ibm linux technology center - guug
TRANSCRIPT

© 2008 IBM Corporation
IBM Linux Technology Center
The Linux Scheduler, today and looking forward
Dhaval [email protected]
IBM Linux Technology Center
© 2008 IBM Corporation
Agenda
IntroductionOld SchedulerNeed for the new schedulerCFSGroup schedulingLoad BalancingFuture

IBM Linux Technology Center
© 2008 IBM Corporation
The O(1) Scheduler
Known as the ultra scalable schedulerThe typical scheduling operations were O(1)
enqueue
dequeue
Used rotating priority arraysBasically a Weighted Round Robin scheduler
Used nice values for determining time slice
Used two arrays, active and expired.
– Task finishes its timeslice and goes to the expired array
– When active is empty, the arrays are exchanged and expired becomes active and active, expired

IBM Linux Technology Center
© 2008 IBM Corporation
Need for a new scheduler
O(1) had problems
IBM Linux Technology Center
© 2008 IBM Corporation
Need for a new scheduler
O(1) had problems Determinism
– Was not
– Erratic scheduling patterns

IBM Linux Technology Center
© 2008 IBM Corporation
Need for a new scheduler
O(1) had problems Determinism
– Was not
– Erratic scheduling patterns
Runtime Accounting
– Was statistical
– Or too coarse
IBM Linux Technology Center
© 2008 IBM Corporation
Need for a new scheduler
Led to problems
IBM Linux Technology Center
© 2008 IBM Corporation
Need for a new scheduler
Led to problems Fair allocation

IBM Linux Technology Center
© 2008 IBM Corporation
Need for a new scheduler
Led to problems Fair allocation
– Did not provide equal bandwidth to tasks at same priority esp on SMP systems

IBM Linux Technology Center
© 2008 IBM Corporation
Need for a new scheduler
Led to problems Fair allocation
– Did not provide equal bandwidth to tasks at same priority esp on SMP systems
– Similar workloads finish at varying times. Not good!

IBM Linux Technology Center
© 2008 IBM Corporation
Need for a new scheduler
Led to problems Fair allocation
– Did not provide equal bandwidth to tasks at same priority esp on SMP systems
– Similar workloads finish at varying times. Not good!
Desktop experience

IBM Linux Technology Center
© 2008 IBM Corporation
Need for a new scheduler
Led to problems Fair allocation
– Did not provide equal bandwidth to tasks at same priority esp on SMP systems
– Similar workloads finish at varying times. Not good!
Desktop experience
– Desktop Applications,
• Sleep long
• Short time on CPU

IBM Linux Technology Center
© 2008 IBM Corporation
Need for a new scheduler
Led to problems Fair allocation
– Did not provide equal bandwidth to tasks at same priority esp on SMP systems
– Similar workloads finish at varying times. Not good!
Desktop experience
– Desktop Applications,
• Sleep long
• Short time on CPU
– Need to get CPU fast
• Otherwise noticeable effects, for example, audio stutters

IBM Linux Technology Center
© 2008 IBM Corporation
The Completely Fair Scheduler or just the CFS
Written by Ingo Molnar, and merged in v2.6.23 of the kernel
IBM Linux Technology Center
© 2008 IBM Corporation
The Completely Fair Scheduler or just the CFS
Written by Ingo Molnar, and merged in v2.6.23 of the kernelMoved from priority arrays to time based queues

IBM Linux Technology Center
© 2008 IBM Corporation
The Completely Fair Scheduler or just the CFS
Written by Ingo Molnar, and merged in v2.6.23 of the kernelMoved from priority arrays to time based queuesFairness
Equal bandwidth for same priority
Provided over __sched_period()

IBM Linux Technology Center
© 2008 IBM Corporation
The Completely Fair Scheduler or just the CFS
Written by Ingo Molnar, and merged in v2.6.23 of the kernelMoved from priority arrays to time based queuesFairness
Equal bandwidth for same priority
Provided over __sched_period()
Uses an RB Tree to implement the queue Uses vruntime as its index
vruntime is weight proportional runtime
– That means heavier tasks run for longer and get charged lesser

IBM Linux Technology Center
© 2008 IBM Corporation
The Completely Fair Scheduler or just the CFS
Written by Ingo Molnar, and merged in v2.6.23 of the kernelMoved from priority arrays to time based queuesFairness
Equal bandwidth for same priority
Provided over __sched_period()
Uses an RB Tree to implement the queue Uses vruntime as its index
vruntime is weight proportional runtime
– That means heavier tasks run for longer and get charged lesser
Nice is now exponential and not linear

IBM Linux Technology Center
© 2008 IBM Corporation
Interactivity
Interactivity improved, but how?

