hadoop and hdfs overview -...
TRANSCRIPT

Hadoop and HDFS OverviewMadhu Ankam

Why Hadoop
• We are gathering more data than ever
• Examples of data :• Server logs
• Web logs
• Financial transactions
• Analytics
• Emails and text messages
• Social media like Facebook, twitter etc.
• Data is value and we must process that to extract the value.
4/27/2016 Madhu Ankam 2

Data Accessibility
• How can we process all that information
• There are actually two problems• Large-scale data storage
• Large-scale data analysis
• Although we can process data more quickly (because of faster processors), accessing is slow (this is true for both reads and writes).
• For example, reading a single disk for terabytes of data take hours, so we cannot process the data until we have read it and we are limited by the speed of the single disk.
4/27/2016 Madhu Ankam 3

Data Accessibility
• Traditional computation is processor-bound, bigger and powerful machines. But they are highly costly and limited scalability.
• So the solution is distributed computing across machines using powerful compute nodes, data storage and fast network to connect.
4/27/2016 Madhu Ankam 4

4/27/2016 Madhu Ankam 5

HDFS: The Hadoop Distributed File System
• Based on Google’s GFS (Google File System)
• Provides redundant storage for massive amounts of data (Using Industry-standard hardware)
• At load time, data is distributed across all nodes, provides for efficient processing.
4/27/2016 Madhu Ankam 6

HDFS Features
• It is suitable for the distributed storage and processing.
• Hadoop provides a command interface to interact with HDFS.
• The built-in servers of namenode and datanode help users to easily check the status of cluster.
• Streaming access to file system data.
• HDFS provides file permissions and authentication.
4/27/2016 Madhu Ankam 7

HDFS Design Assumptions
• High component failure rates – inexpensive components fail all the time
• Files are write-once
• Large streaming reads, not random access
4/27/2016 Madhu Ankam 8

HDFS Blocks
• Generally the user data is stored in the files of HDFS.
• The file in a file system will be divided into one or more segments and/or stored in individual data nodes. These file segments are called as blocks.
• In other words, the minimum amount of data that HDFS can read or write is called a Block.
• The default block size is 64MB, but it can be increased as per the need to change in HDFS configuration.
4/27/2016 Madhu Ankam 9

