informe cassandra
TRANSCRIPT

CONTENIDO
INTRODUCCIÓNOBJETIVOS
2.1 Objetivo Generales2.2 Objetivo Específicos
DESARROLLO3.1 Apache Cassandra
3.1.1 Ventajas de Apache Cassandra3.2 DataStax OpsCenter
3.2.1 Característica Principales de OpsCenter3.2.2 OpsCenter Architecture3.2.3 Data Modeling with Cassandra3.2.1.1 Ejemplo de Modelo de Datos3.2.4 Requerimiento para DataStax OpsCenter.3.3 Ejemplo de una BD con CassandraCONCLUSIÓREFERENCIAS BIBLIOGRÁFICAS

I. INTRODUCCIÓN
Según estadísticas, el hombre ha generado más información en los últimos años que en el resto de su existencia en la tierra, esto y el avance en las comunicaciones y las tecnologías basadas en la web han hecho que nos veamos en la necesidad de generar nuevas formas de guardar, organizar y distribuir nuestra información. Es por tal motivo que diversas empresas comenzaron a desarrollar nuevas tecnologías, es así como la famosa red social Facebook desarrollo Cassandra con el fin de dar soporte a los requerimientos de los usuarios los cuales no podían ser satisfacidos con el modelo clásico relacional de las bases de datos SQL.
En el siguiente informe presentamos a un sistema gestor de base de datos no relacional Casssandra, sus características, sus ventajas como desventajas, su modelo de datos, su gestor y monitoreo visual y finalmente las conclusiones a las que se llegaron tras la investigación.
II. OBJETIVOS
2.1 Objetivo Generales
Desarrollar a través de un ejemplo teorico, la aplicación del concepto base de datos NoSQL mediante la utilización de Cassandra.
2.2 Objetivo Específicos
❏ Conocer el concepto de NoSQL.❏ Conocer y entender la terminología propia de Cassandra.❏ Conocer las distintas formas de acceder al contenido de la BD❏ Conocer cuáles son las formas de estructurar la información en Cassandra.

III. DESARROLLO
3.1 Apache Cassandra
Apache Cassandra es una base de datos NoSQL distribuida y basada en un modelo de almacenamiento de «clave-valor», escrita en Java. Permite grandes volúmenes de datos de forma distribuida. Por ejemplo, Twitter usa Cassandra como base de datos para su plataforma.
El objetivo principal de Cassandra es la escalabilidad lineal y la disponibilidad. La arquitectura distribuida de Cassandra está basada en una serie de nodos iguales que se comunican con un protocolo P2P (Peer to Peer) y la redundancia de los datos es máxima.
Cassandra está desarrollada por Apache Software Foundation.
En las versiones iniciales de Cassandra utilizaba API propia para poder acceder a la base de datos. En los últimos tiempos están apostando por un lenguaje denominado CQL (Cassandra Query Language) que posee una sintaxis similar a SQL, aunque con menos funcionalidades. Esto hace que sea más fácil usar Cassandra y también Cassandra permite acceder en Java desde JDBC.
3.1.1 Ventajas de Apache Cassandra
Figura 1: Ventajsa de Cassandra

Open Source:
Cassandra es un proyecto de código abierto de Apache, esto significa que está disponible de forma libre. Puede descargar la aplicación y darle el uso que desee. Esto ha permitido que nazca una gran comunidad de Cassandra en donde personas puedan dar sus ideas y compartan sus opiniones, consultas, sugerencias relacionadas con Big Data.
Arquitectura Peer to Peer:
Cassandra sigue una arquitectura de Peer to Peer, en vez, de la arquitectura maestro-esclavo. Por lo tanto, no hay ningún punto de Tolerancia a Fallo en Cassandra. Además, Cassandra soporta cualquier cantidad de servidores o nodos que se quiera agregar a un Cluster en cualquiera de los Data Center. Como todas las máquinas están en el mismo nivel, cualquier servidor puede atender a las peticiones de cualquier cliente. Sin lugar a dudas, con es una arquitectura robusta y con características excepcionales, Cassandra ha levantado un listón sobre otras bases de datos.

