lecture 1 connecting the mind with the world: an empirical introduction zenon pylyshyn, rutgers...
TRANSCRIPT

Lecture 1 Connecting the mind with the
world: An empirical introduction
Zenon Pylyshyn, Rutgers University
http://ruccs.rutgers.edu/faculty/pylyshyn.html

Plan of the lectures1. I will introduce a mechanism that I believe to be
part of the autonomous vision module. This mechanism, which I call a Visual Index or FINST, is able to keep track of several token individual things in a visual scene while the scene is being encoded or is changing. I will illustrate this mechanism with some experimental findings and demonstrations. I will conclude the first lecture by beginning to building a bridge from the empirically-based assumptions about FINSTs to certain philosophical issues– particularly issues of nonconceptual representation.

2. In the second lecture will discuss the generality and importance of attention and selection for this set of problems, and will relate these to the FINST proposal. I will then discuss the proposal that FINSTs pick out things rather than places. This will lead me to examine Austen Clark’s views of sentience and his claim that in sentience, spatiotemporal regions are picked out nonconceptually – i.e., a version of the Feature-Placing hypothesis initially proposed by Peter Strawson.

3. Lecture 3 will introduce the topic of the nonconceptual representation of space, including the question of the status of conscious experience in perception science. I will then attempt to cast the problem of spatial representation in a general framework – one to which Jean Nicod contributed important insights. This framework will draw heavily on the insights of Henri Poincaré and will introduce the role of visuomotor coordination and the general coordinate transformation problem. From this I will argue that there is no unitary spatial coordinate system nor any representations of empty places – only indexes to sensory individuals.

4. Following the discussion of space, the final lecture will examine contemporary views concerning how properties of space are captured in thought, namely the view that our ability to represent space in reasoning derives from some form of internalization of space. I will argue that a popular version of this approach, based on neuroimaging data, is misguided and I will suggest a different approach – one that relies on the function provide by visual indexes.

Some background ….
The early origins and motivation for this entire story … a personal introduction

Different types of mind-world interfaces “I say that vision occurs when the image of the whole
hemisphere of the world that is before the eye … is fixed in the reddish white concave surface of the retina. How the image or picture is composed by the visual spirits that reside in the retina and the [optic] nerve, and whether it is made to appear before the soul or the tribunal of the visual faculty by a spirit within the hollows of the brain, or whether the visual faculty, like a magistrate sent by the soul, goes forth from the administrative chamber of the brain into the optic nerve and the retina to meet this image, as though descending to a lower court – I leave to be disputed by [others]. For the armament of the opticians does not take them beyond this first opaque wall encountered within the eye.” (Johannes Kepler, quoted in Lindberg, 1976)

From geometrical optics to Information, and from information to reference
Two distinct types of mind-world connectionsThe nonconceptual connection: causeThe semantic connection: satisfaction
The question how we make the transition from cause to meaning/reference is one of the great mysteries of mind (Brentano’s Problem). I will address a (very small) corner of that problem – the question how perception picks out individuals without already having concepts – as the first nononceptual step in the mind-world relation.

Why do we need to be able to pick out individuals without concepts?
We need to make nonconceptual contact with the world through perception in order to stop the regress of concepts being defined in terms of other concepts which are defined in terms of still other concepts …This is known as the Grounding Problem
The question of where to stop has received different answers by different philosophical schools. But sensory transduction by itself will not work: most concepts cannot be reduced to sense data. It has to be something more abstract that sensory properties
Our candidate is individuals as the forerunner of predication To explain why, I will begin with a personal experience
trying to developing a computer model of reasoning about geometry by drawing a diagram.

Begin by drawing a line….

Now draw a second line….

