general-purpose computation on graphics hardware adapted from: david luebke (university of virginia)...
TRANSCRIPT

General-Purpose Computation on General-Purpose Computation on Graphics HardwareGraphics Hardware
General-Purpose Computation on General-Purpose Computation on Graphics HardwareGraphics Hardware
Adapted from: David Luebke (University of Virginia) and NVIDIA

Your PresentationsYour Presentations
• Everyone Must attend• 10% loss of presentation points if a day is missed
• Presentation Grading Criteria posted online
• Everyone must present• Grades are given to the group, not individual

OutlineOutline
• Overview / Motivation
• GPU Architecture Fundamentals
• GPGPU Programming and Usage
• New NVIDIA Architectures (FERMI)
• More Infromation

Motivation: Computational PowerMotivation: Computational Power
• GPUs are fast…– 3 GHz Pentium4 theoretical: 6 GFLOPS, 5.96 GB/sec peak– GeForceFX 5900 observed: 20 GFLOPS, 25.3 GB/sec peak– GeForce 6800 Ultra observed: 53 GFLOPS, 35.2 GB/sec peak– GeForce 8800 GTX: estimated at 520 GFLOPS, 86.4 GB/sec
peak (reference here)• That’s almost 100 times faster than a 3 Ghz Pentium4!
• GPUs are getting faster, faster– CPUs: annual growth 1.5× decade growth 60× – GPUs: annual growth > 2.0× decade growth > 1000
Courtesy Kurt Akeley,Ian Buck & Tim Purcell, GPU Gems (see course notes)

Motivation: Computational PowerMotivation: Computational Power
Courtesy Naga Govindaraju
GPU
CPU

Motivation:Computational PowerMotivation:Computational Power
Courtesy Ian Buck
GFL
OPS
multiplies per second
NVIDIA NV30, 35, 40
ATI R300, 360, 420
Pentium 4
July 01 Jan 02 July 02 Jan 03 July 03 Jan 04

An Aside: Computational PowerAn Aside: Computational Power
• Why are GPUs getting faster so fast?– Arithmetic intensity: the specialized nature of GPUs makes
it easier to use additional transistors for computation not cache
– Economics: multi-billion dollar video game market is a pressure cooker that drives innovation

Motivation: Flexible and preciseMotivation: Flexible and precise
• Modern GPUs are deeply programmable– Programmable pixel, vertex, video engines– Solidifying high-level language support
• Modern GPUs support high precision– 32 bit floating point throughout the pipeline– High enough for many (not all) applications

Motivation: The Potential of GPGPUMotivation: The Potential of GPGPU
• The power and flexibility of GPUs makes them an attractive platform for general-purpose computation
• Example applications range from in-game physics simulation to conventional computational science
• Goal: make the inexpensive power of the GPU available to developers as a sort of computational coprocessor

The Problem: Difficult To UseThe Problem: Difficult To Use
• GPUs designed for and driven by video games– Programming model is unusual & tied to computer graphics– Programming environment is tightly constrained
• Underlying architectures are:– Inherently parallel– Rapidly evolving (even in basic feature set!)– Largely secret
• Can’t simply “port” code written for the CPU!

GPU Fundamentals:The Graphics PipelineGPU Fundamentals:The Graphics Pipeline
• A simplified graphics pipeline– Note that pipe widths vary– Many caches, FIFOs, and so on not shown
GPUCPU
ApplicationApplication TransformTransform RasterizerRasterizer ShadeShade VideoMemory
(Textures)
VideoMemory
(Textures)VerticesVertices
(3D)(3D)Xformed,Xformed,
LitLitVerticesVertices
(2D)(2D)
FragmentsFragments(pre-pixels)(pre-pixels)
FinalFinalpixelspixels
(Color, Depth)(Color, Depth)
Graphics StateGraphics State
Render-to-textureRender-to-texture

GPU Fundamentals:The Modern Graphics PipelineGPU Fundamentals:The Modern Graphics Pipeline
• Programmable vertex processor!
• Programmable pixel processor!
GPUCPU
ApplicationApplication VertexProcessor
VertexProcessor RasterizerRasterizer Pixel
ProcessorPixel
ProcessorVideo
Memory(Textures)
VideoMemory
(Textures)VerticesVertices
(3D)(3D)Xformed,Xformed,
LitLitVerticesVertices
(2D)(2D)
FragmentsFragments(pre-pixels)(pre-pixels)
FinalFinalpixelspixels
(Color, Depth)(Color, Depth)
Graphics StateGraphics State
Render-to-textureRender-to-texture
VertexProcessor
VertexProcessor
FragmentProcessorFragmentProcessor

