glenn k. lockwood, ph.d. user services group san diego supercomputer center understanding the...
TRANSCRIPT

Glenn K. Lockwood, Ph.D.User Services Group
San Diego Supercomputer Center
Understanding the Computational Challenges in Large-Scale
Genomic Analysis

AcknowledgmentsSTSI• Kristopher Standish*
• Tristan M. Carland• Nicholas J. Schork*
SDSC• Wayne Pfeiffer• Mahidhar Tatineni• Rick Wagner• Christopher Irving
Janssen R&D• Chris Huang• Sarah Lamberth• Zhenya Cherkas• Carrie Brodmerkel• Ed Jaeger• Martin Dellwo• Lance Smith• Mark Curran• Sandor Szalma• Guna Rajagopal
* Now at the J. Craig Venter Institute

SAN DIEGO SUPERCOMPUTER CENTER
Outline
• What's the problem?• The 438-genome project with Janssen
• The scientific premise• 4-step computational procedure
• Gained insight• Costs of population-scale sequencing• Designing systems for genomics• Final remarks

SAN DIEGO SUPERCOMPUTER CENTER
COMPUTATIONAL DEMANDSComputational Challenges in Large-Scale Genomic Analysis
SAN DIEGO SUPERCOMPUTER CENTER
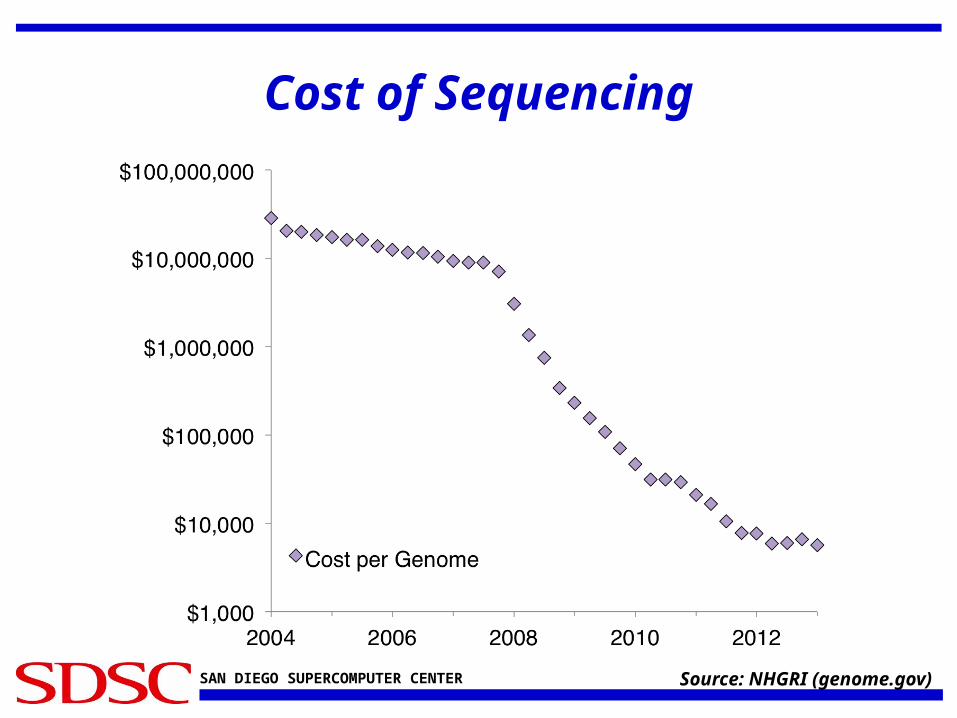
Cost of Sequencing
Source: NHGRI (genome.gov)
SAN DIEGO SUPERCOMPUTER CENTER
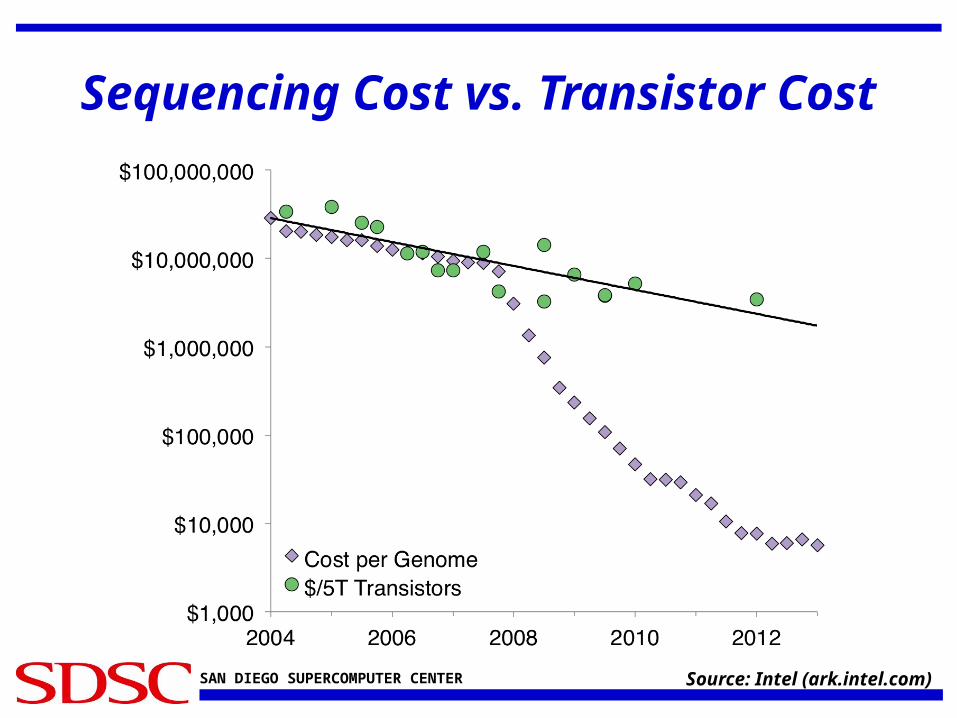
Sequencing Cost vs. Transistor Cost
Source: Intel (ark.intel.com)