IBM Linux Technology Center
© 2008 IBM Corporation
Interactivity
Interactivity improved, but how?Two major “features”
IBM Linux Technology Center
© 2008 IBM Corporation
Interactivity
Interactivity improved, but how?Two major “features”
Shorter time slices: On an average, the CFS has shorter time slices.
– With the help of these, tasks which are further behind, get to run faster

IBM Linux Technology Center
© 2008 IBM Corporation
Interactivity
Interactivity improved, but how?Two major “features”
Shorter time slices: On an average, the CFS has shorter time slices.
– With the help of these, tasks which are further behind, get to run faster
Wakeup behavior
– Typical interactive task -> sleeps for long, and then has a short burst
– Waiting for CPU, not good. Shows up as stutters in amarok
– So we queue up a newly woken up task to the head of the queue

IBM Linux Technology Center
© 2008 IBM Corporation
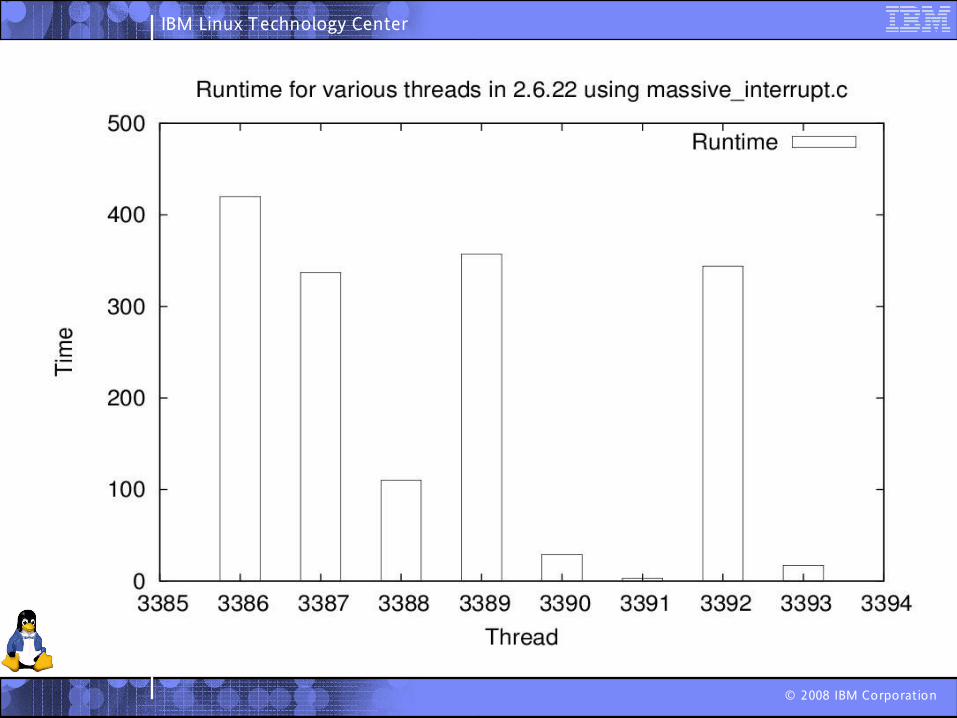
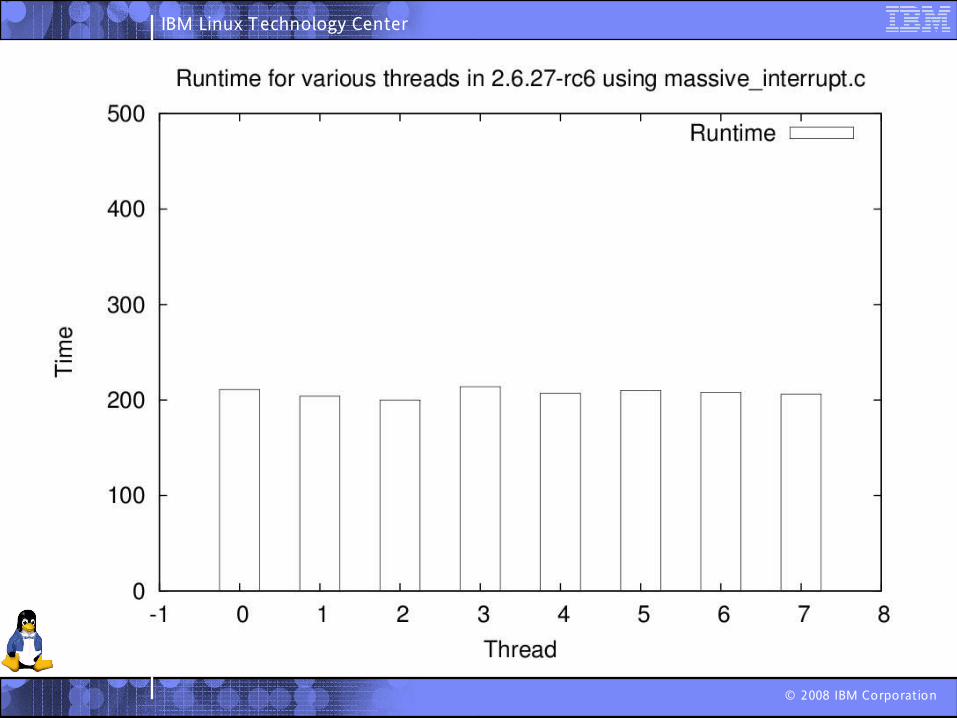
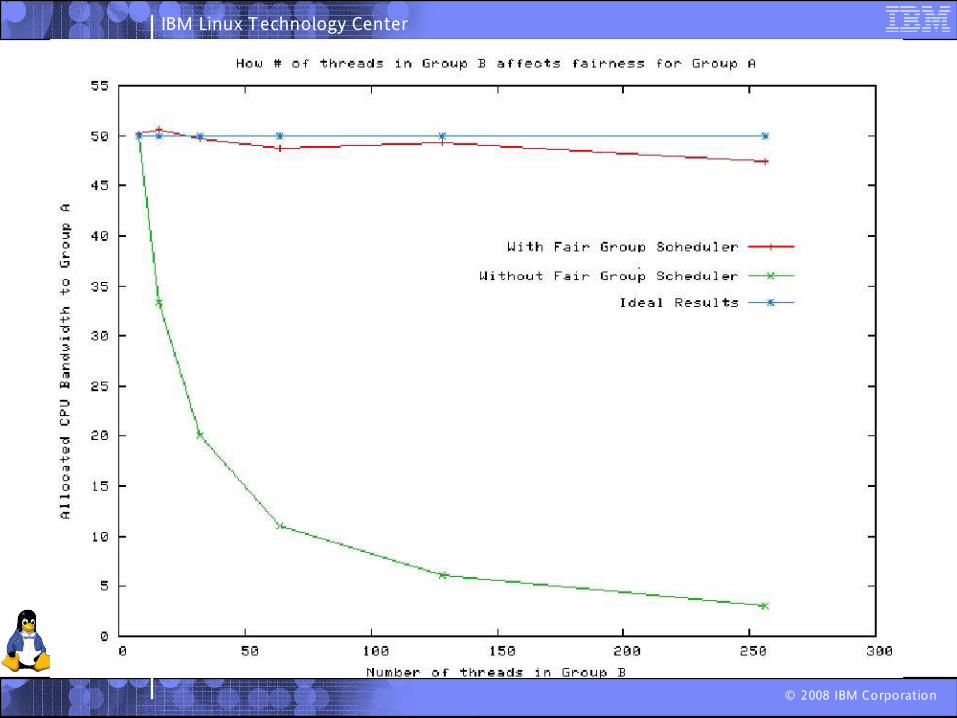
So how fair is the CFS?
Tried out massive_intr.c

