flick: developing and running application- specific
TRANSCRIPT

This paper is included in the Proceedings of the 2016 USENIX Annual Technical Conference (USENIX ATC ’16).
June 22–24, 2016 • Denver, CO, USA
978-1-931971-30-0
Open access to the Proceedings of the 2016 USENIX Annual Technical Conference (USENIX ATC ’16) is sponsored by USENIX.
FLICK: Developing and Running Application-Specific Network Services
Abdul Alim, Richard G. Clegg, Luo Mai, Lukas Rupprecht, and Eric Seckler, Imperial College London; Paolo Costa, Microsoft Research and Imperial College London;
Peter Pietzuch and Alexander L. Wolf, Imperial College London; Nik Sultana, Jon Crowcroft, Anil Madhavapeddy, Andrew W. Moore, and Richard Mortier, University of Cambridge;
Masoud Koleni, Luis Oviedo, and Derek McAuley, University of Nottingham; Matteo Migliavacca, University of Kent
https://www.usenix.org/conference/atc16/technical-sessions/presentation/alim

USENIX Association 2016 USENIX Annual Technical Conference 1
FLICK: Developing and Running Application-Specific Network Services
Abdul Alim†, Richard G. Clegg†, Luo Mai†, Lukas Rupprecht†, Eric Seckler†,Paolo Costa�†, Peter Pietzuch†, Alexander L. Wolf†, Nik Sultana∗,
Jon Crowcroft∗, Anil Madhavapeddy∗, Andrew W. Moore∗, Richard Mortier∗,Masoud Koleini�, Luis Oviedo�, Derek McAuley�, Matteo Migliavacca‡
†Imperial College London, �Microsoft Research, ∗University of Cambridge,�University of Nottingham, ‡University of Kent
AbstractData centre networks are increasingly programmable,with application-specific network services proliferating,from custom load-balancers to middleboxes providingcaching and aggregation. Developers must currently im-plement these services using traditional low-level APIs,which neither support natural operations on applicationdata nor provide efficient performance isolation.
We describe FLICK, a framework for the programmingand execution of application-specific network serviceson multi-core CPUs. Developers write network servicesin the FLICK language, which offers high-level pro-cessing constructs and application-relevant data types.FLICK programs are translated automatically to efficient,parallel task graphs, implemented in C++ on top of auser-space TCP stack. Task graphs have bounded re-source usage at runtime, which means that the graphsof multiple services can execute concurrently withoutinterference using cooperative scheduling. We evaluateFLICK with several services (an HTTP load-balancer,a Memcached router and a Hadoop data aggregator),showing that it achieves good performance while reduc-ing development effort.
1 IntroductionDistributed applications in data centres increasingly wantto adapt networks to their requirements. Application-specific network services, such as application load-balancers [23, 40], request data caches [36], and in-network data aggregators [29], therefore blur the bound-ary between the network fabric at the core and applica-tions at the edge. For example, a Memcached requestrouter can transparently scale deployments by routing re-quests using knowledge of the Memcached protocol [36].In this paper, we explore how application developers, not
Authors are ordered alphabetically, grouped by institution andnon-faculty/faculty status.
network engineers, can be supported when implementingnew application-specific network services.
Existing software middlebox platforms, such as Click-OS [30], xOMB [3] and SmartSwitch [53], supportonly application-independent network services, i.e. IProuters, firewalls or transport-layer gateways. Usingthem to interact with payload data in network flows leadsto an impedance mismatch due to their byte-oriented,per-packet APIs. Instead, application developers wouldprefer high-level constructs and data types when express-ing processing logic. For example, when defining thedispatching logic of a Memcached request router, a de-veloper would ideally treat key/value pairs as a first-classdata type in their program.
Today’s middlebox platforms also force develop-ers to optimise their code carefully to achieve highthroughput—implementing a new Click module [24, 30]in C++ that can process data at 10 Gbps line rate is chal-lenging. As a result, many new application-specific net-work services [40, 29] are built from scratch rather thanleveraging the above platforms.
Considerable work went into developing new high-level languages for network control within software-defined networking (SDN) [16, 33, 8, 48]. While thesesimplify the specification of network management poli-cies, they typically operate on a per-packet basis and sup-port a limited set of per-packet actions once matched,e.g. forwarding, cloning or dropping. In contrast, app-lication-specific network services must refer to payloaddata, e.g. messages, key/value pairs or deserialised ob-jects, and carry out richer computations, e.g. arbitrarypayload transformations, caching or data aggregation.
Our goal is to enable developers to express appli-cation-specific network services in a natural high-levelprogramming model, while executing such programs inan efficient and scalable manner. This is challenging forseveral reasons: (i) in many cases, the cost of data de-serialisation and dynamic memory management reduces
1

2 2016 USENIX Annual Technical Conference USENIX Association
achievable processing throughput. While high-level pro-gramming languages such as Java or Python can manipu-late complex application objects, they struggle to providepredictable processing throughput for line-rate process-ing of network data; (ii) a typical data centre may hosthundreds of applications, with each potentially requir-ing its own network service. Services must thus shareresources, e.g. CPU and memory, without interference.Existing middlebox platforms use coarse-grained virtu-alisation [30], which carries a context-switching over-head of hundreds of microseconds. This is too high forfine-grained resource sharing between many application-specific network services; and (iii) most of the applica-tions use TCP for transport, and an application-specificmiddlebox needs to terminate TCP connections to accessdata. Performance and scalability of such middleboxesare often bounded by the high cost of connection termi-nation and frequent socket reads/writes.
We describe FLICK, a framework for developers toprogram and execute application-specific network ser-vices. It consists of the FLICK language for definingnetwork services, and the FLICK platform for executingcompiled programs efficiently on multi-core CPUs.
Programs in the FLICK language have bounded re-source usage and are guaranteed to terminate. This ispossible because most application-specific network ser-vices follow a similar pattern: they deserialise and ac-cess application data types, iterate over these data typesto perform computation, and output the results as net-work flows. The language is therefore statically typed,and all built-in types (e.g. integer, string, and array)must have a maximum size to avoid dynamic memoryallocation. Programs can refer to complex application-defined data types, such as messages or key/value pairs,for which efficient parsers are synthesised from the typedefinitions in the program. Since functions can only per-form finite iteration over fixed-length data types, FLICKprograms with finite input must terminate.
A compiler translates FLICK programs into taskgraphs implemented in C++. Tasks graphs are designedto permit the efficient and safe execution of many con-current network services on a shared platform. A taskgraph consists of parallel tasks that define the computa-tion of the FLICK program, and channels that propagatedata between concurrently executing tasks. Input/out-put tasks perform the serialisation/deserialisation of datato and from application objects. Since FLICK programsexplicitly specify accesses to application data fields, thecompiler can generate custom parsing code, eliminatingthe overheads of general-purpose parsers.
The FLICK platform executes multiple task graphs be-longing to different services. To reduce the overheadof frequent connection termination and socket opera-tion, task graphs use a modified version of a highly-
scalable user-space TCP stack (mTCP [21]) with Intel’sData Plane Development Kit (DPDK) [20]. Task graphsare also scheduled cooperatively, avoiding context-switching overhead. They cannot interfere with eachother, both in terms of performance and resources, dueto their safe construction from FLICK programs.
We evaluate a prototype implementation of FLICKusing both micro-benchmarks and three application-specific network services: an HTTP load balancer, aMemcached proxy and a Hadoop data aggregator. Ourresults show that FLICK can execute these services withthroughput and latency that matches that of specialisedmiddlebox implementations. In addition, it scales witha larger number of compute tasks. This paper focuseson the design, implementation and performance of a sin-gle FLICK middlebox. However, the wider vision is of anumber of such boxes within a data centre [10].
2 Application-Specific Network Services
FLICK focuses on a specific context: data centres inwhich multiple, complex, distributed applications runconcurrently. In this case, to achieve higher performance,flexibility or efficiency, it is advantageous to execute por-tions of these applications, e.g. related to load-balancing,caching or aggregation, as application-specific networkservices directly on network elements.
To do this, application developers must add code tonetwork elements such as software middleboxes. Todaythis typically means that they must implement compli-cated features of the underlying network protocols (e.g.TCP flow construction, HTTP parsing and applicationdata deserialisation). For performance reasons, networkservices must be highly parallel, which requires consid-erable developer expertise to achieve. Network resourcesare also inherently shared: even if hosts can be assignedto single applications, network elements must host manyservices for different applications.
The goal of FLICK is to allow developers to easily andefficiently introduce application-specific processing intonetwork elements. Present approaches are unsatisfactoryfor three key reasons: (i) they provide only low-levelAPIs that focus on the manipulation of individual pack-ets, or at best, individual flows; (ii) they do not permit de-velopers to implement services in high-level languages,but typically rely on the use of low-level languages suchas C; and (iii) they provide little support for the high de-grees of concurrency that are required to make networkservice implementations perform well.
Next we elaborate on some of these challenges as en-countered in our example applications (§2.1), and thencontrast our approach with existing solutions (§2.2).
2

USENIX Association 2016 USENIX Annual Technical Conference 3
2.1 Use casesWe consider three sample uses for application-specificservices: HTTP load balancing, Memcached requestrouting, and Hadoop data aggregation.
HTTP load balancer. To cope with a large number ofconcurrent requests, server farms employ load balancersas front ends. These are implemented by special-purposehardware or highly-optimised software stacks and bothsacrifice flexibility for performance. As a result, loadbalancers must often be reimplemented for each appli-cation to tailor them to specific needs. For example,this may be necessary to ensure consistency when mul-tiple TCP connections are served by the same server; toimprove the efficiency of clusters running Java code, aload balancer may avoid dispatching requests to serversthat are currently performing garbage collection [27]; fi-nally, there is increasing interest from Internet companiesto monitor application-specific request statistics—a taskthat load balancers are ideally placed to carry out [13].