HDFS Blocks
4/27/2016 Madhu Ankam 10

HDFS Replications
• These blocks are replicated to nodes throughout the cluster, based on the replication factor (default is three).
• Replication increases reliability and performance.
• Reliability: data can tolerate loss of all but one replica
• Performance : more opportunities for data locality.
4/27/2016 Madhu Ankam 11
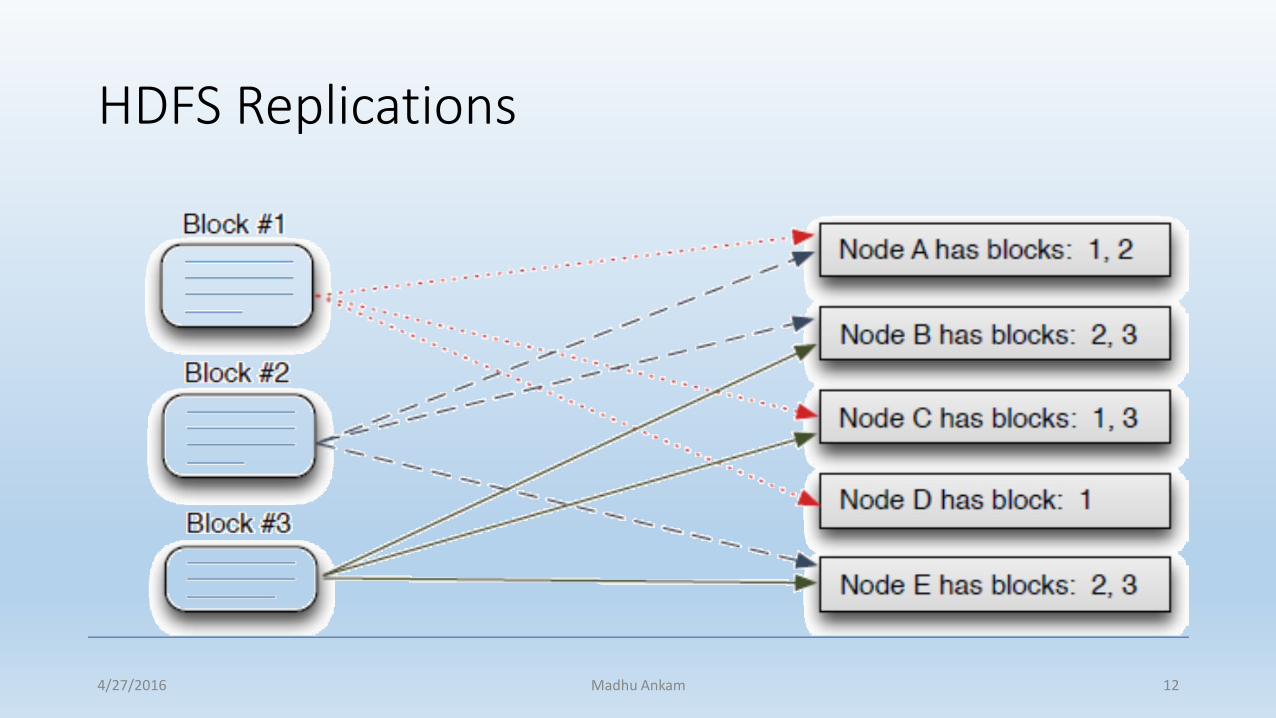
HDFS Replications
4/27/2016 Madhu Ankam 12
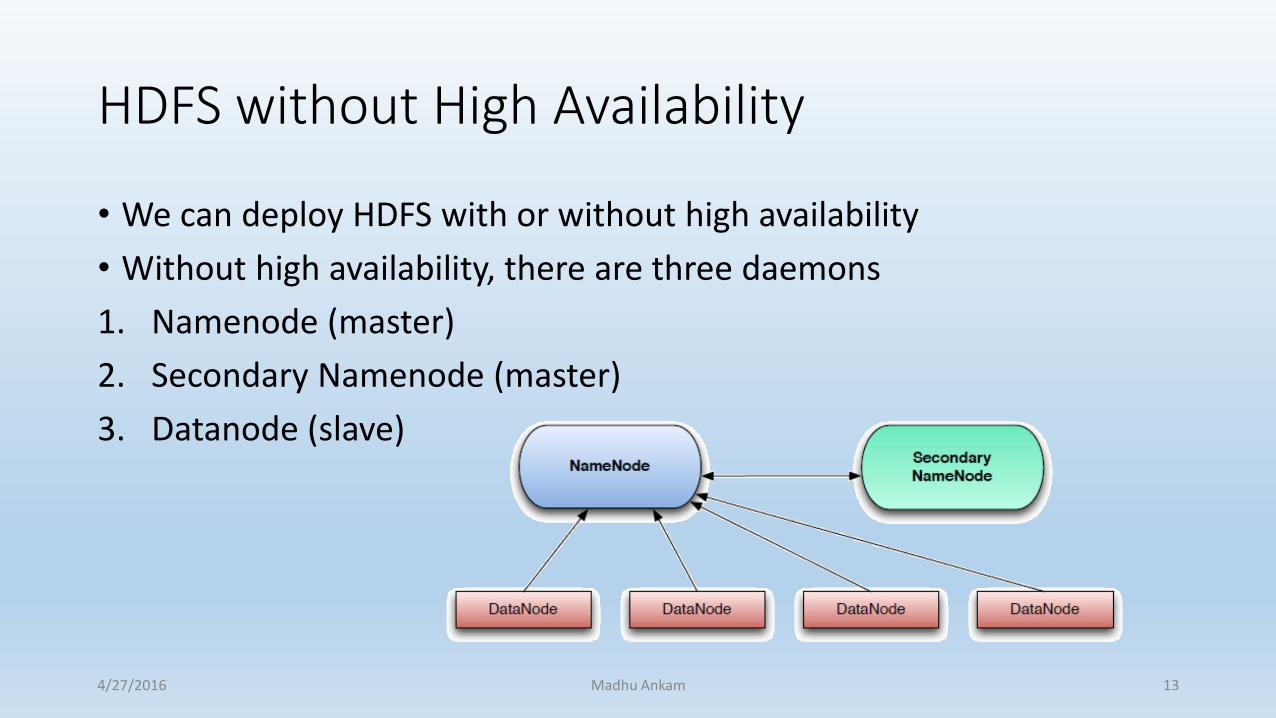
HDFS without High Availability
• We can deploy HDFS with or without high availability
• Without high availability, there are three daemons
1. Namenode (master)
2. Secondary Namenode (master)
3. Datanode (slave)
4/27/2016 Madhu Ankam 13