IBM Linux Technology Center
© 2008 IBM Corporation
So how fair is the CFS?
Tried out massive_intr.cWritten by Satoru Takeuchi
IBM Linux Technology Center
© 2008 IBM Corporation
So how fair is the CFS?
Tried out massive_intr.cWritten by Satoru TakeuchiTakes two arguments.
Number of threads
How long to run the program

IBM Linux Technology Center
© 2008 IBM Corporation
So how fair is the CFS?
Tried out massive_intr.cWritten by Satoru TakeuchiTakes two arguments.
Number of threads
How long to run the program
Very simple Runs a thread for 8ms and then puts it to sleep for 1ms
At the end of the time, it kills all the threads, and prints out the time each thread got
IBM Linux Technology Center
© 2008 IBM Corporation
IBM Linux Technology Center
© 2008 IBM Corporation
IBM Linux Technology Center
© 2008 IBM Corporation
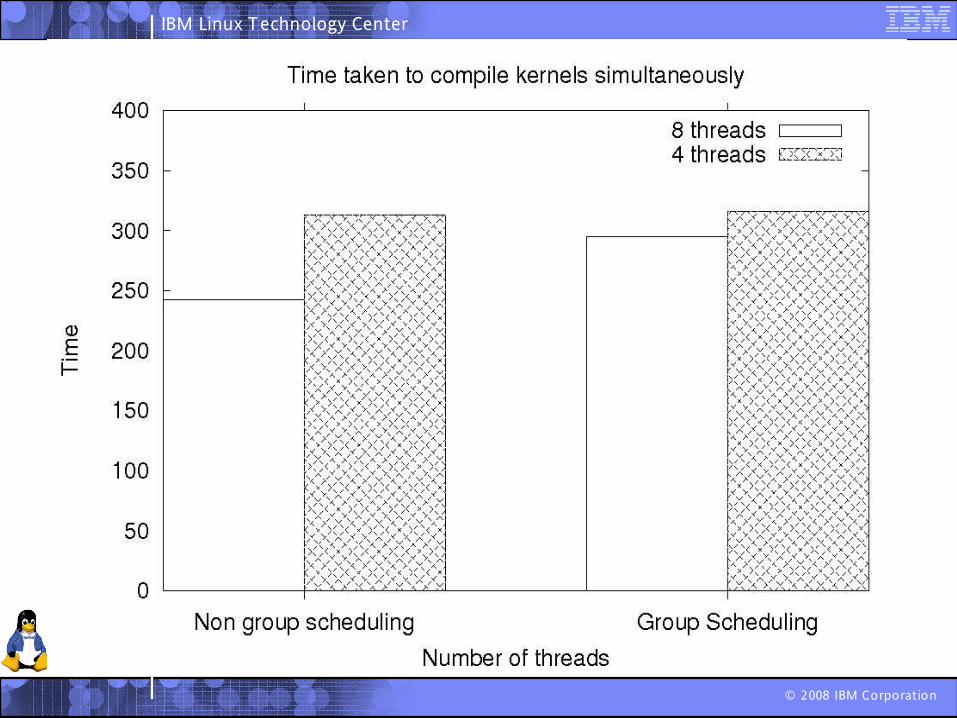
Refining the CFS: Group Scheduling
Administrator finds it easier to control groups Database vs pids 4213,4214,4215...
IBM Linux Technology Center
© 2008 IBM Corporation
Refining the CFS: Group Scheduling
Administrator finds it easier to control groups Database vs pids 4213,4214,4215...
Control Groups provided the ability to group threads arbitrarily So, group “blog”, could consist of webserver and database threads

