generic query toolkit: a query interface generator
TRANSCRIPT

Generic Query Toolkit: A Query Interface Generator Integra ting Data Mining
Lichun Zhu, C.I. Ezeife, R.D. [email protected], [email protected], [email protected]
School of Computer Science, University of WindsorWindsor, Ontario, Canada N9B 3P4
Abstract
Construction of flexible query interface constitutes a veryimportant part in the design of information systems. Themajor goal is that new queries can easily be built by either the developers or the end-users of information systems. Someinformation systems would provide a list of predefined queries and future additional queries would need to be reconstructedfrom scratch. Thus, the low degree of reusability of query modules is a limitation of the database query report systems thatthese information systems are based on. This paper presentsGeneric Query Toolkit, a software package that automatesthe query interface generation process. It consists of a parser and an interpreter for a newly defined Generic Query ScriptLanguage, a background query processing unit, a presentation layer service provider and the presentation layer component.Data mining querying feature has been integrated into this query language. Future work will integrate more data miningquerying and other advanced features.
Keywords Business Intelligence, Query Automation, Data Mining
1. Introduction
The original idea for developing the Generic Query Toolkit (GQT) came from the projects of building data mart and reportsystems for business clients. In these projects, users’ requirements (business logic) are constantly changing. Thereis need tobuild fast prototypes to speed up the communication cycle between the developer and end users. To meet these requirements,we developed a software solution to automate the query interface generation process, which makes the prototyping processmore efficient. In this solution, we defined a SQL-like query language (called Generic Query Language or GQL). A languageparser parses the GQL script and generates inner object structures to represent the query interface, such as criteria input fields,display attributes and so on. These inner object structuresare serialized into XML schema and stored in the database. Thequery toolkit generates the query interface based on this schema, and then binds the end users’ input to generate sequencesof target GQL statements. These statements are then processed by an interpreter to generate final query results. At last,a setof presentation tools will render the result to the end user in an interactive way.
The original version of GQL script only supports SQL statements. Recently we have added control flow statements,variable declaration statements and others to make it a functional script language. We also added a set of language featuresto make it support XML based dataset manipulation and data mining functionalities.
The ultimate goal of the GQT system is to provide solutions inBusiness Intelligence area. Business Intelligence(BI)[1] software typically includes data warehousing, data mining, analyzing, reporting and planning capabilities. BI helpsdecision makers utilize their data and make decisions more efficiently and accurately. To construct a BI solution, varioustechnologies can be integrated, such as Online Analytical Processing (OLAP), Data warehousing, Data mining, DecisionSupport Systems (DSS) and scheduling/workflowcontrol. Data mining is a very important part of BI solution because it turnsdata into knowledge by extracting useful patterns or rules from vast amounts of data, using various algorithms.
The GQT system being proposed in this paper, provides solutions for quickly building queries for end-users. It alsointegrates data mining support at its language level. Compared with other commercial BI solutions such as BusinessObjects[9], Cognos [10], our method is fairly light-weighted and can be widely integrated with software projects of various scales.

In fact, the original version of this toolkit has already been integrated with information systems ranging either from personalsmall desktop Management Information Systems to commercial distributed large data marketing / data warehouse systems,or from fat client applications to web-based applications.
The rest of the paper is organized as follows: Section 2 summarizes relevant related work and paper contributions. Section3 presents the design of the GQT and its script query language, GQL. Section 4 discusses the integration of data miningquerying and algorithms into this toolkit. Section 5 presents the testing environment. Section 6 discusses future workandsection 7 presents conclusions.
2. Related Work
There are many commercial BI solutions available now, such as BusinessObjects, Cognos, Oracle Business IntelligenceSuite [11]. However, most current commercial BI tools have the following weak points:1. They are highly complicated systems, requiring sharp learning curve.2. These software tools are expensive choices for small projects, due to high cost of the software and expenses on thecustomization and training process.The open source resources related to our work are:• The Pentaho Business Intelligence Project [2]: This systemprovides a complete open source BI solution that integratesother open source components within a process-centric, solution-oriented framework.• Mondrian OLAP server [15]: an open source OLAP server written in Java. It serves as a component of the Pentaho project,and supports the Multi-Dimensional Expressions (MDX) [14]query language to perform OLAP query.• JPivot project [16]: JPivot is a JSP custom tag library that renders an OLAP table and lets users perform typical OLAPnavigations like slice and dice, drill down and roll up. It uses Mondrian as its OLAP Server. It also supports XML forAnalysis (XMLA) standard [7], which is an open industry-standard web service interface designed specifically for OLAPand data mining functions.• Weka Data Mining project [3]: WEKA is a collection of machinelearning algorithms for data mining tasks. It providesuser interface that can be applied directly to a dataset for data analysis. It also provides a java library that can be called fromour own Java code. Section 4 provides more discussion of WEKA.These open source projects provide insights that may be useful in the development of the GQT. Another related work isMichalis’s QURSED system [4], which uses XML based query setspecification and XHTML to generate Web-based queryforms and reports (QFRs) for semistructured XML data. The difference is QURSED uses a compiler to convert XMLschema into dynamic server pages, and generates queries in XQuery syntax, while GQT uses interpretive approach to renderthe dynamic user interface and maintain target query language GQL as a script consisting of SQL and new GQL statements.
2.1. Contributions
This paper proposes GQT a query automation tool and its script language GQL. The GQT generates query forms andreport pages and focuses on automating the whole query process from user input, query submission to result presentation.Three contributions of GQT system that distinguish it from existing work are:1. Loose coupling of logical and visual part: By using GQL script language to define the query process, users can focus onthe logic part and need not be concerned about how the query form is generated and how the result is displayed. The couplingbetween the logical and the visual part is loose, simple, andeasy to build.2. Powerful functionalities provided by the script: The GQLscript language provides easy-to-understand statements forbuilding user query logic. It also provides powerful interfaces for user to manipulate the dataset and invoke other serviceslike data mining and OLAP. Currently, the features providedby GQL are still in the process of expansion.3. Background query model: GQT parses the user defined query process which is in GQL syntax and transforms it into XMLschema which contains information about the query form, result form and user input. The XML schema is nested in queuedtasks that are persistent during the whole life-cycle of a submitted query and can be shared by different query processingstages. This model allows submitted queries to run in the background, and different parts of the system to collaborate witheach other using the GQL script and the generated XML schema.Thus, end-users can do other tasks while waiting for theresults of their GQT queries. This feature is especially useful for a query that will span a long period.