Elastic Scalability:
Una de las mayores ventajas del uso de Cassandra es su Elastic Scalability. Cassandra Clusterpuede escalar o bajar durante la ejecución del Cluster con facilidad. Curiosamente, cualquier número de nodos puede ser añadido o eliminado en el Cassandra Cluster sin mucho alboroto. Usted no tiene que reiniciar el Cluster o realizar consultas a la aplicación Cassandra mientra escala arriba o hacia abajo. Esta es la razón por la cual Cassandra es popular de tener un muy alto rendimiento para el mayor número de nodos. Como ocurre en el escalamiento, leer y escribir procesamiento tanto al aumentar simultáneamente con tiempo de inactividad en cero o alguna pausa en las aplicaciones.
Alta Disponibilidad y Tolerancia a Fallos:
Otra característica notable de Cassandra es la replicación de datos que hace Cassandra graciaa la Alta Disponibilidad y Tolerancia a Fallos que posee. La Replicación significa que cada dato
se almacena en más de una ubicación. Esto es porque, si un nodo falla, el usuario debe sercapaz de recuperar los datos con facilidad desde otro lugar. En un Cluster Cassandra, cada filase replica en base a la clave de fila. Puede establecer el número de réplicas que desea crear.Al igual que la escala, la replicación de datos también puede ocurrir a través de múltiples DataCentres. Esto además conduce a un alto nivel de respaldo y recuperación de competencias en
Cassandra.

Alto Rendimiento:
La idea básica detrás de desarrollar Cassandra era aprovechar las capacidades ocultas de varias máquinas multinúcleo. Cassandra ha hecho de este sueño una realidad! Cassandra ha demostrado un rendimiento brillante debajo de grandes conjuntos de datos. Por lo tanto, Cassandra es amado por las organizaciones que se ocupan de la enorme cantidad de datos detodos los días y al mismo tiempo no puede permitirse el lujo de perder estos datos.
Columna Oriented:
Cassandra tiene un modelo de datos de muy alto nivel llamada Orientada a Columnas. Estosignifica que Cassandra almacena columnas basadas en los nombres de las columnas, lo quelleva a corte muy rápido. A diferencia de las Bases de Datos Tradicionales, donde los nombresde columna sólo consisten en metadatos, en Cassandra los nombres de las columnas puede
constar de los datos reales. Por lo tanto, las filas en Cassandra pueden consistir en variascolumnas, en contraste con una Base de Datos Relacional que consiste en un escaso número
de columnas. Cassandra está dotado de un modelo de ricos datos.
Tunable Consistency:
Características como Tunable Consistency, hace que Cassandra sea una base de datos incomparable.