Namenode
• The namenode is the commodity hardware that contains the GNU/Linux operating system and the namenode software. It is a software that can be run on commodity hardware. The system having the namenode acts as the master server and it does the following tasks:
• Manages the file system namespace.
• Regulates client’s access to files.
• It also executes file system operations such as renaming, closing, and opening files and directories.
4/27/2016 Madhu Ankam 14

Datanode
• The datanode is a commodity hardware having the GNU/Linux operating system and datanode software. For every node (Commodity hardware/System) in a cluster, there will be a datanode. These nodes manage the data storage of their system.
• Datanodes perform read-write operations on the file systems, as per client request.
• They also perform operations such as block creation, deletion, and replication according to the instructions of the namenode.
4/27/2016 Madhu Ankam 15

Secondary Namenode
• The secondary namenode is not a failover namenode.
• It performs memory-intensive administrative functions for the namenode.
• Namenode keeps information about files and blocks (the metadata) in memory.
• Namenode writes metadata changes to an edit log
• Secondary namenode periodically combines a prior snapshot of the file sytem metadata and edit log into a new snapshot.
• New snapshot is transmitted back to the namenode.
4/27/2016 Madhu Ankam 16

HDFS with High Availability
• We can deploy HDFS with high availability to eliminate the namenodeSingle Point of Failure.
• Two Namenodes: one active and one standby.
• Standby namenode takes over when active namenode fails.
• Standby namenode also does checkpointing (secondary namenode no longer needed).
4/27/2016 Madhu Ankam 17

