from amateurs to connoisseurs: modeling the evolution of...
TRANSCRIPT

From Amateurs to Connoisseurs:Modeling the Evolution of User Expertise
through Online Reviews
Julian McAuleyStanford University
Jure LeskovecStanford University
ABSTRACTRecommending products to consumers means not only understand-ing their tastes, but also understanding their level of experience.For example, it would be a mistake to recommend the iconic filmSeven Samurai simply because a user enjoys other action movies;rather, we might conclude that they will eventually enjoy it—oncethey are ready. The same is true for beers, wines, gourmet foods—or any products where users have acquired tastes: the ‘best’ prod-ucts may not be the most ‘accessible’. Thus our goal in this pa-per is to recommend products that a user will enjoy now, whileacknowledging that their tastes may have changed over time, andmay change again in the future. We model how tastes change dueto the very act of consuming more products—in other words, asusers become more experienced. We develop a latent factor rec-ommendation system that explicitly accounts for each user’s levelof experience. We find that such a model not only leads to betterrecommendations, but also allows us to study the role of user expe-rience and expertise on a novel dataset of fifteen million beer, wine,food, and movie reviews.
Categories and Subject DescriptorsH.3.3 [Information Search and Retrieval]: Information Searchand Retrieval
Keywordsrecommender systems, expertise, user modeling
1. INTRODUCTION
“Even when experts all agree, they may well be mis-taken”
– Bertrand Russell
In order to predict how a user will respond to a product, we mustunderstand the tastes of the user and the properties of the prod-uct. We must also understand how these properties change andevolve over time. As an example, consider the Harry Potter filmseries: adults who enjoy the films for their special effects may nolonger enjoy them in ten years, once their special effects are obso-lete; children who enjoy the films today may simply outgrow themin ten years; future children who watch the films in ten years maynot enjoy them, once Harry Potter has been supplanted by anotherwizard.
Copyright is held by the International World Wide Web ConferenceCommittee (IW3C2). IW3C2 reserves the right to provide a hyperlinkto the author’s site if the Material is used in electronic media.WWW 2013, May 13–17, 2013, Rio de Janeiro, Brazil.ACM 978-1-4503-2035-1/13/05.
This example highlights three different mechanisms that causeperceptions of products to change. Firstly, such change may be tiedto the age of the product. Secondly, it may be tied to the age (ordevelopment) of the user. Thirdly, it may be tied to the state (orzeitgeist) of the community the user belongs to.
These mechanisms motivate different models for temporal dy-namics in product recommendation systems. Our goal in this paperis to propose models for such mechanisms, in order to assess whichof them best captures the temporal dynamics present in real productrating data.
A variety of existing works have studied the evolution of prod-ucts and online review communities. The emergence of new prod-ucts may cause users to change their focus [19]; older movies maybe treated more favorably once they are considered ‘classics’ [20];and users may be influenced by general trends in the community,or by members of their social networks [26].
However, few works have studied the personal development ofusers, that is, how users’ tastes change and evolve as they gainknowledge, maturity, and experience. A user may have to be ex-posed to many films before they can fully appreciate (by awarding ita high rating) Citizen Kane; a user may not appreciate a Romanée-Conti (the ‘Citizen Kane’ of red wine) until they have been exposedto many inferior reds; a user may find a strong cheese, a smokeywhiskey, or a bitter ale unpalatable until they have developed a tol-erance to such flavors. The very act of consuming products willcause users’ tastes to change and evolve. Developing new modelsthat take into account this novel viewpoint of user evolution is oneof our main contributions.
We model such ‘personal development’ through the lens of userexperience, or expertise. Starting with a simple definition, expe-rience is some quality that users gain over time, as they consume,rate, and review additional products. The underlying hypothesisthat we aim to model is that users with similar levels of experiencewill rate products in similar ways, even if their ratings are tem-porally far apart. In other words, each user evolves on their own‘personal clock’; this differs from other models of temporal dy-namics, which model the evolution of user and product parameterson a single timescale [20, 40, 41].
Naturally, some users may already be experienced at the timeof their first review, while others may enter many reviews whilefailing to ever become experienced. By individually learning foreach user the rate at which their experience progresses, we are ableto account for both types of behavior.
