leveraging hadoop in polyglot architectures
TRANSCRIPT

LEVERAGING HADOOP IN POLYGLOT
ARCHITECTURES
Thanigai Vellore
Enterprise Architect at Art.com
@tvellore

AGENDA
Background on Art.com
Polyglot Architecture at Art.com
Hadoop Integration Use cases
Frameworks and Integration Components
Q&A

BACKGROUND ON ART.COM

OUR MISSION

5
POLYGLOT ARCHITECTURE
WEB
.NET JAVA NODE.JS
SERVICES/API
.NET NODE.JSJAVA
DATABASE SEARCH
SQL Server
Mongo ENDECA SOLR

HADOOP @ ART.COM
Use Hadoop to implement data-driven capabilities
via centralized platform that can be consumed by all
our brands
Intelligent data platform that supports different types
of workloads (batch, stream processing, search, etc)
Use frameworks that enable interoperability between
different technologies and teams
We use Cloudera’s Enterprise Data Hub (EDH) Data Governance
Centralized Management
Security and Compliance

HADOOP
USECASES

CLICKSTREAM ANALYTICS

GOALS
Platform to collect, ingest, analyze and report
aggregate information on clickstream activities at
scale
Seamless integration with existing systems Traditional BI tools (Business Objects)
Web analytics (Google Analytics)
Marketing platforms (Email, SEM, etc)
Provide foundation for building near real time closed
loop predictive engines

HIGH LEVEL ARCHITECTURE
CLICKSTREAM SERVICE
JAVA .NET NODE.JS
GA LOGGER
WEBSITES
AVRO SOURCE
ETL - MORPHLINES
AVRO SERIALIZER
AP
AC
HE
FLU
ME
CLICKSTREAM
APACHE OOZIE
APACHE CRUNCH
HIVE ODBC DRIVER
SESSIONIZATION
BUSINESS OBJECTS
HDFS
SESSIONS(HIVE)
HDFS

CLICKSTREAM COLLECTION
Google Analytics provides local logging capability
(_setLocalRemoteServerMode)
Capture all pageviews and GA events via simple
javascript file which is included on all pages
Clickstream events are sent to clickstream service that
transforms incoming events and emit Avro records
Flume Client SDK (NettyAvroRpcClient) is used to
send data into the agent Factory – org.apache.flume.api.RpcClientFactory:
RpcClient getInstance(properties)

CLICKSTREAM INGESTION
Clickstream Ingested using Apache Flume from an AvroSource
Kite Morphlines (used as Flume Source Interceptor) is
used for ETL transformation into Avro
AvroSerializer used to write Avro records to HDFS (HDFS
Sink)

AVRO
Storage format (Persistence) and wire protocol
(Serialization)
Self describing (schema stored with data)
Supports compression of data and map-reduce
friendly
Supports easier schema evolution
Read/write data in Java, C, C++, Python, PHP, and
other languagesPlatform Library Link
.NET Microsoft Avro Library https://hadoopsdk.codeplex.com/
Node.js node-avro-io https://www.npmjs.com/package/node-avro-io

KITE SDK
Open source SDK (www.kitesdk.org) - Apache 2.0
licensed
High level data layer for Hadoop
Codify best practices for building data-oriented
systems
Loosely coupled modular Design Kite Data Module
Kite Morphlines
Kite Maven Plugin

