hc17.s1t1 a novel simd architecture for the cell ... · a novel simd architecture for the cell...
TRANSCRIPT

Broadband Processor Architecture
© 2005 IBM Corporation
A novel SIMD architecture for the Cellheterogeneous chip-multiprocessor
Michael Gschwind, Peter Hofstee,Brian Flachs, Martin Hopkins,Yukio Watanabe, Takeshi Yamazaki

Broadband Processor Architecture
© 2005 IBM Corporation2
Acknowledgements
Cell is the result of a partnership betweenSCEI/Sony, Toshiba, and IBM
Cell represents the work of more than 400 peoplestarting in 2000 and a design investment of about$400M

Broadband Processor Architecture
© 2005 IBM Corporation3
Cell Design Goals
Provide the platform for the future of computing
– 10× performance of desktop systems shipping in 2005
– Ability to reach 1 TF with a 4-node Cell system
Computing density as main challenge
– Dramatically increase performance per X
• X = Area, Power, Volume, Cost,…
Single core designs offer diminishing returns on investment
– In power, area, design complexity and verification cost
Exploit application parallelism to provide a quantum leap inperformance

Broadband Processor Architecture
© 2005 IBM Corporation4
Shifting the Balance of Power with Cell
Today’s architectures are built on a 40 year old data model
– Efficiency as defined in 1964
– Big overhead per data operation
– Data parallelism added as an after-thought
Cell provides parallelism at all levels of systemabstraction
– Thread-level parallelism multi-core design approach
– Instruction-level parallelism statically scheduled & poweraware
– Data parallelism data-paralleI instructions
Data processor instead of control system
Broadband Processor Architecture
© 2005 IBM Corporation5
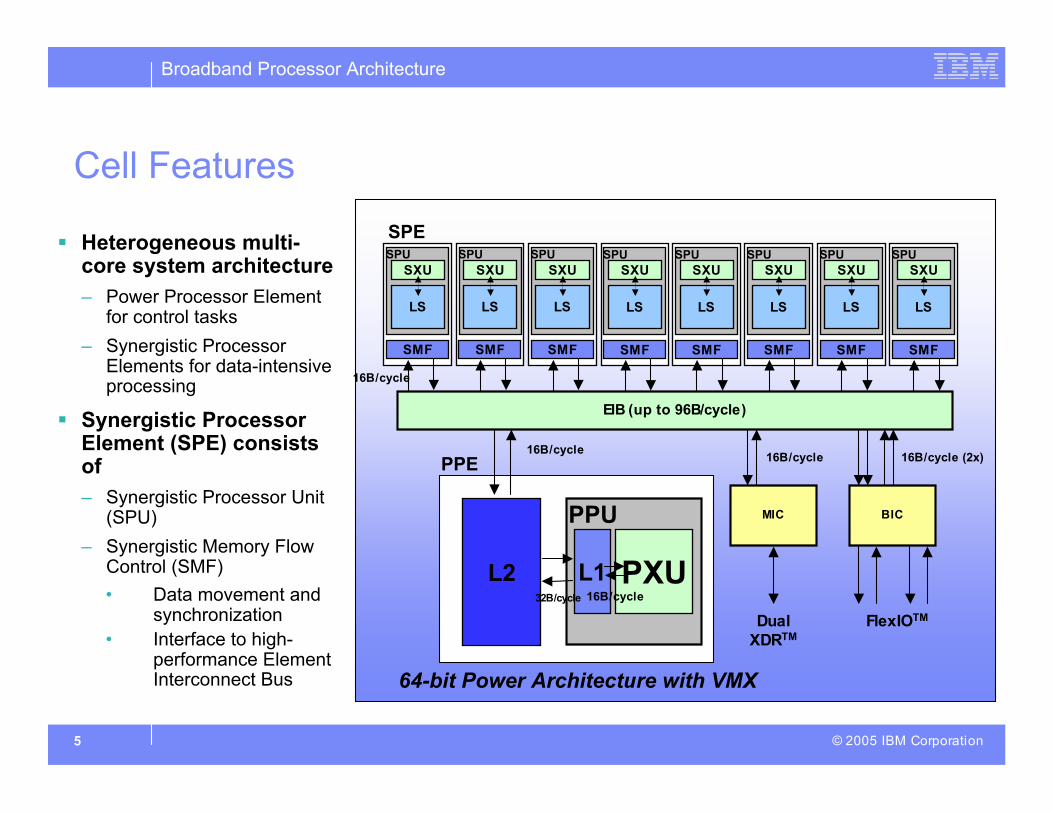
Cell Features
Heterogeneous multi-core system architecture
– Power Processor Elementfor control tasks
– Synergistic ProcessorElements for data-intensiveprocessing
Synergistic ProcessorElement (SPE) consistsof
– Synergistic Processor Unit(SPU)
– Synergistic Memory FlowControl (SMF)
• Data movement andsynchronization
• Interface to high-performance ElementInterconnect Bus
16B/cycle (2x)16B/cycle
BIC
FlexIOTM
MIC
DualXDRTM
16B/cycle
EIB (up to 96B/cycle)
16B/cycle
64-bit Power Architecture with VMX
PPE
SPE
LS
SXUSPU
SMF
PXUL1
PPU
16B/cycle
L232B/cycle
LS
SXUSPU
SMF
LS
SXUSPU
SMF
LS
SXUSPU
SMF
LS
SXUSPU
SMF
LS
SXUSPU
SMF
LS
SXUSPU
SMF
LS
SXUSPU
SMF

