introduction to high performance computing and ...ernst/lehre/hpc/slides/hpcchapter1.pdf ·...
TRANSCRIPT

Institut für Numerische Mathematik und Optimierung
Introduction toHigh Performance Computingand OptimizationOliver Ernst
Audience: 1./3. CMS, 5./7./9. Mm, doctoral studentsWintersemester 2012/13
Contents
1. Introduction
2. Processor Architecture
3. Optimization of Serial Code
4. Parallel Computers
5. Parallelisation Fundamentals
6. OpenMP Programming
7. MPI Programming
Oliver Ernst (INMO) HPC Wintersemester 2012/13 1

Contents
1. Introduction
2. Processor Architecture
3. Optimization of Serial Code
4. Parallel Computers
5. Parallelisation Fundamentals
6. OpenMP Programming
7. MPI Programming
Oliver Ernst (INMO) HPC Wintersemester 2012/13 5

High Performance ComputingComputing
Three broad domains:Scientific ComputingEngineering, earth sciences, medicine, finance, . . .Consumer ComputingAudio/image/video processing, graph analysis, . . .Embedded ComputingControl, communication, signal processing, . . .
Limited number of critical kernelsDense and sparse linear algebraConvolution, stencils, filter-type operationsGraph algorithmsCodecs. . .
Cf. the 13 dwarfs/motifs of computinghttp://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.pdf
source: IPAM, TU München
source: Apple Inc.
source: Drexel U
Oliver Ernst (INMO) HPC Wintersemester 2012/13 6

High Performance ComputingHardware then and now
ENIAC (1946)IBM 360 Series (1964)
Cray 1 (1976)
Connection Machine 2(1987) SGI Origin 2000 (1996)
IBM Blue Gene/Q (2012)
Oliver Ernst (INMO) HPC Wintersemester 2012/13 7