Specifically, we model each user’s level of experience using aseries of latent parameters that are constrained to be monotonicallynon-decreasing as a function of time, so that each user becomesmore experienced (or stays at least as experienced) as they rate ad-ditional products. We learn latent-factor recommender systems for
different experience levels, so that users ‘progress’ between recom-mender systems as they gain experience.
‘Experience’ and ‘expertise’ are interpretations of our model’slatent parameters. In our context they simply refer to some unob-served quantity of a user that increases over time as they consumeand review more products. Intuitively, our monotonicity require-ment constrains users to evolve in the same ‘direction’, so that whatwe are really learning is some property of user evolution that iscommon to all users, regardless of when they arrive in the com-munity. We perform extensive qualitative analysis to argue that‘experience’ is a reasonable interpretation of such parameters. Inparticular, our goal is not to say whether experienced/expert usersare ‘better’ or ‘more accurate’ at rating products. We simply modelthe fact that users with the same level of experience/expertise rateproducts in a similar way.
Our experimental findings reveal that modeling the personal evo-lution of each user is highly fruitful, and often beats alternativesthat model evolution at the level of products and communities. Ourmodels of user experience also allow us to study the differencesbetween experienced and novice users, and to discover acquiredtastes in novel corpora of fifteen million beer, wine, food, andmovie reviews.
A Motivating ExampleWe demonstrate the evolution of user tastes and differences be-tween novices and experts (i.e., experienced users) by consideringthe beer-rating website RateBeer, which consists of around threemillion beer reviews.
In this data we find a classic example of an acquired taste: hops.The highest-rated beers on the website are typically the hoppiest(American Pale Ales, India Pale Ales, etc.); however, due to theirbitterness, such beers may be unpalatable to inexperienced users.Thus we might argue that even if such beers are the best (i.e., thehighest rated), they will only be recognized as the best by the mostexperienced members of the community.
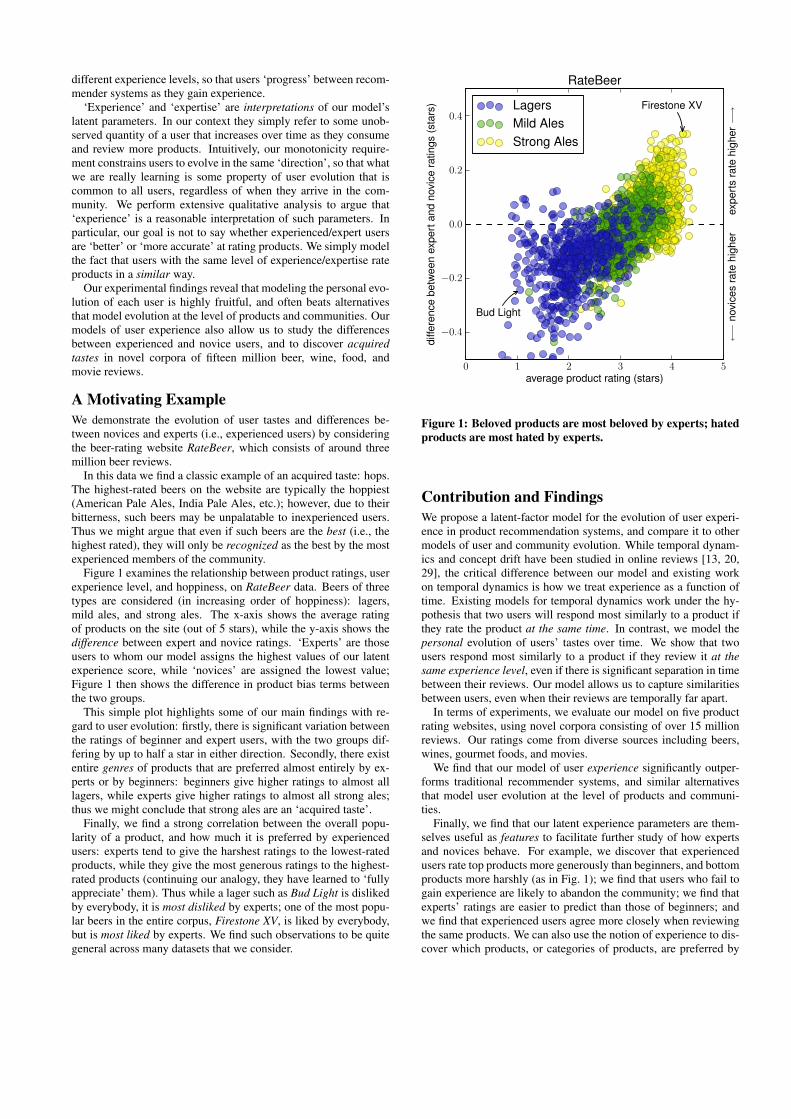
Figure 1 examines the relationship between product ratings, userexperience level, and hoppiness, on RateBeer data. Beers of threetypes are considered (in increasing order of hoppiness): lagers,mild ales, and strong ales. The x-axis shows the average ratingof products on the site (out of 5 stars), while the y-axis shows thedifference between expert and novice ratings. ‘Experts’ are thoseusers to whom our model assigns the highest values of our latentexperience score, while ‘novices’ are assigned the lowest value;Figure 1 then shows the difference in product bias terms betweenthe two groups.
