haystack: a platform for creating, organizing and ... · pdf filehaystack: a platform for...
TRANSCRIPT

Haystack: A Platform for Creating, Organizing and VisualizingInformation Using RDF
David Huynh
MIT Artificial Intelligence Laboratory200 Technology SquareCambridge, MA 02139
David Karger
MIT Laboratory for Computer Science200 Technology SquareCambridge, MA 02139
Dennis Quan
MIT Artificial Intelligence Laboratory200 Technology SquareCambridge, MA 02139
IBM Internet Technology Division1 Rogers Street
Cambridge, MA [email protected]
AbstractThe Resource Definition Framework (RDF) is designed tosupport agent communication on the Web, but it is alsosuitable as a framework for modeling and storing personalinformation. Haystack is a personalized informationrepository that employs RDF in this manner. This flexiblesemistructured data model is appealing for several reasons.First, RDF supports ontologies created by the user andtailored to the user’s needs. At the same time, systemontologies can be specified and evolved to support a varietyof high-level functionalities such as flexible organizationschemes, semantic querying, and collaboration. In addition,we show that RDF can be used to engineer a componentarchitecture that gives rise to a semantically rich anduniform user interface. We demonstrate that by aggregatingvarious types of users’ data together in a homogeneousrepresentation, we create opportunities for agents to makemore informed deductions in automating tasks for users.Finally, we discuss the implementation of an RDFinformation store and a programming language specificallysuited for manipulating RDF.
IntroductionThe Resource Definition Framework (RDF) has beendeveloped to provide interoperability between applicationsthat exchange machine-understandable information on theWeb [6]. In other words, RDF is well-suited for facilitatingWeb Services in resource discovery, cataloging, contentrating, and privacy policies.
Of course, the expressive power of RDF is more far-reaching than just agent communication. We postulate thatRDF can be well exploited for managing users’information. The semistructured nature of RDF lends itselfwell to the heterogeneous disposition of personalinformation corpora. In addition, since RDF provides astandard, platform-neutral means for exchanging metadata,it naturally facilitates sophisticated features such asannotation and collaboration. In this paper, we propose anddemonstrate a personal information management systemthat employs RDF as its primary data model.
MotivationThe goal of the Haystack project is to develop a tool thatallows users to easily manage their documents, e-mailmessages, appointments, tasks, and other information.Haystack is designed to address four specific expectationsof the user.
First, the user should be allowed maximum flexibility inhow he or she chooses to describe and organize his or herinformation. The system should allow the user to structurehis or her data in the most suitable fashion as perceived bythe user. Section 2 elaborates on Haystack’s support foruser-defined ontologies.
Second, the system should not create artificial distinctionsbetween different types of information that would seemunnatural to the user. This point is related to the previouspoint in that the system should not partition a corpussimply because different programs are used to manipulatedifferent parts of that corpus. Rather, the system shouldstore all of the user’s information in one homogeneousrepresentation and allow the user to impose semantics thatpartition the data appropriately.
Third, the system should allow the user to easilymanipulate and visualize his or her information in waysappropriate to the task at hand. The user interface shouldbe aware of the context in which arbitrary information isbeing displayed and should present an appropriate amountof detail. We address these issues later in Section 3 wherewe discuss Haystack’s user interface.
Fourth, the user should be able to delegate certaininformation processing tasks to agents. Regardless of howpowerful a user interface we provide, there will still bemany repetitive tasks facing users, and we feel that userswill benefit from automation. The details of Haystack’sagent infrastructure are given in Section 4.
From: AAAI Technical Report WS-02-11. Compilation copyright © 2002, AAAI (www.aaai.org). All rights reserved.

ContributionBy addressing these four needs, we show that Haystack isable to use RDF to extend several profound benefits tousers. First, RDF can be readily exploited to add semanticsto existing information management frameworks and toserve as a lingua franca between different corpora. On topof this, we provide an ontology that supports capabilitiesincluding collection-based organization, semanticcategorization, and collaboration and trust management. Byontology we are referring to a vocabulary that specifies aset of classes and the properties possessed by objects ofthese classes. This ontology enables the user interface topresent the user’s information in a meaningful manner, andit also provides an abstraction on which agents can run.
Next, we show that RDF can be used to describe the meansfor visualizing heterogeneous data. In addition to theobvious registration metadata found in all componentframeworks, RDF can be used to build user interfacespecification abstractions that can be directly manipulatedby the user just as other metadata. This capability opensmany doors for user interface engineering including therealization of a truly uniform interface.
Finally, we discuss the use of RDF for modelingimperative computational processes. We present alanguage called Adenine as a natural means formanipulating metadata and thus writing agents forHaystack. Adenine programs compile into an RDFrepresentation, affording them the same ability to beannotated, distributed, and customized as other documentsand information.
HistoryThe information overload problem has become more andmore evident in the past decade, driving the need for betterinformation management tools. Several research projectshave been initiated to address this issue. The Haystackproject [8] [9] was started in 1997 to investigate possiblesolutions to this very problem. It aims to create a powerfulplatform for information management. Since its creation,the project has sought a data modeling framework suitablefor storing and manipulating a heterogeneous corpus ofmetadata in parallel with a user’s documents. With theintroduction of RDF, a good match was found between theversatility and expressiveness of RDF and the primary needof Haystack to manage metadata. The project has recentlybeen reincarnated to make use of RDF as its primary datamodel.
Related WorkThere have been numerous efforts to augment the user’sdata with metadata. The Placeless Documents project atXerox PARC [3] developed an architecture for storingdocuments based on properties specified by the user and bythe system. Like Haystack, Placeless Documents supportedarbitrary properties on objects and a collection mechanism
for aggregating documents. It also specified in its schemaaccess control attributes and shared properties useful forcollaboration. The Placeless Documents architectureleveraged existing storage infrastructure (e.g. web servers,file systems, databases, IMAP, etc.) through a driver layer.Similarly, Haystack takes advantage of the same storageinfrastructure, using URLs to identify documents.
On the surface, the main difference between Placeless’architecture and Haystack’s is the adaptation of RDF as astandard for information storage and exchange. AlthoughHaystack and Placeless share a lot of similarities in the datamodel layer, Haystack takes a more ambitious approach tothe user interface problem. Placeless’ Presto user interfacefocused on facilitating management of data in generalusing a predetermined set of interfaces. In developingHaystack, we are experimenting with ways to incorporatethe customization of user interfaces into the bigger problemof personalized information management by providing aplatform upon which user interfaces can be modeled andmanipulated with the same facility as other metadata.