En Cassandra, Consistency puede ser de dos tipos - Consistency Eventual y ConsistencyFuerte. Usted puede adoptar cualquiera de ellos, en función de sus necesidades. Consistencia
eventual se asegura de que el cliente esté aprobado, en cuanto el grupo acepta la escritura.Considerando que, la Consistency Fuerte significa que cualquier actualización se transmite a
todas las máquinas o todos los nodos, en donde el dato en particular esté situado. Ustedtambién tiene la libertad para mezclar tanto la Consistency Eventual y Fuerte. Por ejemplo,
usted puede ir para la Consistency Eventual en el caso de los Data Centers Remotos donde lalatencia es bastante alta, e ir a por la Consistency Fuerte para Data Centers Local donde la
latencia es baja.
Esquema Gratuito:
Desde su creación, Cassandra es famosa por ser una base de datos de Schema-less/schema-free en su column family. En Cassandra, las columnas se pueden crear a su voluntad dentro delas filas. Modelo de datos Cassandra también es famosa como modelo de datos de esquema opcional. En contraste con una base de datos tradicional, en Cassandra no hay necesidad de mostrar todas las columnas que necesita su aplicación en la superficie como cada fila no se espera que tenga el mismo conjunto de columnas.
3.2 DataStax OpsCenter
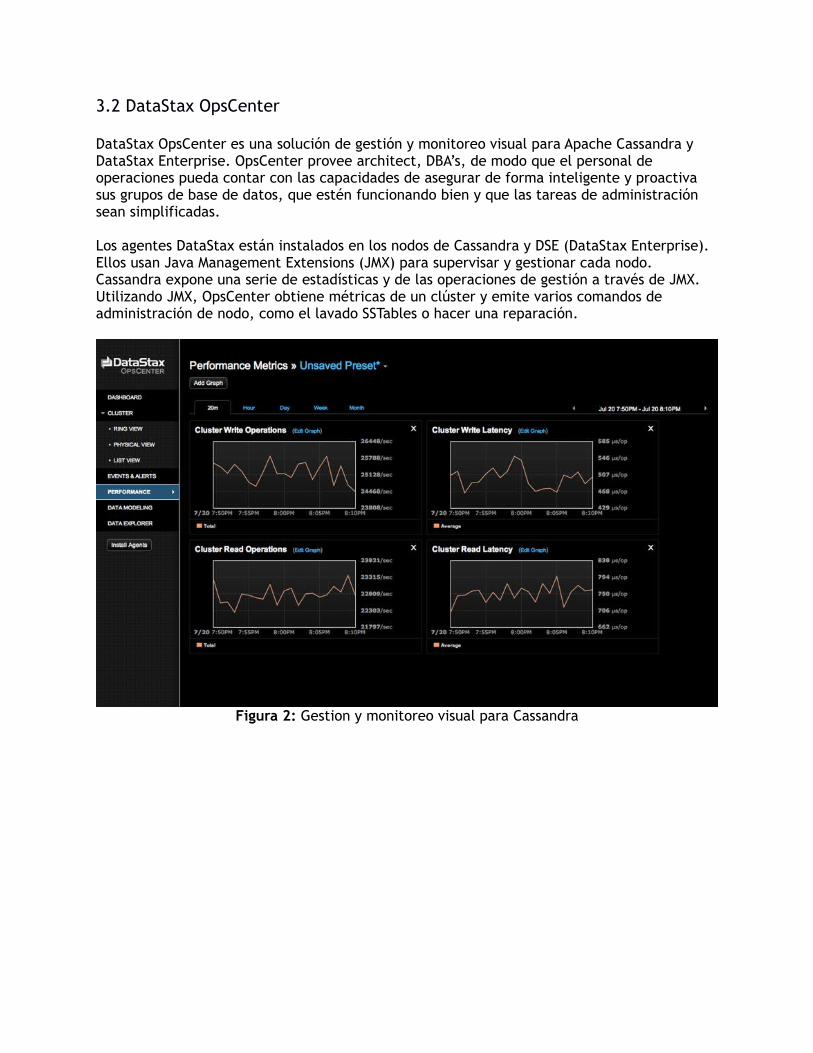
DataStax OpsCenter es una solución de gestión y monitoreo visual para Apache Cassandra y DataStax Enterprise. OpsCenter provee architect, DBA’s, de modo que el personal de operaciones pueda contar con las capacidades de asegurar de forma inteligente y proactiva sus grupos de base de datos, que estén funcionando bien y que las tareas de administración sean simplificadas.
Los agentes DataStax están instalados en los nodos de Cassandra y DSE (DataStax Enterprise). Ellos usan Java Management Extensions (JMX) para supervisar y gestionar cada nodo. Cassandra expone una serie de estadísticas y de las operaciones de gestión a través de JMX. Utilizando JMX, OpsCenter obtiene métricas de un clúster y emite varios comandos de administración de nodo, como el lavado SSTables o hacer una reparación.
Figura 2: Gestion y monitoreo visual para Cassandra

