linear models - companyname.com - super slogan 35.21 on 10 and 98 df, p-value: < 2.2e-16 goodness...
TRANSCRIPT

Linear ModelsStat 430

Outline
• Project
• Normal Model
• F test
• Model Comparison and Selection

Flights Project
• Accuracy is measured as
(lower is better)
• What YOU should do: divide data set into 90% Training Set and 10% Test Data Set
• Fit model on training set, compute accuracy of your model on test set.
• Compute accuracy on test data.
1
n
�
i
(yi − yi)2
log θij = logmi+1,j+1mij
mi+1,jmi,j+1= ... = βi+1 − βi
log θij = logmi+1,j+1mij
mi+1,jmi,j+1= ... = β
k =(s21 + s
22)
2
s41/(n1 − 1) + s
42/(n2 − 1)
X1 − X2 − d�s21/n1 + s
22/n2
X − µ0
s/√n
p− p0�p(1− p)/n
p1 − p2 − d�p1(1− p1)/n1 + p2(1− p2)/n2
λXYij = βuivj
λXYij = βivj
λXYij = βjui
λXYij = βiβj
�X − t · σ√
n, X + t · σ√
n
�
Ho : πijk = πi++π+j+π++k
Ho : πijk = πi++π+jk
Ho : πijk = πij+π+jk/π++k
p1 − p2 ± z ·�
p1(1− p1)/n1 + p2(1− p2)/n2
1

Example: Running in OZ
• http://www.statsci.org/data/oz/ms212.html
• Students in an introductory statistics class participated in a simple experiment: The students took their own pulse rate. They were then asked to flip a coin. If the coin came up heads, they were to run in place for one minute. Otherwise they sat for one minute. Then everyone took their pulse again. The pulse rates and other physiological and lifestyle data are given in the data.

Linear Model
• y = a + b1x1 + b2x2 + b3x3 + ... + bpxp
• Matrix definitionY = Xßwhere Y is column vector of length n and X is model matrix of dimension n by (p+1)
• some considerations w.r.t. X

factor(Gender)
dPulse
0
20
40
60
80
1 2interaction(factor(Gender), factor(Ran))
dPulse
0
20
40
60
80
1.1 2.1 1.2 2.2
Age
dPulse
0
20
40
60
80
20 25 30 35 40 45Weight
dPulse
0
20
40
60
80
40 60 80 100
First step: look at difference in Pulse2 - Pulse1

Running in OZ
• graphically not much support for any variable but “Ran”
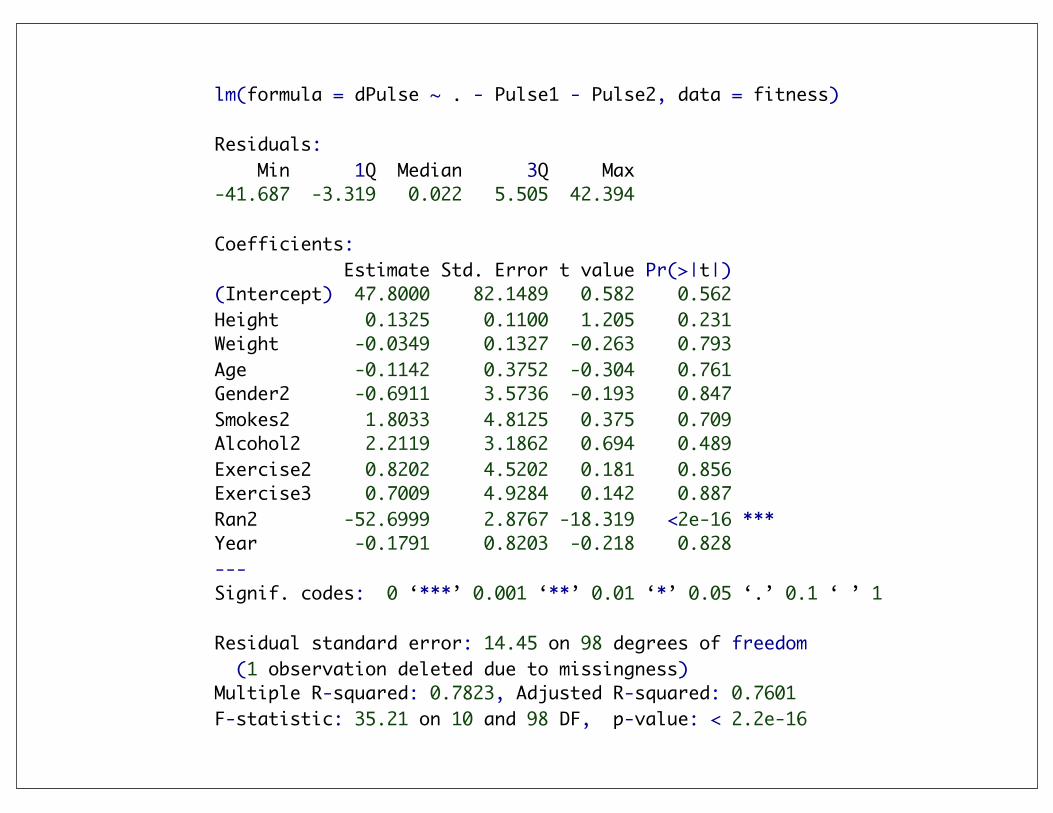
lm(formula = dPulse ~ . - Pulse1 - Pulse2, data = fitness)
Residuals: Min 1Q Median 3Q Max -41.687 -3.319 0.022 5.505 42.394
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 47.8000 82.1489 0.582 0.562 Height 0.1325 0.1100 1.205 0.231 Weight -0.0349 0.1327 -0.263 0.793 Age -0.1142 0.3752 -0.304 0.761 Gender2 -0.6911 3.5736 -0.193 0.847 Smokes2 1.8033 4.8125 0.375 0.709 Alcohol2 2.2119 3.1862 0.694 0.489 Exercise2 0.8202 4.5202 0.181 0.856 Exercise3 0.7009 4.9284 0.142 0.887 Ran2 -52.6999 2.8767 -18.319 <2e-16 ***Year -0.1791 0.8203 -0.218 0.828 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 14.45 on 98 degrees of freedom (1 observation deleted due to missingness)Multiple R-squared: 0.7823,Adjusted R-squared: 0.7601 F-statistic: 35.21 on 10 and 98 DF, p-value: < 2.2e-16