SAN DIEGO SUPERCOMPUTER CENTER
Sequencing is only the Beginning

SAN DIEGO SUPERCOMPUTER CENTER
Scaling up to Populations
Petco Park = 40,000 people
Gordon = 16,384 cores65,536 GB memory
307,200 GB solid-state disk

SAN DIEGO SUPERCOMPUTER CENTER
Core Computational Demands
1. Read mapping and variant calling• Required by almost all (human) genomic studies• Multi-step pipeline to refine mapped genome• Pipelines are similar in principle, different in detail
2. Statistical analysis (science)• Population-scale solutions don't yet exist• Difficult to define computational requirements
3. Storage• Short-term capacity for study• Long-term archiving• Cost: store vs. re-sequence

SAN DIEGO SUPERCOMPUTER CENTER
438 PATIENTS: A CASE STUDYComputational Challenges in Large-Scale Genomic Analysis
SAN DIEGO SUPERCOMPUTER CENTER
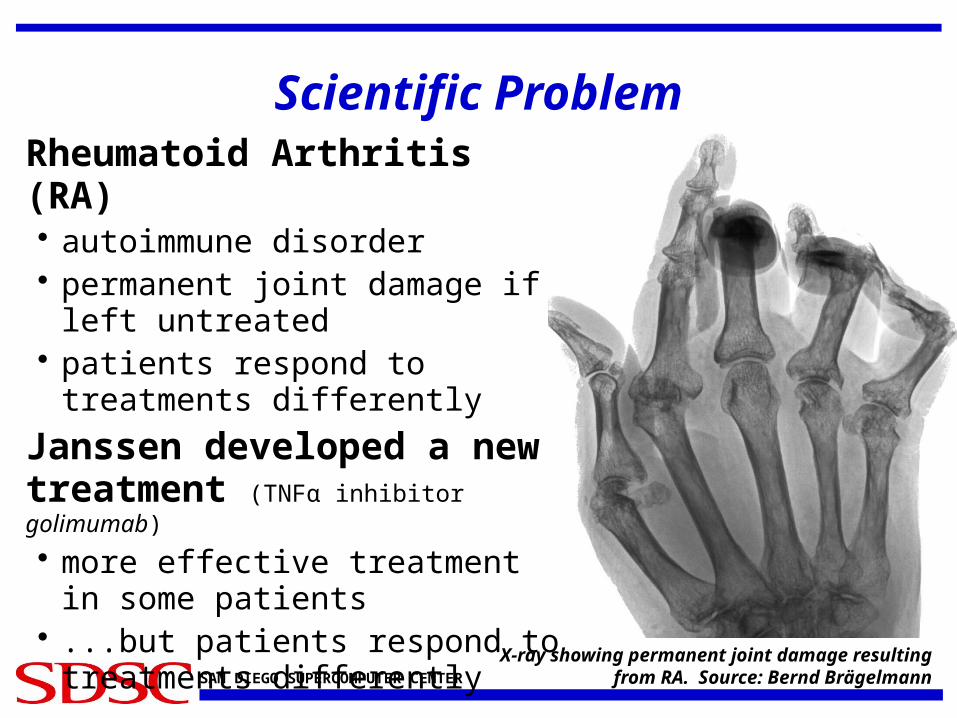
Scientific ProblemRheumatoid Arthritis (RA)• autoimmune disorder• permanent joint damage if left
untreated• patients respond to treatments
differently
Janssen developed a new treatment (TNFα inhibitor golimumab)
• more effective treatment in some patients
• ...but patients respond to treatments differently
X-ray showing permanent joint damage resulting from RA. Source: Bernd Brägelmann

SAN DIEGO SUPERCOMPUTER CENTER
Scientific Goals
Can we predict if a patient will respond to the new treatment?
1. Sequence whole genome of patients undergoing treatment in clinical trials
2. Correlate variants (known and novel) with patients' response/non-response to treatment
3. Develop a predictive model based on called variants and patient response

SAN DIEGO SUPERCOMPUTER CENTER
Computational Goals
• Problem: original mapped reads and individually called variants provided no insight• BWA -aln pipeline• SOAPsnp and SAMtools pileup to call SNPs and indels
• Solution: Re-align all reads with newer algorithms and employ group variant calling• BWA -mem pipeline• GATK HaplotypeCaller high-quality called variants

SAN DIEGO SUPERCOMPUTER CENTER
Computational Approach
1. Understand computational requirements
2. Develop workflow
3. Load dataset into HPC resource
4. Perform full-scale computations

SAN DIEGO SUPERCOMPUTER CENTER
Computational Approach
1. Understand computational requirements
2. Develop workflow
3. Load dataset into HPC resource
4. Perform full-scale computations

SAN DIEGO SUPERCOMPUTER CENTER
Step #1: Data Requirements• Input Data
• raw reads from 438 full human genomes (fastq.gz)• 50 TB of compressed data from Janssen R&D
• Output Data• + 50 TB of high-quality mapped reads• + small amount (< 1 TB) of called variants
• Intermediate (Scratch) Data• + 250 TB (more = better)
• Performance• Data must be stored online • High bandwidth to storage (> 10 GByte/s)