3.2.1 Característica Principales de OpsCenter
OpsCenter ofrece una serie de características para ayudar a gestionar las agrupaciones tanto DataStax Enterprise y Apache Cassandra y hacer su vida más fácil.
Las características principales de OpsCenter incluyen:
Dashboard
❏ Un "Dashboard" que muestra una visión general de las métricas de desempeño comúnmente vistos.
❏ Adición de sus gráficos favoritos para el Dashboard.❏ Una visión general que muestra las alertas y condensa los Dashboards de varios
clústeres.
Configuración y administración
❏ Básico de configuración del Cluster❏ Las tareas de administración, como la adición de un cluster.❏ Creación Visual del Clusters❏ Gestión de múltiples Clusters desde una sola máquina con OpsCenter por medio
de un agentes.❏ Gestión de múltiples nodos.❏ Reequilibrio de datos a través de un Cluster cuando se añadan nuevos nodos.❏ Descargable informe de Report del clúster en PDF.
Alertas y métricas de rendimiento ❏ Construido en capacidades de notificación externos.❏ Avisos de alerta de problemas inminentes.❏ Las métricas son recogidos en cada minuto en Cassandra.

Las operaciones de copia de seguridad y restauración de copias de seguridad ❏ Las operaciones Automáticas de copia de seguridad, incluyen la programación y
la eliminación de copias de seguridad antiguas.❏ Restauración de copias de seguridad.
Funcionalidad solo para DataStax Enterprise.
Funcionalidad empresarial en OpsCenter sólo está habilitado en racimos DataStax Enterprise. La siguiente es una lista de características que incluye:
❏ Seguridad , la capacidad de definir los roles de usuario.❏ DataStax Enterprise Management Services.❏ Alertas.❏ Copia de seguridad y restauración de datos.❏ Gestión en Masa.❏ Ver las medidas históricas más de una semana.❏ Reequilibrar.❏ Diagnóstico tarball.❏ Hadoop JobTracker Integration.
3.2.2 OpsCenter Architecture
Hay tres componentes principales de OpsCenter:
The User Interface. The OpsCenter Daemon. The OpsCenter Agent.
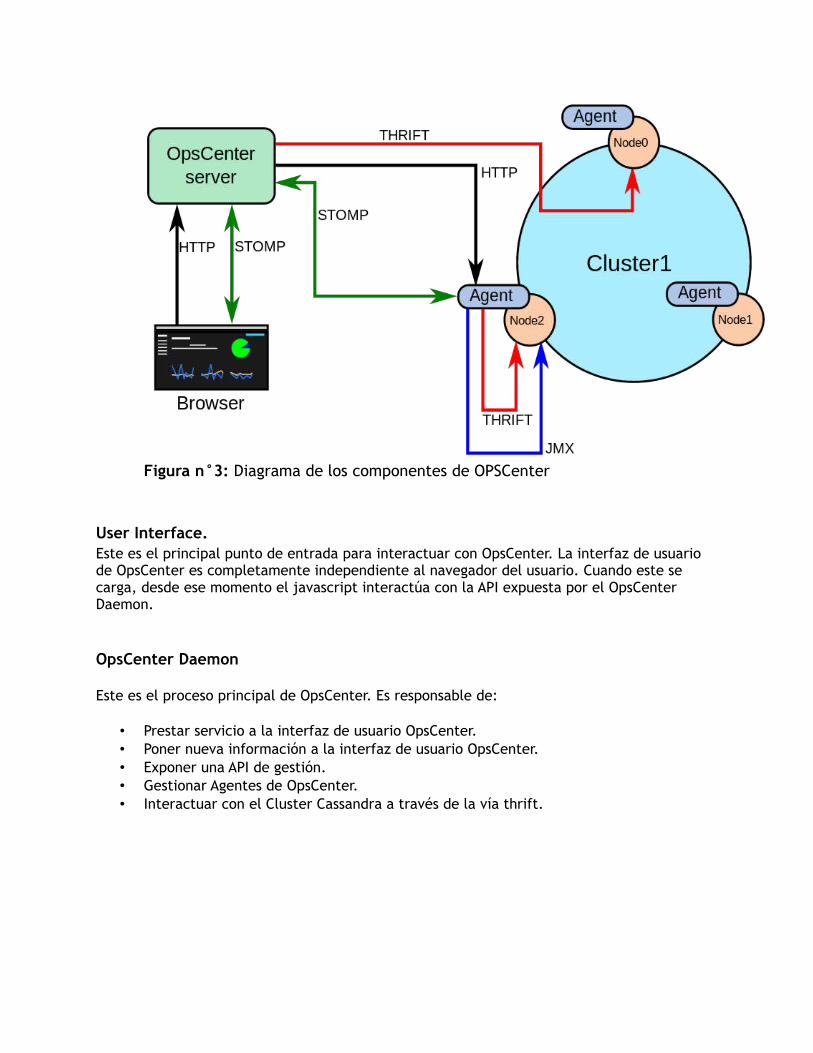
Figura n°3: Diagrama de los componentes de OPSCenter
User Interface.Este es el principal punto de entrada para interactuar con OpsCenter. La interfaz de usuario de OpsCenter es completamente independiente al navegador del usuario. Cuando este se carga, desde ese momento el javascript interactúa con la API expuesta por el OpsCenter Daemon.
OpsCenter Daemon
Este es el proceso principal de OpsCenter. Es responsable de:
• Prestar servicio a la interfaz de usuario OpsCenter.• Poner nueva información a la interfaz de usuario OpsCenter.• Exponer una API de gestión.• Gestionar Agentes de OpsCenter.• Interactuar con el Cluster Cassandra a través de la vía thrift.