IBM Linux Technology Center
© 2008 IBM Corporation
Refining the CFS: Group Scheduling
Administrator finds it easier to control groups Database vs pids 4213,4214,4215...
Control Groups provided the ability to group threads arbitrarily So, group “blog”, could consist of webserver and database threads
Srivatsa Vaddagiri extended the CFS to provide group scheduling, which would give control over groups such as “blog”
Merged in v2.6.24
IBM Linux Technology Center
© 2008 IBM Corporation
Scheduler Entity
The CFS as well as the O(1) scheduler deal with just tasks
IBM Linux Technology Center
© 2008 IBM Corporation
Scheduler Entity
The CFS as well as the O(1) scheduler deal with just tasksGroup scheduling requires scheduler to deal with “task groups”

IBM Linux Technology Center
© 2008 IBM Corporation
Scheduler Entity
The CFS as well as the O(1) scheduler deal with just tasksGroup scheduling requires scheduler to deal with “task groups”Enter sched_entity

IBM Linux Technology Center
© 2008 IBM Corporation
Scheduler Entity
The CFS as well as the O(1) scheduler deal with just tasksGroup scheduling requires scheduler to deal with “task groups”Enter sched_entity
Helped with reuse of the code
Can mean either a task or a task group. Basically something that can be “scheduled”
Keeps track of vital scheduling data, such vruntime
Scheduler core modified to work entities rather than tasks
IBM Linux Technology Center
© 2008 IBM Corporation
Group Scheduling
Take 1 Scheduling a two step decision
IBM Linux Technology Center
© 2008 IBM Corporation
Group Scheduling
Take 1 Scheduling a two step decision
First we choose which group to schedule in
IBM Linux Technology Center
© 2008 IBM Corporation
Group Scheduling
Take 1 Scheduling a two step decision
First we choose which group to schedule in
Then, which task in the group selected in the previous step gets to run

IBM Linux Technology Center
© 2008 IBM Corporation
Group Scheduling
Take 1 Scheduling a two step decision
First we choose which group to schedule in
Then, which task in the group selected in the previous step gets to run
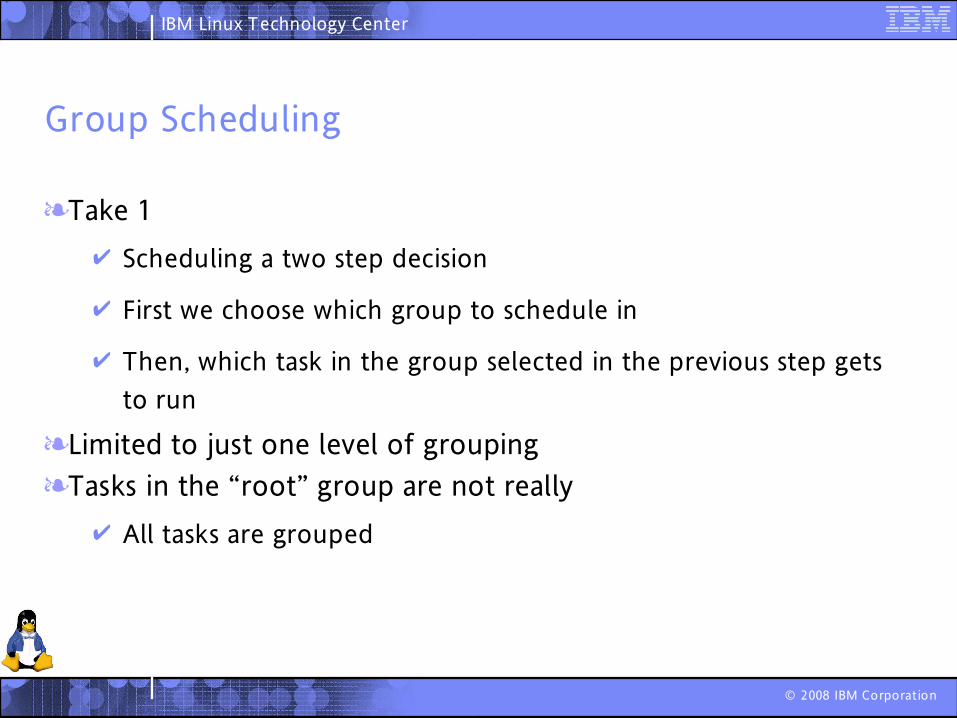
Limited to just one level of grouping
IBM Linux Technology Center
© 2008 IBM Corporation
Group Scheduling
Take 1 Scheduling a two step decision
First we choose which group to schedule in
Then, which task in the group selected in the previous step gets to run
Limited to just one level of groupingTasks in the “root” group are not really
All tasks are grouped

IBM Linux Technology Center
© 2008 IBM Corporation
Group Scheduling
Take 1 Scheduling a two step decision
First we choose which group to schedule in
Then, which task in the group selected in the previous step gets to run
Limited to just one level of groupingTasks in the “root” group are not really
All tasks are grouped
Those which are not grouped, form a group :-)
IBM Linux Technology Center
© 2008 IBM Corporation

IBM Linux Technology Center
© 2008 IBM Corporation
Group Scheduling
Not really fair

IBM Linux Technology Center
© 2008 IBM Corporation
Group Scheduling
Not really fairDid not allow multiple levels of grouping