SAN DIEGO SUPERCOMPUTER CENTER
Step #1: Compute & Other Requirements
• Processing Requirements• perform read mapping on all genomes; 9-step pipeline to achieve high-quality read mapping
• perform variant calling on groups of genomes 5-step pipeline to do group variant calling
• Engineering Requirements• FAST turnaround (all 438 genomes done in < 2 months) requires high capacity supercomputer (many CPUs)
• EFFICIENT (minimum core-hours used) requires data-oriented architecture (RAM, SSDs, IO)

SAN DIEGO SUPERCOMPUTER CENTER
Can we even satisfy these requirements?
Data Requirements: SDSC Data Oasis• 1,400 terabytes of project data storage• 1,600 terabytes of fast scratch storage• Data available to every compute node
Processing/Eng'g Requirements: SDSC Gordon• 1024 compute nodes• 64 GB of RAM each• 300 GB local SSD each• Access Data Oasis at up to 100 GB/s

SAN DIEGO SUPERCOMPUTER CENTER
Computational Approach
1. Understand computational requirements
2. Develop workflow
3. Load dataset into HPC resource
4. Perform full-scale computations

SAN DIEGO SUPERCOMPUTER CENTER
Workflow Engine
Step #2: The Workflow
Compute Hardware Resource PoliciesStorage
Applications
00 f6 0b 3f bf 0c 49 46 80 3d 99 a8 0f a099 8f 65 f8 b7 94 4f 9b 3f 44 00 fc 50 ac4a db 5d a2 69 ce d1 70 ce bc ab b3 76 9060 fe e5 96 23 9b d6 c5 8d b9 56 a6 d5 2e14 15 40 36 8a c4 4c 09 de 9e 89 92 34 4a64 1e f4 f9 66 e0 15 74 36 64 f0 b1 7f a296 a0 0d 3c 78 83 87 74 5b b3 7a 07 79 b38b 54 5e 91 ba d3 6f 23 2f 7c 49 a0 df 849e 46 a8 93 7c ca 6d e1 0e 52 76 12 19 6970 03 6b 6d b1 93 de 6a 65 f0 61 bd 6c 7380 25 db 90 4c e4 1a cc 43 17 ae c9 e1 6819 88 9a be 9b 9e 3a 1f a5 07 98 a0 8d 43ae aa cd 71 83 3d ef ba 43 80 81 3d 84 f4
Input Data
##fileformat=VCFv4.1##FILTER=<ID=LowQual,Description="Low quali##FORMAT=<ID=AD,Number=.,Type=Integer,Descr##FORMAT=<ID=DP,Number=1,Type=Integer,Descr##FORMAT=<ID=GQ,Number=1,Type=Integer,Descr##FORMAT=<ID=GT,Number=1,Type=String,Descri##FORMAT=<ID=PL,Number=G,Type=Integer,Descr##INFO=<ID=AC,Number=A,Type=Integer,Descrip##INFO=<ID=AF,Number=A,Type=Float,Descripti##INFO=<ID=AN,Number=1,Type=Integer,Descrip##INFO=<ID=BaseQRankSum,Number=1,Type=Float##INFO=<ID=DB,Number=0,Type=Flag,Descriptio##INFO=<ID=DP,Number=1,Type=Integer,Descrip
ResultsUser

SAN DIEGO SUPERCOMPUTER CENTER
Step #2: The Workflow
1. Automate as much as you can• tired researchers are frequent causes of failure• self-documenting and reproducible
2. Understand the problem• your data - volume, metadata• your applications - in, out, and in between• your hardware - collaborate with user services!
3. Don't rely on prepackaged workflow engines*• every parallel computing platform is unique• work with user services
* Unless you really know what you are doing

SAN DIEGO SUPERCOMPUTER CENTER
Step #2: The Workflow
2. Understand the problem• your data - volume, metadata• your applications - in, out, and in between• your hardware - collaborate with user services!
How do we "understand the problem?"
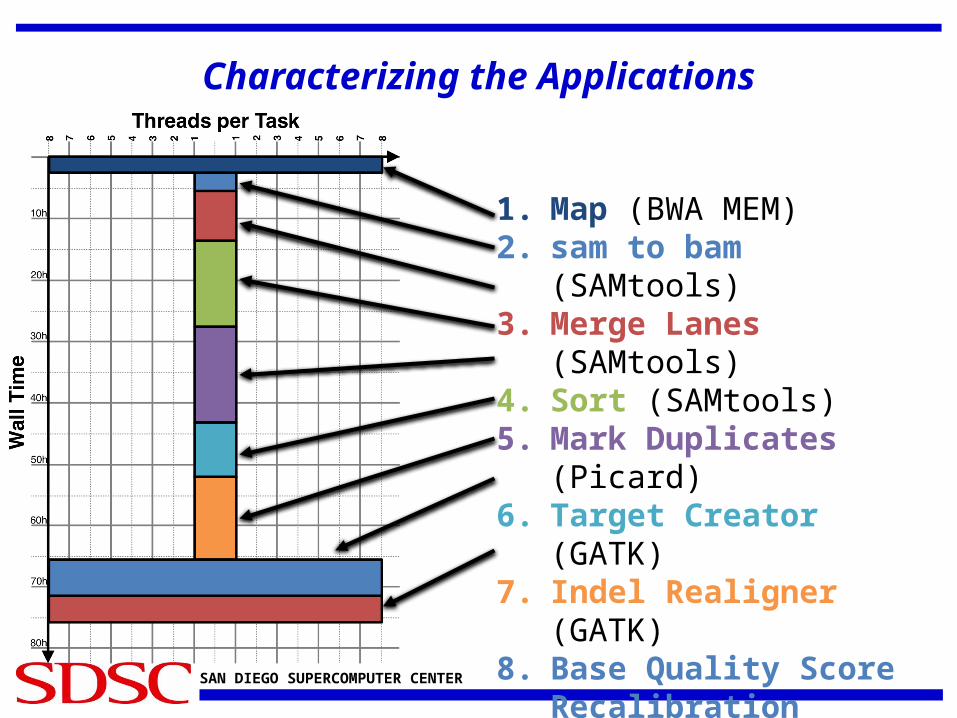
Test a pilot pipeline on a subset of input and thoroughly characterize it.
SAN DIEGO SUPERCOMPUTER CENTER
Characterizing the Applications
1. Map (BWA MEM)2. sam to bam (SAMtools)3. Merge Lanes (SAMtools)4. Sort (SAMtools)5. Mark Duplicates (Picard)6. Target Creator (GATK)7. Indel Realigner (GATK)8. Base Quality Score
Recalibration (GATK)9. Print Reads (GATK)

