introduction à l'identification des paramètres
TRANSCRIPT

Introductiona
L’identificationdes
Parametres
G. Sallet
Reunion RTP M3D Cargese
1 Introduction
On dispose d’un ensemble de donnees, que l’on a obtenu par mesures et/ouobservations. On voudrait que ces donnees soit representees/expliquees parun modele. Cela signifie que l’on dispose d’un modele candidat, ce modeleappartient a une famille de modeles d’une structure donnee. Les modeles decette famille dependent de certains parametres. On veut ajuster ces para-metres de telle facon que le modele approche au mieux les donnee mesurees.Le principe est toujours le meme. On defini une fonction «cout» qui mesureen un certain sens l’accord entre les mesures observees et celles donnees parle modele. La fonction cout est telle qu’a une petite valeur est associee unbon accord. Les parametres sont alors ajustes de telle facon que la fonctioncout soit minimale.L’identification est d’abord un probleme d’optimisation. Il s’agit de minimiser(ou de maximiser, il suffit de changer de signe) une fonction de Rn dans R.Il est bien connu que cela est un des problemes les plus difficile de l’analysenumerique. La situation ideale est celle ou la fonction a un unique minimum.Mais il arrive tres souvent que la fonction «cout» a plusieurs (voire memeune infinite) de minima. On peut aussi avoir un minimum global et plusieurs
1

minima locaux. Il est tres difficile de developper des methodes qui trouventle minimum global avec certitude.Pour donner une idee des algorithmes possibles, voici une figure extraite de[11] qui donne une classification des algorithmes d’optimisation globaux :
1.1 A Classi�cation of Optimization Algorithms 5
Algorithms
Evolutionary
Arti�cial
Computational
Deterministic
BoundAlgebraicGeometrySearch
Probabilistic
MemeticAlgorithms
Swarm
Optimization (ACO)
Optimization )(PSO
Evolutionary
Genetic
EvolutionaryProgramming
Evolution
Programming
Di�erential
Programming
Prograaming
(Stochastic)
RandomOptimization
Simulated
(TS)
ParallelTempering
StochasticTunneling
Harmonic
The taxonomy of global optimization algorithms.
Figure 1 – Algorithmes d’optimisation
Cela dit d’autre problemes sont en jeu. Tout d’abord les donnees sont brui-
2

tees. Elle sont sujettes a des erreurs : ce que l’on appelle le «bruit» en theoriedu controle ou en theorie du signal. Par consequent les donnees ne s’ajustentpas exactement au modele, meme si celui-ci est exact.Il faut donc un moyen pour mesurer la qualite de l’ajustement. Ceci pourdecider si le modele est correct ou pas.On a aussi besoin de savoir avec quelle precision les parametres sont deter-mines.Enfin, on l’ a deja dit, il n’est pas inhabituel de decouvrir que la fonction decout n’ a pas un seul minimum. Autrement dit, plusieurs jeux de parametresvont pouvoir donner la meme qualite d’ajustement. C’est le probleme del’identifiabilite.De plus on peut obtenir un resultat local pour le minimum. Comment peut-on etre sur qu’il n’ y a pas un autre jeu de parametres meilleurs dans unezone eloignee de l’espace des parametres ? L’identification fait partie de ceque l’on appelle les problemes inverses. En effet on cherche a determiner lesparametres a partir des solutions.
Pour resumer, l’identification ou l’ajustement de parametres ou l’estimationde parametres, trois termes synonymes ne constituent pas une fin en soi. Ilfaut
1. Identifier les parametres
2. Donner une estimation de l’erreur
3. Donner une mesure statistique de la qualite de l’ajustement.
Si 3 indique que le modele a peu de chance de correspondre aux donnees,alors il y a de fortes chances que 1 et 2 soient sans valeurs.
2 Un exemple
Un ajustement suppose un modele. Meme si celui-ci n’est qu’implicite : sup-posons que vous lanciez une piece de monnaie. Au bout d’un certain nombred’experiences on se demande comment mesurer la probabilite d’obtenir pile.En faisant cela, on a implicitement suppose que pour chaque lance la pro-babilite est la meme pour pile. Il est impossible de parler de parametres oude probabilite si l’on a pas presuppose un modele. On a donc suppose qu’achaque lance la probabilite d’obtenir pile est la meme
P(pile) = p et P(face) = 1− p
3

Ce qui revient a dire que le resultat de chaque lance est independant desautres. Le modele est ainsi decrit par une variable aleatoire de Bernoulli quirealise le resultat de chaque lance.L’etape suivant est d’estimer p. Supposons que l’on a fait n lances et que l’onait obtenu k fois pile. Intuitivement on a envie de poser p = k
n.
C’est ce que l’on va appeler un estimateur du «vrai» parametre p.Comment le justifier ? La probabilite d’obtenir k observations a partir dumodele est
P(k|p) = (observer k pile en n lances |p) =
(k
n
)pk (1− p)n−k
Ici on n’ a pas un cout, mais plutot une vraisemblance. Plus la valeur seraelevee, plus la valeur du parametre sera vraisemblable. On va donc chercherun maximum de vraisemblance.On verifie immediatement que la fonction ϕ(p) =
(kn
)pk (1 − p)n−k a un
maximum pour p =k
n. C’est le maximum de la fonction vraisemblance.
3 Estimation par maximum de vraisemblance
Cette partie concerne les modeles stochastiques ou encore les modeles deter-ministes ou les erreurs sont modelisees par des variables aleatoires.Le postulat de modelisation sur lequel toute etude statistique est basee est lesuivant : Les donnees observees sont des realisations de variables aleatoires.L’ensemble des donnees observees constitue un echantillon. Le resultat d’uneexperience n’est pas reproductible exactement. On suppose qu’il est la reali-sation d’une variable aleatoire, souvent consideree comme une variable deter-ministe a laquelle on ajoute une erreur (de mesure, d’observation) aleatoire.Quand on observe un caractere statistique sur une population, si l’ordre danslequel on prend les individus n’a pas d’importance, on choisira de considererque les donnees sont des realisations de variables aleatoires i.i.d. autrementdit independantes et de meme loi de distribution (independantes et identique-ment distribuees). Cette loi de probabilite decrit la variabilite du caractere.Meme dans le cas ou les individus ne sont pas interchangeables, comme pourune serie chronologique ou un probleme de regression, la modelisation consis-tera a se ramener, en soustrayant au besoin une fonction deterministe, au casd’un echantillon de variables aleatoires independantes.
4

L’hypothese de modelisation consiste a voir l’echantillon (observe) commeune realisation d’un echantillon (theorique) d’une certaine loi de probabi-lite P . En d’autres termes, on considere que les donnees auraient pu etreproduites en simulant de facon repetee la loi de probabilite P .On appelle probleme d’ajustement le probleme consistant a determiner, dansune famille de lois de probabilite donnee, quelle est celle qui coıncide le mieuxavec l’echantillon observe. Dans la situation la plus courante, celle que nousconsiderons ici, la famille depend d’un ou plusieurs parametres reels inconnus.Le probleme est donc de determiner quelle valeur du parametre est la mieuxadaptee aux donneesQuand une famille de lois, dependant du parametre inconnu θ a ete choisie,c’est de l’echantillon et de lui seul, que l’on peut tirer les informations.
Soit X une variable aleatoire de densite de probabilite f(x, θ) ou θ ∈ Rp. Onnote θ = (θ1, · · · , θ2).On rappelle que dans le langage de la statistique, un echantillon est une suite(X1, X2, · · · , Xn) de variables aleatoires independantes et identiquement dis-tribuees (i.i.d.).On dispose d’un echantillon de donnees independantes X1,X2, · · · , Xn.
Definition 3.1 (fonction de vraisemblance, lilelihood function) :La fonction de vraisemblance associee est definie par
L(θ) =n∏i=1
f(xi, θ)
Definition 3.2 (estimateur de maximum vraisemblance) :La valeur θ qui maximise la fonction de vraisemblance L(θ) est l’estimationmaximum de vraisemblance de θ.
θ = arg maxθL(θ)
L’application qui associe aux donnee θ
(x1, · · · , xn) 7−→ θ
s’appelle l’estimateur du maximum de vraisemblance. Une fonction d’un echan-tillon s’appelle une statistique.
L’estimateur du maximum de vraisemblance est une statistique particuliere.
5

Definition 3.3 (Estimateur sans biais) :Le biais est l’ecart entre la moyenne de l’estimateur et ce que l’on cherche aestimer, i.e. E(θ)− θ.Un estimateur est sans biais quand cet ecart est nul.
Comme la fonction de vraisemblance est un produit de termes positifs, quela fonction ln est strictement croissante, on peut chercher le maximum dulogarithme de la fonction de vraisemblance.
Definition 3.4 (fonction log-vraisemblance) :La fonction log-vraisemblance est definie par
LL(θ) = ln(L(θ))
Si une approche analytique n’est pas possible, ce qui est souvent le cas alorsil faut chercher numeriquement ce maximum en utilisant des algorithmesd’optimisation.Cet estimateur peut tres bien ne pas etre unique, voire meme ne pas exister.
3.1 Proprietes de l’estimateur maximum de vraisem-blance
Cet estimateur est asymptotiquement (i.e. quand n → +∞ sans biais et sadistribution tend vers une loi normale N(θ, I−1(θ)) ou I(θ) est la matriced’information de Fischer.Cet estimateur est invariant par transformation fonctionnelle. Plus precise-ment si γ = g(θ) est un parametre fonction du parametre θ alors
γ = g(γ)
3.2 Exemple : le modele Gaussien
On considere la loi Gaussienne (ou loi normale) N (µ, σ2). Sa densite de pro-babilite est
f(x, µ, σ2) =1√
2σ2 πe−
(x−µ)2
2σ2
Cette loi depend de deux parametre µ et σ2
6

La log-vraisemblance est
LL(x, µ, σ2) = −n2
ln(2π)− n
2(σ2)− 1
2σ2
n∑i=1
(xi − µ)2
Soit encore, si l’on pose X = 1n
∑ni=1 xi et V = 1
n
∑ni=1 (xi − xn)2 :
LL(x, µ, σ2) = −n2
ln(2π)− n
2(σ2)− n 1
2σ2
((X − µ)2 + V )
)Pour chercher un extremum on calcule les derivees partielles par rapport auxparametres
∂
∂µLL(x, µ, σ2) = n
X − µσ2
∂
∂(σ2)LL(x, µ, σ2) = − n
2σ2+ n
(X − µ)2 + V
2σ4
On verifie que pour µ = X et σ2 = V la log-vraisemblance est maximale.L’estimateur du maximum de vraisemblance est
µ = X σ2 =1
n
n∑i=1
(xi − X)2
On voit qu’un estimateur de σ est donne par la moyenne de la somme descarres des residus xi − X.On note RSS la somme des carres des residus ( «Residual Sum Square»).
4 La methodes des moindres carres
La methode des moindres carres designe une methode tres populaire chez lesexperimentateurs et ingenieurs. On a une serie de mesures yi dependant devaleurs xi. On a un modele dependant d’un parametres β ∈ Rp reglable. Lemodele pour la valeur β du parametre et la valeur xi predit la valeur yi(xi, β).La methode des moindres carres va chercher va minimiser sur β la quantite
n∑i=1
‖yi − yi(xi, β)‖2
somme des carres entre ce qui est observe et predit. C’est RSS.
7

4.1 Un exemple : les donnees de Gause
Si on considere une population de protistes (autrement dit etres des unicel-lulaires). Si on suppose que leur taux d’accroissement est proportionnel onobtient comme modele en temps continu, pour la population N(t) :
N = r N
Le parametre r est la vitesse d’accroissement par individu. En effet si onregarde les chiffres de demographie, les taux d’accroissement sont donnescomme le rapport de l’accroissement (bilan naissance-deces) a la populationmoyenne pour une annee (i.e. unite de temps). Du point de vue de l’analysedimensionnelle le parametre r est le quotient de deux nombres d’individus(ou le quotient de deux biomasses) par unite de temps. Sa dimension est doncT−1. L’EDO est bien coherente.
Cette equation differentielle est aussi connue sous le nom de Malthus. Ceciest en reference avec le celebre enonce de Malthus en 1798 «Population,when unchecked, increases in a geometrical ratio». Cela fonde le principe dela croissance exponentielle d’une part et de son impossibilite a long termed’autre part.En effet si on considere une culture de bacteries, peu nombreuses au de-part, sur un milieu riche en nutriement , l’experience montre que ce modeleexponentiel est correct pendant quelque temps. Il n’existe pas, pour une rai-son evidente de limitation de l’espace, de population pour laquelle le modeleexponentiel soit valable jusqu’a la fin des temps !
C’est pourquoi on a rapidement cherche a modifier ce modele de facona «freiner» sa croissance quand la taille de la population augmente. L’ideeest de remplacer la constante r par une fonction r(x) qui decroıt quandN augmente et qui finit par devenir negative. La population a un taux decroissance de moins en moins fort au fur et a mesure que la populationcroit (les cellules ont de plus en plus de mal a se reproduire) au point dedevenir negatif (pour une population trop abondante les cellules commencenta mourir). La fonction la plus simple ayant cette propriete est la fonctionlineaire :
r
(1− N
K
)Cela donne le modele dit logistique, encore appele EDO de Pearl-Verhulst.
8

