hadoop and your enterprise data warehouse
TRANSCRIPT

Welcome to Today’s
DBTA Roundtable Web Event

Stephen Faig
Business Development Manager
Unisphere Media
Publishers of DBTA

Hadoop and Your Enterprise Data Warehouse

Nitin Bandugula
Product Marketing Manager
MapR Technologies
Kevin Petrie
Senior Director
Attunity
George Corugedo
Chief Technology Officer & Co-Founder
RedPoint Global Inc.

© 2015 MapR Technologies 5© 2015 MapR Technologies

© 2015 MapR Technologies 6
Empowering “as it happens”
businesses by speeding up the
data-to-action cycle

© 2015 MapR Technologies 7
Top-Ranked NoSQL
Top-Ranked HadoopDistribution
Top-Ranked SQL-on-HadoopSolution

© 2015 MapR Technologies 8
Topics
• The Need for EDW Optimization
• Different Stages of the Optimization
• MapR Customer Examples
• The MapR Advantage

© 2015 MapR Technologies 9© 2015 MapR Technologies
The Need for EDW Optimization

© 2015 MapR Technologies 10
Technical Best-Practices Driving Change in Data Architecture
2Speed of
operations
1Scale of
analytics
Source: TDWI, April 2014

© 2015 MapR Technologies 11
Unused Data,
Related LoadsEDW
ELT
Unused
Tables
(72%)
ELT
• 70% of data is unused
• Almost 60% of CPU capacity is ETL/ELT
• 15% of CPU consumed by ETL to load
unused data
• 30% of CPU consumed by 5% of resource
consuming ETL workloads.
Meanwhile…The Industry Norm in the DW
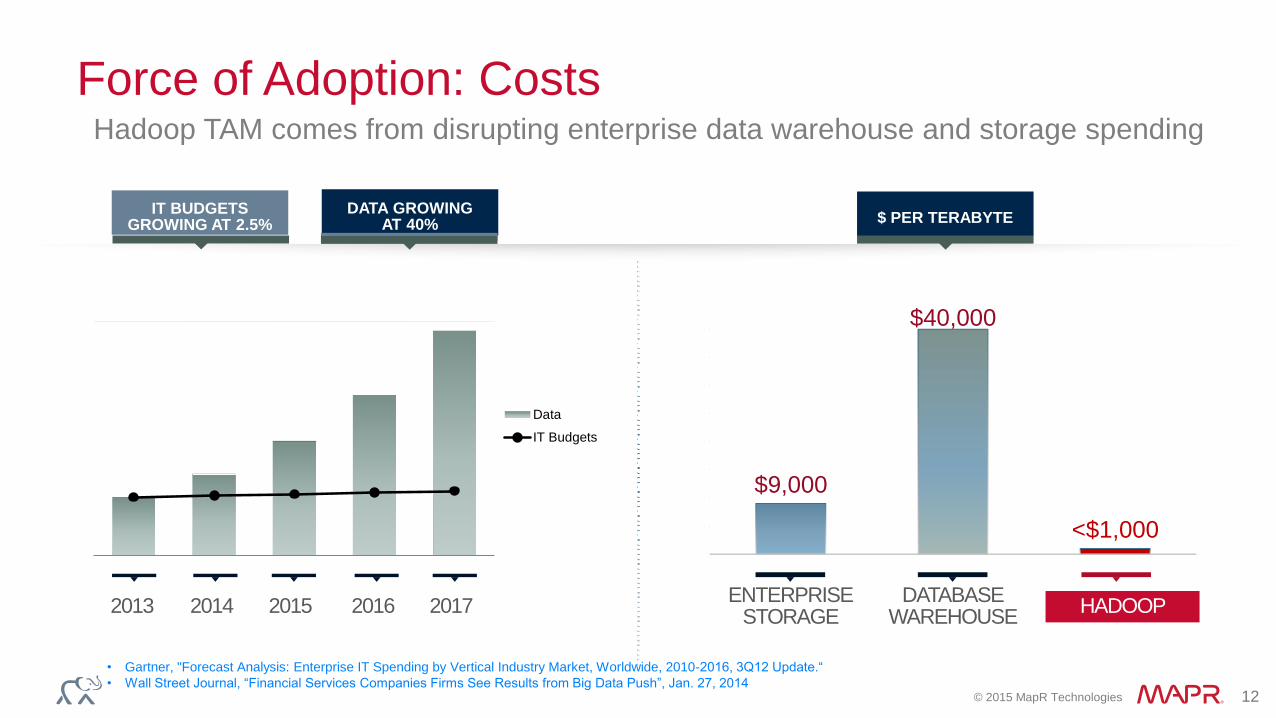
© 2015 MapR Technologies 12
Data
IT Budgets
Force of Adoption: CostsHadoop TAM comes from disrupting enterprise data warehouse and storage spending
• Gartner, "Forecast Analysis: Enterprise IT Spending by Vertical Industry Market, Worldwide, 2010-2016, 3Q12 Update.“
• Wall Street Journal, “Financial Services Companies Firms See Results from Big Data Push”, Jan. 27, 2014
$9,000
$40,000
<$1,000
DATA GROWING AT 40%
2013ENTERPRISE
STORAGE
IT BUDGETS GROWING AT 2.5%
2014 2015 2016 2017DATABASE
WAREHOUSE
$ PER TERABYTE
HADOOP

© 2015 MapR Technologies 13
SCALE: New Data Sources Unlock New Insights & Apps
Existing structured data
• Well-defined and well-
understood schema
– OLTP data
– Data warehouse data
– End user data stores (e.g.,
Excel, Access)
New multi-structured data
• Typically un-modeled,
different in format
– Log data
– Clickstream data
– Sensor data
– Rich media (e.g., audio, video)
– Documents
Both types needed today for deeper insights

