ieee transaction on pattern recognition and machine ...elgammal/pub/torustracking_tpami.pdf · ieee...
TRANSCRIPT

IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 1
Tracking People on a TorusAhmed ElgammalMember, IEEE,and Chan-Su Lee,Student Member, IEEE,
Department of Computer Science, Rutgers UniversityPiscataway, NJ, USA
Abstract— We present a framework for monocular 3D kine-matic posture tracking and viewpoint estimation of periodic andquasi-periodic human motions from an uncalibrated camera.Theapproach we introduce here is based on learning both the visualobservation manifold and the kinematic manifold of the motionusing a joint representation. We show that the visual manifoldof the observed shape of a human performing a periodic motion,observed from different viewpoints, is topologically equivalent toa torus manifold. The approach we introduce here is based onsupervised learning of both the visual and kinematic manifolds.Instead of learning an embedding of the manifold, we learn thegeometric deformation between an ideal manifold (conceptualequivalent topological structure) and a twisted version ofthemanifold (the data). Experimental results show accurate estima-tion of the 3D body posture and the viewpoint from a singleuncalibrated camera.
Index terms Human Motion Analysis, Tracking, ManifoldLearning, Supervised Manifold Learning, Periodic Motion
I. I NTRODUCTION
Tracking the human body and recovering the 3D bodyposture from images is a challenging computer vision problemwith many applications such as visual surveillance, human-machine interface, video archival and retrieval, computeran-imation, autonomous driving, virtual reality, etc. Tradition-ally, these problems have been addressed through generativemodel-based approaches. Such approaches typically requirea body model and a calibrated camera in order to obtainobservation hypotheses from configurations. The recovery ofthe 3D configuration is formulated as a search problem forthe best model configuration that minimizes an error metricgiven the visual observation. Similarly, 2D view-based bodymodels can be used. Alternatively, discriminative approacheshave been suggested, which learn mapping functions from thevisual observation to the 3D body configuration. Whether, theapproach is generative or discriminative, the main challengeis in the high dimensionality of both the body configurationspace and the input space. Another challenge stems from thelarge variability in human appearance in images.
Despite the high dimensionality of the body configura-tion space, many human activities lie intrinsically on low-dimensional manifolds. Recently, researchers (e.g. [1], [2],[3], [4], [5], [6]) have been increasingly interested in exploitingthe manifold structures of different human motions. For manymotions such as locomotion, kicking, golf swing, gestures,etc., the body configuration changes along a one-dimensionalmanifold. Such body configuration manifolds can be closed
Chan-Su Lee is currently with the School of Electronic Eng.,Communica-tion Eng. & Computer Science, Yeungnam University, Republic of Korea.
This research is partially funded by NSF CAREER award IIS-0546372.
for periodic motion, such as walking or running, or it canbe an open trajectory for non periodic motions, such as agolf swing or kicking. It follows that, the observed motion,in terms of body shape or other feature configurations, lieson low-dimensional manifolds as well (we call that the vi-sual manifold or the observation manifold). Exploiting suchproperties, as well as the relation between the configurationmanifolds and the visual manifolds, is essential to constrainthe solution space for many problems such as tracking, postureestimation, and activity recognition. However, it is not clearwhat is the best way to exploit such manifold constraints. Isit through learning the visual observation manifold, the bodyconfiguration manifold, or both?
When dealing with the visual manifold of a motion, weneed to model the different sources of perceptual variabilityaffecting this manifold, including the view and the bodyconfiguration. Modeling the visual manifold for human motionwith both the view and body configuration factors jointly isa very challenging task and is useful for tracking, postureestimation, and view estimation. In this paper, we considerthisproblem for simple classes of motion. We consider learningthe visual manifold (in terms of shape) of a person performinga one-dimensional manifold motion, such as walking, running,or golf swing, observed from different viewpoints. Such asetting, although limited, is very useful for many applicationssuch as surveillance where walking and running are the mostfrequent motions. Similarly, this setting is useful in sportanalysis where motions such as golf swings, baseball pitches,tennis serves, etc., are all one-dimensional manifold motion.No previous work has addressed the full modeling of viewsand configurations for tracking and inference even for suchsimple motions.
The approach we introduce in this paper is based on learn-ing the visual observation manifold in a supervised manner.Traditional manifold learning approaches are unsupervised,where the goal is to find a low-dimensional embedding of thedata. However, for manifolds with known topology, manifoldlearning can be formulated in a different way. Manifoldlearning is then the task of learning a mapping from/to atopological structure to/from the data where that topologicalstructure is homeomorphic to the data. In this paper we arguethat this supervised setting is suitable to model human motionsthat lie intrinsically on one-dimensional manifolds, whetherclosed and periodic (such as walking, jogging, running, etc.)or open (such as golf swing, kicking, tennis serve, etc.). Weshow that we can model the visual manifold of such motions(in terms of shape) as observed from different viewpoints bymapping that manifold to a toroid topological structure.
There are different ways to see the contribution of this

IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 2
paper:• A generative model for dynamic shapes: the approach
presented here serves as a generative model (a generativefunction) for the observed shapes of human motion fromdifferent viewpoints and for different people’s shapes.For example, for gait, the model can generate walkingfigures at different body configurations, from differentviewpoints, and for different people’s shapes, where eachof these factors is parameterized in a low-dimensionalcontinuous space. The generative model does not useany 3D body model to generate observations; rather, it isbased on learning the manifold of the observed shapes.
• Supervised manifold learning: the approach presented inthis paper is a supervised approach to learn manifoldswith known topology. In such cases, we can think ofmanifold learning as learning the deformation from anidealistic structure to the data. In other words, we learna generative model of the manifold.
• The approach presented in the paper links together boththe visual manifold (input) with the kinematic manifold(output) through a shared representation. By linking thesetwo manifolds, we can track visual observations (input)and infer body posture (output) in a direct way.
• Efficient tracking: The approach presented in the paperprovides a practical solution for tracking a certain classof human motions. The resulting state space is low indimensionality, and therefore, efficient tracking can beachieved.
The organization of the paper is as follows: Section IIdiscusses the relation to previous work in different areas.Sec-tion III describes the general solution framework. Sections IVand V describe using a torus manifold for jointly modelingboth view and configurations. Section VI describes how theapproach fits in the Bayesian tracking framework. Section VIIdescribes several experimental results and evaluations per-formed to validate the approach and its applicability.
II. RELATED WORK
There are different bodies of research related to this paper.Here we focus on closely related work to put this paper intocontext.
A. Human Motion Analysis - generative vs. discriminative
In the last two decades, extensive research has focusedon understanding human motion from image sequences. Werefer the reader to excellent surveys covering this topic, suchas [7], [8], [9]. The problems of tracking and recoveringbody configuration have been traditionally addressed throughgenerative model-based approaches, e.g., [10], [11], [12], [13],[14], [15], [16]. In such approaches, explicit 3D articulatedmodels of the body parts, joint angles, and their kinematics(or dynamics), as well as models for camera geometry andimage formation, are used. Recovering body configuration inthese approaches involves searching high-dimensional spaces(body configuration and geometric transformation), which canbe formulated deterministically as a nonlinear optimizationproblem, e.g. [17], [13], or probabilistically as a maximum
likelihood problem, e.g. [16]. Such approaches achieve sig-nificant success when the search problem is constrained as inthe tracking context. However, initialization remains themostchallenging problem. The dimensionality of the initializationproblem increases as models for variations between individualsin physical body style, variations of action style, and/or modelsfor clothing are incorporated. Partial recovery of body configu-ration can also be achieved through view-based representations(models), e.g. [18], [19], [20], [21], [22], [23], [24]. In suchcases, constancy of the local appearance of individual bodyparts is exploited. The main limitation with such approachesis that they deal with limited view configurations, i.e., a singleview or a small set of discrete views.
Alternatively, discriminative approaches have been pro-posed. In such approaches, recovering the body posture can beachieved directly from the visual input by posing the problemas a supervised learning problem through searching a pre-labeled database of body postures [25], [26], [27] or throughlearning regression models from input to output [28], [26],[29], [30]. All these approaches pose the problem as a machinelearning problem, where the objective is to learn an input-output mapping from input-output pairs of training data. Suchapproaches have great potential for solving the initializationproblem for model-based vision. However, these approachesare challenged by the existence of a wide range of variability inthe input domain. Another challenge is the high dimensionalityof the input and output spaces of the mapping, which makessuch a mapping hard to generalize.
The approach we introduce in this paper is generative.However, unlike traditional generative approaches, thereis noexplicit 3D or 2D body model. The observations are generatedthrough a regression model based on an embedded repre-sentation of the motion manifold. Similar to discriminativeapproaches, an input-output mapping is learned. However,unlike discriminative approaches, the mapping in our caseis from a shared manifold representation to both the inputand the output. Therefore, instead of being “model-based”,the representation we use is “manifold-based”. Instead of anexplicit 3D model, a continuous view-based representationisused.
B. Manifold-based Human Motion Analysis
Despite the high dimensionality of both the human bodyconfiguration space and the visual input space, many humanactivities lie on low-dimensional manifolds. In the last fewyears, there has been increasing interest in exploiting thisfact by using intermediate activity-based manifold represen-tations [31], [32], [1], [33], [34], [3], [4], [6], [35]. In ourearlier work [1], the visual manifolds of human silhouettedeformations, due to motion, have been learned explicitly andused for recovering 3D body configuration from silhouettes ina closed-form. In that work, knowing the motion provided astrong prior to constrain the mapping from the shape spaceto the 3D body configuration space. However, the approachproposed in [1] is a view-based approach; a manifold waslearned for each of the discrete views. In contrast, in this paperthe manifold of both the configuration and view is learned in a

IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 3
continuous way. In [33], manifold representations learnedfromthe body configuration space were used to provide constraintsfor tracking. In both [1] and [33] learning an embeddedmanifold representation was decoupled from learning thedynamics and from learning a regression function between theembedding space and the input space. In [35], coupled learningof the representation and dynamics was achieved throughintroducing Gaussian Process Dynamic Model [36] (GPDM),in which a nonlinear embedded representation and a nonlinearobservation model were fitted through an optimization process.GPDM is a very flexible model since both the state dynamicsand the observation model are nonlinear. The problem ofsimultaneously estimating a latent state representation coupledwith a nonlinear dynamic model was earlier addressed in [37].Similarly, in [6], models that coupled learning dynamics withembedding were introduced.
Manifold-based representations of the motion can be learnedfrom kinematic data, or from visual data, e.g., silhouettes. Theformer is suitable for generative model-based approaches andprovides better dynamic-modeling for tracking, e.g., [33], [3].Learning motion manifolds from visual data, as in [1], [38],[4], provides useful representations for recovery and trackingof body configurations from visual input without the need forexplicit body models. The approach we introduce in this paperlearns a shared representation for both the visual manifoldand the kinematic manifold. Learning a representation of thevisual motion manifold can be used in a generative manneras in [1] or as a way to constrain the solution space fordiscriminative approaches as in [2]. The representation weintroduce in this paper can be used as both: a generative modelfor tracking or as a discriminative model for recovering thebody configuration from a visual input.
C. Modeling Visual Manifolds
The approach we introduce in this paper focuses on learningthe visual manifold of deformable shapes where the defor-mation is due to both the underlying motion and the viewvariability. Learning the view and illumination manifoldsofrigid objects has been studied in [39]. In that work, PCAwas used to achieve a linear embedding for the joint viewand illumination manifold for object recognition. Learningmotion manifolds can be achieved through a linear subspaceapproximation, as in [40], [41]. Alternatively, exemplar-basedapproaches, such as [42], [43], implicitly model nonlinearmanifolds of observations through points (exemplars) alongthe manifold. Such exemplars were represented in the visualinput space. Hidden Markov Models (HMM) were used toprovide a probabilistic piecewise linear approximation, whichcan be used to learn nonlinear manifolds as in [31]. Recently,unsupervised nonlinear manifold learning techniques, such asLLE [44], Isomap [45], etc., have been popular for learninglow-dimensional representations of visual manifolds. Unlikemost previous work on learning the visual manifolds thatfocused on unsupervised embedding of the visual manifolds,the approach we introduce here uses the knowledge about thetopology of the manifold to achieve an embedded representa-tion of the visual data.
Also, related to this paper, is research on multilinear mod-els, which extends subspace analysis to decompose multipleorthogonal factors using bilinear models and multilinear tensoranalysis [46], [47]. Tenenbaum and Freeman [46] formulatedthe separation of style and content using a bilinear modelframework [48]. In [47], multilinear tensor analysis was usedto decompose face images into orthogonal factors control-ling the appearance of the face including geometry (people),expressions, head pose, and illumination. N-mode SVD [49]is used to fit multilinear models. Multilinear tensor analysiswas also used in [50] to factorize human motion styles. Theapplications of bilinear and multilinear models in [46], [47],[50] to decompose variations into orthogonal factors wereperformed in the original observation space. In contrast, inour earlier work [51], bilinear and multilinear analysis wereused in the space of the mapping functions between an averagemanifold representation and the observations to decomposethevariability factors in such functions. In this paper, we used asimilar approach to decompose shape “style” variabilitiesinthe space of the mapping functions between the embeddedmanifold representation and visual observations.
III. F RAMEWORK
A. Graphical Model
This section aims to discuss the characteristics of usefulrepresentations for tracking the visual observation of articu-lated motion. In particular, we consider visual observationsdeforming through a one-dimensional manifold motion, suchas gait, golf swings, etc. We start by defining the basicmanifold terms, which we are going to use throughout thepaper, and then we will explain their relationships.
Let us consider an articulated object motion observed froma camera (stationary or moving). Such a motion can berepresented as a kinematic sequenceZ1:T = z1, · · · , zT andobserved as an observation sequenceY1:T = y1, · · · , yT . Inthis paper, without loss of generality, by observations wemainly mean shape contours. A similar argument appliesto any vector representation of the observations. With anaccurate 3D body model, camera calibration, and geometrictransformation information, we can explainY1:T as a projec-tion of an articulated model. However, in this paper, we areinterested in a different interpretation of the relation betweenthe observations and the kinematics that does not involve anybody model.
The dynamic sequenceZ1:T lies on a manifold. Let usdenote this bythe kinematic manifold. The kinematic manifoldis the manifold of body configuration changes in the kinematicspace. In addition, the observations lie on a manifold,thevisual manifold. Obviously, the observation is a function of notonly the body configuration but also the viewpoint, person’sappearance, etc. What is the relation between the kinematicmanifold and the visual manifold? We can think of a graph-ical model connecting the two manifolds through two latentvariables: a body configuration variable,bt, and a viewpointvariable,vt. The body configuration variable is shared betweenboth the kinematic manifold and the visual manifold. Theviewpoint variable represents the camera location relative to

IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 4
Fig. 1. A graphical model relating the different manifold structures
a human-centered coordinate system. The body configurationvariable moves on a manifold in the latent space; we denoteit by the latent body configuration manifold. Similarly, theviewpoint variable lies on a manifold, denoted bythe latentview manifold.
Another variable affecting the observation is the shapevariability among different subjects, i.e., the human shapespace, or the shape style as was denoted in [51]. We denotethis variable bys, which is a time invariant variable. Giventhis graphical model, the tracking problem is an inferenceproblem where, given the observationyt at timet, we want torecover the state, which consists of three components: bodyconfigurationbt, viewpointvt, and shape styles. The Bayesiantracking framework can be used to recursively update thestate posterior where the latent space manifold representationshould provide a constraint on the state’s dynamics.
Given the definition of the various manifolds, we cansummarize the goals of the our representation as follows:
1) We want to relate the kinematic manifold with the visualmanifold in order to be able to infer the configuration of thejoint angles from input.
2) We want to model the visual manifold with all itsvariabilities, due to the motion, the viewpoint, and shape style.In particular, we want to be able to deal with both bodyconfiguration and viewpoints as continuous variables. Thisfacilitates tracking subjects from varying viewpoints duetocamera motion or changing subject view w.r.t. the camera.
3) We want the tracking state space to be low in dimension-ality and continuous. The low dimensionality of the trackingstate space is preferred for efficient particle filter tracking.Moreover, despite the nonlinearity in dynamics in both thekinematics and the observations, it is preferred that the latentbody configuration variable would exhibit simple dynamics,i.e., linear dynamics or even constant speed dynamics.
Given these goals stated, there are certain questions weneed to answer: What manifolds do we need to learn, the
visual manifold, the kinematic manifold, or both? What arethe tools we need to learn such manifolds? Here we arguein favor of a representation that is conceptual, central, andgenerative. Conceptual means thatthe representation is notlearned from the data, but the data is fitted to a manifold modelin a supervised way.Central meansthe representation jointlymodels both the kinematics and observations as well as jointlymodels different people’s manifolds.Generative means thatthesame representation is used to generate both the kinematicsand observations .
B. Supervised Manifold Learning
Unsupervised nonlinear dimensionality reduction (NLDR)techniques, such as LLE [44], Isomap [45], GPLVM [52],etc., have been popular recently in learning low-dimensionalrepresentations of both visual and kinematic data, as de-tailed in Section II. Such techniques aim to achieve low-dimensional embedded representations of high-dimensionaldata for visualization and other data analysis purposes. Themain assumptions in such approaches are: 1) the data lie ona manifold; 2) enough dense data are available in order to beable to recover the manifold structure from the local structureof the data.
Perceptually, we might think the visual data lie on alow-dimensional manifold with certain topology. However,inreality, visual data might not exhibit such manifold structure.In other words, the manifold structure might not be recover-able from the data using unsupervised nonlinear embeddingapproaches. There are many reasons for this problem thatwe will discuss shortly, but we first show an example todemonstrate the point. Let us consider the visual manifoldof a simple motion, such as gait, observed from a view circlearound the person. Such data can be seen in Fig. 2-a . Here,for illustration, we have no other variations in the data, e.g.,no translation, scaling, noise, or shape styles. The observed

IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 5
shapes represent a product space of two one-dimensional man-ifolds representing body configuration and view. Therefore,the data is expected to lie on a two-dimensional manifoldrepresenting the body configuration and view variations. Aswill be shown in Section IV, this manifold is expected toresemble a distorted torus.
Figs. 2-d and 2-e show the resulting embedding when LLEand Isomap are used to embed such visual data1. We arguethat the resulting embedding is not necessarily useful, nordesirable as a latent embedded representation for tracking.The resulting embedding using any NLDR approach, althoughit preserves the local manifold structure, depends on manyother aspects including: 1) the way the visual data is rep-resented (shape representation in this case); 2) the distancemetric used between visual instances; 3) the choice of theobjective function; 4) the existence noise and other sourcesof variations. As a result, the embedding obtained is stretchedat some parts and squashed at others to fit the actual datalocal manifold structure. These stretches reflect the factorsmentioned above and do not reflect the conceptual distancebetween instances. This results in a representation that isnotcontinuous. Continuity is very important in any latent statespace, since sampling on the surface of the manifold is neededfor tracking. Notice that the embeddings shown in Figs. 2-dand 2-e are 3D embeddings and sampling on the surface ofthe manifold will be needed while tracking.
For manifolds with known topology, instead of unsupervisedembedding, a conceptual supervised topology-preserving rep-resentation would be advantageous for tracking. Before wefurther justify the use of such a conceptual representation, wewill first explain the framework. If the manifold topology isknown, manifold learning can be formulated in a different way.Manifold learning is then the task of learning the nonlineardeformation of the data manifold from anideal manifoldmodel. For example, for a periodic motion, such as gait, thedata lie on a closed trajectory in the space, and hence, the datamanifold is homeomorphic to a unit circle. We can think ofthe data as a deformed circle and the task of learning would beto learn the nonlinear function that deforms a unit circle tothedata. In other words, how can the data be generated, knowingan equivalent “idealistic” topological structure? In fact, thisview can be even extended to the case where the data manifolddoes not share the exact topology with the ideal manifold. Forexample, the gait manifold can intersect itself in the visualspace but, still, we can learn the deformation from a unitcircle to the data. We will show in the next section that a torusmanifold is a good manifold model for visual data similar tothe one we consider in this section (periodic motion observedfrom a view circle), as in Fig. 2-a. Enforcing a topologicalstructure can also be achieved by adding a constraint to theobjective function in unsupervised NLDR as was done in [53].
There are several reasons why such a supervised approach isadvantageous and more suitable when the topology is known.
1- The ideal manifold model would be advantageous as a
1To obtain these results we represent shapes as implicit level set functions toimpose smoothness between shape instances in order to recover the manifold.The shape representation is described in section VI. Other shape representationmight be used with more or less qualitatively similar results.
state representation over a data-driven representation (such asthe one obtained through unsupervised learning as shown inFigs. 2-d, 2-e) because of its low dimensionality, continuity,and unambiguity. The ideal manifold would also be more uni-form and would not exhibit stretches or squashes, yet it wouldpreserve the topological structure of the data manifold sincethey are topologically equivalent. The nonlinear deformationfunction will take care of stretching and/or squashing the idealmanifold to fit the data.
2- Using a conceptual representation provides a commonrepresentation for different people’s manifolds. The visualmanifolds for different people are expected to twist differentlydepending on the shape of the person performing the motion.Therefore, a representation learned from a certain person willnot be useful to generalize to other people. On the otherhand, learning such embedded representations from multiplepeople is not easily achievable since nonlinear dimensionalityreduction techniques, as mentioned above, deal with onemanifold and would have trouble dealing with inter-person andintra-person manifolds. Many researchers are actively pursuingstyle-content separation approaches that can learn embeddedrepresentations of the posture from multiple data sets invariantto the identity of the person [54], [51]. Specifying the topologyof the posture manifold, as we do here, achieves a conceptualcontent representation, invariant to the identity. Modeling thestyle variability is achieved by factorizing the deformationfunctions as will be shown in Section V-C.
3- The ideal manifold is a shared latent (common) repre-sentation between both the visual (input) manifold and thekinematic (output) manifold since it is topologically equivalentto both of them. Therefore, the ideal manifold would serveboth in tracking the visual observation and in recovering theconfiguration of the body joints. Learning a shared manifoldrepresentation between an input and an output manifold canalso be achieved in unsupervised way as in [55], [56]. Here,the shared representation is specified by enforcing the knowntopology.
4- Instead of learning nonlinear dynamics from the actualdata, we can impose simpler dynamic models on the idealmanifold. The nonlinear deformation function would transformsuch simple dynamics to the nonlinear dynamics of the data.For example, for a periodic motion, moving along a unitcircle with equal steps would correspond to nonlinear stepsin the data space. This yields a simple constant-speed lineardynamic system in the latent space and, therefore, simplifiesthe tracking.
5- This model is generative, and therefore, can be directlyused for synthesizing data. This fits directly into the Bayesiantracking framework, since in such a setting we need to generateobservation hypotheses given a state representation to evaluatethe state posterior.
IV. V IEW AND CONFIGURATION JOINT REPRESENTATION
A. Why a Torus Manifold?
In this section, we show that a torus manifold is topologi-cally equivalent to the visual manifold resulting from a certainclass of motion observed from a view circle. We will start with

IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 6
(a)
(b) −2
0
2
−2
−1
0
1
2
−2
−1.5
−1
−0.5
0
0.5
1
1.5
−2
0
2
4−2
02
−2.5
−2
−1.5
−1
−0.5
0
0.5
1
1.5
−5
0
5 −4
−2
0
2
−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
−5
0
5 −2
−1
0
1
2
3
−1.5
−1
−0.5
0
0.5
1
1.5
2
−2
0
2
4
−2
0
2
−1.5
−1
−0.5
0
0.5
1
1.5
2
(c) −2
0
2
−2
−1
0
1
2
−2
−1.5
−1
−0.5
0
0.5
1
1.5
−4
−2
0
2
−2
0
2
4
−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
−2
0
2
−2
−1
0
1
2
−1.5
−1
−0.5
0
0.5
1
1.5
2
−2
0
2
4
−2
−1
0
1
2
−2
−1.5
−1
−0.5
0
0.5
1
1.5
−2
0
2
4
−4
−2
0
2
−1.5
−1
−0.5
0
0.5
1
1.5
2
2.5
(d) −3 −2 −1 0 1 2 3−5 0 5−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
2.5
(e) −1000
−500
0
500
1000
−600−400
−2000
200400
600
−400
−200
0
200
400
Fig. 2. Data-driven view and body configuration manifolds:(a) Examples of sample data with different views and configurations. Rows: body posture at0, 1
5T, 2
5T, 3
5T, 4
5T . Cols:view0, 30, 60, · · · , 330. (b) The intrinsic configuration manifolds when the view angle is 0, 60, 120, 180, and240. (c) The view
manifolds for five different fixed body postures. (d) (e) The combined view and body configuration manifold embedding by LLE and Isomap.
a simple periodic motion, such as a simple aerobic exercise orgait, observed from a view circle around the person. Later, weshow how to deal with other motions and extend the approachto the whole view sphere. For illustration, we will use the gaitmotion. The gait motion, observed from the same viewpoint,is a one-dimensional closed manifold, which is topologicallyequivalent to a unit circle. This was earlier shown in [1] andcan be noticed from embedding view-based observations asshown in the examples in Fig. 2-b. We can think of the gaitmanifold as a twisted or deformed circle in the visual inputspace. Similarly, the view manifold of a certain body postureis topologically equivalent to a unit circle, as can be seen inFig. 2-c. For a joint configuration and view manifold, wherethe view varies along a view circle, this is a product spaceand the resulting manifold is the product of two circles, i.e.,either a torus or a sphere. Since the configuration manifoldof a given view and the view manifold of a give postureintersect at exactly one point, this is equivalent to a torusmanifold. Therefore, the data in Fig. 2-a lie on a deformedtorus in the visual input space. This is also observable fromtheembeddings shown in Figs. 2-d, 2e. The supervised learningtask in this case reduces to learning the deformation from atorus to the data.
On the other hand, the kinematic manifold, which is invari-ant to the viewpoint, is also a deformed circle in the kinematicspace. Starting from a torus, the kinematic manifold can beachieved through collapsing the torus along one of its axesto form a circle and then deforming that circle. Therefore, atorus manifold acts as an “ideal” manifold to represent boththe latent body configuration and view variables,bt, vt. Onone hand, the torus can deform to form the visual manifold,where the observations lie. On the other hand, the torus can
deform to form the kinematic manifold, where the kinematicdata lie.
B. Torus Manifold Geometry
A torus manifold, is a two-dimensional manifold embeddedin a three-dimensional space with a single hole. The torusmanifold can be constructed from a rectangle with two or-thogonal coordinates with the range[0 1] × [0 1] by gluingboth pairs of opposite edges together with no twists [57].Therefore, the torus surface can be parameterized by twovariablesµ, ν ∈ [0 1]. Let the radius from the center ofthe hole to the center of the torus tube beRc, and the radiusof the tube beRa, then an azimuthally symmetric torus aboutthe z axis can be described
(
Rc −√
x2 + y2)2
+ z2 = Ra,
and the parametric equations are
x = (Rc +Ra cos 2πν) cos 2πµ,
y = (Rc +Ra cos 2πν) sin 2πµ,
z = Ra sin 2πν. (1)
Fig. 3-a shows a torus manifold whenRc = 2, Ra = 1.As justified above, the torus is an ideal representation for a
periodic motion observed from a view circle and, therefore,itcan be used as a conceptual representation for both the view-point (along one viewing circle) and the body configurationjointly. The view and body configuration manifolds can beparameterized in the rectangle coordinate system with the twoorthogonal axes of the torus. Any point on the torus has two

IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 7
(a)
X
Y
Z
µ
ν
(b)
(c)
(d)
(e)
Fig. 3. Torus representation for continuous view-variant dynamic humanmotion:(a) The coordinate system on the torus: 3D Cartesiancoordinatesand theµ and ,ν axes. TheZ axis is perpendicular to the paper plane (b)Three different trajectories on the torus manifold according to the view andconfiguration changes shown in parts c,d, and e. (c) Syntheses of body posturevariations with a fixed view (µ = 0.25, ν : 0 → 1). (d) Syntheses of viewvariations with a fixed body configuration.µ : 0 → 1, ν = 0.3. (e) Synthesesof both view and body configuration variation:µ : 0 → 1, ν : 0.25 → 0.75
orthogonal circles2: one is in the plane of the torus, which weuse to model the view variable and is parameterized withµ.The other circle is perpendicular to the torus plane, which weuse to represent the body configuration and is parameterizedby ν.
C. Embedding points on the torus
Given a sequence of kinematic data,Z = {z1, · · · , zN},representing a motion, we use graphics software to renderbody silhouettes from different viewpoints along a givenviewing circle. Let us denote the silhouette sequence froma given viewpoint,v ∈ [0, 2π), by Y v = {yv
1 , · · · , yvN}.
Here, we are dealing with the data as a discrete set of pointsrather than a temporal sequence. By embedding points on thetorus, we mean to find the corresponding torus coordinates
2Actually, two additional circles called Villareau circlescan be drawn atthe any given point, but we focus on the two simple perpendicular ones.
(µ(i,v), ν(i,v)) for an input instance(zi, yvi ). The torus coor-
dinatesµ and ν are used to indicate the view and the bodyconfiguration respectively. We propose two ways to achievesuch an embedding.
1) Constant Speed Dynamics:For tracking, we not onlyknow the topology of the manifold but also may know thedesired dynamics in the state space. It is desired to embed thedata on a torus in a conceptual way that does not necessarilyreflect their Euclidean distance neither in the kinematic spacenor in the visual input space. Instead, the objective is to embedthem on the torus in a way to simplify the tracking. Forexample, for periodic motion, such as walking and running,despite the nonlinearity of the dynamics in both the kinematicand the visual input manifolds, we need the latent statevariable to reflect a constant speed on the latent manifold. Thenonlinear mapping, which will be described in Section V, willtransform this linear dynamics to nonlinear dynamics. Thiscanbe achieved by embedding the points on equidistant pointsalong the configuration axis of the torus. Therefore, given asequence(zi, y
vi ), i = 1, · · · , N, v ∈ [0, 2π) for one cycle of
the motion (starting and ending with the same posture), thecorresponding torus coordinates are set to
µ(i,v) = v/2π,
ν(i,v) = i/N.
2) Geodesics-based Embedding:The torus representationis not only suitable for periodic motion but also suitable forquasi-periodic and non-periodic motions. By a quasi-periodicmotion we mean a motion that starts and ends with a similarbody posture (e.g. a jump motion, or a facial expressionstarting and ending with a neutral expression) and, therefore,the motion lies on a closed (or almost closed) trajectories.Obviously, for such motions, similar to the periodic case, thetorus is a good representation to model the visual manifoldunder viewpoint and configuration variability. On the otherhand, the torus representation is also useful for non-periodicmotions where the body configuration manifold is a one-dimensional open trajectory (e.g., a golf swing), and themotion starts and ends at different body posture. In suchcases, any linear embedding is also homeomorphic to theconfiguration manifold. For example, a cylinder can be usedto represent the visual manifold of such a motion. A torus canalso be used in this case, where a part of the torus configurationaxis can be used to represent the open trajectory. In thissection, we will describe how to use the torus for representingboth quasi-periodic and non-periodic open-trajectory motions.
The approach described here is suitable in general formotions where the data might exhibit different accelerationalong the course of the motion, and therefore, constant speeddynamics might not be achievable in the latent space. It isdesired to embed the data on the torus in a way that preservestheir kinematic manifold structure. This can be achievedthrough embedding the points such that the geodesic distanceson the torus are proportional to the geodesic distances on thekinematic manifold.
To achieve this, we first embed the kinematic manifold usingan unsupervised nonlinear dimensionality reduction approach
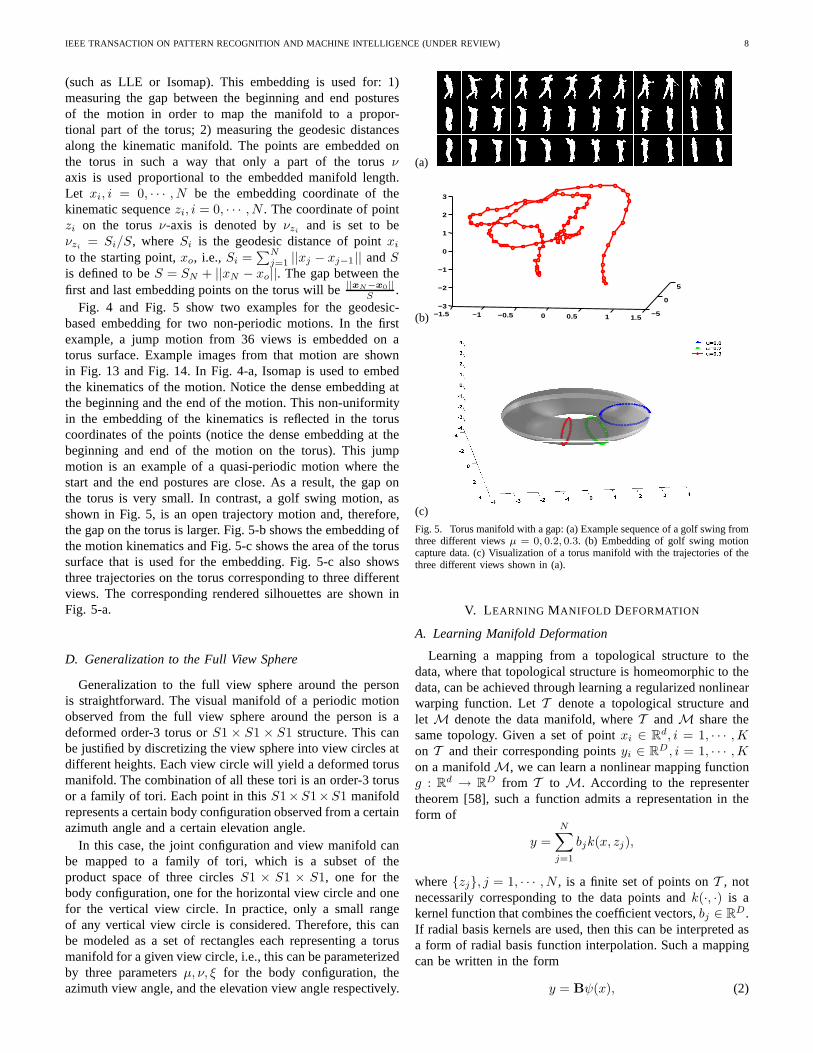
IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 8
(such as LLE or Isomap). This embedding is used for: 1)measuring the gap between the beginning and end posturesof the motion in order to map the manifold to a propor-tional part of the torus; 2) measuring the geodesic distancesalong the kinematic manifold. The points are embedded onthe torus in such a way that only a part of the torusνaxis is used proportional to the embedded manifold length.Let xi, i = 0, · · · , N be the embedding coordinate of thekinematic sequencezi, i = 0, · · · , N . The coordinate of pointzi on the torusν-axis is denoted byνzi
and is set to beνzi
= Si/S, whereSi is the geodesic distance of pointxi
to the starting point,xo, i.e.,Si =∑N
j=1 ||xj − xj−1|| andSis defined to beS = SN + ||xN − xo||. The gap between thefirst and last embedding points on the torus will be||xN−x0||
S.
Fig. 4 and Fig. 5 show two examples for the geodesic-based embedding for two non-periodic motions. In the firstexample, a jump motion from 36 views is embedded on atorus surface. Example images from that motion are shownin Fig. 13 and Fig. 14. In Fig. 4-a, Isomap is used to embedthe kinematics of the motion. Notice the dense embedding atthe beginning and the end of the motion. This non-uniformityin the embedding of the kinematics is reflected in the toruscoordinates of the points (notice the dense embedding at thebeginning and end of the motion on the torus). This jumpmotion is an example of a quasi-periodic motion where thestart and the end postures are close. As a result, the gap onthe torus is very small. In contrast, a golf swing motion, asshown in Fig. 5, is an open trajectory motion and, therefore,the gap on the torus is larger. Fig. 5-b shows the embedding ofthe motion kinematics and Fig. 5-c shows the area of the torussurface that is used for the embedding. Fig. 5-c also showsthree trajectories on the torus corresponding to three differentviews. The corresponding rendered silhouettes are shown inFig. 5-a.
D. Generalization to the Full View Sphere
Generalization to the full view sphere around the personis straightforward. The visual manifold of a periodic motionobserved from the full view sphere around the person is adeformed order-3 torus orS1 × S1 × S1 structure. This canbe justified by discretizing the view sphere into view circles atdifferent heights. Each view circle will yield a deformed torusmanifold. The combination of all these tori is an order-3 torusor a family of tori. Each point in thisS1×S1×S1 manifoldrepresents a certain body configuration observed from a certainazimuth angle and a certain elevation angle.
In this case, the joint configuration and view manifold canbe mapped to a family of tori, which is a subset of theproduct space of three circlesS1 × S1 × S1, one for thebody configuration, one for the horizontal view circle and onefor the vertical view circle. In practice, only a small rangeof any vertical view circle is considered. Therefore, this canbe modeled as a set of rectangles each representing a torusmanifold for a given view circle, i.e., this can be parameterizedby three parametersµ, ν, ξ for the body configuration, theazimuth view angle, and the elevation view angle respectively.
(a)
(b) −1.5 −1 −0.5 0 0.5 1 1.5−5
0
5
−3
−2
−1
0
1
2
3
(c)
Fig. 5. Torus manifold with a gap: (a) Example sequence of a golf swing fromthree different viewsµ = 0, 0.2, 0.3. (b) Embedding of golf swing motioncapture data. (c) Visualization of a torus manifold with thetrajectories of thethree different views shown in (a).
V. L EARNING MANIFOLD DEFORMATION
A. Learning Manifold Deformation
Learning a mapping from a topological structure to thedata, where that topological structure is homeomorphic to thedata, can be achieved through learning a regularized nonlinearwarping function. LetT denote a topological structure andlet M denote the data manifold, whereT andM share thesame topology. Given a set of pointxi ∈ R
d, i = 1, · · · ,Kon T and their corresponding pointsyi ∈ R
D, i = 1, · · · ,Kon a manifoldM, we can learn a nonlinear mapping functiong : R
d → RD from T to M. According to the representer
theorem [58], such a function admits a representation in theform of
y =
N∑
j=1
bjk(x, zj),
where{zj}, j = 1, · · · , N , is a finite set of points onT , notnecessarily corresponding to the data points andk(·, ·) is akernel function that combines the coefficient vectors,bj ∈ R
D.If radial basis kernels are used, then this can be interpreted asa form of radial basis function interpolation. Such a mappingcan be written in the form
y = Bψ(x), (2)
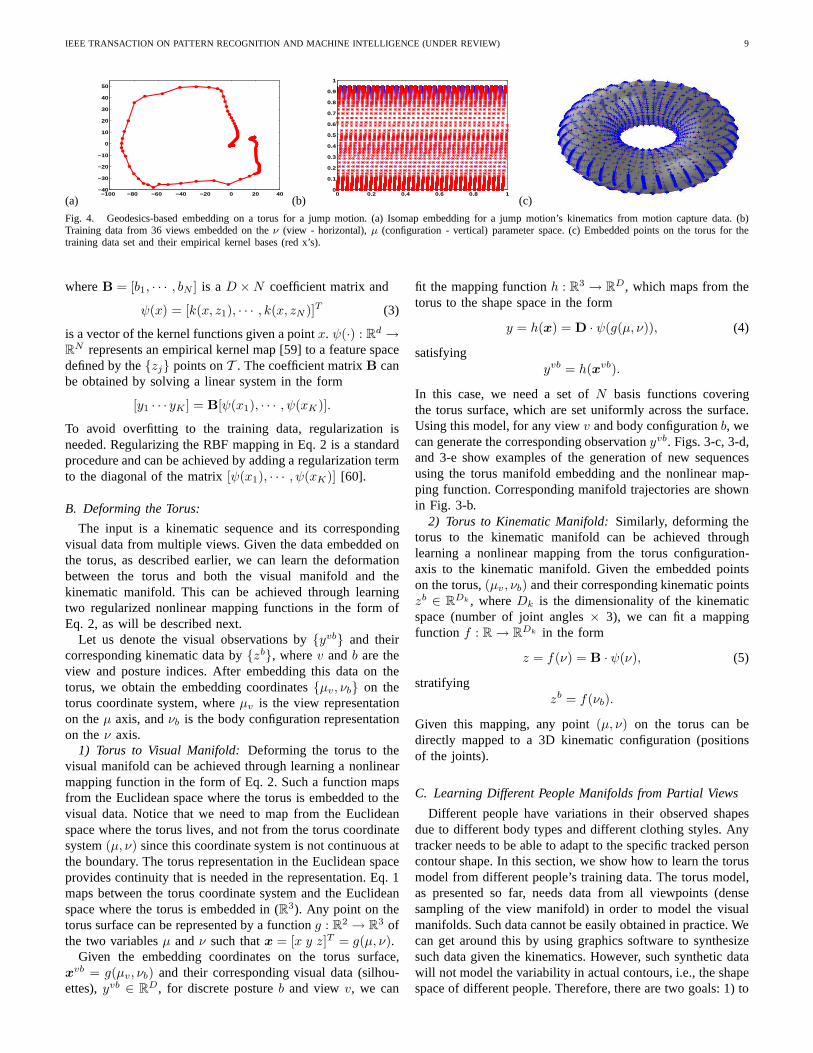
IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 9
(a)−100 −80 −60 −40 −20 0 20 40
−40
−30
−20
−10
0
10
20
30
40
50
(b)0 0.2 0.4 0.6 0.8 1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
(c)
Fig. 4. Geodesics-based embedding on a torus for a jump motion. (a) Isomap embedding for a jump motion’s kinematics from motion capture data. (b)Training data from 36 views embedded on theν (view - horizontal),µ (configuration - vertical) parameter space. (c) Embedded points on the torus for thetraining data set and their empirical kernel bases (red x’s).
whereB = [b1, · · · , bN ] is aD ×N coefficient matrix and
ψ(x) = [k(x, z1), · · · , k(x, zN )]T (3)
is a vector of the kernel functions given a pointx. ψ(·) : Rd →
RN represents an empirical kernel map [59] to a feature space
defined by the{zj} points onT . The coefficient matrixB canbe obtained by solving a linear system in the form
[y1 · · · yK ] = B[ψ(x1), · · · , ψ(xK)].
To avoid overfitting to the training data, regularization isneeded. Regularizing the RBF mapping in Eq. 2 is a standardprocedure and can be achieved by adding a regularization termto the diagonal of the matrix[ψ(x1), · · · , ψ(xK)] [60].
B. Deforming the Torus:
The input is a kinematic sequence and its correspondingvisual data from multiple views. Given the data embedded onthe torus, as described earlier, we can learn the deformationbetween the torus and both the visual manifold and thekinematic manifold. This can be achieved through learningtwo regularized nonlinear mapping functions in the form ofEq. 2, as will be described next.
Let us denote the visual observations by{yvb} and theircorresponding kinematic data by{zb}, wherev andb are theview and posture indices. After embedding this data on thetorus, we obtain the embedding coordinates{µv, νb} on thetorus coordinate system, whereµv is the view representationon theµ axis, andνb is the body configuration representationon theν axis.
1) Torus to Visual Manifold:Deforming the torus to thevisual manifold can be achieved through learning a nonlinearmapping function in the form of Eq. 2. Such a function mapsfrom the Euclidean space where the torus is embedded to thevisual data. Notice that we need to map from the Euclideanspace where the torus lives, and not from the torus coordinatesystem(µ, ν) since this coordinate system is not continuous atthe boundary. The torus representation in the Euclidean spaceprovides continuity that is needed in the representation. Eq. 1maps between the torus coordinate system and the Euclideanspace where the torus is embedded in (R
3). Any point on thetorus surface can be represented by a functiong : R
2 → R3 of
the two variablesµ andν such thatx = [x y z]T = g(µ, ν).Given the embedding coordinates on the torus surface,
xvb = g(µv, νb) and their corresponding visual data (silhou-
ettes),yvb ∈ RD, for discrete postureb and viewv, we can
fit the mapping functionh : R3 → R
D, which maps from thetorus to the shape space in the form
y = h(x) = D · ψ(g(µ, ν)), (4)
satisfyingyvb = h(xvb).
In this case, we need a set ofN basis functions coveringthe torus surface, which are set uniformly across the surface.Using this model, for any viewv and body configurationb, wecan generate the corresponding observationyvb. Figs. 3-c, 3-d,and 3-e show examples of the generation of new sequencesusing the torus manifold embedding and the nonlinear map-ping function. Corresponding manifold trajectories are shownin Fig. 3-b.
2) Torus to Kinematic Manifold:Similarly, deforming thetorus to the kinematic manifold can be achieved throughlearning a nonlinear mapping from the torus configuration-axis to the kinematic manifold. Given the embedded pointson the torus,(µv, νb) and their corresponding kinematic pointszb ∈ R
Dk , whereDk is the dimensionality of the kinematicspace (number of joint angles× 3), we can fit a mappingfunction f : R → R
Dk in the form
z = f(ν) = B · ψ(ν), (5)
stratifyingzb = f(νb).
Given this mapping, any point(µ, ν) on the torus can bedirectly mapped to a 3D kinematic configuration (positionsof the joints).
C. Learning Different People Manifolds from Partial Views
Different people have variations in their observed shapesdue to different body types and different clothing styles. Anytracker needs to be able to adapt to the specific tracked personcontour shape. In this section, we show how to learn the torusmodel from different people’s training data. The torus model,as presented so far, needs data from all viewpoints (densesampling of the view manifold) in order to model the visualmanifolds. Such data cannot be easily obtained in practice.Wecan get around this by using graphics software to synthesizesuch data given the kinematics. However, such synthetic datawill not model the variability in actual contours, i.e., theshapespace of different people. Therefore, there are two goals: 1) to

IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 10
learn different people posture-view manifolds from only sparsepartial views’ data to achieve successful tracking. 2) to adaptthe model to new people as we track them. In this section wepropose solutions for these two problems.
In our earlier work [51], we showed that shape “style”variations can be decomposed in the space of the coefficientsof the nonlinear mapping functions from an embedded man-ifold representation to the observation space. In this paperwe use a similar approach to learn style-dependent mappings,in the form of Eq. 4, from the torus to each person’s data.The torus is a unified manifold representation invariant topeople’s appearance. This results in a general generative modelfor contours for different postures, different views, and fordifferent shape styles in a tensor product form
ysvb = A ×1 a
s ×2 ψ(µv, νb). (6)
Such a model combines a body configuration parameterνb, aview parameterµv, and a shape style vectoras to generatean observationys
vb of style s and viewv and postureb. ThetensorA is a third order tensor with dimensionsD× S ×N ,which controls the correlation between the configuration, viewand style, whereS is the dimensionality of the shape space.The product notation×n is the tensor multiplication as definedin [49].
We now show how to fit the model in Eq. 6 from sparseview-based data for different people performing the samemotion. Given different persons’ sequences from differentsparse viewpoints, each sequence can be embedded on thetorus as described in Sec. IV. LetY s
vkbe sequences of visual
data for persons, wheres = 1, · · · ,K, from viewpointsvk.Such sequences can be embedded on the torus, which leadsto a set of torus coordinates(µvk
, νb). The viewpoints do notneed to be the same across subjects and the sequences do notneed to be of the same length; only the beginning and endof the motion is needed to be aligned on the torusν-axis.Given the embedding points and their corresponding contoursfor pesons, a person-specific mapping function in the form ofEq. 4 can be fitted, which leads to aD×N coefficient matrixD
s. Notice that the kernel space, defined byψ(·) in Eq. 4 isthe same across all subjects since the same RBF centers areused on the torus.
Given the learned nonlinear mapping coefficientsD
1,D2, · · · ,DK , for training people1, · · · ,K, the shapestyle parameters are decomposed by fitting an asymmetricbilinear model [46] to the coefficient space such that
[d1 · · ·dK ] = AS, (7)
where eachds is theDN -dimensional vector representationof the matrixD
s using column stacking. The matrixA is aDN ×K matrix containing the style basis for the coefficientspace. The style matrix,S, is an orthonormal matrix contain-ing the style vectors for the training data. This decompositioncan be obtained using the Singular Value Decomposition(SVD). The correlation tensorA in Eq. 6 can be directlyobtained by restacking the matrixA to aD × S ×N tensor,where the firstS style bases are retained to represent the shapesubspace.
The model in Eq. 6 generalizes the model we previouslyproposed in [51], which was a view-based model. The modelproposed here provides a continuous representation of theviewpoint and the body configuration in one latent represen-tation space.
VI. BAYESIAN TRACKING ON THE TORUS
Tracking is the recursive estimation of the state on the torus,i.e., the estimation of the configuration, the viewpoint, and theshape style parameters given new observations. In our case,the observations are the body contours; either extracted usingbackground subtraction or just fragmented edges detected inthe image. Recovering the state on the torus directly yieldsthe body kinematics in 3D through the mapping function inEq. 5. The Bayesian tracking framework recursively updatesthe posterior densityP (Xt|Y
t) of the object stateXt at timet given all observationsY t = Y 1,Y 2, ..,Y t up to timet
P (Xt|Yt) ∝ P (Y t|Xt)
∫
Xt−1
P (Xt|Xt−1)P (Xt−1|Yt−1)dXt−1.
The state can be updated based on observation likeli-hood estimationP (Y t|Xt) given the transition probabil-ity P (Xt|Xt−1) and the previous frame state posteriorP (Xt−1|Y
t−1).On a torus manifold, the view and body configuration
are represented together. The manifold provides a naturalcontinuous, low-dimensional representation of the joint (view-configuration) distribution for a particle filter tracker. The statehas three components: viewpoint, body configuration on themanifold and shape parameter. We denote the state at timetby Xt = [λt, µt, νt], whereµt andνt are the torus coordinatescorresponding to view and body configurations respectively. λt
is the shape state, where the shape at timet is assumed to bea convex combination of the shape classes in the training set.That is, the shape style vectorat at timet is written as a linearcombination ofK shape style vectorssk in the style space
at =
K∑
k=1
wkt s
k,
K∑
k=1
wkt = 1.
The shape state is represented by the coefficientswkt , i.e.,
λt = [w1t , · · · , w
Kt ]T .
A. Dynamic Model
Since the posture, view, and shape style parts of the stateare independent given the observations, the dynamic modelis a product of three dynamic models, i.e.P (Xt|Xt−1) =P (λt|λt−1)P (µt|µt−1)P (νt|νt−1). Therefore, the state modelwe use has the general form
µt = aµt−1 + nµ,
νt = bνt−1 + nν ,
λt = Cλt−1 + nλ,
yt = h(µt, νt, λt; A) + ny, (8)
wherenµ, nν , nλ, andny are zero mean white Gaussian noise.The scalarsa and b and the matrixC are the linear state

IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 11
dynamics. The nonlinear mapping functionh(µt, νt, λt; A)maps the state to the observation and has the form
h(µt, νt, λt; A) = A ×1 (Sλt) ×2 ψ(µt, νt),
where the matrixS = [s1, · · · sk] contains the shape stylevectors representing the shape style space.
The shape state is supposed to be time-invariant. However,in tracking, since the tracked person’s shape style is notknown, the shape style needs to change with frames until itadapts to the correct shape style. Therefore, the propagationof particles in the shape space is controlled by a variancevariable that decays with time. As introduced in Sec. IV,the configuration can be embedded on the torus in a way toachieve constant speed dynamics in the state space, which isvery suitable in the case of periodic motion. Therefore, thepropagation of the particle in the body configuration domainuses a constant speed model, which adapts to each person’sdynamics through tracking.
B. Observation Model
For learning the model, we represent each shape instance asan implicit functiony(x) at each pixelx such thaty(x) = 0on the contour,y(x) > 0 inside the contour, andy(x) < 0outside the contour. We use a signed-distance function suchthat
y(x) =
dc(x) x inside c0 x on c−dc(x) x outside c
where thedc(x) is the distance to the closest point on thecontourc with a positive sign inside the contour and a neg-ative sign outside the contour. Such a representation imposessmoothness on the distance between shapes. Given such arepresentation, the input shapes are points inRd, whered isthe dimensionality of the input space. This implicit functionrepresentation is typically used in level-set methods.
The model in Eq. 8 fits directly to the Bayesian frameworkto generate observation hypotheses from the particles. Thetracker is realized using a traditional particle filter. Theview,configuration, and shape style joint state is represented withNξ particles{ξ(k)
t , ξπ(k)t }
Nξ
k=1 with weightsπ. We can generatesamples for a given particleξ(k)
t+1 = [λ(k)t+1, µ
(k)t+1, ν
(k)t+1] by
y(k)t+1 = A × Sλ
(k)t+1 × ψ(µ
(k)t+1, ν
(k)t+1),
i.e., each particle will directly generate a hypothesis contourin a given configuration, in a given view, in the form of alevel-set function.
The observation itself can be in the form of extracted sil-houettes (using background subtraction) or just edges extracteddirectly from the images. For the case of tracking background-subtracted silhouettes, each input silhouette is represented as alevel set and the observation likelihood is computed using theEuclidean distance between the two implicit function repre-sentations. In the case of edge features, observation likelihoodis estimated using probabilistic Chamfer matching [61].
VII. E XPERIMENTAL RESULTS
We have designed and performed several experiments toevaluate the proposed approach for tracking, view estimation,and 3D posture estimation, including: 1) quantitative evalua-tion of the 3D reconstruction of the body joints’ locations withground truth data; 2) comparison to other representations toshow the advantage of the proposed supervised learning overunsupervised approaches; 3) evaluation of the tracking andthe 3D reconstruction with style adaptation. The evaluationinvolved two different kinds of observations: background sub-tracted silhouettes and edge-based tracking. The experimentsfocused on tracking gait because of the availability of ground-truth data for gait. However, we also show several experimentsusing other types of motions such as golf swings and jumpmotions where the subject changes his viewpoint with respectto the camera during the motion.
A. Quantitative Evaluation:
The goal of this experiment is to evaluate the accuracy of thetracking approach in terms of recovering the 3D positions ofthe joints with ground truth data. For this purpose, we used theBrown HUMANEVA-I dataset [62], which provides groundtruth data for the 3D locations of the joints for different typesof motions. The data set provides sequences for training andevaluation for the same subjects. In particular, we used threewalking sequences where the subject walks along an ellipticaltrajectory. Therefore, the subject’s viewpoint with respect tothe camera is continuously changing throughout the sequences.We did not use any camera calibration information for thisdata since we want to show that a learned model from a fixedview circle would generalize to track subjects from similarsittings without knowledge of the camera parameters. We alsodid not use any visual data from the HUMANEVA-I to trainthe model.Training: We generated synthetic training data of walk-ing silhouettes from our own motion capture data usingthe animation software PoserR©. Twelve different views(10o, 30o, · · · , 360o) were rendered for one walking cycle.The motion capture data used for synthesis is not part of theHUMANEVA-I dataset. Given this synthetic visual data, thedata was embedded on a torus, as described in Section IV,and the manifold deformation from the torus was learned aswas described in Section V. The model learned with suchsynthetic data would be enough for tracking and recoveringthe posture and the view parameters on the torus. However,for the reconstruction of the 3D joints’ locations we also needto learn the deformation from the torus to the kinematic space.For this purpose, we used one training cycle of the joints’locations for each of the subjects from the HUMANEVA-Idataset.Evaluation: Given the validation sequences from theHUMANEVA-I dataset, we extracted silhouettes using back-ground subtraction after learning a background model usinga nonparametric approach [63]. On the other hand, locationsof the joints in the validation set are normalized to representnormalized posturein a body centered coordinate systemwhich is invariant to subject’s rotation and translation. This

IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 12
was performed for the three subjects’ validation sequences(S1, S2, S3) to estimate the performance of inferring 3D bodyposture.
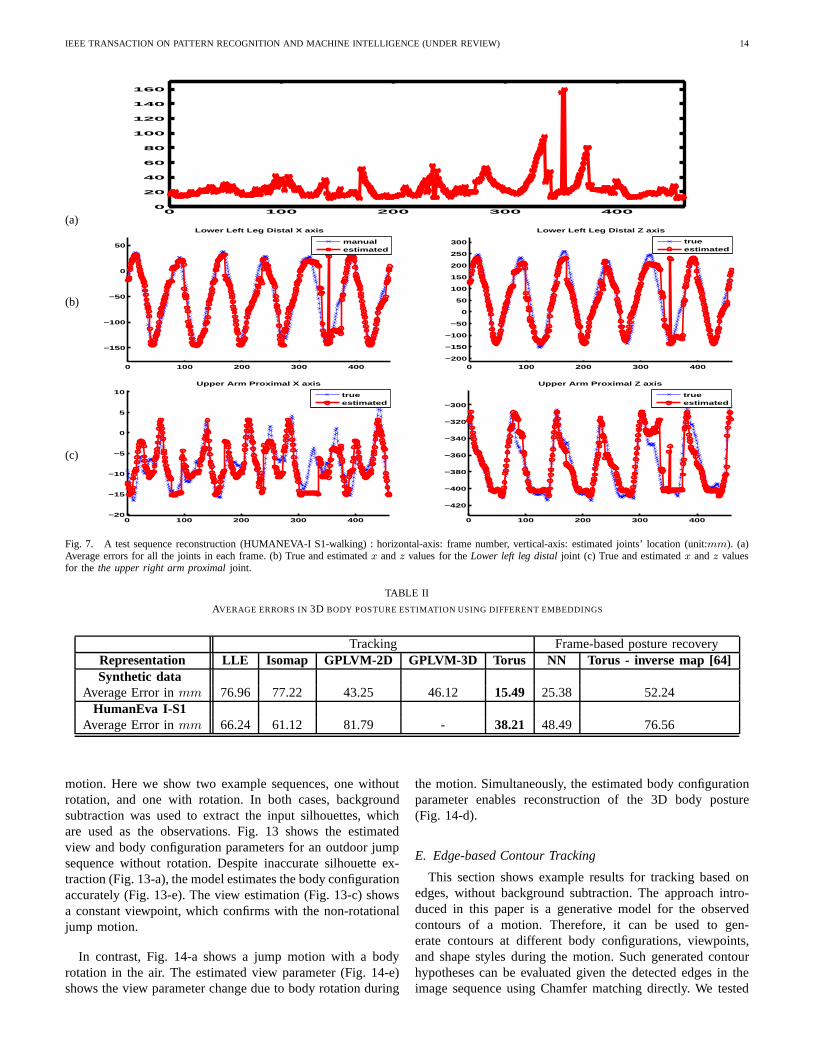
For tracking, we used 900 particles to represent the view andbody configuration on the torus manifold. We estimated the 3Dbody posture from the maximum-a-posterior (MAP) estimateof the body configuration from the particles in the particlefilter. Figs. 6-e and 6-f show the estimated body configurationand view parameters on the torus as well as the reconstructed3D posture (Fig. 6-d). As can be seen, the estimated bodyconfiguration parameter on the torus clearly exhibits constant-speed linear dynamics in tracking nonlinear deformation inthe observations throughout the sequence. The walking cyclescan be seen clearly in the sawtooth-like shape of the estimatedbody configuration. The estimated view parameter (Fig. 6-e) clearly exhibits constant change in viewpoint due to theellipse-like trajectory of the subject’s motion.
We measured the errors in the estimated body posture usingthe average absolute distance between individual markers,as in [62]. Fig. 7-a shows the average reconstruction errorfor all the joints’ locations in each frame for subject ‘S1’.The true and the estimated limb endpoints are compared inFig. 7-b and Fig. 7-c. Table I shows the average errors ineach of the subject’s test sequences3. We tested the trackingperformance with and without considering the dynamics ofthe body configuration and view. First, we used a randomwalk dynamic model, i.e., particles just drift randomly in eachframe. Then we applied constant-speed dynamics for the bodyconfiguration state and the view state, assuming a constantvelocity for the view and the body configuration variables onthe torus. As can be seen from Table I, the experiments showedbetter body configuration estimation when a constant-speeddynamic model is used in the particle propagation. Overall,the average error in each joint’s location from three subjectsis 31.36 millimeters (mm).
B. Comparison of Different Representations:
The goal of this experiment is to compare different embed-ded representations of the visual manifold for tracking. Givena set of training data, representing the visual manifold of awalking motion viewed from different viewpoints (similar tothe data in Fig. 2-a), we want to compare different embeddedrepresentations of the manifold, which can be used as a low-dimensional state space for Bayesian tracking as well as forframe-based posture estimation (without tracking).Training Data: To learn the visual manifold, we used motioncapture data of a walking cycle to render silhouettes fromdifferent viewpoints along one view circle at a fixed height.39 frames from each of 12 views were rendered representinga walking cycle, i.e., a total of 468 frames.Evaluation Data: For evaluation, we used two different sets:1- Synthesized data: we used another rendered walking silhou-ette sequence containing three walking cycles with continuousview variability along a view circle (0-360 degrees). The
3We discard theHeadProximal location of subjectS3 during the errorestimation since the validation data has inconsistency.
sequence contained 139 frames with 3 degrees of view anglechange between frames.2- We used the HumanEva-I subject ‘I’ data set, as describedearlier.For this purpose we compared:
• The torus representation: the proposed approach, whichtakes advantage of the knowledge about the topologicalstructure of the manifold. We evaluated the torus for bothtracking using a particle filter and, for comparison, wealso evaluated frame-based posture estimation based ona torus using inverse mapping as was introduced earlierin [64].
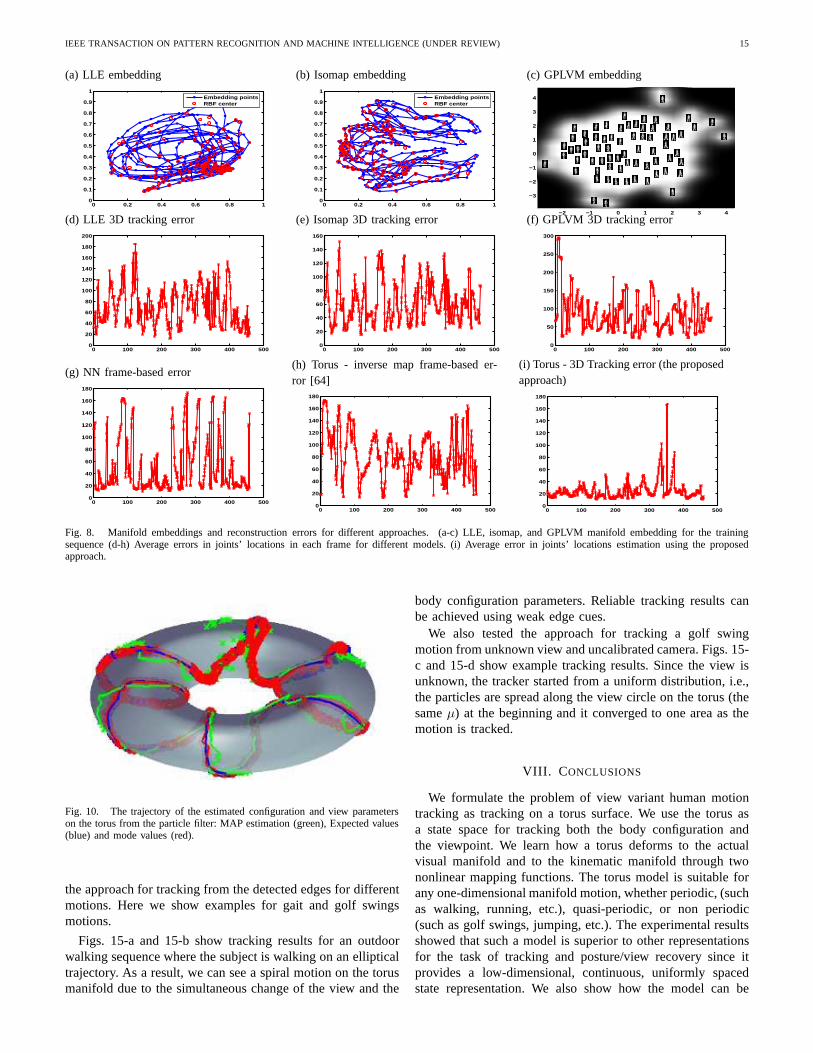
• Unsupervised learning of the manifold using nonlineardimensionality reduction techniques: in particular weused LLE [44], Isomap [45], and GPLVM [52] as populartechniques to achieve a two-dimensional embedding ofthe visual manifold. We used a two-dimensional embed-ding space to be comparable to the torus, i.e., the statespace for tracking both the body configuration and theview was two-dimensional. Figs. 8-a, 8-b, and 8-c showthe two-dimensional embeddings for the training shapesusing each of the approaches. We also compared a three-dimensional embedding for the case of GPLVM.
• We compared a nearest neighbor search to see the bestresult we can get from the collected data itself. Thenearest neighbor approach can be seen as an implicit wayto represent the manifold of the data by keeping all thesamples on the manifold as exemplars. Nearest neighborsearch is used for frame-based posture estimation bysearching for the nearest silhouette from the training dataand using its corresponding 3D joints’ location as the 3Dreconstruction.
For each of the cases of the torus and the unsupervisedembeddings, we fit nonlinear mappings, in the form of Eq. 2,from the embedding space to the shape space. Such mappingswill serve as the observation model to generate observationhypotheses given the particles in the embedding space. Thesame number of RBF centers is used in all cases (we used148 centers), except GPLVM. For LLE and Isomap, the RBFcenters were set on the cluster centers obtained after fitting aGaussian mixture to the embedded points using the EM algo-rithm. For the torus case, the RBF centers are set at equidistantpoints on the torus surface. For the case of GPLVM, the RBFcenters are chosen as a part of the optimization process (weused 200 centers for GPLVM). For tracking, we used the samenumber of particles in the embedding space for each of theapproaches.
Table II shows the average error in the recovered joints’locations for the different approaches. The torus embeddingshows much better performance than the unsupervised man-ifold representation. Fig. 9 shows examples of the recoveredpostures at the sample frames from the HumanEva-I sequencefor all the approaches. Fig. 10 shows the resulting trajectoryof the estimated configuration and view on the torus surface.Itshould be noted that the goal of this experiment is to comparedifferent representations for embedding the visual manifold.The same approaches compared here can be used in differentways for tracking. For example, GPLVM was earlier used[3],

IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 13
(a)
(b)
(c)
(d)
(e)0 100 200 300 400 500
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
manualestimated
(f)0 100 200 300 400 500
−0.2
0
0.2
0.4
0.6
0.8
1
1.2manualestimated
Fig. 6. Reconstruction of 3D body posture: (a) Input silhouettes. (b) Input as implicit functions used in the estimation. (c) Reconstructed silhouettes fromestimated MAP parameters on the torus. (d) Reconstructed 3Dposture shown from a fixed viewpoint. (e) Estimated values for the view parameter (µ). (f)Estimated values for the body configuration parameter (ν).
TABLE I
AVERAGE ERRORS IN3D BODY POSTURE ESTIMATION FROM A SINGLE CAMERA
Subject Start End Duration Cycle Mean Error(No Dyn.) Mean Error(With Dyn.)
S1 76 534 459 6 26.16mm 24.71mmS2 21 436 416 5 37.11mm 31.16mmS3 91 438 348 5 40.47mm 38.21mm
S1,S2,S3 34.58mm 31.36mm
[35] to embed the kinematic manifold within a model-basedapproach and was shown to achieve good results. The point wecan conclude from this experiment is that enforcing the knownmanifold topology leads to better results than unsupervisedlearning of an embedded representation.
C. Shape Style Adaptation:
The goal of this experiment is to show the ability of thetracker to adapt to different people’s shape styles while track-ing the body configuration and the viewpoint, as describedin Section V-C. We fit the model in Eq. 6 with real datafrom multiple people. To fit the model, we used sequencesfrom four different people walking on a treadmill obtainedfrom seven different views using synchronized cameras. Forevaluation, we used the HUMANEVA-I subject ‘S1’ dataset,i.e., the person’s shape style is not in the training data. Thesubject in the evaluation sequence is walking on an ellipticaltrajectory and captured from a stationary camera. The tracker
adapts to the observed shapes by estimating the style factoras in Eq. 6. The tracker starts from a mean style and adaptsto the correct person’s shape style. Fig. 11 shows the trackingresults. As can be seen, after large errors at the beginning,the3D reconstruction errors decreased as the model adapted tothe correct person’s style. Fig. 12 shows tracking for a subjectwalking on an ellipse-like trajectory in an outdoor scene.
D. Tracking a Non-Periodic Motion
We evaluated the approach with non-periodic open trajec-tory motions such as jump motions and golf swing motions.We used motion capture data to learn the model for “jump inthe air” motion using geodesics-based embedding on the torus.We rendered silhouettes from 12 viewpoints to model thevisual manifold. For evaluation, we used jumping sequenceswhere the subject jumps in the air and may rotate whilejumping. The tracker’s job is to recover the body configurationand viewpoint, which is changing due to the rotation during the
IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 14
(a)0 100 200 300 400
0
20
40
60
80
100
120
140
160
(b)
0 100 200 300 400
−150
−100
−50
0
50
Lower Left Leg Distal X axis
manualestimated
0 100 200 300 400−200
−150
−100
−50
0
50
100
150
200
250
300
Lower Left Leg Distal Z axis
trueestimated
(c)
0 100 200 300 400−20
−15
−10
−5
0
5
10Upper Arm Proximal X axis
trueestimated
0 100 200 300 400
−420
−400
−380
−360
−340
−320
−300
Upper Arm Proximal Z axis
trueestimated
Fig. 7. A test sequence reconstruction (HUMANEVA-I S1-walking) : horizontal-axis: frame number, vertical-axis: estimated joints’ location (unit:mm). (a)Average errors for all the joints in each frame. (b) True and estimatedx andz values for theLower left leg distaljoint (c) True and estimatedx andz valuesfor the the upper right arm proximaljoint.
TABLE II
AVERAGE ERRORS IN3D BODY POSTURE ESTIMATION USING DIFFERENT EMBEDDINGS
Tracking Frame-based posture recoveryRepresentation LLE Isomap GPLVM-2D GPLVM-3D Torus NN Torus - inverse map [64]Synthetic data
Average Error inmm 76.96 77.22 43.25 46.12 15.49 25.38 52.24HumanEva I-S1
Average Error inmm 66.24 61.12 81.79 - 38.21 48.49 76.56
motion. Here we show two example sequences, one withoutrotation, and one with rotation. In both cases, backgroundsubtraction was used to extract the input silhouettes, whichare used as the observations. Fig. 13 shows the estimatedview and body configuration parameters for an outdoor jumpsequence without rotation. Despite inaccurate silhouetteex-traction (Fig. 13-a), the model estimates the body configurationaccurately (Fig. 13-e). The view estimation (Fig. 13-c) showsa constant viewpoint, which confirms with the non-rotationaljump motion.
In contrast, Fig. 14-a shows a jump motion with a bodyrotation in the air. The estimated view parameter (Fig. 14-e)shows the view parameter change due to body rotation during
the motion. Simultaneously, the estimated body configurationparameter enables reconstruction of the 3D body posture(Fig. 14-d).
E. Edge-based Contour Tracking
This section shows example results for tracking based onedges, without background subtraction. The approach intro-duced in this paper is a generative model for the observedcontours of a motion. Therefore, it can be used to gen-erate contours at different body configurations, viewpoints,and shape styles during the motion. Such generated contourhypotheses can be evaluated given the detected edges in theimage sequence using Chamfer matching directly. We tested
IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 15
(a) LLE embedding
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Embedding pointsRBF center
(b) Isomap embedding
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Embedding pointsRBF center
(c) GPLVM embedding
−2 −1 0 1 2 3 4
−3
−2
−1
0
1
2
3
4
(d) LLE 3D tracking error
0 100 200 300 400 5000
20
40
60
80
100
120
140
160
180
200
(e) Isomap 3D tracking error
0 100 200 300 400 5000
20
40
60
80
100
120
140
160
(f) GPLVM 3D tracking error
0 100 200 300 400 5000
50
100
150
200
250
300
(g) NN frame-based error
0 100 200 300 400 5000
20
40
60
80
100
120
140
160
180
(h) Torus - inverse map frame-based er-ror [64]
0 100 200 300 400 5000
20
40
60
80
100
120
140
160
180
(i) Torus - 3D Tracking error (the proposedapproach)
0 100 200 300 400 5000
20
40
60
80
100
120
140
160
180
Fig. 8. Manifold embeddings and reconstruction errors for different approaches. (a-c) LLE, isomap, and GPLVM manifoldembedding for the trainingsequence (d-h) Average errors in joints’ locations in each frame for different models. (i) Average error in joints’ locations estimation using the proposedapproach.
Fig. 10. The trajectory of the estimated configuration and view parameterson the torus from the particle filter: MAP estimation (green), Expected values(blue) and mode values (red).
the approach for tracking from the detected edges for differentmotions. Here we show examples for gait and golf swingsmotions.
Figs. 15-a and 15-b show tracking results for an outdoorwalking sequence where the subject is walking on an ellipticaltrajectory. As a result, we can see a spiral motion on the torusmanifold due to the simultaneous change of the view and the
body configuration parameters. Reliable tracking results canbe achieved using weak edge cues.
We also tested the approach for tracking a golf swingmotion from unknown view and uncalibrated camera. Figs. 15-c and 15-d show example tracking results. Since the view isunknown, the tracker started from a uniform distribution, i.e.,the particles are spread along the view circle on the torus (thesameµ) at the beginning and it converged to one area as themotion is tracked.
VIII. C ONCLUSIONS
We formulate the problem of view variant human motiontracking as tracking on a torus surface. We use the torus asa state space for tracking both the body configuration andthe viewpoint. We learn how a torus deforms to the actualvisual manifold and to the kinematic manifold through twononlinear mapping functions. The torus model is suitable forany one-dimensional manifold motion, whether periodic, (suchas walking, running, etc.), quasi-periodic, or non periodic(such as golf swings, jumping, etc.). The experimental resultsshowed that such a model is superior to other representationsfor the task of tracking and posture/view recovery since itprovides a low-dimensional, continuous, uniformly spacedstate representation. We also show how the model can be

IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 16
(a) Input frames
(b) Tracking using an LLE embedding:
(c) Tracking using an Isomap embedding:
(d) Tracking using a GPLVM embedding:
(e) Frame-based posture recovery using a nearest neighbor search:
(f) Frame-based posture recovery using Torus - inverse mapping:
(f) Tracking using Torus embedding (the proposed approach):
Fig. 9. Example results for posture recovery using different embedded representations.
generalized to the full view sphere and how to adapt todifferent persons’ shapes.
The approach introduced in this paper is a parameterizedgenerative function for the visual manifold of an observed mo-tion. Therefore, it can be used to generate contours at differentbody configurations, viewpoints, and shape styles during themotion, without a 3D body model. From a perceptual pointof view, the models we developed provide a computationalapproach that is in line with the view-based theory of objectrepresentation.
An interesting research direction is to determine how todeal with complex human motions. We believe that complexmotions can be segmented into motion primitives where suchprimitives are one-dimensional manifold motions, whetheropen or closed trajectories. Segmenting complex motion intomotion primitives is an active research direction that we arepursuing. Given this view, the torus representation presentedin this paper can be useful for modeling motions that aremore complex. In addition, complex human motions can be
dealt with through hierarchal models where different latentrepresentations for different body joints can be achieved.Acknowledgment This research is partially funded by NSFCAREER award IIS-0546372.
REFERENCES
[1] A. Elgammal and C.-S. Lee, “Inferring 3D body pose from silhouettesusing activity manifold learning,” inProceedings of the IEEE Com-puter Society Conference on Computer Vision and Pattern Recognition(CVPR), vol. 2, 2004, pp. 681–688.
[2] T.-P. Tian, R. Li, and S. Sclaroff, “Articulated pose estimation in alearned smooth space of feasible solutions,” inWorkshop on Learningin Computer Vision and Pattern Recgnition, 2005.
[3] R. Urtasun, D. J. Fleet, A. Hertzmann, and P. Fua, “Priorsfor peopletracking from small training sets.” inProceedings of the InternationalConference on Computer Vision (ICCV), 2005, pp. 403–410.
[4] V. I. Morariu and O. I. Camps, “Modeling correspondencesfor multi-camera tracking using nonlinear manifold learning and target dynamics.”in Proceedings of the IEEE Computer Society Conference on ComputerVision and Pattern Recognition (CVPR), 2006, pp. 545–552.

IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 17
(a) Input silhouettes:
(b) Estimated silhouettes:
(c) 3D average reconstruction error
0 100 200 300 4000
50
100
150
(d) True and estimated lower left leg distal -x andz values
0 100 200 300 400
−150
−100
−50
0
50
Lower Left Leg Distal X axis
manualestimated
0 100 200 300 400−200
−150
−100
−50
0
50
100
150
200
250
300
Lower Left Leg Distal Z axis
trueestimated
Fig. 11. Style adaptive tracking: (a) Original test silhouettes of a subject walking on an elliptical trajectory from the HumanEva-I dataset. (b) The estimatedsilhouettes with style adaptation. (c) Average 3D reconstruction errors in joints’ locations in each frame. (d) True and estimatedx andz values for theLowerleft leg distal joint.
(a)
(b)
(c)
(d)
(e)
(f)
Fig. 12. Evaluation of view-variant gait tracking from realdata: (a) Sample input frames (b) Input silhouettes. (c) Theestimated body configuration parametervalues (d) The estimated view parameter values. (e) The distributions of the particles on the torus. (f) The recovered shape from the estimated configurationand view
[5] H. Lim, O. I. Camps, M. Sznaier, and V. I. Morariu, “Dynamic appearance modeling for human tracking,” inProceedings of the IEEE
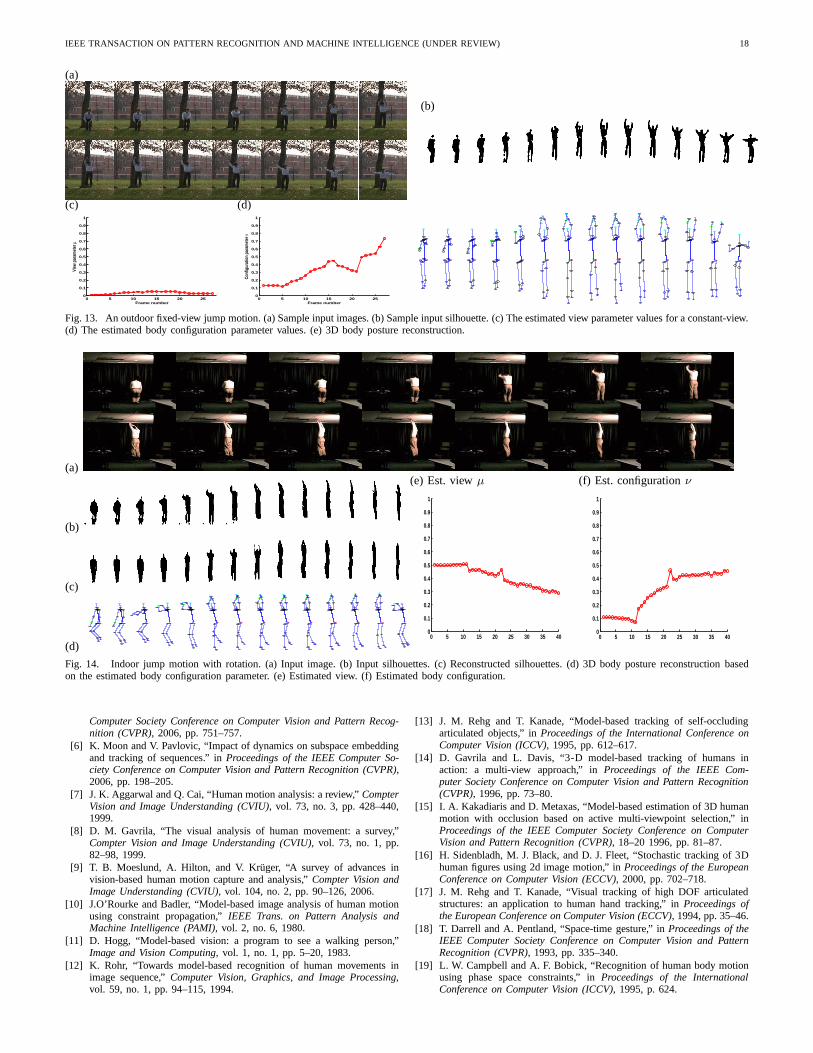
IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 18
(a)
(b)
(c)
0 5 10 15 20 250
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Frame number
View
par
amet
er µ
(d)
0 5 10 15 20 250
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Frame number
Conf
igura
tion
para
met
er
ν
(e)
Fig. 13. An outdoor fixed-view jump motion. (a) Sample input images. (b) Sample input silhouette. (c) The estimated view parameter values for a constant-view.(d) The estimated body configuration parameter values. (e) 3D body posture reconstruction.
(a)
(b)
(c)
(d)
(e) Est. viewµ
0 5 10 15 20 25 30 35 400
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
(f) Est. configurationν
0 5 10 15 20 25 30 35 400
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Fig. 14. Indoor jump motion with rotation. (a) Input image. (b) Input silhouettes. (c) Reconstructed silhouettes. (d) 3D body posture reconstruction basedon the estimated body configuration parameter. (e) Estimated view. (f) Estimated body configuration.
Computer Society Conference on Computer Vision and PatternRecog-nition (CVPR), 2006, pp. 751–757.
[6] K. Moon and V. Pavlovic, “Impact of dynamics on subspace embeddingand tracking of sequences.” inProceedings of the IEEE Computer So-ciety Conference on Computer Vision and Pattern Recognition (CVPR),2006, pp. 198–205.
[7] J. K. Aggarwal and Q. Cai, “Human motion analysis: a review,” CompterVision and Image Understanding (CVIU), vol. 73, no. 3, pp. 428–440,1999.
[8] D. M. Gavrila, “The visual analysis of human movement: a survey,”Compter Vision and Image Understanding (CVIU), vol. 73, no. 1, pp.82–98, 1999.
[9] T. B. Moeslund, A. Hilton, and V. Kruger, “A survey of advances invision-based human motion capture and analysis,”Compter Vision andImage Understanding (CVIU), vol. 104, no. 2, pp. 90–126, 2006.
[10] J.O’Rourke and Badler, “Model-based image analysis ofhuman motionusing constraint propagation,”IEEE Trans. on Pattern Analysis andMachine Intelligence (PAMI), vol. 2, no. 6, 1980.
[11] D. Hogg, “Model-based vision: a program to see a walkingperson,”Image and Vision Computing, vol. 1, no. 1, pp. 5–20, 1983.
[12] K. Rohr, “Towards model-based recognition of human movements inimage sequence,”Computer Vision, Graphics, and Image Processing,vol. 59, no. 1, pp. 94–115, 1994.
[13] J. M. Rehg and T. Kanade, “Model-based tracking of self-occludingarticulated objects,” inProceedings of the International Conference onComputer Vision (ICCV), 1995, pp. 612–617.
[14] D. Gavrila and L. Davis, “3-D model-based tracking of humans inaction: a multi-view approach,” inProceedings of the IEEE Com-puter Society Conference on Computer Vision and Pattern Recognition(CVPR), 1996, pp. 73–80.
[15] I. A. Kakadiaris and D. Metaxas, “Model-based estimation of 3D humanmotion with occlusion based on active multi-viewpoint selection,” inProceedings of the IEEE Computer Society Conference on ComputerVision and Pattern Recognition (CVPR), 18–20 1996, pp. 81–87.
[16] H. Sidenbladh, M. J. Black, and D. J. Fleet, “Stochastictracking of 3Dhuman figures using 2d image motion,” inProceedings of the EuropeanConference on Computer Vision (ECCV), 2000, pp. 702–718.
[17] J. M. Rehg and T. Kanade, “Visual tracking of high DOF articulatedstructures: an application to human hand tracking,” inProceedings ofthe European Conference on Computer Vision (ECCV), 1994, pp. 35–46.
[18] T. Darrell and A. Pentland, “Space-time gesture,” inProceedings of theIEEE Computer Society Conference on Computer Vision and PatternRecognition (CVPR), 1993, pp. 335–340.
[19] L. W. Campbell and A. F. Bobick, “Recognition of human body motionusing phase space constraints,” inProceedings of the InternationalConference on Computer Vision (ICCV), 1995, p. 624.

IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 19
(a)
(b)
(c)
(d)
Fig. 15. Edge-based tracking: (a,b) A gait sequence tracking : (a) Estimated shape contours. (b) View and configuration particle distributions on the torus.(c,d) Golf swing tracking: (c) Estimated shape contours (d)View and configuration particle distributions on the torus.
[20] C. R. Wren, A. Azarbayejani, T. Darrell, and A. P. Pentland, “Pfinder:Real-time tracking of the human body,”IEEE Trans. on Pattern Analysisand Machine Intelligence (PAMI), vol. 19, no. 7, pp. 780–785, 1997.
[21] S. X. Ju, M. J. Black, and Y. Yacoob, “Cardboard people: Apa-rameterized model of articulated motion,” inProceedings of the IEEEInternational Conference on Automatic Face and Gesture Recognition(FGR), Killington, Vermont, 1996, pp. 38–44.
[22] G. Shakhnarovich, J. W. Fisher, and T. Darrell, “Face recognition fromlong-term observations,” inProceedings of the European Conference onComputer Vision (ECCV), 2002, pp. 851–865.
[23] S. X. Ju, M. J. Black, and Y. Yacoob, “Cardboard people: Aparame-terized model of articulated image motion.” inProceedings of the IEEEInternational Conference on Automatic Face and Gesture Recognition(FGR), 1996, pp. 38–44.
[24] Y. Yacoob and M. J. Black, “Parameterized modeling and recognition ofactivities.” Compter Vision and Image Understanding (CVIU), vol. 73,no. 2, pp. 232–247, 1999.
[25] G. Mori and J. Malik, “Estimating human body configurations usingshape context matching,” inProceedings of the European Conferenceon Computer Vision (ECCV), 2002, pp. 666–680.
[26] K. Grauman, G. Shakhnarovich, and T. Darrell, “Inferring 3D structurewith a statistical image-based shape model,” inProceedings of theInternational Conference on Computer Vision (ICCV), 2003, p. 641.
[27] G. Shakhnarovich, P. Viola, and T. Darrell, “Fast pose estimationwith parameter-sensitive hashing,” inProceedings of the InternationalConference on Computer Vision (ICCV), 2003, pp. 750–759.
[28] R. Rosales, V. Athitsos, and S. Sclaroff, “3D hand pose reconstructionusing specialized mappings,” inProceedings of the International Con-ference on Computer Vision (ICCV), 2001, pp. 378–387.
[29] A. Agarwal and B. Triggs, “3D human pose from silhuettesby relevancevector regression,” inProceedings of the IEEE Computer Society Con-ference on Computer Vision and Pattern Recognition (CVPR), vol. 2,2004, pp. 882–888.
[30] C. Sminchisescu, A. Kanaujia, Z. Li, and D. N. Metaxas, “Discriminativedensity propagation for 3D human motion estimation.” inProceedings ofthe IEEE Computer Society Conference on Computer Vision andPatternRecognition (CVPR), 2005, pp. 390–397.
[31] M. Brand, “Shadow puppetry,” inProceedings of the InternationalConference on Computer Vision (ICCV), vol. 2, 1999, pp. 1237–1244.
[32] D. Ormoneit, H. Sidenbladh, M. J. Black, and T. Hastie, “Learning andtracking cyclic human motion,” inProceedings of Advances in NeuralInformation Processing (NIPS), 2000, pp. 894–900.
[33] C. Sminchisescu and A. Jepson, “Generative modeling ofcontinuousnon-linearly embedded visual inference,” inProceedings of the Interna-tional Conference on Machine Learning (ICML), 2004, pp. 140–147.
[34] A. Rahimi, B. Recht, and T. Darrell, “Learning appearance manifoldsfrom video,” in Proceedings of the IEEE Computer Society Conferenceon Computer Vision and Pattern Recognition (CVPR), vol. 1, 2005, pp.868–875.
[35] R. Urtasun, D. J. Fleet, and P. Fua, “3D people tracking with gaussianprocess dynamical models,” inProceedings of the IEEE Computer So-ciety Conference on Computer Vision and Pattern Recognition (CVPR),2006, pp. 238–245.
[36] J. Wang, D. J. Fleet, and A. Hertzmann, “Gaussian process dynamicalmodels.” inProceedings of Advances in Neural Information Processing(NIPS), 2005.
[37] S. Roweis and Z. Ghahramani, “An EM algorithm for identificationof nonlinear dynamical systems,” inKalman Filtering and NeuralNetworks, S. Haykin, Ed.
[38] C. M. Christoudias and T. Darrell, “On modelling nonlinear shape-and-texture appearance manifolds.” inProceedings of the IEEE Computer So-ciety Conference on Computer Vision and Pattern Recognition (CVPR),2005, pp. 1067–1074.
[39] H. Murase and S. Nayar, “Visual learning and recognition of 3D objectsfrom appearance,”International Journal of Computer Vision (IJCV),vol. 14, no. 1, pp. 5–24, 1995.
[40] R. Fablet and M. J. Black, “Automatic detection and tracking ofhuman motion with a view-based representation,” inProceedings of theEuropean Conference on Computer Vision (ECCV), 2002, pp. 476–491.
[41] R. Goldenberg, R. Kimmel, E. Rivlin, and M. Rudzsky, “‘Dynamismof a dog on a leash’ or behavior classification by eigen-decompositionof periodic motions,” inProceedings of the European Conference onComputer Vision (ECCV). Copenhagen: Springer-Verlag, LNCS 2350,May 2002, pp. 461–475.
[42] K. Toyama and A. Blake, “Probabilistic tracking in a metric space,”in Proceedings of the International Conference on Computer Vision(ICCV), 2001, pp. 50–59.
[43] B. J. Frey and N. Jojic, “Learning graphical models of images, videosand their spatial transformation,” inProceedings of the Sixteenth Con-ference on Uncertainty in Artificial Intelligence - San Francisco, CA,2000, pp. 184 – 191.
[44] S. Roweis and L. Saul, “Nonlinear dimensionality reduction by locallylinar embedding,”Science, vol. 290, no. 5500, pp. 2323–2326, 2000.
[45] J. Tenenbaum, V. de Silva, and J. C. Langford, “A global geometricframework for nonlinear dimensionality reduction,”Science, vol. 290,no. 5500, pp. 2319 – 2323, 2000.
[46] J. B. Tenenbaum and W. T. Freeman, “Separating style andcontent withbiliear models,”Neural Computation, vol. 12, pp. 1247–1283, 2000.
[47] M. A. O. Vasilescu and D. Terzopoulos, “Multilinear analysis of imageensembles: Tensorfaces,” inProceedings of the European Conference onComputer Vision (ECCV), 2002, pp. 447–460.
[48] J. R. Magnus and H. Neudecker,Matrix Differential Calculus withApplications in Statistics and Econometrics. John Wiley & Sons, 1988.
[49] L. D. Lathauwer, B. de Moor, and J. Vandewalle, “A multilinearsingular value decomposiiton,”SIAM Journal On Matrix Analysis andApplications, vol. 21, no. 4, pp. 1253–1278, 2000.
[50] M. A. O. Vasilescu, “Human motion signatures: Analysis, synthesis,

IEEE TRANSACTION ON PATTERN RECOGNITION AND MACHINE INTELLIGENCE (UNDER REVIEW) 20
recogntion,” inProceedings of the International Conference on PatternRecognition (ICPR), vol. 3, 2002, pp. 456–460.
[51] A. Elgammal and C.-S. Lee, “Separating style and content on a nonlinearmanifold,” in Proceedings of the IEEE Computer Society Conference onComputer Vision and Pattern Recognition (CVPR), vol. 1, 2004, pp.478–485.
[52] N. D. Lawrence, “Gaussian process models for visualisation of highdimensional data,” inProceedings of Advances in Neural InformationProcessing (NIPS), 2004.
[53] J. G. Silva, J. S. Marques, and J. M. Lemos, “Non-linear dimension re-duction with tangent bundle approximation,” inProceedings of the IEEEInternational Conference on Acoustics, Speech, and SignalProcessing(ICASSP), 2005, pp. iv/85 – iv/88.
[54] M. Brand and A. Hertzmann, “Style machines,” inSIGGRAPH, 2000,pp. 183–192.
[55] J. H. Ham, D. D. Lee, and L. K. Saul, “Learning high dimensional corre-spondences from low dimensional manifolds,” inICML 2003 Workshopon The Continuum from Labeled to Unlabeled Data in Machine Learningand Data Mining, pp. 34–41.
[56] A. P. Shon, K. Grochow, A. Hertzmann, and R. Rao, “Learning sharedlatent structure for image synthesis and robotic imitation,” in Proceed-ings of Advances in Neural Information Processing (NIPS), 2006, pp.1233–1240.
[57] A. Gray, Modern Differential Geometry of Curves and Surfaces withMathematica, 2nd ed. CRC Press, 1997.
[58] G. S. Kimeldorf and G. Wahba, “A correspondence betweenbayesianestimation on stochastic processes and smoothing by splines.” TheAnnals of Mathematical Statistics, vol. 41, pp. 495–502, 1970.
[59] B. Schlkopf and A. Smola,Learning with Kernels: Support VectorMachines, Regularization, Optimization and Beyond. MIT Press, 2002.
[60] T. Poggio and F. Girosi, “Networks for approximation and learning,”Proceedings of the IEEE, vol. 78, no. 9, pp. 1481–1497, 1990.
[61] A. Elgammal, V. Shet, Y. Yacoob, and L. S. Davis, “Gesture recognitionusing a probabilistic framework for pose matching,” inThe SeventhInternational Conference on Control, Automation, Robotics and Vision,ICARCV 2002, 2002.
[62] L. Sigal and M. J. Black, “Humaneva: Synchronized videoand motioncapture dataset for evaluation of articulated human motion,” BrownUniversity, Tech. Rep. CS-06-08, 2006.
[63] A. Elgammal, D. Harwood, and L. S. Davis, “Non-parametric model forbackground subtraction.” inProceedings of the European Conference onComputer Vision (ECCV), 2000, pp. 751–767.
[64] C.-S. Lee and A. Elgammal, “Simultaneous inference of view andbody pose using torus manifolds.” inProceedings of the InternationalConference on Pattern Recognition (ICPR), 2006, pp. 489–494.