expanding the scope of orthographic effects: evidence from
TRANSCRIPT

Expanding the scope of orthographic effects: Evidence from phoneme counting in first, second, and unfamiliar languages
by
Carolyn Pytlyk B.A., University of Saskatchewan, 1996
M.A., University of Victoria, 2007
A Dissertation Submitted in Partial Fulfillment of the Requirements of the Degree of
DOCTOR OF PHILOSOPHY
in the Department of Linguistics
! Carolyn Pytlyk, 2012 University of Victoria
All rights reserved. This dissertation may not be reproduced in whole or in part, by
photocopy or other means, without permission of the author.

ii
SUPERVISORY COMMITTEE
Expanding the scope of orthographic effects: Evidence from phoneme counting in first, second, and unfamiliar languages
by
Carolyn Pytlyk B.A., University of Saskatchewan, 1996
M.A. University of Victoria, 2007
Supervisory Committee Dr Sonya Bird (Department of Linguistics, University of Victoria) Supervisor Dr John Archibald (Department of Linguistics, University of Victoria) Departmental Member Dr Julia Rochtchina (Department of German and Russian Studies, University of Victoria) Outside Member Dr Patrick Bolger (Department of Spanish and Portuguese, University of S. California) Additional Member

iii
ABSTRACT
Supervisory Committee Dr Sonya Bird (Department of Linguistics, University of Victoria) Supervisor Dr John Archibald (Department of Linguistics, University of Victoria) Departmental Member Dr Julia Rochtchina (Department of German and Russian Studies, University of Victoria) Outside Member Dr Patrick Bolger (Department of Spanish and Portuguese, University of S. California) Additional Member
This research expands our understanding of the relationship between orthographic
knowledge and phoneme perception by investigating how orthographic knowledge
affects phoneme perception not only in the first language (L1) but also in the second
language (L2), and an unfamiliar language (L0). Specifically, this research sought not
only to confirm that L1 orthographic knowledge influences L1 phoneme perception, but
also to determine if L1 orthographic knowledge influences L2 and L0 phoneme
perception, particularly as it relates to native English speakers. Via a phoneme counting
task, 52 participants were divided into two experimental groups—one with a Russian L0
and one with a Mandarin L0—and counted phonemes in words from their L1 (English)
and L0. In addition, two subgroups of participants also counted phonemes in their L2
(either Russian or Mandarin). The stimuli for each language were organized along two
parameters: 1) match (half with consistent letter-phoneme correspondences and half with
inconsistent correspondences) and 2) homophony (half with cross-language
homophonous counterparts and half without homophonous counterparts). The assumption

iv
here was that accuracy and RT differences would indicate an effect of orthographic
knowledge on phoneme perception.
Four-way repeated measures ANOVAs analysed the data along four independent
factors: group, language, homophone, and match. Overall, the results support the
hypotheses and indicate that L1 orthographic knowledge facilitates L1 and L0 phoneme
perception when the words have consistent letter-phoneme correspondences but hinders
L1 and L0 phoneme perception when the words have inconsistent correspondences.
Similarly, the results indicate that L2 orthographic knowledge facilitates L2 phoneme
perception with consistent words but hinders L2 phoneme perception with inconsistent
words. On a more specific level, results indicate that not all letter-phoneme mismatches
are equal in terms of their effect on phoneme perception, for example mismatches in
which one letter represents two sounds (e.g., <x> = /ks/) influence perception more so
than do mismatches in which one or more letters are silent (e.g. <sh> = /!/).
Findings from this research support previous claims that orthographic and
phonological information are co-activated in speech processing even in the absence of
visual stimuli (e.g., Blau et al., 2008; Taft et al., 2008; Ziegler & Ferrand 1998), and that
listeners are sensitive to orthographic information such that it may trigger unwanted
interference when the orthographic and phonological systems provide conflicting
information (e.g., Burnham, 2003; Treiman & Cassar, 1997). More importantly, findings
show that orthographic effects are not limited to L1. First, phoneme perception in
unfamiliar languages (L0) is also influenced by L1 orthography. Second, phoneme
perception in L2 is influenced by L2 orthgraphic interference. In fact, L2 orthographic
effects appear to override any potential L1 orthographic effects, suggesting orthographic

