interleaved pixel lookup for embedded computer vision
DESCRIPTION
Interleaved Pixel Lookup for Embedded Computer Vision. Kota Yamaguchi, Yoshihiro Watanabe, Takashi Komuro , Masatoshi Ishikawa. Outline. Introduction Problems to apply interleaving Techniques Example: Lucas- Kanade Conclusion. Purpose. - PowerPoint PPT PresentationTRANSCRIPT

Ishikawa Komuro LaboratoryThe University of Tokyo
Interleaved Pixel Lookup for Embedded Computer Vision
Kota Yamaguchi, Yoshihiro Watanabe, Takashi Komuro, Masatoshi Ishikawa

Ishikawa Komuro LaboratoryThe University of Tokyo
Outline• Introduction• Problems to apply interleaving• Techniques• Example: Lucas-Kanade• Conclusion
Ishikawa Komuro LaboratoryThe University of Tokyo
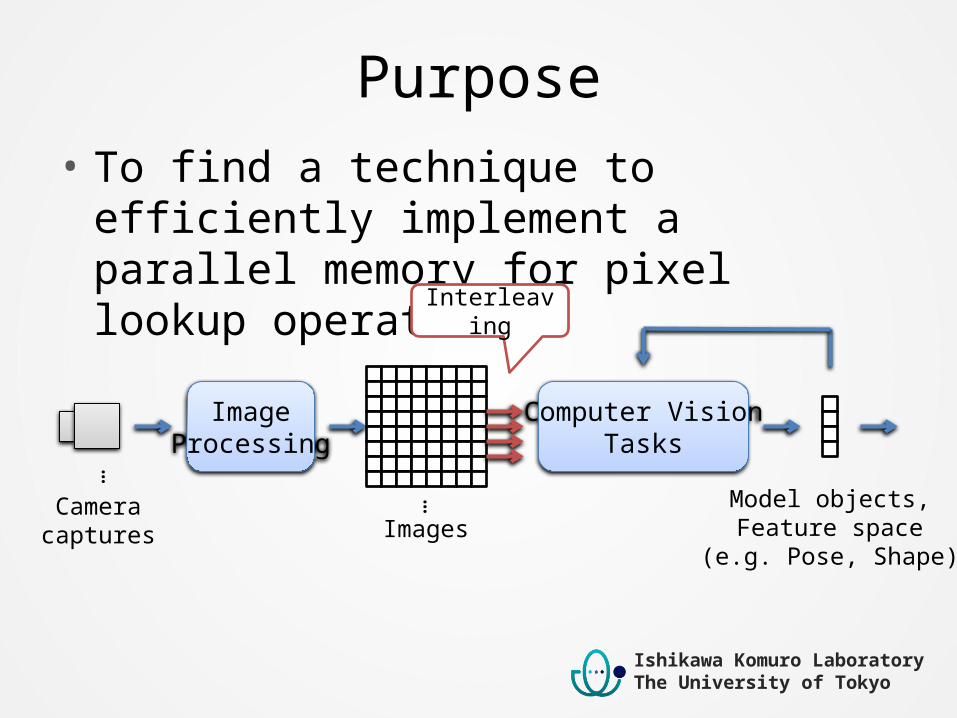
Purpose• To find a technique to efficiently implement a
parallel memory for pixel lookup operations
ImageProcessing
Computer VisionTasks
Model objects,Feature space
(e.g. Pose, Shape)