IBM Linux Technology Center
© 2008 IBM Corporation
Group Scheduling
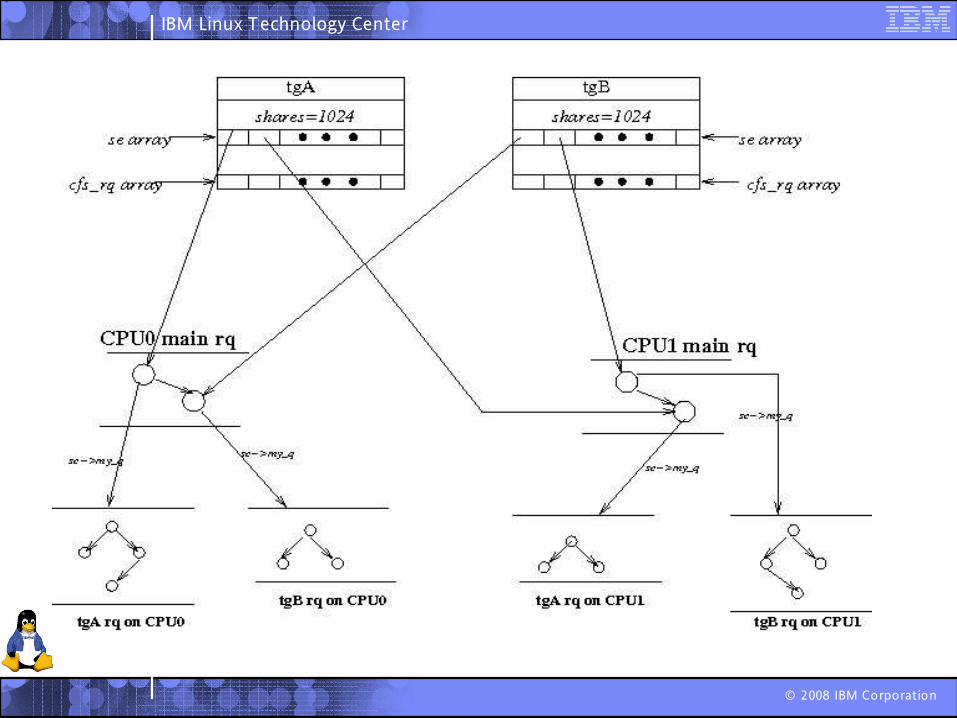
Not really fairDid not allow multiple levels of groupingTake 2
Changed the definition of fairness
– Remember, the root cgroup did not share bandwidth between the tasks and groups fairly

IBM Linux Technology Center
© 2008 IBM Corporation
Group Scheduling
Not really fairDid not allow multiple levels of groupingTake 2
Changed the definition of fairness
– Remember, the root cgroup did not share bandwidth between the tasks and groups fairly
At every level we choose an entity
– If it is a task, we run it
– If it is a group, we choose another entity within it

IBM Linux Technology Center
© 2008 IBM Corporation
Group Scheduling
Not really fairDid not allow multiple levels of groupingTake 2
Changed the definition of fairness
– Remember, the root cgroup did not share bandwidth between the tasks and groups fairly
At every level we choose an entity
– If it is a task, we run it
– If it is a group, we choose another entity within it
Available since v2.6.26
IBM Linux Technology Center
© 2008 IBM Corporation
IBM Linux Technology Center
© 2008 IBM Corporation

IBM Linux Technology Center
© 2008 IBM Corporation
Real Time
The highest priority scheduling class
IBM Linux Technology Center
© 2008 IBM Corporation
Real Time
The highest priority scheduling classImplements the POSIX standard
SCHED_FIFO
SCHED_RR
IBM Linux Technology Center
© 2008 IBM Corporation
Real Time
The highest priority scheduling classImplements the POSIX standard
SCHED_FIFO
SCHED_RR
RT Hard limits

IBM Linux Technology Center
© 2008 IBM Corporation
Real Time
The highest priority scheduling classImplements the POSIX standard
SCHED_FIFO
SCHED_RR
RT Hard limits Introduced in v2.6.25

IBM Linux Technology Center
© 2008 IBM Corporation
Real Time
The highest priority scheduling classImplements the POSIX standard
SCHED_FIFO
SCHED_RR
RT Hard limits Introduced in v2.6.25
Trivial case for the group scheduler

IBM Linux Technology Center
© 2008 IBM Corporation
Real Time
The highest priority scheduling classImplements the POSIX standard
SCHED_FIFO
SCHED_RR
RT Hard limits Introduced in v2.6.25
Trivial case for the group scheduler
sched_rt_runtime_us -> Runtime Budget
sched_rt_period_us -> The refresh rate

IBM Linux Technology Center
© 2008 IBM Corporation
Real Time
The highest priority scheduling classImplements the POSIX standard
SCHED_FIFO
SCHED_RR
RT Hard limits Introduced in v2.6.25
Trivial case for the group scheduler
sched_rt_runtime_us -> Runtime Budget
sched_rt_period_us -> The refresh rate
Prevents RT tasks from taking over the system

IBM Linux Technology Center
© 2008 IBM Corporation
RT Group Scheduling
sched_rt_entity introduced An abstraction similar to sched_entity
IBM Linux Technology Center
© 2008 IBM Corporation
RT Group Scheduling
sched_rt_entity introduced An abstraction similar to sched_entity
Two tunables rt_period_us
rt_runtime_us

IBM Linux Technology Center
© 2008 IBM Corporation
Load Balancing
All what we talked about till now, was with UP in mind
IBM Linux Technology Center
© 2008 IBM Corporation
Load Balancing
All what we talked about till now, was with UP in mindLinux can run on machines with 4096 CPUs

