiro erro global gerado pela rede, ou seja, de índice k = 0. Com esta representação, o
intervalo de variação de εg deverá estar compreendido entre 0 e +1. Se a heurística de
adaptação estiver devidamente sintonizada, a convergência do processo deverá ser
exponencial decrescente. A variável ∆εg deverá variar entre –1 e +1. Se o processo de
convergência for exponencial decrescente os valores de ∆εg deverão ser sempre negativos.
Neste caso, embora a escala de ∆εg varie entre –1 e +1, deve-se empregar, no conjunto de
regras, um ajuste fino entre –1 e 0. No outro intervalo, o ajuste poderá ser mais relaxado.
(a) funções de pertinência para o erro global εg.
(b) funções de pertinência para a variação do erro global ∆εg.
(c) funções de pertinência para a ação de controle ∆γ.
Figura 1. Funções de pertinência para as variáveis εg, ∆εg e ∆γ (ação de controle).
em que:
NG = Negativo Grande;
NP = Negativo Pequeno;
ZE = Próximo de Zero;
PM = Positivo Muito pequeno;

15
PP = Positivo Pequeno;
ME = Médio;
PG = Positivo Grande;
lu = limite de variação de ∆γ.
As funções de pertinência dos conjuntos nebulosos para várias variáveis
envolvidas no treinamento da rede neural com RP com controlador nebuloso são mostradas
na Figura 1.
No controlador nebuloso, as regras são codificadas na forma de uma tabela de
decisões. Cada entrada representa o valor da variável nebulosa ∆γ dados os valores do erro
global εg e variação do erro global ∆εg. O parâmetro γ deve ser arbitrado inicialmente em
função de λ (inclinação da função sigmóide). Da mesma forma, as variações de γ também
devem seguir o mesmo procedimento. Deste modo, o parâmetro lu deve ser ajustado para
atender as especificações de cada problema e em função de λ.
Na Tabela 1 (por exemplo) é apresentado o conjunto de regras nebulosas,
totalizando 25 regras. Deste modo, tomando-se como exemplo o caso em que εg = PM e
∆εg = NG (correspondente à coluna 2 e linha 1 da parte da tabela não sombreada), a regra é
a seguinte:
• If εg é PM and ∆εg é NG, then ∆γ é PG.
As demais regras seguem esta convenção.
Tabela 1. Regras do controlador nebuloso.
εg ∆εg
ZE PM PP ME PG
NG ZE PG ZE PG ZE
NP PG NG NG NP PP
ZE ZE NG NP PP PG
PP PG NP PP PG NG
Se εg é PP e ∆εg é NP, então, ∆γ é NG

16
PG ZE PP PG NG PP
O número de regras poderá ser aumentado visando melhorar o desempenho da
rede no treinamento.
A derivada σ tem forte semelhança com a curva de distribuição normal (de
Gauss). Constitui-se de um corpo central e suas laterais designadas, como forma de
simplificação, caudas esquerda e direita. Nota-se que a diminuição de λ produz uma
suavização na função sigmóide y(s), enquanto que sua derivada σ tende a diminuir a
amplitude da curva e alongar as caudas. No algoritmo retropropagação, a adaptação de
pesos, que concorrem a cada neurônio, é efetuada utilizando-se, basicamente, o erro
propagado no sentido inverso, multiplicado por σ e pela entrada no referido neurônio. Deste
modo, os pesos têm efetivo ajuste somente para valores de s situados no corpo central da
função σ. À medida que os pesos se tornarem significativos, há desaceleração dos ajustes dos
mesmos, tendendo para a completa paralisia, justamente onde se encontram os terminais das
caudas tanto direita como esquerda.
Em vista disto, no caso específico do problema de determinação de tempos
críticos, utiliza-se a função sigmóide com λ relativamente pequeno, proporcionando caudas
mais longas. Isto permitirá a escolha de pesos da rede de forma menos restritiva, se
comparada às adotadas na bibliografia, que de certo modo diminui a possibilidade da
ocorrência de paralisia e aumenta a velocidade de convergência do algoritmo RP. Porém,
com a diminuição de λ, a magnitude dos pesos tende a crescer. Por conseguinte, a escolha de
λ deve ser feita com critério, levando-se em conta a experiência com treinamento.
O parâmetro γ (taxa de treinamento), por conveniência, pode ser redefinido do
seguinte modo:
γ = (2 γ* / λ) (para sigmóide definida pela equação (4)); (21)
ou
γ = (γ* / λ) (para sigmóide definida pela equação (5)). (22)
17
Substituindo-se as expressões de γ (equações (21) e (22)) na equação. (7), será
“anulada” a dependência da amplitude de σ com relação a λ. A amplitude de σ será mantida
constante para qualquer valor de λ. Esta alternativa torna-se mais importante tendo em vista
que λ atuará somente nas caudas esquerda e direita de σ. Assim, arbitrando-se um valor
inicial para γ*, este parâmetro será ajustado via controlador nebuloso, substituindo-se ∆γ por
∆γ*.
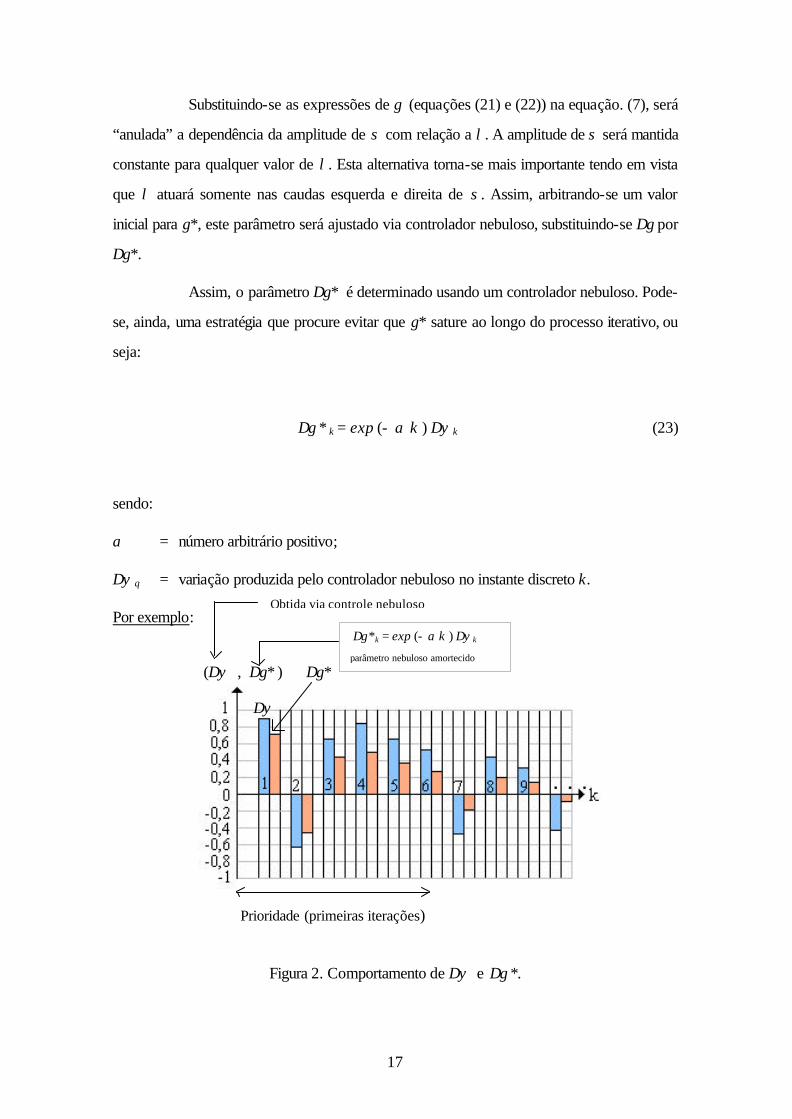
Assim, o parâmetro ∆γ* é determinado usando um controlador nebuloso. Pode-
se, ainda, uma estratégia que procure evitar que γ* sature ao longo do processo iterativo, ou
seja:
∆γ * k = exp (− α k ) ∆ψk (23)
sendo:
α = número arbitrário positivo;
∆ψq = variação produzida pelo controlador nebuloso no instante discreto k.
Por exemplo:
Prioridade (primeiras iterações)
Figura 2. Comportamento de ∆ψ e ∆γ *.
(∆ψ , ∆γ* ) ∆γ*
∆ψ
Obtida via controle nebuloso
∆γ *k = exp (− α k ) ∆ψk
parâmetro nebuloso amortecido

18
Referências
Arabshahi, P.; Choi, J. J.; Marks II, R. J. and Caudell, T.P. (1996). “Fuzzy parameter
adaptation in optimization”, IEEE Computational Science & Engineering, Spring, pp.
57-65.
Fine, T.L. (1999). “Feedforward neural network methodology”, Springer-Verlag, 1999,
USA.