GPU Pipeline: TransformGPU Pipeline: Transform
• Vertex Processor (multiple operate in parallel)– Transform from “world space” to “image space”– Compute per-vertex lighting

GPU Pipeline: RasterizerGPU Pipeline: Rasterizer
• Rasterizer– Convert geometric rep. (vertex) to image rep. (fragment)
• Fragment = image fragment– Pixel + associated data: color, depth, stencil, etc.
– Interpolate per-vertex quantities across pixels

GPU Pipeline: ShadeGPU Pipeline: Shade
• Fragment Processors (multiple in parallel)– Compute a color for each pixel– Optionally read colors from textures (images)

Importance of Data ParallelismImportance of Data Parallelism
• GPU: Each vertex / fragment is independent– Temporary registers are zeroed– No static data– No read-modify-write buffers
• Data parallel processing– Best for ALU-heavy architectures: GPUs
• Multiple vertex & pixel pipelines– Hide memory latency (with more computation)
Courtesy of Ian Buck

Arithmetic IntensityArithmetic Intensity
• Lots of ops per word transferred
• GPGPU demands high arithmetic intensity for peak performance– Ex: solving systems of linear equations– Physically-based simulation on lattices– All-pairs shortest paths
Courtesy of Pat Hanrahan

Data Streams & KernelsData Streams & Kernels
• Streams– Collection of records requiring similar computation
• Vertex positions, Voxels, FEM cells, etc.– Provide data parallelism
• Kernels– Functions applied to each element in stream
• Transforms, PDE, …– No dependencies between stream elements
• Encourage high arithmetic intensity
Courtesy of Ian Buck

Example: Simulation GridExample: Simulation Grid
• Common GPGPU computation style– Textures represent computational grids = streams
• Many computations map to grids– Matrix algebra– Image & Volume processing– Physical simulation– Global Illumination
• ray tracing, photon mapping, radiosity
• Non-grid streams can be mapped to grids

Stream ComputationStream Computation
• Grid Simulation algorithm– Made up of steps– Each step updates entire grid– Must complete before next step can begin
• Grid is a stream, steps are kernels– Kernel applied to each stream element
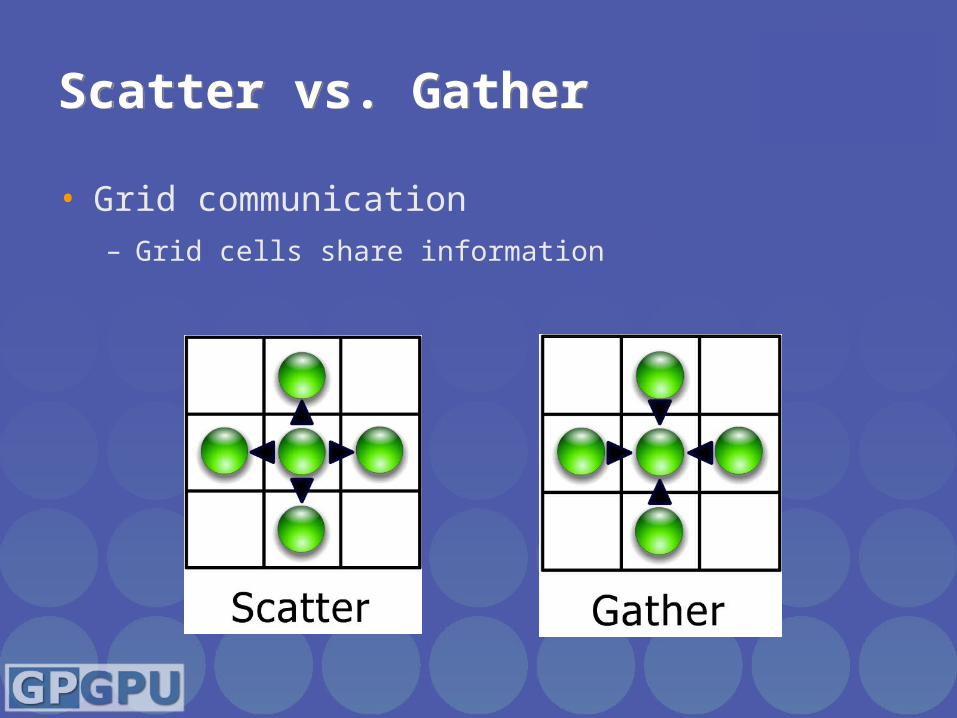
Scatter vs. GatherScatter vs. Gather
• Grid communication– Grid cells share information