IBM Linux Technology Center
© 2008 IBM Corporation
Load Balancing
All what we talked about till now, was with UP in mindLinux can run on machines with 4096 CPUs
At least according to theory

IBM Linux Technology Center
© 2008 IBM Corporation
Load Balancing
All what we talked about till now, was with UP in mindLinux can run on machines with 4096 CPUs
At least according to theory
Scheduler needs to be extended

IBM Linux Technology Center
© 2008 IBM Corporation
Load Balancing
All what we talked about till now, was with UP in mindLinux can run on machines with 4096 CPUs
At least according to theory
Scheduler needs to be extended Global Scheduling: N CPUs, 1 Runqueue

IBM Linux Technology Center
© 2008 IBM Corporation
Load Balancing
All what we talked about till now, was with UP in mindLinux can run on machines with 4096 CPUs
At least according to theory
Scheduler needs to be extended Global Scheduling: N CPUs, 1 Runqueue
Paritioned Scheduling: N CPUs, N Runqueues, no interaction between runqueues

IBM Linux Technology Center
© 2008 IBM Corporation
Load Balancing
All what we talked about till now, was with UP in mindLinux can run on machines with 4096 CPUs
At least according to theory
Scheduler needs to be extended Global Scheduling: N CPUs, 1 Runqueue
Paritioned Scheduling: N CPUs, N Runqueues, no interaction between runqueues
Distributed Scheduling: N CPUs, N Runqueues, loosely coupled to approximate global scheduling

IBM Linux Technology Center
© 2008 IBM Corporation
Load Balancing
All what we talked about till now, was with UP in mindLinux can run on machines with 4096 CPUs
At least according to theory
Scheduler needs to be extended Global Scheduling: N CPUs, 1 Runqueue
Paritioned Scheduling: N CPUs, N Runqueues, no interaction between runqueues
Distributed Scheduling: N CPUs, N Runqueues, loosely coupled to approximate global scheduling
Linux uses distributed scheduling

IBM Linux Technology Center
© 2008 IBM Corporation
Scheduler Domains
Today's hardware Various sizes
Various shapes
In order to handle these, we build sched domains

IBM Linux Technology Center
© 2008 IBM Corporation
Scheduler Domains
Today's hardware Various sizes
Various shapes
In order to handle these, we build sched domains
Domains group processors Based on various properties such as shared pipelines, shared
caches

IBM Linux Technology Center
© 2008 IBM Corporation
Scheduler Domains
Today's hardware Various sizes
Various shapes
In order to handle these, we build sched domains
Domains group processors Based on various properties such as shared pipelines, shared
caches
CPUsets allow the user to carve up CPUs into sets Also used for load balancing decisions

IBM Linux Technology Center
© 2008 IBM Corporation
Load Balancing in SCHED_OTHER
The basic idea is to balance any two runqueues
IBM Linux Technology Center
© 2008 IBM Corporation
Load Balancing in SCHED_OTHER
The basic idea is to balance any two runqueues Converge to a global balance

IBM Linux Technology Center
© 2008 IBM Corporation
Load Balancing in SCHED_OTHER
The basic idea is to balance any two runqueues Converge to a global balance
Balance “near” runqueues more frequently and slow down as we go up

IBM Linux Technology Center
© 2008 IBM Corporation
Load Balancing in SCHED_OTHER
The basic idea is to balance any two runqueues Converge to a global balance
Balance “near” runqueues more frequently and slow down as we go up
Done using sched domains

IBM Linux Technology Center
© 2008 IBM Corporation
Load Balancing in SCHED_OTHER
The basic idea is to balance any two runqueues Converge to a global balance
Balance “near” runqueues more frequently and slow down as we go up
Done using sched domains
Compensates for the fact that memory accesses and migration to “far” CPUs is more expensive

IBM Linux Technology Center
© 2008 IBM Corporation
Load Balancing in SCHED_OTHER
The basic idea is to balance any two runqueues Converge to a global balance
Balance “near” runqueues more frequently and slow down as we go up
Done using sched domains
Compensates for the fact that memory accesses and migration to “far” CPUs is more expensive
Sched groups Basically the child domains of a domain

IBM Linux Technology Center
© 2008 IBM Corporation
Load Balancing in SCHED_OTHER
The basic idea is to balance any two runqueues Converge to a global balance
Balance “near” runqueues more frequently and slow down as we go up
Done using sched domains
Compensates for the fact that memory accesses and migration to “far” CPUs is more expensive
Sched groups Basically the child domains of a domain
Pick the busiest group and try to pull from there as long as we don't pull too much

IBM Linux Technology Center
© 2008 IBM Corporation
SMP NiceIntroduced by Peter Williams, ~2.6.18

IBM Linux Technology Center
© 2008 IBM Corporation
SMP NiceIntroduced by Peter Williams, ~2.6.18Load Balancer introduced to the concept of nice values
IBM Linux Technology Center
© 2008 IBM Corporation
SMP NiceIntroduced by Peter Williams, ~2.6.18Load Balancer introduced to the concept of nice values
Fairness maintained across CPUs
Balance run queues based on weight and not number of tasks

