ディープラーニングによる画像生成の最前線 (応用) ·...
TRANSCRIPT

ディ ープラーニングによる画像生成の最前線(応用)
シモセラ エド ガー
2016年 11月 18日
早稲田大学

自己紹介
• 2015年 7月に BarcelonaTechで博士号を取得• 2015年 8月から早稲田大学の研究院助教• これから日本に住む
1

ディ ープラーニングの応用について
• 数学的に簡単だが、 実際使おう とすると難しい• 細かい実装の違いが大きく 影響• 論文をたく さん読まないといけないが、 どの論文がいい?
2

ディ ープラーニングの応用について
• 数学的に簡単だが、 実際使おう とすると難しい• 細かい実装の違いが大きく 影響• 論文をたく さん読まないといけないが、 どの論文がいい?
2

目次
1. ディ ープラーニングについて1.1 データ1.2 モデル1.3 学習
2. 例1 : データの重要性 (自動線画化)3. 例2 : モデルの重要性 (自動色付け)
ε
!
3

ディ ープラーニングについて
ディ ープラーニングの基礎
1. データ• 量、 品質…
2. モデル• CNN、 深さ、 層の種類…
3. 学習• SGD、 ADADELTA…
入 正
4
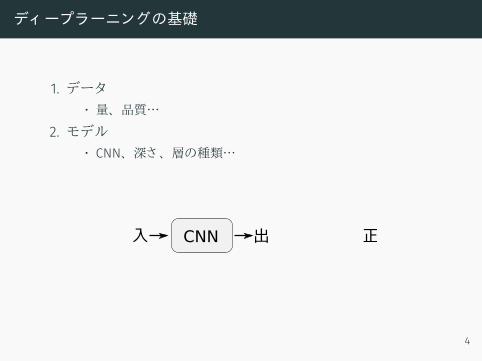
ディ ープラーニングの基礎
1. データ• 量、 品質…
2. モデル• CNN、 深さ、 層の種類…
3. 学習• SGD、 ADADELTA…
入 正出CNN
4

ディ ープラーニングの基礎
1. データ• 量、 品質…
2. モデル• CNN、 深さ、 層の種類…
3. 学習• SGD、 ADADELTA…
ロス逆習
入 正出CNN
4

ディ ープラーニングに向いている問題について
• ディ ープラーニングは万能ではない• 問題を選ぶのが大事• 適切な問題について
• 入力と出力のサイズが決まっているか、 情報処理の問題• 正解が一つの問題 (人間ができる)• データを集められる
5

向いている問題 ・分類
• 分類• 入力 :画像• 出力 : クラスの確率
• ディ ープラーニングの代表的な問題• 入力と出力のサイズが決まっている• 大規模なデータがある (ImageNet)
Krizhevsky et al. ImageNet Classification with Deep Convolutional Neural Networks. NIPS, 2012.6

向いている問題 ・分類
• 分類• 入力 :画像• 出力 : クラスの確率
• ディ ープラーニングの代表的な問題• 入力と出力のサイズが決まっている• 大規模なデータがある (ImageNet)
Krizhevsky et al. ImageNet Classification with Deep Convolutional Neural Networks. NIPS, 2012.
6

向いている問題 ・領域分割
• 領域分割• 入力 :画像• 出力 :画像の各領域のクラス確率
• データ作成が難しい• クラスの数が少ない• ImageNetの学習済みモデルを利用可
Chen et al. The Role of Context for Object Detection and Semantic Segmentation in the Wild. CVPR, 2014.
7
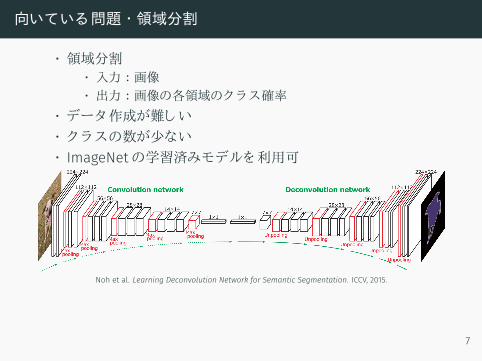
向いている問題 ・領域分割
• 領域分割• 入力 :画像• 出力 :画像の各領域のクラス確率
• データ作成が難しい• クラスの数が少ない• ImageNetの学習済みモデルを利用可
Noh et al. Learning Deconvolution Network for Semantic Segmentation. ICCV, 2015.
7
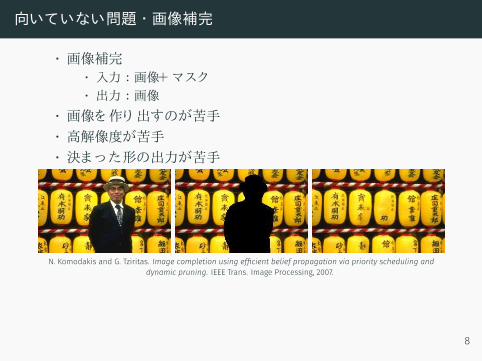
向いていない問題 ・画像補完
• 画像補完• 入力 :画像+ マスク• 出力 :画像
• 画像を作り 出すのが苦手• 高解像度が苦手• 決まった形の出力が苦手
N. Komodakis and G. Tziritas. Image completion using efficient belief propagation via priority scheduling anddynamic pruning. IEEE Trans. Image Processing, 2007.
8

