learning to rank for information retrieval -...
TRANSCRIPT

Learning to Rank for Information Retrieval
Tie-Yan Liu
Lead Researcher
Microsoft Research Asia
4/20/2008 1Tie-Yan Liu @ Tutorial at WWW 2008

The Speaker
• Tie-Yan Liu– Lead Researcher, Microsoft Research Asia.
– Ph.D., Tsinghua University, China.
– Research Interests: Learning to Rank, Large-scale Graph Learning.
– ~70 Papers: SIGIR(9), WWW(3), ICML (3), KDD(2), etc.
– Winner of Most Cited Paper Award, JVCIR, 2004 - 2006.
– Senior PC Member of SIGIR 2008.
– Co-chair, SIGIR Workshop on Learning to Rank, 2008.
– Co-chair, SIGIR Workshop on Learning to Rank, 2007.
– Speaker, Tutorial on Learning to Rank, SIGIR 2008 (to be given in July), AIRS 2008, etc.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 2

This Tutorial
• Learning to rank for information retrieval– But not other generic ranking problems.
• Supervised learning– But not unsupervised or semi-supervised learning.– Mostly discriminative learning but not generative learning.
• Learning in vector space– But not on graphs or other structured data.
• Mainly based on papers published at SIGIR, WWW, ICML, KDD, and NIPS in the past five years.– Papers at other conferences and journals might not be covered
comprehensively in this tutorial.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 3

Background Knowledge Required
• Information Retrieval– We will just briefly introduce, but not comprehensively review
the literature of IR.
• Machine Learning– We will assume you are familiar with regression, classification
and their learning algorithms, such as SVM, Boosting, NN, etc. – No comprehensive introduction to these algorithms and their
principles will be given.
• Probability Theory.• Linear Algebra.• Optimization.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 4

Outline
• Ranking in Information Retrieval
• Learning to Rank
– Overview
– Pointwise approach
– Pairwise approach
– Listwise approach
• Summary
4/20/2008 5Tie-Yan Liu @ Tutorial at WWW 2008

Ranking in Information Retrieval
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 6

We are Overwhelmed by Flood of Information
4/20/2008 7Tie-Yan Liu @ Tutorial at WWW 2008

Information Explosion
4/20/2008 8Tie-Yan Liu @ Tutorial at WWW 2008
2008?

4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 9

Search Engine as A Tool
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 10

Inside Search Engine
Ranking model
2008elcome/wwworg/blog/wwww.iw3c2.
htmlons/index.g/submissiwww2008.or
gwww2008.or
2
1
q
k
q
q
d
d
d
}2008{wwwq
Query
Indexed Document Repository
Ranked List of Documents
idD
4/20/2008 11Tie-Yan Liu @ Tutorial at WWW 2008

IR Evaluation
• Objective
– Evaluate the effectiveness of a ranking model
• A standard test set, containing
– A large number of queries, their associated documents, and the label (relevance judgments) of these documents.
• A measure
– Evaluating the effectiveness of a ranking model for a particular query.
– Averaging the measure over the entire test set to represent the expected effectiveness of the model.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 12

Widely-used Judgments
• Binary judgment
– Relevant vs. Irrelevant
• Multi-level ratings
– Perfect > Excellent > Good > Fair > Bad
• Pairwise preferences
– Document A is more relevant than document B with respect to query q
4/20/2008 13Tie-Yan Liu @ Tutorial at WWW 2008

Evaluation Measures
• MAP (Mean Average Precision)
• NDCG (Normalized Discounted Cumulative Gain)
• MRR (Mean Reciprocal Rank)
– For query , rank position of the first relevant document:
– MRR: average of over all queries
• WTA (Winners Take All)
– If top ranked document is relevant: 1; otherwise 0
– average over all queries
• ……
iriq
ir/1
4/20/2008 14Tie-Yan Liu @ Tutorial at WWW 2008

MAP
• Precision at position n
• Average precision
• MAP: averaged over all queries in the test set
154/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008
n
nnP
}results in top documentsrelevant {#@
}documentsrelevant {#
}relevant is document {@
n
nInP
AP
76.05
3
3
2
1
1
3
1
AP =

NDCG
• NDCG at position n:
• NDCG averaged for all queries in test set
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 16
)1log(/)12()(1
)( jZnNn
j
jr
n
Position discountGainCumulatingNormalization

G: Gain
Relevance Rating Value (Gain)
Perfect 31=25-1
Excellent 15=24-1
Good 7=23-1
Fair 3=22-1
Bad 0=20-1
4/20/2008 17Tie-Yan Liu @ Tutorial at WWW 2008

CG: Cumulative GIf each rank position is treated equal
URL Gain Cumulative Gain
#1 http://abc.go.com/ 31 31
#2 http://www.abcteach.com/ 3 34 = 31 +3
#3 http://abcnews.go.com/sections/scitech/ 15 49 = 31 + 3 + 15
#4 http://www.abc.net.au/ 15 64 = 31 + 3 + 15 + 15
#5 http://abcnews.go.com/ 15 79 = 31 + 3 + 15 + 15 + 15
#6 … … …
Query={abc}
4/20/2008 18Tie-Yan Liu @ Tutorial at WWW 2008

DCG: Discounted CG
URL Gain Discounted Cumulative Gain
#1 http://abc.go.com/ 31 31 = 31x1
#2 http://www.abcteach.com/ 3 32.9 = 31 + 3x0.63
#3 http://abcnews.go.com/sections/scitech/ 15 40.4 = 32.9 + 15x0.50
#4 http://www.abc.net.au/ 15 46.9 = 40.4 + 15x0.43
#5 http://abcnews.go.com/ 15 52.7 = 46.9 + 15x0.39
#6 … … …
• Discounting factor: Log(2) / (Log(1+rank))
4/20/2008 19Tie-Yan Liu @ Tutorial at WWW 2008