Memcached proxy. Memcached [15] is a populardistributed in-memory key/value store for reducing thenumber of client reads from external data sources bycaching read results in memory. In production environ-ments, a proxy such as twemproxy [52] or mcrouter [36]is situated usually between clients and servers to handlekey/value mappings and instance configurations. Thisdecouples clients and servers and allows the servers toscale out or in horizontally.
Past attempts to implement Memcached routers haveinvolved user-space solutions [36], incurring high over-heads due to expensive memory copies between kernel-and user-space. More recent proposals, such as Mem-Switch [53], have shown that a dedicated single-purposesoftware switch that intercepts and processes Mem-cached traffic can be more efficient. To customiseMemSwitch, developers, however, must write com-plex in-network programs that process raw packet pay-loads. This not only compromises the safety and per-formance of the network stack, but also complicatesdevelopment—it requires knowledge about low-level de-tails of networking as well as skills for writing high-performance, parallelisable packet-processing code.
Hadoop data aggregator. Hadoop [54] is a popularmap/reduce framework for data analysis. In many de-ployments, job completion times are network-bound dueto the shuffle phase [9]. This means that performancecan be improved through an application-specific networkservice for in-network data aggregation [29], which ex-ecutes an intermediate in-network reduction within thenetwork topology before data reaches the reducers, thusreducing traffic crossing the network.
Providing an in-network data aggregation for Hadoopserves as a good example of an application-specific ser-
vice that must carry out complex data serialisation anddeserialisation. A developer wishing to implement in-network reduce logic must therefore re-implement thelogic necessary to reconstruct Hadoop key/value pairsfrom TCP flows—a difficult and error-prone task.
2.2 Existing solution spaceThere are several proposals for addressing the challengesidentified in the use cases above. We observe that exist-ing solutions typically fit into one of four classes:(i) Specialised, hand-crafted implementations. Sys-tems such as netmap [43, 44] provide for efficientuser-space implementations of packet-processing appli-cations. Unfortunately, they offer only low-level abstrac-tions, forcing developers to process individual packetsrather than high-level business logic.(ii) Packet-oriented middleboxes. Frameworks for im-plementing software middleboxes, such as ClickOS [30]and SmartSwitch [53], enable high-performance process-ing of network data and can be used to build higher-levelabstractions. However, they fail to support useful high-level language features such as strong and static typing,or simple support for data-parallel processing.(iii) Network programmability. More recently, wesee increasing deployment of software-defined network-ing techniques, usually OpenFlow [31]. More advancedtechnologies have been proposed such as P4 [8] and Pro-tocol Oblivious Forwarding [47]. These enable efficientin-network processing of traffic, selectively forwarding,rewriting and processing packets. However, they sufferfrom many of the same issues as (ii) due to their narrowfocus on packet-level abstractions.(iv) Flow-oriented servers. For in-network processingconcerned with higher-level flow abstractions, it is com-mon to leverage existing server implementations, suchas Nginx [35] or Apache [51], and customise them eitherat the source level or through extensibility mechanismssuch as modules. Another example is Netflix ribbon [34],which provides a number of highly configurable middle-box services along with a Java library to build customservices. While this raises the level of abstraction some-what, the overheads of using such large, complex piecesof software to perform application-specific network ser-vices are substantial.
3 FLICK FrameworkWe motivate our design by outlining requirements (§3.1),and providing a high-level overview (§3.2).
3.1 RequirementsBased on the shortcomings of the approaches highlightedin §2.2, we identify the following three design require-ments for our framework:R1: Application-level abstractions: developers should
3

4 2016 USENIX Annual Technical Conference USENIX Association
compiled
FLICK task graphs
tasks
loaded &executed
1 2 3
FLICK platform
Listing 1: FLICK program for Memcached cache router
1 type cmd: record2 opcode : string {size =1}3 keylen : integer {signed=false , size =2}4 extraslen : integer {signed=false , size =1}5 _ : string {size =3}6 bodylen : integer {signed=false , size =8}7 _ : string {size =12+ extraslen}8 key : string {size=keylen}9 _ : string {size=bodylen -extraslen -keylen}
10
11 proc memcached:12 (cmd/cmd client , [cmd/cmd] backends)13 global cache := empty_dict14 backends => update_cache(cache) => client15 client => test_cache(client , backends , cache)16
17 fun update_cache:18 (cache: ref dict <string*string >, resp: cmd)19 -> (cmd)20 if resp.opcode = 0x0c:21 cache[resp.key] := resp22 resp23
24 fun test_cache:25 (-/cmd client , [-/cmd] backends ,26 cache:ref dict <string*string >, req:cmd)27 -> ()28 if cache[req.key] = None or req.opcode <> 0x0c:29 let target = hash(req.key) mod len(backends)30 req => backends[target]31 else:32 cache[req.key] => client
tions: types (lines 1–9), processes (lines 11–15) and func-tions (lines 17–32).Types provide high-level definitions of middlebox data val-ues and, through serialisation annotations, abstract how val-ues of each type are to be formatted to be sent over or readfrom a channel, each of which represents a byte stream.Types whose values will never cross the network do not needserialisation annotations. In Listing 1, lines 1 to 9 describecmd, the type of Memcached commands, either requests fora key or replies associating a key with a value, which sharea common format.
Serialisation annotations specify either binary or textbased formats using a mix of fixed and variable lengthsfields. The length of the key, field varies and is specified bythe earlier keylen field. Unused fields are anonymised using‘_’, preventing their values being accidentally accessed orchanged anywhere in the program. Processing requests andreplies requires access to the opcode field, to select get keyreplies (GETK, opcode = 0x0c) which are cached by therouter for matching with future get key requests; and the keyfield to perform the match and select the backend to whichto forward the request in case of a cache miss.Processes describe the middlebox’s input/output channelsand core computation. Channels are bi-directional and typedaccording to the type of values produce/consume. In List-
ing 1, lines 11 to 15 show the memcached process’ descrip-tion. Its channels are shown on lines 12: the client channelproduces and accepts values of type cmd, while backends isan array of channels which each produces and accepts valuesof type cmd.
Processes are instantiated by the runtime system whichalso binds channels to the actual byte streams. In this exam-ple, when a client connects to the middlebox, the runtimecreates a new instance of the memcached process and con-nects it to the underlying representations of the client andbackend sockets.
Computation is specified by defining how data is routedand processed as it flows across channels connected to theprocess. The body of a process specifies how a finite amountof input from each channel is consumed; unbounded iter-ation is not permitted, as we will explain §3.2). The bodyof the memcached process, lines 14 and 15 is the core ofthis middlebox. The first line specifies that anything receivedfrom any backend is handled by update_cache function,whose result is then sent on the client channel. The sec-ond line specifies that anything received from the client isprocessed by the test_cache function.
Processes may maintain state between inputs, either beper-instance or per-process (global). For example, line 13specifies that instances of this memcached process share acache.Functions support processes by allowing structuring of codebut they need not be side-effect free. For example, both func-tions in Listing 1 have side-effects: update_cache updatesthe cache if required, while test_cache writes to a channelin the backends array.
Finally the type of a function need not be more generalthan necessary. We saw that processes interact with the en-vironment by means of bidirectional channels, but channelscan also be restricted to be unidirectional, as at line 25: nei-ther the client channel nor any channels in the backendsarray are read from in the test_cache function, so they aretyped as being write-only.
3.2 Higher-order functions and bounded resourcesTo support execution of different processes competing onshared resources without requiring expensive isolation tech-niques, FLICK’s expressive power is restricted to allow onlycomputation guaranteed to terminate.Fold, map and filter. User-defined functions in FLICK arerestricted to be first-order and cannot be recursive (directlyor indirectly). FLICK provides several higher-order functionsto support common functional transformation, starting withfold. Folds are a family of bounded iteration operators de-fined over finite structures (lists). The simplest form of suchfunctions is fold f acc list, which recursively applies thefunction f to each element of list, accumulating the resultinto acc, which it ultimately returns. FLICK provides othercommon higher-order functions such as map and filter.
5 2015/3/26
FLICK programs
cooperative scheduling
Listing 1: FLICK program for Memcached cache router
1 type cmd: record2 opcode : string {size =1}3 keylen : integer {signed=false , size =2}4 extraslen : integer {signed=false , size =1}5 _ : string {size =3}6 bodylen : integer {signed=false , size =8}7 _ : string {size =12+ extraslen}8 key : string {size=keylen}9 _ : string {size=bodylen -extraslen -keylen}
10
11 proc memcached:12 (cmd/cmd client , [cmd/cmd] backends)13 global cache := empty_dict14 backends => update_cache(cache) => client15 client => test_cache(client , backends , cache)16
17 fun update_cache:18 (cache: ref dict <string*string >, resp: cmd)19 -> (cmd)20 if resp.opcode = 0x0c:21 cache[resp.key] := resp22 resp23
24 fun test_cache:25 (-/cmd client , [-/cmd] backends ,26 cache:ref dict <string*string >, req:cmd)27 -> ()28 if cache[req.key] = None or req.opcode <> 0x0c:29 let target = hash(req.key) mod len(backends)30 req => backends[target]31 else:32 cache[req.key] => client
tions: types (lines 1–9), processes (lines 11–15) and func-tions (lines 17–32).Types provide high-level definitions of middlebox data val-ues and, through serialisation annotations, abstract how val-ues of each type are to be formatted to be sent over or readfrom a channel, each of which represents a byte stream.Types whose values will never cross the network do not needserialisation annotations. In Listing 1, lines 1 to 9 describecmd, the type of Memcached commands, either requests fora key or replies associating a key with a value, which sharea common format.
