it's not magic - explaining classification algorithms
TRANSCRIPT

It’s Not Magic
Brian Lange, Data Scientist + Partner at
Explaining classification algorithms

HEADS UP

I work with some really freakin’ smart people.

classification algorithms

popular examples

popular examples
-spam filters
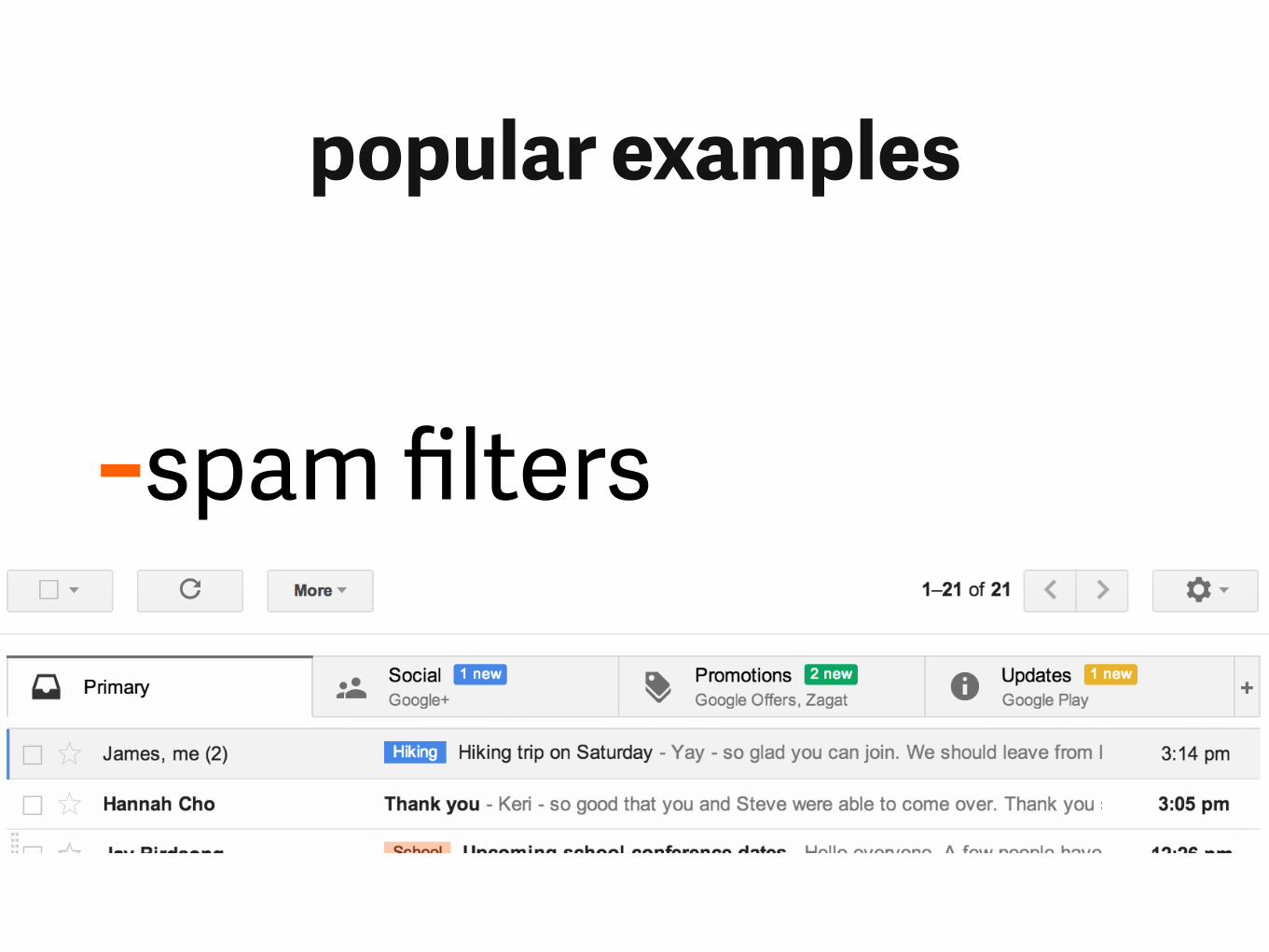
popular examples
-spam filters

popular examples
-spam filters
-the Sorting Hat

things to know

things to know
- you need data labeled with the correct answers to “train” these algorithms before they work

things to know
- you need data labeled with the correct answers to “train” these algorithms before they work
- feature = dimension = column = attribute of the data

things to know
- you need data labeled with the correct answers to “train” these algorithms before they work
- feature = dimension = column = attribute of the data
- class = category = label = Harry Potter house

BIG CAVEATOften times choosing/creating good features or gathering more data will help more than changing algorithms...
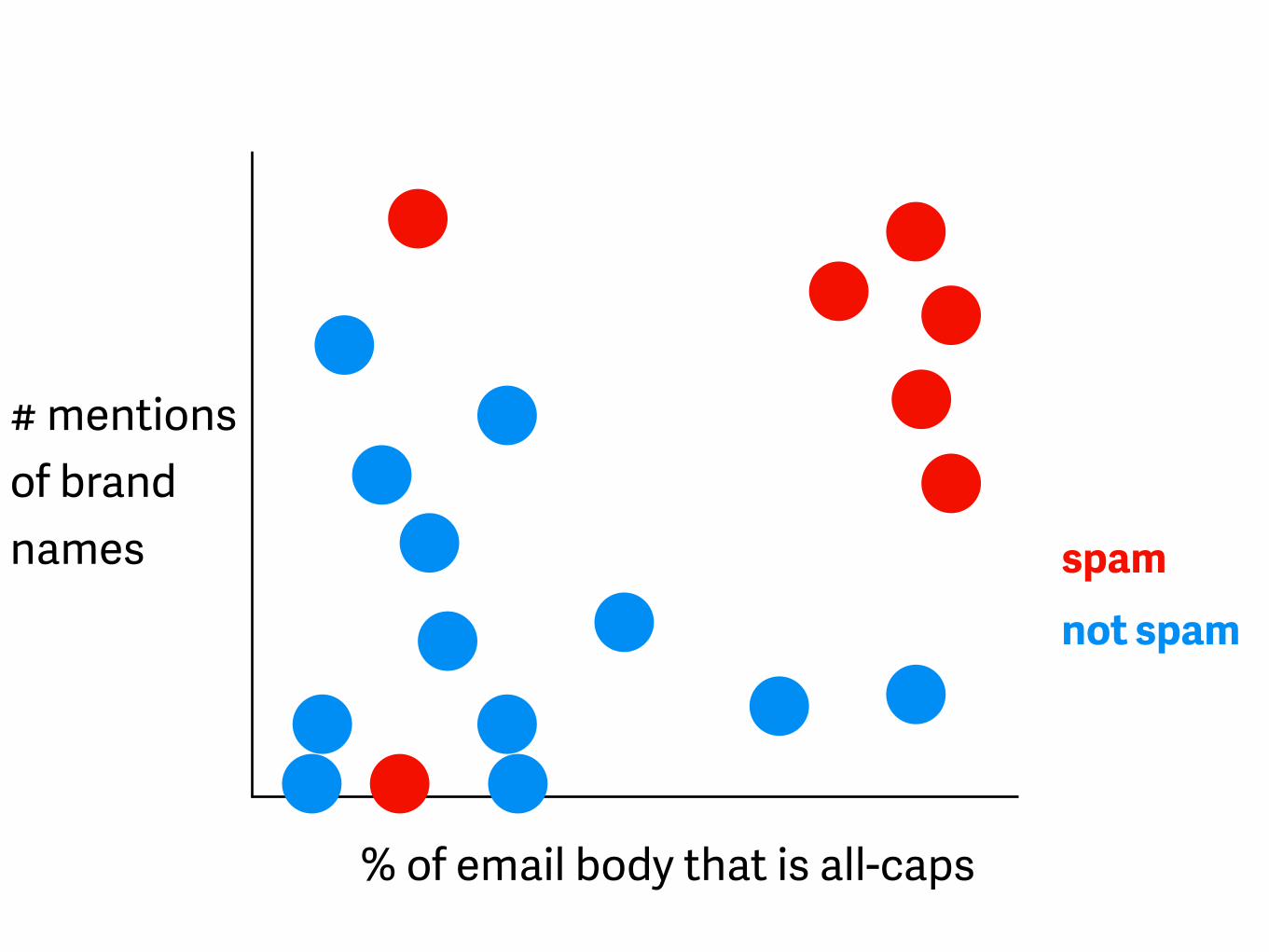
% of email body that is all-caps
# mentions of brand names spam
not spam

