la tecnología de corpus en el contexto profesional y ... · originado una gran oferta y...
TRANSCRIPT

La tecnología de corpus en el contexto profesional y académico de la traducción
y la terminología: panorama actual, recursos y perspectivas
Chelo Vargas Sierra(Universidad de Alicante)
1. CONCEPTOS BÁSICOS DE CORPUS Y TECNOLOGÍAS ASOCIADAS
La lingüística de corpus es un campo de investigación caracterizado en la actualidad por dos aspectos básicos y fundamentales: a) estudiar de forma empírica la lengua en uso con el fin de describirla o analizar algún aspecto intra-/inter-textual o discursivo con un fin concreto; y b) utilizar el ordenador para el almacenamiento y el análisis de los datos. El interés que suscita actualmente la lingüística de corpus tanto en el plano teó-rico como en el aplicado está fuera de toda duda. Buena prueba de ello son el número creciente de revistas, congresos, proyectos, asociaciones y artículos que se dedican a alguno de los aspectos que abarca este tipo de lingüística. La terminología y la traducción no han sido ajenas a esta corriente y se han unido a las posibilidades que ofrece la compilación y explotación de córpora con fines específicos y útiles para las disciplinas.
La posibilidad de analizar un gran número de textos con herramien-tas informáticas destinadas a tal fin y desarrolladas por las industrias de la lengua ha supuesto uno de los mayores avances en la investigación lingüística desde que en los años 80 se popularizasen los ordenadores personales. Asimismo, las publicaciones electrónicas o en Internet han originado una gran oferta y disponibilidad inmediata de textos de di-ferentes contenidos, lo cual proporciona un cúmulo de posibilidades y recursos tanto al traductor como al terminólogo.

68 Chelo Vargas Sierra
En lingüística, ‘corpus’ se utiliza de forma general para referirse a cualquier recopilación de textos o de ejemplos lingüísticos que sirve de base para una investigación. Esta palabra fue utilizada ya en el siglo vi para denominar una colección de textos jurídicos, concretamente Corpus Juris Civilis (Francis 1992: 17). Este término ha conservado su significado de ‘colección de textos’, pero para los lingüistas de corpus esta definición no resulta suficiente, pues, según Leech (1991:10), no se debe denominar corpus a una colección de textos sin más, a menos que cumpla con de-terminados criterios mínimos. Los aspectos que diferencian a un corpus de otras colecciones de textos, como pueden ser una biblioteca o una recopilación de archivos (cf. Vargas, 2005), se definen en función de cómo se lleve a cabo la selección de los textos y con qué propósito se realice la compilación textual.
Según Sinclair (1996: 4) un corpus es “a collection of pieces of lan-guage that are selected and ordered according to explicit linguistic cri-teria in order to be used as a sample of the language”. Esta definición puede considerarse la ‘oficial’, dado que, además de provenir de J. Sinclair —referente de la lingüística de corpus y fundador de uno de los córpora más grandes del mundo (The Bank of English)— es la que adopta EA-GLES (European Advisory Group on Language Engineering Standard1). Hunston (2002: 2) añade a la definición oficial de corpus una dimensión que abarca el aspecto tecnológico, consecuencia de los análisis realizados con ordenador: “collections of texts (or part of texts) that are stored and accessed electronically”. Un análisis pormenorizado de las definiciones anteriores nos lleva a destacar cinco características esenciales de los cór-pora, que son las siguientes:
1) el origen. Se trata de una colección de textos auténticos tanto es-critos como orales. De la naturaleza del corpus dependerá la selec-ción de los tipos de textos (artículos de periódico, transcripciones de conversaciones, novelas, discursos, etc.);
1 EAGLES es una iniciativa fundada por la Unión Europea con el objetivo de crear estándares comunes para la investigación y el desarrollo del procesamiento del len-guaje natural. En la actualidad, la mayoría de los documentos que se elaboran en el seno de EAGLES se convierten en directrices preliminares. La idea es que se establezcan posteriormente como normas.

69La tecnología de corpus en el contexto profesional y académico…
2) la composición. Se seleccionan y organizan los datos textuales que los componen según criterios lingüísticos explícitos. Se descarta que una colección de frases recopiladas para estudiar un sintagma cualquiera constituya un corpus. Los principios de selección de los textos deben seguir un conjunto de reglas establecidas por los compiladores, de modo que el corpus construido se corresponda con las características que se explicitaron en su diseño. Asimismo, no se considera corpus a una colección textual creada al azar, sin que se sigan unos criterios concretos definidos de antemano y sin una selección textual encaminada a que la composición del corpus se adapte a los parámetros de diseño;
3) el propósito. Los córpora tienen una finalidad precisa; por ejem-plo, grandes corpus como el Bank of English o el British National Corpus fueron creados con fines lexicográficos. Es claro que pue-den existir otros córpora con usos y fines diferentes de éste, pero, eso sí, la creación de un corpus se hace siempre según un objetivo concreto;
4) el formato. Los datos del corpus deben ser legibles por ordenador para su almacenamiento y subsiguiente explotación;
5) la representatividad. Un corpus, ya sea general o especializado, debe ser representativo de una determinada población2 de hechos lingüísticos —los textos— que tienen lugar en una lengua concre-ta. El problema que plantea la noción de representatividad es que un corpus es una muestra finita de una población infinita y, consi-guientemente, nunca se alcanza el fin de este conjunto de hechos lingüísticos, pues “there are always new ones coming along that we haven’t seen yet” (Leech, 2002: 4).
Como venimos diciendo, un corpus se diseña siempre teniendo en mente un propósito definido y concreto y el tipo de corpus dependerá en gran medida de este objetivo. La tipología de corpus se precisa y se especifica de acuerdo con diferentes parámetros que lo caracterizan (cf.
2 Utilizamos la palabra población en su sentido estadístico, esto es, para referirnos a todos los elementos que han sido elegidos para un estudio, que en el caso de la lingüística de corpus son los textos.

70 Chelo Vargas Sierra
Vargas, 2006). Así, según su contenido, podemos decir que un corpus es general o especializado; según su tamaño, puede ser clasificado como grande, mediano o pequeño; según la codificación del texto o nivel de procesamiento interno, se puede clasificar como bruto (si el texto no contiene anotación de ningún tipo) o etiquetado (bien porque contie-ne etiquetas descriptivas de los elementos constitutivos de cada texto, bien porque las etiquetas explicitan aspectos lingüísticos de cada ítem del corpus, como sería, por ejemplo, su categoría gramatical). Asimismo, un corpus, según las lenguas de trabajo que contemple, puede ser mo-nolingüe, bilingüe o multilingüe. Dentro de estos dos últimos tipos, un corpus puede ser comparable o paralelo. Se entiende que los córpora son comparables cuando los textos que los componen presentan determina-dos rasgos que comparten, tales como el tema, el tipo de texto, el periodo de tiempo en que se redactaron los textos, la función comunicativa, el grado de especialización, etc. Se dice que un corpus es paralelo cuando contiene textos redactados en una lengua (la original) junto con las tra-ducciones de éstos a otras lenguas.
En términos históricos, la lingüística basada en el análisis de corpus ha estado condicionada por la tecnología, pues es gracias a los avances infor-máticos que los estudios basados en corpus dejan de estar sujetos a la crí-tica de imprecisión y adquieren, por el contrario, una fiabilidad notable en el procesamiento extensivo y organizado de los datos. Así, la historia de esta lingüística está directamente relacionada con la disponibilidad de programas informáticos para llevar a cabo el análisis y la explotación de un corpus.
Las herramientas informáticas que se emplean para el tratamiento y análisis de corpus pueden dividirse en dos grandes grupos: los etiqueta-dores morfosintácticos y los programas de análisis textual, más popular-mente conocidos por ‘programas de concordancias’.
Los etiquetadotes morfosintácticas son programas que llevan a cabo automáticamente la identificación y asignación automática de etiquetas lingüísticas de todas las palabras de un texto. Las etiquetas pueden ser morfológicas, que vinculan cada palabra con su categoría gramatical (sus-tantivo, verbo, adjetivo, etc.), sintácticas (sintagma nominal, verbal, etc.) e incluso semánticas, pragmáticas o discursivas. El corpus etiquetado o