SAN DIEGO SUPERCOMPUTER CENTER
Characterizing the HardwareGordon - 1024 compute nodes• Two 8-core CPUs• 64 GB RAM (4 GB/core)• 300 GB SSD per node*
Resource Policy:• Jobs allocated in half-node
increments (8 cores, 32 GB RAM)
• Jobs are charged per core-hour(8 core-hours per real hour)
How do we efficiently pack each pipeline stage?
* mounted via iSER. Above: 256x 300 GB SSDs

SAN DIEGO SUPERCOMPUTER CENTER
Mapping Application Demands to Hardware
1. Map
8 threads2. sam to bam
1 thread3. Merge Lanes
1 thread4. Sort
1 thread5. Mark Dups
1 thread6. Target Creator
1 thread7. Indel Realigner
1 thread8. BQSR
8 threads9. Print Reads
8 threads
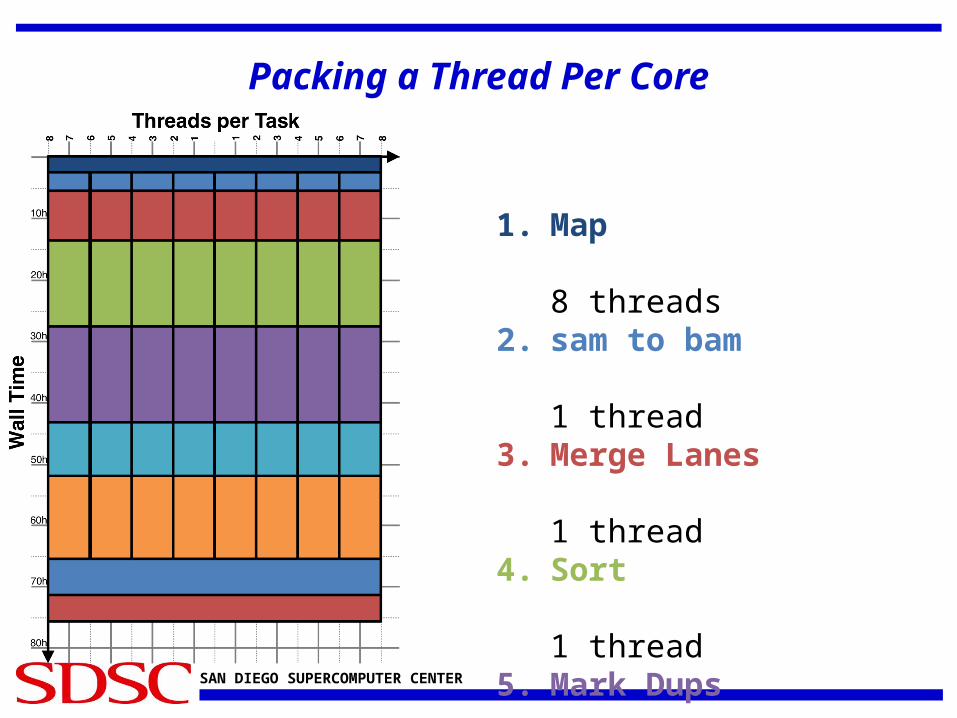
SAN DIEGO SUPERCOMPUTER CENTER
Packing a Thread Per Core
1. Map
8 threads2. sam to bam
1 thread3. Merge Lanes
1 thread4. Sort
1 thread5. Mark Dups
1 thread6. Target Creator
1 thread7. Indel Realigner
1 thread8. BQSR
8 threads9. Print Reads
8 threads
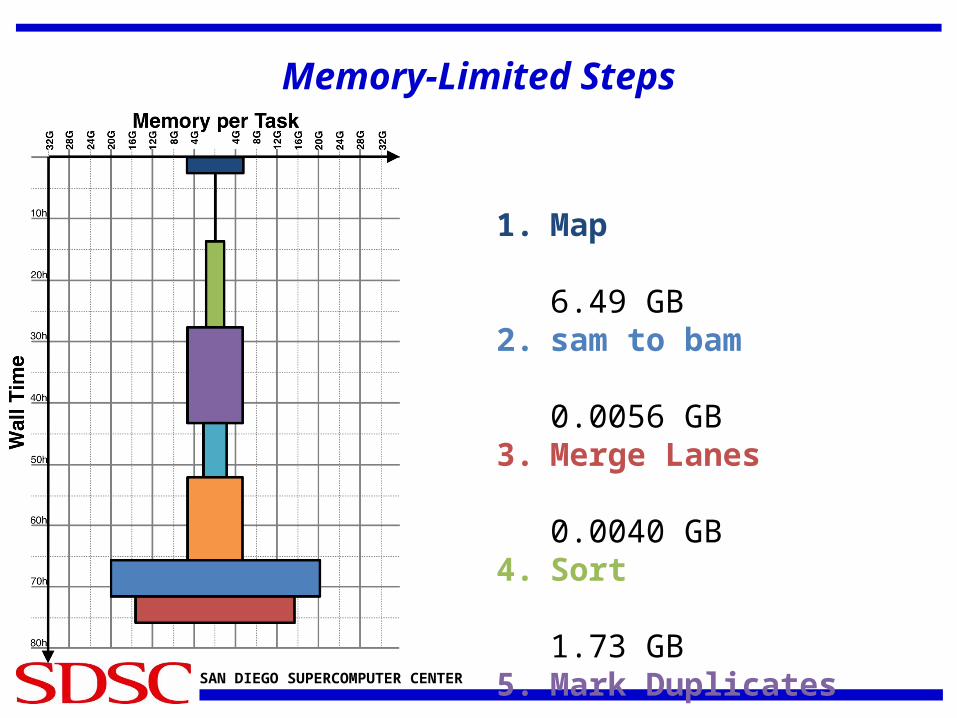
SAN DIEGO SUPERCOMPUTER CENTER
Memory-Limited Steps
1. Map
6.49 GB2. sam to bam
0.0056 GB3. Merge Lanes
0.0040 GB4. Sort
1.73 GB5. Mark Duplicates
5.30 GB6. Target Creator
2.22 GB7. Indel Realigner
5.27 GB8. BQSR
20.0 GB9. Print Reads
15.2 GB
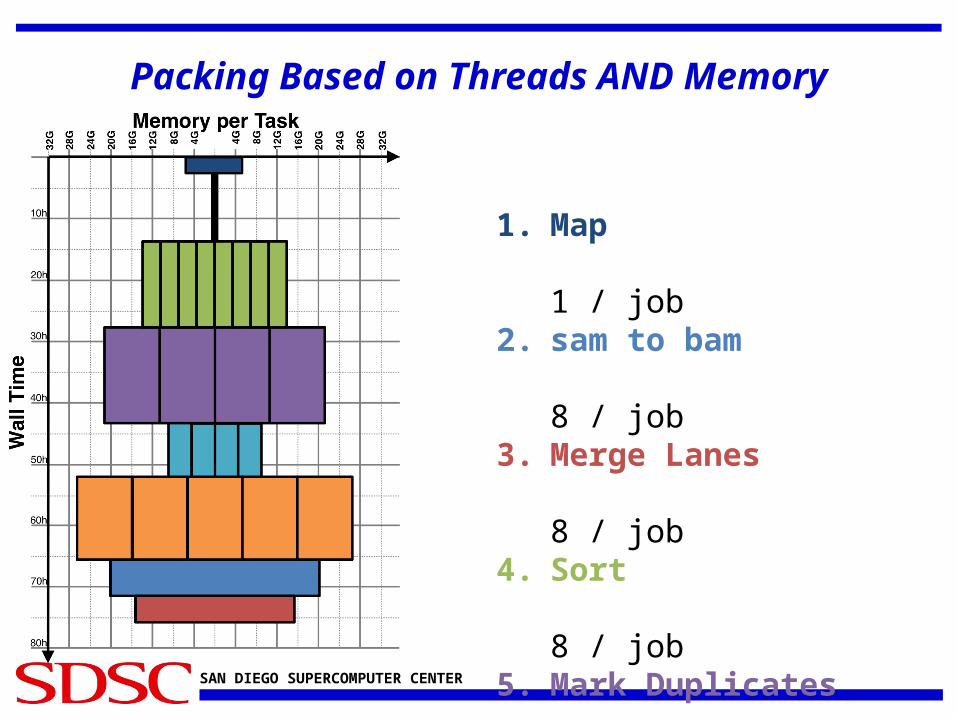
SAN DIEGO SUPERCOMPUTER CENTER
Packing Based on Threads AND Memory
1. Map
1 / job2. sam to bam
8 / job3. Merge Lanes
8 / job4. Sort
8 / job5. Mark Duplicates
4 / job6. Target Creator
4 / job7. Indel Realigner
5 / job8. BQSR
1 / job9. Print Reads
1 / job