Linear discriminants
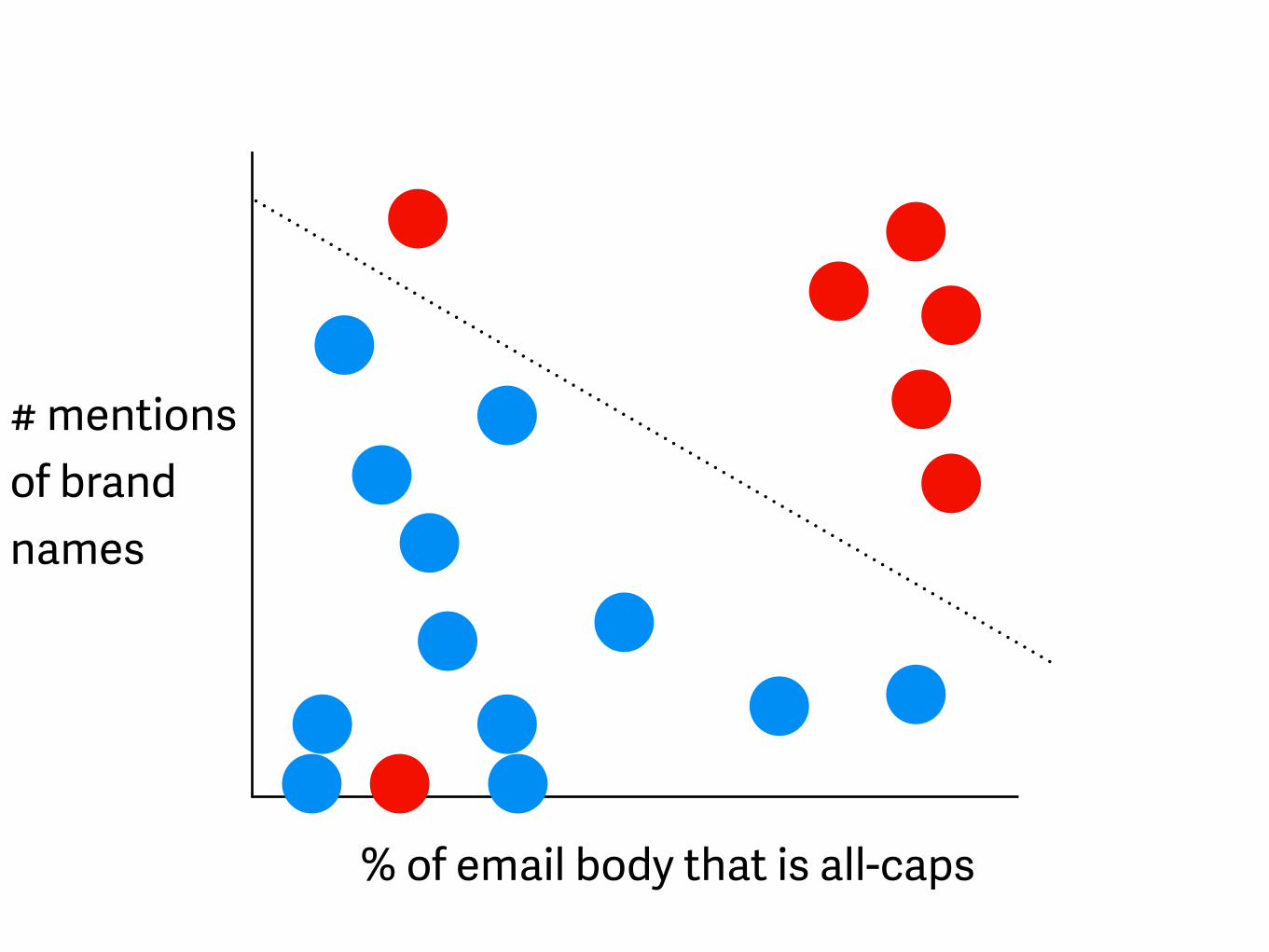
% of email body that is all-caps
# mentions of brand names
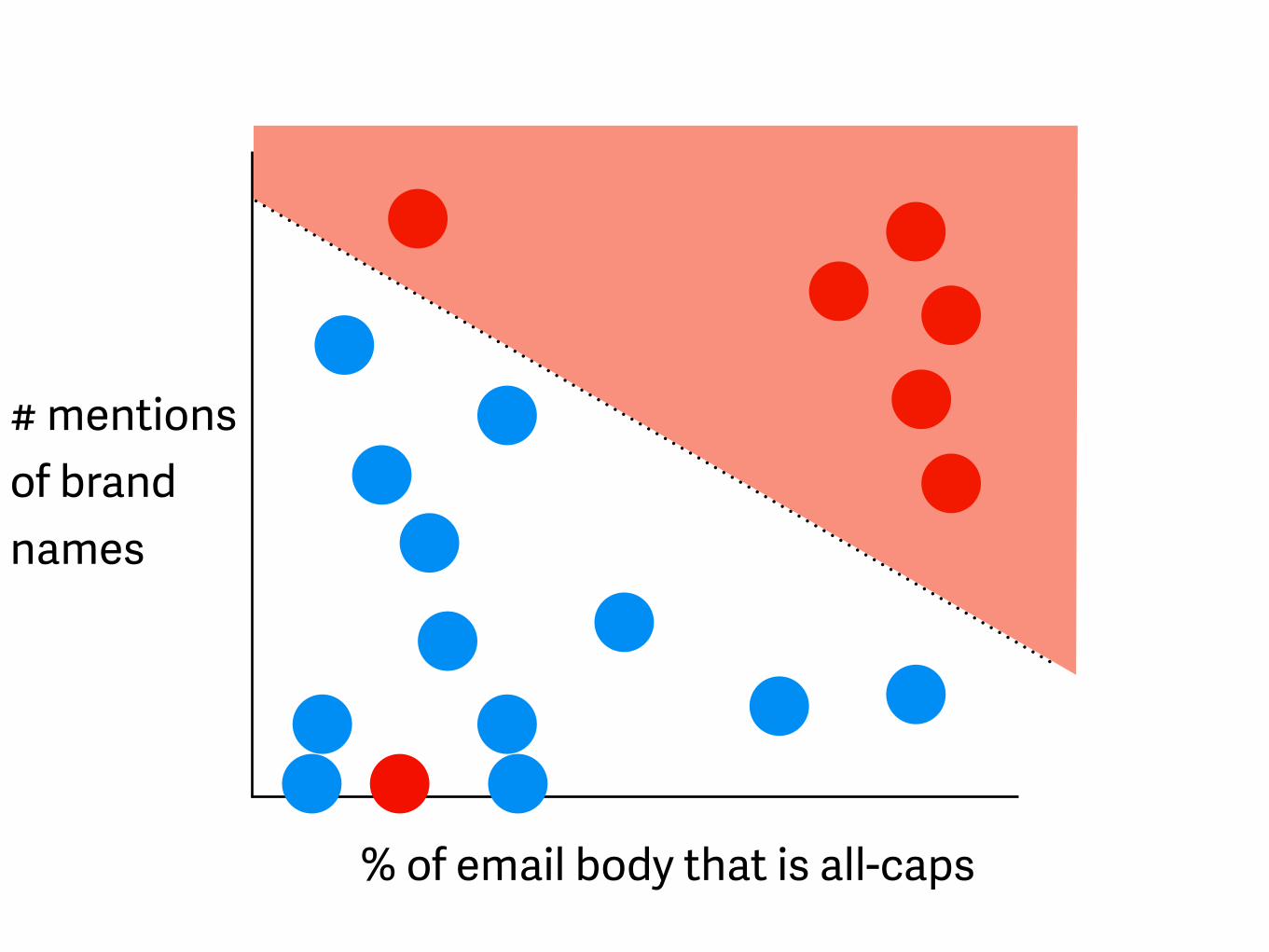
% of email body that is all-caps
# mentions of brand names
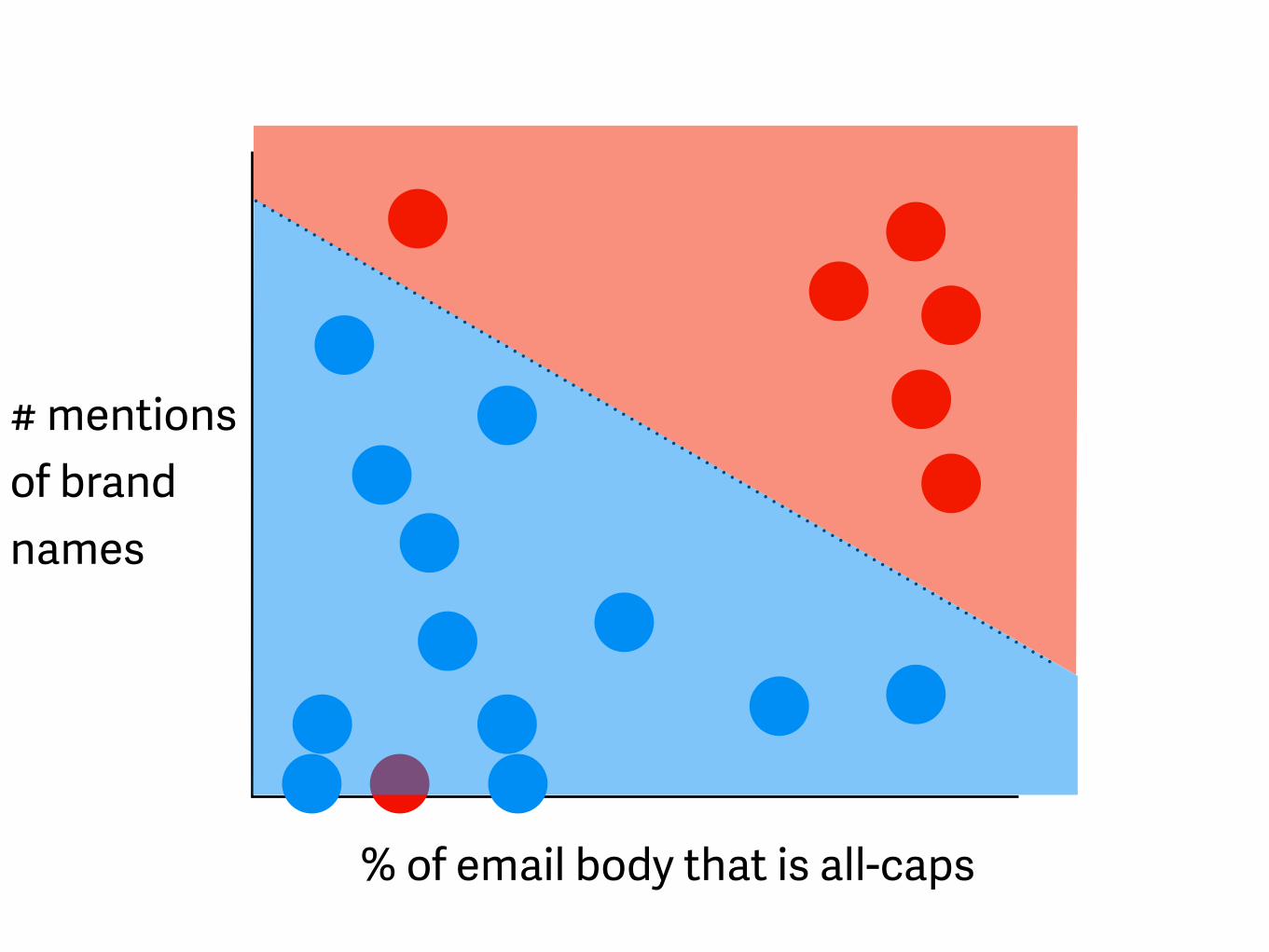
% of email body that is all-caps
# mentions of brand names
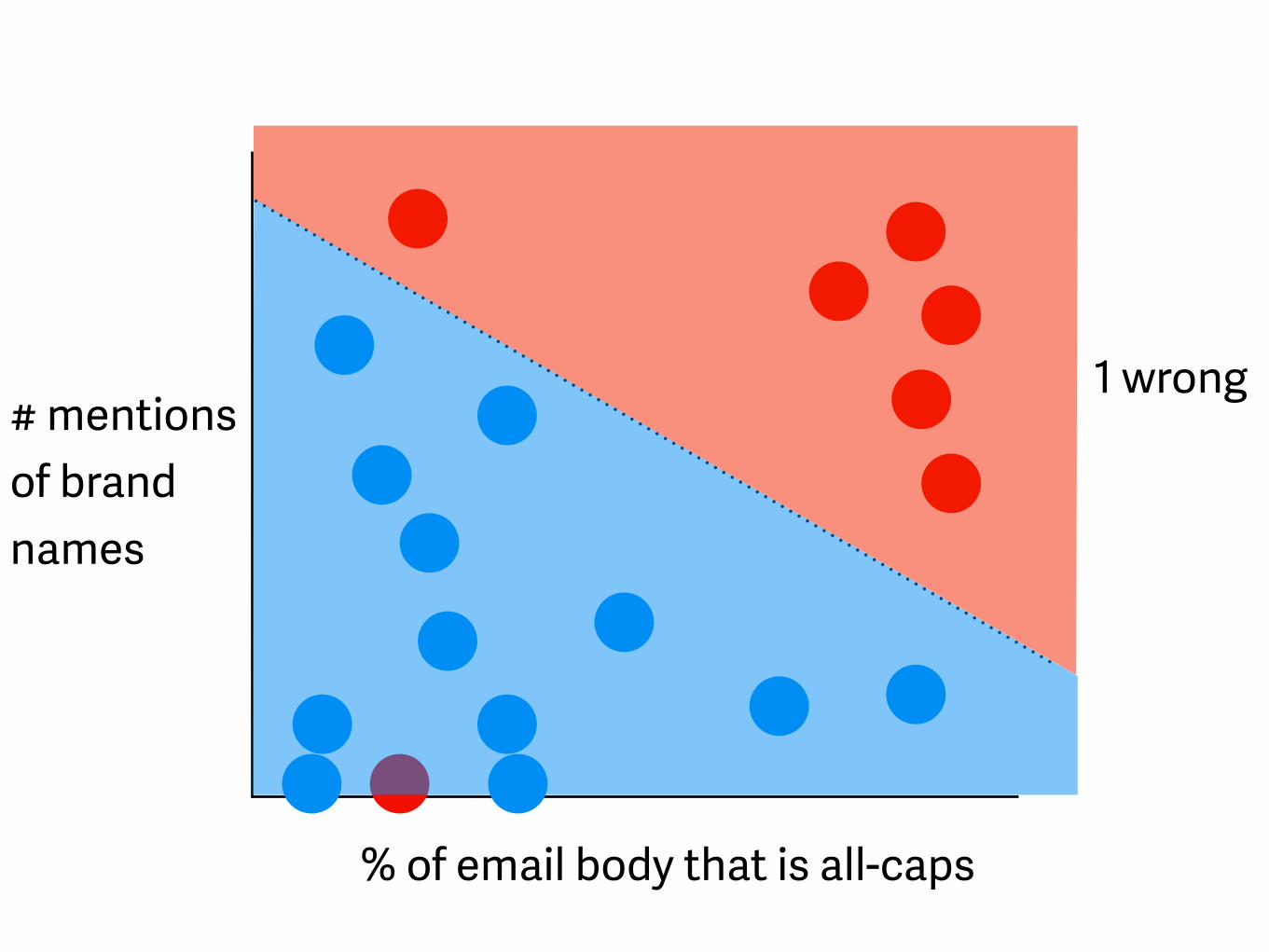
% of email body that is all-caps
# mentions of brand names
1 wrong
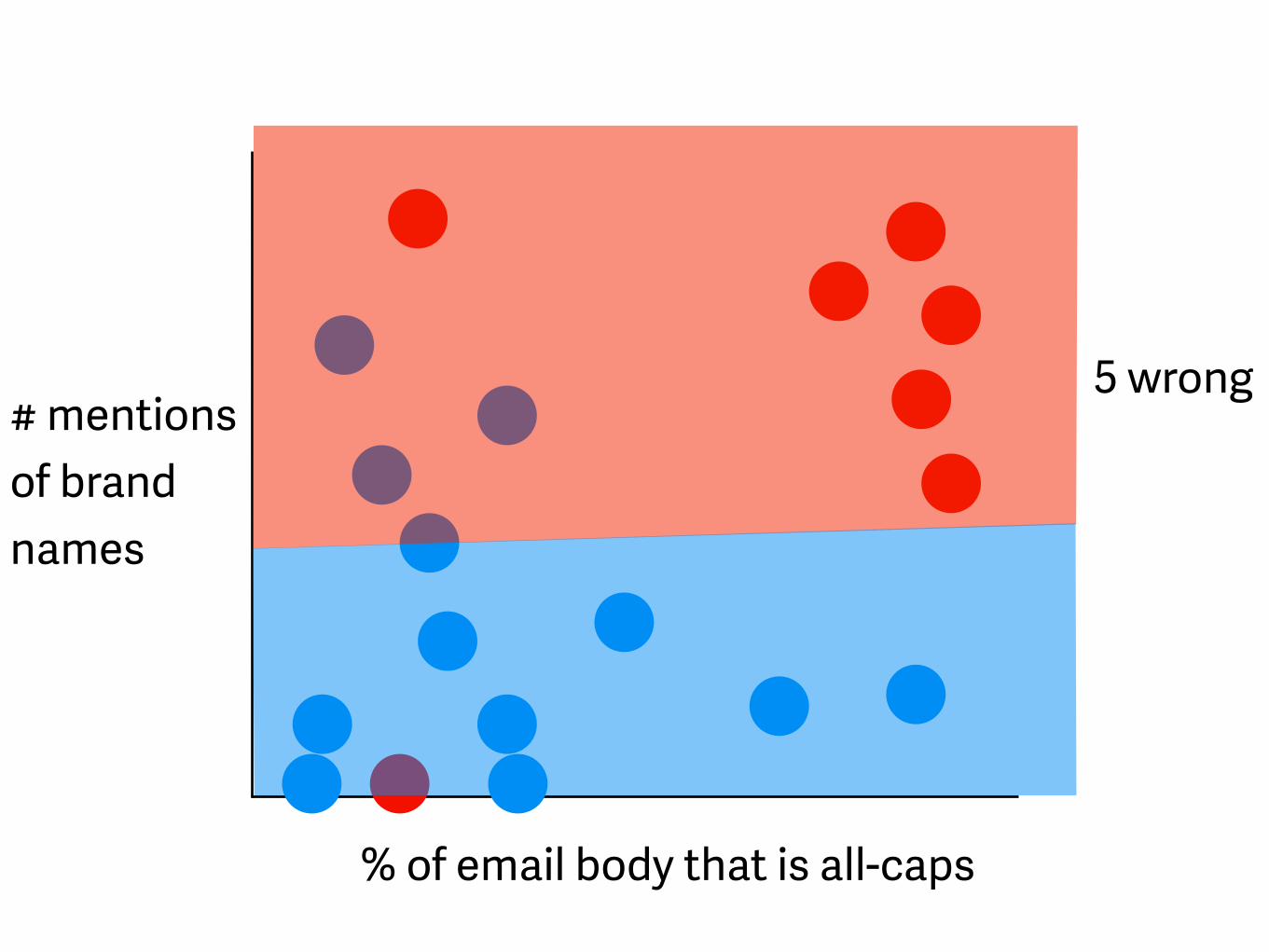
% of email body that is all-caps
# mentions of brand names
5 wrong
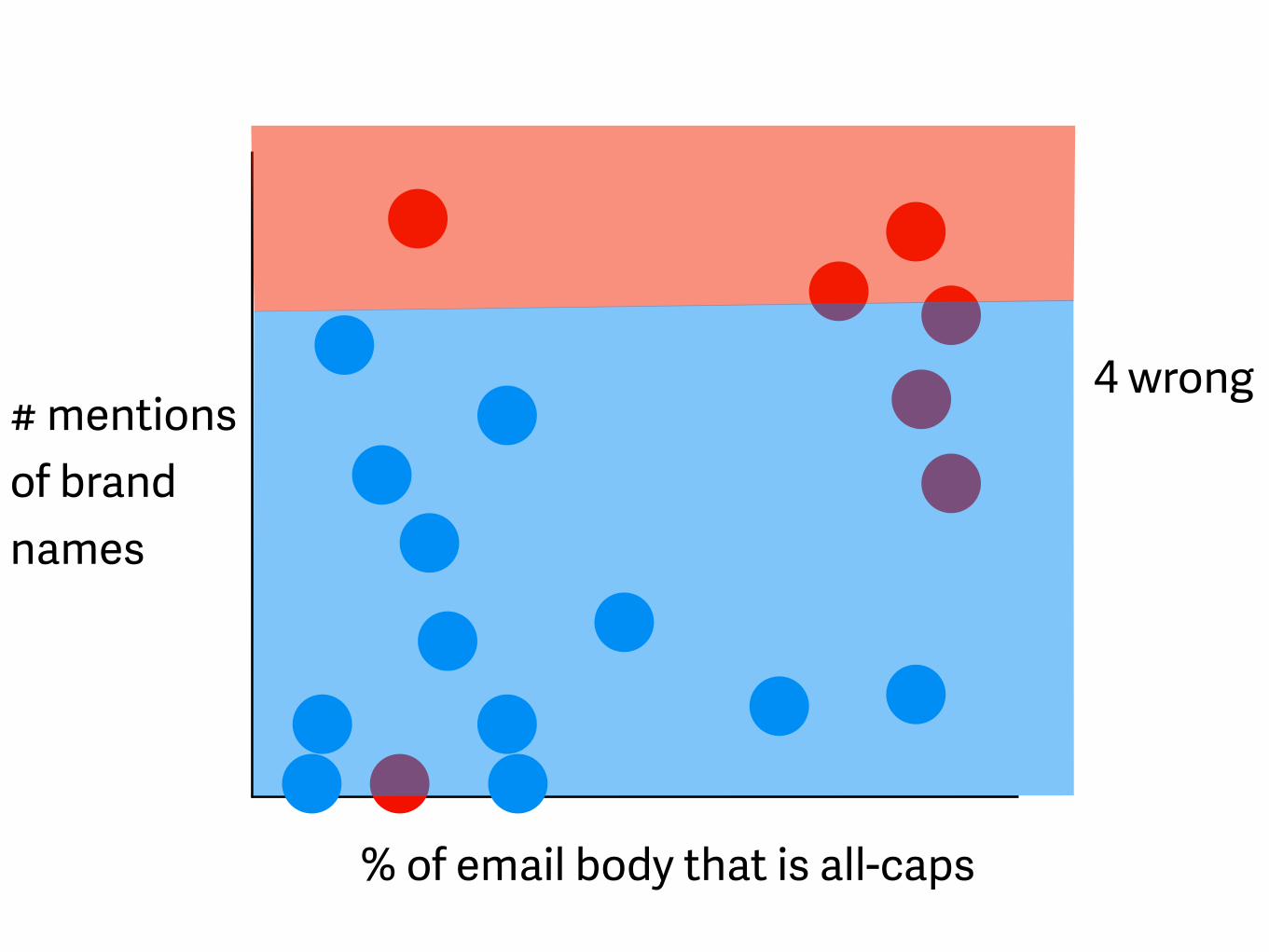
% of email body that is all-caps
# mentions of brand names
4 wrong
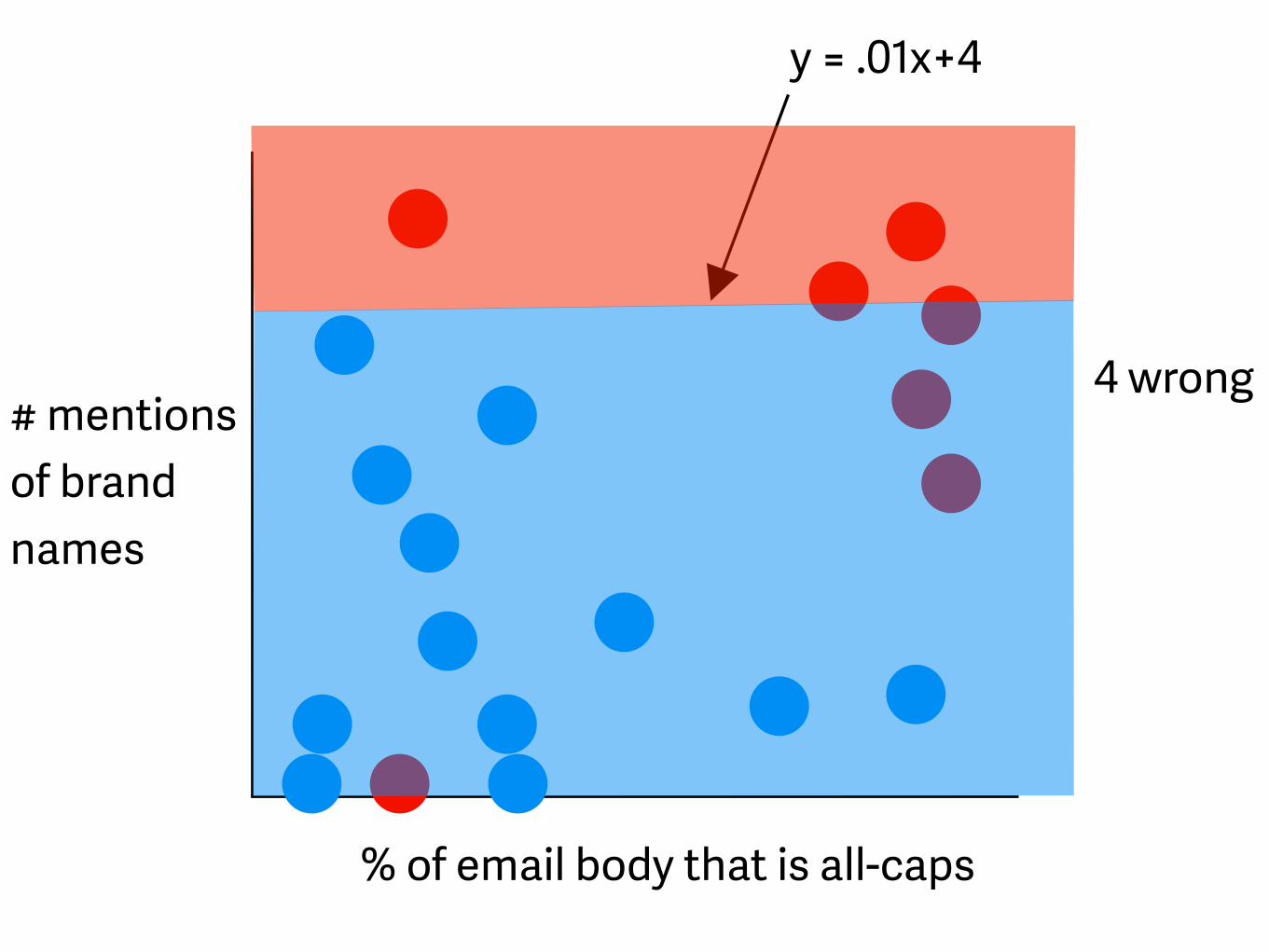
% of email body that is all-caps
# mentions of brand names
4 wrong
y = .01x+4
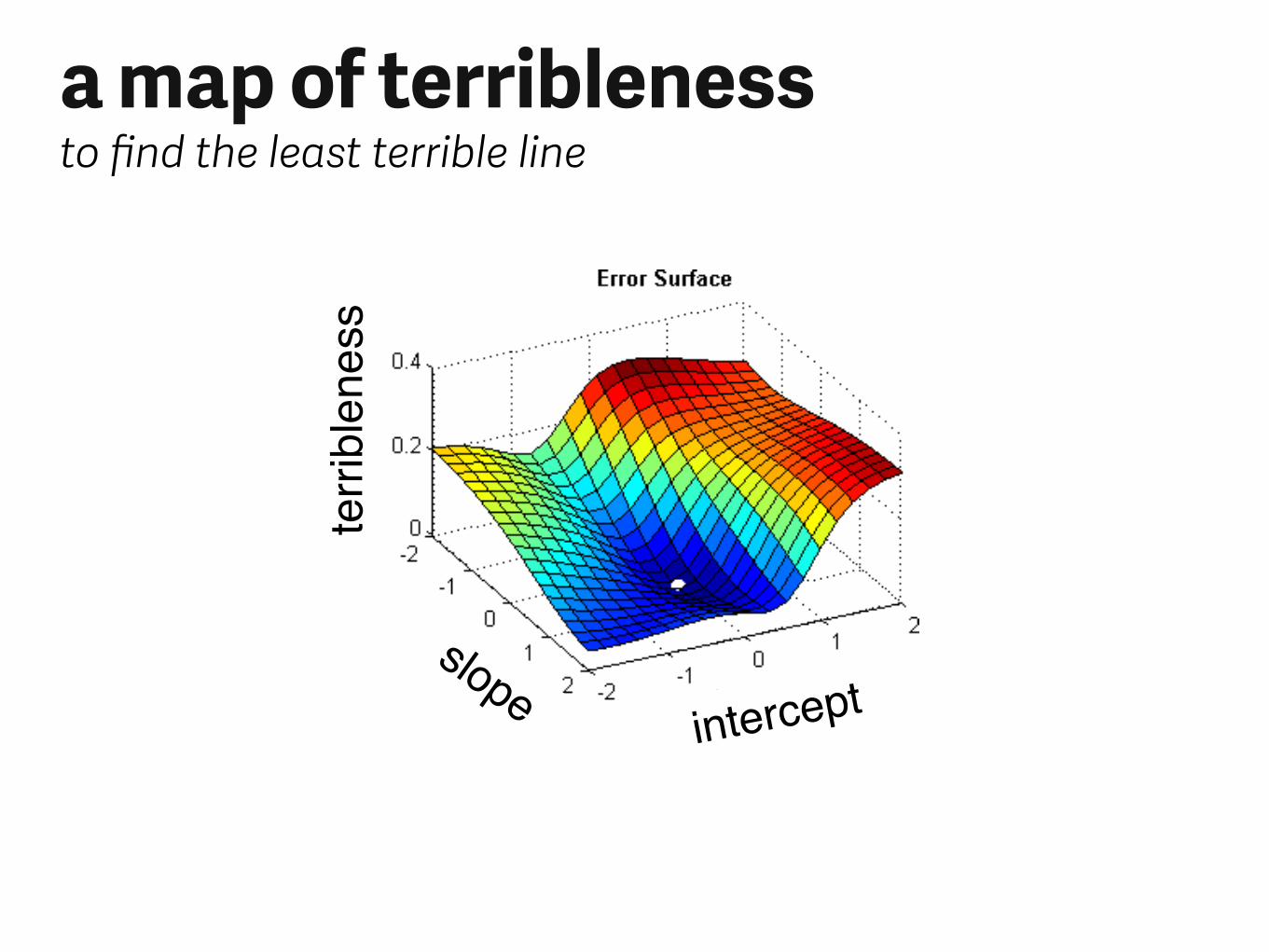
terri
blen
ess
slopeintercept
a map of terriblenessto find the least terrible line
terri
blen
ess
slopeintercept
a map of terriblenessto find the least terrible line
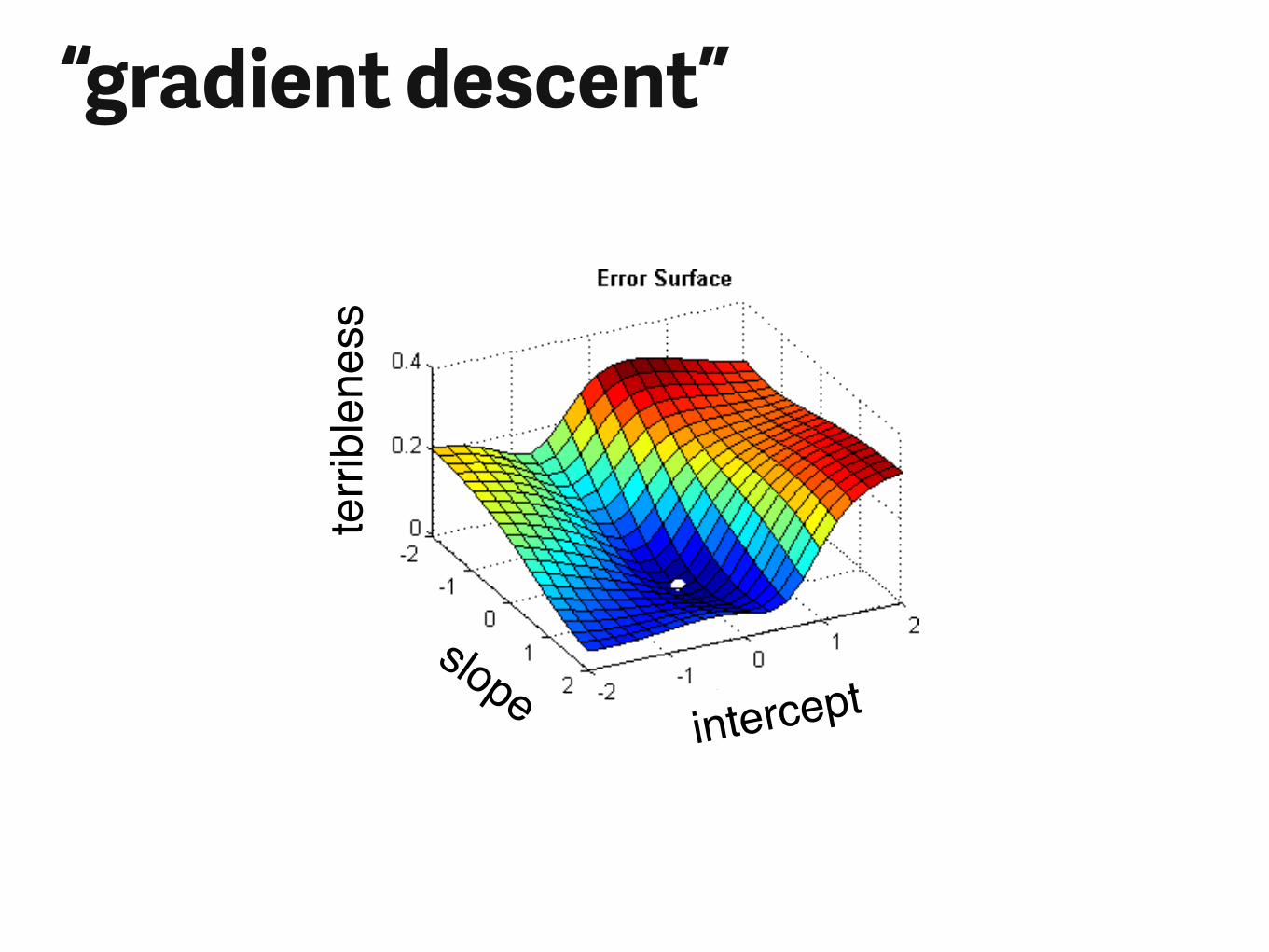
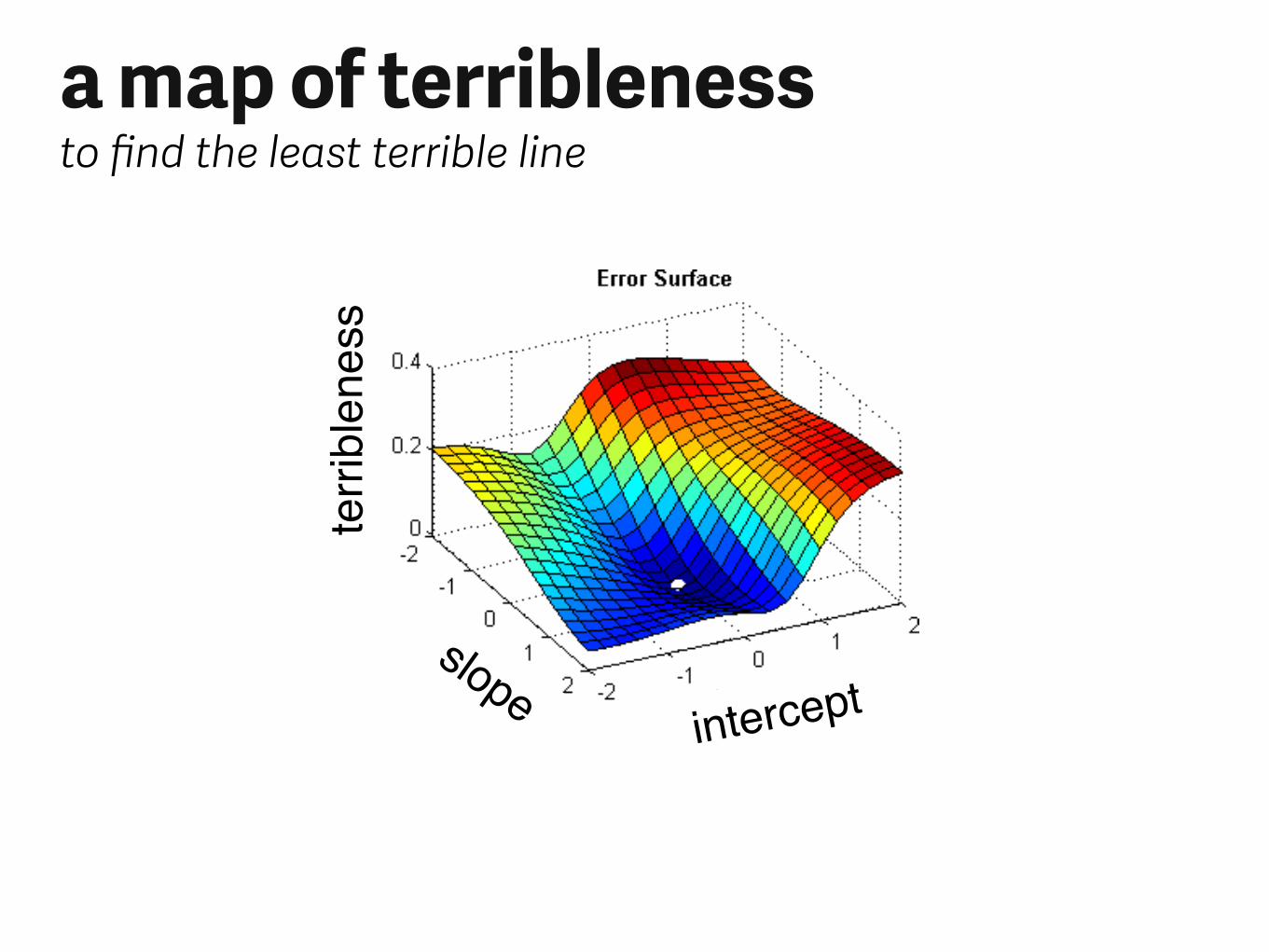
terri
blen
ess
slopeintercept
“gradient descent”
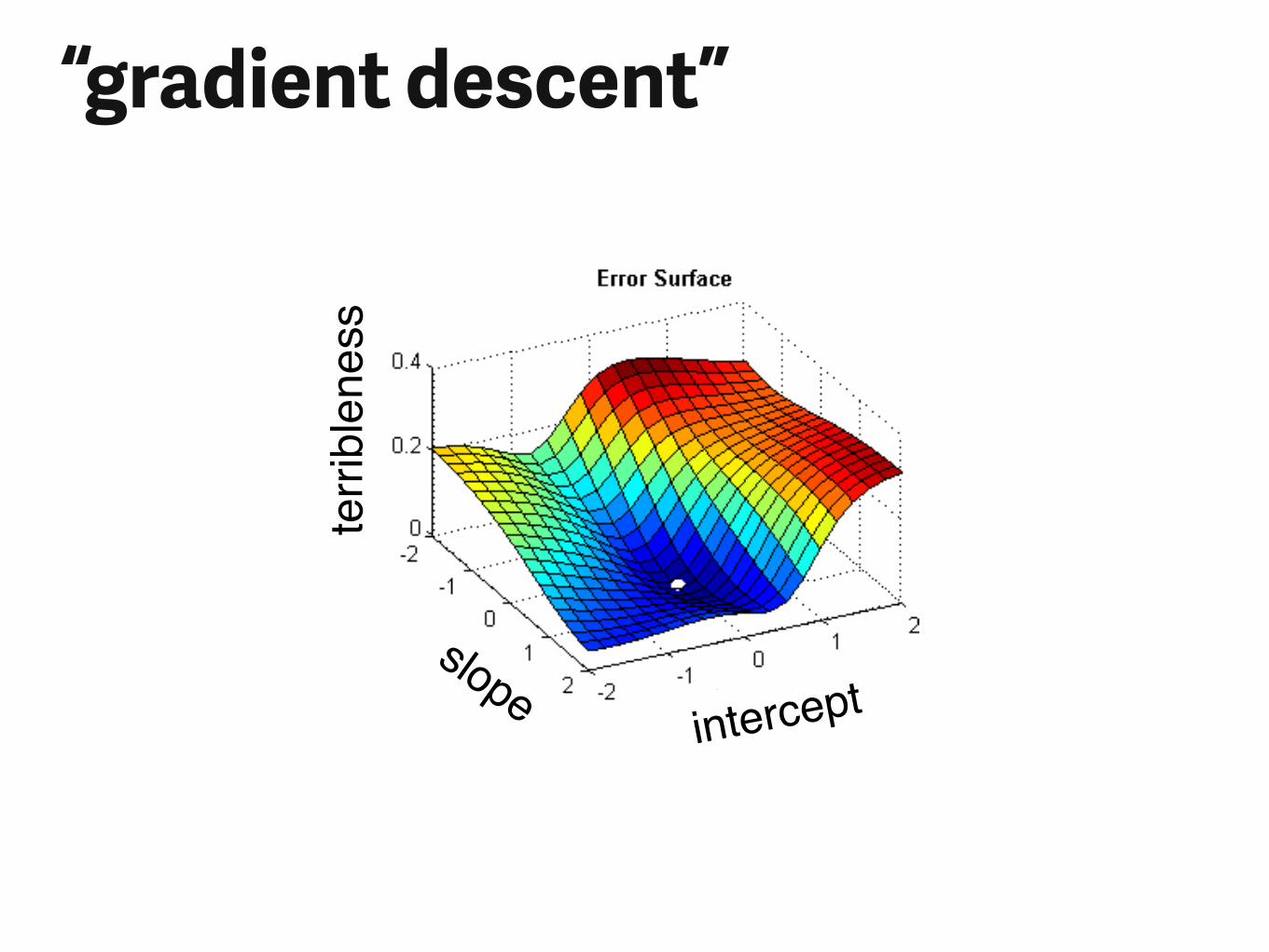
terri
blen
ess
slopeintercept
“gradient descent”
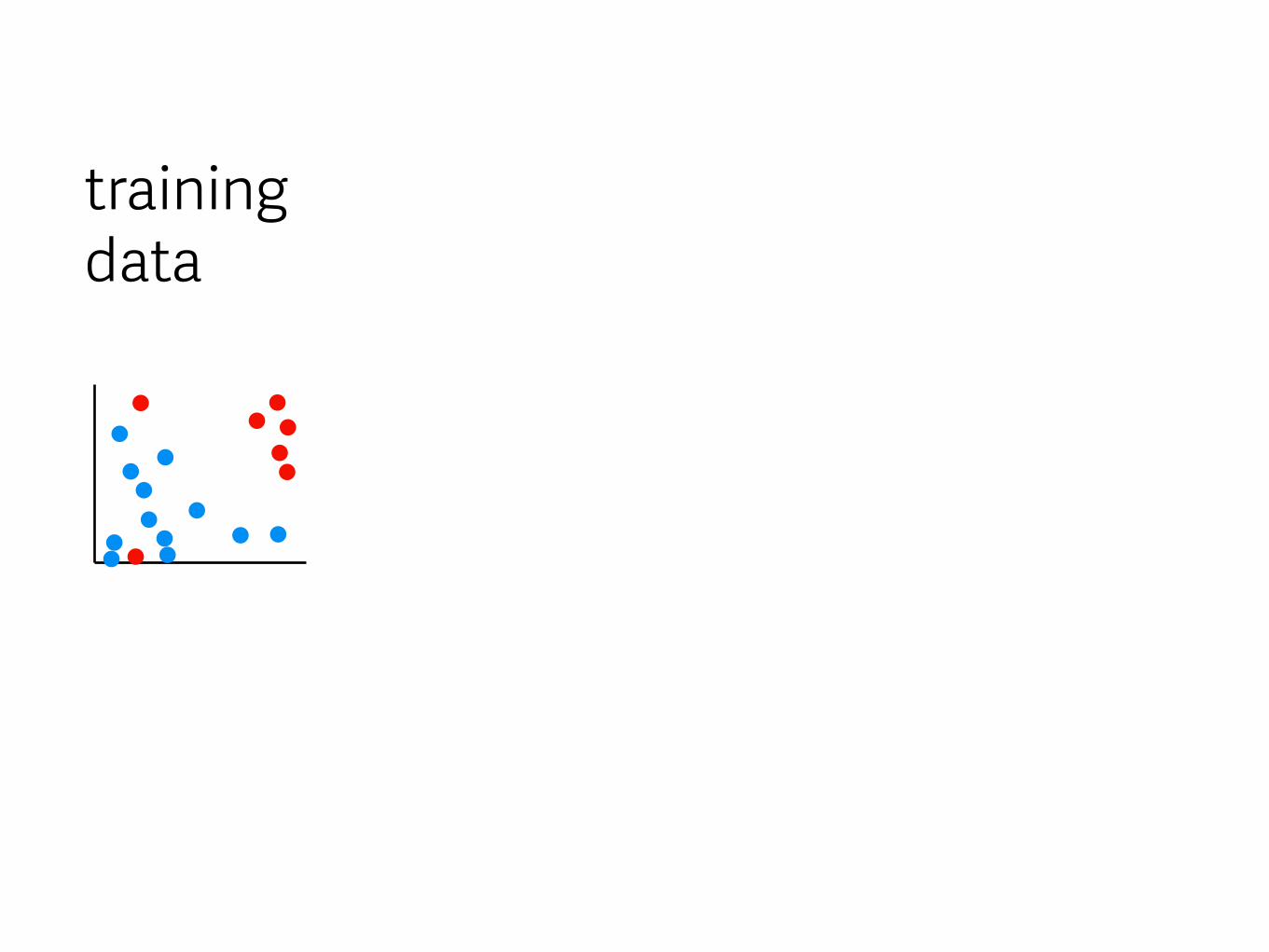
training data