Computational Resources InventoryComputational Resources Inventory
• Programmable parallel processors– Vertex & Fragment pipelines
• Rasterizer– Mostly useful for interpolating addresses (texture coordinates)
and per-vertex constants
• Texture unit– Read-only memory interface
• Render to texture– Write-only memory interface

Vertex ProcessorVertex Processor
• Fully programmable (SIMD / MIMD)
• Processes 4-vectors (RGBA / XYZW)
• Capable of scatter but not gather– Can change the location of current vertex– Cannot read info from other vertices– Can only read a small constant memory
• Future hardware enables gather!– Vertex textures

Fragment ProcessorFragment Processor
• Fully programmable (SIMD)
• Processes 4-vectors (RGBA / XYZW)
• Random access memory read (textures)
• Capable of gather but not scatter– No random access memory writes – Output address fixed to a specific pixel
• Typically more useful than vertex processor– More fragment pipelines than vertex pipelines– RAM read– Direct output

CPU-GPU AnalogiesCPU-GPU Analogies
• CPU programming is familiar– GPU programming is graphics-centric
• Analogies can aid understanding

CPU-GPU AnalogiesCPU-GPU Analogies
CPU GPU
Stream / Data Array = Texture
Memory Read = Texture Sample

CPU-GPU AnalogiesCPU-GPU Analogies
Loop body / kernel / algorithm step = Fragment Program
CPU GPU

FeedbackFeedback
• Each algorithm step depend on the results of previous steps
• Each time step depends on the results of the previous time step

ARB GPU Assembly LanguageArchitecture Review Board
ARB GPU Assembly LanguageArchitecture Review Board
• ABS - absolute value
• ADD - add
• ARL - address register load
• DP3 - 3-component dot product
• DP4 - 4-component dot product
• DPH - homogeneous dot product
• DST - distance vector
• EX2 - exponential base 2
• EXP - exponential base 2 (approximate)
• FLR - floor
• FRC - fraction
• LG2 - logarithm base 2
• LIT - compute light coefficients
• ABS - absolute value
• LOG - logarithm base 2 (approximate)
• MAD - multiply and add
• MAX - maximum
• MIN - minimum
• MOV - move
• MUL - multiply
• POW - exponentiate
• RCP – reciprocal
• RSQ - reciprocal square root
• SGE - set on greater than or equal
• SLT - set on less than
• SUB - subtract
• SWZ - extended swizzle
• XPD - cross product

Nvidia Graphics Card ArchitectureNvidia Graphics Card Architecture• GeForce-8 Series
– 12,288 concurrent threads, hardware managed– 128 Thread Processor cores at 1.35 GHz == 518 GFLOPS peak
TEX L1
SP
SharedMemory
IU
SP
SharedMemory
IU
TF
TEX L1
SP
SharedMemory
IU
SP
SharedMemory
IU
TF
TEX L1
SP
SharedMemory
IU
SP
SharedMemory
IU
TF
TEX L1
SP
SharedMemory
IU
SP
SharedMemory
IU
TF
TEX L1
SP
SharedMemory
IU
SP
SharedMemory
IU
TF
TEX L1
SP
SharedMemory
IU
SP
SharedMemory
IU
TF
TEX L1
SP
SharedMemory
IU
SP
SharedMemory
IU
TF
TEX L1
SP
SharedMemory
IU
SP
SharedMemory
IU
TF
L2
Memory
Work DistributionHost CPU
L2
Memory
L2
Memory
L2
Memory
L2
Memory
L2
Memory

