ベイズ的アプローチに基づく音声認識...
TRANSCRIPT

平成 17 年度 卒業論文
ベイズ的アプローチに基づく音声認識における事前分布の検討
指導教官
徳田 恵一 教授李 晃伸 助教授南角 吉彦 助手
名古屋工業大学 工学部知能情報システム学科
平成 14 年度入学 学籍番号 14117941
橋本 佳
No.9

目次 No. i
目 次
1 まえがき 1
2 隠れマルコフモデル 3
2.1 隠れマルコフモデルの定義 . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2 HMMの学習 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.3 HMMを用いた音声認識 . . . . . . . . . . . . . . . . . . . . . . . . . . 5
3 ベイズ的アプローチに基づく音声認識 7
3.1 ベイズ基準 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.2 変分ベイズ法による近似 . . . . . . . . . . . . . . . . . . . . . . . . . . 8
3.3 事前分布 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3.4 事後分布パラメータの更新 . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.5 予測分布による認識 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4 ベイズ基準によるコンテキストクラスタリング 15
4.1 コンテキスト依存モデル . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4.2 決定木に基づく状態クラスタリング . . . . . . . . . . . . . . . . . . . . 15
4.3 MDL基準による状態共有構造の選択 . . . . . . . . . . . . . . . . . . . 16
4.4 ベイズ基準による状態共有構造の選択 . . . . . . . . . . . . . . . . . . 17
5 事前分布の検討 19
5.1 尤度関数に基づく事前分布 . . . . . . . . . . . . . . . . . . . . . . . . . 19
5.2 無情報事前分布 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.3 周辺尤度による検討 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
6 実験 22
6.1 実験条件 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
6.2 実験結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
6.2.1 T を固定,Bを変化 . . . . . . . . . . . . . . . . . . . . . . . . 23
6.2.2 Bを固定,T を変化 . . . . . . . . . . . . . . . . . . . . . . . . 26
7 むすび 29
謝辞 30
参考文献 31
名 古 屋 工 業 大 学

図目次 No. ii
図 目 次
2.1 隠れマルコフモデルの例 (left-to-right型,スキップなし) . . . . . . . . 4
4.1 決定木による状態クラスタリング . . . . . . . . . . . . . . . . . . . . . 16
5.1 T = B = 1.0のGauss-Wishart分布 . . . . . . . . . . . . . . . . . . . . 205.2 T = B = 0.1のGauss-Wishart分布 . . . . . . . . . . . . . . . . . . . . 205.3 T = B = 0.01のGauss-Wishart分布 . . . . . . . . . . . . . . . . . . . 21
6.1 Bと認識率の関係 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 236.2 Bと閾値の関係 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 246.3 Bと決定木の大きさの関係 . . . . . . . . . . . . . . . . . . . . . . . . . 256.4 BとF の関係 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 256.5 T と認識率の関係 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 266.6 T と閾値の関係 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 276.7 T と決定木の大きさの関係 . . . . . . . . . . . . . . . . . . . . . . . . . 286.8 T とF の関係 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
名 古 屋 工 業 大 学

表目次 No. iii
表 目 次
6.1 データベース . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 226.2 音声データの分析条件 . . . . . . . . . . . . . . . . . . . . . . . . . . . 226.3 各 T における認識率 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 236.4 各Bにおける認識率 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
名 古 屋 工 業 大 学

まえがき No. 1
第1章
まえがき
人間の最も身近な意志伝達手段は会話であり,我々は音声を伝達媒介として日常生活
に必要な様々な情報を交換している.音声は人間の声帯から空気を伝達して送られる
ため,意思伝達に特別な技術や入力機器を必要としない.よって,情報機器端末におけ
る共通のマンマシンインタフェースとして音声を用いることで,利便性の向上が期待
できる.近年,コンピュータとの新しい情報交換の手段として音声対話インタフェース
の開発が盛んに行われており,カーナビゲーションシステムなどの自動案内システムで
は既に実用化されている.今後は,日常生活の様々な場面への音声対話インタフェース
の導入が期待されており,実用化に耐えうる高精度な音声認識器が必要とされている.
音響モデルは,音声データからスペクトルパターンを特徴量として抽出し,音素単
位や言語単位でモデル化する.構築されたモデルと入力音声とを比較し,両者の類似
度を計算して認識を行う.音声認識の分野では,隠れマルコフモデル (Hidden Markov
Model; HMM) が音響モデルとして広く用いられている.HMMは時間とともに変動す
る観測系列を統計的な枠組みで扱うことができるため,音声のモデル化に適している
と考えられる.
音響モデルに基づいて認識を行う際,認識精度を上げるためには各モデルのモデル
の推定精度を向上させる必要がある.一般に,HMMの学習には尤度最大化 (Maximum
Likelihood; ML)基準 [10]が用いられる.しかし,ML基準はモデルパラメータを確定
的変数として点推定するため,学習データが十分に得られない場合,モデルの推定精
度が低下する可能性がある.これに対し,ベイズ基準では,モデルパラメータを確率
変数としてとらえ,学習データに対する事後分布を推定する.事後分布を用いて,す
べての可能なモデルパラメータを考慮することにより,学習データ量が少ない場合に
おいても,高い汎化性能が得られる.しかし,事後分布の推定は困難な積分計算を伴
うため,何らかの近似手法を必要とする.従来,マルコフ連鎖モンテカルロ法 [1] など
のサンプリング手法が用いられてきたが,計算量が膨大となり,大語彙連続音声認識
といった大規模な問題への適用は困難であった.この問題に対し,近年,変分ベイズ
法 [2]が提案され,計算時間が大幅に短縮されたことで,統計モデルの分野において,
名 古 屋 工 業 大 学

まえがき No. 2
ML基準に代わる新たなモデル推定法として期待されている.
音声認識や音声合成において,変分ベイズ法は既に適用されており,有効性が確認
されている [3][4].さらに,コンテキストクラスタリングにおいても,ベイズ基準によ
るコンテキストクラスタリングが提案されており,その有効性が確認されている [5].
ベイズ基準では有限の学習データを有効利用する為に,学習対象に関してあらかじ
め得られる知識をモデル学習に利用することができる.事前知識は事前分布としてモ
デル毎に用意され,事後分布の推定に影響を与える.学習データが少量の場合,事前
分布の影響が強くなり,事前分布を適切に設定することで,事後分布の推定精度が向
上すると考えられる.しかし,学習対象に関する事前知識から適切な事前分布を推定
する手法は確立されていないため,実環境においては,情報の無い状態から適切な事
前分布を設定することが必要となる.
本研究では,ベイズ基準における適切な事前分布の検討を行うことによって事後分
布の推定精度を向上させ,認識率の向上を試みる.
以下,2章で隠れマルコフモデル,3章でベイズ的アプローチに基づく音声認識,4
章でベイズ基準によるコンテキストクラスタリング,5章で事前分布の検討について述
べ,6章では実験結果を示し,7章で全体をまとめる.
名 古 屋 工 業 大 学