向いていない問題 ・画像補完
• 画像補完• 入力 :画像+ マスク• 出力 :画像
• 画像を作り 出すのが苦手• 高解像度が苦手• 決まった形の出力が苦手
Pathak et al. Context Encoders: Feature Learning by Inpainting. CVPR, 2016.
8
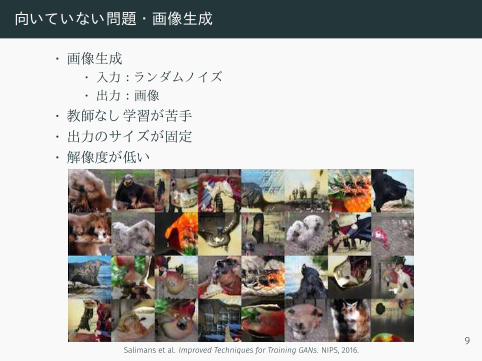
向いていない問題 ・画像生成
• 画像生成• 入力 : ランダムノ イズ• 出力 :画像
• 教師なし学習が苦手• 出力のサイズが固定• 解像度が低い
Salimans et al. Improved Techniques for Training GANs. NIPS, 2016.9

向いていない問題 ・画像生成
• 画像生成• 入力 : ランダムノ イズ• 出力 :画像
• 教師なし学習が苦手• 出力のサイズが固定• 解像度が低い
Salimans et al. Improved Techniques for Training GANs. NIPS, 2016.9

ディ ープラーニングに向いている問題のまとめ
向いている問題
• データが多い• 正解データが決まっている• 入力と出力のサイズが固定されている
• 学習済みのモデルを利用できる
向いていない問題
• データが少ない• 教師なし学習• 入力か出力が固定されていない
• ユーザーの編集• 高解像度
10

データについて
• どれほど必要?• 情報の流れについて考えなければならない• クラスラベルの情報が少ない → 100万枚以上使用• 領域分割ラベルの情報が多い → 1万枚未満
• 品質が大事• データ増加
• 反転、 回転、 明度、 コント ラスト 、 スケーリ ング…
猫
vs
11

データについて
• どれほど必要?• 情報の流れについて考えなければならない• クラスラベルの情報が少ない → 100万枚以上使用• 領域分割ラベルの情報が多い → 1万枚未満
• 品質が大事
• データ増加• 反転、 回転、 明度、 コント ラスト 、 スケーリ ング…
Lin et al. Microsoft COCO: Common Objects in Context. ARXIV, 2014.
11

データについて
• どれほど必要?• 情報の流れについて考えなければならない• クラスラベルの情報が少ない → 100万枚以上使用• 領域分割ラベルの情報が多い → 1万枚未満
• 品質が大事• データ増加
• 反転、 回転、 明度、 コント ラスト 、 スケーリ ング…
11