71La tecnología de corpus en el contexto profesional y académico…
anotado es, por tanto, el que está compuesto de textos que contienen etiquetas analíticas que explicitan alguno de sus aspectos lingüísticos. Se pueden dividir en tres grandes categorías en función de las técnicas que emplean: a) los basados en reglas; b) los estadísticos; y c) los híbridos. Los etiquetadores basados en reglas utilizan conocimiento lingüístico. Dichas reglas responden, lógicamente, a criterios lingüísticos y se representan de forma explícita en el corpus. Los etiquetadores estadísticos, como su propio nombre indica, utilizan métodos probabilísticos para llevar a cabo el análisis. En tercer lugar, los sistemas híbridos combinan los dos tipos de conocimiento anterior, esto es, el estadístico y el lingüístico.
El etiquetado más habitual y canónico es el morfosintáctico (part-of-speech tagging). Se ha convertido en la forma canónica de etiquetado de un corpus por distintas razones, pero la más sobresaliente es que resulta lo suficientemente sencillo como para que el etiquetado de la mayor parte de los textos que componen el corpus se realice de forma automática. El etiquetado de un corpus a este nivel suele comprender las fases de:
1. segmentación: en procesamiento de lenguaje natural esta fase re-cibe el nombre de ‘tokenización’, y consiste en la segmentación del texto en cadenas de caracteres y cifras que se encuentran entre espacios;
2. lematización o especificación de la forma no marcada de cada pa-labra;
3. análisis morfológico y categorial, es decir, donde se asignan las posibles categorías gramaticales y morfológicas; y
4. etiquetado morfosintáctico o desambiguación de las categorías gramaticales dudosas.
En la siguiente tabla se presentan brevemente cuatro de los múltiples etiquetadores de este tipo existentes en la actualidad. La selección la he-mos realizado en función de su popularidad y disponibilidad actual, bien de forma gratuita o bien mediante pago. Otro parámetro que hemos te-nido en cuenta para dicha selección es que los programas debían funcio-nar en distintos sistemas operativos, entre los que se encontrara Windows, por ser éste el más extendido hoy por hoy.

72 Chelo Vargas Sierra
Nombre Tipo SO Distribución Lenguas
CLAWS
Híbrido (esta-dístico y lingüís-tico)
Unix y Win-dows
Comercial, pero con versión on-line
inglés
http://ucrel.lancs.ac.uk/claws/
Freeling Híbrido
Linux, Unix, Windows
Gratuito, con versión online
catalán, español, gallego, italiano, inglés
http://www.lsi.upc.edu/~nlp/freeling/
QTAG Estadístico
Linux, Mac OSX y Windows
Gratuitoindependiente de la lengua
http://phrasys.net/uob/om/software
TreeTagger Estadístico
Linux, Mac OSX y Windows
Gratuito independiente de la lengua
http://www.ims.uni-stuttgart.de/projekte/corplex/TreeTagger/Deci-sionTreeTagger.html
Tabla 1: Etiquetadores morfosintácticos
Los programas de concordancias, por su parte, son un conjunto de aplicaciones informáticas capaces de analizar una base de datos textual (el corpus) y generar diferentes tipos de listas de los resultados. Estas he-rramientas segmentan el corpus y ofrecen los datos resultantes en forma de3:
a) lista con estadísticas (palabras que contiene el corpus en su con-junto, por texto, número de palabras diferentes, etc.);
b) listado monoléxico ordenado alfabéticamente y/o por frecuen-cia;
c) listado poliléxico de todas las palabras del corpus o de una se-lección del usuario. Estos listados pueden ofrecerse a través de agrupamientos léxicos (clusters) o, si el programa tiene la opción, pidiéndole que calcule la información mutua, o cualquier otra
3 Es claro que todos los programas de concordancias no ofrecen los datos de la misma forma. Los resultados expuestos serían los ofrecidos por una herramienta bastante completa, como es el caso de WordSmith Tools.

73La tecnología de corpus en el contexto profesional y académico…
medida estadística que incluya de este tipo (Z Score, MI3, Log Likelihood, etc.);
d) líneas de concordancias o listados de aparición de una palabra es-pecífica —llamada ‘palabra de búsqueda’, ‘palabra base’ y también ‘palabra clave’, que puede estar formada por una unidad, varias o parte de ésta— acompañada del texto que la rodea (co-texto). El tipo de concordancia más común es Key Word In Context (KWIC) o palabra clave en contexto. Una lista KWIC agrupa las aparicio-nes de la palabra de búsqueda, que aparece destacada en el centro, lo cual permite analizar y detectar con rapidez sus colocadores o palabras que aparecen en su entorno.
e) listado de palabras claves (keywords): esta función contrasta una lista de palabras del corpus de estudio con otra lista procedente de un corpus de referencia. El resultado de esta comparación es una nueva lista de palabras clave o palabras cuyas frecuencias son estadísticamente diferentes en el corpus de estudio con respecto al corpus de referencia.
f) gráfico de distribución de la palabra de búsqueda (plot); esta op-ción permite apreciar de forma visual la posición donde aparece y se repite una determinada palabra a lo largo de los textos en los que aparece. El resultado se asemeja a un código de barras, y ha de ser interpretado por el investigador (relevancia de la posición, mayor o menor frecuencia de aparición en una determinada parte del texto, etc.).
g) lista de colocados (collocates): listado de palabras que aparecen alre-dedor de la palabra base, en posiciones determinadas.
Al crear listados de palabras mono y poliléxicos los programas de con-cordancias pueden ser utilizados también como extractores de termino-logía. Con respecto a los extractores, a lo largo del tiempo se han adop-tado distintos enfoques con muy buenos resultados que ahora se aplican en la investigación actual de forma independiente o combinada. Con el enfoque lingüístico se han identificado categorías gramaticales y patro-nes morfosintácticos indicativos del estatus de término. Podemos afirmar que los términos se plasman mayoritariamente en nombres y, después,

74 Chelo Vargas Sierra
en adjetivos; a continuación está la clase de los verbos, aunque en una proporción mucho menor; y, finalmente, encontramos unos pocos adver-bios. En cuanto a la morfología de los términos, los nombres son la clase más productiva, si la comparamos, por ejemplo, con verbos o adverbios. En este sentido, son muchos autores los que afirman que los lenguajes especializados tienen un carácter nominal fuertemente marcado (Sager et al., 1980, Cabré, 1993, Lerat, 1995, entre muchos otros). El estadístico ha permitido obtener listados de las unidades léxicas más repetidas en un corpus especializado, repetición que puede significar que nos hallamos ante una unidad relevante para seguir siendo procesada o estudiada por el terminólogo (cf. Ahmad et al. 1994, 1995; Ahmad y Rogers, 2001; Bergenholt y Tarp, 1995; Bowker, y Pearson, 2002, entre otros). Con el fronterizo se han reconocido los candidatos a término descartando las secuencias de texto con pocas probabilidades de contener términos, como frases que contuviesen verbo y pronombres (Borigault, 1992). El enfoque de la calidad de la palabra clave (keyness) ha permitido abordar la frecuencia inusual de unidades a través del contraste de un corpus es-pecífico con uno de carácter general (Scott, 1997: 236). La frecuencia in-usual puede estar relacionada con su excepcionalidad e implica que una palabra tiene una frecuencia inusual elevada o baja en un texto o en un subcorpus en comparación con su aparición en un corpus denominado ‘de referencia’ (el general). Ninguno de estos enfoques funciona al cien por cien y, además, algunos son dependientes de una lengua o específicos de un dominio, con lo que las posibilidades de investigación están todavía abiertas. Más allá de los términos, otra información que necesita extraerse e identificarse en un corpus es la variación denominativa, las colocacio-nes, las definiciones o las relaciones semánticas.
2. TECNOLOGÍA, CORPUS Y CONTEXTOS PROFESIO-NALES DE TRADUCCIÓN Y TERMINOLOGÍA
Con el desarrollo de herramientas y procesos más eficaces, la tecno-logía se ha convertido en un factor determinante en la industria de la traducción y la terminología, especialmente en lo que se refiere al modo en que traductores y terminólogos desempeñan su labor.

