learning realistic human actions from movieskovashka/cs3710_sp15/actions_nils.pdf · learning...
TRANSCRIPT

Learning Realistic Human
Actions from MoviesIvan Laptev*, Marcin Marszałek**, Cordelia
Schmid**, Benjamin Rozenfeld***
•INRIA Rennes, France** INRIA Grenoble, France
*** Bar-Ilan University, Israel
Presented by: Nils Murrugarra
University of Pittsburgh

Motivation
2
Action recognition useful for:
• Content-based browsing
e.g. fast-forward to the next goal scoring scene
• Human scientists
influence of smoking in movies on adolescent smoking
Internet has tons of video and still growing
Human actions are very common in movies,
TV news, personal video …
150,000 uploads every day

Motivation
3
• Actions in current datasets:
• Actions “In the Wild”:KTH action dataset
[3] Slides version of " Learning realistic human actions from movies.“ Source:
http://www.di.ens.fr/~laptev/actions/

Context
4
Web video search
• Useful for some action classes: kissing, hand shaking
• Noise results and not useful for most action
Web image search
– Useful for learning action context: static scenes and objects
– See also [Li-Jia & Fei-Fei ICCV07]
Goodle Video, YouTube, MyspaceTV, …
How to find real actions?

Context
5
Movies contains many classes and many examples of realistic actions
Problems:
• Only few class-samples per movie
• Manual annotation is very time consuming
How to annotate automatically?

Method – Annotation [1]
6
01:20:17
01:20:23
…
1172
01:20:17,240 --> 01:20:20,437
Why weren't you honest with me?
Why'd you keep your marriage a secret?
1173
01:20:20,640 --> 01:20:23,598
lt wasn't my secret, Richard.
Victor wanted it that way.
1174
01:20:23,800 --> 01:20:26,189
Not even our closest friends
knew about our marriage.
…
subtitles
…
RICK
Why weren't you honest with me? Why
did you keep your marriage a secret?
Rick sits down with Ilsa.
ILSA
Oh, it wasn't my secret, Richard.
Victor wanted it that way. Not even
our closest friends knew about our
marriage.
…
movie script
• Scripts available with no time synchronization
• Subtitles + time information
How to use the previous information?
• Identify an action and transfer time to scripts by text alignment
[1]. Everingham, M., Sivic, J., & Zisserman, A. (2006). Hello! My name is... Buffy--automatic naming of characters in TV
video.

Method – Annotation
7
On the good side:
• Realistic variation of actions: subjects, views, etc…
• Many Classes and many examples per action
• No additional work for new classes
• Character names may be used to resolve “who is doing certain
action?”
Problems:
• No spatial localization (no bounding box)
• Temporal localization may be poor
• Missing actions: e.g. scripts do not always follow the movie (not
aligned)
• Annotation is incomplete, it can’t be a ground truth for test stage
• Large within-class variability per action in text

Method – Annotation - Evaluation
8
1. Annotate action samples in text
2. Perform automatic script-video alignment
3. Check the correspondence based on manual annotation
Example of a “visual false positive”
A black car pulls up, two army
officers get out.a: quality of subtitle-script matching
a = (# matched words)/(# all words)
How to improve?

Method – Annotation – Text Approach
9
“… Will gets out of the Chevrolet. …” “…
Erin exits her new truck…”
Problem: Text can express the same action in different ways:
Action:
GetOutCar
Potential false
positives:“…About to sit down, he freezes…”
Solution: Supervised text classification approach
• Given an scene description, predict if a target action is
present or not
• Based on bag-of-words representation

Method – Annotation – Text Approach
10
Features:
• Words
• Adjacent pair of words
• Non-adjacent pair of words within a small window

Method – Annotation – Data
11
12 m
ovie
s20 d
iffe
ren
t
mo
vie
s
a>0.5
video length <= 1000 frames
60%
Goal
• Compare performance of manual annotated data with automatic version