training data
import numpy as np X = np.array([[1, 0.1], [3, 0.2], [5, 0.1]…]) y = np.array([1, 2, 1])
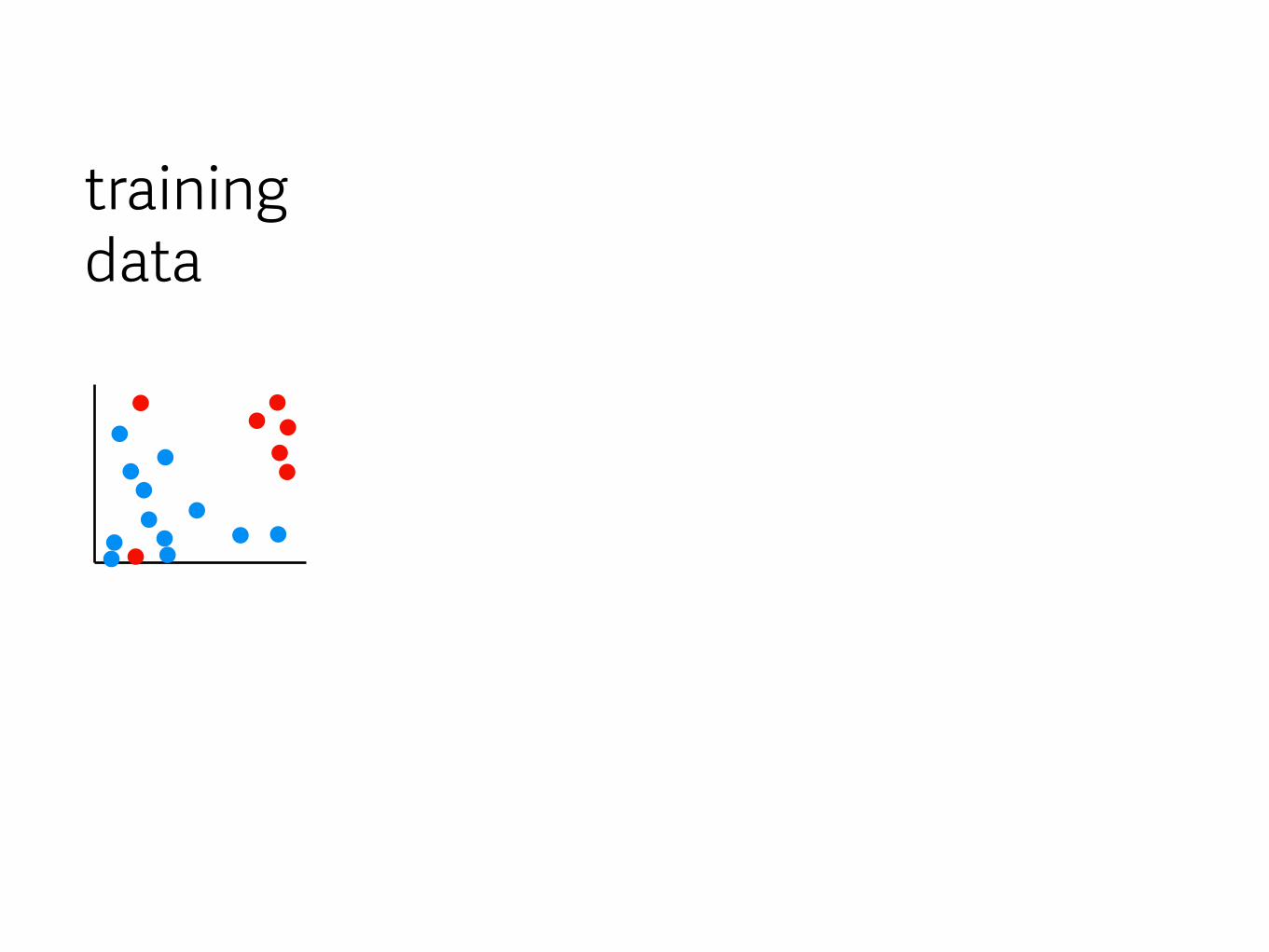
training data

training data

training data
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis model = LinearDiscriminantAnalysis() model.fit(X, y)
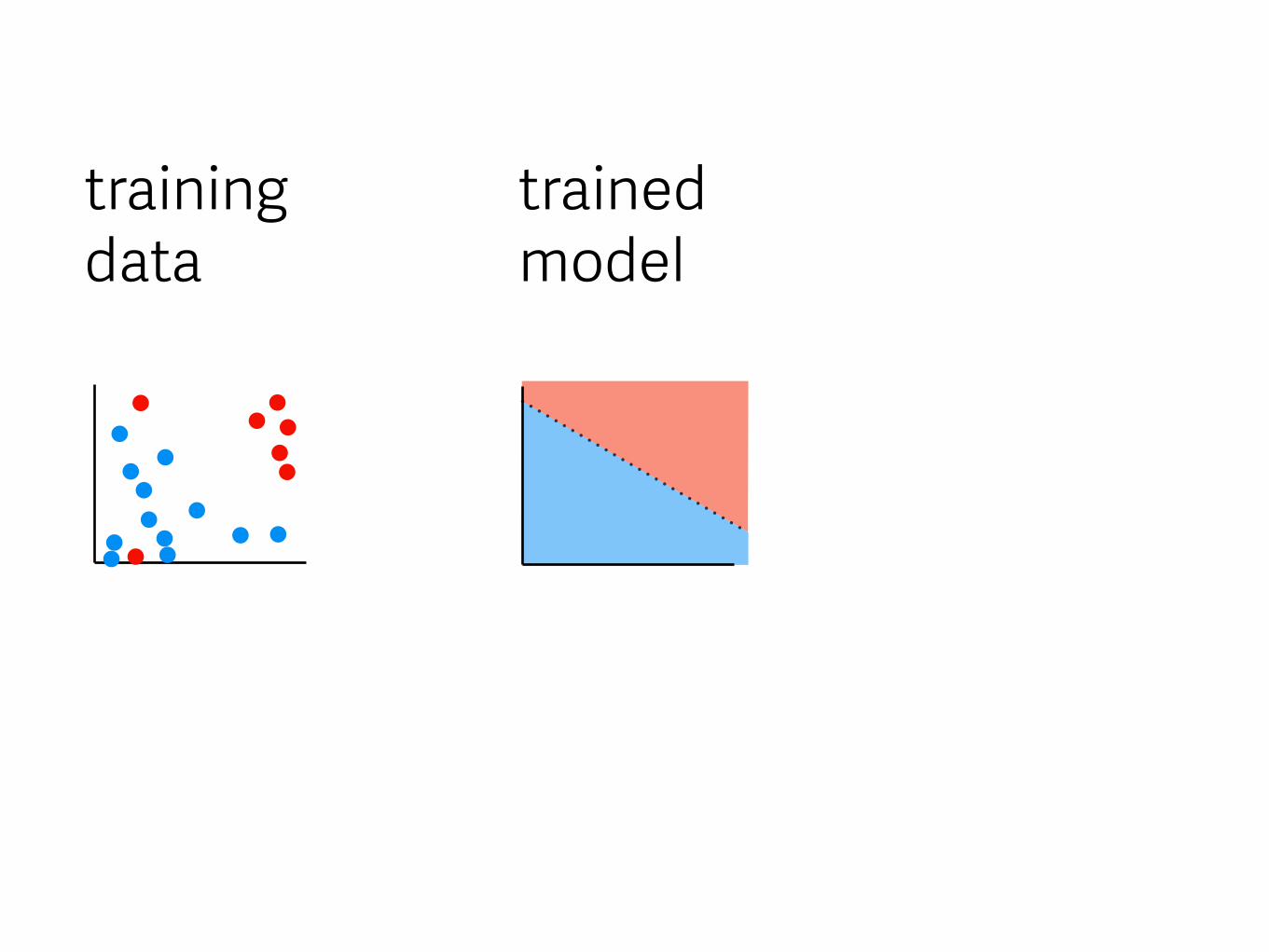
training data
trained model
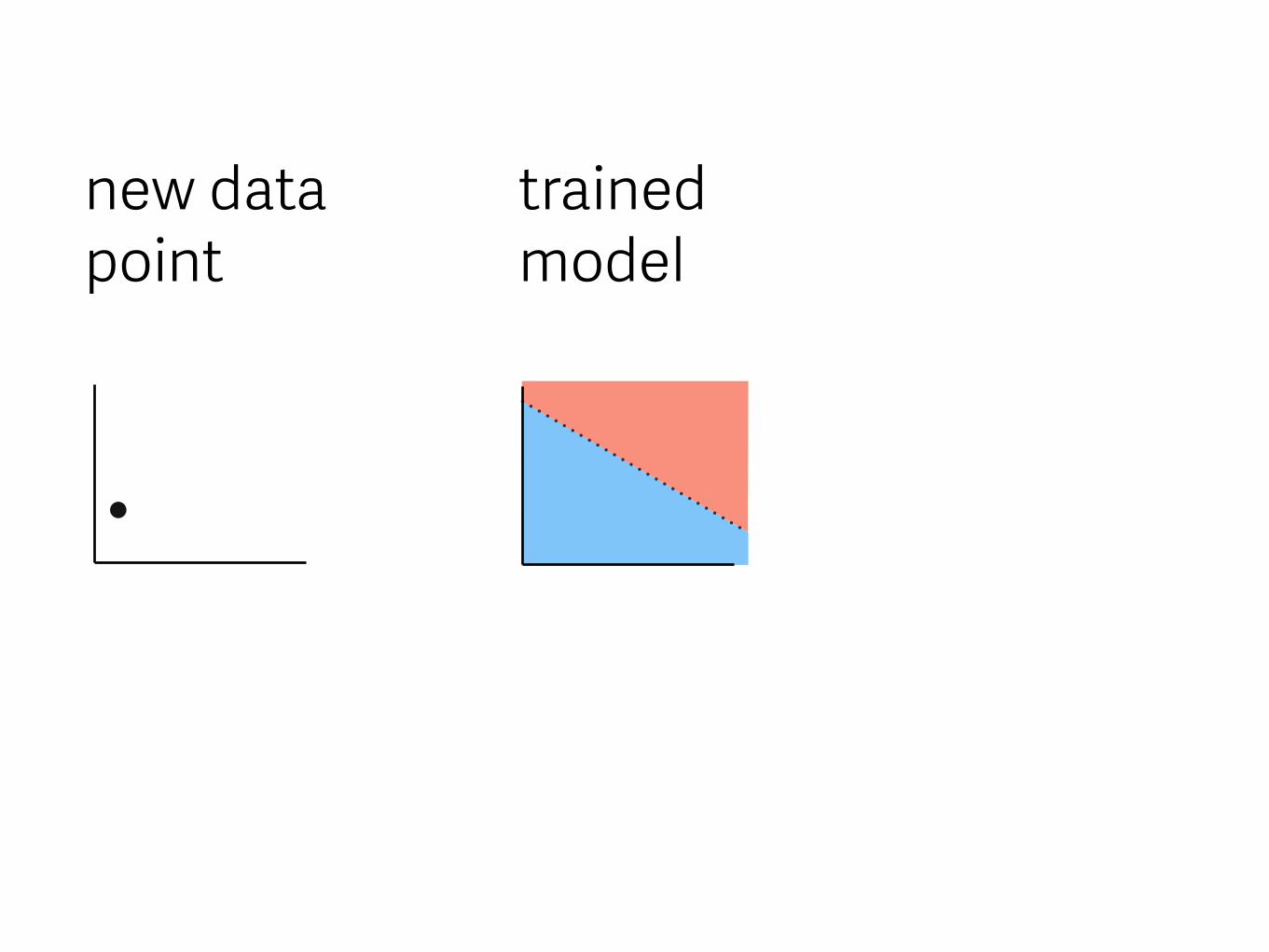
new data point
trained model

trained model

trained model
new_point = np.array([1, .3])

trained model
new_point = np.array([1, .3])print(model.predict(new_point))

trained model
new_point = np.array([1, .3])print(model.predict(new_point))1
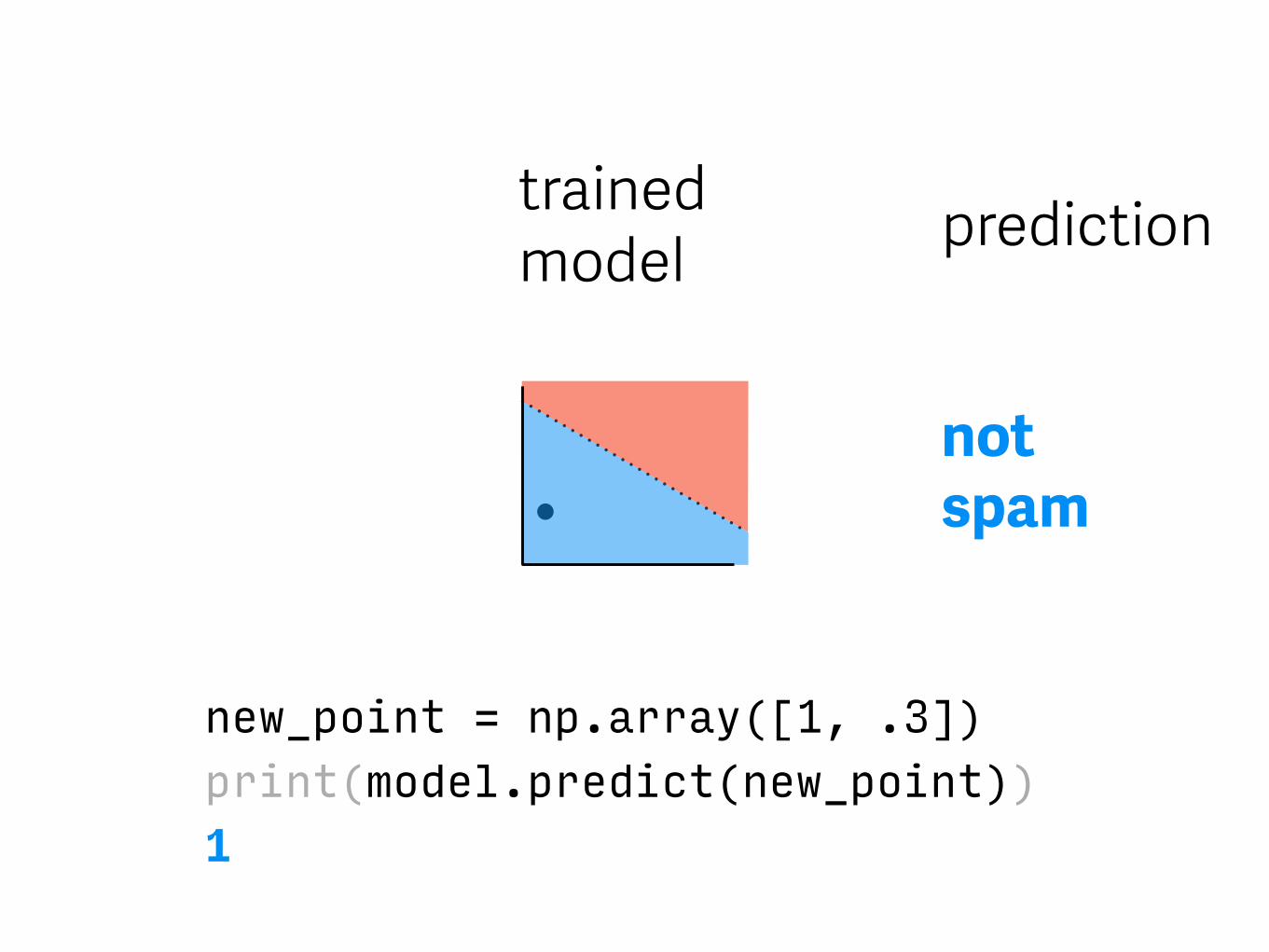
trained model
new_point = np.array([1, .3])print(model.predict(new_point))1
not spam
prediction
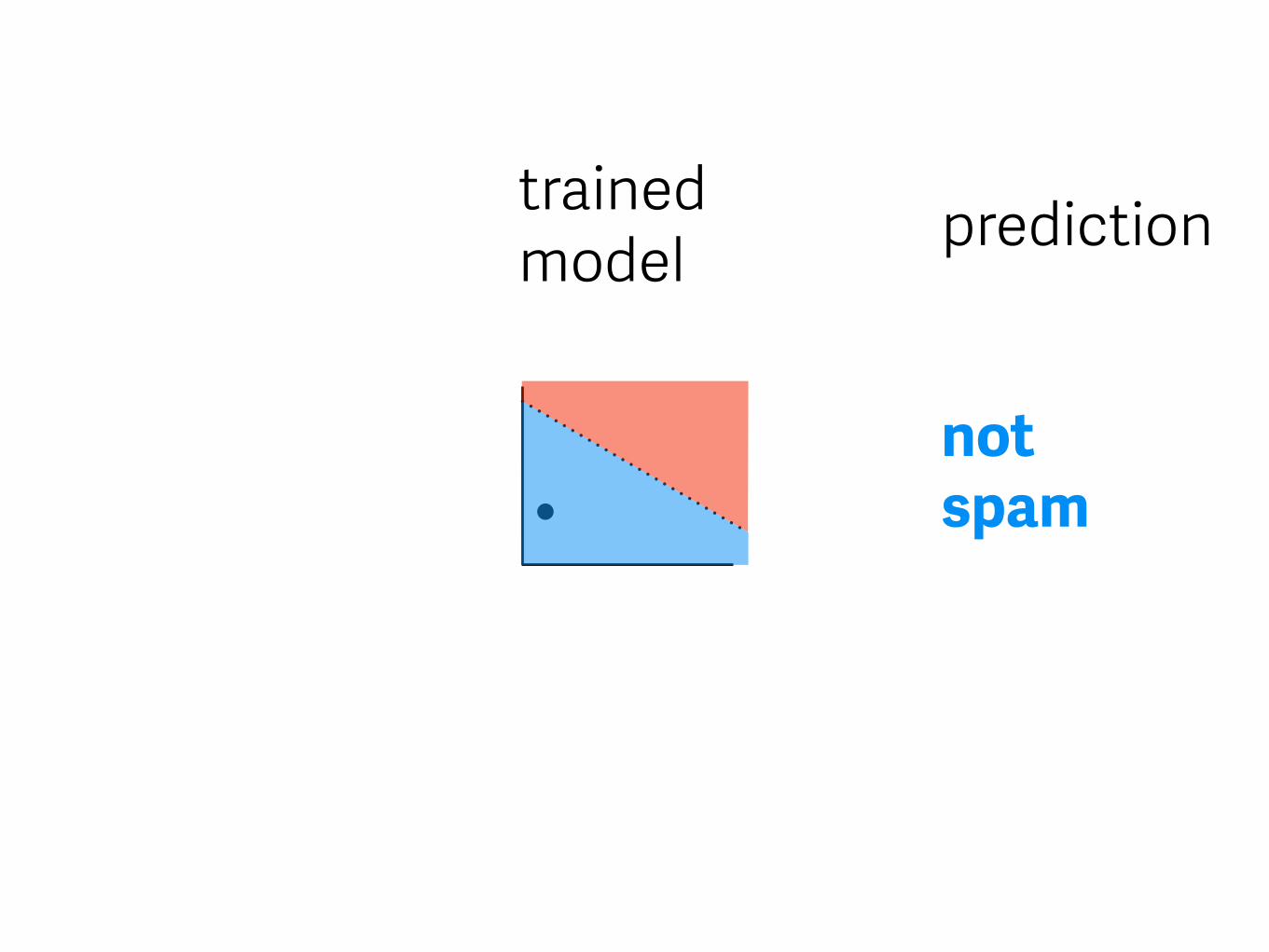
trained model
not spam
prediction

Logistic regression
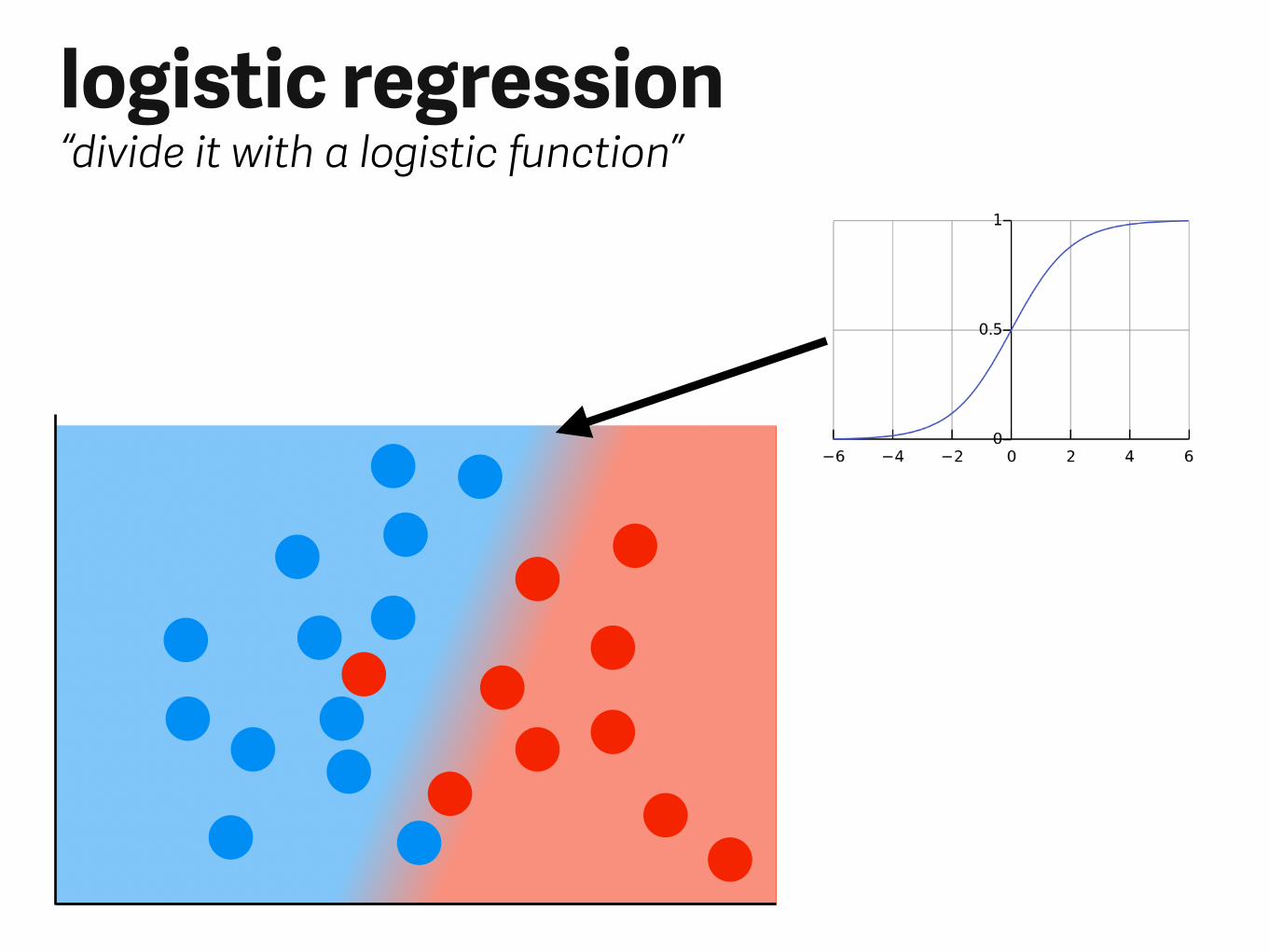
logistic regression“divide it with a logistic function”

logistic regression“divide it with a logistic function”

logistic regression“divide it with a logistic function”
from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X,y) predicted = model.predict(z)

Support Vector Machines
(SVM)

SVMs (support vector machines)“*advanced* draw a line through it”

SVMs (support vector machines)“*advanced* draw a line through it”
- better definition of “terrible”