2

3. The Design of Generic Query Toolkit
The GQL script language syntax is presented in Section 3.1 while GQT architecture and components are discussed inSection 3.2.
3.1. GQL Language Specification
By defining a script language, users can customize their query process using this script. The GQL script language beingproposed in this paper for integrating front-end data retrieval services like OLAP and data mining with back-end databasesystems can specify two broad tasks of:1. User interface definition: Users can describe the data presentation patterns asField Attributeand define the query criteriaasConditionAttribute in this script.2. Process specification: Users can control business workflow and invoke various services (e.g., data mining services likeClassification, Association Rule using WEKA or other miningalgorithms and SQL statements) using this script.The syntax to define data presentation pattern or display attribute list (Field Attribute) is a collection of semi-colon delimitedfields enclosed in curly brackets “{}” as :
Field Attribute ::={Field Name;Field Description;Field Type;Display Attribute [;[AggregateAttribute];[Key Attribute ] ] }
Field Name is unique name of column to be displayed.Field Description is the display label of the column.Field Type is the SQL datatype of the column.Display Attribute specifies the default display attribute of the column, whichcan be SHOW/HIDE.AggregateAttribute can be used to define the aggregation method at client side, which can be any SQL aggregation functionlike SUM, AVG, MAX, MIN;Key Attribute is used to specify whether the column is regarded as a key attribute or group attribute, which can beKEY/GROUP. This is useful for OLAP analysis. If a column is marked as GROUP column, we should specify #se-quencenumber in group/order clause for the corresponding column and user will be able to select/unselect group columnsfrom the generated query form to decide whether this column will be included as a dimension in the final query result. Forexample, we can use “{catelog; Category; STRING; SHOW; ; GROUP}” to specify the display attributes for columncatelog.The display label isCategory. The data type is String. The column will be displayed by default and it will be treated as aselectable dimension column in a multiple dimension query.
To define the query criteria (ConditionAttribute), we use a collection of semi-colon delimited fields enclosed in angulerbrackets “<>” as:
ConditionAttribute ::=<ConditionExpression;ConditionDescription;ConditionType [;[Value Domain];[RequiredAttribute];[Default Attribute];[Hint] ] >
Condition Expressionis unique name for query criteria.Condition Description specifies the display label of the criteria. We can specify “#sequencenumber” in this field to tell theparser that the current criteria shares the same input valuewith the query criteria as the sequence number.Condition Type is the SQL datatype of the column.Value Domain is specified as comma-delimited “value|description” pairs or “#select value, description from tablenamewhere-clause” to generate a pick list for input field.Required Attribute specifies whether the input attribute should be REQUIRED, FIXED or VALUEONLY. REQUIRED
3

means value must be fed in the field before submitting the query. FIXED should be combined with default attribute to makeread only input field that could only take the default value. VALUEONLY serves the same as REQUIRED, the difference isthe parser will only use value itself to replace the macro rather than use the “attrname operator value” expression to replacethe macro.Default Attribute can be used to specify the default value for the input field. Itcan be a string, a number or a “#single valueselect-statement”.Hint can be used to specify a help message that will be displayed when mouse is moved over the input field.
For example, we can use “<id; Item; INTEGER; #select id,name from titem where id between 500 and 999 order byid>” to specify the query condition attributes for condition field id. The display label isItem. The data type is integer. Theselectable value domain can be retrieved by sending SQL statement “select id,name from titem where id between 500 and999 order by id” to the database server.
The query process written in GQL script contains a collection of semi-colon delimited GQL statements. Currently, thelanguage consists of (a) eleven types of statements (SQL statement, Declare, Assignment, If-elif-else, While, Exit, Break,Continue, Call, Display and Mine statement), (b) two built-in functions (today(), substring()) and (c) one built-in object(DataSet). All the statements are case insensitive.(a). The Eleven GQL Statements1. SQL statement: Ordinary SQL statements for specific DBMS.We can place FieldAttribute or ConditionAttribute macrosin the select-list or where/having clause.2. DECLARE statement: We can define variables using the declare statement like:$declare varname1 Integer, varname2 Boolean . . . ;The supported data types include Integer, Numeric, Boolean, Date, Datetime, String and DataSet, corresponding to JavaclassInteger, Double, Boolean, Date, String and a self-defined class to communicate with database server and manipulate the dataresult in XML format. e.g.,$declare counter Integer;3. Assignment statement: We can assign value to a variable using $set statement$set varname = expression; The expres-sion can be any PASCAL style arithmetic, relational or logical expressions and function calls, e.g.,$set counter = counter +1;4. IF - ELIF - ELSE statement: The flow control feature can be used as:
$if (expression)$begin
Statements;$end$elif (expression)$begin
Statements;$end$else$begin
Statements;$end;
The elif and else sub clause are optional. Currently all the statements or single statement should be enclosed within the$begin and $end block. e.g.,
$if (a >= 0)$begin
select * from tdace where income>= 0 into temp t1;$end$else$begin
select * from tdace where outcome< 0 into temp t1;$end;
5. WHILE statement: We can also define the iteration using $while statement
$while (expression)
4

$beginStatements;
$end;
All the statements or single statement should also be enclosed within the $begin and $end block. e.g.,
$while (counter< 10)$begin
update titem set balance=0.0 where id = :counter;$set counter = counter + 1;
$end;
6. EXIT statement: We can use $exit statement to quit the execution of the statements.7. BREAK statement: We can use $break statement to break a while-loop.8. CONTINUE statement: We can use $continue statement to skip the rest of the statements in a while-loop and jump to thecondition judgment step directly.9. CALL statement: We can use $call statement to invoke a built-in function or method of a built-in object when we do notneed the returned object.$callfunction/method name([parameters]); e.g.,$call ds.union(ds1);– merge dataset ds1 intodataset ds.10. Display statement:
$display datasetvar using FieldAttribute, FieldAttribute,Field Attribute,. . . ;
Set Datasetvar as primary dataset, dump it into file system using specified fields for display.11. Mine statement:
$mine datesetvar classifier using attr1,attr2,attr3,. . .class classattrmodel ‘modelfile name’;
This uses WEKA pre-generated classifier model to classify data in datasetvar. Attributes specified as attr1, attr2, ... are predic-tive attributes. The classattr is the attribute that is used to classify the dataset tuple. The model stored in the modelfile namecontains algorithm information and its tuned parameters. Section 4.2 has examples of using Mine statement and Displaystatements.(b). GQL built-in functions : Currently, GQL supports today() function to get current system date and substring() functionto retrieve substring from a String variable.