© 2015 MapR Technologies 14© 2015 MapR Technologies
Stages of the Optimization

© 2015 MapR Technologies 15
Stage 1: Offload Cold Data – Free up DW space
Structured
Data
ETLIncoming
Data
Data Warehouse
Hadoop Platform
• Unused data
moved out
• ETL done the
traditional way
• Critical data
available for query
Data Access:
– BI through ODBC
– Hive Connectors
Cold Data
Offload
Restored
Disk
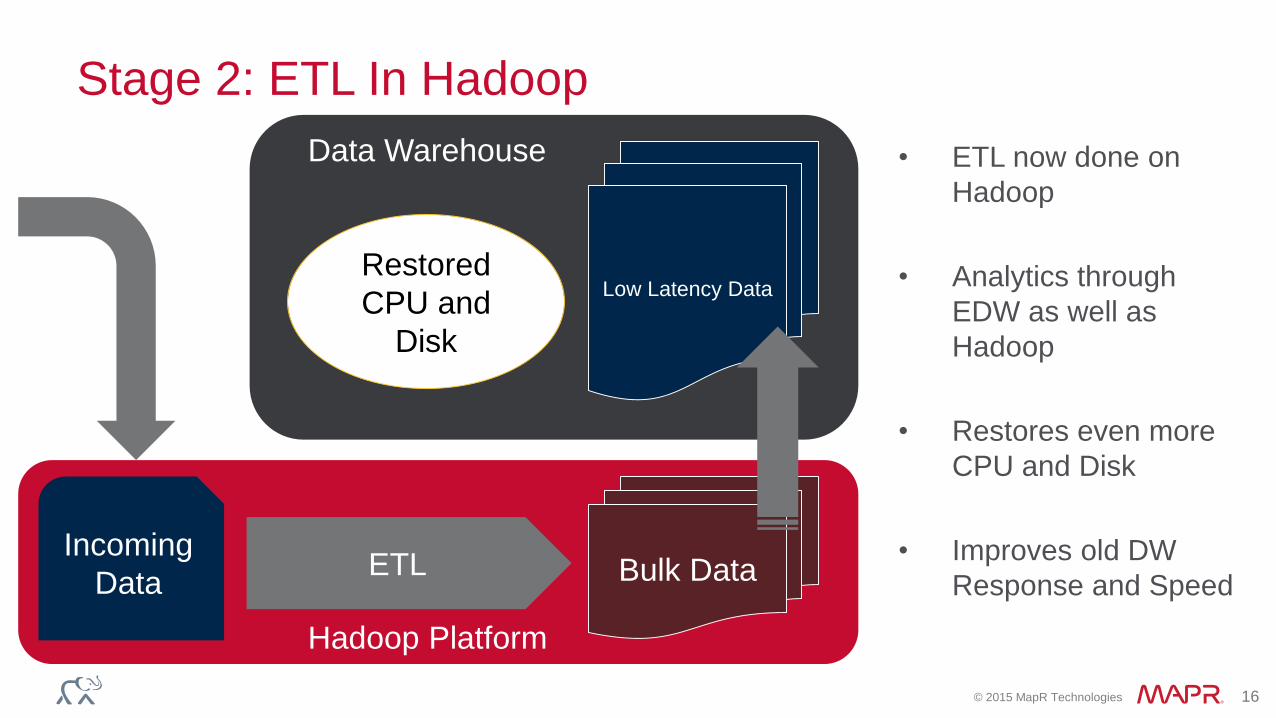
© 2015 MapR Technologies 16
Stage 2: ETL In Hadoop
Low Latency Data
ETLIncoming
Data
Data Warehouse
Hadoop Platform
Bulk Data
Restored
CPU and
Disk
• ETL now done on
Hadoop
• Analytics through
EDW as well as
Hadoop
• Restores even more
CPU and Disk
• Improves old DW
Response and Speed
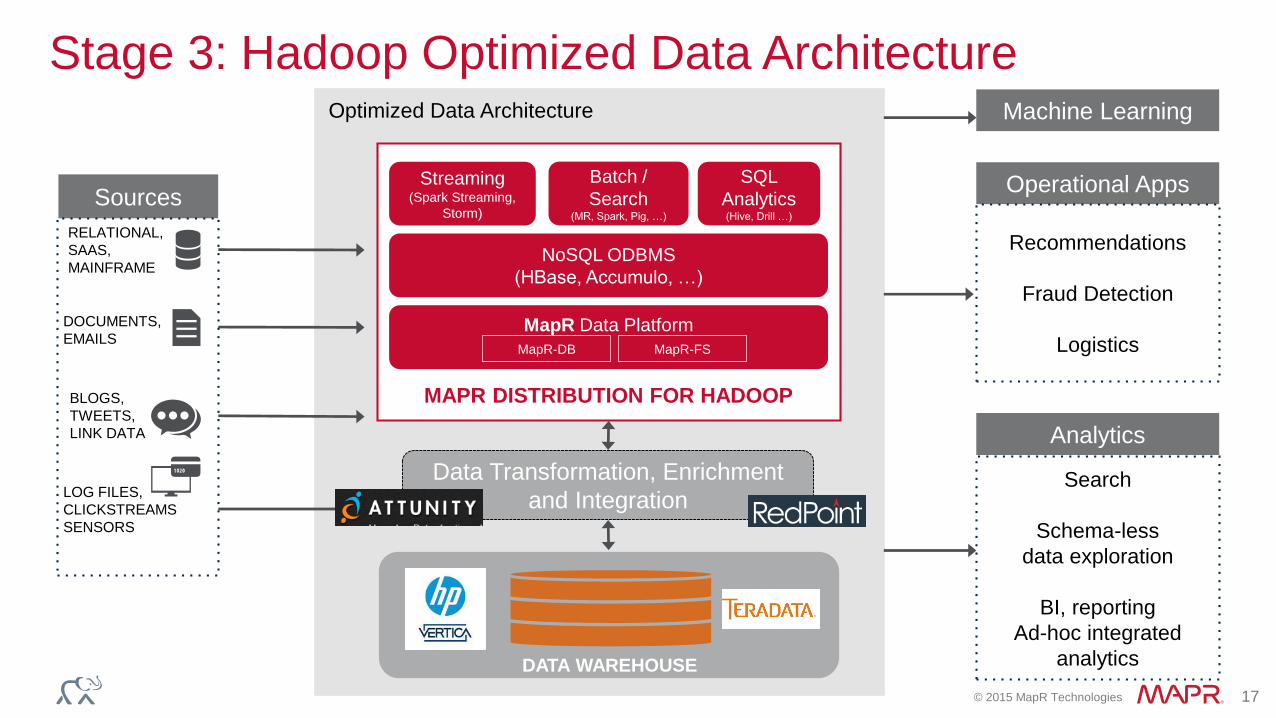
© 2015 MapR Technologies 17
Stage 3: Hadoop Optimized Data Architecture
Sources
RELATIONAL,
SAAS,
MAINFRAME
DOCUMENTS,
EMAILS
LOG FILES,
CLICKSTREAMS
SENSORS
BLOGS,
TWEETS,
LINK DATA
DATA WAREHOUSE
Data Movement
Data Access
Analytics
Search
Schema-less
data exploration
BI, reporting
Ad-hoc integrated
analytics
Data Transformation, Enrichment
and Integration
MAPR DISTRIBUTION FOR HADOOP
Streaming(Spark Streaming,
Storm)
NoSQL ODBMS
(HBase, Accumulo, …)
MapR Data Platform
MapR-DB
MAPR DISTRIBUTION FOR HADOOP
Batch /
Search(MR, Spark, Pig, …)
MapR-FS
Operational Apps
Recommendations
Fraud Detection
Logistics
Optimized Data Architecture Machine Learning
SQL
Analytics(Hive, Drill …)

