icde 2014参加報告資料
DESCRIPTION
ACM SIGMOD日本支部第56回支部大会でお話しした、ICDE 2014の参加報告についての資料です。以下のような6部構成になっています。全190ページです。 ・ICDE 2014を俯瞰してみる(5p~) ・ビッグデータ時代の新発想:もうデータは蓄えない(32p~) Keynote, Running with Scissors: Fast Queries on Just-in-Time Databases ・見えない相手と協調作業:センサネットワーク上のデータ集約(64p~) 10 Year Most Influential Paper, Approximate Aggregation Techniques for Sensor Databases ・メインメモリデータベースがハードウェアトランザクショナルメモリを使ったら…(96p~) Best Paper, Exploiting Hardware Transactional Memory in Main-Memory Databases ・過去の結果を再利用:ビューを用いた大規模グラフからのパターン発見(126p~) Best Paper Runner-up, Answering Graph Pattern Queries Using Views ・アルゴリズムでゴリゴリ解決:大量のベクトルから類似ペアを厳密に見つけたい(155p~) 気になる論文, L2AP: Fast Cosine Similarity Search With Prefix L-2 Norm BoundsTRANSCRIPT


自己紹介
白川真澄(Masumi Shirakawa)
大阪大学 大学院情報科学研究科 西尾研究室 特任助教
Webマイニング(Wikipedia, Twitter),知識ベースの自動構築
現在は知識ベースや機械学習手法を利用した応用の研究がメイン
データベースコア技術とかはあんまりよく知らない(すみません)
2011年4~9月 Microsoft Research Asiaインターン
2013年3月 博士号取得
2013年4月~ 逆選挙管理委員会メンバー
ねこ,温泉,ぐうたら
2

目次
前半
• ICDE 2014を俯瞰してみる
• ビッグデータ時代の新発想:もうデータは蓄えない[Keynote] Running with Scissors: Fast Queries on Just-in-Time Databases
• 見えない相手と協調作業:センサネットワーク上のデータ集約[10 Year Most Influential Paper] Approximate Aggregation Techniques for Sensor Databases
後半
• メインメモリデータベースがハードウェアトランザクショナルメモリを使ったら…[Best Paper] Exploiting Hardware Transactional Memory in Main-Memory Databases
• 過去の結果を再利用:ビューを用いた大規模グラフからのパターン発見[Best Paper Runner-up]Answering Graph Pattern Queries Using Views
• アルゴリズムでゴリゴリ解決:大量のベクトルから類似ペアを厳密に見つけたい[気になる論文]L2AP: Fast Cosine Similarity Search With Prefix L-2 Norm Bounds
途中で会場の雰囲気などもお伝えします3

目次
前半
• ICDE 2014を俯瞰してみる
• ビッグデータ時代の新発想:もうデータは蓄えない[Keynote] Running with Scissors: Fast Queries on Just-in-Time Databases
• 見えない相手と協調作業:センサネットワーク上のデータ集約[10 Year Most Influential Paper] Approximate Aggregation Techniques for Sensor Databases
後半
• メインメモリデータベースがハードウェアトランザクショナルメモリを使ったら…[Best Paper] Exploiting Hardware Transactional Memory in Main-Memory Databases
• 過去の結果を再利用:ビューを用いた大規模グラフからのパターン発見[Best Paper Runner-up]Answering Graph Pattern Queries Using Views
• アルゴリズムでゴリゴリ解決:大量のベクトルから類似ペアを厳密に見つけたい[気になる論文]L2AP: Fast Cosine Similarity Search With Prefix L-2 Norm Bounds
途中で会場の雰囲気などもお伝えします4

30th IEEE International Conference on Data Engineering(ICDE 2014)
• データベース系のトップカンファレンスの一つと言われている(データ工学なのでSIGMODやVLDBよりもちょっと幅広い?)
• 本会議:4月1~3日(ワークショップは3月31日)
• 開催地:イリノイ州シカゴ(アメリカのこのへん)
• 会場:Holiday Inn Chicago Mart Plaza
5

ICDE 2014のスポンサー
Platinum
Silver
Bronze
6

ICDE 2014のスポンサー
Platinum
Silver
Bronze
Nokia発,すごい地図サービス カタールのすごい研究所DB, NLP, IR, Web, HCIなど幅広い
パデュー大学
7
ノースウェスタン大学
すごい会社
すごい会社

ICDE 2014の投稿数など
投稿数• Research paper: 446件
• Industrial paper: 33件
• Demo paper: 65件
査読• 16のトピック&area chairs
• 1つの論文に査読者3人
• 査読者総数• Research paper: 158人
• Industrial paper: 20人
• Demo paper: 13人
採択数,採択率• Research paper: 89件(20.0%)
• Industrial paper: 10件(30.3%)うちショート3件
• Demo paper: 28件(43.1%)
キーノート:2件
チュートリアル:6件
ワークショップ:7件
パネルディスカッション:2件
8

キーノート:2件
Running with Scissors: Fast Queries on Just-in-Time Databases
Anastasia Ailamaki
Ecole Polytechnique Federalede Lausanne (EPFL)
Transforming Big Data into Smart Data: Deriving Value via Harnessing Volume, Variety and Velocity Using Semantics and Semantic Web
Amit ShethKno.e.sis, Wright State University
9
こちらはあとで詳しく紹介

チュートリアル:6件
Tutorial 1: Linked Data Query Processing
Tutorial 2: Data Stream Warehousing
Tutorial 3: Data Quality: The other Face of Big Data
Tutorial 4: Just-in-time Compilation for SQL Query Processing
Tutorial 5: Managing Uncertainty in Spatial and Spatio-temporal Data
Tutorial 6: Distributed Execution of Continuous Queries
10
チュートリアルはDBコア技術に偏っている

ワークショップ:7件• 5th International Workshop on Graph Data Management: Techniques and
Applications (GDM 2014)
• 10th International Workshop on Information Integration on the Web (IIWeb 2014)
• BDCA 2014: Workshop on Big Data Customer Analytics
• Long Term Preservation for Big Scientific Data (LOPS)
• 6th International Workshop on Cloud Data Management (CloudDB 2014)
• 5th International Workshop on Data Engineering meets the Semantic Web (DESWeb 2014)
• 9th International Workshop on Self-Managing Database System (SMDB 2014)
11
ワークショップはDBコア技術だけでなく,Webやグラフなど,多様である

パネルディスカッション:2件
Panel 1 Main-Memory Database Systems
Panel Moderators: Alfons Kemper (Technische Universität München), Thomas Neumann (Technische Universität München)
Panelists: Daniel Abadi (Yale University), Anastasia Ailamaki (EPFL), Paul Larson (Microsoft Research), Guy Lohman (IBM Research Almaden), Stefan Manegold (Centrum Wiskunde & Informatica), Eric Sedlar (Oracle Labs)
Panel 2: Automated Mobility: How Environment Awareness Technologies will “Drive” the Intelligent Transportation of the Future
Panel Moderators: Xin Chen (HERE)
Panelists: Vlad Zhukov (HERE), Ouri Wolfson (Dept. of CS, UIC), Wende Zhang(Sr. Researcher, GM), Hai Lin (Dept. of EE, Notre Dame University)
12

初日のタイムテーブル
13
つめすぎ

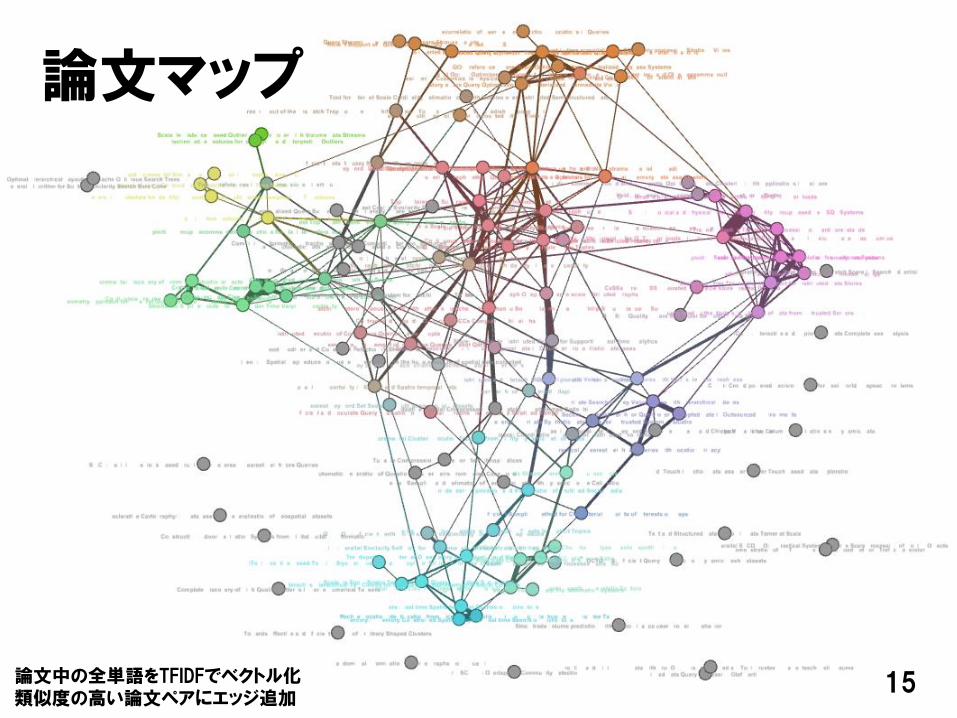
15
論文マップ
論文中の全単語をTFIDFでベクトル化類似度の高い論文ペアにエッジ追加
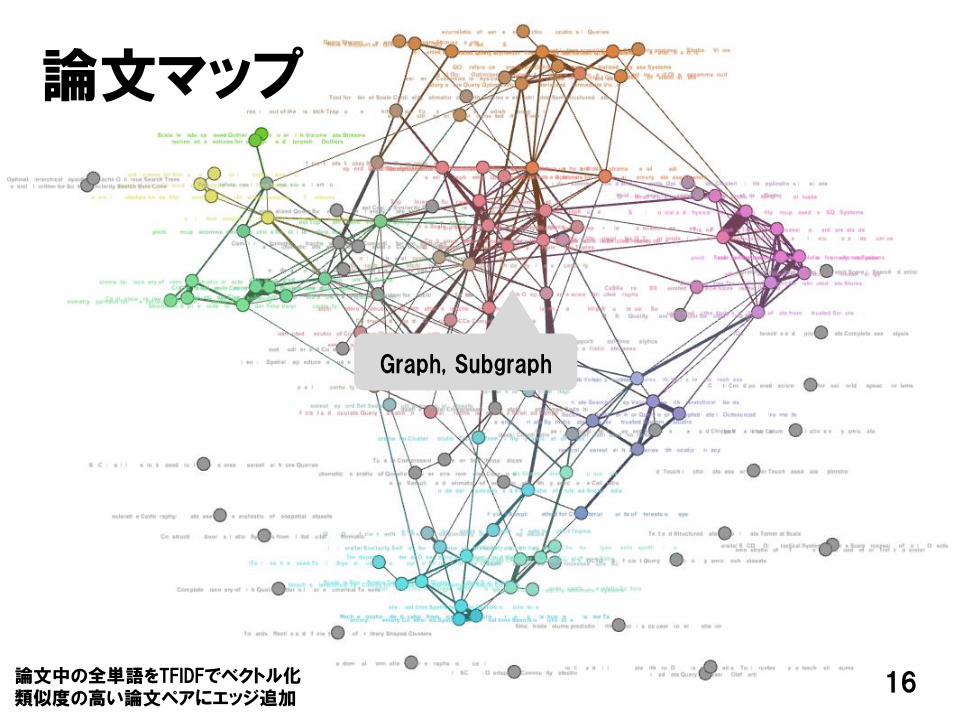
16
論文マップ
Graph, Subgraph
論文中の全単語をTFIDFでベクトル化類似度の高い論文ペアにエッジ追加
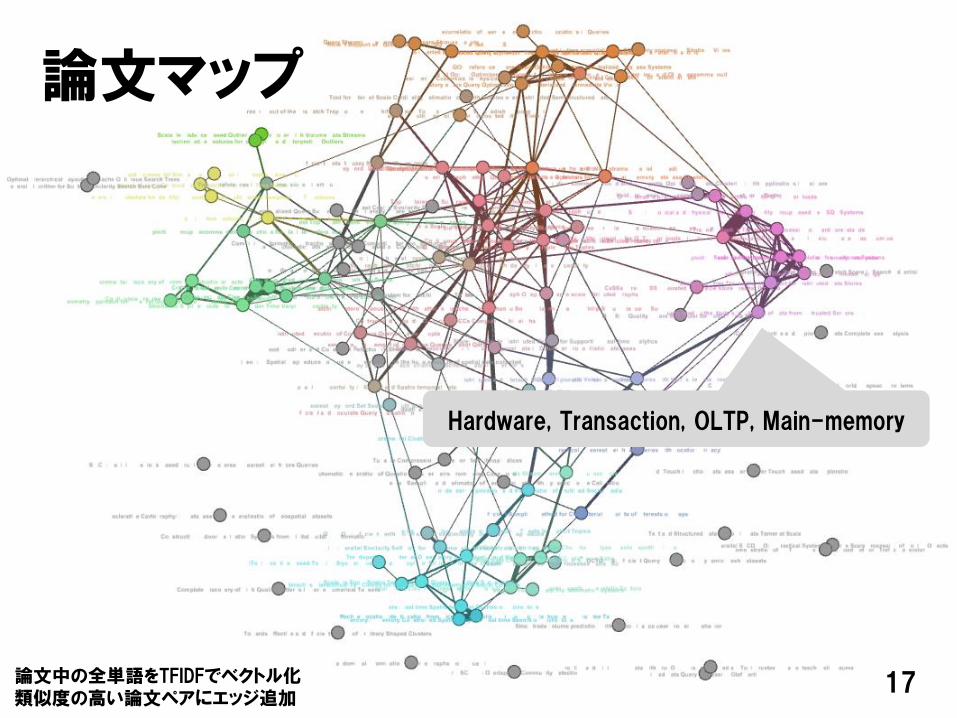
17
論文マップ
Hardware, Transaction, OLTP, Main-memory
論文中の全単語をTFIDFでベクトル化類似度の高い論文ペアにエッジ追加
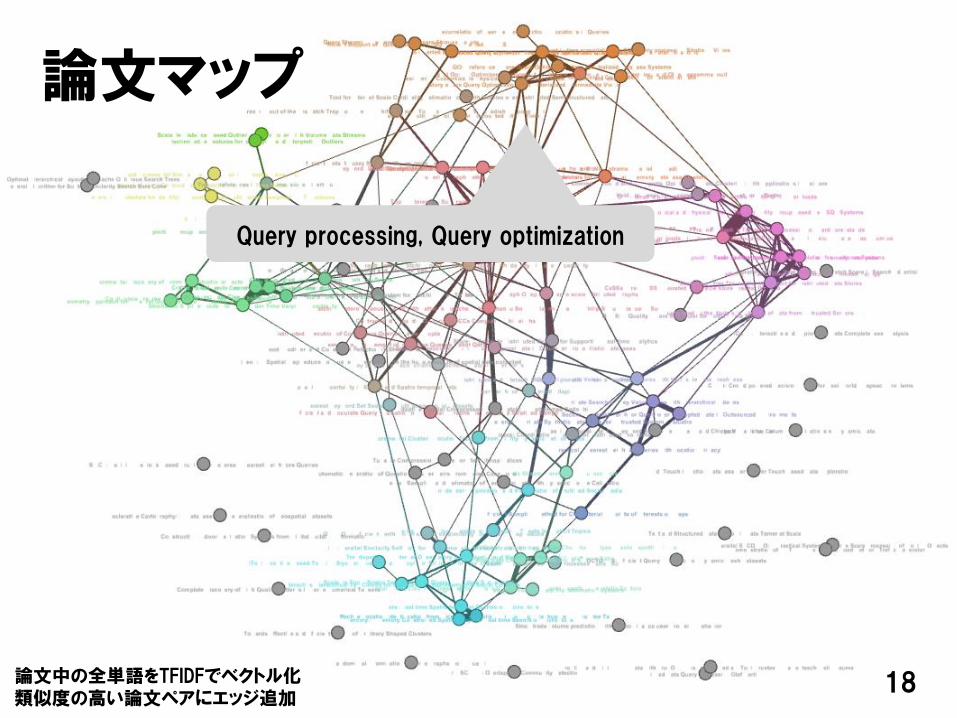
18
論文マップ
Query processing, Query optimization
論文中の全単語をTFIDFでベクトル化類似度の高い論文ペアにエッジ追加

19
論文マップOutlier
Top-k, Ranking
Skyline
論文中の全単語をTFIDFでベクトル化類似度の高い論文ペアにエッジ追加

20
論文マップ
Crowdsourcing
論文中の全単語をTFIDFでベクトル化類似度の高い論文ペアにエッジ追加
21
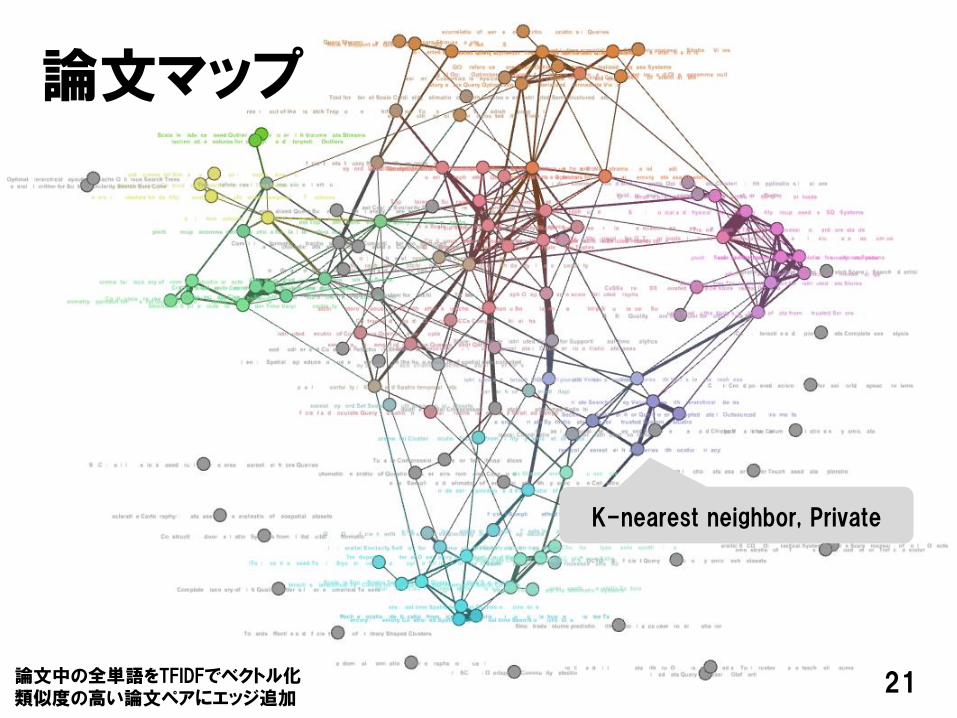
論文マップ
K-nearest neighbor, Private
論文中の全単語をTFIDFでベクトル化類似度の高い論文ペアにエッジ追加

22
論文マップ
Data cleaning, Data quality
論文中の全単語をTFIDFでベクトル化類似度の高い論文ペアにエッジ追加
23
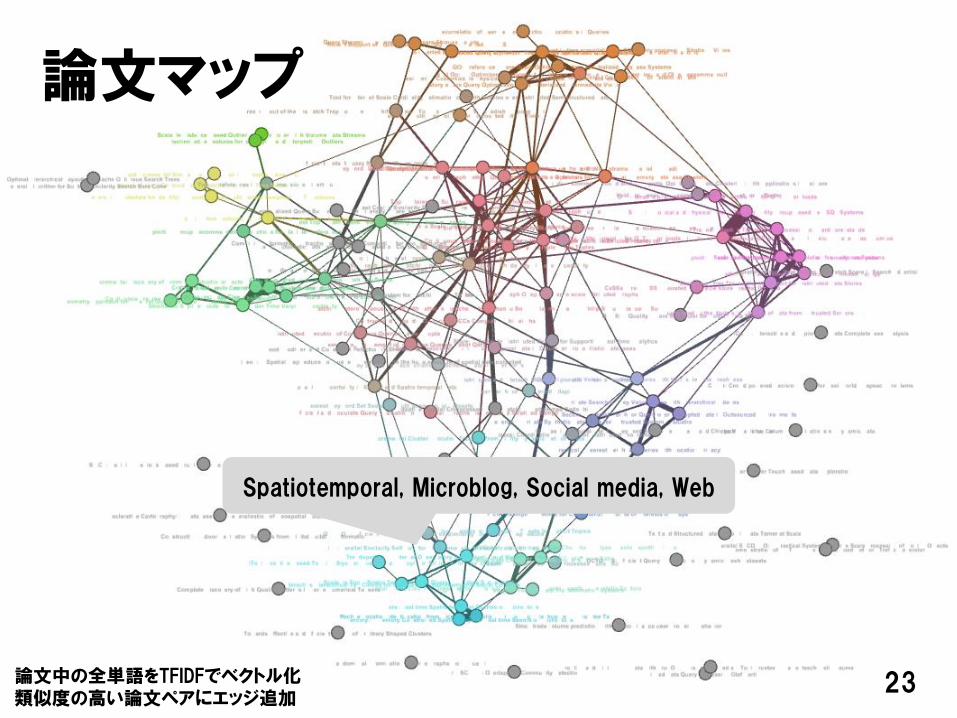
論文マップ
Spatiotemporal, Microblog, Social media, Web
論文中の全単語をTFIDFでベクトル化類似度の高い論文ペアにエッジ追加
24
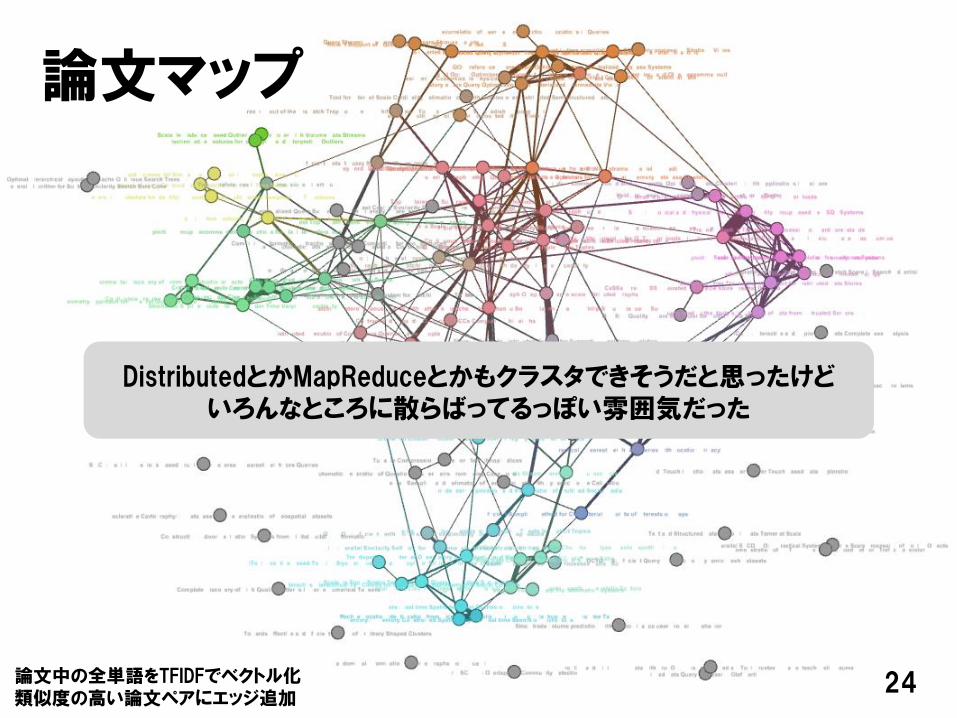
論文マップ
DistributedとかMapReduceとかもクラスタできそうだと思ったけどいろんなところに散らばってるっぽい雰囲気だった
論文中の全単語をTFIDFでベクトル化類似度の高い論文ペアにエッジ追加