Lopes, M. L. M. e Minussi, C. R. “Treinamento de redes neurais via Retropropagação com
controlador nebuloso”, XIII Congresso Brasileiro de Automática, Setembro-200,
Florianópolis-SC, pp. 1616-1621.
Terano, T.; Asai, K. and Sugeno, M. (1991). “Fuzzy systems theory and its applications”,
Academic Press, USA.
Werbos, P. J. (1974). "Beyond regression: New tools for prediction and analysis in the
behavioral sciences”, Master Thesis, Harvard University.
Widrow, B.; Lehr, M.A. (1990). “30 years of adaptive neural networks: perceptron,
madaline, and backpropagation”, Proceedings of the IEEE, pp. 1415-1442, Vol. 78,
no 9.

Universidade estadual Paulista – UNESP Campus de Ilha Solteira
Programa de Pós-Graduação em Engenharia Elétrica
Disciplina: Lógica Nebulosa
Carlos Roberto Minussi
Ilha Solteira-SP, agosto-2009.
Controlador Takagi-Sugeno

1
Controlador Takagi-Sugeno A concepção de controle nebuloso, anteriormente apresentada, é comumente conhecida
como controlador Mamdani [5] (em homenagem à primeira publicação na literatura
sobre o controlador fuzzy);
Existem concepções mais modernas, e.g., os controladores Takagi-Sugeno (T-S) [1],
[4];
Os controladores T-S apresentam duas principais vantagens sobre os controladores
Mamdani:
1. o processo de defuzzificação é mais fácil e mais rápido. Portanto, os controladores
T-S são mais apropriados para aplicações em tempo real;
2. os controladores T-S envolvem somente aprendizado paramétrico, enquanto que os
controladores Mamdani necessitam, também, do aprendizado estrutural.
Este processo consiste na obtenção de uma função complexa, via técnica de
aprendizado, baseada em regras nebulosas (e.g., redes neurais, mais especificamente, os
sistemas neuro-fuzzy);
Um sistema complexo (representado por equação não-linear) pode ser dividido por um
conjunto de modelos matemáticos locais (aproximações locais). Trata-se, por
conseguinte, de um algoritmo que cria modelos matemáticos que aproximam,
localmente, a função a ser aprendida;
Tais aproximações podem ser: (1) não-lineares e (2) lineares. As aproximações lineares
(vide Figura 1) são as mais empregadas na literatura especializada;
Deve-se ressaltar que estas aproximações lineares não devem ser confundidas com
tangentes à curva a ser determinada. Tratam-se de aproximações que buscam garantir
uma melhor representação da função, considerando-se a estabilidade do controlador.
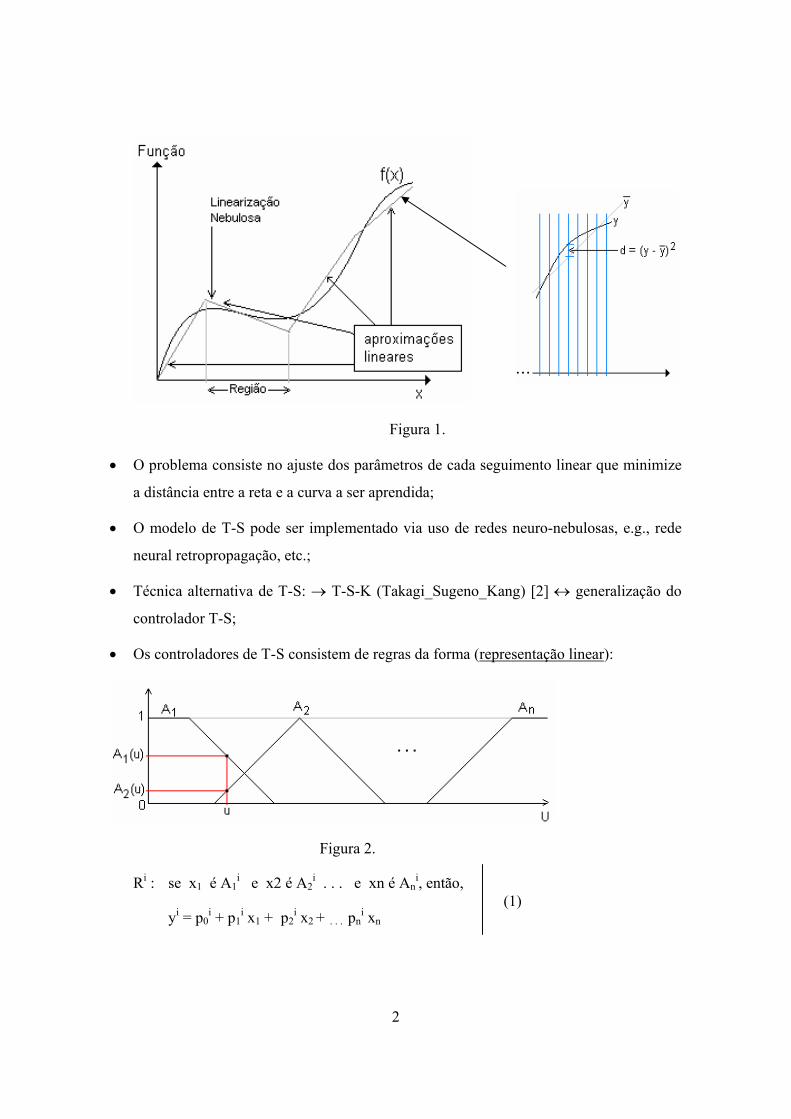
2
Figura 1.
O problema consiste no ajuste dos parâmetros de cada seguimento linear que minimize
a distância entre a reta e a curva a ser aprendida;
O modelo de T-S pode ser implementado via uso de redes neuro-nebulosas, e.g., rede
neural retropropagação, etc.;
Técnica alternativa de T-S: T-S-K (Takagi_Sugeno_Kang) [2] generalização do
controlador T-S;
Os controladores de T-S consistem de regras da forma (representação linear):
Figura 2.
Ri : se x1 é A1i e x2 é A2
i . . . e xn é Ani, então,
yi = p0i + p1
i x1 + p2i x2 + . . . pn
i xn
(1)

3
sendo:
Ri = i-ésima regra nebulosa;
xj = j-ésima variável de entrada;
Aji = i-ésimo conjunto fuzzy associado à variável xj. Os Aj
i são conjuntos caracteri-
zados, e.g., por triângulos, tais como abordados anteriormente funções de
pertinência;
yi = variável de saída da i-ésima regra;
pji = valor (ganho) real. Estes parâmetros deverão ser identificados.
Se yi = p0i (pj0
i = 0, para j > 1), o sistema (1) corresponde ao controlador ordem-zero.
Formato baseado na equação de estado:
Ri : se x1 é A1i e x2 é A2
i . . . e xn é Ani, então,
.x = [P] x + [Q] u
y = [M] x + [N] u
sendo:
M, N, P e Q são matrizes;
y = saída;
x = estado;
u = controle.
Se as funções de pertinência forem triangulares, então:
Aji = Máx
0,
b
ax21
ij
ijj
ou seja, cada termo lingüístico, para cada variável Aji, é descrita por dois parâmetros aj
i
e bji;

4
sendo:
aji e bj
i = coeficientes que devem ser determinados por algum método, e.g., via redes
neurais (formulação por um problema de otimização), LMI (Linear Matrix
Inequality) [3], [4].
Se i = j
ijA , a saída final y é dada por:
y =
m
1i
i
m
1i
ii
μ
yμ
(processo de defuzzificação).
A saída de cada regra é um valor real;
O número de regras é determinado pelo usuário.
Um exemplo (aproximação “linear”) é mostrado na Figura 3. Tratam-se de trechos
superpostos relacionados à transferência de entrada e saída, e os conseqüentes (partes
ENTÃO) definem aproximações lineares para estes trechos.
