identificacion de sistemas teoria de … · teoria de estimaciÓn set-membership ... a...
TRANSCRIPT

IDENTIFICACION DE SISTEMASIDENTIFICACION DE SISTEMAS
Ing. Fredy Ruiz [email protected]
Maestría en Ingeniería ElectrónicaPontificia Universidad JaverianaPontificia Universidad Javeriana
20132013
TEORIA DE ESTIMACIÓN SET-MEMBERSHIPTEORIA DE ESTIMACIÓN SET-MEMBERSHIPFUNDAMENTOS E IDENTIFICACIÓN DE SISTEMASFUNDAMENTOS E IDENTIFICACIÓN DE SISTEMAS

Introducción• Diversos problemas como las regresiones lineales y no
lineales, la estima de parámetros de un sistema dinámico,
la predicción de una serie de tiempo, la interpolación de
una función, etc, tienen una estructura común y se
enmarcan dentro de un ámbito general llamado
PROBLEMA DE ESTIMACION GENERALIZADO
• En todos estos problemas se debe evaluar una variable
desconocida usando una cantidad de datos limitada, con
una incertidumbre asociada. Es necesario evaluar cómo
esta incertidumbre afecta la variable estimada.

Introducción• La solución del problema depende del tipo de
suposiciones que se hacen sobre la incertidumbre.– Hasta el momento hemos estudiado métodos en los
que se asume una fuente de incertidumbre dada por ruido estocástico aditivo, con distribución parcialmente conocida. En este contexto el estimador óptimo es dado por la MLE.
– En muchos contextos, hacer una hipótesis estocástica sobre la incertidumbre es cuestionable. Por ejemplo cuando se identifica un proceso complejo (no lineal) con una estructura de modelos sencilla.

Introducción• Una alternativa interesante, conocida como
aproximación Set Membership o Unknown but bounded UBB fue propuesta al final de los años 60 por Witsenhusen y Schweppe.
• En esta formulación, la incertidumbre se describe como ruido aditivo, del cual solo son conocidos limites superiores e inferiores, usualmente medidos en alguna norma.
• La formulación no tuvo una gran acogida. Solo hasta finales de los 80 inicio un “boom” de trabajos alrededor de este tipo de formulación.
• Durante los 90 se publican muchos trabajos aplicados a identificación de sistemas, motivados por el auge de la teoría de control robusto.

Introducción• A pesar de no ser tan conocida como las metodologías
PEM o Sub-Espacios, la teoría Set membership posee una formulación bien estructurada.
• Diversos grupos en el mundo trabajan activamente en esta formulación– Dahleh – MIT– Kacewicz – Traub (Alemania)– Chen, Gu – (Loussiana state – California)– Van den Hof – (Delf -Holanda)– Vicino – (U. Parma – Italia)– Milanese – (Politecnico di Torino - Italia)

Formulación basica• Ejemplo: estima del valor de una resistencia.Se realizan N medidas de voltaje y corriente, suponiendo
que la resistencia tiene una característica linealV = I R
Las medidas son afectadas por ruido aditivo desconocido
Se tienen entonces N ecuaciones lineales:

Formulación basica• Ejemplo:De manera matricial:
En general se tiene:
En este caso la función F es lineal
El objetivo es encontrar una estima de R mediante un algoritmo de estima o estimador aplicado al vector de datos y.

Formulación basica• Ejemplo2: estimar los parámetros de un modelo ARX.

Formulacion basica• Ejemplo2: de forma matricial:

Solución por mínimos cuadrados• Un algoritmo de estima para el caso lineal es mínimos
cuadrados.Teniendo en cuenta que los datos se relacionan como
La incertidumbre sobre las medidas produce el siguiente efecto sobre la estima:

Solución por mínimos cuadrados
• Las propiedades del error de estima dependen de las hipótesis que se realcen del ruido:– Ruido Aleatorio -> estima estadística– Ruido con amplitud limitada– Ruido con energía limitada– Ruido limitado en norma p
Estima Set Membership

Ruido Set Membership (UBB)• Se hace la hipótesis de que el vector de ruido que
afecta las medidas pertenece a un conjunto limitado.