論文マップについて
グラフ生成用のコード:https://github.com/iwnsew/papermap
PDFからテキスト抽出→TFIDFベクトル生成→類似度の高い論文をつないだグラフ生成
pythonで実装,gensimパッケージが必要(easy_installとかpipでインストールできる)
ICDE 2014の論文マップデータ(GEXF形式):上のやつに入ってる
グラフ可視化に定評のあるgephiで開くのがおすすめ
さっきのやつの色付けは手作業
こんな人におすすめ!
国際会議に参加してその報告を2時間半ぐらいしろという依頼がきた人とか
25

ICDE 2014にみるデータ工学の概観
(大規模)グラフ系はまだまだすごい盛り上がってる
論文マップの真ん中にあったしDBのいろんな研究と親和性あるのかな
DBコア技術はハードウェアまで気にしないといけない時代
DBのプロダクトに詳しくないと大変そう,なかなか日本の大学で学べるところとか少なそう
分散処理,並列処理に関する研究も非常に多い
DBコア技術だけでなく,既存の問題を分散環境に持っていったような研究もたくさん
全部「ビッグデータ」を扱うための研究らしい
26

ビッグデータとは? by Prof. Dan Ariely
27at CIKM 2013

ビッグデータとは? by Prof. Dan Ariely
ビッグデータとは10代のセックスのようなものだ。
皆がそれについて話し、
誰も本当はそのやり方について知らず、
皆が他の人は全員それをやっているものだと思い、
だから皆が自分もそれをやっていると主張する。
28at CIKM 2013

この後にはこう続くはず
ビッグデータとは10代のセックスのようなものだ。
皆がそれについて話し、
誰も本当はそのやり方について知らず、
皆が他の人は全員それをやっているものだと思い、
だから皆が自分もそれをやっていると主張する。
しかし実際にはそのやり方を知っている者もいる。
29at CIKM 2013

ビッグデータとは?
ただデータ量が大きいというだけでこれまで通用していたやり方が通用しなくなる,そんな規模のデータ
単語の出現頻度を数えることすら,今までのやり方ではできなくなったりする
別にビッグだろうがスモールだろうが,データを分析してより意味のある情報を抜き出すことは可能だし,実際これまでもされてきたので,「データを使って何をやるか」は関係ない
そんなビッグデータを取り扱うための研究・技術が必要
特に大量のデータを「蓄える」ことよりも「高速に処理する」ことが肝要
ICDE 2014でも分散処理,メインメモリデータベースなど,ビッグデータに立ち向かうための研究が盛り上がっていた
30

目次
前半
• ICDE 2014を俯瞰してみる
• ビッグデータ時代の新発想:もうデータは蓄えない[Keynote] Running with Scissors: Fast Queries on Just-in-Time Databases
• 見えない相手と協調作業:センサネットワーク上のデータ集約[10 Year Most Influential Paper] Approximate Aggregation Techniques for Sensor Databases
後半
• メインメモリデータベースがハードウェアトランザクショナルメモリを使ったら…[Best Paper] Exploiting Hardware Transactional Memory in Main-Memory Databases
• 過去の結果を再利用:ビューを用いた大規模グラフからのパターン発見[Best Paper Runner-up]Answering Graph Pattern Queries Using Views
• アルゴリズムでゴリゴリ解決:大量のベクトルから類似ペアを厳密に見つけたい[気になる論文]L2AP: Fast Cosine Similarity Search With Prefix L-2 Norm Bounds
途中で会場の雰囲気などもお伝えします31

Running with Scissors: Fast Queries on Just-in-Time Databases
Anastasia AilamakiEcole Polytechnique Federale de Lausanne (EPFL)
ICDE 2014 Keynote
I appreciate Professor Anastasia Ailamaki for giving me a deck of slides.
間に合わせの~
32

データ量 V.S. 記憶容量
データ量の勝ち!
データ量のほうが成長速度が速く,全部のデータをずっとDBMSに蓄え続けることは難しくなってくるだろう,というかもうなってる
33
もうストレージに全部蓄えられない!
でも全部蓄える必要あるの?
キーノート資料より

どのデータがアクセスされる?[VLDB12][IISWC12]
アクセスされるデータは局所的
80%のCloudera customer jobsが1~8%のデータにアクセス
90%のFacebook jobsが10%未満のデータを読み込み
しかも新しいデータばかり
80%のデータの再利用が3時間以内
85%のアクセスは1日以内に新しく発生したデータが対象
34
[VLDB12] Chen et al., Interactive Query Processing in Big Data Systems: A Cross-Industry Study of MapReduce Workloads, VLDB 2012.[IISWC12] Abad et al., A Storage-Centric Analysis of MapReduce Workloads: File Popularity, Temporal Locality and Arrival Patterns, IISWC 2012.
やっぱ全部蓄える必要なくね?

データの取捨選択が必要
データを有益な情報に変える
→「生データ」から「有益な情報」までの間で不要なデータをScissors(ハサミ)で切り落とすことになる
35キーノート資料より

Traditionalなやり方
汎用的なDBで何にでも対応
その結果,無駄なデータをたくさん抱えることになる
36キーノート資料より
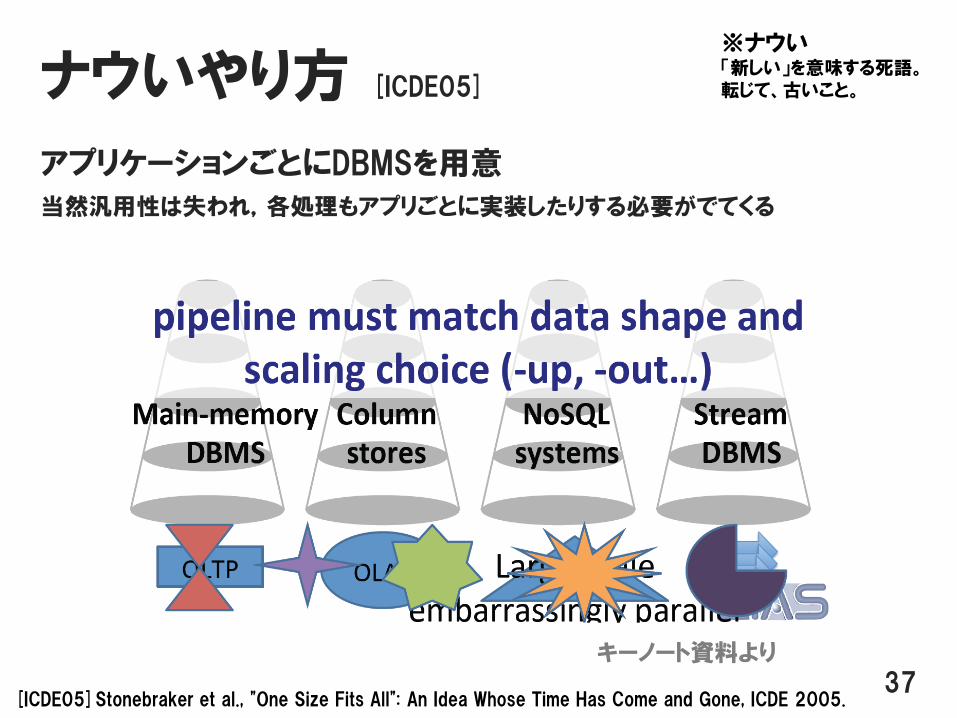
ナウいやり方 [ICDE05]
アプリケーションごとにDBMSを用意
当然汎用性は失われ,各処理もアプリごとに実装したりする必要がでてくる
37キーノート資料より
[ICDE05]Stonebraker et al., "One Size Fits All": An Idea Whose Time Has Come and Gone, ICDE 2005.
※ナウい「新しい」を意味する死語。転じて、古いこと。

そこでRunning with Scissorsだ!
「走りながら(クエリ処理しながら)」不要なデータを切り落とす
1. 処理の流れを無駄なく! → アプリの要求を理解し,それに合わせてDBを最適化
2. 処理の流れをアジャイルに!
38
キーノート資料より

おさらい:TraditionalなDBMSでは…
実運用では全データが必要なわけではない
しかしどのデータが必要かは(データ格納時には)分からない
生データをDBにコピーしてるようなもの → 冗長
ベンダーごとに制約あり
39キーノート資料より
データやアプリをクエリエンジンに合わせる形に
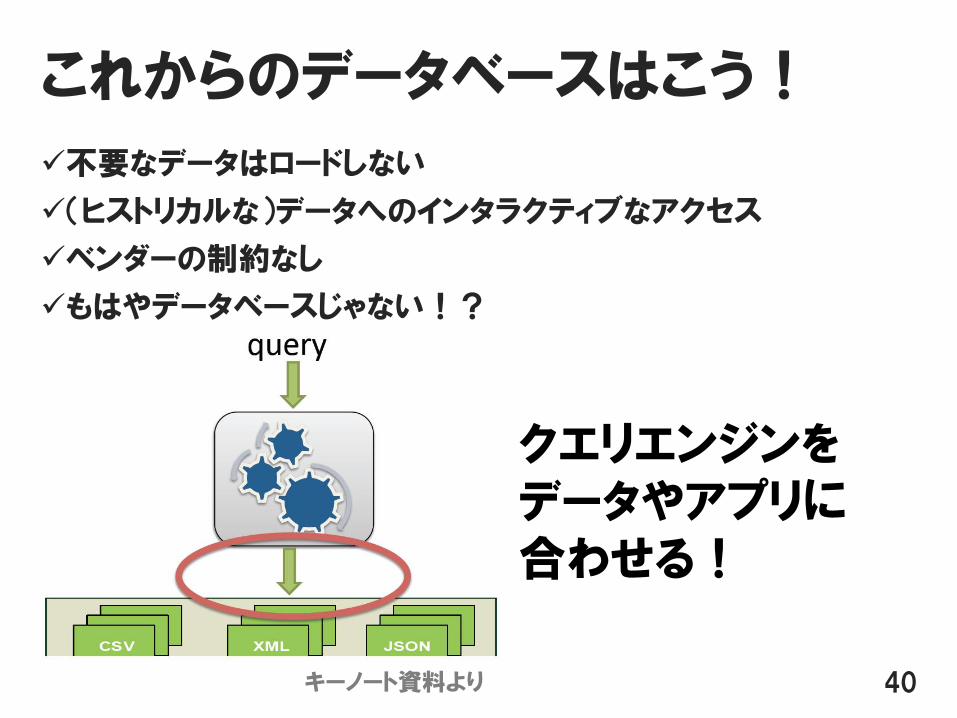
これからのデータベースはこう!
不要なデータはロードしない
(ヒストリカルな)データへのインタラクティブなアクセス
ベンダーの制約なし
もはやデータベースじゃない!?
40
クエリエンジンをデータやアプリに合わせる!
キーノート資料より

NoDB: In-situ queries on raw data[CIDR11][SIGMOD12]
そう、もはやデータベースじゃない。
といっても一応はJust-in-timeな(=間に合わせの)データベースを作ることになる
クエリ処理しながらキャッシュしたりインデクシングしたりする → 徐々に高速化
41[CIDR11] Idreos et al., Here are my Data Files. Here are my Queries. Where are my Results?, CIDR 2011.[SIGMOD12] Alagiannis et al., NoDB: Efficient Query Execution on Raw Data Files, SIGMOD 2012.
キーノート資料より

NoDBの評価 (1/2)
PostgresRAW: PostgreSQLをNoDB用に拡張したもの
データロードないけどクエリ処理にはちゃんと対応できてて高速!
42キーノート資料よりとある商用のシステム,どことは書かれていない
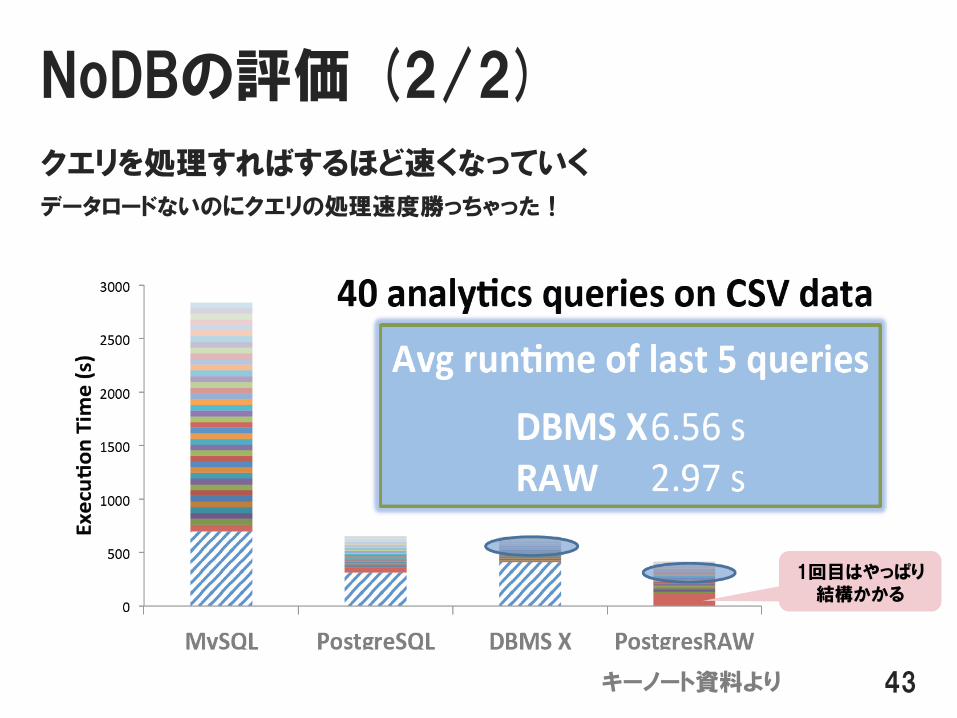
NoDBの評価 (2/2)
クエリを処理すればするほど速くなっていく
データロードないのにクエリの処理速度勝っちゃった!
43キーノート資料より
1回目はやっぱり結構かかる

NoDBの評価 (2/2)
クエリを処理すればするほど速くなっていく
データロードないのにクエリの処理速度勝っちゃった!
44キーノート資料より
1回目はやっぱり結構かかる
なぜNoDBは速い?
Traditionalなデータベースとクエリ処理の動作を比較してみよう
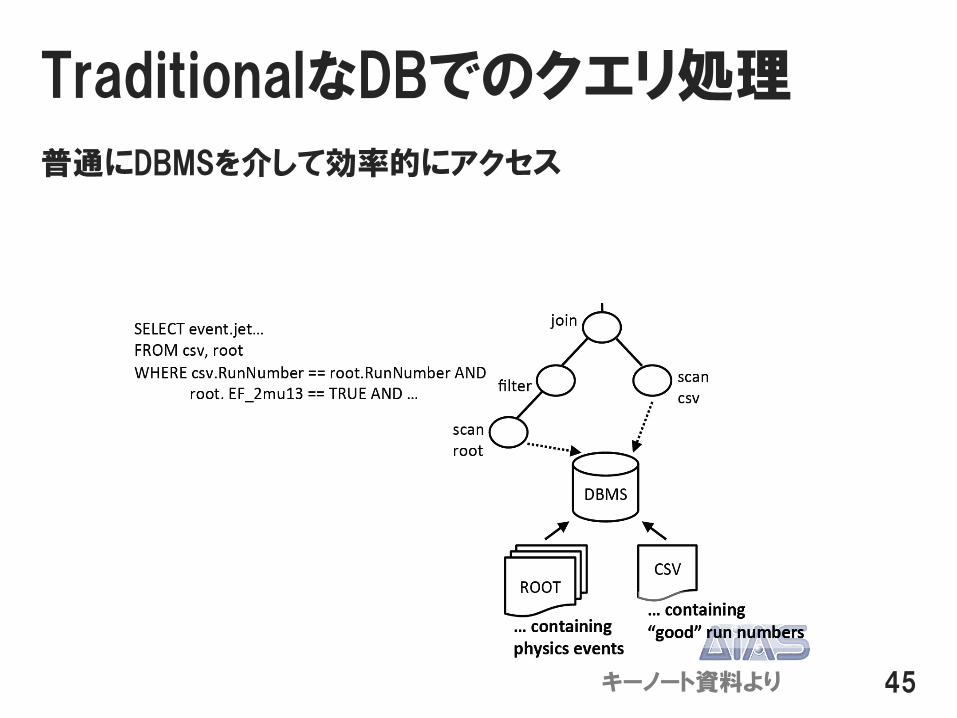
TraditionalなDBでのクエリ処理
普通にDBMSを介して効率的にアクセス
45キーノート資料より

NoDBでのクエリ処理
クエリを処理しながら以降のクエリのために色々備える
実世界のデータのアクセスパターンが偏っていることを利用して,クエリを処理しながらアクセスパターンを学習し,より効率的に有益なデータの在り処をマーキングしていく
46キーノート資料より

NoDBでのクエリ処理
クエリを処理しながら以降のクエリのために色々備える
実世界のデータのアクセスパターンが偏っていることを利用して,クエリを処理しながらアクセスパターンを学習し,より効率的に有益なデータの在り処をマーキングしていく
47キーノート資料より
こうなってくるとデータマイニングや機械学習っぽくてDBコアな人以外も結構興味が湧いてくるのでは!?
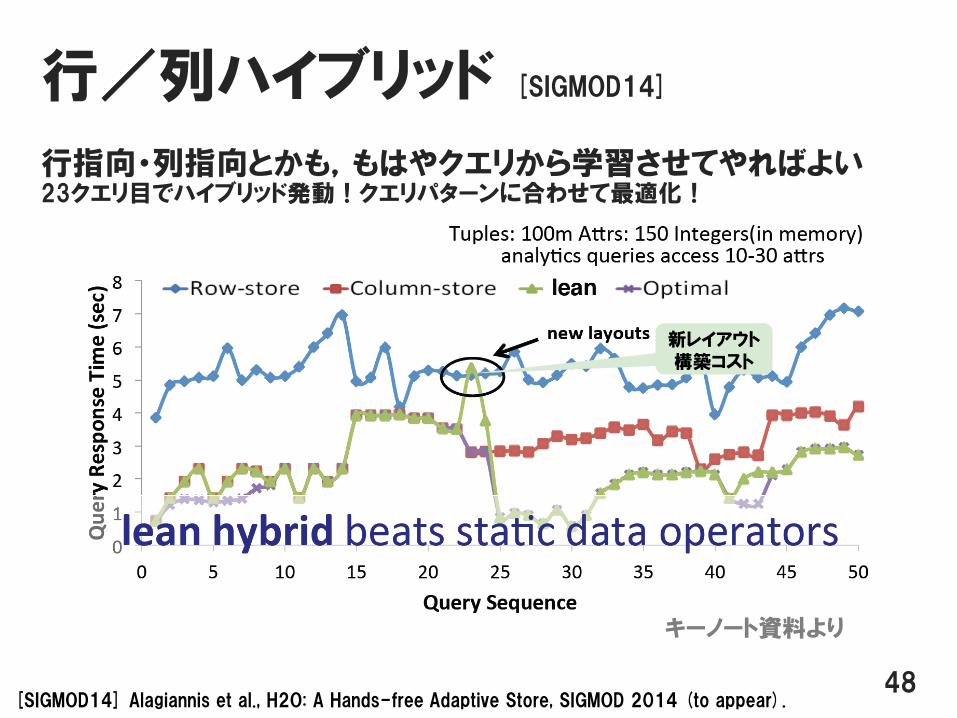
行/列ハイブリッド [SIGMOD14]
行指向・列指向とかも,もはやクエリから学習させてやればよい23クエリ目でハイブリッド発動!クエリパターンに合わせて最適化!
48[SIGMOD14] Alagiannis et al., H2O: A Hands-free Adaptive Store, SIGMOD 2014 (to appear).
キーノート資料より
新レイアウト構築コスト

結局のところ,NoDBとは?
クエリを走らせながら,それらのクエリの処理を高速化するように最適化させたJust-in-timeなDBを構築していく,というもの
実環境ではデータアクセスは偏ってる,だからこそうまくキマる
準備(=データをDBMSに格納する部分)が不要,なのに準備した場合よりも速くできる
49

他のJust-in-TimeなDBたち
DBToaster: custom embedded query engines [VLDB12]
HyPer: efficiency through data centric code generation [VLDB11]
Database cracking: data driven indexing [CIDR07]
MonetDB: data vaults [SSDBM12]
Hadapt: invisible loading [EDBT13]
50
[VLDB12] Ahmad et al., DBToaster: Higher-order Delta Processing for Dynamic, Frequently Fresh Views, VLDB 2012.[VLDB11] Neumann et al., Efficiently Compiling Efficient Query Plans for Modern Hardware, VLDB 2011.[CIDR07] Idreos et al., Database Cracking, CIDR 2007.[SSDBM12] Ivanova et al., Data Vaults: A Symbiosis between Database Technology and Scientific File Repositories, SSDBM 2012.[EDBT13] Abouzied et al., Invisible Loading: Access-Driven Data Transfer from Raw Files into Database Systems, EDBT 2013.

Running with Scissors
「走りながら(クエリ処理しながら)」不要なデータを切り落とす
1. 処理の流れを無駄なく! → アプリの要求を理解し,それに合わせてDBを最適化
2. 処理の流れをアジャイルに! → ワークをスライスしてローカリティをフォロー(!?)
※ここから先は雑になります
51
キーノート資料より

ムーアの法則の終焉
Mooreの法則
半導体の集積密度が2年で2倍になるとかいう経験則
2020~2022年ぐらいに限界がくると言われている
Dennardスケーリング
小型化により速度,集積度,消費電力が全部良くなる
例:トランジスタサイズを1/k倍 → 消費電力は1/k2倍に
52
データはどんどんビッグになってくけれど,もうハード的な性能改善に頼れないから,リソースを無駄遣いする余裕はもうない

スケールアップしたいが…
階層的にするとストール(待機=無駄な待ち)が発生しやすくなるキャッシュミス → メモリストール発生
53キーノート資料より

CloudSuiteベンチマーク [ASPLOS12]
クラウドでのワークロードはストールに苦しんでいる
54
キーノート資料より
[ASPLOS12] Ferdman et al., Clearing the Clouds: A Study of Emerging Scale-out Workloads on Modern Hardware, ASPLOS 2012.
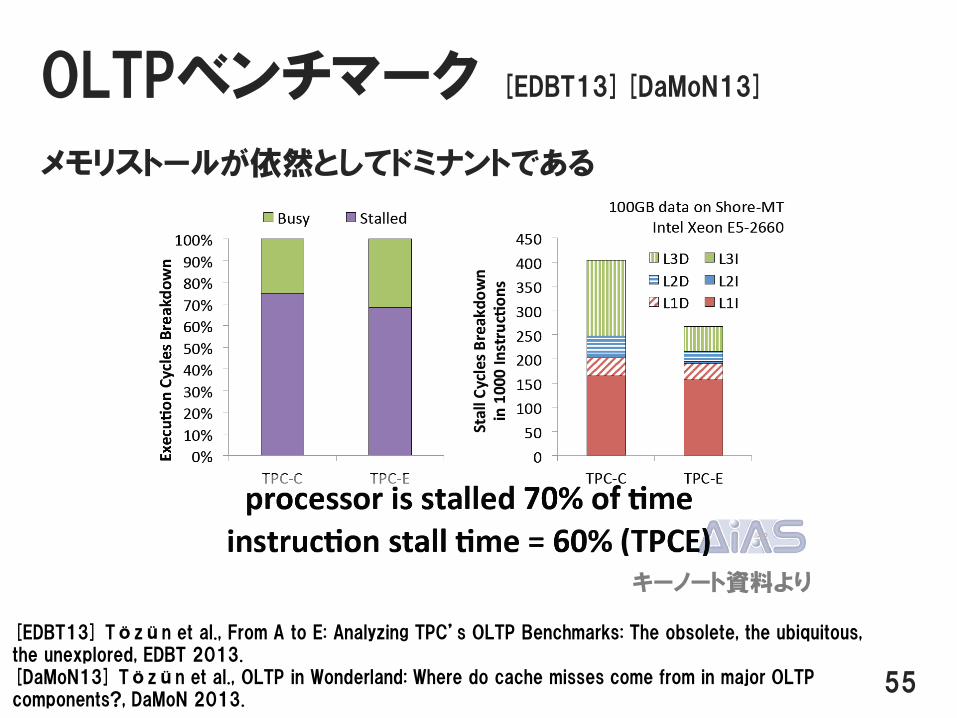
OLTPベンチマーク [EDBT13][DaMoN13]
メモリストールが依然としてドミナントである
55
キーノート資料より
[EDBT13] Tözün et al., From A to E: Analyzing TPC’s OLTP Benchmarks: The obsolete, the ubiquitous, the unexplored, EDBT 2013.[DaMoN13] Tözün et al., OLTP in Wonderland: Where do cache misses come from in major OLTP components?, DaMoN 2013.