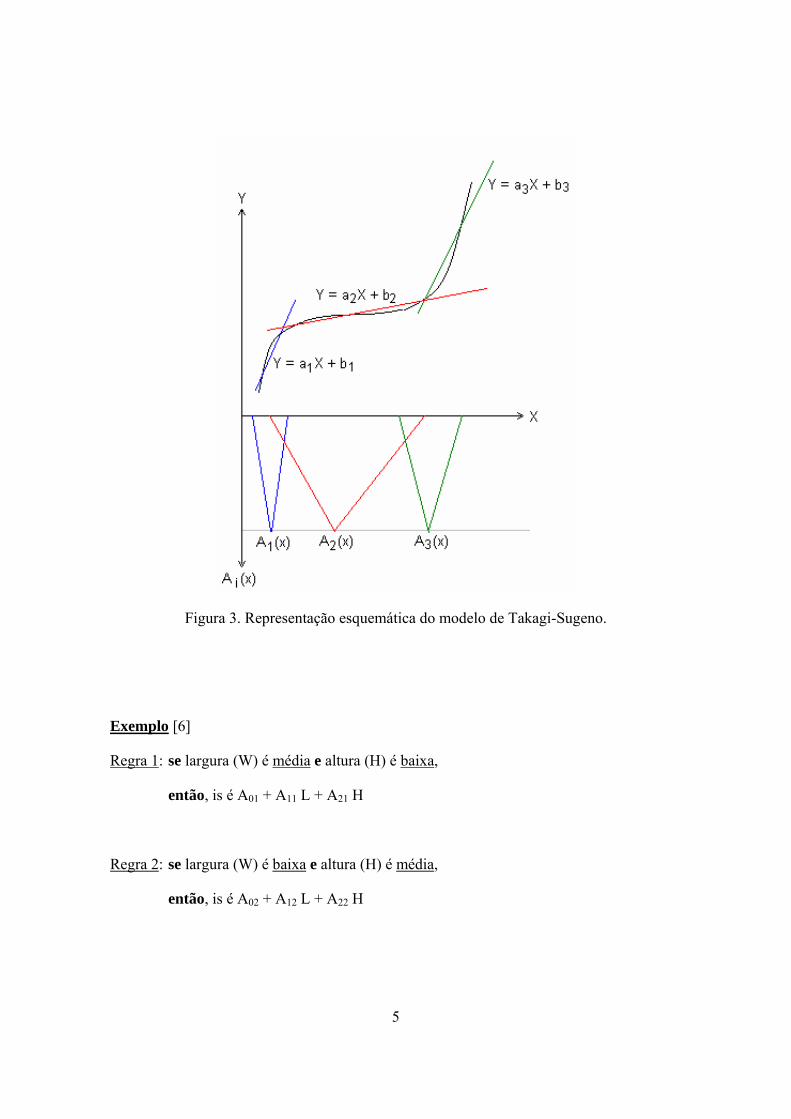
5
Figura 3. Representação esquemática do modelo de Takagi-Sugeno.
Exemplo [6]
Regra 1: se largura (W) é média e altura (H) é baixa,
então, is é A01 + A11 L + A21 H
Regra 2: se largura (W) é baixa e altura (H) é média,
então, is é A02 + A12 L + A22 H

6
Figura 4.
Referências
[1] Takagi, T. and Sugeno, M. “Fuzzy Identification of Systems and Its Applications to
Modeling and Control”, IEEE Transactions on SMC, Vol. 15, No. 1, pp. 116-132, 1985.
[2] Sugeno, M. and Kang, K.T. “Structure Identification of Fuzzy Model”, Fuzzy Sets
Systems, Vol. 28, pp. 15-33, 1988.
[3] Van Antwerp J. G. and. Braatz R. D “A Tutorial on Linear and Bilinear Matrix
Inequalities, Journal of Process Control, Volume 10, Issue 4, August 2000, Pages 363-
385.
[4] Sala, A.; Guerra T. M. and Babuška, R. “Perspectives of Fuzzy Systems and Control”,
Fuzzy Sets and Systems, Volume 156, Issue 3, 16 December 2005, Pages 432-444.
[5] Mamdani, E. H. “Application of Fuzzy Algorithms For Control of Simple Dynamic
Plant”, Proceedings of IEE, 121, Vol. 12, pp. 1585-1588, 1974.
[6] Shaw, I. Simões, M.G. “Controle e Modelagem Fuzzy”, Editora Edgard Blücher Ltda.,
São Paulo-SP, 1999.

Abstract:This paperprovides anintroductionto and anoverview oftype-2 fuzzysets (T2 FS) andsystems. It doesthis by answeringthe following ques-tions: What is a T2FS and how is it dif-ferent from a T1 FS?Is there new terminol-ogy for a T2 FS? Arethere important repre-sentations of a T2 FS and,if so, why are they impor-tant? How and why are T2FSs used in a rule-based sys-tem? What are the detailedcomputations for an intervalT2 fuzzy logic system (IT2FLS) and are they easy to under-stand? Is it possible to have anIT2 FLS without type reduction?How do we wrap this up andwhere can we go to learn more?
©19
94 D
IGIT
ALS
TO
CK
CO
RP
.
Jerry M. MendelUniversity of Southern California, USA
20 IEEE COMPUTATIONAL INTELLIGENCE MAGAZINE | FEBRUARY 2007 1556-603X/07/$25.00©2007IEEE
Authorized licensed use limited to: UNIV ESTADUAL PAULISTA JULIO DE MESQUITA FILHO. Downloaded on August 20, 2009 at 12:27 from IEEE Xplore. Restrictions apply.

Introduction
Iwas recently asked “What’s the difference between thepopular term fuzzy set (FS) and a type-1 fuzzy set (T1 FS)”?Before I answer this question, let’s recall that Zadeh intro-duced FSs in 1965 and type-2 fuzzy sets (T2 FSs) in 1975
[12]. So, after 1975, it became necessary to distinguish betweenpre-existing FSs and T2 FSs; hence, it became common to referto the pre-existing FSs as “T1 FSs.” So, the answer to the ques-tion is “There are different kinds of FSs, and they need to bedistinguished, e.g. T1 and T2.” I will do this throughout thisoverview article about T2 FSs and T2 fuzzy systems.
Not only have T1 FSs been around since 1965, they havealso been successfully used in many applications. However,such FSs have limited capabilities to directly handle datauncertainties, where handle means to model and minimize theeffect of. That a T1 FS cannot do this sounds paradoxicalbecause the word fuzzy has the connotation of uncertainty.This paradox has been known for a long time, but it is ques-tionable who first referred to "fuzzy" being paradoxical, e.g.[3], p. [12].
Of course, uncertainty comes in many guises and is inde-pendent of the kind of FS or methodology one uses to han-dle it. Two important kinds of uncertainties are linguistic andrandom. The former is associated with words, and the factthat words can mean different things to different people, and thelatter is associated with unpredictability. Probability theory isused to handle random uncertainty and FSs are used to han-dle linguistic uncertainty, and sometimes FSs can also beused to handle both kinds of uncertainty, because a fuzzysystem may use noisy measurements or operate under ran-dom disturbances.
Within probability theory, one begins with a probabilitydensity function (pdf) that embodies total information aboutrandom uncertainties. However, in most practical applica-tions, it is impossible to know or determine the pdf; so, thefact that a pdf is completely characterized by all of itsmoments is used. For most pdfs, an infinite number ofmoments are required. Unfortunately, it is not possible, inpractice, to determine an infinite number of moments; so,instead, enough moments are computed to extract as muchinformation as possible from the data. At the very least, twomoments are used—the mean and variance. To just use first-order moments would not be very useful because randomuncertainty requires an understanding of dispersion about themean, and this information is provided by the variance. So,the accepted probabilistic modeling of random uncertaintyfocuses, to a large extent, on methods that use at least the firsttwo moments of a pdf. This is, for example, why designsbased on minimizing mean-squared errors are so popular.
Just as variance provides a measure of dispersion aboutthe mean, an FS also needs some measure of dispersion tocapture more about linguistic uncertainties than just a sin-gle membership function (MF), which is all that is obtainedwhen a T1 FS is used. A T2 FS provides this measure ofdispersion.
A T2 FS and How It is Different From a T1 FSWhat is a T2 FS and how is it different from a T1 FS? A T1 FShas a grade of membership that is crisp, whereas a T2 FS hasgrades of membership that are fuzzy, so it could be called a“fuzzy-fuzzy set.” Such a set is useful in circumstances where itis difficult to determine the exact MF for an FS, as in modelinga word by an FS.
As an example [6], suppose the variable of interest is eye con-tact, denoted x, where x ∈[0, 10] and this is an intensity rangein which 0 denotes no eye contact and 10 denotes maximumamount of eye contact. One of the terms that might character-ize the amount of perceived eye contact (e.g., during an airportsecurity check) is “some eye contact.” Suppose that 50 menand women are surveyed, and are asked to locate the ends ofan interval for some eye contact on the scale 0–10. Surely, thesame results will not be obtained from all of them becausewords mean different things to different people.
One approach for using the 50 sets of two end points is toaverage the end-point data and to then use the average valuesto construct an interval associated with some eye contact. A trian-gular (other shapes could be used) MF, M F(x), could then beconstructed, one whose base end points (on the x-axis) are atthe two end-point average values and whose apex is midwaybetween the two end points. This T1 triangular MF can bedisplayed in two dimensions, e.g. the dashed MF in Figure 1.Unfortunately, it has completely ignored the uncertaintiesassociated with the two end points.
A second approach is to make use of the average end-pointvalues and the standard deviation of each end point to establishan uncertainty interval about each average end-point value. Bydoing this, we can think of the locations of the two end pointsalong the x-axis as blurred. Triangles can then be located sothat their base end points can be anywhere in the intervalsalong the x-axis associated with the blurred average end points.Doing this leads to a continuum of triangular MFs sitting onthe x-axis, as in Figure1. For purposes of this discussion, sup-pose there are exactly N such triangles. Then at each value ofx , there can be up to N MF values (grades),M F1(x), M F2(x), …, M FN (x) . Each of the possible MFgrades has a weight assigned to it, say wx1, wx2, …, wxN (seethe top insert in Figure 1). These weights can be thought of asthe possibilities associated with each triangle’s grade at this valueof x. Consequently, at each x, the collection of grades is afunction {(M Fi(x), wxi), i = 1, …, N } (called secondary MF).The resulting T2 MF is 3-D.
