gpgpus, cuda and opencl - aalto university wiki · includes compiler, pro ler, debugger, manual...
TRANSCRIPT

GPGPUs, CUDA and OpenCL
Timo Lilja
January 21, 2010
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 1 / 42

Course arrangements
Course code: T-106.5800 Seminar on Software Techniques
Credits: 3
Thursdays 15�16 at A232, lecture period III only
Mandatory attendance but you can skip 1 session
PresentationOne hour presentationTwo presentations per session
Programming projectSmall programming project from a given topic or your own topic if youhaven't received credits from it from some other courseThe goal is to parallelize the given programYou can choose whether you want to use Cuda or OpenCLWe provide a development environment for this programming project.More information will be announced later, check the wiki page
Check the course wiki pagehttp://wiki.tkk.fi/display/GPGPUK2010/Home
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 2 / 42

Introduction
Contents
1 Introduction
2 NVidiaHardwareCuda
3 OpenCL
4 Conclusion
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 3 / 42

Introduction
Why GPGPU?
GPGPU can in many cases o�er a hundredfold increase inperformance, tenfold decrease in price and threefold increase in powere�ciency over traditional CPU in many scienti�c computing e�orts.
Business opportunities in various �elds: medical technology,data mining, . . .
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 4 / 42

Introduction
What is a GPGPU?
Original application in computer graphics and games
General-Purpose Computing on Graphics Processing Units
Origins in programmable vertex and fragment shaders
First GPGPU programs where done by using normal graphics APIs inlate 90s
In early 2000s �rst programmable shaders fully programmable GPUcores
Ca. 2005 �rst fully-programmable shaders
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 5 / 42
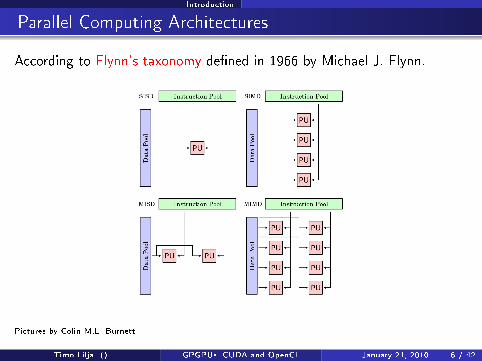
Introduction
Parallel Computing Architectures
According to Flynn's taxonomy de�ned in 1966 by Michael J. Flynn.
Pictures by Colin M.L. Burnett
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 6 / 42

Introduction
Stream Processing
Programming paradigm related to SIMD
Given a stream of data and a series of operations, calledkernel functions
The kernel function is applied to all elements of a stream concurrently
Memory is very hierarchical: local memory easily accessible, globalmemory much more expensive
Memory accesses usually in bulk so memory optimized or highbandwidth and not to low latency
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 7 / 42

Introduction
GPU vs. CPU
To support SIMD parallelism, ALUs must be abundant whereascontrol logic and data caches are not needed that much
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 8 / 42

NVidia Hardware
NVIDIA GPU
Implementation of a stream processor system
Uni�ed architecture
vertex, pixel and other shaders use the same GPU facilities
Highly hierarchical hardware
Streaming-Processor core (SP)Streaming multiprocessor (SM)Texture/processor cluster (TPC)Streaming processor array (SPA)
Limitations and di�erences when compared to CPU
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 9 / 42

NVidia Hardware
Streaming Multiprocessor (SM)
8 Streaming Processor (SP) cores
scalar multiply-add (MAD) and ALU unitssingle precision �oats and ALU operations in 4 cycles
Fused Multiply-Add unit (FMAD)
IEEE 754R double precision �oating points1 per/processor: double precision �oats are slow
2 special function units (SFU)
provide transcendental functionsother complex functions: reciprocalslow latencies 16-32 cycles or more
low-latency interconnect network between SPs andshared-memory banks
multi-threaded instruction fetch and issue unit
caches: instruction cache and read-only constant cache
16K read/write shared memory
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 10 / 42

NVidia Hardware
Texture/Processor Cluster (TPC)
Geometry controller
maps the operations into StreamingMultiprocessorsProvides 2-dimenisional texture cache thatuses (x , y)-spatial locality
Streaming multiprocessor (SM) controller
Older NVidia's cards (G80) have 2 SMs/TPC,newer have (GT200) 3 SMs/TPC
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 11 / 42