© 2015 MapR Technologies 18© 2015 MapR Technologies
MapR Customer Examples

© 2015 MapR Technologies 19
MapR Customer Success for Enterprise Data Hub
• EDH most common use case
• Across industries including
- Financial services
- Telecommunications
- Government
- Healthcare
- Technology

© 2015 MapR Technologies 20
Cisco - 360° Customer ViewDeepening customer relationships and increasing sales opportunities
• Improve customer satisfaction and sales opportunities by integrating all
customer data into one dashboard, accessible across company divisions
• Provide a consistent and proactively knowledgeable customer experience• Integrate all customer data across silos into a central data repository• Continually feed real-time customer data into the repository• Provide a real-time view of each customer across company divisions:
marketing, support, finance, point of sale, etc.
OBJECTIVES
CHALLENGES
SOLUTION
Cisco’s 360° customer view solution enabled them to analyze service sales
opportunities in 1/10 the time, at 1/10 the cost, and generated $40 million in
incremental service bookings in the first year.
Business Impact
• Central data repository results in lower cost and reduced complexity
• Accelerates analysis cycle time and rapid actions
• Provides high availability and disaster recovery

© 2015 MapR Technologies 21
F100 Telco - Data Warehouse OptimizationImprove data services to customers while reducing enterprise architecture costs
• Provide cloud, security, managed services, data center, & comms
• Report on customer usage, profiles, billing, and sales metrics
• Improve service: Measure service quality and repair metrics
• Reduce customer churn – identify and address IP network hotspots
• Cost of ETL & DW storage for growing IP and clickstream data; >3 months
• Reliability & cost of Hadoop alternatives limited ETL & storage offload
• MapR Data Platform for data staging, ETL, and storage at 1/10th the cost
• MapR provided smallest datacenter footprint with best DR solution
• Enterprise-grade: NFS file management, consistent snapshots & mirroring
OBJECTIVES
CHALLENGES
SOLUTION
• Increased scale to handle network IP and clickstream data
• Reduced workload on DW to maintain reporting SLA’s to business
• Unlocked new insights into network usage and customer preferences
Business Impact
FORTUNE 100
TELCO

