furong huang, ph.d. candidate, uc irvine at mlconf nyc - 4/15/16
TRANSCRIPT

Discovery of Latent Factors in High-dimensionalData Using Tensor Methods
Furong Huang
University of California, Irvine
Machine Learning Conference 2016 New York City
1 / 25

Machine Learning - Modern Challenges
Big Data Challenging Tasks
Success of Supervised Learning
Image classification Speech recognition Text processing
Computation power growth
Enormous labeled data
2 / 25

Machine Learning - Modern Challenges
Big Data Challenging Tasks
Real AI requires Unsupervised Learning
Filter bank learning Feature extraction Embeddings; Topics
2 / 25

Machine Learning - Modern Challenges
Big Data Challenging Tasks
Real AI requires Unsupervised Learning
Filter bank learning Feature extraction Embeddings; Topics
Summarize key features in data: Machines vs Humans
Foundation for successful supervised learning
2 / 25
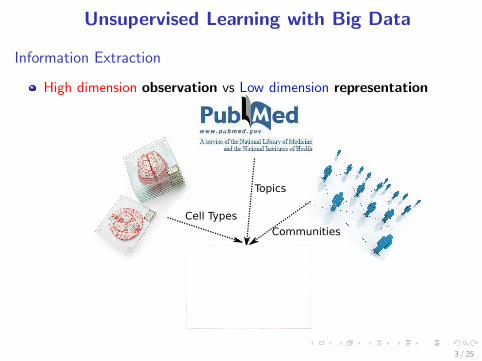
Unsupervised Learning with Big Data
Information Extraction
High dimension observation vs Low dimension representation
Cell Types
Topics
Communities
3 / 25

Unsupervised Learning with Big Data
Information Extraction
High dimension observation vs Low dimension representation
Cell Types
Topics
Communities
Finding Needle In the Haystack Is Challenging3 / 25

Unsupervised Learning with Big Data
Information Extraction
Solution for Unsupervised Learning
A Unified Tensor Decomposition Framework
3 / 25

Automated Categorization of DocumentsMixed topics
Topics
Education
Crime
Sports
4 / 25

Community Extraction From Connectivity Graph
Mixed memberships
5 / 25

Tensor Methods Compared with Variational Inference
PubMed on Spark: 8 million docs
103
104
105
Perplexity
TensorVariational
0
2
4
6
8
10 ×104
RunningTim
e(s)
6 / 25

Tensor Methods Compared with Variational Inference
PubMed on Spark: 8 million docs
103
104
105
Perplexity
TensorVariational
0
2
4
6
8
10 ×104
RunningTim
e(s)
Facebook: n ∼ 20k Yelp: n ∼ 40k DBLP: n ∼ 1 million
10-2
10-1
100
101
Error/group
FB YP DBLPsub DBLP 102
103
104
105
106
RunningTim
es(s)
FB YP DBLPsub DBLP
6 / 25

Tensor Methods Compared with Variational Inference
PubMed on Spark: 8 million docs
103
104
105
Perplexity
TensorVariational
0
2
4
6
8
10 ×104
RunningTim
e(s)
Facebook: n ∼ 20k Yelp: n ∼ 40k DBLP: n ∼ 1 million
10-2
10-1
100
101
Error/group
FB YP DBLPsub DBLP 102
103
104
105
106
RunningTim
es(s)
FB YP DBLPsub DBLP
Orders
ofMag
nitude Fa
ster &
MoreAc
curat
e
“Online Tensor Methods for Learning Latent Variable Models”, F. Huang, U. Niranjan, M. Hakeem, A. Anandkumar, JMLR14.“Tensor Methods on Apache Spark”, by F. Huang, A. Anandkumar, Oct. 2015.
6 / 25
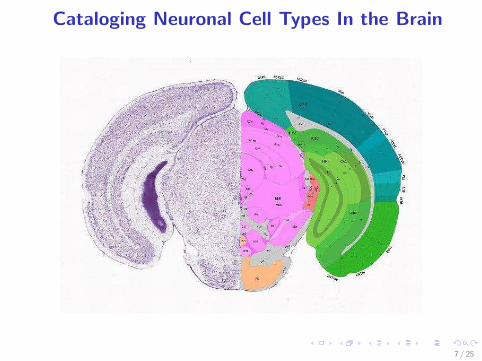
Cataloging Neuronal Cell Types In the Brain
7 / 25

Cataloging Neuronal Cell Types In the BrainOur method vs Average expression level [Grange 14’]
0.5
1.0
1.5
2.0
2.5
kSpatial point process (ours)
Average expression level ( )previous
Recovered known cell types
1 astrocytes
2 interneurons
3 oligodendrocytes
” Discovering Neuronal Cell Types and Their Gene Expression Profiles Using a Spatial Point Process Mixture Model ” by F.Huang, A. Anandkumar, C. Borgs, J. Chayes, E. Fraenkel, M. Hawrylycz, E. Lein, A. Ingrosso, S. Turaga, NIPS 2015 BigNeuro
workshop.
8 / 25