KITE DATA MODULE
Set of APIs for interacting data with Hadoop
Entities A single record in a dataset
Simple or complex and nested (avro or POJO)
Dataset A collection of entities/records
Data types and field names defined by Avro schema
Dataset Repository Physical storage location for datasets
Kite Abstractions Relational Equivalent
Entities Record
Dataset Table
Dataset Repository Database
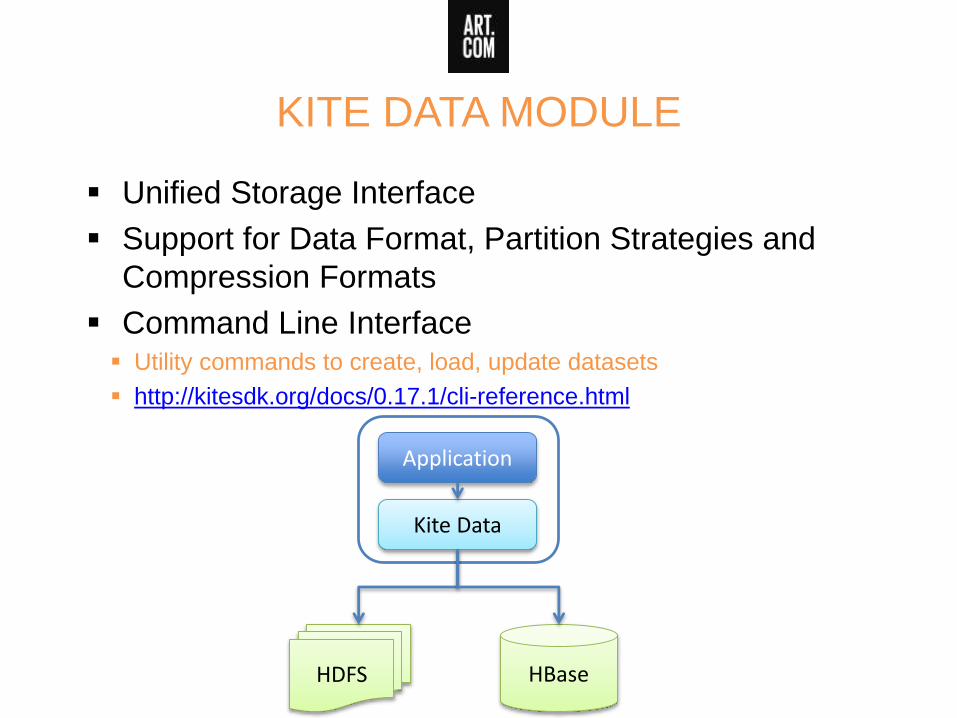
KITE DATA MODULE
Unified Storage Interface
Support for Data Format, Partition Strategies and
Compression Formats
Command Line Interface Utility commands to create, load, update datasets
http://kitesdk.org/docs/0.17.1/cli-reference.html
Kite Data
HBaseHDFS
Application

KITE MORPHLINES
Open source framework for simple ETL in Hadoop
Applications
Consume any kind of data from any kind of dat
a source, process and load into any app or stor
age system
Simple and flexible data mapping and transformation
Similar to Unix pipelines with extensible set of
transformation commands

KITE MAVEN PLUGIN
Maven goals for packaging, deploying, and running
distributed applications
Create, update and delete datasetsmvn kite:create-dataset -Dkite.rootDirectory=/data
-Dkite.datasetName=clickstream \
-Dkite.avroSchemaFile=/etc/flume-ng/schemas/clickstream.avsc
Submit Jobs to oozie
mvn package kite:deploy-app -Dkite.applicationType=coordinator
mvn kite:run-app -Dkite.applicationType=coordinator -Dstart="$(date -d '1
hour ago' +"%Y-%m-%dT%H:%MZ")"

SESSIONIZATION
MapReduce program to transform raw clickstream
logs into aggregate session summary using Apache
Crunch
Hourly Coordinator job scheduled using Apache
Oozie
Triggered based on presence of HDFS partition
folder

KITE CRUNCH INTEGRATION
Enables loading Kite Dataset into Crunch Programs
CrunchDatasets helper class CrunchDatasets.asSource(View view)
PCollection<Clickstream> clickstreamEvents =
getPipeline().read(CrunchDatasets.asSource(“dataset:hdfs/data/clickstream”,
Clickstream.class);
CrunchDatasets.asTarget(View view)
Supports Crunch write modes and repartitioningPCollection<Clickstream> clickstreamLogs = getPipeline().read(
CrunchDatasets.asSource(“dataset:hdfs/data/clickstream”, Clickstream.class);
DatasetRepository hcatRepo = DatasetRepositories.open(hiveRepoUri);
View<Session> sessionView = hcatRepo.load(“sessions”);
PCollection<Session> sessions = clickstreamLogs
.by(new GetSessionId(), Avros.strings())
.groupByKey()
.parallelDo(new MakeSession(), Avros.specifics(Session.class));
getPipeline().write(sessions,CrunchDatasets.asTarget(sessionView), Target.WriteMode.APPEND