1. Date Today() – gets system date.
2(i). String<expression>.SubString(Integer startpos) – retrieves substring from the start position of current variable string.
2(ii). String<expression>.SubString(Integer startpos, Integer len) – retrieves substring from the start position of currentvariable string, and stops at length of len. e.g.,$set str2 = str1.substring(1,12);
(c). GQL built-in DataSet object : The DataSet object provides five methods (ExecQuery, ReadTable, ReadFile, DumpFileand Union):1. DataSet.ExecQuery(String sqlstatement)This is a static function to send a SQL statement to the database, retrieve query result and convert it into XML document. Itreturns a DataSet object. e.g.,$set ds = Dataset.ExecQuery(‘select * from t1’);2. DataSet.ReadTable(String dbtablename)This is equivalent to ExecQuery function with “select * from<tablename>” statement as parameter. It retrieves query resultand converts it into XML document. It returns a DataSet object, e.g.,$set ds = Dataset.readtable(‘t1’);3. DataSet.ReadFile(String filename)We can use this static method to load a Delphi ClientDataSet [20] compatible XML document from the cache directory (thelocation of the cache directory is configurable in the systemproperty file. For how the query result is generated, see section3.2.3). The return object is a DataSet object. e.g.$set ds = DataSet.readFile(‘t1img’); – loads cache image having ‘t1img’
5

postfix into memory. The cache file can either have .xml or .xml.z extension. The naming pattern for a cache file containsfour parts: “g[query id][submit datetime in yyyyMMddHHmmss format][operator ID] [optional postfix name string]”. e.g.g5 060607194722jack t1 img.xml4. DataSet.DumpFile(Integer order, Boolean compress)We can use this method to dump the memory image of the current DataSet object into cache directory as Delphi ClientDataSetcompatible XML document. By default, the order is zero, and compress is true. This means the data will be saved as theprimary data package in compressed XML format. A GQL query can return multiple results, each result data package shouldbe assigned a unique number to tell its order before being dumped into the cache directory. e.g.$call ds.DumpFile(0,true);5. DataSet.Union(DataSet ds)Merge the data in ds into the current dataset.For backward compatibility, and because some database servers already support the declaration and flow control statements,such as T-SQL for Sybase, all the non-SQL statements are marked with a prefix “$”. This way, all the statements without“$” prefix will be sent to database server directly and all thestatements having “$” prefix will be executed by the interpreteritself. The following sample script displays the tuples in tablet dace:
select{id;Item;INTEGER;SHOW;;GROUP},{mark;Type;STRING;SHOW;;GROUP},{catelog;Category;STRING;SHOW;;GROUP},{cdate;Date;DATE;SHOW;;GROUP},{sum(income) incom;Credit;MONEY;SHOW;SUM},{sum(outcome) outcom;Debit;MONEY;SHOW;SUM},{sum((income-outcome)) net;Net;MONEY;SHOW;SUM}
from t dacewhere
<id;Item;INTEGER;#select id,name from titemwhere id between 500 and 999 order by id> and
<note;Description;STRING> and<mark;Type;STRING;#1> and<catelog;Category;STRING;#3> and<cdate;Date;DATE> and<income*exrate;Credit;MONEY> and<outcome*exrate;Debit;MONEY>
group by #1, #2, #3, #4order by #1, #2, #3, #4;
The references defined in “group by” clause correspond to thecolumns with “GROUP” attributes. The user can decidewhether these group columns will be included in the final dataresult. References also can be defined in the value domainpart of the conditions. For example, we can use “#select id, name from titem where id between 500 and 999 order by id” togenerate a dropdown list from the specified SQL statement. Figure 1 shows the generated user interface. After inputting thequery criteria and submitting the query, the parser generates the following target statement.
selectmark, catelog, sum(income) incom, sum(outcome) outcom,sum((income-outcome)) net
from t dacewhere id between 501 and 512 and
mark = ’P’ and cdate>= ’01-01-2006’group by mark, catelogorder by mark, catalog
Please note that those input criteria whose values are emptywill be removed from the where clause of the final GQL statement.
6

Figure 1. Generated user Interface
3.2. Architecture of the GQL Toolkit
The java-based architecture of this toolkit is shown in Figure 2. The major five components of this toolkit are Metadatarepository, GQL Parser, GQL Daemon, GQL Server and GQL Viewer.
3.2.1 Metadata repository
All the pre-defined query plans, which include plan name, description, GQL script, access right information etc, and usersubmitted query tasks are stored in the metadata repository. It also contains system information like operators, data dictionaryand system audit. We use Hibernate [12], a Java toolkit for mapping Entity Relation Model to Object Model, to map thesetables into java classes. In this way, the manipulation on the database records is converted into manipulation on the generatedmapping objects.