N = r N
(1− N
K
)Le parametre r est appele le taux intrinseque d ’accroissement et K la capa-cite biotique du milieu.Cette equation peut encore se reecrire
N = r N − r
KN2
Le terme rKN2 s’interprete alors comme un terme de mortalite proportionnel
a la probabilite de rencontre de deux individus. Cela represente une compe-tition entre especes. On dit intra-sepcifique. Il faut evidemment, pour etrevalable que la population soit grande et homogene (bien melangee). Autre-ment dit tout le monde a la meme probabilite de rencontrer l’autre.
Cette equation etablie dans les annees 1920 a ete immediatement l’objetd’intenses controverses. La raison en etait qu’elle n’avait pas ete validee ex-perimentalement, meme pour des predictions a court terme. Le travail d’unchercheur sovietique G.F. Gause [4](1934) a ete fondamental a cet egard.R.F. Gause a fourni plusieurs exemples de tests experimentaux de theories,qui maintenant sont devenus centraux en ecologie moderne.
Dans un livre recent Gause [5] donne les donnees de l’experience suivante :Dans deux recipients distincts, qui contiennent la meme quantite de nutri-ment, une population de Paramecium caudatum pour l’un et de Parameciumaurelia pour l’autre.On mesure chaque jour les populations. Les donnees de population, qui sontsupposees bien melangees dans chaque recipient, sont donnees en nombred’individu pour 0.5 cm3
Si on trace la population de Paremecium caudatum on obtient
9
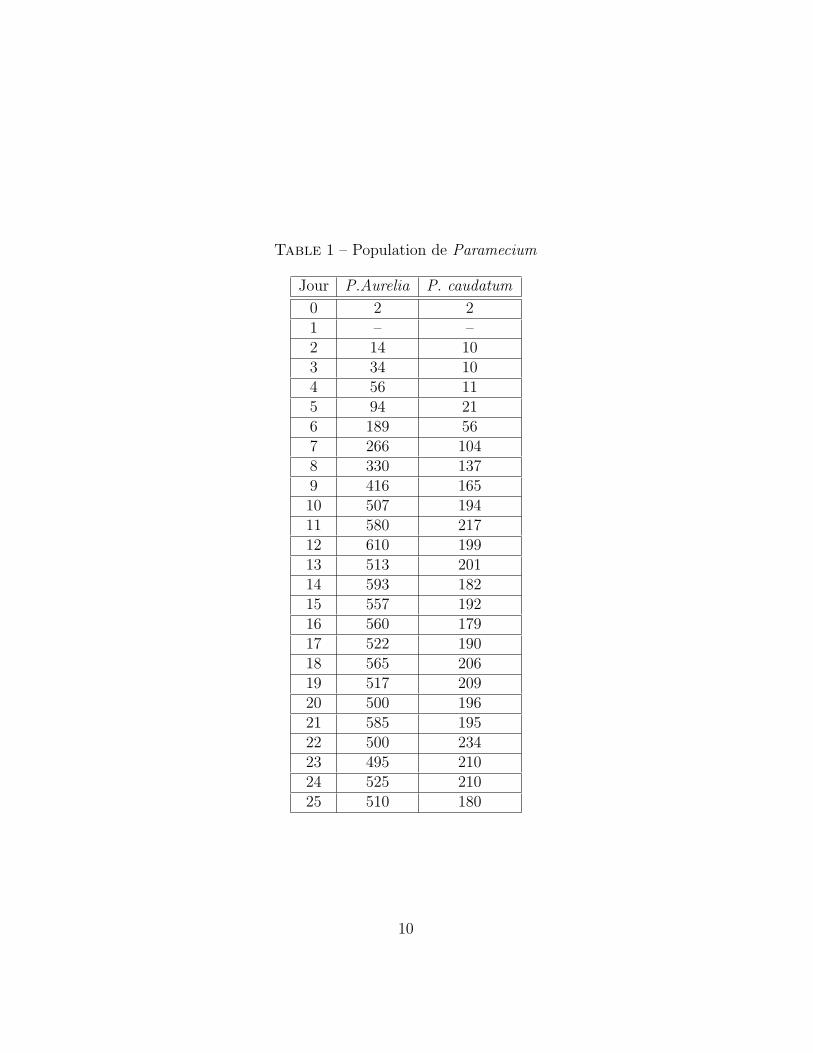
Table 1 – Population de Paramecium
Jour P.Aurelia P. caudatum
0 2 21 – –2 14 103 34 104 56 115 94 216 189 567 266 1048 330 1379 416 16510 507 19411 580 21712 610 19913 513 20114 593 18215 557 19216 560 17917 522 19018 565 20619 517 20920 500 19621 585 19522 500 23423 495 21024 525 21025 510 180
10
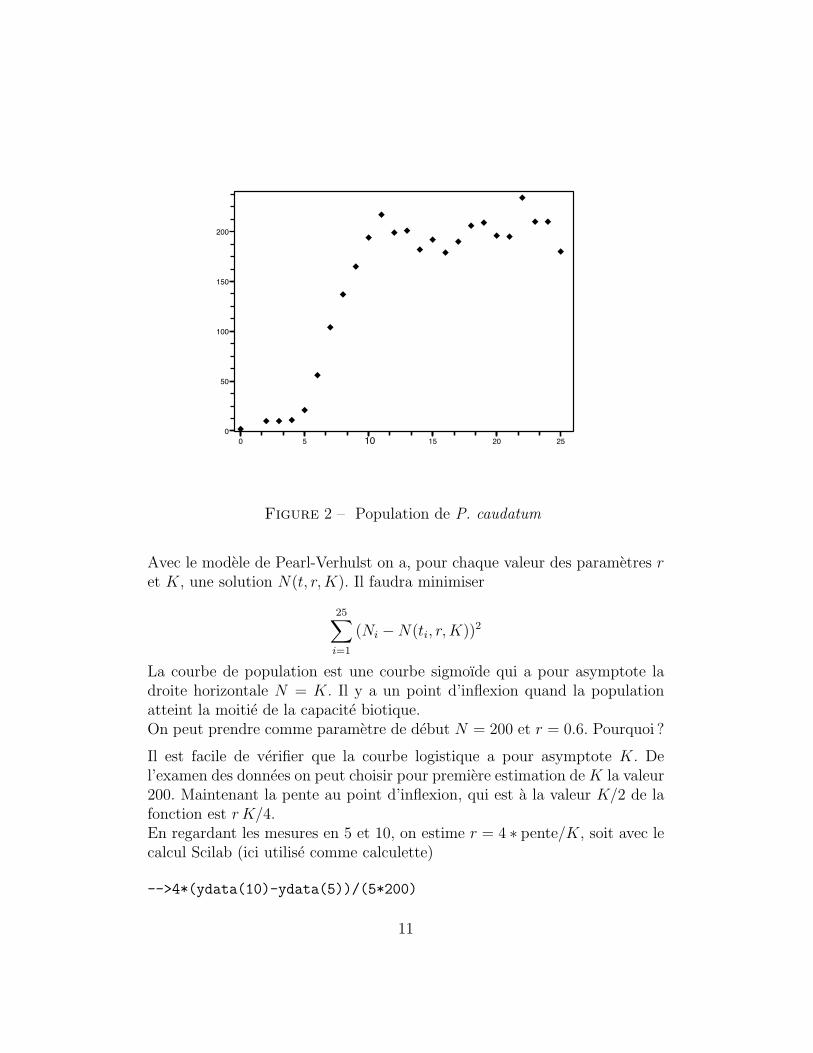
0 5 10 15 20 250
50
100
150
200
Figure 2 – Population de P. caudatum
Avec le modele de Pearl-Verhulst on a, pour chaque valeur des parametres ret K, une solution N(t, r,K). Il faudra minimiser
25∑i=1
(Ni −N(ti, r,K))2
La courbe de population est une courbe sigmoıde qui a pour asymptote ladroite horizontale N = K. Il y a un point d’inflexion quand la populationatteint la moitie de la capacite biotique.On peut prendre comme parametre de debut N = 200 et r = 0.6. Pourquoi ?
Il est facile de verifier que la courbe logistique a pour asymptote K. Del’examen des donnees on peut choisir pour premiere estimation de K la valeur200. Maintenant la pente au point d’inflexion, qui est a la valeur K/2 de lafonction est r K/4.En regardant les mesures en 5 et 10, on estime r = 4 ∗ pente/K, soit avec lecalcul Scilab (ici utilise comme calculette)
-->4*(ydata(10)-ydata(5))/(5*200)
11

ans =
0.616
On ecrit une fonction qui va calculer le vecteur d’erreur, on la sauvegardesous le nom errologis.sci . Elle est facile a comprendre, si on se donne leparametre (un vecteur), comme on a les conditions initiales, on resout l’EDO,puis on compare les donnees de sortie du modele et celle observees. Il fautsimplement faire attention a la syntaxe et savoir ce que l’on manipule.
function y=errorlogis(param)
T=[0,2:25]
// ydata doit etre le nom dans la fenetre de commande
// du vecteur des donnees.
ydata=ydata(:)
x0=2; t0=0;
sol=ode(x0,t0,T,logistic);
sol=sol(:)
y=(ydata-sol);
//////////////////
function xdot =logistic(t,x,param)
xdot=param(1)*x*(1-x/param(2))
Puis dans la fenetre de commande on fait
-->getf(’errorlogis.sci’)
-->[RSS,paramopt]=leastsq(errorlogis,[0.6;200])
paramopt =
0.6619516 202.5
RSS =
4838.1355
On peut maintenant resoudre l’equation differentielle avec ces valeurs deparametres
12
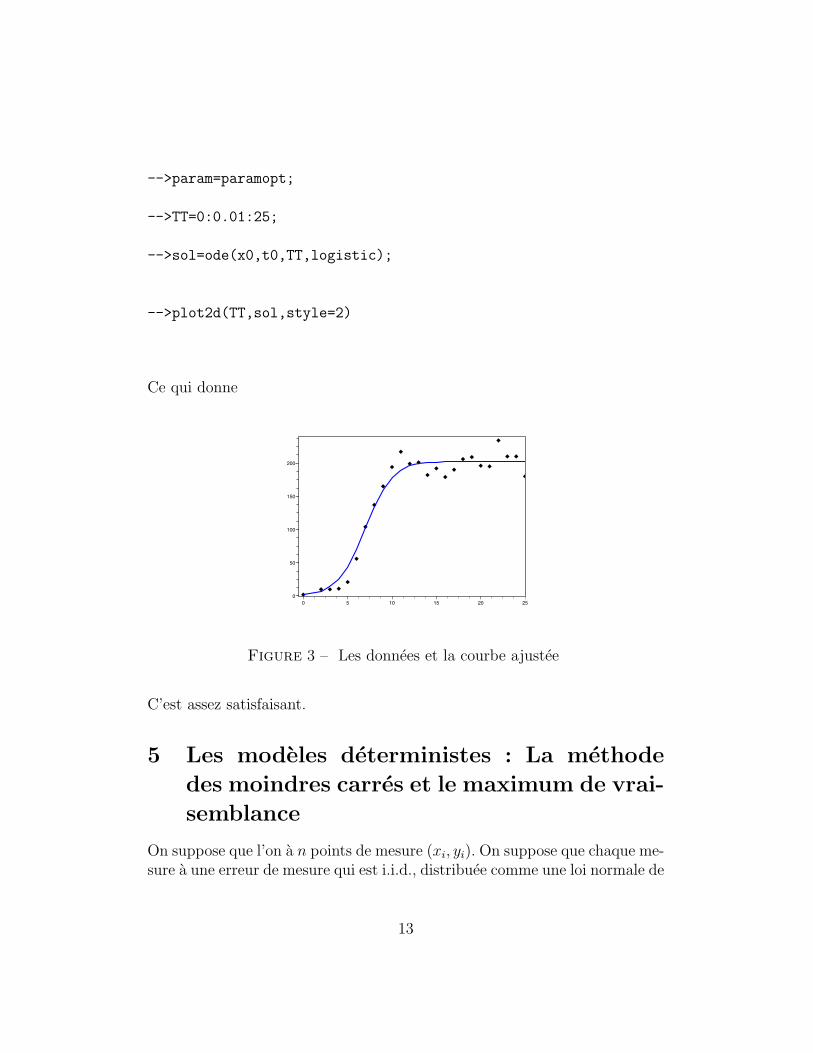
-->param=paramopt;
-->TT=0:0.01:25;
-->sol=ode(x0,t0,TT,logistic);
-->plot2d(TT,sol,style=2)
Ce qui donne
0 5 10 15 20 250
50
100
150
200
Figure 3 – Les donnees et la courbe ajustee
C’est assez satisfaisant.
5 Les modeles deterministes : La methode
des moindres carres et le maximum de vrai-
semblance
On suppose que l’on a n points de mesure (xi, yi). On suppose que chaque me-sure a une erreur de mesure qui est i.i.d., distribuee comme une loi normale de
13

