file management lecture 3. what is a file? file is term applied to anything held on secondary...
TRANSCRIPT

File Management
Lecture 3

What is a file?
• File is term applied to anything held on secondary storage
• Includes programs (source and executable) text files such as word documents, spreadsheet files, database files etc.

File naming
• MS DOS format is generally up to eight character name followed by a dot and then a three character extension.
• Example Letter1.doc , hello.exe , stock.dat
• Linux/Unix file naming is more flexible can have something like myfile.example.doc normally .bin files are equivelent to exe files in windows.

Objectives of O.S.
• Hide complexity of how files are saved from user• Problems with physical addressing, perform
error checking, i/o tasks to storage.• Develop file management strategies• Explore files and folders• Create, name, copy, move, and delete folders• Name, copy, move, and delete files• Work with compressed files

Organizing Files and Folders• A file, or document, is a collection of data that
has a name and is stored in a computer• You organize files by storing them in folders• Disks contain folders that hold documents, or
files– Floppy disks– Zip disks– Compact Discs (CDs)– Hard Disks
• Removable disks are inserted into a drive

Organizing Files and Folders

Understanding the Need for Organizing Files and Folders
• Windows organizes the folders and files in a hierarchy, or file system
• Windows stores folders and important files that it needs when you turn on the computer in the root directory
• Folders stored within other folders are called subfolders
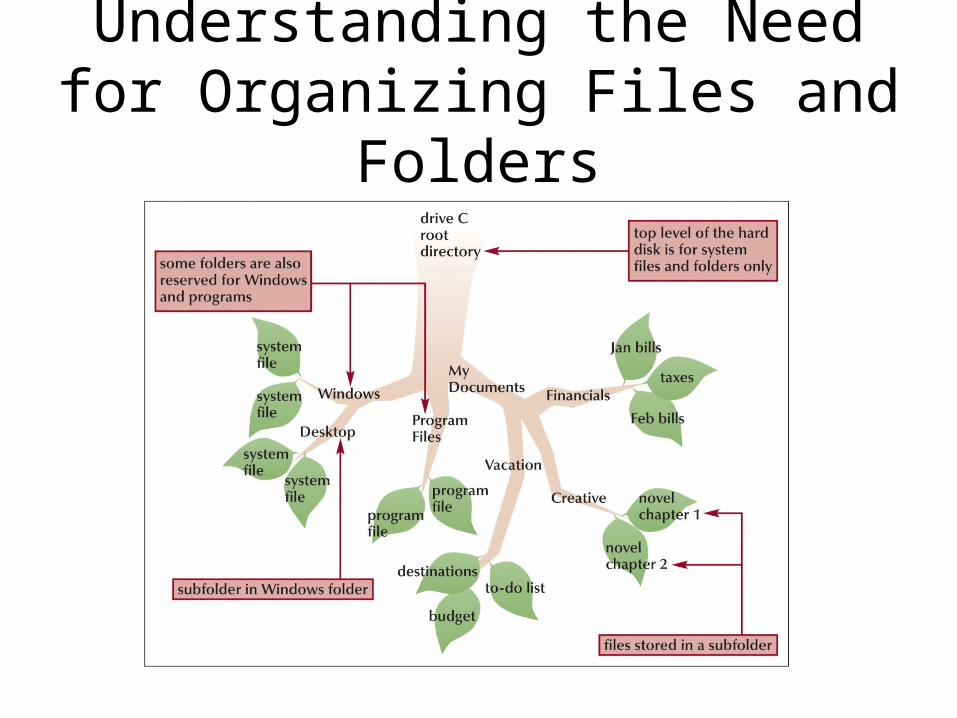
Understanding the Need for Organizing Files and Folders

Directories
• A directory is a logical grouping of files
• All modern operating systems have a directory structure
• Why security and housekeeping on system
• Example on Linux system only root user will have access to sbin directory.

Linux/Unix file structure

File Management System
• Provides a logical view for the user and hides the physical implementation
• Where a file is located and how it is stored on disk is role of OS
• Manages directory structures and space allocation for each I/O device
• Permits manipulation of data within a file• Requests data transfers from I/O device drivers• File security and protection of file integrity

File Management and I/O Functions
Separation between the two allows
1. I/O devices can change while keeping the file system the same
2. Redirecting of data is simple

File Manager Request Handling

File Storage
• Over time file sizes change this can be a problem for OS. As files reduce get deleted, compressed etc spaces develop on disk – fragmentation.
• OS provides fixed size blocks for storing data, called cluster.
• Problem is clusters are often not sequential.