© 2015 MapR Technologies 22© 2015 MapR Technologies
MapR Enterprise Data Hub Solution
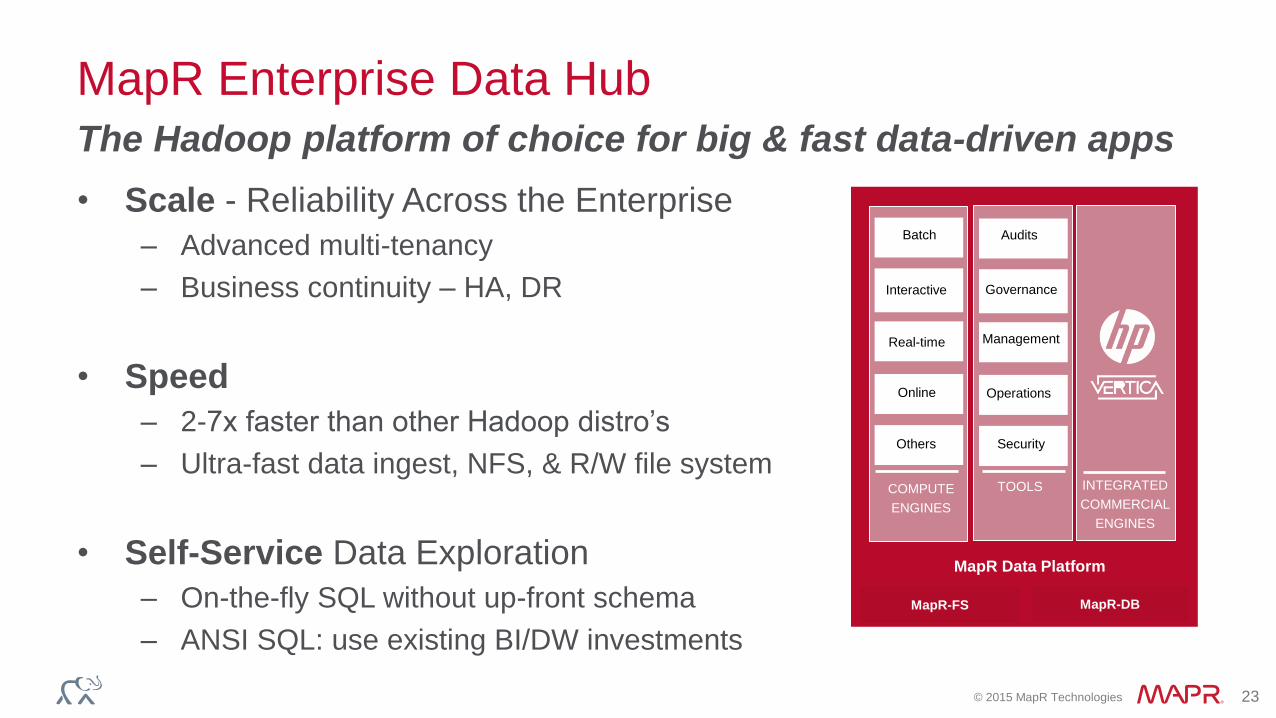
© 2015 MapR Technologies 23
MapR Enterprise Data Hub
• Scale - Reliability Across the Enterprise
– Advanced multi-tenancy
– Business continuity – HA, DR
• Speed
– 2-7x faster than other Hadoop distro’s
– Ultra-fast data ingest, NFS, & R/W file system
• Self-Service Data Exploration
– On-the-fly SQL without up-front schema
– ANSI SQL: use existing BI/DW investments
The Hadoop platform of choice for big & fast data-driven apps
Security
Streaming
NoSQL & Search
Provisioning &
coordination
ML, Graph
W orkflow & Data Governance
Batch
SQL
INTEGRATED
COMMERCIAL
ENGINES
TOOLSCOMPUTE
ENGINES
Batch
Interactive
Real-time
Online
Others
Management
Operations
Governance
Audits
Security
MapR-FS MapR-DB
MapR Data Platform
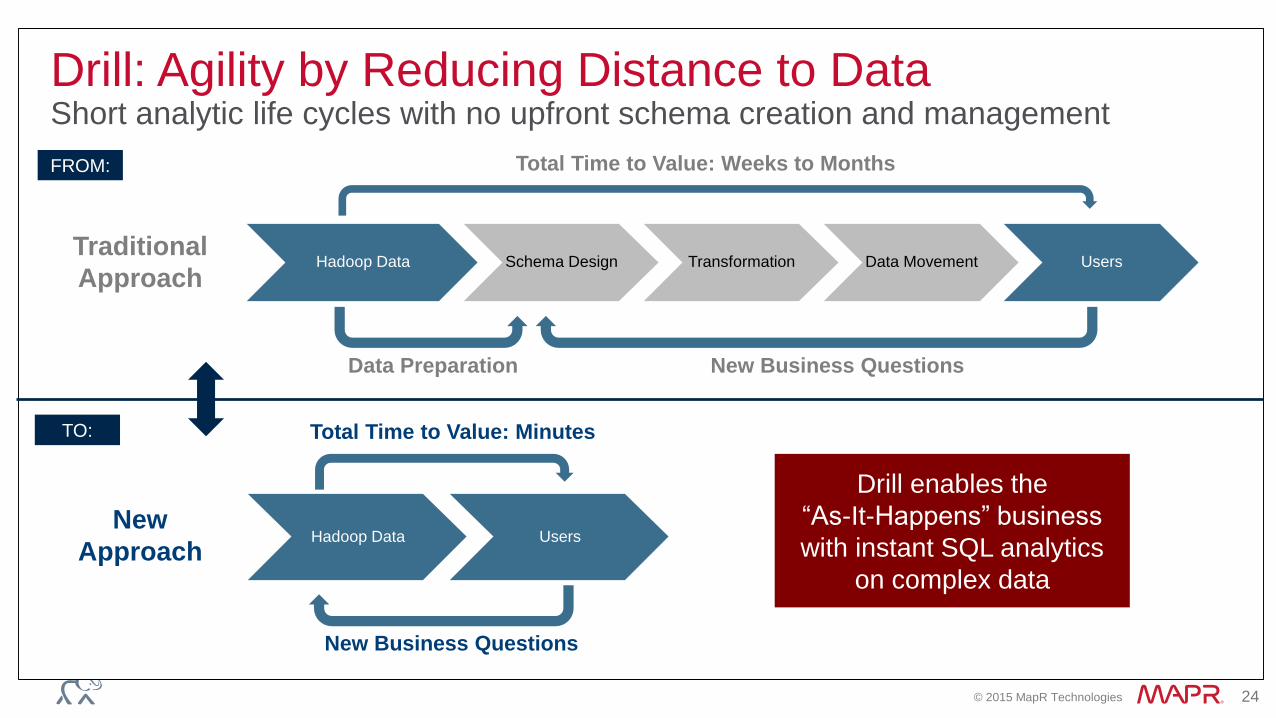
© 2015 MapR Technologies 24
Traditional
Approach
Drill: Agility by Reducing Distance to DataShort analytic life cycles with no upfront schema creation and management
Hadoop Data Schema Design Transformation Data Movement Users
Hadoop Data Users
New Business Questions
Total Time to Value: Weeks to Months
Total Time to Value: Minutes
New
Approach
Data Preparation
New Business Questions
Drill enables the
“As-It-Happens” business
with instant SQL analytics
on complex data
FROM:
TO:

© 2015 MapR Technologies 25
Thank You
@mapr maprtech
MapRTechnologies
maprtech
mapr-technologies
Free on-demand
Hadoop training leading to certification
Start becoming an expert now
mapr.com/training

Data Quality in the Data HubFebruary 2015

27 RedPoint Global Inc. 2015 Confidential
Overview of RedPoint Global
Launched 2006
Founded and staffed by industry veterans
Headquarters: Wellesley, Massachusetts
Offices in US, UK, Australia, Philippines
Global customer base
Serves most major industries MAGIC QUADRANTData Quality
MAGIC QUADRANTMultichannel Campaign
Management
MAGIC QUADRANTIntegrated Marketing
Management