Cameracaptures Images
…
…
Interleaving
Ishikawa Komuro LaboratoryThe University of Tokyo
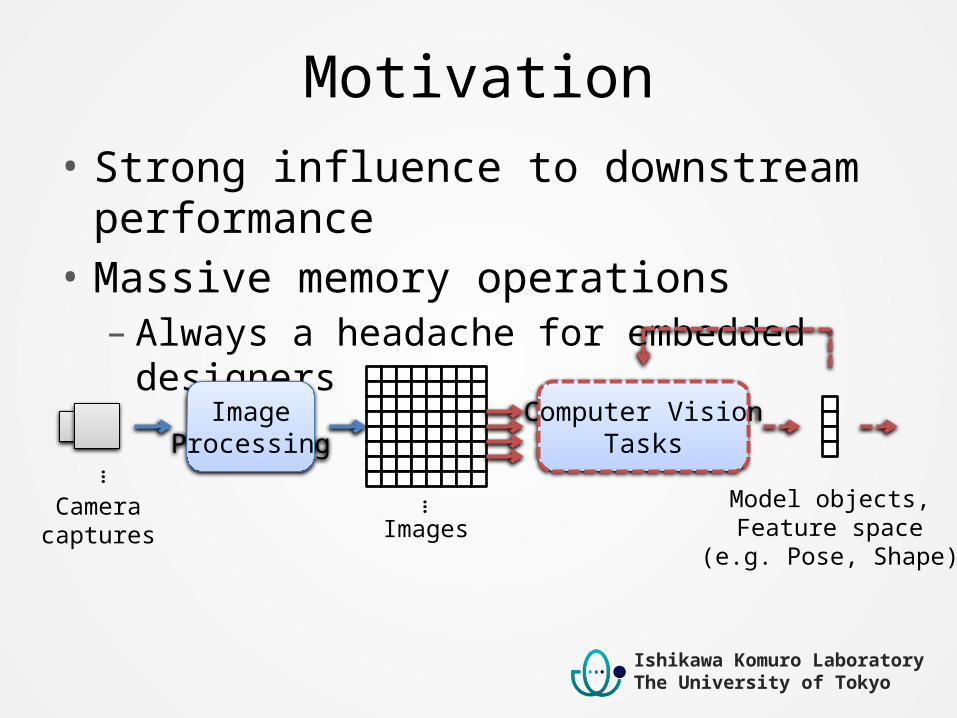
Motivation• Strong influence to downstream performance• Massive memory operations– Always a headache for embedded designers
ImageProcessing
Computer VisionTasks
Cameracaptures Images
…
… Model objects,Feature space
(e.g. Pose, Shape)

Ishikawa Komuro LaboratoryThe University of Tokyo
Motivation• Interleaving in graphics hardware– Texram [Schilling, 96]– Texture memory in Recent GPUs
• Is it also beneficial to an embedded computer vision hardware?– Yes, if appropriately implemented
Ishikawa Komuro LaboratoryThe University of Tokyo
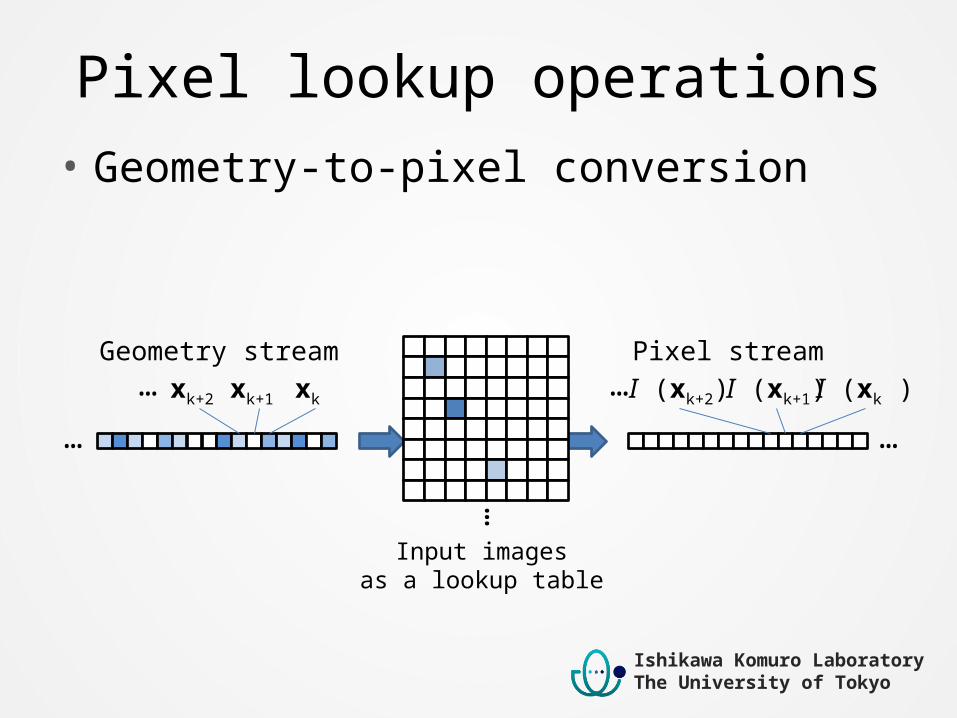
Pixel lookup operations• Geometry-to-pixel conversion
Input imagesas a lookup table
Geometry stream Pixel streamxk … …
xk+1 xk+2 … I (xk )I (xk+1)I (xk+2)…
…
Ishikawa Komuro LaboratoryThe University of Tokyo
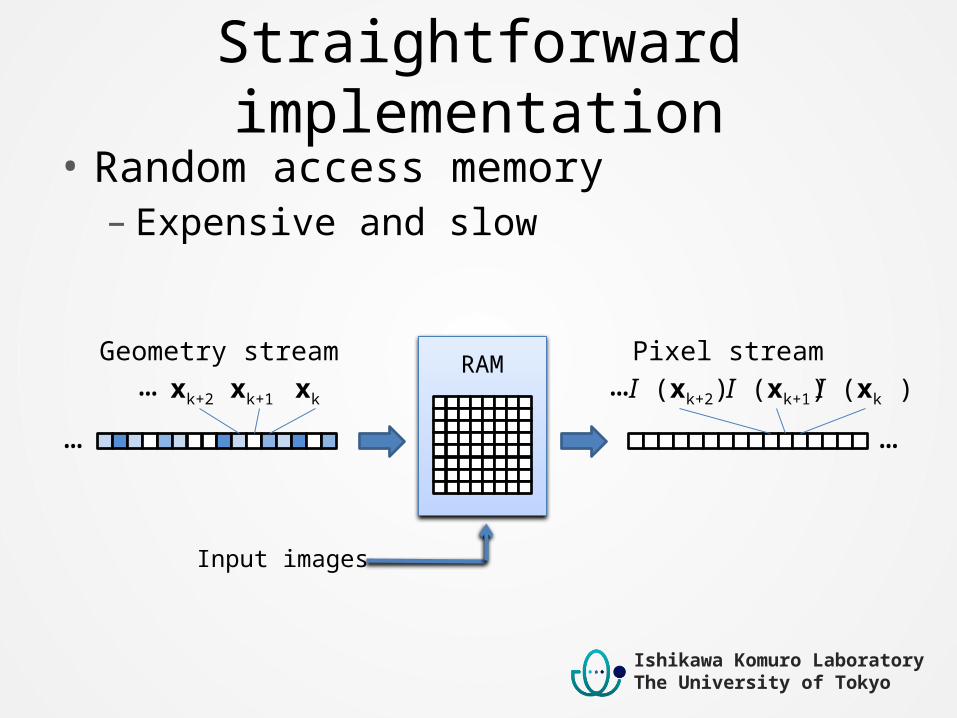