3.2.2 GQL Parser
The GQL Parser is the core component of the whole system. Its function is to parse the GQL script, look up displayfields and conditional fields, get their attributes then generate internal object structures and syntax tree that will beused byGQL Daemon and data presentation module. It is developed using java based lexical analyzer generator Jflex and java basedLALR parser generator Java Cup [13]. The GQL Parser acts as a two-phase parser engine. The first-phase parse happens atthe time that user generates a new query task. It parses the GQL script to locate the Field Attributes and Condition Attributesand provide information for building the user interface, then uses the Macro replacement mechanism to replace the FieldAttributes and Condition Attributes with the real expressions, removes redundant query conditions and generates a collectionof target GQL statements.
The second-phase parse happens at the time that GQL Daemon executes the submitted task in the background. It interpretsthe target GQL statements in sequential order, submits SQL statements to datatbase server and manipulates the data based onuser defined logic.
3.2.3 GQL Daemon
This module acts as the background query processing unit. Itawakes every few seconds to browse the task queue, lookingfor tasks in waiting status. When a waiting task is detected,the daemon program creates a thread to execute the task. Thealgorithm for the main process is:
Procedure callbackmain()Begin
1. Load parameters;2. While Exists(thread(s) in the CriticalSection) Do wait;3. Enter CriticalSection;
7

Metadata
Repository
p_query,
p_queryq ...
Database/
Datamart
GQL App At Server Side
GQL Daemon JDBC
Application Server - Tomcat
GQL Server
(Web Services
Based on Axis)
GQLViewer
(JSP, Servlet,Struts…
TODO: Report tools,
Jpivot OLAP, Data
Mining)
GQL Parser
Client App Web Browser
File System
Cache Directory
(in compressed
XML format)
SOAP/WSDL
Hibernate
O-R Mapping
1.get waiting tasks
2.set task status
Hibernate
O-R Mapping
1. get script,
2. put into queue
3. get task info
Write query result
into the cache
directory
Read cached
query results for
display
HTTP
Figure 2. GQT Architecture
4. If (At House-Cleaning Time) Then4.1. Call house-cleaning procedure to clear expired tasks;
5. For each item in task queue with status as “Waiting”Begin5.1. If numof threads<= MAXTHREADS ALLOWED Then
Begin5.1.1. numof threads = numof threads + 1;5.1.2. Set the status of current task to “Running”;5.1.3. Create a new thread to execute the current task
defined as procedure “run” below;End
End6. Exit CriticalSection; End.
The algorithm for executing a task in the thread is:
Procedure run()Begin
1. Get script from metadata repository;2. Create new instance of GQL Parser class and call itsParse method to parse the script;3. Get XML schema which contains user input from thecurrent task queue item;4. Call GQLParser.XMLBindFieldsAndConditions to bind theXML schema;5. Call GQLParser.Execute to get a list of target GQLstatements;6. Using the GQL interpreter to execute the target GQLstatements one by one, submit all SQL statements to DBMSvia JDBC;
8

7. Export the query results and save them into the cachedirectory that is a system parameter, as compressed XMLdocument.8. While Exists(thread(s) in the CriticalSection) Do wait;9. Enter CriticalSection;10. Set the status of the task to “Success”;11. numof threads = numof threads - 1;12. Exit CriticalSection; End.
The following XML document is an example of generated query result in uncompressed form:
<?xml version=“1.0” encoding=“UTF-8” standalone=“yes”?><DATAPACKET Version=“2.0”>
<METADATA ><FIELDS>
<FIELD attrname=“date” fieldtype=“date”WIDTH=“23”/><FIELD attrname=“accountno” fieldtype=“string”WIDTH=“9”/ ><FIELD attrname=“transnum” fieldtype=“r8”/><FIELD attrname=“transamt” fieldtype=“r8”SUBTYPE=“Money”/>
</FIELDS><PARAMS LCID=“1033”/>
</METADATA ><ROWDATA>
<ROW date=“20040128” accountno=“11000”transnum=“2” transamt=“240.34” /><ROW date=“20040129” accountno=“11004”transnum=“1” transamt=“436.40” /><ROW date=“20040130” accountno=“11000”transnum=“2” transamt=“1240.75” />...
</ROWDATA></DATAPACKET>
The above XML represents the data shown below:Date AccountNo Transnum Transamt
Jan 28, 2004 11000 2 240.34Jan 29, 2004 11004 1 436.40Jan 30, 2004 11000 2 1240.75
... ... ... ...In case of too many requests to be submitted to the database server, the maximum number of concurrent threads can be
configured in the property settings.This daemon also performs house-cleaning work to clear outdated query results at specific house cleaning time. The
cleaning strategy currently used is based on the frequency of references to the result dataset. If a cached data file is cleared,its corresponding queue item will also be erased.