Broadband Processor Architecture
© 2005 IBM Corporation6
Powering Cell – the Synergistic Processor Unit
VRFVRF
PERMPERM LSULSUVV FF PP UU VV FF XX UU
Local StoreLocal Store
Single Port Single Port SRAMSRAM
Issue /Issue /BranchBranch
Fetch
ILB
16B x 2
2 instructions
16B x 3 x 2
64B64B
16B16B
128B128B

Broadband Processor Architecture
© 2005 IBM Corporation7
Density Computing in SPEs
Today, execution units only fraction of core area and power
– Bigger fraction goes to other functions• Address translation and privilege levels• Instruction reordering• Register renaming• Cache hierarchy
Cell changes this ratio to increase performance per areaand power
– Architectural focus on data processing• Wide datapaths• More and wide architectural registers• Data privatization and single level processor-local store• All code executes in a single (user) privilege level• Static scheduling

Broadband Processor Architecture
© 2005 IBM Corporation8
Streamlined Architecture
Architectural focus on simplicity
– Aids achievable operating frequency
– Optimize circuits for common performance case
– Compiler aids in layering traditional hardware functions
– Leverage 20 years of architecture research
Focus on statically scheduled data parallelism
– Focus on data parallel instructions
• No separate scalar execution units• Scalar operations mapped onto data parallel dataflow
– Exploit wide data paths
• data processing• instruction fetch
– Address impediments to static scheduling
• Large register set• Reduce latencies by eliminating non-essential functionality
Broadband Processor Architecture
© 2005 IBM Corporation9
dataparallelselect
staticprediction
simpler µarch
sequentialfetch
localstore
highfrequency
shorterpipeline
largebasic
blocks
determ.latency
largeregister
file
ILPopt.
instructionbundling
DLP
widedata
paths
computedensity
Synergistic Processing
singleport
staticscheduling
scalarlayering
Broadband Processor Architecture
© 2005 IBM Corporation10
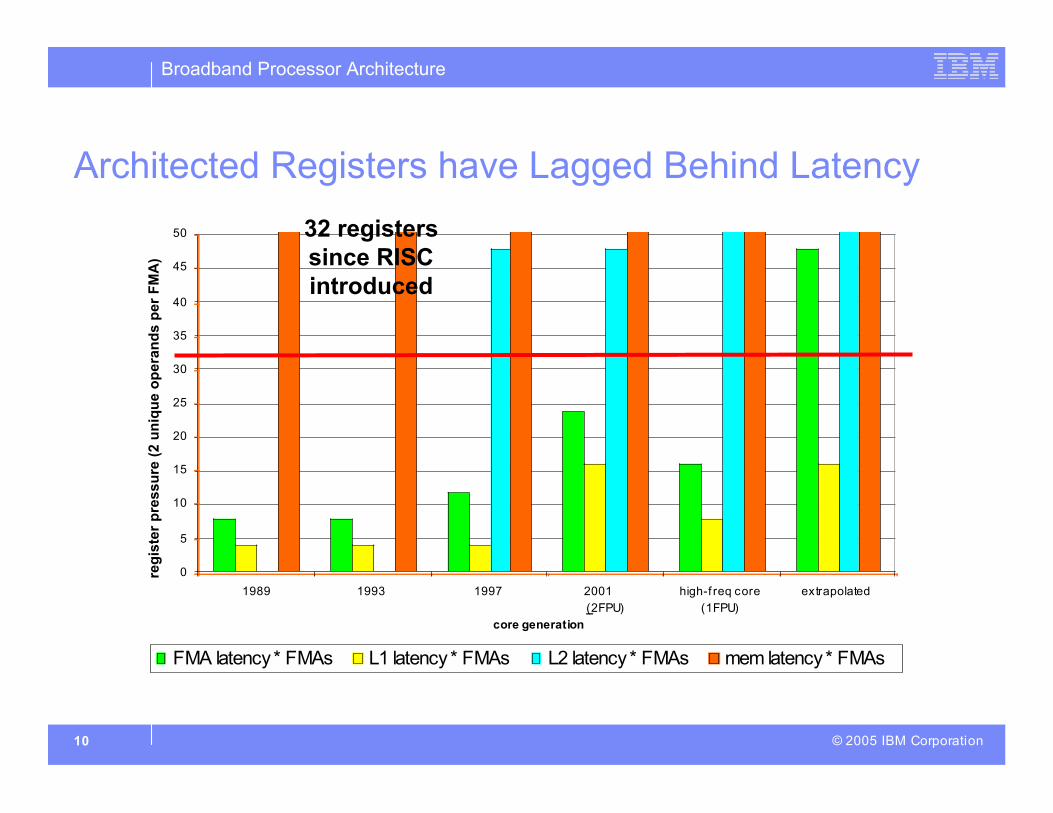
Architected Registers have Lagged Behind Latency
0
5
10
15
20
25
30
35
40
45
50
1989 1993 1997 2001
__(2FPU)
high-f req core
(1FPU)
extrapolated
core generation
reg
iste
r p
ressu
re (
2 u
niq
ue o
pera
nd
s p
er
FM
A)
FMA latency * FMAs L1 latency * FMAs L2 latency * FMAs mem latency * FMAs
32 registerssince RISCintroduced

