local neighborhoods as early predictors of innovation adoption
TRANSCRIPT

Marketing Science Institute Working Paper Series 2010 Report No. 10-104 Local Neighborhoods as Early Predictors of Innovation Adoption Jacob Goldenberg, Sangman Han, Donald Lehmann, Janghyuk Lee, and Kyung Young Ohk “Local Neighborhoods as Early Predictors of Innovation Adoption” © 2010 Jacob Goldenberg, Sangman Han, Donald Lehmann, Janghyuk Lee, and Kyung Young Ohk; Report Summary © 2010 Marketing Science Institute MSI working papers are distributed for the benefit of MSI corporate and academic members and the general public. Reports are not be to reproduced or published, in any form or by any means, electronic or mechanical, without written permission.

Report Summary Managers spend considerable effort trying to find ways to predict the behavior of large populations, particularly in marketing new products. In this report, Goldenberg, Han, Lehmann, Lee, and Ohk examine the role of predictive neighborhoods (groups of connected individuals whose adoption patterns evolve similarly to, yet earlier than, overall population behavior) in forecasting adoption of new products. With data drawn from Cyworld.com, a social network website in Korea, they create a network of 114 neighborhoods and track the diffusion process over the network of new items introduced by CyWorld to users. They begin by examining individual adoption within neighborhoods, specifically the influence of local characteristics on the timing and speed of adoptions. They find that an individual’s local neighborhood has a significant influence on his or her adoption behavior. Individuals who receive information from a greater number of sources (greater in-strength) become exposed to information, and hence tend to adopt, earlier. Individuals who share information with a greater number of sources (greater out-strength) also tend to adopt more products, consistent with the opinion leadership literature. Consistent with findings that hubs increase the speed of adoption, their study shows that density—how tightly connected members of a neighborhood are—affects the speed of adoption. The betweenness of the neighborhood (that is, how closely linked it is to other parts of the network) increases the number of adoptions. This is consistent with the neighborhood’s role as a broker of information to different neighborhoods, increasing the likelihood of exposure to products and consequently increasing the number of adoptions. In a second analysis, the authors examine whether some neighborhoods can be reliably used at an early stage of the product introduction process to predict overall network adoption behavior. Using the same set of 114 neighborhoods from the Cyworld.com data, they identify the top 10 items adopted (the “mega hits”). To determine how well particular neighborhoods predicted adoption in the total network, they used the correlation between (1) adoption of the mega-hit in a neighborhood at the time that 5%, 16%, and 50% of the eventual market had adopted it and (2) eventual total network adoptions. They then examined which characteristics were associated with the neighborhoods that were the best predictors of overall adoption. They found that large and central neighborhoods that adopted early were the best predictors and their predictions were more accurate than those of random sample of the same size. By contrast, small dense neighborhoods were relatively poor predictors of eventual adoption, possibly because of their closed and isolated nature. Overall their study demonstrates the potential of using identifiable clusters (predictive neighborhoods) to improve the accuracy of new product adoption predictions within a market.
Marketing Science Institute Working Paper Series 1

While the study focused on post-launch predictions, firms might use predictive neighborhoods as the basis for pre-launch tests as well. Jacob Goldenberg is Professor of Marketing, School of Business Administration, The Hebrew University of Jerusalem and a member in the research center at Ono. Sangman Han is Professor of Marketing at Sungkyunkwan University, Korea. Donald Lehmann is George E. Warren Professor of Business, Graduate School of Business, Columbia University. Janghyuk Lee is AssociateProfessor of Marketing, Korea University Business School, Seoul. Kyung Young Ohk is a postdoctoral fellow at the Massachusetts Institute of Technology. Acknowledgments The authors would like to thank Dominique Hanssens, Scott Neslin, Vithala Rao, Danny Shapira, and Olivier Toubia for their valuable comments.
Marketing Science Institute Working Paper Series 2

Introduction
“As Maine goes, so goes the nation,” This proverb of U.S. politics suggests that what happens
in a particular neighborhood (in this case, the sparsely populated state of Maine) can be a good
predictor of a much larger population (in this case the United States, or more precisely who wins
the presidential election). More generally, both political scientists and managers spend
considerable effort trying to find ways to predict the behavior of large populations. This paper
focuses on predicting innovation adoption based on what we term predictive neighborhoods
(groups of connected individuals whose adoption patterns evolve similarly to, yet earlier than,
overall population behavior). We demonstrate that some neighborhoods can indeed be used to
predict overall adoption and that their predictions are superior to those of random samples.
Much of the research on innovation adoption has focused at the aggregate level, i.e., on
forecasting the rate of adoption in the overall population (for example the work on diffusion
models). Another major stream of research has concentrated on individual adoption and the role
of word of mouth in general and opinion leaders (influentials) in particular. More recently,
researchers have adopted a social network perspective on innovation diffusion (see Van den Bulte
and Wuyts 2007). This paper extends this later work by focusing on the role of (local) sub-
networks in the diffusion process. The main finding is that in a large network, some clusters (the
predictive neighborhoods) can be used as predictors of overall network adoption of new products
and the predictions are superior to those of random samples. These clusters have identifiable
characteristics, e.g., their size, centrality in the network and tendency to include early adopters.
Our paper begins by examining the influence of local neighborhood characteristics on
individual adoption within the neighborhood. We then show that the behavior of some local
Marketing Science Institute Working Paper Series 3

neighborhoods closely mirrors that of the entire population and can be used as early predictors of
the success or failure of the overall adoption process.
Background
Social networks
The social network literature can be classified into two principle research themes: (1) network
formation and depiction (e.g., Stephen and Toubia, 2009a) and (2) information dissemination and
diffusion in networks (see among others: Brown 1981; Goldenberg et al. 2001a; Kocsis and Kun
2008; Rogers et al. 1970; Valente 1995; Young 2006). The focus here is on diffusion in
networks.
Previous research has shown that product adoption decisions are influenced by social peers
and relationships (see Godes et al. 2005; Goldenberg et al. 2009; Goldenberg et al. 2006; Hogan
et al. 2005; Libai 2005; Libai et al. 2009; Libai et al. 2005; Rogers 2003; Trusov et al. 2008b;
Valente 1995; Van den Bulte and Joshi 2007; Van den Bulte and Wuyts 2007; Watts and Dodds
2007b)). Research also provides evidence of the benefits garnered from an advantageous network
position and the structural properties of one's local network. These properties include the
resources of one's direct network (Burt 1997; Lin 2001), the number and strength of ties (e.g.,
Granovetter 1973) and closure or local clustering (Coleman 1990; Lin 2001).
A few studies have found that the individual adoption process is driven by group adoption
(Jones and Ritz 1991; Kim and Srivastava 1998). However, these studies focus on cases where
group adoption precedes individual adoption within that group. Here we consider the case of
social networks characterized by a high clustering coefficient (Watts and Strogatz 1998). This
paper first investigates how the individual adoption decisions within a neighborhood are
Marketing Science Institute Working Paper Series 4