moyenne nulle et d’ecart type σ. Le modele predit une relation fonctionnelleentre la variable x et y, dependant de p parametres β = (β1, β2, · · · , βp)
y(x) = Φ(x, β1, · · · , βp)
Ce que l’on observe est donc
y(x) = Φ(x) + ε
ou ε est une variable aleatoire suivant une loi normale de moyenne nulleet variance σ2 inconnue. La densite de probabilite de ε est N (0, σ2).
ε ∼ N (0, σ2)
On sait que si X ∼ N (µ, σ2) alors aX + b ∼ N (a µ+ b, a2 σ2)
Par consequent chaque observation est la realisation d’une variable aleatoireY ∼ N (φ(x), σ2)On suppose evidemment que les erreurs sont i.i.d. (toutes de meme ecart typeen particulier).
La fonction de vraisemblance pour un echantillon de n observation est , a unfacteur constant positif pres :
L(β) =n∏i=1
(exp
[−1
2
(yi − Φ(xi, β)
σ
)2])
Maximiser cette quantite revient a maximiser son logarithme LL(θ), ou mi-nimiser l’oppose du logarithme soit
minβ
n∑i=1
(yi − yi(xi, β)
2σ2
)2
Ce qui revient a un probleme de moindres carres. En effet il s’agit de mini-miser la somme des carres des ecarts entre ce qui est mesure yi et ce qui estpredit par le modele Φ(xi, β).On n’a fait aucune supposition sur la linearite de Φ(x, β), ni sur la valeur dela variance σ2.
Si maintenant on suppose que chaque mesure a son propre ecart type σi lecalcul precedent conduit a la minimisation de
14

χ2 =n∑i=1
(yi − yi(xi, β)
σi
)2
Cela suppose que l’on connaıt ou que l’on a une bonne idee de l’ecart typede la i-eme erreur. Si le probleme est lineaire, il suffit alors de modifier lamatrice de conception, en divisant chaque ligne i par σi et on fait de memepour le vecteur de mesure y. On obtient alors un probleme de moindre carrestandard.
6 Identifiabilite des parametres
On considere un systeme donne par une equation differentielle.
x = f(x, u, β)
x(0) = x0
y = h(x) ∈ Rp
x ∈ Rn u ∈ Rm
(1)
On designe par x ∈ Rn l’etat du systeme et par u ∈ Rm une fonction qui sertde commande. Ce systeme admet comme parametres β.La fonction h est une fonction d’observation. Il est parfois difficile, voireimpossible, d’observer tout l’etat d’un systeme.Il s’agit d’un systeme entree-sortie : on connaıt le signal d’entree u et onobserve le signal de sortie y(t).
x(0)=x0
u(t) y(t)x=f(x,θ,β).
Figure 4 – Un systeme entree sortie
15

L’identifiabilite est la possibilite, connaissant le systeme, autrement dit soncomportement entree-sortie, de determiner les parametres. Cela veut dire quel’on entre le signal d’ entree que l’on veut et on mesure la sortie. A partir de lapeut-on determiner les parametres. Cela est-il possible ?. Malheureusement lareponse est non. Meme avec des systemes aussi sympathiques que les systemeslineaires.On considere le systeme compartimental lineaire suivant
x1k1
k2
k3
x2
x3
u(t)
y(t)+
Figure 5 – Un modele compartimental entree-sortie
Les parametres sont k1, k2 et k3. Ce sont des vitesse constantes de transfertsde matiere par unite de masse, donc strictement positifs.La mesure est y(t) = x1(t) + x2(t).Le systeme s’ecrit facilement
x1 = −k1 x1 + k2 x2 + u(t)
x2 = k1 x1 − (k2 + k3)x2
x3 = k3 x2
y = x1 + x2
(2)
On peut encore ecrire
16

x = Ax+ u b
y = C x(3)
ou A,b et C sont les matrices
A =
[−k1 k2
k1 −(k2 + k3)
]b =
[10
]C =
[1 1
]La transformee de Laplace de y(t) est Y (t) et
Y (s) = C (s I − A)−1 b U(s)
On verifie facilement que
Y (t) =s+ k1 + k2 + k3
s2 + (k1 + k2 + k3) s+ k2 k3
U(s)
Le comportement du systeme est entierement determine par ce que l’on ap-pelle la fonction de transfert
G(s) =s+ k1 + k2 + k3
s2 + (k1 + k2 + k3) s+ k2 k3
On voit que plusieurs jeux de parametres peuvent alors donner le memecomportement entree-sortie.Par exemple (k1 = 2, k2 = 2, k3 = 2) et (p1 = 1 , p2 = 1, p3 = 4)Il y a une infinite de parametres possibles.
7 La methode des moindres carres : un peu
d’histoire
Le probleme des moindres carres est connu sous d’autres noms dans dif-ferentes disciplines scientifiques. Par exemple les mathematiciens peuventconsiderer le probleme des moindres carres comme celui-ci :
etant donne un point, trouver le point le plus proche dans un sous-espacevectoriel (eventuellement un sous-espace fonctionnel). On considere egale-ment cette formulation en analyse numerique, ce qui a pour consequenced’ignorer les erreurs sur les donnees.
17

Les statisticiens introduiront des distributions de probabilites dans leur concep-tion du probleme et utilisent le terme d’analyse de regression. L’analyse deregression est un constituant de base de l’econometrie moderne. On rencontrela regression en Biologie, Medecine, Physique, Chimie, Marketing, Sociologie,Economie . . .Les ingenieurs designent ce type de probleme sous le nom d’estimation deparametres, filtrage ou encore identification de modeles. On parle aussi deproblemes inverses ou encore d’assimilation de donnees. Ces differents nomsrecouvrent la meme problematique.La methode des moindres carres, decouverte de facon independante par Gausset Legendre permet de comparer des donnees experimentales, generalemententachees d’erreurs de mesure, a un modele mathematique cense decrire cesdonnees.Carl Friedrich Gauss est ne en 1777. Apres avoir fait de nombreuses decou-vertes majeures (resolution d’un probleme d’Euclide vieux de 2000 ans- poly-gone a 17 cotes, une preuve rigoureuse du theoreme fondamental de l’algebre. . .), en 1801 Gauss s’est interesse aux applications des mathematiques. Cetteannee la, Giuseppe Pazzi decouvre l’asteroıde Ceres. Ceres fut seulement vi-sible 41 jours avant de disparaıtre derriere le soleil. Les astronomes voulaientsavoir ou Ceres allait reapparaıtre. A cette epoque les astronomes pouvaientcalculer (au prix de calculs dits astronomiques) les orbites des grandes pla-netes et des cometes, mais leur techniques etaient insuffisantes pour predirel’orbite de Ceres. Le grand probleme etait le manque de donnees, 22 observa-tions. C’est alors que Gauss, utilisant 3 observations, la methode des moindrescarres et une centaine d’heures de calcul, fut capable de predire l’orbite deCeres avec une telle precision qu’elle fut immediatement observee des sa re-apparition. Ce resultat accorda a Gauss une celebrite immediate. Apres cettereussite il accepta un poste d’astronome a l’observatoire de Gottingen. Il fautnoter que Gauss avait developpe sa methode des moindres carres a 17 ans,mais ne l’avait pas publiee. Gauss publia sa methode en 1809 en un articleintitule « Theoria motus corporum coelestium in sectionibus conicus solemambientium ». Cette methode decrite dans cet article est encore utilisee enastronomie, avec de simples adaptations pour le calcul par ordinateur. Faitremarquable dans cet article y est decrite la celebre loi normale (ou loi deLaplace-Gauss) pour l’estimation des erreurs.Legendre retrouve independamment la methode des moindres carres en 1806en etudiant les orbites de certaines cometes. Une querelle d’anteriorite l’op-posera a Gauss.
18

8 Comparaison des modeles
On attribue a Von Neumann [3] la citation suivante
avec 4 parametres je peux ajuster un elephant, avec 5, je peux luifaire remuer la trompe
La question se pose de savoir avec combien de parametres construire le mo-dele ? Par exemple si on approxime des donnees reelles dependant d’une va-riable reelle, par une fonction polynomiale, on sait que pour n donnees, unpolynome de de degre n− 1 passera exactement par ces donnees. (c’est simi-laire a la remarque de Von Neumann). Si n est pair alors le modele tendravers +∞Un principe dit de parcimonie ou encore rasoir d’Occam incite aminimiser le nombre de parametres, tout en conservant le meme resultat.Il existe un critere pour comparer des modeles avec des parametres differents[1, 9]
Definition 8.1 (AIC Akaike Information Criterion) :
AIC = 2np − 2LL(θ)
ou np est le nombre de parametres et LL la log-vraisemblance minimisee pourles parametres.
Dans le cas particulier ou le modele est deterministe et les erreurs i.i.d. nor-malement distribuees N (0, σ2) alors
AIC = 2np + n ln σ2
On peut estimer la variance par σ2 par 1n
∑ε2i .
La somme des carres des erreurs (entre le modele et les mesures) est donnepar le carre des residus
RSS =n∑i=1
(yi − Φ(x, θ))2
Le terme RSS pour «Residual Sum Square»Finalement, pour un modele deterministe
AIC = 2np + n ln(RSS
n)
19

Quand l’echantillon est faible nnp≤ 40 alors on corrige le critere AIC
AICc = AIC +2np (np + 1)
n− np − 1
L’importance c’est la comparaison des modeles. Plus faible est le critere AICet meilleur est le modele. Noter que pour retrouver les moindres carres, on aintroduit la log-vraisemblance LL par son oppose
8.1 Une etude de cas
On va reconsiderer le cas de Paramecium caudatum deja analyse. On connaıtdeja le modele logistique. Il existe deux autres modeles utilises en dynamiquede population :
Le modele de Bernoulli
N = r N
[1−
(N
K
)θ]Le modele de Gompertz
N = r N ln
(K
N
)On a la session Scilab suivante : On cree deux nouvelles fonctions
errorbernoulli.sci et errorgompertz.sci . Il suffit de modifier le nomet la definition de l’equation differentielle dans la fonction errorlogis.sci.Pour Gompertz on a un parametre de plus a ajouter dans la procedure d’op-timisation par moindre carres.
-->;getf("/Users/gauthiersallet/scilabUY08/errorbernoulli.sci");
-->[RSSber,paramoptber]=leastsq(errorbernoulli,[0.6,200,1])
paramoptber =
0.5615906 199.97579 2.2464691
RSSber =
3650.0757
20

-->;getf("/Users/gauthiersallet/scilabUY08/errorgompertz.sci");
-->[RSSGom,paramoptGom]=leastsq(errorgompertz,[1,200])
paramoptGom =
0.2801553 211.28483
RSSGom =
11837.136
Cela donne la figure
0 5 10 15 20 250
50
100
150
200
250
Logistique
GompertzBernoulli
Figure 6 – Les 3 modeles ajustes
On a d’apres les calculsLe modele de Bernoulli assure un meilleur ajustement et son critere AIC estmeilleur.
Remarque 8.1 On pourra trouver d’autres definition equivalentes a AIC.Nous avons choisi de minimiser ce critere. D’autres on fait le choix de maxi-miser. Ces criteres sont a une transformation affine pres (i.e. un cœfficientmultiplicatif pres et une translation par une constante. Les valeurs nume-riques pourront etre differentes, mais le meilleur critere sera le meme.
21

