grin – a graph based rdf index octavian udrea andrea pugliese v. s. subrahmanian presented by...
TRANSCRIPT

GRIN – A Graph Based RDF Index
Octavian Udrea Andrea Pugliese
V. S. Subrahmanian
Presented by Tulika Thakur

- Indexing mechanism for Graph based Queries.-GRIN : a tree data structure .-Large RDF datasets used :TAP, ChefMoz-Comparison with DB systems: Jena, Sesame, RDFBroker- Measure parameters -1) Size of Index2) Time taken to answer graph queries3) Time taken to build the index

RDF graph queriesThe GRIN Index structure
Query AnsweringExperimental evaluation

RDF Graph Example(extracted from ChefMox dataset)

RDF Graph Representation :
An RDF triple has the form
(s, p, v) where s U∈ , p U∈ p, v R∈ .
U denote a set whose elements are called URI
References.
L denote a set whose elements are called literals.
Up U ⊆ denotes the set of properties.
R = U L denotes the set of resources∪

Introduction to P-pathGiven an RDF graph D and a set P U⊆ p, a P-path in D is a set {e1, . . . , eq}, with ej = (sj, pj, vj), such that
• ∀j ∈ [1, q] ej ∈ D;
• ∀j ∈ [1, q − 1] vj = sj+1;
• ∀j ∈ [1, q] pj ∈ P.
Intuitively, a P-path is a path in the RDF graph whose edge
labels are all drawn from the set P.
For Example Let P = {location, locatedIn}. The triples
(ColdStone, location, Lincoln) and (Lincoln, locatedIn,NE/USA)
constitute a P-path of length two in the graph .

Introduction to P-path
P = {location,locatedIn}
d(ColdStone ,NE/USA) = 2
Triples = (ColdStone, location, Lincoln) and (Lincoln, locatedIn,NE/USA)

RDF Graph Query
An RDF graphical query
is a 4-tuple (N, V, E, λn) where:
• N is a set of vertices;
• V is a set of variables;
• E = Es ∪ Ed is a set of edges, where Es ⊆ N × N ×
(V U∪ p) and Ed ⊆ N × N × 2^Up × IN. We call Es the
set of single edges and Ed the set of double edges.
• λn : N →R∪V is a vertex labeling function.

RDF Graph Query
The query can be expressed in SPARQL as:
SELECT ?v1 ?v2 ?v3WHERE {{(?v1 attire ?v3) . (?v1 cuisine Italian)}{(?v2 attire ?v3) . (?v2 cuisine Italian) .(?v2 location Norfolk)}{(Norfolk locatedIn NE/USA)}}
P-path

RDF graph queriesThe GRIN Index structure
Query AnsweringExperimental evaluation

GRIN Index
-Resources “closer” in the RDF graph are more likely to be part of the same answerHence they should appear on the same page.
-GRIN will group resources in circles around selected center resources-Query evaluation:Find the smallest circle that contains the answer
-Evaluate query only on resources in that circle

Building a GRIN IndexA GRIN index is a balanced binary tree such that:
• Each leaf node contains a set Nl R⊆ of nodes s.t. for
all leaf nodes l != l' , Nl ∩ Nl' = ∅;
• Each non-leaf node t contains a pair (c, r), with c R∈
and r ∈ IN. This is a very succinct representation
of the set of resources in the graph at distance at
most r of the resource c . We write this set as
Nt = {c' R|∈ d(c, c') ≤ r}.
• For any nodes x, y in the tree such that x is a parent of y,
Nx ⊇ Ny.

Building a GRIN Index
M = maximum number of RDF graph vertices per page.
C = number of leaf nodes .
|R|/C <= M
dc = inter cluster distance function
(i) Single link defines dc(S, S') =
Min (dc(x, y)) where x∈S,y∈S'
(ii) Complete link defines dc(S, S') =
Max (dc(x, y)) where x∈S,y∈S'
(iii) Average link defines dc(S, S') =
(Σ(dc(x,y)))/ ( |S|×|S'| ) Where x∈S,y∈S'

Building a GRIN Index
Cluster the vertices in C disjoint Sets using PAM Clustering algorithm.
Repeat untill equilibrium is reached?
For each intermediate leve , GRINBuld chooses a random node u, Computes its closest node v, and assignes a parent node (c,r) where c is selected from Nu U Nv