influenced by the properties of the neighborhoods to which they belong, and second, whether
certain local neighborhoods can be reliable predictors of overall network adoption (i.e., are
predictive neighborhoods).
Predictive Neighborhoods
Rapid post-launch evaluation of new product performance is critical because of the large
expenditures involved and the short window of opportunity available to make decisions about
improvements or pulling the plug (Goldenberg et al. 2001b; Golder and Tellis 1997). However,
extant diffusion models are hard to calibrate at early stages of the diffusion process based on
aggregate adoption data only (see for example Hauser et al. 2006; Mahajan et al. 1990; Van Den
Bulte and Lilien 1997). Early forecasts based on aggregate adoption data are also sometimes
quite far off. Some of the reasons for this are that 1) the early (pre take-off) stages of product
introduction do not necessarily fit easily into existing “diffusion of innovation” frameworks; 2)
only a small number of data points exist before takeoff; and 3) in the presence of the volatility
which is quite common during introduction stages, the search for explicit solutions for nonlinear
differential equations through linear approximations can lead to multiple (dis)equilibria (e.g.,
Nijkamp and Reggiani 1998) and fail to account for discontinuities. Indeed, reviews of diffusion
models (e.g., Mahajan et al. 2000; Parker 1994) find little utilization of growth models around
take-off. Several studies have proposed generalized models of new product growth that capture
the effect of sales volatility by adding a stochastic term to the sales equation (see for example
Boswijk and Franses 2005; Goldenberg, Lowengart and Shapira, 2009).
There is growing consensus on the fundamental role that the structure of social networks plays
in how information reaches consumers, channel members, and suppliers. This is particularly
important in the marketing of new products and the creation of marketing collaborations (Achrol
Marketing Science Institute Working Paper Series 5

and Kotler 1999; Iacobucci 1996; Rosen 2002). Attempts have been made to directly link social
network properties to the success of marketing activities such as pricing or promotion (Mayzlin
2002; Shi 2003) and sales (Stephen and Toubia, 2009b). Yet much of the research in this area has
focused on relatively small networks, for example intra- or inter-organizational networks (see
Houston et al. 2004 for a review), tie-strength (Brown and Reingen 1987; Rindfleisch and
Moorman 2001), or social capital (Ronchetto et al. 1989).
Largely because networks and other more complex structures make modeling and estimation
procedures much more complex, most of the diffusion literature has implicitly assumed that the
market is homogeneous. Nonetheless, in order to better capture the mechanism through which
new products penetrate the marketplace, several attempts have been made to divide the total
market into submarkets and model the interactions among them. For instance, market structures
for new product introduction in international markets (i.e., “international diffusion”) have been
examined to determine which market should be penetrated first (e.g., countries with a higher
connectivity level, etc.). For example, Putsis, Balasubramanian, Kaplan, and Sen (1997)
examined how adoption in one country affects adoption in others by modeling a mixing pattern
(interaction between countries) that is grounded in communications within and across countries.
While this is an important direction to pursue, the size of the network used (i.e., only several
dozen nodes) and the resolution are limited (i.e., the nodes are countries rather than individual
consumers).
When new products are introduced into a market, they diffuse over time and space (Allaway et
al. 1991; Bell and Song 2007; Bronnenberg and Mahajan 2001; Mahajan et al. 1979). The spatial
aspect of diffusion is strongly related to interactions between adopters and potential adopters
(normally termed word of mouth or internal influence). For communication to take place,
Marketing Science Institute Working Paper Series 6

adopters and potential adopters typically must be in proximity to each other. Indeed, the diffusion
literature reports a clear correlation between geographic proximity and the strength and speed of
word-of-mouth spread, sometimes labeled the “neighborhood effect” (Baptista 2000; Case 1991;
Mahajan et al. 1979). Garber, Goldenberg, Libai and Muller (2004) showed how such spatial
clusters of communication can be used as a strong predictor of take-off by calculating the cross-
entropy of the spatial distribution: When a product is successful, geographic clusters of adopters
emerge. Even when a product is a failure, some consumers adopt, mainly as a result of external
effects (marketing efforts). However, because the effect of their adoption on other consumers will
be negligible or negative, adopters become randomly distributed in space in close to a uniform
geographical distribution. Thus, the lack of contiguous units adopting a product may be a strong
signal of likely product failure.
The interest in spatial distribution is mainly a result of the availability of spatial data. Yet
spatial distribution is only a proxy for the underlying social networks that account for the growth
curve. If, for example, we know the structure of the social network, we can calculate predictors
such the cross–entropy of the distribution, using more accurate propagation measures. While the
improvement of communication technologies in general, and the Internet in particular, has
reduced the dependence of word of mouth communication on geographical proximity, it is still
useful to examine communities (local neighborhoods) defined based on communication among
members.
Importantly, it is possible that certain local neighborhoods consistently behave like the entire
network (“as Maine goes…”). If these neighborhoods also adopt early, they can be used to
predict product success or failure. In this paper we examine web-based social networks and
Marketing Science Institute Working Paper Series 7

communications among potential adopters, and demonstrate the existence of local neighborhoods
that provide early and accurate predictions of eventual overall population adoption.
Factors That Influence Adoption
Individual decisions are strongly influenced by the others to whom the individual is linked.
Although there is a debate over the exact mechanism behind this effect (e.g. cohesion vs.
contagion), there is agreement that network properties influence adoption. We examined several
common network properties in this work. Below is a brief glossary of some key terms. More
precise definitions appear in the Appendix.
Term Description
Centrality The importance of a node within the network (i.e. are they in the center or on the periphery?)
Betweenness centrality
Nodes that lie on the shortest paths between other nodes have higher betweenness centrality.
Neighborhood
A group of connected nodes (people) with more connections inside the group then outside it.
Degree
The numbers of ties (links) a node (person) has.
Density Number of ties divided by the number of possible ties in a cluster, i.e. how tightly connected members of a neighborhood are.
Path length Smallest number of links between two nodes (i.e., the shortest distance between them.)
Tie strength Frequency and strength of communication between the two nodes (people).
Social Capital
The value (e.g. productivity knowledge, information accessibility) a person has due to his/her position in the social network.
These properties can be classified into individual based properties (how an individual is
connected to peers in the network) and overall properties of the network to which the individual
Marketing Science Institute Working Paper Series 8

belongs. We next describe each of the properties, and present the variable definitions and
operationaliztion used here which are summarized in the appendix.
Individual-based properties
The way individuals are connected to the network can influence their own adoption as well as
the resulting cascade of adoption by others (Watts, 2002). Several properties exist which describe
how individuals relate to their neighborhoods. Here we focus on the two most prominent
properties: overall tie-strength to neighbors and individual relationships with local hubs.
Tie-strength. The strength of the ties is known to influence the adoption process (Goldenberg
et al. 2007; Granovetter 1973; Reingen and Kernan 1986). Granoveter (1973) showed that weak
ties in some cases may be more influential in influencing others than strong ties (coined “the
strength of weak ties”). Specifically, in the case of a successful product with mainly positive
word-of-mouth, weak ties accelerate the diffusion process at least as much as strong ties if there
are many sub-networks (cliques/local neighborhoods) in the market. However, in the case of a
less successful product when negative w-o-m appears, strong ties become more important and
have more influence on adoption (Goldenberg et al. 2007). We utilize two measures of tie-
strength here: InStrength and OutStrength (the number of visits a person receives from others and
the number of visits a person makes to others).
Relationship with hubs. Social hubs are often referred to as influentials. One key characteristic
of influentials (along with knowledge and persuasiveness) is their number of ties; social hubs
have an exceptionally large number of ties (but they are not necessarily experts). Although some
work argues that the influence of social hubs is not large (Watts and Dodds 2007a; Watts and
Dodds 2007b), there is evidence that social hubs adopt early in the process, even if they are not
innovative, because they are exposed to the new product early in the process (Goldenberg et al.
Marketing Science Institute Working Paper Series 9