If all uncertainty disappears, then a T2 FS reduces to a T1FS, as can be seen in Figure 1, e.g. if the uncertainties about theleft- and right-end points disappear, then only the dashed trian-gle survives. This is similar to what happens in probability, whenrandomness degenerates to determinism, in which case the pdfcollapses to a single point. In brief, a T1 FS is embedded in a T2FS, just as determinism is embedded in randomness.
It is not as easy to sketch 3-D figures of a T2 MF as it isto sketch 2-D figures of a T1 MF. Another way to visualize aT2 FS is to sketch (plot) its footprint of uncertainty (FOU) on
FEBRUARY 2007 | IEEE COMPUTATIONAL INTELLIGENCE MAGAZINE 21
Authorized licensed use limited to: UNIV ESTADUAL PAULISTA JULIO DE MESQUITA FILHO. Downloaded on August 20, 2009 at 12:27 from IEEE Xplore. Restrictions apply.
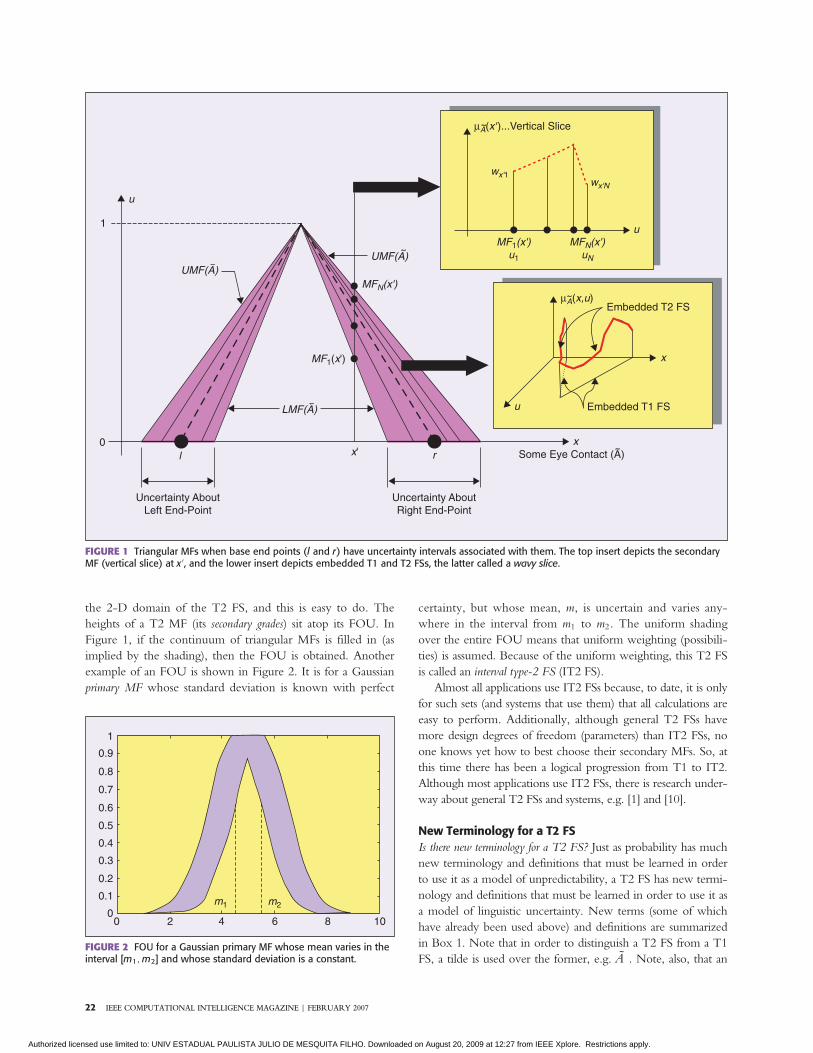
the 2-D domain of the T2 FS, and this is easy to do. Theheights of a T2 MF (its secondary grades) sit atop its FOU. InFigure 1, if the continuum of triangular MFs is filled in (asimplied by the shading), then the FOU is obtained. Anotherexample of an FOU is shown in Figure 2. It is for a Gaussianprimary MF whose standard deviation is known with perfect
certainty, but whose mean, m, is uncertain and varies any-where in the interval from m1 to m2. The uniform shadingover the entire FOU means that uniform weighting (possibili-ties) is assumed. Because of the uniform weighting, this T2 FSis called an interval type-2 FS (IT2 FS).
Almost all applications use IT2 FSs because, to date, it is onlyfor such sets (and systems that use them) that all calculations areeasy to perform. Additionally, although general T2 FSs havemore design degrees of freedom (parameters) than IT2 FSs, noone knows yet how to best choose their secondary MFs. So, atthis time there has been a logical progression from T1 to IT2.Although most applications use IT2 FSs, there is research under-way about general T2 FSs and systems, e.g. [1] and [10].
New Terminology for a T2 FSIs there new terminology for a T2 FS? Just as probability has muchnew terminology and definitions that must be learned in orderto use it as a model of unpredictability, a T2 FS has new termi-nology and definitions that must be learned in order to use it asa model of linguistic uncertainty. New terms (some of whichhave already been used above) and definitions are summarizedin Box 1. Note that in order to distinguish a T2 FS from a T1FS, a tilde is used over the former, e.g. A . Note, also, that an
FIGURE 2 FOU for a Gaussian primary MF whose mean varies in theinterval [m1, m2] and whose standard deviation is a constant.
FIGURE 1 Triangular MFs when base end points (l and r) have uncertainty intervals associated with them. The top insert depicts the secondaryMF (vertical slice) at x′, and the lower insert depicts embedded T1 and T2 FSs, the latter called a wavy slice.
22 IEEE COMPUTATIONAL INTELLIGENCE MAGAZINE | FEBRUARY 2007
Authorized licensed use limited to: UNIV ESTADUAL PAULISTA JULIO DE MESQUITA FILHO. Downloaded on August 20, 2009 at 12:27 from IEEE Xplore. Restrictions apply.

IT2 FS is completely characterizedby its 2-D FOU that is bound by alower MF (LMF) and an upperMF (UMF) (Figure 3), and, itsembedded FSs are T1 FSs.
Important Representationsof a T2 FSAre there important representations ofa T2FS and, if so, why are theyimportant? There are two veryimportant representations for aT2 FS; they are summarized inBox 2. The vertical-slice repre-sentation is the basis for mostcomputations, whereas the wavy-slice representation is the basis formost theoretical derivations. Thelatter is also known as theMendel-John Representation Theo-rem (RT) [8]. For an IT2 FS, bothrepresentations can also be inter-preted as covering theorems becausethe union of all vertical slices andthe union of all embedded T1FSs cover the entire FOU.
FIGURE 3 Interval T2 FS and associated quantities.
BOX 2. Two Very Important Representations of a T2 FS
Name of Representation Statement CommentsVertical-Slice Representation A = ⋃
∀x∈XVertical slices (x) Very useful for computation
Wavy-Slice Representation A = ⋃∀ j
Embedded T2 FS ( j) Very useful for theoretical derivations; also known as the Mendel-John Representation Theorem [8]
BOX 1. New Terms for T2 FSs
Term Literal Definition (see Figure 1 for many of the examples)
Primary variable— x ∈ X The main variable of interest, e.g. pressure, temperature, anglePrimary membership— Jx Each value of the primary variable x has a band (i.e., an interval) of MF values, e.g.
Jx′ = [MF1(x′), MFN(x′)]Secondary variable— u ∈ Jx An element of the primary membership, Jx′, e.g. u1, . . . , uN
Secondary grade— fx(u) The weight (possibility) assigned to each secondary variable, e.g. fx′(u1) = wx′1
Type-2 FS— A A three-dimensional MF with point-value (x, u, μA(x, u)), where x ∈ X, u ∈ Jx , and 0 ≤ μA(x, u) ≤ 1. Note that fx(u) ≡ μA(x, u)
Secondary MF at x A T1 FS at x, also called a vertical slice, e.g. top insert in Figure 1Footprint of Uncertainty of The union of all primary memberships; the 2-D domain of A; the area between UMF (A) and A − FOU(A) LMF (A), e.g. lavender shaded regions in Figure 1Lower MF of A − LMF(A) or μ
A(x) The lower bound of FOU(A) (see Figure 1)
Upper MF of A − UMF(A) or μA(x) The upper bound of FOU(A) (see Figure 1)Interval T2 FS A T2 FS whose secondary grades all equal 1, described completely by its FOU, e.g. Figure 3;
A = 1/FOU(A) where this notation means that the secondary grade equals 1 for all elements of FOU(A)
Embedded T1 FS— Ae(x) Any T1 FS contained within A that spans ∀x ∈ X; also, the domain for an embedded T2 FS, e.g. the wavy curve in Figure 3, LMF(A) and UMF(A)
Embedded T2 FS— Ae(x) Begin with an embedded T1 FS and attach a secondary grade to each of its elements, e.g. see lower insert in Figure 1
Primary MF Given a T1 FS with at least one parameter that has a range of values. A primary MF is any one of the T1 FSs whose parameters fall within the ranges of those variable parameters, e.g. the dashed MF in Figure 1
FEBRUARY 2007 | IEEE COMPUTATIONAL INTELLIGENCE MAGAZINE 23
Authorized licensed use limited to: UNIV ESTADUAL PAULISTA JULIO DE MESQUITA FILHO. Downloaded on August 20, 2009 at 12:27 from IEEE Xplore. Restrictions apply.