Ideal Ordering: Max DCG
URL Gain Max DCG
#1 http://abc.go.com/ 31 31 = 31x1
#2 http://abcnews.go.com/sections/scitech/ 15 40.5 = 31 + 15x0.63
#3 http://www.abc.net.au/ 15 48.0 = 40.5 + 15x0.50
#4 http://abcnews.go.com/ 15 54.5 = 48.0 + 15x0.43
#5 http://www.abc.org/ 15 60.4 = 54.5 + 15x0.39
#6 … … …
4/20/2008 20Tie-Yan Liu @ Tutorial at WWW 2008
• Sort the documents according to their labels

NDCG: Normalized DCG
URL Gain DCG Max DCG NDCG
#1 http://abc.go.com/ 31 31 31 1 = 31/31
#2 http://www.abcteach.com/ 3 32.9 40.5 0.81=32.9/40.5
#3 http://abcnews.go.com/sections/scitech/ 15 40.4 48.0 0.84=40.4/48.0
#4 http://www.abc.net.au/ 15 46.9 54.5 0.86=46.9/54.5
#5 http://abcnews.go.com/ 15 52.7 60.4 0.87=52.7/60.4
#6 … … … … …
4/20/2008 21Tie-Yan Liu @ Tutorial at WWW 2008
• Normalized by the Max DCG

More about Evaluation Measures
• Query-level– Averaged over all testing queries.
– The measure is bounded, and every query contributes equally to the averaged measure.
• Position– Position discount is used here and there.
• Non-smooth– Computed based on ranks of documents.
– With small changes to parameters of the ranking model, the scores will change smoothly, but the ranks will not change until one document’s score passes another.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 22

Conventional Ranking ModelsCategory Example Models
Similarity-based models
Boolean model
Vector space model
Latent Semantic Indexing
……
Probabilistic models
BM25 model
Language model for IR
…
Hyperlink-basedmodels
HITS
PageRank
……
4/20/2008 23Tie-Yan Liu @ Tutorial at WWW 2008

Discussions on Conventional Ranking Models
• For a particular model
– Parameter tuning is usually difficult, especially when there are many parameters to tune.
• For comparison between two models
– Given a test set, it is difficult to compare two models, one is over-tuned (over-fitting) while the other is not.
• For a collection of models
– There are hundreds of models proposed in the literature.
– It is non-trivial to combine them effectively.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 24

Machine Learning Can Help
• Machine learning is an effective tool
– To automatically tune parameters
– To combine multiple evidences
– To avoid over-fitting (regularization framework, structure risk minimization, etc.)
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 25

Learning to Rank for IR
OverviewPointwise Approach
Pairwise ApproachListwise Approach
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 26

Framework of Learning to Rank for IR
27
Learning System
Ranking System
Model
),,( wdqf
),,(,
),,(,
),,(,
22
11
wdqfd
wdqfd
wdqfd
inin
ii
ii
1,
2,
4,
)1(
)1(
2
)1(
1
)1(
)1(nd
d
d
q
2,
3,
5,
)(
)(
2
)(
1
)(
)(
m
n
m
m
m
md
d
d
q
Labels: multiple-level ratings for example.
queries
do
cum
en
ts
Training Data
Test data
?),(......,
?),(?),,( 21
nd
dd
q
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008

Learning to Rank Algorithms
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 28
Ranking SVM (ICANN 1999)
RankBoost (JMLR 2003)
Discriminative model for IR (SIGIR 2004)
LDM (SIGIR 2005)
RankNet (ICML 2005)IRSVM (SIGIR 2006)
LambdaRank (NIPS 2006) Frank (SIGIR 2007)
GBRank (SIGIR 2007)QBRank (NIPS 2007)
MPRank (ICML 2007)
McRank (NIPS 2007) AdaRank (SIGIR 2007)
SVM-MAP (SIGIR 2007)
SoftRank (LR4IR 2007)
GPRank (LR4IR 2007)
CCA (SIGIR 2007)
MHR (SIGIR 2007)
RankCosine (IP&M 2007)
ListNet (ICML 2007)
ListMLE (ICML 2008)
Query refinement (WWW 2008)
Supervised Rank Aggregation (WWW 2007)Relational ranking (WWW 2008)
SVM Structure (JMLR 2005)
Nested Ranker (SIGIR 2006)

Categorization: Relation to Conventional Machine Learning
• With certain assumptions, learning to rank can be reduced to conventional learning problems
– Regression• Assume labels to be scores
– Classification• Assume labels to have no orders
– Pairwise classification • Assume document pairs to be independent of each other
4/20/2008 29Tie-Yan Liu @ Tutorial at WWW 2008

Categorization: Relation to Conventional Machine Learning
• Ranking in IR has unique properties– Query determines the logical structure of the ranking
problem. • Loss function should be defined on ranked lists w.r.t. a query, since
IR measures are computed at query level.
– Relative order is important• No need to predict category, or value of f(x).
– Position sensitive• Top-ranked objects are more important.
– Rank based evaluation • Learning objective is non-smooth and non-differentiable.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 30

Categorization: Basic Unit of Learning
• Pointwise
– Input: single documents
– Output: scores or class labels
• Pairwise
– Input: document pairs
– Output: partial order preference
• Listwise
– Input: document collections
– Output: ranked document List
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 31