2009). A more generalized positive correlation between degree and adoption time was recently
found by Katona, Zubcsek and Sarvary (2009). Due to their many ties, hubs accelerate the
diffusion process and increase the market size. In cases where social hubs are relevant (i.e., when
w-o-m activity exists), individual adoption may be influenced by how many direct links to hubs
an individual has, as well as the strength of those ties.
Neighborhood-level properties
To function as a useful predictor, a neighborhood must: 1) be similar to the entire network
in its eventual adoption behavior, and 2) adopt early in the diffusion process, hopefully at a rapid
rate. Assuming neighborhoods in a network “function” as entities that influence individual
adoption, standard network measures that differentiate between them should be relevant. Here we
focus on four general properties: density, centrality, the number and strength of connections
among hubs in a neighborhood, and neighborhood size.
Density. One distinctive property of neighborhoods is their density. When the number of links
among nodes is larger, each individual node is exposed to more influence, and hence information
travels faster and is shared sooner by more nodes in the network. This means that the individuals
in a dense neighborhood may share similar preferences, and a product that successfully matches
this preference profile will be adopted by most of this neighborhood. This type of clustering
effect was explored by Katona, Zubcsek and Sarvary (2009) who found that the density of
connections in a group of adopters has a positive effect on the adoption of individuals connected
to this cluster. Two common measures of cluster density are path length (the distance between
pairs of nodes in the network, measured by the number of nodes that separate a pair of nodes;
Newman 2001), and the clustering coefficient (the number of links among one’s neighbors
divided by the total possible links between all pairs of these neighbors; Watts and Strogatz 1998).
Marketing Science Institute Working Paper Series 10

Neighborhood centrality. A neighborhood whose nodes are connected to more other social
worlds (neighborhoods) is likely to have access to a wider range of information. The correlation
of neighborhood and overall market adoption is expected to be stronger when the neighborhood
is connected to several different neighborhoods rather than when the majority of its connections
are within that single neighborhood. For example, Burt (1992) relates the information advantage
of an actor in a network to the extent to which the actor spans structural holes, that is uniquely
links separate parts of the network. We follow this logic, with the difference being that we use the
centrality measure at the neighborhood (and not the node) level, in effect assuming
neighborhoods can act as brokers in a network by bridging to other neighborhoods.
Here we concentrate on betweenness centrality (Girvan and Newman 2002), which measures
which parts of the network are connected through a node (or a group of nodes, in our case).
Neighborhoods with high betweenness are more closely linked to other parts of the network,
exposing their members to more, and possibly varied, information earlier in the product adoption
process. Other centrality measures, e.g., degree centrality, are less relevant to the neighborhood
level. Since the different centrality measures are highly correlated (in a common scale-free
network, the correlations are typically around .8), and because we obtained similar results when
we used other centrality measures, we focus on betweenness centrality here.
Size. We define size as the number of nodes (individuals) in a given neighborhood. Being a
member of a large neighborhood means that an individual is exposed (directly or indirectly) to a
greater number of peer adoptions, and therefore has a better chance of being informed on a
variety of products.
Hub-related characteristics. The greater the number of hubs in each neighborhood, the faster
we expect dissemination to be (as demonstrated in Goldenberg et al. 2009). In addition, the
Marketing Science Institute Working Paper Series 11

greater the tie-strength among the hubs, and the more densely the hubs in the cluster are
connected, the greater their influence on adoption. We use two measures of hubs here – the
number of hubs/size (number of hubs in the same cluster divided by cluster size) and the tie-
strength among hubs (the sum of tie-strength among hubs divided by the number of hubs in a
given neighborhood). Of course if no hubs are linked, this measure is zero.
Data
To examine the role of neighborhoods, data is needed to map a large network, and information
about the timing of individual adoption for multiple diffusion processes must be available. One
such data set that was available for this research comes from Cyworld.com, a social network
website in Korea.
Cyworld was founded in 1999. In the period of this study, the number of members in the
Cyworld database grew from 2,492,036 in December 2003 to 12,685,214 in July 2005. In
October 2006, there were about 22 million registered members (compared to about 100 million
for Myspace), and an average of 20 million monthly unique visitors (compared to 24.2 million
unique daily visitors in MySpace, according to wikipedia.com, 2006, and Businessweek, 2006).
Many people considered Cyworld a part of their everyday life and as a tool for building
relationships and sharing information about their lives on their homepages.
A key aspect of the service, for our purpose, allows people to customize their homepages by
including documents, photos, and other "goodies" at no charge. Members can also decorate their
minihompy (personal homepage) with paid items such as virtual household items—furniture,
electronics, wallpaper (Cyworld generates money from sales of these items and from
advertising). People can also adopt items such as pictures or video clips directly from the
Marketing Science Institute Working Paper Series 12

minihompies they visit (called “scrapping” in Cyworld.). This study focuses on this latter type of
adoption, using data from December 2003 to July 2005.
The data contain information on “scrapped” items – the item number, time of scrapping, and
creator ID of each item. By combining network information with information on “scrapped”
items, we track the diffusion process over the network of new items introduced by CyWorld.
There are multiple ways to define links between people, in particular based on the level of
activity or on the existence of a “pointer” between them (as in Facebook). Here we define links
between nodes based on the direct activity between them (e.g., visits) rather than by pointers such
as membership in address books. (Trusov, Bodapati and Bucklin 2008a). Importantly, a pointer
between two individuals in a social networking site, such as LinkedIn or Face Book, does not
necessarily imply influence.
Once a link is established, all the variables defined above can be measured (see appendix). For
example, the degree of each node (person) is the number of links (connections) to other nodes
(people) in the network. We measure out-degree in our data set as the number of other nodes ever
visited by the hub and in-degree as the number of other nodes that have visited the hub.
Consistent with Goldenberg, Han, Lehmann, and Hong (2009), we define hubs as people with
both in- and out- degrees more than three standard deviations above the mean. In this dataset,
hubs comprised between 1.28% and 3.30% of the dataset over time, averaging 2.63%.
The Role of Local Neighborhoods in Individual Adoption
We first explore adoption speed and scope across products at the individual level, and
how they are influenced by the properties of the individual and the individual’s neighborhood.
We measure the adoption timing of persons as the average percent of other people who
Marketing Science Institute Working Paper Series 13

eventually adopt a product before person j adopted it, and adoption extent (size) as the total
number of scraps adopted by the individual.
In order to allow for random errors at both the individual and neighborhood levels, we
utilize hierarchical linear models (Bryk amd Raudenbush 1992). The hierarchical linear model
estimates the individual and neighborhood levels simultaneously.
Level 1: individual
ij
Q
qqijqjjij rX ++= ∑
=10 ββη
Level 2: neighborhood
qjsj
S
sqsqqj uW
q
++= ∑=1
0 γγβ
where the Xs are individual-level variables (in strength, out strength, closeness to hubs, and tie-
strength to hubs), and the Ws are neighborhood characteristics (path length, clustering
coefficient, cluster betweenness centrality, tie-strength among hubs, and number of
hubs/neighborhood size).
Basic Analyses
To create a manageable size database to analyze, 24,368 minihompies were sampled using a
“snowballing” method. The corresponding individuals were then classified into 114
clusters/neighborhoods according to Newman and Girvan’s modularity method (2003) based on
declared links.1 Basic statistics (see Table 1, following References). Essentially, the sample is
made up of young people (average age of 21) who made an average of about 10 visits to other
members and received an average of 10 visits from other members in the network. Individuals
Marketing Science Institute Working Paper Series 14