3.2.4 GQL Server
The GQL Server module provides service interfaces used by the presentation layer(i.e. the GQL Viewer or client ap-plication discussed in Section 3.2.5). It is either deployed as a jar package or as web service based on Apache Axis [17].Therefore, it can be called directly or via web service connection using Simple Object Access Protocol (SOAP) [18] and WebServices Description Language (WSDL) [19]. This is an essential component for Service-Oriented-Architecture. Therearetwo major services currently provided:
9

1. AccessServiceProvides system related services such as user login, get environment etc. Service Interfaces include three operations(AddWorklog, GetSysInfo, OperChangPswd), whose input and output parameters are summarized below.AddWork-Log: Writes system log into database.Input Parameters: operid - user login ID; optype - type of operation; sucflag - success flag; note - detailed messageGetSysInfo: User login authenticate. If login succeeds, returns user information.Input Parameters: SysID - id of the sub-system; Group - reserved; OperID - user’s login id; Operpass - password;Output Parameters: OpBankNo - user’s branchno; OpName - user’s name, Oplevel - user’s access right vector; Sysdate- business date of the systemOper ChangPswd: Changes operator’s password.Input Parameters: FOperID - user’s login id; FBankNo - user’s branchno; OldPassword - user’s old password; New-Password - user’s new password;
2. GQL ServiceProvides GQL related services, including nine major operations (getXMLSchema, getDBType, getAllScriptList, Ex-tractData, ClearData, getCondflds, CheckCachedQuery, ApplyQuery and MarkQuery):getXMLSchema: Parses theGQL script, returns parsed results (XML schema) that is usedto generate user input interface.Input Parameters: Seq - primary key of query plan table.Output Parameters: XML schema string.Each time the query is accessed, the reference counter of this query is increased by 1.getDBType: Returns the current database dialect of the server.getAllScriptList : Gets directory of published querys.Input Parameters:Level - vector of user’s administrative level.Output Parameters: Query directory in CSV format.ExtractData: Extract data results from cache directory.Input Parameters: Uid - queues id of the task; Num - Sequence number of the file if multiple datasets are returned.Output Parameters: Data result stream.Each time the data result of a task is viewed, the reference counter of this task is increased by 1.ClearData: Clears the task and its cached query result.Input Parameters: Uid - queue id of the taskgetCondflds: Gets XML schema of submitted tasks which contains user input criteria.Input Parameters: Uid - queue id of the task.Output Parameters: XML schema in string stream.CheckCachedQuery: This service function checks whether there is already a cached result using the same XMLschema and if “Yes”, users will have a choice to fetch the dataresult directly from cache rather than submit to thedatabase server.Input Parameters: Seq - primary id of query plan table; Operno - user id; Condflds - user submitted XML schema.Output Parameters:Lstime - submitted time if the matching task exists; Loper - the creator id of the matching task;Luid - the uid of the matching task; ldatapath - the data result file path of the matching task.ApplyQuery : Submits a query by adding a new task in task queue.Input Parameters: Seq - primary id of query plan table; Operno - user id; Condflds - user submitted XML schema.MarkQuery : Adds footnotes on an existing task.Input Parameters: Uid - the uid of the existing task; Mark - The foot note string to be added.
3.2.5 GQL Viewer and Client Application
A typical multi-tiered application usually consists of three layers: the database server in the first tier to manage the data forthe application, the application server and GQLServer in the second tier that provide the business logic for the application,and the presentation layer stays in the third tier to provideuser interface and handle interactions with the user. The GQLViewer and Client Application represent the presentation layer of GQT system. There are seven major functions providedbythe viewer:1. Providing User authentication interface. Currently, the system supports user login and change password interface andperforms the actions by calling methods defined in GQLServer-AccessService.
10

2. Presenting Query directory to the user. The viewer calls getAllScriptList service at first to extract query directorythendisplays it via a Treeview component.3. Generating a screen for query criteria input after user selects a query. The viewer calls getXMLSchema service to get theinformation needed to build the interface, then deserializes the XML schema and stores its information into an instanceof aninternal class. A self-defined jsp tag class has been designed to co-operate with this internal class to generate HTML inputareas, with dynamic selections and checks.4. Binding user input into GQL XML schema and adding the querytask queue. The viewer uses the internal class to collectinput field values, generate XML schema that is combined withuser input, then checks the availability of cached data resultby calling CheckCachedQuery service and sending it back to the query queue by calling ApplyQuery service.5. Monitoring the task queue, adding notes or deleting a task. The viewer reads and displays the list of queued tasks submittedby the current user. The listed items can be selected. For theselected tasks, user can add footnotes by calling MarkQueryservice; delete selected task by calling ClearData serviceor click “view” to display the query result to screen.6. Displaying the query result to the screen. To view a completed query, the viewer first gets the XML schema which containsall the query criteria of the completed task from the queue item, then uses this information to replace the current web formsettings. At last, the viewer calls ExtractData service to extract the query result from cache and uses a XSLT schema totransform it into HTML code.7. Reporting, data export and other interactive data analysis support. These features are to be implemented by integratingother third party software packages.The current version of GQL Viewer is developed using Jsp, Struts based on Tomcat application server. Most of the actionsare completed through communication with the services provided by GQL Server.
3.2.6 The Integrated Workflow of Background Query Process
Because all the submitted tasks are executed by GQL Daemon program in background, this software toolkit supportsbackground query. This way, users can leave to do other work and come back hours or days later to check whether their longdata analysis processes are completed. The integrated workflow sequence of a task is:1. User selects a query from the query directory displayed byGQLViewer.2. GQLViewer calls getXMLSchema service to get XML schema ofa query and builds input user interface.3. User inputs query criteria, aggregate group informationthen submits the query.4. The GQLViewer calls CheckCachedQuery service to check the task queue for a cached query with the same input criteriaso that user is given the option using the cached result or rerunning the query.5. GQLDaemon detects a new task and generates a new thread to run it using the procedure described in section 3.2.3. Thegenerated query result is saved as a compressed XML documentin the cache directory.6. User checks the status of submitted query via GQLViewer.7. User extracts the query result and views the data via GQLViewer.
4. Integrating Data Mining features into Generic Query Toolkit
4.1. Overview of WEKA system
The GQT prototype integrates data classifier by selecting WEKA data mining toolkit. WEKA [8] stands for WaikatoEnvironment for Knowledge Analysis. It is a collection of machine learning algorithms written in Java. The algorithms fallinto three major categories:1. Classifiers: Many popular mining algorithms such as J48, ID3, NaiveBayes, BayesNet, MultilayerPerceptron(NeronNetwork Based) and M5 are found.2. Clusterers: Including SimpleKMeans, FarthestFirst(k-center), EM and Cobweb are found.3. Association rule finders: Including Apriori, Tertius arehere.
