infrastructure considerations for analytical workloads
TRANSCRIPT

Infrastructure Considerations for Analytical WorkloadsBy applying Hadoop clusters to big data workloads, organizations can achieve incredible performance gains that can vary based on physical versus virtual infrastructure.
Executive SummaryOn the list of technology industry buzzwords, “big data” is among the most intriguing ones. As data volume, velocity and variety proliferate, and the search for veracity escalates, organiza-tions across industries are placing new bets on various new data sources such as machine sensor data, medical images, financial information, retail sales, radio frequency identification and Web tracking data. This is creating huge challenges for decision-makers to make meaning and untangle trends from input larger than ever before.
From a technological perspective, the so-called four V’s of big data (volume, velocity, variety and veracity) make it ever more difficult to process big data on a single system. Even if one disregarded the storage constraints of a single system, and utilized a storage area network (SAN) to store the petabytes of incoming data, processing speed remains a huge bottleneck. Whether a single-core or multi-core processor is used, a single system would take substantially more time to process data than if the data was partitioned across an
array of systems used in parallel. That’s not to say that the processing conundrum shouldn’t be confronted and overcome. Big data plays a vital role in improving organizational profitabil-ity, increasing productivity and solving scientific challenges. It also enables decision-makers to understand customer needs, wants and desires, and to see where markets are heading.
One of the major technologies that helps orga-nizations make sense of big data is the open source distributed processing framework known as Apache Hadoop. Based on our engagement experiences and through intensive benchmark-ing, this white paper analyzes the infrastructure considerations for running analytical workloads on Hadoop clusters. The primary emphasis is to compare and contrast the physical or virtual infra-structure requirements to support typical business workloads from performance, cost, support and scalability perspectives. Our goal is to arm the reader with the insights necessary for assessing whether physical or virtual infrastructure would best suit your organization’s requirements.
cognizant 20-20 insights | april 2016
• Cognizant 20-20 Insights

cognizant 20-20 insights 2
Hadoop: A PrimerTo solve many of the aforementioned big data issues, the Apache Foundation developed Apache Hadoop, a Java-based framework that can be used to process large amounts of data across thousands of computing nodes. It consists of two main components – HDFS1 and MapReduce.2 Hadoop Distributed File System (HDFS) is designed to run on commodity hardware, while MapReduce provides the processing framework for distributed data across thousands of nodes.
HDFS shares many attributes with other distribut-ed file systems. However, Hadoop has implement-ed numerous features that allow the file system to be significantly more fault-tolerant than typical hardware solutions such as redundant arrays of inexpensive disks (RAIDs) or data replica-tion alone. What follows is a deep dive into the reasons Hadoop is considered a viable solution for the challenges created by big data. The HDFS components explored are the NameNode and DataNodes (see Figure 1).
The MapReduce framework processes large data sets across numerous computer nodes (known as data nodes) where all nodes are on the same local network and use similar hardware. Computational processing can occur on data stored either in a file system (either semi-structured or unstructured) or in a database (structured). MapReduce can take advantage of data locality. In MapReduce version 1, the components are JobTracker and TaskTrack-ers, whereas in MapReduce version 2 (YARN), the components are the ResourceManager and Node-Managers (see next page, Figure 2).
Hadoop’s RoleHadoop provides performance enhancements that enable high throughput access to applica-tion data. It also handles streaming access to file system resources, which are increasingly chal-lenging when attempting to manipulate larger data sets. Many of the design considerations can be subdivided into the following categories:
• Data asset size.
• Transformational challenges.
• Decision-making.
• Analytics.
Hadoop’s ability to integrate data from different sources (databases, social media, etc.), systems (network/machine/sensor logs, geo-spatial data, etc.) and file types (structured, unstructured and semi-structured) enable organizations to respond to business questions such as:
• Do you test all of your decisions to compete in the market?
• Can new business models be created based on the available data in the organization?
• Can you drive new operational efficiencies by modernizing extract, transform and load (ETL) and optimizing batch processing?
• How can you harness the hidden value in your data that until now has been archived, discarded or ignored?