This simple plot highlights some of our main findings with re-gard to user evolution: firstly, there is significant variation betweenthe ratings of beginner and expert users, with the two groups dif-fering by up to half a star in either direction. Secondly, there existentire genres of products that are preferred almost entirely by ex-perts or by beginners: beginners give higher ratings to almost alllagers, while experts give higher ratings to almost all strong ales;thus we might conclude that strong ales are an ‘acquired taste’.
Finally, we find a strong correlation between the overall popu-larity of a product, and how much it is preferred by experiencedusers: experts tend to give the harshest ratings to the lowest-ratedproducts, while they give the most generous ratings to the highest-rated products (continuing our analogy, they have learned to ‘fullyappreciate’ them). Thus while a lager such as Bud Light is dislikedby everybody, it is most disliked by experts; one of the most popu-lar beers in the entire corpus, Firestone XV, is liked by everybody,but is most liked by experts. We find such observations to be quitegeneral across many datasets that we consider.
0 1 2 3 4 5average product rating (stars)
−0.4
−0.2
0.0
0.2
0.4
diffe
renc
ebe
twee
nex
pert
and
novi
cera
tings
(sta
rs) Firestone XV
Bud Light
RateBeer
LagersMild AlesStrong Ales
←−no
vice
sra
tehi
gher
expe
rts
rate
high
er−→
Figure 1: Beloved products are most beloved by experts; hatedproducts are most hated by experts.
Contribution and FindingsWe propose a latent-factor model for the evolution of user experi-ence in product recommendation systems, and compare it to othermodels of user and community evolution. While temporal dynam-ics and concept drift have been studied in online reviews [13, 20,29], the critical difference between our model and existing workon temporal dynamics is how we treat experience as a function oftime. Existing models for temporal dynamics work under the hy-pothesis that two users will respond most similarly to a product ifthey rate the product at the same time. In contrast, we model thepersonal evolution of users’ tastes over time. We show that twousers respond most similarly to a product if they review it at thesame experience level, even if there is significant separation in timebetween their reviews. Our model allows us to capture similaritiesbetween users, even when their reviews are temporally far apart.
In terms of experiments, we evaluate our model on five productrating websites, using novel corpora consisting of over 15 millionreviews. Our ratings come from diverse sources including beers,wines, gourmet foods, and movies.
We find that our model of user experience significantly outper-forms traditional recommender systems, and similar alternativesthat model user evolution at the level of products and communi-ties.