隠れマルコフモデル No. 3
第2章
隠れマルコフモデル
2.1 隠れマルコフモデルの定義
隠れマルコフモデル (HMM)[6]は信号 (ベクトル)otを出力する確率が bi(ot)である
ような信号源 (状態)が,初期状態確率 πi,状態遷移確率 aij をもって接続されたもの
として定義される.ただし,i,jは状態番号とする.このように,複数の定常信号源を
確率に基づいて遷移することによって,音声などの非定常信号をモデル化する.
観測ベクトル列O = (o1,o2, ..., oT ) と状態遷移を表す隠れ変数列Z = (z1, z2, ..., zT )
からなる完全データ {O,Z}の対数尤度は次式で定義される.
log P (O,Z | Λ) =N∑
i=1
zi1 log πi
+T−1∑
t=1
N∑
i=1
N∑
j=1
zitz
jt+1 log aij +
T∑
t=1
N∑
i=1
zit logN (ot | µi,S
−1i ) (2.1)
ただし,
zit = δ(zt, i) =
{1 (zt = i)
0 (zt 6= i)
である.HMMの状態数をN としたとき,HMMのパラメータΛ = (a, b,π)は,初期
状態確率 π = {πi}Ni=1, πi = P (z1 = i),状態遷移確率 a = {aij}N
i,j=1, aij = P (zt =
j | zt−1 = i) 及び出力確率 b = {bi(· )}Ni=1, bi(ot) = P (ot | zt = i) = N (ot |µi, S
−1i ) によ
り与えられる.ただし,N (· | µi,S−1i ) は,µiと Siをそれぞれ,平均ベクトルと,共
分散行列の逆行列として持つガウス分布である.
音声のモデル化においては,時間方向に対して連続的かつ不可逆的であるといった
性質を考慮し,トポロジーに関してスキップなしの left-to-right型とする,すなわち,
aij = 0 (i > jまたは j ≥ i + 2)
πi ={
1 (i = 1)
0 (i 6= 1)
のようにパラメータを制限することが多い.
名 古 屋 工 業 大 学

隠れマルコフモデル No. 4
a11 a22 a33
a12 a23
b1(·) b2(·) b3(·)
π1
o1 o2 o3 o4 o5 o6 oT
1 1 1 1 1 2 332
O :
Z :
図 2.1 隠れマルコフモデルの例 (left-to-right型,スキップなし)
2.2 HMMの学習
一般に,HMMの学習はML基準によって行われる.このとき,HMMのモデルパラ
メータΛMLは,
ΛML = arg maxΛ
P (O | Λ) (2.2)
によって定められる.最尤推定値ΛMLを求めるためのパラメータ推定式は期待値最大
化 (Expectation Maximization; EM)アルゴリズムに基づいて導出することができる.
EMアルゴリズムでは,対数尤度 P (O |Λ)を直接最大化する代わりに,次式で定義す
る完全データ対数尤度関数のO, Λ(t)を与件とする条件付き期待値
Q(Λ | Λ(t)) = EZ
{log P (O, Z | Λ) | O,Λ(t)
}
=∑
Z
P (Z | O,Λ(t)) log P (O,Z | Λ) (2.3)
をΛに関して,以下に示すように逐次最大化する.
名 古 屋 工 業 大 学

隠れマルコフモデル No. 5
EMアルゴリズム
(1) 初期値Λ(0)を設定し,t = 0とする
(2) 以下を収束するまで繰り返す
E-step : Q(Λ | Λ(t))を計算
M-step : Λ(t+1) = arg maxΛ
Q(Λ | Λ(t)) とし,t = t + 1とする
E-stepは期待値 (Expectation)操作で,M-stepは最大化 (Maximization) 操作を意味す
る.Q関数を単調増加させることにより対数尤度関数も単調増加する.対数尤度関数
の上限値が存在する限り,EMアルゴリズムは対数尤度関数の局所最適値に収束する.
しかし,実際にすべての状態系列に対してP (Z |O,Λ(t))を求めるためには,膨大な
計算量が必要となる.そこで,効率的に期待値計算をするForward-Backwardアルゴリ
ズムを用いることが一般的である.Forward-Backwardアルゴリズムは,モデルと出力
信号が与えられた下で,時間 tにおいて,状態 iに至る確率と,時間 tにおいて,状態
jを出発して時刻 T + 1に状態N(終了状態)に到達する確率とを,あらかじめ計算して
おくことで,計算量の削減を図る.
また,一つのHMMは,音素などの微小な音声単位をモデル化するのが一般的であ
る.初期モデルを k-means法に基づいて作成し,その後大量の学習データにより連結
学習を行う.連結学習とはトランスクリプション (発声内容に対応した音素の系列) に
従って音素HMMを連結することで,全てのHMMの学習を一度に行う方法である.適
切な初期モデルを用いる場合連結学習は音素境界情報を必要としないため,自動学習
に適していると言える.
2.3 HMMを用いた音声認識
HMMを用いた音声認識とは,音素 HMMの連結によって与えられる I 個の単語あ
るいは文章に対応するHMM {Λ1,Λ2, ...,ΛI}から,観測系列 xに対して
imax = arg maxi
P (Λi | x)
= arg maxi
P (x | Λi)P (Λi)
P (x)(2.4)
を求める操作である.ただし,全てのZの組み合わせについて P (O | Λi) を求めるこ
とは計算量の観点から困難であるため,次式のようにして P (O | Λi)の近似を行う.
P (x | Λi) =∑
allZ
P (x,Z | Λi)
' maxZ
P (x,Z | Λi) (2.5)
名 古 屋 工 業 大 学

隠れマルコフモデル No. 6
このような最適状態遷移列 Z の発見には,Viterbiアルゴリズムが広く用いられる.
ViterbiアルゴリズムはDP演算を利用したものであり,最適経路を高速に求めること
ができるという利点がある.Viterbiアルゴリズムによる近似を行った場合にも,全て
のZの組み合せを考慮した場合と同程度の認識性能を得られることが示されている.
名 古 屋 工 業 大 学

