ivan herman, w3c, w3c brazil office meeting são paulo, brazil, 2010-10-15
TRANSCRIPT

What is the Semantic Web?
Ivan Herman, W3C,W3C Brazil Office Meeting
São Paulo, Brazil, 2010-10-15

(2)
Let’s organize a trip from Amsterdam to Budapest using the Web!

(3)
You try to find a proper flight with …

(4)
… a big, reputable airline, or …
(5)
… the airline of the country, or …

(6)
… or a low cost one

(7)
You have to find a hotel, so you look for…

(8)
… a very cheap accommodation, or …

(9)
… or a really luxurious one, or …

(10)
… an intermediate one …

(11)
oops, that is no good, the page is in Hungarian that almost nobody
understands, but…
(12)
… this one could work

(13)
Of course, you could decide to trust a specialized site…

(14)
… like this one, or…

(15)
… this one

(16)
You may want to know something about Budapest; look for some
photographs…

(17)
… on flickr …

(18)
… on Google …

(19)
… or you can look at mine

(20)
but you can also look at a (social) travel site

(21)
You had to consult a large number of sites, all different in style, purpose, possibly language…
You had to mentally integrate all those information to achieve your goals
We all know that, sometimes, this is a long and tedious process!
What happened here?

(22)
The real “meat” is the data!
All those pages are only tips of respective icebergs:◦ the real data is hidden
in databases, XML files, Excel sheets, …
◦ you only have access to what the Web page designers allow you to see

(23)
Specialized sites (Expedia, TripAdvisor) do a bit more: ◦ they gather and combine data from other sources
(usually with the approval of the data owners)◦ but they still control how you see those sources
But sometimes you want to personalize: access the original data and combine it yourself!

(24)
Another example: social sites. I have a list of “friends” by…

(25)
… Dopplr,

(26)
… LinkedIn,

(27)
… and, of course, Facebook

(28)
I have to type the same data again and again…
This is even worse: I feed the icebergs…
and it gets boring…

(29)
The raw data should be available on the Web◦ let the community figure out what applications are
possible…
What would we like to have?

(30)
But wait! Isn’t what mashup sites are already using?

(31)
A “mashup” example:

(32)
Yes, and it shows the power of accessing data directly!

(33)
Mashup sites are forced to do very ad-hoc jobs◦ various data sources expose their data via Web
Services, API-s◦ each with a different API, a different logic, different
structure◦ mashup sites are forced to reinvent the wheel many
times because there is no standard way getting to the data!
but…

(34)
The raw data should be available in a standard way on the Web◦ i.e., using URI-s to access data◦ dereferencing that data should lead to something
useful
What would we like to have?

(35)
What makes the current (document) Web work?◦ people create different documents◦ they give an address to it (ie, a URI) and make it
accessible to others on the Web
Why is that so important?

(36)
An example: Steven’s site on Amsterdam

(37)
Others discover the site and they link to it The more they link to it, the more important
and well known the page becomes◦ remember, this is what, eg, Google exploits!
This is the “Network effect”: some pages become important, and others begin to rely on it even if the author did not expect it…
Then some magic happens…
(38)
This could be expected…

(39)
…but this one, from the other side of the Globe, was not…

(40)
The same network effect works on the raw data◦ Many people link to the data, use it◦ Much more (and diverse) applications will be created
than the “authors” would even dream of!
Network effect on the data

(41)
Is that it? Ie: let us publish the data on the Web and we are done?

(42)
Not quite…

(43)
We would end up with data in isolation, in “silos”
Photo credit “nepatterson”, Flickr

(44)
A “Web” where◦ documents are available for download on the Internet◦ but there would be no hyperlinks among them
This is certainly not what we want!
Imagine…

(45)
Those relationships already exist in the data!

(46)
Those relationships already exist in the data!

(47)
Those relationships already exist in the data!

(48)
Those relationships already exist in the data!