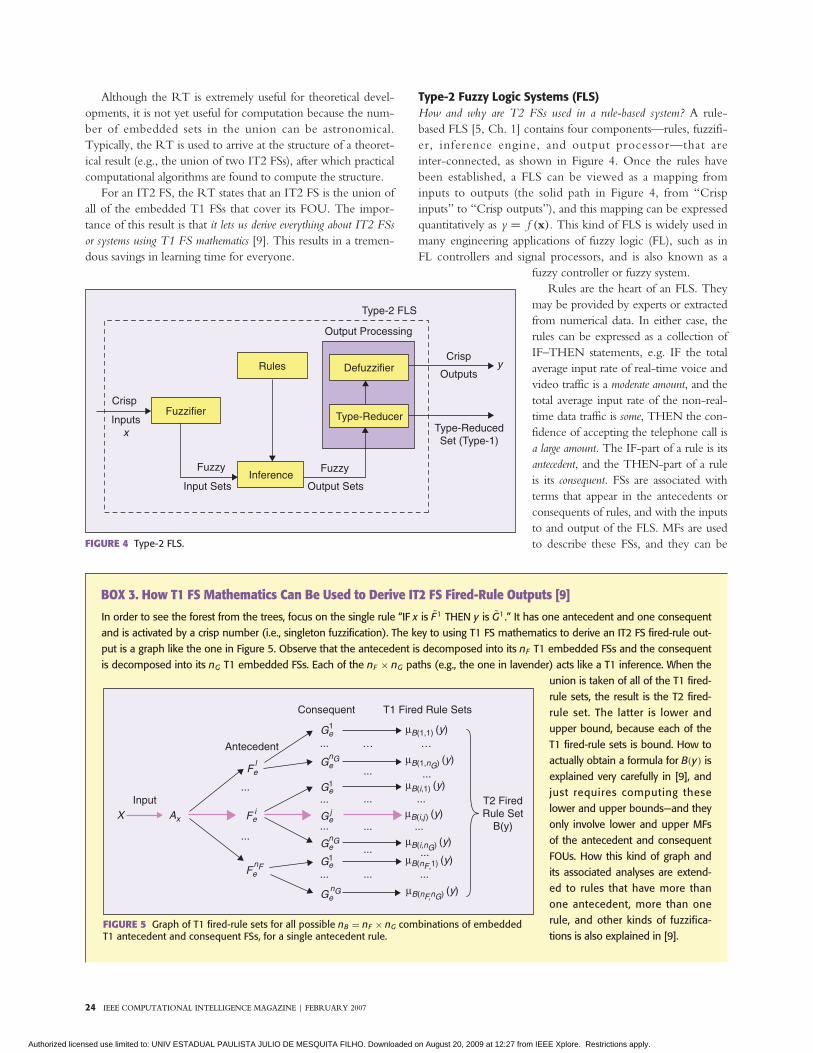
Although the RT is extremely useful for theoretical devel-opments, it is not yet useful for computation because the num-ber of embedded sets in the union can be astronomical.Typically, the RT is used to arrive at the structure of a theoret-ical result (e.g., the union of two IT2 FSs), after which practicalcomputational algorithms are found to compute the structure.
For an IT2 FS, the RT states that an IT2 FS is the union ofall of the embedded T1 FSs that cover its FOU. The impor-tance of this result is that it lets us derive everything about IT2 FSsor systems using T1 FS mathematics [9]. This results in a tremen-dous savings in learning time for everyone.
Type-2 Fuzzy Logic Systems (FLS)How and why are T2 FSs used in a rule-based system? A rule-based FLS [5, Ch. 1] contains four components—rules, fuzzifi-er, inference engine, and output processor—that areinter-connected, as shown in Figure 4. Once the rules havebeen established, a FLS can be viewed as a mapping frominputs to outputs (the solid path in Figure 4, from “Crispinputs” to “Crisp outputs”), and this mapping can be expressedquantitatively as y = f (x). This kind of FLS is widely used inmany engineering applications of fuzzy logic (FL), such as inFL controllers and signal processors, and is also known as a
fuzzy controller or fuzzy system.Rules are the heart of an FLS. They
may be provided by experts or extractedfrom numerical data. In either case, therules can be expressed as a collection ofIF–THEN statements, e.g. IF the totalaverage input rate of real-time voice andvideo traffic is a moderate amount, and thetotal average input rate of the non-real-time data traffic is some, THEN the con-fidence of accepting the telephone call isa large amount. The IF-part of a rule is itsantecedent, and the THEN-part of a ruleis its consequent. FSs are associated withterms that appear in the antecedents orconsequents of rules, and with the inputsto and output of the FLS. MFs are usedto describe these FSs, and they can beFIGURE 4 Type-2 FLS.
In order to see the forest from the trees, focus on the single rule “IF x is F1 THEN y is G1.” It has one antecedent and one consequentand is activated by a crisp number (i.e., singleton fuzzification). The key to using T1 FS mathematics to derive an IT2 FS fired-rule out-put is a graph like the one in Figure 5. Observe that the antecedent is decomposed into its nF T1 embedded FSs and the consequentis decomposed into its nG T1 embedded FSs. Each of the nF × nG paths (e.g., the one in lavender) acts like a T1 inference. When the
union is taken of all of the T1 fired-rule sets, the result is the T2 fired-rule set. The latter is lower andupper bound, because each of theT1 fired-rule sets is bound. How toactually obtain a formula for B(y) isexplained very carefully in [9], andjust requires computing theselower and upper bounds—and theyonly involve lower and upper MFsof the antecedent and consequentFOUs. How this kind of graph andits associated analyses are extend-ed to rules that have more thanone antecedent, more than onerule, and other kinds of fuzzifica-tions is also explained in [9].
FIGURE 5 Graph of T1 fired-rule sets for all possible nB = nF × nG combinations of embeddedT1 antecedent and consequent FSs, for a single antecedent rule.
BOX 3. How T1 FS Mathematics Can Be Used to Derive IT2 FS Fired-Rule Outputs [9]
24 IEEE COMPUTATIONAL INTELLIGENCE MAGAZINE | FEBRUARY 2007
Authorized licensed use limited to: UNIV ESTADUAL PAULISTA JULIO DE MESQUITA FILHO. Downloaded on August 20, 2009 at 12:27 from IEEE Xplore. Restrictions apply.