ベイズ的アプローチに基づく音声認識 No. 7
第3章
ベイズ的アプローチに基づく音声認識
3.1 ベイズ基準
未知データ x = (x1, x2, ..., xT )の識別において,ML基準では式 (2.2)に示されたよ
うにP (O |Λ) が最大となるモデルΛMLが選択され,予測分布P (x |ΛML)が推定され
ていた.ベイズ基準においては,事後分布 P (Λ |O)を用いて未知データの予測分布を
推定し,これを用いて識別を行う.予測分布は以下のように定義される.
P (x | O) =∫
P (x | Λ)P (Λ | O)dΛ (3.1)
この式から分かるように,ベイズ基準では,未知データxに対し,学習データOが与
えられた下でのΛの事後分布で仮説 P (x | Λ)を重み付き平均した予測分布 P (x | O)
を求める.このように,事後分布による平均化を行っているため,ML基準に比べ過学
習が緩和される.すなわち,学習データが少量であるとき,ベイズ基準は潜在的にML
基準よりも汎化能力の高い学習が可能となる.しかし,予測分布は式 (3.1)に示される
ような積分計算をともなう期待値計算が必要となり,特殊な場合を除いて解析的に求
めることが困難である.そのため,ベイズ基準を表現するには何らかの近似を用いる
必要がある.最も代表的な手法は事後分布最大化 (Maximum A Posterior; MAP)法 [7]
であり,事後分布を最大化するパラメータΛMAP を推定値とする.推定値ΛMAP は次
式により求まる.
ΛMAP = arg maxΛ
P (Λ | O)
' arg maxΛ
P (O | Λ)P (Λ) (3.2)
MAP法はML基準にペナルティが付加された形となり,ペナルティ付きEMアルゴリ
ズムを用いることによって分布パラメータが一意に推定される.そのため,MAP法は
予測分布 P (x | ΛMAP )を用いて識別を行う.つまり,ML基準と同様に予測分布に積
分計算を用いないため,学習データが少量の場合過学習がおこるという問題点がある.
近年,変分近似を用いた事後分布推定に基づくベイズ基準 (変分ベイズ法)が提案さ
名 古 屋 工 業 大 学

ベイズ的アプローチに基づく音声認識 No. 8
れた.変分ベイズ法は漸近性を用いないため,MAP法の問題点を克服することができ
る.次節より変分ベイズ法による音声認識について述べる.
3.2 変分ベイズ法による近似
ML基準では,モデルパラメータを点推定するのに対し,ベイズ基準では,学習デー
タの事後確率分布を計算し,すべてのモデルパラメータを重み付けして分布として推
定する.変分ベイズ法によるHMMを以下に示す.
変分ベイズ学習ではすべての未知量を周辺化した次式の周辺尤度を考える.
L(O) = log P (O)
= log∑
Z
∫P (O,Z,Λ)dΛ (3.3)
任意の分布Q(Z,Λ)を導入し,対数関数に対する Jensenの不等式を適用することによ
り,L(O)の下限F を定義する.
L(O) = log∑
Z
∫Q(Z,Λ)
P (O,Z,Λ)
Q(Z,Λ)dΛ
≥∑
Z
∫Q(Z,Λ) log
P (O, Z,Λ)
Q(Z,Λ)dΛ
= F (3.4)
ここで,下限F は,Q(Z,Λ)を変関数とする汎関数であり,不等式における L(O)と
F の差は,Q(Z,Λ)と P (Z,Λ | O)のKL-divergenceで表される.
F = L(O) − KL(Q(Z,Λ) || P (Z,Λ | O)) (3.5)
ここで,周辺尤度 L(O) は Z,Λ に関して定数であるため,Q(Z,Λ) に関して F を最大化することは KL-divergenceを最小化することと等価である.また,Q(Z,Λ) =
P (Z,Λ | O)のとき,KL-divergenceは 0となり,L(O) = F となる.よって,変関数Q(Z,Λ)に,積分計算が可能となるような拘束条件を与えた上で,下限F を最大化することにより,最適なL(O)の近似分布を求めることができる.ここでは以下の拘束条
件を与える.
Q(Z,Λ) = Q(Z)Q(Λ) (3.6)
このとき,下限F は次式で表される.
F =∑
Z
∫ {Q(Z)Q(Λ) log {P (O, Z | Λ)P (Λ)} − Q(Z)Q(Λ) log {Q(Z)Q(Λ)}
}dΛ
名 古 屋 工 業 大 学

ベイズ的アプローチに基づく音声認識 No. 9
=∑
Z
∫ {Q(Z)Q(Λ) log P (O,Z | Λ) + Q(Z)Q(Λ) log P (Λ)
−Q(Z)Q(Λ) log Q(Z) − Q(Z)Q(Λ) log Q(Λ)}dΛ (3.7)
まず,関数Q(Λ)について,F を最大化する.変関数Q(Λ)は,式 (3.4)の不等式が成
り立つため,∫
Q(Λ)dΛ = 1を満たす必要があり,ラグランジュ係数 λΛを用いて次式
を最大化する.
FΛ = F − λΛ
(∫Q(Λ)dΛ − 1
)
=∫
fΛ(Λ, Q(Λ))dΛ − λΛ
(∫Q(Λ)dΛ − 1
)
=∫ {
fΛ(Λ, Q(Λ)) − λΛQ(Λ)}dΛ + λΛ (3.8)
ただし,
fΛ(Λ, Q(Λ)) =∑
Z
{Q(Z)Q(Λ) log P (O,Z | Λ) + Q(Z)Q(Λ) log P (Λ)
−Q(Z)Q(Λ) log Q(Z) − Q(Z)Q(Λ) log Q(Λ)}
= Q(Λ)∑
Z
Q(Z) log P (O,Z | Λ) + Q(Λ) log P (Λ)
−Q(Λ)∑
Z
Q(Z) log Q(Z) − Q(Λ) log Q(Λ) (3.9)
ここで,FΛを最大にする関数Q(Λ) を得るため,変分法を適用する.変分法では,次
式で表される変分導関数 δFΛを 0と置くことにより,関数の最適化問題を解く.
δFΛ =∫ ∂
∂Q(Λ)
{fΛ(Λ, Q(Λ)) − λΛQ(Λ)
}δQ(Λ)dΛ = 0 (3.10)
ただし,δQ(Λ)はQ(Λ)の変分であり,Q(Λ)の微細なずれを表す任意の関数である.
ここで,FΛは,Q(Λ)の微分項を含まない単純な形であるため,すべてのΛにおいて
次式が成り立てば良い.
∂
∂Q(Λ)
{fΛ(Λ, Q(Λ)) − λΛQ(Λ)
}= 0 (3.11)
よって,最適な近似分布は,
Q(Λ) = CΛP (Λ) exp{ ∑
Z
Q(Z) log P (O, Z | Λ)}
(3.12)
となる.ただし,CΛは∫
Q(Λ)dΛ = 1 を満たすための正規化定数である.同様の導出
方法により,
Q(Z) = CZ exp{ ∫
Q(Λ) log P (O,Z | Λ)dΛ}
(3.13)
名 古 屋 工 業 大 学

