introduction to artificial intelligence massimo poesio lecture: support vector machines
TRANSCRIPT

INTRODUCTION TO ARTIFICIAL INTELLIGENCE
Massimo Poesio
LECTURE: Support Vector Machines

Recall: A SPATIAL WAY OF LOOKING AT LEARNING
• Learning a function can also be viewed as learning how to discriminate between different types of objects in a space
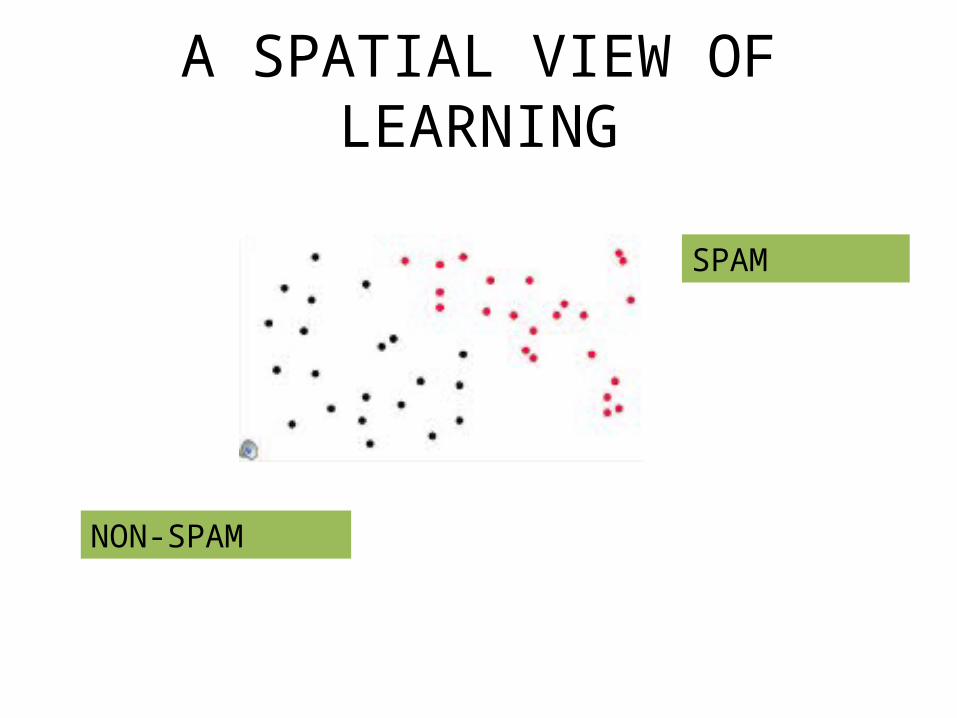
A SPATIAL VIEW OF LEARNING
SPAM
NON-SPAM

03/19/12
Vector Space Representation
• Each document is a vector, one component for each term (= word).
• Normalize to unit length.• Properties of vector space
– terms are axes– n docs live in this space– even with stemming, may have 10,000+
dimensions, or even 1,000,000+