There are other systems, many in common use today, thatpermit arbitrary metadata annotations on files. TheWindows NT file system (NTFS) supports file system-level user-definable attributes. WebDAV [2], a distributedHTTP-based content management system, also permitsattributes on documents. Lotus Notes and MicrosoftExchange, two common knowledge management serversolutions, both support custom attributes on objects withintheir databases. However, the metadata are not readilyinterchangeable among different environments. Further, thestructure of metadata in these systems is highly constrainedand makes the expression of complex relationshipsbetween objects difficult. For example, these systems donot have first class support for making assertions aboutpredicates, making it difficult for the user interface andagents to analyze data conforming to a foreign ontologydynamically.
The Semantic Web project at the World Wide WebConsortium (W3C), like Haystack, is using RDF to addressthese issues of interchangeability [4]. The focus of theSemantic Web effort is to proliferate RDF-formattedmetadata throughout the Internet in much the same fashionthat HTML has been proliferated by the popularity of webbrowsers. By building agents that are capable ofconsuming RDF, data from multiple sources can becombined in ways that are presently impractical. Thesimplest examples involve resolving scheduling problemsbetween different systems running different calendaringservers but both speaking RDF. A more complex exampleis one where a potential car buyer can make automatedcomparisons of different cars showcased on vendors' websites because the car data is in RDF. Haystack is designedto work within the framework of the Semantic Web.However, the focus is on aggregating data from users' livesas well as from the Semantic Web into a personalizedrepository.

Describing and Organizing HeterogeneousInformation
In this section we examine strategies for managing aheterogeneous corpus. First we examine how users candefine objects using their own ontology. Then we discussone means for aggregating objects—the collection—andhow it is used in Haystack to help users organize theirinformation.
Personalized OntologiesOne of Haystack’s objectives is to facilitate the use of anontology for organizing, manipulating and retrievingpersonal information. Some classes will be defined in thesystem ontology, such as those used for describing queriesand collections of objects. Also, some properties, such astitle, language, and description, will be defined by standardontologies such as the Dublin Core. Other classes andproperties can be defined by the user to suit his or her ownorganization method.
On the surface, the Haystack model may not seem verydifferent from those of current systems. Programs such asLotus Notes and Microsoft Outlook support classes such ase-mail message, contact, and appointment and providedefault properties, including subject, from, and date.However, whereas the focus of these products is inproviding an efficient and user-friendly means formaintaining objects with these standardized schemata,Haystack attempts to facilitate the entry of data using theuser’s own class definitions. This functionality is typicallyfound in relational database products, where users firstspecify a structured schema that describes the data they areentering before populating the table. In reality however,schema design is usually left for database and systemadministrators, who circulate their designs toward endusers of Notes or Outlook.
This “one size fits all” approach for schema design is farfrom perfect. End users are a fundamentally diversepopulace, and people often have their own ideas of whatattributes to store for particular classes of objects. A goodexample is an address book. Some people only care aboutstoring one or two phone numbers and a mailing address,while sales managers may be concerned with a breakdownof all past contact with a customer as well as importantdates in the customer’s life, such as his or her birthday. Thecurrent approach of making more and more fields built-into an address book product is problematic. Softwareadopting this approach is often overloading to the user whojust wants a simple address book, yet perhaps notfunctional enough for the sales manager. Using a personaldatabase such as Microsoft Access or FileMaker Pro onlyaggravates this problem, since users are forced to rebuildtheir address books from generic templates and genericdata types.
To solve this mismatch problem, we must examine meansfor describing per-user customization. Technologies such
as RDF provide flexible data frameworks upon whichcustomized schema definitions and metadata can bespecified. RDF’s data model encourages the creation ofcustom vocabularies for describing the relationshipsbetween different objects. Furthermore, RDF’s XMLsyntax makes these personalized vocabulary specificationsportable between different systems. This will be importantfor allowing agents to enhance the user’s information, as isdiscussed later.
The challenge exists in how to bring this ability tocustomize a personal information store to the end user whohas no experience with database administration. Toaccomplish this, we have devised tools for helping peoplemanipulate unstructured, semi-structured, and structureddata, abstracting the details of schema management fromend users. These tools are built upon a flexible, semi-structured RDF data store that Haystack uses to manageusers’ information according to ontologies they choose.
We generalize the problem of editing data based onarbitrary ontologies by providing a generic metadata editor.This editor takes advantage of the RDF Schema [7] datawithin Haystack’s RDF store in order to present the userwith a useful interface to their data. Future versions willallow users to assign arbitrary properties (not just thosespecified by the schema) to objects by simply typing thename of the property and its value. In this way users neednot be conscientious about schemata, and incidentalproperties specific to one object and not to the class can beentered.
A customized view of an object will often provide a betterinterface to the user than a generic tool, when one isavailable. To support this we provide a sophisticatedplatform for describing these customizations in ourprototype user interface tool called Ozone, discussed inSection 0.
In addition to editing properties of specific objects, it isoften useful to the user to be able to manipulate therelationship between objects. A graph editor allows usersto see a collection of objects and add and/or removerelationships between these objects. This idea has beenpopularized in tools such as Microsoft Visio, wherestructures such as flow charts, organization charts, andbusiness processes can be modeled in a similar fashion.Further, tools for drawing semantic diagrams by makingconnections between concepts have become available. TheHaystack graph editor provides these functionalities to theuser but records this data in RDF, making the semanticdiagrams true representations of “live” data.
Classifying InformationWhile users may be interested in customizing how theircontact information is stored in their address books, someabstractions we argue are best defined by the base system.This prevents the user from being too bogged down with

details of semantic modeling, while providing the user without-of-the-box functionality. Here we discuss one of thesekey classes, Collection.
A big problem with many document management systems,including paper-based ones, is the inability to convenientlyfile documents in more than one category. Althoughhierarchical folders are a useful and efficient means forstoring documents, the hierarchical folder system presentschallenges to users who attempt to use it to categorizedocuments. Does a document named “Network AdminDepartment Budget for 2001” belong in the “Budget”folder, the “2001” folder, or the “Network Admin” folder?Supposing an individual finds justification for placing it injust one of these folders, it is very possible that other usersmay have different views on classification and expect thedocument to be in a different folder. It may also be the casethat some days a user will be interested in a time-basedclassification and other days a department-basedclassification.