モデルについて
• 問題によって決める → 畳み込み層、 全結層…• バッチ正規化! [Ioffe and Szegedy 2015]
• 最初に解像度を下げる → メモリ 削減、 学習加速• 必要なら元の解像度に戻す• 全結層
• 重みが多く てオーバーフィ ッティ ングしやすい• 畳み込み層
• 3 x 3 カーネルで重みを減らす• 空間サポート が大事
Krizhevsky et al. ImageNet Classification with Deep Convolutional Neural Networks. NIPS, 2012.12
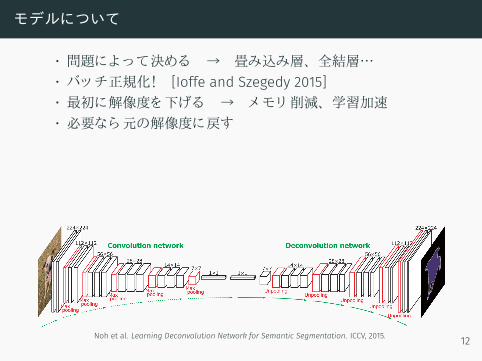
モデルについて
• 問題によって決める → 畳み込み層、 全結層…• バッチ正規化! [Ioffe and Szegedy 2015]• 最初に解像度を下げる → メモリ 削減、 学習加速• 必要なら元の解像度に戻す
• 全結層• 重みが多く てオーバーフィ ッティ ングしやすい
• 畳み込み層• 3 x 3 カーネルで重みを減らす• 空間サポート が大事
Noh et al. Learning Deconvolution Network for Semantic Segmentation. ICCV, 2015. 12
モデルについて
• 問題によって決める → 畳み込み層、 全結層…• バッチ正規化! [Ioffe and Szegedy 2015]• 最初に解像度を下げる → メモリ 削減、 学習加速• 必要なら元の解像度に戻す• 全結層
• 重みが多く てオーバーフィ ッティ ングしやすい• 畳み込み層
• 3 x 3 カーネルで重みを減らす• 空間サポート が大事
12

学習の基礎
1. データセッ ト を訓練用と検証用とテスト 用に分け1.1 訓練用データでモデルの重みを学習させ1.2 検証用データでハイパパラメータを決め1.3 テスト 用データは最後の評価のためのみ!
2. データセッ ト をランダムな順番に3. バッチで学習させ
3.1 小さすぎると不安定3.2 大きすぎると遅く てさらに精度がさがる3.3 問題によって違う (分類〜128、 領域分割〜8)
4. 誤差逆伝播法でロス関数を最小化5. 二点の問題点
5.1 アンダーフィ ッティ ング5.2 オーバーフィ ッティ ング
13

学習の基礎
1. データセッ ト を訓練用と検証用とテスト 用に分け1.1 訓練用データでモデルの重みを学習させ1.2 検証用データでハイパパラメータを決め1.3 テスト 用データは最後の評価のためのみ!
2. データセッ ト をランダムな順番に3. バッチで学習させ
3.1 小さすぎると不安定3.2 大きすぎると遅く てさらに精度がさがる3.3 問題によって違う (分類〜128、 領域分割〜8)
4. 誤差逆伝播法でロス関数を最小化5. 二点の問題点
5.1 アンダーフィ ッティ ング5.2 オーバーフィ ッティ ング
13