75La tecnología de corpus en el contexto profesional y académico…
El uso de la tecnología en estos contextos profesionales se ha incre-mentado de forma notable y podemos afirmar que aumenta día tras día. Existen razones prácticas que explican esta tendencia hacia lo electró-nico en profesiones que, en definitiva, trabajan con textos. Por un lado, se incrementa la productividad, pues la tecnología ofrece la posibilidad de procesar datos más rápidamente. Por el otro, se incrementa la calidad, dado que es posible encontrar información —como por ejemplo, las colocaciones, los ejemplos múltiples de uso, contextos más ilustrativos, datos de frecuencia, por citar unos pocos— a la que no se puede acceder fácilmente con otros tipos de recursos. De hecho, hay estudios que han demostrado que los traductores que han tenido la oportunidad de tener como material de referencia un corpus electrónico especializado en el idioma materno mejoraron su productividad y cometieron menos erro-res de contenido, de selección terminológica y de estilo (Bowker, 1998). Y mayor aún es la utilidad de este recurso cuando se hace traducción especializada inversa, pues, como ya afirmamos en un trabajo anterior (Vargas, 2002), permite contrastar la competencia lingüística al otro idio-ma en un conjunto de textos elaborados por los propios expertos.
Existen investigaciones y encuestas que se han realizado en torno al uso que los traductores hacen de las herramientas de traducción asistida por ordenador (TAO). A partir de distintas encuestas estudiadas, Bowker y Marshman (2008) estiman que un promedio del 52.6% de traduc-tores son usuarios de sistemas de memoria de traducción (MT). Más recientemente, en un estudio realizado sobre traductores autónomos pertenecientes a la Red de Traductores e Intérpretes de la Comunidad Valenciana, Palacios (2011) expone que casi el 74% de los traductores encuestados empleaban MT de forma habitual. Mayor es el porcentaje (del 70 al 100%) cuando se trata de consultar bancos terminológicos y diccionarios electrónicos, emplear herramientas ofimáticas o usar moto-res de búsqueda.
No ha sido un fenómeno ocurrido de la noche al día, pero sí es cierto que se ha producido un cambio que, si bien ha sido gradual, es considera-ble en lo que respecta al maridaje, que nosotros consideramos indisoluble, entre tecnología y traducción o terminología. Así, podemos observar que la enseñanza de tecnología específica se ha incorporado en los estudios de traducción, las universidades y asociaciones profesionales ofrecen talleres,

76 Chelo Vargas Sierra
cursos y webinarios sobre herramientas y tecnología, las revistas recogen artículos sobre esta temática, es objeto de debate y reflexión en foros y blogs de traducción, y suele ser un requisito en los anuncios de trabajo que los traductores manejen con soltura las herramientas de traducción. Es claro que la tecnología no va a sustituir a los profesionales de la tra-ducción, pero aquéllos que la utilicen sí que sustituirán a los que no.
Desde el punto de vista de un traductor profesional, los córpora pa-ralelos son vistos como un recurso con distintas aplicaciones, además de tener un enorme potencial como herramienta de ayuda en el proceso de producción o codificación del texto meta. Una de las aplicaciones más destacables de un corpus paralelo es servir de material de referencia donde encontrar coincidencias exactas o parciales para el proyecto de tra-ducción con el que se está trabajando. Para ello, es preciso que el corpus verse sobre el tema objeto de traducción. Si disponemos de tal recurso, su utilidad se incrementa exponencialmente si hemos importado este corpus paralelo a una memoria de traducción y el sistema de traducción asistida que empleamos puede hacer búsquedas de concordancias.
En lo que respecta al trabajo terminológico dentro de un contexto de traducción (cf. Vargas, 2011), otra de las posibles aplicaciones de un corpus paralelo es que permite realizar una extracción de terminología bilingüe para elaborar un glosario a partir de dicho recurso con una he-rramienta destinada para ello, esto es, un extractor de terminología. Del mismo modo, este tipo de corpus puede emplearse para validar las selec-ciones terminológicas, fraseológicas o combinatorias realizadas durante la traducción bien contrastando la selección con datos de frecuencia, o bien visualizando el comportamiento de una determinada unidad terminoló-gica en distintos contextos de uso. Comprender los conceptos a fin de producir una traducción precisa y carente de ambigüedades, encontrar el equivalente terminológico y producir un texto meta con el mismo estilo que lo haría un experto —todo ello sin ser necesariamente expertos en la materia— son otras de las necesidades de un traductor especializado cuando se enfrenta a la terminología y a su colocación en contexto y aquí los córpora no sólo ayudan, sino que pensamos que pueden mejorar la calidad del texto producido garantizando la consistencia y la adecua-ción terminológica del proyecto de traducción especializada.

77La tecnología de corpus en el contexto profesional y académico…
Cabría añadir también que otra de las aplicaciones de estos recursos tiene que ver con el análisis textual. Con ellos es posible observar las estrategias de traducción empleadas, adquirir conocimiento lingüístico o conocimiento experto, o descubrir equivalencias semánticas, discursivas, estilísticas o pragmáticas entre los textos paralelos.
En lo que se refiere específicamente al contexto profesional de la ter-minología es hoy en día impensable realizar actividades terminológicas sin el concurso de herramientas informáticas, como bien lo afirman Pavel y Nolet en su Manual de Terminología (2001: xx):
Cualquier actividad terminológica, desde la identificación de los términos hasta la entrega del producto final, puede realizarse de forma manual. Sin embargo, la informática permite una mejora sin precedentes de la producti-vidad, calidad y accesibilidad. Esta realidad se aplica especialmente al caso de los terminólogos que trabajan en una empresa, organismo gubernamental o servicio de traducción en el que deben crear, actualizar y explotar grandes ficheros terminológicos informatizados concebidos para un gran número de usuarios, respondiendo a necesidades de comunicación claramente de-finidas.
En efecto, las aportaciones de la informática al campo de la termi-nología han influido de forma manifiesta en los métodos del trabajo terminográfico, especialmente en la gestión terminológica —o estable-cimiento de una metodología para recopilar, validar, organizar, almace-nar, actualizar, intercambiar y hacer acopio de términos individuales o conjunto de términos de un dominio especializado— y también en la propia organización de los proyectos. Este salto cualitativo se ha sentido, fundamentalmente, en cuatro aspectos:
1) en el acceso fácil y rápido a la información mediante el uso de sis-temas de almacenamiento y recuperación de información (SRI);
2) gracias a este acceso a la información, la compilación de un corpus de textos electrónicos representativo del ámbito de especialidad sobre el que se trabaja es más ágil y viable;
3) a partir de este corpus, es posible extraer conocimiento especia-lizado utilizando los extractores (semi)automáticos de terminolo-gía.

78 Chelo Vargas Sierra
4) en la utilización, el acceso y la explotación de bancos de datos terminológicos, lexicográficos y de conocimiento.
En resumen, en esta última década han surgido cuatro grandes con-ceptos importantes de naturaleza tecnológica dentro de los métodos de trabajo terminológico: Internet, los córpora electrónicos, las herramien-tas para su explotación y extracción terminológica, y las bases de datos terminológicas.
3. TECNOLOGÍA, CORPUS Y CONTEXTOS ACADÉMI-COS
No contamos con datos precisos sobre la adopción generalizada de las tecnologías, incluidas las de corpus, en la investigación en terminología y traducción, si bien parece que va por detrás de lo que ocurre en con-textos profesionales. Las exigencias del mercado rigen y determinan los métodos de trabajo de profesionales de la traducción y la terminología y estas exigencias no se dan necesariamente en el mundo académico, que en ocasiones se muestra reticente a la hora de incorporar métodos nuevos sobre los tradicionales, ya contrastados y refutados como válidos por la comunidad.
La actitud que muestran algunos investigadores ante instrumentos tecnológicos novedosos es muy variopinta. Hay investigadores que se aferran al modo tradicional de hacer investigación y se resisten a hacer cambios; hay quienes piensan que investigar con corpus requiere las ha-bilidades propias de un informático; están los que hacen investigación teórica o literaria y piensan que la investigación con corpus no les puede servir de mucho; hay investigadores que dicen no tener tiempo para aprender a explotar un corpus con instrumentos para ello; y hay a quie-nes les gustaría trabajar con este recurso pero no cuentan con el corpus que precisan ni con las tecnologías para analizarlo. Veamos en qué modo la adopción de técnicas de corpus puede ser beneficiosa para los anterio-res perfiles investigadores.
En el pasado, un bueno número de las investigaciones que se realiza-ban en terminología y traducción eran de naturaleza prescriptiva, refe-