ベイズ的アプローチに基づく音声認識 No. 10
が得られる.これらの近似分布は相互に関係しているため,個別に更新を繰り返すこ
とにより,結果的にF を極大に導くことができる.また,各更新において,F は必ず増加するため収束性が保証されている.
さらに,Q(Λ)に関して,π = {πi}Ni=1,ai = {aij}N
j=1,bi = {µi, Si} とし,事前分布を
P (Λ) = P (π)N∏
i=1
P (ai)N∏
i=1
P (bi) (3.14)
と設定すると,
Q(Λ) = Q(π)N∏
i=1
Q(ai)N∏
i=1
Q(bi) (3.15)
Q(π) = CπP (π) exp{ N∑
i=1
〈zi1〉 log πi
}(3.16)
Q(ai) = CaiP (ai) exp
{ N∑
j=1
T−1∑
t=1
〈zitz
jt+1〉 log aij
}(3.17)
Q(bi) = CbiP (bi) exp
{ T∑
t=1
〈zit〉 logN (ot | µi,S
−1i )
}(3.18)
となる.ただし,
〈zit〉 =
∑
Z
Q(Z)zit, 〈zi
tzjt+1〉 =
∑
Z
Q(Z)zitz
jt+1 (3.19)
である.また,Cπ,Cai,Cbi
はそれぞれQ(π),Q(ai),Q(bi)を正規化する定数であり,
CΛ = Cπ
N∏
i=1
Cai
N∏
i=1
Cbi(3.20)
である.Q(Z)についてもこれらの分布を用いて,
Q(Z) = CZ
N∏
i=1
exp{zi1〈log πi〉Q(π)
} T−1∏
t=1
N∏
i=1
N∏
j=1
exp{zi
tzjt+1〈log aij〉Q(ai)
}
×T∏
t=1
N∏
i=1
exp{zi
t〈logN (ot | µi,S−1i )〉Q(µi,Si)
}(3.21)
と書ける.ここで,Q(Z)はHMMの尤度関数と同じ形となっており,式 (3.19)の期待
値は,Forward-Backwardアルゴリズムを用いて計算することができる.
3.3 事前分布
モデルパラメータの事前分布P (Λ)の最適設定法はなく,通常は数学的な取り扱いの
良さから共役事前分布を用いる.共役事前分布とは,事前分布と事後分布が同じ分布族
名 古 屋 工 業 大 学

ベイズ的アプローチに基づく音声認識 No. 11
となる事前分布のことである.尤度関数が式 (2.1)のHMMでは,遷移確率はDirichlet
分布,出力確率はGauss-Wishart分布となる.つまり,事後分布の近似分布であるQ(π),
Q(ai)は Dirichlet分布,Q(bi)は Gauss-Wishart分布となる.以下に事前分布を定義
する.
P (π) = D(π | φ) =Γ (
∑Ni=1 φi)∏N
i=1 Γ (φi)
N∏
i=1
πφi−1i (3.22)
P (ai) = D(ai | αi) =Γ
(∑Nj=1 αij
)
∏Nj=1 Γ (αij)
N∏
j=1
aαij−1ij (3.23)
P (bi) = N (µi | νi, (ξiSi)−1)W(Si | ηi, Bi) (3.24)
N (µi | νi, (ξiSi)−1) = CNi
|Si|12 exp
{−1
2Tr(ξiSi(µi − νi)(µi − νi)
>}
(3.25)
W(Si | ηi, Bi) = CWi|Si|
12(ηi−d−1) exp
{−1
2Tr(SiBi)
}(3.26)
CNi= (2π)−
d2 ξ
d2i (3.27)
CWi=
|Bi|12ηi
2ηid
2 πd(d−1)
4∏d
j=1 Γ(
ηi+1−j2
) (3.28)
ここでΓ(·)はガンマ関数,dは特徴ベクトルの次元数である.事前分布を表すパラメー
タをまとめると,{φi, αij, ξi, ηi,νi,Bi}Ni,j=1 となる.これらはモデルパラメータを表す
パラメータであり,ハイパーパラメータと呼ぶ.また,共役事前分布を用いているた
め,事後分布も同様に {φi, αij, ξi, ηi, νi, Bi}Ni,j=1 というパラメータセットで表すことが
できる.
3.4 事後分布パラメータの更新
具体的な事後分布パラメータの更新方法を示す.まず,事前分布のパラメータ変数
とQ(Z)から計算される期待値変数を以下に定義する.
Ni =T∑
t=1
〈zit〉 (3.29)
Nij =T−1∑
t=1
〈zitz
jt+1〉 (3.30)
oi =1
Ni
T∑
t=1
〈zit〉ot (3.31)
Ci =1
Ni
T∑
t=1
〈zit〉(ot − oi)(ot − oi)
> (3.32)
名 古 屋 工 業 大 学

ベイズ的アプローチに基づく音声認識 No. 12
これらを用いることで,モデルパラメータの事後分布Q(Λ)は,次式のように更新さ
れる.
φi = φi + 〈zi1〉 (3.33)
αij = αij + Nij (3.34)
ξi = ξi + Ni (3.35)
ηi = ηi + Ni (3.36)
νi =Nioi + ξiνi
Ni + ξi
(3.37)
Bi = NiCi + Bi +Niξi
Ni + ξi
(oi − νi)(oi − νi)> (3.38)
また,Q(Z)の更新に用いられる期待値は,
〈log πi〉Q(π) = Ψ(φi) − Ψ
(N∑
k=1
φk
)(3.39)
〈log aij〉Q(ai) = Ψ(αij) − Ψ
(N∑
k=1
αkj
)(3.40)
〈logN (ot | µi,S−1i )〉Q(µi,Si) = −1
2
{d log π +
d
ξi
−d∑
j=1
Ψ(
ηi + 1 − j
2
)+ log |Bi|
+Tr{ηiB
−1i (ot − νi)(ot − νi)
>}}
(3.41)
となる.ここで,Ψ(·)は digamma関数である.これらの期待値を用いて,Forward-
Backwardアルゴリズムを実行することにより,Ni, Nij, oi, Ciを更新する.
事後分布の更新による学習手順を以下に示す.
変分ベイズ法
(1) 事前分布パラメータを与える
(2) 以下を収束するまで繰り返す
step1 : Q(Z)の更新 (式 (3.39)–(3.41))
step2 : Forward-Backwardアルゴリズム (式 (3.29)–(3.32))
step3 : Q(Λ)の更新 (式 (3.33)–(3.38))
以上の手順によってF を最大化することにより,最適な対数尤度関数 L(O)の近似分
布を求めることができる.
名 古 屋 工 業 大 学

ベイズ的アプローチに基づく音声認識 No. 13
3.5 予測分布による認識
ベイズ基準によって学習したモデルパラメータを用いた音声認識では,観測系列 x
に対して予測分布 P (x | O)を用いて認識を行う.
P (x | O) =∑
Z
∫P (x, Z | Λ)P (Λ | O)dΛ (3.42)
ここで,事後分布を推定した変分事後分布よりP (Λ |O) ← Q(Λ) と近似する.さらに
対数をとり以下のように近似を行う.
log P (x | O) = log∑
Z
∫P (x,Z | Λ)P (Λ | O)dΛ
'∑
Z
∫Q(Z)Q(Λ) log
P (x,Z | Λ)P (Λ | O)
Q(Z)Q(Λ)dΛ
=∑
Z
∫Q(Z)Q(Λ) log P (x,Z | Λ)dΛ −
∑
Z
Q(Z) log Q(Z)
=∑
Z
∫Q(Z)Q(Λ) log P (x,Z | Λ)dΛ
−∑
Z
Q(Z)〈log P (O, Z | Λ)〉Q(Λ) − log CZ
= − log CZ
= F(x | O) (3.43)
ここで,式 (3.13)よりC−1Z は,
∑
Z
Q(Z) = CZ
∑
Z
exp{∫
Q(Λ) log P (O,Z | Λ)dΛ}
= 1 (3.44)
から計算できる.これより
F(x | O) = log∑
Z
exp{∫
Q(Λ) log P (O,Z | Λ)dΛ}
= log∑
Z
{ N∏
i=1
exp{zi1〈log πi〉Q(π)
}×
T−1∏
t=1
N∏
i=1
N∏
j=1
exp{zi
tzjt+1〈log aij〉Q(ai)
}
×T∏
t=1
N∏
i=1
exp{zi
t〈logN (ot | µi,S−1i )〉Q(µi,Si)
}}(3.45)
となる.よって,F(x|O)は,exp{zi1〈log πi〉Q(π)
}を初期確率,exp
{zi
tzjt+1〈log aij〉Q(ai)
}
を遷移確率,exp{zi
t〈logN (ot | µi,S−1i )〉Q(µi,Si)
}}を出力確率にそれぞれ対応させると
式 (2.1)と同様の式となり,Forward-Backwardアルゴリズムによって求めることがで
きる.したがって,
imax = arg maxi
F(x | Oi) (3.46)
名 古 屋 工 業 大 学