学習の基礎
1. データセッ ト を訓練用と検証用とテスト 用に分け1.1 訓練用データでモデルの重みを学習させ1.2 検証用データでハイパパラメータを決め1.3 テスト 用データは最後の評価のためのみ!
2. データセッ ト をランダムな順番に3. バッチで学習させ
3.1 小さすぎると不安定3.2 大きすぎると遅く てさらに精度がさがる3.3 問題によって違う (分類〜128、 領域分割〜8)
4. 誤差逆伝播法でロス関数を最小化5. 二点の問題点
5.1 アンダーフィ ッティ ング5.2 オーバーフィ ッティ ング
13
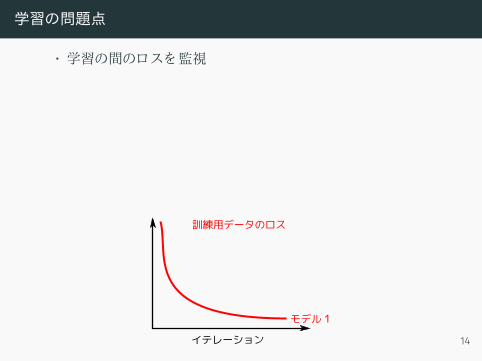
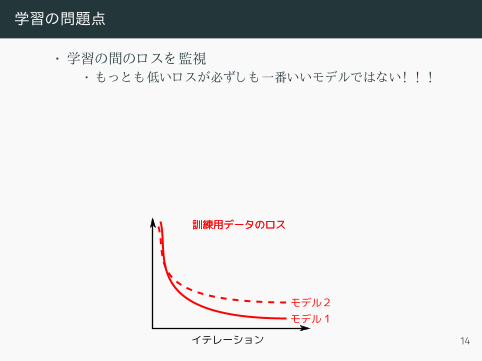
学習の問題点
• 学習の間のロスを監視
• もっとも低いロスが必ずしも一番いいモデルではない! ! !• 検証用データの精度を使おう
• アンダーフィ ッティ ング• モデルの重みが足り ない• 解決方法 :重みを増やす
• オーバーフィ ッティ ング• データが足り なく て汎化性能がさがる• 解決方法 : dropout、 データ増加…
イテレーション
モデル1
訓練用データのロス
14
学習の問題点
• 学習の間のロスを監視• もっとも低いロスが必ずしも一番いいモデルではない! ! !
• 検証用データの精度を使おう• アンダーフィ ッティ ング
• モデルの重みが足り ない• 解決方法 :重みを増やす
• オーバーフィ ッティ ング• データが足り なく て汎化性能がさがる• 解決方法 : dropout、 データ増加…
イテレーション
モデル1
訓練用データのロス訓練用データのロス
モデル2
14
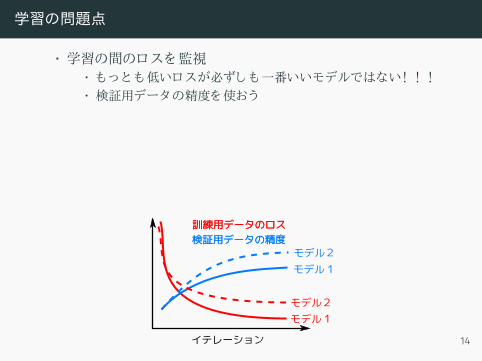
学習の問題点
• 学習の間のロスを監視• もっとも低いロスが必ずしも一番いいモデルではない! ! !• 検証用データの精度を使おう
• アンダーフィ ッティ ング• モデルの重みが足り ない• 解決方法 :重みを増やす
• オーバーフィ ッティ ング• データが足り なく て汎化性能がさがる• 解決方法 : dropout、 データ増加…
イテレーション
モデル1
訓練用データのロス
モデル1
検証用データの精度訓練用データのロス
モデル2
検証用データの精度モデル2
14
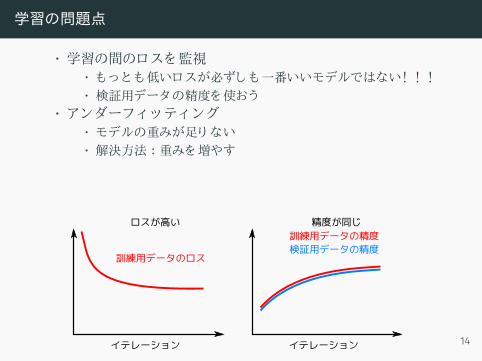
学習の問題点
• 学習の間のロスを監視• もっとも低いロスが必ずしも一番いいモデルではない! ! !• 検証用データの精度を使おう
• アンダーフィ ッティ ング• モデルの重みが足り ない• 解決方法 :重みを増やす
• オーバーフィ ッティ ング• データが足り なく て汎化性能がさがる• 解決方法 : dropout、 データ増加…
イテレーション
訓練用データのロス
ロスが高い
イテレーション
検証用データの精度訓練用データの精度
精度が同じ
14
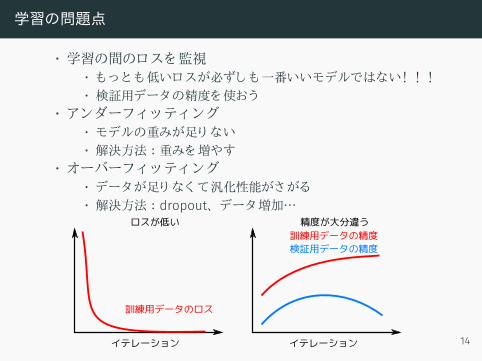
学習の問題点
• 学習の間のロスを監視• もっとも低いロスが必ずしも一番いいモデルではない! ! !• 検証用データの精度を使おう
• アンダーフィ ッティ ング• モデルの重みが足り ない• 解決方法 :重みを増やす
• オーバーフィ ッティ ング• データが足り なく て汎化性能がさがる• 解決方法 : dropout、 データ増加…
イテレーション
訓練用データのロス
ロスが低い
イテレーション
検証用データの精度訓練用データの精度
精度が大分違う
14

まとめ
• データ• 学習前に確認• データ増加
• モデル• バッチ正規化• 解像度が下げていく
• 学習• オーバーフィ ッティ ングに気をつける• 学習中ロスや検証用データの精度を監視
15