Broadband Processor Architecture
© 2005 IBM Corporation11
Restoring the Architectural Register Balance
Unified 128 entry, 128b wide register file
– Used as 128x1, 64x2, 32x4, 16x8, 8x16, 1x128
– Emphasis on 32x4 integer and FP arithmetic
– Register file also stores addresses and condition values
Unified register file gives programmers more flexibility inresource allocation
– Stores all data types
• address, integer, SP/DP FP, Boolean
– Stores scalar and vector SIMD data
Large register file facilitates static scheduling and loopoptimization for latency hiding

Broadband Processor Architecture
© 2005 IBM Corporation12
Pervasive Data Parallel Computing (PDPC)
Scalar processing supported on data-parallelsubstrate
– All instructions are data parallel and operate on vectorsof elements
– Scalar operation defined by instruction use, not opcode
• Vector instruction form used to perform operation
Preferred slot paradigm
– Scalar arguments to instructions found in “preferred slot”
– Computation can be performed in any slot

Broadband Processor Architecture
© 2005 IBM Corporation13
Register Scalar Data Layout
Preferred slot in bytes 0-3
– By convention for procedure interfaces
– Used by instructions expecting scalar data
• Addresses, branch conditions, generate controls for insert

Broadband Processor Architecture
© 2005 IBM Corporation14
PDPC Memory Access Architecture
Data memory interface optimized for quadword access
– Simplified alignment network
– Always access 128 bits of data
Processing scalar data
– Extracted using rotate
– Stored with read-modify-write sequence
Four address formats
– register + displacement, register-indexed
– PC-relative, absolute address
Local Store Limit Register (LSLR)
– Address mask register to define maximum address range
– Addresses wrap at LSLR value

Broadband Processor Architecture
© 2005 IBM Corporation15
PDPC Branch Architecture
Register-indirect target address in preferred slotof general purpose register
– Indirect branch (function return)
– Indirect prepare-to-branch
Link address deposited in preferred slot ofspecified general purpose register
– Register 0 ($ra) used as return register by softwareconvention

Broadband Processor Architecture
© 2005 IBM Corporation16
A Statically Scheduled PDPC Architecture
Bundle concept
– Sequential semantics
– Static scheduling key ingredient to great performance
– Strong performance bias to properly aligned instructions
• Align instructions to map on simplified issue routing logic• Maximize fetch group utilization
Branch and control architecture
– Static branch prediction with Prepare-to-branch instruction
– Simplify implementations, improve utility of sequential fetch
Explicit inline instruction fetch
– To avoid fetch starvation during bursts of high-priority load/store traffic
– Compiler manages 256KB unified, single ported memory