A SPATIAL VIEW OF LEARNING
The task of the learner is to learn a function that divides the space of examples into black and red
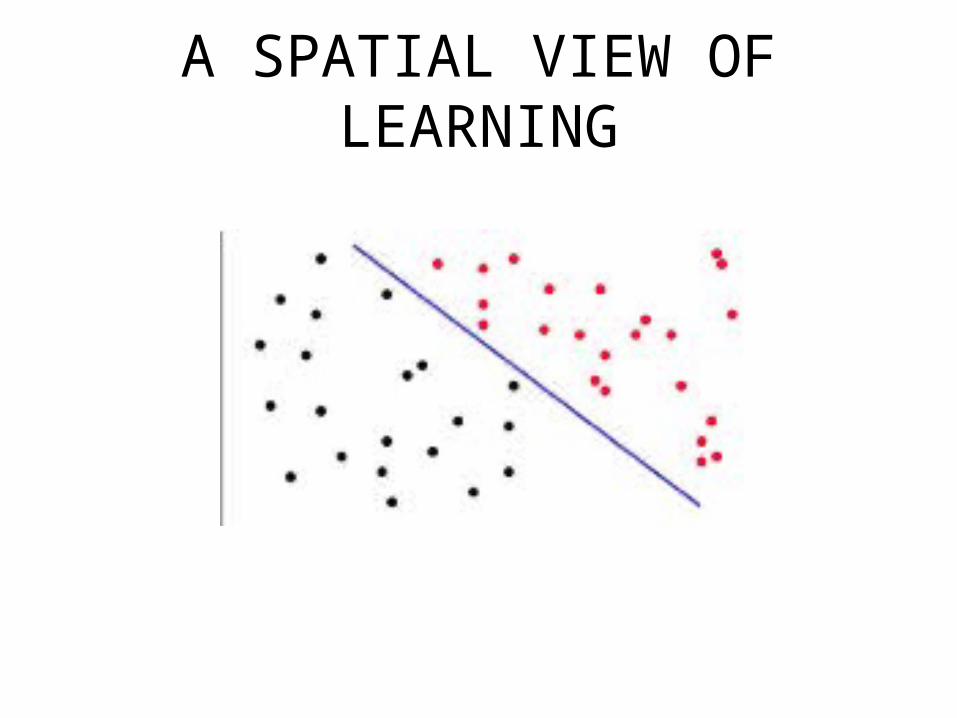
A SPATIAL VIEW OF LEARNING
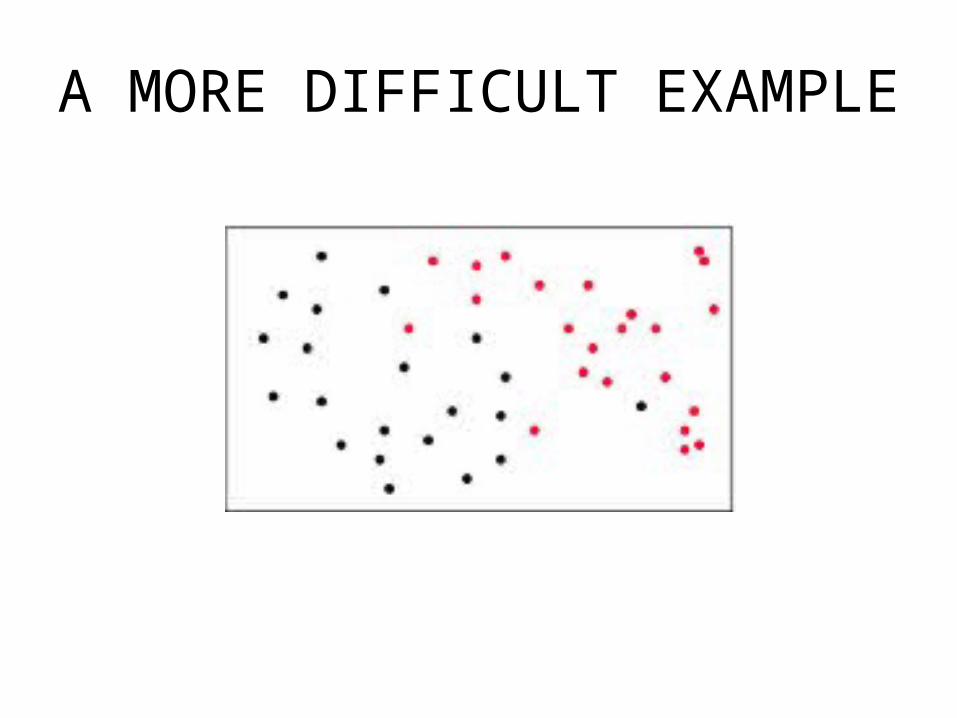
A MORE DIFFICULT EXAMPLE