Serialisation annotations specify either binary or textbased formats using a mix of fixed and variable lengthsfields. The length of the key, field varies and is specified bythe earlier keylen field. Unused fields are anonymised using‘_’, preventing their values being accidentally accessed orchanged anywhere in the program. Processing requests andreplies requires access to the opcode field, to select get keyreplies (GETK, opcode = 0x0c) which are cached by therouter for matching with future get key requests; and the keyfield to perform the match and select the backend to whichto forward the request in case of a cache miss.Processes describe the middlebox’s input/output channelsand core computation. Channels are bi-directional and typedaccording to the type of values produce/consume. In List-
ing 1, lines 11 to 15 show the memcached process’ descrip-tion. Its channels are shown on lines 12: the client channelproduces and accepts values of type cmd, while backends isan array of channels which each produces and accepts valuesof type cmd.
Processes are instantiated by the runtime system whichalso binds channels to the actual byte streams. In this exam-ple, when a client connects to the middlebox, the runtimecreates a new instance of the memcached process and con-nects it to the underlying representations of the client andbackend sockets.
Computation is specified by defining how data is routedand processed as it flows across channels connected to theprocess. The body of a process specifies how a finite amountof input from each channel is consumed; unbounded iter-ation is not permitted, as we will explain §3.2). The bodyof the memcached process, lines 14 and 15 is the core ofthis middlebox. The first line specifies that anything receivedfrom any backend is handled by update_cache function,whose result is then sent on the client channel. The sec-ond line specifies that anything received from the client isprocessed by the test_cache function.
Processes may maintain state between inputs, either beper-instance or per-process (global). For example, line 13specifies that instances of this memcached process share acache.Functions support processes by allowing structuring of codebut they need not be side-effect free. For example, both func-tions in Listing 1 have side-effects: update_cache updatesthe cache if required, while test_cache writes to a channelin the backends array.
Finally the type of a function need not be more generalthan necessary. We saw that processes interact with the en-vironment by means of bidirectional channels, but channelscan also be restricted to be unidirectional, as at line 25: nei-ther the client channel nor any channels in the backendsarray are read from in the test_cache function, so they aretyped as being write-only.
3.2 Higher-order functions and bounded resourcesTo support execution of different processes competing onshared resources without requiring expensive isolation tech-niques, FLICK’s expressive power is restricted to allow onlycomputation guaranteed to terminate.Fold, map and filter. User-defined functions in FLICK arerestricted to be first-order and cannot be recursive (directlyor indirectly). FLICK provides several higher-order functionsto support common functional transformation, starting withfold. Folds are a family of bounded iteration operators de-fined over finite structures (lists). The simplest form of suchfunctions is fold f acc list, which recursively applies thefunction f to each element of list, accumulating the resultinto acc, which it ultimately returns. FLICK provides othercommon higher-order functions such as map and filter.
5 2015/3/26
Listing 1: FLICK program for Memcached cache router
1 type cmd: record2 opcode : string {size =1}3 keylen : integer {signed=false , size =2}4 extraslen : integer {signed=false , size =1}5 _ : string {size =3}6 bodylen : integer {signed=false , size =8}7 _ : string {size =12+ extraslen}8 key : string {size=keylen}9 _ : string {size=bodylen -extraslen -keylen}
10
11 proc memcached:12 (cmd/cmd client , [cmd/cmd] backends)13 global cache := empty_dict14 backends => update_cache(cache) => client15 client => test_cache(client , backends , cache)16
17 fun update_cache:18 (cache: ref dict <string*string >, resp: cmd)19 -> (cmd)20 if resp.opcode = 0x0c:21 cache[resp.key] := resp22 resp23
24 fun test_cache:25 (-/cmd client , [-/cmd] backends ,26 cache:ref dict <string*string >, req:cmd)27 -> ()28 if cache[req.key] = None or req.opcode <> 0x0c:29 let target = hash(req.key) mod len(backends)30 req => backends[target]31 else:32 cache[req.key] => client
tions: types (lines 1–9), processes (lines 11–15) and func-tions (lines 17–32).Types provide high-level definitions of middlebox data val-ues and, through serialisation annotations, abstract how val-ues of each type are to be formatted to be sent over or readfrom a channel, each of which represents a byte stream.Types whose values will never cross the network do not needserialisation annotations. In Listing 1, lines 1 to 9 describecmd, the type of Memcached commands, either requests fora key or replies associating a key with a value, which sharea common format.
Serialisation annotations specify either binary or textbased formats using a mix of fixed and variable lengthsfields. The length of the key, field varies and is specified bythe earlier keylen field. Unused fields are anonymised using‘_’, preventing their values being accidentally accessed orchanged anywhere in the program. Processing requests andreplies requires access to the opcode field, to select get keyreplies (GETK, opcode = 0x0c) which are cached by therouter for matching with future get key requests; and the keyfield to perform the match and select the backend to whichto forward the request in case of a cache miss.Processes describe the middlebox’s input/output channelsand core computation. Channels are bi-directional and typedaccording to the type of values produce/consume. In List-
ing 1, lines 11 to 15 show the memcached process’ descrip-tion. Its channels are shown on lines 12: the client channelproduces and accepts values of type cmd, while backends isan array of channels which each produces and accepts valuesof type cmd.
Processes are instantiated by the runtime system whichalso binds channels to the actual byte streams. In this exam-ple, when a client connects to the middlebox, the runtimecreates a new instance of the memcached process and con-nects it to the underlying representations of the client andbackend sockets.
Computation is specified by defining how data is routedand processed as it flows across channels connected to theprocess. The body of a process specifies how a finite amountof input from each channel is consumed; unbounded iter-ation is not permitted, as we will explain §3.2). The bodyof the memcached process, lines 14 and 15 is the core ofthis middlebox. The first line specifies that anything receivedfrom any backend is handled by update_cache function,whose result is then sent on the client channel. The sec-ond line specifies that anything received from the client isprocessed by the test_cache function.
Processes may maintain state between inputs, either beper-instance or per-process (global). For example, line 13specifies that instances of this memcached process share acache.Functions support processes by allowing structuring of codebut they need not be side-effect free. For example, both func-tions in Listing 1 have side-effects: update_cache updatesthe cache if required, while test_cache writes to a channelin the backends array.
Finally the type of a function need not be more generalthan necessary. We saw that processes interact with the en-vironment by means of bidirectional channels, but channelscan also be restricted to be unidirectional, as at line 25: nei-ther the client channel nor any channels in the backendsarray are read from in the test_cache function, so they aretyped as being write-only.
3.2 Higher-order functions and bounded resourcesTo support execution of different processes competing onshared resources without requiring expensive isolation tech-niques, FLICK’s expressive power is restricted to allow onlycomputation guaranteed to terminate.Fold, map and filter. User-defined functions in FLICK arerestricted to be first-order and cannot be recursive (directlyor indirectly). FLICK provides several higher-order functionsto support common functional transformation, starting withfold. Folds are a family of bounded iteration operators de-fined over finite structures (lists). The simplest form of suchfunctions is fold f acc list, which recursively applies thefunction f to each element of list, accumulating the resultinto acc, which it ultimately returns. FLICK provides othercommon higher-order functions such as map and filter.
5 2015/3/26
threads
channels
Figure 1: Overview of the FLICK framework
be able to express their network services using familiarconstructs and abstractions without worrying about thelow-level details of per-packet (or per-flow) processing;R2: High parallelism: to achieve line-rate performan-ce, programs for application-specific network servicesmust exploit both data and task parallelism without re-quiring significant effort from the developers;R3: Safe and efficient resource sharing: middleboxesare shared by multiple applications/users, therefore, weneed to ensure that programs do not interfere with oneanother, both in terms of CPU and memory resources.
To meet these requirements, FLICK follows thescheme shown in Figure 1. For the desired level of ab-straction (R1), it provides a novel high-level language(�; §4). The language allows developers to focus onthe business logic of their network services ignoring low-level details (e.g. serialisation or TCP reassembly).
Compared to general-purpose languages such as Cor Java, the FLICK language offers a constrained pro-gramming environment. This makes it easier to compileFLICK programs to parallel FLICK task graphs (�; §5).The division of programs into tasks allows the platformto take advantage of both data and task parallelism, thusexploiting multi-core CPUs (R2).
Finally, the FLICK language bounds the resource us-age for each invocation of a network service. This al-lows task graphs to be executed by the FLICK platformaccording to a cooperative scheduling discipline (�; §5),permitting a large number of concurrent task graphs toshare the same hardware resources with little interfer-ence (R3). A pool of worker threads execute tasks co-operatively, while channels move data between tasks.
3.2 OverviewWe now give a more detailed overview of how a devel-oper uses the FLICK framework (see Figure 1). First theywrite the logic of their application-specific network ser-vices in the FLICK language. After compilation by theFLICK compiler, the FLICK platform runs a program asan instance, consisting of a set of task graphs. Each taskgraph comprises of a directed acyclic graph of tasks con-nected by task channels. Depending on the program se-mantics, multiple instances of the task graph can be in-stantiated for each network request, or a single graph canbe used by multiple requests.
A task is a schedulable unit of computation. Each taskprocesses a stream of input values and generates a streamof output values. Initial input to the task graph is han-dled by one or more input tasks, which consume datafrom a single input channel, i.e. the byte stream of a TCPconnection. An input task then deserialises bytes to val-ues using deserialisation/parsing code generated by theFLICK compiler from the types specified in the FLICKprogram. Deserialisation splits data into the smallestunits appropriate for the task being considered. For ex-ample, if the input is from a web client, the byte streamwould be deserialised into individual complete HTTP re-quests; for Hadoop, a key/value pair is more appropriate.
Received data is then processed by one or more com-pute tasks and, finally, output from the task graph is emit-ted to the outside world via an output task, representinga single outgoing TCP connection. The output task alsoexecutes efficient serialisation code generated from theFLICK program, converting values into a byte stream thatis placed onto an output channel for transmission.
4 FLICK Programming ModelFLICK provides a domain-specific language (DSL)targeting application-specific middlebox programming.While a difficult task, we decided to design a new lan-guage because we found existing general-purpose lan-guages inappropriate for middlebox programming due totheir excessive expressive power. Even safe redesignsof widely-used languages, such as Cyclone [22], aretoo powerful for our needs because, by design, theydo not restrict the semantics of programs to terminateand bound the used resources. Existing specialised lan-guages for network services, such as PLAN [18], are typ-ically packet-centric. This makes it hard to implementapplication-specific traffic logic that is flow-centric. Anew domain-specific language presents us with the op-portunity to incorporate primitive abstractions that betterfit the middlebox domain.