Categorization of Learning to Rank Algorithms
PointwiseApproach
Pairwise Approach Listwise Approach
Reduced to classification or regression
Discriminative model for IR (SIGIR 2004)McRank (NIPS 2007)…
Ranking SVM (ICANN 1999)RankBoost (JMLR 2003)LDM (SIGIR 2005)RankNet (ICML 2005)Frank (SIGIR 2007)GBRank (SIGIR 2007)QBRank (NIPS 2007)MPRank (ICML 2007)…
Make use of unique properties of Ranking for IR
IRSVM (SIGIR 2006)…
LambdaRank (NIPS 2006)AdaRank (SIGIR 2007)SVM-MAP (SIGIR 2007)SoftRank (LR4IR 2007)GPRank (LR4IR 2007)CCA (SIGIR 2007)RankCosine (IP&M 2007)ListNet (ICML 2007)ListMLE (ICML 2008)…
4/20/2008 32Tie-Yan Liu @ Tutorial at WWW 2008

Learning to Rank for IR
Overview
Pointwise ApproachPairwise ApproachListwise Approach
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 33

Overview of Pointwise Approach
• Reduce ranking to regression or classification on single documents.
• Examples:
– Discriminative model for IR.
– McRank: learning to rank using multi-class classification and gradient boosting.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 34

Discriminative Model for IR(R. Nallapati, SIGIR 2004)
• Features extracted for each document
• Treat relevant documents as positive examples, while irrelevant documents as negative examples.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 35

Discriminative Model for IR
• Learning algorithms– Max Entropy
– Support Vector Machines
• Experimental results– Comparable with LM
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 36

McRank(P. Li, et al. NIPS 2007)
• Loss in terms of DCG is upper bounded by multi-class classification error
• Multi-class classification:
• Multiple ordinal classification:
• Regression:
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 37
)( kyP i
)( kyP i 1
2)(min
iy
ixf

Different Reductions
• From classification to ranking
– Learn a classifier for each category
– Classifier outputs converted to probabilities using logistic function
– Convert classification to ranking:
• Experimental results
– Multiple ordinal classification > Multi-class classification > Regression
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 38

Discussions
• Assumption
– Relevance is absolute and query-independent.
– E.g. documents associated with different queries are put into the same category, if their labels are all “perfect”.
• However, in practice, relevance is query-dependent
– An irrelevant document for a popular query might have higher term frequency than a relevant document for a rare query.
– If simply put documents associated with different queries together, the training process may be hurt.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 39

Learning to Rank for IR
OverviewPointwise Approach
Pairwise ApproachListwise Approach
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 40

Overview of Pairwise Approach
• No longer assume absolute relevance.
• Reduce ranking to classification on document pairs w.r.t. the same query.
• Examples
– RankNet, FRank, RankBoost, Ranking SVM, etc.
Transform
2,
3,
5,
)(
)(
2
)(
1
)(
)(
i
n
i
i
i
id
d
d
q
)()(
2
)()(
1
)(
2
)(
1
)(
)()( ,,...,,,, i
n
ii
n
iii
i
ii dddddd
q
5 > 3 5 > 2 3 > 2
414/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008

• Target probability:
– (1 means i ⊳ j; 0 mean i ⊲ j).
• Modeled probability:
–
– Where
• Cross entropy as the loss function–
RankNet(C. Burges, et al. ICML 2005)
4/20/2008 42Tie-Yan Liu @ Tutorial at WWW 2008

RankNet (2)
• Use Neural Network as model, and gradient descent as algorithm, to optimize the cross-entropy loss.
• Evaluate on single documents: output a relevance score for each document w.r.t. a new query.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 43

FRank(M. Tsai, T. Liu, et al. SIGIR 2007)
• Similar setting to that of RankNet
• New loss function: fidelity
4/20/2008 44Tie-Yan Liu @ Tutorial at WWW 2008
* *( ) 1 ( (1 ) (1 ))ij ij ij ij ij ijF F o P P P P

FRank (2)
RankNet (Cross entropy loss)
• Non-zero minimum loss
• Unbounded
• Convex
FRank (Fidelity loss)
• Zero minimum loss
• Bounded within [0,1]
• Non-convex
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 45
Experimental results show:FRank can outperform RankNet in many cases

RankBoost(Y. Freund, et al. JMLR 2003)
• Given: initial distribution D1 over
• For t=1,…, T:
– Train weak learning using distribution Dt
– Get weak ranking ht: X R
– Choose
– Update:
where
• Output the final ranking:
0 1 0 1
1 0 1
( , )exp ( ( ) ( ))( , ) t t t t
t
t
D x x h x h xD x x
Z
0 1
0 1 0 1
,
( , )exp ( ( ) ( ))t t t t t
x x
Z D x x h x h x
t R
1
( ) ( )T
t t
t
H x h x
4/20/2008 46Tie-Yan Liu @ Tutorial at WWW 2008
Use AdaBoost to perform pairwise classification

Weak Learners
• Feature values
• Thresholding
• Note: many theoretical properties of AdaBoost can be inherited by RankBoost.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 47

Ranking SVM(R. Herbrich, et al. ICANN 1999)
0
1,
||||2
1min
)2()1(
2
,
i
iiii
iw
xxwz
Cw
xwwxf ,ˆ)ˆ;(
4/20/2008 48Tie-Yan Liu @ Tutorial at WWW 2008
Use SVM to perform pairwise classification
x(1)-x(2) as positive instance of learning
Use SVM to perform binary classification on these instances,
to learn model parameter w
Use w for testing