ベイズ的アプローチに基づく音声認識 No. 14
を計算することにより,観測系列 xに対する認識結果 imaxを得ることができる.ベイ
ズ推定は学習データが少ない場合でも,事後確率分布P (Λ |O)によるパラメータΛの
周辺化操作を行うため,ML推定に比べて過学習による性能劣化を回避することがで
きる.
名 古 屋 工 業 大 学

ベイズ基準によるコンテキストクラスタリング No. 15
第4章
ベイズ基準によるコンテキストクラスタリング
4.1 コンテキスト依存モデル
音声は連続的な観測系列であるため,同一音素でも,文脈的な要因 (コンテキスト)
により音響的な特徴が変化することが知られている.従って,このようなコンテキス
トを考慮してモデル化を行うことで,認識性能が向上すると考えられ,直前,直後の
音素を考慮した triphone HMMが音響モデルとして現在広く用いられている.しかし,
音素の種類は数十種類に上るため,これらの組み合わせにより,総モデル数は膨大な
ものとなってしまう.それに伴い,各モデルに割り当てられる学習データの量は減少
し,モデルパラメータの推定精度が低下する.そのため,有限の学習データでは十分
な学習を行うことが困難となる.また,大量の学習データを用意しても,可能なコン
テキストの組み合わせを全てを網羅することは難しいため,学習データ中に含まれな
いコンテキスト依存モデルは学習できないという問題が生じる.
4.2 決定木に基づく状態クラスタリング
前節の問題を解決するための方法として,決定木に基づくコンテキストクラスタリ
ング [8][9]が広く利用されている.音響的特徴が類似するモデルのパラメータを共有化
することで十分な量の学習データを割り当てられるようになる.決定木に基づく状態
クラスタリングでは,HMMの状態を一つにまとめた初期クラスタを,コンテキストに
関する質問によってトップダウンに分割し,何らかの停止基準を設けることで状態の
共有構造を決定する.このとき,分割の結果は決定木と呼ばれる二分木構造で表現で
きる.決定木による状態クラスタリングの例を図 4.1に示す.決定木の各ノードは分割
に用いた質問を保持するため,ルートノードからそれぞれの質問に従って木をたどる
ことで,未知のコンテキストに対しても適切なリーフノードを一意に決定することが
できる.
名 古 屋 工 業 大 学

ベイズ基準によるコンテキストクラスタリング No. 16
yes no
no
nono no
no
nono
yes
yes yes
yes yes
yes
yes
L-unvoiced?
R-vowel? R-end?
図 4.1 決定木による状態クラスタリング
4.3 MDL基準による状態共有構造の選択
前節で述べたように,音声認識におけるモデル構造は,決定木によって表現される.
小さな決定木では周辺データの補完によりロバストな学習が行われるため,未知の観
測系列への適応力は高まるが,学習データに対する明瞭度は低下する.一方,大きな
決定木では学習データをよく表現するモデル選択が行われるため,学習データに類似
した観測系列への適応力は高まるが,未知の観測系列に対しての対応が困難となる.
このように,コンテキストクラスタリングによる状態共有型HMMの構築において
は,モデル構造,すなわち状態共有の仕方や総状態数を適切に選択する必要がある.従
来,このモデル構造選択基準としてML基準が用いられてきた.しかしながら,尤度
は総状態数の増加に伴い単調に増加するため,ML基準ではモデル構造変化後の尤度差
分値や総状態数等に対して実験的に決めた閾値を設定する必要があった.この問題に
対処するため,最小記述長 (Minimum Descrition Length; MDL)基準 [10]やベイズ的
名 古 屋 工 業 大 学

ベイズ基準によるコンテキストクラスタリング No. 17
情報基準 (BIC)[11] を用いたモデル構造選択法が提案され,モデル構造の自動決定手法
として現在広く利用されている.
MDL基準に基づく状態共有構造選択では,以下の式 (4.1)に示す目的関数FMDLが
最小となるように音響モデルΛの共有構造が決定される.
FMDL = − log P (O | Λ) + KN log T (S0) (4.1)
ここで,T (·)は各クラスタに割り当てられたデータ量,Kは各特徴ベクトルの次元数,
N はクラスタの総数,S0は決定木のルートノードを表す.ここで,log P (O | Λ)は観
測系列に対するモデルの対数尤度であるため,クラスタを分割し,N を増加させるこ
とで式 (4.1)の第 1項を減少させることができる.しかし,N を増加させることは,
式 (4.1)の第 2項の増加を意味するため,Nが増加しても必ずしも目的関数FMDLが減
少するとは限らない.このように,式 (4.1)の第 1項と第 2項の間にはトレードオフの
関係があり,両者の和を最小にすることでクラスタの分割停止点を導く.
MDL基準に基づく状態共有構造選択において質問 qを用いてクラスタ Sq を Sq(yes)
と Sq(no)に分割する場合,クラスタ分割前後のMDL基準の評価関数 FMDLの変化量
δFMDLは式 (4.2)のように表すことができる.
δFMDL = − log P (O | ΛSq(yes)) − log P (O | ΛSq(no)
)
+ log P (O | ΛSq) + K log T (S0) (4.2)
そのため,評価関数FMDLを最小化するように分割を行うためには,変化量 δFMDL < 0
の時のみ分割を行えばよい.ここでK log T (S0)はML基準の閾値と同じ働きをするが,
経験的に設定する必要がなく,分割停止条件を計算的に求めることができる.また,評
価関数FMDLはML基準における評価関数にペナルティを加えた形となり,MDL基準
において適切な質問 qはML基準と同様の質問が選択される.
しかしながら,MDL基準はデータ量無限大の極限における大数の法則に基づいてお
り,少量の学習データに対しては適用範囲外であるため,適切なモデル構造の選択が
保証されないという問題がある.BICもデータ量無限大を仮定した漸近性を用いて導
出されているため同様の問題を抱える.
4.4 ベイズ基準による状態共有構造の選択
MDL基準の問題点に対して,データ量無限大を仮定しないベイズ基準による状態共
有構造の選択が提案されており,有効性が確認されている.ベイズ基準によるコンテ
キストクラスタリングでは,Q(Z), Q(π), Q(a)を固定した状態で尤度関数 F を最大
名 古 屋 工 業 大 学