Finally, we find that our latent experience parameters are them-selves useful as features to facilitate further study of how expertsand novices behave. For example, we discover that experiencedusers rate top products more generously than beginners, and bottomproducts more harshly (as in Fig. 1); we find that users who fail togain experience are likely to abandon the community; we find thatexperts’ ratings are easier to predict than those of beginners; andwe find that experienced users agree more closely when reviewingthe same products. We can also use the notion of experience to dis-cover which products, or categories of products, are preferred by

Hidden Factors and Hidden Topics:Understanding Rating Dimensions with Review Text
Julian McAuleyStanford University
Jure LeskovecStanford University
ABSTRACTIn order to recommend products to users we must ultimately pre-dict how a user will respond to a new product. To do so we mustuncover the implicit tastes of each user as well as the properties ofeach product. For example, in order to predict whether a user willenjoy Harry Potter, it helps to identify that the book is about wiz-ards, as well as the user’s level of interest in wizardry. User feed-back is required to discover these latent product and user dimen-sions. Such feedback often comes in the form of a numeric ratingaccompanied by review text. However, traditional methods oftendiscard review text, which makes user and product latent dimen-sions difficult to interpret, since they ignore the very text that justi-fies a user’s rating. In this paper, we aim to combine latent ratingdimensions (such as those of latent-factor recommender systems)with latent review topics (such as those learned by topic modelslike LDA). Our approach has several advantages. Firstly, we ob-tain highly interpretable textual labels for latent rating dimensions,which helps us to ‘justify’ ratings with text. Secondly, our approachmore accurately predicts product ratings by harnessing the informa-tion present in review text; this is especially true for new productsand users, who may have too few ratings to model their latent fac-tors, yet may still provide substantial information from the text ofeven a single review. Thirdly, our discovered topics can be usedto facilitate other tasks such as automated genre discovery, and toidentify useful and representative reviews.
Categories and Subject DescriptorsH.3.3 [Information Search and Retrieval]: Information Searchand Retrieval
Keywordsrecommender systems, topic models
1. INTRODUCTIONRecommender systems have transformed the way users discover
and evaluate products on the web. Whenever users assess products,there is a need to model how they made their assessment, eitherPermission to make digital or hard copies of all or part of this work for personal orclassroom use is granted without fee provided that copies are not made or distributedfor profit or commercial advantage and that copies bear this notice and the full citationon the first page. Copyrights for components of this work owned by others than theauthor(s) must be honored. Abstracting with credit is permitted. To copy otherwise, orrepublish, to post on servers or to redistribute to lists, requires prior specific permissionand/or a fee. Request permissions from [email protected]’13, October 12–16, 2013, Hong Kong, China.Copyright is held by the owner/author(s). Publication rights licensed to ACM.ACM 978-1-4503-2409-0/13/10 ...$15.00.http://dx.doi.org/10.1145/2507157.2507163.
to suggest new products they might enjoy [20], to summarize theimportant points in their reviews [13], or to identify other userswho may share similar opinions [27]. Such tasks have been studiedacross a variety of domains, from hotel reviews [6] to beer [21].
To model how users evaluate products, we must understand thehidden dimensions, or facets, of their opinions. For example, tounderstand why two users agree when reviewing the movie SevenSamurai, yet disagree when reviewing Casablanca, it helps to knowthat these films belong to different genres; these users may havesimilar preferences toward action movies, but opposite preferencesfor romantic dramas.
Modeling these hidden factors is key to obtaining state-of-the-artperformance on product recommendation tasks [2]. Crucially, rec-ommender systems rely on human feedback, which typically comesin the form of a plain-text review and a numeric score (such as a starrating). This type of feedback is used to train machine learning al-gorithms, whose goal is to predict the scores that users will give toitems that they have not yet reviewed [12].
In spite of the wealth of research on modeling ratings, the otherform of feedback present on review websites—namely, the reviewsthemselves—is typically ignored. In our opinion, ignoring this richsource of information is a major shortcoming of existing work onrecommender systems. Indeed, if our goal is to understand (ratherthan merely predict) how users rate products, we ought to rely onreviews, whose very purpose is for users to explain why they rated aproduct the way they did. As we show later, ‘understanding’ thesefactors helps us to justify users’ reviews, and can aid us in taskslike genre discovery and identification of informative reviews.
Thus our goal in this paper is to develop statistical models thatcombine latent dimensions in rating data with topics in review text.This leads to natural interpretations of rating dimensions, for in-stance we automatically discover that movie ratings are dividedalong topics like genre, while beer ratings are divided along topicslike beer style. Rather than performing post-hoc analysis to makethis determination, we discover both rating dimensions and reviewtopics in a single learning stage, using an objective that combinesthe accuracy of rating prediction (in terms of the mean squared er-ror) with the likelihood of the review corpus (using a topic model).We do this using a transform that aligns latent rating and reviewterms, so that both are determined by a single parameter. Essen-tially, the text likelihood acts as a ‘regulariser’ for rating prediction,ensuring that parameters that are good at predicting ratings are alsolikely in terms of the review text.