例1 : データの重要性 (自動線画化)
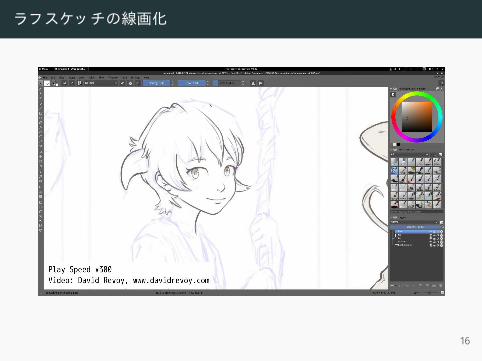
ラフスケッ チの線画化
16

ラフスケッ チの線画化
入力 : ラフスケッチ 出力 :線画
17

ラフスケッ チの線画化
ラフスケッチ 線画 ラフスケッチ 線画
18

関連研究
1. 線画化1.1 Progressive Online
Modification1.2 スト ローク除去1.3 スト ロークをまとめる1.4 入力はベクタ画像
2. ベクタ化2.1 モデルフィ ッティ ング2.2 画像勾配を利用2.3 入力は比較的綺麗なスケッチ
Liu et al. 2015
19

関連研究
1. 線画化1.1 Progressive Online
Modification1.2 スト ローク除去1.3 スト ロークをまとめる1.4 入力はベクタ画像
2. ベクタ化2.1 モデルフィ ッティ ング2.2 画像勾配を利用2.3 入力は比較的綺麗なスケッチ
Noris et al. 2013
19
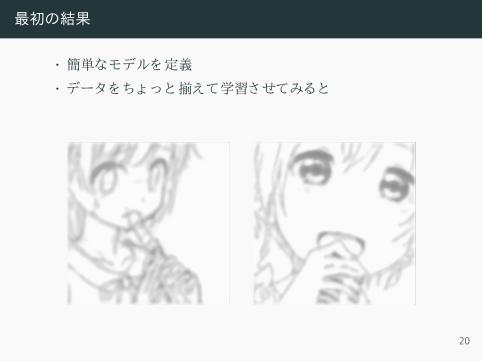
最初の結果
• 簡単なモデルを定義• データをちょ っと揃えて学習させてみると
• ラフスケッチと正解データを合わせてみると
20

最初の結果
• 簡単なモデルを定義• データをちょ っと揃えて学習させてみるとぼける• ラフスケッチと正解データを合わせてみると
20

逆方向データ制作
• データの品質が重要• ラフを線画化すると合わない (通常のデータ作成)• 線画をラフ化するとぴったり (逆方向データ作成)
通常のデータ作成 逆方向データ作成
21

ラフスケッ チデータセッ ト
• 68枚のラフスケッチと線画のペア• 5人のイラスト レーター• 424× 424画素の画像パッチを使用
・・・
Extracted patchesSketch dataset
・・・
22

データ拡大
• 68枚のデータセッ ト では足り ない• 訓練データの画像をスケーリ ング• 学習する間にランダムに回転と反転• 入力画像をさらに加工 : ト ーン調整、 ぶれ、 ノ イズ
入力 ト ーン調整 ぶれ ノ イズ
23

全層畳み込みニューラルネッ ト ワーク
スト ライド 数による三種類の畳み込みレイヤー
1. Flat-convolution1.1 カーネル 3× 3, パディ ング 1× 1, スト ライド 1
2. Down-convolution2.1 カーネル 3× 3, パディ ング 1× 1, スト ライド 2
3. Up-convolution3.1 カーネル 4× 4, パディ ング 1× 1, スト ライド 1/2
Down-convolution
Flat-convolution
Up-convolution
stride
stride
stride
24

モデル
• 23層• 出力の解像度は入力と同じ• エンコーダー ・ ディ ーコーダー型
• メモリ ーを減らす• 空間解像度を上げる
Flat-convolution
Up-convolution
2×2
4×4
8×8
4×4
2×2
×
×
Down-convolution
25

学習
• 全層ランダムの重みから学習• 損失関数として重みつき平均二乗誤差を使用• バッチ正規化 [Ioffe and Szegedy 2015]が必要• ADADELTA [Zeiler 2012]で最小化
入力 出力 正解
26

ベクタ化
• potraceでベクタ化• オープンソースのソフト ウェア• ハイパスフィ ルタと 2 値化
• 入力の解像度で簡略化の度合いが変化
入力 出力 ベクタ
27