Broadband Processor Architecture
© 2005 IBM Corporation17
Data Selection Architecture
Branch is scalar, select is data parallel
– Branch inherently inefficient
No exception safe to compute both paths throughconditional assignment
Use data parallel compute flow
– Data parallel if-conversion
– Select instruction independently selects result for each slot
– Compare instructions generate type-specific mask fields

Broadband Processor Architecture
© 2005 IBM Corporation18
Data Parallel Select Operation
for (i =0; i< VL; i++)
if (a[i]>b[i])
m[i] = a[i]*2;
else
m[i] = b[i]*3;
a[0]>b[0]
m[0]=a[0]*2; m[0]=b[0]*3;
a[1]>b[1]
m[1]=a[1]*2; m[1]=b[1]*3;
a[2]>b[2]
m[2]=a[2]*2; m[2]=b[2]*3;
a[3]>b[3]
m[3]=a[3]*2; m[3]=b[3]*3;
a’[0] =a[0]*2; b’[0]=b[0]*3;
s[0]=a[0]>b[0]
m[0]=s[0]?a’[0]:b’[0]
a’[1]=a[1]*2; b’[1]=b[1]*3;
s[1]=a[1]>b[1]
m[1]=s[1]?a’[1]:b’[1]
a’[2]=a[2]*2; b’[2]=b[2]*3;
s[2]=a[2]>b[2]
m[2]=s[2]?a’[2]:b’[2]
a’[3]=a[3]*2; b’[3]=b[3]*3;
s[3]=a[3]>b[3]
m[3]=s[3]?a’[3]:b’[3]
Exploit data parallelism
Lo
ng
late
ncy

Broadband Processor Architecture
© 2005 IBM Corporation19
Compare and Data Selection Architecture
Only limited number of compares
– Compare for equality
• CEQ
– Compare for ordering
• CGT, CGTL
– Other conditions can be derived
• operand order, inverted condition
Generates mask of data type width for use with select
– Data-parallel conditional operation

Broadband Processor Architecture
© 2005 IBM Corporation20
Integer Data Processing for Advanced Media Computing
Ensure data fidelity
– Avoid accumulated saturation error in content creation
– Emphasis on data quality first, quantity second
– Concentrate on 16b and 32b integer data
– Concentrate on modulo arithmetic• Consistent with common C/C++/Java semantics
Selected byte operations to maximize performance on keyoperations
– Encryption/decryption performance• Security in electronic transactions will be key to enable future
business models
– Motion estimation• Video encoding

Broadband Processor Architecture
© 2005 IBM Corporation21
Reconciling Data Fidelity and Compact Data Representation
Use wide data types for intermediate results in computation
– Avoid saturation of intermediate results
– Prevent loss of dynamic range
Pack-and-saturate operation to store data in dense memoryformat
– Keep data footprint in memory compact
– Pack and saturate once for bulk data storage in memory
Saturating computation only important for low-cost contentrendering devices
– No/less accumulation of error across rendering steps
– e.g., MPEG synchronize with I-frame

Broadband Processor Architecture
© 2005 IBM Corporation22
Floating Point Processing in the SPE
Support standard IEEE FP and graphics-optimized arithmetic
– Floating-point naturally saturating
– Always use IEEE data layout
Graphics oriented SP-FP using IEEE compatible data layout
– Extended range / Simplified format
• Improved estimate instructions to reduce “banding”
– Media workloads impose realtime processing requirements
• No floating point exceptions
– Graphics oriented SP-FP mode added to Cell PowerProcessor Element
DP-FP follows IEEE conventions

Broadband Processor Architecture
© 2005 IBM Corporation23
Cell: a Synergistic System Architecture
Cell is not a collection of different processors, but a synergistic whole
– Operation paradigms, data formats and semantics consistent
– Share address translation and memory protection model
SPE optimized for efficient data processing
– SPEs share Cell system functions provided by Power Architecture
– SMF implements interface to memory
• Copy in/copy out to local storage
Power Architecture provides system functions
– Virtualization
– Address translation and protection
– External exception handling
EIB (Element Interconnect Bus) integrates system as data transport hub