And draw a third line….
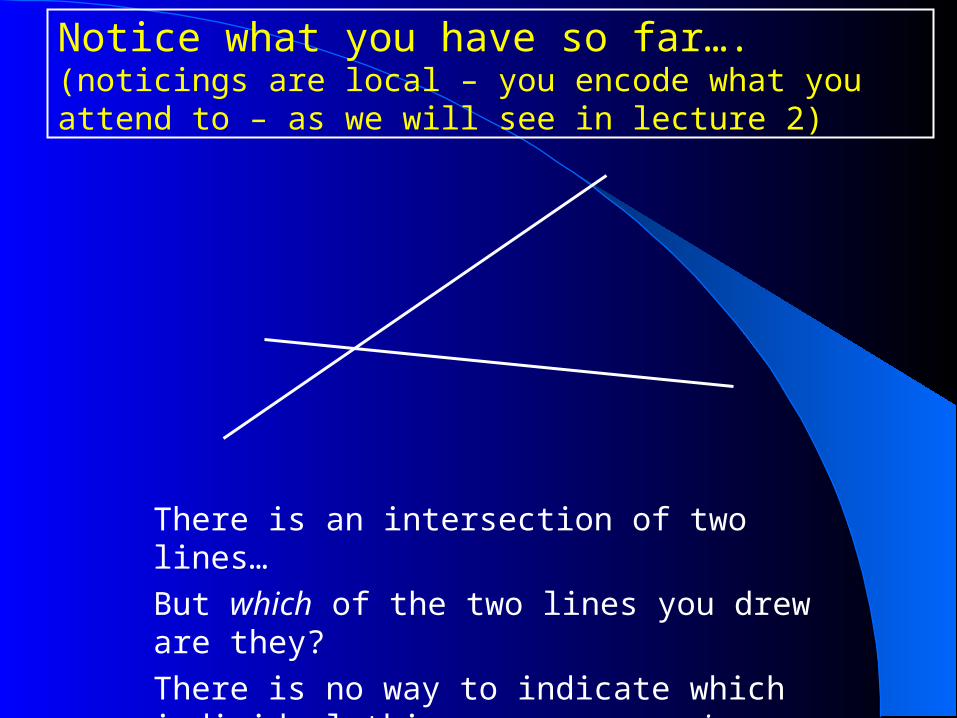
Notice what you have so far….(noticings are local – you encode what you attend to – as we will see in lecture 2)
There is an intersection of two lines…
But which of the two lines you drew are they?
There is no way to indicate which individual things are seen again unless there is a way to refer to individual things

Look around some more to see what is there ….
Here is another intersection of two lines…
Is it the same intersection as the one seen earlier?
To be able to tell without a reference to individuals you would have to encode unique properties of the individual lines. Which properties should you encode?

Footnote It would not help this problem at all if you labelled
the diagram as you drew it. Why? Because to refer to the line with label L1 you would
have to be able to think “This is line L1” and you could not think that unless you had a way to think “this” and the label would not help you to do that.
Being able to think “this” is another way to view the very problem I will be concerned with in these lectures. You still need an independent way to pick out and refer to an individual element even if it is labelled! And you need to do it for several individuals
That is exactly the point of John Perry’s claim about the “essential indexical”

Keeping track by encoding unique properties of individual items will not work in general
No description can work when items are moving or changing their appearance during the representation-construction process No description is guaranteed to remain unique if the scene is
changing But a visual representation is always changing since it is
always built up over time as properties are noticed An observer can pick out several individuals even if they are
in a field of identical individuals – e.g., pick out a dot in a uniform field of dots
Many writers have postulated a “marking” process. But where is the “mark” placed? It can’t be placed in the representation, because it is supposed to help keep track of which things in the world correspond to which things in the representation!

Pick out a single dot (or pick out 4 dots)? Can you keep track of the dots you picked if you move your eyes?
(Only for 4 or fewer, Irwin, 1996)

The requirements for picking out individual things and keeping track of them reminded me of an
early comic book character called “Plastic Man”

Imagine being able to place your fingers on things in the world without being able to detect their properties in this way, but being able to refer to those things so you could move your gaze or attention to them. If you could you would possess FINgers of INSTantiation (FINSTs)!