Overlap across transactions [EPFL14]
インストラクション(命令)はオーバーラップ(似た順序のもの)が多い
ということは,命令は複数のトランザクションで共有できそう!?
56
キーノート資料より
[EPFL14] Tözün et al., ADDICT: Advanced Instruction Chasing for Transactions, EPFL technical report, 2014.

L1キャッシュの自己組織化 [MICRO12]
似たような命令がきたらトランザクションの命令を別のコアにコピー
命令のキャッシュミスをできる限り防ぐ!すなわちメモリストールをできる限り減らす!
57
キーノート資料より
[MICRO12] Atta et al., SLICC: Self-Assembly of Instruction Cache Collectives for OLTP Workloads, MICRO 2012.

Fine-grain instruction overlap [VLDB15]
L1キャッシュ間で命令を使いまわすことでスループットが劇的に改善
58
キーノート資料より
[VLDB15] 情報がまだ出ていない!

まとめ
データの成長にもう追いつけない!DBに蓄えきれない!
→ じゃあもう全部蓄えるのはやめにしよう
生データの中から必要なところだけすぐにアクセスできればいい
→ NoDB(もうDBじゃない)な考え方
データをいちいちDBMSに格納するのではなく,生データに対してクエリを処理しながら,それらのクエリに最適化したキャッシングとかインデクシングとかをする
実世界の「偏り」を分析し,それをうまく利用することが大事
ノーフリーランチ定理:あらゆるパターンに万能な手法は存在しない
だから現実に発生しやすいパターンにだけすごい性能を出せるようなやり方を模索している
59

まとめ:今後研究が必要な技術(キーノート資料そのままです)
Declarative tools (e.g., list comprehensions)
Dynamic code generation
Stream processing
Synopses
60

Transforming Big Data into Smart Data:Deriving Value via Harnessing Volume, Variety and
Velocity Using Semantics and Semantic Web
Amit ShethKno.e.sis, Wright State University
ICDE 2014 Keynote
今回の報告では紹介しません
61

キーノート資料
Slideshareで公開されている
http://www.slideshare.net/apsheth/transforming-big-data-into-smart-data-deriving-value-via-harnessing-volume-variety-and-velocity-using-semantic-techniques-and-technologies
62

目次
前半
• ICDE 2014を俯瞰してみる
• ビッグデータ時代の新発想:もうデータは蓄えない[Keynote] Running with Scissors: Fast Queries on Just-in-Time Databases
• 見えない相手と協調作業:センサネットワーク上のデータ集約[10 Year Most Influential Paper] Approximate Aggregation Techniques for Sensor Databases
後半
• メインメモリデータベースがハードウェアトランザクショナルメモリを使ったら…[Best Paper] Exploiting Hardware Transactional Memory in Main-Memory Databases
• 過去の結果を再利用:ビューを用いた大規模グラフからのパターン発見[Best Paper Runner-up]Answering Graph Pattern Queries Using Views
• アルゴリズムでゴリゴリ解決:大量のベクトルから類似ペアを厳密に見つけたい[気になる論文]L2AP: Fast Cosine Similarity Search With Prefix L-2 Norm Bounds
途中で会場の雰囲気などもお伝えします63

Approximate Aggregation Techniquesfor Sensor Databases
Jeffrey Considine, Feifei Li,George Kollios, John W. Byers
Computer Science Dept., Boston University
ICDE 2014 10 Year Most Influential Paper(Originally presented at ICDE 2004)
64

10 Year Most Influential Paper Awardsとは?
ICDEで10年以上前に発表された論文の中から,その後にデータ工学の分野でものすごい影響を与えた論文に授与される賞である
ICDE 2005から始まった
ICDE Influential Paper Awardsのページ
http://tab.computer.org/tcde/icde_inf_paper.html
65

この論文が10 Year Most Influential Paper Awardsに選ばれた理由
The paper describes novel methods to handle duplicate-sensitive aggregates over distributed datasets.
It carefully extends the duplicate-insensitive Flajolet-Martin method, adapting it to require little computation and communication efforts, and make it robust to link losses.
This work has been highly impactful in the area of sensor networks, and has been shown to be applicable to any setting with multiple data sources that may suffer network failures, such as distributed data centers of today.
つまり…
センサネットワークだけでなく,複数データソースがあって互いのコミュニケーションが難しいようなあらゆるケース(昨今の分散データセンタとか)に適用できるから
66
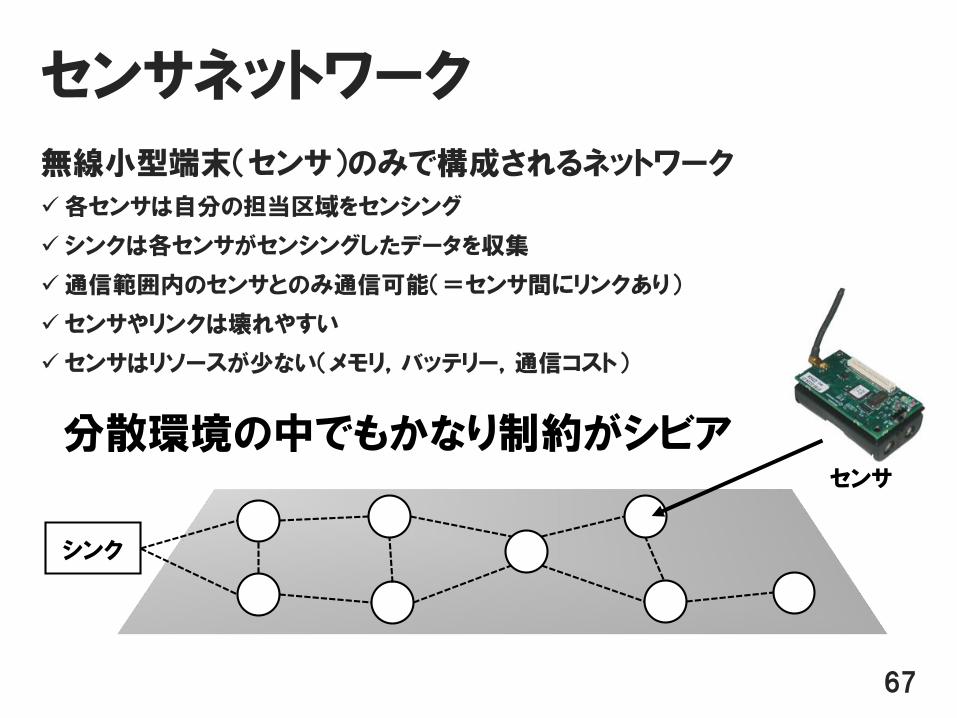
センサネットワーク
無線小型端末(センサ)のみで構成されるネットワーク
各センサは自分の担当区域をセンシング
シンクは各センサがセンシングしたデータを収集
通信範囲内のセンサとのみ通信可能(=センサ間にリンクあり)
センサやリンクは壊れやすい
センサはリソースが少ない(メモリ,バッテリー,通信コスト)
67
シンク
センサ
分散環境の中でもかなり制約がシビア

センサデータベース
センサネットワーク全体を「分散データベース」とみなす
ただしデータはシンクに集められる
各センサはデータを一時的に持つのみ
シンクがクエリを投げてデータを収集する
COUNT/SUM/AVG, MIN/MAX
システムにて有効性は実証済み
TAG (Berkeley/MIT), Cougar (Cornell)
68
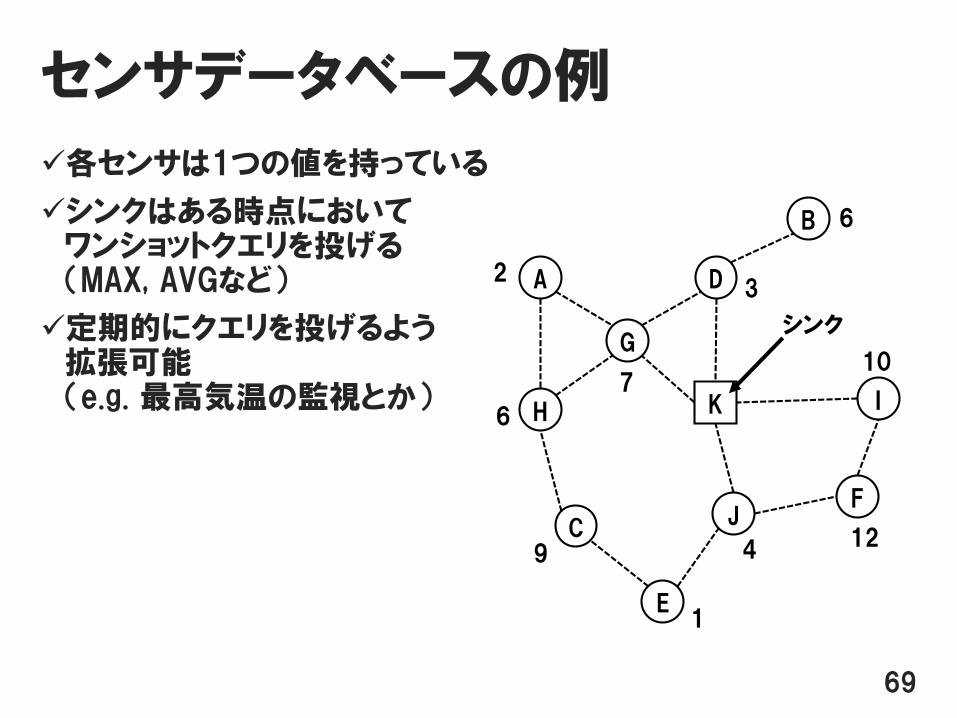
センサデータベースの例
各センサは1つの値を持っている
シンクはある時点においてワンショットクエリを投げる(MAX, AVGなど)
定期的にクエリを投げるよう拡張可能(e.g. 最高気温の監視とか)
69
A
E
B
D
C
K
F
G
H
J
I
6
32
7
6
9 4
1
10
12
シンク
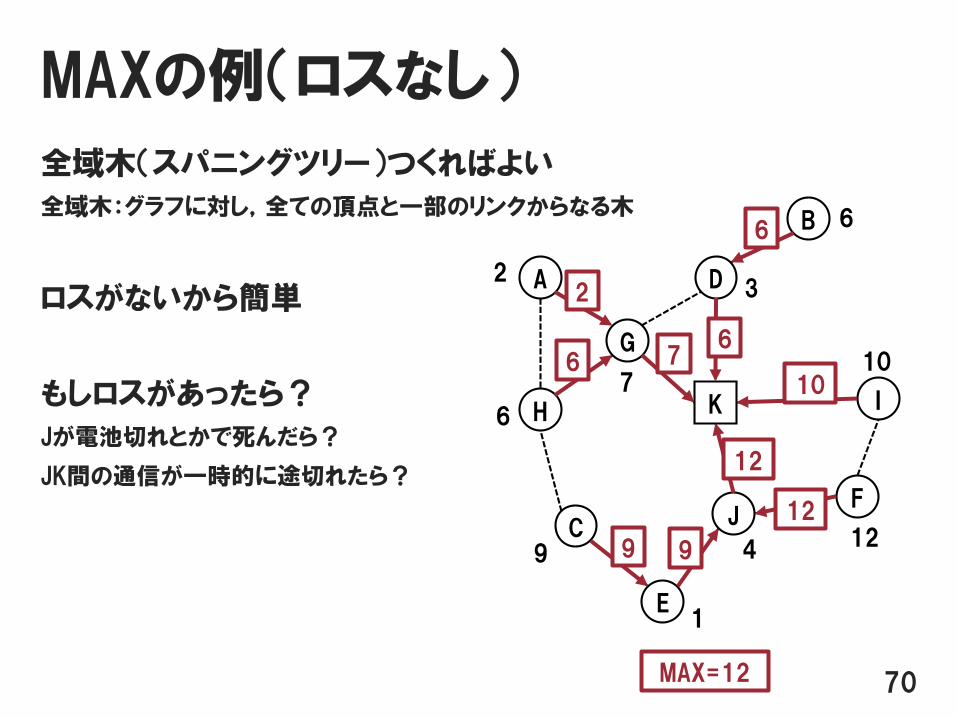
MAXの例(ロスなし)
全域木(スパニングツリー)つくればよい
全域木:グラフに対し,全ての頂点と一部のリンクからなる木
ロスがないから簡単
もしロスがあったら?
Jが電池切れとかで死んだら?
JK間の通信が一時的に途切れたら?
70
A
E
B
D
C
K
F
G
H
J
I
6
32
7
6
9 4
1
10
12
6
2
6 76
10
9
12
9
12
MAX=12

MAXの例(ロスあり)
パスを冗長化(=データを複製)するとロバストになる
Jが死んだりJK間が途切れても,別経路でシンクに12が届く
MAX(とかMIN)は簡単
シンクまでのパスが1つでも通ればよい
複製したデータが悪さすることはない
71
A
E
B
D
C
K
F
G
H
J
I
6
32
7
6
9 4
1
10
12
6
2
6 76
12
9 9
12
MAX=12
12
12

AVGの例(ロスなし)
ロスなしなら全域木でOK
和(SUM)とデータ数(COUNT)を集めて,最後にデータ数で割ればよい
72
A
E
B
D
C
K
F
G
H
J
I
6
32
7
6
9 4
1
10
12
6,1
2,1
6,1 15,39,2
10,1
9,1
12,1
10,2
26,4
AVG=60/10=6

AVGの例(ロスあり,ナイーブ手法)
パスを冗長化する
和とデータ数を集めて,最後にデータ数で割れば…アカーン!
複製したデータが悪さする
73
A
E
B
D
C
K
F
G
H
J
I
6
32
7
6
9 4
1
10
12
6,1
2,1
6,1 15,39,2
22,2
9,1
12,1
10,2
26,4
AVG=72/11≠6
12,1

AVGの例(ロスあり,TAG++[OSDI02] )
パスを冗長化し,そのときにデータは値と重みを分ける
和とデータ数を集めて,最後にデータ数で割れば…大丈夫?
ロスしたら6にならなくなるっぽい
でもナイーブ手法よりちょっとはマシか?
74
A
E
B
D
C
K
F
G
H
J
I
6
32
7
6
9 4
1
10
12
6,1
2,1
6,1 15,39,2
16,1.5
9,1
6,0.5
10,2
20,3.5
AVG=60/10=6
6,0.5
[OSDI02] Madden et al., TAG: A Tiny AGgregation Service for Ad-Hoc Sensor Networks, OSDI 2002.
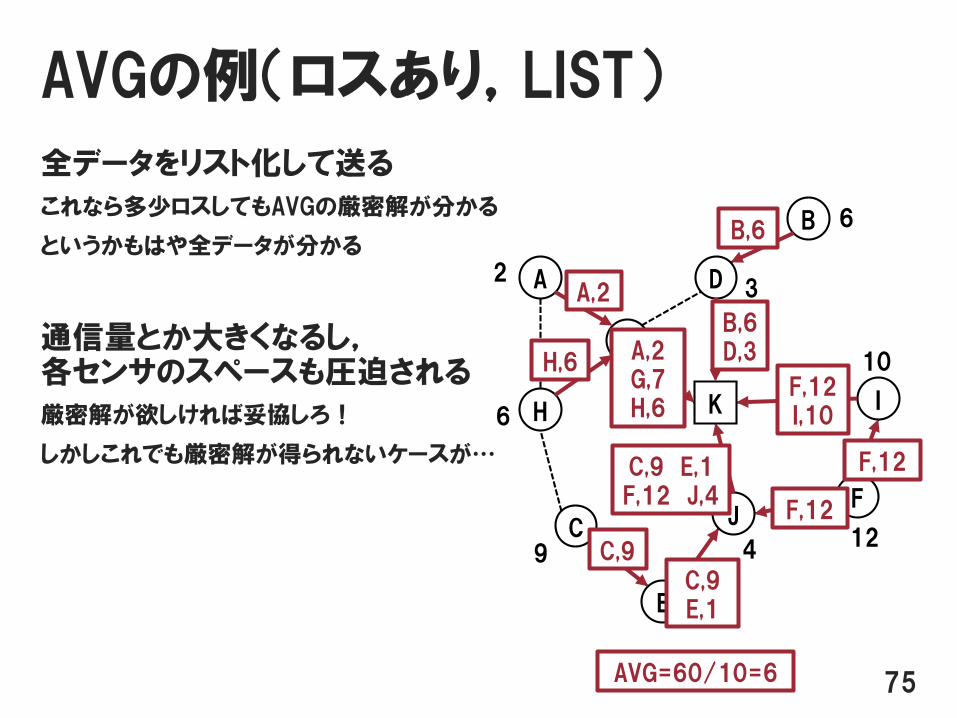
AVGの例(ロスあり,LIST)
全データをリスト化して送る
これなら多少ロスしてもAVGの厳密解が分かる
というかもはや全データが分かる
通信量とか大きくなるし,各センサのスペースも圧迫される
厳密解が欲しければ妥協しろ!
しかしこれでも厳密解が得られないケースが…
75
A
E
B
D
C
K
F
G
H
J
I
6
32
7
6
9 4
1
10
12
B,6
A,2
H,6 A,2G,7H,6
B,6D,3
F,12I,10
C,9
F,12
C,9E,1
C,9 E,1F,12 J,4
AVG=60/10=6
F,12

本研究の目的とアプローチ
センサネットワークの環境ではAVGなどの厳密解を求めるのは難しすぎるので,近似解でいい感じの方法を模索する
主にCOUNT/SUM/AVG(複製が悪さする系の集約)を対象とする
通信エラー(リンクロス)に強いアルゴリズムを!
スケッチと呼ばれる確率的な手法を取り入れる
Sketch [Flajolet85] : 記憶スペースがO(log N), 処理時間がO(1)
ちなみにカウントで厳密解欲しければ記憶スペースO(N)は必要
76[Flajolet85] Flajolet et al., Probabilistic Counting Algorithms for Data Base Applications, Journal of Computer and System Sciences, 1985.
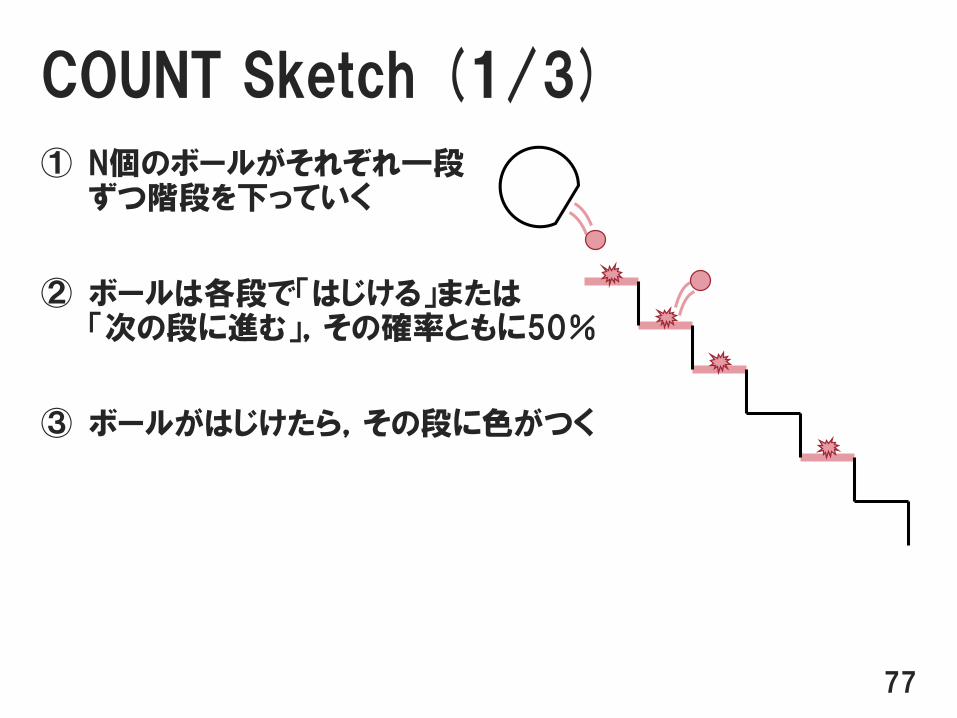
COUNT Sketch (1/3)
① N個のボールがそれぞれ一段ずつ階段を下っていく
② ボールは各段で「はじける」または「次の段に進む」,その確率ともに50%
③ ボールがはじけたら,その段に色がつく
77
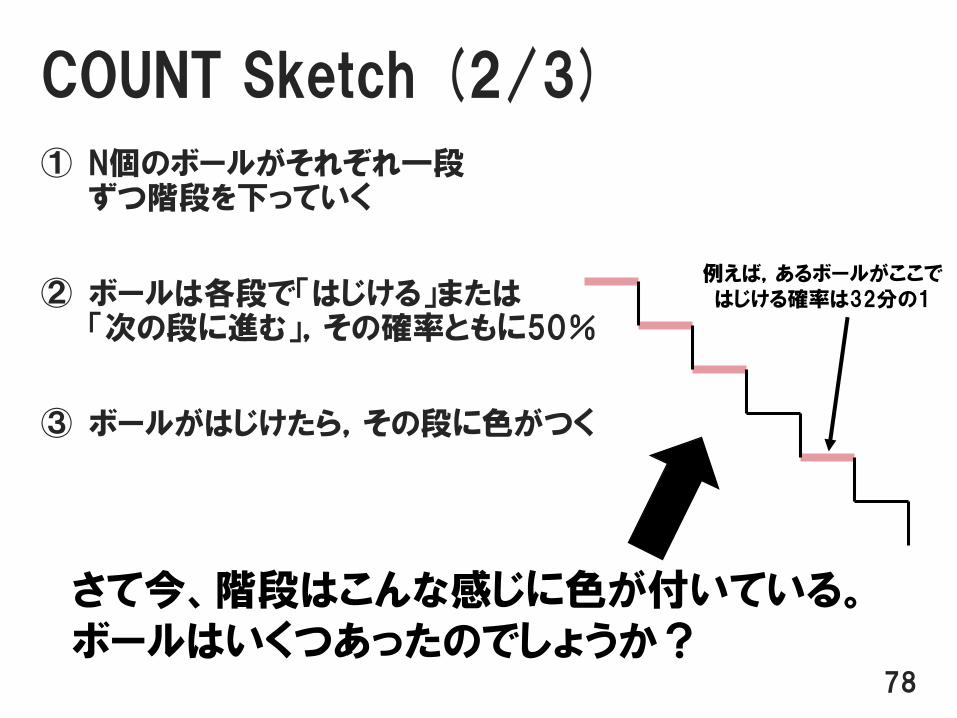
COUNT Sketch (2/3)
① N個のボールがそれぞれ一段ずつ階段を下っていく
② ボールは各段で「はじける」または「次の段に進む」,その確率ともに50%
③ ボールがはじけたら,その段に色がつく
78
さて今、階段はこんな感じに色が付いている。ボールはいくつあったのでしょうか?
例えば,あるボールがここではじける確率は32分の1
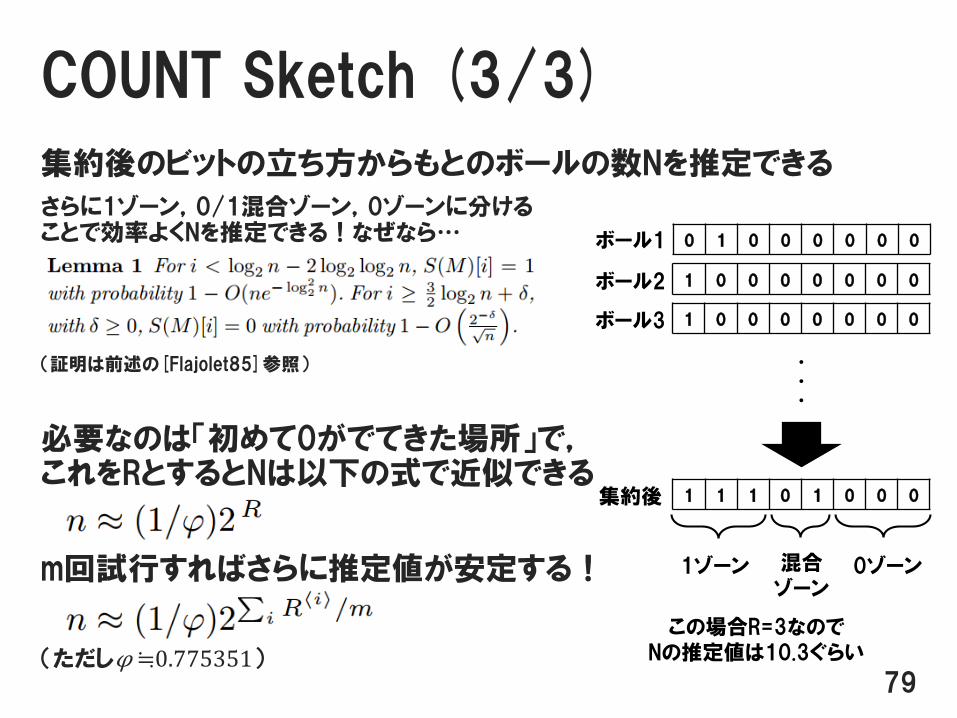
COUNT Sketch (3/3)
集約後のビットの立ち方からもとのボールの数Nを推定できる
さらに1ゾーン,0/1混合ゾーン,0ゾーンに分けることで効率よくNを推定できる!なぜなら…
(証明は前述の[Flajolet85]参照)
必要なのは「初めて0がでてきた場所」で,これをRとするとNは以下の式で近似できる
m回試行すればさらに推定値が安定する!
(ただしφ ≒0.775351)79
0 1 0 0 0 0 0 0
1 0 0 0 0 0 0 0
1 1 1 0 1 0 0 0
・・・
ボール1
ボール2
集約後
1ゾーン 混合ゾーン
0ゾーン
1 0 0 0 0 0 0 0ボール3
この場合R=3なのでNの推定値は10.3ぐらい
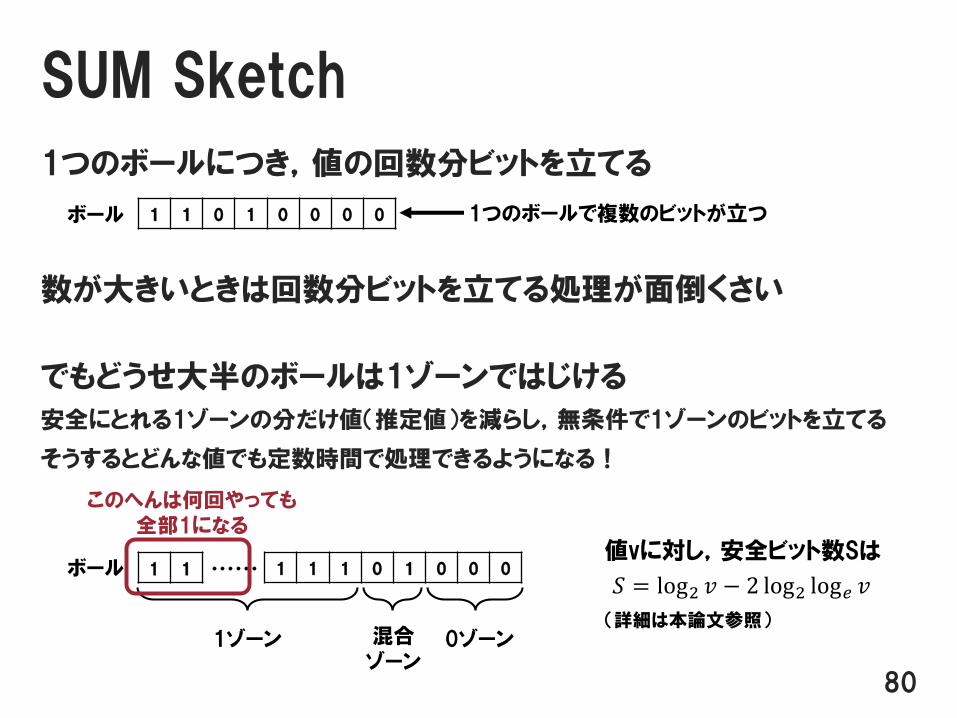
SUM Sketch
1つのボールにつき,値の回数分ビットを立てる
数が大きいときは回数分ビットを立てる処理が面倒くさい
でもどうせ大半のボールは1ゾーンではじける
安全にとれる1ゾーンの分だけ値(推定値)を減らし,無条件で1ゾーンのビットを立てる
そうするとどんな値でも定数時間で処理できるようになる!
80
1 1 0 1 0 0 0 0ボール 1つのボールで複数のビットが立つ
1 1 1 0 1 0 0 0
1ゾーン 混合ゾーン
0ゾーン
1 1 ・・・・・・ボール
このへんは何回やっても全部1になる
𝑆 = log2 𝑣 − 2 log2 log𝑒 𝑣
値vに対し,安全ビット数Sは
(詳細は本論文参照)