Simply supporting files being in more than one folder atonce is not sufficient. Commonly used modern operatingenvironments such as Windows and MacOS alreadyprovide mechanisms (called “shortcuts” and “aliases”respectively) for placing objects in more than one folder.On UNIX systems users can create hard links to files inmore than one directory at once. However, we findrelatively little use of these features for simultaneouslyclassifying documents into multiple categories.
We postulate that this is because the user interface does notencourage simultaneous classification. How manyprograms can be found whose file save feature prompts theuser for all the possible directories into which to place afile? Many users place their files into a single directorybecause they are not willing to expend the effort to classifyfiles. Of the fraction that are willing, there is yet a smallerfraction who would be willing to save their files in oneplace, then go to the shell to create the hard links into theother directories.
Collections, like folders, are aggregations of objects; anobject may be a member of more than one collection,unlike folders, whose interface encourages a strictcontainment relationship between folders and objects. Thisflexible system for grouping objects together is animportant tool for allowing users to organize objects in anyway they choose.
Throughout the Haystack user interface, we provide simplefacilities for specifying membership in more than onecollection. Of course, we support direct manipulationschemes such as drag and drop between collections.However, as noted earlier, the system must itself facilitatethe placement of objects in multiple collections in order tobe useful. For example, Haystack generates collections tostore the results of queries. Whereas in some systems, suchas Microsoft Outlook, first class membership in multiple
collections is only supported when the collection is asearch result set, this functionality is supported naturallywithin Haystack. Still, we envision the greatest source ofmultiple classification will be from agents automaticallycategorizing documents for the user.
Semantic User InterfaceIn addition to modeling data, RDF is used as the mediumfor specifying Haystack’s user interface and how Haystackpresents the user’s data. Haystack’s prototype userinterface, named Ozone, uses a custom componentarchitecture, and the user interface is constructeddynamically at runtime based on metadata. In this section,we introduce this metadata-based component architecture,show how it helps construct a uniform user interface, anddescribe the benefits such an interface might bring.
Component ArchitectureThe Ozone user interface is constructed from aconglomeration of parts. An Ozone part is a code-backedcomponent that can contribute to the user interface in someway. Attributes of each part are provided in metadata. Inparticular, the part’s implementation, the types of data itcan render, and the functionality it provides are described.
Types of Parts. There are four types of parts: layout parts,informative parts, decorative parts, and view parts. Layoutparts are responsible for segmenting the visual display intodistinct spaces and for positioning other parts in thesespaces. Informative parts present textual and graphicalinformation to the user. Decorative parts providedecorations such as white margins, line dividers, textspacing, list separators, etc. Finally, view parts use layoutparts, informative parts, and decorative parts as buildingblocks in constructing a unified view of a single object tothe user.
Figure 1 shows an example of how the various types ofparts work together to present a meeting. Part (a) of thefigure shows the end result while part (b) shows theinternal wiring. The view part responsible for displayingthe meeting employs a vertically splitting layout part topartition the display into two rows: the top row embeds aninformative part that renders the title of the meeting; thebottom row contains the details of the meeting. The bottomrow in turn contains a stacking layout part that stacks thethree fields “Time,” “Location,” and “Attendees”vertically.

Figure 1. Example of different types of parts workingtogether
The “Location” field consists of a decorative part thatrenders the label “Location:” and a view part that displaysthe room where the meeting is held. Note that because theroom is a separate entity, the meeting view part does notattempt to present the room itself but rather employsanother view part specialized to present the room. (Theroom is a separate entity because it has been modeled as aresource rather than as a literal property of the meeting.)The room view part includes an informative part to displaythe room’s title “Room 102,” two decorative parts to showthe parentheses, and yet another view part to display thebuilding where the room is located.
The “Attendees” field consists of a decorative part thatrenders the label “Attendees:” and a view part that showsthe collection of attendees. The collection view part uses alist layout that positions the collection memberssequentially, with decorative parts showing comma and“and” separators in between. The collection members arerendered by their own appropriate view parts.
Note that each view part is responsible for displayingexactly one semantic entity. In Figure 1, there are sevendistinct semantic entities: the meeting, the room, thebuilding, the attendee collection, and the three individualattendees. If a semantic entity is related to other semanticentities, the view part for that entity may incidentallyembed view parts for the other entities. The parent viewpart determines the appropriate type of each child view partto embed, so that the nested presentation looks pleasing.For instance, a small parent view part embeds only smallchild view parts.
Part Metadata. Given a semantic entity to present, Ozonequeries the RDF store for the part suitable for displayingthe entity. Figure 2 shows an example of the metadata thatlinks the entity to the suitable part.
an objecta view
instance
a javaimplement-
ation
a part
a viewclass
a daml:Class
hs:view
rdf:type
hs:viewClass
ozone:viewDomain
hs:javaImplementation
rdf:type
“edu.mit.lcs.haystack.ozone.parts.ListViewPart”
hs:className
ozone:listViewPart
ozone:ListViewhs:Collection
hs:favorites
Figure 2. Part metadata example
In order to display the hs:favorites entity, Ozone queriesfor any view instance associated with the entity through thehs:view predicate.1 If no view instance is found, Ozonedetermines the type of the entity (in this case,hs:Collection) and the view class corresponding to thattype (ozone:ListView). Ozone then instantiates a uniqueresource that serves as a view instance for the hs:favoritesentity and asserts that the view instance is of that viewclass type. The view instance will be persisted thereafterand it will serve to store custom settings applied by theuser while viewing the corresponding semantic entity. Inthis example, such settings include the columns and theirorder in the list view. Each type of view instances persistsits settings in its own custom ontology.
Once a view instance exists and its view class is known,Ozone queries for a part whose view domain(ozone:viewDomain) is the class of the given view 1 The hs: prefix denotes a URI belonging tothe Haystack namespace. Note that the ideaof views is inherent to the Haystackontology, whereas the view parts used todisplay them are inherent to Ozone.

instance. In this example, the part ozone:listViewPart isfound. Ozone then finds the implementation of this part,instantiates the corresponding Java class, and initializes itwith the semantic entity.