Straightforward implementation• Random access memory– Expensive and slow
Input images
Geometry stream Pixel streamxk … …
RAMxk+1 xk+2 … I (xk )I (xk+1)I (xk+2)…
Ishikawa Komuro LaboratoryThe University of Tokyo
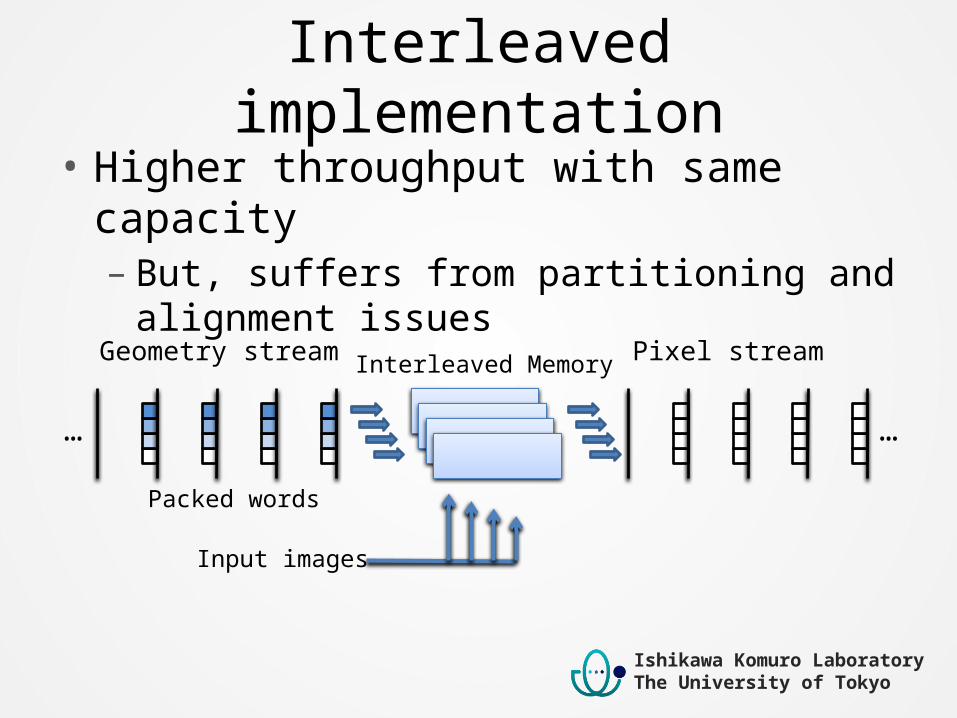
Interleaved implementation• Higher throughput with same capacity– But, suffers from partitioning and alignment issues
… …
Interleaved Memory
Input images
Packed words
Geometry stream Pixel stream

Ishikawa Komuro LaboratoryThe University of Tokyo
Partitioning issue• Parallel word does not match to operations– e.g. packing neighboring 1x4 pixels into a word,
but required 4x1 pixels at each operation
read
read
Pixel
align
read
read

Ishikawa Komuro LaboratoryThe University of Tokyo
• Unaligned access requires multiple reads and sub-word alignment
Misalignment issue
read
read
align
Word boundary

Ishikawa Komuro LaboratoryThe University of Tokyo