Building a GRIN Index

Building the index: the tree
16

Building the index: the tree
17

Building the index: the tree
18

RDF graph queriesThe GRIN Index structure
Query AnsweringExperimental evaluation

Query Answering
Derive Contraints from the query .
Evaluate constraints against the nodes of GRIN Index
d(?v1,NE/USA) ≤ 2, d(?v2, NE/USA) ≤ 2, d(?v2, Norfolk) ≤ 1),d(?v1, Norfolk) ≤ 3, d(?v1, Italian) ≤ 1, d(?v2, Italian) ≤1, d(?v3, NE/USA) ≤ 3, d(?v3, Norfolk) ≤ 2, d(?v3,Italian) ≤ 2.
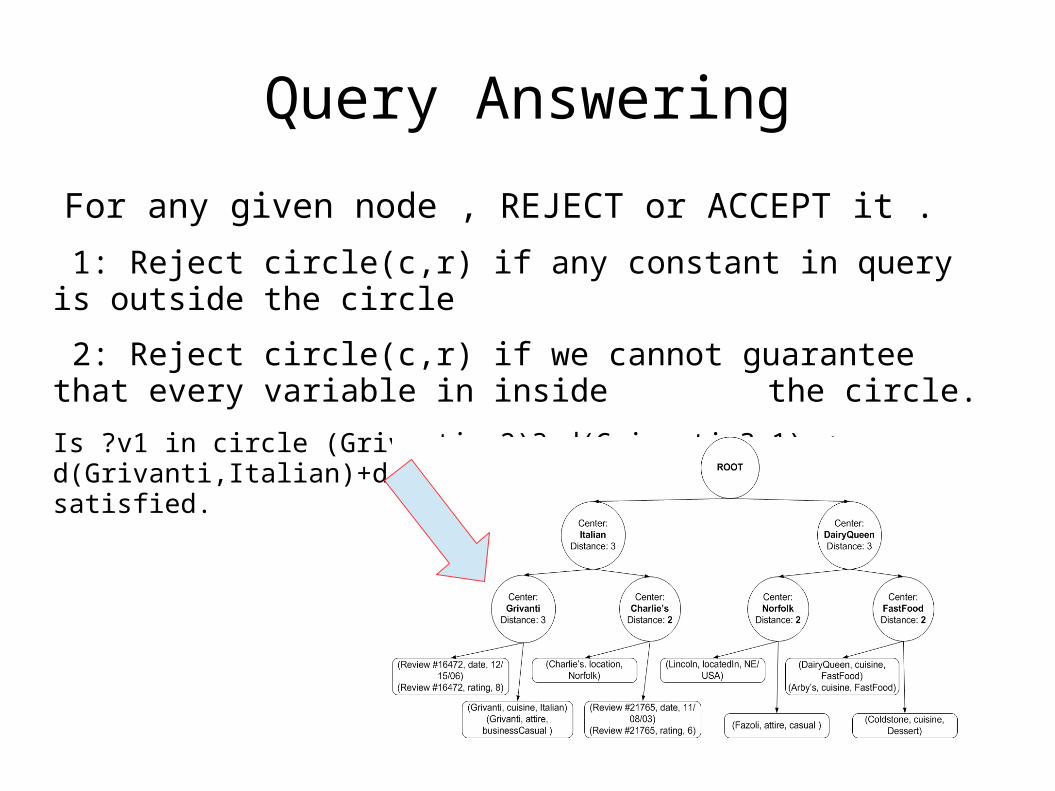
Query Answering
For any given node , REJECT or ACCEPT it .
1: Reject circle(c,r) if any constant in query is outside the circle
2: Reject circle(c,r) if we cannot guarantee that every variable in inside the circle.
Is ?v1 in circle (Grivanti, 2)? d(Grivanti,?v1) ≤ d(Grivanti,Italian)+d(?v1,Italian) ≤ 2 So ?v1 can be satisfied.

RDF graph queriesThe GRIN Index structure
Query AnsweringExperimental evaluation

RDF System : GRIN
Does not store the data in the index , but points to it .
The data is stored in a hash table. Only one computationaly iintensive operation –
Clustering the leaf nodes . For 300MB data , indexi stored in 75MB and
320 MB is used for the hash table .