Benefits. The ability to encode the user interface inmetadata and then render the interface from that metadatais appealing for a number of reasons. First, it allows thecomponent architecture to construct the user interfacedynamically at run-time; any change made to the metadatacan be applied immediately. This is not possible withconventional user interface programming models for whichuser interface layouts are compiled into binary resources orcode and loaded at runtime. Any change to such layoutsrequires recompilation unless the code is specificallyparameterized to accept runtime customization. Even inrapid application development tools like Microsoft VisualBasic in which user interfaces can be built by drag anddrop operations, there are two distinct edit and runtimemodes. The user is only allowed to interact with theapplication in runtime mode when the user interface isalready fixed and unchangeable. Skinnable applicationsalso have a similar limitation. Skins are made by skindesigners and then published to users. The users can selectwhich skins to apply to the applications, but they cannotcustomize the skins themselves. Again, there are twodistinct design and use modes that deny the users the powerof customizing the user interfaces themselves. Likewise,web pages have two edit and view modes: in view mode,the user cannot make modifications. Our Ozone interfacearchitecture imposes no such modes and allows the user tomake changes to the user interface at runtime.
Note that user interface changes performed by the user arehigh-level: they are to programmers’ user interface work asinterior design is to carpentry. In other words, customizingthe user interface is akin to editing a word processingdocument or manipulating a spreadsheet. The user isallowed to arrange parts and apply visual themes overthem; all the necessary “carpentry work” is handledautomatically by Ozone. Since arguably there is nouniversal interface that suits the needs of every user, thisability to customize one’s user interface is desirable. Infact, such personalization features have been explored insimple forms on several portal web sites likehttp://my.yahoo.com. We would like to bringpersonalization to our information management platform.In addition to arranging pre-installed parts, the user isoffered to select new parts from a part repository and dragthem to desired locations in the Ozone interface.
One might argue that similar component architectures andpersonalization engines have been implemented withoutthe need for RDF. In fact, anything implemented usingRDF can be done with custom formats. However, whatRDF offers is a unified and extensible framework muchneeded in the presence of several incompatible customformats.
The second benefit of user interface metadata is that, likeany other type of data, the user interface metadata can besaved, published, and shared. The ability to publish userinterface metadata is particularly attractive. Consider ascenario in which a new employee enters a company with alarge intranet. This intranet offers countless usefulresources to the new employee, but because of its sheervolume, it is intimidating to get used to. Fortunately, otheremployees have over time collected a selection of Ozoneparts that provide access to the most useful features of theintranet. The new employee can simply make use of theseparts as a starting point. These parts are brought into theemployee’s Haystack and tailored based on his or herpreferences. These parts can interact with the employee’sHaystack and perform automatic customization that makesHaystack much more powerful than a static web pagelisting a set of useful links to the intranet.
User interfaces, hence, can be evolved by the users forthemselves as their needs emerge and coalesce. Users withdifferent needs tailor their interfaces differently. Thosewith similar needs share their interface layouts. Thisphilosophy relieves the interface designers from theimpossible task of making universal interfaces that satisfyboth expert and novice users. Instead, we provide tools forthe user to tailor his or her own user interface. In addition,by providing an ontology describing user interfaceinteractions, such interactions can be tracked automaticallyand agents can apply machine learning algorithms to betterfit the user interface to the user’s implicit needs andpreferences.
The third benefit of user interface metadata is that the userinterface designer is encouraged to think semantically as heor she encodes the interface in metadata. Since theinterface is rendered automatically by the componentarchitecture based on a unified set of semantics, the barrierto creating user interfaces is much lowered. By removingthe burden of fiddling with the interface “until it works” or“so it looks nice,” we encourage the designer to think at thelevel of the user’s semantics rather than at the level of howthe user interface is syntactically constructed. Suchabstraction leads to consistency, the most advocatedproperty of user interface [10].
Finally, because the user interface is modeled in RDF justas the user’s data is, the tools offered by Ozone forallowing the user to manipulate his or her data are the sameas those used when manipulating the interface itself. Forexample, the mechanism for changing a contact’s name isalso used for changing the caption of a button. Themechanism for changing the font in an email message bodycan be used to change the font in which all labels aredisplayed. In fact, the mechanism for looking up a word inthe body of a document is made available for looking up amenu command that one does not understand. This uniformfashion in which all things can be manipulated makes theinterface of Ozone consistent and hence, natural andpowerful.

Figure 3. Actions for a contact name in a list view(Microsoft Outlook XP)
Uniform User InterfaceUsing the power of the component architecture, we explorethe concept of a uniform user interface [10]. In such aninterface, any two user interface elements that looksemantically identical to the user afford the same set ofactions regardless of context. For instance, a contact nameshown in the “From” column for an email message in a listview (Figure 3) should expose the same actions as the samecontact name shown in the “From” text field in the emailmessage window (Figure 4). In Microsoft Outlook XP andother existing email clients, those two elements providealmost entirely different sets of actions. The formerelement is a dead text string painted as part of the wholelist view item representing the email message. Right-clicking on it is equivalent to right-clicking anywhere inthat list view item. The same context menu for the wholemessage is always shown regardless of the right-clicklocation. The latter element is a control by itself. Itrepresents a contact object and shows the context menuapplicable to that object when right-clicked. To the user,both elements represent the same contact object and shouldgive the same context menu. (Uniformity in this caseimplies modelessness.)
Figure 4. Actions for a contact name in the email composewindow (Microsoft Outlook XP)
Context menus have been adopted by most operatingsystems as the mechanism to query for actions applicableto the indicated object. However, context menus are rarelyused consistently throughout any user interface. Some userinterface elements afford context menus while others donot. Furthermore, some context menus do not expose allpossible actions that the user associates semantically withtheir corresponding objects. Their inconsistency andincompleteness make context menus less powerful, andhence, less useful and less widely adopted by users thanthey should be. We aim to fix such inconsistency andincompleteness by providing context menus for all userinterface elements and by systematically constructing themenus from metadata.1 We believe that this uniformity willmake the interface much easier to use.