Techniques1. 2D partitioning2. Indirect addressing3. Data switching

Ishikawa Komuro LaboratoryThe University of Tokyo
2D partitioning• See an entire image as tiled spatial patterns– Packed word = spatial pattern required– Avoids partitioning issue
Packed word
SpatialPattern
Memory banks
Ishikawa Komuro LaboratoryThe University of Tokyo
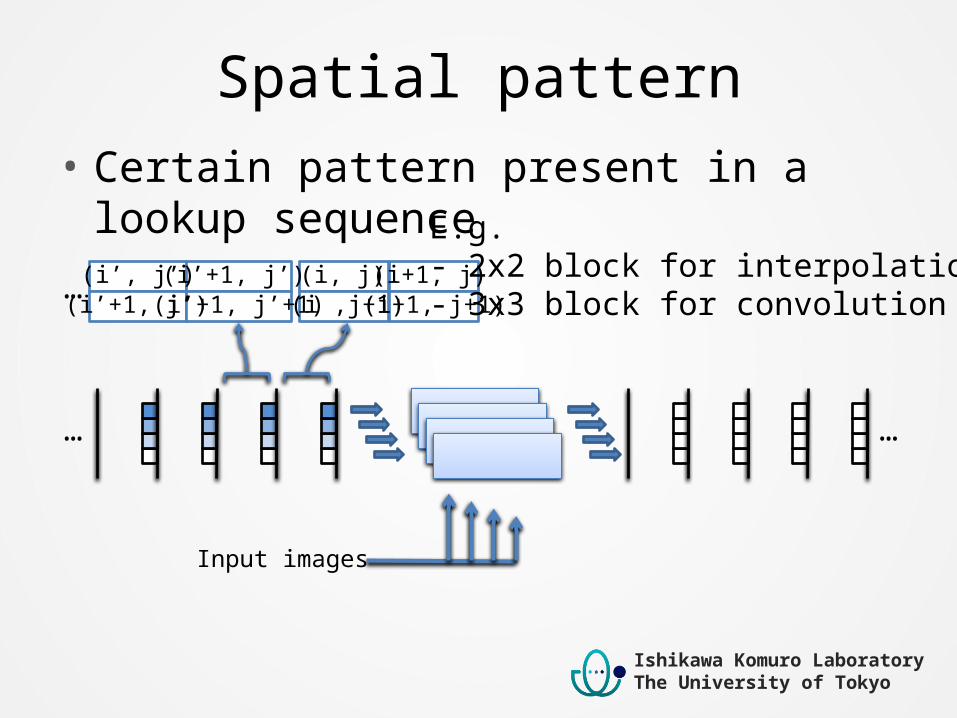
Spatial pattern• Certain pattern present in a lookup sequence
… …
Input images
(i ,j+1)(i+1, j)(i, j)
(i+1, j+1)(i’+1, j’)(i’+1, j’)(i’, j’)
(i’+1, j’+1)…
E.g.- 2x2 block for interpolation- 3x3 block for convolution
Ishikawa Komuro LaboratoryThe University of Tokyo
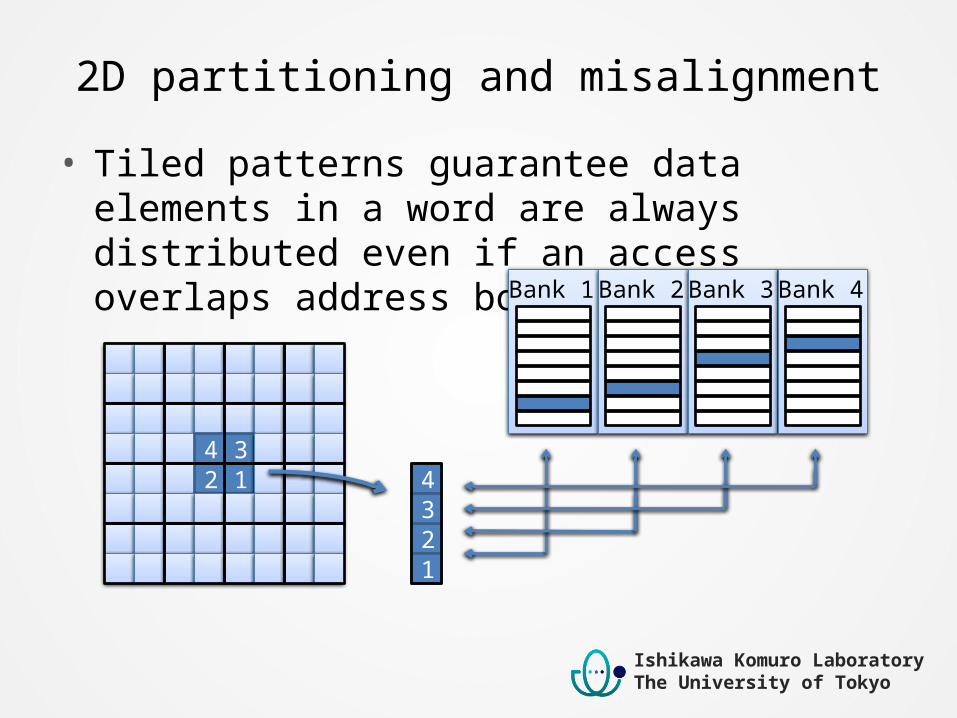
2D partitioning and misalignment• Tiled patterns guarantee data elements in a word are
always distributed even if an access overlaps address boundaries
Bank 1 Bank 2 Bank 3 Bank 4
4 32 1 4
23
1
Ishikawa Komuro LaboratoryThe University of Tokyo
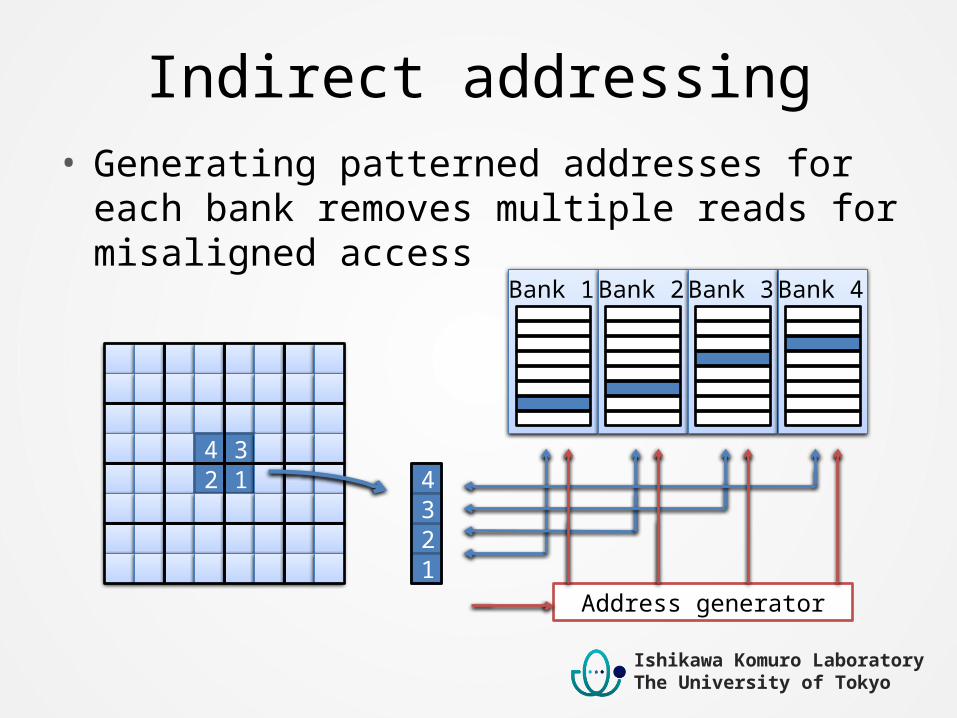