その他のSketch
AVG:SUMとCOUNTが分かれば計算できる
2乗和:SUMと同じやり方(値の回数分ビット立てる)
Sketchの拡張性は高い
81

Sketchのセンサデータベースへの適用
シンクからクエリを(フラッディングなどにより)投げる
このとき各センサはシンクからのホップ数や親ノードを覚えておく
各センサがSketchでビット列生成
末端ノードから順にビット列を送る
自分のと子ノードからのビット列をORで集約
子からデータを受け取る or タイマなどでデータ送信のタイミングを制御
最後にシンクで集約したビット列から値を推定
82
A
E
B
D
C
K
F
G
H
J
I
6
32
7
6
9 4
1
10
12
1 1 1 1 1 0 1 0
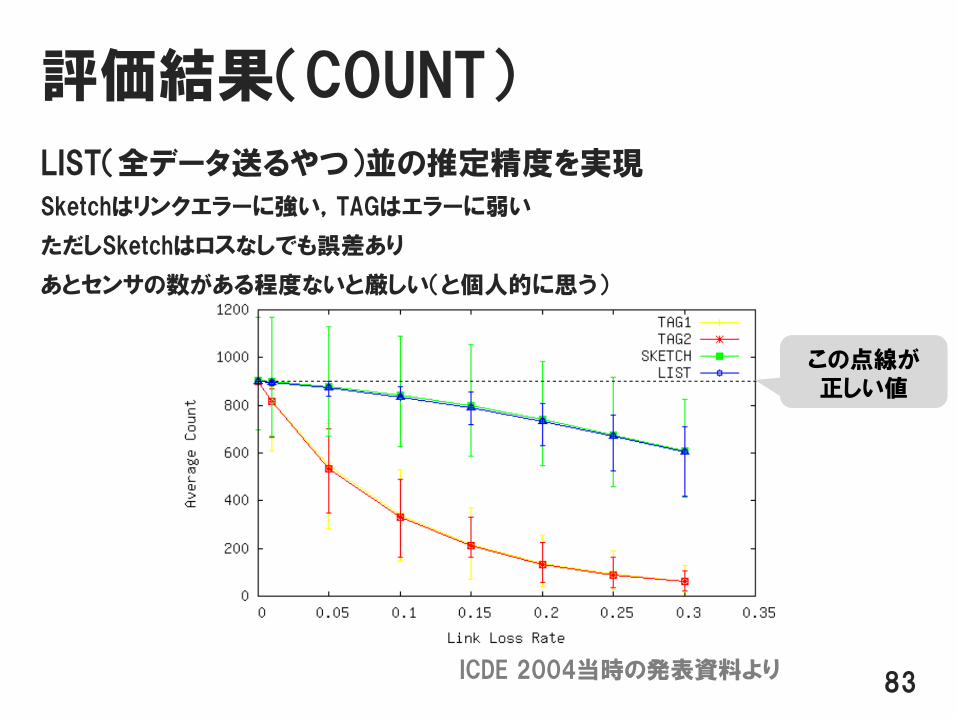
評価結果(COUNT)
LIST(全データ送るやつ)並の推定精度を実現
Sketchはリンクエラーに強い,TAGはエラーに弱い
ただしSketchはロスなしでも誤差あり
あとセンサの数がある程度ないと厳しい(と個人的に思う)
83ICDE 2004当時の発表資料より
この点線が正しい値
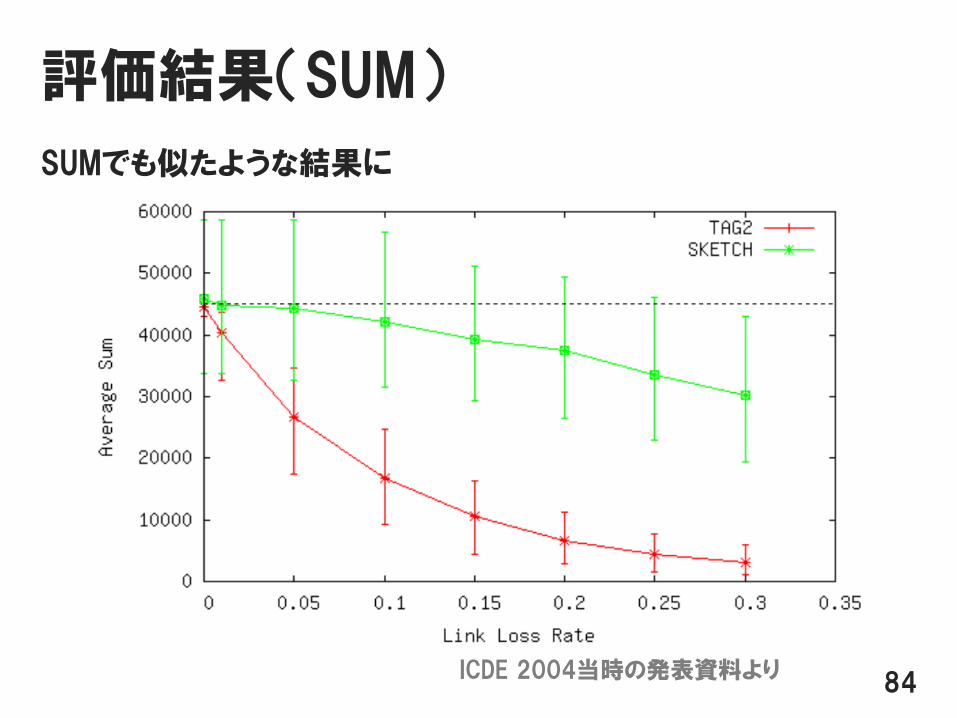
評価結果(SUM)
SUMでも似たような結果に
84ICDE 2004当時の発表資料より
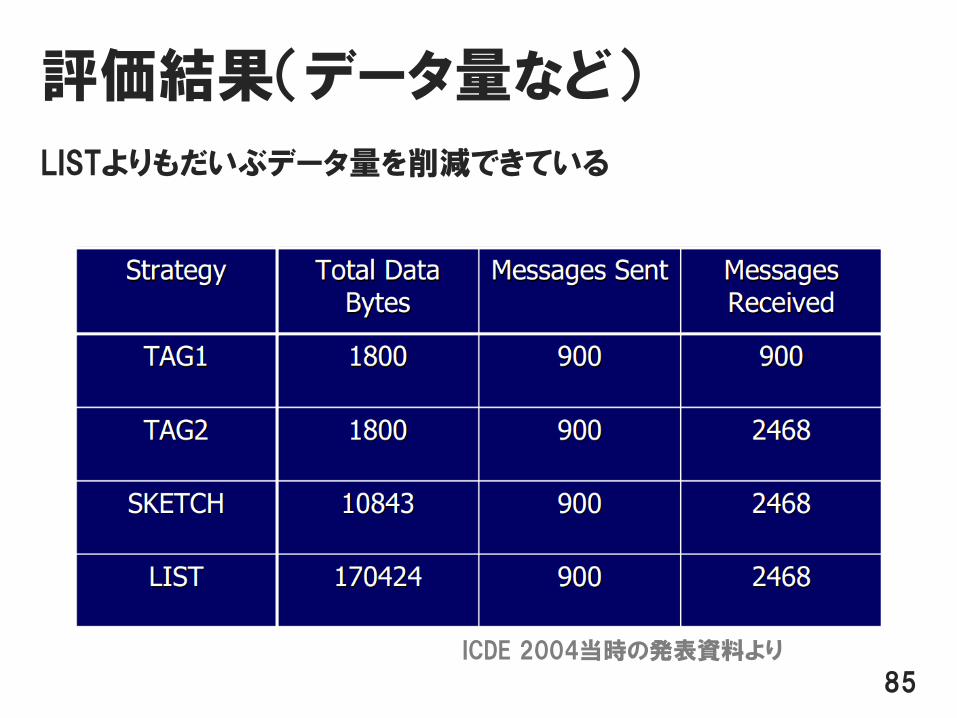
評価結果(データ量など)
LISTよりもだいぶデータ量を削減できている
85ICDE 2004当時の発表資料より

この研究がなぜすごい(すごかった)のか?
センサネットワークなどのエラーが起こりやすい環境では,近似解をできるだけ精度良くかつ効率的に求めるため,データをマルチパスで送る(=データを複製する)ことで冗長化していた
その冗長化の副作用として,複製したデータがCOUNTやSUMなどの集約において悪い影響を与えていた
しかしこの研究では,複製したデータが悪さをしないようなやり方が新たに発見された!
これまでの手法(TAG)にボロ勝ち!
86
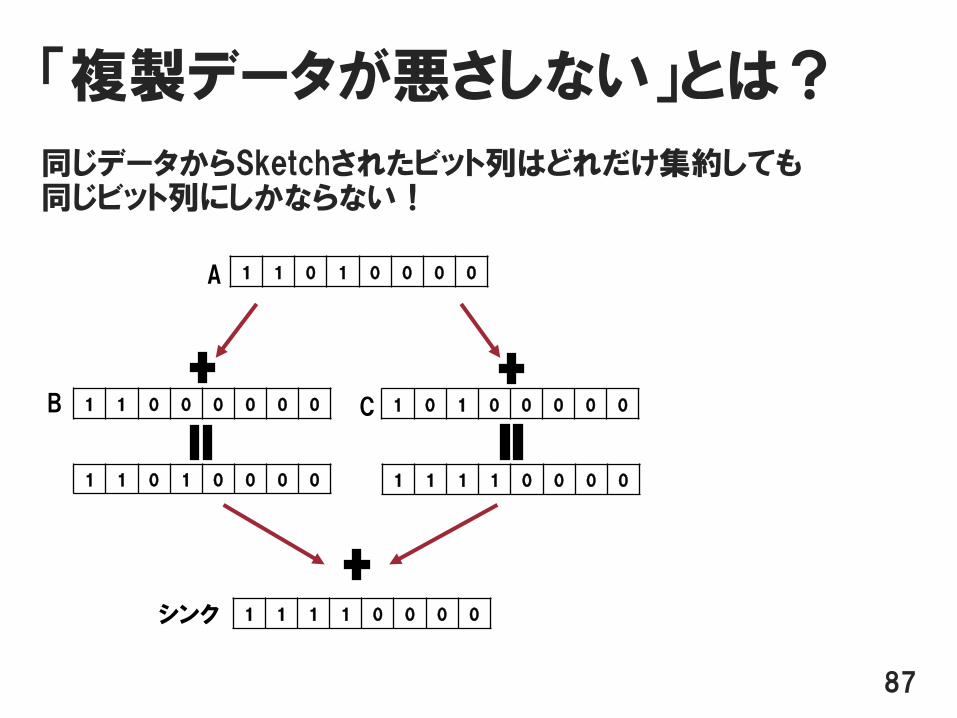
「複製データが悪さしない」とは?
同じデータからSketchされたビット列はどれだけ集約しても同じビット列にしかならない!
87
1 1 0 1 0 0 0 0
1 1 0 1 0 0 0 0 1 1 1 1 0 0 0 0
1 1 0 0 0 0 0 0 1 0 1 0 0 0 0 0
1 1 1 1 0 0 0 0
A
B C
シンク
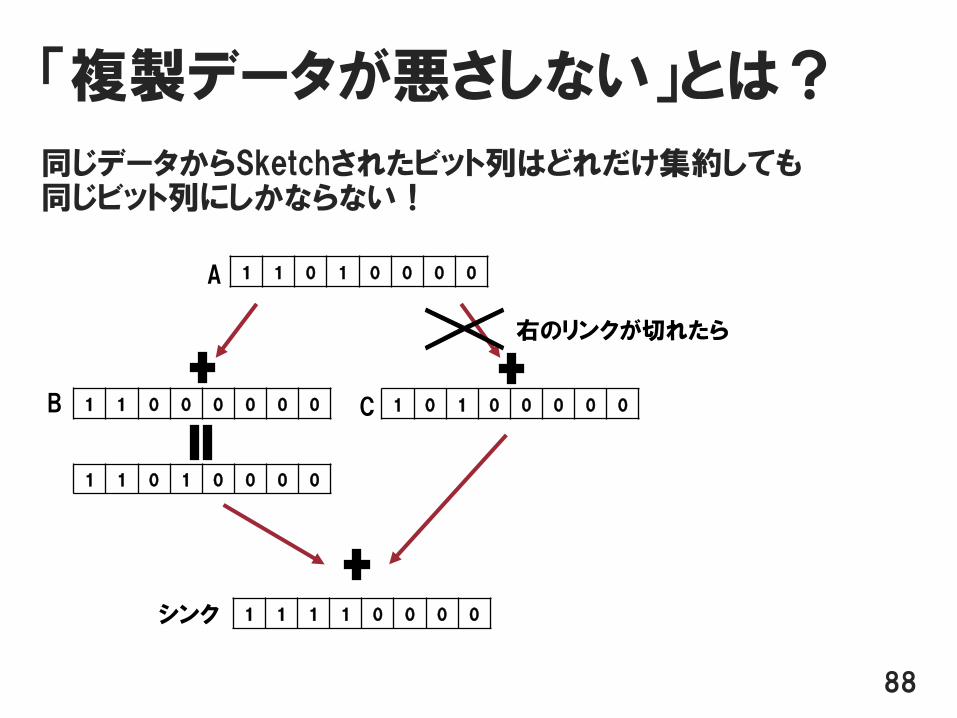
「複製データが悪さしない」とは?
同じデータからSketchされたビット列はどれだけ集約しても同じビット列にしかならない!
88
1 1 0 1 0 0 0 0
1 1 0 1 0 0 0 0
1 1 0 0 0 0 0 0 1 0 1 0 0 0 0 0
1 1 1 1 0 0 0 0
A
B C
シンク
右のリンクが切れたら

「複製データが悪さしない」とは?
同じデータからSketchされたビット列はどれだけ集約しても同じビット列にしかならない!
89
1 1 0 1 0 0 0 0
1 1 1 1 0 0 0 0
1 1 0 0 0 0 0 0 1 0 1 0 0 0 0 0
1 1 1 1 0 0 0 0
A
B C
シンク
左のリンクが切れたら

「複製データが悪さしない」とは?
同じデータからSketchされたビット列はどれだけ集約しても同じビット列にしかならない!
90
1 1 0 1 0 0 0 0
1 1 0 1 0 0 0 0 1 1 1 1 0 0 0 0
1 1 0 0 0 0 0 0 1 0 1 0 0 0 0 0
1 1 1 1 0 0 0 0
A
B C
シンク
両方のリンクが使えたら
シンクで集約されるビット列に影響なし!

この研究を引用している論文の例
センサネットワーク上でのデータ集約に関する論文
“Considine et al. [6] independently proposed using duplicate-insensitive sketches for robust aggregation in sensor networks and demonstrated the advantages of a broadcast-based multi-path routing topology over previous tree-based approaches. However, they primarily focused on energy-efficient computation of the Sum aggregate, and did not address the other contributions listed above.” (Nath et al., Synopsis Diffusion for Robust Aggregation in Sensor Networks, SenSys 2004.)
→ 電力消費以外の問題(コネクティビティの変化への迅速な対応とか)を解決していない
Distributedな集約プロトコルに関する論文(こちらはセンサネットワークだけではない)
“(probabilistic counting) This protocol is based on ideas from [11] for counting distinct elements of a database and in [12] was adapted to produce a protocol for averaging. The outcome is random, with variance that becomes arbitrarily small as the number of nodes grows. However, for moderate numbers of nodes, say tens of thousands, high variance makes the protocol impractical.” (Moallemi et al., Consensus Propagation, IEEE TOIT, 2006.)
→ 確率的な手法として紹介,ノード数が少ないと誤差が大きくなり実用的でない
91他の論文ではこき下ろされているようである

しかし分散環境における集約手法の礎に
多くの論文は他の論文を「問題を指摘するため」に引用する
引用とはそういうものだ(違)(あまりそういう引用の仕方ばかりすると性格悪くなりそうです)
この論文では…
Distributedなネットワークにおいて,COUNTやSUMなどの集約を効率的に行う近似手法を提案した
ただし,問題が…
ネットワークのコネクティビティの変化にはあまり対応できないし,ネットワークの規模が小さいと誤差が大きくなる
92他の論文が問題を引き継ぎ,解決していった

ICDE 2014参加報告前半おわり
93

ICDE 2014参加報告後半スタート!
94

目次
前半
• ICDE 2014を俯瞰してみる
• ビッグデータ時代の新発想:もうデータは蓄えない[Keynote] Running with Scissors: Fast Queries on Just-in-Time Databases
• 見えない相手と協調作業:センサネットワーク上のデータ集約[10 Year Most Influential Paper] Approximate Aggregation Techniques for Sensor Databases
後半
• メインメモリデータベースがハードウェアトランザクショナルメモリを使ったら…[Best Paper] Exploiting Hardware Transactional Memory in Main-Memory Databases
• 過去の結果を再利用:ビューを用いた大規模グラフからのパターン発見[Best Paper Runner-up]Answering Graph Pattern Queries Using Views
• アルゴリズムでゴリゴリ解決:大量のベクトルから類似ペアを厳密に見つけたい[気になる論文]L2AP: Fast Cosine Similarity Search With Prefix L-2 Norm Bounds
途中で会場の雰囲気などもお伝えします95

Exploiting Hardware Transactional Memory in Main-Memory Databases
Viktor Leis, Alfons Kemper, Thomas NeumannTechnische Universität München
ICDE 2014 Best Paper
96
※ここから先の引用文献は論文を参照してください