Testing
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 49

Other Work in this Category
• Linear discriminant model for information retrieval (LDM), (J. Gao, H. Qi, et al. SIGIR 2005)
• A Regression Framework for Learning Ranking Functions using Relative Relevance Judgments (GBRank), (Z. Zheng, H. Zha, et al. SIGIR 2007)
• A General Boosting Method and its Application to Learning Ranking Functions for Web Search (QBRank), (Z. Zheng, H. Zha, et al. NIPS 2007)
• Magnitude-preserving Ranking Algorithms (MPRank), (C. Cortes, M. Mohri, et al. ICML 2007)
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 50

Discussions
• Progress made as compared to pointwise approach
– No longer assume absolute relevance
• However,
– Unique properties of ranking in IR have not been fully modeled.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 51

Problems with Pairwise Approach (1)
• Number of instance pairs varies according to query
– Two queries in total
– Same error in terms of pairwise classification780/790 = 98.73%.
– Different errors in termsof query level evaluation99% vs. 50%.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 52

Problems with Pairwise Approach (2)
• Negative effects of making errors on top positions– Same error in terms of pairwise classification– Different errors in terms of position-discounted evaluation.
p: perfect, g: good, b: bad
Ideal: p g g b b b b
ranking 1: g p g b b b b one wrong pair Worseranking 2: p g b g b b b one wrong pair Better
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 53

As a Result, …
• Users only see ranked list of documents, but not document pairs
• It is not clear how pairwise loss correlates with IR evaluation measures, which are defined on query level.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 54
Pairwise loss vs. (1-NDCG@5)TREC Dataset

Incremental Solution to Problems (1)
IRSVM: Change Loss of Ranking SVM(Y. Cao, J. Xu, T. Liu, et al. SIGIR 2006)
Query-level normalizer
4/20/2008 55Tie-Yan Liu @ Tutorial at WWW 2008

Experimental Results
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 56
Web Data

Theoretical Analysis(Y. Lan, T. Liu, et al. ICML 2008)
• Stability theory on query-level generalization bound
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 57
Loss function
Learning instance
Ground truth
Loss on a single query Risks on a set

Theoretical Analysis (2)
• Stability– Represents the degree of
change in the loss when randomly removing a query and its associated documents from the training set.
• Generalization Ability– If an algorithm has query-
level stability, with high probability, expected query-level risk can be bounded by empirical risk as follows.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 58
Query qj removed from training set
Bound depending on query number and stability coefficientStability coefficient

Generalization Bounds for Ranking SVM and IRSVM
• For Ranking SVM
• For IRSVM
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 59
When number of document pairs per query varies largely, the generalization bound of IRSVM will be much tighter than that of Ranking SVM
<<

Distribution of Pair Numbers
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 60
Web Data
Variance is large
IR SVM will have a better generalization ability than Ranking SVM

Incremental Solution to Problems (2)
IRSVM: Change Loss of Ranking SVM(Y. Cao, J. Xu, T. Liu, et al. SIGIR 2006)
Implicit Position Discount: Larger weight for more critical type of pairs
Learned from a labeled set
4/20/2008 61Tie-Yan Liu @ Tutorial at WWW 2008

Experimental Results
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 62
Web Data

More Fundamental Solution
Listwise Approach to Ranking
• Directly operate on ranked lists
– Directly optimize IR evaluation measures• AdaRank, SVM-MAP, SoftRank, LambdaRank, RankGP, …
– Define listwise loss functions• RankCosine, ListNet, ListMLE, …
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 63

Contextual Ads
• SIGIR 2008 workshop on learning to rank for IR
– http://research.microsoft.com/users/LR4IR-2008/
– Paper submission due: May 16, 2008.
– Organizer: Tie-Yan Liu, Hang Li, Chengxiang Zhai
• We organized a successful workshop on the same topic at SIGIR 2007 (the largest workshop, with 100+ registrations)
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 64

Contextual Ads (2)
• SIGIR 2008 tutorial on learning to rank for IR
– Speaker: Tie-Yan Liu
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 65
• Differences from this WWW tutorial
– Include more new algorithms (SIGIR 2008, ICML 2008, etc.)
– Discussions on the whole pipeline of learning to rank (feature extraction, ground truth mining, loss function, ranking function, post processing, etc.)
Contextual Ads (3)
• LETOR: Benchmark Dataset for Learning to Rank– http://research.microsoft.com/users/LETOR/– 500+ downloads till now.– Released by Tie-Yan Liu, Jun Xu, et al.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 66

- Next –Listwise Approach to Learning to Rank
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 67

Learning to Rank for IR
OverviewPointwise Approach
Pairwise Approach
Listwise Approach
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 68

Overview of Listwise Approach
• Instead of reducing ranking to regression or classification, perform learning directly on document list.
– Treats ranked lists as learning instances.
• Two major types
– Directly optimize IR evaluation measures
– Define listwise loss functions
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 69

Directly Optimize IR Evaluation Measures
• It is a natural idea to directly optimize what is used to evaluate the ranking results.
• However, it is non-trivial.
– Evaluation measures such as NDCG are usually non-smooth and non-differentiable since they depend on the ranks.
– It is challenging to optimize such objective functions, since most of the optimization techniques were developed to work with smooth and differentiable cases.
704/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008

Tackle the Challenges
• Use optimization technologies designed for smooth and differentiable problems– Embed the evaluation measure in the logic of existing
optimization technique (AdaRank)
– Optimize a smooth and differentiable upper bound of the evaluation measure (SVM-MAP)
– Soften (approximate) the evaluation measure so as to make it smooth and differentiable (SoftRank)
• Use optimization technologies designed for non-smooth and non-differentiable problems– Genetic programming (RankGP)
– Directly define gradient (LambdaRank)
4/20/2008 71Tie-Yan Liu @ Tutorial at WWW 2008

AdaRank(J. Xu, et al. SIGIR 2007)
• The optimization process of AdaBoost
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 72
Use the loss function to update the distributions of learning instances and to determine the parameter α

AdaRank(J. Xu, et al. SIGIR 2007)
• Use Boosting to perform the optimization.
• Embed IR evaluation measure in the distribution update of Boosting.– Focus on those hard
queries.
– Weak learner that canrank important queriesmore correctly will havelarger weight α
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 73

Theoretical Analysis
• Training error will be continuously reduced during learning phase when <1
744/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008
Assumes the linearity of the IR evaluation measure.

