fdb: a query engine for factorised relational databases · 2017-03-22 · fdb: a query engine for...
TRANSCRIPT

FDB: A Query Engine for Factorised RelationalDatabases
Nurzhan Bakibayev, Dan Olteanu, and Jakub Zavodny — Oxford CS
Christan [email protected]
University of Florida
November 1, 2013
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 1 / 39

Contents
1 Intro
2 F-Representation
3 F-Trees
4 Query EvaluationNormalisation OperatorSwap OperatorCartesian Product OperatorSelection Operator
Merge Selection OperatorAbsorb Selection OperatorSelection with Constant Operator
Projection Operator
5 Query OptimizationCost of an F-PlanExhaustive SearchGreedy Heuristic
6 ExperimentsExperiment #1Experiment #2Experiment #2Experiment #3Experiment #4
7 Conclusion8 Thanks
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 2 / 39

Intro
Intro
A succinct representation for large relations.
It is used in Google’s F1 data management system for ML.
Used for large incomplete/uncertain relations.
FDB can speed up expected queries.
This paper discusses basics FDB system.
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 3 / 39

Intro
Intro
A succinct representation for large relations.
It is used in Google’s F1 data management system for ML.
Used for large incomplete/uncertain relations.
FDB can speed up expected queries.
This paper discusses basics FDB system.
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 3 / 39
Intro
TL;DR
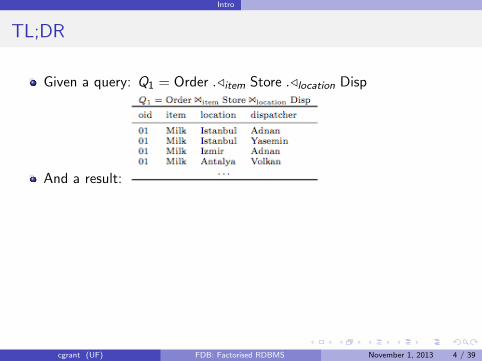
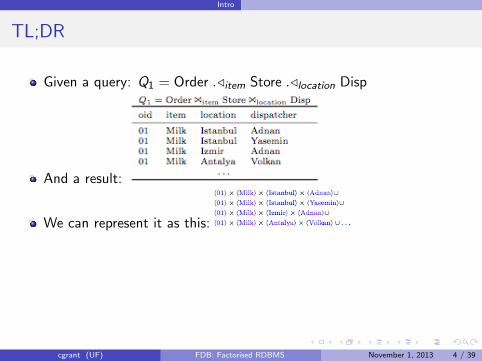
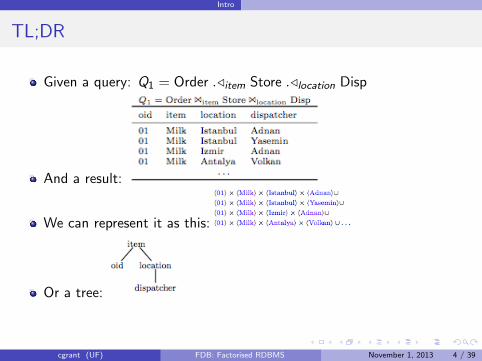
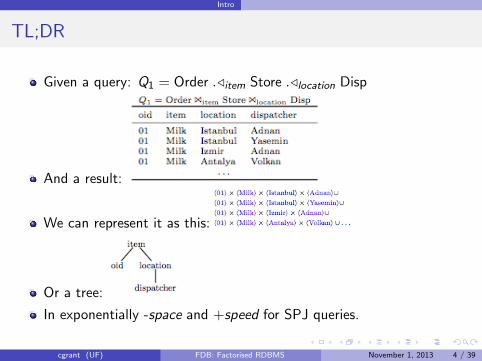
Given a query: Q1 = Order ./item Store ./location Disp
And a result:
We can represent it as this:
Or a tree:
In exponentially -space and +speed for SPJ queries.
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 4 / 39
Intro
TL;DR
Given a query: Q1 = Order ./item Store ./location Disp
And a result:
We can represent it as this:
Or a tree:
In exponentially -space and +speed for SPJ queries.
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 4 / 39
Intro
TL;DR
Given a query: Q1 = Order ./item Store ./location Disp
And a result:
We can represent it as this:
Or a tree:
In exponentially -space and +speed for SPJ queries.
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 4 / 39
Intro
TL;DR
Given a query: Q1 = Order ./item Store ./location Disp
And a result:
We can represent it as this:
Or a tree:
In exponentially -space and +speed for SPJ queries.
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 4 / 39
Intro
TL;DR
Given a query: Q1 = Order ./item Store ./location Disp
And a result:
We can represent it as this:
Or a tree:
In exponentially -space and +speed for SPJ queries.
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 4 / 39