79La tecnología de corpus en el contexto profesional y académico…
ridas a la planificación lingüística, a la normas lingüísticas y culturales, o encaminadas a enseñar o normalizar el modo en que debemos utilizar la lengua o los términos, y pasando por alto la observación del uso que realmente se hace de la lengua o de los términos. No cabe duda de que hay ciertos tipos de investigación que exigen adoptar esta línea normati-va, pero en otros es posible aprender y obtener beneficios investigadores realizando estudios de tipo descriptivo, y es en estos casos en donde los córpora se convierten en un recurso extremadamente valioso, por no decir imprescindible, para llevarlos a cabo.
Parte de la investigación de corte tradicional que se realiza en traduc-ción y terminología está basada, de un modo u otro, en un conjunto de textos que son objeto de estudio; en traducción con unos propósitos y en terminología con otros. Utilizar un corpus electrónico junto con sus herramientas comporta ciertas ventajas, como son:
1. la posibilidad de realizar estudios a mayor escala, pues el análisis se puede efectuar sobre un mayor volumen textual.
2. el uso de una metodología de suma eficacia desde el punto de vista del método científico por la posibilidad que ofrece de observar empíricamente los datos y de verificar de forma objetiva los resul-tados.
3. la obtención de datos cuantitativos —que complementen a los cualitativos— que ayuden a identificar y predecir el patrón gene-ral (Halliday, 1991: 32); así, el conocimiento de esta frecuencia puede posibilitar la realización de generalizaciones.
4. comisión de menos errores que si se realiza un análisis manual, sobre todo en el caso de obtención de frecuencias e identificación de patrones.
Tras este perfil del investigador tradicional hicimos referencia al que muestra cierta fobia hacia el empleo de herramientas informáticas. Es cierto que algunas herramientas y técnicas de la lingüística de corpus exigen mayor conocimiento informático que otras, pues el abanico de posibilidades de dificultad es extenso y las hay muy simples y otras muy complicadas, al menos desde el punto de vista de un lingüista que no es necesariamente un experto en lingüística computacional. Dicha comple-

80 Chelo Vargas Sierra
jidad depende de varios factores. Uno de ellos es el grado de detalle al que queramos llegar con el procesamiento del corpus, esto es, si se va a trabajar sobre un corpus simple —aquél cuyas muestras textuales se guar-dan en formato ASCII o plano y que no contienen ningún tipo de codi-ficación interna— o anotado, que, como apuntamos anteriormente, son aquéllos cuyos textos contienen etiquetas analíticas que explicitan alguno de sus aspectos lingüísticos; otro depende de las lenguas involucradas en el estudio, es decir, si el corpus es monolingüe o paralelo, en cuyo caso necesitaremos alinear los textos previamente; también es importante el tipo de análisis que se desea realizar; léxico, sintáctico, estilístico, pragmá-tico, etc.
La utilidad de un corpus se ve incrementada cuando éste ha sido etiquetado, dado que cada texto se convierte en un repositorio de in-formación lingüística; los datos implícitos del texto se vuelven explícitos a través de un proceso de etiquetado concreto. El sistema de anotación morfosintáctica permite hacer análisis más complejos que sí trabajamos únicamente con datos de frecuencia. Así, en casos de homonimia es po-sible centrarse en una categoría gramatical (por ejemplo, nombre vs ad-jetivo) y en estudios sobre la formación de términos permite realizar comparaciones sobre el número de compuestos con el patrón ‘término base + adjetivo’ o ‘nombre + término base’, por poner dos ejemplos.
Consideramos que no es necesario ser experto en informática, sino tener conocimientos en este campo y querer profundizar en ellos. Los programas disponen de buenas ayudas para llevar a cabo con éxito la anotación de un corpus o la alineación de textos paralelos. Además, la mayoría de los programas de concordancias son bastante intuitivos y fá-ciles de utilizar. En definitiva, es la labor del lingüista lo que cuenta, pues los programas no son inteligentes; no hacen más que mostrar los datos de un modo que facilita el filtrado y la visualización de la información o la detección de patrones o frecuencias, y no pueden ni desarrollar metodo-logías ni interpretar los datos.
¿Y qué puede aportar un corpus a los investigadores que trabajan aspectos teóricos o literarios de la traducción? El trabajo comienza con la posibilidad de recopilar textos paralelos y alinearlos a fin de comparar las diferentes traducciones de una obra con fines concretos. Según Baker

81La tecnología de corpus en el contexto profesional y académico…
(1995: 247) el acceso a corpus electrónicos brinda la oportunidad de investigar aspectos teóricos de la traducción difíciles de realizar mediante análisis a menor escala. Así, este recurso permite estudiar el tamaño y la naturaleza de la unidad de traducción o el tipo de equivalencia consegui-da y en qué nivel. Otros tipos de análisis que pueden verse favorecidos por el empleo de esta metodología son la comparación de las distintas traducciones de un mismo traductor a fin de hallar si, por ejemplo, hace empleo de alguno idiolecto independientemente del texto original, o las distintas versiones traducidas de una misma obra para estudiar dónde están sus diferencias y similitudes, o el grado de creatividad de los textos meta en relación a sus originales.
Con respecto a la falta de tiempo que se arguye para aprender a traba-jar con corpus, es cierto que son necesarias algunas horas para aprender las técnicas de esta metodología, pero en nuestra opinión esta cuestión debe tomarse como una inversión a corto plazo y sacar el máximo prove-cho de los distintos materiales didácticos disponibles en la web y talleres o cursos en torno al tema. Una vez que se aprende lo básico, se abren nuevos caminos para explorar, algunos de ellos difíciles de realizar de forma manual, como por ejemplo lo que Louw (1997) denomina ‘pro-sodia semántica’, un fenómeno colocacional referido a las connotaciones semánticas positivas o negativas que puede adquirir una unidad léxica según los términos que normalmente la acompañan. Stubbs (1995) indi-ca que cause posee una prosodia semántica negativa ya que se emplea fre-cuentemente acompañado de palabras como accident, catastrophe, damage, death, etc. En español encontramos connotaciones similares para esta uni-dad, como demuestra la consulta al Corpus del español y la visualización de los datos con las líneas de concordancias, que nos indican que ‘causar’ se combina con ‘trastornos’, ‘daño’, ‘extrañeza’, ‘temor’, ‘problema’, entre otras unidades, también de connotación negativa:

82 Chelo Vargas Sierra
Figura 1: Consulta de ‘causar’ en http://www.corpusdelespanol.org/x.asp
Todavía queda mucha investigación que hacer sobre el fenómeno de la prosodia semántica, especialmente a nivel contrastivo. Un caso de estu-dio sería averiguar si determinados cognados muestran la misma prosodia semántica en dos lenguas distintas o si coincide o no el grado de simili-tud semántica entre ellos y hasta qué punto. Realizar el contraste de una unidad léxica pero ahora entre el lenguaje general y uno especializado (informática, genética, biología, etc.) también ofrece una vía de estudio abierta o poco explorada.
Hay investigadores que ante la inexistencia del corpus adecuado pre-fieren abandonar la idea de emplear la metodología de corpus. En este sentido, es cierto que hay tipos textuales que abundan más que otros y también hay predominancia de textos escritos en idiomas concretos, como el inglés. Suponemos que con el tiempo este problema irá dismi-nuyendo dado que cada vez son más los documentos electrónicos que de todo tipo y en cualquier idioma se distribuyen a través de Internet. Las nuevas redes de comunicación junto con las tecnologías han hecho posi-ble que proliferen los archivos y bibliotecas virtuales. Iniciativas como el Project Gutenberg y la Biblioteca Virtual Cervantes, dedicadas a digitalizar y difundir obras literarias de autores clásicos, constituyen un claro ejemplo de una tendencia que va en aumento y que es, a todas luces, imparable.
A continuación presentamos centros virtuales que comparten la ca-racterística de poner a disposición de todos materiales electrónicos de diferente naturaleza. Hemos divido estos centros en dos categorías en nuestro ánimo de poner orden con respecto al tipo de fondos que con-tienen y que difunden. El primer listado que ofrecemos corresponde a la categoría ‘archivos y bibliotecas de textos electrónicos’, y contienen