All applications utilizing HDFS tend to have large data sets that range from gigabytes to petabytes. HDFS has been calibrated to adjust to
HDFS Architecture
Figure 1
Rack 1 Rack 2
NameNode Client
Read Write DataNodes
Block Ops
Metadata Ops
Replication

cognizant 20-20 insights 3
such large data volumes. By providing substan-tial aggregated data bandwidth, HDFS should scale to thousands of nodes per cluster. Hadoop is a highly scalable storage platform because it can store and distribute very large data sets across hundreds of commodity servers operating in parallel. This enables businesses to run their applications on thousands of nodes involving thousands of terabytes of data.
In legacy environments, traditional ETL and batch processes can take hours, days or even weeks – in a world where businesses require access to data in minutes or even seconds. Hadoop excels at high-volume batch processing. Because the processing is in parallel, Hadoop is said to perform batch processing multiple times faster than on a single server.
Likewise, when Hadoop is used as an enterprise data hub (EDH), it can ease the ETL bottleneck by establishing a single version of truth that can be accessed and transformed by business users without the need for a dedicated infrastructure setup. This makes Hadoop one place to store all data, for as long as desired or required – and in its original fidelity – that is integrated with existing
infrastructure and tools. Doing this provides the flexibility to run a variety of enterprise workloads, including batch processing, inter-active SQL, enterprise search and advanced analytics. It also comes with the built-in security, governance, data protection and management that enterprises require.
With EDH, leading organizations are changing the way they think about data, transforming it from a cost to an asset.
For many enterprises, data streams from all directions. The challenge is to synthesize and quantify it and convert bits and bytes into insights and foresights by applying analytical procedures on the historical data collected. Hadoop enables organizations not only to store the data collected but also to analyze it. With Hadoop, business value can be elevated by:
• Mining social media data to determine customer sentiments.
• Evaluating Web clickstream data to improve customer segmentation.
• Proactively identifying and responding to security breaches.
MapReduce v1 YARN* - MapReduce v2
* YARN – Yet Another Resource Negotiator
Client Client
JobTracker
NameNode
r
r
Client Client
Resource Manager
NameNode
Node Manager
DataNode
Container
Node Manager
DataNode
Container
Node Manager
DataNode
Container
Node Manager
DataNode
Container
Node Manager
DataNode
Application Master
Node Manager
DataNode
Application Master
TaskTracker
DataNode
TaskTracker
DataNode
TaskTracker
DataNode
Input Split Map [Combine]Shuffle &
SortReduce Output
MapReduce Logical Data Flow
Figure 3
MR vs. YARN Architecture
Figure 2

• Predicting a customer’s next buy.
• Fortifying security and compliance using server/machine logs and analyzing various data sets across multiple data sources.
Understanding Hadoop InfrastructureHadoop can be deployed in either of two environ-ments:
• Physical-infrastructure-based.
• Virtual-infrastructure-based.
Physical Infrastructure for Hadoop Cluster Deployment
Hadoop and its associated ecosystem components are deployed on physical machines with large amounts of local storage and memory. Machines are racked and stacked with high-speed network switches.
The merits:
• Delivers the full benefits of Hadoop’s perfor-mance, especially with locality-aware computa-tion. In the case where a node is too busy to accept additional work, the JobTracker can still schedule work near the node and take advantage of the switch’s bandwidth.
• The HDFS file system is persistent over cluster restarts (provided the data on the NameNode is protected and a secondary NameNode exists to keep up with the data, or the high availability has been configured).
• When writing files to HDFS, data blocks can be streamed to multiple racks; importantly, if a switch fails or a rack loses power, a copy of the data is still retained.
The demerits:
• Unless there is enough work to keep the CPUs busy, hardware becomes a depreciating investment, particularly if servers aren’t being used to their full potential – thereby increasing
the effective cost of the entire cluster.
• The cluster hostnames and IP addresses needs to be copied into /etc/hosts of each server in the cluster, to avoid DNS load.
Virtual Infrastructure for Hadoop Cluster Deployment
Virtual machines (VMs) are created only up to the duration of the Hadoop cluster. In this approach, a cluster configuration with the NameNode and JobTracker hostnames is created, usually in the same machine for a small cluster. Network rules can ensure that only authorized hosts have access to the master and slave nodes. Persistent data must be kept in an alternate file system to avoid data loss.