Indirect addressing• Generating patterned addresses for each bank
removes multiple reads for misaligned access
Bank 1 Bank 2 Bank 3 Bank 4
Address generator
4 32 1 4
23
1
Ishikawa Komuro LaboratoryThe University of Tokyo
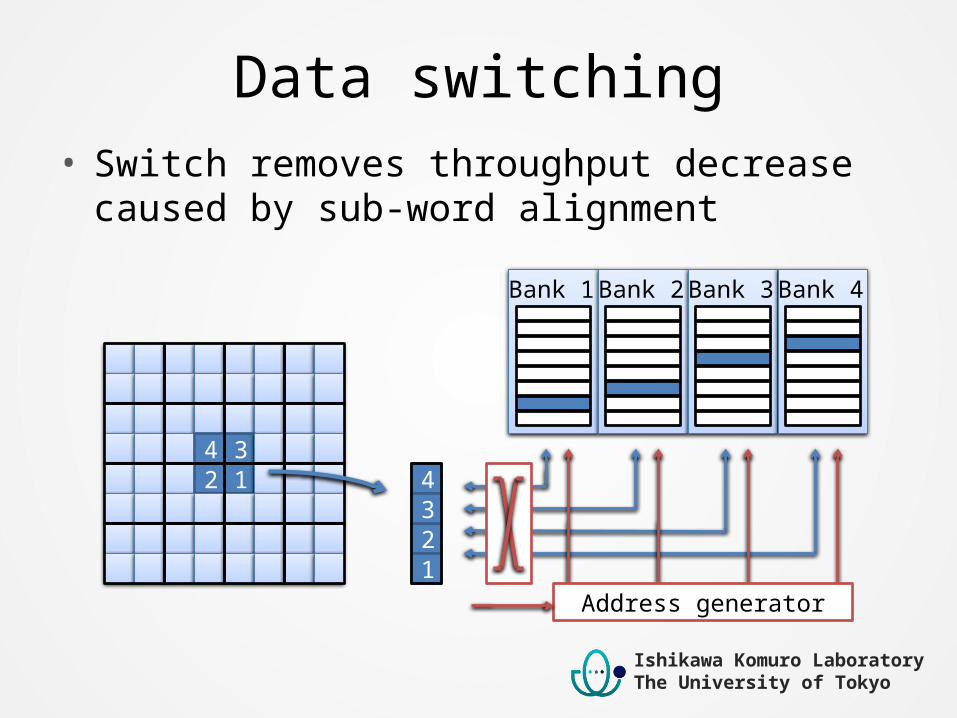
Data switching• Switch removes throughput decrease caused by sub-
word alignment
Bank 1 Bank 2 Bank 3 Bank 4
Address generator
4 32 1 4
23
1
Ishikawa Komuro LaboratoryThe University of Tokyo
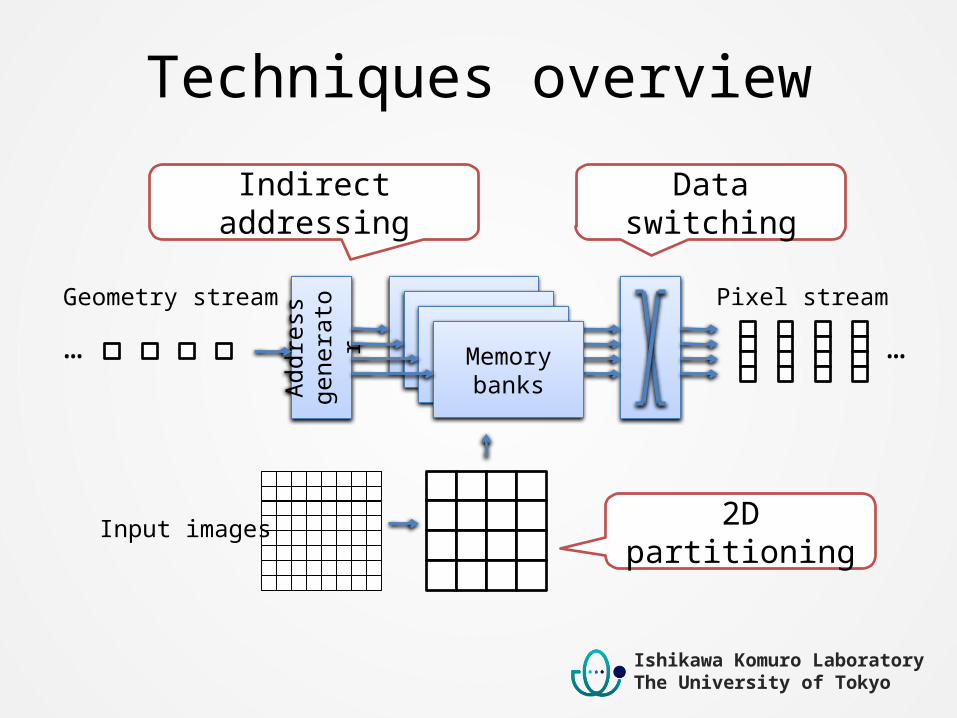
Techniques overview
Addr
ess
gene
rato
r…… Memory
banks
Indirect addressing Data switching
2D partitioningInput images
Geometry stream Pixel stream
Ishikawa Komuro LaboratoryThe University of Tokyo
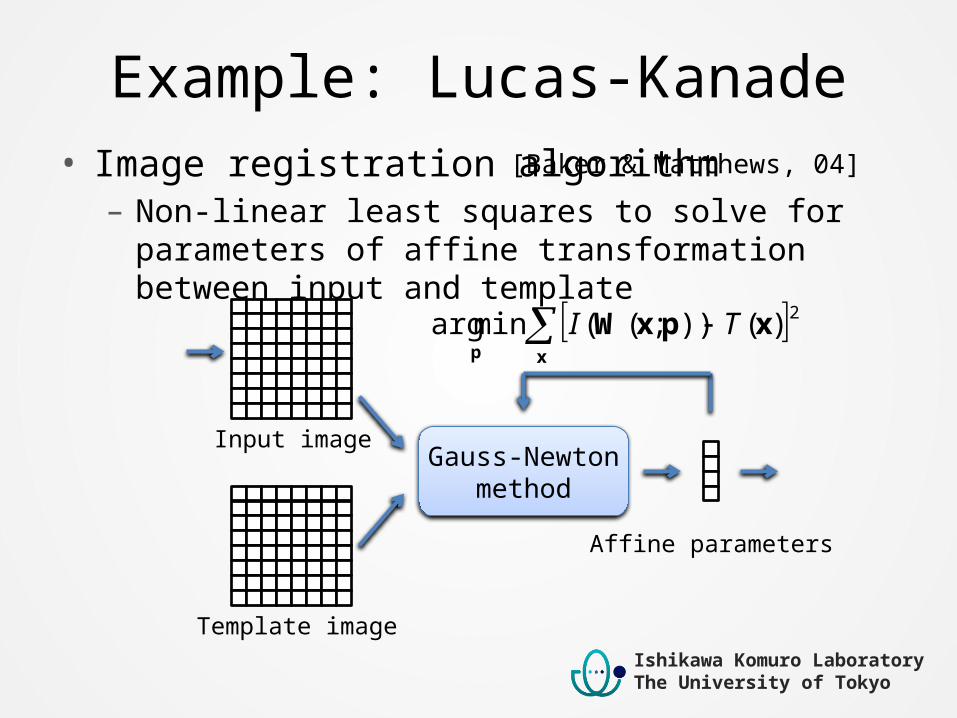
Example: Lucas-Kanade• Image registration algorithm– Non-linear least squares to solve for parameters of affine
transformation between input and template
Gauss-Newtonmethod
Affine parameters
Input image