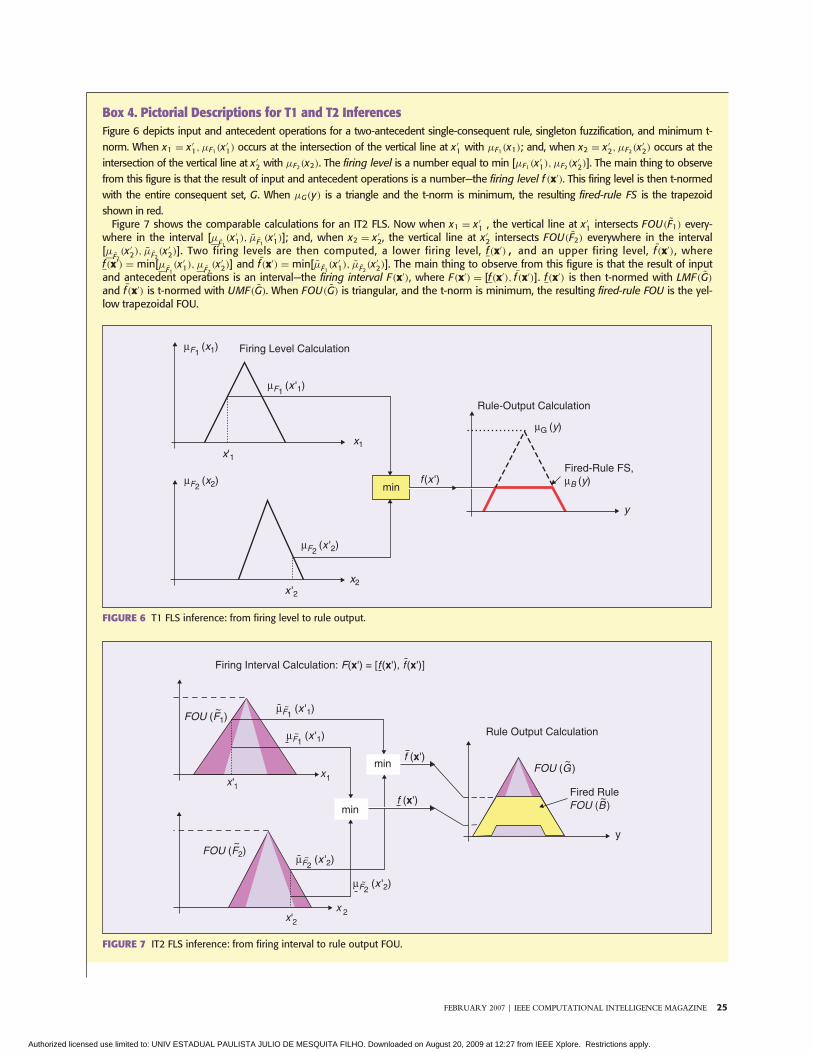
Figure 6 depicts input and antecedent operations for a two-antecedent single-consequent rule, singleton fuzzification, and minimum t-norm. When x1 = x′
1, μF1(x′1) occurs at the intersection of the vertical line at x′
1 with μF1(x1); and, when x2 = x′2, μF2(x
′2) occurs at the
intersection of the vertical line at x′2 with μF2(x2). The firing level is a number equal to min [μF1(x
′1), μF2(x
′2)]. The main thing to observe
from this figure is that the result of input and antecedent operations is a number—the firing level f (x′). This firing level is then t-normedwith the entire consequent set, G. When μG(y) is a triangle and the t-norm is minimum, the resulting fired-rule FS is the trapezoidshown in red.
Figure 7 shows the comparable calculations for an IT2 FLS. Now when x1 = x′1 , the vertical line at x′
1 intersects FOU(F1) every-where in the interval [μ
F1(x′
1), μF1(x′
1)]; and, when x2 = x′2, the vertical line at x′
2 intersects FOU(F2) everywhere in the interval[μ
F2(x′
2), μF2(x′
2)]. Two firing levels are then computed, a lower firing level, f(x′), and an upper firing level, f(x′), wheref(x′) = min[μ
F1(x′
1), μF2(x′
2)] and f(x′) = min[μF1(x′
1), μF2(x′
2)]. The main thing to observe from this figure is that the result of inputand antecedent operations is an interval—the firing interval F(x′), where F(x′) = [f(x′), f(x′)]. f(x′) is then t-normed with LMF(G)
and f(x′) is t-normed with UMF(G). When FOU(G) is triangular, and the t-norm is minimum, the resulting fired-rule FOU is the yel-low trapezoidal FOU.
FIGURE 6 T1 FLS inference: from firing level to rule output.
FIGURE 7 IT2 FLS inference: from firing interval to rule output FOU.
FOU (B)
x 2
x 2
x 1
x1
Box 4. Pictorial Descriptions for T1 and T2 Inferences
FEBRUARY 2007 | IEEE COMPUTATIONAL INTELLIGENCE MAGAZINE 25
Authorized licensed use limited to: UNIV ESTADUAL PAULISTA JULIO DE MESQUITA FILHO. Downloaded on August 20, 2009 at 12:27 from IEEE Xplore. Restrictions apply.
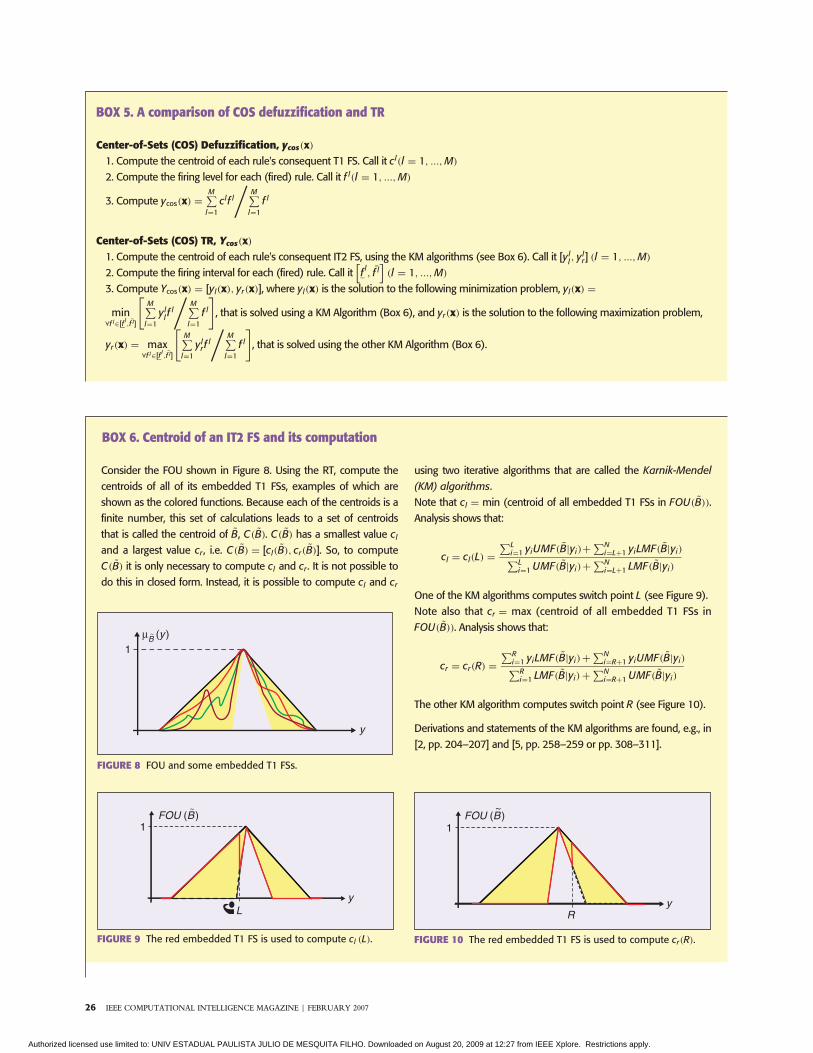
BOX 5. A comparison of COS defuzzification and TR
Center-of-Sets (COS) Defuzzification, ycos(x)
1. Compute the centroid of each rule's consequent T1 FS. Call it cl(l = 1, ..., M)
2. Compute the firing level for each (fired) rule. Call it f l(l = 1, ..., M)
3. Compute ycos(x) =M∑
l=1clf l
/M∑
l=1f l
Center-of-Sets (COS) TR, Ycos(x)
1. Compute the centroid of each rule's consequent IT2 FS, using the KM algorithms (see Box 6). Call it [yll , yl
r] (l = 1, ..., M)
2. Compute the firing interval for each (fired) rule. Call it [f l, f l
](l = 1, ..., M)
3. Compute Ycos(x) = [yl(x), yr(x)], where yl(x) is the solution to the following minimization problem, yl(x) =
min∀f l∈[f l
,f l]
[M∑
l=1yl
l fl
/M∑
l=1f l
], that is solved using a KM Algorithm (Box 6), and yr(x) is the solution to the following maximization problem,
yr(x) = max∀f l∈[f l
,f l]
[M∑
l=1yl
rfl
/M∑
l=1f l
], that is solved using the other KM Algorithm (Box 6).
Consider the FOU shown in Figure 8. Using the RT, compute thecentroids of all of its embedded T1 FSs, examples of which areshown as the colored functions. Because each of the centroids is afinite number, this set of calculations leads to a set of centroidsthat is called the centroid of B, C(B). C(B) has a smallest value cl
and a largest value cr, i.e. C(B) = [cl(B), cr(B)]. So, to computeC(B) it is only necessary to compute cl and cr. It is not possible todo this in closed form. Instead, it is possible to compute cl and cr
using two iterative algorithms that are called the Karnik-Mendel(KM) algorithms.Note that cl = min (centroid of all embedded T1 FSs in FOU(B)).Analysis shows that:
cl = cl(L) =∑L
i=1 yiUMF(B|yi)+∑N
i=L+1 yiLMF(B|yi)∑Li=1 UMF(B|yi)+ ∑N
i=L+1 LMF(B|yi)
One of the KM algorithms computes switch point L (see Figure 9).Note also that cr = max (centroid of all embedded T1 FSs inFOU(B)). Analysis shows that:
cr = cr(R) =∑R
i=1 yiLMF(B|yi)+ ∑Ni=R+1 yiUMF(B|yi)∑R
i=1 LMF(B|yi) + ∑Ni=R+1 UMF(B|yi)
The other KM algorithm computes switch point R (see Figure 10).
Derivations and statements of the KM algorithms are found, e.g., in[2, pp. 204–207] and [5, pp. 258–259 or pp. 308–311].