ベイズ基準によるコンテキストクラスタリング No. 18
にするQ(b)の共有構造を決定する.Fに近似事後分布を代入し,クラスタリングに関係のある項だけを考慮すると,
F = − log CΛ −∑
Z
Q(Z) log Q(Z)
= − log Cπ −N∑
i=1
log Cai−
N∑
i=1
log Cbi−
∑
Z
Q(Z) log Q(Z)
= −N∑
i=1
log Cbi+ Const (4.3)
となる.ただし,
− log Cbi= − log
CNiCWi
CNiCWi
(2π)Nid
2 (4.4)
である.簡単のため,事前分布は全ての音響モデルで等しいと仮定し,その正規化項を
CN0 , CW0とする.あるクラスタが分割された時のF の変化量 δF は次式で表される.
δF = − log Cby − log Cbn + log Cbp
= − log CNyCWy − log CNnCWn + log CNpCWp + log CN0CW0
= δfy + δfn − δfp − δf0 (4.5)
ただし,
δfi = −d
2log ξi −
ηi
2log |Bi| +
d∑
j=1
log Γ(
ηi + 1 − j
2
)(4.6)
である.ここで,Cbpは分割前,Cby , Cbnは分割後の事後分布の正規化項であり,各ク
ラスタの統計量 Ni, oi, Ci から計算される.また,δf0はML基準における閾値と同様
の働きをするが,事前分布によって一意に定まるため,経験的に設定する必要がない.
δF を最大にする質問とノードのセットを選択しながら分割を繰り返し,δF ≤ 0で分
割を停止することにより,ベイズ基準による適切なモデル構造を選択できる.また,ベ
イズ基準における評価関数F はML基準における評価関数と異なり,事前分布を考慮
した形になっている.そのため,ベイズ基準における適切な質問 qはML基準とは異
なる質問が選択される.
名 古 屋 工 業 大 学

事前分布の検討 No. 19
第5章
事前分布の検討
これまで,ベイズ基準を用いた音声認識の研究において事前分布の設定はあまり考
慮されていなかった.しかし,ベイズ基準によるコンテキストクラスタリングにおい
て,事前分布は閾値を一意に定めるものであり,状態共有構造を決定する際に事前分
布が重要となることは明らかである.本章では,ベイズ基準における適切な事前分布
についての考察を行う.
5.1 尤度関数に基づく事前分布
ベイズ基準では確率分布の条件を満たす任意のハイパーパラメータを与えることが
できるが,HMMの一つの状態におけるガウス分布の平均がµ,分散がΣ,情報量が T
のとき,尤度関数は次式で表される.
P (O | Λ) =T∏
t=1
N (ot | µ,Σ)
= (2π)−T2 |Σ|−
T2 exp
{− 1
2
T∑
t=1
Tr{Σ−1(ot − µ)(ot − µ)>}}
= (2π)−T2 |Σ|−
T2 exp
{− T
2Σ(µ − µ)(µ − µ)>
}× exp
{− 1
2Σ(T Σ)
}
∝ N (µ | µ, (TS)−1)W(S | T + 1, (T Σ)) (5.1)
ただし,
µ =1
T
T∑
t=1
ot (5.2)
Σ =1
T
T∑
t=1
oto>t − µµT (5.3)
とする.よって,このガウス分布の出力確率は,Gauss-Wishart分布と比例関係にな
り,事前分布と比較すると次の条件を得る.
ξ = T (5.4)
η = T + 1 (5.5)
名 古 屋 工 業 大 学

事前分布の検討 No. 20
T=B=1
-10-5
0 5
10µ 0 1 2 3 4 5 6 7 8 9 10
S
0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14
図 5.1 T = B = 1.0のGauss-Wishart分布
T=B=0.1
-10-5
0 5
10µ 0 1 2 3 4 5 6 7 8 9 10
S
0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14
図 5.2 T = B = 0.1のGauss-Wishart分布
ここで,T は ξと ηの関係式を表すもので一意に定まっているものではない.以後,ξ
と ηは T を用いて表現する.
5.2 無情報事前分布
前節で得られた事前分布条件を考慮した無情報事前分布を検討する.本研究では,無
情報事前分布は一様分布であるとする.確率変数を 1次元としたGauss-Wishart分布
のパラメータ T とBによる分布形状の変化を図 5.1–5.3 に表す.図より,T とBを小
さくするほど事前分布は一様分布に近づき,T とBを十分に小さくすることでほぼ一
様な無情報事前分布が設定可能であることがわかる.無情報事前分布を用いることで
事前分布が事後分布の推定に与える影響が一定となり,事後分布はほぼ学習データの
みから推定されることになる.
名 古 屋 工 業 大 学

事前分布の検討 No. 21
T=B=0.01
-10-5
0 5
10µ 0 1 2 3 4 5 6 7 8 9 10
S
0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14
図 5.3 T = B = 0.01のGauss-Wishart分布
5.3 周辺尤度による検討
変分ベイズ法では,周辺尤度 L(O)の下限F が最大となるように事後分布の推定を行う.つまり,F が大きいほど事後分布の推定精度が高いといえる.また,ベイズ基準によるコンテキストクラスタリングでは事前分布によって閾値が定まるため,事前
分布が変化することによって状態共有構造は変化する.
変分ベイズ法における反復アルゴリズムは自然勾配法の一種であるため,高速な収
束が期待される一方で,アルゴリズムの初期条件,つまり,事前分布のハイパーパラ
メータに依存して局所最適解に収束する.この局所最適解の良さは,さらにモデル構
造にも依存する.
そこで,コンテキストクラスタリング後のF が最大となるような事前分布を設定することによって,適切な状態共有構造を求めることができ,精度の高い事後分布の推
定が可能となると考えられる.
名 古 屋 工 業 大 学

実験 No. 22
第6章
実験
本実験の目的は,ベイズ基準における事前分布のハイパーパラメータを変化させて
認識実験を行い,事前分布が変化することによる認識率,状態共有構造を表す決定木
の大きさ,コンテキストクラスタリング後のF に与える影響を考察し,適切な事前分布の検討を行うことである.
比較実験のため,最尤学習を行いMDL基準を用いて状態共有構造を決定したモデル
を従来法として用いた.
6.1 実験条件
本実験では実験データとしてATR日本語データベースB-setを用いた.実験データ
の詳細を表 6.1に示す.また,音声の分析条件を表 6.2に示す.
表 6.1 データベース学習データ ATR日本語データベースB-Set
男性話者 450文章× 6人mho,mht,mmy,msh,mtk,myi
テストデータ ATR日本語データベースB-Set
男性話者 53文章× 6人mho,mht,mmy,msh,mtk,myi
表 6.2 音声データの分析条件サンプリング周波数 16kHz
分析窓長 25ms
分析周期 5ms
窓関数 Blackman窓分析 24次メルケプストラム分析
分析で得られたメルケプストラム係数 (25次元)とその動的特徴,2次動的特徴を結合
し,75次元の特徴ベクトルとした.使用したHMMはスキップなしの 3状態 left-to-right
モデルである.また,HMMの一つの状態における出力確率には単混合ガウス分布を用
い,分散には対角共分散行列を用いた.
名 古 屋 工 業 大 学