File Access Methods
• Sequential Access– File is read in sequence from beginning to end– Majority of all files– Program source and binary files
• Random Access– Assumes file is made up of fixed length logical records– Hashing is a common method used to calculate the location of
an internal logical record
• Indexed Access– Additional means for accessing and viewing records in a file– Key indexes

Physical File Storage
• Contiguous• Non-contiguous
– Linked– Indexed
• Examples– DOS/Windows FAT– UNIX i-nodes– Windows NTFS– Free space management

Contiguous Storage Allocation
• Assign blocks (all in a row) to hold the file• Access is simple for both sequential and random
methods• Disadvantages
– Space must be large enough– Have to take into account file growth– May need to be moved if it outgrows its space– Fragmentation of disk
• Allocation strategies to minimize fragmentation– First-fit, best-fit
• Eventually disk becomes fragmented
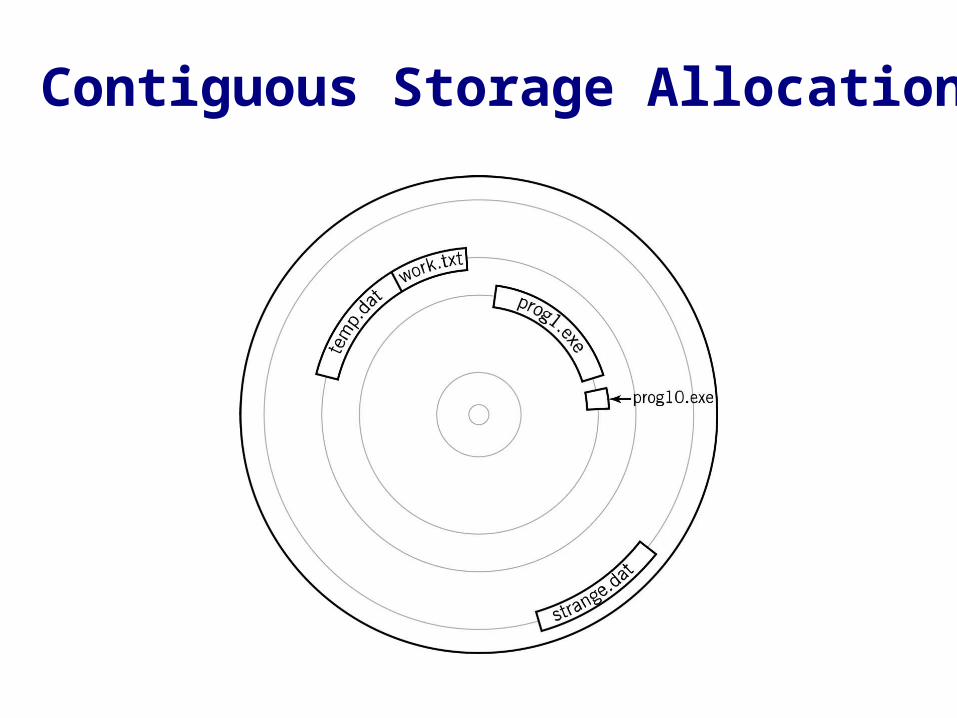
Contiguous Storage Allocation

Linked Allocation
• Non-contiguous• Each block contains a link to the next physical block• Variant – links in both directions• Advantages
– no fragmentation– Adding to a file is easy
• Disadvantages– Not usable for random access– Additional disk head searching– Overhead in storing the pointers– Recovery of a defective block is difficult
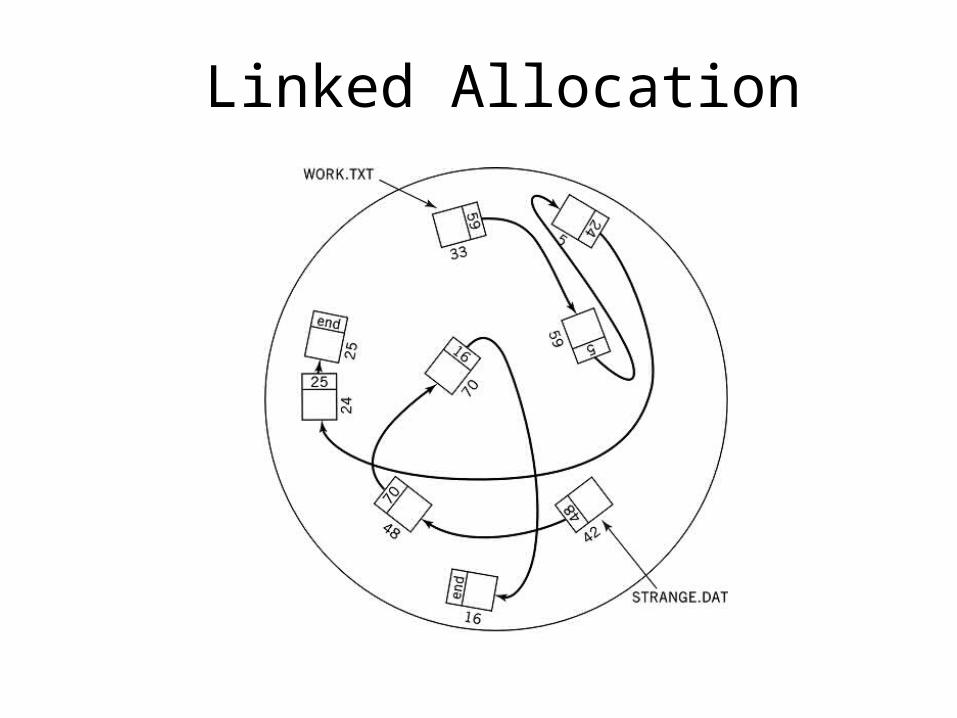
Linked Allocation