In order to construct context menus from metadata, we firstnote that every pixel on the screen corresponds to aparticular Ozone part that renders that pixel. If that part is aview part, there is a corresponding semantic entity that it isresponsible for displaying. That view part can be containedin other outer view parts. All of these view parts togetherspecify a collection of semantic entities that underlie thepixel. We postulate that one of these semantic entities isthe thing with which the user wants to interact. Toconstruct a context menu when that pixel is right-clicked,we simply list all actions applicable to those semanticentities.
Like semantic entities, Ozone parts can also afford actions.For instance, the informative part that displays the text“Vineet Sinha” in Figure 3 allows the user to copy its text. 1 Context menus are not widely adopted alsobecause they are not currentlydiscoverable. Once discovered, they arevery memorable. We propose labeling theright mouse button “Show Commands” tomake context menus more discoverable.

The layout part that shows the messages in a list viewformat allows the user to reorder the columns.
Figure 5 gives a sample context menu that will beimplemented for an upcoming release. The menu is dividedinto several sections, each listing the commands for aparticular semantic entity or Ozone part. The email authorentity named “Vineet Sinha” is given the first section. Theemail message entity is given the next section. Finally thetext label used to display the contact’s name is given thethird section. Commands for other semantic entities andparts can be accessed through the “More…” item at thebottom of the menu. This is only an example of howcontext menus can be constructed. The exact order of thesections will be optimized by user study and feedback.
Figure 5. Sample context menu
Of note in Figure 5 are some capabilities not provided inexisting email clients. In particular, the “Text” section inthe menu offers ways to copy, look up, and spell-check anotherwise dead piece of text. In other email clients, onlytext inside email bodies can be spell-checked. One can alsoimagine the usefulness of spell-checking file names [10]and email subjects.
It is arguable that when a user interface element isassociated with several semantic entities and parts, itscontext menu will be overloaded. We believe that withproper modeling of prioritization of commands and in-depth user study, we can heuristically select the mostuseful commands to list in the menu. Other commands arestill accessible through “More…” links. Further, becausemenu commands are simply members of the collection of
all actions applicable to some semantic entity, the user canuse the mechanism provided by Ozone for browsing andsearching collections to locate particular menu commands.In existing software, menu commands can only be foundby visual scans.
Agent InfrastructureWe now turn our attention to agents, which play animportant role in not only improving the user experiencewith regards to keeping information organized, but also inperforming tedious tasks or well-defined processes for theuser. We also describe some underlying infrastructureneeded to make writing and using agents in Haystackefficient and secure.
AgentsIn the past, programs that aggregated data from multiplesources, such as mail merge or customer relationshipmanagement, had to be capable of speaking numerousprotocols with different back-ends to generate their results.With a rich corpus of information such as that present in auser’s Haystack, the possibility for automation becomessignificant because agents can now be written against asingle unified abstraction. Furthermore, agents can bewritten to help users deal with information overload byextracting key information from e-mail messages and otherdocuments and presenting the user with summaries.
As we alluded to earlier, collections can be maintainedautomatically by agents. Modern information retrievalalgorithms are capable of grouping documents bysimilarity or other metrics, and previous work has foundthese automatic classifications to be useful in manysituations. Additionally, users can build collectionsprescriptively by making a query. An agent, armed with aspecification of what a user is looking for, can create acollection from the results of a query, and it can watch fornew data entering the system that matches the query.
For example, agents can automatically filter a user’s e-mailfor documents that appear to fit in one or more collectionsdefined by the user, such as “Website Project” or “Lettersfrom Mom”. Because membership in collections is notone-to-one, this classification can occur even while themessage remains in the user’s inbox.
Agents are used in Haystack to automatically retrieve andprocess information from various sources, such as e-mail,calendars, the World Wide Web, etc. Haystack includesagents that retrieve e-mail from POP3 servers, extractplaintext from HTML pages, generate text summaries,perform text-based classification, download RSSsubscriptions on a regular basis, fulfill queries, andinterface with the file system and LDAP servers.
The core agents are mostly written in Java, but some arewritten in Python. We utilize an RDF ontology derivedfrom WSDL [5] for describing the interfaces to agents as

well as for noting which server processes hosts whichagents. As a consequence, we are able to support differentprotocols for communicating between agents, from simplypassing in-process Java objects around to using HTTP-based RPC mechanisms such as HTTP POST and SOAPError! Reference source not found..
BeliefWhen multiple agents are used to generate the sameinformation, issues arise as to how to deal with conflicts.For instance, if one agent is tasked with determining thedue date of a document by using natural languageprocessing and another agent does the same by extractingthe first date from a document, which is to be believedwhen there is a conflict? In instances such as this, it isimportant that information be tagged with authorshipmetadata so the user can make an informed choice ofwhich statement to choose.
To accomplish this we discuss a part of the systemontology that is used for describing attributes about actualstatements themselves, such as who asserted them andwhen they were asserted. Under the premise that only threevalues, namely subject, predicate, and object, are requiredto describe statements in our model, it is possible to givestatements identifiers and to assert an author and creationtime to the original statement. In fact, the RDF modelprescribes that in order to make statements aboutstatements, the referent statement must be reified into aresource and assigned a URI, and the referring statementscan then use the reified resource in the subject or objectfield.
This use of reification brings up a subtle issue concerningRDF. In a document containing RDF, it is assumed that allstatements are asserted to be true by the author. In order tomake a statement about another statement that the authordoes not necessarily believe is true, the target statementmust exist only in reified form. In essence, the author isbinding a name to a specific statement with a certainsubject, predicate, and object, but is not asserting thestatement to be true, only instead asserting other propertiesabout that statement using the name.
Keeping track of various levels of trustworthiness isimportant in a system that contains statements made bynumerous independent agents, as well as information fromusers’ colleagues, friends, family, solicitors, and clients. Inorder to maintain metadata on the statements themselves inan information store, one solution is to have theinformation store become a “neutral party”, recording whosaid what and when those things were said, but notasserting their truth. This is accomplished by having allstatements made by parties other than the information storereified. (An alternative is to have one entity—perhaps theuser--be at the same trust level as the data store. However,this results in statements made by the user being handled inone fashion and those made by others (which have been
reified) handled in a different fashion. For simplicity ofimplementation, we keep the data store neutral.)