SAN DIEGO SUPERCOMPUTER CENTER
Our Final Read Mapping Pipeline
1. Map
1 / job2. sam to bam
8 / job3. Merge Lanes
8 / job4. Sort
8 / job5. Mark Duplicates
4 / job6. Target Creator
4 / job7. Indel Realigner
5 / job8. BQSR
1 / job9. Print Reads
1 / job
SAN DIEGO SUPERCOMPUTER CENTER
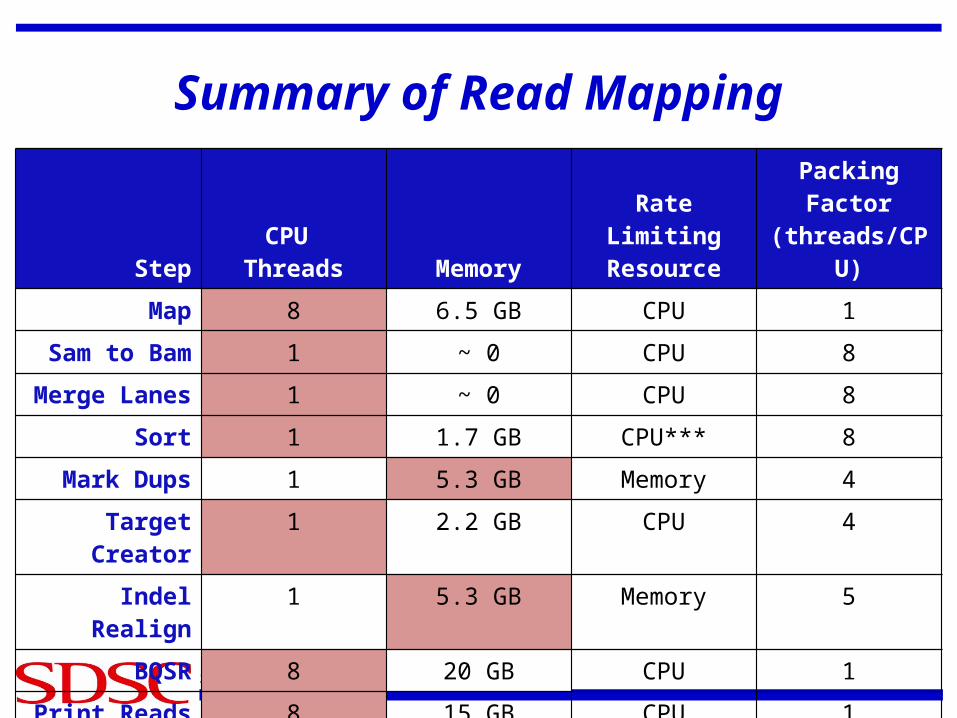
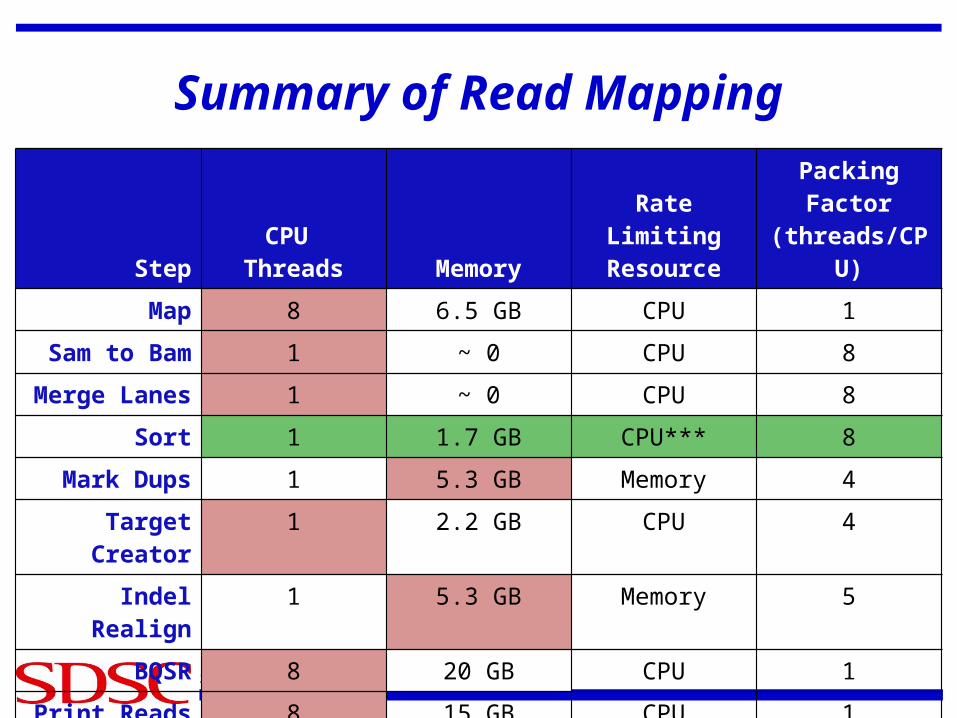
Summary of Read Mapping
StepCPU
Threads MemoryRate Limiting
Resource
Packing Factor
(threads/CPU)
Map 8 6.5 GB CPU 1
Sam to Bam 1 ~ 0 CPU 8
Merge Lanes 1 ~ 0 CPU 8
Sort 1 1.7 GB CPU*** 8
Mark Dups 1 5.3 GB Memory 4
Target Creator 1 2.2 GB CPU 4
Indel Realign 1 5.3 GB Memory 5
BQSR 8 20 GB CPU 1
Print Reads 8 15 GB CPU 1
SAN DIEGO SUPERCOMPUTER CENTER
Summary of Read Mapping
StepCPU
Threads MemoryRate Limiting
Resource
Packing Factor
(threads/CPU)
Map 8 6.5 GB CPU 1
Sam to Bam 1 ~ 0 CPU 8
Merge Lanes 1 ~ 0 CPU 8
Sort 1 1.7 GB CPU*** 8
Mark Dups 1 5.3 GB Memory 4
Target Creator 1 2.2 GB CPU 4
Indel Realign 1 5.3 GB Memory 5
BQSR 8 20 GB CPU 1
Print Reads 8 15 GB CPU 1