FIGURE 8 FOU and some embedded T1 FSs.
FIGURE 9 The red embedded T1 FS is used to compute cl (L). FIGURE 10 The red embedded T1 FS is used to compute cr(R).
BOX 6. Centroid of an IT2 FS and its computation
26 IEEE COMPUTATIONAL INTELLIGENCE MAGAZINE | FEBRUARY 2007
Authorized licensed use limited to: UNIV ESTADUAL PAULISTA JULIO DE MESQUITA FILHO. Downloaded on August 20, 2009 at 12:27 from IEEE Xplore. Restrictions apply.

either T1 or T2. The latter lets us quantify different kinds ofuncertainties that can occur in an FLS.
Four ways in which uncertainty can occur in an FLS are:(1) the words that are used in antecedents and consequents ofrules can mean different things to different people; (2) conse-quents obtained by polling a group of experts will often be dif-ferent for the same rule, because the experts will notnecessarily be in agreement; (3) only noisy training data areavailable for tuning (optimizing) the parameters of an IT2 FLS;and (4) noisy measurements activate the FLS.
An FLS that is described completely in terms of T1 FSs iscalled a T1 FLS, whereas an FLS that is described using at leastone T2 FS is called a T2 FLS. T1 FLSs are unable to directlyhandle these uncertainties because they use T1 FSs that arecertain. T2 FLSs, on the other hand, are very useful in circum-stances where it is difficult to determine an exact MF for anFS; hence, they can be used to handle these uncertainties.
Returning to the Figure 4 FLS, the fuzzifier maps crisp num-bers into FSs. It is needed to activate rules that are in terms oflinguistic variables, which have FSs associated with them. Theinputs to the FLS prior to fuzzification may be certain (e.g., per-fect measurements) or uncertain (e.g., noisy measurements). TheMF for a T2 FS lets us handle either kind of measurement.
The inference block of the Figure 4 FLS maps FSs intoFSs. The most commonly used inferential procedures for aFLS use minimum and product implication models. Theresulting T2 FLSs are then called Mamdani T2 FLSs. TSKT2 FLSs are also available [5].
BOX 7. Uncertainty Bounds and Related Computations1. Compute Centroids of M Consequent IT2 FSs
yil and yi
r(i = 1, ..., M), the end points of the centroids of the M consequent IT2 FSs, are computed using the KM algorithms (Box 6). These computations can be performed after the design of the IT2 FLS has been completed and they only have to be doneonce.
2. Compute Four Boundary Type-1 FLS Centroids
y(0)
l (x) =M∑
i=1
f iyil
/M∑
i=1
f i y(())r (x) =
M∑i=1
f iyir
/M∑
i=1
f i
y(M)
l (x) =M∑
i=1
f iyil
/M∑
i=1
f i y(M)r (x) =
M∑i=1
f iyir
/M∑
i=1
f i
3. Compute Four Uncertainty Bounds
yl(x) ≤ yl(x) ≤ yl(x) y
r(x) ≤ yr(x) ≤ yr(x)
yl(x) = min{y(0)
l (x), y(M)
l (x)}
yr(x) = max
{y())
r (x), y(M)r (x)
}
yl(x) = yl(x) −
⎡⎢⎢⎢⎣
M∑i=1
(f i − f i)
M∑i=1
f iM∑
i=1f i
yr(x) = yr(x) +
⎡⎢⎢⎢⎣
M∑i=1
(f i − f i)
M∑i=1
f iM∑
i=1f i
×
M∑i=1
f i (yil − y1
l
) M∑i=1
f i(yM
l − yil
)M∑
i=1f i (yi
l − y1l
) +M∑
i=1f i
(yM
l − yil
)⎤⎥⎥⎥⎦ ×
M∑i=1
f i(yi
r − y1r
) M∑i=1
f i (yMr − yi
r
)M∑
i=1f i
(yi
r − y1r
) +M∑
i=1f i (yM
r − yir
)⎤⎥⎥⎥⎦
Note: The pair yt(x), yr(x) are called inner (uncertainty) bounds, whereas the pair y
l(x), yr(x) are called outer (uncertainty) bounds.
4. Compute Approximate TR Set
[yl(x), yr(x)] ≈ [yl(x), yr(x)] = [(yl(x) + yl(x))/2, (y
r(x) + yr(x))/2]
5. ComputeApproximate Defuzzified Output y(x) ≈ y(x) = 1
2 [yl(x) + yr(x)]
Almost all applications use IT2 FSsbecause all calculations are easyto perform.
FEBRUARY 2007 | IEEE COMPUTATIONAL INTELLIGENCE MAGAZINE 27
Authorized licensed use limited to: UNIV ESTADUAL PAULISTA JULIO DE MESQUITA FILHO. Downloaded on August 20, 2009 at 12:27 from IEEE Xplore. Restrictions apply.
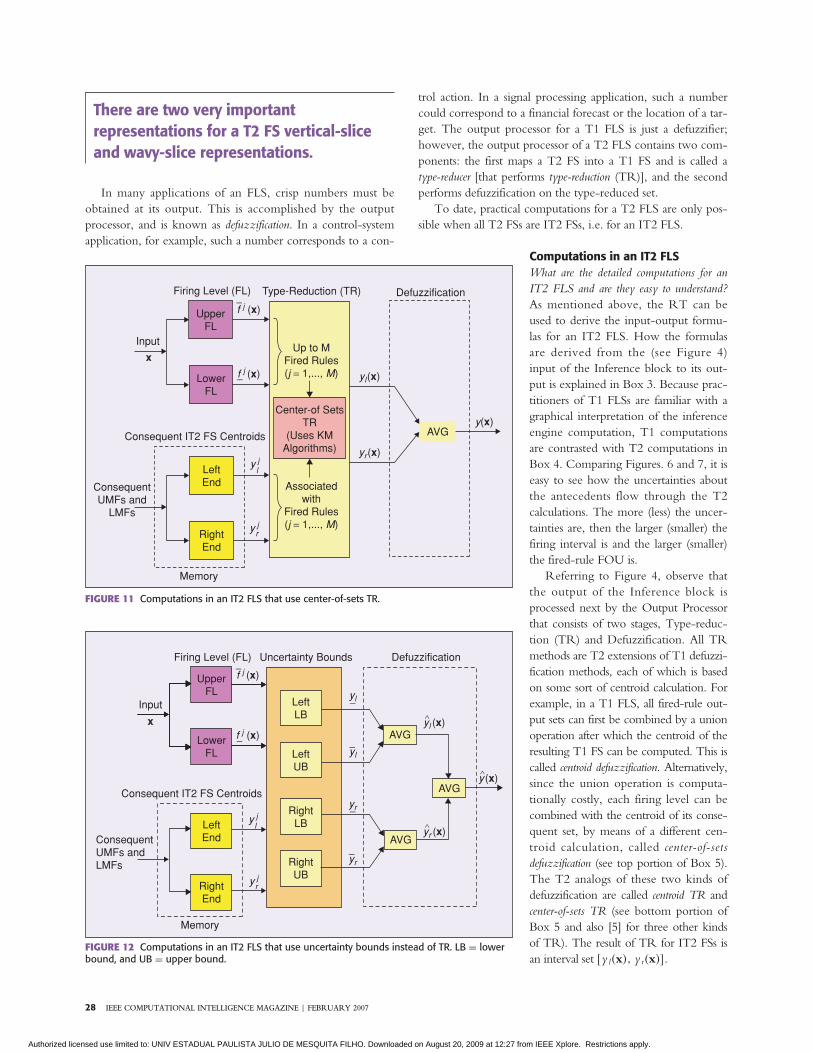
In many applications of an FLS, crisp numbers must beobtained at its output. This is accomplished by the outputprocessor, and is known as defuzzification. In a control-systemapplication, for example, such a number corresponds to a con-
trol action. In a signal processing application, such a numbercould correspond to a financial forecast or the location of a tar-get. The output processor for a T1 FLS is just a defuzzifier;however, the output processor of a T2 FLS contains two com-ponents: the first maps a T2 FS into a T1 FS and is called atype-reducer [that performs type-reduction (TR)], and the secondperforms defuzzification on the type-reduced set.
To date, practical computations for a T2 FLS are only pos-sible when all T2 FSs are IT2 FSs, i.e. for an IT2 FLS.
Computations in an IT2 FLSWhat are the detailed computations for anIT2 FLS and are they easy to understand?As mentioned above, the RT can beused to derive the input-output formu-las for an IT2 FLS. How the formulasare derived from the (see Figure 4)input of the Inference block to its out-put is explained in Box 3. Because prac-titioners of T1 FLSs are familiar with agraphical interpretation of the inferenceengine computation, T1 computationsare contrasted with T2 computations inBox 4. Comparing Figures. 6 and 7, it iseasy to see how the uncertainties aboutthe antecedents flow through the T2calculations. The more (less) the uncer-tainties are, then the larger (smaller) thefiring interval is and the larger (smaller)the fired-rule FOU is.