4.2. Integrating WEKA Classifier into GQT
The general procedure for applying WEKA classifier includestwo major stages. In the first stage, we use WEKA analyzingtool to do the offline research, which includes studying the data characteristic, selecting the best classification algorithm,tuning the parameters and generating the analyzing model based on the pre-collected training data and testing data. The
11
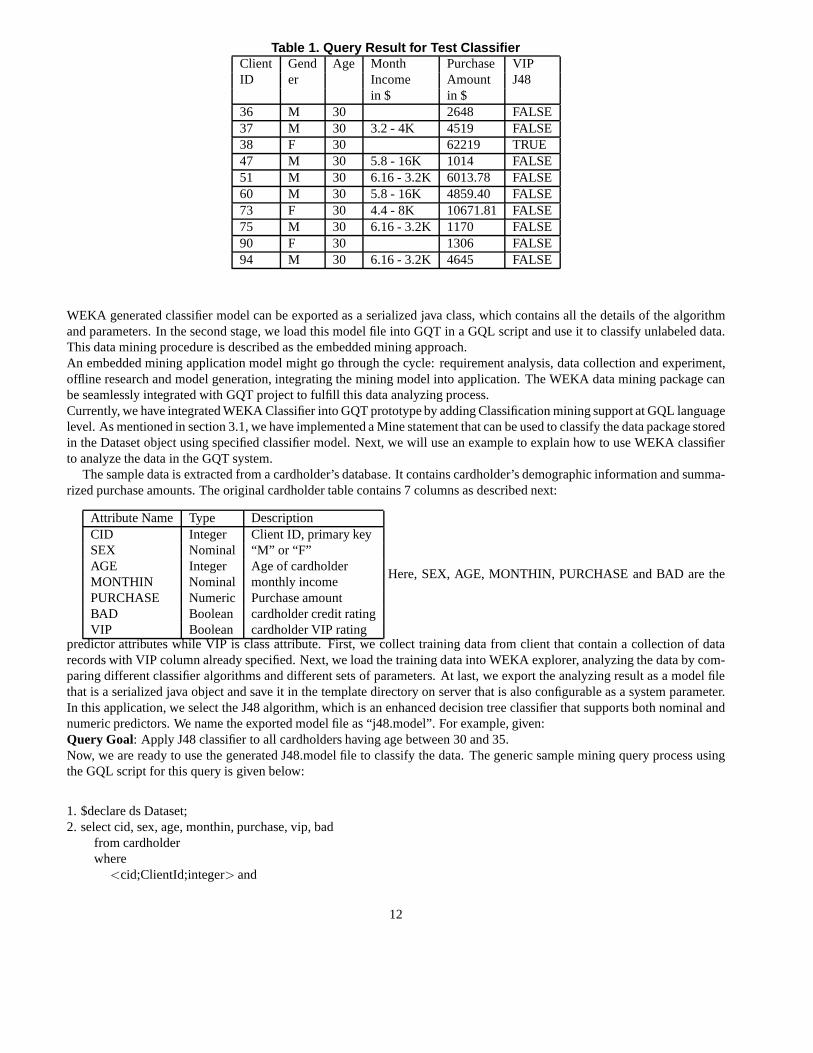
Table 1. Query Result for Test ClassifierClient Gend Age Month Purchase VIPID er Income Amount J48
in $ in $36 M 30 2648 FALSE37 M 30 3.2 - 4K 4519 FALSE38 F 30 62219 TRUE47 M 30 5.8 - 16K 1014 FALSE51 M 30 6.16 - 3.2K 6013.78 FALSE60 M 30 5.8 - 16K 4859.40 FALSE73 F 30 4.4 - 8K 10671.81 FALSE75 M 30 6.16 - 3.2K 1170 FALSE90 F 30 1306 FALSE94 M 30 6.16 - 3.2K 4645 FALSE
WEKA generated classifier model can be exported as a serialized java class, which contains all the details of the algorithmand parameters. In the second stage, we load this model file into GQT in a GQL script and use it to classify unlabeled data.This data mining procedure is described as the embedded mining approach.An embedded mining application model might go through the cycle: requirement analysis, data collection and experiment,offline research and model generation, integrating the mining model into application. The WEKA data mining package canbe seamlessly integrated with GQT project to fulfill this data analyzing process.Currently, we have integrated WEKA Classifier into GQT prototype by adding Classification mining support at GQL languagelevel. As mentioned in section 3.1, we have implemented a Mine statement that can be used to classify the data package storedin the Dataset object using specified classifier model. Next,we will use an example to explain how to use WEKA classifierto analyze the data in the GQT system.
The sample data is extracted from a cardholder’s database. It contains cardholder’s demographic information and summa-rized purchase amounts. The original cardholder table contains 7 columns as described next:
Attribute Name Type DescriptionCID Integer Client ID, primary keySEX Nominal “M” or “F”AGE Integer Age of cardholderMONTHIN Nominal monthly incomePURCHASE Numeric Purchase amountBAD Boolean cardholder credit ratingVIP Boolean cardholder VIP rating
Here, SEX, AGE, MONTHIN, PURCHASE and BAD are the
predictor attributes while VIP is class attribute. First, we collect training data from client that contain a collection of datarecords with VIP column already specified. Next, we load the training data into WEKA explorer, analyzing the data by com-paring different classifier algorithms and different sets of parameters. At last, we export the analyzing result as a model filethat is a serialized java object and save it in the template directory on server that is also configurable as a system parameter.In this application, we select the J48 algorithm, which is anenhanced decision tree classifier that supports both nominal andnumeric predictors. We name the exported model file as “j48.model”. For example, given:Query Goal: Apply J48 classifier to all cardholders having age between 30 and 35.Now, we are ready to use the generated J48.model file to classify the data. The generic sample mining query process usingthe GQL script for this query is given below:
1. $declare ds Dataset;2. select cid, sex, age, monthin, purchase, vip, bad
from cardholderwhere
<cid;ClientId;integer> and
12

<vip;VIP;integer;0|False,1|True> and<purchase;PurchaseAmt;Money> and<age;Age;Integer>
into temp t1;3. $set ds = Dataset.readtable(‘t1’);4. $mine ds classifier using sex, age, monthin, purchase, bad
class vipj48 model ‘j48.model’;5. drop table t1;6. $display ds using
{cid;ClientId;Integer;SHOW},{sex;Gender;String;SHOW},{age;Age;Integer;SHOW},{monthin;MonthlyIncome;String;SHOW},{purchase;PurchaseAmt;Money;SHOW;SUM},{vip;VIP;integer;SHOW},{bad;Bad;integer;SHOW},{vip j48;VIP J48;String;SHOW};
In statementNo.1, we declare a Dataset variable to store the query result thatwill be classified. In statementNo.2, we writea SQL statement that accepts user input query criteria to query the cardholder table. The query result will be written to atemporary table called “t1”. In statementNo.3, we use Dataset.ReadTable() member function to read the data from temporarytable “t1” into ds object. In statementNo.4, we use “Mine” statement to classify the data, using sex, age, monthin, purchase,bad as predictor attributes, and file “j48.model” as the model. The classification result will be written in a new column called“vip j48”. In statementNo.5, we drop the temporary table “t1”. In statementNo.6, we specify the output format using“Display” statement.