FINST Theory postulates a limited number of pointer mechanisms in early vision that are elicited by causal
events in the visual field and that enable vision to refer to things without doing so under concept or description

The assumption is that you have a way to directly pick out individual distal elements as sensory individuals –
not as bearers of certain known properties
Examples where such indexes are needed: Incremental construction of visual representations – the
correspondence problem over time (geometry example) Encoding relational predicates; e.g., Collinear (x,y,z,..);
Closed (C); Inside (x, C); Above (x,y); Square (w,x,y,z), requires simultaneously binding the arguments of n-place predicates to n elements in the visual scene Evaluating such visual predicates requires individuating
and referencing the objects over which the predicate is evaluated: i.e., the arguments in the predicate must be bound to individual objects in the scene.

Several objects must be picked out at once in making relational judgments
When we judge that certain objects are collinear, we must have picked out the relevant individual objects first.

Several objects must be picked out at once in making relational judgments
The same is true for other relational judgments like inside or on-the-same-contour… etc. We must pick out the relevant individual objects first.

Demonstrating FINSTs in action withMultiple Object Tracking
In a typical experiment, 8 simple identical objects are presented on a screen and 4 of them are briefly distinguished in some visual manner – usually by flashing them on and off.
After these 4 targets are briefly identified, all objects resume their identical appearance and move randomly. The subjects’ task is to keep track of the ones designated as targets.
After a period of 5-10 seconds the motion stops and subjects must indicate, using a mouse, which objects were the targets.
People are very good at this task (85%-98% correct). The question is: How do they do it?

Keep track of the objects that flash

It even works if objects are allowed to self occlude

How do we do it? What properties of individual objects do we use?
If we had such a mechanism, what should we be able to do?

Basic finding: Most people (even 5 year old children) can track at least 4 individual objects that have no unique visual properties
How is it done? We have shown that it is unlikely that the tracking
is done by keeping a record of target locations, and updating them while serially visiting the objects
We have proposed that individuating and keeping track of certain kinds of individuals uses the mechanism of visual indexes or FINSTs
Analysing Multiple Object Tracking

So what are FINSTs? They are a primitive reference mechanism that refer to
individual visual objects in the world (FINGs?) Objects are picked out and referred to without using any
encoding of their properties, including their location. Picking out objects is prior to encoding any properties!
Indexing is nonconceptual because it does not represent the individuals as members of some conceptual category.
FINSTs function something like visual demonstratives (like this or that); they pick out and refer to individual visual objects without appealing to their properties to do so.
An important function of FINST indexes is to bind arguments of visual predicates or of motor commands to things in the world to which they refer. Only predicates with bound arguments can be evaluated.

Going behind occluding surfaces does not distrupt tracking

Objects can be tracked without recalling which was which!

Not all well-defined features can be tracked

MOT with occlusion MOT with virtual occluders MOT with matched nonoccluding disappearance Track endpoints of lines Track rubber-band linked boxes Track and remember ID by location Track and remember ID by name (number) Track while
everything briefly disappears (½ sec) and goes on moving while invisible
Track while everything briefy disappears and reappears where they were when they disappeared
Additional examples of MOT

Another example: Subitizing vs CountingHow many squares are there?
Concentric squares cannot be subitized because individuating them requires the serial operation of curve tracing
Subitizing indexed objects is fast, accurate and independent of how many items there are. Only the squares on the right can be subitized because only automatically indexed items can be subitized

Signature subitizing phenomena only appear when objects are automatically
individuated and indexed

Example of the operation of Visual Indexes: Subset selection for search
singlefeaturesearch
conjunctionfeaturesearch
Target =
+ + +
+
Subset search results:
Only the properties of the subset matter – but properties of the entire subset are taken into account (since that is what distinguishes a feature search from a conjunction search)
If the subset is a single-feature search it is fast and the slope is very shallow
If the subset is a conjunction search set, it takes longer and is more sensitive to the set size
The dispersion among the targets does not matter

singlefeaturesearch
conjunctionfeaturesearch
Target =
+ + +
+
A saccadeoccurshere
The selective search experiment with a saccade induced between the late onset cues and start of search