Method – Action Classifier [Overview]
12
Bag of space-time features + multi-channel SVM
Histogram of visual words
Multi-channel
SVM
Classifier
Collection of space-time patches
HOG & HOF
patch
descriptors
[4], [5], [6]
[3] Slides version of " Learning realistic human actions from movies.“ Source:
http://www.di.ens.fr/~laptev/actions/

Method – Action Classifier - Features
13
Space-time corner detector
[7]
Dense scale sampling (no explicit scale selection)
Multi-scale detection

Method - Action Classifier - Descriptor
14
Histogram of oriented spatial
grad. (HOG)
Histogram of optical
flow (HOF)
3x3x2x4bins HOGdescriptor
3x3x2x5bins HOF descriptor
Public code available at www.irisa.fr/vista/actions
Multi-scale space-time patches from corner detector

Method - Action Classifier - Descriptor
15
Visual Vocabulary ConstructionUsed a subset of 100’000 features sampled from training
videos
Identified 4000 clusters with k-means
Centroids = Visual Vocabulary Words
Bag-of-features

Method - Action Classifier - Descriptor
16
Vector BOF GenerationCompute all features
Assign each feature to the closest vocabulary word
Compute vector of visual word occurrences.
17 8 . . . 2 39
vw1 vw2 vw3 . . . vwn

Method - Action Classifier - Descriptor
17
Global spatio-temporal grids
In the spatial domain:1x1 (standard BoF)
2x2, o2x2 (50% overlap)
h3x1 (horizontal), v1x3 (vertical)
3x3
In the temporal domain:t1 (standard BoF), t2, t3 and centre-focused ot2
Spatio-temporal grids Examples

Method - Action Classifier - Descriptor
18
Global spatio-temporal grids
Entire Action Sequence
17 8 . . . 2 39
vw1 vw2 vw3 . . . vwn
Action Sequence
Action Sequence Splitted on 2
over time
17 8 . . . 2 39
vw1 vw2 vw3 . . . vwn
1st half
10 8 . . . 35 1
vw1 vw2 vw3 . . . vwn
2nd half
Normalized

Method - Action Classifier - Descriptor
19
Global spatio-temporal grids

Method - Action Classifier - Learning
20
Non-Linear SVM:
• Map original space to a higher space, where the data is separable

Method - Action Classifier - Learning
21
Channel c is a combination of a descriptor (HOG or HOF) and a spatio-
temporal grid
Dc(H
i, H
j) is the chi-square distance between histograms
Ac
is the mean value of the distances between all training samples for
the channel c
The best set of channels C for a given training set is found based on a
greedy approach
Multi-channel chi-square kernel

Evaluation - Action Classifier
22
Findings
• Different grids and channels combination are beneficial to
increment performance
• HOG performs better for realistic actions (context, image
content)

Evaluation - Action Classifier
23
Number of occurrences for each channel component within the optimized channel combinations for the KTH action dataset and our manually labelled
movie dataset

Evaluation - Action Classifier
24
Sample frames from the KTH actions sequences, all classes (columns) and scenarios (rows) are presented