SVMs (support vector machines)“*advanced* draw a line through it”
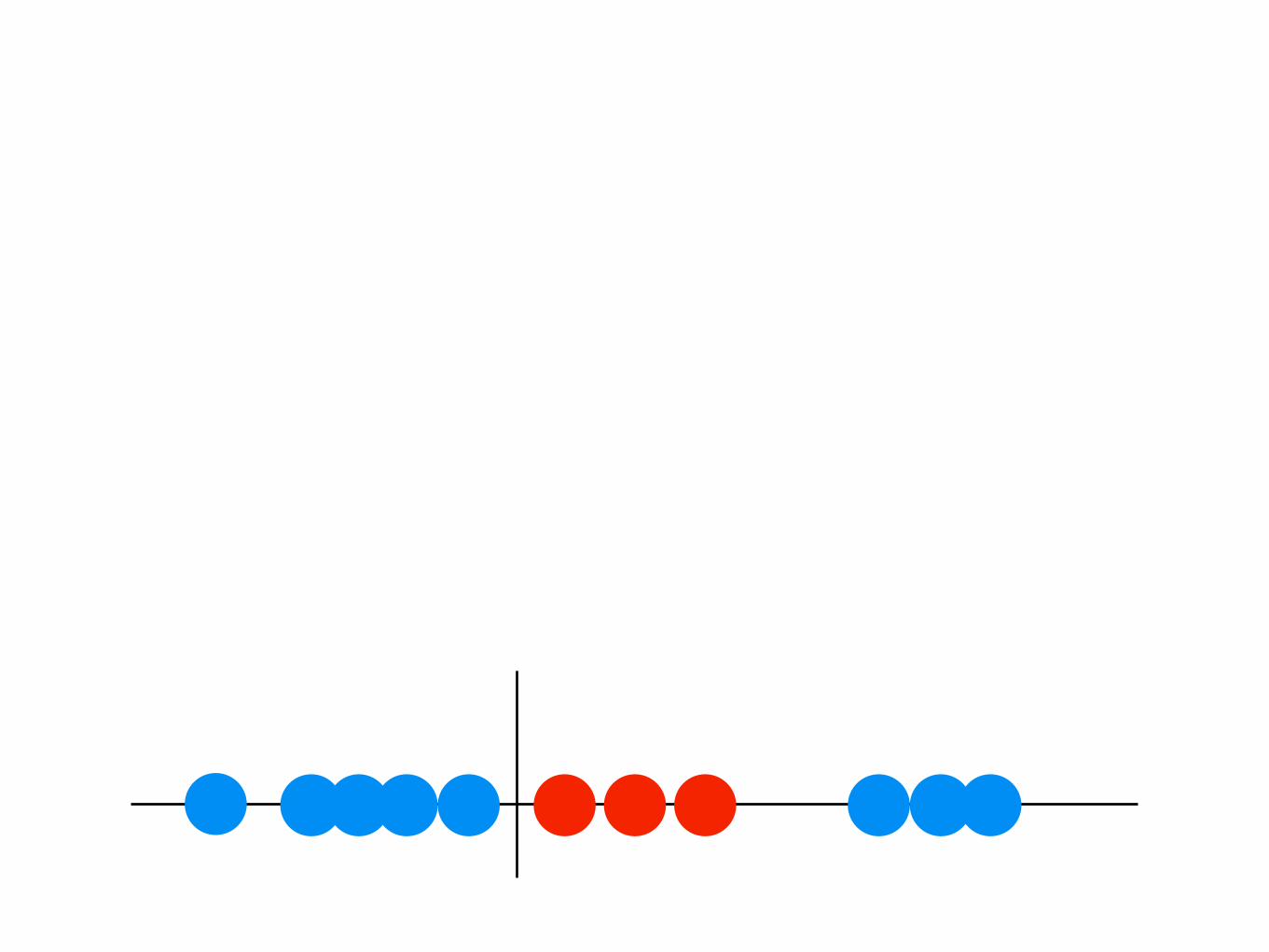
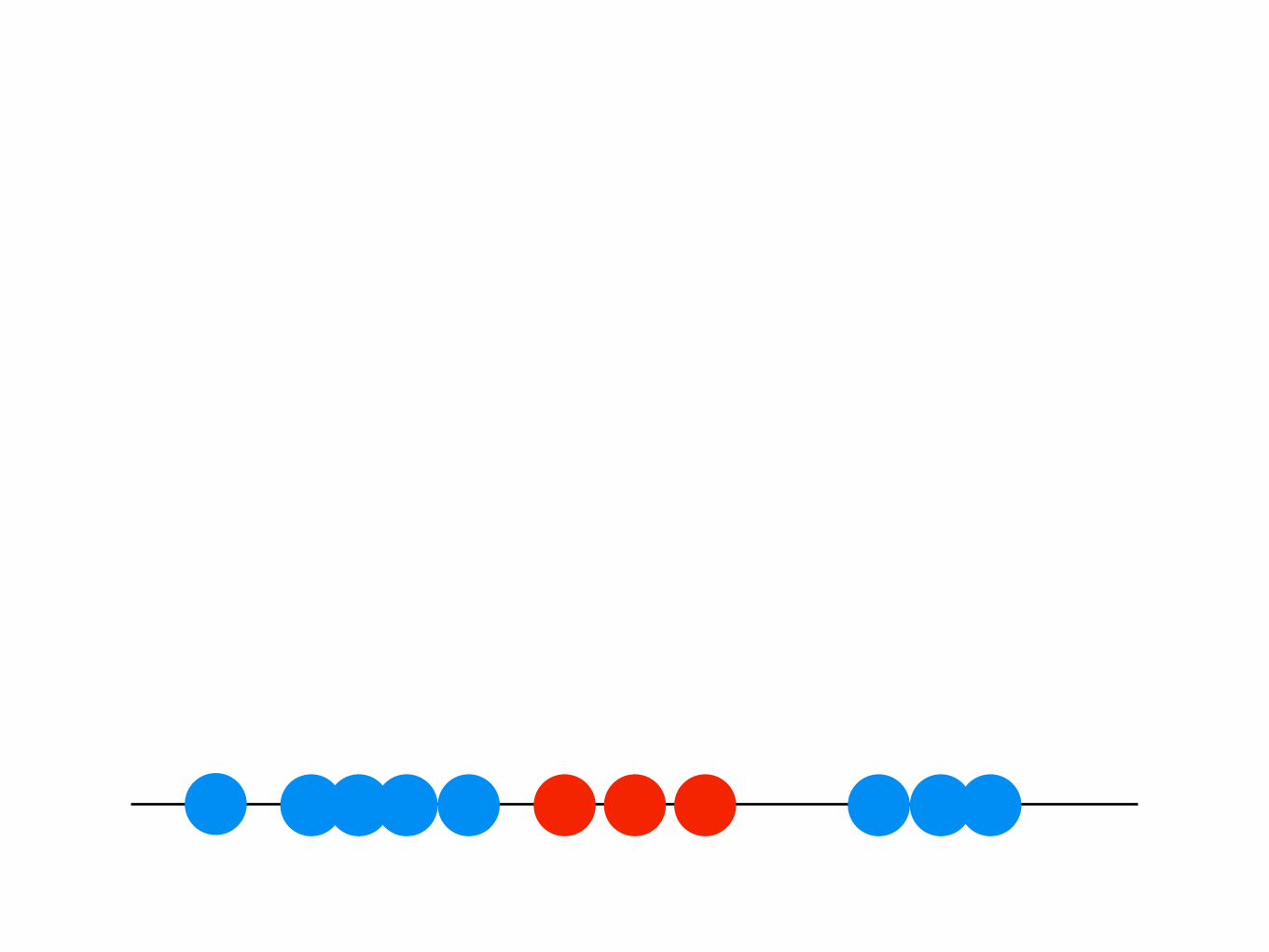
- better definition of “terrible”- lines can turn into non-linear shapes if you transform your data
💩
💩
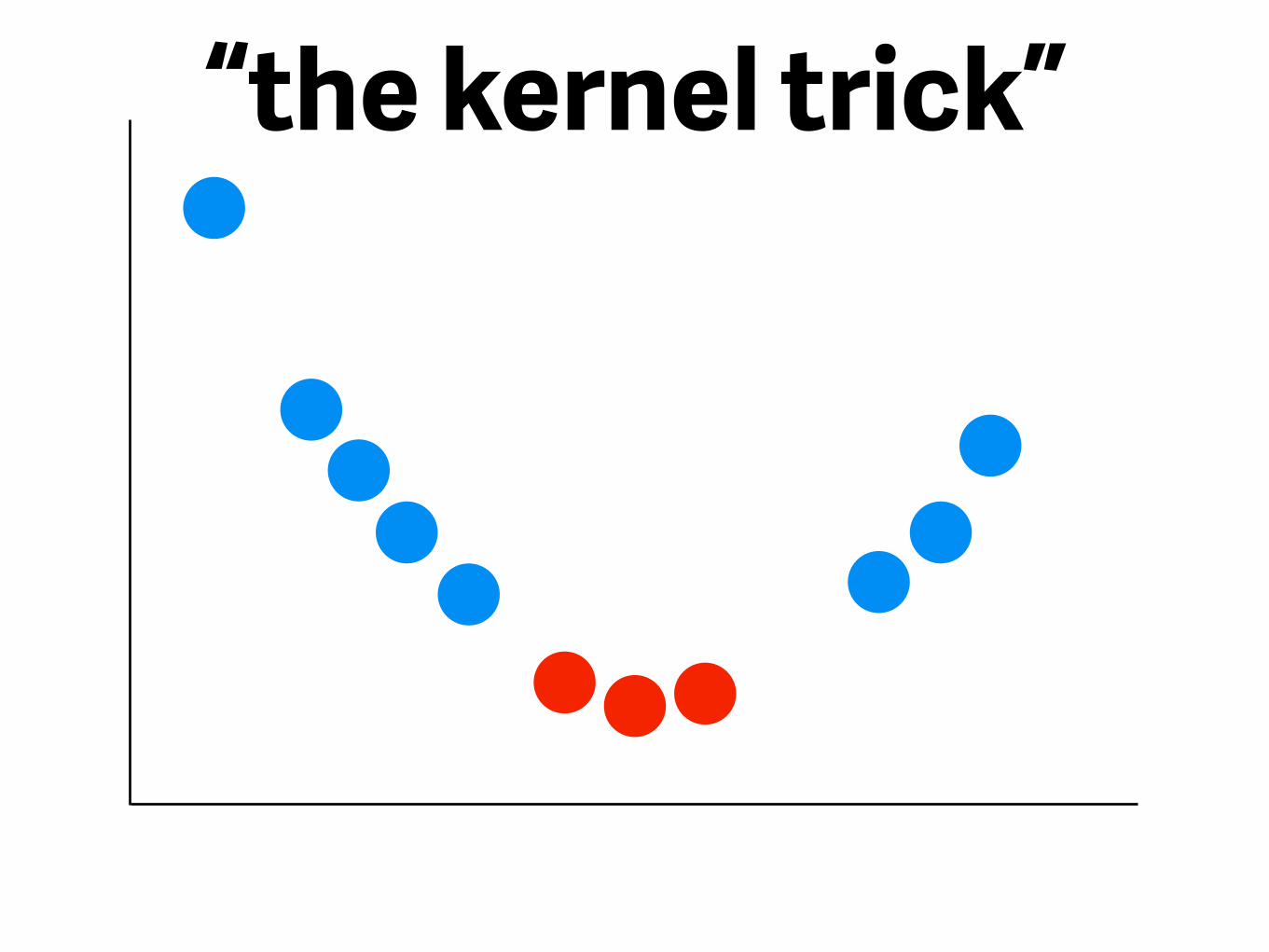
“the kernel trick”
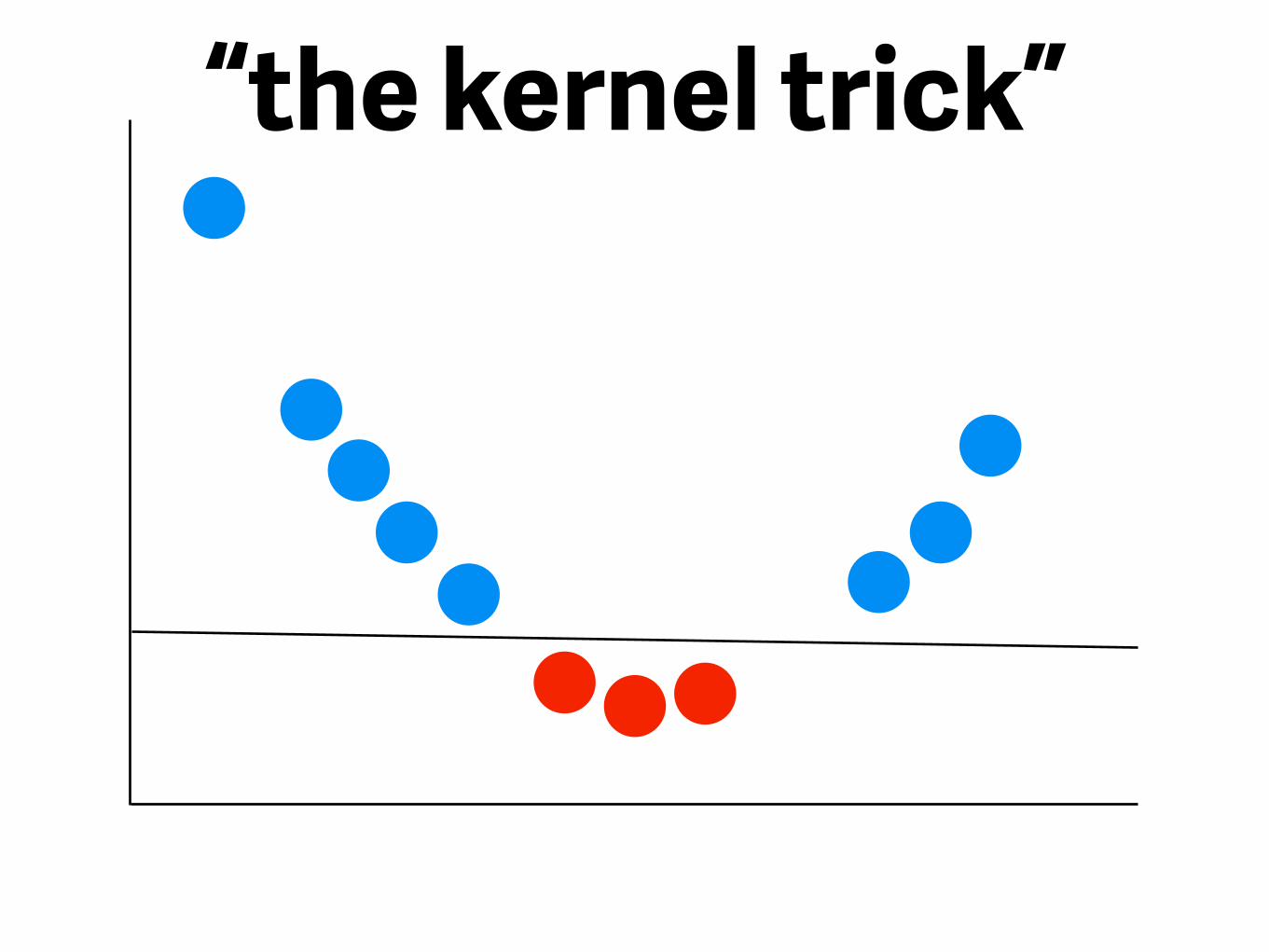
“the kernel trick”

SVMs (support vector machines)“*advanced* draw a line through it”
figure credit: scikit-learn documentation
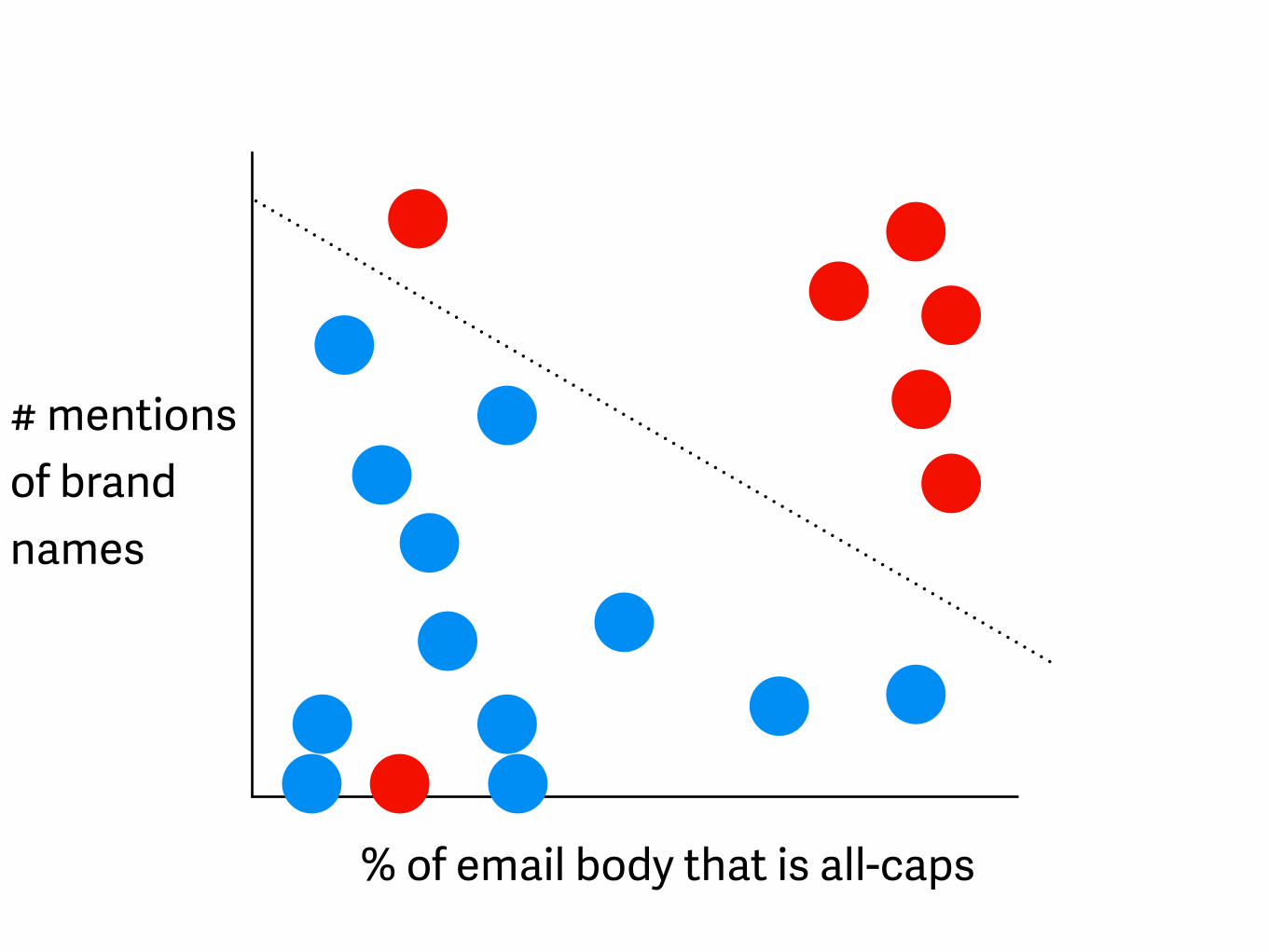
% of email body that is all-caps
# mentions of brand names
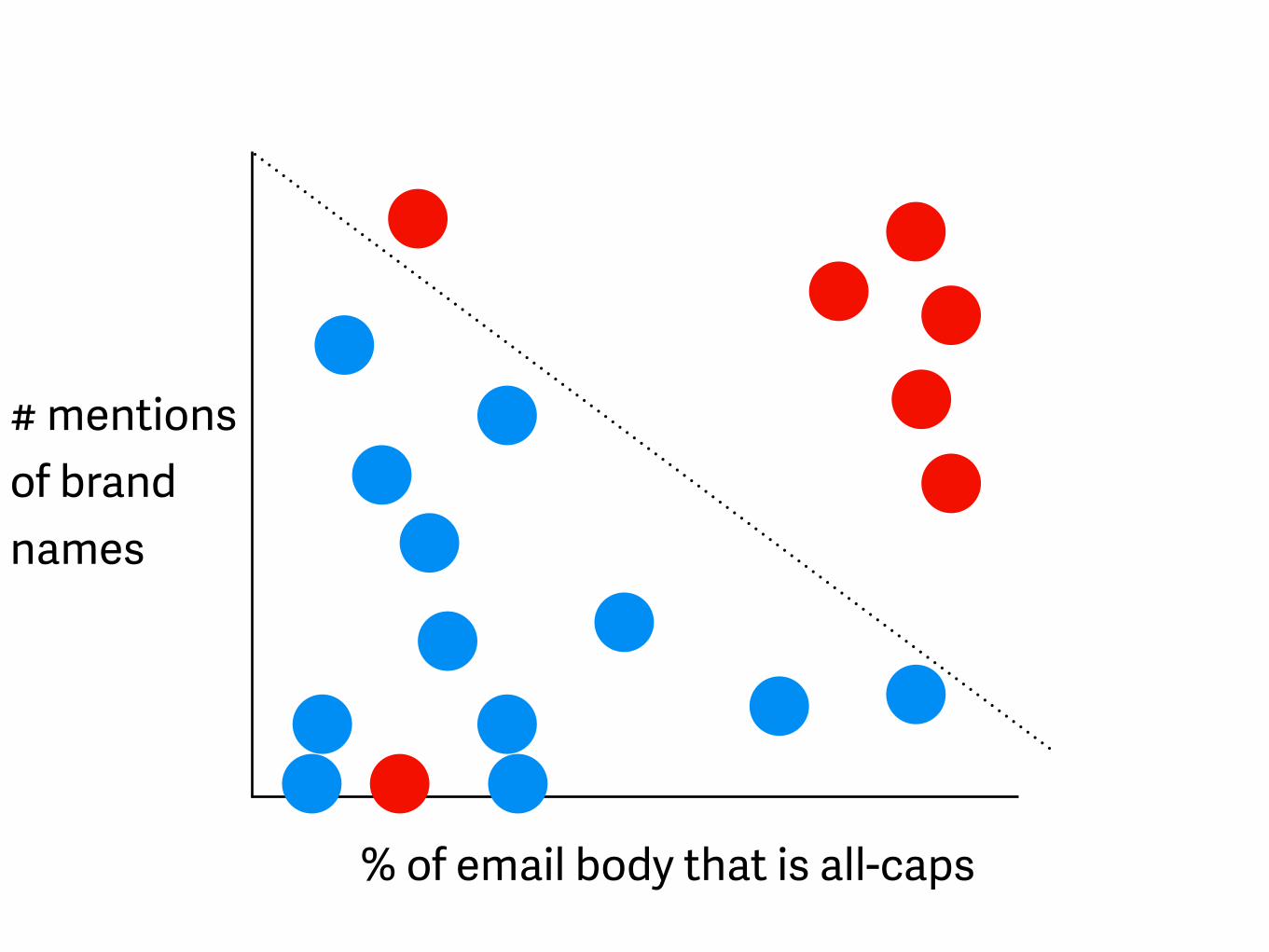
% of email body that is all-caps
# mentions of brand names
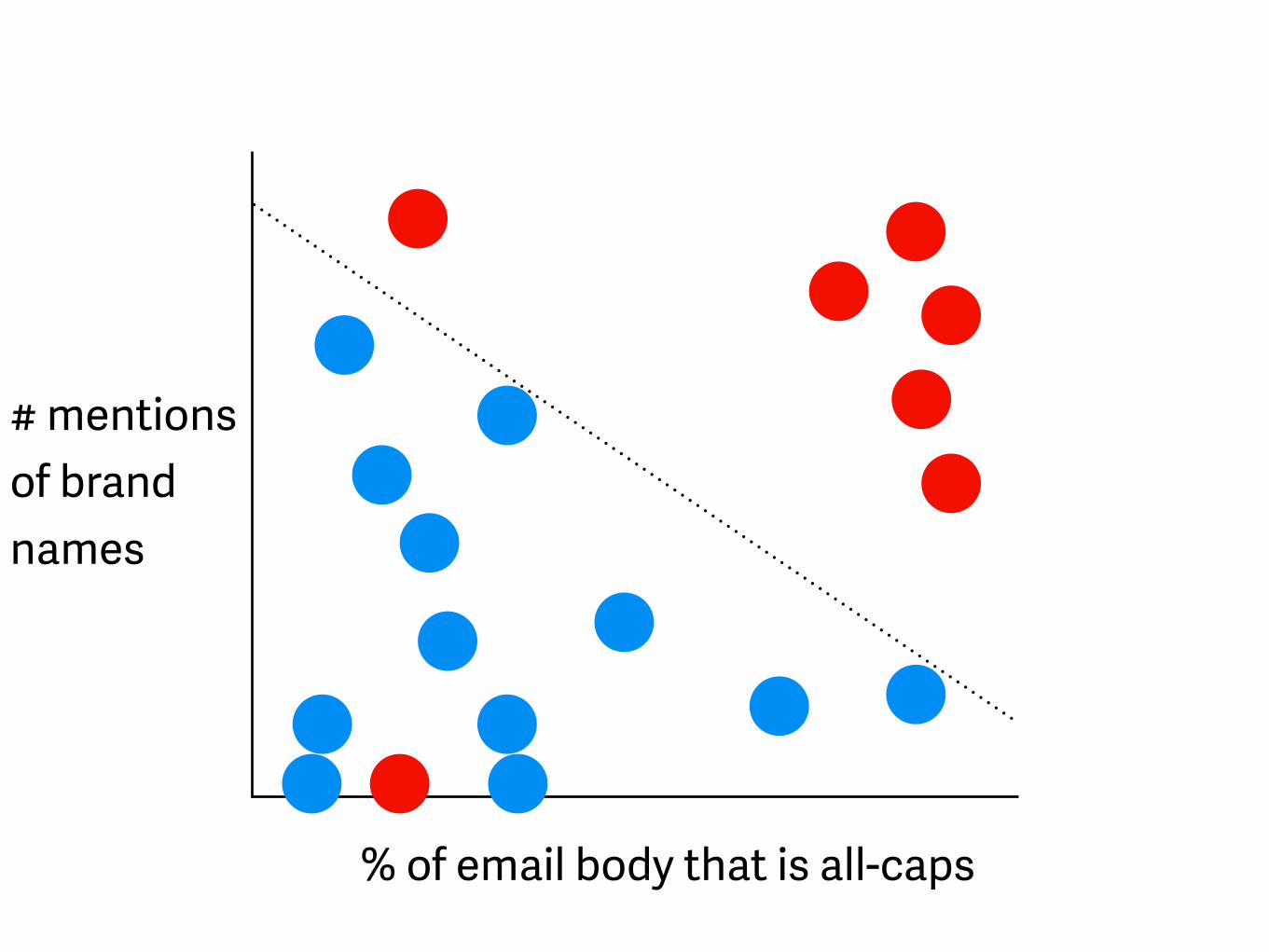
% of email body that is all-caps
# mentions of brand names
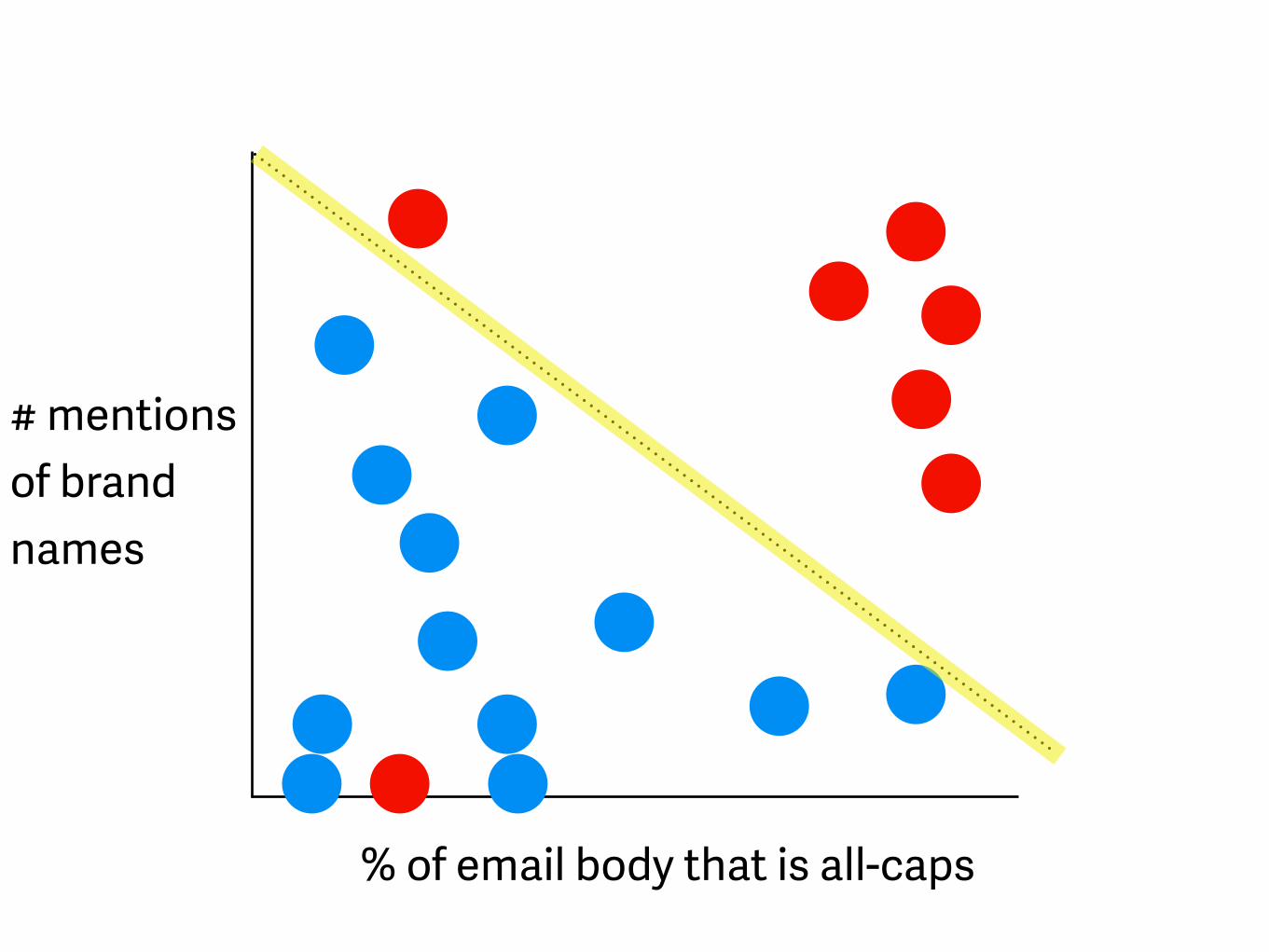
% of email body that is all-caps
# mentions of brand names
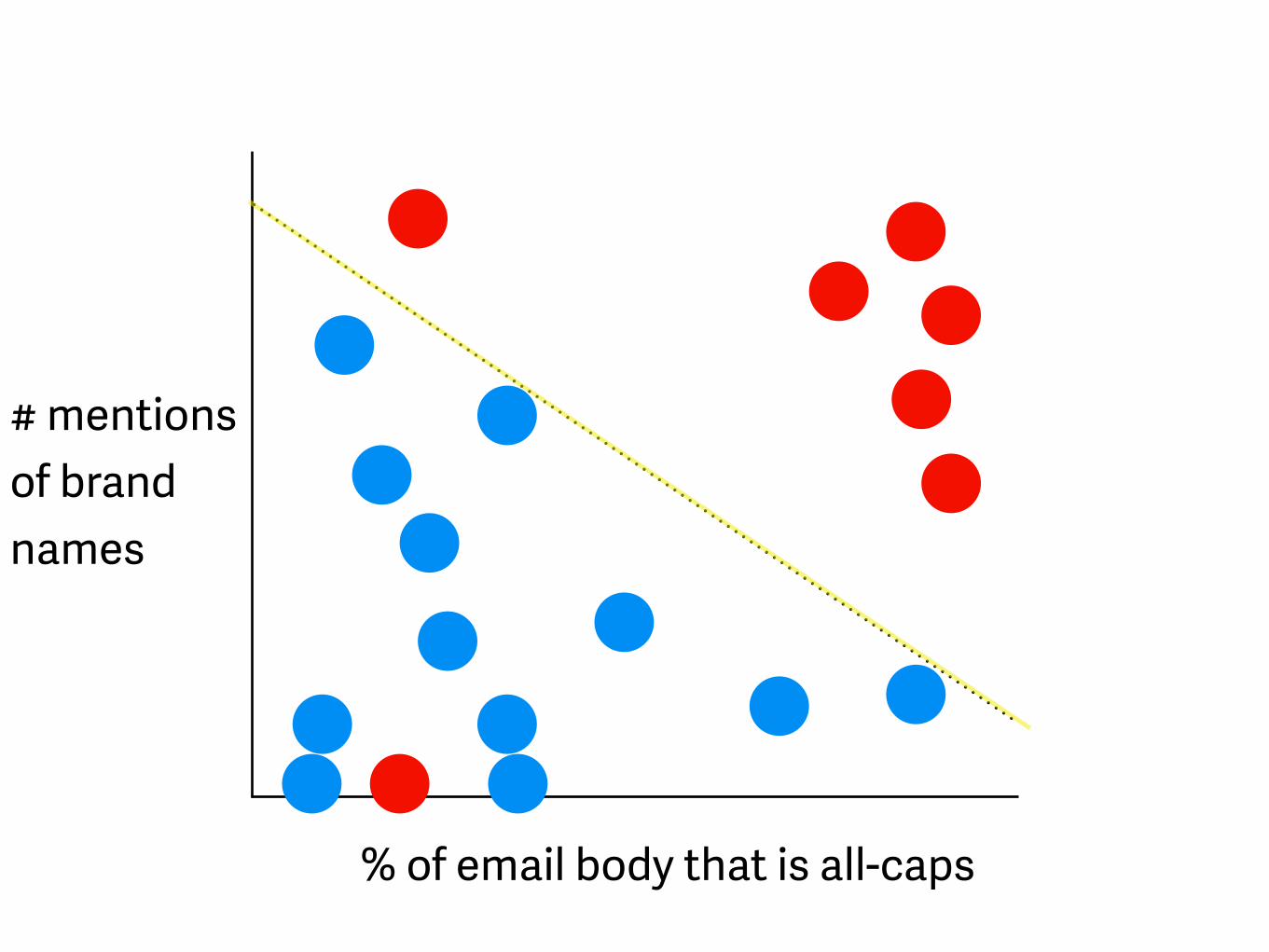
% of email body that is all-caps
# mentions of brand names
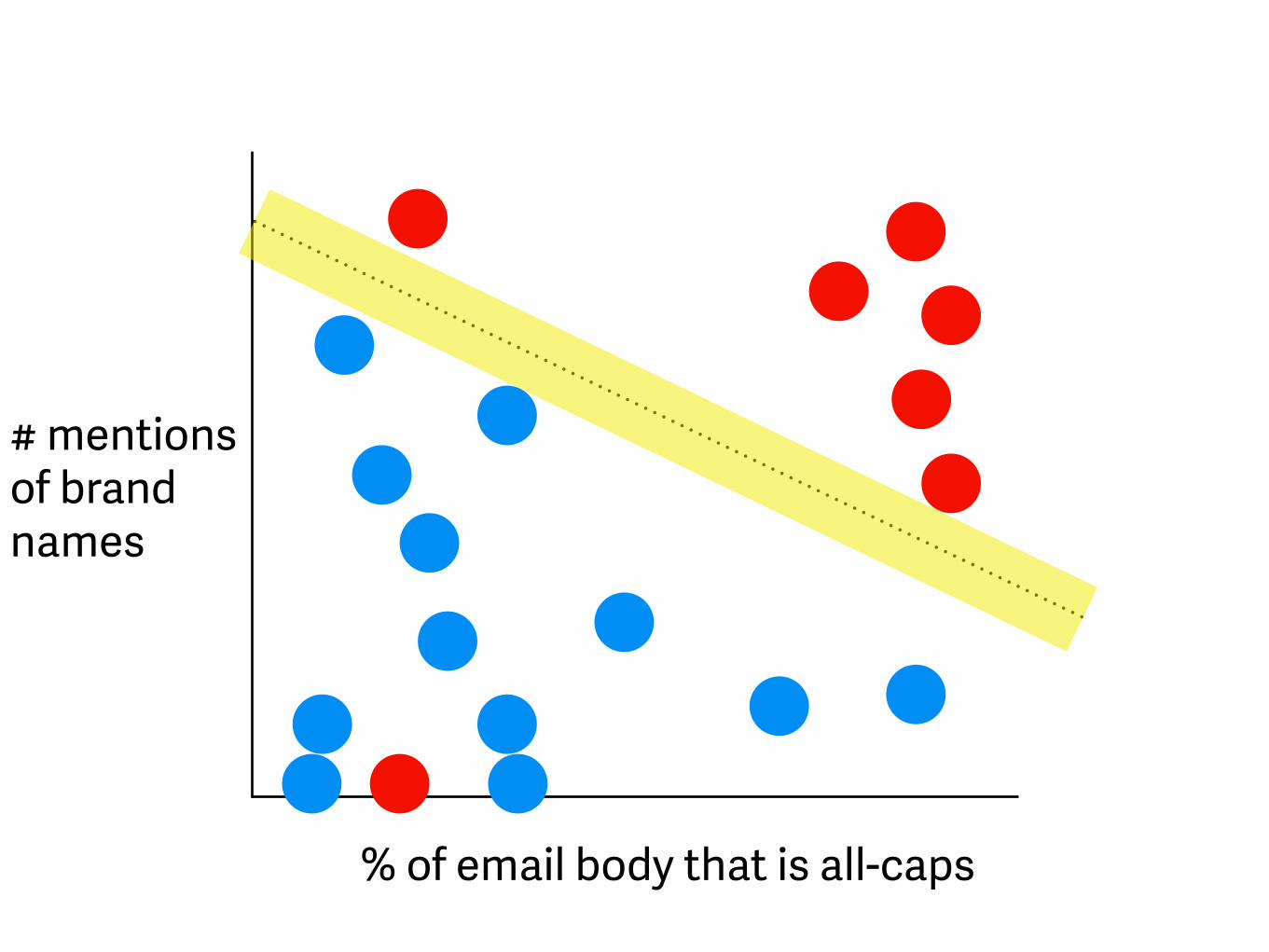
% of email body that is all-caps
# mentions of brand names