Goodness of Fit
• for simple linear model: R2 is square of correlation between X and Y
• if Model 1 is simpler form of Model 2: R2 of model 1 is smaller than R2 of model 2
• Instead: use adjusted R2 for model with p variables X1, X2, ..., Xp
R2adj = 1 - (SSE/(n-p-1)) / (SST/(n-1))

Parameter Estimates
• ß = (X’X)-1 X’Y
• (X’X)-1 exists, if X has full column rank, i.e. no dependencies between columns of X
• we can use a generalized inverse if X does not have full column rank

Individual Parameters
• in the model result we see that no other variable is significant
• How do we get significances?

Distributional Assumption
• Y = X ß + error
• Normal Model: errors are independent, identically distributed with N(0, sigma2)
• Then (Y-Xß) ~ N(0, sigma2)and Y ~ N(Xß, sigma2)and (X’X)-1 X’Y ~ N( ß, (X’X)-1 sigma2)

Confidence Intervals
• for ßi i=1, ..., p+1: bi/Var(bi) ~ tn-1
• R commands: coef, vcov, confint

Compare Models
• Often we want to test hypothesis of the form:H0: ß1 = ß2 = ... = ßk=0
• Equivalent to comparison of two models M1 and M2, where M1 is sub-model of M2
• M1 is sub-model of M2, when M2 has all parameters that M1 has and additional parameters
• H0: parameters in M2 but not in M1 are 0H1: at least one parameter is not 0

F-test
• Assume model M1 has p parameters and model M2 has p+k parameters
• let SSE1 be the sum of squared errors in model M1 and SSE2 the errors in M2, then
• [(SSE1 - SSE2)/k]/[SSE2/(n-p-k)] ~ Fk,n-p-k
• i.e. for a small p-value we reject the null hypothesis in favor of model M2;a large p-value makes us keep the simpler model

F distribution
• F has two parameters: n1 and n2, called degrees of freedom
• domain is R+
• for n1=1 F = t2
• use tables/applets for significant values

Example: Running• M1: Ran
• M2: Ran and all other variables
Conclusion: no variable besides Ran contributes significantly
> base <- lm(dPulse~Ran, data=fitness)> anova(base, model)Analysis of Variance Table
Model 1: dPulse ~ RanModel 2: dPulse ~ (Height + Weight + Age + Gender + Smokes + Alcohol + Exercise + Ran + Pulse1 + Pulse2 + Year) - Pulse1 - Pulse2 Res.Df RSS Df Sum of Sq F Pr(>F)1 107 20969 2 98 20454 9 514.59 0.2739 0.9803

Residual Plots: fitted vs residuals
• under model assumptions fitted values are independent of residuals - we should not see trends or patterns
• residuals should have same error variance - we should see a “band” around zero of same height across Y
• only 5% of residual values should be above 2 or below -2

Residual Plots: explanatory vs residuals
• under model assumptions X values are independent of residuals - we should not see trends or patterns
• residuals should have same error variance - we should see a “band” around zero of same height across X
• only 5% of residual values should be above 2 or below -2

Problematic residual plots
fitted(m)
resid(m)
-0.3
-0.2
-0.1
0.0
0.1
0.2
0.3
0.0 0.5 1.0 1.5
fitted(m)
resid(m)
-0.2
-0.1
0.0
0.1
0.2
0.2 0.4 0.6 0.8

From Fitness Data
• Two Groups withnon-homogeneous variance
• Large Residuals
fitted(model)
resid(model)
-20
0
20
40
60 80 100 120 140 160 180

Variable Selection
• Forward Selection:include most significant terms until upper limit is reached or no significant improvement can be found
• Backward Selection:Start at complex model, prune least significant terms

Next time:
• Interaction Effects