ベクタ化
• potraceでベクタ化• オープンソースのソフト ウェア• ハイパスフィ ルタと 2 値化
• 入力の解像度で簡略化の度合いが変化
27
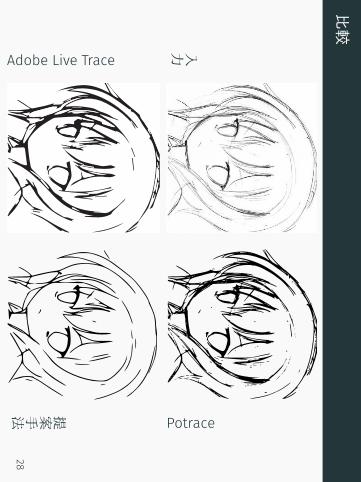
比較
入力
Potrace
Adobe Live Trace
提案手法28

比較
入力
Potrace
Adobe Live Trace
提案手法28

ユーザーテスト
• 15枚の画像を比較• 19人のユーザーが参加 (1 0 人はイラスト レーター)• 絶対評価 (1から 5 の点数)• 相対評価 (2枚を比べる)
提案手法 Live Trace Potrace
スコア 4.53 2.94 2.80
vs提案手法 - 2.5% 2.8%vs Live Trace 97.5% - 30.3%vs Potrace 97.2% 69.7% -
29
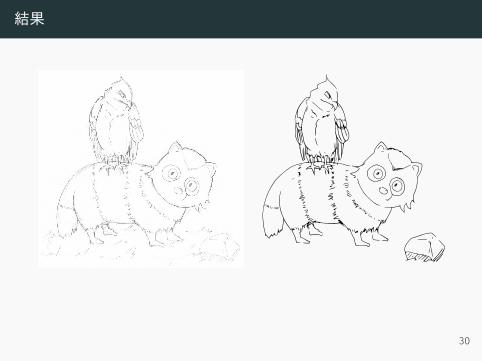
結果
30
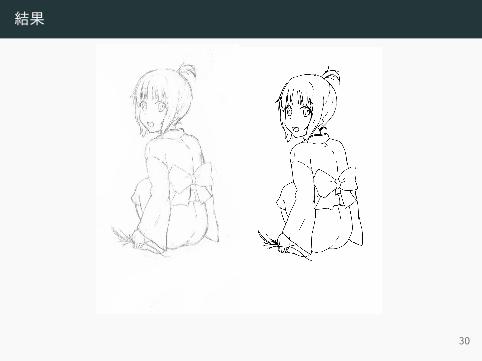
結果
30

結果
30

結果
30

例2 : モデルの重要性 (自動色付け)
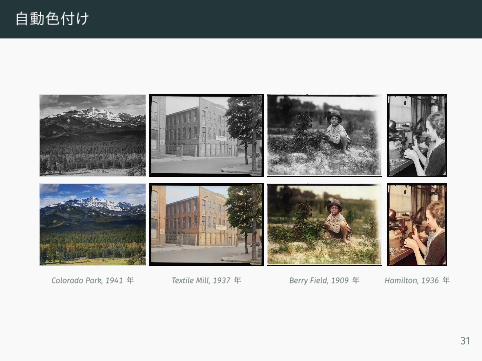
自動色付け
Colorado Park, 1941 年 Textile Mill, 1937 年 Berry Field, 1909 年 Hamilton, 1936 年
31

データについて
• 簡単に作れる• 現代のカラー写真を白黒にする• MITの Placesデータセッ ト を使用 [Zhou et al. 2014]
Abbey Airport terminal Aquarium Baseball field
Dining room Forest road Gas station Gift shop
⋯
⋯
32
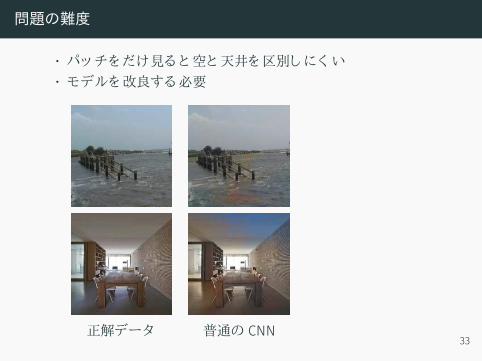
問題の難度
• パッチをだけ見ると空と天井を区別しにく い• モデルを改良する必要
正解データ 普通の CNN33