Referring to Figure 4, observe thatthe output of the Inference block isprocessed next by the Output Processorthat consists of two stages, Type-reduc-tion (TR) and Defuzzification. All TRmethods are T2 extensions of T1 defuzzi-fication methods, each of which is basedon some sort of centroid calculation. Forexample, in a T1 FLS, all fired-rule out-put sets can first be combined by a unionoperation after which the centroid of theresulting T1 FS can be computed. This iscalled centroid defuzzification. Alternatively,since the union operation is computa-tionally costly, each firing level can becombined with the centroid of its conse-quent set, by means of a different cen-troid calculation, called center-of-setsdefuzzification (see top portion of Box 5).The T2 analogs of these two kinds ofdefuzzification are called centroid TR andcenter-of-sets TR (see bottom portion ofBox 5 and also [5] for three other kindsof TR). The result of TR for IT2 FSs isan interval set [y l(x), y r(x)].
FIGURE 11 Computations in an IT2 FLS that use center-of-sets TR.
Firing Level (FL) Type-Reduction (TR) Defuzzification
UpperFL
LowerFL
Input
AVGy(x)
Up to MFired Rules(j = 1,..., M)
Center-of SetsTR
(Uses KMAlgorithms)
Associatedwith
Fired Rules(j = 1,..., M)
Memory
Consequent IT2 FS Centroids
x
ConsequentUMFs and
LMFs
LeftEnd
RightEnd
yl(x)
yr(x)
f j (x)−
f j (x)−
y j
y j
l
r
FIGURE 12 Computations in an IT2 FLS that use uncertainty bounds instead of TR. LB = lowerbound, and UB = upper bound.
Firing Level (FL) Uncertainty Bounds Defuzzification
UpperFL
LowerFL
Input
Memory
Consequent IT2 FS Centroids
x
ConsequentUMFs andLMFs
LeftEnd
RightEnd
LeftLB
LeftUB
RightLB
RightUB
AVG
AVG
AVG
f j (x)−
f j (x)−
y j
y j
yl−
yr−
yl−
yr−
∧yl (x)
∧y(x)
∧yr (x)
l
r
There are two very importantrepresentations for a T2 FS vertical-sliceand wavy-slice representations.
28 IEEE COMPUTATIONAL INTELLIGENCE MAGAZINE | FEBRUARY 2007
Authorized licensed use limited to: UNIV ESTADUAL PAULISTA JULIO DE MESQUITA FILHO. Downloaded on August 20, 2009 at 12:27 from IEEE Xplore. Restrictions apply.

Regardless of the kind of TR, they all require computingthe centroid of an IT2 FS. Box 6 explains what this is and howthe centroid is computed. The two iterative algorithms fordoing this are known as the Karnik-Mendel (KM) algorithms [2],and they have the following properties: 1) they are very sim-ple, 2) they converge to the exact solutions monotonically andsuper-exponentially fast, and 3) they can be run in parallel,since they are independent.
Defuzzification, the last computation in the Figure 4 IT2FLS, is performed by taking the average of y l(x) and y r(x).
The entire chain of computations is summarized in Fig. 11.Firing intervals are computed for all rules, and they dependexplicitly on the input x. For center-of-sets TR (see Box 5),off-line computations of the centroids are performed for eachof the M consequent IT2 FSs using KM algorithms, and arethen stored in memory. Center-of-sets TR combines the firingintervals and pre-computed consequent centroids and uses theKM algorithms to perform the actual calculations.
An IT2 FLS for Real-Time ComputationsIs it possible to have an IT2 FLS without TR? TR is a bottleneckfor real-time applications of an IT2 FLS because it uses theiterative KM algorithms for its computations. Even though thealgorithms are very fast, there is a time delay associated withany iterative algorithm. The good news is that TR can bereplaced by using minimax uncertainty bounds for both y l (x)
and y r (x). These bounds are also known as the Wu-Mendeluncertainty bounds [11]. Four bounds are computed, namelylower and upper bounds for both y l (x) and y r (x). Formulasfor these bounds are only dependent upon lower and upperfiring levels for each rule and the centroid of each rule’s conse-quent set, and, because they are needed in two of the otherarticles in this issue, are given in Box 7.
Figure 12 summarizes the computations in an IT2 FLS thatuses uncertainty bounds. The front end of the calculations isidentical to the front end using TR (see Figure 11). After theuncertainty bounds are computed, the actual values of y l (x′)and y r (x′) (that would have been computed using TR, as inFigure 11) are approximated by averaging their respectiveuncertainty bounds, the results being y l(x′) and y r(x′).Defuzzification is then achieved by averaging these twoapproximations, the result being y(x), which is an approxima-tion to y(x). Remarkably, very little accuracy is lost when theuncertainty bounds are used. This is proven in [11] and hasbeen demonstrated in [4]. See [7] for additional discussions onIT2 FLSs without TR.
In summary, IT2 FLSs are pretty simple to understand andthey can be implemented in two ways, one that uses TR andone that uses uncertainty bounds.
ConclusionsHow do we wrap this up and where can we go to learn more? Inschool, we learn about determinism before randomness. Learn-ing about T1 FSs before T2 FSs fits a similar learning model(Figure 13). IT2 FSs and FLSs let us capture first-order uncer-
tainties about words. It is anticipated that by using more gen-eral T2 FSs and FLSs it will be possible to capture higher-orderuncertainties about words. Much remains to be done.
For readers who want to learn more about IT2 FSs andFLSs, the easiest way to do this is to read [9]; for readers whowant a very complete treatment about general and interval T2FSs and FLSs, see [5]; and, for readers who may already befamiliar with T2 FSs and want to know what has happenedsince the 2001 publication of [5], see [7].
AcknowledgementsThe author acknowledges the following people who read thedraft of this article and made very useful suggestions on how toimprove it: Simon Coupland, Sarah Greenfield, Hani Hagras,Feilong Liu, Robert I. John and Dongrui Wu.
ReferencesNote: This is a minimalist list of references. For many more references about T2 FSs and FLSs,see [5] and [7]. Additionally, the T2 Web site http://www.type2fuzzylogic.org/ is loaded withreferences and is being continually updated with new ones.
[1] S. Coupland and R.I. John, “Towards more efficient type-2 fuzzy logic systems,” Proc.IEEE FUZZ Conf., pp. 236–241, Reno, NV, May 2005.[2] N.N. Karnik and J.M. Mendel, “Centroid of a type-2 fuzzy set,” Information Sciences, vol.132, pp. 195–220, 2001.[3] G.J. Klir and T.A. Folger, “Fuzzy Sets, Uncertainty, and Information,” Prentice Hall, Engle-wood Cliffs, NJ, 1988.[4] C. Lynch, H. Hagras and V. Callaghan, “Using uncertainty bounds in the design of anembedded real-time type-2 neuro-fuzzy speed controller for marine diesel engines,” Proc.IEEE-FUZZ 2006, pp. 7217–7224, Vancouver, CA, July 2006.[5] J.M. Mendel, “Uncertain Rule-Based Fuzzy Logic Systems: Introduction and New Directions,”Prentice-Hall, Upper-Saddle River, NJ, 2001.[6] J.M. Mendel, “Type-2 fuzzy sets: some questions and answers,” IEEE Connections,Newsletter of the IEEE Neural Networks Society, vol. 1, pp. 10–13, 2003.[7] J.M. Mendel, “Advances in type-2 fuzzy sets and systems,” Information Sciences, vol. 177, pp.84–110, 2007.[8] J.M. Mendel and R.I. John, “Type-2 fuzzy sets made simple,” IEEE Trans. on Fuzzy Sys-tems, vol. 10, pp. 117–127, April 2002.[9] J.M. Mendel, R.I. John, and F. Liu, “Interval type-2 fuzzy logic systems made simple,”IEEE Trans. on Fuzzy Systems, vol. 14, pp. 808–821, Dec. 2006. [10] J.T. Starczewski, “A triangular type-2 fuzzy logic system,” Proc. IEEE-FUZZ 2006, pp.7231–7238, Vancouver, CA, July 2006.[11] H. Wu and J.M. Mendel, “Uncertainty bounds and their use in the design of intervaltype-2 fuzzy logic systems,” IEEE Trans. on Fuzzy Systems, vol. 10, pp. 622–639, Oct. 2002.[12] L.A. Zadeh, “The concept of a linguistic variable and its application to approximate rea-soning–1,” Information Sciences, vol. 8, pp. 199–249, 1975.
FIGURE 13 Educational perspective of T2 FSs and FLSs.
FEBRUARY 2007 | IEEE COMPUTATIONAL INTELLIGENCE MAGAZINE 29
Authorized licensed use limited to: UNIV ESTADUAL PAULISTA JULIO DE MESQUITA FILHO. Downloaded on August 20, 2009 at 12:27 from IEEE Xplore. Restrictions apply.