ONE SOLUTION
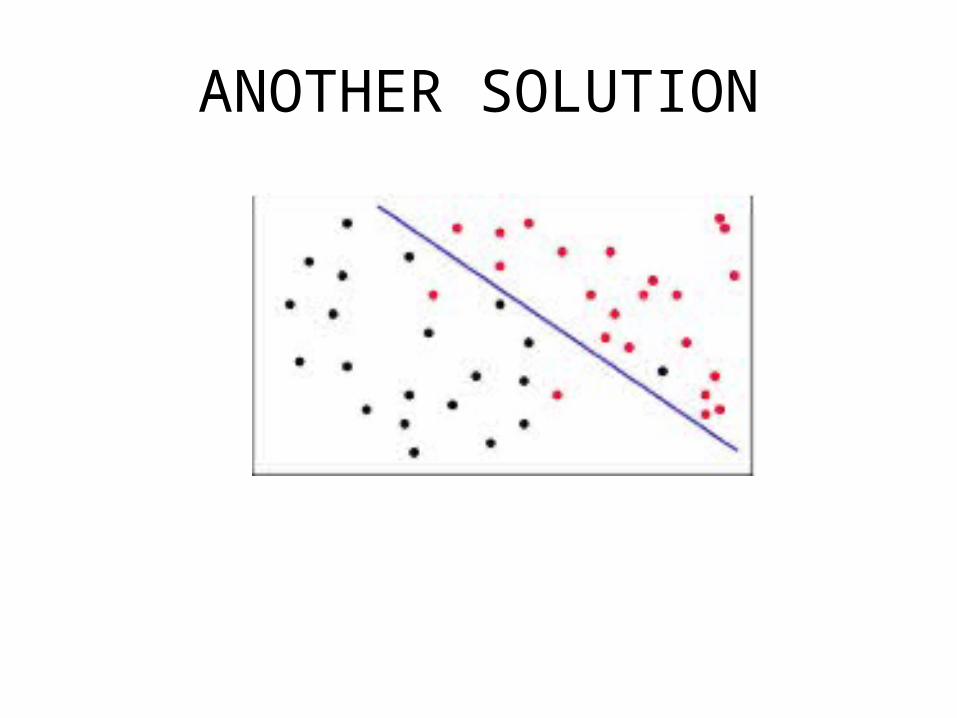
ANOTHER SOLUTION

03/19/12
Multi-class problems
Government
Science
Arts

Support Vector Machines
This lecture: an overview of
• Linear SVMs (separable problems)• Linear SVMs (non-separable problems)• Kernels

03/19/12
Separation by Hyperplanes
• Assume linear separability for now:– in 2 dimensions, can separate by a line– in higher dimensions, need hyperplanes
• Can find separating hyperplane by linear programming (e.g. perceptron):– separator can be expressed as ax + by = c

Linear separability
Not linearly separable Linearly separable

03/19/12
Linear Classifiers
denotes +1
denotes -1
f(x,w,b) = sign(w x + b)
How would you classify this data?
w x
+ b
=0
w x + b<0
w x + b>0
03/19/12
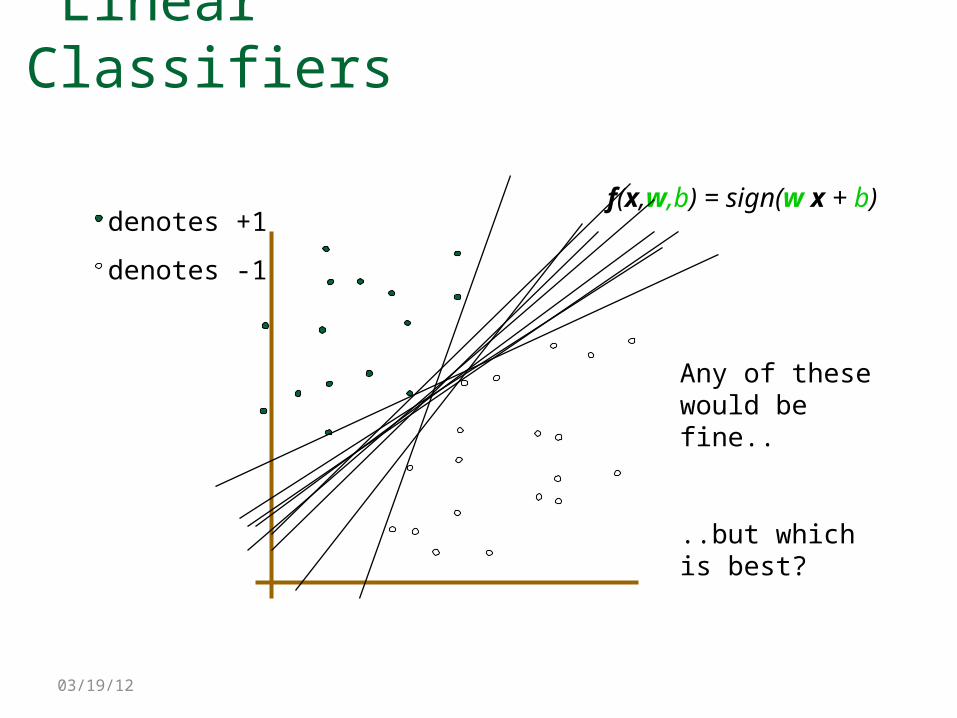
Linear Classifiers
denotes +1
denotes -1
f(x,w,b) = sign(w x + b)
Any of these would be fine..
..but which is best?
03/19/12
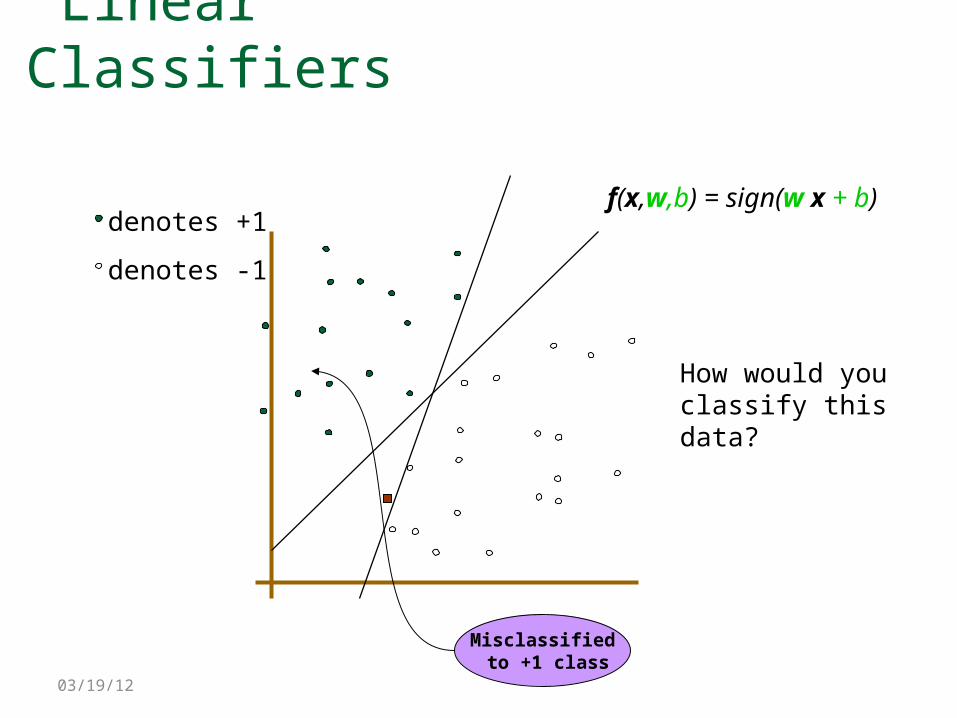
Linear Classifiers
denotes +1
denotes -1
f(x,w,b) = sign(w x + b)
How would you classify this data?
Misclassified to +1 class