Table 2 – Comparaison des modeles
Modele RSS σ2 LL AICc
Logistique 4838.1355 201.58898 127.34954 131.92097Gompertz 11837.136 493.21401 148.82264 153.39406Bernoulli 3650.0757 152.08649 120.58678 127.78678
9 Etude de cas : un modele de competition
Dans [5] Gause donne la suite de l’experience sur les paramecies. Dans unmeme recipient on met simultanement Paramecium aurelium et Parameciumcaudatum.On ecrit le modele classique de competition
N1 = r1
(1− N1
K1
)− β12N1N2
N1 = r2
(1− N2
K2
)− β21N1N2
(4)
La competitions extra-specifique est modelisee par les termes −β12N1N2 et−β21N1N2.Si on choisit pour parametres ri et Ki ceux determines dans la section (4.1),il reste a determiner β12 et β21.
Les donnees sont les suivantes :On trace d’abord les courbes des mesures
-->;load(’ParameciumCompet);
-->T=0:25;
-->plot2d(T’,compet,style=[-3,-4],rect=[-1,-5,26,410])
22
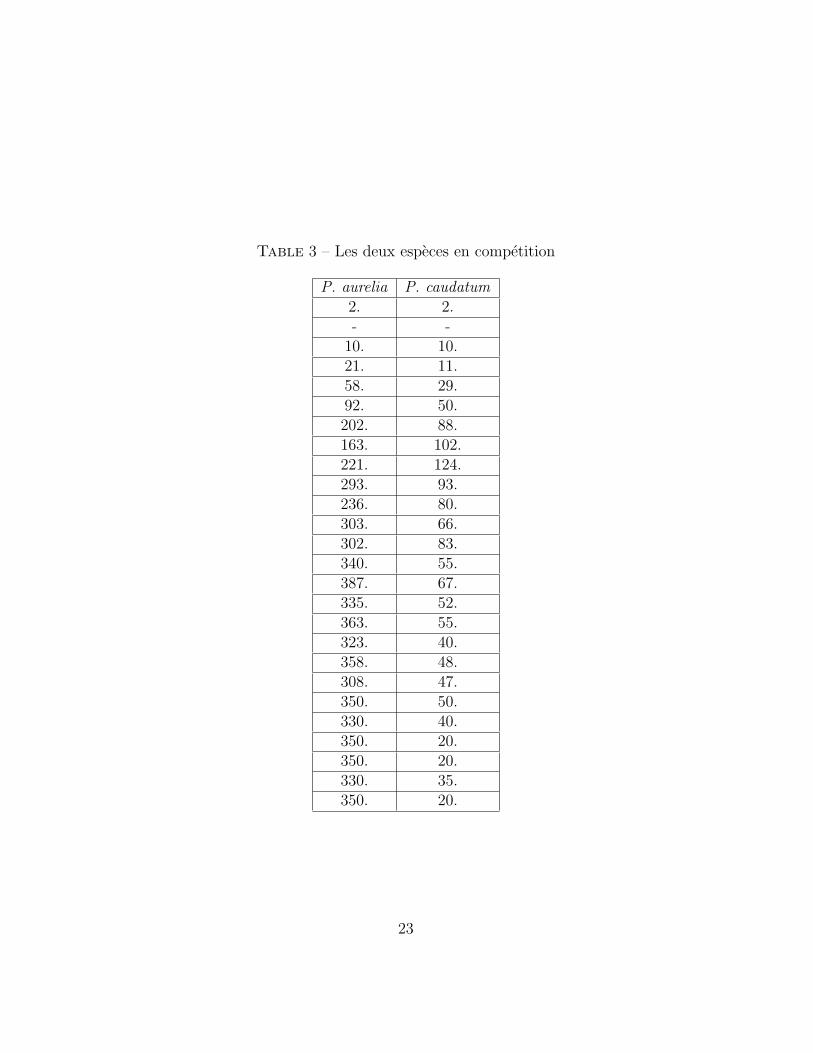
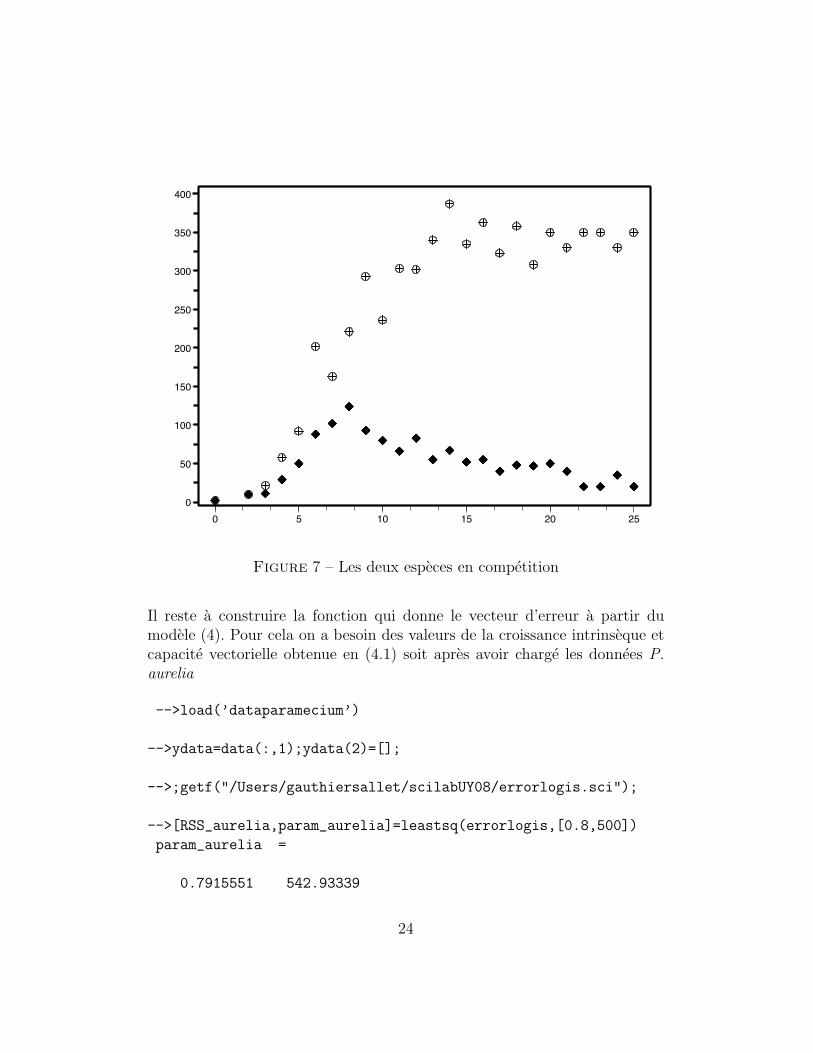
Table 3 – Les deux especes en competition
P. aurelia P. caudatum2. 2.- -
10. 10.21. 11.58. 29.92. 50.202. 88.163. 102.221. 124.293. 93.236. 80.303. 66.302. 83.340. 55.387. 67.335. 52.363. 55.323. 40.358. 48.308. 47.350. 50.330. 40.350. 20.350. 20.330. 35.350. 20.
23
0 5 10 15 20 250
50
100
150
200
250
300
350
400
Figure 7 – Les deux especes en competition
Il reste a construire la fonction qui donne le vecteur d’erreur a partir dumodele (4). Pour cela on a besoin des valeurs de la croissance intrinseque etcapacite vectorielle obtenue en (4.1) soit apres avoir charge les donnees P.aurelia
-->load(’dataparamecium’)
-->ydata=data(:,1);ydata(2)=[];
-->;getf("/Users/gauthiersallet/scilabUY08/errorlogis.sci");
-->[RSS_aurelia,param_aurelia]=leastsq(errorlogis,[0.8,500])
param_aurelia =
0.7915551 542.93339
24

RSS_aurelia =
27831.835
-->r1=param_aurelia(1);K_1=param_aurelia(2);
Puis on introduit les r2 et K2 pour P. caudatum
-->ydata=data(:,2);ydata(2)=[];
-->[RSS_cauda,param_cauda]=leastsq(errorlogis,[0.6,200])
param_aurelia =
0.6619516 202.5
RSS_aurelia =
4838.1355
-->r2=param_cauda(1);K_2=param_cauda(2);
On ecrit la fonction d’erreur
T=[0,2:25]
// ydata c’est le vecteur des donnees
ydata=ydata(:)
x0=[2;2]; t0=0;
sol=ode(x0,t0,T,competition);
sol=sol’;sol=sol(:)
y=(ydata-sol);
endfunction
//////////////////
function xdot =competition(t,x,param)
xdot(1)=r1*x(1)*(1-x(1)/K_1)-param(1)*x(1)*x(2)
xdot(2)=r2*x(2)*(1-x(2)/K_2)-param(2)*x(1)*x(2)
endfunction
Puis le vecteur des mesures
25

-->ydata=compet;ydata(2,:)=[]
-->ydata=ydata(:);
Le probleme est difficile. On constate que si l’on fait
-->[RRS,param]=leastsq(errorcompet,[0,1])
param =
0.8011874 0.8786569
RRS =
692836.92
-->[RRS,param]=leastsq(errorcompet,[1,1])
param =
0.9889889 1.1
RRS =
693493.56
-->[RRS,param]=leastsq(errorcompet,[0.1,0.1])
param =
0.0901093 0.0980854
RRS =
689212.82
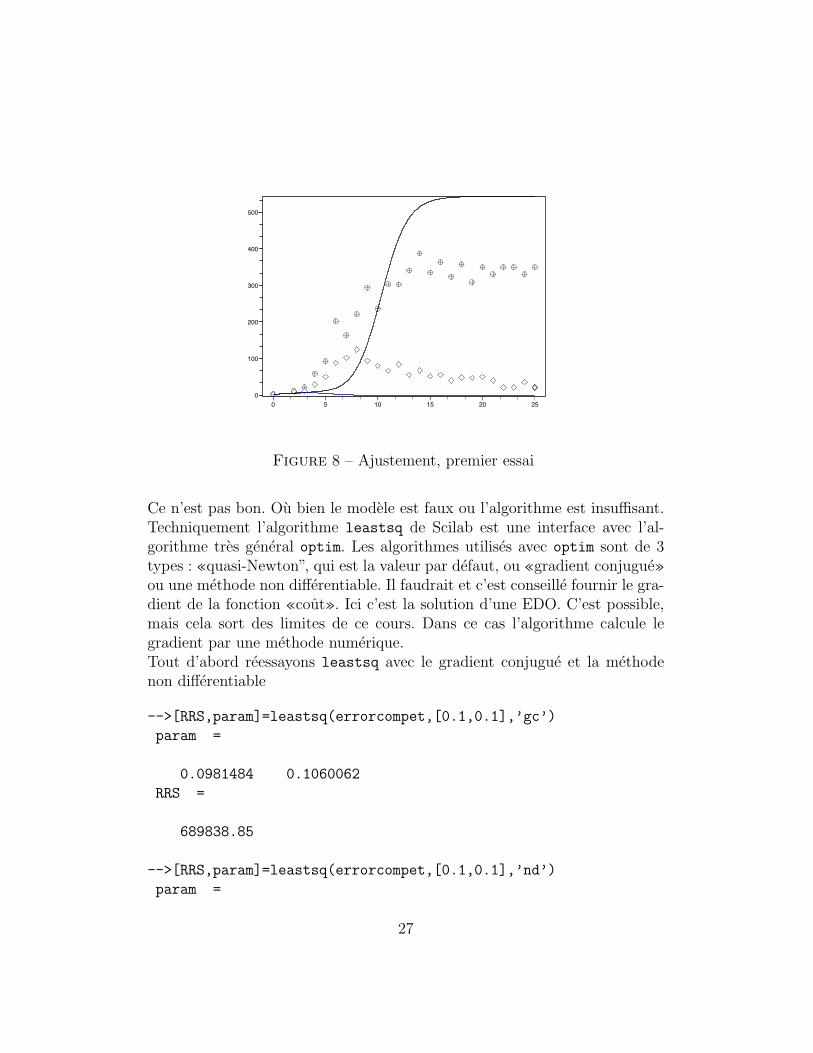
On constate, apres ces calculs, que cela prend un peu de temps. Et qu’enfinles resultats sont peu fiables. On regarde ce que cela donne sur le graphe :
26
0 5 10 15 20 250
100
200
300
400
500
Figure 8 – Ajustement, premier essai
Ce n’est pas bon. Ou bien le modele est faux ou l’algorithme est insuffisant.Techniquement l’algorithme leastsq de Scilab est une interface avec l’al-gorithme tres general optim. Les algorithmes utilises avec optim sont de 3types : «quasi-Newton”, qui est la valeur par defaut, ou «gradient conjugue»ou une methode non differentiable. Il faudrait et c’est conseille fournir le gra-dient de la fonction «cout». Ici c’est la solution d’une EDO. C’est possible,mais cela sort des limites de ce cours. Dans ce cas l’algorithme calcule legradient par une methode numerique.Tout d’abord reessayons leastsq avec le gradient conjugue et la methodenon differentiable
-->[RRS,param]=leastsq(errorcompet,[0.1,0.1],’gc’)
param =
0.0981484 0.1060062
RRS =
689838.85
-->[RRS,param]=leastsq(errorcompet,[0.1,0.1],’nd’)
param =
27