Practical Solution
• In practice, we cannot guarantee <1, therefore, AdaRank might not converge.
• Solution: when a weak ranker is selected, we test whether <1, if not, the second best weak ranker is selected.
754/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008

Experimental Results
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 76
TD 2003 Data

SVM-MAP(Y. Yue, et al. SIGIR 2007)
• Use SVM framework for optimization
• Incorporate IR evaluation measures in the listwise constraints: – The score w.r.t true labeling should be higher than that w.r.t. incorrect labeling.
• Sum of slacks ∑ξ upper bounds ∑ (1-E(y,y’)).
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 77
i
iN
Cw 2
2
1min
)),'(1()',,(),,( :' yyydydyy EqFqF

Challenges in SVM-MAP
• For Average Precision, the true labeling is a ranking where the relevant documents are all ranked in the front, e.g.,
• An incorrect labeling would be any other ranking, e.g.,
• Exponential number of rankings, thus an exponential number of constraints!
4/20/2008 78Tie-Yan Liu @ Tutorial at WWW 2008

Structural SVM Training
• STEP 1: Perform optimization on only current working set of constraints.
• STEP 2: Use the model learned in STEP 1 to find the most violated constraint from the exponential set of constraints.
• STEP 3: If the constraint returned in STEP 2 is more violated than the most violated constraint in the working set, add it to the working set.
STEP 1-3 is guaranteed to loop for at most a polynomial number of iterations. [Tsochantaridis et al. 2005]
4/20/2008 79Tie-Yan Liu @ Tutorial at WWW 2008

Finding the Most Violated Constraint
• Most violated y:
• If the relevance at each position is fixed, E(y,y’) will be the same. But if the documents are sorted by their scores in descending order, F(q,d,y’) will be maximized.
• Strategy– Sort the relevant and irrelevant documents and form a perfect
ranking.– Start with the perfect ranking and swap two adjacent relevant
and irrelevant documents, so as to find the optimal interleaving of the two sorted lists.
– For real cases, the complexity is O(nlogn).
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 80
)',,(),'(1maxarg'
ydyy qFEYy

Experimental Results
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 81
Comparison with other SVM methods
0.1
0.12
0.14
0.16
0.18
0.2
0.22
0.24
0.26
0.28
0.3
TREC 9 Indri TREC 10 Indri TREC 9
Submissions
TREC 10
Submissions
TREC 9
Submissions
(without best)
TREC 10
Submissions
(without best)
Dataset
Mea
n A
vera
ge
Pre
cisi
on
SVM-MAP
SVM-ROC
SVM-ACC
SVM-ACC2
SVM-ACC3
SVM-ACC4

SoftRank(M. Taylor, et al. LR4IR 2007)
• Key Idea:
– Avoid sorting by treating scores as random variables
• Steps
– Construct score distribution
– Map score distribution to rank distribution
– Compute expected NDCG (SoftNDCG) which is smooth and differentiable.
– Optimize SoftNDCG by gradient descent.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 82
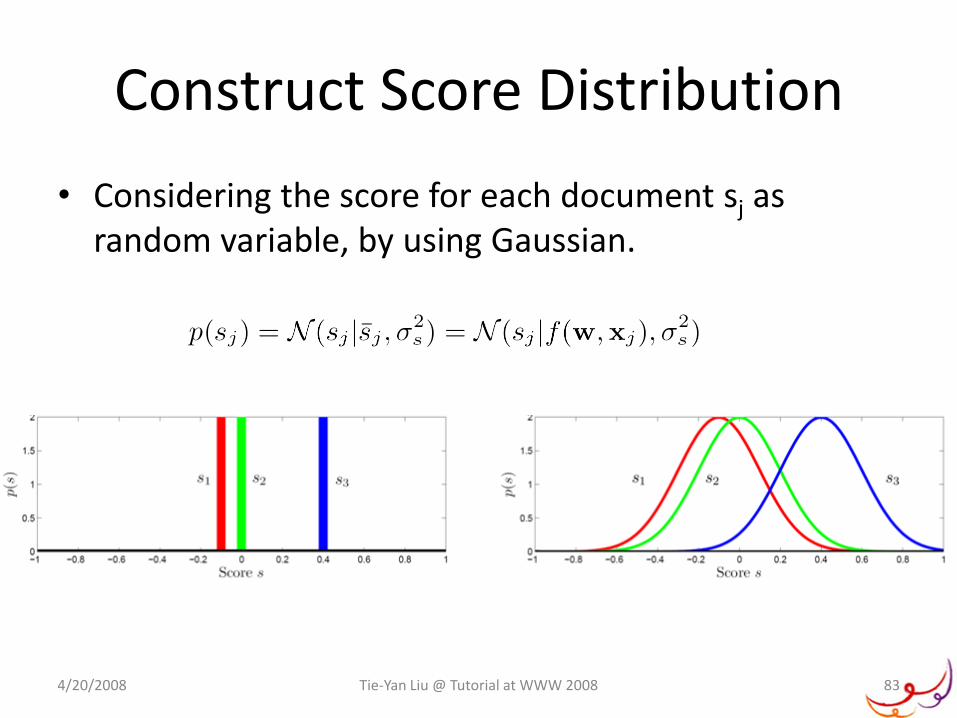
Construct Score Distribution
• Considering the score for each document sj as random variable, by using Gaussian.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 83