v
effects are language-specific. Finally, the preliminary findings on the different types of
letter-phoneme mismatches show that future research must tease apart the behaviours of
different kinds of letter-phoneme inconsistencies.
Based on the findings, this dissertation proposes the Bipartite Model of Orthographic
Knowledge and Transfer. The model identifies two components within L1 orthographic
knowledge: abstract and operational. The model predicts that abstract L1 orthographic
knowledge (i.e., the general assumptions and principles about the function of orthography
and its relationship to phonology) transfers into nonnative language processing regardless
of whether the listeners/speakers are familiar with the nonnatiave language (e.g., Bassetti,
2006; Vokic, 2011). In contrast, the model predicts that operational knowledge (i.e.,
what letters map to what phonemes) transfers into the nonnative language processing in
the absence of nonnative orthographic knowledge (i.e., the L0), but does not transfer in
the presence of nonnative orthographic knowledge (i.e., the L2). Rather, L2-specific
operational knowledge is created based partly on the transferred abstract knowledge.
The research here contributes to the body of literature in four ways. First, the current
research supports previous findings and claims regarding orthographic knowledge and
native language speech processing. Second, the L2 findings provide insight into the
relatively sparse—but growing—understanding of the relationship between L1 and L2
orthography and nonnative speech perception. Third, this research offers a unified (albeit
preliminary) account of orthographic knowledge and previous findings by way of the
Bipartite Model of Orthographic Knowledge and Transfer.

vi
TABLE OF CONTENTS
SUPERVISORY COMMITTEE ..................................................................................... ii ABSTRACT ...................................................................................................................... iii TABLE OF CONTENTS ................................................................................................ vi LIST OF TABLES ............................................................................................................ x LIST OF FIGURES ........................................................................................................ xii ACKNOWLEDGEMENTS .......................................................................................... xiv DEDICATION ................................................................................................................ xvi Chapter One INTRODUCTION ............................................................................................................. 1
1.1 Background ............................................................................................................ 1 1.2 The Current Study .................................................................................................. 2
1.2.1 Research Questions ..................................................................................... 3 1.2.2 Research Hypotheses ................................................................................... 5
1.3 Dissertation outline ................................................................................................ 9 Chapter Two BACKGROUND RESEARCH ...................................................................................... 11
2.1 Second Language Acquisition ............................................................................. 11 2.1.1 Early models: First language transfer ...................................................... 12 2.1.2 Current models: The L1 filter .................................................................... 14
2.2 Alphabetic Knowledge ........................................................................................ 17 2.2.1 Acquisition and development of phoneme awareness ............................... 18 2.2.2 Word/phoneme recognition and automatic co-activation ......................... 26 2.2.3 Letter-phoneme associations ..................................................................... 33 2.2.4 Misperception of phonemes ....................................................................... 35 2.2.5 Orthographic depth ................................................................................... 37
2.3 Summary and relevance to the current research .................................................. 42 Chapter Three ORTHOGRAPHIC REPRESENTATION ................................................................... 46
3.1 Writing Systems ................................................................................................... 46 3.1.1 Important definitions ................................................................................. 47 3.1.2 Creation of writing systems ....................................................................... 50 3.1.3 Types of writing systems ............................................................................ 54
3.1.3.1 Morpheme-based writing systems ..................................................... 54 3.1.3.2 Sound-based writing systems ............................................................ 55