03/19/12
Linear Classifiers: summary
• Many common text classifiers are linear classifiers
• Despite this similarity, large performance differences– For separable problems, there is an infinite
number of separating hyperplanes. Which one do you choose?
– What to do for non-separable problems?
03/19/12
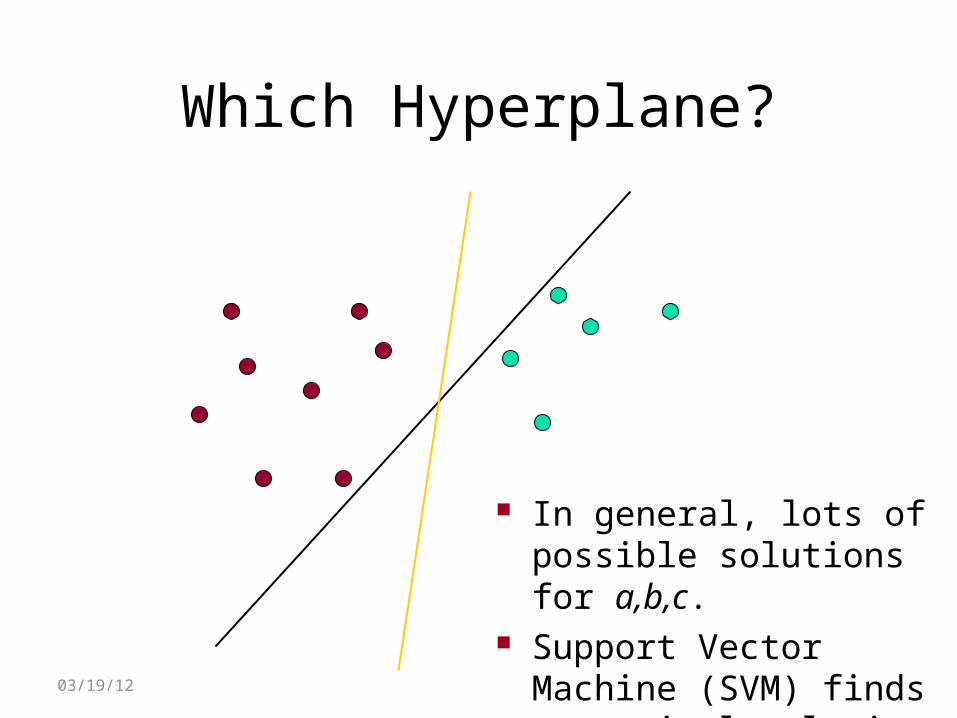
Which Hyperplane?
In general, lots of possible solutions for a,b,c.
Support Vector Machine (SVM) finds an optimal solution.