Not only does our model help us to ‘explain’ users’ review scoresby better understanding rating dimensions, but it also leads to betterpredictions of the ratings themselves. Traditional models (basedon ratings alone) are difficult to apply to new users and products,that have too few ratings to model their many latent dimensions

or factors [15, 23]. In contrast, our model allows us to accuratelyuncover such factors from even a single review.
Furthermore, by understanding how hidden rating dimensionsrelate to hidden review dimensions, our models facilitate a varietyof novel tasks. For instance, we apply our models to automaticallydiscover product categories, or ‘genres’, that explain the variationpresent in both ratings and reviews. We also apply our models tofind ‘informative’ reviews [24], whose text is good at explainingthe factors that contributed to a user’s rating.
1.1 Contributions and FindingsOur main contribution is to develop statistical models that com-
bine latent dimensions in rating data with topics in review text. Inpractice, we claim the following benefits over existing approaches.
Firstly, the topics we obtain readily explain the variation presentin ratings and reviews. For example, we discover that beer style(e.g. light versus dark) explains the variation present in beer rat-ing and review data; platform (e.g. console versus PC) explains thevariation present in video game data; country (e.g. Italian versusMexican) explains the variation present in restaurant data, etc.
Secondly, combining ratings with review text allows us to predictratings more accurately than approaches that consider either of thetwo sources of data in isolation. This is especially true for ‘new’products: product factors cannot be fit from only a few ratings,though we can accurately model them from only a few reviews. Weimprove upon state-of-the-art models based on matrix factorizationand LDA by 5-10% in terms of the mean squared error.
Thirdly, we can use our models to facilitate novel tasks. Weapply our models to the task of automatic genre discovery, wherethey are an order of magnitude more accurate than methods basedon ratings or reviews alone. We also apply our models to the taskof identifying informative reviews; we discover that those reviewswhose text best ‘explains’ the hidden factors of a product are ratedas being ‘useful’ by human annotators on sites like yelp.com.
Last, we apply our models to novel corpora consisting of overforty million reviews, from nine million users and three millionproducts. To our knowledge, this is the largest-scale study of pub-lic review data conducted to date. Our methods readily scale todatasets of this size.
1.2 Further Related WorkAlthough many works have studied ratings and review text in
isolation, few works attempt to combine the two sources of infor-mation. The most similar line of work is perhaps that of aspectdiscovery [6, 28, 32]. Aspects generally refer to features that arerelevant to all products. Individual users may assign such aspectsdifferent weights when determining their overall score; for examplea spendthrift hotel reviewer might assign a low weight to ‘price’ buta high weight to ‘service’, thus explaining why their overall ratingdiffers from a miserly reviewer who is only interested in price [6].
Though our work shares similarities with such studies, the top-ics we discover are not similar to aspects. ‘Aspects’ explain di-mensions along which ratings and reviews vary, which is also ourgoal. Yet while aspects are dimensions common to every individualreview, they may not explain the variation present across entire re-view corpora. For instance, although one may learn that individualusers assign different weights to ‘smell’ and ‘taste’ when reviewingbeers [21], this fails to explain why one user may love the smell ofa beer, while another believes the same beer smells terrible.
An early work that combines review text and ratings is [6]. Theyobserve that reviews often discuss multiple aspects, and that a user’srating will depend on the importance that they ascribe to each as-pect. They find that these dimensions can be recovered from review
Symbol Description
ru,i rating of item i by user udu,i review (‘document’) of item i by user urec(u, i) prediction of the rating for item i by user uα global offset termβu bias parameter for user uβi bias parameter for item iγu K-dimensional latent features for user uγi K-dimensional latent features for item iK number of latent dimensions/topicsθi K-dimensional topic distribution for item iφk word distribution for topic kψk unnormalized word distribution for topic kwu,i,j j th word of user u’s review of item izu,i,j topic for the j th word of user u’s review of item iNd number of words in document d
Table 1: Notation.
text, and that this information can be harnessed for rating predic-tion. However, their method differs from ours in that their ‘aspects’are provided by human annotators (e.g. they use domain knowledgeto determine that the ‘aspects’ of a restaurant are price, service,etc.) for each of which a sentiment classifier must be trained.