Once we have a system for recording statement metadata,we can examine issues of retraction, denial, and expirationof assertions, i.e., statements asserted by specific parties.Consider an example where an agent is responsible forgenerating the title property for web pages. Some webpages, such as those whose contents are updated daily,have titles that change constantly. Often users want to beable to locate pages based on whatever it is they rememberabout the page. One approach for handling constantmutations in the information store is to allow agents todelete a previous assertion and to replace it with an up-to-date version. However, it would be powerful to allow usersto make queries of the form “Show me all web pages thathad the title Tips for Maintaining Your Car at some pointin time.” By allowing agents to retract their assertions,queries can still be made to retrieve past or obsoleteinformation because this information is not deleted.Additionally, this system permits users to override anassertion made by an agent by denying the assertion, yetretains the denied assertion for future reference.
In a system such as this where multiple parties and agentsprovide information, we are often concerned withimpersonation and forgery. To solve these problems, wepropose supporting digitally signed RDF. The digitalsignature permits the information store to determine andverify the author of statements with certainty. In an idealsystem, users and agents sign all RDF they produce withassigned digital signatures. However, the W3C is stillworking on the details of supporting signed RDF at thestatement level, and the implementation of a digitalsignature system is beyond the scope of this project. Forour current prototype, identifier strings are used in place oftrue signatures.
AdenineIn a system such as Haystack, a sizeable amount of code isdevoted to creation and manipulation of RDF-encodedmetadata. We observed early on that the development of alanguage that facilitated the types of operations wefrequently perform with RDF would greatly increase ourproductivity. As a result, we have created Adenine. Anexample snippet of Adenine code is given inFigure 6.
The motivation for creating this language is twofold. Thefirst key feature is making the language’s syntax supportthe data model. Introducing the RDF data model into astandard object-oriented language is fairly straightforward;after all, object-oriented languages were designedspecifically to be extensible in this fashion. Normally, onecreates a class library to support the required objects.However, more advanced manipulation paradigms specificto an object model begin to tax the syntax of the language.In languages such as C++, C#, and Python, operator

overloading allows programmers to reuse built-in operatorsfor manipulating objects, but one is restricted to theexisting syntax of the language; one cannot easily constructnew syntactic structures. In Java, operator overloading isnot supported, and this results in verbose APIs beingcreated for any object oriented system. Arguably, thisverbosity can be said to improve the readability of code.
On the other hand, lack of syntactic support for a specificobject model can be a hindrance to rapid development.Programs can end up being three times as long as necessarybecause of the verbose syntactic structures used. This is thereason behind the popularity of domain-specificprogramming languages, such as those used in Matlab,Macromedia Director, etc. Adenine is such a language. Itincludes native support for RDF data types and makes iteasy to interact with RDF containers and services.
Figure 6. Sample Adenine code
The other key feature of Adenine is its ability to becompiled into RDF. The benefits of this capability can beclassified as portability and extensibility. Since 1996, p-code virtual machine execution models have resurged as a
result of Java’s popularity. Their key benefit has beenportability, enabling interpretation of software written forthese platforms on vastly different computingenvironments. In essence, p-code is a set of instructionswritten to a portable, predetermined, and byte-encodedontology.
Adenine takes the p-code concept one step further bymaking the ontology explicit and extensible and byreplacing byte codes with RDF. Instead of dealing with thesyntactic issue of introducing byte codes for newinstructions and semantics, Adenine takes advantage ofRDF’s ability to extend the directed “object code” graphwith new predicate types. One recent example of a systemthat uses metadata-extensible languages is Microsoft’sCommon Language Runtime (CLR). In a language such asC#, developer-defined attributes can be placed on methods,classes, and fields to declare metadata ranging from threadsafety to serializability. Compare this to Java, where
serializability was introduced only through the creation of anew keyword called transient. The keyword approachrequires knowledge of these extensions by the compiler;the attributes approach delegates this knowledge to theruntime and makes the language truly extensible. InAdenine, RDF assertions can be applied to any statement.
These two features make Adenine very similar to Lisp, inthat both support open-ended data models and both blur thedistinction between data and code. However, there aresome significant differences. The most superficialdifference is that Adenine’s syntax and semantics areespecially well-suited to manipulating RDF data. Adenineis mostly statically scoped, but has dynamic variables thataddress the current RDF containers from which existingstatements are queried and to which new statements arewritten. Adenine’s runtime model is also better adapted tobeing run off of an RDF container. Unlike most modernlanguages, Adenine supports two types of program state:in-memory, as is with most programming languages, andRDF container-based. Adenine in effect supports two kindsof closures, one being an in-memory closure as is in Lisp,and the other being persistent in an RDF container. Thisaffords the developer more explicit control over thepersistence model for Adenine programs and makes itpossible for agents written in Adenine to be distributed.
The syntax of Adenine resembles a combination of Pythonand Lisp, whereas the data types resemble Notation3 [11].As in Python, tabs denote lexical block structure.Backslashes indicate a continuation of the current line ontothe next line. Curly braces ({}) surround sets of RDFstatements, and identifiers can use namespace prefixes (e.g.rdf:type) as shorthand for entering full URIs, which areencoded within angle brackets (<>). Literals are enclosedwithin double quotes.
Adenine is an imperative language, and as such containsstandard constructs such as functions, for loops, arrays, andobjects. Function calls resemble Lisp syntax in that theyare enclosed in parentheses and do not use commas toseparate parameters. Arrays are indexed with squarebrackets as they are in Python or Java. Also, because theAdenine interpreter is written in Java, Adenine code cancall methods and access fields of Java objects using the dotoperator, as is done in Java or Python. The executionmodel is quite similar to that of Java and Python in that anin-memory environment is used to store variables; inparticular, execution state is not represented in RDF.Values in Adenine are represented as Java objects in theunderlying system.
Adenine methods are functions that are named by URI andare compiled into RDF. To execute these functions, theAdenine interpreter is passed the URI of the method to berun and the parameters to pass to it. The interpreter thenconstructs an initial in-memory environment bindingstandard names to built-in functions and executes the codeone instruction at a time. Because methods are simply
# Prefixes for simplifying input of URIs@prefix : <urn:test-namespace:>
:ImportantMethod rdf:type rdfs:Class
method :expandDerivedClasses ; \rdf:type :ImportantMethod ; \rdfs:comment \"x rdf:type y, y rdfs:subClassOf z => x rdf:type z"
# Perform query# First parameter is the query specification# Second is a list of the variables to return,
# in order= data (query {
?x rdf:type ?y?y rdfs:subClassOf ?z
} (List ?x ?z))
# Assert base class typesfor x in data
# Here, x[0] refers to ?x# and x[1] refers to ?z
add { x[0] rdf:type x[1] }

resources of type adenine:Method, one can also specifyother metadata for methods. In the example given, anrdfs:comment is declared and the method is given anadditional type, and these assertions will be entereddirectly into the RDF container that receives the compiledAdenine code.