adopted an average of 3 items in the time period studied. The average cluster/neighborhood size
is 214, with a range between 102 and 1452. Each neighborhood contains an average of 4.8 hubs.
Correlations among the individual-based variables (see Table 2, following References). The
largest individual-level correlation is between tie-strength to hubs and in strength. At the cluster
level, the strongest correlations are among betweenness centrality, the number of hubs, and
cluster size (see Table 3, following References).
Model Results
Number of adoptions
Table 4 (following References) presents the results for predicting the number of
individual adoptions based on the individual’s position in his or her cluster and the characteristics
of the cluster. Two of the four individual variables (out-strength, tie-strength to hubs) are
significant in Model 1. We therefore dropped the insignificant variables (in-strength, closeness to
hub) from the analysis. Model 2 adds the neighborhood-level variables (path length, clustering
coefficient, betweenness centrality, tie-strength among hubs, and number of hubs/size.) Only one
neighborhood variable is significant: the betweenness centrality of the neighborhood has a
positive impact. Model 3 includes only the significant individual-level and neighborhood-level
variables. Finally, in Model 4 we added demographic variables (gender and age) to the model to
control for their effect. (Basically the number of adoptions was greater for males and for younger
people).
At the individual level, out-strength has a significant positive relationship to adoption size in
Model 4. This implies that influential members (individuals with high out-strength) tend to adopt
more actively than non-influential members. This gives them more to talk about as well as
credibility as information sources given their greater use of the product category. Interestingly,
Marketing Science Institute Working Paper Series 15

tie-strength to hubs also has a significant positive influence on adoption size, consistent with
previous findings (Goldenberg et al. 2009) that demonstrated that hubs influence individual
adoption. At the neighborhood level, only betweenness centrality significantly influences
adoption size. This implies that individuals in central neighborhoods tend to adopt more.
Neighborhoods with high betweenness are more connected to other parts of the network,
allowing their members to be exposed to diverse information earlier. Because individuals in
central neighborhoods have more information earlier, they tend to adopt more.
Because of the high correlation between neighborhood size and betweenness centrality (.88)
we substituted size for centrality and re-ran all the analyses. It was not surprising to find that size
was significant and the coefficients of the other variables remained essentially unchanged.
Because the log likelihoods were slightly smaller when betweenness centrality was used, we only
report these latter results (see Table 4). One interpretation of these results is that neighborhood
size is a major driver of centrality, or at least that central neighborhoods are larger.
Adoption speed. Adoption speed was modeled in a manner parallel to adoption size (see
Table 5, following References). In the initial model, in-strength was significant at the 5% level
while out-strength was not. In Model 2, we added the cluster-level variables—path length,
clustering coefficient, betweenness centrality, tie-strength among hubs, and number of hubs/size.
Of these, only the clustering coefficient was significant at the .01 level. In Model 3, we estimated
a parsimonious model with individual in-strength and the clustering coefficient, which improves
the likelihood from -1451.12 to -1439.86. In Model 4, we added the demographic variables
gender and age, which improves the likelihood from -1439.86 to -1410.42.
At the individual level, in-strength has a significant negative coefficient, while out-strength
does not. This means that individuals who are visited more often by others tend to adopt new
products faster. Interestingly, the central position of a neighborhood does not affect the adoption
Marketing Science Institute Working Paper Series 16

speed of its members even though it has significant influence on the number of items adopted of
its members. Further, in denser neighborhoods, individuals tend to adopt new products faster.
Key findings
Overall the results lead to at least three key findings. First, at the individual level, out-
strength affects the number of adoptions while in-strength affects adoption speed. Individuals
who receive information from a greater number of sources (in-strength) become exposed to
information, and hence tend to adopt, earlier. Furthermore, those people who adopt more
products tend to speak to others more, consistent with the opinion leadership literature. Finally, at
the neighborhood level, density (the clustering coefficient) affects adoption speed, while
centrality affects the number of adoptions. The density effect on speed is consistent with findings
that hubs increase the speed of adoption by influencing a larger “area” of their network. The
effect of the position of the neighborhood (its betweenness) on the number of adoptions is
consistent with the neighborhood’s role as a broker of information to different neighborhoods,
thereby increasing the likelihood of exposure to products and consequently increasing the number
of adoptions. More generally, the results demonstrate that an individual’s local neighborhood has
a significant influence on his or her adoption behavior.
Uncovering Predictive Neighborhoods
The previous analyses examined adoption within the neighborhood. In the following analysis,
we examine whether some neighborhoods can be reliably used at an early stage of the product
introduction process to predict overall network adoption behavior.
Marketing Science Institute Working Paper Series 17

Method
We examine the same set of 114 neighborhoods analyzed earlier. We identified the number of
scraps (adoptions) for each item and eliminated those with fewer than 20 adoptions (i.e., niche
products and abject failures which had very sparse data on which to base analyses). Of the
remaining products, the top 10 items (in effect the “mega hits”) were adopted by between 104
and 7952 people while the bottom 30 were adopted by 20-25 individuals, meaning highly
successful items were adopted at a rate of at least four times greater, and in many cases at an
order of magnitude greater, than less successful ones.
As a measure of how well a local neighborhood predicts adoption in the total network, we
used the correlation between adoption in a neighborhood at the time 5%, 16%, and 50% of the
eventual market had adopted it (i.e., early adoption in the neighborhood), and eventual total
network adoptions after the adoption process is completed. Using these 40 items, (the top 10 plus
the bottom 30), we then compared the ability to predict total adoption in the overall market based
on a) a random sample (the “gold standard” of market research) of size 200, similar to the
average cluster size of 214, b) the average of all the neighborhoods in the network, and c) the 20
clusters with the highest correlation between their adoption at the time 16% of the market had
adopted and eventual market adoption.
We also examined which characteristics were associated with the neighborhoods that were the
best predictors of overall adoption. More specifically, for each neighborhood, we analyzed the
following local neighborhood-level variables: path length, clustering coefficient, betweenness
centrality, cluster size, tie-strength among hubs, and number of hubs/size.
Marketing Science Institute Working Paper Series 18