APACHE HIVE ODBC DRIVER
Used to read Hive Tables from Business Objects
Fully compliant ODBC driver supporting multiple
Hadoop distributions
High performance and throughput with support for
Hive2
Supports Hive grammar, standard SQL and with
range of data types

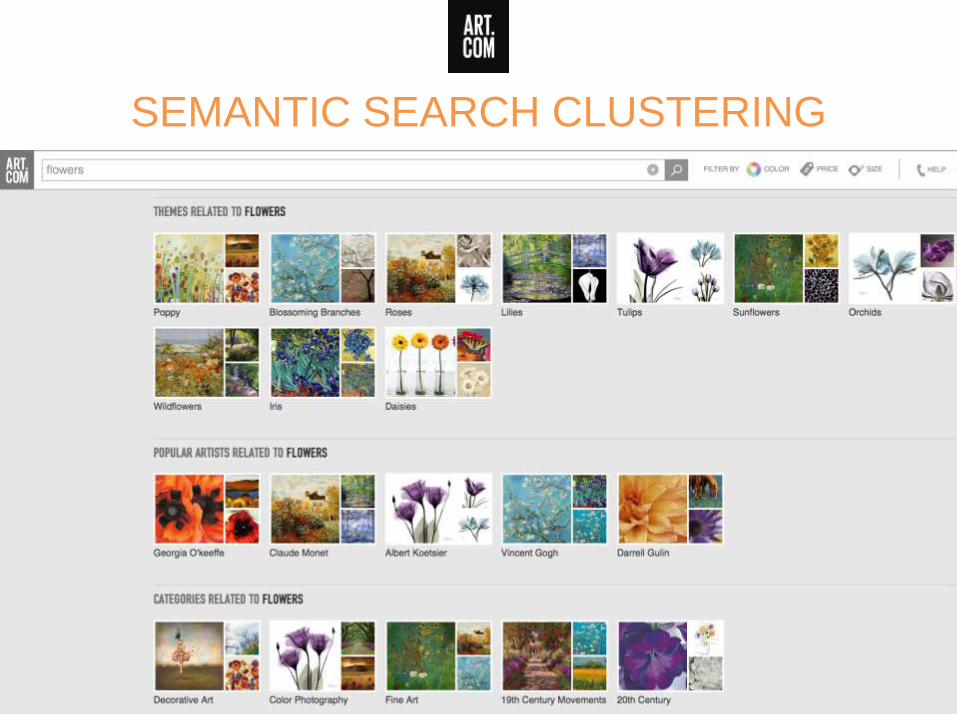
SEMANTIC SEARCH CLUSTERING
Objectives here

HIGH LEVEL ARCHITECTURE
WEBSITES
SEARCH SERVICE(NODE.JS)
SOLRCLOUD
RABBITMQSEARCH PROCESSOR
(NODE.JS)
HBASELILY HBASE INDEXER
HUE
CLUSTERING ENGINE
(CARROT2)

CLUSTERING ENGINE
Carrot2 – open source search results clustering
engine
Allows to dynamically identify semantically related
“clusters” based on search results
Multiple clustering algorithms – Lingo, STC, K-means
Pluggable Search Component in SOLR - runs on top
of SOLR search results
SEARCH PROCESSOR
SEARCHCLUSTERING
SEARCHRESULTS

NODE.JS & BIG DATA INTEGRATION
NODE.JS Evented, non-blocking I/O – built on V8 runtime
Ideal for scalable concurrent applications
Componen
t
Protoc
ol
NPM module
HBASE Thrift https://www.npmjs.com/package/node-
thrift
REST https://www.npmjs.com/package/hbase
HDFS REST https://www.npmjs.com/package/node-
webhdfs
Hive Thrift https://github.com/forward/node-hive
SOLR REST https://github.com/artlabs/solr-node-
client
Zookeeper C API https://www.npmjs.com/package/zookee
per

LILY HBASE INDEXER
Acts as a Hbase Replication Sink
Horizontal Scalability via Zookeeper
Automatic Failure Handling (inherits Hbase
replication system)
Memstore
HLog(WAL)
SEP Replication
Source
Hbase Region Server
HbaseIndexer
SOLRCLOUD
Morphlines