83La tecnología de corpus en el contexto profesional y académico…
fondos bibliográficos y/o documentales, en su mayoría son de orden literario, pero que no pueden ser considerados como córpora per se, en el sentido estricto desde la lingüística de corpus. En un segundo listado es-pecificaremos los centros de los que tenemos constancia y desde donde sí se recopilan y distribuyen córpora, además de otras herramientas, tecno-logías y recursos relacionados con el trabajo con corpus. Pasamos a conti-nuación a enumerar y describir brevemente algunos centros y bibliotecas virtuales a través de los que se pueden obtener textos electrónicos.
Limitamos el siguiente listado de ‘archivos y bibliotecas de textos elec-trónicos’ según popularidad e idioma; así referenciamos los que albergan textos en inglés y en español, por ser las dos lenguas que abordamos en este trabajo. Asimismo, obsérvese que, además de ser de una relativa re-ciente creación (1999), escasean este tipo de recursos en español, y los que hay están dedicados, principalmente, a la literatura:
➣ Oxford Text Archive (http://ota.ahds.ac.uk/). Fundada en 1976, se trata de una organización sin ánimo de lucro impulsada por el centro Oxford University Computing Service. Su objetivo es recopilar y catalogar textos electrónicos, así como mantenerlos en buen estado, para ponerlos a disposición de investigadores y profesores. En la actualidad, este centro distribuye recursos en más de 25 lenguas diferentes. El contenido de su catálogo se amplía constantemente. Contiene versiones electrónicas de obras litera-rias clásicas y contemporáneas. También cuenta con una amplia variedad de obras de referencia y otro tipo de textos de diferente naturaleza;
➣ Project Gutenberg (http://www.gutenberg.org/catalog/). El ob-jetivo de este proyecto es poner a disposición del público libros y otros materiales electrónicos. Contiene ediciones electrónicas de libros (más de 33.000), escritos por distintos autores, obras de referencia, como la Biblia, diccionarios monolingües y bilingües, etc.;
➣ Alex Catalogue of Electronic Texts (http://infomotions.com/alex/). Es una colección de documentos sobre literatura inglesa, norteamericana y de filosofía occidental. Los documentos se pue-den descargar gratuitamente;

84 Chelo Vargas Sierra
➣ Open Library (http://openlibrary.org/). Es un proyecto de In-ternet Archive, una organización sin ánimo de lucro patrocinada parcialmente por una beca de la California State Library.
➣ ManyBooks.net (http://www.manybooks.net/): contiene libros electrónicos gratuitos catalogados por autores, idiomas, géneros y títulos.
➣ Ufumes Scholars (http://scholars.ufumes.com/OnlineResources/SiteReview.html): sitio que proporciona un listado de centros en la web desde donde descargar libros electrónicos gratuitos, clasifi-cados además por temática (medicina, ciencia, negocios, etc.).
➣ La Biblioteca Virtual Miguel de Cervantes (http://www.cervan-tesvirtual.com/). Se trata de una iniciativa de la Universidad de Alicante que fue inaugurada en julio de 1999. Es un proyecto de edición digital del patrimonio bibliográfico, documental y crítico español e hispanoamericano. Su objetivo es impulsar la expansión universal de las culturas hispánicas a través de la utilización y apli-cación de los medios tecnológicos más avanzados;
Una pequeña muestra de los centros desde donde se pueden obtener córpora ya confeccionados es la siguiente lista:
➣ La Evaluations and Language Resources Distribution Agency (http://www.elda.org/). Se creó de forma paralela a ELRA en febrero de 1995. Se encarga del desarrollo y la ejecución de los objetivos y tareas de ELRA. Contiene un catálogo divido en cua-tro tipos de recursos: escritos, hablado, terminológicos, y multi-modal/multimedia;
➣ El International Computer Archive of Modern and Medieval En-glish (http://icame.uib.no/). Se fundó en 1977 con los siguien-tes objetivos: a) recopilar y distribuir información tanto en lo referente al material lingüístico en inglés disponible en formato electrónico, como a la investigación relacionada con estos ma-teriales; b) compilar un archivo de córpora textuales del inglés en formato electrónico; y c) poner este material a disposición de instituciones académicas y de investigación. Cuenta con los tres córpora más utilizados (el Brown, el LOB y el London-Lund),

85La tecnología de corpus en el contexto profesional y académico…
con otros grandes córpora (FLOB, FROWN, ACE, ICE, etc.), algunos con anotación gramatical, y otros históricos. Todo es-te material lo distribuye en un CD-ROM que, además, incluye programas informáticos para el tratamiento de corpus (WordSmith Tools, LEXA, Linguafont). ICAME organiza un congreso anual (cuyas actas publica la editorial Rodopi Publishers) y publica una revista, también anual, sobre temas relacionados con los córpora;
➣ El Linguistic Data Consortium Corpus Catalog (http://www.ldc.upenn.edu/Catalog/). Distribuye un gran número de córpora es-critos, orales, especializados y también en varias lenguas;
➣ El TELRI Research Archive of Computational Tools and Re-sources (http://tractor.bham.ac.uk/tractor/catalogue.html). Este archivo contiene córpora en más de 20 lenguas (principalmente de Europa Central y del Este), textos y herramientas informáticas para el tratamiento de corpus, lexicones y otros recursos lingüísti-cos.
El corpus que cumpla con las exigencias específicas del investigador puede que ni esté todavía confeccionado ni se encuentre entre los que ofrecen los centros anteriormente mencionados, luego habrá que diseñar-lo y compilarlo, tareas que exigen una inversión importante de tiempo y esfuerzo. Una herramienta que puede ayudar a la compilación textual es aquélla que permite localizar y descargar automáticamente, y de una vez, un conjunto de textos disponibles en Internet que satisfacen la sintaxis de búsqueda empleada. Dos ejemplos son: Webgetter, aplicación incluida en el programa de concordancias WordSmith Tools, y BootCat front end, espe-cíficamente diseñada para este fin y gratuita (cf. Baroni et al 2006). Otros rastreadores conocidos son los que se presentan en la siguiente tabla:
NombreInstalación local/en web
Distribución Lenguas
BootCaT front-end
Local. Sistemas operativos: Win-dows, Ubuntu, Debian, MacOSX, Linux
gratuita
26, entre las que incluye el inglés, español, francés, catalán, portugués, alemán...
http://bootcat.sslmit.unibo.it/?section=frontend

86 Chelo Vargas Sierra
Wüska, módulo de Jaguar
En web. Aplicación en Java
gratuita 9
http://melot.upf.edu/cgi-bin/jaguar/jaguar.pl
WebBootCaT
Integrado como un formulario dentro de la herramienta Sketch Engine (en web)
Comercial, por sus-cripción
42, entre las que incluye el inglés, español, francés, catalán, portugués, alemán...
http://beta.sketchengine.co.uk/login/
WeBoCaEn web. Aplicación en Java
gratuita No se especifica
http://code.google.com/p/weboca/
We b A s C o r p u s .com
Aplicación en web gratuita
40, entre las que incluye el inglés, español, francés, catalán, portugués, alemán...
http://webascorpus.org/searchwac.html
Webgetter
Local. Sistema ope-rativo: Windows.(utilidad de WordS-mith Tools)
comercial todas
http://www.lexically.net/wordsmith/version5/index.html
TerminoWeb, v. 2.0Aplicación en web
gratuita, con sus-cripción
inglés y francés
http://terminoweb.iit.nrc.ca/terminoWeb-v2_e.html
Terminus
Integrado como un formulario dentro de la herramienta Terminus
comercial
http://melot.upf.edu/Terminus2009/index_es.html
Tabla 2: Rastreadores y recuperadores automáticos de ficheros web
Las herramientas de procesamiento y explotación de corpus son re-lativamente sencillas. En lo que se refiere a los programas de concordan-cias, instrumentos consolidados ya como indispensables en el estudio de, por ejemplo, colocaciones y patrones léxicos, estas herramientas pueden