Word Sequence Embedding Extraction
football
soccer
tree
Word Embedding
The weather is good.
Her life spanned years of
incredible change for women.Mary lived through an era of
liberating reform for women.
Word Sequence Embedding
9 / 25

Word Sequence Embedding Extraction
football
soccer
tree
Word Embedding
The weather is good.
Her life spanned years of
incredible change for women.Mary lived through an era of
liberating reform for women.
Word Sequence Embedding
Paraphrase Detection
MSR paraphrase data: 5800 pairs of sentences
Method Outside Information F score
Vector Similarity (Baseline) word similarity 75.3%Convolutional Tensor (Proposed) none 80.7%Skip-thought (NIPS’15) train on large corpus 81.9%
“Convolutional Dictionary Learning through Tensor Factorization”, by F. Huang, A. Anandkumar, conference and workshopproceeding of JMLR, vol.44, Dec 2015.
9 / 25
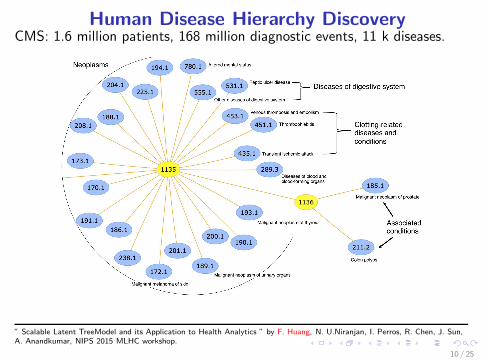
Human Disease Hierarchy DiscoveryCMS: 1.6 million patients, 168 million diagnostic events, 11 k diseases.
” Scalable Latent TreeModel and its Application to Health Analytics ” by F. Huang, N. U.Niranjan, I. Perros, R. Chen, J. Sun,A. Anandkumar, NIPS 2015 MLHC workshop.
10 / 25

Unsupervised Learning via Probabilistic Models
Words
Topics
Choice Variable
life gene data DNA RNA
k1 k2 k3 k4 k5
h
A A A A A
Unlabeled data Probabilistic admixture model Learning Algorithm Inference
11 / 25

Unsupervised Learning via Probabilistic Models
Words
Topics
Choice Variable
life gene data DNA RNA
k1 k2 k3 k4 k5
h
A A A A A
Unlabeled data Probabilistic admixture model MCMC Inference
MCMC: random sampling, slow◮ Exponential mixing time
11 / 25

Unsupervised Learning via Probabilistic Models
Words
Topics
Choice Variable
life gene data DNA RNA
k1 k2 k3 k4 k5
h
A A A A A
Unlabeled data Probabilistic admixture model Likelihood Methods Inference
MCMC: random sampling, slow◮ Exponential mixing time
Likelihood: non-convex, not scalable◮ Exponential critical points
11 / 25

Unsupervised Learning via Probabilistic Models
Words
Topics
Choice Variable
life gene data DNA RNA
k1 k2 k3 k4 k5
h
A A A A A
Unlabeled data Probabilistic admixture model Likelihood Methods Inference
MCMC: random sampling, slow◮ Exponential mixing time
Likelihood: non-convex, not scalable◮ Exponential critical points
Solution
A unified tensor decomposition framework
11 / 25

Unsupervised Learning via Probabilistic Models
Words
Topics
Choice Variable
life gene data DNA RNA
k1 k2 k3 k4 k5
h
A A A A A
Unlabeled data Probabilistic admixture model Te���� �e���p������� Inference
= + +
tensor decomposition → correct model
12 / 25

Unsupervised Learning via Probabilistic Models
Words
Topics
Choice Variable
life gene data DNA RNA
k1 k2 k3 k4 k5
h
A A A A A
Unlabeled data Probabilistic admixture model T�� ����������� Inference
� � �
tensor decomposition → correct model
Contributions
Guaranteed online algorithm with global convergence guarantee
Highly scalable, highly parallel, random projection
Tensor library on CPU/GPU/Spark
Interdisciplinary applications
Extension to model with group invariance
12 / 25

What is a tensor?
Matrix: Second Order Moments
M2: pair-wise relationship.
[x⊗ x]i1,i2 = xi1xi2 → [M2]i1,i2
=
i1
i2
Tensor: Third Order Moments
M3: triple-wise relationship.
[x⊗ x⊗ x]i1,i2,i3 = xi1xi2xi3 → [M3]i1,i2,i3=
i1
i2
i3
13 / 25