The top level of an Adenine file is used for data andmethod declarations and cannot contain executable code.This is because Adenine is in essence an alternate syntaxfor RDF. Within method declarations, however, is codethat is compiled into RDF; hence, methods are likesyntactic sugar for the equivalent Adenine RDF“bytecode”.
Development on Adenine is ongoing, and Adenine is beingused as a platform for testing new ideas in writing RDF-manipulating agents.
Data StorageRDF StoreThroughout this paper we have emphasized the notion ofstoring and describing all metadata in RDF. It is the job ofthe RDF store to manage this metadata. We provide twoimplementations of the RDF store in Haystack. The first isone built on top of a conventional relational databaseutilizing a JDBC interface. We have adopted HSQL, an in-process JDBC-compatible database written in Java.However, early experiments showed that for the small butfrequent queries we were performing to render Ozone userinterfaces, the RDF store was overloaded by the fixedmarshalling and query parsing costs. Switching to a largerscale commercial database appears to result in worseperformance because of the socket connection layer that isadded in the process.
To solve these problems we developed an in-process RDFdatabase written in C++ (we use JNI to connect it to therest of our Java code base). By making it specifically suitedto RDF, we were able to optimize the most heavily usedfeatures of the RDF store while eliminating a lot of themarshalling and parsing costs. However, we acknowledgethis to be a temporary solution, and in the long term wewould prefer to find a database that is well-suited to thetypes of small queries that Haystack performs.
Storing Unstructured ContentIt is important for us to address how Haystack interactswith unstructured data in the existing world. Today, URLsare used to represent files, documents, images, web pages,newsgroup messages, and other content accessible on a filesystem or over the World Wide Web. The infrastructure forsupporting distributed storage has been highly developedover the past decades. With the advent of technologies suchas XML Namespaces and RDF, a larger class of identifierscalled URIs subsumed URLs. Initially, RDF provided ameans for annotating web content. Web pages, identifiedby URL, could be referred to in RDF statements in the
subject field, and this connected the metadata given in RDFto the content retrievable by the URL. This is a powerfulnotion because it makes use of the existing storageinfrastructure.
However, with more and more content being described inRDF, the question naturally arises: why not store content inRDF? While this is certainly possible by our initialassumption that RDF can describe anything, we argue thisis not the best solution for a couple of reasons. First,storing content in RDF would be incompatible withexisting infrastructure. Second, leveraging existinginfrastructure is more efficient; in particular, using file I/Oand web protocols to retrieve files is more efficient thanusing XML encoding.
Hence, we do not require that existing unstructured contentbe stored as RDF. On the contrary, we believe it makessense to store some of the user’s unstructured data usingexisting technology. In our prototype, we provide storageproviders based on HTTP 1.1 and standard file I/O. Thismeans that storing the content of a resource in Haystackcan be performed with HTTP PUT, and retrieving thecontent of a resource can be performed with HTTP GET,analogously to how other resources’ contents (e.g., webpages) are retrieved. Our ontology uses the Content classand its derivatives, HTTPContent, FilesystemContent, andLiteralContent to abstract the storage of unstructuredinformation.
Putting It TogetherAt this point, we have described ontologies for personalinformation management and user interfaces, as well as anagent infrastructure and a data storage layer. In order togain a fuller understanding of how these components worktogether, we illustrate an example interaction between theuser and Haystack
Figure 7 shows the user’s home page, which is displayedwhen Ozone is first started. Like a portal, the Ozone homepage brings together in one screen information important tothe user. This information is maintained by agents workingin the background. The actual presentation of thisinformation is decoupled from the agents and is theresponsibility of Ozone view parts. For instance, the homepage displays the user’s incoming documents collection,which is managed by the Incoming Agent. When messagesarrive, the Incoming Agent may decide to enter them intothe incoming documents collection. Similarly, when readmessages have been in the incoming documents collectionfor some period of time, the Incoming Agent may decide toremove them. These mutations to the incoming documentscollection are automatically detected by the collection viewpart sitting on the home page; the view part updates thedisplay accordingly. One can envision the Incoming Agenttaking on more intelligent behaviors in the future, such asmoving a message deduced to be important but yet unreadto the top of the collection
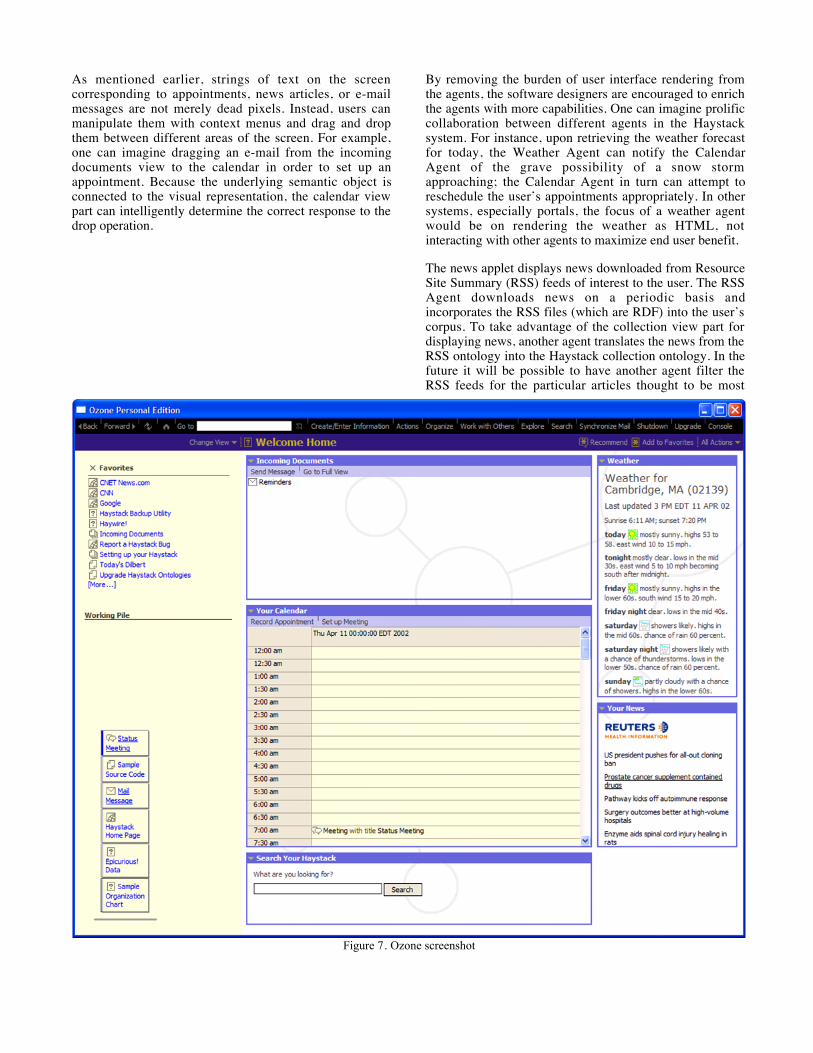
As mentioned earlier, strings of text on the screencorresponding to appointments, news articles, or e-mailmessages are not merely dead pixels. Instead, users canmanipulate them with context menus and drag and dropthem between different areas of the screen. For example,one can imagine dragging an e-mail from the incomingdocuments view to the calendar in order to set up anappointment. Because the underlying semantic object isconnected to the visual representation, the calendar viewpart can intelligently determine the correct response to thedrop operation.
