kernel-kernel communication in a shared- memory multiprocessor eliseu chaves, et. al. may 1993...
TRANSCRIPT

Kernel-Kernel Communication in a Shared-memory Multiprocessor Eliseu Chaves, et. al. May 1993
Presented by Tina SwensonMay 27, 2010

AgendaAgendaIntroductionRemote InvocationRemote Memory AccessRI/RA CombinationsCase StudyConclusion

IntroductionIntroduction

IntroductionIntroductionThere’s more than one way to
handle large shared memory systems◦Remote Memory
we’ve studied this a lot!
◦Remote Invocation message passing
Trade-offs are discussedTheories tested with a case study

MotivationMotivationUMA design won’t scaleNUMA was seen as the future
◦It is implemented in commercial CPU’s
NUMA allows programmers to choose shared memory or remote invocation
The authors discuss the trade-offs

Kernel-kernel Kernel-kernel CommunicationCommunicationEach processor has:
◦Full range of kernel services◦Reasonable performance◦Access to all memory on the machine
Locality – key to RI success◦Previous kernel experience shows that
most memory access tend to be local to the “node”
“...most memory accesses will be local even when using remote memory accesses for interkernel communication, and that the total amount of time spent waiting for replies from other processors when using remote invocation will be small...”

NUMANUMANUMA without cache-coherence3 methods of kernel-kernel
communication◦Remote Memory Access
Operation executes on node i, accessing node j’s memory as needed.
◦Remote Invocation Node i processor sends a message to node j
processor asking j to perform i’s operations.
◦Bulk data transfer Kernel moves data from node to node.

Remote InvocationRemote Invocation

Remote Invocation (RI)Remote Invocation (RI)Instead of moving data around
the architecture, move the operations to the data!
Message Passing

Interrupt-Level RI (ILRI)Interrupt-Level RI (ILRI)FastFor operations that can be safely
executed in an interrupt handlerLimitations:
◦Non-blocking (thus no locks) operations only interrupt handles lack process context
◦Deadlock Prevention severely limits when we can use ILRI

Process-Level RI (PLRI)Process-Level RI (PLRI)SlowerRequires context switch and
possible synchronization with other running processes
Used for longer operationsAvoid deadlocks by blocking

Remote Memory Remote Memory AccessAccess

Memory ConsiderationsMemory ConsiderationsIf remote memory access is used
how is it affected by memory consistency models (not in this paper)?◦Strong consistency models will incur
contention◦Weak consistency models widen the
cost gap between normal instructions and synchronization instructions And require use of memory barriers
From Professor Walpole’s slides.

RI/RA CombinationsRI/RA Combinations

Mixing RI/RAMixing RI/RAILRI, PLRI and shared memory
are compatible, as long as guidelines are followed.
“It is easy to use different mechanisms for unrelated data structures.”

Using RA with PLRIUsing RA with PLRIRemote Access and Process-level
Remote Invocation can be used on the same data structure if:◦synchronization methods are
compatible

Using RA with ILRIUsing RA with ILRIRemote Access and Interrupt-
level Remote Invocation can be used on the same data structure if:◦A Hybrid lock is used
interrupt masking AND spin locks

Using RA with ILRI – Hybrid Using RA with ILRI – Hybrid LockLock

Using PLRI and ILRIUsing PLRI and ILRIPLRI & ILRI on the same data
structure if:◦Avoid deadlock ◦Always be able to perform incoming
invocations while waiting for outgoing invocation.
◦Example: Cannot make PLRI with ILRIs blocked in order to access data that is shared by normal and interrupt-level code (from Professor Walpole’s slides)

The CostsThe CostsLatencyImpact on local operationsContention and ThroughputComplement or clash
conceptually with the kernel’s organization

LatencyLatencyWhat’s the latency between
performing RA and RI?If (R-1)n < C
◦then implement using RAIf operations require a lot of time
◦then implement using RI

Impact on Local Impact on Local OperationsOperationsImplicit Synchronization:
◦PLRI is used for all remote accesses, then it could allow the data structure
◦This solution depends on the no pre-emption
Explicit Synchronization:◦Bus-based nodes

Contention and Contention and ThroughputThroughputOperations are serialized at some
point!RI: Serialize on processor
executing those operations◦Even if there is no data in common
RA: Serialize at the memory◦If access competes for same lock

Complement or ClashComplement or ClashTypes of kernels
◦procedure-based no distinction between user & kernel space user program enters kernel via traps fits RA
◦message-based each major kernel resource is its own
kernel process ops require communication among these
kernel processes fits RI