RDF System : Jena
Stores RDF as (subject, property, value) in a relational table.
Indexes on each of the three attributes. Translates SPARQL/RDQL into SQL. Too many self joins. Used 403MB for indexing on 300MB data.

RDF System : Sesame
Supports RDF Schema inference Separates RDFS from the triple table Supports database schema generation based
on the underlying RDF schema of a dataset The problem of too many joins still remain.
Used 825MB for indexing on 300MB data.

RDF System : RDF Broker
The database schema is built based on signatures – the set of properties used on a resource.
Reduces the number of joins between tables. Used 950MB for indexing on 300MB data.



Discussiom
Vertices in GRIN = resources in underlying RDF. Resources can be atmost |R|. Therefore , number of leaf nodes = O|R| GRIN s a binary tree , so height of tree = O(log2|R|) Worst Case complexity for index building =
O(|R|^4*log2(|R|) ) Good for small sized data only .

Discussion
Time complexity for Query Answering :
Best Case - O(N)
Worst Case - O(N!)
Where N is the total number of vertices in the graphs to be matched,
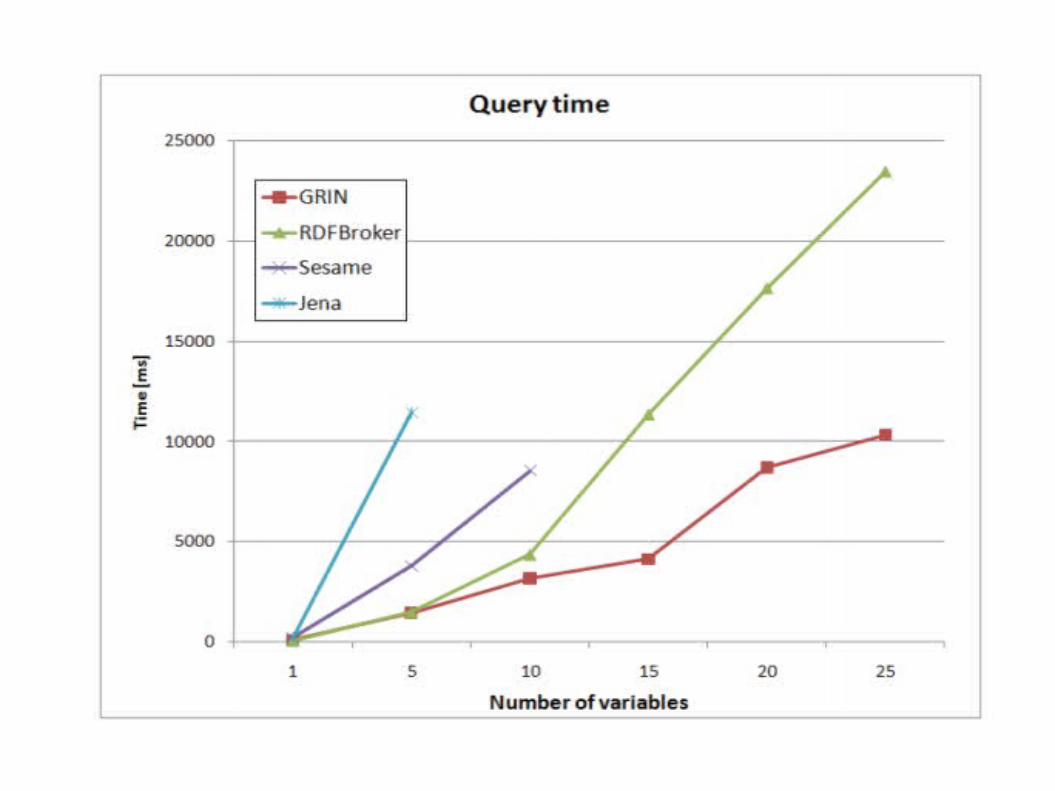
“Our experimental results
show that GRINAnswer is often faster than Jena, Sesame and
RDFBroker for certain types of graph-based queries.”

Discussion
The query can be expressed in SPARQL as:
SELECT ?v1 ?v2 ?v3WHERE {{(?v1 attire ?v3) . (?v1 cuisine Italian)}{(?v2 attire ?v3) . (?v2 cuisine Italian) .(?v2 location Norfolk)}{(Norfolk locatedIn NE/USA)}}
No Way to represent P-path in SPARQL !!
P-path

ThankYou!