03/19/12
Maximum Margin
denotes +1
denotes -1
f(x,w,b) = sign(w x + b)
The maximum margin linear classifier is the linear classifier with the, um, maximum margin.
This is the simplest kind of SVM (Called an LSVM)Linear SVM
Support Vectors are those datapoints that the margin pushes up against
1. Maximizing the margin is good according to intuition and PAC theory
2. Implies that only support vectors are important; other training examples are ignorable.
3. Empirically it works very very well.
03/19/12
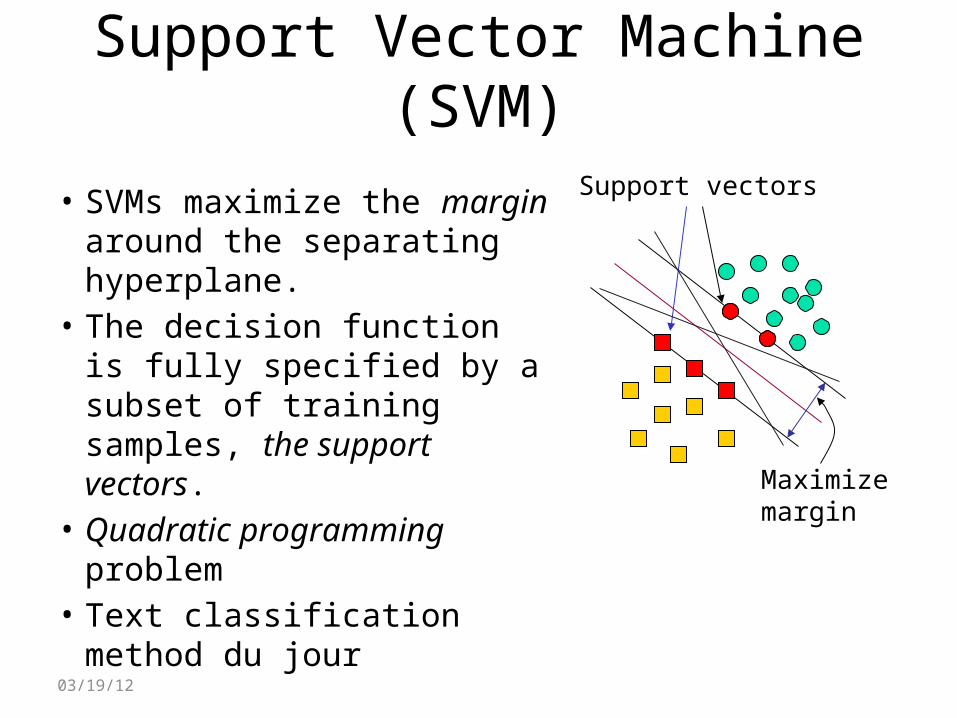
Support Vector Machine (SVM)Support vectors
Maximizemargin
• SVMs maximize the margin around the separating hyperplane.
• The decision function is fully specified by a subset of training samples, the support vectors.
• Quadratic programming problem
• Text classification method du jour

03/19/12
• w: hyperplane normal• x_i: data point i• y_i: class of data point i (+1 or -1)
• Constraint optimization formalization:
• (1)
• (2) maximize margin: 2/||w||
Maximum Margin: Formalization