NVIDIA FERMINVIDIA FERMI

FERMI: Streaming Multiprocessor (SM)FERMI: Streaming Multiprocessor (SM)
• Each SM contains
• 32 Cores
• 16 Load/Store units
• 32,768 registers
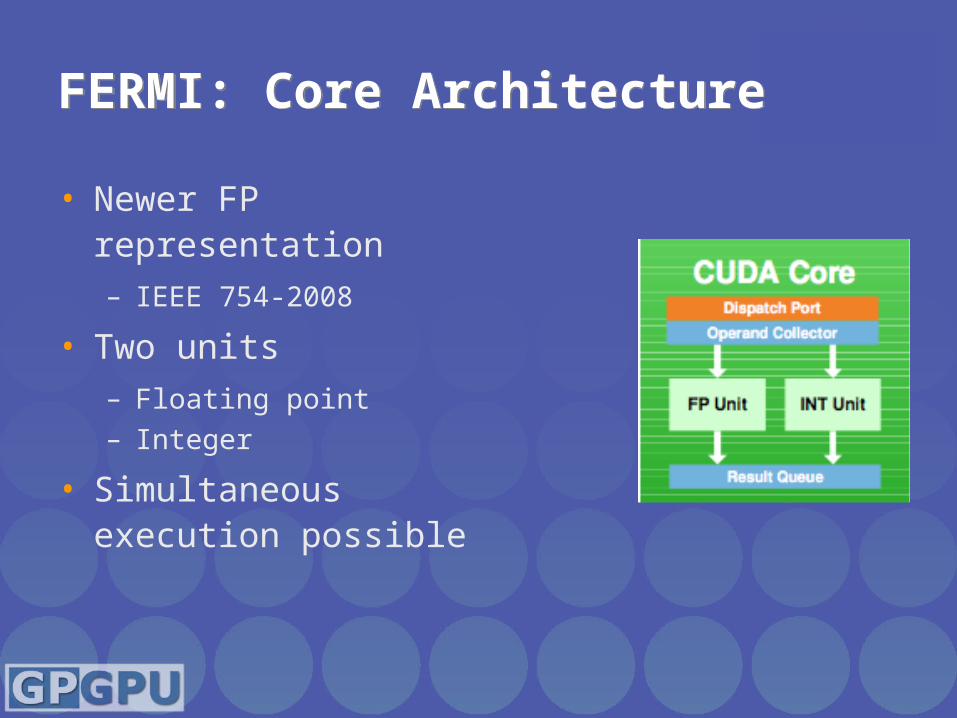
FERMI: Core ArchitectureFERMI: Core Architecture
• Newer FP representation– IEEE 754-2008
• Two units– Floating point– Integer
• Simultaneous execution possible

FERMI: ComparisonFERMI: Comparison

FERMI: ResultsFERMI: Results
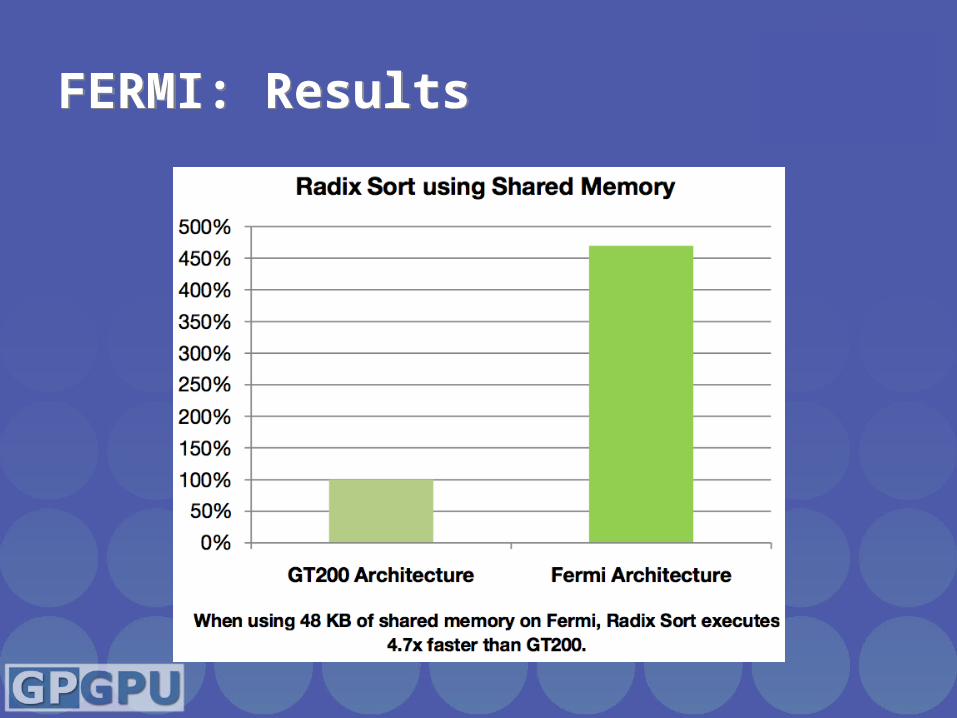
FERMI: ResultsFERMI: Results

What it looks like!What it looks like!

ApplicationsApplications
• Includes lots of sample applications– Ray-tracer– FFT– Image segmentation– Linear algebra

Brook performanceBrook performance
2-3x faster than CPU implementation
compared against 3GHz P4:• Intel Math Library• FFTW• Custom cached-blocked segment C code
GPUs still lose against SSEcache friendly code.Super-optimizations
• ATLAS• FFTW
ATI Radeon 9800 XT
NVIDIA GeForce 6800

GPGPU ExamplesGPGPU Examples
• Fluids
• Reaction/Diffusion
• Multigrid
• Tone mapping