From Scores to Rank Distribution
• Probability of doci being ranked before docj
• Expected rank
• Rank Distribution
4/20/2008 84Tie-Yan Liu @ Tutorial at WWW 2008
Define the probability of a document being ranked at a particular position

Soft NDCG
• From hard to soft
• Since depends on , the optimization can be done if we know .
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 85

Experimental Results
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 86
Here Gn means NDCG @ position n

RankGP(J. Yeh, et al. LR4IR 2007)
• RankGP = Preprocessing + Learning + Prediction
• Preprocessing– Query-based normalization on features
• Learning– Single-population GP
– Widely used to optimize non-smoothing non-differentiable objectives.
• Prediction–
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 87

Ranking Function Learning
• Define ranking function as a tree
• Use GP to learn the optimal tree• Evolution mechanism
– Crossover, mutation, reproduction, tournament selection.
• Fitness function– IR evaluation measure (MAP).
4/20/2008 88Tie-Yan Liu @ Tutorial at WWW 2008

Experimental Results
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 89
TD 2003 Data

LambdaRank(C. Burges, et al. NIPS 2006)
• Basic idea– IR evaluation measures are non-smooth and non-
differentiable.
– It is usually much easier to specify rules determining how to change rank order of documents than to construct a smooth loss function.
• Example– Two relevant documents
D1 and D2;
– WTA as the evaluation measure.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 90
To achieve WTA=1

Lambda Function, Instead of Loss Function
• Instead of explicitly defining the loss function, directly define the gradient:
• A lambda which was shown to effectively optimize NDCG.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 91
),,...,,( 11 nnj
j
lslss
C
S: score; l: label.

Experimental Results
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 92Web Data

Other Work in this Category
• A combined component approach for finding collection-adapted ranking functions based on genetic programming (CCA), (H. Almeida, M. Goncalves, et al. SIGIR 2007).
• A Markov random field model for term dependencies, (D. Metzler, W. Croft. SIGIR 2005).
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 93

Discussions
• Progress has been made as compared to pointwise and pairwise approaches
• Unsolved problems– Is the upper bound in SVM-MAP tight enough?– Is SoftNDCG really correlated with NDCG?– Is there any theoretical justification on the correlation
between the implicit loss function used in LambdaRankand NDCG?
– Multiple measures are not necessarily consistent with each other: which to optimize?
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 94

Define Listwise Loss Function
• Indirectly optimizing IR evaluation measures– Consider properties of ranking for IR.
• Examples– RankCosine: use cosine similarity between score vectors as
loss function– ListNet: use KL divergence between permutation
probability distributions as loss function– ListMLE: use negative log likelihood of the ground truth
permutation as loss function
• Theoretical analysis on listwise loss functions
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 95

RankCosine(T. Qin, T. Liu, et al. IP&M 2007)
• Loss function define as
• Properties
– Loss is computed by using all documents of a query.
– Insensitive to number of documents / document pairs per query
– Emphasize correct ranking by setting high scores for top in ground truth.
– Bounded:
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 96

Optimization
• Additive model as ranking function
• Loss over queries
• Gradient descent for optimization
4/20/2008 97Tie-Yan Liu @ Tutorial at WWW 2008

Experimental Results
4/20/2008 98Tie-Yan Liu @ Tutorial at WWW 2008

More Investigation on Loss Functions
• A Simple Example:– function f: f(A)=3, f(B)=0, f(C)=1 ACB
– function h: h(A)=4, h(B)=6, h(C)=3 BAC
– ground truth g: g(A)=6, g(B)=4, g(C)=3 ABC
• Question: which function is closer to ground truth?– Based on pointwise similarity: sim(f,g) < sim(g,h).– Based on pairwise similarity: sim(f,g) = sim(g,h)
– Based on cosine similarity between score vectors?f: <3,0,1> g:<6,4,3> h:<4,6,3>
• However, according to position discount, f should be closer to g!
994/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008
sim(g,h)=0.93sim(f,g)=0.85
Closer!

Permutation Probability Distribution
• Question:
– How to represent a ranked list?
• Solution
– Ranked list ↔ Permutation probability distribution
– More informative representation for ranked list: permutation and ranked list has 1-1 correspondence.
1004/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008

Luce Model: Defining Permutation Probability
• Probability of permutation 𝜋 is defined as
• Example:
)(sP
n
jn
jk k
j
s
s
1 )(
)(
)(
)(
)C(
)C(
)C()B(
)B(
)A()B()A(
)A(ABC
f
f
ff
f
fff
fPf
P(A ranked No.1)
P(B ranked No.2 | A ranked No.1)= P(B ranked No.1)/(1- P(A ranked No.1))
P(C ranked No.3 | A ranked No.1, B ranked No.2)
1014/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008

Properties of Luce Model
• Nice properties
– Continuous, differentiable, and convex w.r.t. score s.
– Suppose g(A) = 6, g(B)=4, g(C)=3, P(ABC) is largest and P(CBA) is smallest; for the ranking based on f: ABC, swap any two, probability will decrease, e.g., P(ABC) > P(ACB)
– Translation invariant, when
– Scale invariant, when
)exp()( ss
sas )(
1024/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008

Distance between Ranked Lists
dis(f,g) = 0.46
dis(g,h) = 2.56
φ = exp
1034/20/2008
Using KL-divergenceto measure difference between distributions
Tie-Yan Liu @ Tutorial at WWW 2008

ListNet Algorithm(Z. Cao, T. Qin, T. Liu, et al. ICML 2007)
• Loss function = KL-divergence between two permutation probability distributions (φ = exp)
• Model = Neural Network
• Algorithm = Gradient Descent
Qq jjG
n
tn
tu jy
jyn
tn
tu jy
jy
ku
t
u
t
Xw
Xw
s
swL
),...,( 1 )(
)(
1 )(
)(
1 )exp(
)exp(log
)exp(
)exp()(
1044/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008

Experimental Results
Pairwise (RankNet)
1054/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008
Training Performance on TD2003 Dataset
Listwise (ListNet)
More correlated!