03/19/12
• One can show that hyperplane w with maximum margin is:
• alpha_i: Lagrange multipliers• x_i: data point i• y_i: class of data point i (+1 or -1)• Where the alpha_i are the solution to maximizing:
Quadratic Programming
Most alpha_i will be zero.
03/19/12
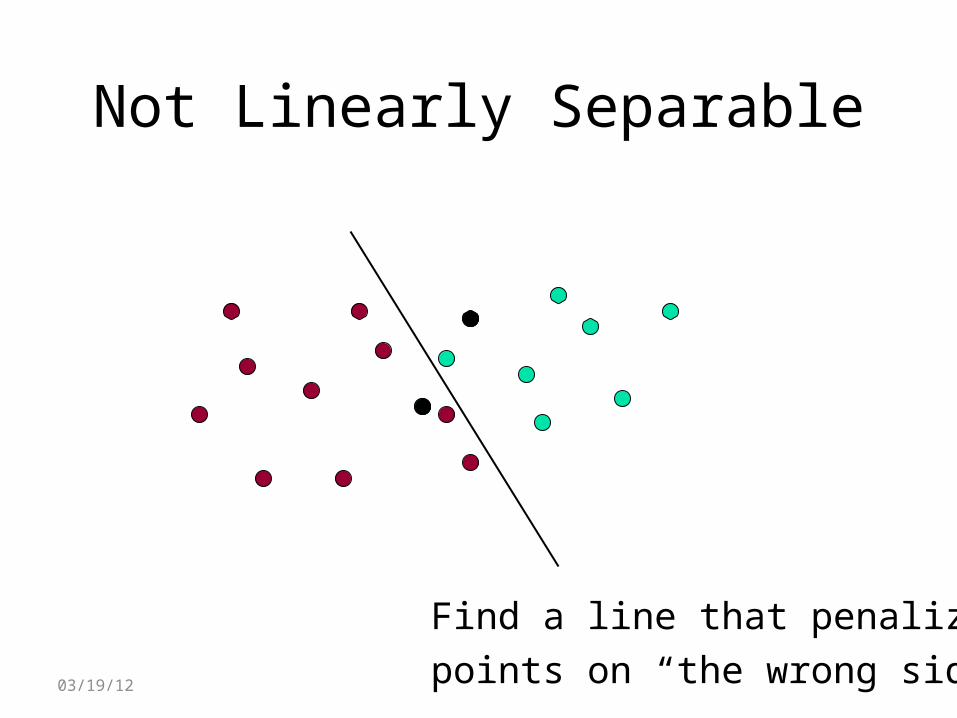
Not Linearly Separable
Find a line that penalizespoints on “the wrong side”.
03/19/12
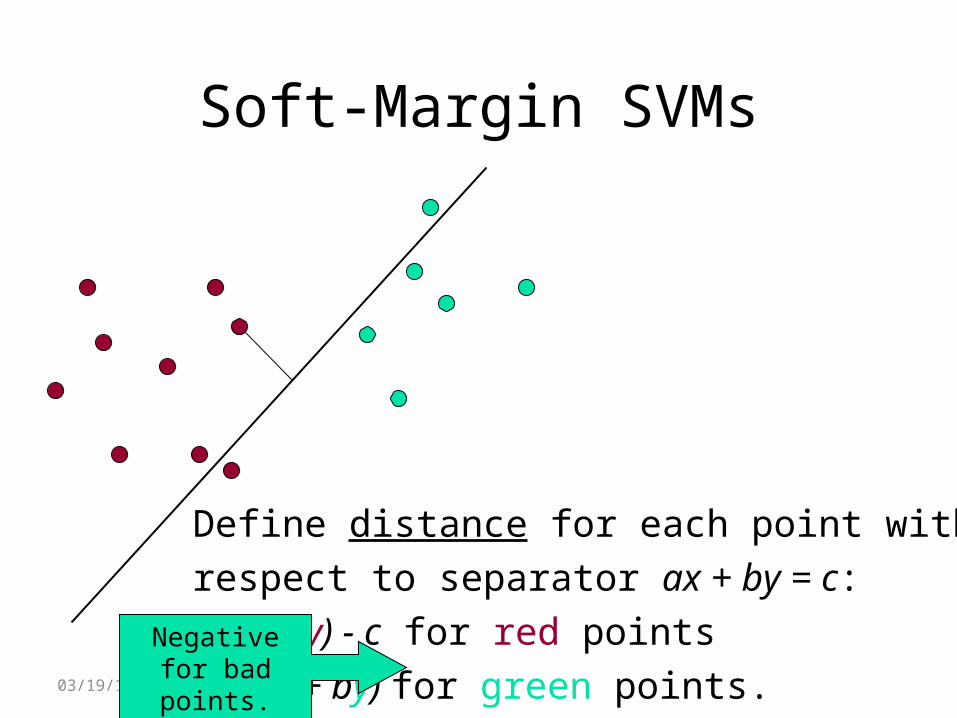
Soft-Margin SVMs
Define distance for each point withrespect to separator ax + by = c: (ax + by) - c for red pointsc - (ax + by) for green points.
Negative for bad points.

03/19/12
Solve Quadratic Program
• Solution gives “separator” between two classes: choice of a,b.
• Given a new point (x,y), can score its proximity to each class:– evaluate ax+by.– Set confidence threshold.
35
7

03/19/12
Predicting Generalization for SVMs
• We want the classifier with the best generalization (best accuracy on new data).
• What are clues for good generalization?– Large training set– Low error on training set– Low capacity/variance (≈ model with few
parameters)• SVMs give you an explicit bound based on
these.