87La tecnología de corpus en el contexto profesional y académico…
realizar tareas en las que las personas no somos tan eficientes al no poder abordar un número elevado de textos impresos. Nos referimos a cuestio-nes como, por ejemplo:
a) determinar la relevancia de una palabra en función del número de veces que aparece en un texto, a través de listados de palabras ordenados por frecuencia:
Figura 2: Listado ordenado por frecuencia
b) comparar patrones léxicos para distintos propósitos de traducción o terminología, en forma monolingüe o bilingüe:

88 Chelo Vargas Sierra
Figura 3: Líneas de concordancias (monolingüe)
Figura 4: Líneas de concordancias (bilingüe) (obtenidas de Linguee.com)
c) agrupar palabras que aparecen alrededor de una palabra base, en posiciones determinadas, para detectar su combinatoria prototípi-ca:

89La tecnología de corpus en el contexto profesional y académico…
Word 1 Freq. Word 2 Freq. Texts
METAL 525 ION 1481 13
MOLECULAR 725 ION 1481 12
NEGATIVE 148 ION 1481 10
POSITIVE 158 ION 1481 7
FREE 372 ION 1481 3
FLUORIDE 66 ION 1481 3
PRECURSOR 49 ION 1481 3
SECONDARY 176 ION 1481 7
ANALYTE 792 ION 1481 4
CHARGED 148 ION 1481 8
CHLORIDE 229 ION 1481 7
FRAGMENT 120 ION 1481 8
SINGLE 646 ION 1481 7
AMMONIUM 103 ION 1481 7
PRIMARY 239 ION 1481 3
INTERFERING 64 ION 1481 3
HYDROGEN 336 ION 1481 5
MAJOR 451 ION 1481 4
NITRATE 131 ION 1481 3
HYDROXIDE 81 ION 1481 2
SILVER 125 ION 1481 4
ELUENT 97 ION 1481 2
NITRITE 45 ION 1481 1
POLYATOMIC 22 ION 1481 2
HEAVY 7 ION 1481 3
IODIDE 73 ION 1481 3
Figura 5: Coocurrentes de ‘ion’
d) encontrar construcciones contrastivas específicas; los programas de concordancias multilingües permiten visualizar frases o párrafos de un texto original (TO) alineados con los correspondientes en el texto meta (TM):

90 Chelo Vargas Sierra
Figura 6: Pantalla de Multiconcord con los resultados de la búsqueda
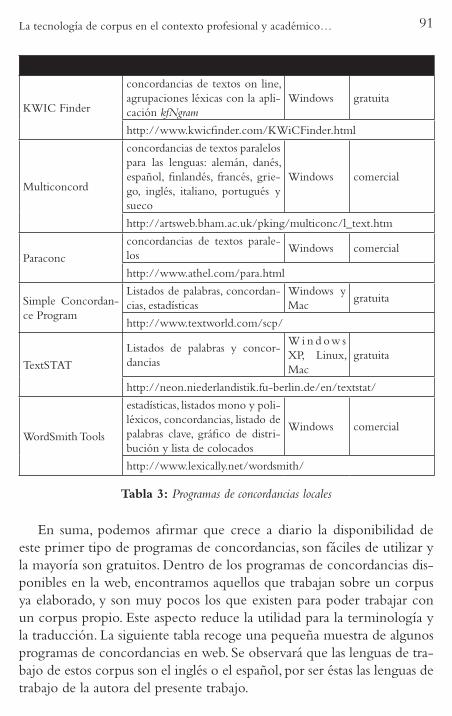
A continuación mostramos algunos programas de concordancias en las tablas que siguen (Tabla 1 y 2). La siguiente recoge once programas de concordancias de instalación local, para textos monolingües y paralelos, seleccionados según su disponibilidad y facilidad de uso.
Nombre Aplicaciones SO Distribución
AntConc
concordancias, listados de pala-bras y palabras clave por frecuen-cia, listas de colocados y agru-paciones de una palabra base, gráfico de distribución
Linux y Windows
gratuita
http://www.antlab.sci.waseda.ac.jp/antconc_index.html
Conc concordancias, índices y listados de palabras
Mac gratuita
http://www.sil.org/computing/conc/
ConcApp
concordancias, listados de fre-cuencias
Windows comercial
http://www.edict.com.hk/pub/concapp/
Concordance
concordancias, listados de pala-bras y frecuencias, análisis de pa-labras clave
Windows comercial
http://www.concordancesoftware.co.uk/
ConcGram
co-ocurrencias de una palabra (congrams), concordancias
Windows comercial
h t t p : / /www.ben j am in s . com/cg i -b in/ t_bookv i ew.cgi?bookid=cls%201
91La tecnología de corpus en el contexto profesional y académico…
Nombre Aplicaciones SO Distribución
KWIC Finder
concordancias de textos on line, agrupaciones léxicas con la apli-cación kfNgram
Windows gratuita
http://www.kwicfinder.com/KWiCFinder.html
Multiconcord
concordancias de textos paralelos para las lenguas: alemán, danés, español, finlandés, francés, grie-go, inglés, italiano, portugués y sueco
Windows comercial
http://artsweb.bham.ac.uk/pking/multiconc/l_text.htm
Paraconc
concordancias de textos parale-los
Windows comercial
http://www.athel.com/para.html
Simple Concordan-ce Program
Listados de palabras, concordan-cias, estadísticas
Windows y Mac
gratuita
http://www.textworld.com/scp/
TextSTAT
Listados de palabras y concor-dancias
W i n d ow s XP, Linux, Mac
gratuita
http://neon.niederlandistik.fu-berlin.de/en/textstat/
WordSmith Tools
estadísticas, listados mono y poli-léxicos, concordancias, listado de palabras clave, gráfico de distri-bución y lista de colocados
Windows comercial
http://www.lexically.net/wordsmith/
Tabla 3: Programas de concordancias locales
En suma, podemos afirmar que crece a diario la disponibilidad de este primer tipo de programas de concordancias, son fáciles de utilizar y la mayoría son gratuitos. Dentro de los programas de concordancias dis-ponibles en la web, encontramos aquellos que trabajan sobre un corpus ya elaborado, y son muy pocos los que existen para poder trabajar con un corpus propio. Este aspecto reduce la utilidad para la terminología y la traducción. La siguiente tabla recoge una pequeña muestra de algunos programas de concordancias en web. Se observará que las lenguas de tra-bajo de estos corpus son el inglés o el español, por ser éstas las lenguas de trabajo de la autora del presente trabajo.

92 Chelo Vargas Sierra
Nombre AplicacionesAutor/Institu-
ciónAcceso
A collection of En-glish corpora
Concordancias y colocacio-nes de varios corpus: BNC, Internet, Reuters, British News, Brown corpus.
Centre for Trans-lation Studies, University of Leeds
gratuito
http://corpus.leeds.ac.uk/protected/query.html
BNC Simple Search
Búsquedas sencillas sobre el corpus BNC, resultados en frases completas, no presen-ta concordancias en formato KWIC
British National Corpus
gratuito, pero con resultados limitados a 50 ejemplos
http://www.natcorp.ox.ac.uk/
Corpus Concordan-ce Sampler
Líneas de concordancias y colocaciones sobre el corpus Cobuild.
Cobuild
gratuito, pero con resultados limitados a 40 ejemplos
http://kitt.cl.uzh.ch/kitt/cltools/index.php/Corpus_Concor-dance_Sampler
Online KWIC Concordancer
Líneas de concordancias so-bre un corpus en inglés de cartas comerciales
Yasumasa Someya, Aoyama Gakuin University, Tokyo
gratuito
http://www.someya-net.com/concordancer/index.html
VIEW
Acceso a la consulta de seis córpora, en inglés, español y portugués. Las consultas se pueden hacer de palabras, frases, categorías gramatica-les, lemas, sinónimos, colo-cados, etc.
Mark Davies gratuito
http://view.byu.edu/
The Web Concor-dancer
Sitio web con varias aplica-ciones. Posibilidad de reali-zar concordancias y co-ocu-rrencias (congrams)
VLC gratuito
http://vlc.polyu.edu.hk/concordance/
Corpus de Refe-rencia del Español Actual
Datos estadísticos de las con-sultas, opciones de filtrado, concordancias, vistas amplia-das de los ejemplos mostra-dos
RAE gratuito
http://corpus.rae.es/creanet.html
Tabla 4: Programas de concordancias en web