Results
The correlation between early neighborhood adoption and total population adoption
ranged between -.07 and + .99. (see Table 6, following References). At the time when 5%, l6%,
or 50% of the overall market has adopted a product, an average neighborhood predicts total
market adoption slightly, but not significantly, better than the average of 20 random samples of
200 individuals. More importantly, in all three cases, the top 20 (of the 114) clusters substantially
and significantly outperformed the random samples with correlations of .96, .96 and .98 vs. .62,
.72, and .84 respectively. Even more impressively, when the sample of products is split in half,
the holdout sample performance of the top 20 clusters remains strong (average correlations of
.79, .95, and .96 respectively), whereas the results for the 20 random samples degrades noticeably
(to .21, .40, and .53 respectively).
A key question is how to identify a predictive neighborhood. Obviously if a database with
multiple adoptions over a mapped network is available, managers can use the data directly.
Absent such data, one option is to use characteristics of the network itself. To examine which
types of local neighborhoods predict best, we regressed the correlation between local
neighborhood and overall market adoption against the characteristics previously analyzed (cluster
size, path-length, clustering coefficient, betweenness centrality, tie-strength among hubs, number
of hubs/size, time to first adoption, time to 16% adoption.) We use neighborhood size and
betweenness centrality separately because they are highly correlated (.88).
Table 7 (following References) shows the results of a regression predicting the correlation
between neighborhood and overall adoption across the products studied. Notably, only
neighborhood size and centrality (which is highly correlated with size) showed any significant
predictive power (except for the regression on the correlation of neighborhood adoption at 50%
Marketing Science Institute Working Paper Series 19

of eventual market adoption and total network adoption) for identifying which local
neighborhoods were the most effective at predicting overall adoption. Basically, large and central
neighborhoods that adopt early predict overall adoption better than average neighborhoods or
random samples. By contrast, smaller dense neighborhoods are relatively poor predictors,
possibly because of their relatively closed and isolated nature. However, the average size of the
20 best predictive neighborhoods is not particularly large. the average size of them is 214, 193, or
233 depending on whether you select them at the time of 5%, 16%, or 50% adoption respectively
(see Table 6). Further, 12 of the 20 best predictive neighborhoods have fewer than 200 members
at the time 5% or 16% have adopted. This suggests that small (e.g., Maine), but not isolated, test
markets may be useful for prediction purposes.
Discussion
The literature generally recommends using either random samples to represent the overall
population or some kind of stratified sample with representation of all strata. When there is no
information about the population or about the network structure, this strategy is probably the
most reliable. However, when the social structure is known, specific groups of people can better
represent the entire population than randomly selected individuals. In this paper we argue that it
is possible to identify such predictive groups and use one such group (similar to a single stratum)
to predict overall adoption. The following are the key findings of this study:
First, local neighborhoods have an influence on individual adoption within the neighborhood.
In particular, the number of individual new product adoptions is influenced by the centrality of
the neighborhood to which the individual belongs. We also found that individual adoption speed
is influenced by the density of the individual’s neighborhood.
Marketing Science Institute Working Paper Series 20

Second, certain local neighborhoods tend to perform quite well in predicting overall adoption.
The range of correlation of early adoption within the top 20 neighborhoods with overall adoption
was between .81 –.99. By tracing the adoption pattern of these predictive neighborhoods we can
predict the success/failure of the new products better than when we use random samples.
Third, we identified key variables that are significantly related to predictive neighborhoods.
Interestingly, of the neighborhood-level variables, only cluster size and centrality (which is
highly correlated with size) show any significant predictive power.
One limitation of this research is the focus on post launch predictions. However, once
predictive neighborhoods are identified, firms can, and probably should, use them as the basis for
pre-launch tests as well.
Clearly, this research is only a first step. Several additional areas for future research may be
identified. First, although our application provided support for our approach, other field
applications should be examined and the predictive ability of alternative models should be tested
further. Second, the models may be extended to capture effects such as negative word-of-mouth
(Mahajan et al. 1984), complex network structures (Shaikh et al. 2005), and different types of ties
or relationships (Ansari et al. 2008; Iyengar et al. 2008). Third, the analysis should be extended to
include covariates such as marketing mix variables (Bass et al. 1994; Horsky and Simon 1983;
Kalish and Sen 1986; Robinson and Lakhani 1975). Fourth, the proposed models use discrete
time intervals, making the parameters a function of the data frequency. Future research may
explore continuous-time versions. Finally, future research may develop new methods for
collecting the social interactions data both online and offline. Hopefully this research will spur
further exploration in these and other directions.
Marketing Science Institute Working Paper Series 21

In practice, one rarely has full information on the networks that comprise the potential market.
Internet based social networks often provide information about linkages (ties) among individuals
so that the network can be identified using a clustering algorithm based on the number of contacts
between individuals. However, in order to identify clusters (neighborhoods) in other situations,
firms may need to develop creative ways to identify such clusters, perhaps by using observed
behavior and characteristics to infer links between members. Naturally, this requires efforts and
resources which small firms may be reluctant to invest. Market research firms may thus benefit
from building panels of people who are socially connected and offering these panels for use in
monitoring reactions to new products.
Marketing Science Institute Working Paper Series 22

Appendix: Variables Definitions and Operationalizations
Variable Definition Operationalization Individual Level
Tie Strength
In-strength Total number of visits an individual receives in a given period
where visit(jik) is the number of times person j visits individual i.
Out-strength
Total number of visits an individual makes in a given period
where visit(ijk) is the number of times individual i visits person j .
Relationship to Hubs
Closeness to hubs
The number of hubs an individual is directly connected with
where d_hub(h) is 1 if hub h is connected with individual i, otherwise 0.
Tie-strength to hubs
The total number of hubs an individual is directly connected with
where in_strength_hub(h) is the total number of visits individual i receives from hub h, and out_strength_hub(h) is the total number of visits individual i makes to hub h. i.e., in strength plus out strength.
Neighborhood level
Density
Average path length
Average shortest distance between all the pairs of two members in the same neighborhood
where path-length(ij) is the shortest distance between member i and j in the same cluster, and n is the number of members in the cluster.
Clustering coefficient
Average clustering coefficient member in the same neighborhood
where the clustering coefficient is the number of triangles connected to member i divided by the number of triples centered on member i, and n stands for the number of members in the cluster
Centrality
Cluster betweenness
Betweenness centrality of the cluster in the network
Marketing Science Institute Working Paper Series 23

centrality of neighborhood where we take each cluster (neighborhood) as a node, and d_cluster(ij) is the number of times the cluster is on the shortest path between all the pairs of clusters i and j, C stands for the total number of clusters.
Neighborhood size Size of the Neighborhood Total number of members in each neighborhood Hub characteristics
Number of hub/ size
Number of hubs in the same cluster divided by cluster size
(Number of hubs in the cluster) / cluster size
Tie-strength among hubs
The sum of tie-strength among hubs divided by number of hubs in the cluster
where tie strength hub(i,j) is the total in-strength and out-strength of the pair of hubs i and j in the same neighborhood, and Hc stands for the number of hubs in the neighborhood..
Marketing Science Institute Working Paper Series 24

Note
1. In this algorithm the link betweenness centrality is calculated for all links. By removing each link (starting with the one with the highest centrality) and recalculating the centrality of all links, the links that span clusters are identified. After the process is completed, the set of separating links is used to define the clusters.
Marketing Science Institute Working Paper Series 25

References
Achrol, Ravi S., and Philip Kotler (1999), "Marketing in the Network Economy," Journal of
Marketing 63, 146-63.
Allaway, Arthur W., Barry J. Mason, and William C. Black (1991), "The Dynamics of Spatial
and Temporal Diffusion in a Retail Setting." In Spatial Analysis in Marketing, eds. Avijit
Ghosh, and Charles A. Ingene ,. New York , NY: JAI Press, Inc.
Ansari, Asim, Oded Koenigsberg, and Florian Stahl (2008), "Modeling Multiple
Relationships in Online Social Networks," Working Paper, Columbia Business School:
Columbia University.
Baptista, Rui (2000), "Do Innovations Diffuse Faster within Geographical Clusters?,"
International Journal of Industrial Organization 18 (3), 515-35.
Bass, Frank M., Trichy V. Krishnan, and Dipak C. Jain (1994), "Why the Bass Model Fits
without Decision Variables," Marketing Science 13 (3), 203-23.
Bell, David, and Sangyoung Song (2007), "Neighborhood Effects and Trial on the Internet:
Evidence from Online Grocery Retailing," Quantitative Marketing and Economics 5 (4), 361-
400.
Boswijk, H. Peter, and Philip H. Franses (2005), "The Econometrics of the Bass Diffusion
Model," Journal of Business and Economic Statistics 23 (3), 255-68.
Marketing Science Institute Working Paper Series 26