0.1032634 0.1123961
RRS =
689981.35
Pas mieux !on va essayer d’utiliser optim
9.1 Syntaxe de l’algorithme optim
Pour utiliser optim sans calculer de gradient il faut utiliser la fonction NDcost.On ecrit une fonction cout sans calculer le gradient.
~ : attention la fonction est un scalaire.La syntaxe est alors
[cost_opt,p_opt] = optim ( list (NDcost, costfunction], param_guess)
On reecrit la fonction erreur pour avoir un scalaire
function y=costcompet(param)
T=[0,2:25]
//ydata c’est ainsi que le vecteur des donnees
// doit etre dans la fenetre de commande
ydata=ydata(:);
x0=[2;2]; t0=0;
sol=ode("stiff",x0,t0,T,1e-3,1e-4,competition);
sol=sol’;sol=sol(:)
y=(ydata-sol);
y=sum(y.^2)
endfunction
//////////////////
function xdot =competition(t,x,param)
xdot(1)=r1*x(1)*(1-x(1)/K_1)-param(1)*x(1)*x(2)
xdot(2)=r2*x(2)*(1-x(2)/K_2)-param(2)*x(1)*x(2)
endfunction
Apres quelques tests on obtient
28

-->[cost,p_opt]=optim(list(NDcost,costcompet),p_opt)
p_opt =
0.0743556
0.0802351
cost =
687703.44
Toujours pas terrible. On a augmente le nombre d’iteration et diminue aprecision pour le solveur de l’ODE.Il existe un autre algorithme qui est tres efficace : Levenberg-Marquardt.
9.2 Levenberg-Marquardt
On va utiliser lsqrsolve, qui utilise la methode de Levenberg-Marquardt.La syntaxe est encore differente.Il faut modifier la fonction d’erreur, qui doit comporter comme parametre mla dimension de sortie du critere a minimiser. Ici m = 50
function y=errorcompet2(param,m)
T=[0,2:25]
//ydata c’est le vecteur des donnees
x0=[2;2]; t0=0;
sol=ode(x0,t0,T,compet);
sol=sol’;sol=sol(:)
y=(ydata-sol);
endfunction
//////////////////
function xdot =compet(t,x,param)
xdot(1)=r1*x(1)*(1-x(1)/K_1)-param(1)*x(1)*x(2)
xdot(2)=r2*x(2)*(1-x(2)/K_2)-param(2)*x(1)*x(2)
endfunction
Dans la fenetre de commande on a, apres quelques essais et erreurs
-->[xsol,vv]=lsqrsolve([0.031;0.0012],errorcompet2,50);
29

-->sum(vv.^2)
ans =
48214.865
-->xsol
xsol =
0.0034334
0.0012763
-->[xsol,vv]=lsqrsolve([0.031;0.0012],errorcompet2,50);
-->sum(vv.^2)
ans =
48214.865
-->xsol
xsol =
0.0034334
0.0012763
-->param=xsol
param =
0.0034334
0.0012763
-->tt=0:0.01:25;
-->sol=ode([2;2],0,tt,compet);
-->plot2d(tt’,sol’)
30
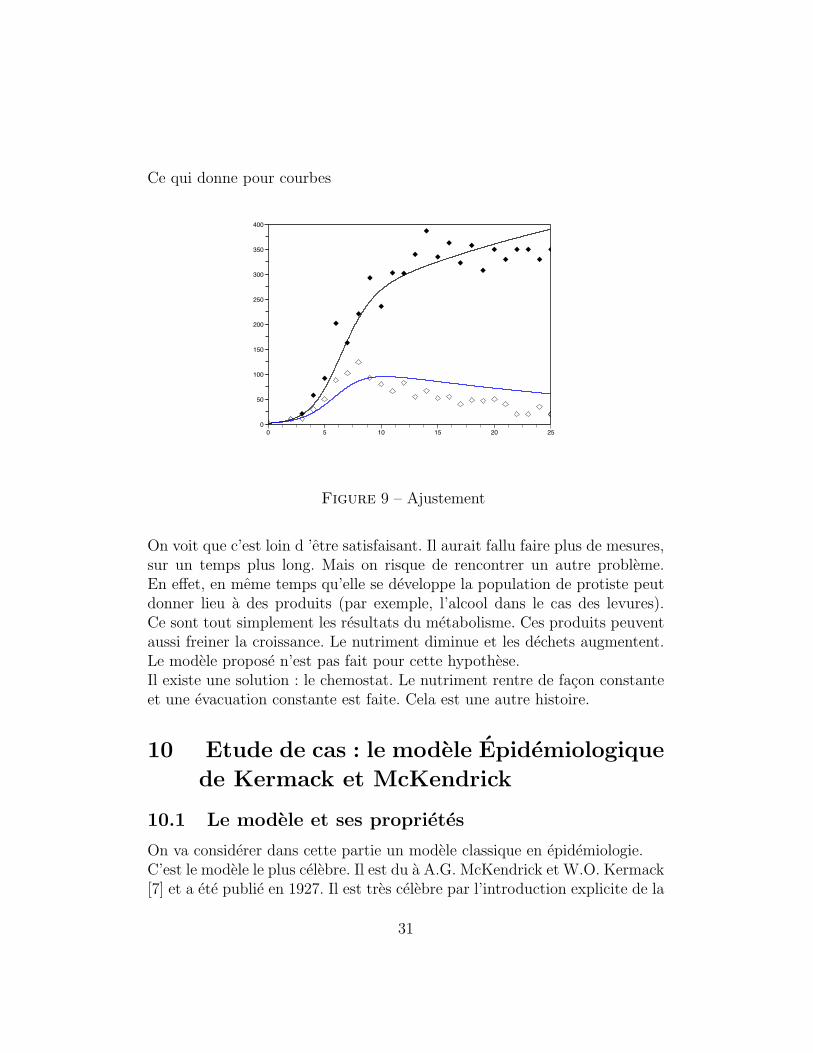
Ce qui donne pour courbes
0 5 10 15 20 250
50
100
150
200
250
300
350
400
Figure 9 – Ajustement
On voit que c’est loin d ’etre satisfaisant. Il aurait fallu faire plus de mesures,sur un temps plus long. Mais on risque de rencontrer un autre probleme.En effet, en meme temps qu’elle se developpe la population de protiste peutdonner lieu a des produits (par exemple, l’alcool dans le cas des levures).Ce sont tout simplement les resultats du metabolisme. Ces produits peuventaussi freiner la croissance. Le nutriment diminue et les dechets augmentent.Le modele propose n’est pas fait pour cette hypothese.Il existe une solution : le chemostat. Le nutriment rentre de facon constanteet une evacuation constante est faite. Cela est une autre histoire.
10 Etude de cas : le modele Epidemiologique
de Kermack et McKendrick
10.1 Le modele et ses proprietes
On va considerer dans cette partie un modele classique en epidemiologie.C’est le modele le plus celebre. Il est du a A.G. McKendrick et W.O. Kermack[7] et a ete publie en 1927. Il est tres celebre par l’introduction explicite de la
31

notion de seuil. Dans cet article Kermack et McKendrick donnent clairementleurs hypotheses. La population est constante. La raison invoquee est que laduree d’une epidemie est courte relativement a la duree de vie d’un individu.Les changements demographiques ne sont pas pris en compte. Ils supposentque les individus sont tous egalement susceptibles et qu’une infection conduitsoit au deces soit confere une complete immunite.Nous rappelons ce modele, appele modele SIR.
S = −β S II = β S I − γ IR = γ I
(5)
Dans ce modele S designe la densite de la population des susceptibles, I celledes infectieux et R ceux des « removed », c’est a dire les immunises ou morts,autrement dit ceux qui ont cesse de transmettre l’infection. Quand on parlede densite cela peut-etre une densite relative, par exemple un pourcentageou une densite par unite de surface . . . Dans le papier original il s’agit d’unnombre par unite de surface.Comme la population est constante, il suffit de considerer et de resoudreles deux premieres equations qui ne dependent que de S et I, puis de faireR = N − S − I {
S = −β S II = β S I − γ I (6)
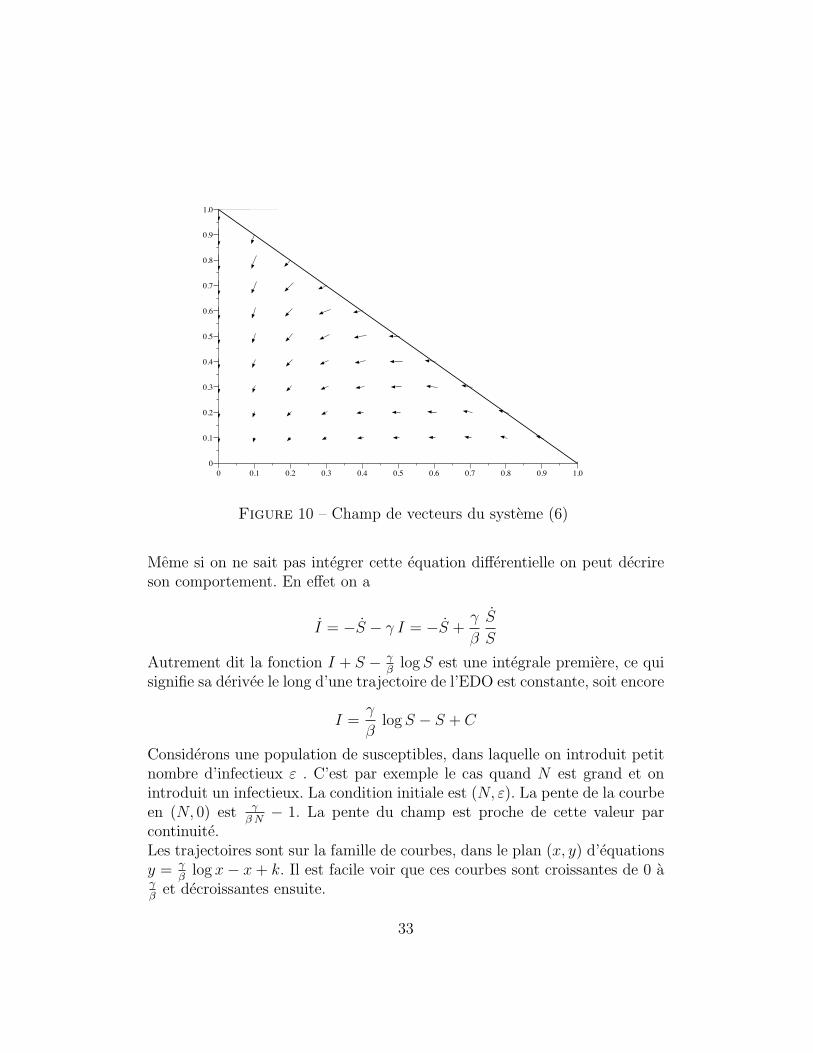
Ce systeme est considere sur le simplexe
∆ = {0 ≤ S ≤ N ; 0 ≤ I ≤ N ; 0 ≤ S + I ≤ N}
32
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.00
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Figure 10 – Champ de vecteurs du systeme (6)
Meme si on ne sait pas integrer cette equation differentielle on peut decrireson comportement. En effet on a
I = −S − γ I = −S +γ
β
S
S
Autrement dit la fonction I + S − γβ
logS est une integrale premiere, ce quisignifie sa derivee le long d’une trajectoire de l’EDO est constante, soit encore
I =γ
βlogS − S + C
Considerons une population de susceptibles, dans laquelle on introduit petitnombre d’infectieux ε . C’est par exemple le cas quand N est grand et onintroduit un infectieux. La condition initiale est (N, ε). La pente de la courbeen (N, 0) est γ
β N− 1. La pente du champ est proche de cette valeur par
continuite.Les trajectoires sont sur la famille de courbes, dans le plan (x, y) d’equationsy = γ
βlog x− x+ k. Il est facile voir que ces courbes sont croissantes de 0 a
γβ
et decroissantes ensuite.
33