Las primeras responsabilidades del OpsCenter daemon, se refieren a la interacción con la interfaz de usuario. OpsCenter ejecuta un servidor HTTP con el fin de servir a la componente de interfaz de usuario de OpsCenter. Una vez que la interfaz de usuario se ha servido, el restode la interacción con el daemon se producirá a través de la API REST o vía STOMP. La única interacción adicional entre la interfaz de usuario y el demonio es a través de STOMP. Esto se utiliza para permitir que el demonio actualice la interfaz de usuario sin necesidad de especificar una solicitud de HTTP. Esto es útil para las cosas que necesitan ser actualizados con mucha frecuencia. Por ejemplo, la carga del servidor en la interfaz de usuario se actualiza cada 5 segundos.
Las otras responsabilidades de OpsCenter en la actualidad se refiere a las managing/monitoring del Cassandra Cluster. El demonio es el punto central para la información del Cluster agregado, de modo que pueda ser expuesto a la interfaz de usuario. Algo de esto se puede hacer de forma independiente por el demonio (sin los agentes) a travésde thrift. La información recogida sobre el thrift incluye cosas como la información básica de clúster (nodo/token list, partitioner, snich), información de esquema y los datos de la familia de la columna. Para obtener información adicional, el daemon se basa en el Agente OpsCenterpara ser instalado en los propios nodos Cassandra. La interacción entre el demonio y los agentes es bastante similar a la forma en la interfaz de usuario interactúa con el demonio. Agentes dispone de una API REST por el demonio para consultar, así como el pushing de datos actualizados con frecuencia (como carga del servidor) para el demonio.
OpsCenter Agent
El OpsCenter Agent es el proceso que OpsCenter ejecuta en cada servidor del Cluster
Cassandra Cluster y es responsable de:
● Disponer de una interfaz para el OpsCenter Daemon para gestionar ese nodo.● El envío de información sobre ese nodo al OpsCenter Daemon.● Recogida de métricas sobre ese nodo.● La escritura de datos métricos para Cassandra a través de thrift.