We also considered restricting an existing language tosuit our needs (for example OCaml restricted so it per-forms no unbounded loops and no garbage collection).This, however, presented two difficulties: (i) exposingprogrammers to a familiar language but with altered se-mantics would be confusing; and (ii) it would preventus from including language features for improved safety,such as static type-checking.
Numerous systems programming tasks have been sim-plified by providing DSLs to replace general-purposeprogramming languages [26, 28, 6, 39, 11]. The FLICKlanguage is designed (i) to provide convenient, famil-iar high-level language abstractions targeted specificallyat middlebox development, e.g. application-level types,processes and channels alongside traditional functionsand primitive types; (ii) to take advantage of execution
4

USENIX Association 2016 USENIX Annual Technical Conference 5
Listing 1: FLICK program for Memcached proxy1 type cmd: record2 key : string3
4 proc Memcached: (cmd/cmd client , [cmd/cmd] backends)5 | backends => client6 | client => target_backend(backends)7
8 fun target_backend: ([-/cmd] backends , req:cmd) -> ()
9 let target = hash(req.key) mod len(backends)10 req => backends[target]
parallelism for high throughput; and (iii) to enable effi-cient and safe handling of multiple programs and manyrequests on shared hardware resources by making it im-possible to express programs with undesirable behaviour,such as unbounded resource consumption.
In the FLICK language, developers describeapplication-specific network services as a collection ofinterconnected processes. Each process manipulatesvalues of the application’s data types, in contrast toearlier work which described network services as simplepacket processors [24, 7, 30]. Application data is carriedover channels, which interconnect processes with oneanother and with network flows. Processes interactwith channels by consuming and processing inputdata read from them, and by transmitting output overthem. Processes, channels and network interactions arehandled by the FLICK platform.
The FLICK language is designed to achieve efficientparallel execution on multi-core CPUs using high-levelparallel primitives. By default, the language offers par-allelism across multiple requests, handling them concur-rently. It supports the safe sharing of resources by bound-ing the resource use of an individual program. Process-ing of continuous network flows belonging to an applica-tion is subdivided into discrete units of work so that eachprocess consumes only a bounded amount of resource.To achieve this, FLICK control structures are restricted tofinite iteration only. This is not a significant limitation,however, as application-specific network services typi-cally carry out deterministic transformations of networkrequests to generate responses. User-defined functionsare written in FLICK itself, rather than in a general pur-pose language as in Click [24] or Pig [37]), which pre-serves the safety of network services expressed in FLICK.
After presenting the FLICK language by exam-ple (§4.1), we describe its application data types (§4.2),primitives and compilation (§4.3).
4.1 OverviewListing 1 shows a sample FLICK program that imple-ments a Memcached proxy. Programs are composed ofthree types of declarations: data types (lines 1–2), pro-cesses (lines 4–6) and functions (lines 8–10).
Processes have signatures that specify how they con-
nect to the outside world. In this case, a process calledMemcached declares a signature containing two channels(line 4): the client channel produces and accepts val-ues of type cmd, while backends is an array of channels,each of which produces and accepts values of type cmd.
Processes are instantiated by the FLICK platform,which binds channels to underlying network flows (§5).In this example, when a client sends a request, the FLICKplatform creates a new Memcached task graph and assignsthe client connection to this graph. Giving each clientconnection a new task graph ensures that responses arerouted back to the correct client.
A process body describes how data is transformedand routed between channels connected to a process.The language design ensures that only a finite amountof input from each channel is consumed. The bodyof the Memcached process describes the application-specific network service: data received from any chan-nel in backends is sent to the client channel (line 5);data received from the client is processed by thetarget_backend function (line 6), which in turn writesto a suitable channel in the backends array (line 10).
4.2 Supporting application data typesFLICK programs operate on application data types rep-resenting the exchanged messages. After an input taskreads such messages from the network, they are parsedinto FLICK data types. Similarly, before processed datavalues are transmitted by an output task, they are seri-alised into the appropriate wire format representation.
The transformation of messages between wire formatand FLICK data types is defined as a message grammar.During compilation, FLICK generates the correspondingparsing and serialisation code from the grammar, whichis then used in the input and output tasks of the taskgraph, respectively. The generated code is optimised forefficiency in three ways: (i) it does not dynamically al-locate memory; (ii) it supports the incremental parsingof messages as new data arrives; and (iii) it is adaptedautomatically to specific use cases.
The syntax to define message grammars is based onthat of the Spicy (formerly Binpac++ [46]) parser gen-erator. The language provides constructs to define mes-sages and their serialised representation through units,fields, and variables, and their composition: units areused to modularise grammars; fields describe the struc-ture of a unit; and variables can compute the value ofexpressions during parsing or serialisation, e.g. to deter-mine the size of a field. FLICK grammars can express anyLL(1)-parsable grammar as well as grammars with de-pendent fields, in a manner similar to Spicy. The FLICKframework provides reusable grammars for common pro-tocols, such as the HTTP [14] and Memcached proto-cols [50]. Developers can also specify additional mes-
5

6 2016 USENIX Annual Technical Conference USENIX Association
Listing 2: Partial grammar for Memcached protocol1 type cmd = unit {2 %byteorder = big;3
4 magic_code : uint8;5 opcode : uint8;6 key_len : uint16;7 extras_len : uint8;8 : uint8; # anonymous field ,
reserved for future use9 status_or_v_bucket : uint16;
10 total_len : uint32;11 opaque : uint32;12 cas : uint64;13
14 var value_len : uint3215 &parse = self.total_len -16 (self.extras_len + self.key_len)17 &serialize = self.total_len =18 self.key_len + self.extras_len + $$;19 extras : bytes &length = self.extras_len;20 key : string &length = self.key_len;21 value : bytes &length = self.value_len;22 };
sage grammars for custom formats, such as application-specific Hadoop data types.
Listing 2 shows a simplified grammar for Memcached.The cmd unit for the corresponding FLICK data typeis a sequence of fixed-size fields (lines 4–12), a vari-able (lines 14–18), and variable-size fields (lines 19–21).Each field is declared with its wire-format data type, e.g.the opcode field is an 8-bit integer (line 5). The sizesof the extras, key, and value fields are determined bythe parsed value of the extras_len and key_len fieldsas well as the value_len variable, which is computedduring parsing according to the expression in lines 15and 16. During serialisation, the values of extras_len,key_len, and value_len are updated according to thesizes of the values stored in the extras, key, and valuefields. Subsequently, the value of total_len is up-dated according to the variable’s serialisation expressionin lines 17 and 18. The %byteorder property decla-ration in line 2 specifies the wire format encoding ofnumber values—the generated code transforms such val-ues between the specified big-endian encoding and thehost byte-order. More advanced features of the gram-mar language include choices between alternative fieldsequences, field repetitions (i.e. lists), and transforma-tions into custom FLICK field types (e.g. enumerations).
FLICK grammars aim to be reusable and thus in-clude all fields of a given message format, even thoughapplication-specific network services often only require asubset of the information encoded in a message. To avoidgenerated parsers and serialisers handling unnecessarydata, FLICK programs make accesses to message fieldsexplicit by declaring a FLICK data type correspondingto the message (Listing 1, lines 1–2). This enables theFLICK compiler to generate input and output tasks thatonly parse and serialise the required fields for these datatypes and their dependencies. Other fields are aggre-
Listing 3: FLICK program for Hadoop data aggregator1 type kv: record2 key : string3 value : string4
5 proc hadoop: ([kv/-] mappers , -/kv reducer):6 if (all_ready(mappers)):7 let result = foldt on mappers8 ordering elem e1, e2 by elem.key as e_key:9 let v = combine(e1.val , e2.val)
10 kv(e_key , v)11 result => reducer12
13 fun combine(v1: string , v2: string) -> (string): ...
gated into either simplified or composite fields, and thenskipped or simply copied in their wire format representa-tion. Developers can thus reuse complete message gram-mars to generate parsers and serialisers, while benefit-ing from efficient execution for their application-specificnetwork service.
The current FLICK implementation does not supportexceptions, but data type grammars could provide a de-fault behaviour when a message is incomplete or not inan expected form.
4.3 Primitives and compilationThe FLICK language is strongly-typed for safety. To fa-cilitate middlebox programming, it includes channels,processes, explicit parallelism, and exception handlingas native features. For example, events such as brokenconnections can be caught and handled by FLICK func-tions, which can notify a backend or record to a log. Statehandling is essential for describing many middleboxes,and the language supports both session-level and long-term state, whose scope extends across sessions. The lat-ter is provided through a key/value abstraction to taskgraph instances by the FLICK platform. To access it,the programmer declares a dictionary and labels it with aglobal qualifier. Multiple instances of the service sharethe key/value store.
The language is restricted to allow only computa-tions that are guaranteed to terminate, thus avoiding ex-pensive isolation mechanisms while supporting multipleprocesses competing for shared resources. This restric-tion allows static allocation of memory and cooperativetask scheduling (see §5).
The FLICK language offers primitives to support com-mon datatypes such as bytes, lists and records. Itera-tion may only be carried out on finite structures (e.g.lists). It also provides primitives such as fold, map andfilter but it does not offer higher-order functions: func-tions such as fold are translated into finite for-loops.Datatypes may be annotated with cardinalities to deter-mine statically the required memory. Loops and branch-ing are compiled to their native counterparts in C++.Channel- and process-related code is translated to APIcalls exposed by the platform (see §5). The language re-
6

USENIX Association 2016 USENIX Annual Technical Conference 7
lies on the C++ compiler to optimise the target code.Channels are typed, and at compile time the platform
determines that FLICK programs only send valid datainto channels. Due to the language’s static memory re-strictions, additional channels cannot be declared at run-time, though channels may be rebound, e.g. to connect toa different backend server.