93La tecnología de corpus en el contexto profesional y académico…
Sketch Engine y WMatrix, ambos mediante suscripción de pago, son programas de concordancias en web que permiten analizar corpus cons-truidos por el investigador o ad hoc. El primero, que va ampliando las lenguas con las que puede trabajar, muestra concordancias, listados de palabras, combinatoria, a través de los ‘esquemas léxicos’ (en inglés word sketch), sinónimos y similitudes/diferencias de combinatoria de dos le-mas. De este sistema cabe destacar la generación de los esquemas léxicos, que son resúmenes automáticos presentados en una página basados en el corpus analizado que representan el comportamiento gramatical y co-locacional de una palabra. Wmatrix, por su parte, es una herramienta de análisis y comparación de corpus, pero sólo reconoce el inglés. Propor-ciona una interfaz web de acceso a las herramientas de anotación USAS y CLAWS, así como metodologías estándar de lingüística de corpus, esto es, la lista de frecuencias y las concordancias. Amplía el método de pala-bras clave a categorías gramaticales y a dominios semánticos clave.
Los córpora paralelos han atraído el interés de investigadores de dife-rentes áreas de especialización y se han desarrollado métodos de explo-tación de este recurso lingüístico con el fin de obtener distintos datos y para distintas aplicaciones, como puede ser el entrenamiento de sistemas de traducción automática basada en ejemplos, la elaboración de léxicos multilingües, el aprendizaje de lenguas, etc. Las investigaciones realizadas sobre las distintas aplicaciones de los córpora paralelos en traducción y/o terminología (Baker, 1995; Bowker, 2003; Bowker y Pearson, 2002; King, 2003; Laviosa, 2002; Zanettin, 1998, entre muchos otros) han demostrado que este recurso resulta muy valioso para mejorar las destrezas traducto-ras de los estudiantes, extraer terminología bilingüe, construir glosarios especializados, visualizar expresiones o términos en contexto, analizar es-trategias de traducción, y, en definitiva, profundizar en el conocimiento contrastivo de la lengua original y de la meta en múltiples aspectos macro y microtextuales.
Debido a la utilidad que este tipo de instrumento presenta tanto en la traducción como en terminología multilingüe, finalizaremos este apar-tado presentando algunas herramientas de consulta de corpus paralelos a los que se accede vía web:

94 Chelo Vargas Sierra
Nombre Descripción Lenguas Notas
CABAL
Corpus periodístico de acceso web con más de 200 artículos procedentes de la prensa, y prin-cipalmente de Le Monde diplo-matique
EN, FR Ofrece concordan-cias bilingües
http://cabal.rezo.net/
CLUVI para-llel corpus
Contiene más de 23 millones de palabras y está constituido, a su vez, de varios subcópora: TEC-TRA: textos literarios inglés-gallegoFEGA: textos literarios francés-gallego;LEGA: textos jurídicos gallego-español;UNESCO: textos de divulgación científica en inglés-gallego-fran-cés-español;LOGALIZA: textos de localiza-ción de software inglés-gallego;CONSUMER: textos de infor-mación al consumidor en espa-ñol-gallego-catalán-vasco.LEGE-BI: textos legales vasco-españolTURIGAL: textos de turismo portugúes-inglés
EN, FR, ES, gallego
Ofrece concor-dancias bilingües o multilingües, según el sucorpus que se consulte
http://sli.uvigo.es/CLUVI/index_en.html
Corpus pa-ralelo inglés-alemán
Corpus paralelo que contiene textos alineados de Europarl y German News
EN, DEOfrece concordan-cias bilingües
http://corpus.leeds.ac.uk/paraquery.html
Tr a n s l a t i o n Corpus Explo-rer for the Web, WebTCE
Herramienta de consulta de cor-pus paralelo con varias subcór-pora consultables clasificados por combinación lingüística.
EN, DE, FR, ES, DA, NO
Ofrece concordan-cias bilingües
http://khnt.hit.uib.no/webtce.htm

95La tecnología de corpus en el contexto profesional y académico…
T E R M A -COR. Termi-nology and corpus
Herramienta de consulta de cor-pus paralelo multilingüe basado en los datos de la Comisión eu-ropea.
Las 22 len-guas de la UE
Ofrece concor-dancias bilingües y también el término de búsqueda junto con su equivalente a otros idiomas
http://evrokorpus.gov.si/k2/index.php?jezik=angl
COMPARA
Corpus paralelo bidireccional portugués-inglés que contiene más de tres millones de palabras
PT, ENOfrece concordan-cias bilingües
http://www.linguateca.pt/COMPARA/
Termsearch
Corpus inglés>ruso, francés<>ruso, francés<>inglés, ruso>inglés que contiene tratados internacionales, convenciones y otros acuerdos, unos 792 docu-mentos en total.
EN, RU, FR
Ofrece concordan-cias bilingües
http://www.bible-study-in-geneva.info/termsearch/
Linguee
Herramienta de consulta de bi-textos basada en 100 millones de textos paralelos en línea. Las bús-quedas son bidreccionales inglés-alemán, inglés-español, inglés-francés e inglés portugués.
EN, FR, ES, DE, PT
Ofrece concordan-cias bilingües. Las palabras clave junto con sus traducciones se destacan en los resultados
http://www.linguee.es/
WeBiText
Herramienta de consulta de bi-textos que contiene varios sub-corpora categorizados según la temática (Unión europea, finan-zas, salud, jurídico y general)
Multilingue, varía según el sucorpus selecciona-do
Ofrece concordan-cias bilingües. Pro-porciona un vínculo directo de búsqueda en TERMIUM.
http://webitext.com/bin/webitext.cgi
Corpus Lin-güístico Con-sumer
Contiene artículos publicados en la revista CONSUMER EROS-KI.
ES, catalán, gallego y vasco
Ofrece concordan-cias bilingües.
http://corpus.consumer.es/corpus/
OPUS
Colección de textos traducidos recogidos de la web. Contiene va-rios subcorpora de consulta
Multilingue, varía según el sucorpus selecciona-do
Ofrece concordan-cias multilingües
http://opus.lingfil.uu.se/

96 Chelo Vargas Sierra
LinearB
Se define en su página web como una memoria de traducción con-sultable
Multilingüe
Ofrece concordan-cias bilingües. Agru-pa los resultados según la traducción del término de bús-queda
http://linearb.co.uk/
Tabla 5: Corpus paralelos consultables en web
5. CONSIDERACIONES FINALES
Tras la presentación de los conceptos básicos de la lingüística de cor-pus, este capítulo ha presentado un panorama actual de la investigación con corpus en los ámbitos concretos de la traducción y la terminología. Hemos ido indicando las posibilidades que ofrece trabajar con esta me-todología al contextualizar las aplicaciones o uso del corpus en las dos disciplinas, tanto en la esfera profesional como en la académica. Durante esta contextualización, se has esbozado algunas de las múltiples posibili-dades que la investigación con corpus ofrece, junto con recursos actual-mente disponibles. También hemos citando brevemente algunos temas de investigación que todavía están poco explorados.
Hemos intentado en este estudio dejar constatada la utilidad de un corpus en diferentes cuestiones dentro de la traducción y la terminología, así como la multitud de recursos a nuestro alcance que permiten realizar investigación de tipo empírica avalada por los datos que proporciona una muestra real. No quedan muchas excusas para no reconocer los bene-ficios que pueden aportar los córpora a la investigación, pues con estos recursos es posible realizar estudios a mayor escala, confirmar de forma empírica la intuición, adoptar una perspectiva descriptiva más empren-der nuevas áreas de investigación, realizar hallazgos de tipo cuantitativo y cualitativo, correr un riesgo menor de pasar por alto información que pueda ser relevante, etc. Sin embargo, somos conscientes de que un cor-pus no es la panacea, en el sentido de que no toda investigación puede o debe estar exclusivamente basada en corpus, pues en ciertos casos lo ideal es combinar y complementar los métodos de esta lingüística con otros en