SAN DIEGO SUPERCOMPUTER CENTER
Disk IO: Another Limiting Resource
SAMtools Sort• External sort - data does not fit into memory• Breaks BAM file into 600 - 800 smaller BAMs• Constantly shuffles data to/from disk to RAM
16 cores (2 CPUs) per node, so...• 16 BAMs processed per node 1.8 TB of input data
• 10,000 - 12,000 files generated and accessed 3.6 TB of intermediate data

SAN DIEGO SUPERCOMPUTER CENTER
16 files, 1.8 TB of input data
10,000 files, 3.6 TB of scratch data
repeatedly open/close 10,000 files
Disk IO: Another Limiting Resource
High-performance parallel filesystems - can Data Oasis handle this?
Local SSDs necessary to deliver the IOPS

SAN DIEGO SUPERCOMPUTER CENTER
16 files, 1.8 TB of input data
10,000 files, 3.6 TB of scratch data
repeatedly open/close 10,000 files
Disk IO: Another Limiting Resource
Can using an SSD work around this?
Each node's SSD cannot handle 3.6 TB of data

SAN DIEGO SUPERCOMPUTER CENTER
BigFlash Nodes
Aggregate 16x SSDs on a single compute node to get• 4.4 TB RAID0 array• 3.8 GB/s bandwidth• 320,000 IOPS

SAN DIEGO SUPERCOMPUTER CENTER
SAMtools Sort I/O Profile
Fully loaded compute node sustained for 5h:• 3,500 IOPS• 1.0 GB/s read
For reference, spinning disk can deliver:• 200 IOPS• 175 MB/s

SAN DIEGO SUPERCOMPUTER CENTER
Characterizing the Applications
What about the variant calling pipeline?

