論文輪読資料「gated feedback recurrent neural networks」
TRANSCRIPT

Gated Feedback Recurrent Neural Networks
Matsuo lab. paper reading session Jul.17 2015
School of Engineering, The University of TokyoHiroki Kurotaki

Contents
3
・ Paper information
・ Introduction
・ Related Works
・ Proposed Methods
・ Experiments, Results and Analysis
・ Conclusion

Contents
4
・ Paper information
・ Introduction
・ Related Works
・ Proposed Methods
・ Experiments, Results and Analysis
・ Conclusion

Paper Information
・ Gated Feedback Recurrent Neural Networks
・ Junyoung Chung, Caglar Gulcehre, Kyunghyun Cho, Yoshua Bengio
Dept. IRO, Universite de Montreal, CIFAR Senior Fellow
・ Proceedings of The 32nd International Conference on Machine Learning, pp. 2067–2075, 2015 (ICML 2015)
・ 1st submission to arXiv.org is on 9 Feb 2015
・ Cited by 9 (Google Scholar, Jul 17 2015)
・ http://jmlr.org/proceedings/papers/v37/chung15.html
5

Contents
6
・ Paper information
・ Introduction
・ Related Works
・ Proposed Methods
・ Experiments, Results and Analysis
・ Conclusion

Introduction 1/3
・ They propose a novel recurrent neural network(RNN) architecture,Gated-feedback RNN (GN-RNN).
・ GN-RNN allows connections from upper layers to lower layers, then controlls the signals by global gating unit.
7
(Each circle represents a layer consists of recurrent units (i.e. LSTM-Cell))

Introduction 2/3
・ The proposed GF-RNN outperforms the baseline methods in these tasks.
8
1. Character-level Lauguage Modeling
(from a subsequence of structured data, predict the rest of the characters.)

Introduction 3/3
・ The proposed GF-RNN outperforms the baseline methods in these tasks.
9
2. Python Program Evaluation
(predict script execution results from the input as a raw charater sequence.)
( [Zaremba 2014] Figure 1)

Contents
10
・ Paper information
・ Introduction
・ Related Works
・ Proposed Methods
・ Experiments, Results and Analysis
・ Conclusion
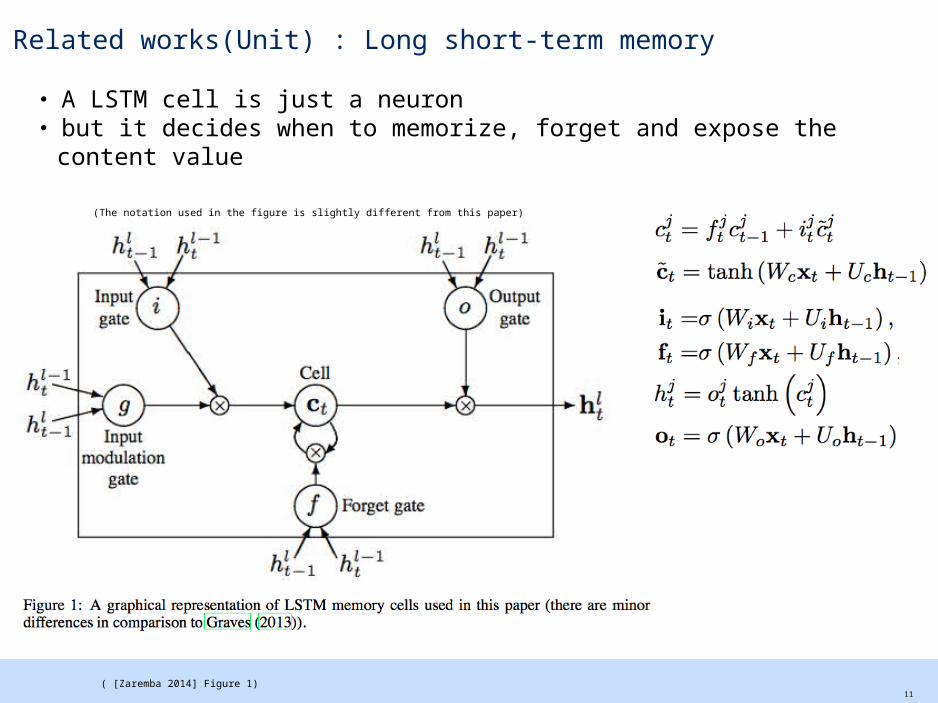
Related works(Unit) : Long short-term memory
・ A LSTM cell is just a neuron・ but it decides when to memorize, forget and expose the content value
11 ( [Zaremba 2014] Figure 1)
(The notation used in the figure is slightly different from this paper)