High Performance ComputingDevelopments
70 years of electronic computinginitially unique pioneering machinesLater (1970s-1990s) specialized designs and hardware industry (CDC, Cray,TMC)Up to here: leading edge in computing determined by HPC requirements.Last 20 years: commodity hardware designed for other purposes (businesstransactions, gaming) adapted/modified for HPCDominant design: general-purpose microprocessor with hierarchical memorystructure
Oliver Ernst (INMO) HPC Wintersemester 2012/13 8
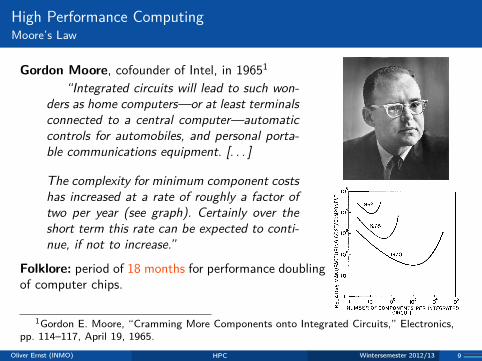
High Performance ComputingMoore’s Law
Gordon Moore, cofounder of Intel, in 19651“Integrated circuits will lead to such won-
ders as home computers—or at least terminalsconnected to a central computer—automaticcontrols for automobiles, and personal porta-ble communications equipment. [. . . ]
The complexity for minimum component costshas increased at a rate of roughly a factor oftwo per year (see graph). Certainly over theshort term this rate can be expected to conti-nue, if not to increase.”
Folklore: period of 18 months for performance doublingof computer chips.
duction—low compared to that of discrete components—itoffers reduced systems cost, and in many systems improvedperformance has been realized.Integrated electronics will make electronic techniques
more generally available throughout all of society, perform-ing many functions that presently are done inadequately byother techniques or not done at all. The principal advantageswill be lower costs and greatly simplified design—payoffsfrom a ready supply of low-cost functional packages.For most applications, semiconductor integrated circuits
will predominate. Semiconductor devices are the only rea-sonable candidates presently in existence for the activeelements of integrated circuits. Passive semiconductor el-ements look attractive too, because of their potential forlow cost and high reliability, but they can be used only ifprecision is not a prime requisite.Silicon is likely to remain the basic material, although
others will be of use in specific applications. For example,gallium arsenide will be important in integrated microwavefunctions. But silicon will predominate at lower frequenciesbecause of the technology which has already evolvedaround it and its oxide, and because it is an abundant andrelatively inexpensive starting material.
IV. COSTS AND CURVESReduced cost is one of the big attractions of integrated
electronics, and the cost advantage continues to increaseas the technology evolves toward the production of largerand larger circuit functions on a single semiconductorsubstrate. For simple circuits, the cost per component isnearly inversely proportional to the number of components,the result of the equivalent piece of semiconductor inthe equivalent package containing more components. Butas components are added, decreased yields more thancompensate for the increased complexity, tending to raisethe cost per component. Thus there is a minimum costat any given time in the evolution of the technology. Atpresent, it is reached when 50 components are used percircuit. But the minimum is rising rapidly while the entirecost curve is falling (see graph). If we look ahead fiveyears, a plot of costs suggests that the minimum cost percomponent might be expected in circuits with about 1000components per circuit (providing such circuit functionscan be produced in moderate quantities). In 1970, themanufacturing cost per component can be expected to beonly a tenth of the present cost.The complexity for minimum component costs has in-
creased at a rate of roughly a factor of two per year(see graph). Certainly over the short term this rate can beexpected to continue, if not to increase. Over the longerterm, the rate of increase is a bit more uncertain, althoughthere is no reason to believe it will not remain nearlyconstant for at least ten years. That means by 1975, thenumber of components per integrated circuit for minimumcost will be 65 000.I believe that such a large circuit can be built on a single
wafer.
Fig. 1.
V. TWO-MIL SQUARES
With the dimensional tolerances already being employedin integrated circuits, isolated high-performance transistorscan be built on centers two-thousandths of an inch apart.Such a two-mil square can also contain several kilohmsof resistance or a few diodes. This allows at least 500components per linear inch or a quarter million per squareinch. Thus, 65 000 components need occupy only aboutone-fourth a square inch.On the silicon wafer currently used, usually an inch or
more in diameter, there is ample room for such a structure ifthe components can be closely packed with no space wastedfor interconnection patterns. This is realistic, since efforts toachieve a level of complexity above the presently availableintegrated circuits are already under way using multilayermetallization patterns separated by dielectric films. Such adensity of components can be achieved by present opticaltechniques and does not require the more exotic techniques,such as electron beam operations, which are being studiedto make even smaller structures.
VI. INCREASING THE YIELD
There is no fundamental obstacle to achieving deviceyields of 100%. At present, packaging costs so far exceedthe cost of the semiconductor structure itself that there is noincentive to improve yields, but they can be raised as highas is economically justified. No barrier exists comparableto the thermodynamic equilibrium considerations that oftenlimit yields in chemical reactions; it is not even necessaryto do any fundamental research or to replace presentprocesses. Only the engineering effort is needed.In the early days of integrated circuitry, when yields were
extremely low, there was such incentive. Today ordinaryintegrated circuits are made with yields comparable withthose obtained for individual semiconductor devices. Thesame pattern will make larger arrays economical, if otherconsiderations make such arrays desirable.
MOORE: CRAMMING COMPONENTS ONTO INTEGRATED CIRCUITS 83
1Gordon E. Moore, “Cramming More Components onto Integrated Circuits,” Electronics,pp. 114–117, April 19, 1965.
Oliver Ernst (INMO) HPC Wintersemester 2012/13 9