28 RedPoint Global Inc. 2015 Confidential
Extensive experience with a diverse customer base

29 RedPoint Global Inc. 2015 Confidential
Cloudera Stack
30 RedPoint Global Inc. 2015 Confidential
Andrew Brust, GigaOm Research
31 RedPoint Global Inc. 2015 Confidential
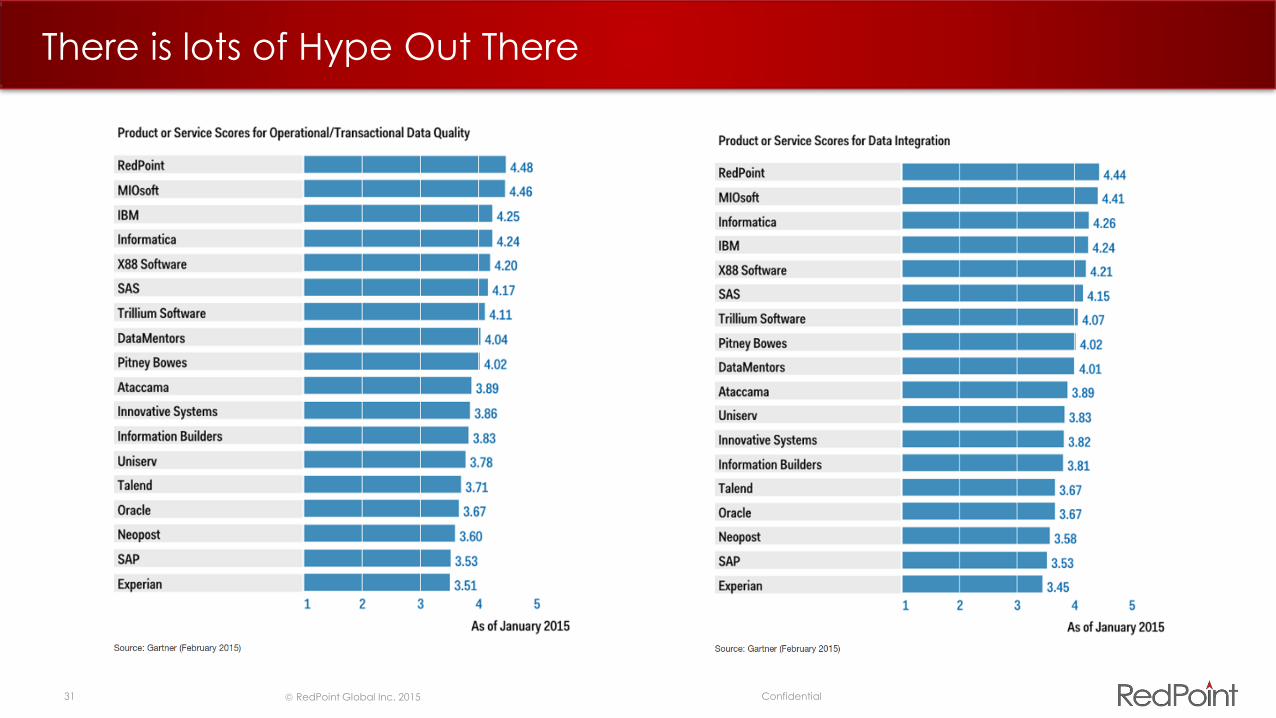
There is lots of Hype Out There
32 RedPoint Global Inc. 2015 Confidential
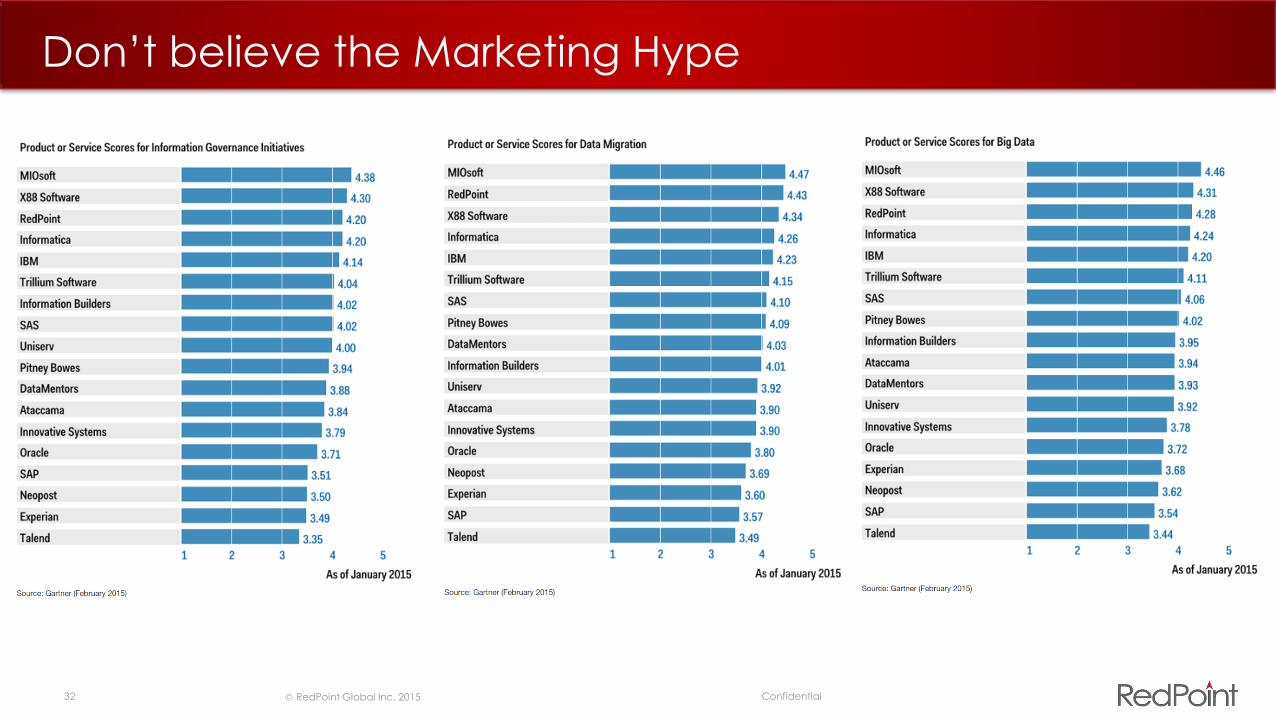
Don’t believe the Marketing Hype
33 RedPoint Global Inc. 2015 Confidential
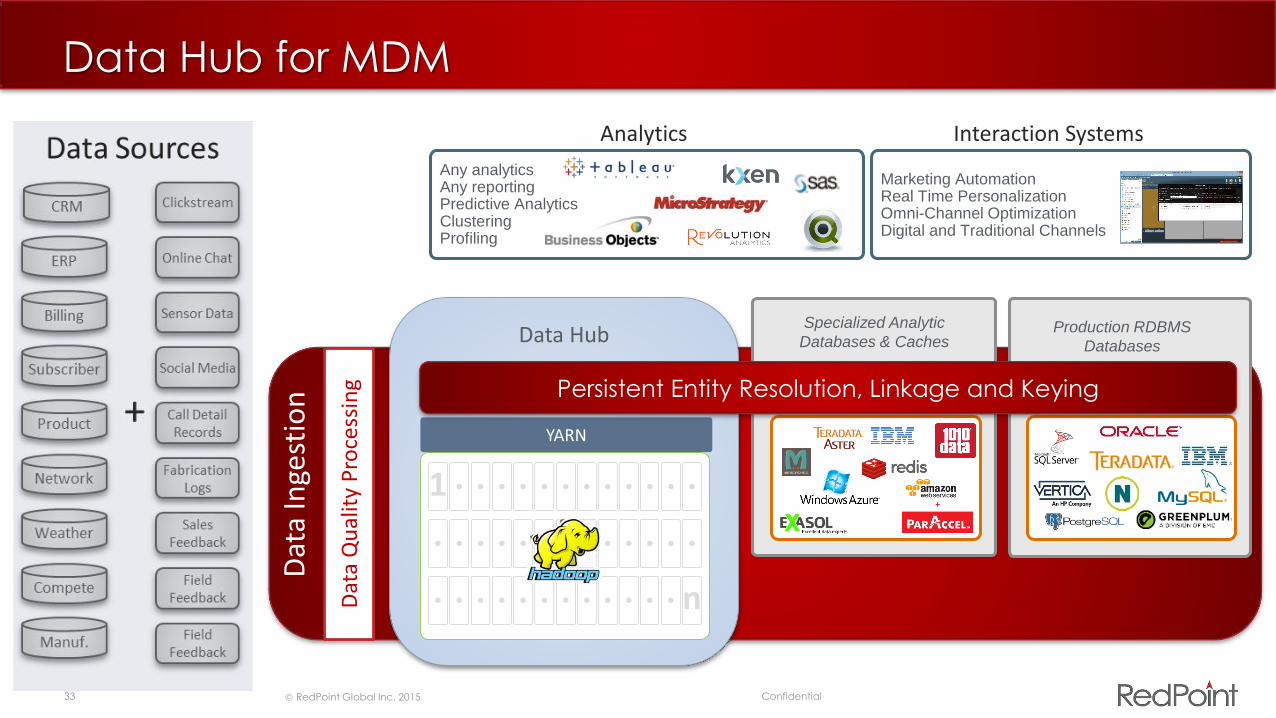
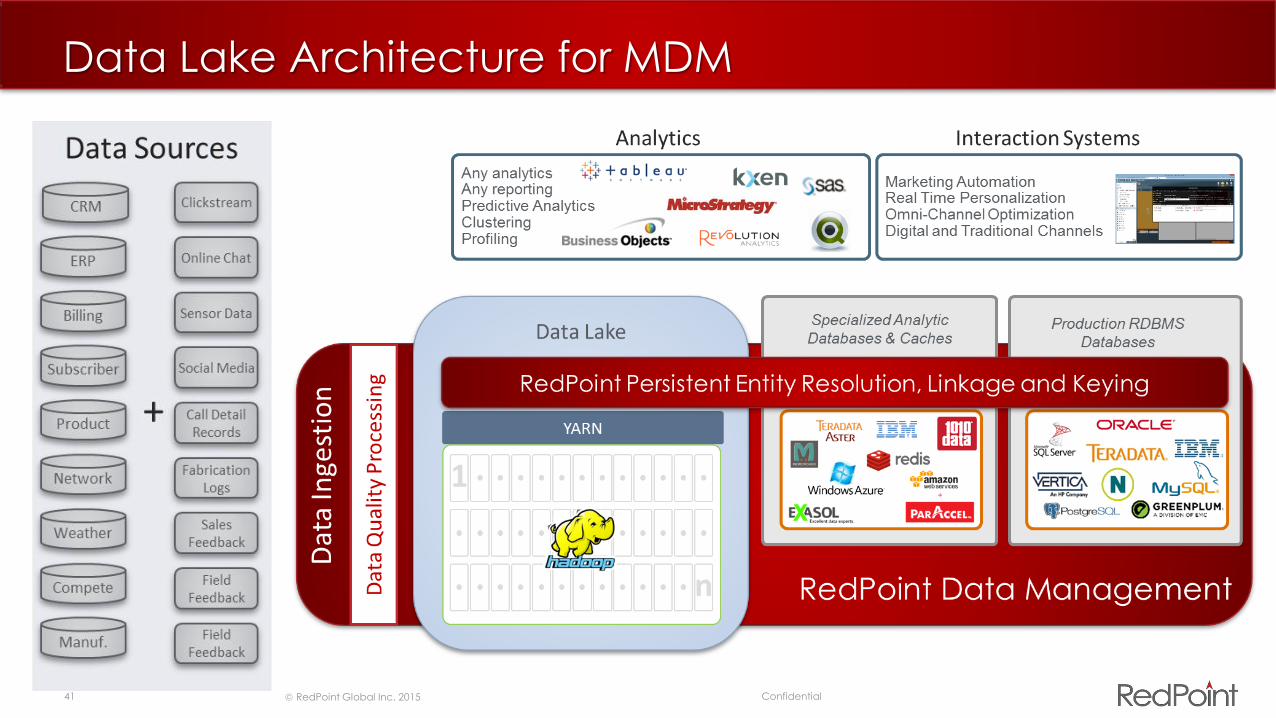
Data Hub for MDM
Data Hub
1
n
YARN
Production RDBMS
Databases
Dat
a In
gest
ion
Specialized Analytic
Databases & Caches
Any analyticsAny reportingPredictive AnalyticsClusteringProfiling
Analytics
Marketing AutomationReal Time PersonalizationOmni-Channel OptimizationDigital and Traditional Channels
Interaction Systems
Dat
a Q
ual
ity
Pro
cess
ing Persistent Entity Resolution, Linkage and Keying