SVMs (support vector machines)“*advanced* draw a line through it”
from sklearn.svm import SVC model = SVC(kernel='poly', degree=2) model.fit(X,y) predicted = model.predict(z)

SVMs (support vector machines)“*advanced* draw a line through it”
from sklearn.svm import SVC model = SVC(kernel='rbf') model.fit(X,y) predicted = model.predict(z)

KNN (k-nearest neighbors)
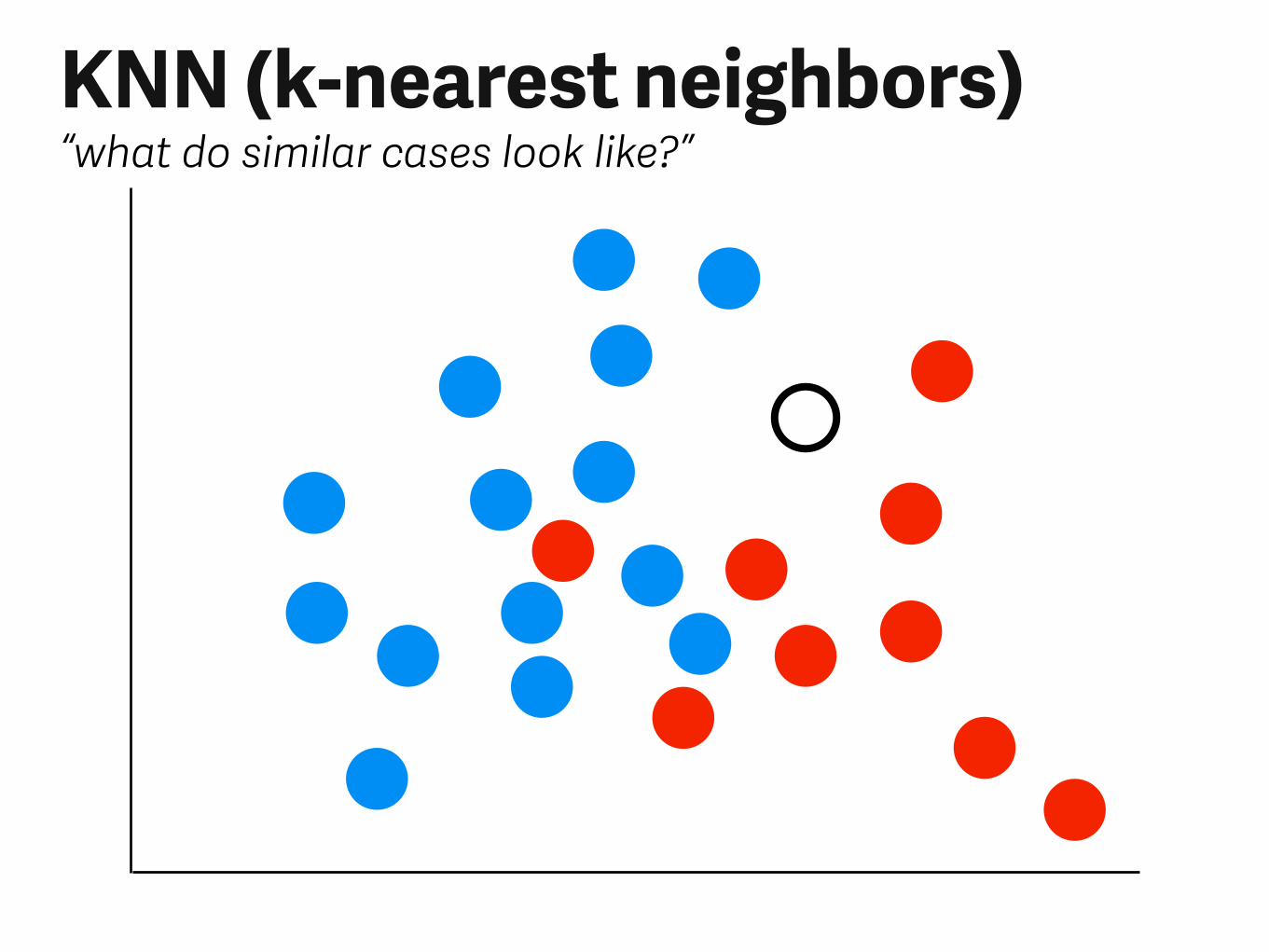
KNN (k-nearest neighbors)“what do similar cases look like?”
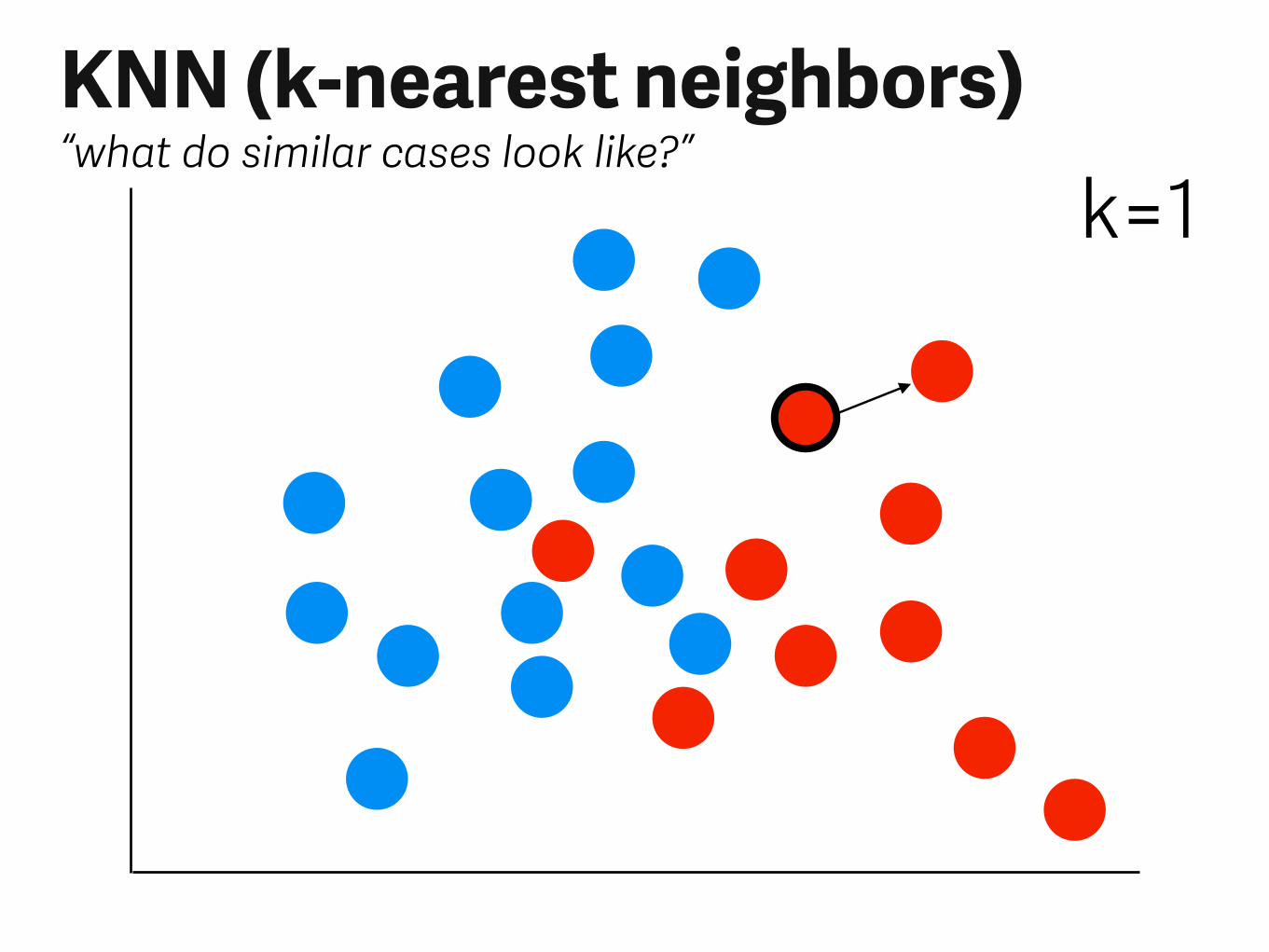
KNN (k-nearest neighbors)“what do similar cases look like?”
k=1
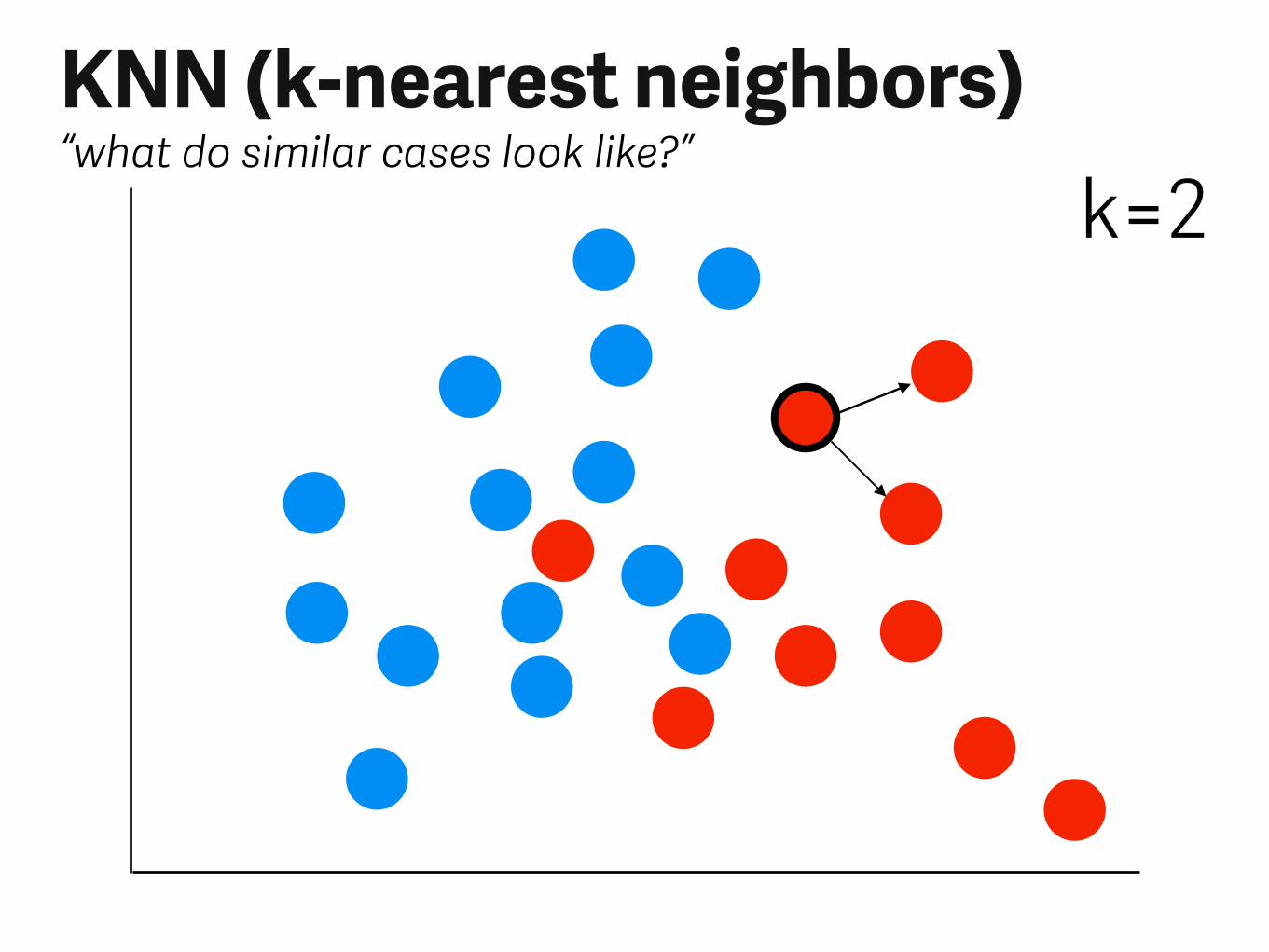
KNN (k-nearest neighbors)“what do similar cases look like?”
k=2

KNN (k-nearest neighbors)“what do similar cases look like?”
figure credit: scikit-learn documentation
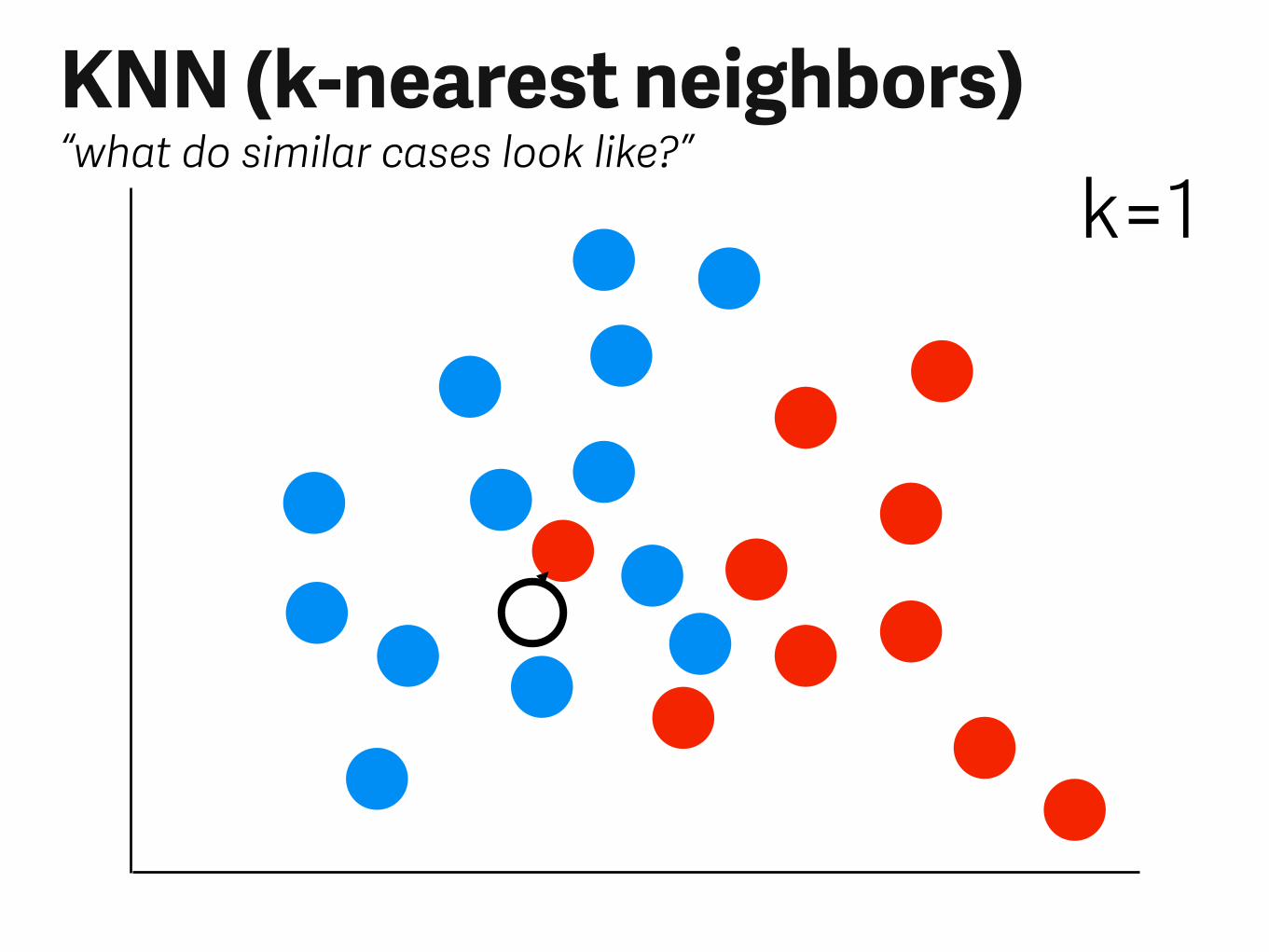
KNN (k-nearest neighbors)“what do similar cases look like?”
k=1
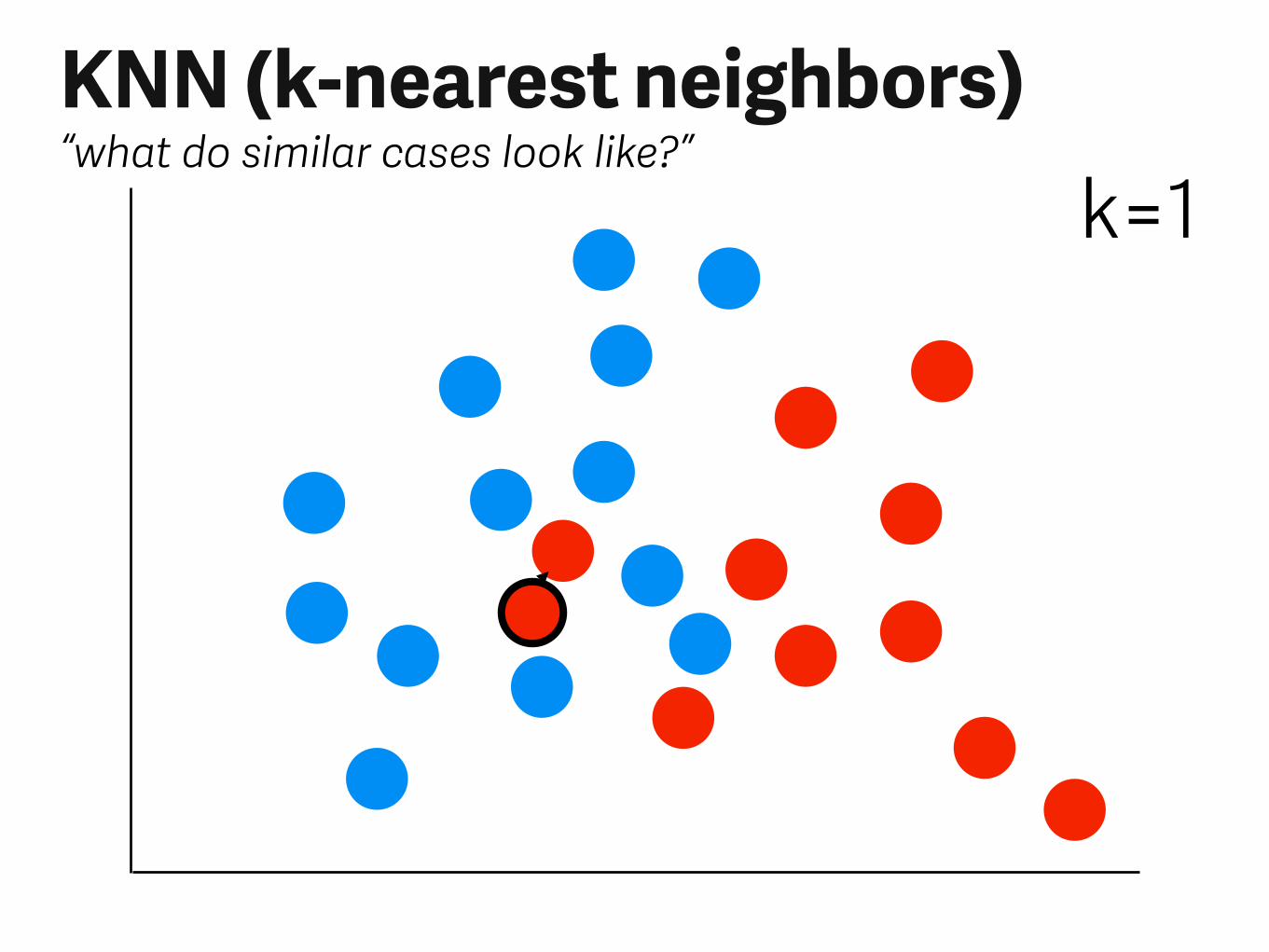
KNN (k-nearest neighbors)“what do similar cases look like?”
k=1
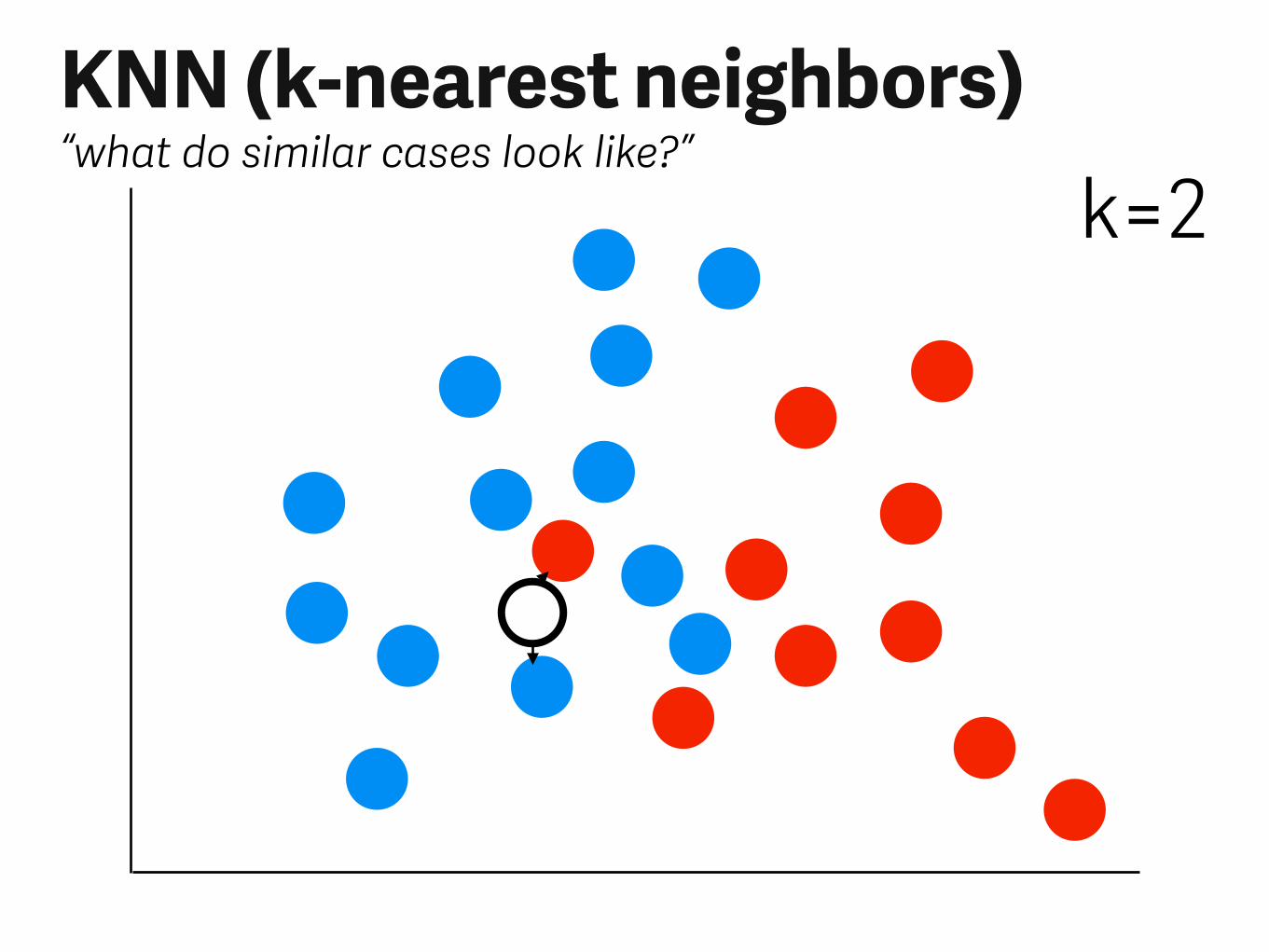
KNN (k-nearest neighbors)“what do similar cases look like?”
k=2
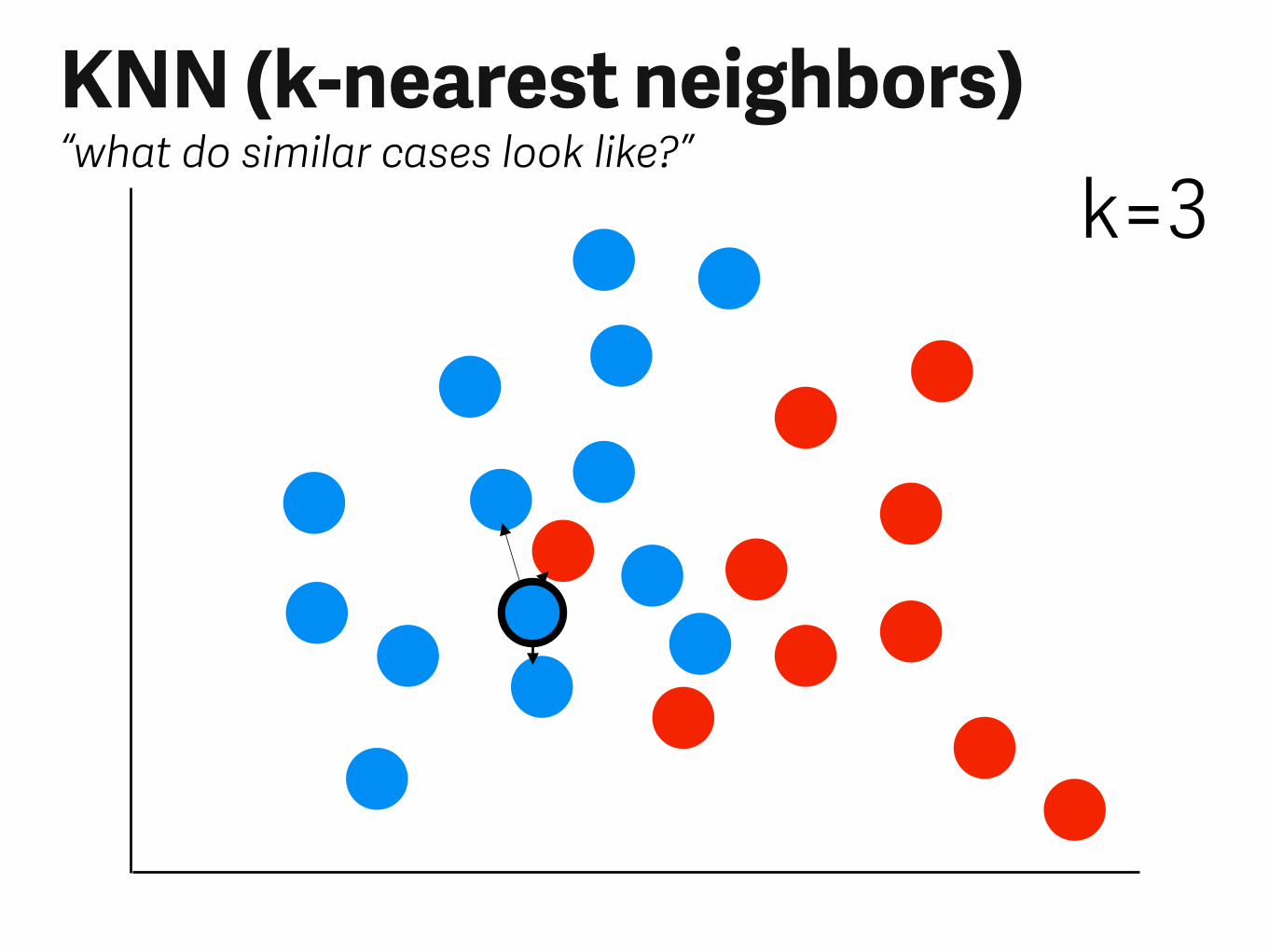
KNN (k-nearest neighbors)“what do similar cases look like?”
k=3
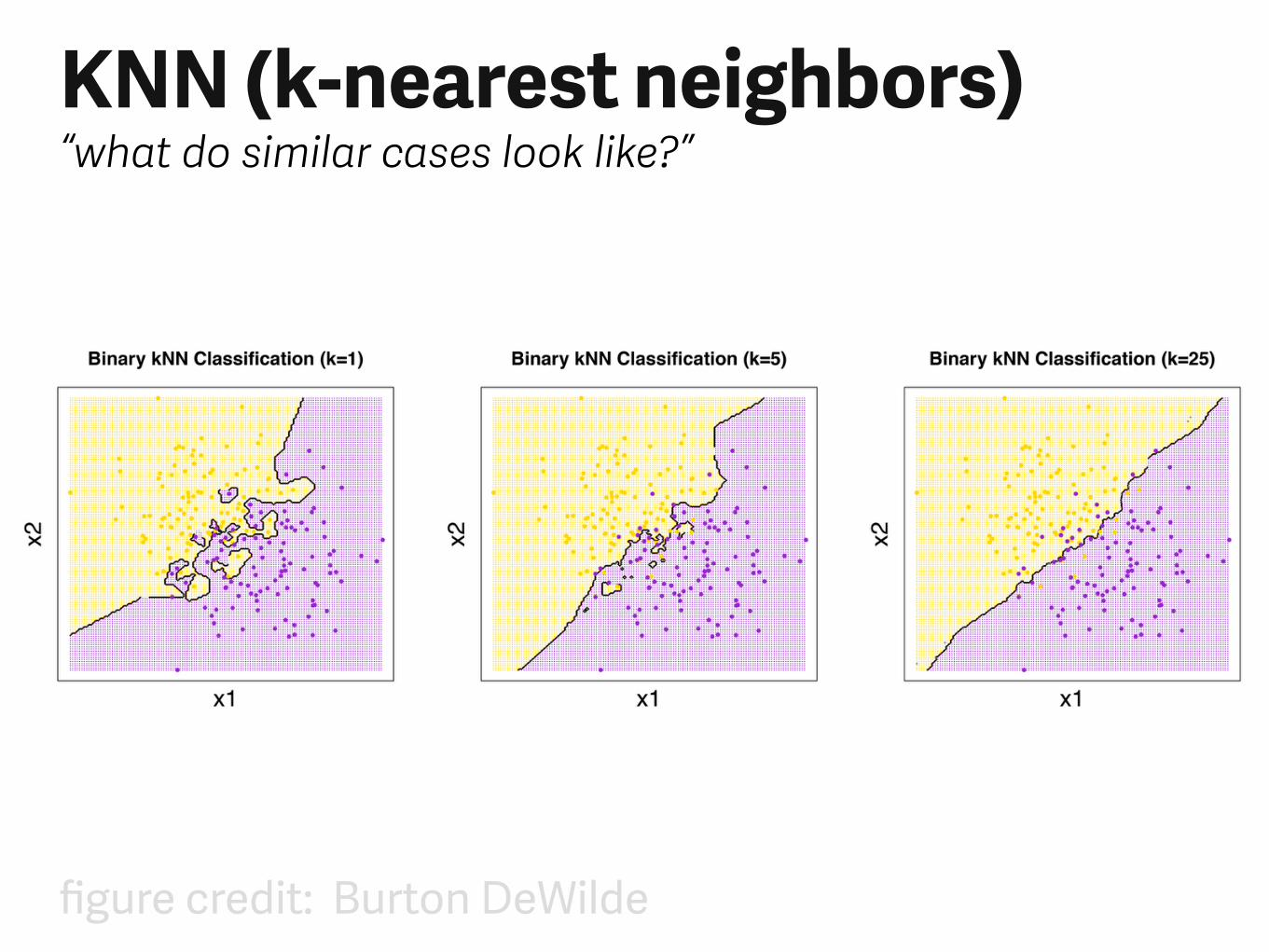
KNN (k-nearest neighbors)“what do similar cases look like?”
figure credit: Burton DeWilde