vii
3.1.4 The Alphabets ............................................................................................ 58 3.1.4.1 The Roman Alphabet ......................................................................... 58 3.1.4.2 The Cyrillic Alphabet ........................................................................ 60 3.1.4.3 The Pinyin Alphabet .......................................................................... 63
3.2 Language backgrounds ........................................................................................ 65 3.2.1 English ....................................................................................................... 65
3.2.1.1 English phoneme inventory ............................................................... 66 3.2.1.2 English syllable structure ................................................................... 67 3.2.1.3 English orthographic system .............................................................. 68
3.2.2 Russian ...................................................................................................... 69 3.2.2.1 Russian phoneme inventory ............................................................... 69 3.2.2.2 Russian syllable structure .................................................................. 72 3.2.2.3 Russian orthographic system ............................................................. 73
3.2.3 Mandarin ................................................................................................... 75 3.2.3.1 Mandarin phoneme inventory ............................................................ 75 3.2.3.2 Mandarin syllable structure ............................................................... 77 3.2.3.3 Mandarin orthographic system .......................................................... 78
3.3 Letter-Phoneme correspondences in English, Russian, and Mandarin ................ 79 3.4 Orthographic representation and the current project ........................................... 81 3.5 Summary .............................................................................................................. 84
Chapter Four METHODOLOGY ......................................................................................................... 85
4.1 The pilot study ..................................................................................................... 85 4.2 The primary study ................................................................................................ 86
4.2.1 Participants ............................................................................................... 87 4.2.2 Experimental stimuli .................................................................................. 89
4.2.2.1 Target words ...................................................................................... 89 4.2.2.2 Creation of stimuli ........................................................................... 101
4.2.3 Experimental materials ........................................................................... 102 4.2.4 Experimental tasks ................................................................................... 103 4.2.5 Procedure ................................................................................................ 106 4.2.6 Data analyses .......................................................................................... 109
4.2.6.1 Independent factors .......................................................................... 110 4.2.6.2 Dependent factors ............................................................................ 112 4.2.6.3 Discarded data ................................................................................. 115 4.2.6.4 Statistical analyses ........................................................................... 118
4.3 The secondary study .......................................................................................... 120 4.3.1 Participants ............................................................................................. 121 4.3.2 Experimental stimuli ................................................................................ 121 4.3.3 Experimental task and procedure ............................................................ 122
4.4 Summary ............................................................................................................ 124

viii
Chapter Five ANALYSES AND RESULTS ...................................................................................... 125
5.1 Outline of research questions, comparisons, and predictions ............................ 125 5.2 Descriptive statistics for the overall data ........................................................... 130 5.3 Research question 1: L1 orthographic effect on L1 phoneme counting ............ 135
5.3.1 Comparisons of L1 matched and mismatched words (both NH and H) .. 136 5.3.2 Comparisons of L1 and L0 matched and mismatched NH ...................... 141 5.3.3 Summary for primary research question 1 .............................................. 146
5.4 Research question 2: L1 orthographic effect on L0 phoneme counting ............ 149 5.4.1 Comparison of L0 matched and mismatched H ...................................... 151 5.4.2 Comparison of L0 NH and H ................................................................... 154 5.4.3 Summary for primary research question 2 .............................................. 162
5.5 Descriptive statistics for the subgroup data ....................................................... 164 5.6 Primary research question 3: Orthographic effect on L2 phoneme counting .... 168 5.7 Primary research question 4: strength of orthographic effect ............................ 179 5.8 General summary ............................................................................................... 185
Chapter Six DISCUSSION ................................................................................................................ 188
6.1 Research overview ............................................................................................. 189 6.2 General Discussion ............................................................................................ 194
6.2.1 Orthographic knowledge’s influences on phoneme perception .............. 194 6.2.2 The language-specific nature of orthographic effects ............................. 200 6.2.3 Bipartite Model of Orthographic Knowledge and Transfer .................... 212 6.2.4 The experience-dependency of orthographic effects ............................... 227
6.3 Unanticipated Effects ......................................................................................... 230 6.3.1 Familiarity and word effects ................................................................... 230 6.3.2 Phonological Effects ................................................................................ 235 6.3.3 Subcategory effects .................................................................................. 237
6.4 Phonemicisation of diphthongs .......................................................................... 247 6.5 Summary ............................................................................................................ 255
Chapter Seven CONCLUSION ............................................................................................................. 259
7.1 Summary of research ......................................................................................... 259 7.2 Limitations ......................................................................................................... 263 7.3 Future research ................................................................................................... 265 7.4 Contributions ..................................................................................................... 267
REFERENCES .............................................................................................................. 270 APPENDIX A: Glossary ............................................................................................... 288 APPENDIX B: Translated versions of “The North Wind and the Sun” ................. 294

ix
APPENDIX C: Secondary data collect response sheet .............................................. 295 APPENDIX D: Dictation response sheet .................................................................... 298 APPENDIX E: Participant Consent Form ................................................................. 300 APPENDIX F: Background Questionnaire ................................................................ 302 APPENDIX G: Boxplots identifying RT outliers ....................................................... 303 APPENDIX H: Response summaries .......................................................................... 304