Ruido Set Membership (UBB)• Gráficamente
Hipótesis: Be es simétrico respecto al origen de RN

Ruido Set Membership (UBB)• El conjunto de incertidumbre B
e introduce
incertidumbre en la estima del vector de parámetros, nos interesa evaluar la incertidumbre resultante.

Ruido Set Membership (UBB)

Ruido Set Membership (UBB)• Es de interés conocer el intervalo de incertidumbre de
cada una de las componentes del vector de parámetros, llamada Estimate Uncertainty Intervals (EUI):
• Se cumple que• Un limite superior de la distancia entre la estima y el
valor verdadero del parámetro es:

Ruido Set Membership (UBB)
• Graficamente:

Ruido Set Membership (UBB)• En el caso de ruido limitado en amplitud:
El conjunto de incertidumbre es un cubo en RN, que en el espacio de parámetros se transforma en un politopo.

Ruido Set Membership (UBB)• Es posible calcular los EUI como:

Ruido Set Membership (UBB)• En el caso de ruido limitado en energía:
El conjunto de incertidumbre es una esfera en RN, que en el espacio de parámetros se transforma en un elipsoide.

Ruido Set Membership (UBB)• Es posible computar los EUI como:

Estima optima Hemos analizado la incertidumbre de la estima por
mínimos cuadrados, pero:• Es el EUS el mas pequeño conjunto que contiene el
parámetro verdadero?• La estima por mínimos cuadrados produce los más
pequeños EUI?

Estima optima Hemos analizado la incertidumbre de la estima por
mínimos cuadrados, pero:• Es el EUS el mas pequeño conjunto que contiene el
parámetro verdadero?• La estima por mínimos cuadrados produce los más
pequeños EUI?La respuesta es NO. Consideremos el siguiente conjunto:
Un parámetro es compatible con los datos si:

Estima optima • El FPS es independiente del algoritmo de estima.• Si los datos fueron generados por un parámetro
“verdadero” y la hipótesis sobre la incertidumbre es verdadera, entonces pertenece al FPS.
Ademas:

Estima optima • Análogamente se pueden definir los intervalos de
incertidumbre de los parámetros compatibles (PUI):
• Que a su vez cumplen:

Estima optimaSi , entonces
Es decir que el FPS es un politopo ( un poliedro convexo) generado por desigualdades lineares del tipo:

Estima optimaAdemas los intervalos de parámetros compatibles son:
donde pueden ser obtenidos resolviendo problemas de programación lineal.

Estima optimaEn el caso de ruido limitado en energía:
Ademas:

Estima óptimaPara evaluar la calidad de una estima se realizan las
siguientes definiciones.• El error de una estima es
• Una estima es optima si
• Estima de mínimos cuadrados
• Estima central

Estima óptimaSe tienen los siguientes resultados:• La estima central es optima tanto en el caso
como en el caso , ademas:
• La estima de mínimos cuadrados es central en el caso y por lo tanto es óptima.

EjemploSe desea obtener un modelo estático de un transductor de
posición con la siguiente característica:
Usando un modelo lineal de la forma:

EjemploEn el intervalo de linealidad:
El mayor error se comete en la medida de la posición, por lo tanto el modelo se reescribe como:
Con e limitado a máximo 5mm.Los parámetros desconocidos son:

EjemploSe realizan N=23 medidas, que se pueden agrupar
matricialmente como:
con y la incógnita
Inicialmente se realiza una estima por mínimos cuadrados

EjemploInicialmente se realiza una estima por mínimos cuadrados
y se determinan los intervalos de incertidumbre de los parámetros:

Ejemplo y se determinan los intervalos de incertidumbre de los
parámetros:

Ejemplo

EjemploAhora se determinan los intervalos de parámetros
compatibles

Ejemplo
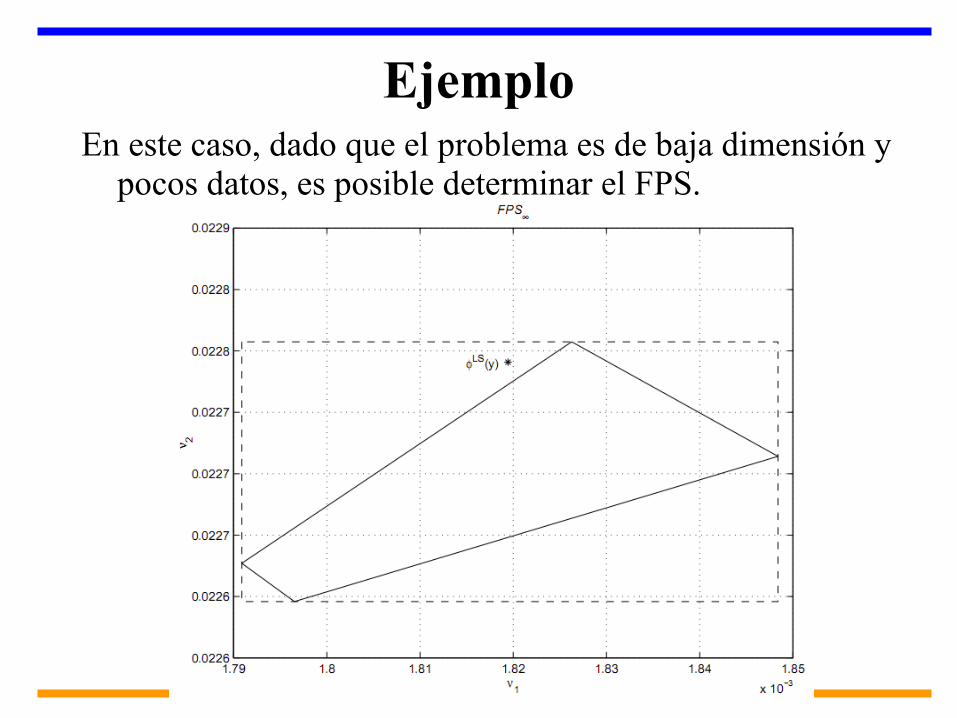
EjemploEn este caso, dado que el problema es de baja dimensión y
pocos datos, es posible determinar el FPS.

Ahora, cómo se aplica esta teoría a la estima de sistemas dinámicos?

Motivacion• PROBLEMA: Realizar una estima sobre un sistema
dinámico real S o, inicialmente en reposo, al cual se aplica
una entrada conocida u
Ejemplos de estima:– Predecir salidas futuras– Controlar las salidas futuras– Detección de fallas
Vector de medidas
(conocido)
Operador información(conocido)
Ruido de medida
(desconocido)

• Información experimental:– Medidas en el tiempo: N muestras de la salida del
sistema S o, inicialmente en reposo, ante una entrada conocida u
El operador información es:

• Información experimental:– Medidas en frecuencia: N/2 muestras de las partes real
e imaginaria de la respuesta en frecuencia del sistema So(ω
k).
El operador información es:

• Enfoque: – Estimar un modelo – Hacer la estima sobre – Calcular el error de estima E( ) cometido al hacer la
estima sobre y no sobre So.• Problemas:
– Dado un modelo , calcular el error E( ) – Buscar un modelo que de un error E( ) pequeño – Analizar el comportamiento de E( ) para N→∞– Diseñar un experimento tal que E( ) sea pequeño
• Sin realizar hipótesis sobre So y eN, el error E( ) es ilimitado.

• Hipótesis:– : Conjunto de modelos
dinámicos parametrizados.– : Ruido estocástico con f.d.p. conocida,
posiblemente filtrado.• Problema de estima paramétrica estadística:Dada la estructura de modelos:
Encontrar p tal que la secuencia eN es la más verosímil de acuerdo a las hipótesis estadísticas hechas sobre el error, por ejemplo ruido blanco.
Identificación estadistica

• Si , como sucede en muchos casos, entonces:
=
y(k) = Mn(p)*u(k) + Δ*u(k)
Como tener en cuenta el efecto de la dinámica no modelada?
Identificación estadistica
S0
Δ
Mn(p)
u(k) y(k) u(k) y(k)

• Hipótesis:– : El sistema pertenece a un subconjunto del
espacio de sistemas dinámicos LTI, con parametrización no necesariamente finita.
– : ruido UBB, eN es una señal limitada en amplitud pero NO se realizan hipótesis estadísticas sobre ella.
Identificacion de model-set

Identificacion de model-setFEASIBLE SYSTEM SET:
Conjunto de todos los
sistemas consistentes con las
hipótesis y con los datos
experimentales
(Unfalsified system set)