Experimental Results
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 106

Limitations of ListNet
• Still too complex in practice: O(n⋅n!)
• Performance of ListNet depends on the mapping function from ground truth label to scores
– Ground truths are permutations (ranked list) or group of permutations; but not naturally scores.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 107

Solution
• Never assume ground truth to be scores.
• Given the scores outputted by the ranking model, compute the likelihood of a ground truth permutation, and maximize it to learn the model parameter.
• The complexity is reduced from O(n⋅n!) to O(n).
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 108

Likelihood Loss
• Permutation Likelihood
• Likelihood Loss
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 109

ListMLE Algorithm(F. Xia, T. Liu, et al. ICML 2008)
• Loss function = likelihood loss
• Model = Neural Network
• Algorithm = Stochastic Gradient Descent
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 110

Experimental Results
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 111
TD2004 Dataset

Listwise Ranking Framework
• Input space: X
– Elements in X are sets of objects to be ranked
• Output space: Y
– Elements in Y are permutations of objects
• Joint probability distribution: PXY
• Hypothesis space: H
–
• Expected loss
–
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 112

True Loss in Listwise Ranking
• To analysis the theoretical properties of listwise loss functions, the “true” loss of ranking is to be defined.
– The true loss describes the difference between a given ranked list (permutation) and the ground truth ranked list (permutation).
• Ideally, the “true” loss should be cost-sensitive, but for simplicity, we investigate the “0-1” loss.
–
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 113

Surrogate Loss in Listwise Approach
• Widely-used ranking function
–
• Corresponding empirical loss
–
• Challenges
– Due to the sorting function and the 0-1 loss, the empirical loss is non-differentiable.
– To tackle the problem, a surrogate loss is used.
–
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 114

Surrogate Loss Minimization Framework
• RankCosine, ListNet and ListMLE can all be well fitted into this framework of surrogate loss minimization.
– RankCosine
– ListNet
– ListMLE
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 115

Evaluation of Surrogate Loss
• Continuity, differentiability and convexity
• Computational efficiency
• Statistical consistency
• Soundness
These properties have been well studied in classification, but not sufficiently in ranking.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 116

Continuity, Differentiability, Convexity, Efficiency
Loss Continuity Differentiability Convexity Efficiency
Cosine Loss(RankCosine)
√ √ X O(n)
Cross-entropy loss(ListNet)
√ √ √ O(n·n!)
Likelihood loss(ListMLE)
√ √ √ O(n)
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 117

Statistical Consistency
• When minimizing the surrogate loss is equivalent to minimizing the expected 0-1 loss, we say the surrogate loss function is consistent.
• A theory for verifying consistency in ranking.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 118
The ranking of an object is inherently determined by its own.
Starting with a ground-truth permutation, the loss will increase after exchanging the positions of two objects in it, and the speed of increase in loss is sensitive to the positions of objects.

Statistical Consistency (2)
• It has been proven (F. Xia, T. Liu, et al. ICML 2008)
– Cosine Loss is statistically consistent.
– Cross entropy loss is statistically consistent.
– Likelihood loss is statistically consistent.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 119

Soundness
• Cosine loss is not very sound
– Suppose we have two documents D2 ⊳ D1.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 120
g1
g2 g1=g2
α
Correct rankingIncorrect Ranking

Soundness (2)
• Cross entropy loss is not very sound
– Suppose we have two documents D2 ⊳ D1.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 121
g2 g1=g2
g1
Correct rankingIncorrect Ranking

Soundness (3)
• Likelihood loss is sound
– Suppose we have two documents D2 ⊳ D1.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 122
g2 g1=g2
g1
Correct rankingIncorrect Ranking

Discussion
• Progress has been made as compared to pointwiseand pairwise approaches
• Likelihood loss seems to be one of the best listwiseloss functions, according to the above discussions.
• In real ranking problems, the true loss should be cost-sensitive.
– Need further investigations.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 123

Summary
• Ranking is a new application, and also a new machine learning problem.
• Learning to rank: from pointwise, pairwise to listwiseapproach.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 124

4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 125
po
inw
ise
pai
rwis
elis
twis
e
2000 2001 2002 2003 2004 2005 2006 2007
MCRankDiscriminative IR model
RankNetRankingSVM
RankBoostFRank
IRSVM
AdaRank
SVM-MAP
SoftRankRankCosine
RankGP
MHR
ListNet* Papers published by our group
Supervised Rank Aggregation
LambdaRank
ListMLE
LDMGBRank
MPRank
QBRank
CCA
Relational Ranking
Rank Refinement

Future Work
• From loss function to ranking function.– Beyond the ranking function on single documents.
– Beyond single ranking model for all kinds of queries.
• From learning process to preprocessing and post-processing.– Automatic ground truth mining
– Feature extraction and selection might be even more important than selecting learning algorithms in practice.
– Dedup and diversification are helpful.
• From discriminative learning to generative learning
• From algorithms to learning theory.– “True loss” for ranking.
– Generalization ability of listwise approach.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 126