Why are tensors powerful?
Matrix Orthogonal Decomposition
Not unique without eigenvalue gap[
1 00 1
]
= e1e⊤1+e2e
⊤2= u1u
⊤1+u2u
⊤2 e1
e2
u1 = [√2
2, −
√2
2]
u2 = [√2
2,√2
2]
14 / 25

Why are tensors powerful?
Matrix Orthogonal Decomposition
Not unique without eigenvalue gap[
1 00 1
]
= e1e⊤1+e2e
⊤2= u1u
⊤1+u2u
⊤2 e1
e2
u1 = [√2
2, −
√2
2]
u2 = [√2
2,√2
2]
Tensor Orthogonal Decomposition
Unique: eigenvalue gap not needed
+=
≠14 / 25

Why are tensors powerful?
Matrix Orthogonal Decomposition
Not unique without eigenvalue gap[
1 00 1
]
= e1e⊤1+e2e
⊤2= u1u
⊤1+u2u
⊤2 e1
e2
u1 = [√2
2, −
√2
2]
u2 = [√2
2,√2
2]
Tensor Orthogonal Decomposition
Unique: eigenvalue gap not needed
Slice of tensor has eigenvalue gap
+=
≠14 / 25

Why are tensors powerful?
Matrix Orthogonal Decomposition
Not unique without eigenvalue gap[
1 00 1
]
= e1e⊤1+e2e
⊤2= u1u
⊤1+u2u
⊤2 e1
e2
u1 = [√2
2, −
√2
2]
u2 = [√2
2,√2
2]
Tensor Orthogonal Decomposition
Unique: eigenvalue gap not needed
Slice of tensor has eigenvalue gap
+=
≠14 / 25

Outline
1 Introduction
2 LDA and Community ModelsFrom Data Aggregates to Model ParametersGuaranteed Online Algorithm
3 Conclusion
15 / 25

Outline
1 Introduction
2 LDA and Community ModelsFrom Data Aggregates to Model ParametersGuaranteed Online Algorithm
3 Conclusion
16 / 25

Probabilistic Topic Models - LDA
Bag of words
Topics
Topic Proportion
police
witness
campus
police
witness
campus
police
witness
campus
17 / 25

Probabilistic Topic Models - LDA
Bag of words
Topics
Topic Proportion
police
witness
campus
police
witness
campus
police
witness
campus
police
witness
crime
Sports
Educa�
on
campus
17 / 25

Probabilistic Topic Models - LDA
Bag of words
Topics
Topic Proportion
police
witness
campus
police
witness
campus
police
witness
campus
police
witness
crime
Sports
Educa�on
campus
Goalcampus
police
witness Topic-word matrix P[word = i|topic = j]
17 / 25

Mixture Form of Moments
Goal: Linearly independent topic-word tablecampus
police
witness
18 / 25

Mixture Form of Moments
Goal: Linearly independent topic-word tablecampus
police
witness
M1: Occurrence of Words
= + +campus
police
witness
crime
Sports
Educa�on
campus
police
witness
campus
police
witness
18 / 25

Mixture Form of Moments
Goal: Linearly independent topic-word tablecampus
police
witness
M1: Occurrence of Words
= + +campus
police
witness
crime
Sports
Educa�on
campus
police
witness
campus
police
witness
No unique decomposition of vectors
18 / 25

Mixture Form of Moments
Goal: Linearly independent topic-word tablecampus
police
witness
M2: Modified Co-occurrence of Word Pairs
= + +campus
police
witness
crime
Sports
Educa�on
campus
police
witness
campus
police
witness
18 / 25

Mixture Form of Moments
Goal: Linearly independent topic-word tablecampus
police
witness
M2: Modified Co-occurrence of Word Pairs
= + +campus
police
witness
crime
Sports
Educa�on
campus
police
witness
campus
police
witness
Matrix decomposition recovers subspace, not actual model
18 / 25
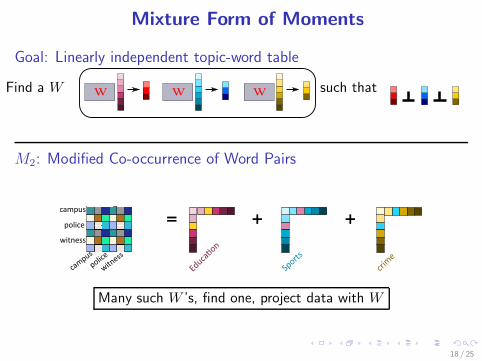
Mixture Form of Moments
Goal: Linearly independent topic-word table
Find a W W W W such that
M2: Modified Co-occurrence of Word Pairs
= + +campus
police
witness
crime
Sports
Educa�on
campus
police
witness
campus
police
witness
Many such W ’s, find one, project data with W
18 / 25

