incremental validation of xml documents yannis papakonstantinou victor vianu presented by claudia...
Post on 21-Dec-2015
224 views
TRANSCRIPT

Incremental Validation of XML Documents
Yannis PapakonstantinouVictor Vianu
Presented by Claudia Levin

Introduction
Here are investigated
Incremental validation algorithm for XML document presented as DTD (Data Type Definition) in O(m log n).
Incremental validation algorithm for XML schema in O(m log2 n).
Using the auxiliary structure of size O(n) for both.

Example of an XML document<dealer>
<UsedCars>
<ad>
<model>Honda</model>
<year>92</year>
</ad>
</UsedCars>
<NewCars>
<ad>
<model>BMW</model>
</ad>
</NewCars>
</dealer>

An XML document as Labeled Ordered Tree
Dealer
UsedCars NewCars
Ad Ad AdAd
Model Year ModelModelModelYear
Honda 92 Subaru 99 BMW Mazda

Abstraction of Document Type Definitions (DTDs)
The basic mechanism for specifying the type of XML documents.
root : dealer
dealer → UC NC
UC → ad*
NC → ad*
ad → model (year| ε)
model → ε
year → ε

Specialized DTD abstraction (XML Schema)
A specialized DTD is a 4-tuple ‹,t,d,μ› where is a finite alphabet of labels, t is a finite alphabet of types, d is a DTD over and μ is a mapping from t to .

Specialized DTD (XML Schema) example
root : dt
dt → UCt NCt μ(dt) = dealer
UCt → adu* μ(UCt) = UC
NCt → adn* μ(NCt) = NC
adu → mt yt μ(adu) = ad
adn → mt μ(adn) = ad
mt → ε μ(mt) = model
yt → ε μ(yt) = year

Specialized DTD example
Dealer
UC NC
Ad Ad AdAd
Model Year ModelModelModelYear
dt
NCt
adu
ytytmt mt mt mt
aduadn adn
UCt

Incremental Validation Problem
Given a specialized DTD , a tree sat(), and a sequence of updates to yielding another tree ’, we wish to efficiently check if ’ sat().
Use and maintain the auxiliary structure () to help in the validation.

Update types
Replace the current label of a specified node by another label;
Insert a new leaf node after a specified node;
Insert a new leaf node as the first child of a specified node;
Delete a specified leaf node.

Node label renaming u(ai,b)
r
…
ai-1 ai ai+1
…
c1 c2 cn
… …
…

New node inserting
Insert air
…
ai-1 ai ai+1
…
… …

Deleting of a node
Delete air
…
ai-1 ai ai+1
…
… …

Warmup: incremental validation of Strings
Check the validity of a string a1 … an with respect to NFA N = ‹,Q,Q0,F,δ› after a sequence of element renames u(ai1,b1)…u(aim,bm), where i1 < i2 <…< im.
Validating the new string from scratch by running it throw N takes O(n |Q2| log|Q|)

Incremental validation of Strings (the first attempt)
Consider a single renaming u(i,b) for 1≤i≤n.
Pre(i)= δ(q0,a1…ai-1)
Post(i)={s | δ(s,ai+1…an) F}
bs2
Pre(i)Post(i)
S2 δ(b,s1)

Definition of Transition Relation
For each I,j 1≤ I < j ≤ n
Ti,j = {‹p,q› | p,q Q, q δ(p, ai…aj)}
δb = {<r,s>| r,s Q, s δ(r,b)}
qai+1
pai
aj
sb
r

Checking of validity with Transition Relation
The updated string
a1…ai1-1b1ai1+1…aim-1bmaim+1…an
is valid iff
<qo,f> To(i1-1)o δb1
o T(i1+1)(i2-1) o …oT(im+1)(n)
Time complexity here is O(m|Q2| log |Q|)

Divide-and-conquer validation with Transition Relation Tree
Validates a sequence of m renamings to a string of length n.
The time taken is O(m|Q|2 log|Q| log n) The auxiliary structure size is O(|Q|2 n)

Transition Relation Tree example
Τ18
Τ14 Τ58
Τ12 Τ34 Τ56 Τ78
Τ11 Τ22 Τ33 Τ 44 Τ55 Τ66 Τ77 Τ88
a1 a2a3 a4 a5 a6 a7 a8
The number of nodes in T1n is 2n-1. Its depth is log n.