Bronnenberg, Bart J., and Vijay Mahajan (2001), "Unobserved Retailer Behavior in
Multimarket Data: Joint Spatial Dependence in Market Shares and Promotion Variables,"
Marketing Science 20 (3), 284-99.
Brown, Jacqueline Johnson, and Peter H. Reingen (1987), "Social Ties and Word-of-Mouth
Referral Behavior," The Journal of Consumer Research 14 (3), 350-62.
Brown, Lawrence A. (1981), Innovation Diffusion: A New Perspective. London and New
York: Methuen.
Bryk, Anthony S., and Stephen W. Raudenbush (1992), Hierarchical Linear Models:
Applications and Data Analysis Methods. Newbury Park, CA: Sage.
Burt, Ronald S. (1997), "The Contingent Value of Social Capital," Administrative Science
Quarterly 42 (2), 339-65.
Burt, Ronald S. (1992), Structural Holes: The Social Structure of Competition. Cambridge,
Mass: Harvard University Press.
Case, Anne C. (1991), "Spatial Patterns in Household Demand," Econometrica 59 (4), 953-
65.
Marketing Science Institute Working Paper Series 27

Coleman, James S. (1990), Foundations of Social Theory. Cambridge, Mass. : Belknap Press
of Harvard University Press.
Garber, Tal, Jacob Goldenberg, Barak Libai, and Eitan Muller (2004), "From Density to
Destiny: Using Spatial Dimension of Sales Data for Early Prediction of New Product
Success," Marketing Science 23 (3), 419-28.
Girvan, Mark, and M. E. J. Newman (2002), "Community Structure in Social and Biological
Networks," Proceedings National Academy of Sciences USA 99, 7821-26.
Godes, David, Dina Mayzlin, Yubo Chen, Sanjiv Das, Chrysanthos Dellarocas, Bruce
Pfeiffer, Barak Libai, Subrata K. Sen, Mengze Shi, and Peeter Verlegh (2005), "The Firm's
Management of Social Interactions," Marketing Letters 16 (3), 415-28.
Goldenberg, Jacon, Donald R. Lehmann, and David Mazursky (2001b), "The Idea Itself and
the Circumstances of its Emergence as Predictors of New Product Success," Management
Science 47 (1), 69.
Goldenberg, Jacob, Barak Libai, and Eitan Muller (2001a), "Talk of the Network: A Complex
Systems Look at the Underlying Process of Word-of-Mouth," Marketing Letters 12 (3), 211-
23.
Goldenberg, Jacob, Barak Libai, Sarit Moldovan, and Eitan Muller (2007), "The NPV of Bad
News," International Journal of Research in Marketing 24 (3), 186-200.
Marketing Science Institute Working Paper Series 28

Goldenberg, Jacob, Barak Libai, Eitan Muller, and Renana Peres (2006), "Blazing Saddles:
Early and Main Markets in Product-Life-Cycle in High-Tech Industries," The Economic
Quarterly 53, 249-71.
Goldenberg, Jacob, Lowengart Oded ,and Daniel Shapira (2009) “Zooming In: Self-
Emergence of Movements in New Product Growth,” Marketing Science 28 (2, March-April),
274-292.
Goldenberg, Jacob, Sangman Han, Donald R. Lehmann, and Jae Weon Weon-Hong (2009),
"The Role of Hubs in the Adoption Processes," Journal of Marketing 73, 1-13.
Golder, Peter N., and Gerard J. Tellis (1997), "Will It Ever Fly? Modeling the Takeoff of
Really New Consumer Durables," Marketing Science 16 (3), 256-70.
Granovetter, Mark S. (1973), "The Strength of Weak Ties," American Journal of Sociology
78 (6), 1360-80.
Hauser, John R., Gerard J. Tellis, and Abbie Griffin (2006), "Research on Innovation: A
Review and Agenda for Marketing Science," Marketing Science 25 (6), 687-717.
Hogan, John E., Kathherine N. Lemon, and Barak Libai (2005), "Quantifying the Ripple:
Word-of-Mouth and Advertising Effectiveness," Journal of Advertising Research 44 (03),
271-80.
Marketing Science Institute Working Paper Series 29

Horsky, Dan, and Leonard S. Simon (1983), "Advertising and the Diffusion of New
Products," Marketing Science 2 (1), 1-17.
Houston, Mark, Mike Hutt, Christine Moorman, Peter H. Reingen, Aric Rindfleisch, Vanitha
Swaminathan, and Beth Walker (2004), "Marketing Networks and Firm Performance." In
Assessing Marketing Strategy Performance, eds. Christine Moorman, and Donald R.
Lehmann, 227-68, Cambridge, MA: Marketing Science Institute.
Iacobucci, Dawn (1996), Networks in Marketing. Thousand Oaks, Calif.: Sage Publications.
Iyengar, Raghuram, Thomas Valente, and Christophe Van den Bulte (2008), "Opinion
Leadership and Social Contagion in New Product Diffusion," Working Paper, University of
Pennsylvania.
Jones, Morgan J., and Christopher J. Ritz (1991), "Incorporating Distribution into New
Product Diffusion Models," International Journal of Research in Marketing 8 (2), 91-112.
Kalish, Shlomo, and Syamal K. Sen (1986), "Diffusion Models and the Marketing Mix for
Single Products." In Innovation Diffusion Models of New Product Acceptance, eds. Vijay
Mahajan, and Yoram Wind, 87-115. Cambridge, Mass. : Ballinger.
Katona Zsolt, Zubcsek Peter, and Miklos Sarvary (2009), “Network Effects and Personal
Influences: Diffusion of an Online Social Network,” Working Paper.
Marketing Science Institute Working Paper Series 30

Kim, Namwoon, and Rajendra K.. Srivastava (1998), "Managing Intraorganizational
Diffusion of Technological Innovations," Industrial Marketing Management 27 (3), 229-46.
Kocsis, Gergely, and Ferenc Kun (2008), "The Effect of Network Topologies on the
spreading of technological developments," Journal of Statistical Mechanics: Theory and
Experiment 10, 10014.
Libai, Barak, Eitan Muller, and Renana Peres (2009), "The Diffusion of Services," Journal of
Marketing Research 46 (2), 163-75.
Libai, Barak, Eitan Muller, and Renana Peres (2005), "The Role of Seeding in Multi-Market
Entry," International Journal of Research in Marketing 22 (4), 375-93.
Lin, Nan (2001), "Building a Network Theory of Social Capital," Social Capital: Theory and
Research 22 (1), 28-51.
Mahajan, Vijay, Eitan Muller, and Frank M. Bass (1990), "New Product Diffusion Models in
Marketing: A Review and Directions for Research," Journal of Marketing 54 (1), 1-26.
Mahajan, Vijay, Eitan Muller, and Roger A. Kerin (1984), "Introduction Strategy for New
Products with Positive and Negative Word-of-Mouth," Management Science 30 (12), 1389-
404.
Marketing Science Institute Working Paper Series 31