Evaluation - Action Classifier
25
Average class accuracy on the KTH actions dataset
Confusion matrix for the KTH actions
Evaluation - Action Classifier
26
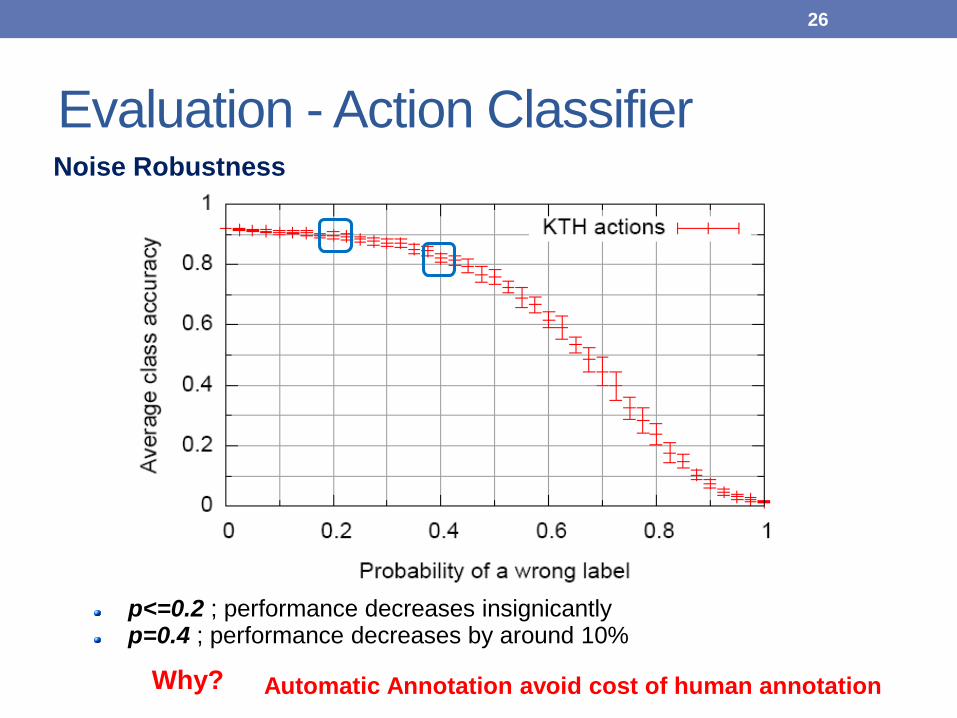
p<=0.2 ; performance decreases insignicantlyp=0.4 ; performance decreases by around 10%
Automatic Annotation avoid cost of human annotation
Noise Robustness
Why?

Evaluation - Action Classifier
27
Correct PredictionClass not present,
prediction says YES
Class present,
prediction says NO
Evaluation in Real-World Videos

Evaluation - Action Classifier
28
Action Classification example results based on automatic annotated data
Evaluation in Real-World Videos

Evaluation - Action Classifier
29
Evaluation based on Average precision (AP) over actions.
Clean = Annotated
Chance = Random Classifier

Demo - Action Classifier
30
Test episodes from movies “The Graduate”, “It’s a wonderful life”,
“Indiana Jones and the Last Crusade”

Conclusion
31
SummaryAutomatic generation of realistic action samples
New action dataset available www.irisa.fr/vista/actions
Bag-of-features expanded to video domain
Best performance on KTH benchmark
Promising results for actions in the “wild”
DisadvantagesStill improvement in automatic annotation is required. Only a 60%
was achieved.
Parameters for the grid of cuboids are not well-justified, how were
determined. Similarly, the # of visual words for k-means algorithm.
K-means is susceptible to outliers.
A greedy approach for determine the best set of channels can
achieve sub-optimal results.
Future directionsAutomatic action class discovery
Internet-scale video search

Questions
32

References
33
[1]. Everingham, M., Sivic, J., & Zisserman, A. (2006). Hello! My name is...
Buffy--automatic naming of characters in TV video.
[2]. Laptev, I., Marszalek, M., Schmid, C., & Rozenfeld, B. (2008, June).
Learning realistic human actions from movies. In Computer Vision and Pattern
Recognition, 2008. CVPR 2008. IEEE Conference on (pp. 1-8). IEEE.
[3]. Slides version of " Learning realistic human actions from movies.“ Source:
http://www.di.ens.fr/~laptev/actions/
[4]. Schuldt, C., Laptev, I., & Caputo, B. (2004, August). Recognizing human
actions: a local SVM approach. In Pattern Recognition, 2004. ICPR 2004.
Proceedings of the 17th International Conference on (Vol. 3, pp. 32-36). IEEE.
[5]. Niebles, J. C., Wang, H., & Fei-Fei, L. (2008). Unsupervised learning of
human action categories using spatial-temporal words. International journal of
computer vision, 79(3), 299-318.
[6]. Zhang, J., Marszałek, M., Lazebnik, S., & Schmid, C. (2007). Local features
and kernels for classification of texture and object categories: A comprehensive
study. International journal of computer vision, 73(2), 213-238.
[7]. Laptev, I. (2005). On space-time interest points. International Journal of
Computer Vision, 64(2-3), 107-123.