(49)
Those relationships should be exposed, too!

(50)
The raw data should be available in a standard way on the Web
There should be links among datasets
What would we like to have?

(51)
I.e.,… connect the silos
Photo credit “kxlly”, Flickr

(52)
On the traditional Web, humans are implicitly taken into account
A Web link has a “context” that a person may use
But it is a little bit more complicated

(53)
Eg: address field on my page:

(54)
… leading to this page

(55)
A human understands that this is where my office is, ie, the institution’s home page
He/she knows what it means ◦ realizes that it is a research institute in Amsterdam
When handling data, something is missing; machines can’t make sense of the link alone

(56)
New lesson learned: ◦ extra information (“label”) must be added to a link:
“this links to my institution, which is a research institute”
◦ this information should be machine readable◦ this is a characterization (or “classification”) of both
the link and its target◦ in some cases, the classification should allow for
some limited “reasoning”

(57)
The raw data should be available in a standard way on the Web
Datasets should be linked Links, data, sites, should be characterized,
classified, etc. The result is a Web of Data
What would we like to have?

(58)
So What is the Semantic Web?

(59)
It is a collection of technologies to realize a Web of Data

(60)
It is that simple… Of course, the devil is in the details
◦ a common data model data has to be provided◦ the “classification” of the terms can become very
complex◦ but these details are fleshed out by experts as we
speak!

(61)
A set of core technologies are in place Lots of data (billions of relationships) are
available in standard format◦ often referred to as “Linked Open Data Cloud”
What has been achieved so far?

(62)
The “Linked Open Data Cloud”

(63)
There is a vibrant community of◦ academics: universities of Southampton, Oxford,
Stanford, PUC◦ small startups: Garlik, Talis, C&P, TopQuandrant,
Cambridge Semantics, OpenLink, …◦ major companies: Oracle, IBM, SAP, …◦ users of Semantic Web data: Google, Facebook,
Yahoo!◦ publishers of Semantic Web data: New York Times, US
Library of Congress, open governmental data (US, UK, France,…)
What has been achieved so far?

(64)
Companies, institutions begin to use the technology:◦ BBC, Vodafone, Siemens, NASA, BestBuy, Tesco,
Korean National Archives, Pfizer, Chevron, … see http://www.w3.org/2001/sw/UseCases
Truth must be said: we still have a way to go◦ deployment may still be experimental, or on some
specific places only
And, of course, applications emerge

(65)
The Music site of the BBC

(66)
The Music site of the BBC
(67)
UK eGov data set
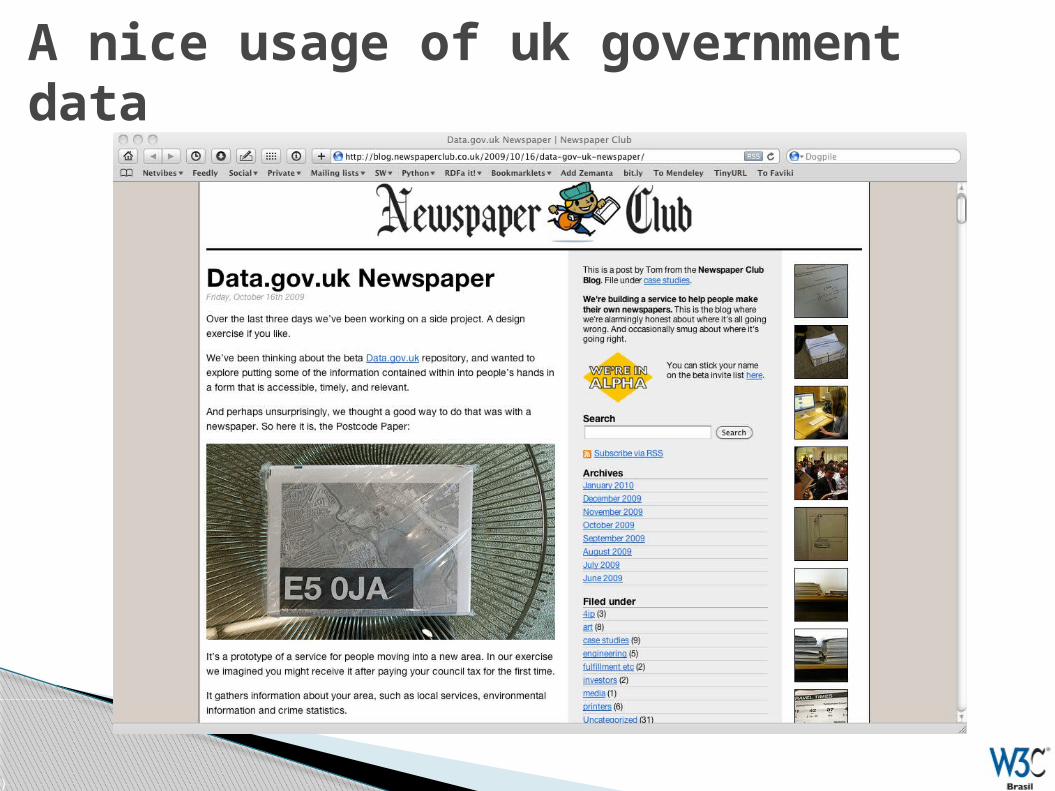
(68)
A nice usage of uk government data