The language also provides foldt, a parallel versionof fold that operates over a set of channels. This allowsthe efficient expression of typical data processing opera-tions, such as a k-way merge sort in which sorted streamsof keys from k channels are combined by selecting ele-ments with the smallest key. The expression foldt fo cs aggregates elements from an array of channels cs,selecting elements according to a function o and aggre-gating according to a function f. As f must be commuta-tive and associative, the aggregation can be performed inparallel, combining elements in a pair-wise manner untilonly the result remains.
As shown in Listing 3, the foldt primitive can beused to implement an application-level network ser-vice for parallel data aggregation in Hadoop. When-ever key/value pairs become available from the map-pers (lines 5–6), foldt is invoked (lines 7–10). El-ements elem are ordered based on elem.key (line 8),and values of elements with the same key (e_key) aremerged using a combine function (line 9) to create a newkey/value pair (line 10).While foldt could be expressedusing core language primitives, the FLICK platform hasa custom implementation for performance reasons.
While designed to achieve higher safety and perfor-mance, the constraints introduced in the design of theFLICK language, e.g. the lack of support for unboundedcomputation or dynamic memory allocation, imply thatnot all possible computations can be expressed in FLICK.For instance, algorithms requiring loops with unboundediterations (e.g. while-like loops) cannot be encoded. Ina general purpose programming language, this would bea severe constraint but for the middlebox functionalitythat FLICK targets we have not found this to cause majorlimitations.
5 FLICK PlatformThe FLICK platform is designed around a task graph ab-straction, composed of tasks that deserialise input datato typed values, compute over those values, and serialiseresults for onward transmission. The FLICK compilertranslates an input FLICK program to C++, which is inturn compiled and linked against the platform runtimefor execution. Figure 2 shows an overview of the FLICKplatform, which handles network connections, the taskgraph life-cycle, the communication between tasks andthe assignment of tasks to worker threads. Task graphsexploit task and data parallelism at runtime as tasks are
Program Instance
1 Application dispatcher
Graph dispatcher
2
4
Graph pool5
Scheduler
Task Queue
Worker Threads
3
6
Figure 2: Main components of the FLICK platform
assigned to worker threads. Even with only one large net-work flow, serialisation, processing and deserialisationtasks can be scheduled to run on different CPU cores.
(i) The application dispatcher manages the life-cycle ofTCP connections: first it maps new incoming connec-tions � to a specific program instance �, typically basedon the destination port number of the incoming connec-tion. The application dispatcher manages the listeningsockets that handle incoming connections, creating a newinput channel for each incoming connection and hand-ing off data from that connection to the correct instance.When a client closes an input TCP connection, the ap-plication dispatcher indicates this to the instance; whena task graph has no more active input channels, it is shutdown. New connections are directly connected to exist-ing task graphs �.
(ii) The graph dispatcher assigns incoming connectionsto task graphs �, instantiating a new one if none suitableexists. The platform maintains a pre-allocated pool oftask graphs to avoid the overhead of construction �. Thegraph dispatcher also creates new output channel connec-tions to forward processed traffic.
(iii) Tasks are cooperatively scheduled by the sched-uler, which allocates work among a fixed number ofworker threads �. The number of worker threads is de-termined by the number of CPU cores available, andworker threads are pinned to CPU cores.
Tasks in a task graph become runnable after receiv-ing data in their input queues (either from the network orfrom another task). A task that is not currently executingor scheduled is added to a worker queue when it becomesrunnable. All buffers are drawn from a pre-allocated poolto avoid dynamic memory allocation. Input tasks usenon-blocking sockets and epoll event handlers to pro-cess socket events. When a socket becomes readable, theinput task attached to the relevant socket is scheduled tohandle the event.
For scheduling, each worker thread is associated withits own FIFO task queue. Each task within a task graphhas a unique identifier, and a hash over this identifier de-
7

8 2016 USENIX Annual Technical Conference USENIX Association
inputtask
computetask
outputtask
inputchannel
outputchanneltask
channel
(a) HTTP load balancer (b) Memcached proxy (c) Hadoop data aggregator
Figure 3: Task graphs for different application-specific network services
termines which worker’s task queue the task should beassigned to. When a task is to be scheduled, it is alwaysadded to the same queue to reduce cache misses.
Each worker thread picks a task from its own queue.If its queue is empty, the worker attempts to scavengework from other queues and, if none is found, it sleepsuntil new work arrives. A worker thread runs a task un-til either all its input data is consumed, or it exceedsa system-defined time quantum, the timeslice threshold(typically, 10–100 µs; see §6). If the timeslice thresholdis exceeded, the code generated by the FLICK compilerguarantees that the task re-enters the scheduler, placingitself at the back of the queue if it has remaining workto do. A task with no work is not added to the taskqueue, but when new items arrive in its input channels, itis scheduled again.
A disadvantage of allocating tasks belonging to thesame task graphs onto different CPU cores is that thiswould incur several cache invalidations as data movefrom one core to another. On the other hand, our designenables higher parallelism as different tasks can executeconcurrently in a pipelined fashion, leading to higherthroughput.
Some middlebox services must handle many concur-rent connections, and they frequently write and readsmall amounts of data. The kernel TCP stack has ahigh overhead for creating and destroying sockets to sup-port the Linux Virtual File System (VFS) interface [17].Socket APIs also require switching between user- andkernel-mode, which adds further overhead. As a result,the FLICK platform uses mTCP [21], a highly scalableuser-space TCP stack, combined with Intel’s DPDK [20]to reduce these overheads. The original mTCP imple-mentation did not support multi-threaded applications,and we modified mTCP so that Flick I/O tasks can ac-cess sockets independently. To take utilise the efficientDPDK runtime environment, mTCP executes as a DPDKtask. All of these optimisations, significantly improveperformance for network-bound services (see §6.3).
6 EvaluationThe goals of our evaluation are to investigate whether thehigh-level programming abstraction that FLICK carries aperformance and scalability cost and whether DPDK and
mTCP improve performance. We implement FLICK pro-grams for the use cases introduced in §2.1, i.e. an HTTPload balancer, a Memcached proxy and a Hadoop dataaggregator, and compare their performance against base-lines from existing implementations.
After describing the implementation of our usecases (§6.1) and the experimental set-up (§6.2), we ex-plore the performance and scalability of FLICK (§6.3).After that, we examine how well the FLICK platform iso-lates resource consumption of multiple FLICK programsusing cooperative scheduling (§6.4).
6.1 Use case implementationFor our three use cases, Figure 3 shows the task graphobtained from the corresponding FLICK program.
HTTP load balancer. This FLICK program implementsan HTTP load balancer that forwards each incomingHTTP request to one of a number of backend webservers. Forwarding is based on a naive hash of thesource IP and port and destination IP and port. Figure 3ashows the corresponding task graph. The application dis-patcher forwards each new TCP connection received onport 80 to the graph dispatcher. The graph dispatchercreates a new task graph, which is later destroyed whenthe connection closes. The input task deserialises the in-coming data into HTTP requests. For the first request, thecompute task calculates a hash value selecting a backendserver for the request. Subsequent requests on the sameconnection are forwarded to the same backend server. Ontheir return path no computation or parsing is needed,and the data is forwarded without change. We also imple-ment a variant of the HTTP load balancer that does notuse backend servers but which returns a fixed responseto a given request. This is effectively a static web server,which we use to test the system without backends.
Memcached proxy. In this use case, the FLICK pro-gram (Listing 1) receives Memcached look-up requestsfor keys. Requests are forwarded based on hash parti-tioning to a set of Memcached servers, each storing a dis-joint section of the key space. Responses received fromthe Memcached servers are returned to clients.
Figure 3b shows the corresponding task graph. Asbefore, a new task graph is created for each new TCPconnection. Unlike the HTTP load balancer, requests
8

USENIX Association 2016 USENIX Annual Technical Conference 9
from the same client can be dispatched to different Mem-cached servers, which means that the compute task musthave a fan-out greater than one.
When a request is received on the input channel, it isdeserialised by the input task. The deserialisation codeis automatically generated from the type specificationin Listing 2. The deserialiser task outputs the Mem-cached request object, containing the request keys andbody, which are passed on to the compute task. The com-pute task implements the dispatching logic. It identifiesthe Memcached server responsible for that key and for-wards the request to it through the serialiser task. Whenthe response is received from the Memcached server, thedeserialiser task deserialises it and passes the responseobject to the compute task, which returns it to the clientthrough the serialiser task.Hadoop data aggregator. The Hadoop data aggregatorimplements the combiner function of a map/reduce jobto perform early data aggregation in the network, as de-scribed in §2.1. It is implemented in FLICK according toListing 3. We focus on a wordcount job in which thecombiner function aggregates word counters producedby mappers over a set of documents.
For each Hadoop job, the platform creates a separatetask graph per reducer (Figure 3c). The input tasks dese-rialise the stream of intermediate results (i.e. key/valuepairs) from the mappers. Compute tasks combine thedata with each compute task taking two input streamsand producing one output. The output task converts thedata to the byte stream, as per the Hadoop wire format.
6.2 Experimental set-upWe deploy the prototype implementation of the FLICKplatform on servers with two 8-core Xeon E5-2690 CPUsrunning at 2.9 Ghz with 32 GB of memory. Clientsand back-end machines are deployed on a cluster of16 machines with 4-core Xeon E3-1240 CPUs run-ning at 3.3 Ghz. All machines use Ubuntu Linux ver-sion 12.04. The clients and backend machines have1 Gbps NICs, and the servers executing the FLICK plat-form have 10 Gbps NICs. The client and backend ma-chines connect to a 1 Gbps switch, and the FLICK plat-form connects to a 10 Gbps switch. The switches havea 20 Gbps connection between them. We examine theperformance of FLICK with and without mTCP/DPDK.