Label renaming with Transition Relation Tree
Consider a1…an L(n) and a sequence of renames u(i1,b1), …,u(im, bm), where i1<i2<…<im. The updated string is a1…ai1b1ai+1…ai,m-1 bm ai,m+1…am .
The relations Tij which are affected by the updates are those laying on the path from a leaf changed to the root of Tn.
The number of relations changed is at most mlogn.
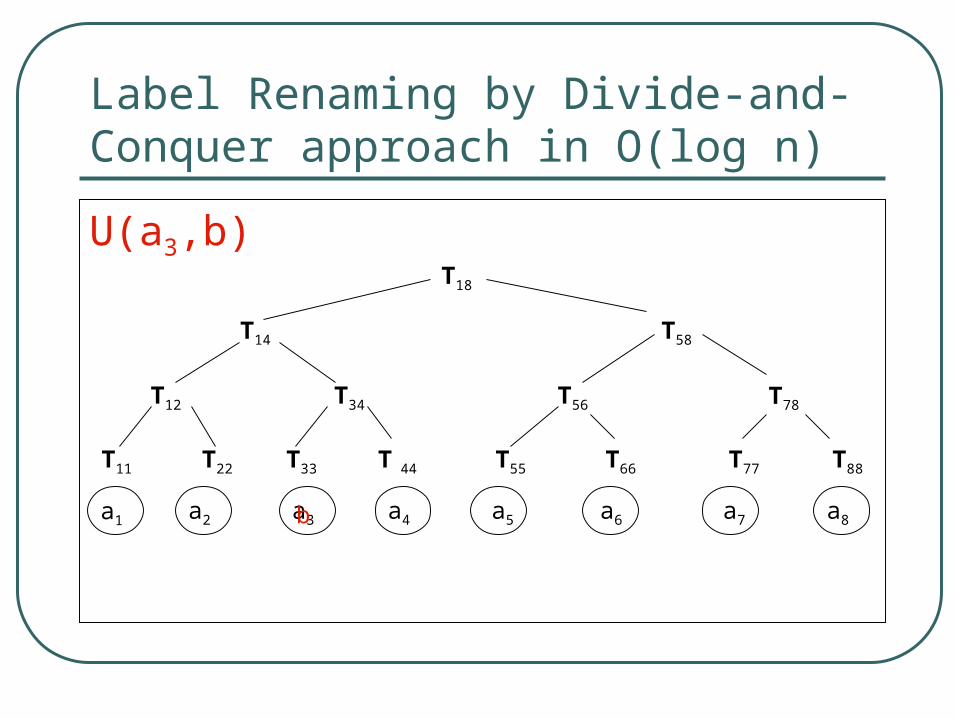
Label Renaming by Divide-and-Conquer approach in O(log n)
U(a3,b)Τ18
Τ14 Τ58
Τ12 Τ34 Τ56 Τ78
Τ11 Τ22 Τ33 Τ 44 Τ55 Τ66 Τ77 Τ88
a1 a2 a3 a4 a5 a6 a7 a8b

Dealing with inserts and deletes: Why B-trees?
Inserts and deletes cause the position of the nodes in the string to change.
The length of the string and the set of relevant intervals used to construct Tn are now dynamic.
Tree should continue to be balanced and have depth O(log n)

B-trees
3 cells in each node; The cell is either empty or contains a set
Ts corresponding to some subsequence s of the string.
At most one of the 3 cells in a node can be empty.
Each nonempty cell is either at a leaf or has one node as a child.