Intro
Contents
1 Intro
2 F-Representation
3 F-Trees
4 Query EvaluationNormalisation OperatorSwap OperatorCartesian Product OperatorSelection OperatorProjection Operator
5 Query Optimization
Cost of an F-PlanExhaustive SearchGreedy Heuristic
6 ExperimentsExperiment #1Experiment #2Experiment #2Experiment #3Experiment #4
7 Conclusion8 Thanks
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 5 / 39
Intro
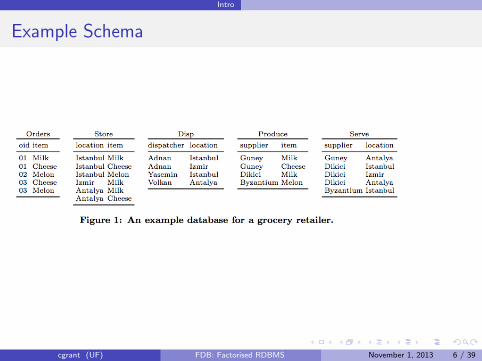
Example Schema
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 6 / 39

F-Representation
Factorized Representations
Relational algebra expressions.
Constructed with singleton relations 〈v〉, the union ∪ and productoperators ×.
exponentially more succinct than relations they encode.
fast (constant-delay) enumeration of tuples
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 7 / 39

F-Representation
Factorized RepresentationsDefinition 1
A factorised representation E , or f-representation for short, over a set S ofattributes and domain D is a relational algebra expression of the form
∅, empty relation over S;
〈〉, the relation consisting of the nullary tuplem if S = ∅;〈A : a〉, the unary relation with a single tuple with value a, if S = {A}and a is a value in the domain D;
(E ), where E is an f-representation over S;
E1 ∪ · · · ∪ En, where each Ei is an f-representation over S;
E1 × · · · × En, where each Ei is an f-representation over Si and S isthe disjoint union over all Si .
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 8 / 39

F-Representation
Factorized RepresentationsSingleton
〈A : a〉 is a singleton
|E | the size is the number of singletons
A single system may have many different f-representations.
The tuples of a given f-representation can be enumerated with O(|S|)additional space and delay.
Factorized Representation Compact Factorized Representation
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 9 / 39

F-Representation
Factorized RepresentationsSingleton
〈A : a〉 is a singleton
|E | the size is the number of singletons
A single system may have many different f-representations.
The tuples of a given f-representation can be enumerated with O(|S|)additional space and delay.
Factorized Representation Compact Factorized Representation
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 9 / 39

F-Trees
F-TreesDefinition
An f-tree for short, over a schema S of attributes is an unordered rootedforest with each node labelled by a non-empty subset of S such that each
attribute of S labels exactly one node.
Q1 F-Tree Q1 Alternate F-Tree
Tree created in O(|S| · |R| · log |R|).
We can go back to R in O(|S| · |R|).
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 10 / 39