To evaluate the performance of the HTTP load bal-ancer, we use multiple instances of ApacheBench(ab) [4], a standard tool for measuring web server per-formance, together with 10 backend servers that run theApache web server [51]. Throughput is measured interms of connections per second as well as requests persecond for HTTP keep-alive connections. We compareagainst the standard Apache (mod_proxy_balancer) andthe Nginx [35] load balancers.
For the Memcached proxy, we deploy 128 clientsrunning libmemcached [1], a standard client libraryfor interacting with Memcached servers. We use10 Memcached servers as backends and compare theperformance against a production Memcached proxy,Moxi [32]. We measure performance in terms of through-put (i.e. requests served per second) and request latency.Clients send a single request and wait for a response be-fore sending the next request.
For the Hadoop data aggregator, the workload is awordcount job. It uses a sum as the aggregation computa-tion and an input dataset with a high data reduction ratio.The datasets used in experiments are 8 GB, 12 GB and16 GB (larger data sets were also used for validation).Here we measure performance in terms of the absolutenetwork throughput.
In all graphs, the plotted points are the mean of fiveruns with identical parameters. Error bars correspond toa 95% confidence interval.
6.3 PerformanceHTTP load balancer. We begin by measuring the per-formance of the static web server with an increasing load.This exercises the following components of the FLICKplatform: HTTP parsing, internal and external chan-nel operation and task scheduling. The results are for100 to 1,600 concurrent connections (above these loads,Apache and Nginx begin to suffer timeouts). Across theentire workload, FLICK achieves superior performance.It achieves a peak throughput of 306,000 requests/secfor the kernel version and 380,000 requests/sec withmTCP. The maximum throughput achieved by Apacheis 159,000 requests/sec and by Nginx is 217,000 re-quests/sec. FLICK also shows lower latency, particu-larly at high concurrency when Apache and Nginx uselarge numbers of threads. This confirms that, whileFLICK provides a general-purpose platform for creatingapplication-specific network functions, it can outperformpurpose-written services.
To investigate the per-flow overhead due to TCP set-up/tear-down, we also repeat the same experiment butwith each web request establishing a separate TCP con-nection (i.e. non-persistent HTTP). This reduces thethroughput in all deployments: 35,000 requests/sec forApache; 44,000 requests/sec for Nginx; and 45,000 re-quests/sec for FLICK, which maintains the lowest la-tency. Here the kernel TCP performance for connectionset-up and tear-down is a bottleneck: the mTCP versionof FLICK handles up to 193,000 requests/sec.
Next, we repeat the experiment using our HTTP loadbalancer implementation to explore the impact of bothreceiving and forwarding requests. The set-up is as de-scribed in §6.2. We use small HTTP payloads (137 byteseach) to ensure that the network and the backends are
9

10 2016 USENIX Annual Technical Conference USENIX Association
100
200
300
100 200 400 800 1600Concurrent clients
Thou
sand
reqs
/sFLICK FLICK mTCP Apache Nginx
(a) Throughput (persistent connections)
0
10
20
100 200 400 800 1600Concurrent clients
Mea
n la
tenc
y (m
s) FLICKFLICK mTCPApacheNginx
(b) Latency (persistent connections)
0
25
50
75
100
100 200 400 800 1600Concurrent clients
Thou
sand
reqs
/s
FLICK FLICK mTCP Apache Nginx
(c) Throughput (non-persistent connections)
0
20
40
60
80
100 200 400 800 1600Concurrent clients
Mea
n la
tenc
y (m
s) FLICKFLICK mTCPApacheNginx
(d) Latency (non-persistent connections)
Figure 4: HTTP load balancer throughput and latency for an increasing number of concurrent connections
never the bottleneck. As for the web server experiment,we first consider persistent connections. Figures 4aand 4b confirm the previous results: FLICK achieves upto 1.4× higher throughput than Nginx and 2.2× higherthan Apache. Using mTCP, the performance is even bet-ter with higher throughput and lower latency: FLICKachieves a maximum throughput 2.7× higher than Ng-inx and 4.2× higher than Apache. In all cases, FLICKhas lower latency.
With non-persistent connections, the kernel versionof FLICK exhibits a lower throughput than Apache andNginx (see Figure 4c). Both Apache and Nginx keeppersistent TCP connections to the backends, but FLICKdoes not, which increases its connection set-up/tear-down cost. When mTCP is used with its lower per con-nection cost, FLICK shows better performance than ei-ther with a maximum throughput 2.5× higher than that ofNginx and 2.1× higher than that of Apache. In addition,both the kernel and mTCP versions of FLICK maintainthe lowest latency of the systems, as shown in Figure 4d.
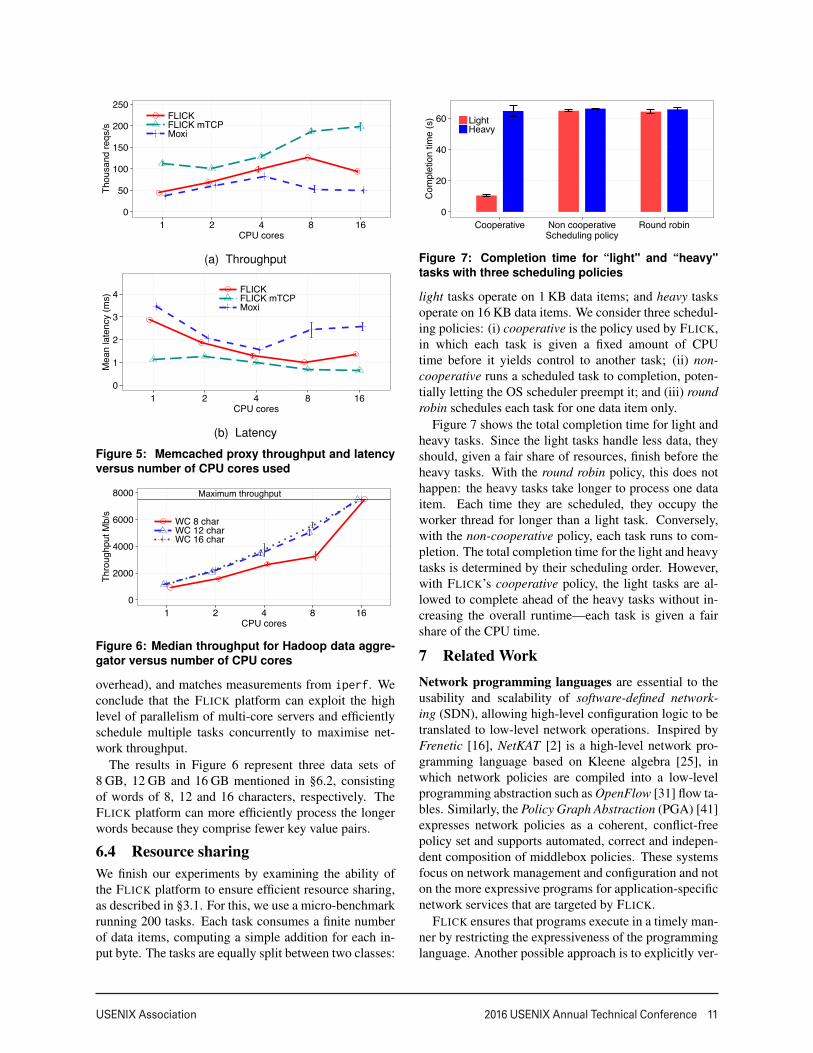
Memcached proxy. For the Memcached proxy usecase, we compare the performance of FLICK againstMoxi [32], as we increase the number of CPU cores. Wechose Moxi because it supports the binary Memcachedprotocol and is multi-threaded. In our set-up, 128 clientsmake concurrent requests using the Memcached binaryprotocol over persistent connections, which are then mul-tiplexed to the backends.
Figures 5a and 5b show the throughput, in terms ofthe number of requests/sec, and the latency, respectively.
With more CPU cores, the throughout initially increasesfor both systems. The kernel version achieves a max-imum throughput of 126,000 requests/sec with 8 CPUcores and the mTCP version achieves 198,000 request-s/sec with 16 CPU cores. Moxi peaks at 82,000 request-s/sec with 4 CPU cores. FLICK’s latency decreases withmore CPU cores due to the larger processing capacityavailable in the system. The latency of Moxi beyond4 CPU cores and FLICK’s beyond 8 CPU cores increasesas threads compete over common data structures.
Hadoop data aggregator. The previous use cases hadrelatively simple task graphs (see Figure 3) and consid-erable overhead comes from the connection set-up andtear-down, with many network requests processed in par-allel. In contrast, the Hadoop data aggregator use casehas a more complex task graph, and we use it to as-sess the overhead of FLICK’s communication channelsand intra-graph scheduling. Here the tasks are computebound, and the impact of the network overhead is limited.We only present the kernel results because the mTCP re-sults are similar.
We deploy 8 mappers clients, each with 1 Gbps con-nections, to connect to the FLICK server. The task graphtherefore has 16 tasks (8 input, 7 processing and 1 out-put). The FLICK Hadoop data aggregator runs on aserver with 16 CPU cores without hyper-threading.
Figure 6 shows that FLICK scales well with the num-ber of CPU cores, achieving a maximum throughput of7,513 Mbps with 16 CPU cores. This is the maximumcapacity of the 8 network links (once accounted for TCP
10
USENIX Association 2016 USENIX Annual Technical Conference 11
0
50
100
150
200
250
1 2 4 8 16CPU cores
Thou
sand
reqs
/sFLICKFLICK mTCPMoxi
(a) Throughput
0
1
2
3
4
1 2 4 8 16CPU cores
Mea
n la
tenc
y (m
s)
FLICKFLICK mTCPMoxi
(b) Latency
Figure 5: Memcached proxy throughput and latencyversus number of CPU cores used
Maximum throughput
0
2000
4000
6000
8000
1 2 4 8 16CPU cores
Thro
ughp
ut M
b/s
WC 8 charWC 12 charWC 16 char
Figure 6: Median throughput for Hadoop data aggre-gator versus number of CPU cores
overhead), and matches measurements from iperf. Weconclude that the FLICK platform can exploit the highlevel of parallelism of multi-core servers and efficientlyschedule multiple tasks concurrently to maximise net-work throughput.