Main-memory Database (MMDB)
インメモリデータベースともいう
メモリ上で動くデータベース
HDDとかSSDとかと比べると爆速 だってメモリだもの
主なメインメモリデータベースシステム
H-Store/VoltDB [Stonebraker, IEEE Data Eng. Bull., 2013]
HyPer [Kemper, ICDE11]
SAP HANA [Färber, SIGMOD Record, 2011]
IBM solidDB [Lindström, IEEE Data Eng. Bull. 2013]
Microsoft Hekaton [Larson, IEEE Data Eng. Bull. 2013]
他にもたくさんある
97Wikipediaより
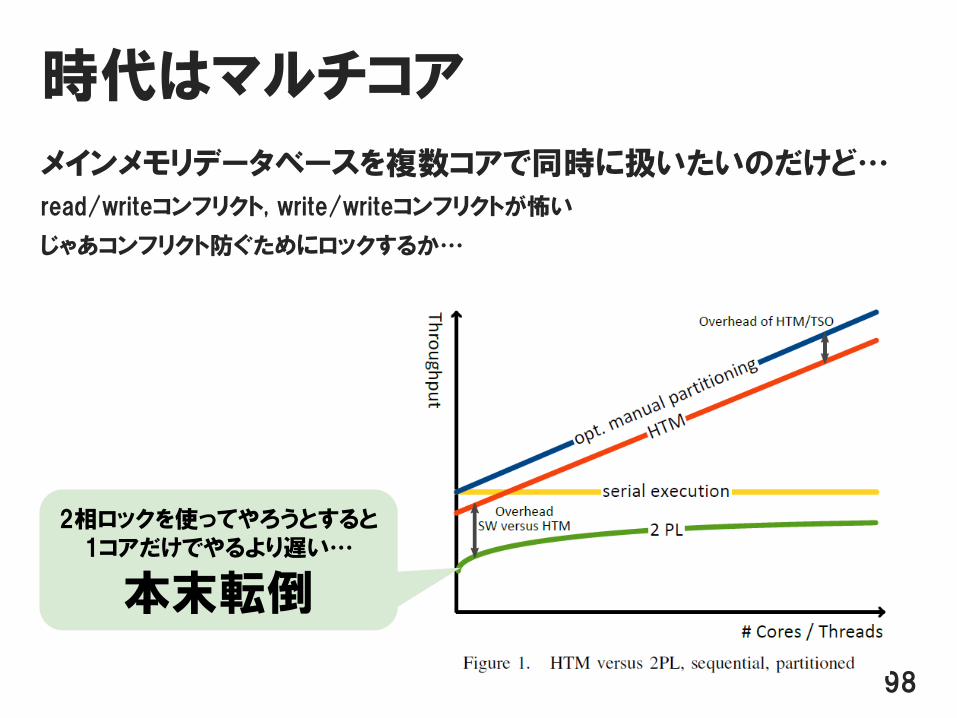
時代はマルチコア
メインメモリデータベースを複数コアで同時に扱いたいのだけど…
read/writeコンフリクト, write/writeコンフリクトが怖い
じゃあコンフリクト防ぐためにロックするか…
98
2相ロックを使ってやろうとすると1コアだけでやるより遅い…
本末転倒
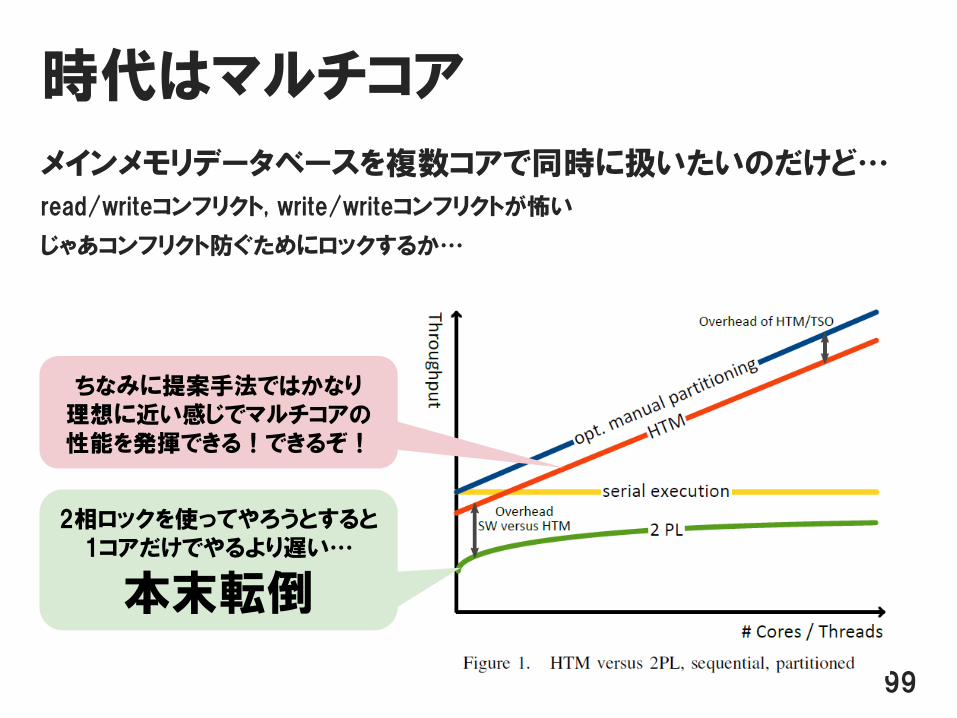
時代はマルチコア
メインメモリデータベースを複数コアで同時に扱いたいのだけど…
read/writeコンフリクト, write/writeコンフリクトが怖い
じゃあコンフリクト防ぐためにロックするか…
99
2相ロックを使ってやろうとすると1コアだけでやるより遅い…
本末転倒
ちなみに提案手法ではかなり理想に近い感じでマルチコアの性能を発揮できる!できるぞ!
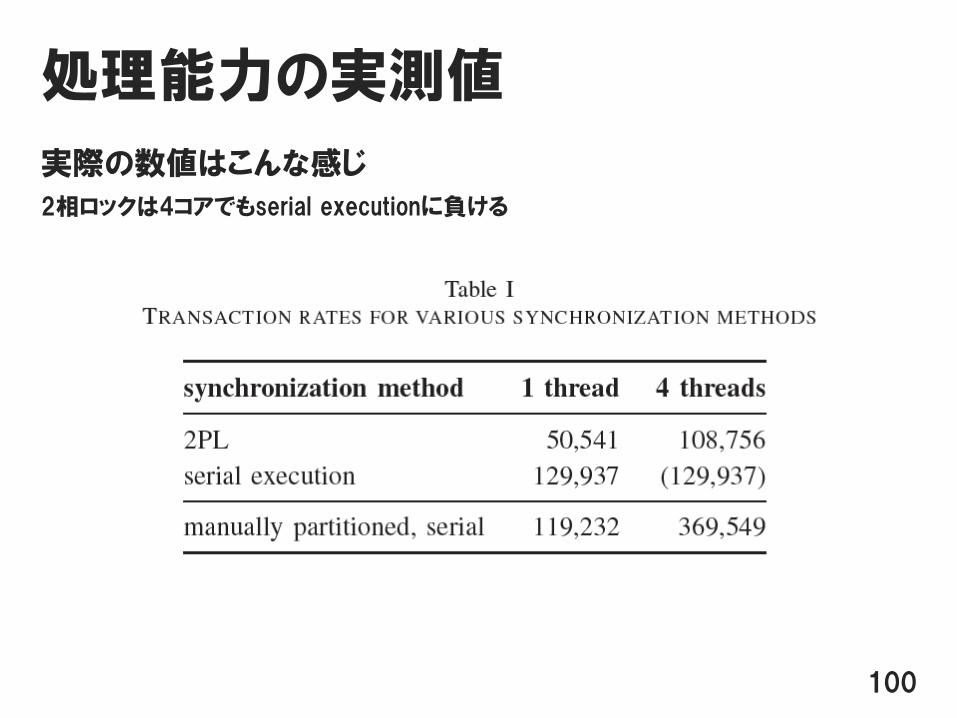
処理能力の実測値
実際の数値はこんな感じ
2相ロックは4コアでもserial executionに負ける
100

ロックはMMDBには不向き
▶ Fine-grained locking (小さい領域を細かくロック)
正しく制御するのが難しい
制御をミスるとデッドロックが発生する
▶ Coarse-grained locking (広い領域を大ざっぱにロック)
制御は簡単
だけど並列性がかなり失われる
どっちにしてもメモリ中心の処理ではロックのオーバヘッドが大きい
場合によってはボトルネックになる[Harizopoulos, SIGMOD08][Muhe, CIDR13]
101

なぜ提案手法は速い?
1. ロックではなくトランザクショナルメモリ(TM)を使ってるからロックだと他のCPUはロックしたメモリ領域にアクセスできなくなるが,トランザクショナルメモリはロックせずにそのまま並列処理するから速い
→「ロックせずにそのまま並列処理」って,それだとコンフリクトするんじゃ…
→するよ
→えっ…
→でもコンフリクトしたらそのときにだけやり直したらいいじゃん
ちなみにコンフリクトが多い場合は遅くなるのでコンフリクトしにくい工夫をしている
2. ソフトウェアトランザクショナルメモリ(STM)ではなくハードウェアトランザクショナルメモリ(HTM)を使ってるからソフトウェア実装よりハードウェア実装のほうが速いのは世界の真理だ
実際にtinySTM ver1.0.3を使って試したけど全然ダメだったらしい
102

トランザクショナルメモリ
「トランザクション」という単位で処理する
一つのトランザクションは「コミット」か「アボート」かのどちらか:原子的
ロックせずに並列処理し,コンフリクトしたときだけトランザクション単位でアボート
ハードウェアトランザクショナルメモリ(HTM)
トランザクションをすべてキャッシュで処理し,コミット時…メモリに処理結果を戻すアボート時…メモリに処理結果を戻さない(破棄)とすることでトランザクション処理を実現
トランザクションの単位は勝手には決まらない
実装する人はどの部分を一つのトランザクションとするかを考える必要がある
103
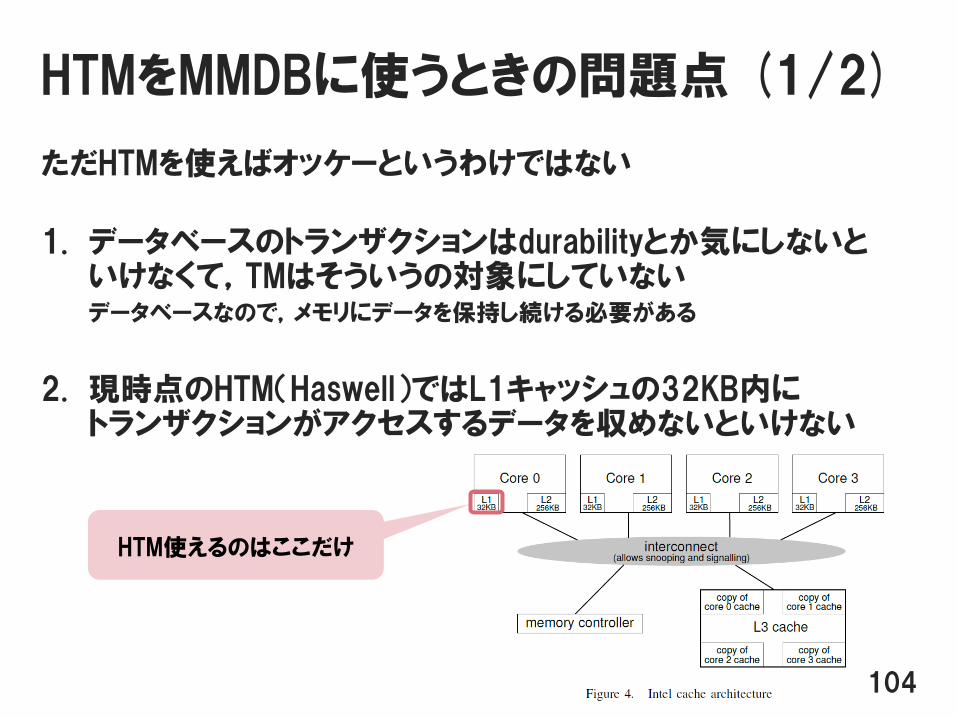
HTMをMMDBに使うときの問題点 (1/2)
ただHTMを使えばオッケーというわけではない
1. データベースのトランザクションはdurabilityとか気にしないといけなくて,TMはそういうの対象にしていないデータベースなので,メモリにデータを保持し続ける必要がある
2. 現時点のHTM(Haswell)ではL1キャッシュの32KB内にトランザクションがアクセスするデータを収めないといけない
104
HTM使えるのはここだけ

HTMをMMDBに使うときの問題点 (2/2)
ただHTMを使えばオッケーというわけではない
3. ハードウェア的事情による予期せぬ事態に備えないといけないキャッシュのデータ格納構造やハードウェア割り込みなどによって衝突が発生
4. 何度やってもおなじ衝突が発生するような「病的」なケースに対して,処理を前に進める対策が必要Associativity collisionは一度起こったらそのままだと抜け出せない
105

本研究の概要(実はあんまり自分ではよく分かってないのですが…)
メインメモリデータベースシステムでHTMを有効に利用するための諸々を工夫した,というのがこの研究の中身らしい
あんまりアカデミックな感じがしない…DBコア技術の研究ってこんなもんなのでしょうか
工夫した諸々
• TMをbuilding blockとして使い,データベーストランザクションを細かく分ける
• まずはトランザクショナルメモリを使ってロックなしで処理させる
• コンフリクトしたらもうちょっと慎重な方法でやり直す
• タイムスタンプ使ってコンフリクトを賢く検知する
• データレイアウトやアクセスパターンをいろいろ工夫する
106

本研究の概要(実はあんまり自分ではよく分かってないのですが…)
メインメモリデータベースシステムでHTMを有効に利用するための諸々を工夫した,というのがこの研究の中身らしい
あんまりアカデミックな感じがしない…DBコア技術の研究ってこんなもんなのでしょうか
工夫した諸々
• TMをbuilding blockとして使い,データベーストランザクションを細かく分ける
• まずはトランザクショナルメモリを使ってロックなしで処理させる
• コンフリクトしたらもうちょっと慎重な方法でやり直す
• タイムスタンプ使ってコンフリクトを賢く検知する
• データレイアウトやアクセスパターンをいろいろ工夫する
107
コンフリクトしにくい工夫
病的なケースからの脱出とか
コンフリクトしにくい工夫

本研究のコントリビューション
明示的にユーザが何かをしなくても,メインメモリデータベースをマルチコア環境で効率的に使えるようにした
HyPer [Kemper, ICDE11]は,データベースをどのように分割(partitioning)するかをユーザが手動でいい感じに決めないとうまく並列処理できない
H-Store [Stonebraker, IEEE Data Eng. Bull., 2013]は自動的に分割する仕組みとしてSchism [Curino, VLDB10]を備えているが,ワークロードが時間的に均質でない場合に良い分割がうまく得られないと報告されている[Larson, VLDB11]
108

本研究のコントリビューション
明示的にユーザが何かをしなくても,メインメモリデータベースをマルチコア環境で効率的に使えるようにした
HyPer [Kemper, ICDE11]は,データベースをどのように分割(partitioning)するかをユーザが手動でいい感じに決めないとうまく並列処理できない
H-Store [Stonebraker, IEEE Data Eng. Bull., 2013]は自動的に分割する仕組みとしてSchism [Curino, VLDB10]を備えているが,ワークロードが時間的に均質でない場合に良い分割がうまく得られないと報告されている[Larson, VLDB11]
さらに…
そもそも複数の分割されたデータベースにアクセスするようなトランザクションでは,データベースを分割するアプローチは効果が減少する
なぜなら,複数のデータベースにアクセスするからといってコンフリクトが絶対に起こるわけではなく,これが並列処理の性能を貶めているからだ
だから理想的な分割をしたときよりも提案手法のほうが速くなることもある
109
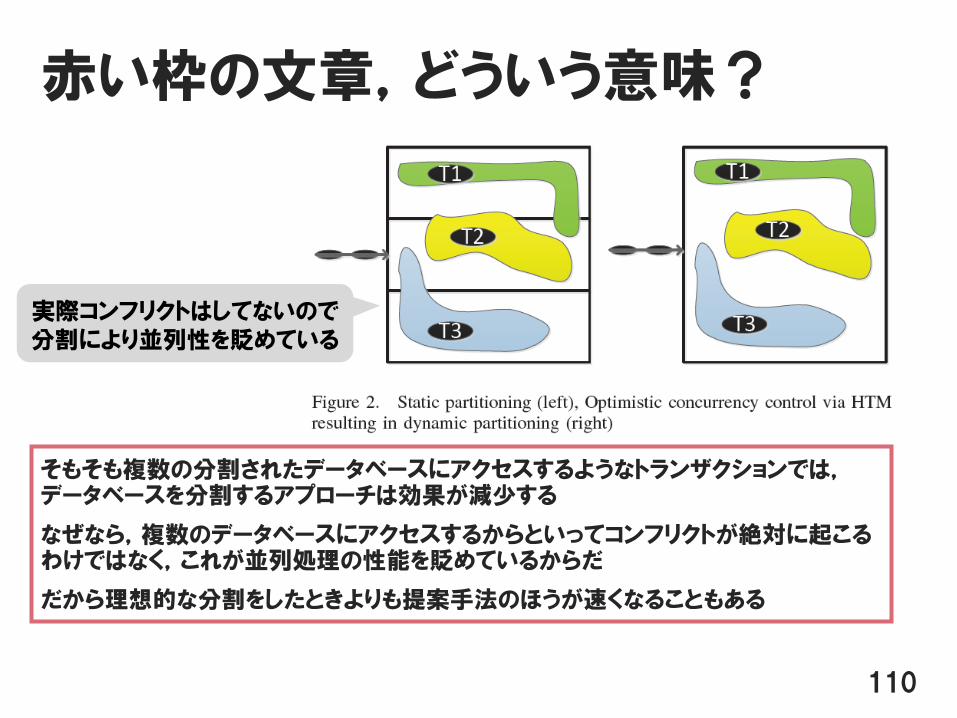
赤い枠の文章,どういう意味?
そもそも複数の分割されたデータベースにアクセスするようなトランザクションでは,データベースを分割するアプローチは効果が減少する
なぜなら,複数のデータベースにアクセスするからといってコンフリクトが絶対に起こるわけではなく,これが並列処理の性能を貶めているからだ
だから理想的な分割をしたときよりも提案手法のほうが速くなることもある
110
実際コンフリクトはしてないので分割により並列性を貶めている
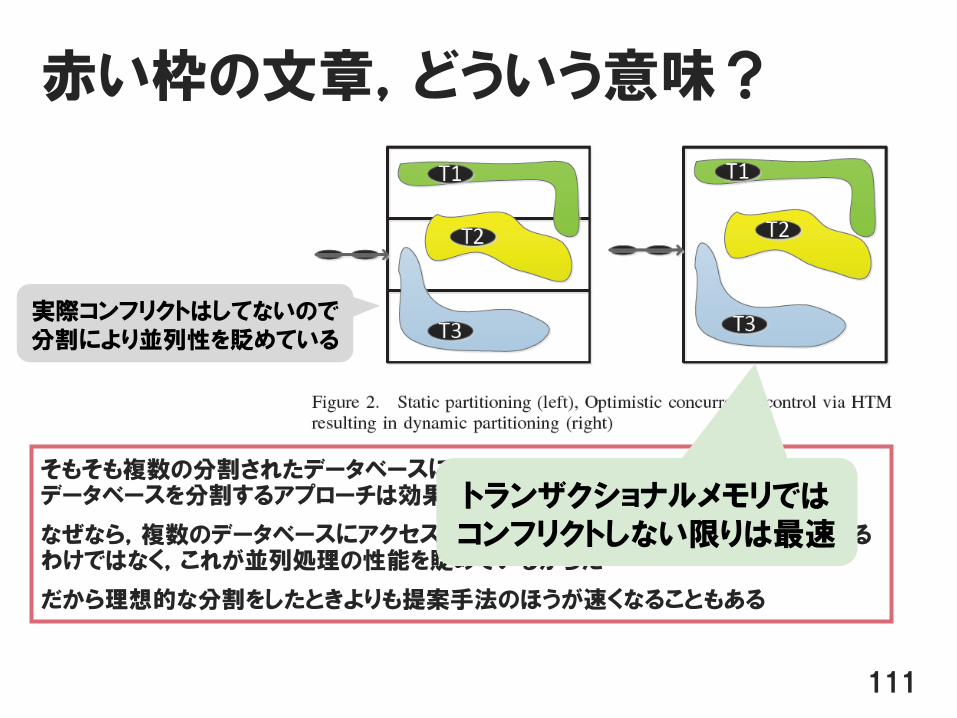
赤い枠の文章,どういう意味?
そもそも複数の分割されたデータベースにアクセスするようなトランザクションでは,データベースを分割するアプローチは効果が減少する
なぜなら,複数のデータベースにアクセスするからといってコンフリクトが絶対に起こるわけではなく,これが並列処理の性能を貶めているからだ
だから理想的な分割をしたときよりも提案手法のほうが速くなることもある
111
実際コンフリクトはしてないので分割により並列性を貶めている
トランザクショナルメモリではコンフリクトしない限りは最速
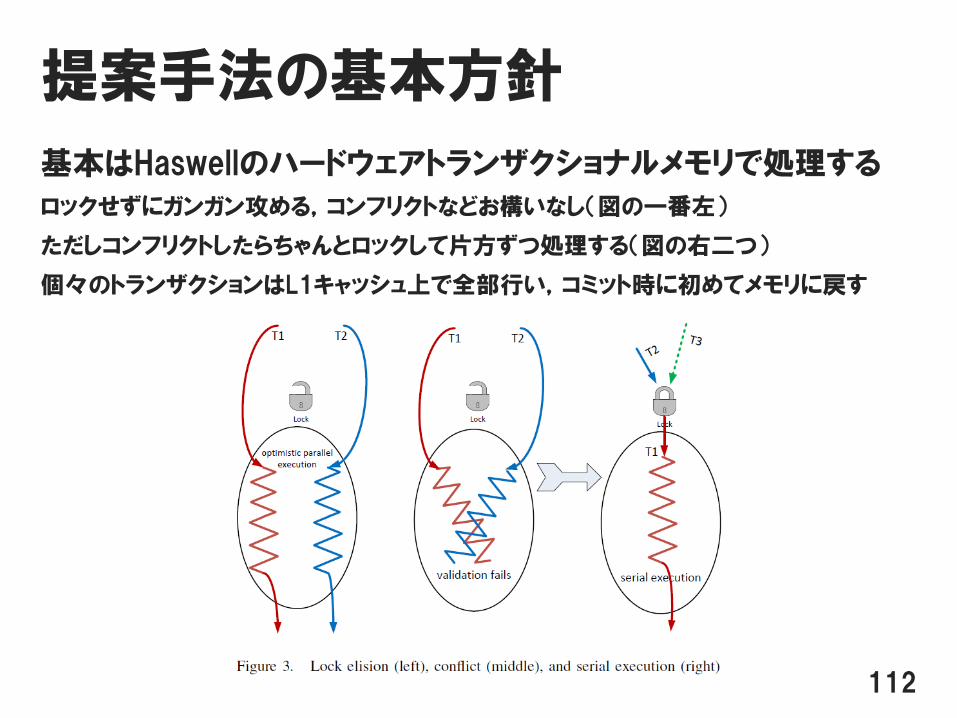
提案手法の基本方針
基本はHaswellのハードウェアトランザクショナルメモリで処理する
ロックせずにガンガン攻める,コンフリクトなどお構いなし(図の一番左)
ただしコンフリクトしたらちゃんとロックして片方ずつ処理する(図の右二つ)
個々のトランザクションはL1キャッシュ上で全部行い,コミット時に初めてメモリに戻す
112
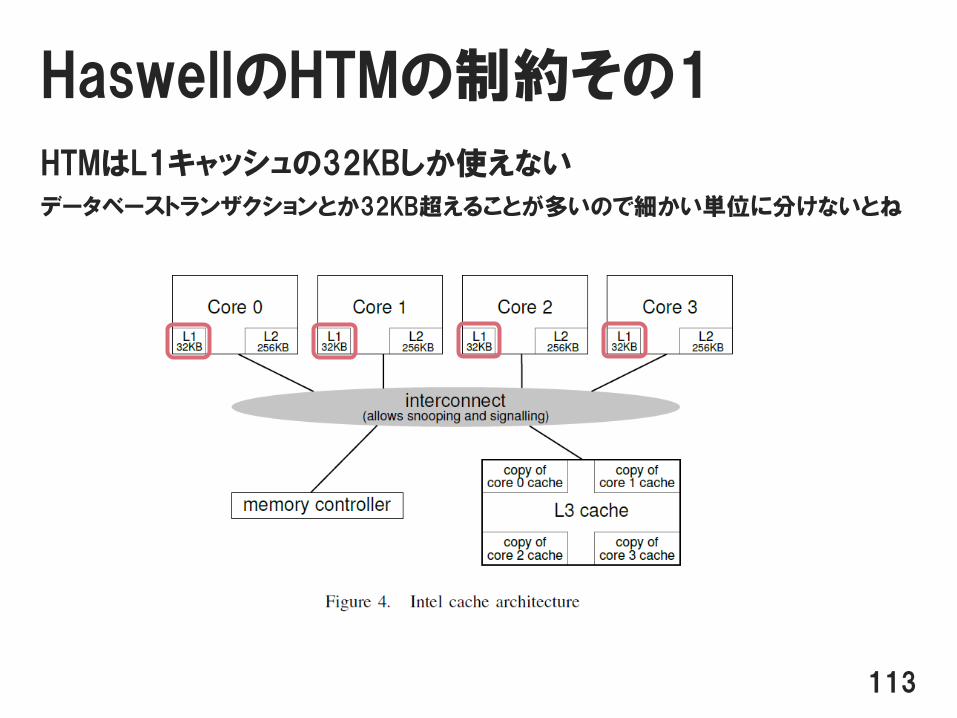
HaswellのHTMの制約その1
HTMはL1キャッシュの32KBしか使えない
データベーストランザクションとか32KB超えることが多いので細かい単位に分けないとね
113
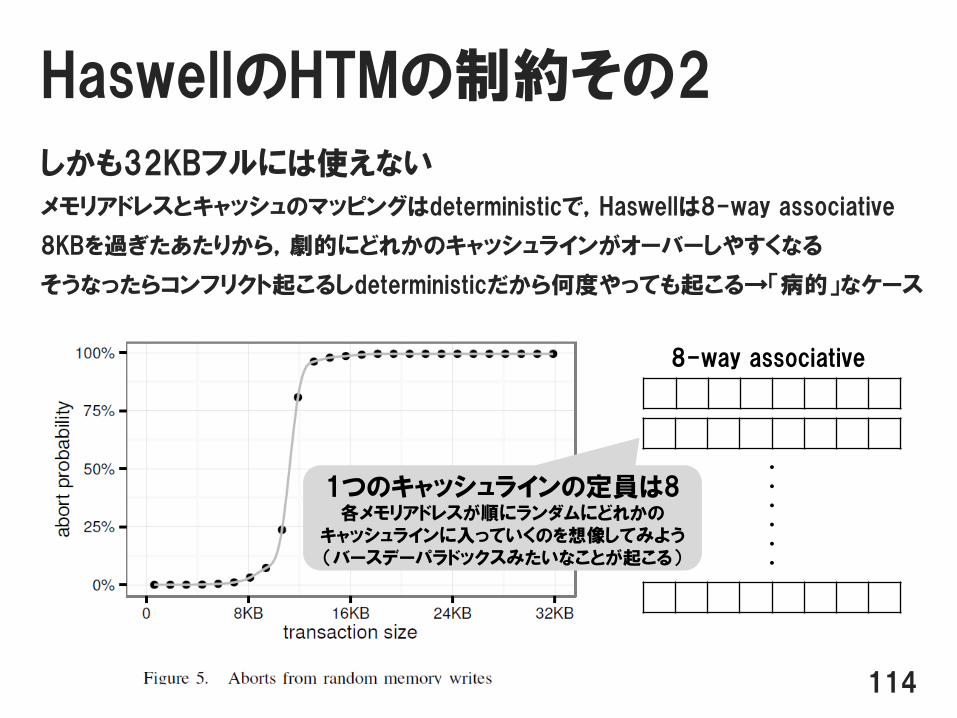
HaswellのHTMの制約その2
しかも32KBフルには使えない
メモリアドレスとキャッシュのマッピングはdeterministicで,Haswellは8-way associative
8KBを過ぎたあたりから,劇的にどれかのキャッシュラインがオーバーしやすくなる
そうなったらコンフリクト起こるしdeterministicだから何度やっても起こる→「病的」なケース
114
8-way associative
・・・・・・
1つのキャッシュラインの定員は8各メモリアドレスが順にランダムにどれかの
キャッシュラインに入っていくのを想像してみよう(バースデーパラドックスみたいなことが起こる)