34 RedPoint Global Inc. 2015 Confidential
How About MDM on a Data Lake?
• Severe shortage of Map Reduce skilled resources
• Inconsistent skills lead to inconsistent results of code based solutions
• Nascent technologies require multiple point solutions
• Technologies are not enterprise grade
• Some functionality may not be possible within these frameworks
Challenges to Data Lake Approach
• Data is ingested in its raw state regardless of format, structure or lack of structure
• Raw data can be used and reused for differing purposes across the enterprise
• Beyond inexpensive storage, Hadoop is an extremely power and scalable and segmentable computational platform
• Master Data can be fed across the enterprise and deep analytics on clean data is immediately enabled
Benefits of a Hadoop Data Lake
35 RedPoint Global Inc. 2015 Confidential
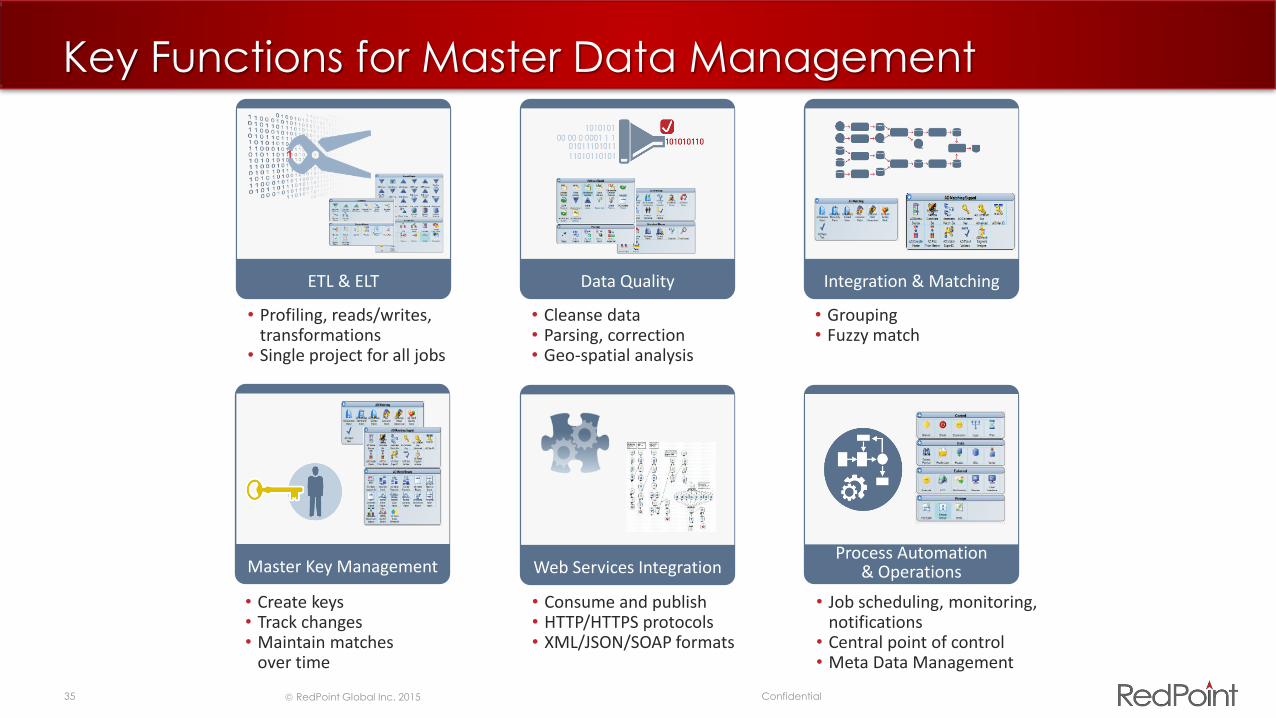
Key Functions for Master Data Management
Master Key Management
ETL & ELT Data Quality
Web Services Integration
Integration & Matching
Process Automation & Operations
• Profiling, reads/writes, transformations
• Single project for all jobs
• Cleanse data• Parsing, correction• Geo-spatial analysis
• Grouping• Fuzzy match
• Create keys• Track changes• Maintain matches
over time
• Consume and publish• HTTP/HTTPS protocols• XML/JSON/SOAP formats
• Job scheduling, monitoring, notifications
• Central point of control• Meta Data Management