MS-DOS FAT
• File Allocation Table (FAT)
• Table contains the first block of each file on the disk or disk partition
• Successive blocks contain a link to the next block
• Requires a tremendous amount of space
• File integrity can be easily compromised

MS-DOS FAT
Linked Allocation and File Allocation Table

Indexed Allocation
Index blocks for indexed allocation of linked files shown in MS-DOS FAT example

Indexed Allocation
• Non-contiguous• All link pointers are stored together in a single
block called the index block• One index block per file• Advantages
– No fragmentation– Can be used for random access
• Disadvantage– Slower due to additional access of the index block– Additional disk head searching– Recovery of a defective block is difficult

Unix i-nodes
• Indexed file allocation• Index block contains
– File attributes– 10 direct blocks– 1 single indirect– 1 double indirect– 1 triple indirect
• Advantages– Fast for small blocks– Can accommodate very large files – 100’s of
gigabytes

Unix i-nodes

Windows 2000 - NTFS
• Dynamically sized volumes
• Volumes may be a fraction of a disk or span many disks
• Master File Table (MFT) of 1kb records– 1st 16 records are attributes of the MFT ie
system files used to manage the volume– Each file has an MFT entry

NTFS Volume Layout

Other Secondary Storage Allocation
• Tape Allocation– Not practical to reallocate space in the middle of the
tape– Files that grow must be re-written– Files are stored contiguously whenever possible
• CD-ROM and DVD-ROM Allocation– Block system described in Chapter 10– Eight levels of subdirectories– Directory format similar to MS-DOS although
extensions permit longer filenames and deeper subdirectory levels
– Files can be stored non-contiguously

Directory Structure
• Provides a means of organization so that files can be located easily and efficiently
• Hide the physical devices from the logical view of the files
• Partitions– Independent subsections of a device
• Volume– Directory structure for a particular partition– Needs to be mounted to be incorporated into the
overall file system structure
• Contain file attributes

Tree-Structure Directory
• Hierarchical with a top-level root directory from which all other directories stem
• All directories and files have names• Separator
– Used to indicate subdirectories and files located in a directory
– / UNIX
– \ DOS, Windows
• Pathname– Absolute – full pathname starting from the root directory
– Relative – pathname is created starting from the current directory
• Search Paths– Directory locations that the operating system uses to locate files

Tree-Structure Directory
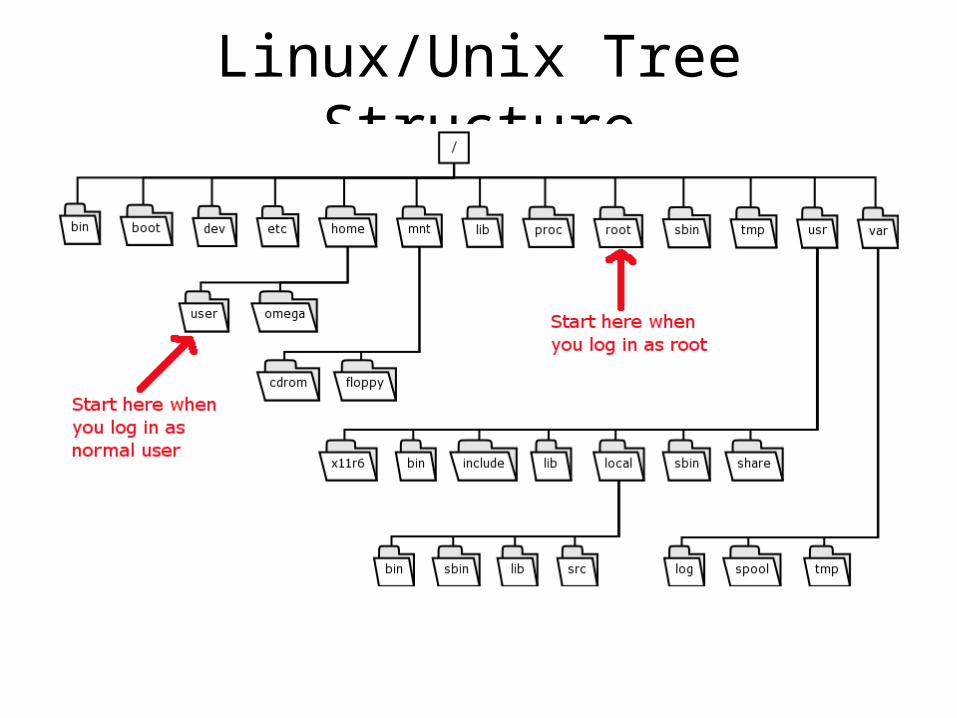
Linux/Unix Tree Structure