The merits:
• Can be cost-effective as the organization is billed based on the duration of cluster usage; when the cluster is not needed, it can be shut down – thus saving money.
• Can scale the cluster up and down on demand.
• Some cloud service providers provide a version of Hadoop that is prepackaged, easy and ready-to-use.
The demerits:
• Prepackaged Hadoop implementations may be older versions or private branches without the code being public. This makes it harder to handle failure.
• Startup can be complex, as the hostnames of the master node(s) are not known until they are allocated; configuration files need to be created on demand and then placed in the VMs.
• There is no persistent storage except through non-HDFS file systems.
• There is no locality in a Hadoop cluster; thus, there is no easy way to determine the location of slave nodes and their relativity to each other.
cognizant 20-20 insights 4
Soft Factors Hard Factors
Performance optimization parameters External factors
Number of maps Environment
Number of reducers Number of cores
Combiner Memory size
Custom serialization The Network
Shuffle tweaks
Intermediate compression
Factors Affecting Hadoop Cluster Performance
Figure 4

cognizant 20-20 insights 5
• DataNodes may be colocated on the same physical servers, and so lack the actual redundancy which they appear to offer in the HDFS.
• Extra tooling is often needed to restart the cluster when the machines are destroyed.
Hadoop Performance EvaluationWhen it comes to Hadoop clusters, performance is critical. These clusters may run on premises on a physical or on a virtualized environment, or both. A performance analysis of individual clusters in each environment aids in determining the best alternative for achieving required performance (see Figure 4, previous page).
Setup Details and Experiment ResultsWe compared the performance of a Hadoop cluster running virtually on Amazon Web Services’ Elastic Map Reduce (AWS-EMR) and a similar hard-wired cluster running on internal physical infrastructure. See Figure 5 for the precise con-figurations.
Figure 6 reveals our benchmark findings of the virtual cluster running Hive and Pig scripts versus the physical machines running Mahout KMeans Clustering.
Figure 7 reveals the nature of benchmark data.
This benchmark was performed to transform
AWS VM Sizes* vCPU x Memory No. of Nodes
m1.medium 1 X 2 GB 4
m1.large 1 X 4 GB 4
m1.xlarge 4 X 16 GB 4
Machine Sizes CPU x Memory
NameNode 4 x 4 GB 1
DataNode 4 x 4 GB 3
Client 4 x 8 GB 1
Processor: Intel Core i3-3220 [email protected] 4 cores
A Tale of the Tape: Physical vs. Virtual Machines
Figure 5
AWS EMR Physical machine
Distribution Apache Hadoop Cloudera Distribution for Hadoop 4
Hadoop Version 1.0.3 2.0.0+1518
Pig 0.11.1.1-amzn (rexported) 0.11.0+36
Hive 0.11.0.1 0.10.0+214
Mahout 0.9 0.7+22
Benchmarking Physical and Virtual Machines*
*Instance details may differ with releases.3
Figure 6
Requirement Generate 1B records and store it on S3 Bucket/HDFS
No. of Columns 37
No. of Files 50 nos.
No. of Records (each file) 20 Million
File Size (each file) 2.7 GB
Total Data Size 135 GB
Cluster Size (4-Node) No. of DataNodes/TaskTrackers: 03 nos.
Data Details
Figure 7

raw data into a standard format using big data tools such as Hive Query Language (HiveQL) and Pig Latin on 40 million records, scaling to 1 billion records. Along with this, Mahout (the machine learning tool for Hadoop) was also run for KMeans Clustering of the data that created five clusters with a maximum of eight iterations on m1.large (1vCPU x 4GB memory), m1.xlarge (4vCPU x 15.3GB memory) and physical machines (4CPU x 4GB memory). The input data was placed in the HDFS for physical machines and on AWS S3 for AWS-EMR.
Consequential Graphs
Figure 8 shows how the cluster performed for the Hive transformation on both physical and virtual environments.