La principal responsabilidad del agente es recoger información sobre el nodo que está
monitoreando. Mucha de la información es usada por el OpsCenter Daemon, ya sea desde el
agente pushing datos para el Daemon a través de STOMP, o desde el Daemon querying la API
REST que el agente posee. Además, el agente recoge la información métrica y el rendimiento
del nodo para que los usuarios puedan visualizar gráficos de rendimiento en la interfaz de
usuario. La información de rendimiento que el agente recoge se almacena en el Cluster
Cassandra usando thrift. El agente se conectará al nodo Cassandra, este esta monitoreando a
través de thrift.
El otro principal responsabilidad del agente es exponer una interfaz de gestión para el nodo
Cassandra que está supervisando. Cassandra expone un buen número de operaciones de
gestión de nodos cassandra a través de un protocolo conocido como JMX. Hay algunas
razones que es difícil para el OpsCenter Daemon interactuar con la interfaz. Principalmente que
el Daemon está escrito en Python y existe preocupación de firewall/Networking. Por esta razón,
el agente actúa como un proxy para interactuar con las funciones de gestión para que el
OpsCenter Daemon puede acceder a ellos.
3.2.3 Data Modeling with Cassandra
Se detallarán brevemente los distintos elementos que componen el Modelo de Datos de Cassandra.
Los conceptos básicos de este modelo de datos son:
Column:
Es la unidad más básica en el modelo de datos de Cassandra. Una column es un triplete de un key (un nombre) un value (un valor) y un timestamp. Los valores son todos suministrados por elcliente. El tipo de dato del key y el value son matrices de bytes de Java, el tipo de dato del timestamp es un long primitive.
❖ Las column son inmutables para evitar problemas de multithreading.❖ Las column se organizan dentro de las columns families.❖ Las column se ordenan por un tipo, que pueden ser uno de los siguientes:
AsciiType BytesType

LongType TimeUUIDType UTF8Type
SuperColumn:
Es una column cuyos values son una o más columns, que en este contexto se llamarán subcolumns. Las subcolumns están ordenadas, y el número de columnas que se puede definir es ilimitada. Las Super columns, a diferencias de las columns, no tienen un timestamp definido.
Column Family:
Es más o menos análogo a una tabla en un modelo relacional. Se trata de un contenedor para una colección ordenada de columns. Cada column family se almacena en un archivo separado.
SuperColumnFamily:

Así cómo las ColumnFamilies contienen filas, y éstas contienen claves y arreglos de columnas,las SuperColumnFamilies también contienen filas, y éstas contienen claves. La diferencia esque las claves no tienen arreglos de columnas, sino que tienen arreglos de SuperColumns.
Keyspace: Es el contenedor para las column family. Es más o menos análogo a una base de datos en un modelo relacional, usado en Cassandra para separar aplicaciones. Un keyspace esuna colección ordenada de columns family.
Clúster: Conjunto de máquinas que dan soporte a Cassandra y son vistas por los clientes como una única máquina.
Tabla comparativa de Modelo Relacional y el Modelo de Cassandra
3.2.1.1 Ejemplo de Modelo de Datos
Tabla de Tweets
Se agrega la columna user_id.