HaswellのHTMの制約その3
トランザクションが長いとアボートされやすくなる
別のCPUがメモリの同じ箇所を書き換えてしまう可能性が高まる
115
1Mサイクル≒0.3ミリ秒

提案手法
データベーストランザクションを細かいHTMトランザクションに分ける
32KBより十分に小さくする
1タプルへのアクセス→1HTMトランザクション
Timestamp Ordering (TSO)でコンフリクトを検知
レガシーなやり方[Carey, PhD thesis, 1983]
だがMMDBでは有効
Safe Timestampの導入
これ以前のトランザクションは全部コミットor アボートしたことを表すタイムスタンプ
雑なやり方だが,これ一つで安全を保証できる
116

コンフリクト検知 からの 処理やり直し
コンフリクトしたら処理を戻さないといけないのは世間では常識
1. HTM conflict (青矢印)
L2 or L3キャッシュにコピーしておいた元の内容をまたL1キャッシュにもってくるだけ
やり直しのときはラッチ(大事な処理のとこを一瞬だけロックするやつ)を使う
2. Timestamp conflict (赤矢印)
いつものログ使うロールバック&ロック獲得&直列処理で確実に処理を終わらせる
117

実装の例
1タプルへのアクセス→1HTMトランザクションに
“Larger statements like non-unique index lookups should be split into multiple HTM transactions, e.g., one for each accessed tuple” (p7より)
118

その他もろもろ
最適化の議論
コンフリクト後すぐに直列処理するのでなく何度かHTMを再チャレンジしてもよいかも
readに関してはタイムスタンプいらないかも(コンフリクトはwriteが絡むと発生するから)
メインメモリ上のデータ配置(左図)・インデックスの構造(右図)
なんか同じアドレスにアクセス集中してコンフリクト起こしやすい
→ トランザクションごとにちょっと余分にスペース開ける(ゾーン作る)と緩和される
119
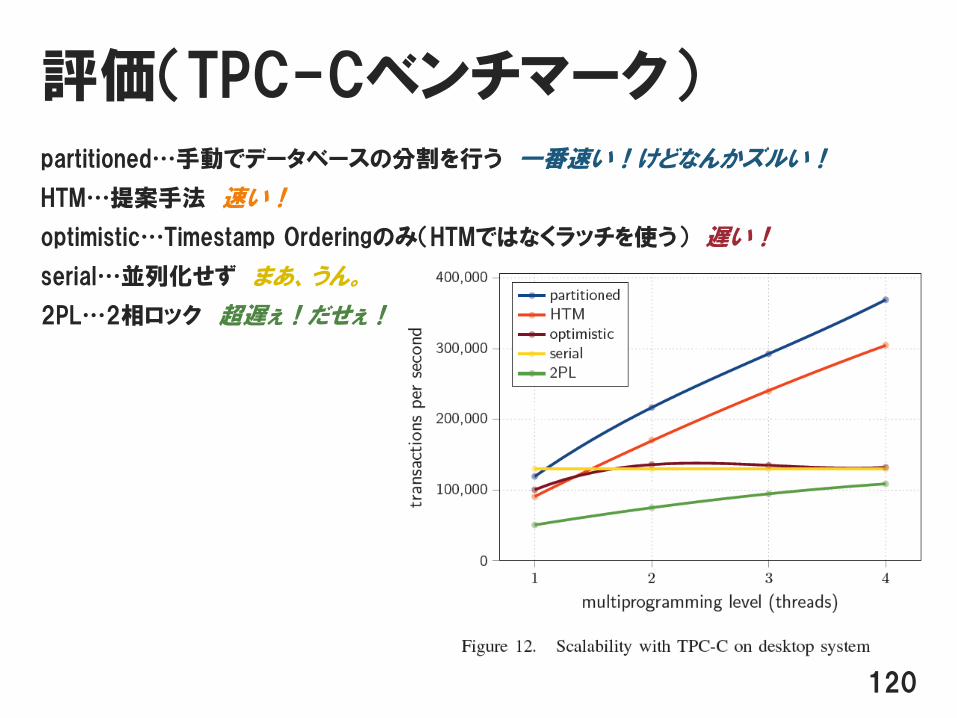
評価(TPC-Cベンチマーク)partitioned…手動でデータベースの分割を行う 一番速い!けどなんかズルい!
HTM…提案手法 速い!
optimistic…Timestamp Orderingのみ(HTMではなくラッチを使う) 遅い!
serial…並列化せず まあ、うん。
2PL…2相ロック 超遅ぇ!だせぇ!
120

評価(TPC-Cベンチマーク改)
複数パーティションにアクセスするトランザクションの割合を変化
人手の介入というズルをしたにも関わらずpartitionedがHTMに劣る結果に
121
実際コンフリクトしない場合もあるので分割により並列性を貶めている
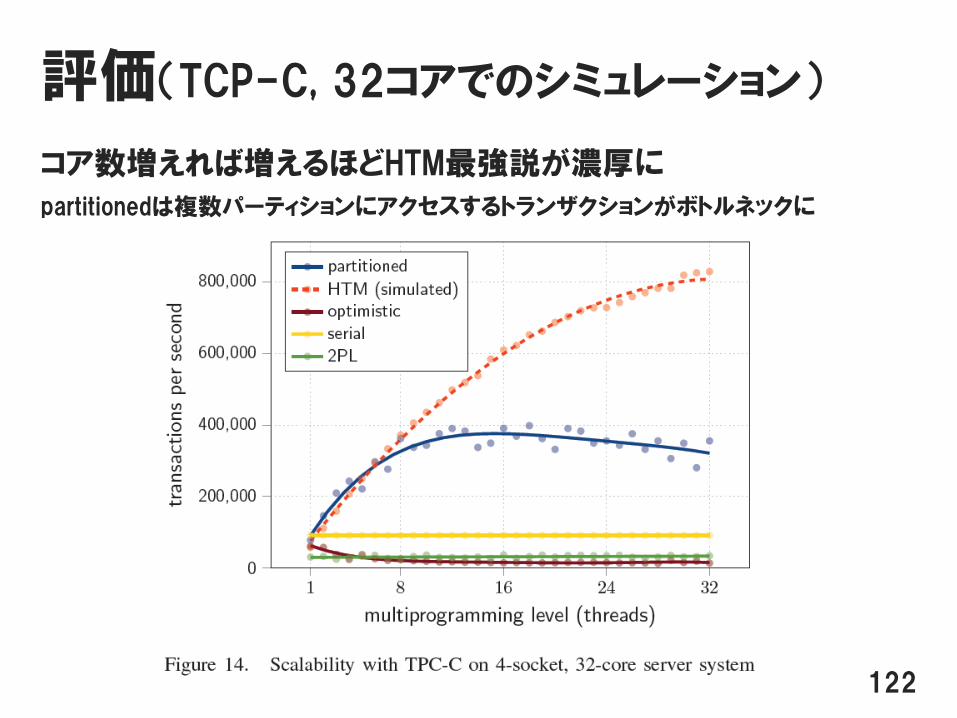
評価(TCP-C, 32コアでのシミュレーション)
コア数増えれば増えるほどHTM最強説が濃厚に
partitionedは複数パーティションにアクセスするトランザクションがボトルネックに
122

コンフリクトについての評価
TPC-Cでは12%のトランザクションがtimestamp conflictした
しかし3回以上のリスタートを要したのは0.5%だった
つまりコンフリクトしてもすぐにロック&直列処理せずとも何度かリスタートすればよさそう
HTM conflictは4コアで6%(右図)
何度かリスタートすればコンフリクトは減らせる
しかしもともとの6%でも十分小さいので,リスタートによる悪影響が出かねない
あとデータ構造とかそのままだと4コアで14%にまで上昇してしまう
123

まとめ
メインメモリデータベースにハードウェア実装のトランザクショナメモリ(HTM)を導入するためのあれこれを提案した
トランザクショナルメモリ:ロックフリーで並列処理させ,コンフリクトしたらトランザクション単位でアボートするだけ!楽ちん!
コンフリクトしない限りは最速だからコンフリクトしないようハードウェアの構造を考えながらデータベーストランザクションを細かくしたりデータ構造やインデックスを工夫したりした
コンフリクト検知にはタイムスタンプを使用,Safe timestampという,「これ以前のトランザクションなら全部終わってるよ」というタイムスタンプ一つでラフに管理
抜群の評価結果でBest Paperをかっさらった
124

目次
前半
• ICDE 2014を俯瞰してみる
• ビッグデータ時代の新発想:もうデータは蓄えない[Keynote] Running with Scissors: Fast Queries on Just-in-Time Databases
• 見えない相手と協調作業:センサネットワーク上のデータ集約[10 Year Most Influential Paper] Approximate Aggregation Techniques for Sensor Databases
後半
• メインメモリデータベースがハードウェアトランザクショナルメモリを使ったら…[Best Paper] Exploiting Hardware Transactional Memory in Main-Memory Databases
• 過去の結果を再利用:ビューを用いた大規模グラフからのパターン発見[Best Paper Runner-up]Answering Graph Pattern Queries Using Views
• アルゴリズムでゴリゴリ解決:大量のベクトルから類似ペアを厳密に見つけたい[気になる論文]L2AP: Fast Cosine Similarity Search With Prefix L-2 Norm Bounds
途中で会場の雰囲気などもお伝えします125

Answering Graph Pattern Queries Using Views
Wenfei Fan1,2, Xin Wang3, Yinghui Wu4
1 University of Edinburgh
2 RCBD and SKLSDE Lab, Beihang University
3 Southwest Jiaotong University
4 UC Santa Barbara
ICDE 2014 Best Paper Runner-up 126

Answering Queries Using Views
「元のデータに対するクエリ」と同じ結果が得られる「ビューに対するクエリ」を探す問題
127
元のデータ(リレーショナルデータ,
XML, グラフなど)
ビュー
ここから探すのは大変だけど
こっちから同じ結果を取得できればそれでいいよね

Answering Queries Using Viewsな研究
Relational Data [Halevy, VLDBJ01][Lenzerini, PODS02]
XML Queries [Miklau, PODS02][Neven, ICDT03][Park, ICDE Workshop, 2005]
Semistructured data and RDF [Zhuge, ICDE98][Le, WWW11]
この研究はグラフパターンマッチング問題にViewを使った最初の研究である“This work is a first step toward understanding graph pattern matching using views, from theory to practical methods.” (論文より)
128
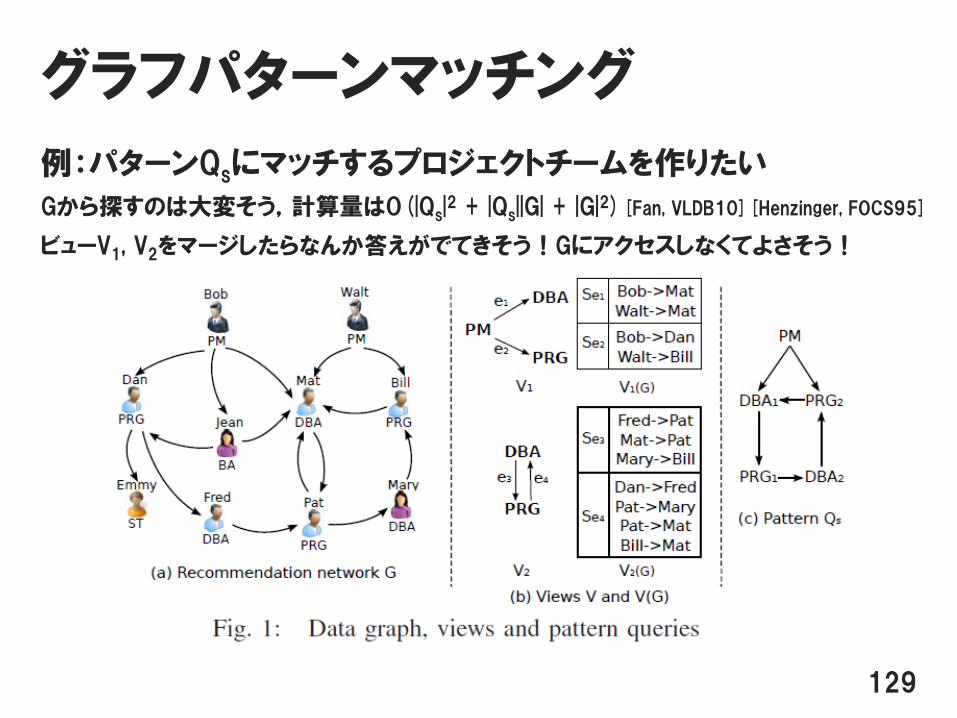
グラフパターンマッチング
例:パターンQsにマッチするプロジェクトチームを作りたい
Gから探すのは大変そう,計算量はO(|Qs|2 + |Qs||G| + |G|2)[Fan, VLDB10][Henzinger, FOCS95]
ビューV1, V2をマージしたらなんか答えがでてきそう!Gにアクセスしなくてよさそう!
129

研究課題
ビューだけでクエリに答えるためには,以下の問題を解決する必要がある
① ビューだけでちゃんと答えを出せるか否かが分かるか?
② 答えがでるとして,どうやって効率的に解を探すか?
③ どのビューを使うべきか?
本研究ではこれらの問題を解決する!
130
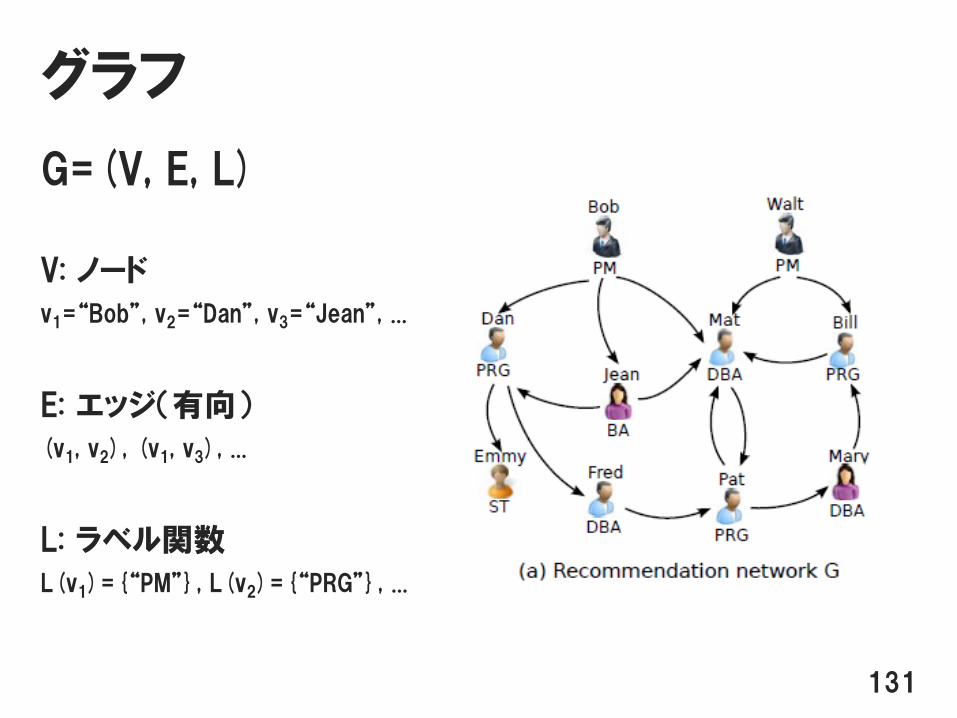
グラフ
G=(V, E, L)
V: ノード
v1=“Bob”, v2=“Dan”, v3=“Jean”, ...
E: エッジ(有向)
(v1, v2), (v1, v3), ...
L: ラベル関数
L(v1)={“PM”}, L(v2)={“PRG”}, ...
131

パターンクエリ
Qs=(Vp, Ep, fv)
Vp: ノード
u1, u2, u3, ...
Ep: エッジ(有向)
(u1, u2), (u1, u3), ...
fv: ラベル関数(複数指定不可)
fv(u1)=“PM”, fv(u2)=“DBA”, ...
132

ついでに…Boundedパターンクエリ
Qb=(Vp, Ep, fv, fe)
Vp: ノード
Ep: エッジ(有向)
fv: ラベル関数(複数指定不可)
fv(u1)=“PM”, fv(u2)=“DBA”, ...
fe: ホップ数関数
fe(u1, u2)=2, ...
間接的に繋がっていてもよい
133
2
1
1
2
* *
QsじゃなくてQb
feが増えた
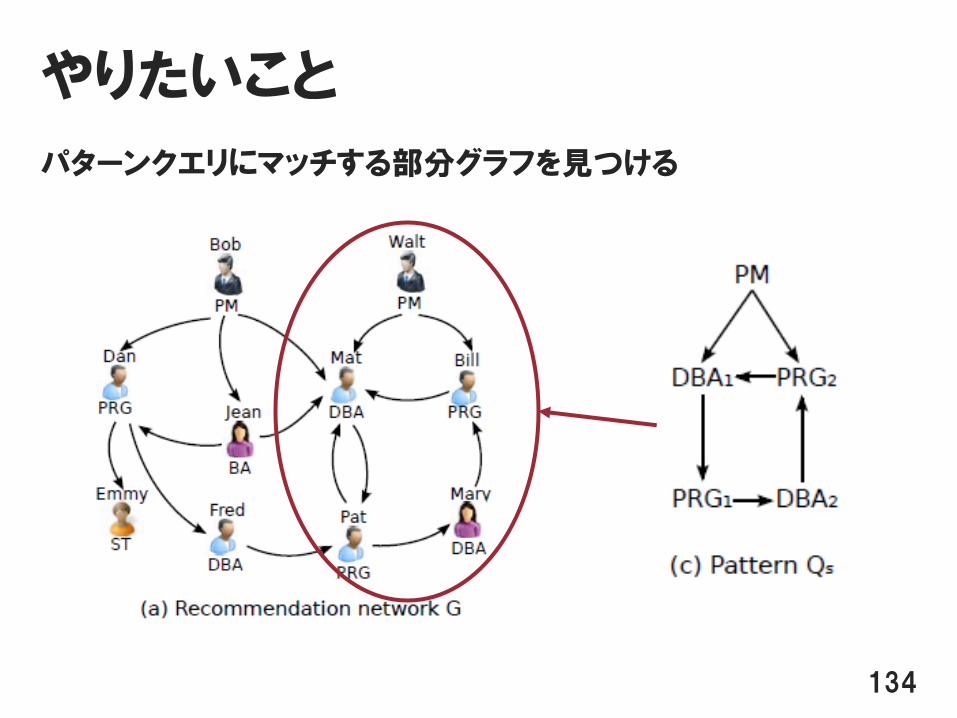
やりたいこと
パターンクエリにマッチする部分グラフを見つける
134