Figure 8 reveals that both workloads took almost the same time for smaller datasets (~40 to ~80 million records). Gradually with increasing data sizes, the physical machines performed better than EMR’s m1.large cluster.
Figure 9, which compares PM versus VM using Pig transformation, shows that the EMR cluster
cognizant 20-20 insights 6
0
2000
4000
6000
8000
40M 80M 160M 320M 640M 1B
Tim
e (i
n s
econ
ds)
No. of Records AWS EMR (m1.large) Physical Machines
Hive Transformation (PM vs. VM)
Figure 8
0
1000
2000
3000
4000
5000
6000
40M 80M 160M 320M
Tim
e (i
n s
econ
ds)
No. of records
AWS EMR (m1.large)-PIG Physical Machines-PIG
Pig Transformation (PM vs. VM)
Figure 9
0 1000 2000 3000 4000 5000 6000
Time (in seconds)
Hive (Query-3)
Hive (Query-2)
Hive (Transformation)
Pig (Transformation)
PM
VM
PM vs. VM (for 320M records)
Figure 10
cognizant 20-20 insights 7
executing Pig Latin script on 40 million records takes longer compared with a workload running the same script on physical machines. Eventually with increasing data sizes, the difference between the time taken by physical and virtual infrastructure expands to a point where physical machines execute significantly faster.
Figure 10 (previous page) shows the time taken for all four operations on a dataset containing 320 million records. This includes running various Hive queries and Pig scripts to compare their per-formance. With the exception of the Hive Trans-
formation, the other operations are faster with physical compared with virtual infrastructure.
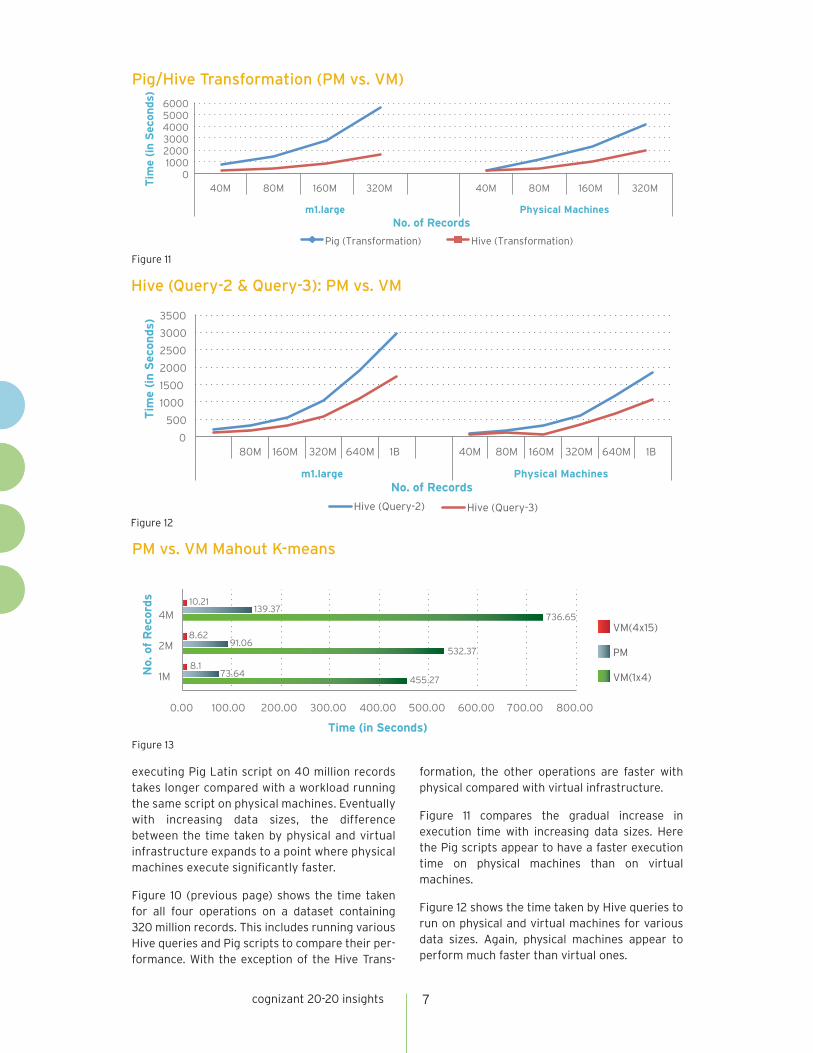
Figure 11 compares the gradual increase in execution time with increasing data sizes. Here the Pig scripts appear to have a faster execution time on physical machines than on virtual machines.