IBM Linux Technology Center
© 2008 IBM Corporation
SMP NiceIntroduced by Peter Williams, ~2.6.18Load Balancer introduced to the concept of nice values
Fairness maintained across CPUs
Balance run queues based on weight and not number of tasks
Group SMP Nice
IBM Linux Technology Center
© 2008 IBM Corporation
SMP NiceIntroduced by Peter Williams, ~2.6.18Load Balancer introduced to the concept of nice values
Fairness maintained across CPUs
Balance run queues based on weight and not number of tasks
Group SMP Nice Significant complication

IBM Linux Technology Center
© 2008 IBM Corporation
SMP NiceIntroduced by Peter Williams, ~2.6.18Load Balancer introduced to the concept of nice values
Fairness maintained across CPUs
Balance run queues based on weight and not number of tasks
Group SMP Nice Significant complication
Weight of a task became proportional to the weight of its supertask

IBM Linux Technology Center
© 2008 IBM Corporation
SMP NiceIntroduced by Peter Williams, ~2.6.18Load Balancer introduced to the concept of nice values
Fairness maintained across CPUs
Balance run queues based on weight and not number of tasks
Group SMP Nice Significant complication
Weight of a task became proportional to the weight of its supertask
But the supertask can be spread across multiple CPUs

IBM Linux Technology Center
© 2008 IBM Corporation
SMP NiceIntroduced by Peter Williams, ~2.6.18Load Balancer introduced to the concept of nice values
Fairness maintained across CPUs
Balance run queues based on weight and not number of tasks
Group SMP Nice Significant complication
Weight of a task became proportional to the weight of its supertask
But the supertask can be spread across multiple CPUs
That means, the weight of a task is dependent on other runqueues.

IBM Linux Technology Center
© 2008 IBM Corporation
SMP NiceIntroduced by Peter Williams, ~2.6.18Load Balancer introduced to the concept of nice values
Fairness maintained across CPUs
Balance run queues based on weight and not number of tasks
Group SMP Nice Significant complication
Weight of a task became proportional to the weight of its supertask
But the supertask can be spread across multiple CPUs
That means, the weight of a task is dependent on other runqueues.
Bad for scalability
IBM Linux Technology Center
© 2008 IBM Corporation
Distributed Group Balancing
Since we have a view of the tasks weight from the root group, we can balance on the weight of the root's runqueue itself
IBM Linux Technology Center
© 2008 IBM Corporation
Distributed Group Balancing
Since we have a view of the tasks weight from the root group, we can balance on the weight of the root's runqueue itself
Just take care that we account only the normalized weight of the task

IBM Linux Technology Center
© 2008 IBM Corporation
Distributed Group Balancing
Since we have a view of the tasks weight from the root group, we can balance on the weight of the root's runqueue itself
Just take care that we account only the normalized weight of the task
Just one tiny problem How do we do it sanely?
IBM Linux Technology Center
© 2008 IBM Corporation
Distributed Group Balancing
Since we have a view of the tasks weight from the root group, we can balance on the weight of the root's runqueue itself
Just take care that we account only the normalized weight of the task
Just one tiny problem How do we do it sanely?
That is, not touch other CPUs

IBM Linux Technology Center
© 2008 IBM Corporation
Distributed Group Balancing
Since we have a view of the tasks weight from the root group, we can balance on the weight of the root's runqueue itself
Just take care that we account only the normalized weight of the task
Just one tiny problem How do we do it sanely?
That is, not touch other CPUs
Use sched domains

IBM Linux Technology Center
© 2008 IBM Corporation
Distributed Group Balancing
Since we have a view of the tasks weight from the root group, we can balance on the weight of the root's runqueue itself
Just take care that we account only the normalized weight of the task
Just one tiny problem How do we do it sanely?
That is, not touch other CPUs
Use sched domains Re-compute shares as we walk up the tree.

IBM Linux Technology Center
© 2008 IBM Corporation
Distributed Load BalancingFew corner cases
IBM Linux Technology Center
© 2008 IBM Corporation
Distributed Load BalancingFew corner cases
Since we do only integer divisions, we can lose shares due to rounding errors

IBM Linux Technology Center
© 2008 IBM Corporation
Distributed Load BalancingFew corner cases
Since we do only integer divisions, we can lose shares due to rounding errors
– Solved by ensuring, the weight at the top domain will be the sum of the shares

IBM Linux Technology Center
© 2008 IBM Corporation
Distributed Load BalancingFew corner cases
Since we do only integer divisions, we can lose shares due to rounding errors
– Solved by ensuring, the weight at the top domain will be the sum of the shares
– Will limit the loses

IBM Linux Technology Center
© 2008 IBM Corporation
Distributed Load BalancingFew corner cases
Since we do only integer divisions, we can lose shares due to rounding errors
– Solved by ensuring, the weight at the top domain will be the sum of the shares
– Will limit the loses
A boot strap problem – A group with no tasks

IBM Linux Technology Center
© 2008 IBM Corporation
Distributed Load BalancingFew corner cases
Since we do only integer divisions, we can lose shares due to rounding errors
– Solved by ensuring, the weight at the top domain will be the sum of the shares
– Will limit the loses
A boot strap problem – A group with no tasks
– Needs instant recalculation on arrival of task, otherwise shares will remain zero till we redistribute shares