High Performance ComputingMoore’s Law: some data
Year of Introduction Transistor Count
Name
1971 2.300 Intel 40041972 3.500 Intel 80081974 4.100 Motorola 68001974 4.500 Intel 80801976 8.500 Zilog Z801978 29.000 Intel 80861979 68.000 Motorola 680001982 134.000 Intel 802861985 275.000 Intel 803861989 1.180.000 Intel 804841993 3.100.000 Intel Pentium1995 5.500.000 Intel Pentium Pro1996 4.300.000 AMD K51997 7.500.000 Pentium II1997 8.800.000 AMD K61999 9.500.000 Pentium III2000 42.000.000 Pentium 42003 105.900.000 AMD K82003 220.000.000 Itanium 22006 291.000.000 Core 2 Duo2007 904.000.000 Opteron 24002007 789.000.000 Power 62008 758.000.000 AMD K102010 2.300.000.000 Nehalem-EX2010 1.170.000.000 Core i7 Gulftown2011 2.600.000.000 Xeon Westmere-EX2011 2.270.000.000 Core i7 Sandy Bridge2012 1.200.000.000 AMD Bulldozer
1E+03
1E+04
1E+05
1E+06
1E+07
1E+08
1E+09
1E+10
1970 1974 1978 1983 1987 1991 1995 1999 2004 2008 2012
CPU Transistor counts 1971-2012
Tran
sist
or C
ount
Year of Introduction
For a long time, increased transistor count translated toreduced cycle time for CPUs . . .
Year of Introduction
Transistor Count
Name
1971 2.300 Intel 40041972 3.500 Intel 80081974 4.100 Motorola 68001974 4.500 Intel 80801976 8.500 Zilog Z801978 29.000 Intel 80861979 68.000 Motorola 680001982 134.000 Intel 802861985 275.000 Intel 803861989 1.180.000 Intel 804841993 3.100.000 Intel Pentium1995 5.500.000 Intel Pentium Pro1996 4.300.000 AMD K51997 7.500.000 Pentium II1997 8.800.000 AMD K61999 9.500.000 Pentium III2000 42.000.000 Pentium 42003 105.900.000 AMD K82003 220.000.000 Itanium 22006 291.000.000 Core 2 Duo2007 904.000.000 Opteron 24002007 789.000.000 Power 62008 758.000.000 AMD K102010 2.300.000.000 Nehalem-EX2010 1.170.000.000 Core i7 Gulftown2011 2.600.000.000 Xeon Westmere-EX2011 2.270.000.000 Core i7 Sandy Bridge2012 1.200.000.000 AMD Bulldozer
Oliver Ernst (INMO) HPC Wintersemester 2012/13 10
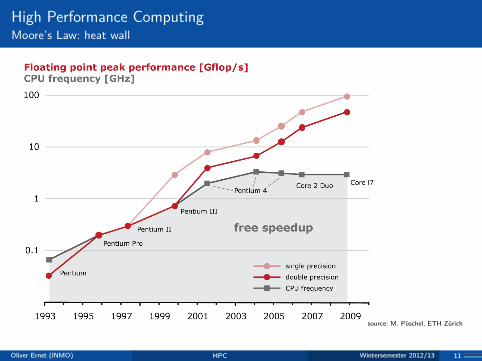
High Performance ComputingMoore’s Law: heat wall
© Markus Püschel Computer Science
Evolution of Processors (Intel)
source: M. Püschel, ETH Zürich
Oliver Ernst (INMO) HPC Wintersemester 2012/13 11