36 RedPoint Global Inc. 2015 Confidential
Overview - What is Hadoop/Hadoop 2.0
Hadoop 1.0
• All operations based on Map Reduce
• Intrinsic inconsistency of code based solutions
• Highly skilled and expensive resources needed
• 3rd party applications constrained by the need to generate code
Hadoop 2.0
• Introduction of the YARN: “a general-purpose, distributed, application management framework that supersedes the classic Apache Hadoop MapReduce framework for processing data in Hadoop clusters.”
• Mature applications can now operate directly on Hadoop
• Reduce skill requirements and increased consistency
37 RedPoint Global Inc. 2015 Confidential
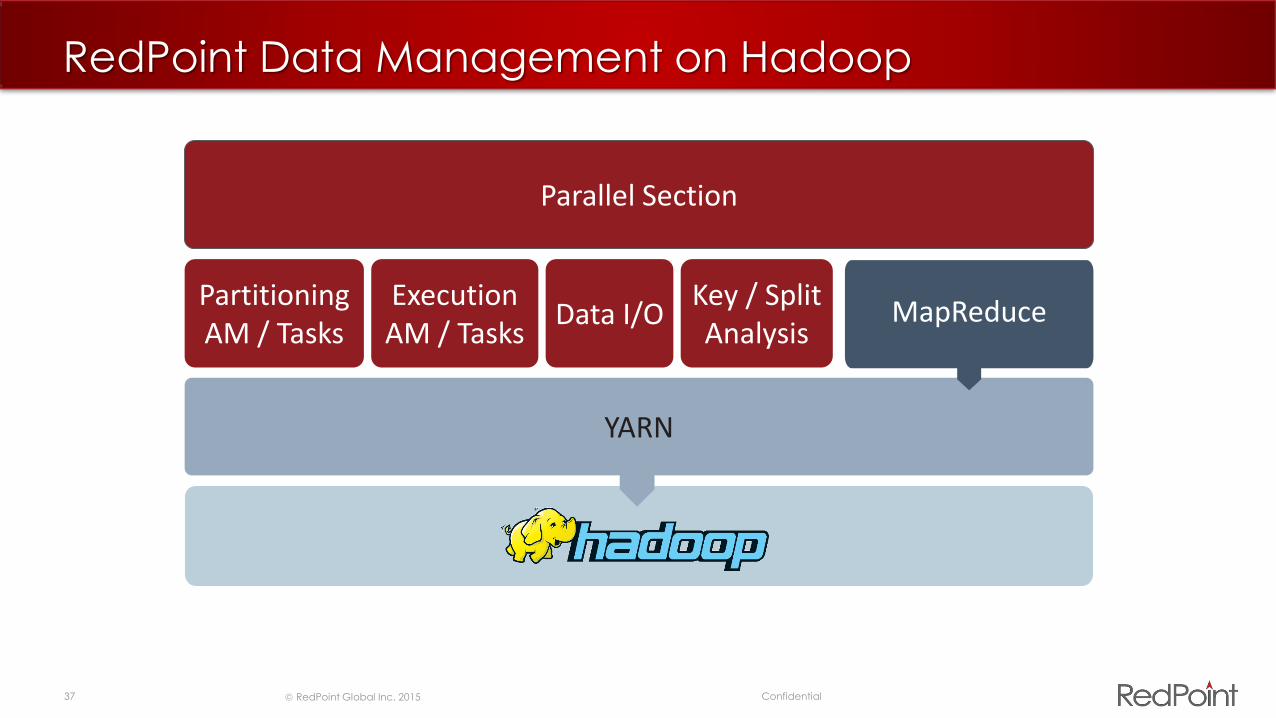
RedPoint Data Management on Hadoop
Partitioning AM / Tasks
Execution AM / Tasks
Data I/OKey / Split Analysis
Parallel Section
YARN
MapReduce
38 RedPoint Global Inc. 2015 Confidential
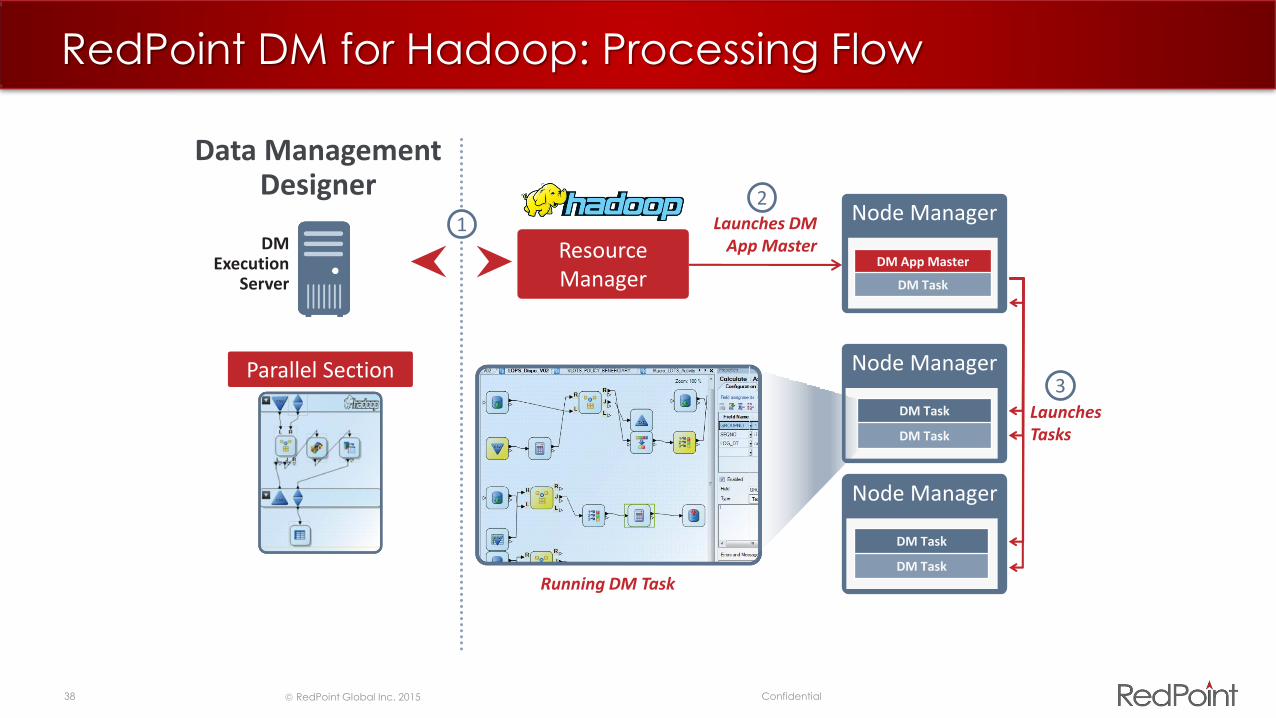
Resource Manager
LaunchesTasks
Node Manager
DM App Master
DM Task
Node Manager
DM Task
DM Task
Node Manager
DM Task
DM Task
Launches DM App Master
Data ManagementDesigner
DM Execution
Server
Parallel Section
Running DM Task
12
3
RedPoint DM for Hadoop: Processing Flow