Mixture Form of Moments
Goal: Linearly independent topic-word table
Know a W W W W such that
M3: Modified Co-occurrence of Word Triplets
= + +campus
police
witness
crime
Sports
Educa�on
campus
police
witness
campus
police
witness
W
W
W
Unique orthogonal tensor decomposition, project result with W †
18 / 25

Mixture Form of Moments
Goal: Linearly independent topic-word table
Know a W W W W such that
M3: Modified Co-occurrence of Word Triplets
= + +campus
police
witness
crime
Sports
Educa�on
campus
police
witness
campus
police
witness
W
W
W
Tensor decomposition uniquely discovers the correct model
Learning Topic Models through Matrix/Tensor Decomposition
18 / 25

Mixed Membership Community Models
Mixed memberships
19 / 25

Mixed Membership Community Models
Mixed memberships
What ensures guaranteed learning?
� � �Alice
Bob
Charlie
Math
ema�
cians
Vegetarian
s
Musician
s
David
Ellen
Frank
Grace
Jack
Kathy
19 / 25

Mixed Membership Community Models
Mixed memberships
What ensures guaranteed learning?
� � �Alice
Bob
Charlie
Math
ema�cian
s
Vegetarian
s
Musician
s
David
Ellen
Frank
Grace
Jack
Kathy
19 / 25

Outline
1 Introduction
2 LDA and Community ModelsFrom Data Aggregates to Model ParametersGuaranteed Online Algorithm
3 Conclusion
20 / 25

How to do tensor decomposition?Model is uniquely identifiable! How to identify?
21 / 25

How to do tensor decomposition?How to find components? Non-convex optimization problem!
21 / 25

How to do tensor decomposition?How to find components? Non-convex optimization problem!
Objective Function
Theorem: We propose an objective function with equivalent local optima.
21 / 25

How to do tensor decomposition?How to find components? Non-convex optimization problem!
Objective Function
Theorem: We propose an objective function with equivalent local optima.
Saddle point: enemy of SGDSaddle Point
Saddle point has 0 gradient
21 / 25

How to do tensor decomposition?How to find components? Non-convex optimization problem!
Objective Function
Theorem: We propose an objective function with equivalent local optima.
Saddle point: enemy of SGDSaddle Point
Saddle point has 0 gradient
Non-degenerate saddle: Hessianhas ± eigenvalue
21 / 25

How to do tensor decomposition?How to find components? Non-convex optimization problem!
Objective Function
Theorem: We propose an objective function with equivalent local optima.
Saddle point: enemy of SGD
escape
stuckSaddle point has 0 gradient
Non-degenerate saddle: Hessianhas ± eigenvalue
Negative eigenvalue: direction ofescape
21 / 25

How to do tensor decomposition?How to find components? Non-convex optimization problem!
Objective Function
Theorem: We propose an objective function with equivalent local optima.
Saddle point: enemy of SGD
escape
stuckSaddle point has 0 gradient
Non-degenerate saddle: Hessianhas ± eigenvalue
Negative eigenvalue: direction ofescape
Guaranteed Global Converge Online Tensor Decomposition
Theorem: For smooth fn. with non-degenerate saddle points,noisy SGD converges to a local minimum in polynomial steps.
21 / 25

How to do tensor decomposition?How to find components? Non-convex optimization problem!
Objective Function
Theorem: We propose an objective function with equivalent local optima.
Saddle point: enemy of SGD
escape
stuckSaddle point has 0 gradient
Non-degenerate saddle: Hessianhas ± eigenvalue
Negative eigenvalue: direction ofescape
Guaranteed Global Converge Online Tensor Decomposition
Theorem: For smooth fn. with non-degenerate saddle points,noisy SGD converges to a local minimum in polynomial steps.
Noise could help!“Escaping From Saddle Points — Online Stochastic Gradient for Tensor Decomposition”,by R. Ge, F. Huang, C. Jin, Y. Yuan,COLT 2015.
21 / 25

Outline
1 Introduction
2 LDA and Community ModelsFrom Data Aggregates to Model ParametersGuaranteed Online Algorithm
3 Conclusion
22 / 25

Contributions
Spectral methods reveal hidden structure
Text/Image processing
Social networks
Neuroscience, heathcare ...
23 / 25

Contributions
Spectral methods reveal hidden structure
Text/Image processing
Social networks
Neuroscience, heathcare ...
Versatile for latent variable models
Flat model → hierarchical model
Sparse coding → convolutionalmodel
Efficient, convergence guarantee
� � �
� � � � � � � � �
� � � � � �M3
escape
stuck
23 / 25

Thank YouCollaborators
Anima Anandkumar
UC Irvine
Rong Ge
Duke University
Srini Turaga
Janelia Research
Chi Jin
UC Berkeley
Jennifer Chayes
MSR
Christian Borgs
MSR
Ernest Fraenkel
MIT
Yang Yuan
Cornell U
UN Niranjan
UC Irvine
24 / 25