Complement or ClashComplement or Clash

Case StudyCase Study

Psyche on Butterfly Plus Psyche on Butterfly Plus Procedure-based OS
Uses share memory as primary kernel communication mechanism
Authors built in message-based ops
RI – reorganized code; grouped together accesses allowing a single RI call.
non-CC-NUMA 1 CPU/node C = 12:1 (remote -to-local access time)

Psyche on Butterfly Plus Psyche on Butterfly Plus High degree of node localityRI implemented optimisticallySpin locks used
◦Test-and-test-and-set used to minimize latency in absence of contention. Otherwise, some atomic instruction is used
◦This can be decided on the fly
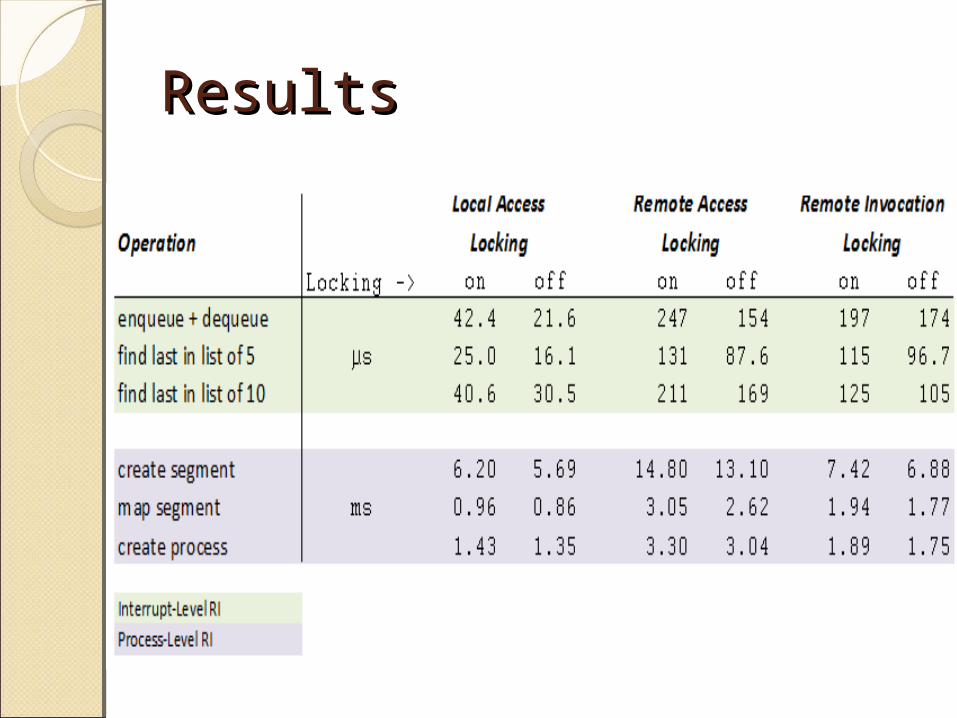
Results Results
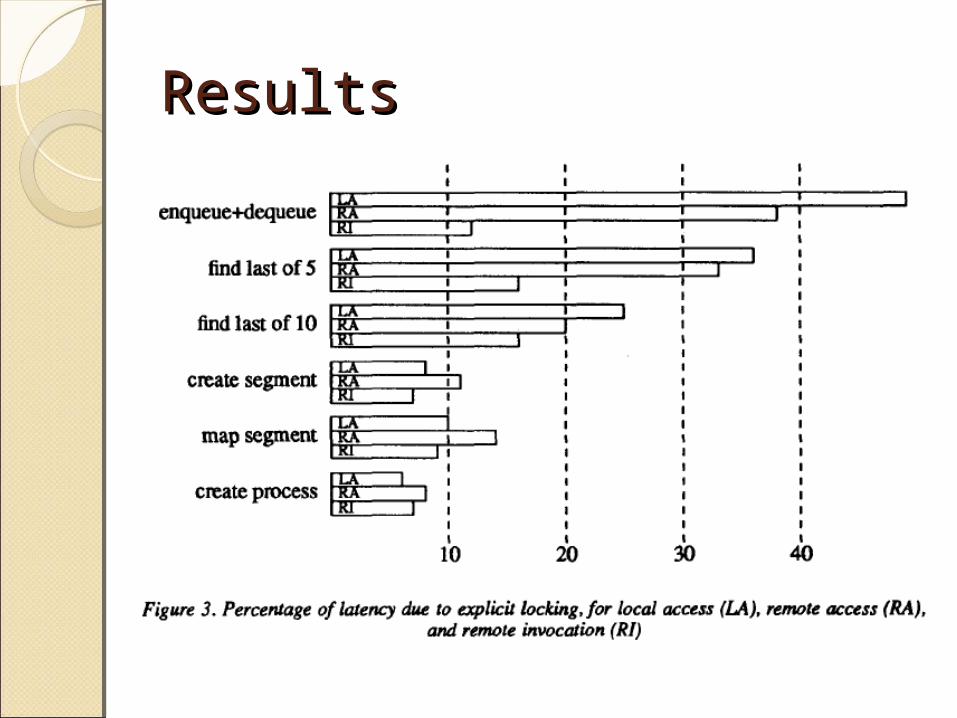
Results Results