By removing the burden of user interface rendering fromthe agents, the software designers are encouraged to enrichthe agents with more capabilities. One can imagine prolificcollaboration between different agents in the Haystacksystem. For instance, upon retrieving the weather forecastfor today, the Weather Agent can notify the CalendarAgent of the grave possibility of a snow stormapproaching; the Calendar Agent in turn can attempt toreschedule the user’s appointments appropriately. In othersystems, especially portals, the focus of a weather agentwould be on rendering the weather as HTML, notinteracting with other agents to maximize end user benefit.
The news applet displays news downloaded from ResourceSite Summary (RSS) feeds of interest to the user. The RSSAgent downloads news on a periodic basis andincorporates the RSS files (which are RDF) into the user’scorpus. To take advantage of the collection view part fordisplaying news, another agent translates the news from theRSS ontology into the Haystack collection ontology. In thefuture it will be possible to have another agent filter theRSS feeds for the particular articles thought to be most
Figure 7. Ozone screenshot

interesting to the user.
Furthermore, the layout of the entire home page and all ofits customizations is described in metadata. As with otherobjects, this layout can be annotated, categorized, and sentto others.
Future WorkHaystack provides a great platform for organizing andmanipulating users’ information. In this section we touchupon two topics we are currently investigating that buildnew abstractions on top of the data model discussed above.
CollaborationEnabling users to work together, exchange information,and communicate has become an absolutely essentialfeature of modern information management tools. Thefocus of current off-the-shelf products has been on e-mailand newsgroup-style discussions. However, the addition ofrich metadata manipulation facilities creates manypossibilities for Haystack in fostering collaboration.
First, Haystack encourages users to have individualizedontologies, so converting between these ontologies whenexchanging data will need to be examined. Agents can beinstructed in the relationships between different ontologiesand can perform conversion automatically. As analternative one can imagine an ontological search enginethat is consulted whenever a user enters data. This wayusers end up using the same ontologies to describesimilarly-structured data.
Second, security issues arise when sharing data. Supportfor belief networks will need to be expanded to allow usersto distinguish their own information from informationobtained from others. Access control and privacy will needto be examined to allow users to feel comfortable aboutstoring information in Haystack.
Finally, metadata describing individual users’ preferencestowards certain topics and documents can be used andexchanged to enable collaborative filtering. Sites such asepinions.com promote user feedback and subjectiveanalysis of merchandise, publications, and web sites.Instead of going to a separate site, users’ Haystacks canaggregate this data and, by utilizing the belief network,present users with suggestions.
Organization SchemesWe have started to investigate the many ways in whichpeople organize their personal information in physicalform, such as bookcases and piles. We believe that eachmethod of organization has different advantages anddisadvantages in various situations. In light of this, wepropose to support several virtual organization schemessimultaneously, such that the user can choose theappropriate organization scheme to use in each situation.Different schemes act like different lenses on the same
corpus of information. We will provide agents that help theuser create and maintain these organization schemes.
References[1] Box, D., Ehnebuske, D., Kavivaya, G., et al. SOAP:
Simple Object Access Protocol.http://msdn.microsoft.com/library/en- us/dnsoapsp/html/soapspec.asp .
[2] Goland, Y., Whitehead, E., Faizi, A., Carter, S., andJensen, D. HTTP Extensions for Distributed Authoring– WEBDAV. http://asg.web.cmu.edu/rfc/rfc2518.html .
[3] Dourish, P., Edwards, W.K., et al. "ExtendingDocument Management Systems with User-SpecificActive Properties." ACM Transactions on InformationSystems, vol. 18, no. 2, April 2000, pages 140–170.
[4] Berners-Lee, T., Hendler, J., and Lassila, O. "TheSemantic Web." Scientific American, May 2001.
[5] Christensen, E., Cubera, F., Meredith, G., andWeerawarana, S. Web Services Description Language(WSDL) 1.1. http://www.w3.org/TR/wsdl .
[6] Resource Description Framework (RDF) Model andSyntax Specification.http://www.w3.org/TR/1999/REC-rdf-syntax- 19990222/ .
[7] Resource Description Framework (RDF) SchemaSpecification. http://www.w3.org/TR/1998/WD-rdf- schema/ .
[8] Adar, E., Karger, D.R., and Stein, L. “Haystack: Per-User Information Environments” in 1999 Conferenceon Information and Knowledge Management.
[9] Karger, D and Stein, L. “Haystack: Per-UserInformation Environments”, February 21, 1997.
[10] Raskin, J. “The Humane Interface.” Addison-Wesley,2000.
[11] Berners-Lee, T. Primer: Getting into RDF & SemanticWeb using N3.http://www.w3.org/2000/10/swap/Primer.html .