問題の難度
• パッチをだけ見ると空と天井を区別しにく い• モデルを改良する必要
?
正解データ 普通の CNN33
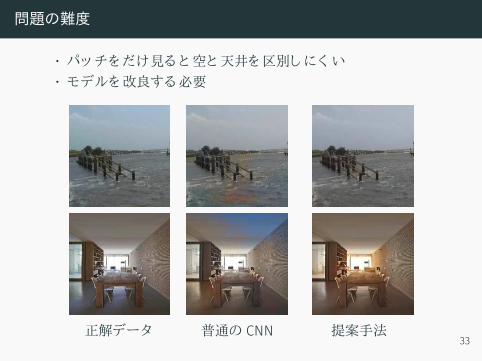
問題の難度
• パッチをだけ見ると空と天井を区別しにく い• モデルを改良する必要
正解データ 普通の CNN 提案手法33
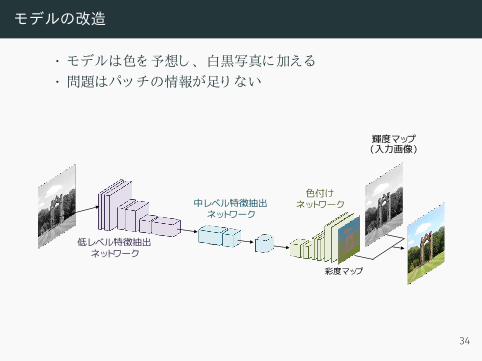
モデルの改造
• モデルは色を予想し 、 白黒写真に加える• 問題はパッチの情報が足り ない
• 解決方法 :大域特徴を利用• 提案の統合レイヤでパッチと大域特徴を結合
彩度マップ
中レベル特徴抽出ネットワーク
色付けネットワーク
輝度マップ(入力画像)
低レベル特徴抽出ネットワーク
34
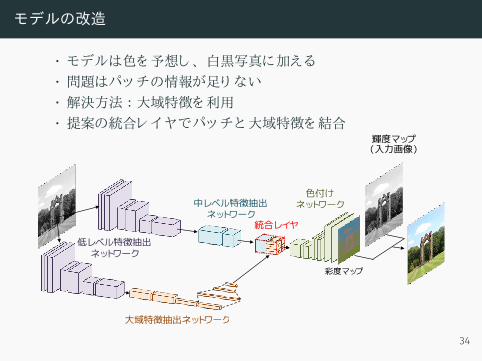
モデルの改造
• モデルは色を予想し 、 白黒写真に加える• 問題はパッチの情報が足り ない• 解決方法 :大域特徴を利用• 提案の統合レイヤでパッチと大域特徴を結合
彩度マップ
中レベル特徴抽出ネットワーク
色付けネットワーク
輝度マップ(入力画像)
低レベル特徴抽出ネットワーク
大域特徴抽出ネットワーク
統合レイヤ
34
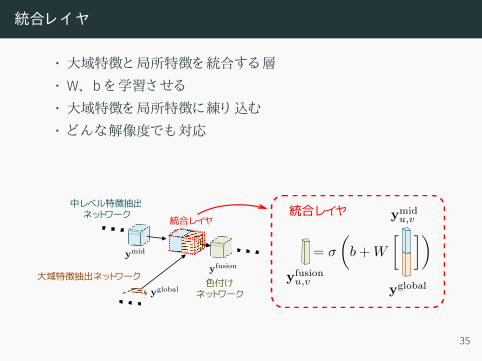
統合レイヤ
• 大域特徴と局所特徴を統合する層• W、 bを学習させる• 大域特徴を局所特徴に練り 込む• どんな解像度でも対応
大域特徴抽出ネットワーク
統合レイヤ...
...
...
色付けネットワーク
中レベル特徴抽出ネットワーク 統合レイヤ
35