Results Results
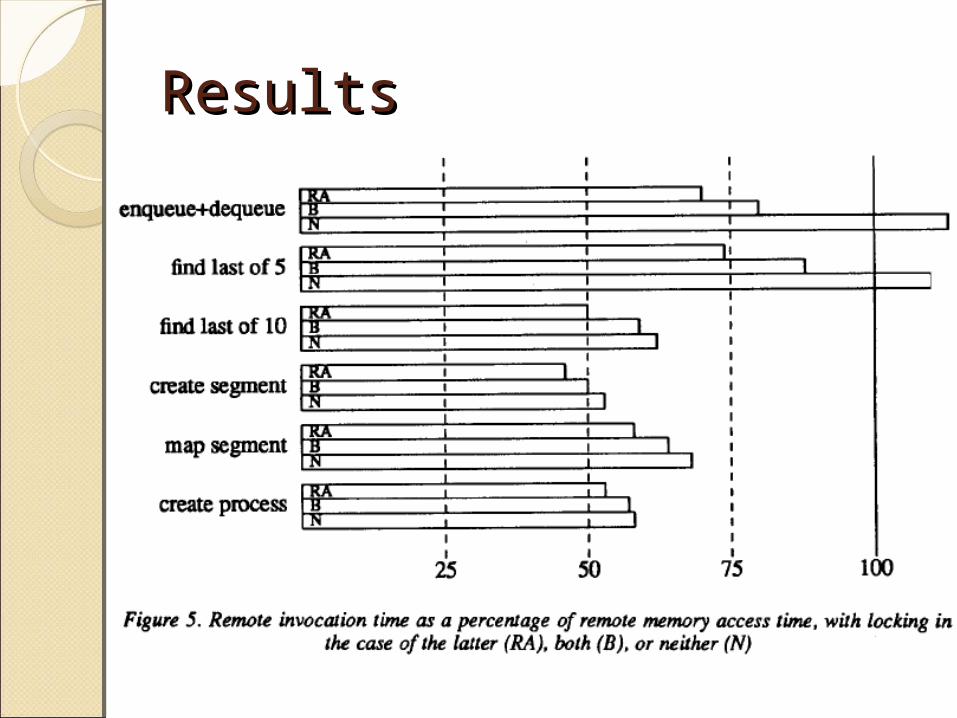
Results Results

ConclusionConclusion

Factors Affecting the choice Factors Affecting the choice of RI/RAof RI/RACost of the RI mechanismCost of atomic operations for
synchronizationRatio of remote to local memory
access timeFor cache-coherent machines:
◦cache line size◦false sharing◦caching effects reducing total cost of
kernel ops.

Using PLRI, ILRI, and RAUsing PLRI, ILRI, and RAPLRI
◦Use it once the cost of PLRI surpasses ILRI◦Must consider latency, throughput,
appeal of eliminating explicitly synchIRLI
◦Node locality is hugely important◦Use it for low-latency ops when you can’t
do RA◦Use it when the remote node is idle.
Authors used IRLI for console IO, kernel debugging and TLB Shootdown.

ObservationsObservationsOn Butterfly Plus:
◦ILRI was fast◦Explicit sync is costly◦Remote references much more
expensive than local references.◦Except for short operations, RI had
lower latency. RI might have lower throughput.

Conclusions?Conclusions?Careful design is required for OSs to
scale on modern hardware!◦ Which means you better understand the
effects of your underlying hardware.Keep communication to a minimum no
matter what solution is used.Where has mixing of RI/RA gone?
◦ Monday’s paper, for one.◦ What else?
ccNUMA is in wide-spread use◦ How is RI/RA affected?

Thank YouThank You