Must we encode location in detecting the presence of a property?
Some researchers claim that “… when an observer detects a target defined by other dimensions, this provides information about the location of the stimulus being detected” (Nissen, 1985) True, but is this information encoded? Is it used?
Because such experiments always confound individuals and locations we cannot distinguish two competing explanations of how vision primitively selects things in the world (by location or by individual)

How can we unconfound locations and individuals in order to study the role of individuals in property encoding?
Study moving objects (e.g., MOT experiments, as well as I.O.R. and Object File priming studies to be descrined in Lecture 2)
Study more general types of “objects” that share the same spatial locus and “move” through a space of properties

Superimposed Gabor patches
Blaser, Pylyshyn & Holcombe (2000)

Changing feature dimensions

Trajectories:
* pseudo-random and independent* frequent changes in speed and direction* Gabors frequently "pass" each other along a dimension(s)
Surfaces in feature-space

Snapshots
snapshots taken every 250 msec
People are able to track this single-location “objects” and
Single-object advantage is obtained

What goes on in MOT?According to the FINST account, some objects
cause a small number of indexes (4-5) to be captured. These indexes remain attached to their objects despite changes in their properties (in fact subjects do not notice property changes)
When objects stop moving the subject can move focal attention to indexed objects and thus is able to indicate which ones are targets.

Following up…
The next 3 lectures will explore several aspects of this idea that FINSTs provide a nonconceptual reference to visual objects in the world, including its implications for sentience, for nonconceptual impressions of space, and for the possible role of mental space in thought (i.e., mental imagery)

Schema for how FINSTs function

Optional Slides (if there is time)

[Extra] Distinguishing several functions associated with indexing
Before objects are indexed they must first be individuated and their spatiotemporal boundaries established – they must undergo what Gestalt Psychologists called figure-ground separation
This Gestalt separation process parses a scene into enduring objects – into individual ‘space-time worms.’ We will call these individuals (or sometimes objects).
In constructing such enduring individuals the visual system must solve the correspondence problem, a central recurring problem in vision
Once such individuals have been isolated, some of the salient ones can capture the small number of available indexes. Those indexed in this way can be referred to and bound to arguments of visual predicates.

Individuation in early vision Individuation is an important function of mind. It is what
enables you to know when two encounters are encounters with the same individual – to distinguish this and that from this and this again. It requires a conceptual apparatus and conditions of individuation
But there is a weaker sense of individuation computed by the early vision system without benefit of identity or of concepts. It is what allows two proximal tokens to be treated as arising from the same distal individual – i.e., to solve the correspondence problem.
Computing correspondence determines same-individual within the framework of early vision. Same-individual is whatever the visual system treats as an enduring individual by placing separate occurrences into correspondence, and by selecting and tracking it as one single thing.

There can’t be indexing without individuation, but can there be individuation without indexing?Two different functions are involved in Indexing
1) Individuating by clustering and establishing correspondences (space-time worms)
2) Establishing a reference relation to bind objects to the arguments of predicates
There are empirical cases where objects appear to be individuated, yet where there does not seem to be a limit of 4 or 5 objects that can be individuated at once Apparent Motion Stereo vision Punctate inhibition of moving objects
Could these involve individuating without reference?

Views from inside and outside of a dome

Structure from Motion Demo
Cylinder Kinetic Depth Effect

The correspondence problem for biological motion

The puzzle of individuation without indexing, and what that might mean!
If objects show punctate inhibition, then inhibition moves with the objects. How can this be unless they are being tracked?
This puzzle may signal the need for a kind of individuation that does not involve indexing – a mere clustering, circumscribing, figure-ground distinction without a pointer or access mechanism – i.e. without reference
Such a circumscribing-clustering is needed often when the correspondence problem arises – in stereo, apparent motion, and other grouping situations
Data show that correspondence is not computed over continuous manifolds but over proximal clusters
But in many of these cases the difficulty of pairing does not increase with the number of elements to be paired
This makes individuating-by-clustering fundamental (see later)