final exam review cs479/679 pattern recognition dr. george bebis 1
TRANSCRIPT

Final Exam Review
CS479/679 Pattern RecognitionDr. George Bebis
1

Final Exam Material
• Midterm Exam Material• Linear Discriminant Functions• Support Vector Machines• Expectation-Maximization Algorithm
2
Case studies are also included in the final exam

Linear Discriminant Functions
• General form of linear discriminant:
• What is the form of the decision boundary? What is the meaning of w and w0?– The decision boundary is a hyperplane ; its
orientation is determined by w and its location by w0.
3
0 01
( )d
ti i
i
g w w x w
x w x

Linear Discriminant Functions
• What does g(x) measure?– Distance of x from the decision boundary
(hyperplane)
4
( )
|| ||
gr
x
w

Linear Discriminant Functions• How do we find w and w0?– Apply learning using a set of labeled training
examples
• What is the effect of each training example?– Places a constraint on the solution
5
feature space (y1, y2)
aa11
aa22 1i y
2j y
solution space (ɑ1, ɑ2)

Linear Discriminant Functions
• Iterative optimization – what is the main idea?– Minimize some error function J(α) iteratively
6
( 1) ( ) ( ) kk k k α α p
( )kα(k)(k) α(k+1)(k+1)( ) kk p kp search directionsearch direction
learning ratelearning rate

Linear Discriminant Functions
• Gradient descent method
• Newton method
• Perceptron rule
7( )
( 1) ( ) ( )Y
k k k
y α
α α y

Support Vector Machines
• What is the capacity of a classifier?• What is the VC dimension of a classifier?• What is structural risk minimization?– Find solutions that (1) minimize the empirical risk and (2) have low VC dimension.– It can be shown that:
8
(log(2 / ) 1) log( / 4)true train
VC n VCerr err
n
with probability (1-δ)

Support Vector Machines
• What is the margin of separation? How is it defined?
• What is the relationship between VC dimension and margin of separation?– VC dimension is minimized by maximizing the
margin of separation.9
support vectors
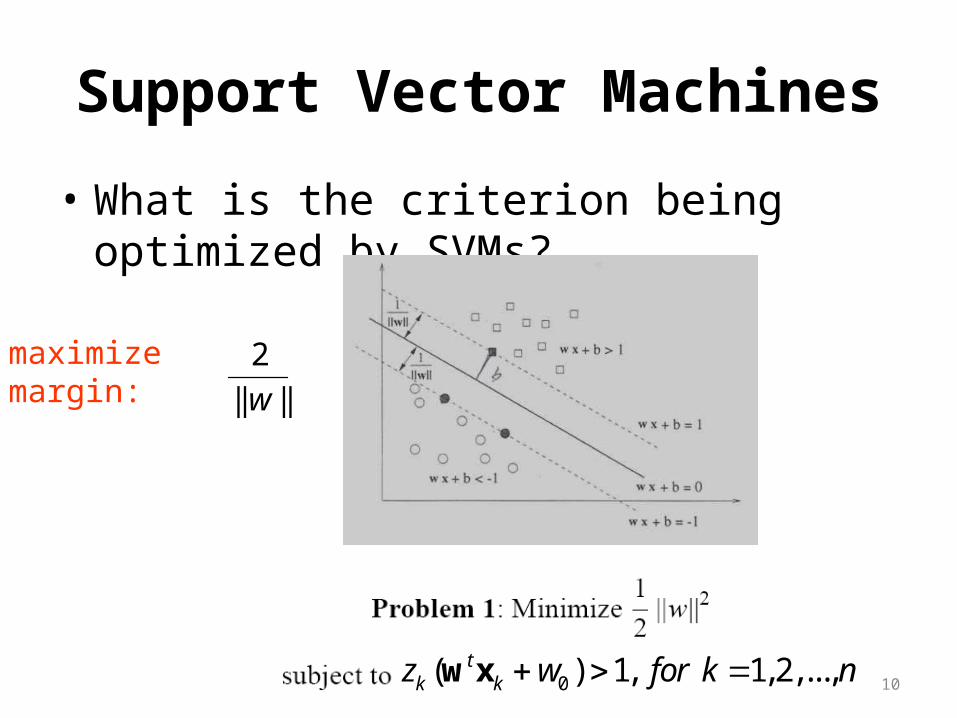
Support Vector Machines
• What is the criterion being optimized by SVMs?
10
maximizemargin:
2
|| ||w
0( ) 1, 1,2,...,tk kz w for k n w x

Support Vector Machines
• SVM solution depends only on the support vectors:
• Soft margin classifier – tolerate “outliers”
11
01
( ) ( . )n
k k kk
g z w
x x x
0( ) 1 , 1,2,...,tk k kz w w k n x

Support Vector Machines
• Non-linear SVM – what is the main idea?– Map data to a high dimensional space h
12
1
2
( )
( )( )
...
( )
k
kk k
h k
x
xx Φ x
x
01
( ) ( ( ). ( ))n
k k kk
g z w
x x x

Support Vector Machines
• What is the kernel trick?– Compute dot products using a kernel function
13
01
( ) ( , )n
k k kk
g z K w
x x x
( , ) ( ). ( )k kK x x x x
01
( ) ( ( ). ( ))n
k k kk
g z w
x x x
K(x,y)=(x . y) de.g., polynomial kernel:

Support Vector Machines
• Important comments about SVMs– SVM is based on exact optimization (no local
optima).– Its complexity depends on the number of support
vectors, not on the dimensionality of the transformed space.
– Performance depends on the choice of the kernel and its parameters.
14

Expectation-Maximization (EM)
• What is the EM algorithm? – An iterative method to perform ML estimation i.e., max p(D/ θ)
• When is EM useful?– Most useful for problems where the data is
incomplete or can be thought as being incomplete.
15

Expectation-Maximization (EM)
• What are the steps of the EM algorithm?– Initialization: θ0
– Expectation Step:– Maximization Step:– Test for convergence:
• Convergence properties of EM ?– Solution depends on the initial estimate θ0
– No guarantee to find global maximum but stable
16
( ; ) (ln ( / ) / , )unobserved
t tx x yQ E p D D
t+1 tθθ arg max (θ;θ )Q
t+1 t|θ -θ |

Expectation-Maximization (EM)
• What is a mixture of Gaussians?
• How are the parameters of MoGs estimated?– Using the EM algorithm
• What is the main idea behind using EM for estimating the MoGs parameters?– Introduce “hidden variables:
17

Expectation-Maximization (EM)
• Explain the EM steps for MoGs
18

Expectation-Maximization (EM)
19
• Explain the EM steps for MoGs