KNN (k-nearest neighbors)“what do similar cases look like?”
from sklearn.neighbors import NearestNeighbors model = NearestNeighbors(n_neighbors=5) model.fit(X,y) predicted = model.predict(z)

Decision tree learners
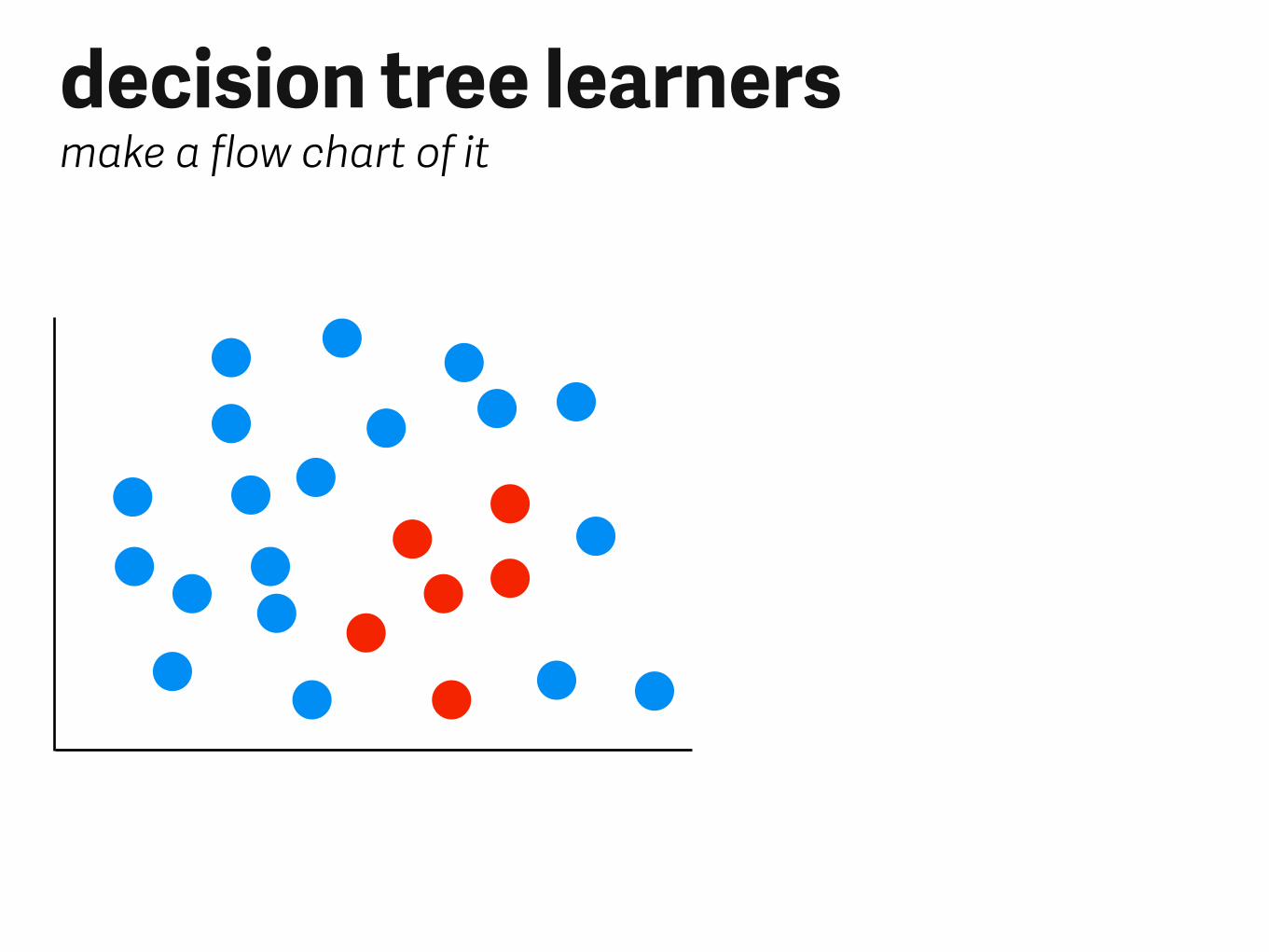
decision tree learnersmake a flow chart of it
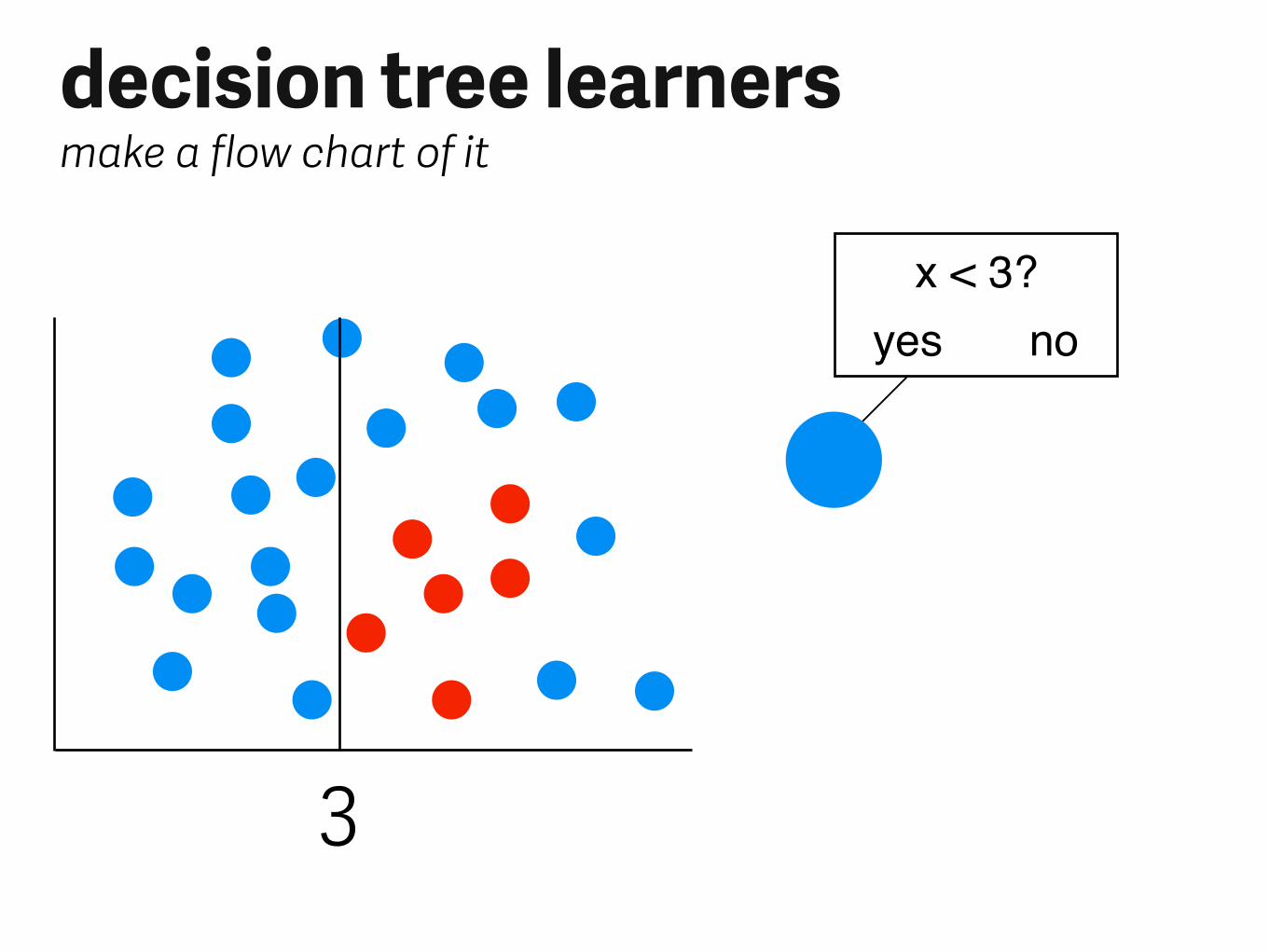
decision tree learnersmake a flow chart of it
x < 3?yes no
3
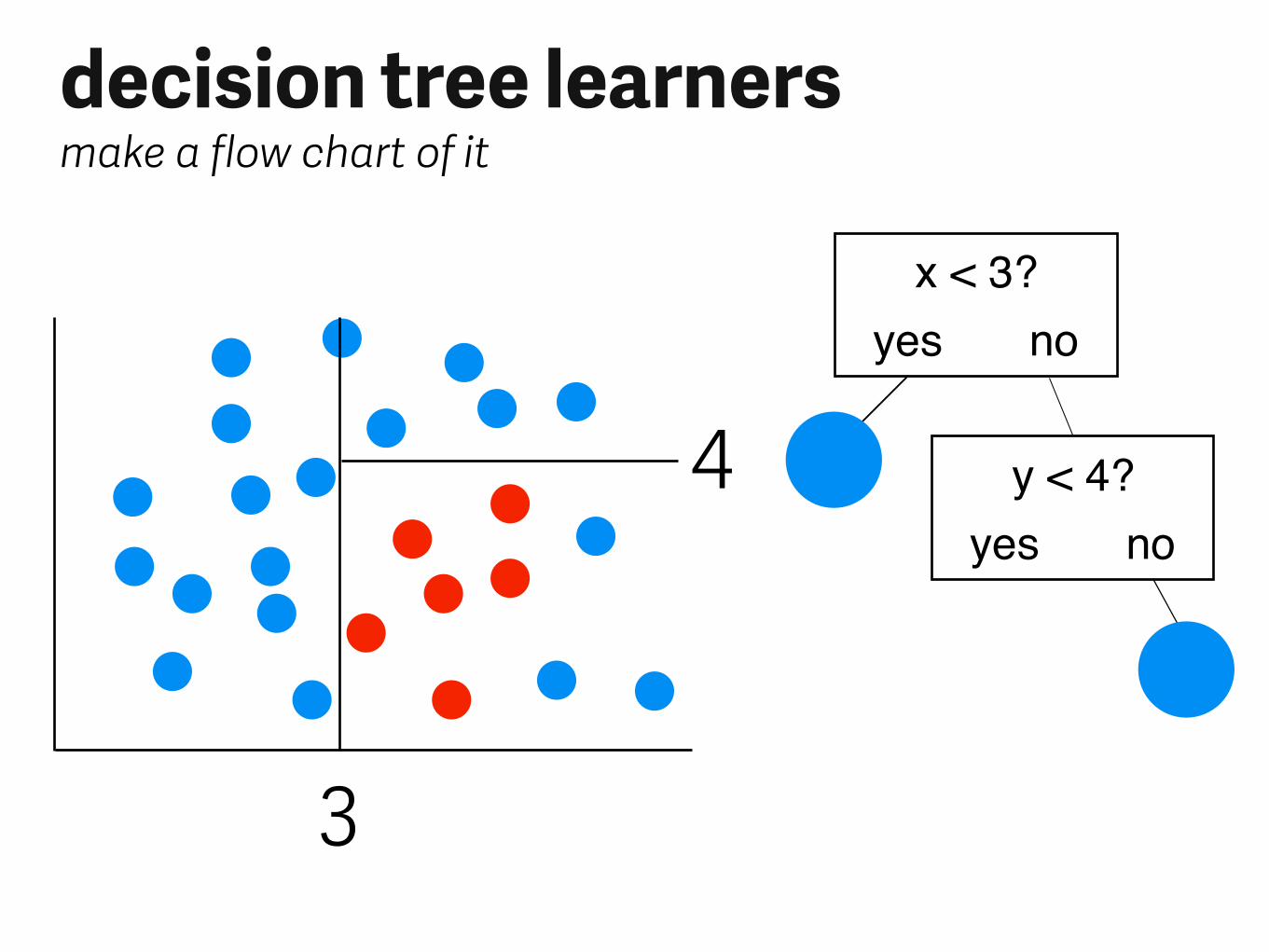
decision tree learnersmake a flow chart of it
x < 3?yes no
y < 4?yes no
3
4

decision tree learnersmake a flow chart of it
x < 3?yes no
y < 4?yes no
x < 5?yes no
3 5
4
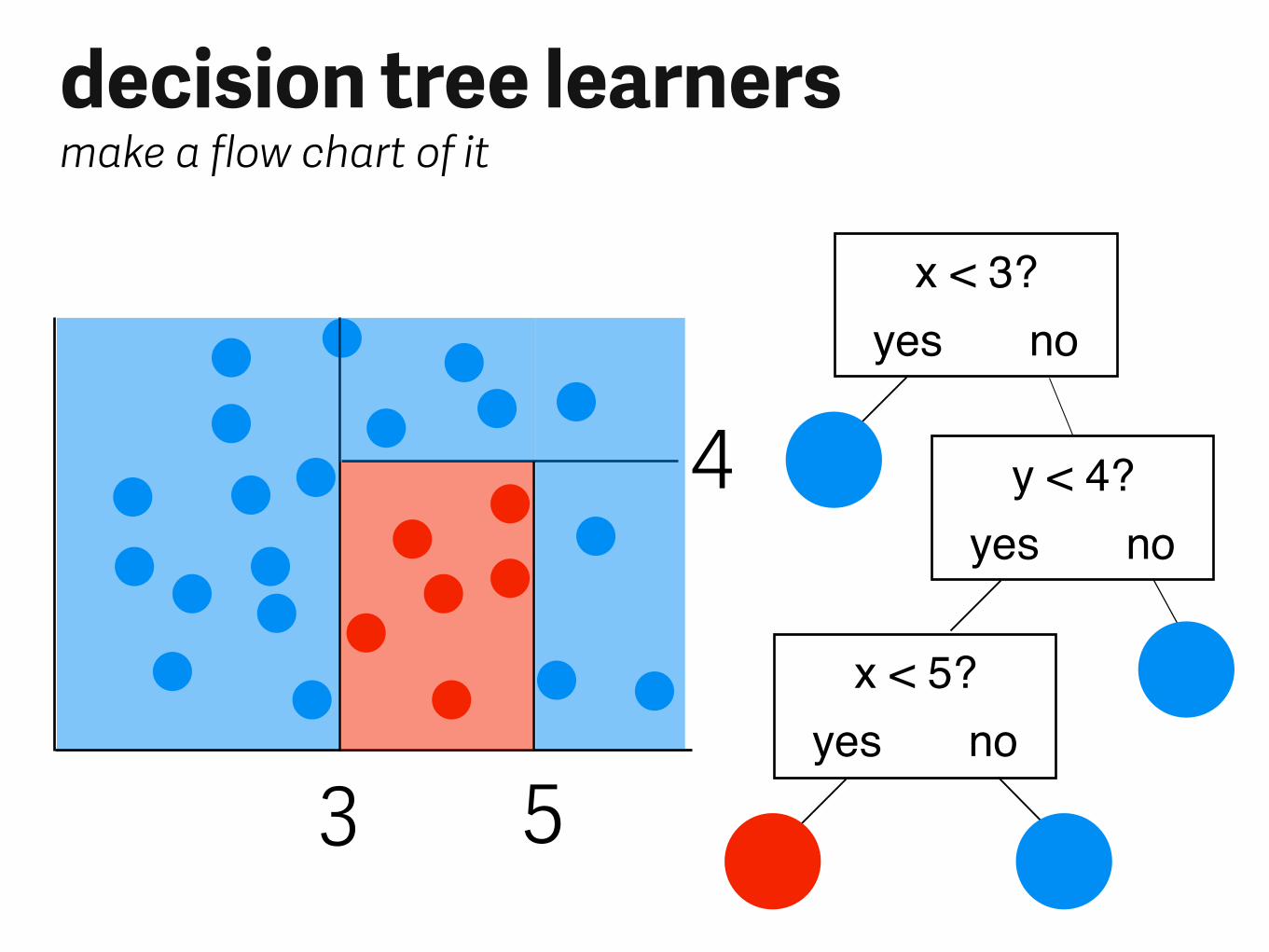
decision tree learnersmake a flow chart of it
x < 3?yes no
y < 4?yes no
x < 5?yes no
3 5
4

decision tree learnersmake a flow chart of it
from sklearn.tree import DecisionTreeClassifier model = DecisionTreeClassifier() model.fit(X,y) predicted = model.predict(z)
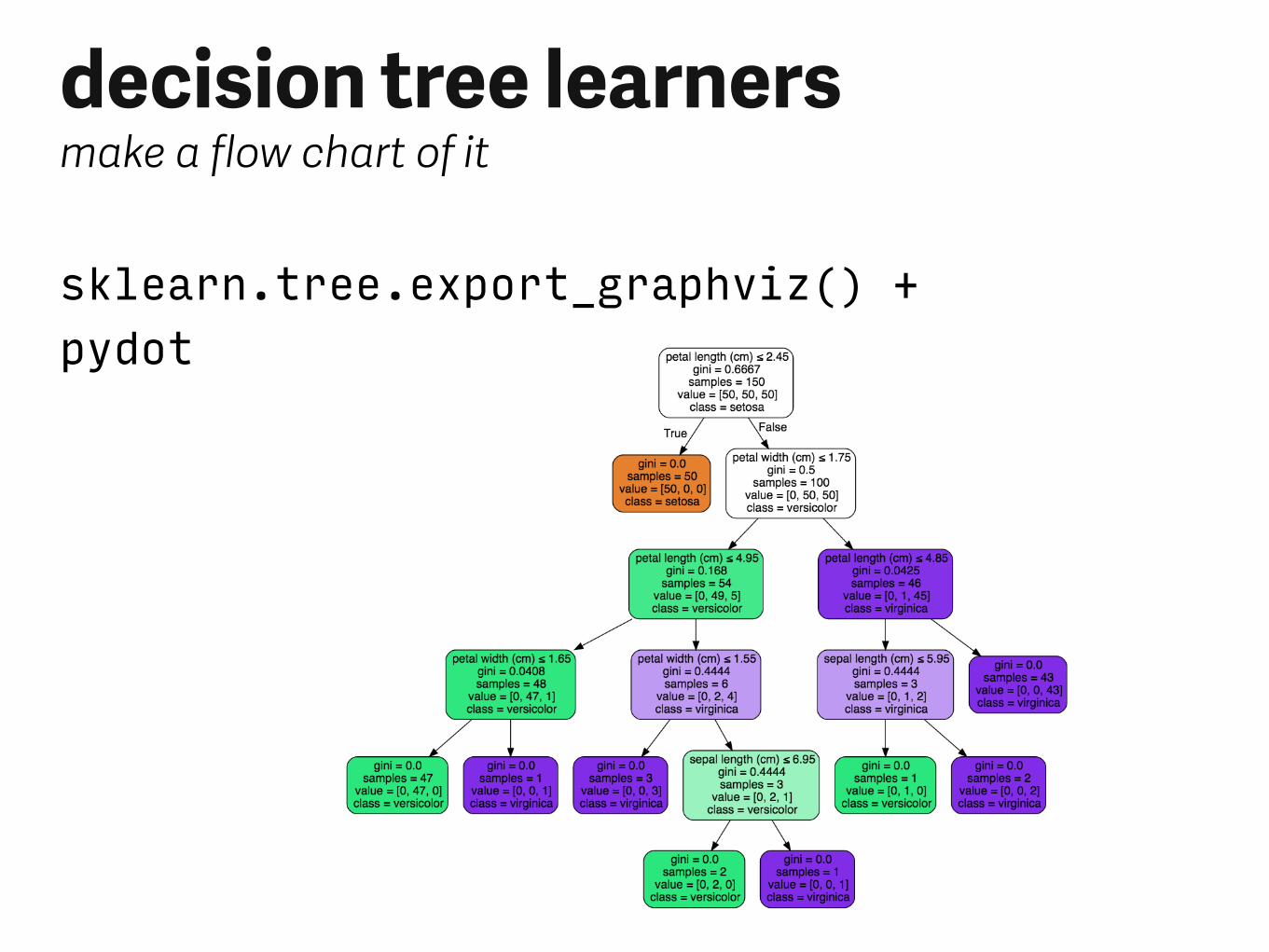
decision tree learnersmake a flow chart of it
sklearn.tree.export_graphviz() + pydot