Se forma familias de Columna.
3.2.4 Requerimiento para DataStax OpsCenter.Los requisitos mínimos de hardware para la máquina, en la que se ejecutará OpsCenter:
● 2 núcleos de CPU.● 2 GB de RAM disponible para OpsCenter.
3.3 Ejemplo de una BD con Cassandra
Entorno de Trabajo: Se trabajará de forma local.Hardware: PC Samsung, procesador intel i3, 4 GB RAM, tarjeta de video Nvidia 520 mx, HHDD 500 GB.Sistema Operativo: Ubuntu Linux 14.04
Lo primero es crear el keyspace lo cual es equivalente a una base de datos, esto lo hacemos con el comando:
CREATE KEYSPACE entradas WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 };
Luego seleccionamos el Keyspace con el comando:
USE entradas;
La manera más sencilla de crear una tabla es la siguiente:

CREATE TABLE usuario( usrid int PRIMARY KEY, nombre text, ape1 text);
Con esta sentencia generamos una tabla como las que conocemos en el modelo sql tradicional
usrid nombre apel
sin embargo, esto nos obliga a que cuando queramos buscar un usuario sepamos de antemano el usrid, ya que no podemos buscar por nombre o apellido. Para solucionar esto vamos a utilizar una estructura un poco más compleja donde además del usuario agregaremos las entradas que ha posteado en su perfil.
CREATE TABLE usuario( usrid int, nombre text, ape1 text, idpost int, cuerpo text, primary key (usrid, idpost));
Al crear la tabla con esta estructura y ejecutar varios insert se nos creará una estructura como la que sigue:
idpost1 idpost2 idpostN nombre ape1
usrid1 cuerpo1 cuerpo2 cuerpoN

Es aqui donde comenzamos a utilizar una de las principales características de Cassandra que es la desnormalización, ya que tendremos tantas columnas como posteos tenga el usuario, cabe destacar que el la cantidad de columnas a utilizar teóricamente alcanza el numero no menor de 2.000.000.000, sin embargo en la práctica al llegar a las 100.000 columnas comienza a bajar el rendimiento.
Una manera de solucionar esto es crear un primary key compuesto, de tal manera de separar los posteos o entradas por año, esto se logra de la siguiente manera:
CREATE TABLE usuario( usrid int, nombre text, ape1 text, idpost int, año int, cuerpo text, primary key ((usrid,año), idpost));
Lo cual nos daria un resultado como el siguiente:
nombre ape1 idpost1 idpost2 idpost3 idpostN
usrid: anio
nom ape1 cuerpo1 cuerpo2 cuerpo3 cuerpoN