Les trajectoires du systeme sont sur ces courbes. Les trajectoires du systemesdecrivent ces courbes avec S decroissant.On note
R0 =β N
γ
Si R0 ≤ 1 le champ est sortant sur le segment [0, N ] de l’axe des S. Si R0 > 1alors le champ est sortant sur le segment [0, 1/R0], rentrant sur [1/R0, N ].Dans le cas R0 > 1, l’introduction d’un infecte dans une population desusceptibles N = S0 >
1R0
declenche une epidemie. Sinon siR0 ≤ 1 l’epidemies’eteint.C’est le theoreme du seuil.La trajectoire du systeme varie de la condition initiale, proche de (N, 0), pointsingulier du systeme, au point S∞ = lim
t→∞S(t). Quand R0 ≤ 1 alors S∞ = N
quand R0 > 1, S∞ > 0 est ce qui reste de susceptibles apres l’epidemie,le reste de la population est compose d’individus immuns (ou morts) dansle compartiment R. Par passage a la limite sur l’integrale premiere (pourt→ ±∞ on a
S + I − γ
βlogS = constante = N − γ
βlogN = S∞ −
γ
βlogS∞
Cette equation donne la taille finale de l’epidemie.
R∞ = N − S∞La taille maximale de l’epidemie, i.e. Imax vaut
Imax = N − γ
βlogN − γ
β+γ
βlog
γ
β
Puisque S = γβ
en Imax
10.2 identifier les parametres
Ces relations permettent d’estimer les parametres du systeme. Si on connaıtla taille de la population (N), les susceptibles initiaux (S0), ainsi que les sus-ceptibles a la fin de l’epidemie (S∞) on a alors d’apres la relation precedente
34

β
γ=
ln S0
S∞
N − S∞En connaissant le pic de l’epidemie, ou la fin de l’epidemie on peut estimerβγ. Comme en general on connaıt approximativement la valeur moyenne pour
passer du stade d’infectieux a celui de « removed », on estime γ et donc onestime aussi β.
10.3 Une application : l’epidemie de peste a Eyam
Le petit village d’Eyam, une localite d’Angleterre pres de Sheffield, a connuune epidemie de grande peste en 1665-1666. Le village fut persuade par sonpasteur de se mettre en quarantaine, afin d’empecher la dissemination de lamaladie. Sur une population de 350 seuls 83 survecurent. Comme les donneesont ete conservees, le cas d’Eyam est un cas d’etude pour la modelisation enepidemiologie.On ecrit une fonction qui donne l’erreur entre ce que predit le modele (6 etles donnees observees. Les valeurs des donnees sont incluses dans la fonction.
function y=KMCK(P)
T=[0:0.5:3,4];
Sdata=[254;235;201;153.5;121;108;97;103];
Idata=[7;14.5;22;29;21;8;8;0];
Z=[Sdata,Idata];
x0=[254;7];
t0=0;
sol=ode(x0,t0,T,kermac);
y=Z-sol’;
y=y(:);
function xdot=kermac(t,x,P)
xdot(1)=-P(1)*x(1)*x(2);
xdot(2)=P(1)*x(1)*x(2)-P(2)*x(2);
On cherche alors les parametres a l’aide des elements initiaux et finaux. Laperiode d’infection est de 11 jours, soit 11/30 en mois. On en deduit γ, puisensuite β
35

-->S0=254;I0=7;Sinf=83;
-->gamovbet=(S0+I0-Sinf)/(log(S0)-log(Sinf))
gamovbet =
159.14261
-->gam=1/(11*1/30)
gam =
2.7272727
-->gam=1/(11*1/30.5)
gam =
2.7727273
-->bet=gam/gamovbet
bet =
0.0174229
Puis on trace la courbe theorique et celle des mesures par les commandes
--T1=[0:0.01:5];
-->x0=[254;7];
--> t0=0;
--> P=[bet ; gam];
--sol2=ode(x0,t0,T1,kermac);
-->plot2d(sol2(1,:)’,sol2(2,:)’,style=2)
-->plot2d(Sdata,Idata,style=-2)
36
80 100 120 140 160 180 200 220 240 2600
4
8
12
16
20
24
28
32
80 100 120 140 160 180 200 220 240 2600
4
8
12
16
20
24
28
32
ª
ª
ª
ª
ª
ªª
ª
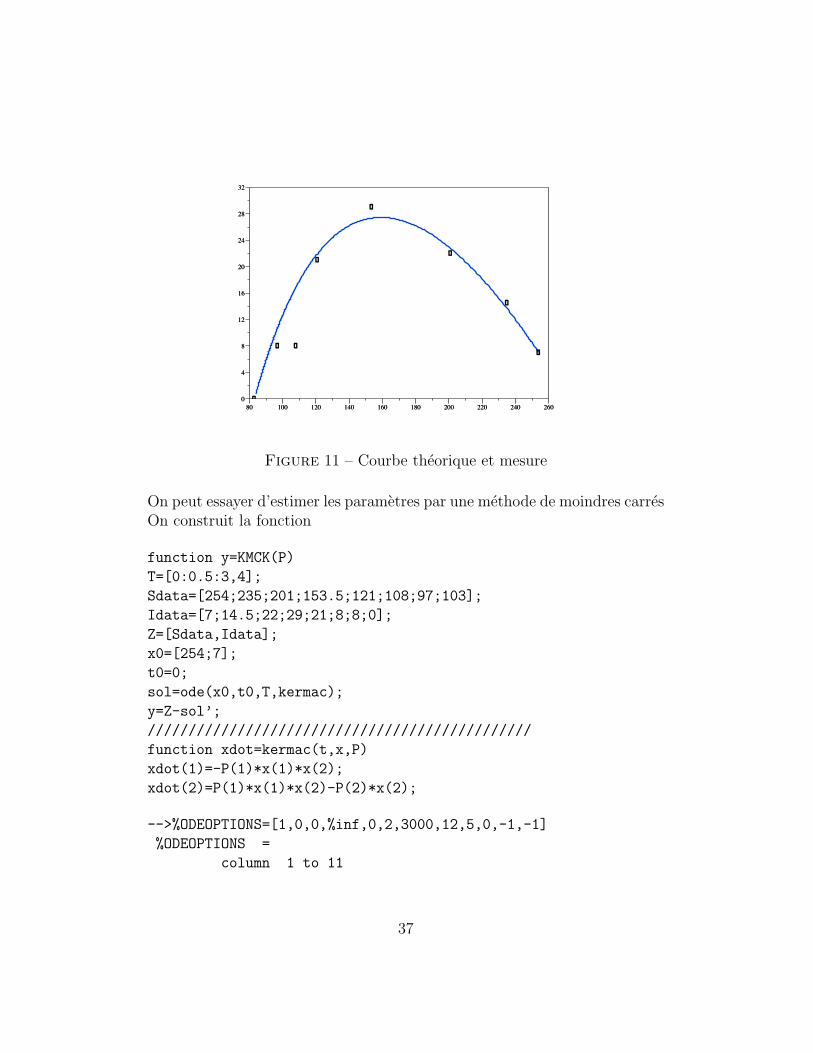
Figure 11 – Courbe theorique et mesure
On peut essayer d’estimer les parametres par une methode de moindres carresOn construit la fonction
function y=KMCK(P)
T=[0:0.5:3,4];
Sdata=[254;235;201;153.5;121;108;97;103];
Idata=[7;14.5;22;29;21;8;8;0];
Z=[Sdata,Idata];
x0=[254;7];
t0=0;
sol=ode(x0,t0,T,kermac);
y=Z-sol’;
///////////////////////////////////////////////
function xdot=kermac(t,x,P)
xdot(1)=-P(1)*x(1)*x(2);
xdot(2)=P(1)*x(1)*x(2)-P(2)*x(2);
-->%ODEOPTIONS=[1,0,0,%inf,0,2,3000,12,5,0,-1,-1]
%ODEOPTIONS =
column 1 to 11
37
! 1. 0. 0. Inf 0. 2. 3000. 12. 5. 0. - 1. !
column 12
! - 1. !
-->[f,opt]=leastsq(KMCK,[0;1])
opt =
! 0.0186324 !
! 3.0881798 !
f =
258.70474
Si on compare l’erreur avec l’autre methode
-->sum(([Sdata,Idata]-sol1’).^2)
ans =
428.87223
C’est moins bon a l’oeil, mais meilleur au sens des moindres carres. Quandon dessine les courbes on comprend pourquoi
80 100 120 140 160 180 200 220 240 260 2800
4
8
12
16
20
24
28
32
80 100 120 140 160 180 200 220 240 260 2800
4
8
12
16
20
24
28
32
80 100 120 140 160 180 200 220 240 260 2800
4
8
12
16
20
24
28
32
ª
ª
ª
ª
ª
ªª
ª
Figure 12 – Autre estimation, comparaison
38

10.3.1 L’exemple de Kermack et McKendrick : une etude histo-rique
Kermack et McKendrick ont applique leur modele sur une epidemie de pestequi a eu lieu a Bombay du 17 decembre 1905 au 21 juillet 1906. Ce modeleest encore significatif dans un nombre surprenant de situations epidemiques.En fait la peste n’est pas une maladie a transmission directe.Le pathogene responsable de la maladie Yersinia pestis circule au sein dereservoirs animaux, en particulier des rongeurs, dans les foyers naturels del’infection que l’on trouve sur tous les continents sauf l’Australie. Les foyersnaturels de la peste sont situes sur une large ceinture a des latitudes tropi-cales et subtropicales ainsi que dans les zones les plus chaudes des latitudestemperees du globe, entre les paralleles 55o N et 40o S. Toutefois, a l’inte-rieur de ces limites, de nombreuses regions sont exemptes de foyers naturelsde peste, notamment les zones desertiques, ou les rongeurs sont absents oupeu nombreux, et de larges zones couvertes de forets continues, en particu-lier sous les tropiques et dans les chaınes de hautes montagnes couvertes deglaciers.La peste se transmet entre rongeurs et a d’autres animaux par l’intermediairedes puces des rongeurs sauvages, par le cannibalisme ou (peutetre) par le solcontamine. La peste domestique est intimement associee aux rongeurs vivantavec l’homme et peut produire des epidemies a la fois chez les populationshumaines et chez les animaux .L’homme est extremement sensible a la peste et peut s’infecter soit directe-ment soit indirectement. La transmission indirecte par la piqure d’une puceest le mode de transmission le plus courant entre les rongeurs infectes etl’homme. L’infection humaine survient le plus souvent lorsqu’une epizootiese developpe parmi les rats dans les centres d’habitations humaines. Les pucesdes rats commensaux, notamment les puces infectees, quittent les cadavresdes rats tues par la peste, cherchant un repas sanguin chez un autre hote,et peuvent ainsi piquer les etres humains. Les etres humains infectes quicontractent la maladie peuvent a leur tour devenir infectieux pour l’homme.La peste s’est largement propagee en Inde, provoquant pres de 13 millions dedeces et faisant de nombreuses victimes dans plusieurs autres pays. Au debutde la pandemie, d’importantes decouvertes ont permis a la prevention de lapeste et a la lutte contre la maladie d’etre abordees de maniere scientifique.En 1894 on a decouvert le micro-organisme responsable de la peste, et il aete etabli que la puce du rat Xenopsylla cheopis en etait le vecteur courant.
39