Related works(Unit) : Gated recurrent unit
・ Cho et al. 2014・ Like LSTM, adaptively reset(forget) or update(input) its memory
content.・ But unlike LSTM, no output gate・ balances between the previous and new memory contents adaptively
12 ( [Cho 2014] Figure 2)
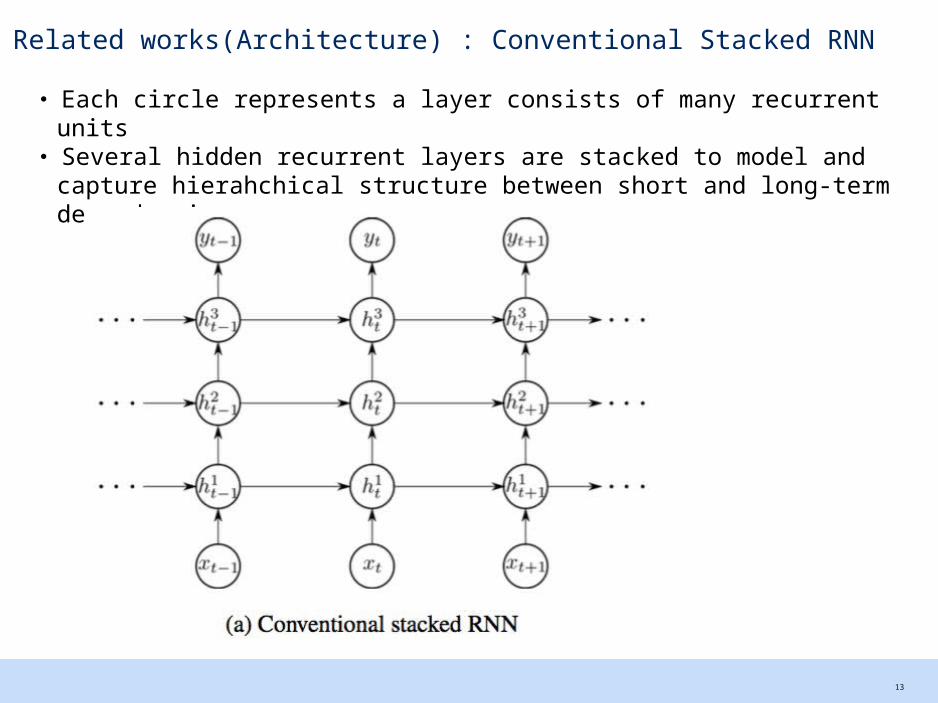
Related works(Architecture) : Conventional Stacked RNN
・ Each circle represents a layer consists of many recurrent units・ Several hidden recurrent layers are stacked to model and capture
hierahchical structure between short and long-term dependencies.
13

Related works(Architecture) : Clockwork RNN
・ i-th hidden module is only updated at the rate of 2^(i-1)・ Neurons in faster module i are connected to neurons in a slower
module j only if a clock period T_i < T_j.
14 ( [Koutnik 2014] Figure 1)

Contents
15
・ Paper information
・ Introduction
・ Related Works
・ Proposed Methods
・ Experiments, Results and Analysis
・ Conclusion

Proposed Method : Gated Feedback RNN
・ Generalize the Clockwork RNN in both connection and work rate・ Flows back from the upper recurrent layers into the lower layers・ Adaptively control when to connect each layer with "global reset gates".
(Small bullets on the edges)
16
: the concatenation of all the hidden states from the
previous timestep (t-1)
: from layer i in timestep (t-1)
to layer j in timestep t
global reset gate

Proposed Method : GF-RNN with LSTM unit
・ Only used when computing new memory state
17 ( [Zaremba 2014] Figure 1)
(The notation used in the figure is slightly different from this paper)

Proposed Method : GF-RNN with GRN unit
・ Only used when computing new memory state
18 ( [Cho 2014] Figure 2)

Contents
19
・ Paper information
・ Introduction
・ Related Works
・ Proposed Methods
・ Experiments, Results and Analysis
・ Conclusion

Experiment : Tasks (Lauguage Modeling)
・ From a subsequence of structured data, predict the rest of the characters.)
20