We briefly mention works where aspects are explicit, i.e., whereusers rate individual features of a product in addition to their overallrating [1, 9, 18, 28], though this work differs from ours in that it re-quires multiple ratings per review. We also briefly mention orthogo-nal work that studies ‘interpretations’ of ratings using sources otherthan reviews, e.g. information from a user’s social network [27].
A few works have considered the task of automatically identify-ing review dimensions [22]. Early works discover such dimensionsbased on frequently occurring noun phrases [7], or more sophisti-cated grammatical rules [26]. More recent works attempt to addressthis problem in an unsupervised manner [5, 29, 33], however thesesophisticated methods are limited to datasets with only a few thou-sand reviews. Furthermore, although related to our work, the goalof such studies is typically summarization [5, 13, 19], or featurediscovery [26], rather than rating prediction per se.
Beyond product reviews, modeling the dimensions of free-text isan expansive topic. The goal of Latent Dirichlet Allocation (LDA)[4], like ours, is to discover hidden dimensions in text. Such modelshave been applied in recommendation settings, e.g. to recommendscientific articles in citation networks [31]. Although related, suchapproaches differ from ours in that the dimensions they discover arenot necessarily correlated with ratings. Variants of LDA have beenproposed whose dimensions are related to output variables (suchas ratings), for example supervised topic models [3]. This is butone of a broad class of works on sentiment analysis [10,16], whosegoal is to model numeric scores from text.
In spite of the similarity between our work and sentiment anal-ysis, there is one critical difference: the goal of such methods—attest time—is to predict sentiment from text. In contrast, in rec-ommendation settings such as our own, our goal at test time is topredict ratings of products that users have not reviewed.
2. MODELS OF RATINGS AND REVIEWSWe begin by briefly describing the ‘standard’ models for latent
factor recommender systems and Latent Dirichlet Allocation, be-fore defining our own model. The notation we shall use throughoutthe paper is defined in Table 1.

Learning to Discover Social Circles in Ego Networks
Julian McAuleyStanford, USA
Jure LeskovecStanford, USA
Abstract
Our personal social networks are big and cluttered, and currently there is no goodway to organize them. Social networking sites allow users to manually categorizetheir friends into social circles (e.g. ‘circles’ on Google+, and ‘lists’ on Facebookand Twitter), however they are laborious to construct and must be updated when-ever a user’s network grows. We define a novel machine learning task of identi-fying users’ social circles. We pose the problem as a node clustering problem ona user’s ego-network, a network of connections between her friends. We developa model for detecting circles that combines network structure as well as user pro-file information. For each circle we learn its members and the circle-specific userprofile similarity metric. Modeling node membership to multiple circles allows usto detect overlapping as well as hierarchically nested circles. Experiments showthat our model accurately identifies circles on a diverse set of data from Facebook,Google+, and Twitter for all of which we obtain hand-labeled ground-truth.
1 Introduction
Online social networks allow users to follow streams of posts generated by hundreds of their friendsand acquaintances. Users’ friends generate overwhelming volumes of information and to cope withthe ‘information overload’ they need to organize their personal social networks. One of the mainmechanisms for users of social networking sites to organize their networks and the content gener-ated by them is to categorize their friends into what we refer to as social circles. Practically allmajor social networks provide such functionality, for example, ‘circles’ on Google+, and ‘lists’ onFacebook and Twitter. Once a user creates her circles, they can be used for content filtering (e.g. tofilter status updates posted by distant acquaintances), for privacy (e.g. to hide personal informationfrom coworkers), and for sharing groups of users that others may wish to follow.
Currently, users in Facebook, Google+ and Twitter identify their circles either manually, or in anaı̈ve fashion by identifying friends sharing a common attribute. Neither approach is particularlysatisfactory: the former is time consuming and does not update automatically as a user adds morefriends, while the latter fails to capture individual aspects of users’ communities, and may functionpoorly when profile information is missing or withheld.