decision tree learnersmake a flow chart of it

Ensemble models
(make a bunch of models and combine them)

baggingsplit training set, train one model each, models “vote”
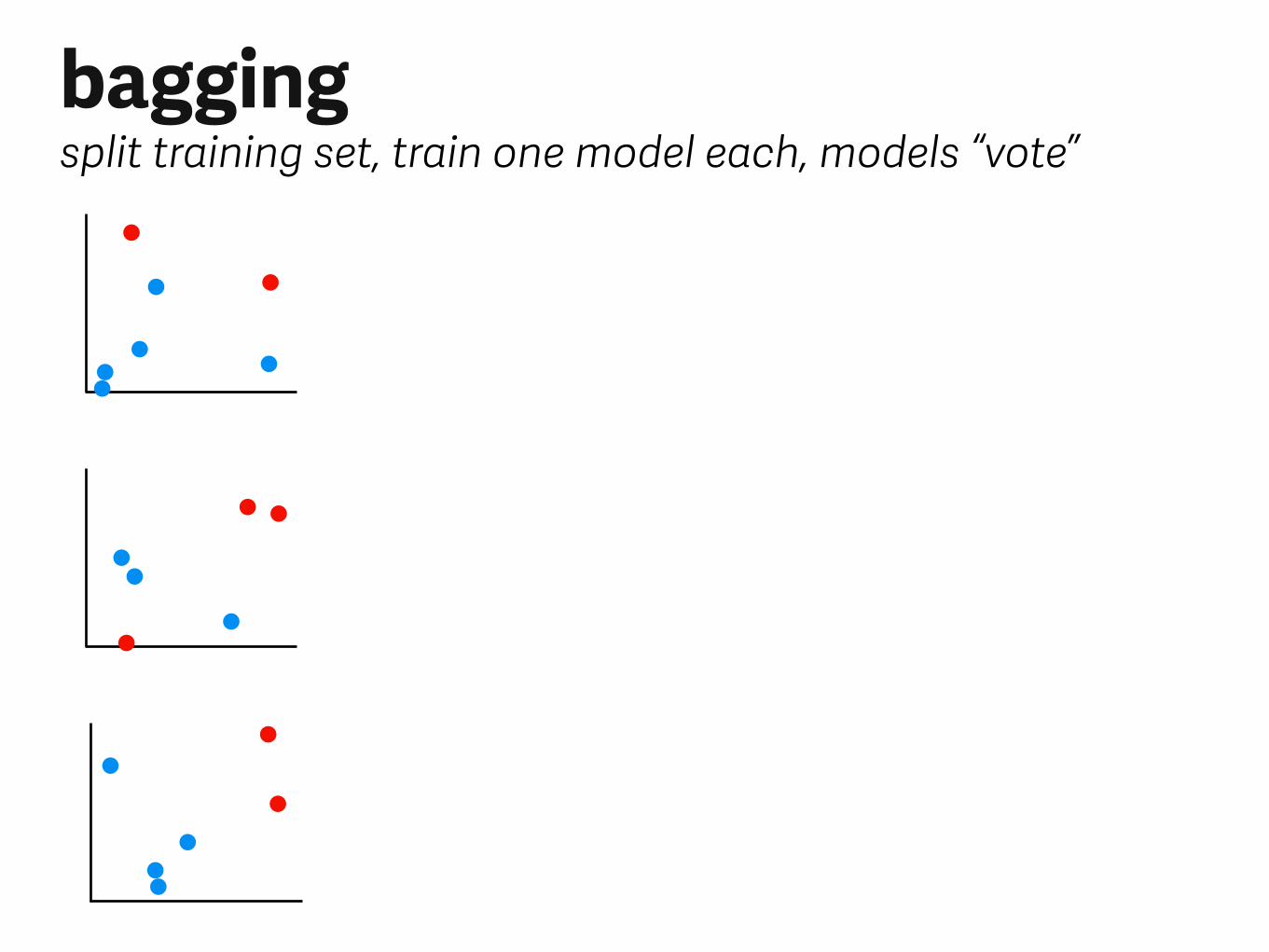
baggingsplit training set, train one model each, models “vote”
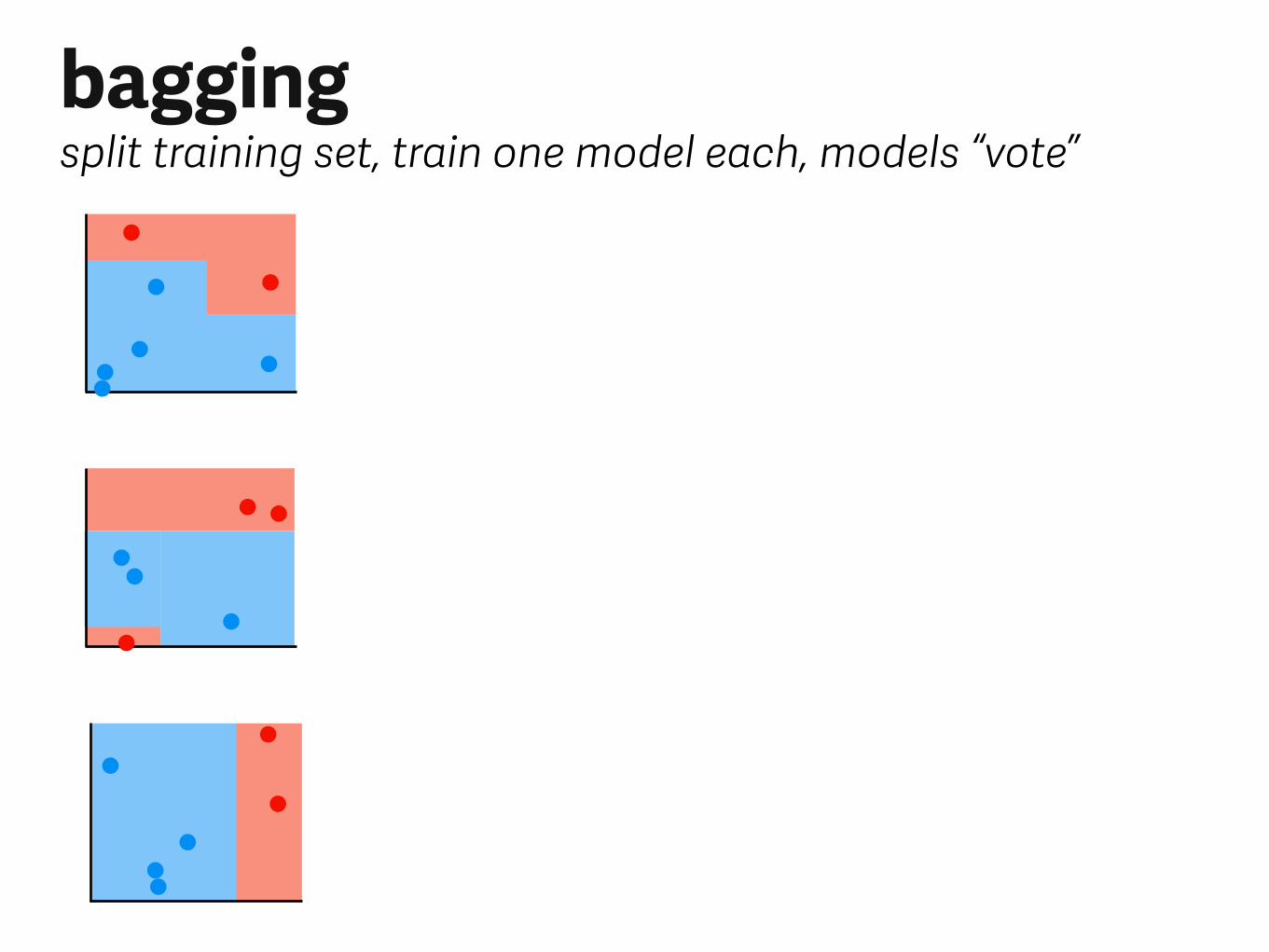
baggingsplit training set, train one model each, models “vote”
baggingsplit training set, train one model each, models “vote”
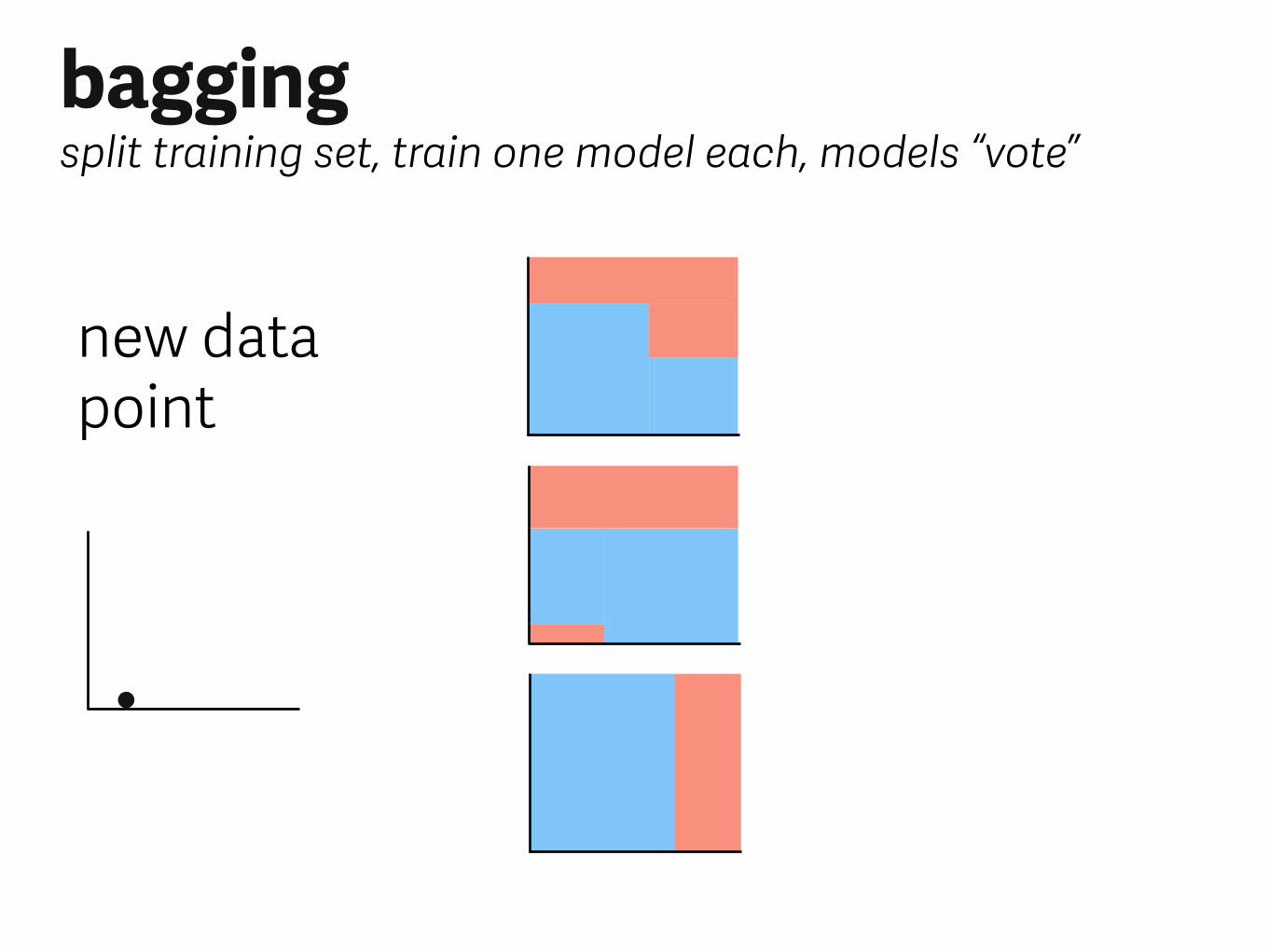
new data point
baggingsplit training set, train one model each, models “vote”
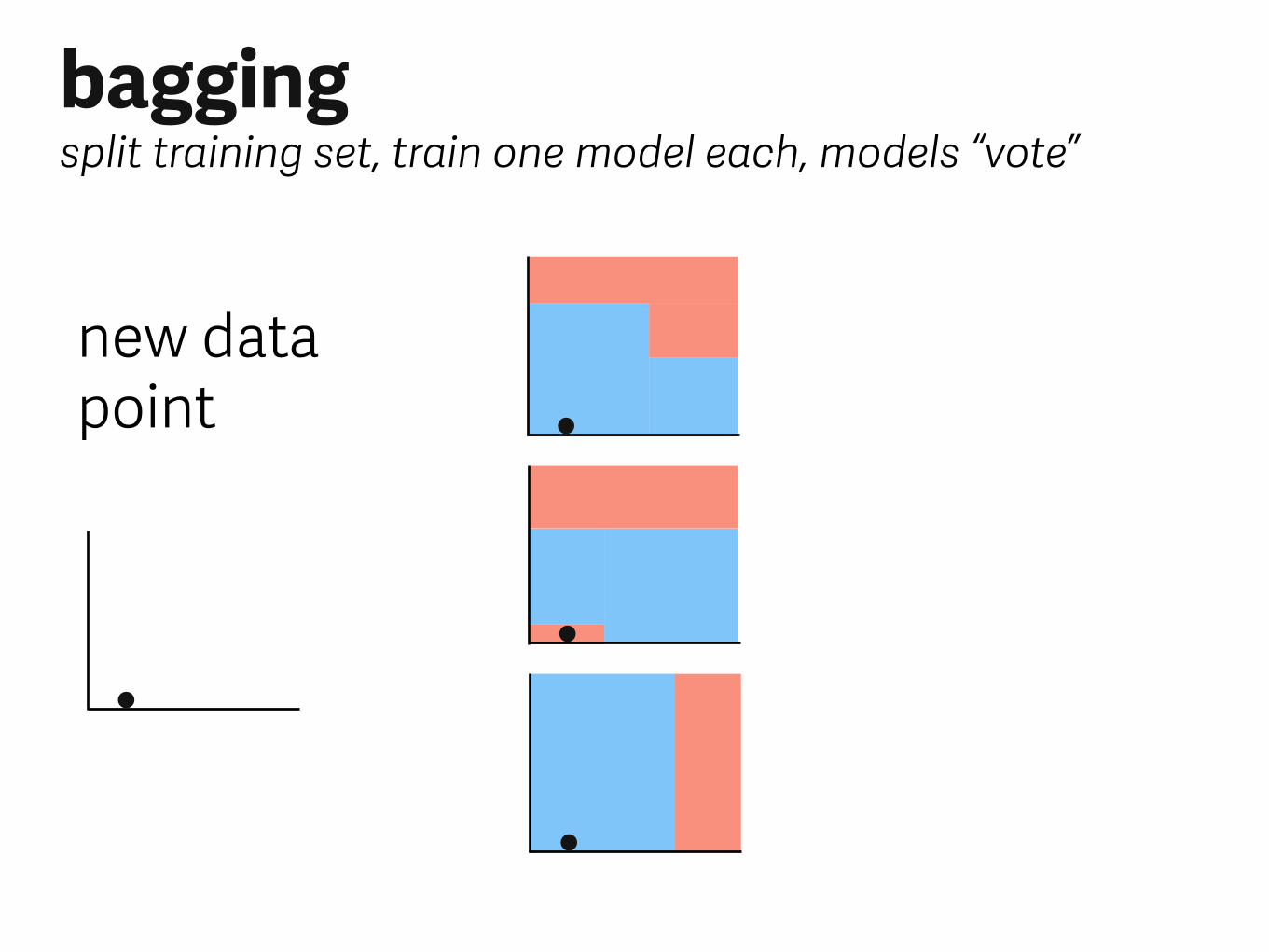
new data point

baggingsplit training set, train one model each, models “vote”
new data point
not spam
spam
not spam

baggingsplit training set, train one model each, models “vote”
new data point
not spam
spam
not spam
not spam
Final Answer:

baggingsplit training set, train one model each, models “vote”

baggingsplit training set, train one model each, models “vote”

other spins on this

other spins on this
Random Forest - like bagging, but at each split randomly constrain features to choose from

other spins on this
Random Forest - like bagging, but at each split randomly constrain features to choose from
Extra Trees - for each split, make it randomly, non- optimally. Compensate by training a ton of trees

other spins on this
Random Forest - like bagging, but at each split randomly constrain features to choose from
Extra Trees - for each split, make it randomly, non- optimally. Compensate by training a ton of trees
Voting - combine a bunch of different models of your design, have them “vote” on the correct answer.

other spins on this
Random Forest - like bagging, but at each split randomly constrain features to choose from
Extra Trees - for each split, make it randomly, non- optimally. Compensate by training a ton of trees
Voting - combine a bunch of different models of your design, have them “vote” on the correct answer.
Boosting- train models in order, make the later ones focus on the points the earlier ones missed
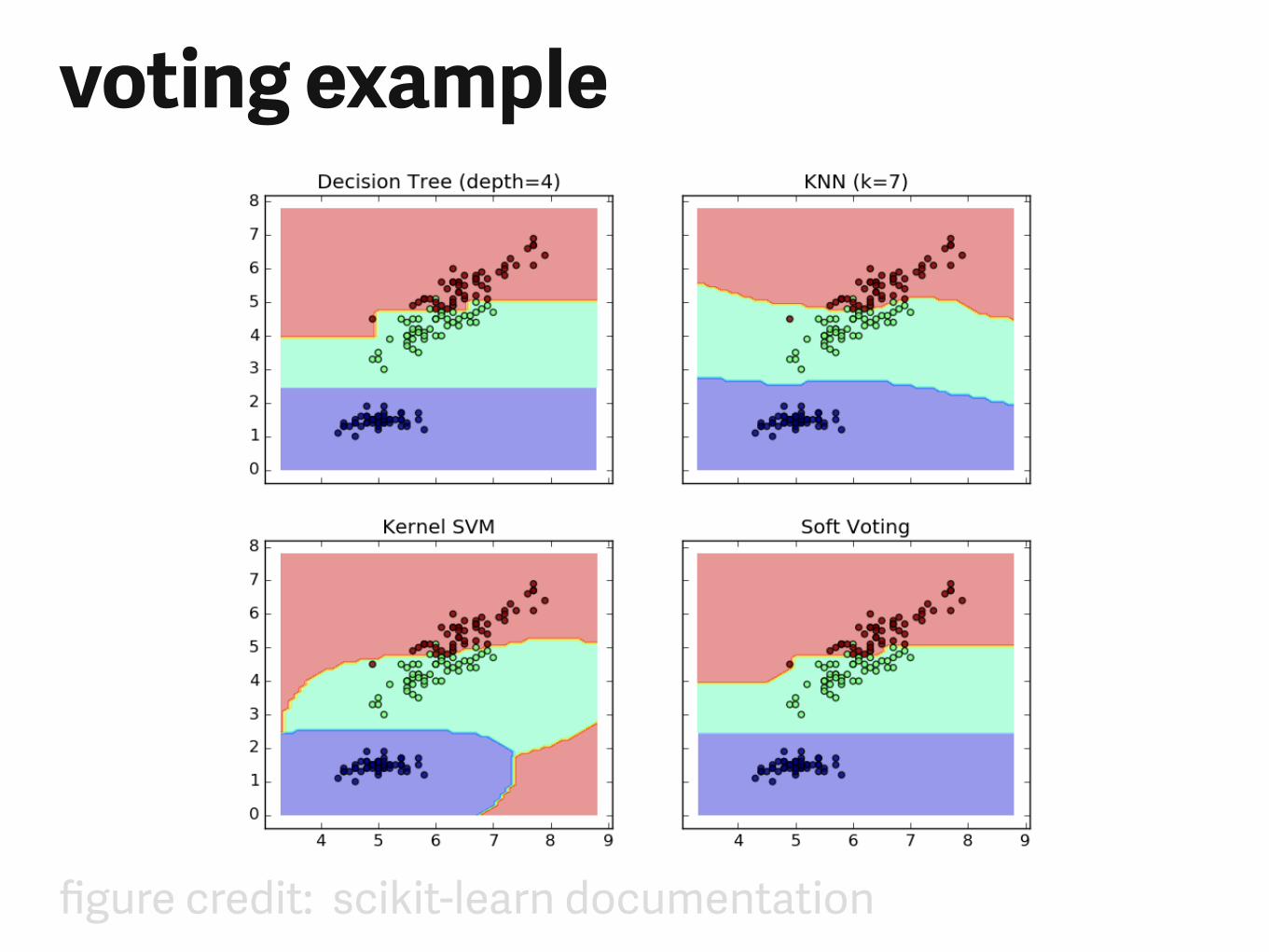
voting example
figure credit: scikit-learn documentation

other spins on this
Random Forest - like bagging, but at each split randomly constrain features to choose from
Extra Trees - for each split, make it randomly, non- optimally. Compensate by training a ton of trees
Voting - combine a bunch of different models of your design, have them “vote” on the correct answer.
Boosting- train models in order, make the later ones focus on the points the earlier ones missed

from sklearn.ensemble import BaggingClassifierRandomForestClassifier ExtraTreesClassifier VotingClassifier AdaBoostClassifier GradientBoostingClassifier


which one do I pick?

which one do I pick?
try a few!


Nonlinear decision boundary
provide probability estimates
tell how important a feature is to the model