F-Trees
F-TreesDefinition
An f-tree for short, over a schema S of attributes is an unordered rootedforest with each node labelled by a non-empty subset of S such that each
attribute of S labels exactly one node.
Q1 F-Tree Q1 Alternate F-Tree
Tree created in O(|S| · |R| · log |R|).
We can go back to R in O(|S| · |R|).
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 10 / 39

F-Trees
F-TreesQueries
Given a query Q = πPσϕ(R1 × · · · × Rn)
Given a query Q, an f-tree T is an f-tree of Q if and only if it satisfiesthe path constraint.
all dependent attributes can only label nodes along a sameroot-to-leaf path.
Nodes of a join are only dependent if they are in the P list or thesame Ri .
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 11 / 39

F-Trees
F-TreesSize Bounds
Let sT be the maximal root-to-leaf path edge cover T .
For and database D and f-tree T the result size is at mostO(|P| · |D|s(T ))
If we let s(Q) be the minimal s(T ) over all f-trees.
|P| · |D|s(Q) � Q(D) — This can mean asymptotically smaller,exponential size and time savings
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 12 / 39

F-Trees
F-TreesSize Bounds
Let sT be the maximal root-to-leaf path edge cover T .
For and database D and f-tree T the result size is at mostO(|P| · |D|s(T ))
If we let s(Q) be the minimal s(T ) over all f-trees.
|P| · |D|s(Q) � Q(D) — This can mean asymptotically smaller,exponential size and time savings
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 12 / 39

F-Trees
F-TreesSize Bounds
Let sT be the maximal root-to-leaf path edge cover T .
For and database D and f-tree T the result size is at mostO(|P| · |D|s(T ))
If we let s(Q) be the minimal s(T ) over all f-trees.
|P| · |D|s(Q) � Q(D) — This can mean asymptotically smaller,exponential size and time savings
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 12 / 39
Query Evaluation
Contents
1 Intro
2 F-Representation
3 F-Trees
4 Query EvaluationNormalisation OperatorSwap OperatorCartesian Product OperatorSelection OperatorProjection Operator
5 Query Optimization
Cost of an F-PlanExhaustive SearchGreedy Heuristic
6 ExperimentsExperiment #1Experiment #2Experiment #2Experiment #3Experiment #4
7 Conclusion8 Thanks
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 13 / 39

Query Evaluation
F-plans
Any select-project-join query can be evaluated by a sequentialcomposition of operators called an f-plan.
f-trees uniquely identify f-representations → operators are in treeform.
The time complexity of each f-plan operator is O(|T |2N logN), whereN is the sum of input and output f-representations and T is the inputf-tree.
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 14 / 39

Query Evaluation Normalisation Operator
Normalisation Operator1
push-up operator ψBnormalization η(T )
A tree is normalized if the push up operator can not be applied.
The push-up operator is applied bottom up.
ψB η(T ) — Normalization
1All other operators expect normalized inputscgrant (UF) FDB: Factorised RDBMS November 1, 2013 15 / 39