NVidia Hardware
Streaming Processor Array
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 12 / 42

NVidia Hardware
Memory and other features
Memory is highly hierarchical and cached
Thread local memoryShared memory which is shared inside a Streaming Multiprocessor (SM)Global memory which is accessible to all threadsRaster operation processor (ROP)
Other units are mainly used for computer graphics
Texture unitRasterization: Raster operations processor (ROP)
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 13 / 42

NVidia Hardware
Die micrograph
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 14 / 42

NVidia Hardware
Hardware limitations
Branching can cause the program to run fully sequentially
Double precision �oating point numbers are slow
Bus bandwidth between CPU and GPU can become a bottleneck
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 15 / 42
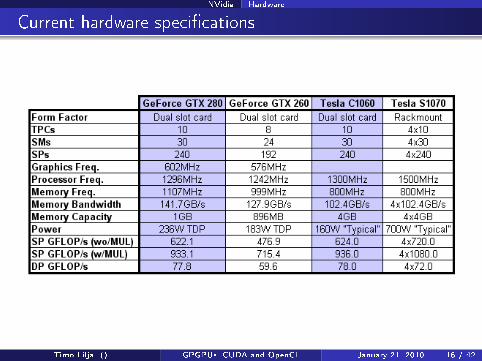
NVidia Hardware
Current hardware speci�cations
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 16 / 42

NVidia Cuda
Cuda
Compute Uni�ed Device Architecture
NVidia's proprietary stream programming language
Available for Linux, Mac OS X and Windows
Current release 2.3, �rst release in 2007
C for Cuda
Compiled through Pathscale's Open64 C compilerStandard C with kernel extensions
Cuda driver API
Standard C API interfacekernels are explicitly loaded
Cuda toolkit
includes compiler, pro�ler, debugger, manual pages, runtime libraries
Cuda SDK
Various code examples, some extra libraries
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 17 / 42

NVidia Cuda
Programming Cuda (1/2)
Consider adding two vectors A and B and storing the result in C .
In ordinary C
void VecAdd(float *A, float *B, float *C){
for (i = 0; i < N; i++)C[i] = A[i] + B[i];
}
In Cuda
__global__ void VecAdd(float* A, float *B, float *C){
int i = threadIdx.x;C[i] = A[i] + B[i];
}
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 18 / 42

NVidia Cuda
Programming Cuda (2/2)
In order to run a parallel program1 Data must be copied to GPU2 The kernel must be invoked from the CPU code with special syntax3 and the data must be copied back to CPU
The language used in Cuda kernels is limited
recursion is not supportedfunction pointers cannot be usedfew other restrictions documented in Cuda programming manual
See example/cuda/vec.cu
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 19 / 42

NVidia Cuda
Processing �ow on CUDA
Picture by Tosaka
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 20 / 42

NVidia Cuda
Threads, Blocks and Grids (1/2)
Threads
perform single scalar operation per cycle
Thread blocks
Can be 1-, 2- or 3-dimensionalcan communicate through shared memorycan synchronize through __syncthreads()
at most 512 threads per blockThread blocks are executed in 32 thread warps in a single SM
Grids
kernel can be executed by multiple thread blocksthread blocks are organized into 1- or 2-dimension grid which can beused indexing the block
Kernel invocation syntax is <<<dimGrid,dimBlock>>>(args);
dimGrid can be 1- or 2-dimensionaldimBlock can be either 1D,2D or 3D
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 21 / 42

NVidia Cuda
Threads, blocks and grids (2/2)
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 22 / 42

NVidia Cuda
Example: matrix addition (1/2)
In normal C
void addMatrix(float *a, float *b, float *c, int N){
int i, j, idx;for (i = 0; i < N; i++)
for (j = 0; j < N; j++)idx = i + j*N;c[idx] = a[idx] + b[idx];
}}
}
int main(void){
...addMatrix(a,b, c, N);
}
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 23 / 42

