human action recognition by learning bases of action attributes and parts
TRANSCRIPT

Human Action Recognition by Learning Bases of Action Attributes and Parts

Outline
• Introduction• Action Recognition with Attributes & Parts• Learning• Experiments and Results

Introduction
• use attributes and parts for recognizing human actions in still images
• use the whole image to represent an action• treat action recognition as a general image
classification problem• PASCAL challenge– spatial pyramid– random forest based methods– No explore the semantically meaningful components


Introduction
• some methods rely on labor-intensive annotations of objects and human body parts during training time
• Inspired by the recent work– using objects and body parts for action recognition– propose an attributes and parts based representation
• The action attributes are holistic image descriptions of human actions– associated with verbs in the human language– E.g. Riding,sitting,repairing,lifting…

Introduction

Introduction
• a large number of possible interactions among these attributes parts in terms of co-occurrence statistics.
• Our challenge is– represent image by using a sparse set of action bases– effectively learn these bases given far-from-perfect
detections of action attributes – parts without meticulous human labeling as proposed in
previous work

Introduction
• our method has theoretical foundations in sparse coding and compressed sensing .
• PASCAL action dataset• Stanford 40 Actions dataset

Attributes and Parts in Human Actions
• Attribute:– Use are related to verbs in human language– E.x: rinding a bike can be “riding” and “sitting”– attribute to correspond to more than one action
• Parts:– Composed of objects– Human poses

Attributes and Parts in Human Actions
• an action image consists– the objects that are closely related to the action– The descriptive local human poses.
• A vector of the normalized confidence scores obtained from these classifiers and detectors is used to represent this image

Action Bases of Attributes and Parts
• Our method learns high-order interactions of image attributes and parts– carry richer information about human actions– improve recognition performance
• Riding – sitting – bike• Using - keyboard - monitor - sitting

Action Bases of Attributes and Parts
• formalize the action bases in a mathematical framework• P: attributes and parts• 1• Action bases: • Coefficients: • 4• 5

Action Classification Using the Action Bases
• the attributes and parts representation A– reconstructed from the sparse factorization coefficients w.– use the coefficients vector w to represent an image
• train an SVM classifier for action classification

Learning the Dual-Sparse Action Bases and Reconstruction Coefficients
• 1• Ai is the vector of confidence scores• there exists a latent dictionary of bases– frequent co-occurrence of attributes– e.g. “cycling” and “bike”
• To identify a set of sparse bases Φ = [ 1.. M]𝝓 𝝓

Learning the Dual-Sparse Action Bases and Reconstruction Coefficients
• learn the bases Φ and find the reconstruction coefficients wi for each ai .
• (2) is non-convex,(3) is convex• Eqn.2 is convex with respect to each of the two
variables Φ and W when the other one is fixed

Learning the Dual-Sparse Action Bases and Reconstruction Coefficients
• This is called the elastic-net constraint set[29]
• λ= 0.1• ϒ= 0.15