Action Recognition Using a
Distributed Representation of
Pose and Appearance
Subhransu Maji1, Lubomir Bourdev 1,2, and Jitendra Malik1
1University of California at Berkeley2 Adobe Systems, Inc.
Presented by: Nils Murrugarra
University of Pittsburgh

Goal
35
[3]-poster http://people.cs.umass.edu/~smaji/presentations/action-cvpr11-poster.pdf

Motivation
Motivation:
• Humans can easily recognize pose and actions from Limited Views of a single image
36
• Action and pose is identified by body parts (occlusions) at different
locations and scales.

Poselets
37
Poselet:
• Body part detectors of joint locations of people in images.
• They are used to find patches related to a given configuration of joints.
[3]-poster http://people.cs.umass.edu/~smaji/presentations/action-cvpr11-poster.pdf

Poselets - People
38
L.Bourdev, S.Maji, T.Brox and J. Malik, Detection People using Mutually Consistent
Poselet Activations,ECCV 2010

Robust Representation of Pose and
Appearance
Poselet Activation Vector
39
• Poselet annotation are reused from a previous article.
• Represent each example by the poselets that are active.
Estimate 3D Orientation of Head and Torso

Data Collection
40
Manual Verification
• Discard images with high disagreement
• Low resolution and high occlusion
• Only used rotation in Y
Amazon Mechanical Turk
Human Error
• Small error in canonical views (front,back, left and right)
• Measured as average of standarddeviation
3D pose of head and torso Annotations

3D Estimation - Goal
41
Goal
• Given a bounding box of a person, estimate its 3D orientation of head and torso.

3D Estimation - Descriptor
42
Procedure
• Discretize 3D orientation [-180, 180] in 8 bins [Classification] .
• Angled estimation based on interpolation
• Highest predicted bin
• Two adjacent neighbors
0.7
Each entry correspond to a poselet type
0.8 . . . 0.2 0.9
pt1 pt2 pt3 . . . ptn

3D Estimation – Example Results
43

3D Estimation – Evaluation
44
Head Orientation: 62.1 % Torso Orientation: 61.71 %

2D Action Classifier - Goal
45
Goal
• Given a bounding box, estimate an action category

2D Action Classifier - Method
46
Joint Locations Annotation
Pose alone can’t learn to identify actions

2D Action Classifier - Method
47
Appearance information would help
Solution
• Learn appearance considering poselets per action category
• Based on HOG and SVM

2D Action Classifier - Method
48
Windows
7
2
• Find Poselet k-Nearest Neighbors
• Select the more discriminative
• Learn appearance model based on
HOG and SVM
Approach

2D Action Classifier - Method
49
Object Interaction can help?
• It was considered an interaction with horse, motorbike, bicycle and TV.
• A people-object model spatial location was learnt [object activation vector]

2D Action Classifier - Method
50
Context can still help us?
Add action classifier for other people in image

2D Action Classifier - Evaluation
51

Conclusion
52
SummaryA method for Action Recognition in static image was presented.
It is based mainly in:
Poselet features
An Appearance model
Object Interaction
Context information
DisadvantagesThe use of bounding-boxes is not realistic. A better scenario is that
given an image, an algorithm should detect all people actions
automatically.
Related to the Poselet Activation Vector, a intersection threshold of
0.15 is defined. How this threshold was determined? . A similar
situation happens with the Spatial Model of Object Interaction.

Questions
53

References
54
[1]. Maji, Subhransu, Lubomir Bourdev, and Jitendra Malik. "Action recognition
from a distributed representation of pose and appearance." In Computer Vision
and Pattern Recognition (CVPR), 2011 IEEE Conference on, pp. 3177-3184.
IEEE, 2011.
[2]. Bourdev, Lubomir, Subhransu Maji, Thomas Brox, and Jitendra Malik.
"Detecting people using mutually consistent poselet activations." In Computer
Vision–ECCV 2010, pp. 168-181. Springer Berlin Heidelberg, 2010.
[3]. Poster Version of "Action recognition from a distributed representation of
pose and appearance.“ Source: poster:
http://people.cs.umass.edu/~smaji/presentations/action-cvpr11-poster.pdf