Query Evaluation Swap Operator
Swap Operator XA,B
Exchanges B with its parent A and promotes children.
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 16 / 39
Query Evaluation Cartesian Product Operator
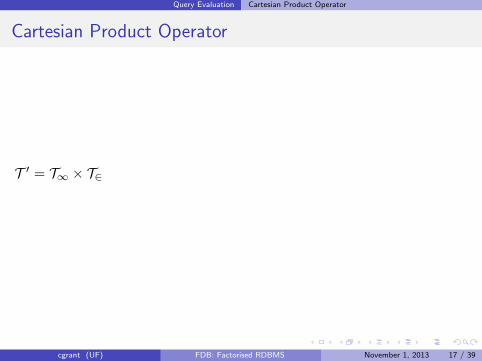
Cartesian Product Operator
T ′ = T∞ × T∈
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 17 / 39
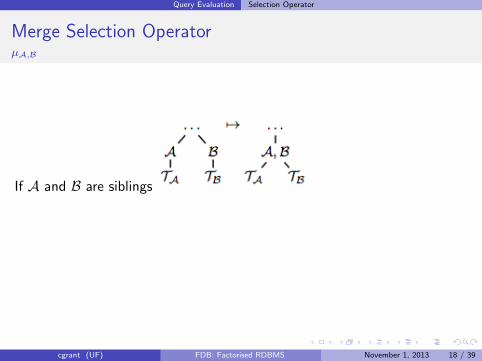
Query Evaluation Selection Operator
Merge Selection OperatorµA,B
If A and B are siblings
µ( , ) =
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 18 / 39
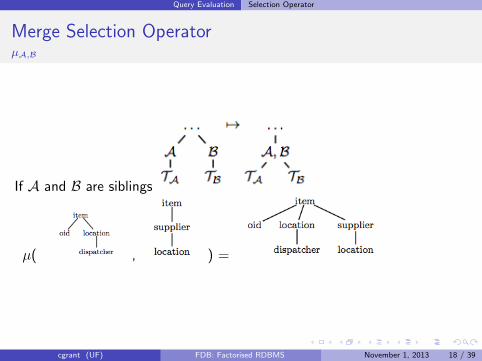
Query Evaluation Selection Operator
Merge Selection OperatorµA,B
If A and B are siblings
µ( , ) =
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 18 / 39
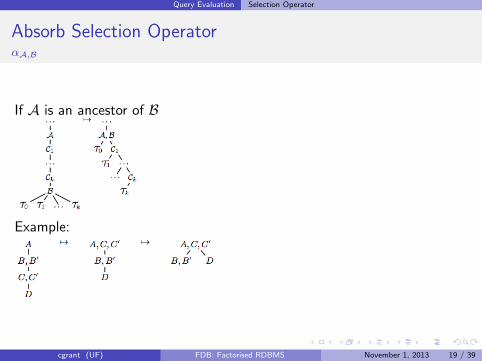
Query Evaluation Selection Operator
Absorb Selection OperatorαA,B
If A is an ancestor of B
Example:
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 19 / 39

Query Evaluation Selection Operator
Selection with Constant OperatorσAθc
Filters out all the values in 〈A : a〉 where a¬θc
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 20 / 39
Query Evaluation Projection Operator
Projection Operatorπ−A
Removes a node from the tree. Only permitted if A is a leaf node or withother attributes.
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 21 / 39
Query Optimization
Contents
1 Intro
2 F-Representation
3 F-Trees
4 Query EvaluationNormalisation OperatorSwap OperatorCartesian Product OperatorSelection OperatorProjection Operator
5 Query Optimization
Cost of an F-PlanExhaustive SearchGreedy Heuristic
6 ExperimentsExperiment #1Experiment #2Experiment #2Experiment #3Experiment #4
7 Conclusion8 Thanks
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 22 / 39

Query Optimization
Query Optimization
Query optimization has two objectives:
minimizing the cost of computing a factorised query result;
minimizing the size of this output representation.
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 23 / 39

Query Optimization
Query Optimization
Optimize the f-tree then the f-representation.
Products and Selections are always evaluated first (cheapest).
Selection (A = B) can only be done if they are on the same path orsiblings
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 24 / 39

Query Optimization Cost of an F-Plan
Cost of an F-Plan
use asymptotic bounds of s(T ).
with an evaluation time ofO(|Ds(f ) · log |D|), where s(f ) = max(s(T0, . . . s(Tk )).
, or, use cardinality of estimate from intermediate f-trees usingRDBMS style techniques
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 25 / 39