モデルと学習
• 全層をランダムから学習• ADADELTAを使用
• 2 つのロスを使用• MSE ロスで色付けを学習させ• 分類誤差で大域特徴の学習を支援
彩度マップ
中レベル特徴抽出ネットワーク
色付けネットワーク
輝度マップ(入力画像)
低レベル特徴抽出ネットワーク
大域特徴抽出ネットワーク
統合レイヤ
36
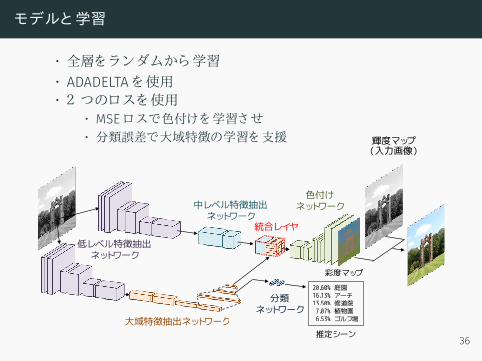
モデルと学習
• 全層をランダムから学習• ADADELTAを使用• 2 つのロスを使用
• MSE ロスで色付けを学習させ• 分類誤差で大域特徴の学習を支援
彩度マップ
中レベル特徴抽出ネットワーク
色付けネットワーク
輝度マップ(入力画像)
低レベル特徴抽出ネットワーク
大域特徴抽出ネットワーク
統合レイヤ
20.60% 庭園16.13% アーチ13.50% 修道院7.07% 植物園6.53% ゴルフ場
推定シーン
分類ネットワーク
36
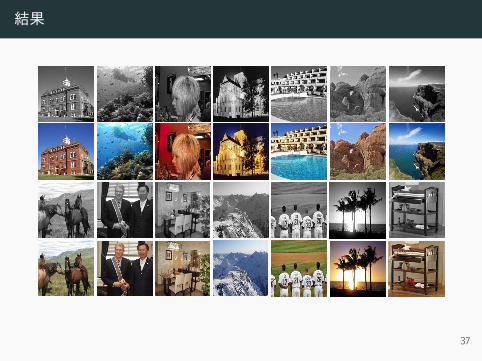
結果
37

結果
• 10人の被験者、 それぞれに 1500枚の画像を提示• 90%の色付け結果を自然と回答
自然 不自然
38

比較
入力画像 [Larsson+ ’16] [Zhang+ ’16] [Iizuka+ ’16]
39
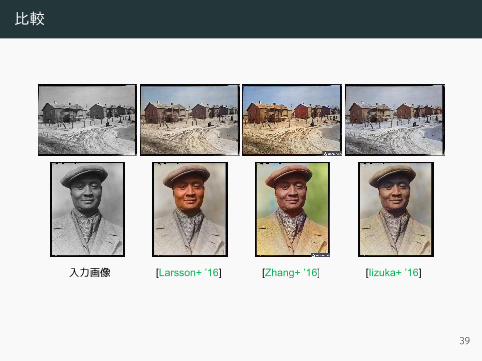
比較
入力画像 [Larsson+ ’16] [Zhang+ ’16] [Iizuka+ ’16]
39

比較
入力画像 [Larsson+ ’16]
[Zhang+ ’16] [Iizuka+ ’16]39

まとめ
• 自動線画化• モデルが簡単• データ作成が難しい
Flat-convolution
Up-convolution
2×2
4×4
8×8
4×4
2×2
×
×
Down-convolution
• 自動色付け• 大規模なデータ• 普通のモデルがあまり う まく いかない
彩度マップ
中レベル特徴抽出ネットワーク
色付けネットワーク
輝度マップ(入力画像)
低レベル特徴抽出ネットワーク
大域特徴抽出ネットワーク
統合レイヤ
20.60% 庭園16.13% アーチ13.50% 修道院7.07% 植物園6.53% ゴルフ場
推定シーン
分類ネットワーク 40
おわりに
• 理論も経験も大事• 3 つのことについて考えないといけない
• データを調べること• モデルの構想• 学習の実装
• ディ ープラーニングは機械学習の民主化• できないことができるよう になった• 研究ペースが恐ろしい• いろいろ試して経験積もう
41

おわりに
• 理論も経験も大事• 3 つのことについて考えないといけない
• データを調べること• モデルの構想• 学習の実装
• ディ ープラーニングは機械学習の民主化• できないことができるよう になった• 研究ペースが恐ろしい
• いろいろ試して経験積もう
41

おわりに
• 理論も経験も大事• 3 つのことについて考えないといけない
• データを調べること• モデルの構想• 学習の実装
• ディ ープラーニングは機械学習の民主化• できないことができるよう になった• 研究ペースが恐ろしい• いろいろ試して経験積もう
41

補助資料
• 飯塚里志 http://hi.cs.waseda.ac.jp/˜iizuka/• シモセラ エド ガー http://hi.cs.waseda.ac.jp/˜esimo/• 自動線画化を試す http://hi.cs.waseda.ac.jp:8081/• 自動色付けを試す http://hi.cs.waseda.ac.jp:8082/
42