After the query is submitted and processed, we get the query result shown in Table 1, where the two columns of VIP andBad are skipped, but only the client with id 38 has a value of TRUE FOR VIP and FALSE for Bad. The computer generatedclassification results are shown as column “VIPJ48”.
5. Testing Environment
We have set up a GQT test bed environment on a PC environment (CPU: Pentium III, Memory: 768MB, OS: Windows XPProfessional) that can be accessed via http://137.207.234.76:8088/gqlview. One can use the test user: zlc, password:9999to access this system. Because the whole application is developed using java, it can be deployed to various platforms. Theapplication has the following prerequisites:1. JDK 1.5
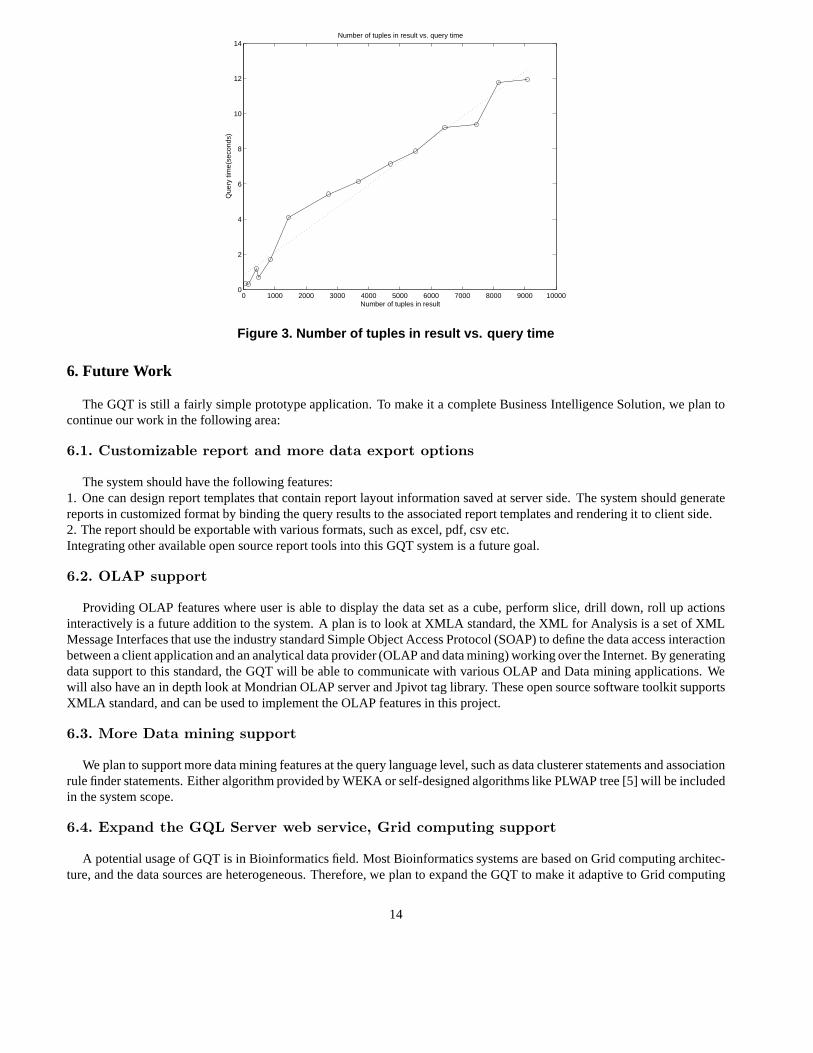
2. Informix Dynamic Server 9.4 and its JDBC driver: Currently the GQT supports Informix, Sybase and Access DBMS.3. Tomcat 5.0.28: The application server for JSP, Servlet.4. Apache Axis 1.3: A Java Web Service library.5. Hibernate 3.1: A Java DB access toolkit that supports Object-Relational Mapping.6. WEKA 3.4: WEKA Data Miner.7. Java Flex 1.4 or above: Java based scanner generator.8. Java Cup v0.10k or above: Java based parser generator.9. JDOM 1.0rc1 or above: Java-based solution for accessing,manipulating, and outputting XML.10. Apache Struts 1.2.4: MVC package used in presentation layer11. Struts-layout 1.1: A tag library for struts which provides easy and fast interface creation.We used the sample cardholder classifier query mentioned in section 4.2 to test the performance of GQT. The result is shownas Figure 3 and Figure 4. Figure 3 shows the relationship between the cardinality of the query result and the time used bythe query. it can be seen that the time used by the query is dependent on the cardinality of the query result. For a query thatreturns about 10000 records, the time to complete the query is about 14 seconds. Figure 4 shows the relationship betweenthe cardinality of the query result and the size of the data packet. The query result in the data packet is stored as compressedXML document by GQT. From it, we can see that the size of the result data packet is strictly linearly dependent upon theresult cardinality. For a query that returns about 10000 records (with about 1MB size before been compressed), the resultdata packet can be compressed to around 130KB, which considerably saves the cache space and bandwidth for data transfer.