SAN DIEGO SUPERCOMPUTER CENTER
Haplotype Caller - Threads
Dimensions approx. drawn to scale
100 hours for ¼ genome25 patients per group
20 groups
MASSIVE data reduction
SNP/Indel recalibration steps were insignificant

SAN DIEGO SUPERCOMPUTER CENTER
Haplotype Caller - Memory
Dimensions approx. drawn to scale
Avg HC job req'd 28 GB
RAM
Up to 42 GB needed

SAN DIEGO SUPERCOMPUTER CENTER
Computational Approach
1. Understand computational requirements
2. Develop workflow
3. Load dataset into HPC resource
4. Perform full-scale computations

SAN DIEGO SUPERCOMPUTER CENTER
Step #3: Loading Data• Input: raw reads from 438 full human genomes
• 50 TB of compressed, encrypted data from Janssen• 4,230 files (paired-end .fastq.gz)
How do you get this data into a supercomputer?
They don't exactly have USB ports
Pictured: 2 of 12 Data Oasis racks; each blue light is 2x4 TB disks

SAN DIEGO SUPERCOMPUTER CENTER
Loading Data via NetworkExternal• 60 Gbit/s connectivity to outside world• 100 Gbit/s connection installed and
being tested
Internal• 60 Tbit/s switching capacity• 100 Gbit/s from Data Oasis to edge
coming in summer
Gordon• 20 Gbit/s from IO nodes to Data
Oasis• 40 Gbit/s dedicated storage fabric (IB)Pictured: 2x Arista 7508 switches, core of the HPC network

SAN DIEGO SUPERCOMPUTER CENTER
Loading Data via NetworkExternal• 60 Gbit/s connectivity to outside world• 100 Gbit/s connection installed and
being tested
Internal• 60 Tbit/s switching capacity• 100 Gbit/s from Data Oasis to edge
coming in summer
Gordon• 20 Gbit/s from IO nodes to Data
Oasis• 40 Gbit/s dedicated storage fabric (IB)Pictured: 2x Arista 7508 switches, core of the HPC network
We can move a lot of data

SAN DIEGO SUPERCOMPUTER CENTER
Loading Data via "Other Means"• Most labs and offices are not wired like SDSC
• Janssen's 50 TB of data behind a DS3 link (45 Mbit/sec)• Highest bandwidth approach...
Left: 18 x 4 TB HDDs from JanssenRight: BMW 328i, capable of > 1 Tbit/sec

SAN DIEGO SUPERCOMPUTER CENTER
Step #3: Loading Data
• Use the network if possible:• .edu, federal labs (Internet2, ESnet, etc)• Cloud (e.g., Amazon S3)
• 100 MB/sec to us-west-2 disk-to-disk• 50 MB/sec to us-east-1 disk-to-disk
• SDSC Cloud Services (> 1.6 GB/sec)• Sneakernet is high bandwidth, high latency
• Sneakernet is error-prone and tedious• Neither scalable nor future-proof• For Janssen, it was more time-effective to transfer results
at 50 MB/s than via USB drives and a car trunk

SAN DIEGO SUPERCOMPUTER CENTER
Computational Approach
1. Understand computational requirements
2. Develop workflow
3. Load dataset into HPC resource
4. Perform full-scale computations
SAN DIEGO SUPERCOMPUTER CENTER
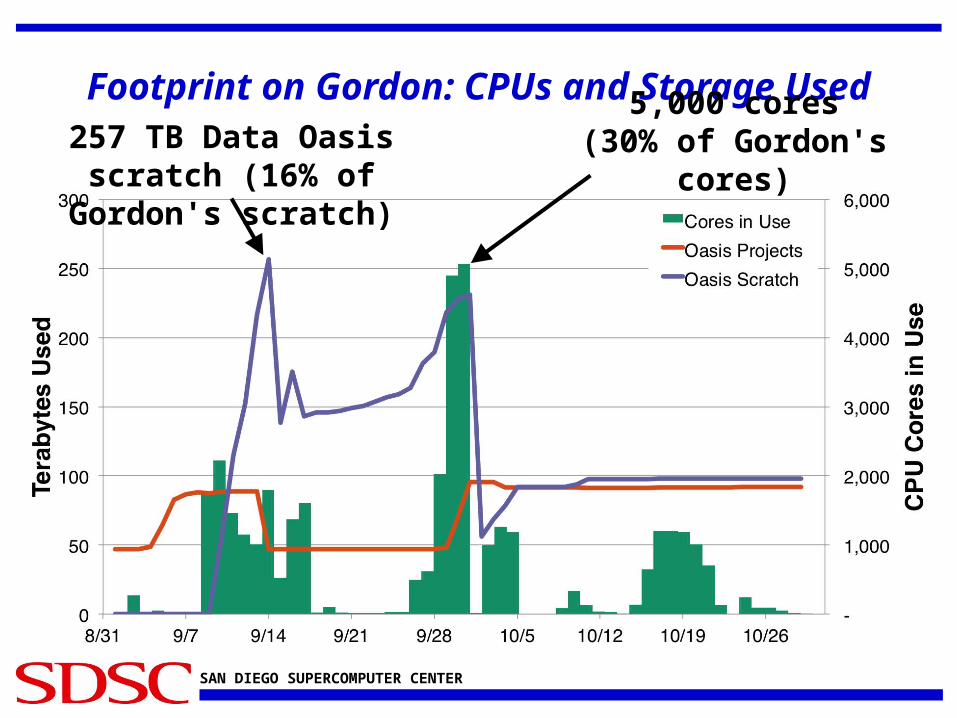
Footprint on Gordon: CPUs and Storage Used5,000 cores
(30% of Gordon's cores)257 TB Data Oasis scratch (16% of Gordon's scratch)