Query Optimization Cost of an F-Plan
Cost of an F-Plan
use asymptotic bounds of s(T ).
with an evaluation time ofO(|Ds(f ) · log |D|), where s(f ) = max(s(T0, . . . s(Tk )).
, or, use cardinality of estimate from intermediate f-trees usingRDBMS style techniques
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 25 / 39
Query Optimization Exhaustive Search
Exhaustive Search
Enumerate plans and the one with the shortest path (Dijkstra)between Tinit to Tfinal is least cost.
Search space is O(n4n) with n − p attributes in the projection list
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 26 / 39
Query Optimization Greedy Heuristic
Greedy Heuristic
Only restructures nodes that appear in selections and projections.
In projection ordering chooses the least cost at each step.
Computing the tree take O(|T |2).
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 27 / 39
Experiments
Contents
1 Intro
2 F-Representation
3 F-Trees
4 Query EvaluationNormalisation OperatorSwap OperatorCartesian Product OperatorSelection OperatorProjection Operator
5 Query Optimization
Cost of an F-PlanExhaustive SearchGreedy Heuristic
6 ExperimentsExperiment #1Experiment #2Experiment #2Experiment #3Experiment #4
7 Conclusion8 Thanks
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 28 / 39

Experiments
Implementation
Compare SQLite and PostgreSQL with FDB and RDB
for SQLite and PostgreSQL tried to disable expensive writing (try tomake it in-memory)
Implemented in C++
Optimal f-representation computed with multi-way merge-sort joinalgorithm.
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 29 / 39