HDFS with High Availability
4/27/2016 Madhu Ankam 18
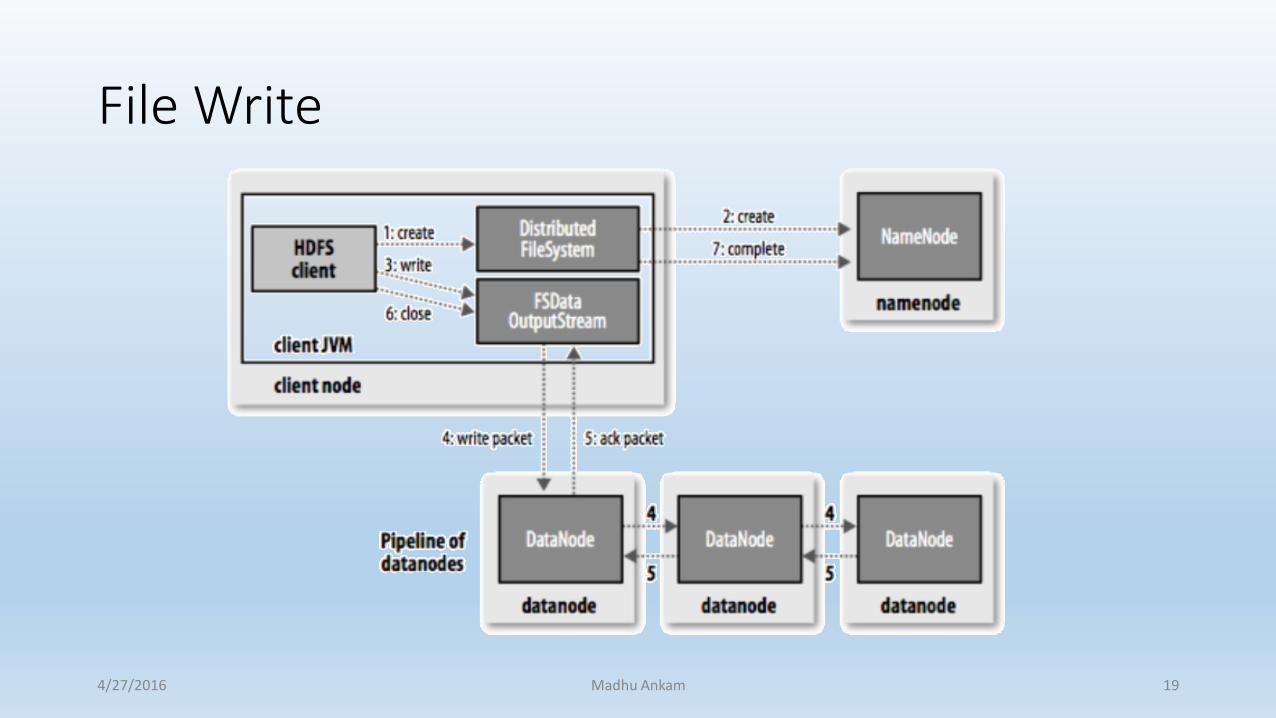
File Write
4/27/2016 Madhu Ankam 19

File Write Process
• Client connects to the namenode, name node places n entry for the file in its metadata, returns name and list of datanodes to the client.
• Client connects to the first datanode and starts sending data.
• As data is received by the first datanode, it connects to the second and starts sending data, second one connects to the third.
• Acknowledgement packets from the pipeline are sent back to the client.
• Client reports to the namenode when the block is written.
4/27/2016 Madhu Ankam 20

File Write Process
• If a Datanode in the pipeline fails, the pipeline is closed. A new pipeline is opened with the two good nodes.
• The data continues to be written to the two good nodes in the pipeline.
• The namenode will realize that the block is under-replicated, and will re-replicate it to another Datanode.
• As blocks of data are written, the client calculates a checksum for each block.
4/27/2016 Madhu Ankam 21

Rack Awareness
• Hadoop understands the concept of rack awareness
• The idea of where nodes are located, relative to one another
• Helps the resource manager allocate processing resources on nodes closest to the data
• Helps the namenode determine the closest block to a client during reads.
• HDFS replicates data blocks on nodes on different racks, provides extra data security in case of catastrophic hardware failure.
4/27/2016 Madhu Ankam 22