IBM Linux Technology Center
© 2008 IBM Corporation
Distributed Load BalancingFew corner cases
Since we do only integer divisions, we can lose shares due to rounding errors
– Solved by ensuring, the weight at the top domain will be the sum of the shares
– Will limit the loses
A boot strap problem – A group with no tasks
– Needs instant recalculation on arrival of task, otherwise shares will remain zero till we redistribute shares
– Expensive. Arrival and departure of tasks is quite frequent

IBM Linux Technology Center
© 2008 IBM Corporation
Distributed Load BalancingFew corner cases
Since we do only integer divisions, we can lose shares due to rounding errors
– Solved by ensuring, the weight at the top domain will be the sum of the shares
– Will limit the loses
A boot strap problem – A group with no tasks
– Needs instant recalculation on arrival of task, otherwise shares will remain zero till we redistribute shares
– Expensive. Arrival and departure of tasks is quite frequent
– Never reduce shares to zero. Inflate shares of idle groups

IBM Linux Technology Center
© 2008 IBM Corporation
Distributed Load BalancingFew corner cases
Since we do only integer divisions, we can lose shares due to rounding errors
– Solved by ensuring, the weight at the top domain will be the sum of the shares
– Will limit the loses
A boot strap problem – A group with no tasks
– Needs instant recalculation on arrival of task, otherwise shares will remain zero till we redistribute shares
– Expensive. Arrival and departure of tasks is quite frequent
– Never reduce shares to zero. Inflate shares of idle groups
– Has some short term unfairness, but not more than what was already present, due to rebalancing
IBM Linux Technology Center
© 2008 IBM Corporation
The Future
The single runqueue approach
IBM Linux Technology Center
© 2008 IBM Corporation
The Future
The single runqueue approach Group scheduling has a hierarchical task selection

IBM Linux Technology Center
© 2008 IBM Corporation
The Future
The single runqueue approach Group scheduling has a hierarchical task selection
– Not good for interactivity

IBM Linux Technology Center
© 2008 IBM Corporation
The Future
The single runqueue approach Group scheduling has a hierarchical task selection
– Not good for interactivity
Need to provide latency isolation
IBM Linux Technology Center
© 2008 IBM Corporation
The Future
The single runqueue approach Group scheduling has a hierarchical task selection
– Not good for interactivity
Need to provide latency isolation
Faster convergence to fairness for group scheduling

IBM Linux Technology Center
© 2008 IBM Corporation
The Future
The single runqueue approach Group scheduling has a hierarchical task selection
– Not good for interactivity
Need to provide latency isolation
Faster convergence to fairness for group schedulingLooking at RT scheduling function, independent of PI

IBM Linux Technology Center
© 2008 IBM Corporation
The Future
The single runqueue approach Group scheduling has a hierarchical task selection
– Not good for interactivity
Need to provide latency isolation
Faster convergence to fairness for group schedulingLooking at RT scheduling function, independent of PI
Allows us to experiment with more advanced RT scheduling
Possibly allow us to extend PI for SCHED_OTHER
IBM Linux Technology Center
© 2008 IBM Corporation
Thank You!
Questions?
IBM Linux Technology Center
© 2008 IBM Corporation
Legal Statement
This work represents the view of the authors and does not necessarily represent the view of IBM.
IBM is a registered trademark of International Business Machines Corporation in the United States and/or other countries.
Linux is a registered trademark of Linus Torvalds.Other company, product, and service names may be trademarks
or service marks of others.
IBM Linux Technology Center
© 2008 IBM Corporation
BACKUP

IBM Linux Technology Center
© 2008 IBM Corporation
Scheduler Classes
Scheduler Classes, a definition,
An extensible hierarchy of scheduler modules which encapsulate scheduling policy details and are handled by the scheduler core without the core code assuming about them too much
Ingo Molnar
Essentially what he said, with a few custom changes :)

IBM Linux Technology Center
© 2008 IBM Corporation
The CFSMore vruntime love
Calculated as follows When a task forks, vruntime set so that it comes as the rightmost
– Ensures that it does not affect the fairness promised to tasks already existing
When a task runs, the it runs is normalized to its weight, and is added to its vruntime
CFS tracks a variable known as cfs_rq->min_vruntime

IBM Linux Technology Center
© 2008 IBM Corporation
Being nice
CFS changed the definition of how nice worked O(1) had liner values for nice
CFS has a exponential scale
Nice0 = 1024
Nicei-1
= 1.25Nicei
Time slice dependent on weightWeight dependent on niceTherefore, nice has a much stronger effect on time slices now.

IBM Linux Technology Center
© 2008 IBM Corporation
Some basic definitions
We have tasks Ti of weight wi running on CPU Pj such that its runqueue has weight
Each task gets wi/rw
j runtime
A task can be a supertask with weight wi with subtasks spread
across every CPU Gives rise to the concept of shares, which is per CPU weight of the
supertask

IBM Linux Technology Center
© 2008 IBM Corporation
Some basic definitions
Another concept Task weight as viewed from the root group
Which gives rise to

IBM Linux Technology Center
© 2008 IBM Corporation
Sched Features
Some key features,NEW_FAIR_SLEEPERS: Provides a bonus to tasks that just wake
up. NORMALIZED_SLEEPERS: Normalizes the aforementioned bonusSTART_DEBIT: Demotes a newly forked task to the right of the
runqueue

IBM Linux Technology Center
© 2008 IBM Corporation
Distributed Load Balancing
Wake Affine Requires precise re-calculation
– Not good!
We know,
So we add in a delta
Express s'-s as a function of delta(w)