グラフパターンマッチング via シミュレーション
𝑄𝑠 ⊴𝑠𝑖𝑚 𝐺: グラフGがパターンクエリQsにシミュレーションでマッチ
以下のようなSが存在するときシミュレーションでマッチする
ノードマッチ:Qsの各ノードu∈Vpについて,(u, v)∈Sを満たすGのノードv∈Vが存在
エッジマッチ:各ノードマッチペア(u, v)∈Sについて,fv(u)∈L(v)であり,さらに各パターンクエリのエッジ(u, u’)∈Epについて,グラフのエッジ(v, v’)∈Eが存在(もちろん(u’, v’)∈S)
S0をユニークな最大のSとする(𝑄𝑠 ⊴𝑠𝑖𝑚 𝐺ならS0は必ず1つだけ存在 [Henzinger, FOCS95])
SeをS0のeに対するエッジマッチの集合とする
クエリQsへのシミュレーション結果をQs(G)={(e, Se)| e∈Ep}とする
135ちょっと何言ってるか分からない
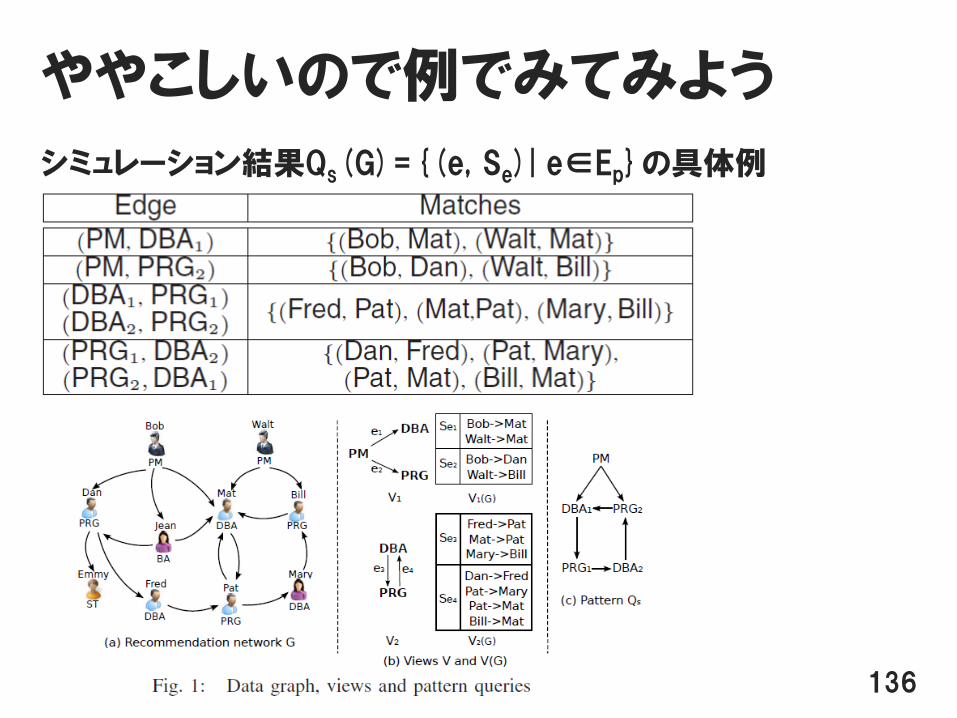
ややこしいので例でみてみよう
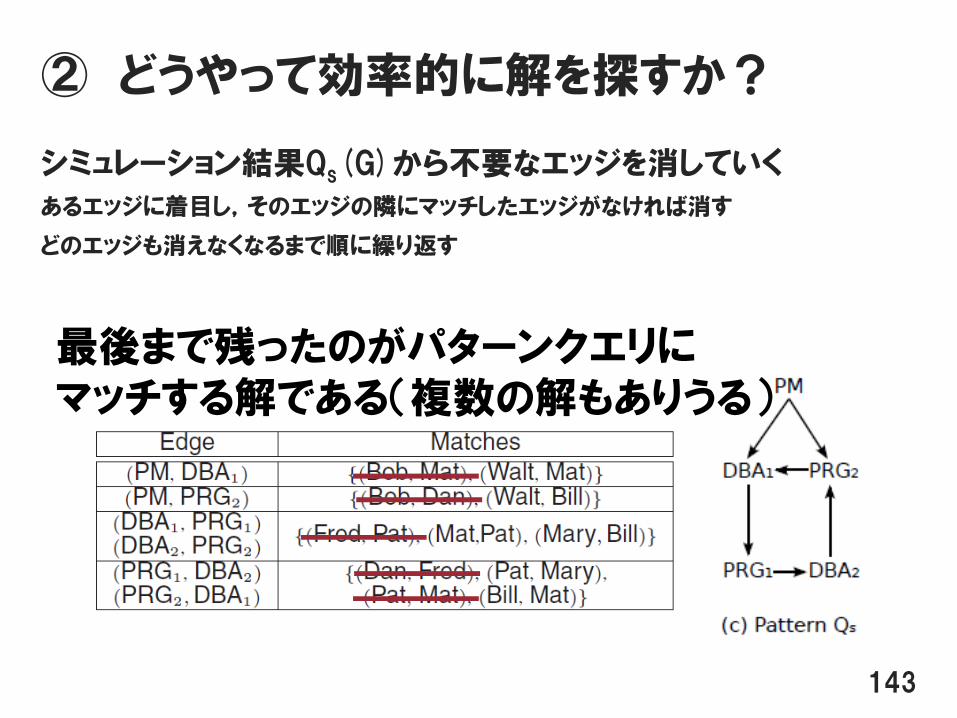
シミュレーション結果Qs(G)={(e, Se)| e∈Ep}の具体例
136
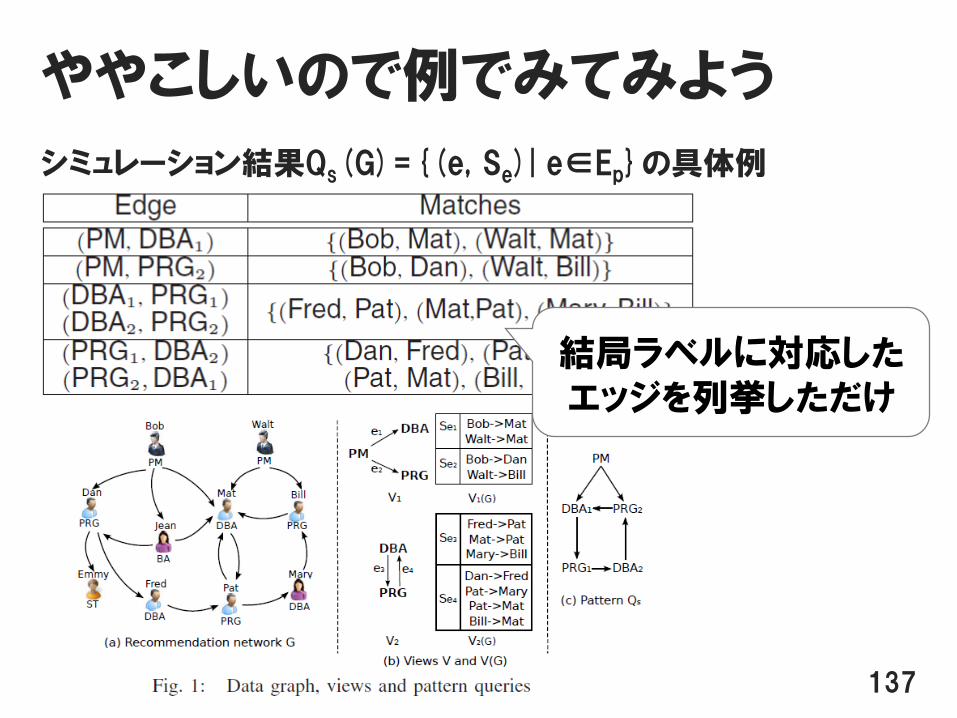
ややこしいので例でみてみよう
シミュレーション結果Qs(G)={(e, Se)| e∈Ep}の具体例
137
結局ラベルに対応したエッジを列挙しただけ

ビュー
シミュレーション結果Qs(G)が新たにビューとなる
138

① ビューだけでちゃんと答えを出せるか否かが分かるか?
ビューを作るとき,「ラベルに対応したエッジ」について,グラフGから該当する全エッジを取得
つまり…
ビューに「ラベルに対応したエッジ」がある場合,Gの該当するエッジを取りこぼさない!
すなわち…
クエリを構成する全ての「ラベルに対応したエッジ」がビューにあれば,ビューのみから結果を出せる!
139

Qsの場合
140
PM→DBA1
PM→PRG2
DBA1→PRG1
DBA2→PRG2
PRG1→DBA2
PRG2→DBA1
分解
e1
e2
e3
e4
全部ビューにある!ということは
ビューからシミュレーション結果Qs(G)が得られる!
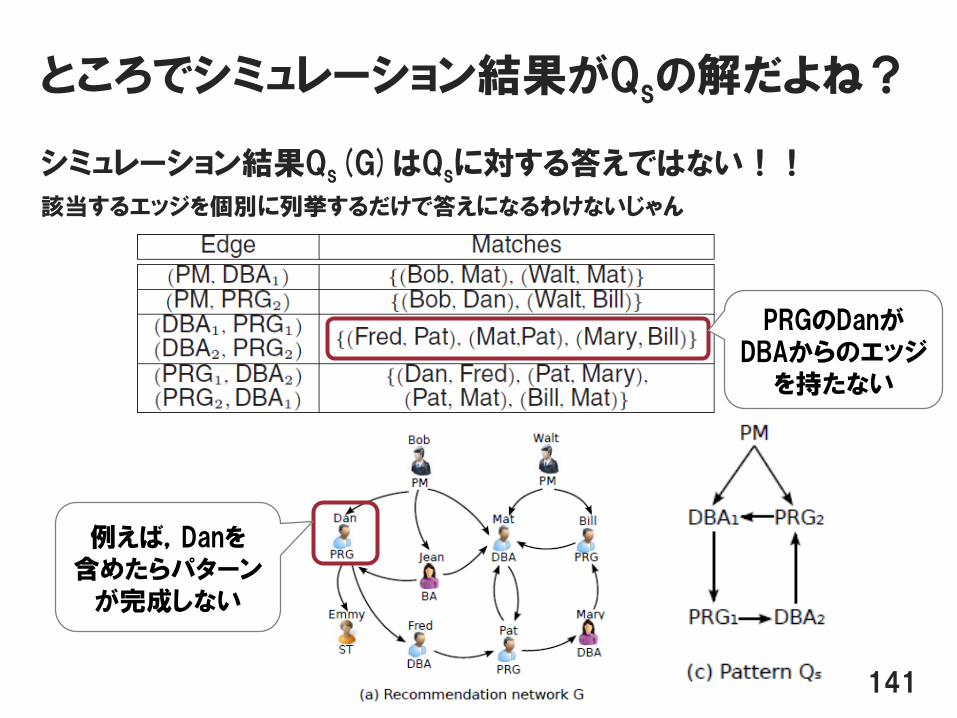
ところでシミュレーション結果がQsの解だよね?
シミュレーション結果Qs(G)はQsに対する答えではない!!
該当するエッジを個別に列挙するだけで答えになるわけないじゃん
141
例えば,Danを含めたらパターン
が完成しない
PRGのDanがDBAからのエッジ
を持たない
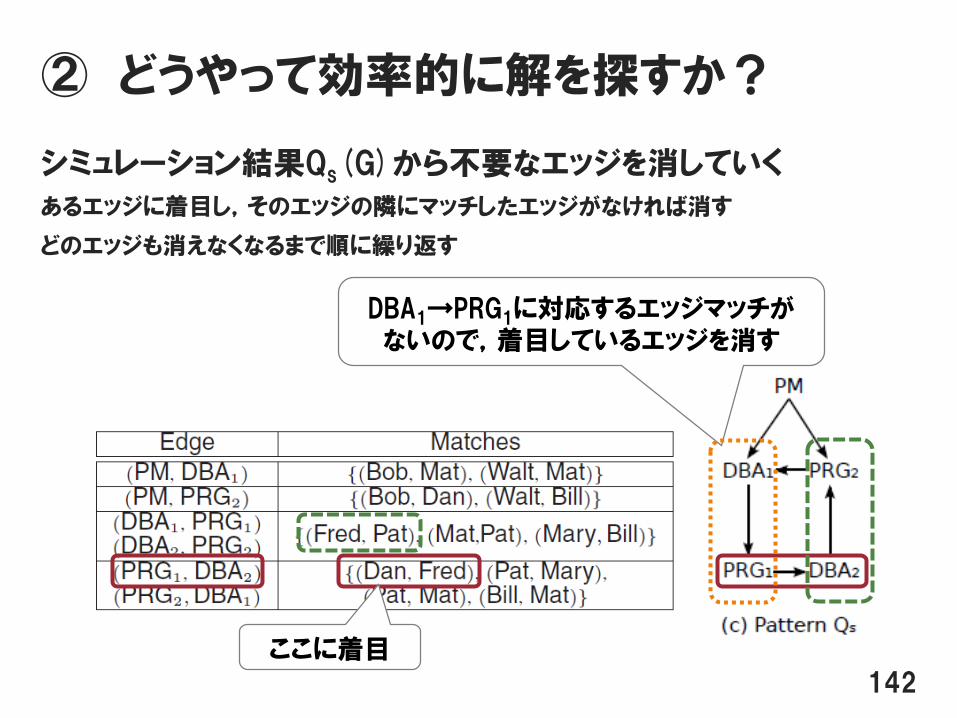
② どうやって効率的に解を探すか?
シミュレーション結果Qs(G)から不要なエッジを消していく
あるエッジに着目し,そのエッジの隣にマッチしたエッジがなければ消す
どのエッジも消えなくなるまで順に繰り返す
142
DBA1→PRG1に対応するエッジマッチがないので,着目しているエッジを消す
ここに着目
② どうやって効率的に解を探すか?
シミュレーション結果Qs(G)から不要なエッジを消していく
あるエッジに着目し,そのエッジの隣にマッチしたエッジがなければ消す
どのエッジも消えなくなるまで順に繰り返す
143
最後まで残ったのがパターンクエリにマッチする解である(複数の解もありうる)

計算量
ビュー のサイズに対して二乗オーダなので,グラフGの大きさを考えたらだいぶ小さい
紙面の都合上,証明は論文ではなく以下の資料で展開されている(※証明の解読に自信のある方以外は開かないほうがいいです)
http://homepages.inf.ed.ac.uk/s0944873/View.pdf
144

③ どのビューを使うべきか?
こちらもインクリメンタルなやり方で簡単にできる
Minimal法
[ビュー追加フェーズ]
ビューを順に走査し,Qsに必要なエッジの情報を持っていたらそのビューを追加
ビューが追加されるごとにQsに必要なエッジが少なくなっていき,すべてのエッジの情報がビューでまかなえるようになったらストップ
ビューを全部チェックしてQsに必要なエッジが全部そろわなかったら失敗(グラフから直接探さないといけない)
[ビュー削除フェーズ]
追加したビューを順に走査し,そのビューを抜いてもQsに必要なエッジがまだそろっていたら,そのビューはなくてもいいということなので削除
より効率的にエッジを被覆するビューを選択していくMinimum法もある
145

ビュー選択例(追加)
上のビューから順に走査してみる
146
PM→DBA1
PM→PRG2
DBA1→PRG1
DBA2→PRG2
PRG1→DBA2
PRG2→DBA1
分解
この段階で全部のエッジがカバーされたので追加終了!(ちょうど全ビュー走査し終わったけどそれとは関係ない)
論文の図を一部改変

ビュー選択例(削除)
追加した順(上から順)に走査してみる
147
PM→DBA1
PM→PRG2
DBA1→PRG1
DBA2→PRG2
PRG1→DBA2
PRG2→DBA1
分解
これを消してもまだ全エッジがカバーされてるので削除!論文の図を一部改変
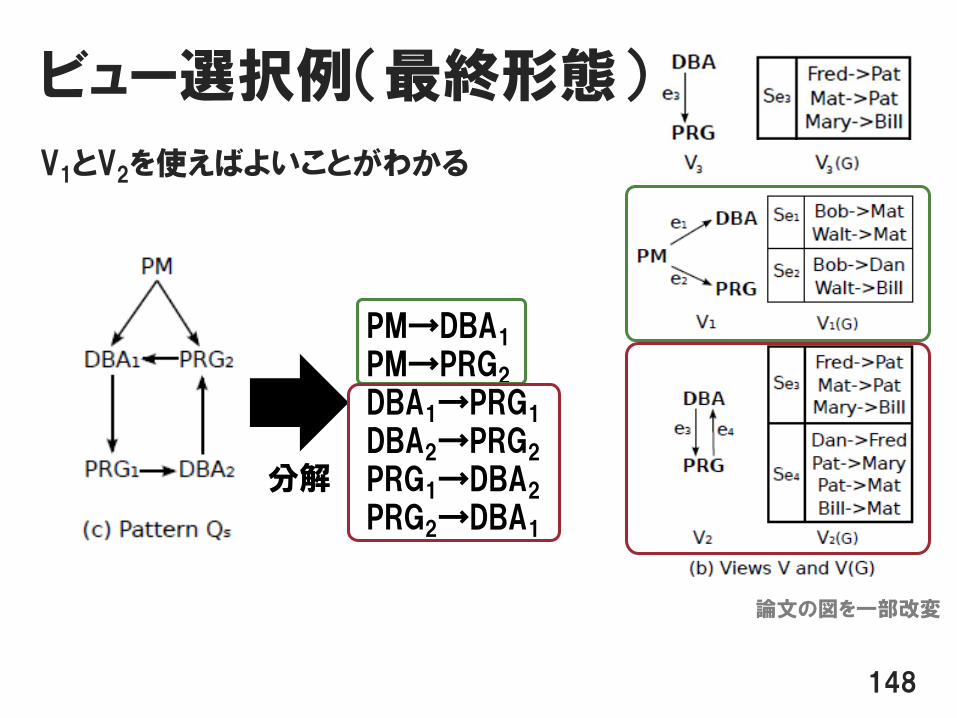
ビュー選択例(最終形態)
V1とV2を使えばよいことがわかる
148
PM→DBA1
PM→PRG2
DBA1→PRG1
DBA2→PRG2
PRG1→DBA2
PRG2→DBA1
分解
論文の図を一部改変

評価用データ
Amazon*1
同時購入グラフ,548Kノード,1.78Mエッジ,属性:タイトル,グループ,ランクなどビュー:12頻出パターン生成[Leskovec, PAKDD06],1パターンで5Kのノードとエッジをカバー
Citation*2
論文引用グラフ,1.4Mノード,3Mエッジ,属性:タイトル,著者,年,開催地などビュー:独自に12のビューを作成,全体の12%をカバー
YouTube*3
推薦グラフ,1.6Mノード,4.5エッジ,属性:カテゴリ,年齢,レートなどビュー:独自に12ビューを生成,1ビューで700ノードとエッジをカバー
149
*1 Amazon dataset. http://snap.stanford.edu/data/index.html.*2 Citation. http://www.arnetminer.org/citation/.*3 Youtube dataset. http://netsg.cs.sfu.ca/youtubedata/.
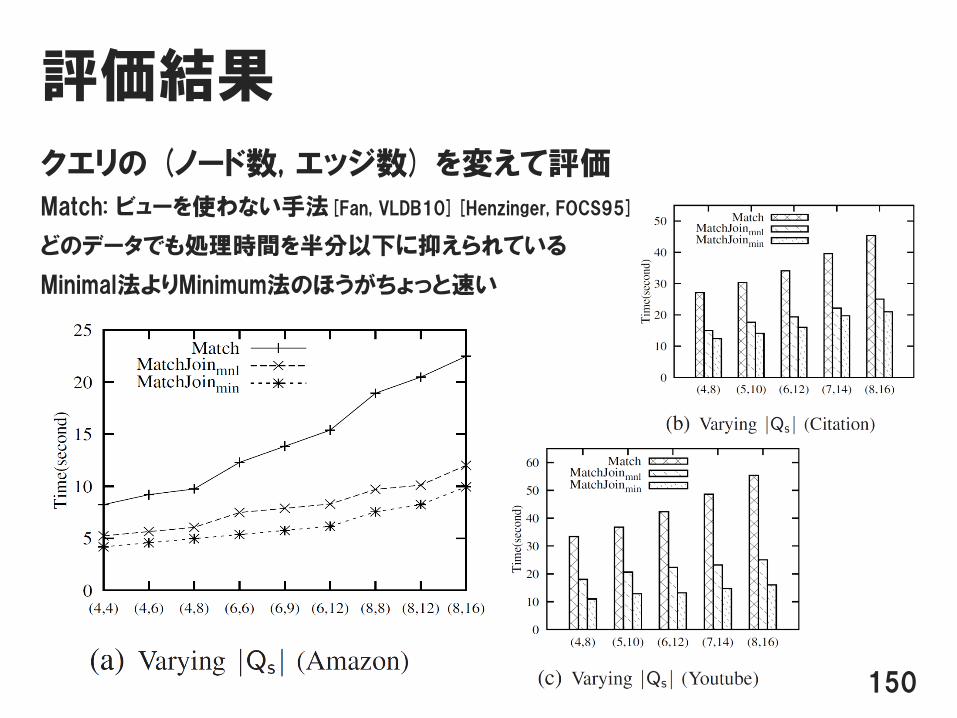
評価結果
クエリの (ノード数, エッジ数) を変えて評価
Match: ビューを使わない手法[Fan, VLDB10][Henzinger, FOCS95]
どのデータでも処理時間を半分以下に抑えられている
Minimal法よりMinimum法のほうがちょっと速い
150
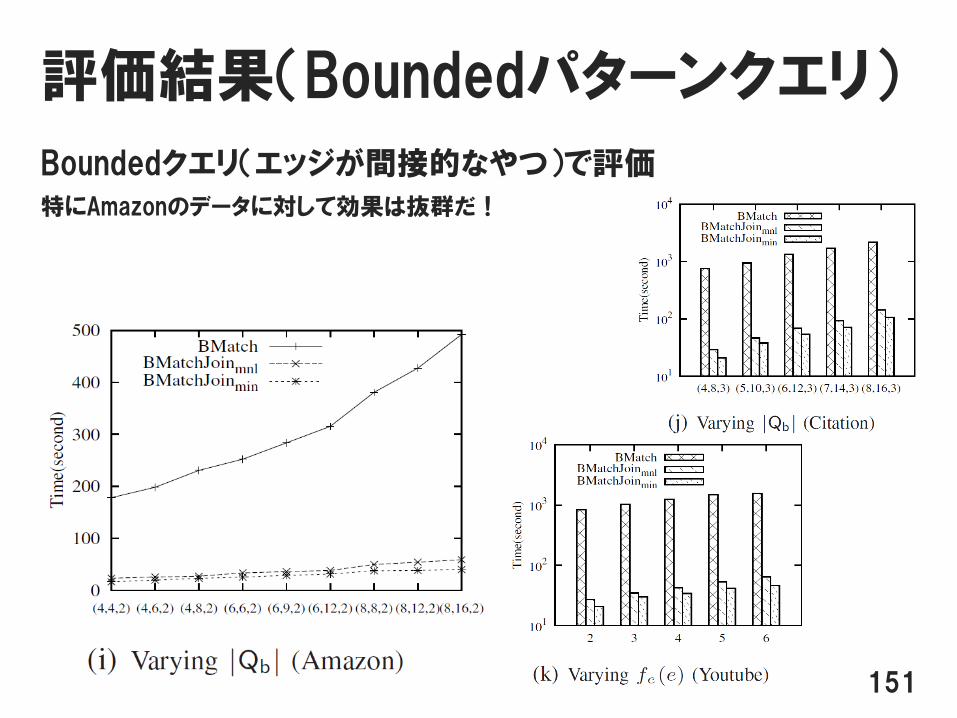
評価結果(Boundedパターンクエリ)
Boundedクエリ(エッジが間接的なやつ)で評価
特にAmazonのデータに対して効果は抜群だ!
151
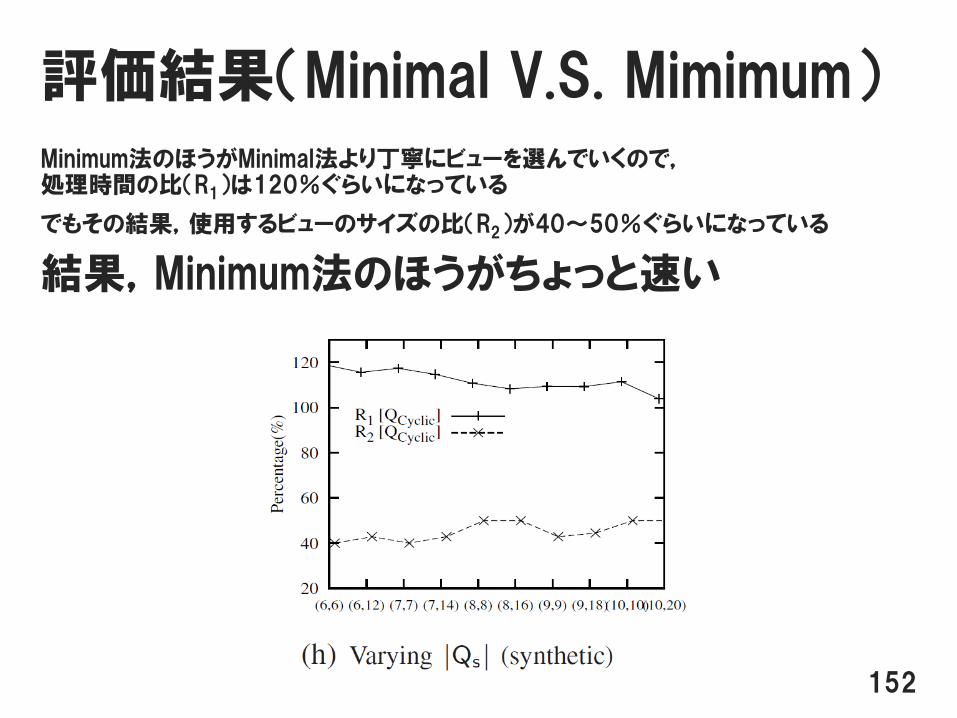
評価結果(Minimal V.S. Mimimum)Minimum法のほうがMinimal法より丁寧にビューを選んでいくので,処理時間の比(R1)は120%ぐらいになっている
でもその結果,使用するビューのサイズの比(R2)が40~50%ぐらいになっている
結果,Minimum法のほうがちょっと速い
152

まとめ
グラフパターンマッチング問題をビューを使って解いた
「グラフ全体に対するクエリ」を「ビューに対する等価な答えを返すクエリ」に変換
実データを使った評価で,ビューを使わない場合と比べて処理時間を半分以下に短縮
手法は割とストレートだが論文中の定理・証明の数が多い
この地味な部分があってこそのIDCE採択&Best Paper Runner-upっぽい
この研究も「実際に発行されるクエリが偏っている」ことを利用し,ビューをキャッシュすることにより高速化している
153

目次
前半
• ICDE 2014を俯瞰してみる
• ビッグデータ時代の新発想:もうデータは蓄えない[Keynote] Running with Scissors: Fast Queries on Just-in-Time Databases
• 見えない相手と協調作業:センサネットワーク上のデータ集約[10 Year Most Influential Paper] Approximate Aggregation Techniques for Sensor Databases
後半
• メインメモリデータベースがハードウェアトランザクショナルメモリを使ったら…[Best Paper] Exploiting Hardware Transactional Memory in Main-Memory Databases
• 過去の結果を再利用:ビューを用いた大規模グラフからのパターン発見[Best Paper Runner-up]Answering Graph Pattern Queries Using Views
• アルゴリズムでゴリゴリ解決:大量のベクトルから類似ペアを厳密に見つけたい[気になる論文]L2AP: Fast Cosine Similarity Search With Prefix L-2 Norm Bounds
途中で会場の雰囲気などもお伝えします154

L2AP: Fast Cosine Similarity Search With Prefix L-2 Norm Bounds
David C. Anastasiu, George KarypisUniversity of Minnesota
ICDE 2014
155
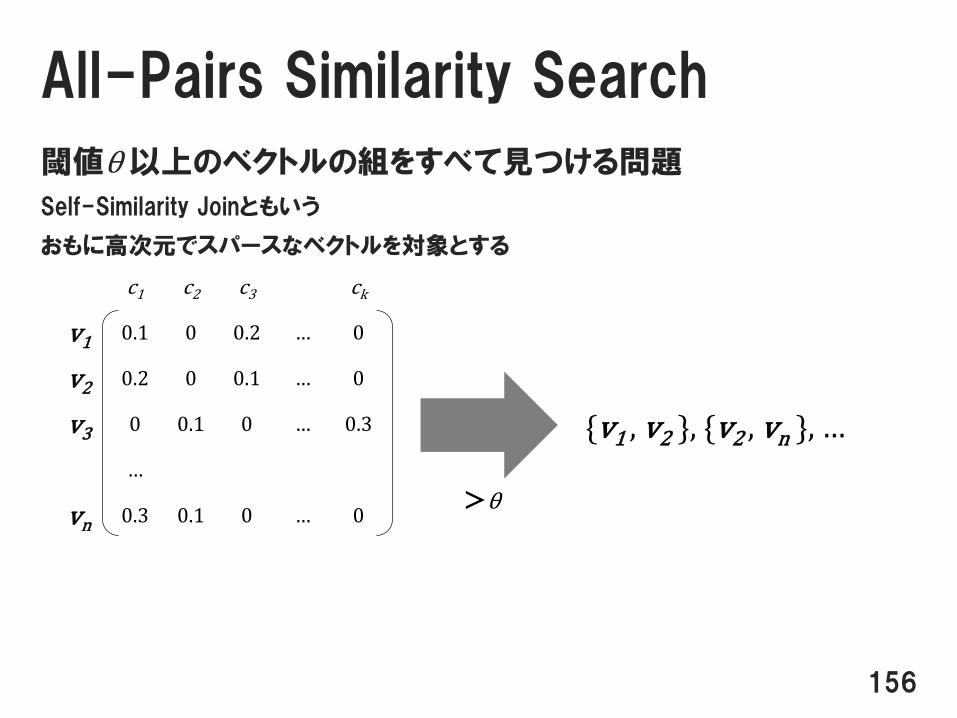
All-Pairs Similarity Search
閾値θ 以上のベクトルの組をすべて見つける問題
Self-Similarity Joinともいう
おもに高次元でスパースなベクトルを対象とする
156
c1 c2 c3 ck
v1 0.1 0 0.2 … 0
v2 0.2 0 0.1 … 0
v3 0 0.1 0 … 0.3
…
vn 0.3 0.1 0 … 0
{v1 , v2 }, {v2 , vn }, …
>θ

よくあるアプローチ
転置インデックスを使うことで非零成分に高速にアクセス
ベクトルが正規化されていれば,コサイン類似度は非零成分同士の積で表される
157
c1 c2 c3 ck
v1 0.1 0 0.2 … 0
v2 0.2 0 0.1 … 0
v3 0 0.1 0 … 0.3
…
vn 0.3 0.1 0 … 0
c1→ {v1 , 0.1},{v2 , 0.2},…,{vn , 0.3}c2→ {v3 , 0.1},…,{vn , 0.1}c3→ {v1 , 0.2},{v2 , 0.1},……
転置インデックス
というかそれ以外にやり方あんの?