NVidia Cuda
Example: matrix addition (2/2)
In Cuda
__global__ void addMatrixG(float *a, float *b, float *c, int N){
int i = blockIdx.x*blockDim.x + threadIDx.x;int j = blockIdx.y*blockDim.y + threadIdx.y;int idx = i + j*N;if (i < N && j < N)
c[idx] = a[idx] + b[idx];}
int main(void){
dim3 dimBlock (blocksize, blocksize);dim3 dimGrid (N/dimBlock.x, N/dimBlock.y)addMatrixG<<<dimGrid, dimBlock>>>(a,b,c, N)
}
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 24 / 42

NVidia Cuda
Compiling Cuda
Cuda for C code is compiled with nvcc compiler andits extension is .cu
The host code is compiled to native x86
The device code is �rst compiled to Parallel Thread Execution PTXassembler and then to cubin binary format
pseudo-assembler with arbitrary large register setalmost entirely in SSA form
NVidia graphics card driver load cubin code compiles and executes thePTX code
With the Cuda C driver API it is possible to upload own, non-nvccgenerated cubin code to the driver
Used in some HLL to provide Cuda support
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 25 / 42

NVidia Cuda
Other features
Asynchronous execution
Memory hierarchy: Device Memory, Shared Memory, Page-LockedHost Memory
Error Handling
Multiple Devices
Debugger, Pro�ler and the Device emulation mode
Performance tuning
Check the SDK examples!
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 26 / 42

OpenCL
OpenCL
Open Computing Language was initially developed by Apple
Now developed by Khoronos Group and OpenCL 1.0 was published onDecember 8, 2008
Both AMD and NVidia support OpenCL 1.0 as of late 2009
Apple's implementation is based on LLVM compiler framework
OpenCL is fully open standard with
The goal is to support GPGPUs, Cells, DSPs
OpenCL language is based on C99
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 27 / 42

OpenCL
Terminology
A OpenCL host is the machine controlling one or more OpenCLdevices
A device consists of one ore more computing cores
A computing core consists of one or more processing elements
Processing elements execute code as SIMD or SPMD (Single ProcessMultiple Data, ordinary OpenMP kind multitasking)
A Program consists of one or more kernels
Computation domains can be 1-, 2- or 3-dimensional
Work-items execute kernels in parallel and are grouper to localworkgroups
Synchronization can be done only within a workgroup
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 28 / 42

OpenCL
Memory Model
Like in Cuda, memory is hierarchical
Private memory is per work-itemLocal Memory is shared with a workgroupUnsynchronized Local Global/Constant MemoryHost Memory
Memory must be copied between host, global and local memory
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 29 / 42

OpenCL
Objects and Running OpenCL
Setup1 Choose the device (GPU, CPU, Cell)2 Create a context, which is a collection of devices3 Create and submit work into a queue
Memory consists of
bu�ers which can be accessed freely, read/writeimages which can be either read or written in a kernel, not both andcan be accessed only by speci�c functions.
Work is run asynchronously, synchronous access requires blocking APIcalls
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 30 / 42

OpenCL
OpenCL kernel language
Based on ISO C99
No function pointers, recursion, variable length arrays, bit �elds
Syntax and other additions
work-items and workgroupsvector types and operationssynchronizationaddress space quali�ers
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 31 / 42

OpenCL
OpenCL, CUDA and Linux
Compiled with ordinary GCC and linked against Cuda's libOpenCL
Kernels must be embedded into C strings or loaded from external �lesthrough OpenCL API, In Cuda kernels are recompiled and linked tothe binary
NVidia Cuda SDK (at least in 3.0) has lots of OpenCL examples
Kernel syntax is di�erent!
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 32 / 42

Conclusion
Conclusion
GPGPUs provide one form of parallelism, namely SIMD
Multi-core CPUs provide MIMD parallelism
Will the future merge these two into a single platform?
NVidia Cuda is strongly stream processing SIMD implementationwhereas OpenCL is far more generic supporting both SIMD andSPMD/MIMD
What kind of applications and who will bene�t from GPGPU streamprocessing?
Will it make O�ce applications run faster?Will it bene�t average user? average programmer? average scientist?At least it will bene�t the average gamer
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 33 / 42