39 RedPoint Global Inc. 2015 Confidential
Reference Hadoop Architecture
Monitoring and Management Tools
Management
MAPREDUCE
REST
DATA REFINEMENT
HIVEPIG
HTTP
STREAM
STRUCTURE
HCATALOG (metadata services)
Query/Visualization/
Reporting/Analytical
Tools and Apps
SOURCE
DATA
- Sensor Logs
- Clickstream
- Flat Files
- Unstructured
- Sentiment
- Customer
- Inventory
DBs
JMS
Queue’s
Fil
esFil
esFiles
Data Sources
RDBMS
EDW
INTERACTIVE
HIVE Server2
LOAD
SQOOP
WebHDFS
Flume
NFS
LOAD
SQOOP/Hive
Web HDFS
YARN
n
1
HDFS
RedPoint Functional Footprint

40 RedPoint Global Inc. 2015 Confidential
>150 Lines of MR Code ~50 Lines of Script Code 0 Lines of Code
6 hours of development 3 hours of development 15 min. of development
6 minutes runtime 15 minutes runtime 3 minutes runtime
Extensive optimization needed
User Defined Functions required prior to running script
No tuning or optimization required
RedPoint
Benchmarks – Project Gutenberg
Map Reduce Pig
Sample MapReduce (small subset of the entire code which totals nearly 150 lines): public static class MapClass extends Mapper<WordOffset, Text, Text, IntWritable> { private final static String delimiters = "',./<>?;:\"[]{}-=_+()&*%^#$!@`~ \\|«»¡¢£¤¥¦©¬®¯±¶·¿"; private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(WordOffset key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer itr = new StringTokenizer(line, delimiters); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } }
Sample Pig script without the UDF: SET pig.maxCombinedSplitSize 67108864 SET pig.splitCombination true A = LOAD '/testdata/pg/*/*/*'; B = FOREACH A GENERATE FLATTEN(TOKENIZE((chararray)$0)) AS word; C = FOREACH B GENERATE UPPER(word) AS word; D = GROUP C BY word; E = FOREACH D GENERATE COUNT(C) AS occurrences, group; F = ORDER E BY occurrences DESC; STORE F INTO '/user/cleonardi/pg/pig-count';
41 RedPoint Global Inc. 2015 Confidential
Data Lake Architecture for MDM

42 RedPoint Global Inc. 2015 Confidential
Recommendations for Data Quality
• There is a gap between current use and the mainstream
• Don’t believe the hype; there’s plenty of it
• Data Quality creates trust in information which enables confident and nimble decision making.
• Look for broad enterprise apps that have solved the parallel scalability problem
• Consider a Data Hub approach for Data Quality for maximum flexibility and scalable performance

43 RedPoint Global Inc. 2015 Confidential
George Corugedo
Chief Technology Officer
781.725.0252
Download our white paper
From Yawn to Yarn: Why You Should be
Excited about Hadoop
Redpoint.net/dbtawebinar

Question and Answer Session
(please submit questions)

Nitin Bandugula
Product Marketing Manager
MapR Technologies
Kevin Petrie
Senior Director
Attunity
George Corugedo
Chief Technology Officer & Co-Founder
RedPoint Global Inc.

Please use the same URL you used to view today’s live event
for the archive event, plus we will be sending you a follow-up
email with that URL once the archive is posted!

Thank you for participating in
today’s roundtable web event
Just by attending this event the winner of the
$100 AmEx Gift Card is…….