Mahajan, Vijay, Eitan Muller, and Yoram Wind (2000), New-Product Diffusion Models.
Boston: Kluwer Academic.
Mahajan, Vijay, Robert A. Peterson, Arun K. Jain, and Naresh Malhotra (1979), "A New
Product Growth Model with a Dynamic Market Potential," Long Range Planning 12 (4), 51-
58.
Mayzlin, Dina (2002), "The Influence of Social Networks on the Effectiveness of
Promotional Strategies," Working Paper, Yale School of Management.
Newman, M. E. J. (2001), "The Structure and Function of Complex Networks," Structure 45
(2), 167-256.
Newman, M. E. J., and Mark Girvan (2003), "Finding and Evaluating Community Structure
in Networks," Physical Review E 69 (2), 26113-28.
Nijkamp, Peter, and Aura Reggiani (1998), The Economics of Complex Spatial Systems. New
York: Elsevier Science B.V.
Parker, Philip M. (1994), "Aggregate Diffusion Forecasting Models in Marketing: A Critical
Review," International Journal of Forecasting 10 (2), 353-80.
Putsis, William P., Sridhar Balasubramanian, Edward W. Kaplan, and Subrata K. Sen (1997),
"Mixing Behavior in Cross-Country Diffusion," Marketing Science 16 (4), 354-69.
Marketing Science Institute Working Paper Series 32

Reingen, Peter H., and Jerome B. Kernan (1986), "Analysis of Referral Networks in
Marketing: Methods and Illustration," Journal of Marketing Research 23 (4), 370-78.
Rindfleisch, Aric, and Christine Moorman (2001), "The Acquisition and Utilization of
Information in New Product Alliances: A Strength-of-Ties Perspective," Journal of
Marketing 65 (2), 1-18.
Robinson, Bruce, and Chet Lakhani (1975), "Dynamic Price Models for New-Product
Planning," Management Science 21 (10), 1113-22.
Rogers, Evertt M. (2003), "Attributes of innovations and their rate of adoption and
Innovativeness and adopter categories Diffusion of Innovations," Free Press, New York.
Rogers, Evertt M., Joseph Ascroft, and Niels G. Rolling (1970), "As Reported in Valente,
Network Models of the Diffusion of Innovations," in: Cresskill, NJ: Hampton Press.
Ronchetto, John R., Michael D. Hutt, and Peter H. Reingen (1989), "Embedded Influence
Patterns in Organizational Buying Systems," The Journal of Marketing 53 (4), 51-62.
Rosen, Emmanuel (2002), The Anatomy of Buzz: How to Create Word-Of-Mouth Marketing.
New York, N.Y.: Doubleday/Currency.
Marketing Science Institute Working Paper Series 33

Shaikh, Nazrul I., Arvind Rangaswamy, and Anant Balakrishnan (2005), "Modeling the
Diffusion of Innovations Using Small-World Networks," Working Paper, Penn State
University.
Shi, Mengze (2003), "Social Network-Based Discriminatory Pricing Strategy," Marketing
Letters 14 (4), 239-56.
Stephen, Andrew T. , and Toubia Olivier (2009a), “Explaining the Power-Law Degree
Distribution in a Social Commerce Community,“ Social Networks 31, 262-270.
Stephen, Andrew T., and Toubia Olivier (2009b), “Deriving Value from Social Commerce
Networks,” Journal of Marketing Research, Forthcoming (January 9).
Trusov, Michael , Anand Bodapati, and Randolph E. Bucklin (2008a), "Determining
Influential Users in Internet Social Networks," Journal of Marketing Research, under second
round review.
Trusov, Michael, Anand V. Bodapati, and Randolph E. Bucklin (2008b), "Determining
Influential Users in Internet Social Networks," Working Paper.
Valente, Thomas W. (1995), Network Models of the Diffusion of Innovations. Cresskill,
N.J.: Hampton Press.
Marketing Science Institute Working Paper Series 34

Van Den Bulte, Christophe, and Gary L. Lilien (1997), "Bias and Systematic Change in the
Parameter Estimates of Macro-Level Diffusion Models," Marketing Science 16 (4), 338-53.
Van den Bulte, Christophe, and Yogeh V. Joshi (2007), "New Product Diffusion with
Influentials and Imitators," Marketing Science 26 (3), 400-21.
Van den Bulte, Christophe, and Stefan Wuyts (2007), Social Networks and Marketing.
Cambridge, MA: Marketing Science Institute.
Watts, Duncan J. (2002), “A Simple Model of Global Cascades on a Random Network,”
PNAS 99( 9), 5766-71.
Watts, Duncan J., and Peter S. Dodds (2007a), "The Accidental Influentials," Harvard
Business Review 85 (2), 22-23.
Watts, Duncan J., and Peter S. Dodds (2007b), "Influentials, Networks, and Public Opinion
Formation," Journal of Consumer Research 34 (4), 441.
Watts, Duncan J., and Steven H. Strogatz (1998), "Collective Dynamics of `Small-World'
Networks," Nature 393 (6684), 440-42.
Young, H. Peyton (2006), "The Diffusion of Innovations in Social Networks." In The
Economy as an Evolving Complex System III: Current Perspectives and Future Directions,
Marketing Science Institute Working Paper Series 35

eds. Lawrence E. Blume, and Steven N. Durlauf, 267-282. New York, N.Y.: Oxford
University Press Inc.
Marketing Science Institute Working Paper Series 36
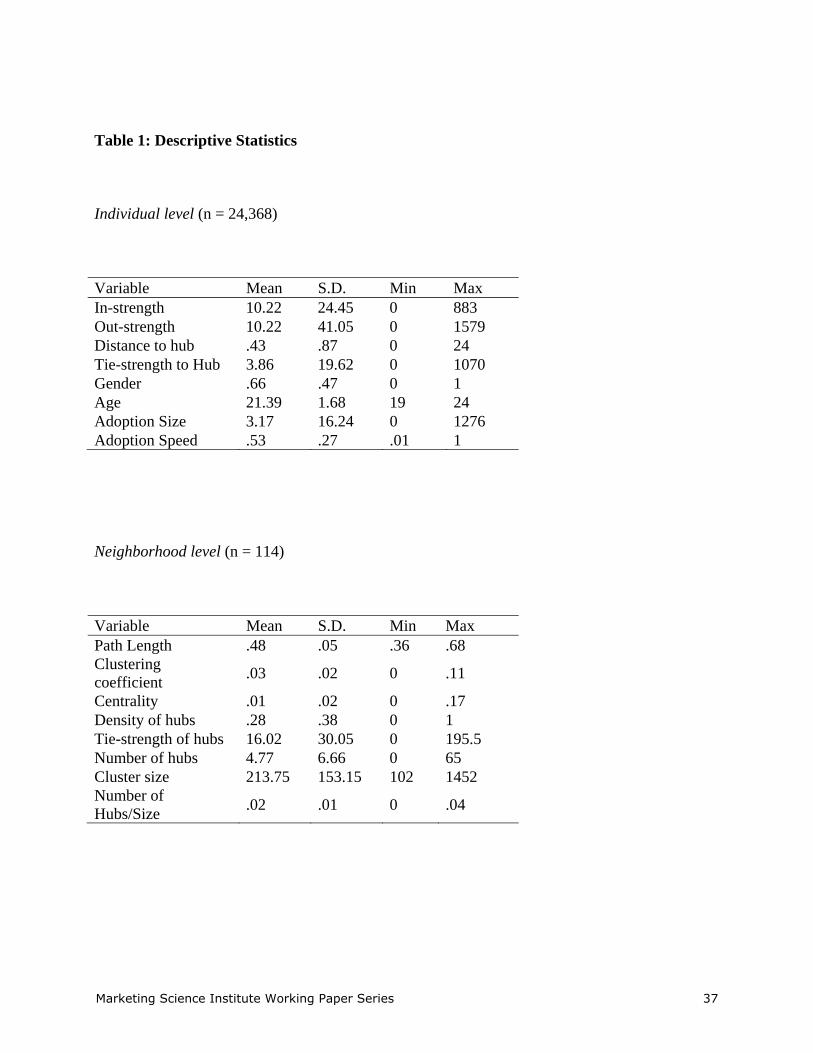
Table 1: Descriptive Statistics
Individual level (n = 24,368)
Variable Mean S.D. Min Max In-strength 10.22 24.45 0 883 Out-strength 10.22 41.05 0 1579 Distance to hub .43 .87 0 24 Tie-strength to Hub 3.86 19.62 0 1070 Gender .66 .47 0 1 Age 21.39 1.68 19 24 Adoption Size 3.17 16.24 0 1276 Adoption Speed .53 .27 .01 1
Neighborhood level (n = 114)
Variable Mean S.D. Min Max Path Length .48 .05 .36 .68 Clustering coefficient .03 .02 0 .11
Centrality .01 .02 0 .17 Density of hubs .28 .38 0 1 Tie-strength of hubs 16.02 30.05 0 195.5 Number of hubs 4.77 6.66 0 65 Cluster size 213.75 153.15 102 1452 Number of Hubs/Size .02 .01 0 .04
Marketing Science Institute Working Paper Series 37