LILY HBASE INDEXER
Indexer Configuration SetupHbase-indexer add-indexer
--name search_indexer
--indexer-conf /.search-indexer.xml
--connection-param solr.zk=ZK_HOST/solr
--connection-param solr.collection=search_meta
--zookeeper ZK_HOST:2181
Search-Indexer.xml<indexer table=“search_meta” mapper="com.ngdata.hbaseindexer.morphline.MorphlineResultToSolrMapper" mapping-type="row" unique-key-field="id" row-field="keyword">
<param name="morphlineFile" value="morphlines.conf"/>
</indexer>

KITE MORPHLINES IN HBASE INDEXER
morphlines : [
{
id : morphline1
importCommands : [”org.kitesdk.morphline.**", "com.ngdata.**”]
commands : [
{
extractHBaseCells {
mappings : [
{
inputColumn : “cf:column1”
outputField : “field1”
type : string
source : value
} ]
}
}
{
sanitizeUnknownSolrFields {
solrLocator : ${SOLR_LOCATOR}
}
}
{ logTrace { format : "output record: {}", args : ["@{}"] } }
]
}
]

MORPHLINE AVRO SUPPORTreadAvroContainer Parses an Apache Avro binary container and emits a morphline
record for each contained Avro datum.
extractAvroPaths Extracts specific values from an Avro object
commands : [ {extractHBaseCells {mappings : [{
inputColumn : “cf:column1”outputField : "_attachment_body" type : "byte[]" source : value
}]}}
{ readAvroContainer {} } { extractAvroPaths {paths : { meta : /meta_data
}}}]
}]

REAL TIME TRENDING

GOALS
Scalable Real time Stream
Processing Engine
Based on Clickstream data,
provide Real-time trending
capability for all websites on Top Products Added to Cart
Top Searches/Galleries visited
Top User Galleries visited
Low latency aggregations on
moving time window and
configurable time slices

Flume
HIGH LEVEL ARCHITECTURE
Avro source
MorphlinesETL
channel
channel
HDFS
HDFS sink
Spark sink
Spark
Spark Streaming
clickstream
Rabbitmq
Node.js Aggregation Processor
Websites
Clic
kstr
eam
eve
nts
Notifications
socket.io
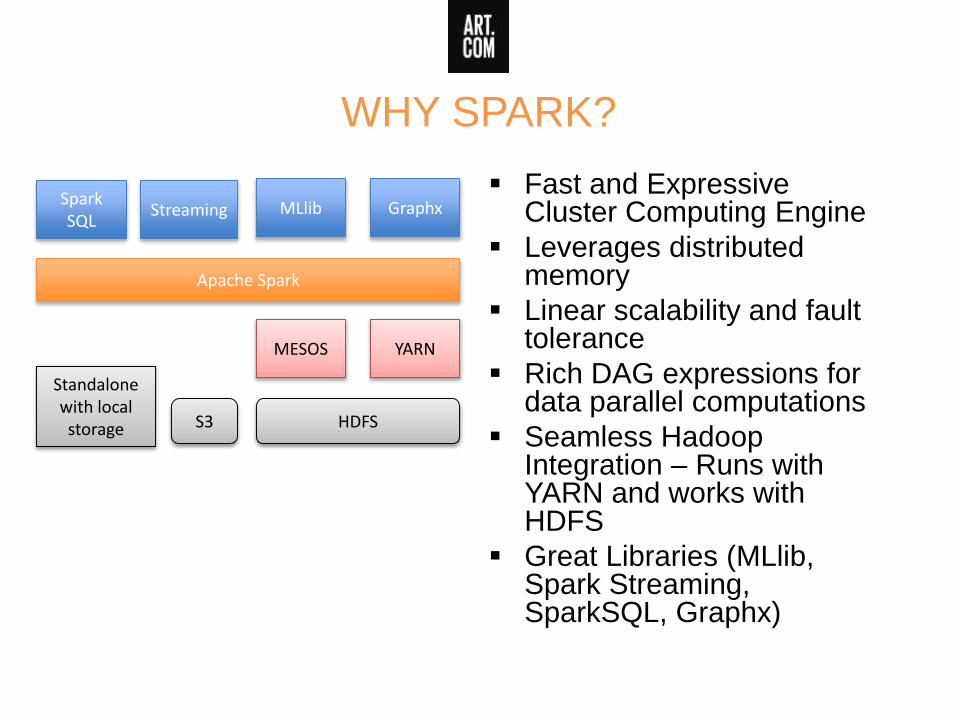
WHY SPARK?
Fast and Expressive Cluster Computing Engine
Leverages distributed memory
Linear scalability and fault tolerance
Rich DAG expressions for data parallel computations
Seamless Hadoop Integration – Runs with YARN and works with HDFS
Great Libraries (MLlib, Spark Streaming, SparkSQL, Graphx)
Spark SQL
Streaming MLlib Graphx
Apache Spark
MESOS YARN
HDFSS3
Standalone with local storage