(69)
Help in finding the best drug regimen for a specific case, per patient
Integrate data from various sources (patients, physicians, Pharma, researchers, ontologies, etc)
Data (eg, regulation, drugs) change often, but the tool is much more resistant against change
Help in choosing the right drug regimen
Courtesy of Erick Von Schweber, PharmaSURVEYOR Inc., (SWEO Use Case)

(70)
Integration of relevant data in Zaragoza
Use rules to provide a proper itinerary
eTourism: provide personalized itinerary
Courtesy of Jesús Fernández, Mun. of Zaragoza, and Antonio Campos, CTIC (SWEO Use Case)

(71)
More an more data should be “published” on the Web◦ this can lead to the
“network effect” on data New breeds of
applications come to the fore◦ “mashups on steroids” ◦ better representation and
usage of community knowledge
◦ new customization possibilities
◦ …
Summary

(72)
A huge amount of data (“information”) is available on the Web
Sites struggle with the dual task of:◦ providing quality data◦ providing usable and attractive interfaces to access
that data
Why is all this good?

(73)
Why is all this good?
“Raw Data Now!” Tim Berners-Lee, TED Talk, 2009http://bit.ly/dg7H7Z
Semantic Web technologies allow a separation of tasks:
1. publish quality, interlinked datasets2. “mash-up” datasets for a better user experience

(74)
The “network effect” is also valid for data There are unexpected usages of data that
authors may not even have thought of “Curating”, using, exploiting the data requires
a different expertise
Why is all this good?

(75)
W3C◦ was one of the initiators of the Semantic Web (Tim
Berners-Lee and others)◦ is the place where Semantic Web Standards are
developed and defined◦ is integral part of the Semantic Web community
What is the role of W3C in the Semantic Web?

(76)
It is done by groups, with W3C members delegating experts
Each group has at least one W3C staff member to help the process and contribute to the technology◦ there is a formal process that has to be followed◦ the price to pay…
Standard creation at W3C

(77)

(78)
The public can comment at specific points in the process
Groups must take all comments into account◦ the number of comments can be in the hundreds...
There is also a public scrutiny

(79)
Regular telecons (usually once a week) Possibly 1-2 face-to-face meetings a year Lots of email discussions Editorial work to get everything properly
written down Average life-span: 2-3 years
Life of a group

(80)
Interested? Join the show!

(81)
Thank you for your attention!
These slides are also available on the Web:
http://www.w3.org/2010/Talks/1015-SaoPaulo-Office-IH/