Experiments
Experiment Design
Generate random data for queries
Repeat a number of times for optimizations time, execution time,representation sizes and f-plan quality
Tuples generated independently with a uniform or Zipf distribution.
Queries are equality joins
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 30 / 39
Experiments Experiment #1
Experiment #1
Average time for optimising a query on flat data.
A = 40 Attributes, R = 1, . . . , 8 relations, K = 1, . . . , 9 selections
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 31 / 39
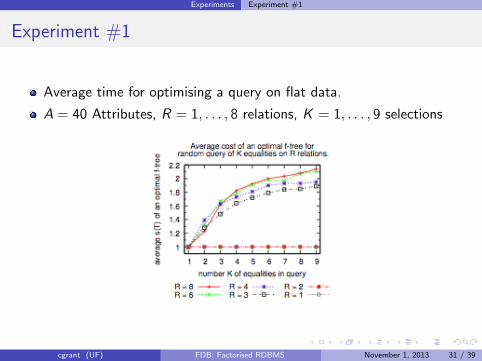
Experiments Experiment #1
Experiment #1
Average time for optimising a query on flat data.
A = 40 Attributes, R = 1, . . . , 8 relations, K = 1, . . . , 9 selections
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 31 / 39
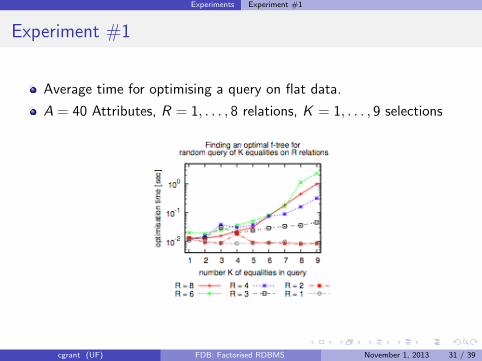
Experiments Experiment #1
Experiment #1
Average time for optimising a query on flat data.
A = 40 Attributes, R = 1, . . . , 8 relations, K = 1, . . . , 9 selections
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 31 / 39
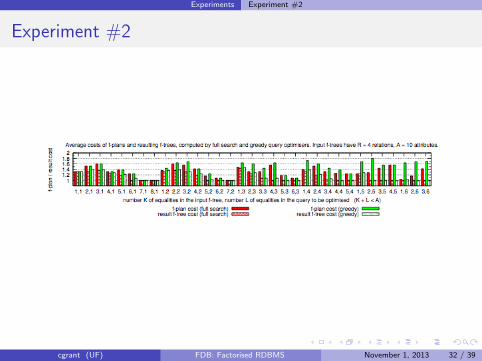
Experiments Experiment #2
Experiment #2
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 32 / 39
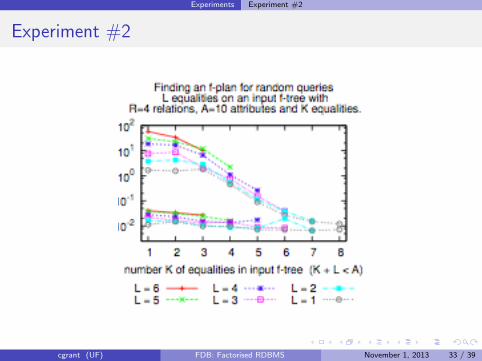
Experiments Experiment #2
Experiment #2
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 33 / 39
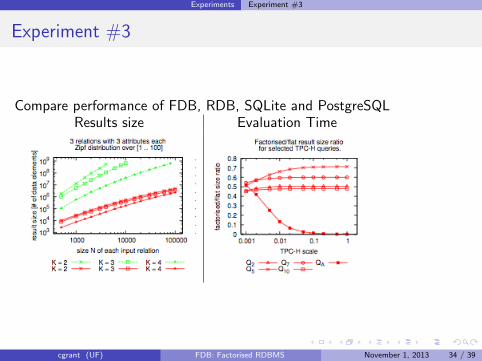
Experiments Experiment #3
Experiment #3
Compare performance of FDB, RDB, SQLite and PostgreSQLResults size Evaluation Time
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 34 / 39
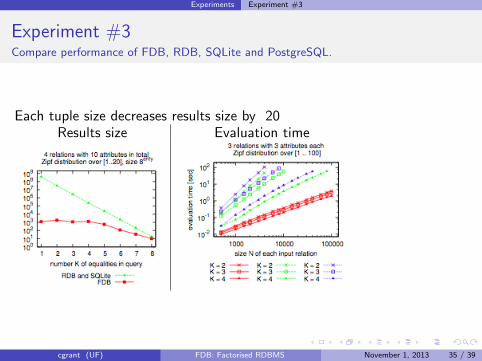
Experiments Experiment #3
Experiment #3Compare performance of FDB, RDB, SQLite and PostgreSQL.
Each tuple size decreases results size by 20Results size Evaluation time
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 35 / 39
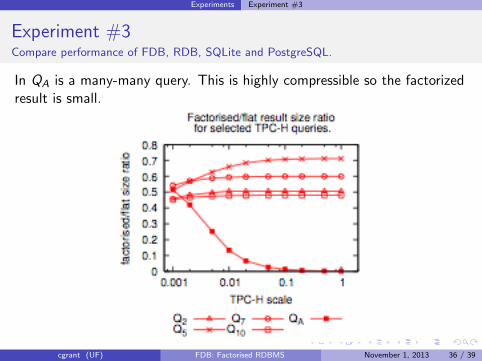
Experiments Experiment #3
Experiment #3Compare performance of FDB, RDB, SQLite and PostgreSQL.
In QA is a many-many query. This is highly compressible so the factorizedresult is small.
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 36 / 39
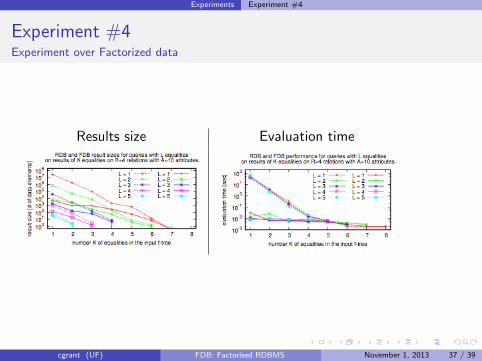
Experiments Experiment #4
Experiment #4Experiment over Factorized data
Results size Evaluation time
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 37 / 39

Conclusion
Conclusion
Factorizing Relational Data prevents the explosion of data size forlarge joins.
This paper described techniques and experiments to decrease this sizeand improving query performance.
For MLNs and other graph DBs that require many joins this cansignificantly improve query performance.
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 38 / 39
Thanks
Thank you
Questions?
cgrant (UF) FDB: Factorised RDBMS November 1, 2013 39 / 39