High Performance ComputingTop 500, June 2012 Video: Supporting Mission Critical
Global Weather Modeling
Job of the Week: IT Manager for HPCSystems at Yale
NASA Ames: Combining Quick-turnaround and Batch Workloads atScale
Hitachi targets 2015 for glass-based datastorage that lasts 100 million years
Interview: General Chair JeffHollingsworth Looks Forward to SC12
Using Supercomputers to Regulate High-Frequency Trading
Adaptive Computing Invites TechEntrepreneurs to Pitch Their Startup atSC12
BigData, meet BigCompute: 1 MillionHours, 78 TB of genomic data analysis,in 1 week
Rise to NASA’s Big Data Challenge
Video: Software Asset Optimization(SAO)
Report Lays Out the Big Data Road Mapfor Government
HyperWorks On-Demand – Altair’s CloudVision
ClusterVision Manages Murex’s Cluster
Video: SGI – Scale-up in your Scale-out
Search
Search
Steve Wozniak
Hard disks have disappointedme more than mosttechnologies.
view the complete list.
Rank Site Computer
1 DOE/NNSA/LLNLUnited States
Sequoia - BlueGene/Q, Power BQC 16C 1.60GHz, CustomIBM
2RIKEN Advanced Institute forComputational Science(AICS)Japan
K computer, SPARC64 VIIIfx 2.0GHz, TofuinterconnectFujitsu
3DOE/SC/Argonne NationalLaboratoryUnited States
Mira - BlueGene/Q, Power BQC 16C 1.60GHz,CustomIBM
4 Leibniz RechenzentrumGermany
SuperMUC - iDataPlex DX360M4, Xeon E5-26808C 2.70GHz, Infiniband FDRIBM
5National SupercomputingCenter in TianjinChina
Tianhe-1A - NUDT YH MPP, Xeon X5670 6C 2.93GHz, NVIDIA 2050NUDT
6DOE/SC/Oak Ridge NationalLaboratoryUnited States
Jaguar - Cray XK6, Opteron 6274 16C 2.200GHz,Cray Gemini interconnect, NVIDIA 2090Cray Inc.
7 CINECAItaly
Fermi - BlueGene/Q, Power BQC 16C 1.60GHz,CustomIBM
8Forschungszentrum Juelich(FZJ)Germany
JuQUEEN - BlueGene/Q, Power BQC 16C1.60GHz, CustomIBM
9 CEA/TGCC-GENCIFrance
Curie thin nodes - Bullx B510, Xeon E5-2680 8C2.700GHz, Infiniband QDRBull
10National SupercomputingCentre in Shenzhen (NSCS)China
Nebulae - Dawning TC3600 Blade System, XeonX5650 6C 2.66GHz, Infiniband QDR, NVIDIA 2050Dawning
Copyright (c) 2000-2012 TOP500.Org | All trademarks and copyrights on this page are owned by their respective owners.
Ranking based on perfor-mance running LINPACK-benchmark, the LU facto-rization of a matrix.
Oliver Ernst (INMO) HPC Wintersemester 2012/13 12

High Performance ComputingTop 500, June 2012
Top ranked system: Sequoia - BlueGene/Q
Location: Lawrence Livermore NationalLaboratory (CA/USA)Purpose: nuclear weapons simulationsManufacturer: IBM source: LLNL
Operating system: Linux1,572,864 coresMemory: 1,572,864 GBPower consumption: 7.89 MWPeak performance: 20,132.7 TFlops2
Sustained performance: 16,324.8 TFlops (81%)Cf. 10,510 TFlops of top system November 2011 (K Computer, Japan)Cf. top system of 1st Top500 (TNC CM5): 273,930 times faster.
21 TFlop = 1012 FlopsOliver Ernst (INMO) HPC Wintersemester 2012/13 13
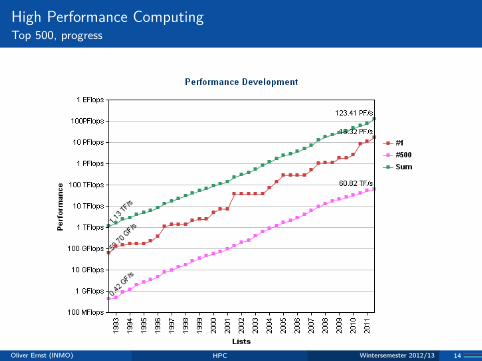
High Performance ComputingTop 500, progress
Oliver Ernst (INMO) HPC Wintersemester 2012/13 14

High Performance ComputingEfficiency
Most numerical code runs at ≈ 10% efficiency.
Coping strategies:
Do nothing and hope hardware gets faster. (Worked up to 2004)Rely on compiler to generate optimal code. (Not yet)Understand intricacies of modern computer architectures and learn to writeoptimized code.Write code which is efficient for any architecture.Know the most efficient numerical libraries and use them.
Oliver Ernst (INMO) HPC Wintersemester 2012/13 15