Figure 12 shows the time taken by Hive queries to run on physical and virtual machines for various data sizes. Again, physical machines appear to perform much faster than virtual ones.
0 1000 2000 3000 4000 5000 6000
40M 80M 160M 320M 40M 80M 160M 320M
m1.large Physical Machines
Tim
e (i
n S
econ
ds)
No. of Records
Pig (Transformation) Hive (Transformation)
Pig/Hive Transformation (PM vs. VM)
Figure 11
0
500
1000
1500
2000
2500
3000
3500
80M 160M 320M 640M 1B 40M 80M 160M 320M 640M 1B
m1.large Physical Machines
Tim
e (i
n S
econ
ds)
No. of Records
Hive (Query-2) Hive (Query-3)
Hive (Query-2 & Query-3): PM vs. VM
Figure 12
455.27
532.37
736.65
750.82
73.64
91.06
139.37
180.86
8.1
8.62
10.21
11.93
0.00 100.00 200.00 300.00 400.00 500.00 600.00 700.00 800.00
1M
2M
4M
6M
Time (in Seconds)
No.
of
Rec
ords
VM(4x15)
PM
VM(1x4)
PM vs. VM Mahout K-means
Figure 13

cognizant 20-20 insights 8
Figure 13 (previous page) displays the K-Means Clustering performance on physical infrastruc-ture, m1.large virtual infrastructure (1 core x 4GB memory) and m1.xlarge virtual infrastruc-ture (4 cores x 15 GB memory). In this test, the best performance was clocked on an m1.xlarge cluster. Hence, the performance achieved depends significantly on the memory consumed for the run. In this case, the ease of scalabil-ity of virtual machines drove the performance advantage over physical machines.
In our experiment, we perceived that AWS EMR up to m1.large instances performs significantly slower than the one running in a physical environ-ment. Whereas with the m1.xlarge instance with a larger memory capacity, virtual performance was faster than on physical machines.
In sum, Hadoop MapReduce jobs are IO bound and, generally speaking, virtualization will not help organizations to boost performance. Hadoop takes advantage of sequential disk IO, for example, by using larger block sizes. Virtualization works on the notion that multiple “machines” do not need full physical resources at all times. IO-intensive data processing applications that operate on dedicated storage are preferred to be non-virtualized.
For a large job, adding more TaskTrackers to the cluster will help boost computational speed, but there is no flexibility for adding or removing nodes from the cluster on physical machines.
Moving Forward Selecting hardware that provides the best balance of performance and economy for a given workload requires testing and validation. It is important to understand your workload and the principles involved for hardware selection (e.g., blades and SANs are preferred to satisfy their grid and processing-intensive workloads). Based on the finding from our benchmark study, we recommend that organizations keep in mind the following infrastructure considerations:
• If your application depends on performance, the application has a longer lifecycle and the data growth is regular, a physical machine would be a better option as it performs better, the deployment cost is a one-time expense and as data growth is regular there might not be a need of highly scalable infrastructure.
• In cases where your application has a balanced workload, is cost-intensive, the data growth is exponential and requires support, virtual machines can prove to be safer as the CPU is well utilized and the memory is scalable. They are also a more cost-efficient option since they come with a more flexible pay-per-use policy. Also, the VM environment is highly scalable in the event of adding or deleting DataNodes/TaskTrackers/NodeManagers.
• In cases where your application depends on performance, has to be cost-efficient, and data growth is regular and requires support, virtual machines can be a better choice.
PERFORMANCE SCALABILITY COSTRESOURCE
UTILIZATION
Comparing the performance of physical and virtual machines with the same configuration, the physical machines have higher performance; with increased memory, however, a VM can perform better.