– FSS agrupa toda la información disponible sobre el sistema a identificar.
– si las hipótesis son ciertas.
– Si las hipótesis son demasiado débiles => FSS es ilimitado
– - Si las hipótesis son demasiado fuertes => FSS es vacío
Identificación del conjunto de modelos

Problema:
FSS es un conjunto definido de una manera compleja, y no viene
representado en una manera útil para el diseño de sistemas de
control. Se busca construir conjuntos de modelos que incluyan
el FSS y que tengan una forma adecuada.
Model set Un conjunto de modelos es un Model set para So si:
En esta formulación se usan model set con incertidumbre aditiva:
:Modelo nominal : Error de modelo (dinámica no modelada) : Norma en el espacio de los sistemas dinámicos

Dado un algoritmo de identificación:
Nos interesa medir el error cometido al usar en vez de So.
El error resultante es el mas bajo posible, garantizado solo
gracias a las hipótesis hechas.
Dado un modelo nominal , el model set aditivo mas pequeño
es:

El error de identificación de un algoritmo o modelo identificado
Model set óptimo:
• Un model set es óptimo si minimiza el error de
identificación par el efectivo conjunto de informaciones
disponible

Algoritmo óptimo:
• Un algoritmo es óptimo si minimiza el error de
identificación para cualquier conjunto de informaciones
posible.
• se denomina el radio de información, y
corresponde al mínimo error de identificación que se puede
cometer dado un conjunto de informaciones

Algoritmo óptimo:
• Es óptimo el algoritmo central:
• Es óptimo a su vez, el correspondiente model set central:
• PERO en muchos casos no existen métodos
computacionalmente viables para calcular el modelo central.
• Una alternativa es considerar Algoritmos Sub-óptimos

Algoritmos
• Existen muchos tipos de algoritmos, que dependen de:– Hipótesis hechas sobre So – Hipótesis hechas sobre eN
– Manera de operar los datos disponibles
• Los principales tipos de algoritmos son:– Lineales “untuned” – Lineales “tuned”– No lineales a dos pasos– Interpoladores -> “almost optimal”

Clasificación de los problemas de identificación
• De acuerdo con la norma que mide el error de
estima, el problema recibe un nombre diferente.
• Si el objetivo es usar el model set identificado para
diseñar un sistema de control usando técnicas de control
robusto, es de interés medir el error como la norma

Clasificación de los problemas de identificación• La hipótesis sobre el ruido puede realizarse considerando
cualquiera de los dos tipos de conjuntos vistos al inicio:
• En el caso de ruido limitado en amplitud, las matrices A y W
e permiten tener en cuenta variaciones de la amplitud
máxima del ruido y posible información sobre la correlación entre las muestras del ruido

Hipótesis sobre el sistema So
• Cada “teoría” de identificación hace hipótesis convenientes sobre el sistema real, en general :
espacio de Banach de los sistemas dinámicos SISO, en tiempo discreto, causales, LTI, BIBO-estables, eventualmente con parámetros distribuidos, con:
respuesta al impulso de
función de transferencia de
sistema real a identificar, con

Hipótesis sobre el sistema So
• Conjunto 1: So es un sistema exponencialmente estable, con un limite máximo del modulo de la función de transferencia dado por M>0, evaluada en un circulo de radio ρ>1.

Hipótesis sobre el sistema So
• Conjunto 2: So es un sistema exponencialmente estable, con una envolvente de la respuesta al impulso, con M>0 y ρ>1.
• Conjunto 3: So es un sistema exponencialmente estable, con un limite superior conocido de la derivada de la función de transferencia γ > 0.

Identificación H infinito• En este momento nos concentramos en la identificación
usando la siguiente norma:
La función de transferencia W permite pesar de manera diversa el error cometido en las diferentes bandas de frecuencia, con base en la aplicación en la cual se usara el modelo.

Identificación H infinito
• Se hace la hipótesis de que So pertenece al subconjunto K de sistemas dinámicos, con
• El ruido de medida pertenece al conjunto:

Identificación H infinito
Dadas todas las hipótesis sobre el sistema y el ruido, el FSS es:
– El FSS es un conjunto definido por vínculos lineales, dados por el subconjunto de sistemas K y por los límites en la amplitud del error,
– El FSS es un politopo convexo en el espacio infinito dimensional de los sistemas lineales.