The results in Figure 6 represent three data sets of8 GB, 12 GB and 16 GB mentioned in §6.2, consistingof words of 8, 12 and 16 characters, respectively. TheFLICK platform can more efficiently process the longerwords because they comprise fewer key value pairs.
6.4 Resource sharingWe finish our experiments by examining the ability ofthe FLICK platform to ensure efficient resource sharing,as described in §3.1. For this, we use a micro-benchmarkrunning 200 tasks. Each task consumes a finite numberof data items, computing a simple addition for each in-put byte. The tasks are equally split between two classes:
0
20
40
60
Cooperative Non cooperative Round robinScheduling policy
Com
plet
ion
time
(s) Light
Heavy
Figure 7: Completion time for “light" and “heavy"tasks with three scheduling policies
light tasks operate on 1 KB data items; and heavy tasksoperate on 16 KB data items. We consider three schedul-ing policies: (i) cooperative is the policy used by FLICK,in which each task is given a fixed amount of CPUtime before it yields control to another task; (ii) non-cooperative runs a scheduled task to completion, poten-tially letting the OS scheduler preempt it; and (iii) roundrobin schedules each task for one data item only.
Figure 7 shows the total completion time for light andheavy tasks. Since the light tasks handle less data, theyshould, given a fair share of resources, finish before theheavy tasks. With the round robin policy, this does nothappen: the heavy tasks take longer to process one dataitem. Each time they are scheduled, they occupy theworker thread for longer than a light task. Conversely,with the non-cooperative policy, each task runs to com-pletion. The total completion time for the light and heavytasks is determined by their scheduling order. However,with FLICK’s cooperative policy, the light tasks are al-lowed to complete ahead of the heavy tasks without in-creasing the overall runtime—each task is given a fairshare of the CPU time.
7 Related WorkNetwork programming languages are essential to theusability and scalability of software-defined network-ing (SDN), allowing high-level configuration logic to betranslated to low-level network operations. Inspired byFrenetic [16], NetKAT [2] is a high-level network pro-gramming language based on Kleene algebra [25], inwhich network policies are compiled into a low-levelprogramming abstraction such as OpenFlow [31] flow ta-bles. Similarly, the Policy Graph Abstraction (PGA) [41]expresses network policies as a coherent, conflict-freepolicy set and supports automated, correct and indepen-dent composition of middlebox policies. These systemsfocus on network management and configuration and noton the more expressive programs for application-specificnetwork services that are targeted by FLICK.
FLICK ensures that programs execute in a timely man-ner by restricting the expressiveness of the programminglanguage. Another possible approach is to explicitly ver-
11

12 2016 USENIX Annual Technical Conference USENIX Association
ify that a specific program meets requirements. This ver-ification apparoach has been used to check simple, state-less Click pipelines [12] but might be harder for morecomplex middlebox programs.
There are proposed extensions to the packet process-ing done by OpenFlow. P4 [8] is a platform- andprotocol-independent language for packet processors,which allows the definition of new header fields and pro-tocols for use in match/action tables. Protocol ObliviousForwarding (POF) [47] also provides a flexible means tomatch against and rewrite packet header fields. PacketLanguage for Active Networks (PLAN) [18] is a state-less and strongly-typed functional language for activenetworking in which packets carry programs to networknodes for execution. In general, these approaches arelimited to expressing control-plane processing of pack-ets in contrast to FLICK, which deals with applicationlayer data.Software middlebox platforms. Recently network ser-vices have been deployed on commodity hardware toreduce costs and increase flexibility. Click [24] pro-cesses packets through a chain of installed elements,and it supports a wide variety of predefined elements.Programmers, however, must write new elements inC++, which can be error-prone. ClickOS [30] com-bines Click with MiniOS and focuses on the consol-idation of multiple software middlebox VMs onto asingle server. It overcomes current hypervisor limita-tions through a redesigned I/O system and by replacingOpen vSwitch [38] with a new software switch basedon VALE [45]. ClickOS targets packet level process-ing, e.g. manipulating header fields or filtering packets;FLICK, by contrast, operates at the application level, andthe approaches can be seen as orthogonal. It would bechallenging for ClickOS to parse and process HTTP datawhen a single data item may span multiple packets orMemcached data when a packet may contain multipledata items.
Merlin [48] is a language that safely translates poli-cies, expressed as regular expressions for encoding paths,into Click scripts. Similarly, IN-NET [49] is an architec-ture for the deployment of custom in-network process-ing on ClickOS with an emphasis on static checking forpolicy safety. In a similar vein, xOMB [3] provides amodular processing pipeline with user-defined logic forflow-oriented packet processing. FlowOS [7] is a flow-oriented programmable platform for middleboxes usinga C API similar to the traditional socket interface. It useskernel threads to execute flow-processing modules with-out terminating TCP connections. Similar to ClickOS,these platforms focus on packet processing rather thanthe application level. SmartSwitch [53] is a platform forhigh-performance middlebox applications built on top ofNetVM [19], but it only supports UDP applications, and
it does not offer a high-level programming model.Eden is a platform to execute application-aware net-
work services at the end hosts [5]. It uses a domain-specific language, similar to F#, and enables users to im-plement different services ranging from load balancing toflow prioritisation. By operating at the end hosts, it limitsthe set of network services that can be supported. For ex-ample, it would be impossible to implement in-networkaggregation or in-network caching.
Split/Merge [42] is a hypervisor-level mechanism thatallows balanced, stateful elasticity and migration of flowstate for virtual middleboxes. Per-flow migration is ac-complished by identifying the external state of networkflows, which has to be split among replicas. Similar elas-ticity support could be integrated with FLICK.
8 ConclusionsExisting platforms for in-network processing typicallyprovide a low-level, packet-based API. This makes ithard to implement application-specific network services.In addition, they lack support for low-overhead perfor-mance isolation, thus preventing efficient consolidation.
To address these challenges, we have developedFLICK, a domain-specific language and supporting plat-form that provides developers with high-level primitivesto write generic application-specific network services.We described FLICK’s programming model and runtimeplatform. FLICK realises processing logic as restrictedcooperatively schedulable tasks, allowing it to exploit theavailable parallelism of multi-core CPUs. We evaluatedFLICK through three representative use cases, an HTTPload balancer, a Memcached proxy and a Hadoop dataaggregator. Our results showed that FLICK greatly re-duces the development effort, while achieving better per-formance than specialised middlebox implementations.
References[1] AKER, B. libmemcached. http://libmemcached.org/
libMemcached.html.
[2] ANDERSON, C. J., FOSTER, N., GUHA, A., JEANNIN, J.-B.,KOZEN, D., SCHLESINGER, C., AND WALKER, D. NetKAT:Semantic Foundations for Networks. In Proc. 41th ACMSIGPLAN-SIGACT Symposium on Principles of ProgrammingLanguages (POPL) (2014).
[3] ANDERSON, J. W., BRAUD, R., KAPOOR, R., PORTER, G.,AND VAHDAT, A. xOMB: Extensible Open Middleboxes withCommodity Servers . In Proc. 8th ACM/IEEE Symposium on Ar-chitectures for Networking and Communications Systems (ANCS)(2012).
[4] APACHE FOUNDATION. Apache HTTP Server Benchmark-ing Tool, 2015. https://httpd.apache.org/docs/2.2/programs/ab.html.
[5] BALLANI, H., COSTA, P., GKANTSIDIS, C., GROSVENOR,M. P., KARAGIANNIS, T., KOROMILAS, L., AND O’SHEA, G.Enabling End-host Network Functions. In Proc. of ACM SIG-COMM (2015).
12

USENIX Association 2016 USENIX Annual Technical Conference 13
[6] BANGERT, J., AND ZELDOVICH, N. Nail: A Practical Tool forParsing and Generating Data Formats. In Proc. 11th USENIXSymposium on Operating Systems Design and Implementation(OSDI) (2014).
[7] BEZAHAF, M., ALIM, A., AND MATHY, L. FlowOS: A Flow-based Platform for Middleboxes. In Proc. 9th International Con-ference on emerging Networking EXperiments and Technologies(CoNEXT) (2013).
[8] BOSSHART, P., DALY, D., GIBB, G., IZZARD, M., MCKEOWN,N., REXFORD, J., SCHLESINGER, C., TALAYCO, D., VAH-DAT, A., VARGHESE, G., AND WALKER, D. P4: ProgrammingProtocol-Independent Packet Processors. ACM SIGCOMM Com-puter Communication Review 44, 3 (2014), 87–95.
[9] CHOWDHURY, M., KANDULA, S., AND STOICA, I. LeveragingEndpoint Flexibility in Data-intensive Clusters. In Proc. of ACMSIGCOMM (2013).
[10] COSTA, P., MIGLIAVACCA, M., PIETZUCH, P., AND WOLF,A. L. NaaS: Network-as-a-Service in the Cloud. In Proc. 2ndUSENIX Workshop on Hot Topics in Management of Internet,Cloud, and Enterprise Networks and Services (Hot-ICE) (2012).
[11] DAGAND, P.-E., BAUMANN, A., AND ROSCOE, T. Filet-o-fish:Practical and Dependable Domain-specific Languages for OS De-velopment. SIGOPS Oper. Syst. Rev. 43, 4 (2010), 35–39.
[12] DOBRESCU, M., AND ARGYRAKI, K. Software dataplane ver-ification. In Proc. USENIX Networked Systems Design and Im-plementation (NSDI) (2014), pp. 101–114.
[13] DONOVAN, S., AND FEAMSTER, N. Intentional Network Mon-itoring: Finding the Needle without Capturing the Haystack. InProc. 13th ACM Workshop on Hot Topics in Networks (HotNets)(2014).