実験 No. 23
85.0
85.5
86.0
86.5
87.0
87.5
88.0
1e-12 1e-10 1e-08 1e-06 1e-04 0.01 1 100 10000
accu
racy
(%)
B
T=1.0e-1T=1.0e-4T=1.0e-8
MDL
図 6.1 Bと認識率の関係
表 6.3 各 T における認識率T 1.0e-1 1.0e-4 1.0e-8
最高認識率 87.50% 87.46% 86.99%
F 最大時の認識率 87.36% 87.41% 86.98%
6.2 実験結果
6.2.1 T を固定,Bを変化
ベイズ基準における事前分布のハイパーパラメータBを 10−12~103の範囲で変化さ
せ認識実験を行った.このとき,νを 0に固定し,T としては 10−1, 10−4, 10−8の 3パ
ターンを用いた.ただし,νは平均を表すモデルパラメータµのハイパーパラメータ,
T は情報量を表すハイパーパラメータ,Bは分散を表すモデルパラメータS−1のハイ
パーパラメータである.
ハイパーパラメータBと認識率の関係を図 6.1に示す.図より,最高認識率は T に
関係なくB = 10−3のときに得られた.それぞれの T における最高認識率を表 6.3に示
す.従来法の認識率 86.58%からの改善がみられ,適切なBを設定することにより認識
率の改善が確認された.また,T とBを十分に小さくし,無情報事前分布を設定した
場合の認識率は従来法との大きな差は見られなかった.
名 古 屋 工 業 大 学

実験 No. 24
-5
0
5
10
15
20
25
1e-12 1e-10 1e-08 1e-06 1e-04 0.01 1 100 10000
thre
shol
d
B
T=1.0e-1T=1.0e-4T=1.0e-8
図 6.2 Bと閾値の関係
ハイパーパラメータBとコンテキストクラスタリングの閾値 δf0の関係を図 6.2に,
Bと状態共有構造を表す決定木の大きさの関係を図 6.3に示す.ベイズ基準によるコ
ンテキストクラスタリングでは,事前分布により閾値が定まる.図 6.2より,Bの増
大に伴って閾値は減少する.決定木の大きさが閾値のみに依存するとすれば,Bが大
きくなると決定木の大きさは大きくなるはずである.しかし,図 6.3より T に関らず
B = 10−12~10−3の範囲では決定木の大きさは順に大きくなっていくが,B > 10−3の
範囲では小さくなり,閾値のみが決定木の大きさを決めるのではないことがわかる.分
割が停止した理由としては,Bの増加によって分散が大きくなりすぎたために,分割
によるF の増加が抑制されたためであると考えられる.ハイパーパラメータBとコンテキストクラスタリング後のFの関係を図 6.4に示す.
ただし,Fはコンテキストクラスタリングに関係する項のみを考慮したものとする.図6.1と図 6.4を比較すると,グラフは類似しており,認識率とF の間に高い相関があることを示している.また,F は T に関らずB = 10−4で最大値をとる.F が最大となるB = 10−4のときの認識率に注目すると,表 6.3で表す結果となり,それぞれの T に
おいて,最高認識率とほぼ等しい認識率が得られた.これにより,5.3より,Fを最大にするBが適切な事前分布のハイパーパラメータであると推察されたが,その有効性
が明らかとなった.
名 古 屋 工 業 大 学

実験 No. 25
0
5
10
15
20
25
30
35
40
45
1e-12 1e-10 1e-08 1e-06 1e-04 0.01 1 100 10000
tree
size
(%)
B
T=1.0e-1T=1.0e-4T=1.0e-8
MDL
図 6.3 Bと決定木の大きさの関係
166.0
166.5
167.0
167.5
168.0
1e-12 1e-10 1e-08 1e-06 1e-04 0.01 1 100 10000
Free
Ene
rgy
B
T=1.0e-1T=1.0e-4T=1.0e-8
図 6.4 BとF の関係
名 古 屋 工 業 大 学

実験 No. 26
86.0
86.2
86.4
86.6
86.8
87.0
87.2
87.4
87.6
87.8
0 1 2 3 4 5 6 7 8 9 10
accu
racy
(%)
T
B=1.0e-3B=1.0e-4
MDL
図 6.5 T と認識率の関係
6.2.2 Bを固定,T を変化
ベイズ基準における事前分布のハイパーパラメータを T を 10−8~10の範囲で変化さ
せ認識実験を行った.このとき,νを 0に固定し,Bは,6.2章より最高認識率が得ら
れたB = 10−3と,コンテキストクラスタリング後のFが最大となったB = 10−4の 2
パターンにを用いた.
ハイパーパラメータ T と認識率の関係を図 6.5に示す.図より,B = 10−3のとき
T = 5で, B = 10−4のとき T = 2でそれぞれ最高認識率を得られた.認識率は表 6.4
に示す.このとき,従来法の認識率 86.58%からの改善がみられ,適切な T を設定する
ことにより認識率の改善が確認された.
ハイパーパラメータ T とコンテキストクラスタリングの閾値 δf0の関係を図 6.6に,
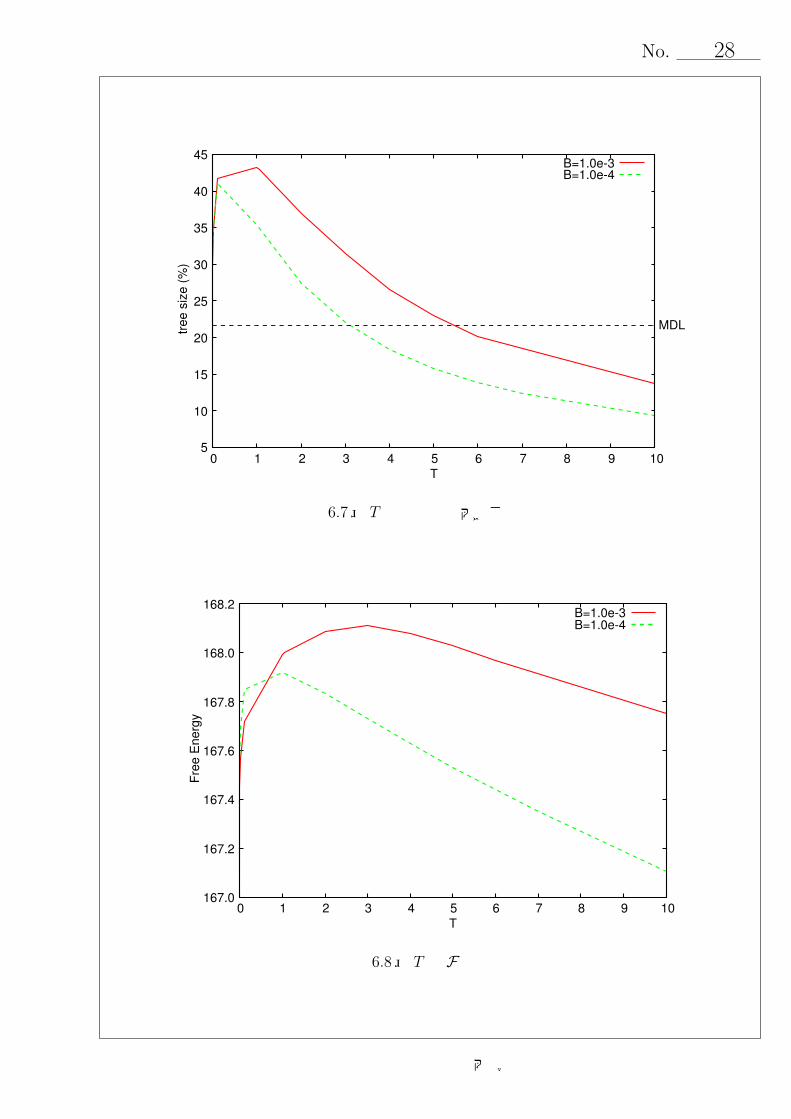
T と状態共有構造を表す決定木の大きさの関係を図 6.7 に示す.図より,T による決定
木の大きさの変化は閾値の変化に依存していることがわかる.決定木の大きさ,閾値,
ともに T = 0付近で急激に変化している.T は情報量を表すハイパーパラメータであ
り,T が極端に小さい,つまり,事前分布が無情報に近い場合には,ほぼ学習データ
のみを考慮して事後分布の推定を行う.このとき,学習データに対する過学習を緩和
するために分割が抑制され,決定木は小さくなると考えられる. ハイパーパラメータ
T とコンテキストクラスタリング後のF の関係を図 6.8に示す.図 6.5と図 6.8を比較
すると,グラフは類似しており,認識率とFの間に高い相関があることを示している.
名 古 屋 工 業 大 学