HDFS block replication strategy
• First copy of the block is placed on the same node as the client, if the client is not part of the cluster, the first block is placed on a random node.
• Second copy of the block is placed on a node residing on a different rack.
• Third copy of the block is placed on different node in the same rack as the second copy.
4/27/2016 Madhu Ankam 23
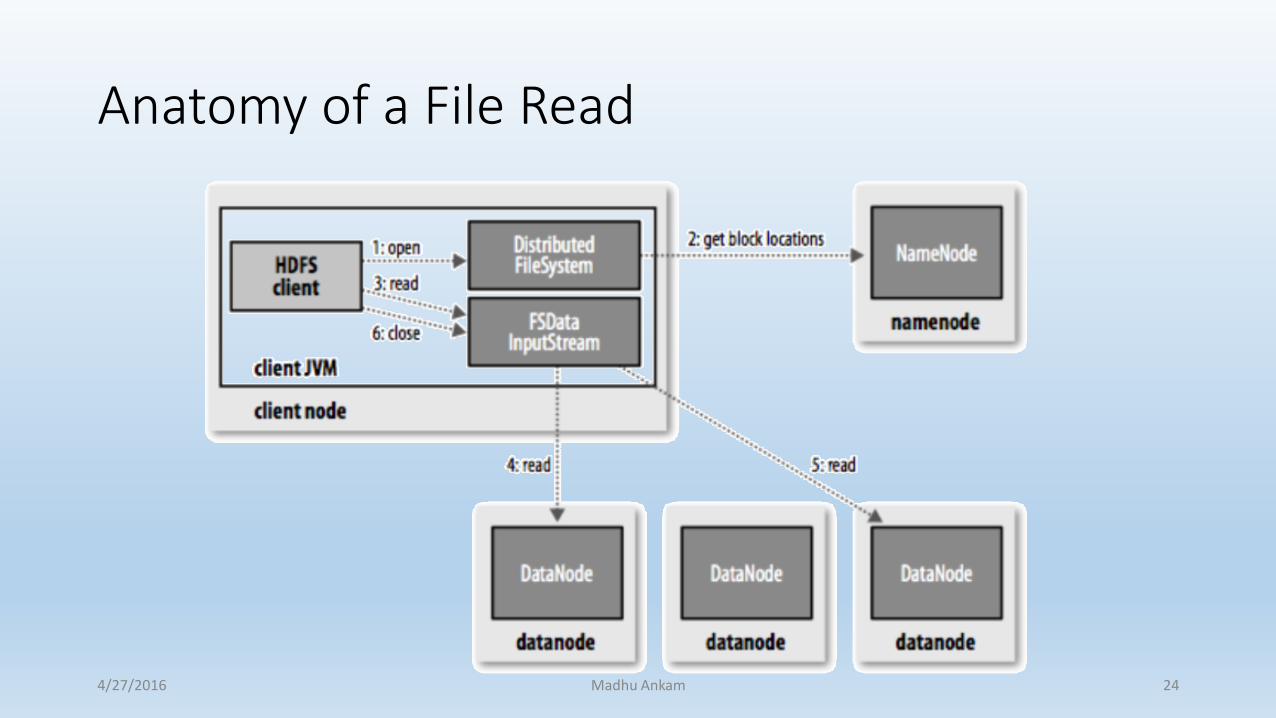
Anatomy of a File Read
4/27/2016 Madhu Ankam 24

Data
• Client connects to the namenode.
• Namenode returns the name and locations of the first few blocks of the file, block locations are returned closest-first.
• Client connects to the first of the datanodes, and reads the block.
• If the datanode fails during the read, the client will seamlessly connects to the next one in the list to read the block.
4/27/2016 Madhu Ankam 25

Dealing with Data corruption
• When a client reading the block, it also verifies the checksum, if they differ, the client reads from the next datanode in the list.
• The datanode also verifies the checksums for blocks on a regular basis to avoid corruption of data. Default is every three weeks after the block was created.
4/27/2016 Madhu Ankam 26

Dealing with data
• The data never travels via a Namenode, for writes, or reads or during the re-replication.
• Datanodes send heartbeats to the namenode every three seconds
• After a period without any heartbeats, a datanode is assumed to be lost. Then namenode finds another datanodes to replicate the data.
• A datanode can rejoin a cluster after being down for a period of time.
4/27/2016 Madhu Ankam 27

HDFS File Permissions
• Files in HDFS have an owner, a group and others permissions very similar to Unix/Linux file permissions.
• File permissions are read (r), write (w) and execute (x) for each owner, group and others.
• X is ignored for files by default, for directories, x means that its children can be accessed.
4/27/2016 Madhu Ankam 28