Identificación H infinito
La primera pregunta que nos debemos hacer es si existe al menos un sistema que pertenezca al FSS.
Este viene llamado el problema de la feasibility.
Validación de las hipótesis “a priori”: Las hipótesis “a priori” se consideran validadas si FSS ≠ Ø

Identificación H infinitoTEOREMA: Dado un sistema , con respuesta impulso
, llamamos el sistema FIR que posee las mismas muestras de la respuesta al impulso de S. Es decir,
Entonces, sea la solución del siguiente problema de programación lineal
• FSS ≠ Ø si y solo si• FSS ≠ Ø si con y

Identificación H infinitoEl teorema anterior permite no solo validar si las hipótesis
realizadas son validas, sino también, seleccionar el subconjunto de modelos K y el nivel de ruido ε.

Identificación H infinitoUna vez se ha verificado que el FSS no es vació, se debe
escoger un sistema dentro del FSS como el sistema nominal:
y determinar su error de identificación.
Recordemos que en identificación H infinito la norma que mide la distancia entre los sistemas es:

VALUE SETLas hipótesis y los datos definen el FSS. Para cada
frecuencia ω, en el intervalo 0 a π, cada elemento S del FSS genera un punto en el plano complejo S(e jω), definido por el valor de su función de transferencia para esa frecuencia.
La transformada z es un operador lineal, por lo tanto, el FSS, que es un polítopo convexo infinitodimensional, viene mapeado como un polítopo convexo en el plano complejo, este polítopo recibe el nombre de value set.
Para una frecuencia dada , se define:

VALUE SETEl value set sigue siendo un conjunto complejo, a pesar de
pertenecer a R2. Es posible aproximar este conjunto, a través de politopos convexos computables mediante programación lineal.

ALGORITMO DE IDENTIFICACION NEARLY OPTIMALEs posible evaluar el value set para una cantidad de
frecuencias en el intervalo 0 a π.

ALGORITMO DE IDENTIFICACION NEARLY OPTIMALSe selecciona como sistema “nearly optimal” resolviendo el
siguiente problema de optimización convexa
con
s*(ωi ) corresponde a los vértices extremos del politopo
que contiene el value set.Se demuestra que el error de identificación del algoritmo
nearly optimal es al máximo

APROXIMACIONES DE BAJO ORDENEl algoritmo presentado da como resultado del proceso de
identificación un sistema FIR de orden υ, que puede ser demasiado alto.
En muchos casos interesa obtener un modelo nominal de bajo orden n, usualmente con algún tipo de parametrización, como:
En este caso el sistema optimo seria:
con
El modelo recibe el nombre de centro de Chebicheff condicionado del FFS y en general el problema de optimización resulta ser altamente no convexo.

APROXIMACIONES DE BAJO ORDENUna aproximación, que evita el tener que resolver un problema
de optimización no convexa es el siguiente:• Evaluar el value set para un numero suficientemente alto de
frecuencias• Obtener el modelo nominal nearly optimal• Utilizar técnicas de reducción de orden, como los métodos de
Hankel o de reducción balanceada, para obtener modelos aproximados , con orden n conveniente.
• Evaluar el nivel de optimalidad del model set resultante• Seleccionar n, como un trade-off entre complejidad y
precisión.• Para el modelo seleccionado, construir una mascara que
aproxima la incertidumbre

EJEMPLODado el sistema:
Se generan 1100 muestras de la salida ante una entrada PRBS, afectadas por ruido blanco limitado como

EJEMPLO
Para obtener una idea inicial del subconjunto de sistemas al que pertenece So, se aplica una estima PEM con clase de modelos ARX y se observa la respuesta al impulso de los modelos identificados.

EJEMPLOLuego se aplica el teorema de validación para seleccionar los
parámetros L y ρ.

EJEMPLOEn seguida se construye el value seten 500frecuenciasequi-espaciadas.

EJEMPLOMuestras de las aproximaciones del value set en algunas
frecuencias.

EJEMPLOLuego se obtiene el modelo nearly optimal.

EJEMPLOPor ultimo, se realiza una reducción de orden.

EJEMPLOLa tabla muestra el error de identificación y el nivel de
optimalidad de los modelos estimados, arriba para el FIR nearly optimal de orden 150 y abajo, para los modelos de bajo orden obtenidos aplicando técnicas de reducción de orden.