B-Trees for dealing with inserts and deletes in O(log n)
Tsa,Tsb,Tsc
Ts1,Ts2 Ts3,Ts5,Ts6 Ts7,Ts9
n1 n3 n5 n6 n7 n9n2
Tsa = Ts1 o Ts2 Tsb = Ts3 o Ts5 o Ts6

Validation with B-trees with respect to NFA N = ‹,Q,Q0,F,δ‹
When T for the updated string is computed, check that for some f F, <qo,f> belongs to the composition of the sets Ts in the cells of the root node of T.
The cost of checking is O(|Q|2 log|Q|)

Insertion to a Transition Relation Tree
Insertion of nodes n4 and n8
Tsa,Tsb,Tsc
Ts1,Ts2 Ts3,Ts5,Ts6 Ts7,Ts9
n1 n3 n5 n6 n7 n9n2
n8n4

Insertion to a Transition Relation Tree
Insertion of nodes n4 and n8
Tse,Tsf
Ts1,Ts2 Ts7,Ts8,Ts9
n1 n3 n5 n6 n7 n9n2 n8n4
Ts3,Ts4 Ts5,Ts6
Tsb’’,TscTsa,Tsb’

B-Tree validation algorithm costs
Renaming: update propagates from the leaf to the root – O(log n) updates.
Insertion or deletion: may involve splits and merges of the cells all the way to the root. The worst case complexity is O(|Q|2 log|Q| log n)

Incremental DTD validation
d → r(d)root
d …
a1 ai-1 ai ai+1 an
…
c1 c2 c3 c4
… …
…
bv

Incremental DTD validation
The auxiliary structure maintained: for each sequence of siblings in the tree the transition relations Ts of the divide-and-conquer algorithm are preemptively computed.
The auxiliary structure size is at most O(|| |d|2 |T|), where |T| is the size of T and |d|=max{|ra| | a → ra d}
The total validation time is O(m || |d|2 log |d| log |T|)

Specialized DTDs: a first attempt
Tree T is valid iff root(d) types(root(T))r
v
ai-1 ai ai+1
c1 c2 c3 c4 cn
… …
…
types(r)
types(v)
types(an)types(ai)
b

Specialized DTDs: a first attempt
The auxiliary structure size is the same as for DTDs, at most O(|| |d|2 |T|), where |T| is the size of T and |d|=max{|ra| | a → ra d} .
The total validation time for DTD is O(m || |d|2 log |d| log |T|).
The total validation time for specialized DTD is O(m |t| |d|2 log |d| depth(T) log |T|).

Binary tree encoding of unranked tree
a
bd
jk
e
f h
g i
a
b kj
#
d
c
#
#
#c# #
e
f
#
i
#h
#
#
#
g #

Binary tree encoding of unranked tree
One of the standard encodings in the literature (F.Neven. Automata, Logic and XML. In Computer Science Logic, 2002)
Lemma: For each specialized DTD = ‹,t,d,μ› there exists a BNTA A over #
whose number of states is O(|t||d|) such that (A) = {enc(T) | T sat(),

Principle lines
a
b kj
#
d #
#
#c# #
e
f
#
i
#h
#
#
#
g #

From BNTA to NFA on principal lines
a
b kj
#
d #
#
#c# #
e
f
#
i
#h
#
#
#
g #
TC, b d, Tj
Tg, f

From BNTA to NFA on principal lines
a b d e f ih
c
k
j g
Tc, b d, Tj Tg, f

NFA construction
We’ll construct NFA N which accepts the string an…a1 iff NTFA A = ‹#,Q,Q0,qf,δ› accepts enc(T)
Let NFA N = ‹’,Q,q0,F’,δ’›, where ’= {#} υ (Q x ) υ ( x Q), F’= {qf}, and δ’(#,q0) = Q0; δ’(‹a,S›,q) = υq’ S
δ(a,q,q’) for a ; δ’(q,‹a,S›) = υq’ S
δ(a,q’,q) for a ;

Line rearrangement for insertions and deletions
vv’
ll0
l’
l’’

Complexity Results
Given sequence of m updates for DTD XML abstraction we get
The auxiliary structure size is at most O(|| |d|2 |T|), where |T| is the size of T and |d|=max{|ra| | a → ra d}
The total validation time is O(m || |d|2 log |d| log |T|)

Complexity Results
Given sequence of m updates for specialized DTD (XML schema) we get
The auxiliary structure size is at most O(|| |d|2 |T|);
The total validation time is
O(m |t|2 |d|2 log (|t||d|) log2 |T|)