03/19/12
Capacity/Variance: VC Dimension
• Theoretical risk boundary:
• Remp - empirical risk, l - #observations, h – VC dimension, the above holds with prob. (1-η)
• VC dimension/Capacity: max number of points that can be shattered
• A set can be shattered if the classifier can learn every possible labeling.
03/19/12
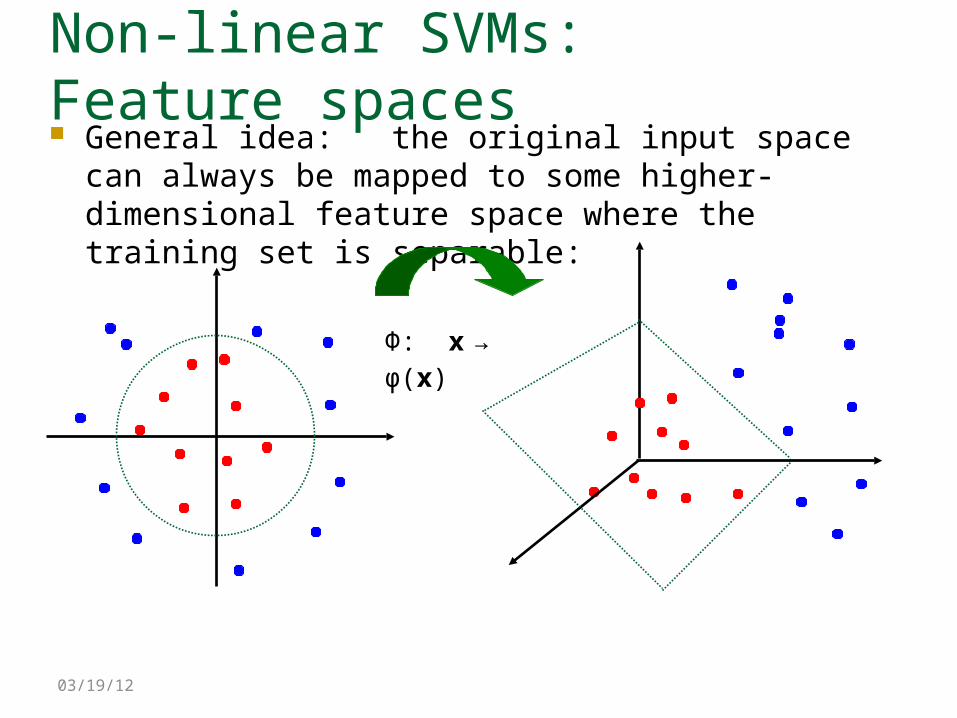
Non-linear SVMs: Feature spaces General idea: the original input space can always be
mapped to some higher-dimensional feature space where the training set is separable:
Φ: x → φ(x)

03/19/12
Kernels• Recall: We’re maximizing:
• Observation: data only occur in dot products.• We can map data into a very high dimensional space (even
infinite!) as long as kernel computable.• For mapping function Ф, compute kernel K(i,j) = Ф(xi)∙Ф(xj)• Example:

03/19/12
The Kernel Trick
• The linear classifier relies on dot product between vectors K(xi,xj)=xi
Txj
• If every data point is mapped into high-dimensional space via some transformation Φ: x → φ(x), the dot product becomes:
K(xi,xj)= φ(xi) Tφ(xj)
• A kernel function is some function that corresponds to an inner product in some expanded feature space
• We don't have to compute Φ: x → φ(x) explicitly, K(xi,xj) is enough for SVM learning

03/19/12
What Functions are Kernels? For some functions K(xi,xj) checking that
K(xi,xj)= φ(xi) Tφ(xj) can be cumbersome.
Mercer’s theorem:
Every semi-positive definite symmetric function is a kernel Semi-positive definite symmetric functions correspond to a
semi-positive definite symmetric Gram matrix:
K(x1,x1) K(x1,x2) K(x1,x3) … K(x1,xN)
K(x2,x1) K(x2,x2) K(x2,x3) K(x2,xN)
… … … … …
K(xN,x1) K(xN,x2) K(xN,x3) … K(xN,xN)
K=

03/19/12
Kernels
• Why use kernels?– Make non-separable problem separable.– Map data into better representational space
• Common kernels– Linear– Polynomial– Radial basis function