もっと賢いアプローチ
明らかに閾値を越えなさそうな組は全部計算する前に捨てる
Prefix filtering [Chaudhuri, ICDE06]
ベクトルの前半部分(prefix)のみの情報を利用,Intersectionの有無で判断
AllPairs [Bayardo, WWW07] (詳細は後述)
Prefix, suffix, 非零成分の数(size)を利用
動的に転置インデックスを作成
上記のような厳密手法だけでなく,近似手法もある
Locality Sensitive Hashing (LSH) [Gionis, VLDB99], BayesLSH [Satuluri, VLDB12]
他にもたくさんあるが詳しくは論文のRelated Work参照158

AllPairsの概要 [Bayardo, WWW07]
1行(ベクトル)ずつ,以下の処理を行う(実際は2, 3, 1の順)
1. 動的インデックス作成
1列ずつ処理し,「この列で初めてヒットしたら最大でこの類似度まで到達できる」という最大類似度が閾値を上回る列以降のみ,インデックスを作る
2. 候補選択
1列ずつ逆から処理し,すでに作成したインデックスを用いて類似度を推定する
ベクトルのサイズや推定した類似度が閾値未満なら候補から外す
3. 候補厳選
候補に残ったベクトルの組について,正確な類似度を算出する
159

AllPairsの動作の雰囲気
160
c1 c2 c3 ck
v1 0.1 0 0.2 … 0
v2 0.2 0 0.1 … 0
v3 0 0.1 0 … 0.3
…
vn 0.3 0.1 0 … 0

AllPairsの動作の雰囲気
161
c1 c2 c3 ck
v1 0.1 0 0.2 … 0
v2 0.2 0 0.1 … 0
v3 0 0.1 0 … 0.3
…
vn 0.3 0.1 0 … 0
左から順に走査し,各非零成分において,ここでヒットしたときの類似度の最大値が閾値を越える場合のみインデックスを保存
(なのではじめのほうはインデックスは作られない)

AllPairsの動作の雰囲気
162
c1 c2 c3 ck
v1 0.1 0 0.2 … 0
v2 0.2 0 0.1 … 0
v3 0 0.1 0 … 0.3
…
vn 0.3 0.1 0 … 0
今度は右から順に走査し,各非零成分において,すでに作成したインデックスと一致するものがあれば,徐々にドットプロダクトを足していく

AllPairsの動作の雰囲気
163
c1 c2 c3 ck
v1 0.1 0 0.2 … 0
v2 0.2 0 0.1 … 0
v3 0 0.1 0 … 0.3
…
vn 0.3 0.1 0 … 0
インデックス作成していない部分から最後までちゃんと計算する

AllPairsの動作の雰囲気
164
c1 c2 c3 ck
v1 0.1 0 0.2 … 0
v2 0.2 0 0.1 … 0
v3 0 0.1 0 … 0.3
…
vn 0.3 0.1 0 … 0
以降,繰り返し(ただし徐々にインデックスされるベクトルが増えていく)

準備:記号の意味など
x (or y ) …ベクトル
|x | …ベクトルのサイズ(非零成分の数)
x ’ …ベクトルのprefix(前半部分)
x ’’ …ベクトルのsuffix(後半部分)
rwi or rwx …行列の i 行目の最大値 or ベクトル x の最大値
cwj …行列の j 列目の最大値
165

AllPairsアルゴリズム(1/2)
166

AllPairsアルゴリズム(1/2)
167
行,列ごとにソート(より効率が上がる)

AllPairsアルゴリズム(1/2)
168
b1 : この列で初めてヒットした場合の x との類似度の最大値これが閾値 t を下回る場合,もはや閾値を越えることはない=インデックス不要
インデックスフィルタリング

AllPairsアルゴリズム(2/2)
169

AllPairsアルゴリズム(2/2)
170
サイズフィルタリング
非零成分の数が少ないと,それだけで閾値超えるの無理になる

AllPairsアルゴリズム(2/2)
171
残余(residual)フィルタリング
最初のヒットが遅くなると徐々に類似度の最大値が減っていく

AllPairsアルゴリズム(2/2)
172
候補に残ったベクトルだけ類似度計算
ここでももう一回おおまかに計算して候補を絞る(16行目)閾値 t を超える見込みがあれば最後まで計算(17行目)
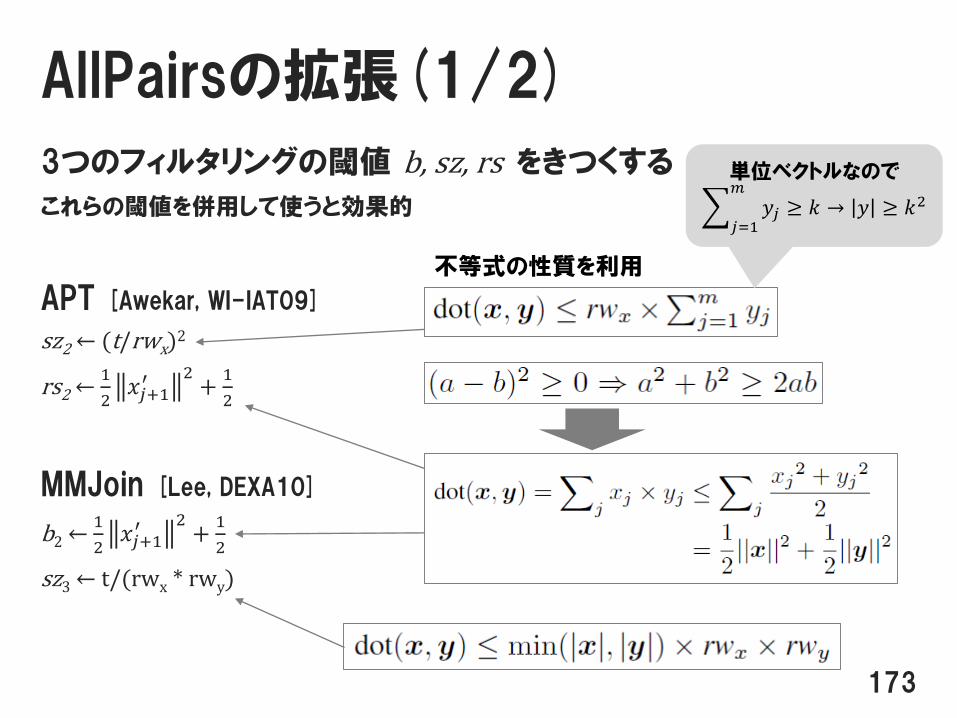
AllPairsの拡張(1/2)
3つのフィルタリングの閾値 b, sz, rs をきつくする
これらの閾値を併用して使うと効果的
APT [Awekar, WI-IAT09]
sz2← (t/rwx)2
rs2←1
2𝑥𝑗+1′ 2+1
2
MMJoin [Lee, DEXA10]
b2← 1
2𝑥𝑗+1′ 2+1
2
sz3← t/(rwx * rwy)
173
不等式の性質を利用
単位ベクトルなので
𝑗=1
𝑚
𝑦𝑗 ≥ 𝑘 → 𝑦 ≥ 𝑘2

AllPairsの拡張(2/2)
最後の「候補をもう一回おおまかに計算する」ところも改善できる
APT [Awekar, WI-IAT09]
174

提案手法:L2AP(1/2)
コーシー=シュワルツの不等式を利用して閾値をさらにきつくする
単位ベクトルを想定しているので
これはAPTやMMJoinよりもあきらかにきつい閾値を設定できるなぜならば
だからだ!
175
コーシー=シュワルツの不等式

提案手法:L2AP(2/2)
同様に,prefix同士でも
よりきつい閾値を設定可能である
そう,L2APならね
176

L2APのアルゴリズム(1/2)
177

L2APのアルゴリズム(1/2)
178
コーシー=シュワルツの不等式から得た新たな閾値b3 を導入そしてもはやb2 はいらない(確実に b2 ≧b3 なので)
インデックスフィルタリングの閾値算出

L2APのアルゴリズム(1/2)
179
インデックス保存の際にはmin(b1 , b3 )も保存

L2APのアルゴリズム(2/2)
180

L2APのアルゴリズム(2/2)
181
sz はMMJoinのやつが一番良いなので採用

L2APのアルゴリズム(2/2)
182
rs は新しく2種類提案rs3 はrs1 を改善したシンプルなやつ
rs4 はコーシー=シュワルツ使ったやつ(こっちのほうが強力)
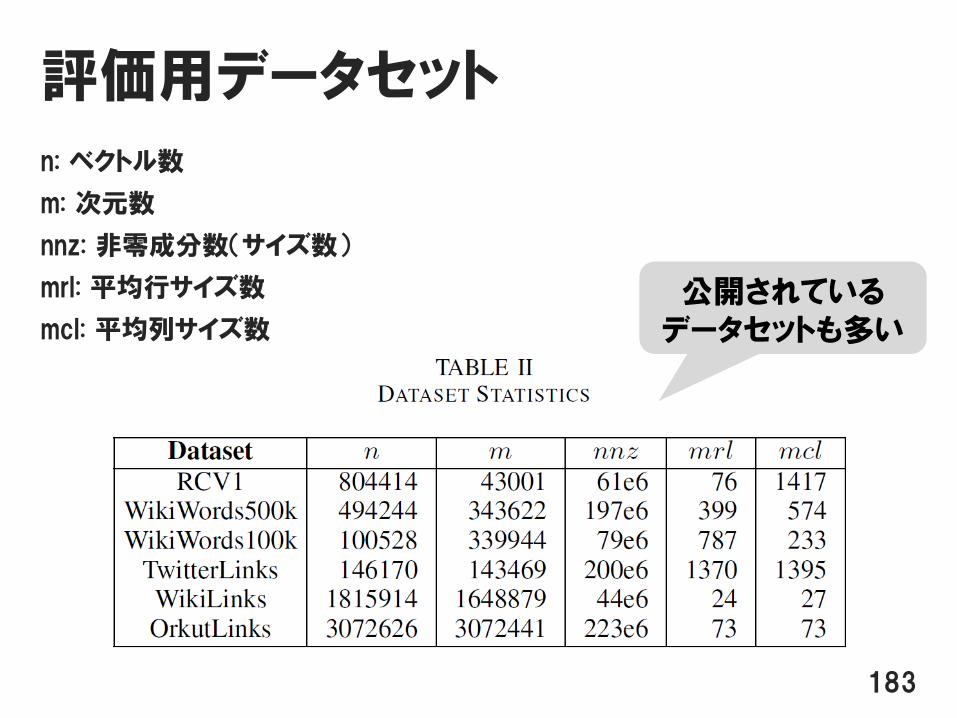
評価用データセット
n: ベクトル数
m: 次元数
nnz: 非零成分数(サイズ数)
mrl: 平均行サイズ数
mcl: 平均列サイズ数
183
公開されているデータセットも多い
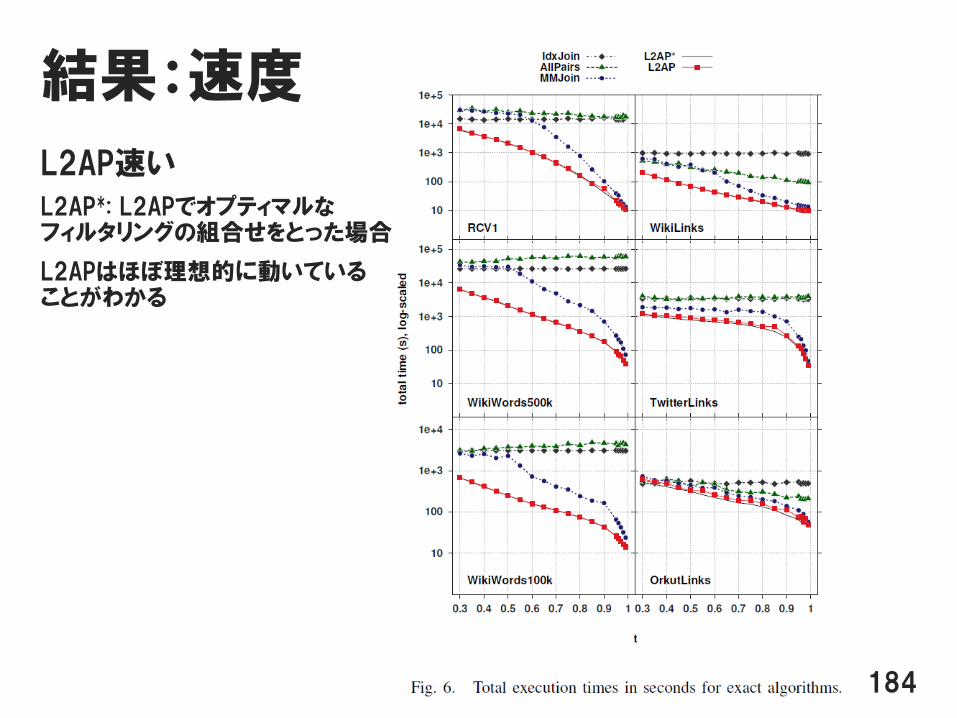
結果:速度
L2AP速い
L2AP*: L2APでオプティマルなフィルタリングの組合せをとった場合
L2APはほぼ理想的に動いていることがわかる
184
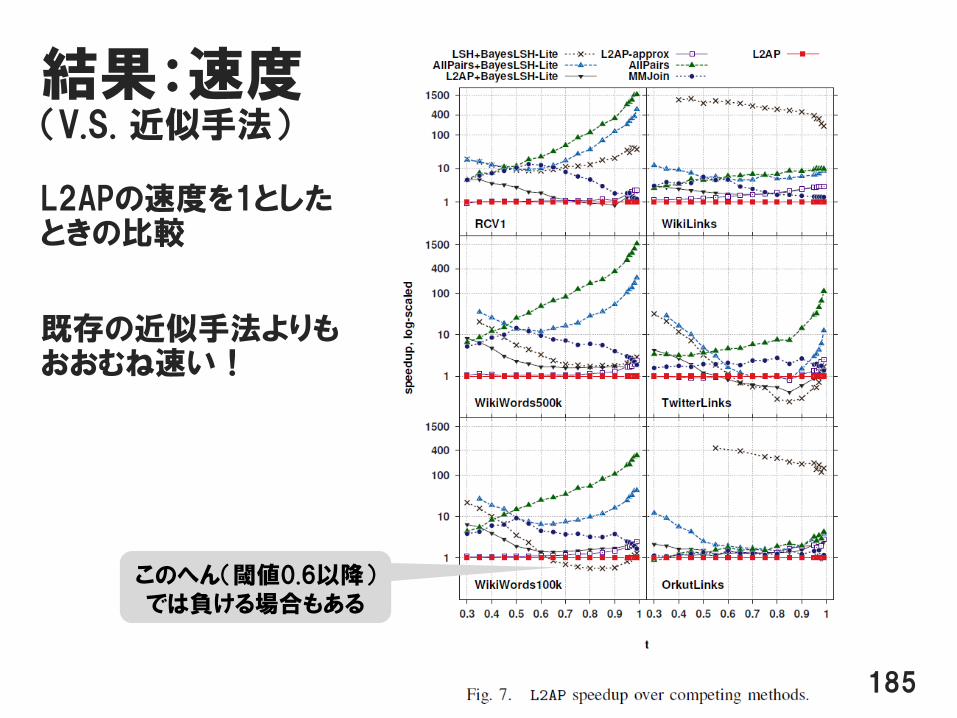
結果:速度(V.S. 近似手法)
L2APの速度を1としたときの比較
既存の近似手法よりもおおむね速い!
185
このへん(閾値0.6以降)では負ける場合もある
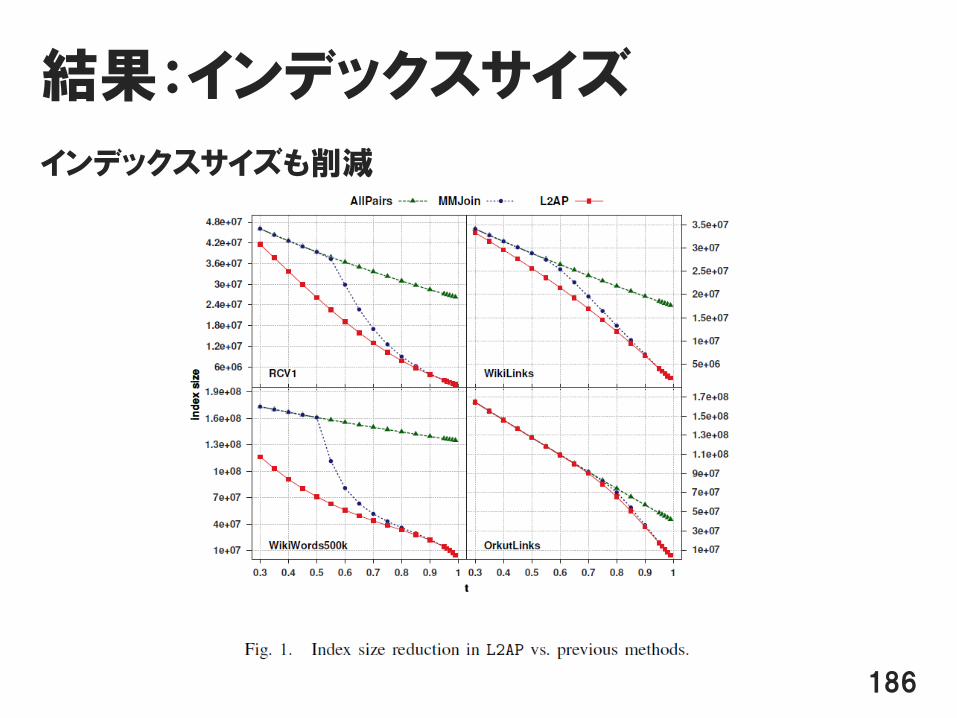
結果:インデックスサイズ
インデックスサイズも削減
186
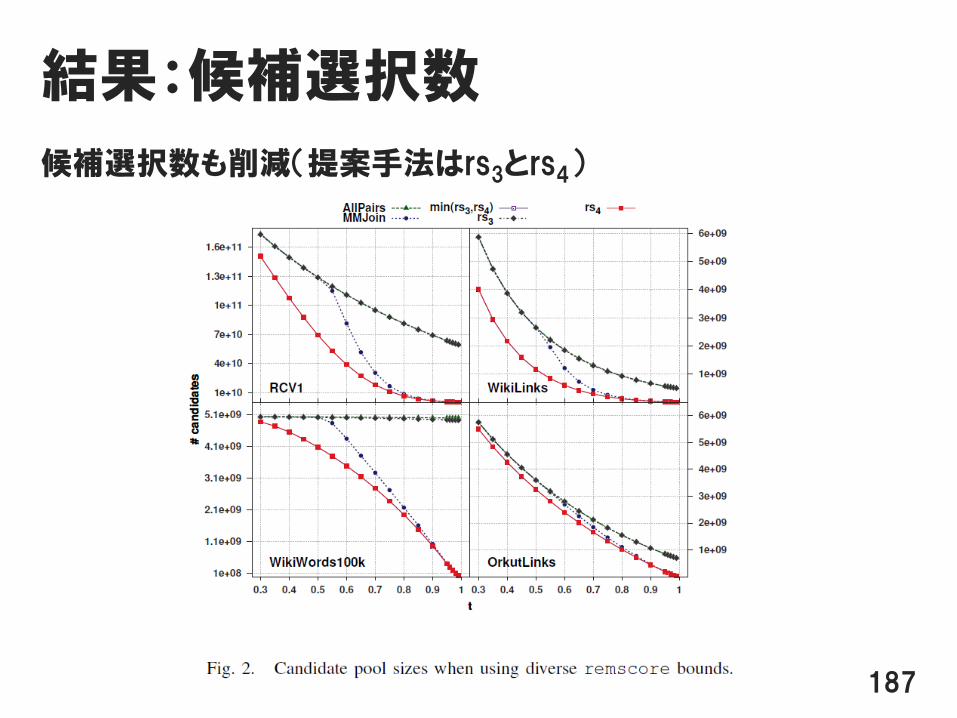
結果:候補選択数
候補選択数も削減(提案手法はrs3とrs4)
187

まとめ
ベクトル集合の中から類似度が閾値以上の組を高速に列挙する手法L2APを提案
手法はAllPairsをベースにしている(動的インデックス作成→候補選択→候補厳選)
コーシー=シュワルツの不等式を利用して可能性のある候補をより精度よくピックアップ
既存の厳密手法だけでなく,近似手法よりも速いという快挙!
高速化だけでなく,インデックスサイズや途中結果のサイズも削減
ソフトウェアがMITライセンスで公開されている
http://www-users.cs.umn.edu/~dragos/l2ap/
188

ICDE 2014参加報告おしまい
189

最後に
ICDE 2014に参加する機会を与えていただきましたことをACM SIGMOD日本支部の関係者の方々に深く感謝いたします。
これまでデータベースコア技術などに馴染みがありませんでしたが、この機会にデータベースの研究というものについて理解を深めることができました。
190