In this paper we study the problem of automatically discovering users’ social circles. In particular,given a single user with her personal social network, our goal is to identify her circles, each of whichis a subset of her friends. Circles are user-specific as each user organizes her personal network offriends independently of all other users to whom she is not connected. This means that we canformulate the problem of circle detection as a clustering problem on her ego-network, the networkof friendships between her friends. In Figure 1 we are given a single user u and we form a networkbetween her friends vi. We refer to the user u as the ego and to the nodes vi as alters. The task thenis to identify the circles to which each alter vi belongs, as in Figure 1. In other words, the goal is tofind nested as well as overlapping communities/clusters in u’s ego-network.
Generally, there are two useful sources of data that help with this task. The first is the set of edgesof the ego-network. We expect that circles are formed by densely-connected sets of alters [20].
1

Figure 1: An ego-network with labeled circles. This network shows typical behavior that we ob-serve in our data: Approximately 25% of our ground-truth circles (from Facebook) are containedcompletely within another circle, 50% overlap with another circle, and 25% of the circles have nomembers in common with any other circle. The goal is to discover these circles given only thenetwork between the ego’s friends. We aim to discover circle memberships and to find commonproperties around which circles form.
However, different circles overlap heavily, i.e., alters belong to multiple circles simultaneously [1,21, 28, 29], and many circles are hierarchically nested in larger ones (Figure 1). Thus it is importantto model an alter’s memberships to multiple circles. Secondly, we expect that each circle is not onlydensely connected but its members also share common properties or traits [18, 28]. Thus we needto explicitly model different dimensions of user profiles along which each circle emerges.
We model circle affiliations as latent variables, and similarity between alters as a function of com-mon profile information. We propose an unsupervised method to learn which dimensions of profilesimilarity lead to densely linked circles. Our model has two innovations: First, in contrast to mixed-membership models [2] we predict hard assignment of a node to multiple circles, which provescritical for good performance. Second, by proposing a parameterized definition of profile similar-ity, we learn the dimensions of similarity along which links emerge. This extends the notion ofhomophily [12] by allowing different circles to form along different social dimensions, an idea re-lated to the concept of Blau spaces [16]. We achieve this by allowing each circle to have a differentdefinition of profile similarity, so that one circle might form around friends from the same school,and another around friends from the same location. We learn the model by simultaneously choosingnode circle memberships and profile similarity functions so as to best explain the observed data.
We introduce a dataset of 1,143 ego-networks from Facebook, Google+, and Twitter, for which weobtain hand-labeled ground-truth from 5,636 different circles.1 Experimental results show that bysimultaneously considering social network structure as well as user profile information our methodperforms significantly better than natural alternatives and the current state-of-the-art. Besides beingmore accurate our method also allows us to generate automatic explanations of why certain nodesbelong to common communities. Our method is completely unsupervised, and is able to automati-cally determine both the number of circles as well as the circles themselves.
Further Related Work. Topic-modeling techniques have been used to uncover ‘mixed-memberships’ of nodes to multiple groups [2], and extensions allow entities to be attributed withtext information [3, 5, 11, 13, 26]. Classical algorithms tend to identify communities based on nodefeatures [9] or graph structure [1, 21], but rarely use both in concert. Our work is related to [30] inthe sense that it performs clustering on social-network data, and [23], which models membershipsto multiple communities. Finally, there are works that model network data similar to ours [6, 17],though the underlying models do not form communities. As we shall see, our problem has uniquecharacteristics that require a new model. An extended version of our article appears in [15].
2 A Generative Model for Friendships in Social Circles
We desire a model of circle formation with the following properties: (1) Nodes within circles shouldhave common properties, or ‘aspects’. (2) Different circles should be formed by different aspects,e.g. one circle might be formed by family members, and another by students who attended the sameuniversity. (3) Circles should be allowed to overlap, and ‘stronger’ circles should be allowed to formwithin ‘weaker’ ones, e.g. a circle of friends from the same degree program may form within a circle
1http://snap.stanford.edu/data/
2