• Google, Bing, and Flickr• 180 300 images for∼• each class
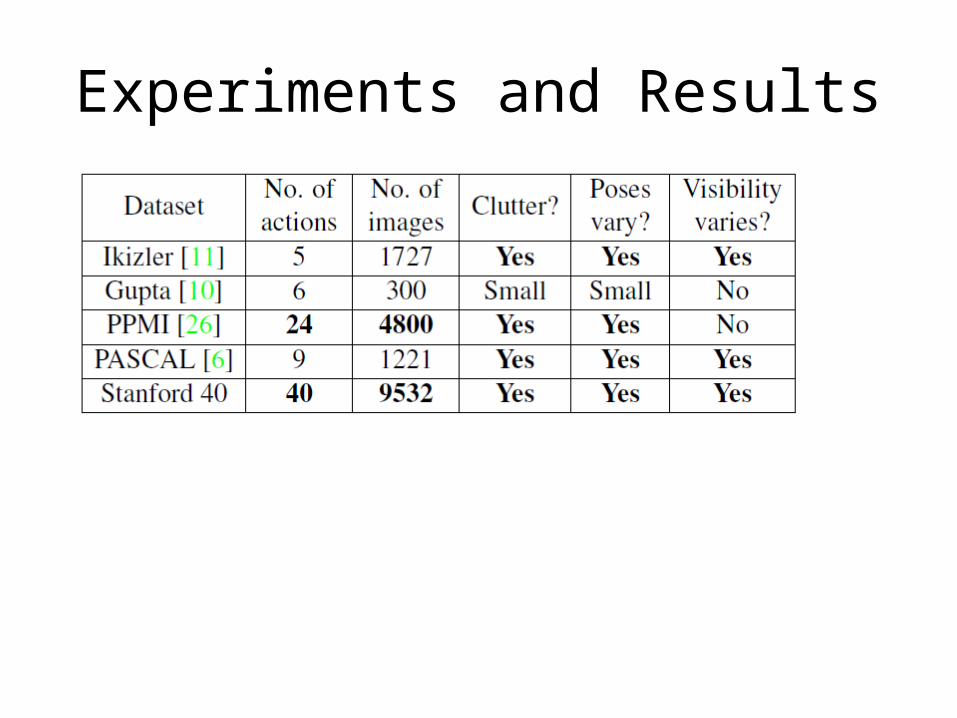
Experiments and Results
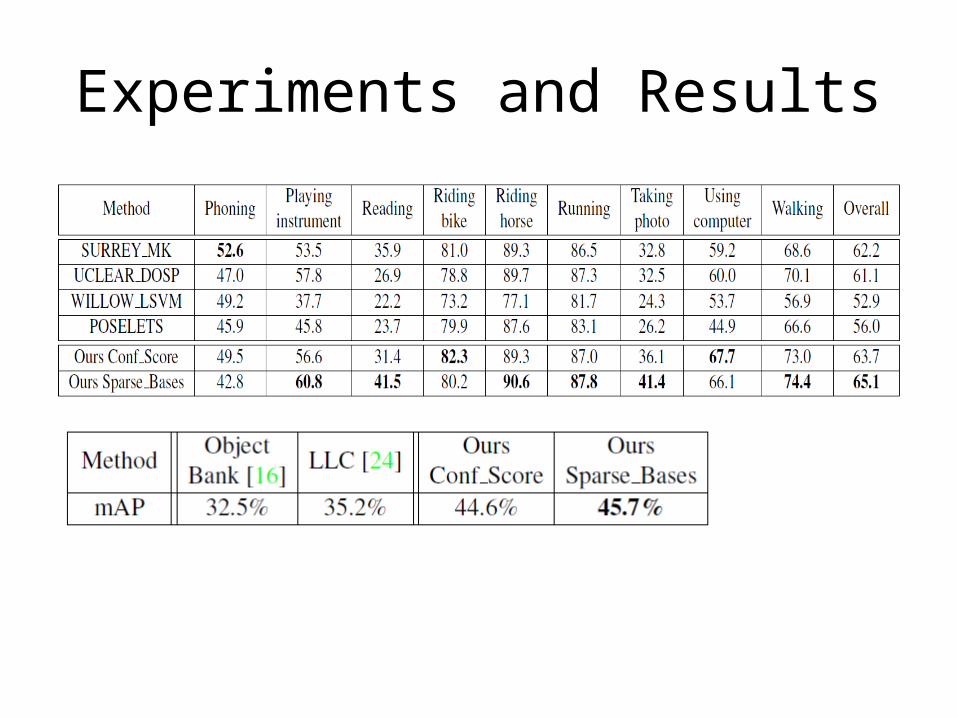
Experiments and Results
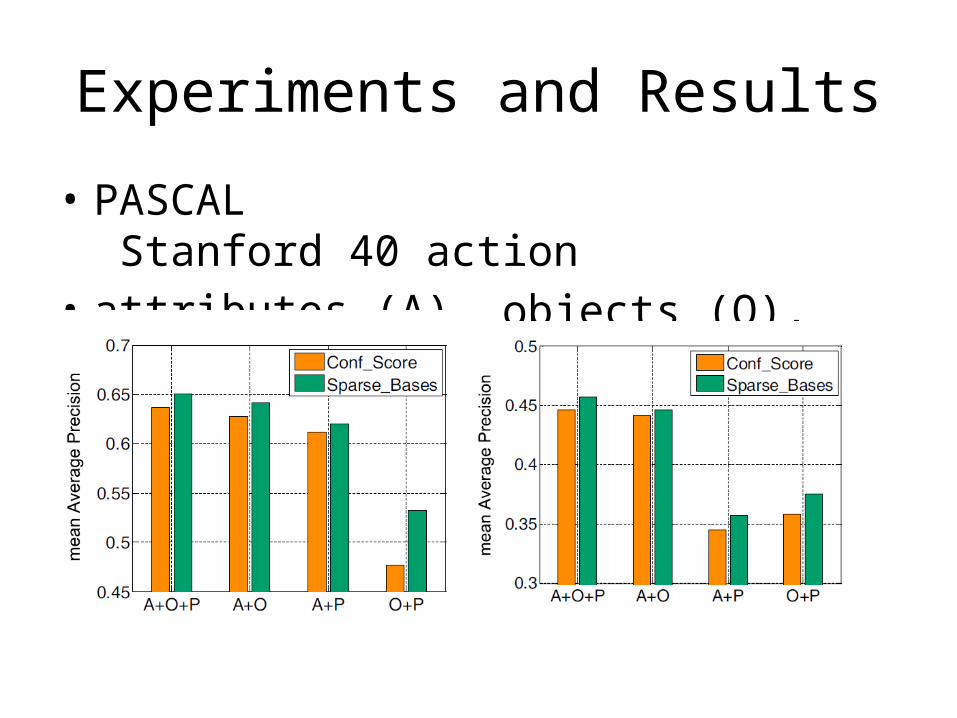
Experiments and Results
• PASCAL Stanford 40 action • attributes (A), objects (O), and poselets (P)
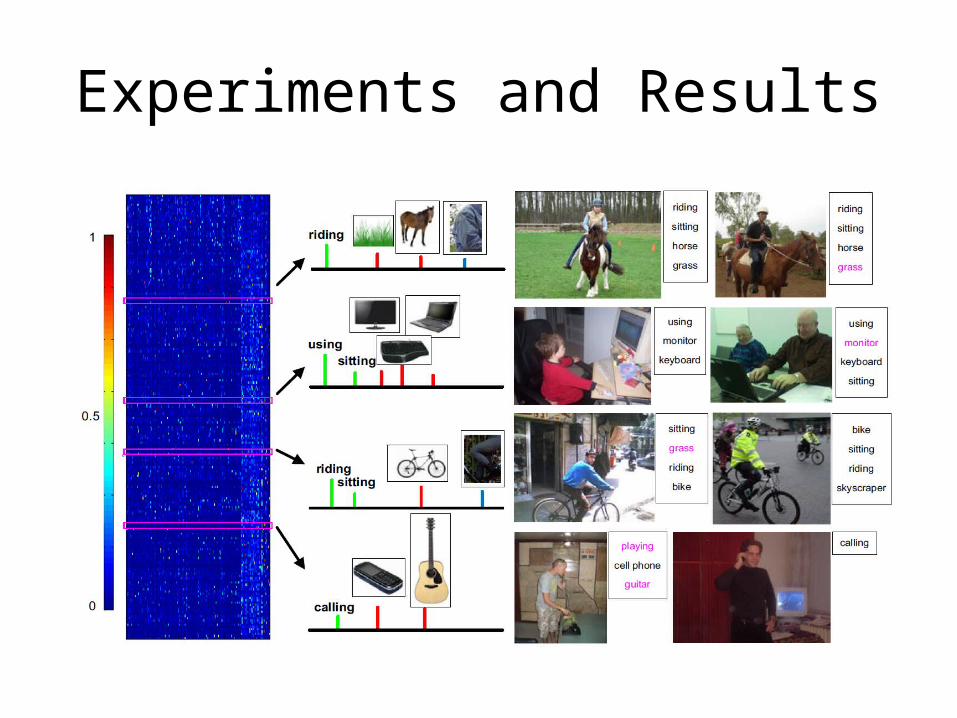
Experiments and Results


Discussion
• use attributes and parts for action recognition– The attributes are verbs– The parts are composed of objects and poselets
• reconstructed by a set of sparse coefficients• our method achieves state-of-the-art performance
on two datasets

Future work
• learned action bases for image tagging• explore more detailed semantic understanding
of human actions in images