Experiment : Tasks (Lauguage Modeling)
・ Hutter dataset・ English Wikipedia, contains 100 MBytes of characters which include
Latin alphabets, non-Latin alphabets, XML markups and special characters
・ Training set : the first 90 MBytes Validation set : the next 5 MBytesTest set : the last 10 MBytes
・ Performance measure : the average number of bits-per-character (BPC)
21

Experiment : Models (Lauguage Modeling)
・ 3 RNN architectures : single, (conventional) stacked, Gated-feedback・ 3 recurrent units : tanh, LSTM, Gated Recurrent Unit (GRU)・ The number of parameters are constrained to be roughly 1000
・ Detail- RMSProp & momentum- 100 epochs- learning rate : 0.001 (GRU, LSTM) 5×10^(-5) (tanh)
- momentum coef. : 0.9
- Each update is done using a minibatch of 100 subsequences of length 100 each.
22

Experiment : Results and Analysis (Lauguage Modeling)
23
・ GF-RNN is good when used together with GRU and LSTM・ But failed to improve the performance with tanh units ・ GF-RNN with LSTM is better than the Non-Gated (The undermost)

Experiment : Results and Analysis (Lauguage Modeling)
24
・ the stacked LSTM failed to close the tags with </username> and </contributor> in both trials
・ However, the GF-LSTM succeeded to close both of them, which shows that it learned about the structure of XML tags

Experiment : Additional results (Lauguage Modeling)
25
・ They trained another GF-RNN with LSTM which includes larger number of parameters, and obtained comparable results.
・ (They wrote it's better than the previously reported best results, but there is a non-RNN work that acheived 1.278)

Experiment : Tasks (Python Program Evaluation)
・ input : a python program ends with a print statement, 41symbolsoutput : the result of a print statement, 13 symbols
・ Scripts used in this task include addition, multiplication, subtraction, for-loop, variable assignment, logical comparison and if-else statement.
・ Both the input & output are sequences of characters.
・ Nesting : [1,5]・ length : [1, 1^10]
26 ( [Zaremba 2014] Figure 1)

Experiment : Models (Python Program Evaluation)
・ RNN encoder-decoder approach, used for translation task previously・ Encoder RNN : the hidden state of the encoder RNN is unfolded for 50
timesteps.・ Decoder RNN : initial hidden state is initialized with the last hidden state
of the encoder RNN.
・ Detail- GRU & LSTM with and without Gated- 3 hidden layers for each Encoder & Decoder RNN- hidden layer contains : 230 units(GRM)
200 units(LSTM)- mixed curriculum strategy [Zaremba '14]- Adam [Kingma '14]- minibatch with 128 sequences- 30 epochs
27 ( [Cho 2014] Figure 1)

Experiment : Results & Analysis (Python Program Evaluation)
・ From the 3rd column, GF-RNN is better with almost all target script.
28
GR
UL
ST
M

Contents
29
・ Paper information
・ Introduction
・ Related Works
・ Proposed Methods
・ Experiments, Results and Analysis
・ Conclusion

Conclusion
・ They proposed a novel architecture for deep stacked RNNs which uses gated-feedback connections between different layers.
・ The proposed method outperformed previous results in the tasks of character-level language modeling and Python program evaluation.
・ Gated-feedback architecture is faster and better (in performance) than the standard stacked RNN even with a same amount of capacity.
・ More thorough investigation into the interaction between the gated- feedback connections and the role of recurrent activation function is required in the future.
(because the proposed gated-feedback architecture works bad with the tanh activation function)
30

References
[Cho 2014] Cho, Kyunghyun, Van Merrienboer, Bart, Gulcehre, Caglar, Bougares, Fethi, Schwenk, Holger, and Bengio, Yoshua. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014.
[Koutnik 2014] Koutnik, Jan, Greff, Klaus, Gomez, Faustino, and Schmidhuber, Ju Trgen. A clockwork rnn. In Proceedings of the 31st International Conference on Machine Learning (ICML’14), 2014.
[Schmidhuber 1992] Schmidhuber, Jurgen. Learning complex, extended sequences using the principle of history compression. Neural Computation, 4(2):234–242, 1992.
[Stollenga 2014] Stollenga, Marijn F, Masci, Jonathan, Gomez, Faustino, and Schmidhuber, Ju Trgen. Deep networks with internal selective attention through feedback connections. In Ad- vances in Neural Information Processing Systems, pp. 3545–3553, 2014.
[Zaremba 2014] Zaremba, Wojciech and Sutskever, Ilya. Learning to execute. arXiv preprint arXiv:1410.4615, 2014.
31