Template image
[Baker & Matthews, 04]
xp
xpxW 2)());((minarg TI
Ishikawa Komuro LaboratoryThe University of Tokyo
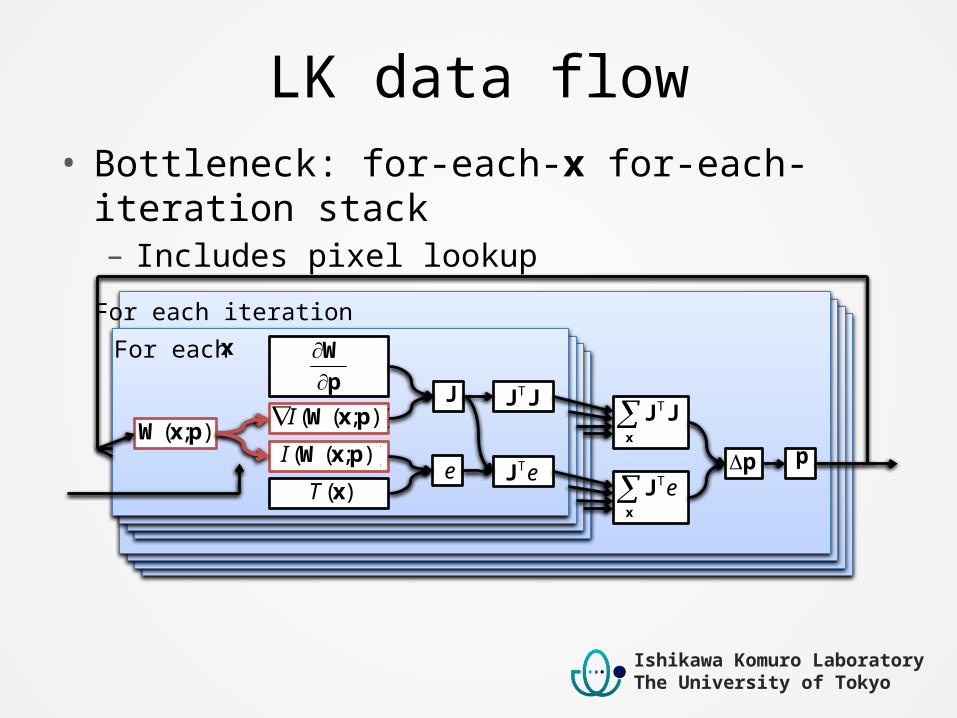
LK data flow• Bottleneck: for-each-x for-each-iteration stack– Includes pixel lookup
For each xFor each iteration
);( pxW
p
W
));(( pxWI
));(( pxWI
)(xT
J
e
JJT
eTJ
x
JJT
x
J eTp p
Ishikawa Komuro LaboratoryThe University of Tokyo
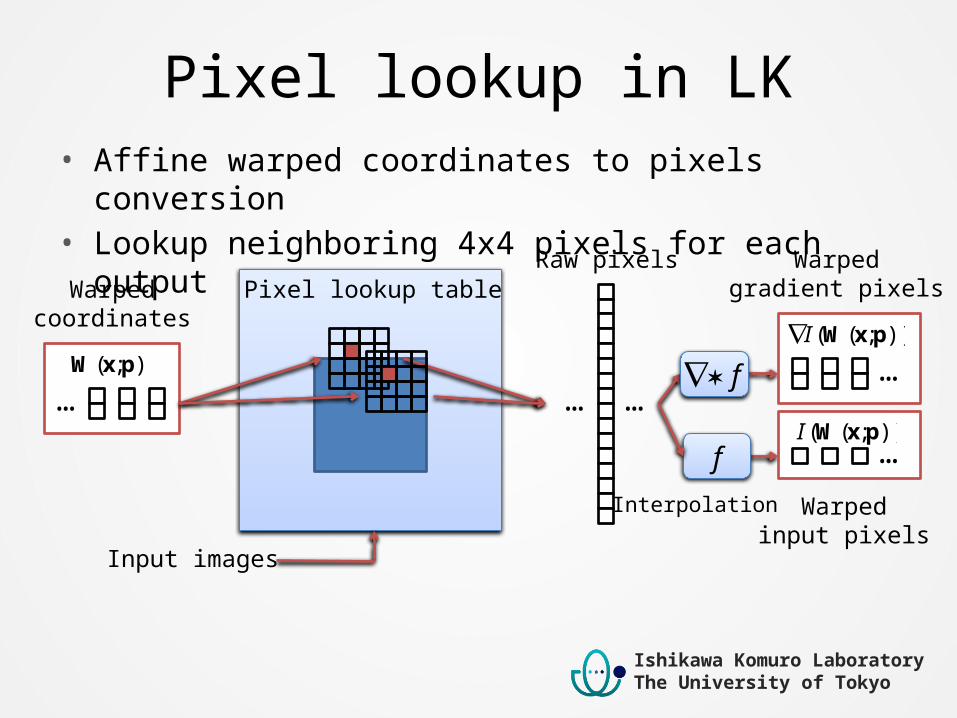
Pixel lookup in LK• Affine warped coordinates to pixels conversion• Lookup neighboring 4x4 pixels for each output
Warpedcoordinates
);( pxW
…
Warpedgradient pixels
Warpedinput pixels
… …
Raw pixels
f
Input images
Pixel lookup table
f
Interpolation
));(( pxWI
));(( pxWI
…
…
Ishikawa Komuro LaboratoryThe University of Tokyo
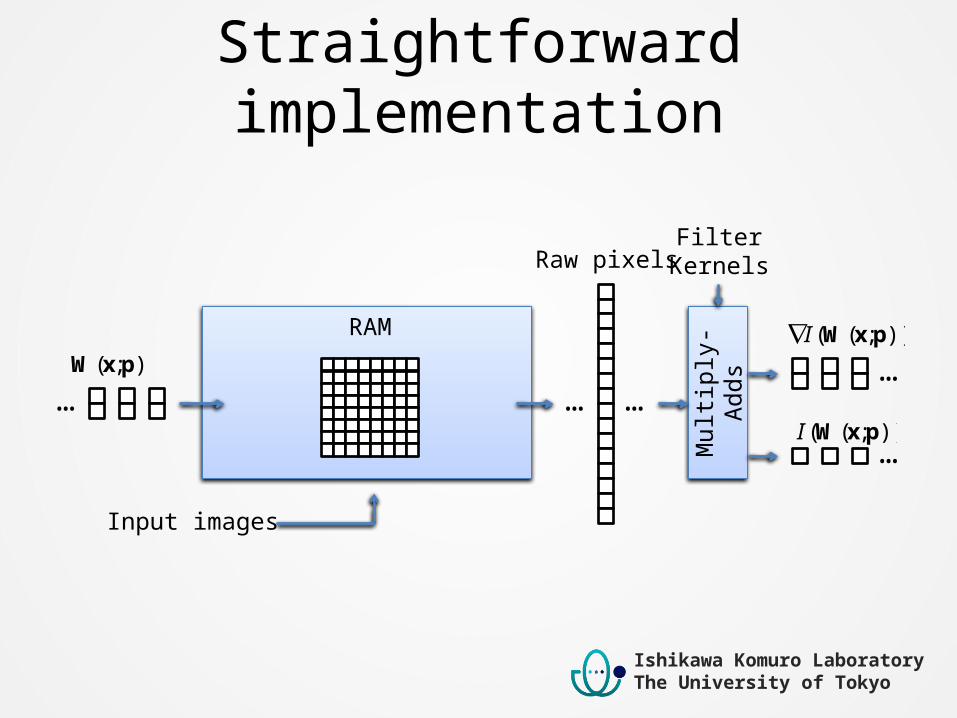
Straightforward implementation
Mul
tiply
-Add
sRAM
);( pxW));(( pxWI
));(( pxWI
…
…
… … …
Input images
Raw pixelsFilter
Kernels
Ishikawa Komuro LaboratoryThe University of Tokyo