Dentro del modelo de datos de Cassandra también podemos encontrar los set, los cuales nos permiten agregar varias entradas para una misma columna, por ejemplo:
CREATE TABLE users ( user_id text PRIMARY KEY, first_name text, last_name text, emails set<text>);
Luego para insertar datos usamos lo siguiente:
INSERT INTO users (user_id, first_name, last_name, emails)VALUES('frodo', 'Frodo', 'Baggins', {'[email protected]', '[email protected]'});
Si queremos agregar una nueva entrada ejecutamos la siguiente CQL
UPDATE users SET emails = emails + {'[email protected]'} WHERE user_id = 'frodo';
Entonces al realizar un select la respuesta sera la siguiente:
user_id | emails---------+------------------------------------------------------------------- frodo | {"[email protected]","[email protected]","[email protected]"}
Para nuestro ejemplo simularemos una red social, en la cual existen usuarios y relaciones entre ellos (amistad), además de esto los usuarios pueden publicar entradas dentro de su perfil.
En el modelo relacional esto seria mas o menos así
En SQL esto implicaba crear la tabla intermedia ‘amistad’ para poder soportar la relación de muchos a muchos, sin embargo para Cassandra esto es más sencillo, simplemente basta con definir un list para los usuarios y una familia de columnas para las entradas, de la siguiente manera:
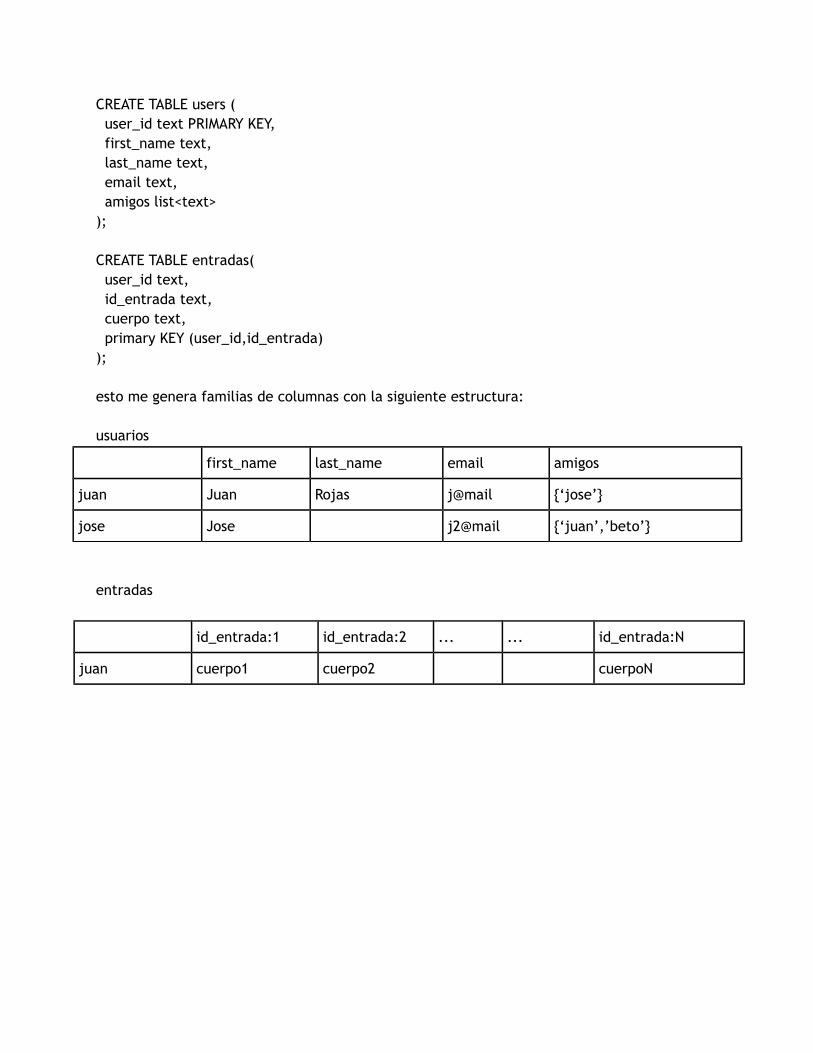
CREATE TABLE users ( user_id text PRIMARY KEY, first_name text, last_name text, email text, amigos list<text>);
CREATE TABLE entradas( user_id text, id_entrada text, cuerpo text, primary KEY (user_id,id_entrada));
esto me genera familias de columnas con la siguiente estructura:
usuarios
first_name last_name email amigos
juan Juan Rojas j@mail {‘jose’}
jose Jose j2@mail {‘juan’,’beto’}
entradas
id_entrada:1 id_entrada:2 ... ... id_entrada:N
juan cuerpo1 cuerpo2 cuerpoN

IV. CONCLUSIÓN
Cassandra se presenta como una gran solución a la problemática de los grandes bancos de datos, aun cuando la forma de modelar dista bastante de el modelo clásico relacional que todos conocemos, además, las herramientas para administrar nuestros Keyspaces, cluster y nodos nos ayudan a mantener un orden al momento de desarrollar y utilizar nuestras aplicaciones.
El lenguaje CQL nos provee funciones bastante parecidas a lo que estábamos acostumbrados con SQL, haciendo más fácil el acostumbrarse a utilizar las diversas funcionalidades de esta tecnología.
V. REFERENCIAS BIBLIOGRÁFICAS
❏ http://www.datastax.com/documentation/opscenter/5.0/opsc/about_c.ht ml ❏ http://www.datastax.com/dev/blog/opscenter-an-architecture-overview ❏ http://www.sinbadsoft.com/blog/cassandra-data-model-cheat-sheet/