実験 No. 27
表 6.4 各Bにおける認識率B 1.0e-3 1.0e-4
最高認識率 87.70% 87.44%
F 最大時の認識率 87.55% 87.42%
5
10
15
20
25
30
35
40
45
50
55
0 1 2 3 4 5 6 7 8 9 10
thre
shol
d
T
B=1.0e-3B=1.0e-4
図 6.6 T と閾値の関係
また,F は,B = 10−3のとき T = 3で,B = 10−4のとき T = 1で最大値をとる.こ
こで,B = 10−3, T = 3のときの認識率,B = 10−4, T = 1のときの認識率はそれぞれ
表 6.4で表す結果となり,それぞれのBにおいて最高認識率とほぼ等しい認識率が得
られた.5.3より,F を最大にする T が適切な事前分布のハイパーパラメータである
と推察されたが,以上のことより,その有効性が明らかとなった.
名 古 屋 工 業 大 学
実験 No. 28
5
10
15
20
25
30
35
40
45
0 1 2 3 4 5 6 7 8 9 10
tree
size
(%)
T
B=1.0e-3B=1.0e-4
MDL
図 6.7 T と決定木の大きさの関係
167.0
167.2
167.4
167.6
167.8
168.0
168.2
0 1 2 3 4 5 6 7 8 9 10
Free
Ene
rgy
T
B=1.0e-3B=1.0e-4
図 6.8 T とF の関係
名 古 屋 工 業 大 学

むすび No. 29
第7章
むすび
本研究では,ベイズ的アプローチに基づく音声認識において事前分布の設定方法に
着目し,適切な事前分布の検討を行った.事前分布を変化させて比較実験を行い,状
態共有構造を表す決定木の大きさと自由エネルギーの変化,その認識率への影響を考
察した.
実験結果より,事前分布によって認識率が変化することを確認し,事前分布が認識
率に影響を与えることを示した.また,適切な事前分布を設定することで認識率が向
上し,従来法や無情報事前分布を設定した場合からの改善がみられた.適切な事前分
布の検討として,コンテキストクラスタリング後のF が最大となる事前分布を設定したとき,最高認識率と同程度の認識率を得ることを確認し,その有効性を示した.
今後の課題としては,適切な事前分布の導出手法の定式化,音素ごとに異なる事前
分布の設定などが挙げられる.
名 古 屋 工 業 大 学

謝辞 No. 30
謝辞
本研究を進めるにあたり,終始適切な御助言と暖かい御指導をいただきました 徳田
恵一教授,李晃伸助教授に深く感謝いたします.また,本論文の執筆,校正にあたり,
親切に御検討,御指摘して下さった徳田 ·李研究室南角吉彦助手,徳田 ·李研究室博士後期課程 3年の全炳河氏,徳田 ·李研究室博士前期課程 1年の中村和寛氏をはじめ皆様
方,ならびに,ともに卒業研究を進め,激励して下さった卒業生のみなさんに,心か
ら感謝致します.
名 古 屋 工 業 大 学

参考文献 No. 31
参 考 文 献
[1] W.R. Gilks, S. Richardson, and D.J. Spiegelhalter, “Markov Chain Monte Carlo
in Practice”, Chapman & Hall, 1996
[2] 上田 修功, “ベイズ学習” (全 4回) 電子情報通信学会誌, Vol.85, No.4,6,7,8, 2002.
[3] 南角 吉彦,“ベイズ的アプローチに基づくHMM音声合成”, 電子情報通信学会技
術研究報告, vol.99, SP2003-77, pp.19–24, 2003.
[4] 渡辺 晋治,南 泰啓,中村 篤,上田 修功, “変分ベイズ法の音声認識への適用” 音
響学会講演論文集, 1-9-23, pp.45–46, 2002.
[5] 渡部晋治,南康浩,中村篤,上田修功, “ベイズ的基準を用いた状態共有型HMM
構造の選択”,信学論 (D-II), vol.J86-D-II, no.6, pp.776-786, 2003.
[6] 鹿野清宏,河原達也,山本幹雄,伊藤克亘,武田一哉, “音声認識システム”,2001.
[7] 山本 泰啓,“ベイズ的アプローチに基づく音声認識のための分散フロアリング”,
名古屋工業大学修士論文,2005.
[8] 片岡 俊介, “HMM音声合成におけるスペクトル,F0,継続長決定木の同時バック
オフ”, 名古屋工業大学修士論文, 2005.
[9] 中村 和寛,“HMM音声認識におけるドメイン依存コンテキストクラスタリング”,
名古屋工業大学卒業論文,2005.
[10] 篠田 浩一,渡辺 隆夫,“情報量基準を用いた状態クラスタリングによる音響モデ
ルの作成”,信学技報,SP96-79, pp.241-242, 2002.
[11] G. Schwarz, “Estimating the dimension of a model,” The Annals of Statistics,
vol.6, pp.461-464, 1978.
名 古 屋 工 業 大 学