RAID
• Redundant Array of Independent Disks • Redundant Array of Inexpensive Disks• 6 levels in common use• Not a hierarchy• Set of physical disks viewed as single logical
drive by O/S• Data distributed across physical drives• Can use redundant capacity to store parity
information

RAID 0
• No redundancy• Data striped across all disks• Round Robin striping• Increase speed
– Multiple data requests probably not on same disk
– Disks seek in parallel– A set of data is likely to be striped across
multiple disks

RAID 1
• Mirrored Disks
• Data is striped across disks
• 2 copies of each stripe on separate disks
• Read from either
• Write to both
• Recovery is simple– Swap faulty disk & re-mirror– No down time
• Expensive

RAID 2• Disks are synchronized• Very small stripes
– Often single byte/word
• Error correction calculated across corresponding bits on disks
• Multiple parity disks store Hamming code error correction in corresponding positions
• Lots of redundancy– Expensive– Not used

RAID 3
• Similar to RAID 2
• Only one redundant disk, no matter how large the array
• Simple parity bit for each set of corresponding bits
• Data on failed drive can be reconstructed from surviving data and parity info
• Very high transfer rates

RAID 4
• Each disk operates independently
• Good for high I/O request rate
• Large stripes
• Bit by bit parity calculated across stripes on each disk
• Parity stored on parity disk

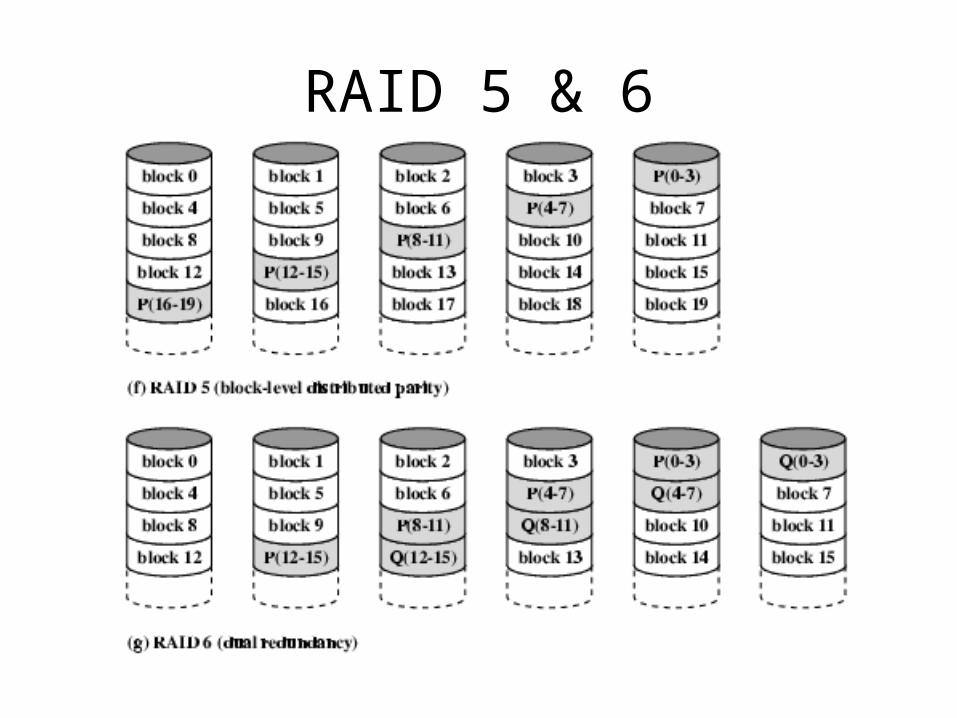
RAID 5
• Like RAID 4
• Parity striped across all disks
• Round robin allocation for parity stripe
• Avoids RAID 4 bottleneck at parity disk
• Commonly used in network servers
• N.B. DOES NOT MEAN 5 DISKS!!!!!

RAID 6
• Two parity calculations
• Stored in separate blocks on different disks
• User requirement of N disks needs N+2
• High data availability– Three disks need to fail for data loss– Significant write penalty

RAID 0, 1, 2

RAID 3 & 4
RAID 5 & 6