13
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 100000
2
4
6
8
10
12
14
Number of tuples in result
Que
ry ti
me(
seco
nds)
Number of tuples in result vs. query time
Figure 3. Number of tuples in result vs. query time
6. Future Work
The GQT is still a fairly simple prototype application. To make it a complete Business Intelligence Solution, we plan tocontinue our work in the following area:
6.1. Customizable report and more data export options
The system should have the following features:1. One can design report templates that contain report layout information saved at server side. The system should generatereports in customized format by binding the query results tothe associated report templates and rendering it to client side.2. The report should be exportable with various formats, such as excel, pdf, csv etc.Integrating other available open source report tools into this GQT system is a future goal.
6.2. OLAP support
Providing OLAP features where user is able to display the data set as a cube, perform slice, drill down, roll up actionsinteractively is a future addition to the system. A plan is tolook at XMLA standard, the XML for Analysis is a set of XMLMessage Interfaces that use the industry standard Simple Object Access Protocol (SOAP) to define the data access interactionbetween a client application and an analytical data provider (OLAP and data mining) working over the Internet. By generatingdata support to this standard, the GQT will be able to communicate with various OLAP and Data mining applications. Wewill also have an in depth look at Mondrian OLAP server and Jpivot tag library. These open source software toolkit supportsXMLA standard, and can be used to implement the OLAP featuresin this project.
6.3. More Data mining support
We plan to support more data mining features at the query language level, such as data clusterer statements and associationrule finder statements. Either algorithm provided by WEKA orself-designed algorithms like PLWAP tree [5] will be includedin the system scope.
6.4. Expand the GQL Server web service, Grid computing support
A potential usage of GQT is in Bioinformatics field. Most Bioinformatics systems are based on Grid computing architec-ture, and the data sources are heterogeneous. Therefore, weplan to expand the GQT to make it adaptive to Grid computing
14

0 1000 2000 3000 4000 5000 6000 7000 8000 9000 100000
2
4
6
8
10
12x 10
5
Number of tuples in result
Res
ult d
ata
pack
et s
ize(
byte
s)
Number of tuples in result vs. result data packet size
Compressed packet size from GQTRegular packet size
Figure 4. Number of tuples in result vs. result packet size
architecture in the following ways:• Standardizing the web services provided by the GQL Server;• Adding language support for GQL script to access distributed resources through web service interface.
7. Summary and Conclusions
This paper presents the design of a Generic Query Toolkit as an economical solution for building reporting and dataanalysis focused applications. We also present the integration of data mining features into this system. By introducing aquery language to automate the query and data presenting process, we can easily glue up the user defined business logictogether with back-end services and front-end presentation modules, which greatly extend the flexibility of the system.
Currently, we are in the process of expanding toolkit into a full Business Intelligent solution. There is still a long waytogo to build a fully functional data analysis software package. Various techniques will be used in this project. The goal of ourproject is to make this tool adaptive to projects of various scales and various areas.
References
[1] M. Golfarelli, S. Rizzi, I. Cella. Beyond Data Warehousing: What’s next in business intelligence?Proceedings 7thInternational Workshop on Data Warehousing and OLAP (DOLAP2004). Washington DC.
[2] James Dixon. (2005) Pentaho Open Source Business Intelligence Platform Technical White Paper. [Online] Available:http://sourceforge.net/project/showfiles.php?groupid=140317. c©2005 Pentaho Corporation.
[3] Ian H. Witten and Eibe Frank. (2005) Data Mining: Practical machine learning tools and techniques, 2nd Edition.Morgan Kaufmann, San Francisco.
[4] Michalis Petropoulos, Yannis Papakonstantinou, Vasilis Vassalos. (2005, May) Graphical query interfaces for semistruc-tured data: the QURSED system.ACM Transactions on Internet Technology (TOIT), Volume 5 Issue 2.
[5] C.I. Ezeife, Yi Lu. (2005) MiningWeb Log Sequential Patterns with Position Coded Pre-Order LinkedWAP-Tree.theInternational Journal of Data Mining and Knowledge Discovery (DMKD), Vol. 10, pp. 5-38, Kluwer Academic Pub-lishers.
[6] Jiawei Han, Micheline Kamber. Data Mining Concepts and Techniques.ISBN 7-111-09048-9/TP.1981. China MachinePress, Morgan Kaufmann, 2001.
15

[7] XML for Analysis Specification Version 1.1. [Online]. Available: http://www.xmla.org/docspub.asp. Microsoft Cor-poration, Hyperion Solutions Corporation, 2002.
[8] WEKA Data Mining Project. [Online]. Available:http://www.cs.waikato.ac.nz/ml/WEKA/.
[9] Business Objects Website. [Online]. Available:http://www.businessobjects.com.
[10] Cognos Website. [Online]. Available:http://www.cognos.com.
[11] Oracle Business Intelligence Suite. [Online]. Available: http://www.oracle.com/appserver/business-intelligence/index.html.
[12] Hibernate Project. [Online]. Available:http://www.hibernate.org.
[13] Java Cup LALR Parser Generator. [Online]. Available:http://www2.cs.tum.edu/projects/cup/.
[14] MDX Language Reference. [Online]. Available:http://msdn2.microsoft.com/en-us/ms145595.aspx. MSDN Library,Microsoft.
[15] Mondrain OLAP Server. [Online]. Available:http://mondrian.sourceforge.net/.
[16] JPivot Project. [Online]. Available:http://jpivot.sourceforge.net/.
[17] Apache Axis Project. [Online]. Available:http://http://ws.apache.org/axis/.
[18] W3C Simple Object Access Protocol (SOAP). [Online]. Available:http://www.w3.org/TR/soap.
[19] W3C Web Services Description Language (WSDL). [Online]. Available: http://www.w3.org/TR/wsdl.
[20] Cary Jensen. (2002) A ClientDataSet in Every Database Application. Borland Developer Network. [Online]. Available:http://bdn.borland.com/article/0,1410,28876,00.html.
16