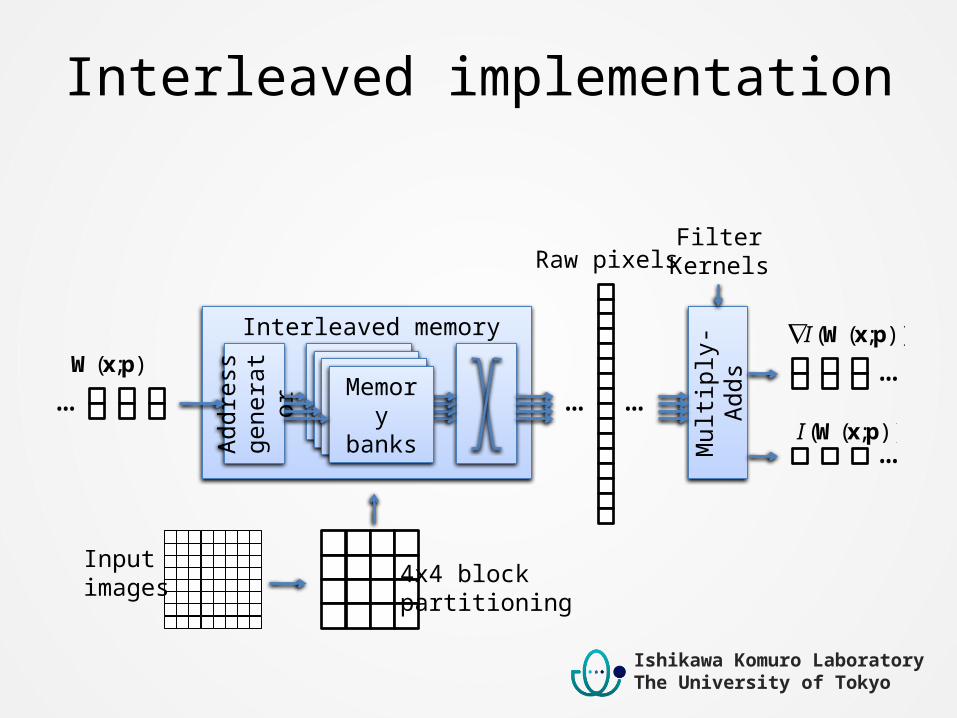
Interleaved implementation
Addr
ess
gene
rato
r
Memorybanks
Mul
tiply
-Add
sInterleaved memory
);( pxW));(( pxWI
));(( pxWI
Inputimages
…
…
… … …
Raw pixelsFilter
Kernels
4x4 blockpartitioning

Ishikawa Komuro LaboratoryThe University of Tokyo
Comparison of memory configurations
Single port 4x4 multi-port 4x4 interleaved (SIMD)
4x4 interleaved with alignment support
Throughput 1 16 5-6 16
Capacity requirement
1 16 1 1
Peripherals None None Switch Address generator and Switch
Easier to implement peripherals than increasing memory capacity
Ishikawa Komuro LaboratoryThe University of Tokyo
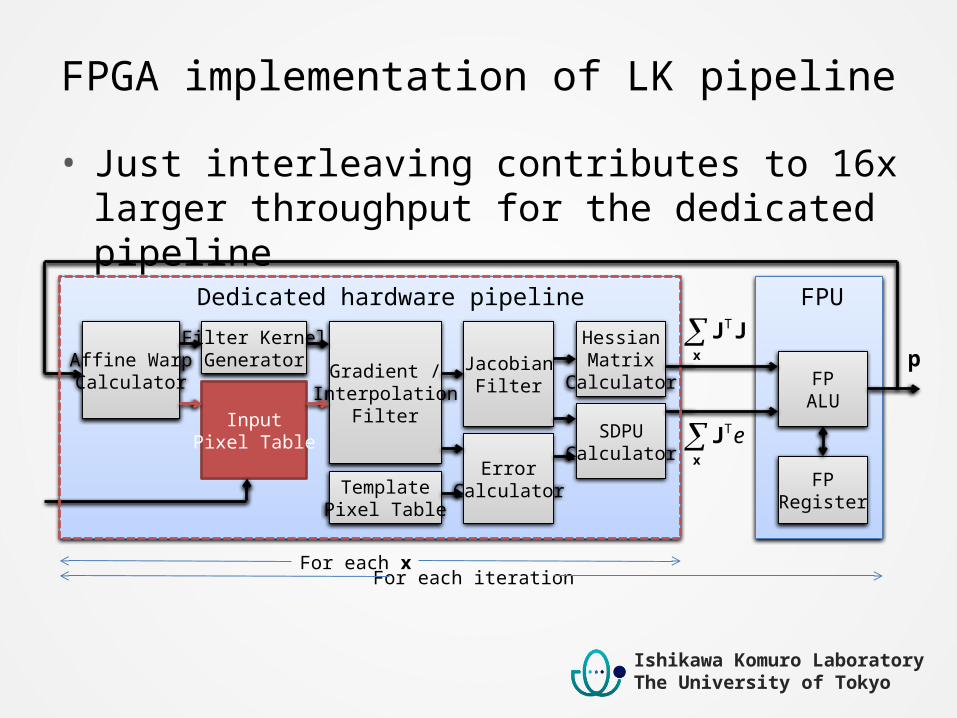
FPGA implementation of LK pipeline• Just interleaving contributes to 16x larger throughput
for the dedicated pipeline
Affine WarpCalculator
Filter KernelGenerator
InputPixel Table
Gradient /Interpolation
Filter
JacobianFilter
ErrorCalculator
HessianMatrix
Calculator
SDPUCalculator
FPALU
FPRegister
TemplatePixel Table
Dedicated hardware pipeline FPU
x
JJT
x
J eT
p
For each xFor each iteration

Ishikawa Komuro LaboratoryThe University of Tokyo
HDL synthesis
• 16x larger throughput, but still same capacity requirement and feasible hardware costs
• Estimated performance: 200 fps for registration of 5 pieces of 64x64 8-bit image patches at 100 MHz– Assumption: all registration converge within 10 iterations
FPGA Xilinx Virtex-4 XC4VLX200
Maximum freq. 264.890 MHz
SlicesDSP slicesRAM blocks
3,108 / 890,833 (3%)75 / 96 (79%)
266 / 336 (78%)(4,788 Kb)

Ishikawa Komuro LaboratoryThe University of Tokyo
Summary• Interleaved pixel lookup– Sub-word parallel memory operations utilizing
spatial pattern in lookup sequences• Techniques– 2D partitioning– Indirect addressing– Data switching
• Example: Lucas-Kanade– 16x larger throughput with same memory capacity
and feasible hardware cost