You May Want to Read…
• Ground Truth Mining– Active Exploration for Learning Rankings from Clickthrough Data (F.
Radlinski, T. Joachims, KDD 2007)
– Query Chains: Learning to Rank from Implicit Feedback (F. Radlinski, T. Joachims, KDD 2005)
• Feature Selection– Feature Selection for Ranking (X. Geng, T. Liu, et al. SIGIR 2007)
• Ranking Function– Multi-hyperplane ranker (T. Qin, T. Liu, et al. SIGIR 2007)
– Multiple Nested Ranker (I. Matveeva, C.J.C. Burges, et al. SIGIR 2006)
– Supervised Rank Aggregation (Y. Liu, T. Liu, et al. WWW 2007)
– Learning to Rank Relational Objects (T. Qin, T. Liu, et al. WWW 2008)
– Ranking Refinement and Its Application to Information Retrieval (R. Jin, H. Valizadegan, et al. WWW 2008)
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 127

• R. Herbrich, T. Graepel, et al. Support Vector Learning for Ordinal Regression, ICANN1999.
• T. Joachims, Optimizing Search Engines Using Clickthrough Data, KDD 2002.
• Y. Freund, R. Iyer, et al. An Efficient Boosting Algorithm for Combining Preferences, JMLR 2003.
• R. Nallapati, Discriminative model for information retrieval, SIGIR 2004.
• J. Gao, H. Qi, et al. Linear discriminant model for information retrieval, SIGIR 2005.
• D. Metzler, W. Croft. A Markov random field model for term dependencies, SIGIR 2005.
• C.J.C. Burges, T. Shaked, et al. Learning to Rank using Gradient Descent, ICML 2005.
• I. Tsochantaridis, T. Joachims, et al. Large Margin Methods for Structured and Interdependent Output Variables, JMLR, 2005.
• F. Radlinski, T. Joachims, Query Chains: Learning to Rank from Implicit Feedback, KDD 2005.
• I. Matveeva, C.J.C. Burges, et al. High accuracy retrieval with multiple nested ranker, SIGIR 2006.
• C.J.C. Burges, R. Ragno, et al. Learning to Rank with Nonsmooth Cost Functions , NIPS 2006
• Y. Cao, J. Xu, et al. Adapting Ranking SVM to Information Retrieval, SIGIR 2006.
• Z. Cao, T. Qin, et al. Learning to Rank: From Pairwise to Listwise Approach, ICML 2007.
4/20/2008 128Tie-Yan Liu @ Tutorial at WWW 2008
References

• T. Qin, T.-Y. Liu, et al, Multiple hyperplane Ranker, SIGIR 2007.
• T.-Y. Liu, J. Xu, et al. LETOR: Benchmark dataset for research on learning to rank for information retrieval, LR4IR 2007.
• M.-F. Tsai, T.-Y. Liu, et al. FRank: A Ranking Method with Fidelity Loss, SIGIR 2007.
• Z. Zheng, H. Zha, et al. A General Boosting Method and its Application to Learning Ranking Functions for Web Search, NIPS 2007.
• Z. Zheng, H. Zha, et al, A Regression Framework for Learning Ranking Functions Using Relative Relevance Judgment, SIGIR 2007.
• M. Taylor, J. Guiver, et al. SoftRank: Optimising Non-Smooth Rank Metrics, LR4IR 2007.
• J.-Y. Yeh, J.-Y. Lin, et al. Learning to Rank for Information Retrieval using Generic Programming, LR4IR 2007.
• T. Qin, T.-Y. Liu, et al, Query-level Loss Function for Information Retrieval, Information Processing and Management, 2007.
• X. Geng, T.-Y. Liu, et al, Feature Selection for Ranking, SIGIR 2007.
4/20/2008 129Tie-Yan Liu @ Tutorial at WWW 2008
References (2)

References (3)
• Y. Yue, T. Finley, et al. A Support Vector Method for Optimizing Average Precision, SIGIR 2007.
• Y.-T. Liu, T.-Y. Liu, et al, Supervised Rank Aggregation, WWW 2007.
• J. Xu and H. Li, A Boosting Algorithm for Information Retrieval, SIGIR 2007.
• F. Radlinski, T. Joachims. Active Exploration for Learning Rankings from Clickthrough Data, KDD 2007.
• P. Li, C. Burges, et al. McRank: Learning to Rank Using Classification and Gradient Boosting, NIPS 2007.
• C. Cortes, M. Mohri, et al. Magnitude-preserving Ranking Algorithms, ICML 2007.
• H. Almeida, M. Goncalves, et al. A combined component approach for finding collection-adapted ranking functions based on genetic programming, SIGIR 2007.
• T. Qin, T.-Y. Liu, et al, Learning to Rank Relational Objects and Its Application to Web Search, WWW 2008.
• R. Jin, H. Valizadegan, et al. Ranking Refinement and Its Application to Information Retrieval, WWW 2008.
• F. Xia. T.-Y. Liu, et al. Listwise Approach to Learning to Rank – Theory and Algorithm, ICML 2008.
• Y. Lan, T.-Y. Liu, et al. On Generalization Ability of Learning to Rank Algorithms, ICML 2008.
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 130

Acknowledgement
• Hang Li (Microsoft Research Asia)
• Wei-Ying Ma (Microsoft Research Asia)
• Jun Xu (Microsoft Research Asia)
• Tao Qin (Tsinghua University)
• Soumen Chakrabarti (IIT)
4/20/2008 Tie-Yan Liu @ Tutorial at WWW 2008 131
[email protected]://research.microsoft.com/users/tyliu/