SPARK STREAMING
• Extension of Spark Core API for large
scale stream processing of live data
streams
• Integrates with Spark’s batch and
interactive processing
• Runs as a series of small, deterministic
batch jobs
• DStream provides a continuous stream
of data (sequence of RDDs)

FLUME SPARK SINK
Pull-based Flume Sink Polling Flume Receiver to pull data from sink
Strong Reliability and Fault Tolerance
Flume Agent Configuration Custom Sink JAR available on Flume Classpath
Flume Configuration
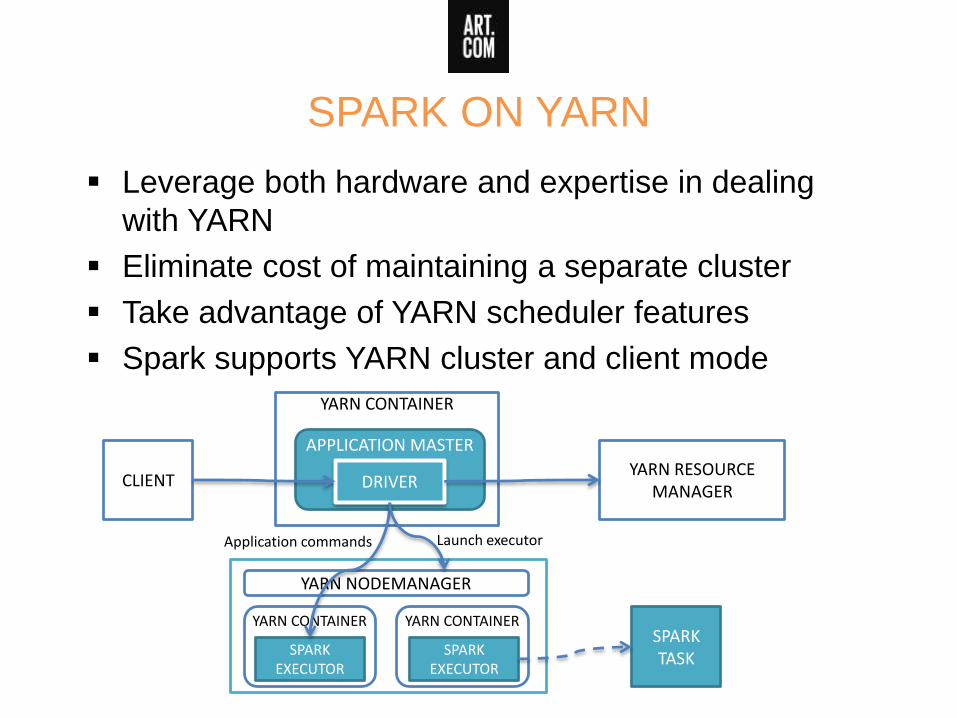
SPARK ON YARN
Leverage both hardware and expertise in dealing
with YARN
Eliminate cost of maintaining a separate cluster
Take advantage of YARN scheduler features
Spark supports YARN cluster and client mode
CLIENT
YARN CONTAINER
YARN RESOURCE MANAGER
APPLICATION MASTER
DRIVER
YARN CONTAINER YARN CONTAINER
SPARK EXECUTOR
SPARK EXECUTOR
SPARK TASK
YARN NODEMANAGER
Launch executorApplication commands

DATA SERIALIZATION & KITE SUPPORT
Data Serialization - Key for good network performance and memory usage
Use Kryo Serialization – compact and faster Initialize with conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
Register classes for best performance
conf.set("spark.kryo.registrator", “com.art.spark.AvroKyroRegistrator");
Kite Dataset Support DatasetKeyInputFormat – read kite dataset from HDFS into RDDs
DatasetKeyOutputFormat – write RDDs as Kite dataset