Chez l’homme, la maladie revet deux formes principales : bubonique (contra-ctee par piqure de puce) et pulmonaire (transmise par voie aerienne). Lapeste bubonique, forme clinique la plus frequente, est caracterisee, apres uneincubation de quelques jours, par un syndrome infectieux tres severe (fortefievre, atteinte profonde de l’etat general), accompagne d’une hypertrophiedu ganglion lymphatique (bubon) drainant le territoire de piqure de la puce.Dans les cas Eyam ou la peste a Bombay il s’agit de peste buboniqueKermack et McKendrick ont admis que la peste chez l’homme etait une re-flexion de la peste chez le rat
– La population non infectee etait uniformement susceptible– Tous les rats susceptibles de l’ıle ont une chance egale d’etre infectes– Que l’infectivite (β), la guerison ou deces sont constants pour les rats
au cours de l’epidemie– Que tous les cas se terminent par l’immunite ou la mort– Que la population de puces est si grande que l’approximation des in-
fections par contact peut-etre admiseAvec ces hypotheses Kermack et Mckendrick avertissent qu’aucune de cesconditions n’est strictement remplie et que par consequent le calcul nume -rique est seulement une approximation tres grossiere et finalement ils ajoutentqu’un ajustement precis ne peut etre fait et qu’aucune conclusion sur lesvaleurs des constantes ne doit en etre tiree.
La courbe originale est cependant remarquable. Les cercles noirs sont lesdonnees reelles [7].
40
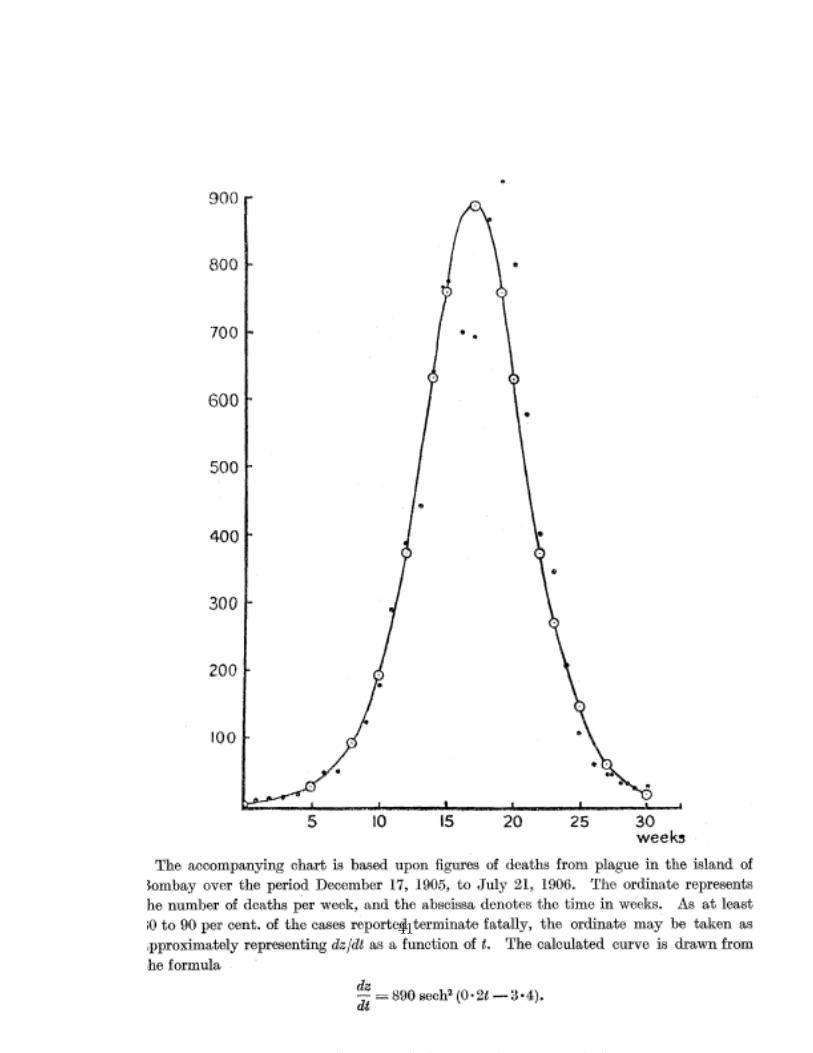
Figure 13 – La courbe originale de Kermack et McKendrick
41

Les deux auteurs concluent cependant que la courbe calculee, qui impliqueque l’infectiosite ne varie pas au cours de l’epidemie, se conforme grossie-rement aux donnees. On ne saurait etre moins modeste. On verra qu’ilsavaient raison. C’etait une epoque ou quand on avait un resultat on le presen-tait modestement. Le renommee devant venir du jugement des pairs. De nosjours, un tel resultat ferait une publication dans Nature . . ., sans se soucierde la rigueur et des precautions scientifiques necessaires.
10.4 Les calculs faits par Kermack et McKendrick
On va essayer de retrouver cette courbe. En 1927 il n’etait pas questiond’ordinateurs et donc de solveurs d’equations differentielles. Comment cesdeux auteurs ont-ils fait ?Tout d’abord ils remarquent que
S
R= −β
γS
SoitS
S= −β
γR
on a avec R(0) = R0 = 0d’ou
S = S0 e−βγR
et finalement
R = γ(N −R− S0 e
−βγR)
On ne sait pas resoudre cette EDO. Les auteurs admettent queβ
γR reste
petit et remplacent le second membre de droite par le developpement limite.
R = γ
(N − S0 +
S0β
γR−R− S0
β2
2 γ2R2
)qui elle s’integre (apres un calcul fastidieux)
R(t) =γ2
β2 S0
[β
γS0 − 1 + α tanh
(1
2α γ t− φ
)]42

avec
φ = arctan
(βγS0 − 1
α
)
α2 =
(β
γS0 − 1
)2
+ 2S0 I0
(β
γ
)2
Ce sont les formules des auteurs. Note : il y a une erreur dans le Murray [10]formule 10.14, donnant R(t) le r2 est un ρ2.Avec cette expression de R(t) on obtient
dR
dt=
1
2
γ3
β2 S0
α1
cosh2(12α γ t− φ)
Kermack et McKendrick appellent R la vitesse a laquelle les cas sont retires(autrement dit γ I) et disent que c’est la forme sous laquelle sont donneesles statistiques. Dans ce cas on ajuste la courbe R(t) aux donnees. Cela estevidemment specifique a l’epidemie. Dans le cas de la peste a Bombay onrelevait les deces et les guerisons.Dans ce modele on a plusieurs parametres : β, γ, N et S0. Si l’on admetqu’au debut de l’epidemie, il n’ y a pas d’immuns, R(0) = 0, ce qui n’est pasforcement vrai. Il y avait deja eu une epidemie a Bombay en 1896 et 1898.Kermack et McKendrick ont ajustes ces parametres (sans ordinateur) et ontobtenu
R(t) = 8901
cosh2(0.2 t− 3.4)(7)
Ils ne disent pas comment ils ont trouves ces parametres. Les points surla courbe de la figure 13 representent les deces par semaine. Ils ajoutentque 80 a 90 % des cas declares decedent et que les ordonnees peuvent prisapproximativement comme representant R (dans nos notations).
On va a partir des calculs de Kermack et McKendrick retrouver les para-metres du modele (5)On ecrit
R(t) = A1
cosh2(B t− Φ)
43

Il nous faut des formules pour passer d’un systeme de parametrisation a unautre.On a
AB =1
4
α2 γ4
β2 S0
α tanh(Φ) =
(β
γ− 1
)On en deduit d’apres la definition de α2
α2 = α2 tanh(φ) + 2S0 I0β2
γ2
Ce qui donne
AB =1
4
α2 γ2
β2 S0
γ2 =1
2
I0(1− tanh(Φ)2)
Finalement
γ =
√2AB (1− tanh(Φ)2)
I0
On a γ d’ou α =2B
γ
Enfin commeβ
γS0 = 1 + α tanh(Φ) et S0 =
γ3 α
2 β2Aon a
β =γ2 α
2A (1 + α tanh(Φ)=
γ B
A (1 + tanh(Φ))
Pour retrouver les parametres β, γ, S0, on ecrit la fonction inverse qui de-termine les parametres de l’EDO en fonction des parametres donnes parKermack et McKendrick.
function [bet,gam,S0]=coef2paramkmk(A,B,phi,I0)
gam=sqrt(2*A*B/I0*(1-(tanh(phi))^2 ))
alpha=2*B^2/gam
44

bet=gam*B/(A*(1+alpha*tanh(phi))
S0=gam^2*B/(bet^2*A)
endfunction
On a ensuite les parametres A,B et Φ en fonction de β, γ, S0 et I0.
function [A,B,phi]=param2coefkmk(bet,gam,S0,I0)
alpha2=(bet/gam*S0-1)^2+2*S0*I0*(bet/gam)^2
phi=atanh((bet/gam*S0-1)/sqrt(alpha2))
A=gam^3*sqrt(alpha2)/(2*bet^2*S0)
B=sqrt(alpha2)*gam/2
endfunction
On obtient les γ, β, S0
-->A=890;B=0.2;phi=3.4;
-->I0=9;
-->[bet,gam,S0]=coef2paramkmk(A,B,phi,I0)
S0 =
16952.295
gam =
0.4193234
bet =
0.0000483
-->[A1,B1,phi1]=param2coefkmk(bet,gam,S0,I0)
phi1 =
3.4
45

B1 =
0.2
A1 =
890.
On trouve que la duree moyenne d’incubation pour la peste est en jours (onmultiplie par 7 car l’unite de temps est la semaine)
-->1/0.4193234*7
ans =
16.693559
On avait pris on avait pris 11 jours pour le modele Eyam.
10.5 Trace de la courbe Kermack et McKendrick avecScilab
On imagine les calculs qu’il a fallu faire pour determiner ces parametres ettracer les courbes. Pour nous il est facile de tracer ces courbes. on a reprisles donnees de Kermack et McKendrick d’apres leur courbe. Les temps ensemaines sont dans T et les ordonnees dans ydata (voir plus loin le tableauen 10.6.1)
-->deff(’y=kmkcurve(t)’,’y=890 ./(cosh(0.2*t-3.4).^2)’)
-->plot2d(T,ydata,style=-3)
-->tt=T(1):0.01:T($)
-->plot2d(tt’,kmkcurve(tt)’,style=2)
~ On a defini «en ligne» dans la fenetre de commande la courbe en utilisantdeff. Noter l’espace entre 890 et le ./
46
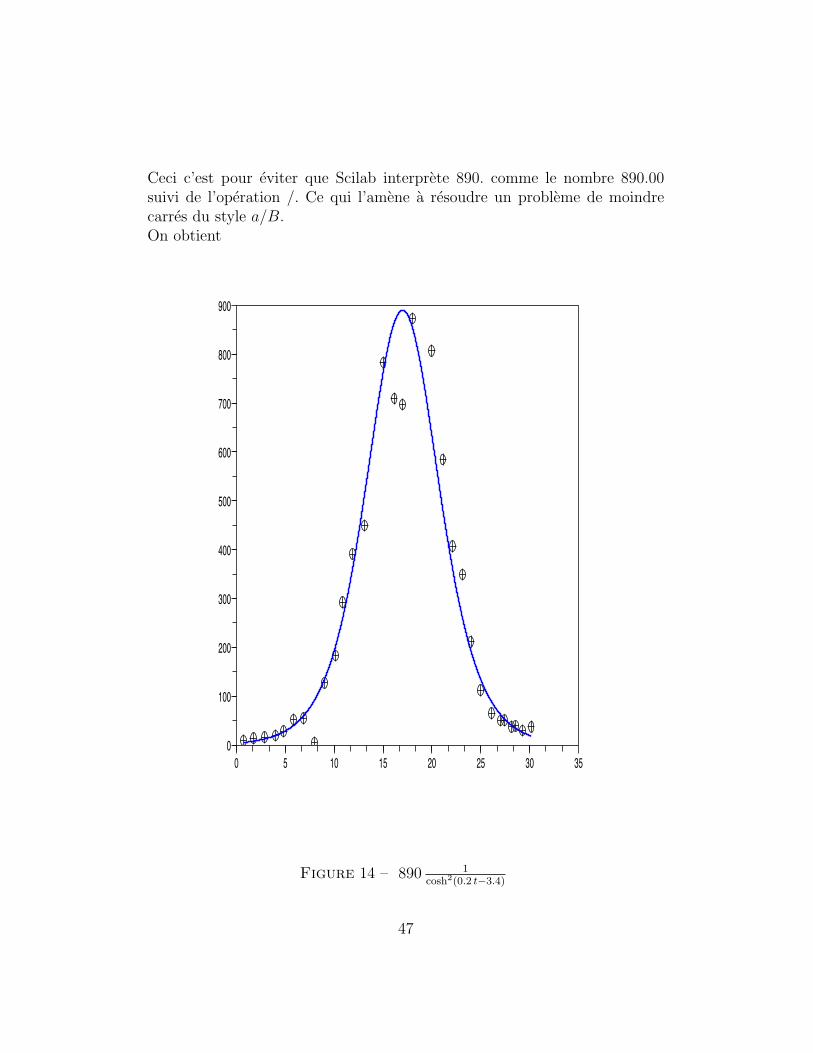
Ceci c’est pour eviter que Scilab interprete 890. comme le nombre 890.00suivi de l’operation /. Ce qui l’amene a resoudre un probleme de moindrecarres du style a/B.On obtient
0 5 10 15 20 25 30 350
100
200
300
400
500
600
700
800
900
Figure 14 – 890 1cosh2(0.2 t−3.4)
47
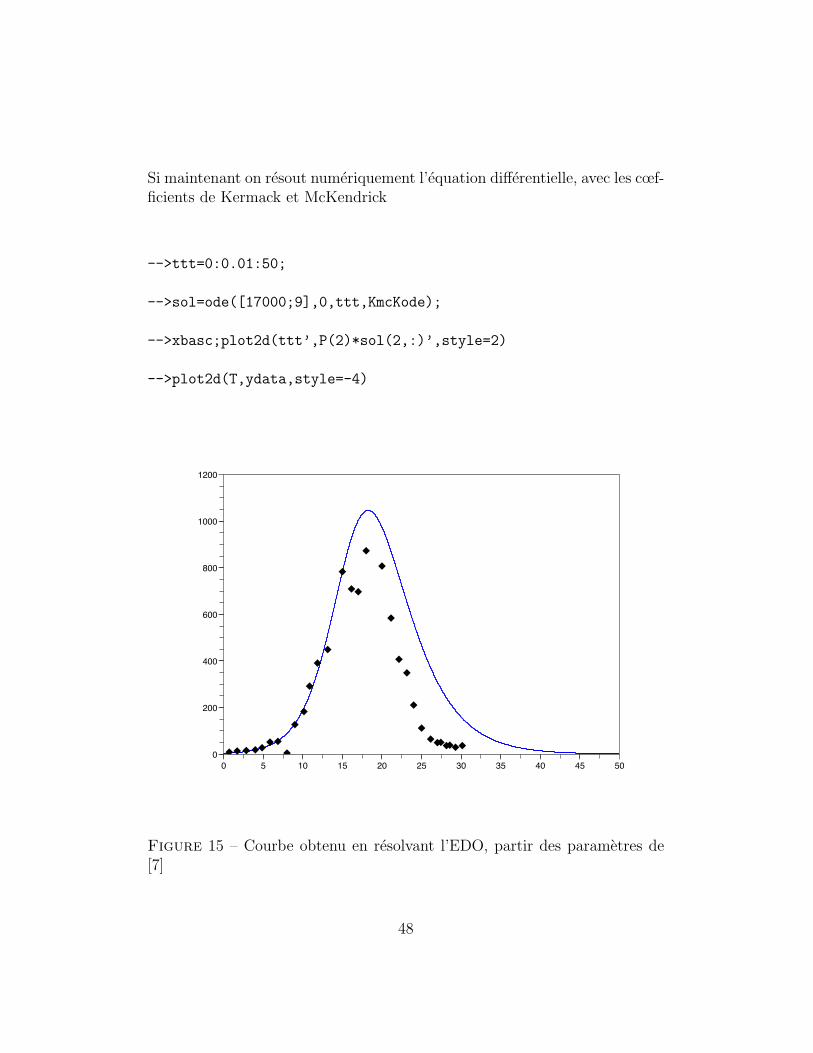
Si maintenant on resout numeriquement l’equation differentielle, avec les cœf-ficients de Kermack et McKendrick
-->ttt=0:0.01:50;
-->sol=ode([17000;9],0,ttt,KmcKode);
-->xbasc;plot2d(ttt’,P(2)*sol(2,:)’,style=2)
-->plot2d(T,ydata,style=-4)
0 5 10 15 20 25 30 35 40 45 500
200
400
600
800
1000
1200
Figure 15 – Courbe obtenu en resolvant l’EDO, partir des parametres de[7]
48