Broadband Processor Architecture
© 2005 IBM Corporation24
Compiling for Cell
The lesson of “RISC computing”
– Architecture provides fast, streamlined primitives to compiler
– Compiler uses primitives to implement higher-level idioms
– If the compiler can’t target it do not include in architecture
Compiler focus throughout project
– Prototype compiler soon after first proposal
– Cell compiler team has made significant advances in
• Automatic SIMD code generation
• Automatic parallelization
• Data privatization

Broadband Processor Architecture
© 2005 IBM Corporation25
Permute Unit
Load-Store Unit
Floating-Point Unit
Fixed-Point Unit
Branch Unit
Channel Unit
Result Forwarding and Staging
Register File
Local Store(256kB)
Single Port SRAM
128B Read 128B Write
DMA Unit
Instruction Issue Unit / Instruction Line Buffer
8 Byte/Cycle 16 Byte/Cycle 128 Byte/Cycle64 Byte/Cycle
On-Chip Coherent Bus
SPE Block Diagram

Broadband Processor Architecture
© 2005 IBM Corporation26
SPE PIPELINE FRONT END
SPE PIPELINE BACK END
Branch Instruction
Load/Store Instruction
IF Instruction Fetch
IB Instruction Buffer
ID Instruction Decode
IS Instruction Issue
RF Register File Access
EX Execution
WB Write Back
Floating Point Instruction
Permute Instruction
EX1 EX2 EX3 EX4
EX1 EX2 EX3 EX4 EX5 EX6
EX1 EX2 WB
WB
RF1 RF2
WB
Fixed Point Instruction
EX1 EX2 EX3 EX4 EX5 EX6 WB
IF1 IF2 IF3 IF4 IF5 IB1 IB2 ID1 ID2 ID3 IS1 IS2
SPE Pipeline

Broadband Processor Architecture
© 2005 IBM Corporation27
Cell Broadband Engine

Broadband Processor Architecture
© 2005 IBM Corporation28
Cell Implementation Characteristics
241M transistors
235mm2
Design operates across widefrequency range
– Optimize for power & yield
> 200 GFlops (SP) @3.2GHz
> 20 GFlops (DP) @3.2GHz
Up to 25.6 GB/s memory bandwidth
Up to 75 GB/s I/O bandwidth
100+ simultaneous bustransactions
– 16+8 entry DMA queue per SPE
Rela
tive
Frequency Increase vs. Power Consumption
Voltage

Broadband Processor Architecture
© 2005 IBM Corporation29
Conclusion
Single chip heterogeneous multicore system takes chipperformance to a new level
– By exploiting thread level parallelism
– By exploiting instruction level parallelism
– By exploiting data level parallelism
Novel pervasive vector-centric architecture
– Data parallelism at the center
– Redefines high-performance architecture
SPE compute engine offers high compute density
– Power-efficient
– Area-efficient
Cell delivers unprecedented supercomputer power forconsumer applications

Broadband Processor Architecture
© 2005 IBM Corporation30
Additional Information
Additional details on the SPE architecture and theCell implementation can be found at
– http://www-306.ibm.com/chips/techlib/techlib.nsf/products/Cell
– http://www.research.ibm.com/cell

Broadband Processor Architecture
© 2005 IBM Corporation31
© Copyright International Business Machines Corporation 2005.All Rights Reserved. Printed in the United States August 2005.
The following are trademarks of International Business Machines Corporation in the United States, or other countries, or both.IBM IBM Logo Power Architecture
Other company, product and service names may be trademarks or service marks of others.
All information contained in this document is subject to change without notice. The products described in this document areNOT intended for use in applications such as implantation, life support, or other hazardous uses where malfunction could resulin death, bodily injury, or catastrophic property damage. The information contained in this document does not affect or changeIBM product specifications or warranties. Nothing in this document shall operate as an express or implied license or indemnityunder the intellectual property rights of IBM or third parties. All information contained in this document was obtained in specificenvironments, and is presented as an illustration. The results obtained in other operating environments may vary.
While the information contained herein is believed to be accurate, such information is preliminary, and should not be reliedupon for accuracy or completeness, and no representations or warranties of accuracy or completeness are made.
THE INFORMATION CONTAINED IN THIS DOCUMENT IS PROVIDED ON AN "AS IS" BASIS. In no event will IBM be liablefor damages arising directly or indirectly from any use of the information contained in this document.