03/19/12
Performance of SVM
• SVM are seen as best-performing method by many.
• Statistical significance of most results not clear.
• There are many methods that perform about as well as SVM.
• Example: regularized regression (Zhang&Oles)
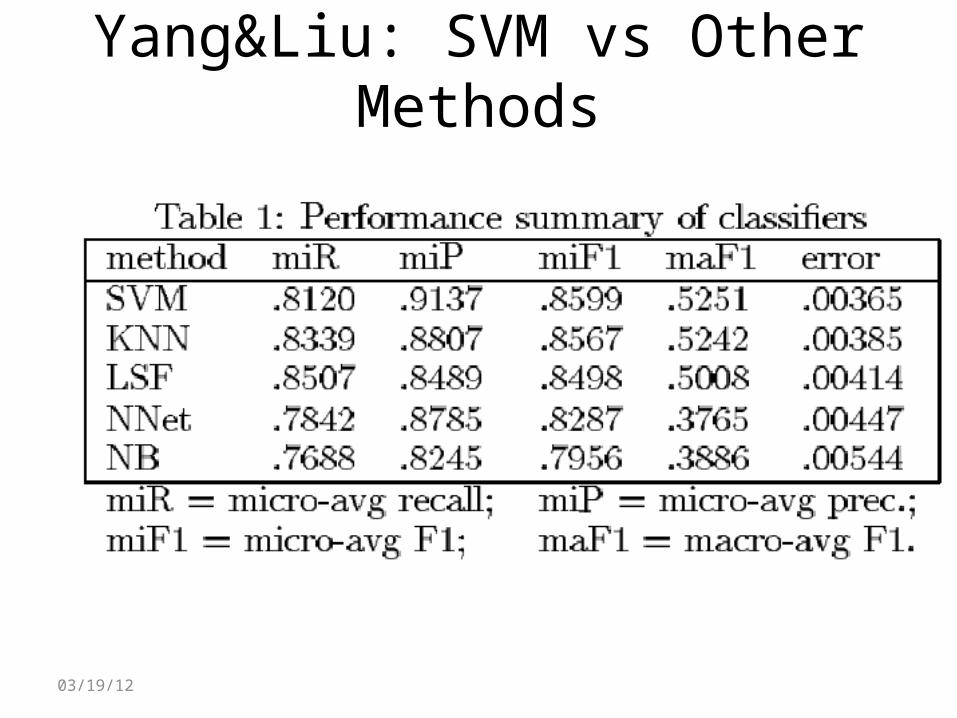
• Example of a comparison study: Yang&Liu
03/19/12
Yang&Liu: SVM vs Other Methods
03/19/12
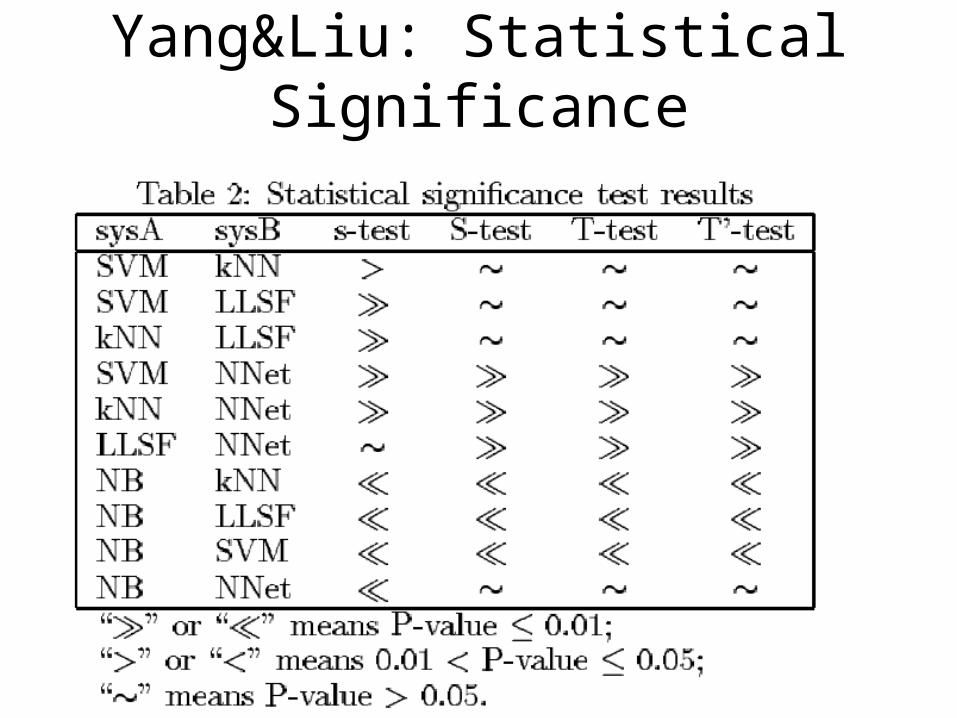
Yang&Liu: Statistical Significance

03/19/12
Yang&Liu: Small Classes

03/19/12
SVM: Summary
• SVM have optimal or close to optimal performance.
• Kernels are an elegant and efficient way to map data into a better representation.
• SVM can be expensive to train (quadratic programming).
• If efficient training is important, and slightly suboptimal performance ok, don’t use SVM?
• For text, linear kernel is common.• So most SVMs are linear classifiers (like many
others), but find a (close to) optimal separating hyperplane.

03/19/12
• Model parameters based on small subset (SVs)• Based on structural risk minimization
• Supports kernels
SVM: Summary (cont.)

03/19/12
Resources• Foundations of Statistical Natural Language
Processing. Chapter 16. MIT Press. Manning and Schuetze.
• Trevor Hastie, Robert Tibshirani and Jerome Friedman, "Elements of Statistical Learning: Data Mining, Inference and Prediction" Springer-Verlag, New York.
• A Tutorial on Support Vector Machines for Pattern Recognition (1998) Christopher J. C. Burges
• ML lectures at DISI

THANKS
• I used material from– Mingyue Tan's course at UBC– Chris Manning course at Stanford