Conclusion
References
GPUs and CUDA http://www.cis.temple.edu/~ingargio/
/cis307/readings/cuda.html
NVIDIA's GT200: Inside a Parallel Processor http://www.
realworldtech.com/page.cfm?ArticleID=RWT090808195242&p=1
NVidia Cuda Programming Guide 2.3
Building NVIDIA's GT200
http://www.anandtech.com/video/showdoc.aspx?i=3334&p=2
iXBT Labs: NVIDIA CUDA
http://ixbtlabs.com/articles3/video/cuda-1-p6.html
Lindholm et al. NVIDIA Tesla: A Uni�ed Graphics and Computing
Architecture. IEEE micro. vol. 28 no. 2, March/April 2008
NVidia OpenCL JumpStart Guide
Khronos group's OpenCL overview
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 34 / 42

Conclusion
Possible topics (1/2)
How to optimize matrix multiplications in Cuda/OpenCL
Section 3.2.2 in Cuda Programming Cude
Starting from CPU multiplication and ending up in GPGPUbenchmarking after each optimization step
Performance tuning and Best practices
Cuda/OpenCL Best practices Guide
Cuda and OpenCL
API comparisonperformance evaluation
User experiences and example applications
NVidia's Cuda/OpenCL SDKOther applicationsLibraries and tools already ported to Cuda/OpenCL
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 35 / 42

Conclusion
Possible topics (2/2)
AMD
Hardware overview and comparison to NVidiaOverview of AMD's implementation of OpenCLAMD currently leading in GPU performance
High-level languages and GPGPU
Python bindings for both Cuda and OpenCLC++, FP languages, Matlab
GPGPU IDEs and development tools
Future GPGPU trends
Merging CPU and GPGPU: will it happen?
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 36 / 42

Conclusion
Arrangements once more
Need two presentantions for the next session
Next session on Jan 28th or Feb 4th?For the rest: e-mail me (timo.lilja@tkk.�) suitable timesand topic suggestions ASAP
You can suggest your own programming project topic tooby emailing me
Check the wiki pages, I will add instructions on how to useCuda/OpenCL in course server environment
http://wiki.tkk.fi/display/GPGPUK2010/Running+CUDA+and+
OpenCL+in+course+server
Would be interesting to get some instructions on running AMD'sOpenCL stack into the course wiki as well
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 37 / 42

Helmholtz Di�erential Equation (1/2)
An elliptic partial DE, in general form:
∇2ψ + k2ψ = 0
�Height of the wave V at coordinates (x , y) accelerates towards thewave height of adjacent places (x − d , y), (x + d , y), (x , y − d),(x , y + d)�
D2tV (x , y) = C
„V (x − d , y) + V (x + d , y) + V (x , y − d) + V (x , y + d)
4− V (x , y)
«
Add a little friction . . .− F DtV (x , y)
and impulse . . .+ I (t, x , y)
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 38 / 42

Helmholtz Di�erential Equation (2/2)
The coe�cient C corresponds to the conductivity of the material,C = 0⇒ the wave can't penetrate this material
The coe�cient F corresponds to the friction of the material,F = 0⇒ no friction, the wave continues forever
d is the distance between two points in the discretized space
We set d = 1 and adjust C and F correspondingly, and store V (x , y)in a two-dimensional table
For a numerical solution to be at least somewhat accurate, C < 1 andthe wavelength > 4
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 39 / 42

Solving the DE Numerically (1/3)
Given a (set of) DE y ′ = y ′(t, y)
Euler's algorithm:yt+h = yt + h y ′(t, yt)
�follow the tangent for a step h�Very inaccurate
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 40 / 42

Solving the DE Numerically (2/3)
Runge-Kutta algorithm, one variation:
yt+h = yt + hα+ 2β + 2γ + δ
6
where
α = y ′(t, yt),
β = y ′(t +h
2, yt +
h
2α),
γ = y ′(t +h
2, yt +
h
2β),
δ = y ′(t + h, yt + hγ)
(Even better algorithms exist, especially for sti� problems likeHelmholtz, but ignored here.)
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 41 / 42

Solving the DE Numerically (3/3)
If the DE is of a higher degree, we can �normalize� it:
V′t (x , y) = hV
′′t (x , y)
V′′t (x , y) = C
„V (x − d , y) + . . .
4− V (x , y)
«− F DtV (x , y)
Timo Lilja () GPGPUs, CUDA and OpenCL January 21, 2010 42 / 42