Commissioning and decommissioning of physical machines’ cluster nodes can prove to be an expensive affair compared to provisioning VMs as per need. Thereby scalability can be highly limited with physical machines.
Provisioning physical machines incurs higher cost than virtual machines, where creation of a VM can be as simple as cloning an instance of a VM and its unique identity.
The processor utilization of physical machines is less than 20%; however, the rest is all available for use. In the case of virtual machines, the CPU is utilized at its best, with high chances of CPU overhead leading to lower performance.
Characteristic Differences Between Physical and Virtual Infrastructure
Figure 14

About Cognizant
Cognizant (NASDAQ: CTSH) is a leading provider of information technology, consulting, and business process outsourcing services, dedicated to helping the world’s leading companies build stronger business-es. Headquartered in Teaneck, New Jersey (U.S.), Cognizant combines a passion for client satisfaction, technology innovation, deep industry and business process expertise, and a global, collaborative workforce that embodies the future of work. With over 100 development and delivery centers worldwide and approxi-mately 221,700 employees as of December 31, 2015, Cognizant is a member of the NASDAQ-100, the S&P 500, the Forbes Global 2000, and the Fortune 500 and is ranked among the top performing and fastest growing companies in the world. Visit us online at www.cognizant.com or follow us on Twitter: Cognizant.
World Headquarters500 Frank W. Burr Blvd.Teaneck, NJ 07666 USAPhone: +1 201 801 0233Fax: +1 201 801 0243Toll Free: +1 888 937 3277Email: [email protected]
European Headquarters1 Kingdom StreetPaddington CentralLondon W2 6BDPhone: +44 (0) 20 7297 7600Fax: +44 (0) 20 7121 0102Email: [email protected]
India Operations Headquarters#5/535, Old Mahabalipuram RoadOkkiyam Pettai, ThoraipakkamChennai, 600 096 IndiaPhone: +91 (0) 44 4209 6000Fax: +91 (0) 44 4209 6060Email: [email protected]
© Copyright 2016, Cognizant. All rights reserved. No part of this document may be reproduced, stored in a retrieval system, transmitted in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the express written permission from Cognizant. The information contained herein is subject to change without notice. All other trademarks mentioned herein are the property of their respective owners.
About the AuthorsApsara Radhakrishnan is an Associate of the Decision Science Team within Cognizant Analytics. She has three years of experience in the areas of big data technology focused on ETL in the Hadoop environment, its administration and AWS Analytics products. She holds a master’s degree in computer applications from Visvesvaraya Technological University. Apsara can be reached at [email protected].
Harish Chauhan is Principal Consultant, Cloud Services, within Cognizant Infrastructure Services. He has over 24 years of IT experience, has numerous technical publications to his credit, and he has also coauthored two patents in the area of virtualization – one of which was issued in January 2015. Harish’s white paper on “Harnessing Hadoop” was released in 2013. His areas of specialization include distributed computing (Hadoop/big data/HPC), cloud computing (private cloud technologies), virtualization/contain-erization and system management/monitoring. Harish has worked in many areas including infrastructure management, product engineering, consulting/assessment, advisory services and pre-sales. He holds a bachelor’s degree in computer science and engineering. In his current role, Harish is responsible for capability building on emerging trends and technologies like big data/Hadoop, cloud computing/virtualiza-tion, private clouds and mobility. He can be reached at [email protected].
TL Codex 1732
Footnotes1 HDFS - http://hadoop.apache.org/docs/r1.2.1/hdfs_design.html.
2 MapReduce - http://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html.
3 AWS Details - http://aws.amazon.com/ec2/previous-generation/.
• In cases where your application requires high performance and data growth is exponential with no required support, virtual machines with higher memory are a better choice.
During the course of our investigation, we found that the commodity systems, while both antiquated and less responsive, performed sig-nificantly better using our implementation than customary virtual machine implementations using standard hypervisors.
From these results, we observe that virtual Hadoop cluster performance is significantly lower than the cluster running on a physical machine due to the overhead of the virtualization on the CPU of the physical host. Any feature that overrides this virtualization overhead of virtual machines with larger memory would boost per-formance.