Nonlinear decision boundary
provide probability estimates
tell how important a feature is to the model
Logistic Regression no yes yes, if you scale
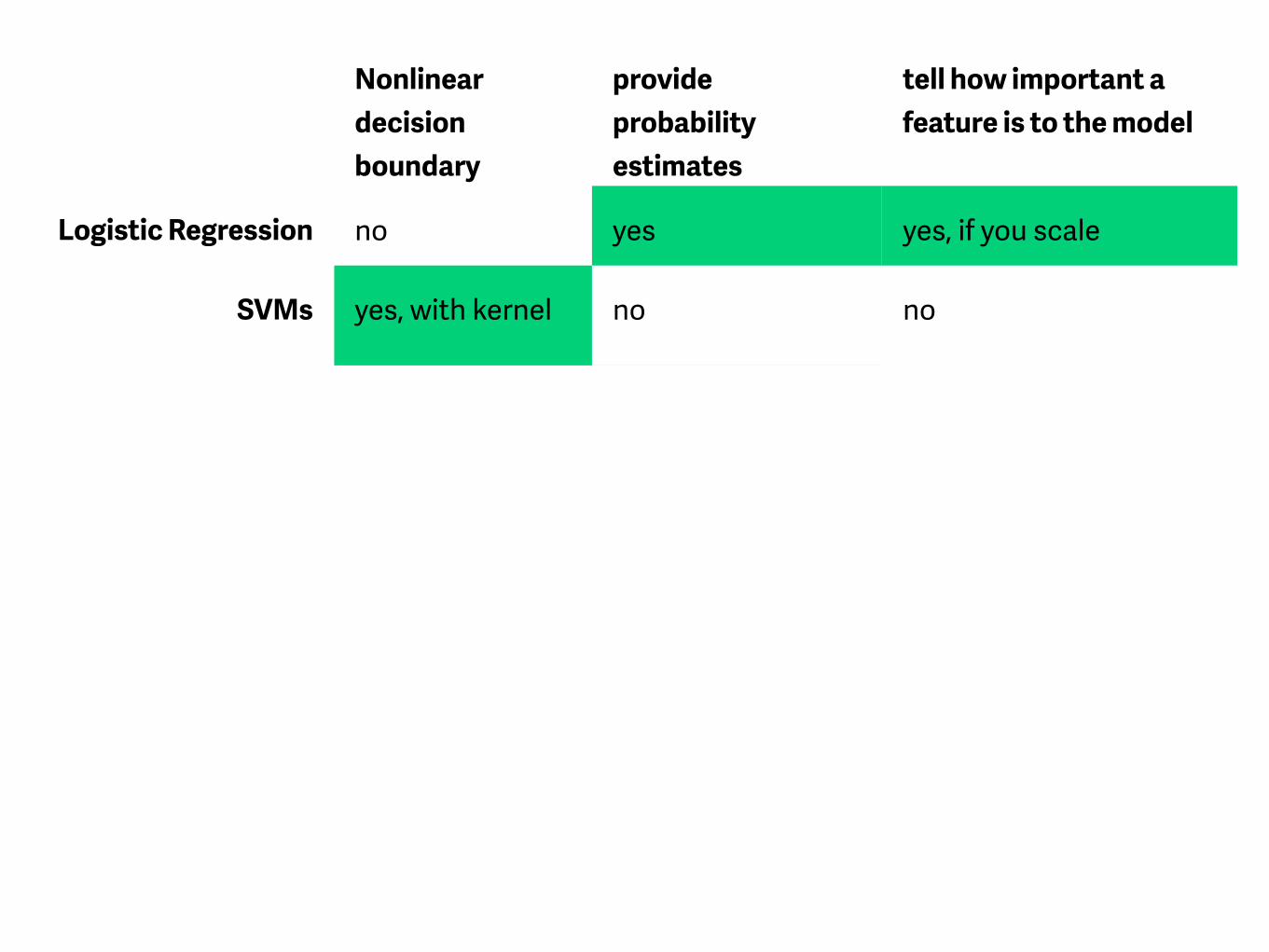
Nonlinear decision boundary
provide probability estimates
tell how important a feature is to the model
Logistic Regression no yes yes, if you scale
SVMs yes, with kernel no no
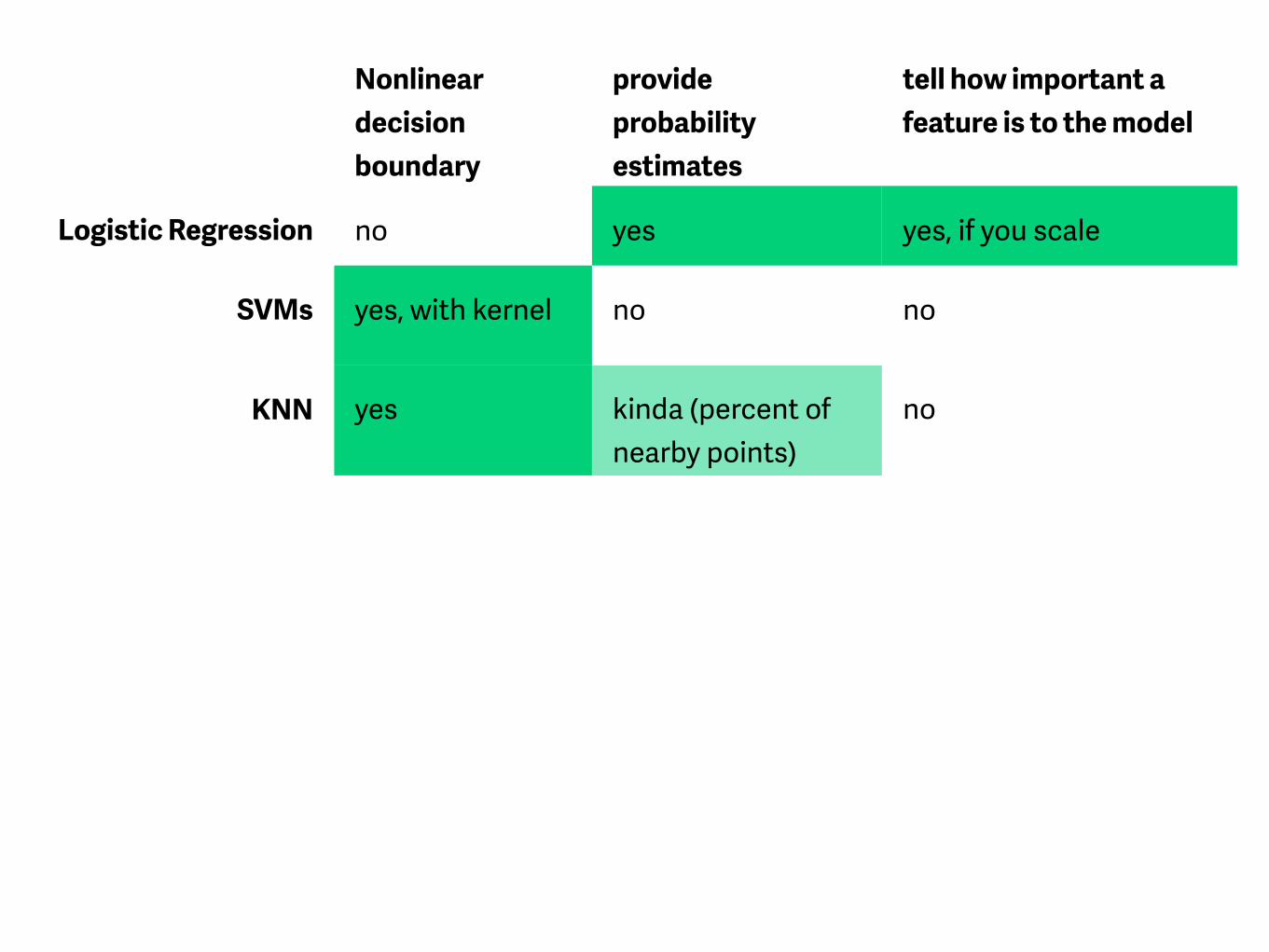
Nonlinear decision boundary
provide probability estimates
tell how important a feature is to the model
Logistic Regression no yes yes, if you scale
SVMs yes, with kernel no no
KNN yes kinda (percent of nearby points)
no
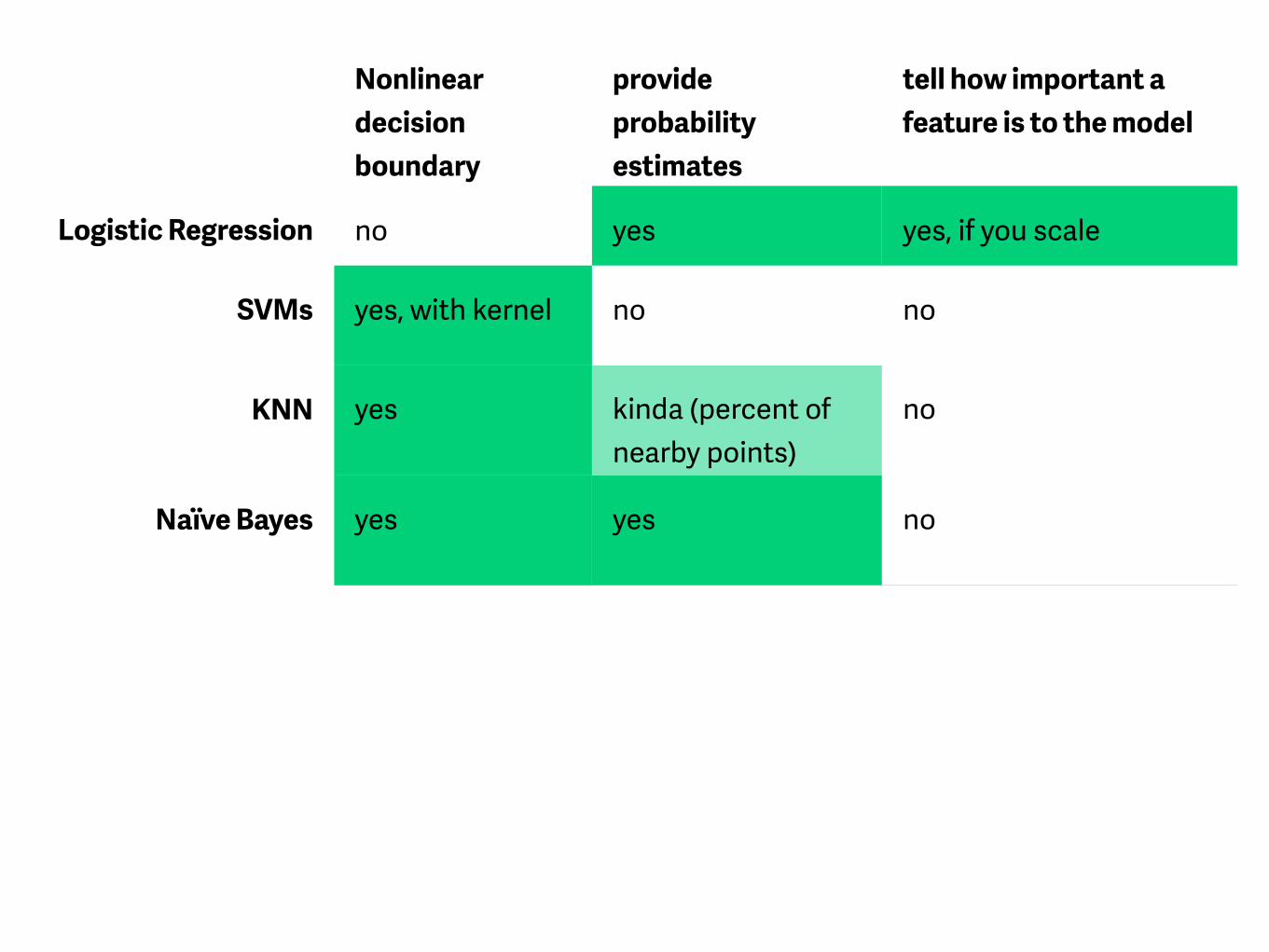
Nonlinear decision boundary
provide probability estimates
tell how important a feature is to the model
Logistic Regression no yes yes, if you scale
SVMs yes, with kernel no no
KNN yes kinda (percent of nearby points)
no
Naïve Bayes yes yes no
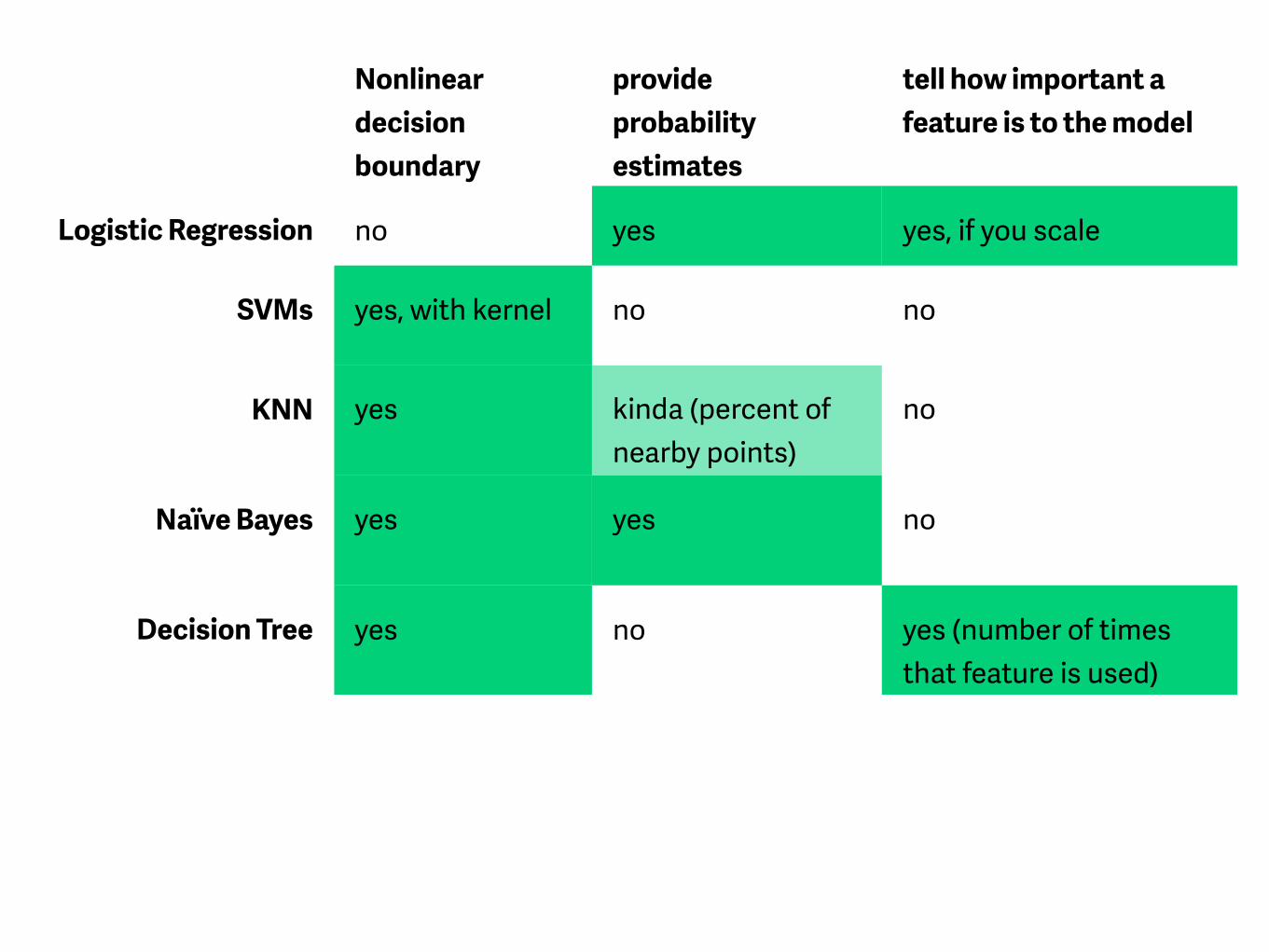
Nonlinear decision boundary
provide probability estimates
tell how important a feature is to the model
Logistic Regression no yes yes, if you scale
SVMs yes, with kernel no no
KNN yes kinda (percent of nearby points)
no
Naïve Bayes yes yes no
Decision Tree yes no yes (number of times that feature is used)
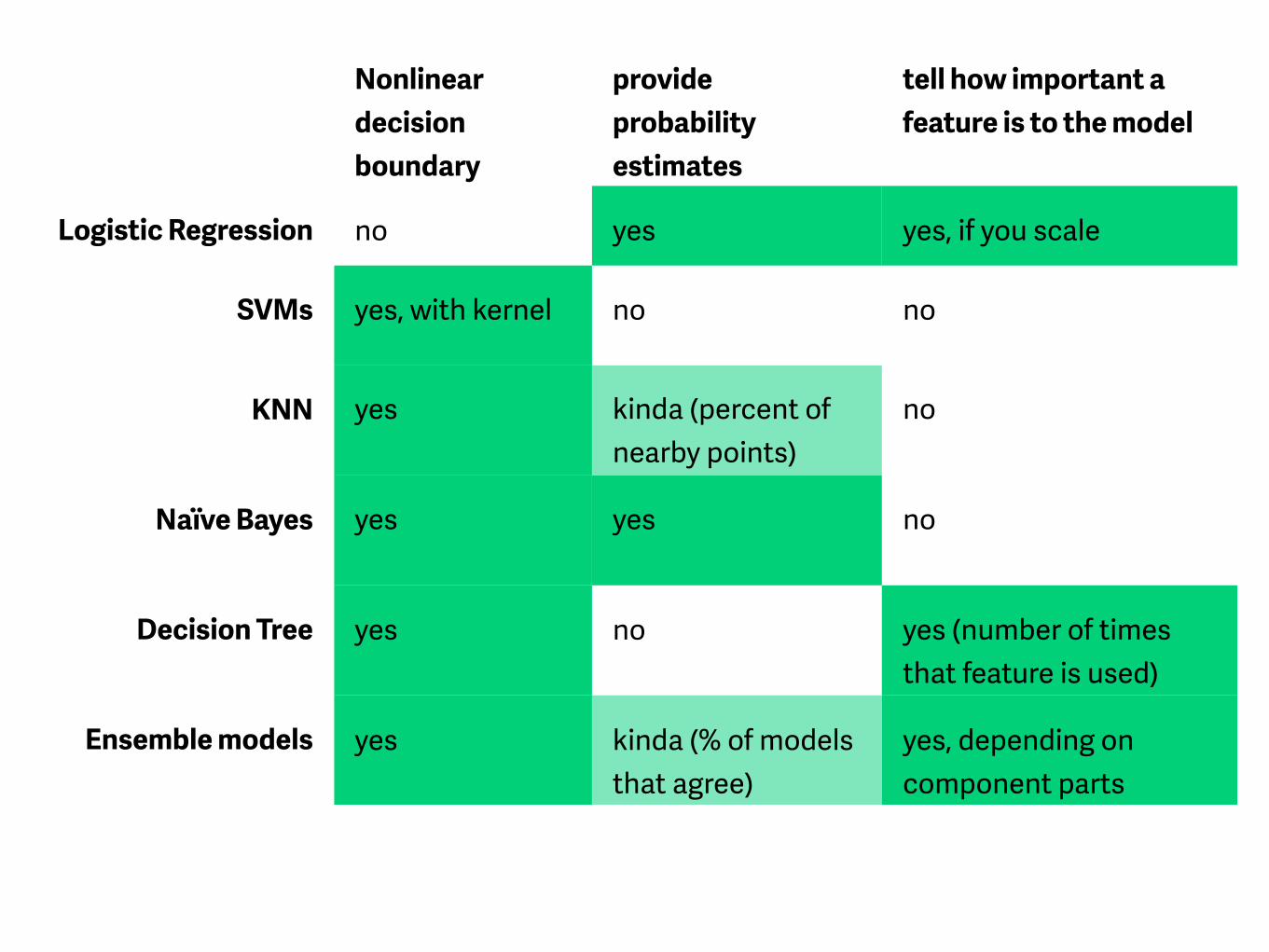
Nonlinear decision boundary
provide probability estimates
tell how important a feature is to the model
Logistic Regression no yes yes, if you scale
SVMs yes, with kernel no no
KNN yes kinda (percent of nearby points)
no
Naïve Bayes yes yes no
Decision Tree yes no yes (number of times that feature is used)
Ensemble models yes kinda (% of models that agree)
yes, depending on component parts

Nonlinear decision boundary
provide probability estimates
tell how important a feature is to the model
Logistic Regression no yes yes, if you scale
SVMs yes, with kernel no no
KNN yes kinda (percent of nearby points)
no
Naïve Bayes yes yes no
Decision Tree yes no yes (number of times that feature is used)
Ensemble models yes kinda (% of models that agree)
yes, depending on component parts
Boosted models yes kinda (% of models that agree)
yes, depending on component parts


can be updated with new training data
easy to parallelize?

can be updated with new training data
easy to parallelize?
Logistic Regression kinda kinda

can be updated with new training data
easy to parallelize?
Logistic Regression kinda kinda
SVMs kinda, depending on kernel yes for some kernels, no for others

can be updated with new training data
easy to parallelize?
Logistic Regression kinda kinda
SVMs kinda, depending on kernel yes for some kernels, no for others
KNN yes yes
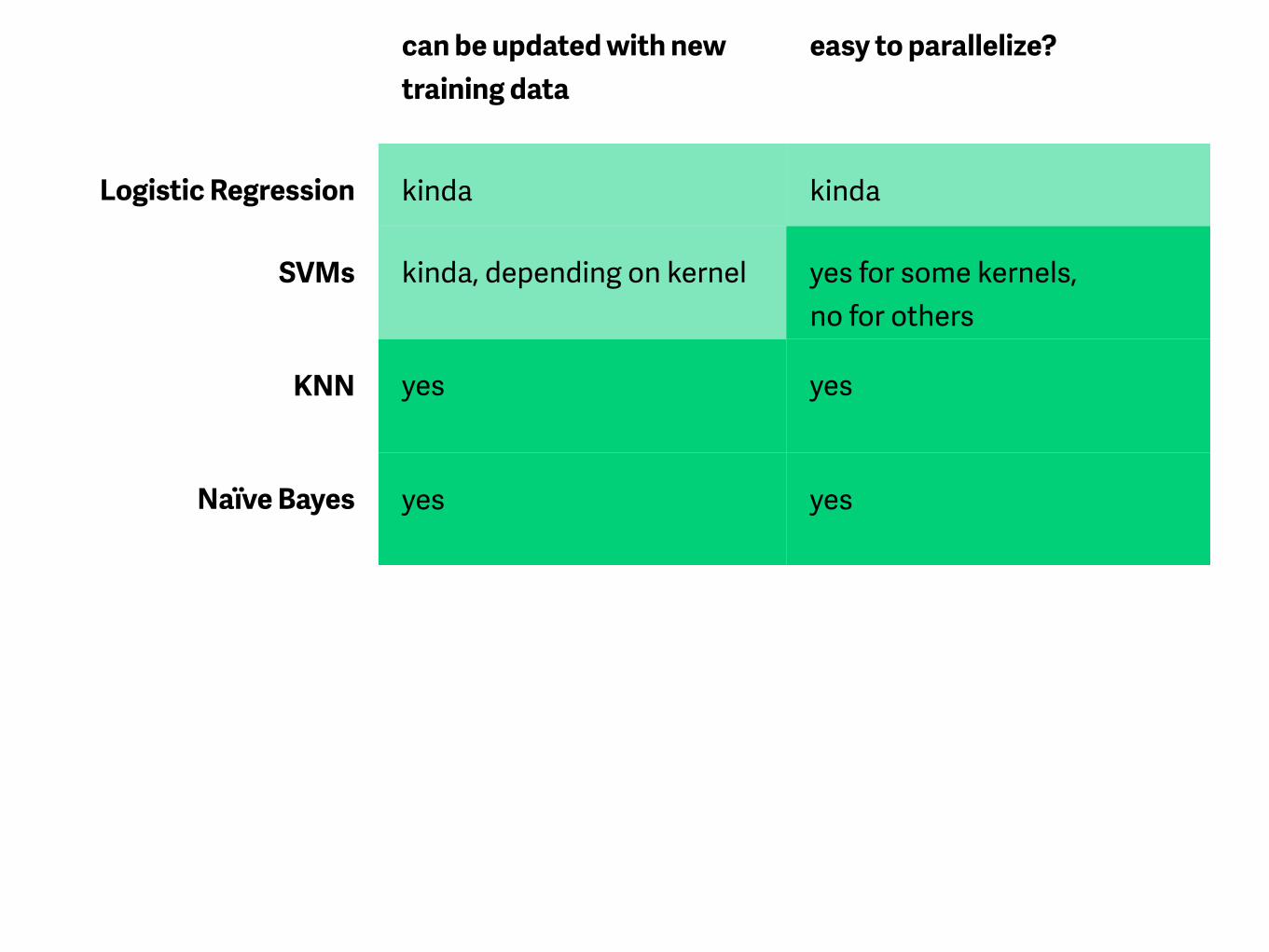
can be updated with new training data
easy to parallelize?
Logistic Regression kinda kinda
SVMs kinda, depending on kernel yes for some kernels, no for others
KNN yes yes
Naïve Bayes yes yes
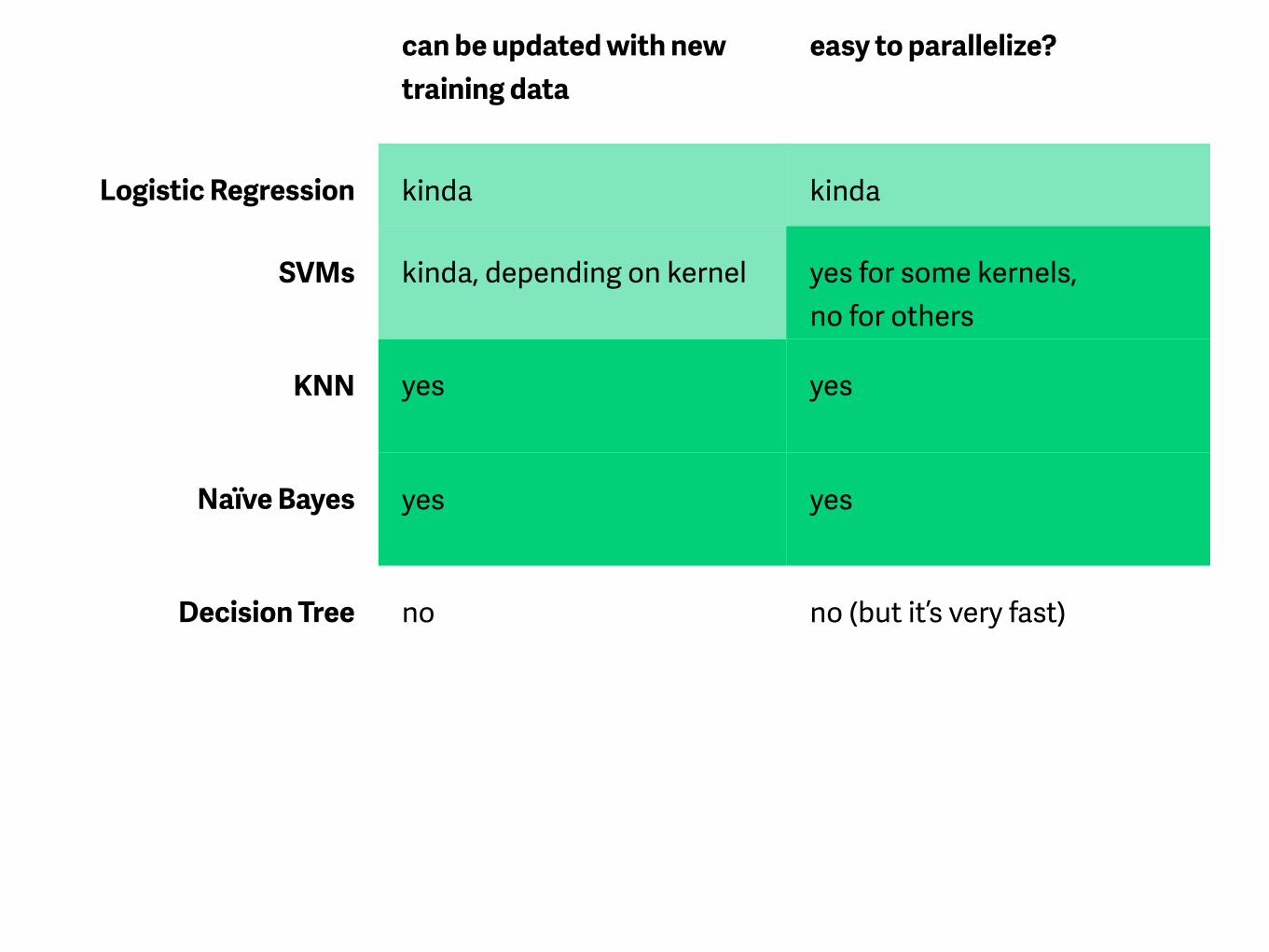
can be updated with new training data
easy to parallelize?
Logistic Regression kinda kinda
SVMs kinda, depending on kernel yes for some kernels, no for others
KNN yes yes
Naïve Bayes yes yes
Decision Tree no no (but it’s very fast)
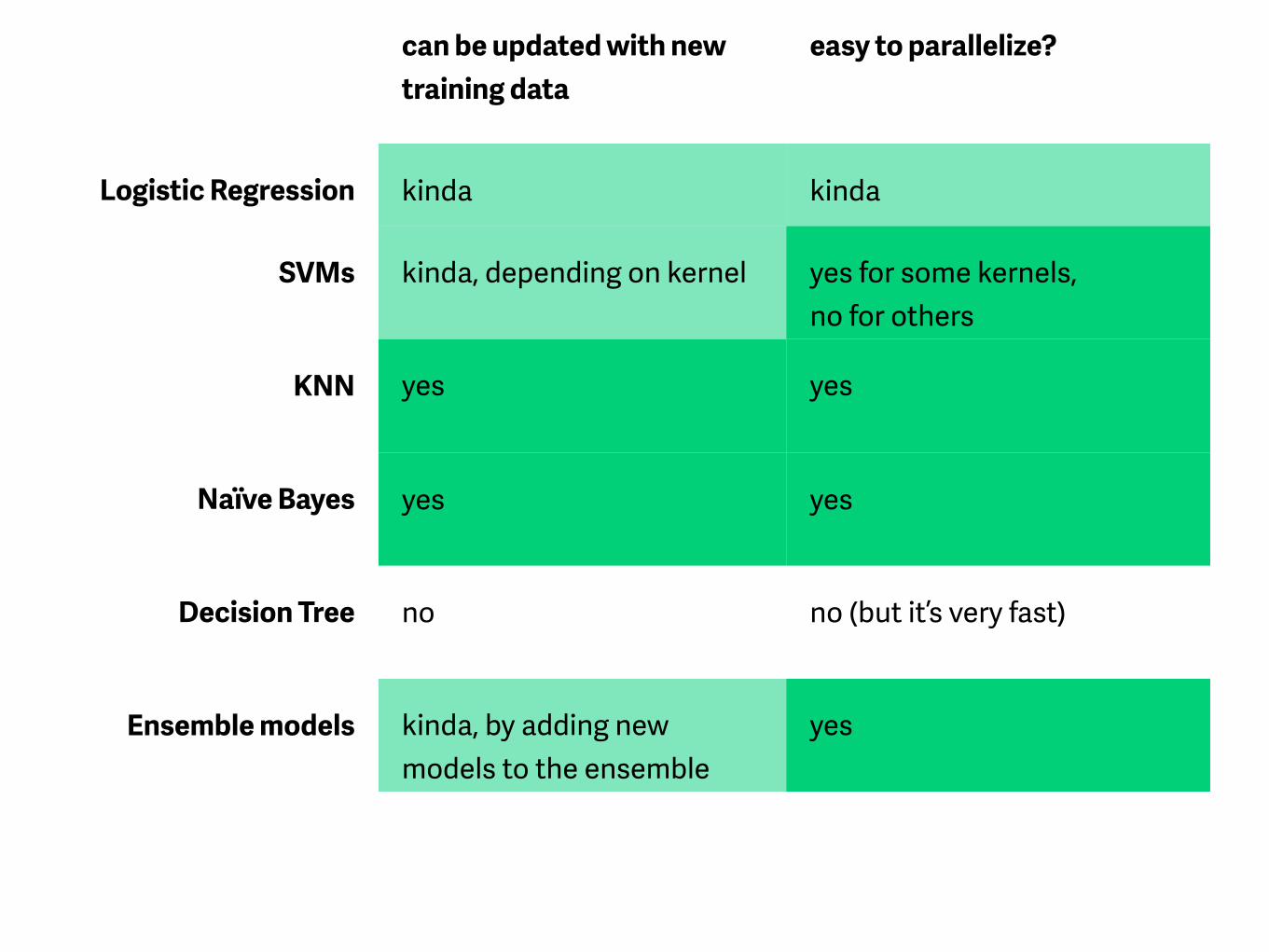
can be updated with new training data
easy to parallelize?
Logistic Regression kinda kinda
SVMs kinda, depending on kernel yes for some kernels, no for others
KNN yes yes
Naïve Bayes yes yes
Decision Tree no no (but it’s very fast)
Ensemble models kinda, by adding new models to the ensemble
yes

can be updated with new training data
easy to parallelize?
Logistic Regression kinda kinda
SVMs kinda, depending on kernel yes for some kernels, no for others
KNN yes yes
Naïve Bayes yes yes
Decision Tree no no (but it’s very fast)
Ensemble models kinda, by adding new models to the ensemble
yes
Boosted models kinda, by adding new models to the ensemble
no

Other quirks

Other quirksSVMs have to pick a kernel

Other quirksSVMs have to pick a kernel
KNN you need to define what “similarity” is in a good way. fast to train, slow to classify (compared to other methods)

Other quirksSVMs have to pick a kernel
KNN you need to define what “similarity” is in a good way. fast to train, slow to classify (compared to other methods)
Naïve Bayes have to choose the distribution can deal with missing data

Other quirksSVMs have to pick a kernel
KNN you need to define what “similarity” is in a good way. fast to train, slow to classify (compared to other methods)
Naïve Bayes have to choose the distribution can deal with missing data
Decision Tree can provide literal flow charts very sensitive to outliers

Other quirksSVMs have to pick a kernel
KNN you need to define what “similarity” is in a good way. fast to train, slow to classify (compared to other methods)
Naïve Bayes have to choose the distribution can deal with missing data
Decision Tree can provide literal flow charts very sensitive to outliers
Ensemble models less prone to overfitting than their component parts

Other quirksSVMs have to pick a kernel
KNN you need to define what “similarity” is in a good way. fast to train, slow to classify (compared to other methods)
Naïve Bayes have to choose the distribution can deal with missing data
Decision Tree can provide literal flow charts very sensitive to outliers
Ensemble models less prone to overfitting than their component parts
Boosted models many parameters to tweak more prone to overfit than normal ensembles most popular Kaggle winners use these


thanks!
question time…
.cohttp:// @bjlange