97La tecnología de corpus en el contexto profesional y académico…
el ánimo de alcanzar el más alto grado de rigor científico y exhaustividad. Para los investigadores queda la difícil tarea de diseñar el corpus, de desa-rrollar metodologías de interrogación y de interpretar los datos.
BIBLIOGRAFÍA
AHMAD, K., DAVIES, A., FULFORD, H. y ROGERS, M. (1994): “What is a term? The semi-automatic extraction of terms from text”. En SNELL-HORNBY, M., PöCHHACKER, F. y KAINDL, K. (eds.): Translation Stu-dies: An Interdiscipline, Amsterdam/Philadelphia: Jon Benjamins, pp. 267-278.
AHMAD, K., HOLMES-HIGGIN, P., ABIDI, S. R., ROGERS, M. y GRIFFIN, S. M. (1995): “Terminology Management: The Extraction, Representation and Retrieval of Specialist Terms”. Department of Mathematical and Com-puting Sciences, University of Surrey, CS-95-08.
AHMAD, K. y ROGERS, M. (2001): “Corpus Linguistics and Terminology Ex-traction”. En WRIGHT, S. E. y BUDIN, G. (eds.): Handbook of Terminology Management, vol. 2, Amsterdam/Philadelphia: John Benjamins, pp. 725-760.
BAKER, M. (1995): “Corpora in translation studies: An overview and some suggestions for future research”. Target 7(2), pp. 223-243
BARONI, M., KILGARRIF, A., POMIKÁLEK, J. and RYCHLý, J. (2006): “WebBootCaT: instant domain-specific corpora to support human transla-tors”. En Proceedings of EAMT 2006 - 11th Annual Conference of the European Association for Machine Translation (Oslo, 2006), pp. 247-252.
BERGENHOLT, H. y TARP, S. (1995): Manual of Specialised Lexicography: the Preparation of Specialised Dictionaries, Amsterdam/Philadelphia: John Benja-mins.
BOURIGAULT, D. (1992): “Surface grammatical analysis for the extraction of terminological noun phrases”. En Proceedings of Fifteenth International Confe-rence on Computational Linguistics
BOWKER, L. (1998): “Using Specialized Monolingual Native-Language Cor-pora as a Translation Resource: a Pilot Study”. En Meta, XLIII, 4, pp. 631-651.
BOWKER, L. (2003): “Corpus-based applications for translation training: explo-ring the possibilities”. En GRANGER, S., LEROT, J y PETCH-TYSON, S. (2003): Corpus-based Approaches to Contrastive Linguistics and Translation Studies, Amsterdam/New York: Rodopi, pp. 169-183.
BOWKER, L. y PEARSON, J. (2002): Working with Specialized Language. A prac-tical guide to using corpora, London/New York: Routledge.
BOWKER, L. y MARSHMAN, E. (2008): “I’ll CERTTainly need to know that: What students (and others) think about the need for translation technologies

98 Chelo Vargas Sierra
in their training and future work”. Ponencia presentada en el 21st Annual Congress of the Canadian Association of Translation Studies (CATS), Vancouver, del 31 de mayo al 2 de junio. [Disponible en línea: http://aix1.uottawa.ca/~certt/CATS08-final-20080529.pdf].
CABRÉ, M. T. (1993): La terminología. Teoría, metodología, aplicaciones, Barcelona: Editorial Antártida/Empúries.
FRANCIS, W. N. (1992): “Language Corpora B. C.”. En Svartvik, J. (ed.): Di-rections in Corpus Linguistics. Proceedings of Nobel Symposium 82, Estocolmo, agosto de 1991, Berlin/New York: Mouton de Gruyter, pp. 17-32.
HALLIDAY, M. A. K. (1991): “Corpus studies and probabilistic grammar”. En AIJMER, K y ALTENBERG, B. (eds.): English Corpus Linguistics: Studies in Honour of Jan Svartvik, London/New York: Longman, pp. 30-43.
HUNSTON, S. (2002): Corpora in Applied Linguistics. Cambridge: Cambridge University Press.
KING, P. (2003): “Parallel concordancing and its applications”. En GRANGER, S., LEROT, J y PETCH-TYSON, S. (2003): Corpus-based Approaches to Con-trastive Linguistics and Translation Studies, Amsterdam/New York: Rodopi, pp. 157-167.
LAVIOSA, S. (2002): Corpus-based Translation Studies. Theory, Findings, Applications, Amsterdam: Rodopi.
LEECH, G. (1991): “The state of the art in corpus linguistics”. En AIJMER K. y ALTENBERG B. (eds.): English Corpus Linguistics: Studies in Honour of Jan Svartvik, London: Longman, pp 8-29.
LEECH, G. (2002): “The Importance of Reference Corpora”. En Jornadas Corpus lingüísticos. Presente y futuro, Donostia, 24 y 25 de octubre de 2002, UZEI.
LERAT, P. (1995): Las lenguas especializadas, Barcelona: Ariel.LOUW, B. (1997): “The Role of Corpora in Critical Literary Appreciation”. En
WICHMANN, A., FLIGELSTONE, S., MCENERY, T. y KNOWLES, G. (eds.): Teaching and Language Corpora. London: Longman, pp. 240-251.
PALACIOS SÁNCHEZ, M. (2011): La estación de trabajo informatizada y libre: una propuesta para traductores autónomos. Trabajo de investigación inédito. Universidad de Alicante.
PAVEL, S. y NOLET, D. (2001): Manual de terminología, Canadá: Ministre des Travaux publics et Services gouvernementaux. Disponible en línea: http://www.fit-ift.org/download/preespagn.pdf. [Última consulta: enero de 2011]
SAGER, J. C., DUNGWORTH, D., MCDONALD, P. F. (1980): English Special Languages: principles and Practice in Science and Technology, Wiesbaden: Oscar Brandstetter.
SCOTT, M. (1997a): “PC Analysis of key words - and key words”, System, 25, pp. 233-245.

99La tecnología de corpus en el contexto profesional y académico…
SINCLAIR, J. (1996): Preliminary recommendations on Corpus Typology, EAG-TCWG-CTYP/P, versión de mayo 1996, Pisa: EAGLES.
STUBBS, M. (1995): “Collocations and semantic profiles: on the cause of the trouble with quantitative methods”. Functions of Language 2: 1-33
VARGAS-SIERRA, C. (2005): Aproximación terminográfica al lenguaje de la piedra natural. Propuesta de sistematización para la elaboración de un diccionario traductoló-gico. Tesis doctoral. Alicante: Universidad de Alicante.
VARGAS-SIERRA, C. (2011): “Translation-oriented terminology management and ICTs: present and future”. In SUAU JIMÉNEZ, F. and PENNOCK, B. (eds.): Interdisciplinarity and languages: Current Issues in Research, Teaching, Pro-fessional Applications and ICT. Bern: Peter Lang Publishing.
VARGAS SIERRA, C. (2006): “Diseño de un corpus especializado con fines terminográficos: el Corpus de la Piedra Natural”. Debate Terminológico, 2 (7/2006). París: RITERM (Red Iberoamericana de Terminología). Disponi-ble en línea: http://riterm.net/revista/ojs/index.php/debateterminologico/article/view/40 [Última consulta: enero 2011].
VARGAS SIERRA, C. (2002): “Utilización de los programas de concordancias en la traducción especializada”. En El español, lengua de traducción. I congreso internacional, Servicio de traducción de la Comisión Europea, pp. 468-483. Disponible en línea: http://www.esletra.org/Almagro/html/vargas_corri_es.htm [Última consulta: enero 2011]
ZANETTIN, F. (1998): “Bilingual comparable corpora and the training of trans-lators”. Meta 43(4), pp. 616-630.