10.6 Kermack et McKendrick re-visites avec Scilbab
Que feraient Kermack et McKendrick de nos jours. Tout d’abord on supposequ’ils connaissaient le nombre d’habitants. Autrement dit N(0) = S(0). Onprend 17 000 d’apres nos calculs precedents.On va construire une fonction qui mesure l’erreur en les donnees de Kermacket McKendrick et la sortie de l’EDO en fonction de deux parametres β et γ.Tout d’abord on a les donnees que l’on a dans une matrice A (30 mesures).La premiere colonne ce sont les jours, la deuxieme le nombre de cas.
~ Les donnes de temps ont pour unite de temps jour. Il faudra passer en unitede temps semaine, pour se conformer a [7] et pouvoir comparer.
10.6.1 Les donnees
-->A
A =
5. 9.
12. 14.
20. 16.
28. 19.
34. 28.
41. 52.
48. 55.
56. 5.
63. 127.
71. 183.
76. 292.
83. 391.
92. 449.
105. 783.
113. 709.
119. 697.
126. 873.
140. 807.
148. 584.
155. 407.
162. 349.
49

168. 211.
175. 112.
183. 65.
189. 50.
192. 51.
197. 37.
200. 39.
205. 30.
211. 37.
La fonction d’erreur
function y=KMCK_1906(P,m)
x0=[17000;9];
t0=T(1);
sol=ode(x0,t0,T,kermac);
sol=sol(2,:); // infectieux
sol=sol(:)
predic=P(2)*sol;
//d’apres MacKendrick on observe la vitesse des "removed"
y=ydata-predic;
y=y(:);
/////////////////////////
function xdot=kermac(t,x,P)
xdot(1)=-P(1)*x(1)*x(2);
xdot(2)=P(1)*x(1)*x(2)-P(2)*x(2);
On a plus qu’a chercher les parametres. On part des chiffres de Kermacket McKendrick. On calcule d’abord l’erreur RSS. Puis on utilise lsqrsolve.Enfin on trace la sortie correspondante en rouge, sur le meme graphe.
-->sum(KMCK_1906(P,30).^2)
ans =
1475240.
-->[p_opt,ervec]=lsqrsolve(P,KMCK_1906,30);
50

-->p_opt
p_opt =
0.0000709 0.8235057
-->sum(ervec.^2)
ans =
130985.
-->sol=ode([17000;9],0,ttt,KmcKode);
-->plot2d(ttt’,P(2)*sol(2,:)’,style=5)
On peut aussi tracer la courbe de l’article et chercher son RSS
-->plot2d(ttt’,kmkcurve(ttt)’,style=3)
-->sum((kmkcurve(T)-ydata).^2)
ans =
130872.93
51
0 5 10 15 20 25 30 35 40 45 500
200
400
600
800
1000
1200
ODE paramètres Kermack
Courbe Kermack
ODE Optimisée
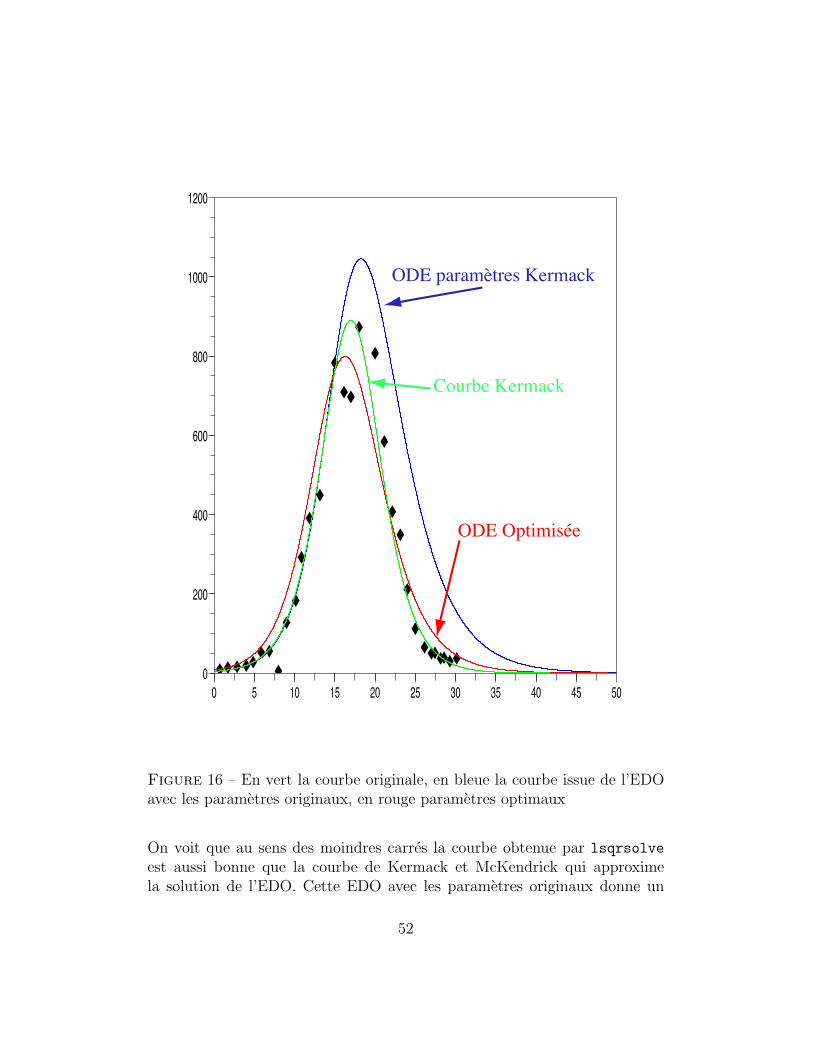
Figure 16 – En vert la courbe originale, en bleue la courbe issue de l’EDOavec les parametres originaux, en rouge parametres optimaux
On voit que au sens des moindres carres la courbe obtenue par lsqrsolve
est aussi bonne que la courbe de Kermack et McKendrick qui approximela solution de l’EDO. Cette EDO avec les parametres originaux donne un
52

resultat plus mauvais au sens des moindres carres.Si on prend pour γ l’estimation obtenue 0.8235057, on trouve pour tempsd’incubation en jours.
-->p_opt(2)
ans =
0.8235052
-->1/p_opt(2)*7
ans =
8.5002497
Ce chiffre est a rapprocher des chiffres obtenus a Eyam. Cela dit il fautmanifester la meme prudence que nos deux auteurs : aucune conclusion surles valeurs des constantes ne doit en etre tiree.La prudence des deux auteurs devient parfaitement claire. Tout d’abord leurmodele est deja une approximation. En effet la courbe donnee par l’equation(7) est une approximation de γ I(t). Les parametres sont ajustes sur cetteapproximation. Nos deux auteurs, tous les deux medecins, savaient egalementque le modele etait aussi une autre approximation avec des hypotheses sim-plificatrices (population constante, pas d’immuns, infection miroir de celledes rats . . .).En fait avec nos moyens modernes de calcul, nos auteurs auraient trouved’autres parametres. Ceux qu’ils donnent, meme pour la fonction, ne sontpas mes meilleurs au sens des moindres carres (faire l’exercice en (10.7) ).S’ils avaient resolu numeriquement l’EDO ils auraient trouve d’autre valeurs. . .comme on l’ a vu.Il reste que ce modele, en depit de toutes ces handicaps, donne quand memeune bonne idee de l’evolution du phenomene.
10.7 Un exercice
Identifier a l’aide des moindre carres avec Scilab les valeurs des parametresA,B,Φ de la fonction
53

z(t) = A1
cosh2(B t− Φ)
qui modelise les observations des cas de peste de [7]. On utilisera les donneesT, ydata du tableau donne en (10.6.1)Tracer la courbe correspondante, ainsi que celle de Kermack et McKendrick.
Reponse
-->[p_opt,ervec]=lsqrsolve([1,1,1],courbeKMcK,30);sum(ervec.^2)
ans =
83327.941
-->p_opt
p_opt =
845.17243 0.1876683 3.2846337
References
[1] H. Akaike, A new look at the statistical model identification, IEEETrans. Autom. Control, 19 (1976), pp. 716–723.
[2] P. Ciarlet, Introduction a l’analyse numerique matricielle et a l’opti-misation, Masson, 1990.
[3] F. Dyson, A meeting with Enrico Fermi, Nature, 427 (2004), p. p297.
[4] G. Gause, The struggle for existence, Williams and Wilkins, reprinted1964 Hafner, 1934.
[5] , The struggle for evidence., Dover, New-York, 2003.
[6] G. H. Golub and C. F. Van Loan, Matrix Computations, JohnHopkins University Press, Baltimore and London, 1993.
[7] W. Kermack and A. McKendrick, A contribution to the mathema-tical theory of epidemics, Proc. R. Soc., A115 (1927), pp. 700–721.
[8] P. Lascaux and R. Theodor, Analyse numerique matricielle appli-quee a l’art de l’ingenieur, tome 1 : Methodes directes, Masson, 1986.
54

[9] L. Ljung, System identification : Theory for the user, Prentice Hall,1999.
[10] J. Murray, Mathematical Biology I : An introduction, vol. 17 of Inter-disciplinary Applied Mathematics, Springer-Verlag, 2002.
[11] T. Weise, Global Optimization Algorithms - Theory and Applica-tion, Self-Published, second ed., Sept. 19, 2008. Online available athttp ://www.it-weise.de/.
55