Table 2: Individual-level Correlations
Pearson Correlation In-Strength Out-Strength
Distance to Hub
Tie-strength to Hub
Adoption Size Adoption Speed
In-Strength 1 .415** .260** .659** .045** -.027
Out-Strength .415** 1 .255** .333** .034** -.021*
Distance to Hub .260** .255** 1 .040** .026** -.009
Tie-strength to Hub .659** .333** .439** 1 .070** -.016
Adoption Size .045** .034** .026** .070** 1 -.011
Adoption Speed1 -.027 -.021* -.009 .-.016 .-.011 1
**. Correlation is significant at the .01 level (2-tailed).
*. Correlation is significant at the .05 level (2-tailed).
1. Observations of adoption speed = 11,625 vs. 24,368 for the other correlations
Marketing Science Institute Working Paper Series 38

Table 3: Cluster-level Correlations
**. Correlation is significant at the 0.01 level (2-tailed).
*. Correlation is significant at the 0.05 level (2-tailed).
Cluster Size
Path Length
Clustering Coefficient
Betweeness Centrality
Tie-Strength among Hubs
Number of Hubs
Time to First
adoption
Time to 16%
adoption (t16)
Correlation
Cluster Size 1.000 -.003 .098 .878** .**315 ** .924 **-.374
.431** .226**
Path Length -.003
1.000 .181 .066 -.117 .031 .100 .038 -.056
Clustering Coefficient
-.098 .181 1.000 -.088 .134 -.029 -.020 -.196* -.012
Betweeness Centrality
.878** .066 -.088 1.000 .279** .811** -.258** .366** .134
Tie-strength among Hubs
**.315 -.117 .134 .279** 1.000 .397** -.188*
.103 .023
Number of Hubs
**.924 .031 -.029 .811** .397** 1.000 -.243** .367** .157
Time to First Adoption
-.374
.100 -.020 -.258** -.188* -.243** 1.000 -.087 -.362**
Time to 16% adoption (t16)
.431** .038 -.196* .366** .103 .367** -.087
1.000 -.248**
Correlation with overall adoption
.226** -.056 -.012 .140 .024 .157 -.362** -.248** 1.000
Marketing Science Institute Working Paper Series 39

Table 4: Predicting Individual Adoption Within Local Neighborhoods
Model 1 Model 2 Model 3 Model 4
Log Likelihood -102338.00 -102375.20 -102379.10 -102342.40
Individual Level Variables coef p-value coef p-value coef p-value coef p-value
Intercept 2.790 .00
In-Strength .009 0.33
Out-Strength .006 .00 .005 .01 .005 .01 .006 .01
Closeness to hubs .062 .56
Tie-strength to hubs .020 .06 .037 .01 .037 .01 .036 .02
Gender -.932 .00
Age .173 .01
Neighborhood Level Variables
Intercept 3.474 .00 2.661 .00 -.136 .92
Path length -1.444 .46
Clustering coefficient 1.889 .74
Betweenness Centrality 7.828 .03 9.333 .00 6.524 .00
Tie-strength among hubs .002 .58
Number of hubs/Size -6.196 .73
Marketing Science Institute Working Paper Series 40

Table 5: Predicting Individual Adoption Speed
Model1 Model2 Model3 Model4
Log Likelihood -1460.53 -1451.12 -1439.86 -1410.42
Individual Level coef p-value coef p-value coef p-value coef p-value
Intercept .5310 .00
In-Strength -.0003 .02 -.0003 .00 -.0003 .00 -.0003 .00
Out-Strength -.0001 .10
Closeness to hub -.0011 .73
Tie-strength to hub .0000 .82
Gender -.0461 .00
Age -.0044 .00 Neighborhood Level
Intercept .5097 .00 .5367 .00 .6590 .00
Path length .0611 .21
Clustering coefficient -.2769 .01 -.2101 .01 -.2176 .01
Betweenness Centrality -.0887 .27
Tie-strength among hubs .0001 .53
Number of hubs/Size -.0318 .92
Marketing Science Institute Working Paper Series 41

Table 6: Average Correlation Between Local Neighborhood and Overall Adoption
Correlations MAPE*
Sample Time Measured
Average Size of Top 20
Neighborhoods
All 114 Clusters
20 Random Samples
Top 20 Neighborhoods
20 Random Clusters
Top 20 Neighborhoods
5% 214 Calibration: Total .70 .62 .96 .62 .34 Calibration: Split-Half
Holdout .77 .70
.21 .99 .79
16% 193 Calibration: Total Calibration: Split-Half Holdout
.75
.81
.72
.76
.40
.96
.99
.95
.55 .18
50% 233 Calibration: Total Calibration: Split-Half Holdout
.90
.91 .84 .87 .53
.98
.99
.96
.50 .18
*The absolute value of the predicted percent adopting in the total population adoption minus actual total population adoption.
Marketing Science Institute Working Paper Series 42

Table 7: Characteristics of Predictive Neighborhoods*
Network Characteristics
Time Period for Determining Predictions 5%
16%
50%
Path Length - .03 - .02 -.03 -.02 -.01 -.01 Clustering Coefficient .02 .03 -.09 .07 -.08 -.07 Betweeness Centrality .11 NA .17c NA .16c NA Cluster Size NA .19c NA .29 a NA .27a
Tie-strength among Hubs -.12 -.12 -.11 -.12 -.03 -.03 Number Hubs/Size .07 .04 -.13 .09 .25a .21b
Time to First Adoption -.38a -.34a -.38a -.32a -.22a -.16 Time to 16% Adoption -.19b -.22b -.37a -.42a -.57a -.61a
R2 .17 .19 .25 .28 .33 .35
*Standardized Regression Coefficients
a = significant at .01
b = significant at .05
c = significant at .10
Marketing Science Institute Working Paper Series 43