[14] FIELDING, R., GETTYS, J., MOGUL, J., FRYSTYK, H., MAS-INTER, L., LEACH, P., AND BERNERS-LEE, T. HypertextTransfer Protocol – HTTP/1.1, June 1999. http://ietf.org/rfc/rfc2616.txt.
[15] FITZPATRICK, B. Distributed Caching with Memcached. LinuxJournal 2004, 124 (2004).
[16] FOSTER, N., HARRISON, R., FREEDMAN, M. J., MONSANTO,C., REXFORD, J., STORY, A., AND WALKER, D. Frenetic: ANetwork Programming Language. In Proc. 16th ACM SIGPLANInternational Conference on Functional Programming (ICFP)(2011).
[17] HAN, S., MARSHALL, S., CHUN, B.-G., AND RATNASAMY, S.MegaPipe: A New Programming Interface for Scalable NetworkI/O. In Proc. 10th USENIX Symposium on Operating SystemsDesign and Implementation (OSDI) (2012).
[18] HICKS, M., KAKKAR, P., MOORE, J. T., GUNTER, C. A., ANDNETTLES, S. PLAN: A Packet Language for Active Networks.In Proc. 3rd ACM SIGPLAN International Conference on Func-tional Programming (ICFP) (1998).
[19] HWANG, J., RAMAKRISHNAN, K. K., AND WOOD, T. NetVM:High Performance and Flexible Networking Using Virtualizationon Commodity Platforms. In Proc. 11th USENIX Symposium onNetworked Systems Design and Implementation (NSDI) (2014).
[20] INTEL. Intel Data Plane Development Kit (DPDK).http://www.intel.com/go/dpdk, 2014.
[21] JEONG, E. Y., WOO, S., JAMSHED, M., JEONG, H., IHM, S.,HAN, D., AND PARK, K. mTCP: A Highly Scalable User-levelTCP Stack for Multicore Systems. In Proc. 11th USENIX Sympo-sium on Networked Systems Design and Implementation (NSDI)(2014).
[22] JIM, T., MORRISETT, J. G., GROSSMAN, D., HICKS, M. W.,CHENEY, J., AND WANG, Y. Cyclone: A Safe Dialect of C. InProc. USENIX Annual Technical Conference (ATC) (2002).
[23] KHAYYAT, Z., AWARA, K., ALONAZI, A., JAMJOOM, H.,WILLIAMS, D., AND KALNIS, P. Mizan: A System for Dy-namic Load Balancing in Large-scale Graph Processing. In Proc.European Conference on Computer Systems (EuroSys) (2013).
[24] KOHLER, E., MORRIS, R., , CHEN, B., JANNOTTI, J., ANDKAASHOEKBENJIE, M. F. The Click Modular Router. ACMTransactions on Computer Systems 18, 3 (2000), 263–297.
[25] KOZEN, D., AND SMITH, F. Kleene Algebra with Tests: Com-pleteness and Decidability. In Proc. 10th International Workshopon Computer Science Logic (CSL) (1996).
[26] LOO, B. T., CONDIE, T., GAROFALAKIS, M., GAY, D. E.,HELLERSTEIN, J. M., MANIATIS, P., RAMAKRISHNAN, R.,ROSCOE, T., AND STOICA, I. Declarative Networking. Com-mun. ACM 52, 11 (2009), 87–95.
[27] MAAS, M., ASANOVIC, K., HARRIS, T., AND KUBIATOWICZ,J. The Case for the Holistic Language Runtime System. In Proc.1st International Workshop on Rack-scale Computing (WRSC)(2014).
[28] MADHAVAPEDDY, A., HO, A., DEEGAN, T., SCOTT, D., ANDSOHAN, R. Melange: Creating a “Functional” Internet. SIGOPSOper. Syst. Rev. 41, 3 (2007), 101–114.
[29] MAI, L., RUPPRECHT, L., ALIM, A., COSTA, P., MIGLI-AVACCA, M., PIETZUCH, P., AND WOLF, A. L. NetAgg:Using Middleboxes for Application-specific On-path Aggrega-tion in Data Centres. In Proc. 10th International Conference onemerging Networking EXperiments and Technologies (CoNEXT)(2014).
[30] MARTINS, J., AHMED, M., RAICIU, C., OLTEANU, V.,HONDA, M., BIFULCO, R., AND HUICI, F. ClickOS and theArt of Network Function Virtualization. In Proc. 11th USENIXSymposium on Networked Systems Design and Implementation(NSDI) (2014).
[31] MCKEOWN, N., ANDERSON, T., BALAKRISHNAN, H.,PARULKAR, G., PETERSON, L., REXFORD, J., SHENKER, S.,AND TURNER, J. OpenFlow: Enabling Innovation in CampusNetworks. ACM SIGCOMM Computer Communication Review38, 2 (2008), 69–74.
[32] MEMBASE. Moxi – Memcached Router/Proxy, 2015. https://github.com/membase/moxi/wiki.
[33] MONSANTO, C., REICH, J., FOSTER, N., REXFORD, J., ANDWALKER, D. Composing Software-defined Networks. In Proc.10th USENIX Symposium on Networked Systems Design and Im-plementation (NSDI) (2013).
[34] NETFLIX. Ribbon Wiki. https://github.com/Netflix/ribbon/wiki.
[35] NGINX Website. http://nginx.org/.
[36] NISHTALA, R., FUGAL, H., GRIMM, S., KWIATKOWSKI, M.,LEE, H., LI, H. C., MCELROY, R., PALECZNY, M., PEEK,D., SAAB, P., STAFFORD, D., TUNG, T., AND VENKATARA-MANI, V. Scaling Memcache at Facebook. In Proc. 10th USENIXSymposium on Networked Systems Design and Implementation(NSDI) (2013).
[37] OLSTON, C., REED, B., SRIVASTAVA, U., KUMAR, R., ANDTOMKINS, A. Pig Latin: A Not-so-foreign Language for DataProcessing. In Proc. ACM SIGMOD International Conferenceon Management of Data (SIGMOD) (2008).
[38] Open vSwitch. http://openvswitch.org/.
[39] PANG, R., PAXSON, V., SOMMER, R., AND PETERSON, L.Binpac: A Yacc for Writing Application Protocol Parsers. InProc. 6th ACM SIGCOMM Conference on Internet Measurement(IMC) (2006).
13

14 2016 USENIX Annual Technical Conference USENIX Association
[40] PATEL, P., BANSAL, D., YUAN, L., MURTHY, A., GREEN-BERG, A., MALTZ, D. A., KERN, R., KUMAR, H., ZIKOS, M.,WU, H., KIM, C., AND KARRI, N. Ananta: Cloud Scale LoadBalancing. In Proc. of ACM SIGCOMM (2013).
[41] PRAKASH, C., LEE, J., TURNER, Y., KANG, J.-M., AKELLA,A., BANERJEE, S., CLARK, C., MA, Y., SHARMA, P., ANDZHANG, Y. PGA: Using Graphs to Express and AutomaticallyReconcile Network Policies. In Proc. of ACM SIGCOMM (2015).
[42] RAJAGOPALAN, S., WILLIAMS, D., JAMJOOM, H., ANDWARFIELD, A. Split/Merge: System Support for Elastic Exe-cution in Virtual Middleboxes. In Proc. 10th USENIX Sympo-sium on Networked Systems Design and Implementation (NSDI)(2013).
[43] RIZZO, L. Netmap: A Novel Framework for Fast Packet I/O. InProc. USENIX Annual Technical Conference (ATC) (2012).
[44] RIZZO, L., CARBONE, M., AND CATALLI, G. TransparentAcceleration of Software Packet Forwarding Using Netmap. InProc. IEEE International Conference on Computer Communica-tions (INFOCOM) (2012).
[45] RIZZO, L., AND LETTIERI, G. VALE, a Switched Ethernetfor Virtual Machines. In Proc. 8th International Conference onemerging Networking EXperiments and Technologies (CoNEXT)(2012).
[46] SOMMER, R., WEAVER, N., AND PAXSON, V. HILTI: AnAbstract Execution Environment for High-Performance NetworkTraffic Analysis. In Proc. 14th ACM SIGCOMM Conference onInternet Measurement (IMC) (2014).
[47] SONG, H. Protocol-oblivious Forwarding: Unleash the Powerof SDN Through a Future-proof Forwarding Plane. In Proc. 2ndACM SIGCOMM Workshop on Hot Topics in Software DefinedNetworking (HotSDN) (2013).
[48] SOULÉ, R., BASU, S., MARANDI, P. J., PEDONE, F., KLEIN-BERG, R., SIRER, E. G., AND FOSTER, N. Merlin: A Languagefor Provisioning Network Resources. In Proc. 10th InternationalConference on emerging Networking EXperiments and Technolo-gies (CoNEXT) (2014).
[49] STOENESCU, R., OLTEANU, V., POPOVICI, M., AHMED, M.,MARTINS, J., BIFULCO, R., MANCO, F., HUICI, F., SMARAG-DAKIS, G., HANDLEY, M., AND RAICIU, C. In-Net: In-Network Processing for the Masses. In Proc. European Confer-ence on Computer Systems (EuroSys) (2015).
[50] STONE, E. Memcache Binary Protocol, 2009. https://code.google.com/p/memcached/wiki/BinaryProtocolRevamped.
[51] THE APACHE SOFTWARE FOUNDATION. The Apache HTTPServer Project. http://httpd.apache.org/.
[52] TWITTER. Twemproxy (nutcracker). https://github.com/twitter/twemproxy.
[53] ZHANG, W., WOOD, T., RAMAKRISHNAN, K., AND HWANG,J. SmartSwitch: Blurring the Line Between Network Infrastruc-ture & Cloud Applications. In Proc. 6th USENIX Workshop onHot Topics in Cloud Computing (HotCloud) (2014).
[54] Apache Hadoop. http://hadoop.apache.org.
14