SAN DIEGO SUPERCOMPUTER CENTER
Time to Completion...• Overall:
• 36 core-years of compute used in 6 weeks• equivalent to 310 cores running 24/7
• Read Mapping Pipeline• 5 weeks including time for learning • 16 days actually computing• Over 2.5 years of 24/7 compute on a single 8-core
workstation (> 4 years realistically)• Variant Calling (GATK 2.7 Haplotype Caller)
• 5 days and 3 hours on Gordon• 10.5 months of 24/7 compute on a 16-core workstation

SAN DIEGO SUPERCOMPUTER CENTER
GAINED INSIGHTComputational Challenges in Large-Scale Genomic Analysis
SAN DIEGO SUPERCOMPUTER CENTER
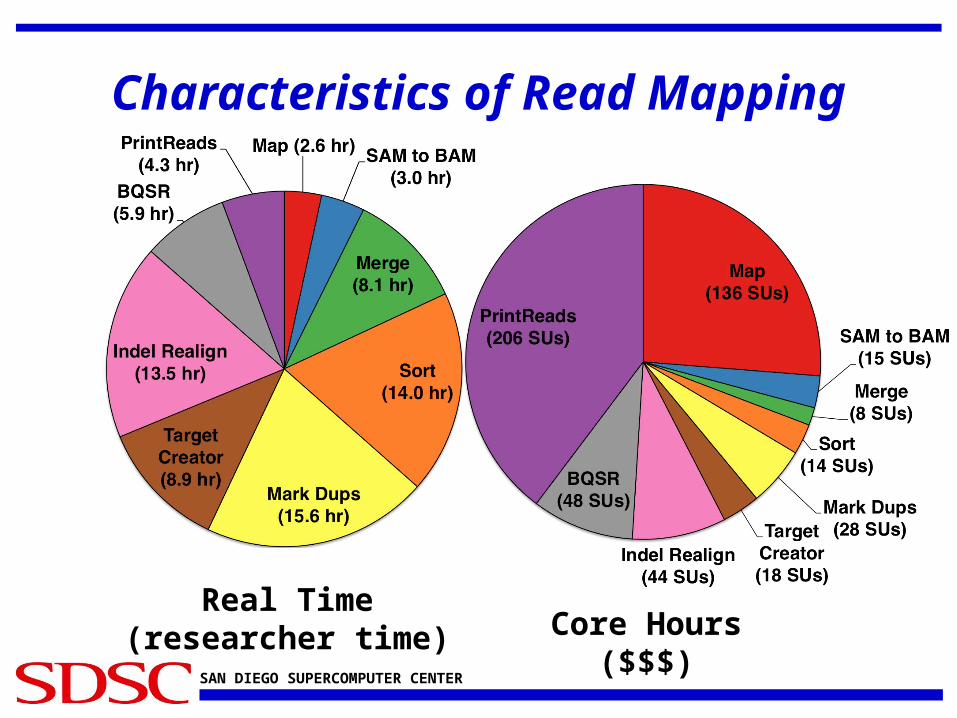
Characteristics of Read Mapping
Real Time(researcher time) Core Hours
($$$)

SAN DIEGO SUPERCOMPUTER CENTER
Characteristics of Both Pipelines
Average Wall Time per Pipeline
Core Hours Consumed per Pipeline

SAN DIEGO SUPERCOMPUTER CENTER
Designing a System for Genomics - Memory
Cray XT/XE
Typical Cluster
SDSC GordonSDSC Comet
Blue Gene/Q
Cray XC30

SAN DIEGO SUPERCOMPUTER CENTER
Designing a System for Genomics - Disk
• Capacity: dictated by size of dataset• 438 genomes:
• 110 GB/genome input, 110 GB/genome output• 600 GB/genome intermediate peak
• Bandwidth: dictated by quantity of genomes• 438 genomes:
• 5,000 cores peak ~ 312 nodes peak• ~200 MB/s ingestion per node (e.g., Sort steps)• 60 GB/s peak
Gordon: 1.6 PB~ 2,700 concurrent
genomes peak
Gordon: 100 GB/s peak

SAN DIEGO SUPERCOMPUTER CENTER
Take-away Message
1. Understand:1. your pipeline's computational requirements2. your hardware (or work with user services)
2. Develop a pipeline specific to your hardware3. Use proper computing resources:
1. enough memory to keep CPU cores busy2. enough high-performance storage to feed nodes3. enough network infrastructure to feed storage

SAN DIEGO SUPERCOMPUTER CENTER
Acknowledgments / Questions?Janssen R&D• Chris Huang• Sarah Lamberth• Zhenya Cherkas• Carrie Brodmerkel• Ed Jaeger• Martin Dellwo• Lance Smith• Mark Curran• Sandor Szalma• Guna Rajagopal
STSI• Kristopher Standish*
• Tristan M. Carland• Nicholas J. Schork*
* Now at the J. Craig Venter Institute
Ask via...• ReadyTalk text chat right now• Email:
[email protected]• XMPP:
[email protected]• Social:
@glennklockwood
+glennklockwood
Next IPP Webinar:"Benchmarking the Xeon Phi Processor"Wednesday, May 14, 2014 @ 11 AM PDTDavid Nadeau, Ph.D.