x
LIST OF TABLES
Table 2.1 Phoneme awareness assessment tasks .............................................................. 20!Table 3.1 Definitions of important terms regarding writing and orthography ................ 48!Table 3.2 Common Russian consonant clusters with unpronounced consonants ........... 75!Table 3.3 English, Russian, and Mandarin letter-phoneme relationships ....................... 80!Table 4.1 Primary data participant demographics ............................................................ 88!Table 4.2 Breakdown of experimental stimuli for the primary study ............................. 95!Table 4.3 English, Russian, and Mandarin nonhomophone wordlists ............................ 97!Table 4.4 English, Russian, and Mandarin homophone wordlists .................................. 98!Table 4.5 List of English, Russian, and Mandarin letters that create the mismatched
target words ............................................................................................................... 99!Table 4.6 Overall results of the spelling dictation ........................................................ 105!Table 4.7 Experimental procedure summary ................................................................ 109!Table 4.8 The 8 conditions for the overall data ............................................................. 113!Table 4.9 The 12 conditions for the subgroup data ....................................................... 114!Table 4.10 Breakdown of token numbers in each experimental condition after
discarding data for the overall data and the subgroup data analyses ...................... 118!Table 4.11 Between-subjects and within-subjects factors for the by-subjects analysis
of the overall data (L1–L0 comparisons) ................................................................ 119!Table 4.12 Between-subjects and within-subjects factors for the by-subjects analysis
of the subgroup data (L1–L2–L0 comparisons) ...................................................... 120!Table 4.13 Secondary data participant demographics .................................................... 121!Table 5.1 Outline of the primary research questions, the comparisons needed to
answer the questions, and the hypotheses associated with the comparisons .......... 129!Table 5.2 Mean nonhomophone (NH) and homophone (H) reflected accuracy
(RACC) and logged response times (RTs) for the MNL0 and RNL0 experimental groups in the L1 and L0 across the matched (M) and mismatched conditions (MM) ..................................................................................................... 133!
Table 5.3 Summary of overall data results addressing the first primary research question, the comparisons, and the predictions ....................................................... 148!
Table 5.4 Summary of overall data results addressing the second primary research question, the comparisons, and the predictions ....................................................... 163!
Table 5.5 Mean nonhomophone (NH) and homophone (H) reflected accuracy (RACC) and logged response times (LRTs) for the RFL and MFL experimental

xi
groups in the L1, L2, and L0 across the matched (M) and mismatched conditions (MM) ....................................................................................................................... 165!
Table 5.6 Summary of subgroup data results addressing the third primary research question, the comparisons, and the predictions ....................................................... 178!
Table 5.7 Summary of subgroup data results addressing the third primary research question, the comparisons, and the predictions ....................................................... 184!
Table 6.1 Primary research questions, predictions, and results revisited ....................... 192!Table 6.2 Mean accuracy rates by mismatched item for English (L1), Russian (L0),
and Mandarin (L0) nonhomophones ....................................................................... 238!Table 6.3 Mean item accuracy rates for English (L1), Russian (L0), and Mandarin
(L0) homophones .................................................................................................... 239!Table 6.4 RFL and MFL subgroups item accuracy for L1, L2, and L0 mismatched
nonhomophones ...................................................................................................... 241!Table 6.5 Raw accuracy rates for English and Mandarin diphthongs ........................... 249!Table 6.6 Original categorisation of target words with diphthongs phonemicised as 2
segments .................................................................................................................. 250!Table 6.7 Recategorised L1 and L0 H data with the diphthongs phonemicised as 1
phoneme .................................................................................................................. 252!Table H.1 Response summaries by item of the English mismatched words for the
overall data (total = 52) ........................................................................................... 305!Table H.2 Response summaries by item of the Russian mismatched words for the
subgroup data (total = 13) ....................................................................................... 306!Table H.3 Response summaries by item of the Mandarin mismatched words for the
subgroup data (total = 12) ....................................................................................... 306!

xii
LIST OF FIGURES
Figure 2.1 Illustration of the levels of phonological awareness ...................................... 19!Figure 2.2 Illustration of “bi-directional flow of activation” .......................................... 28!Figure 2.3 Continuum of orthographic depth ................................................................... 38!Figure 2.4 Example of inconsistent sound-to-spelling correspondences with the
single phoneme /i/ ..................................................................................................... 39!Figure 2.5 Example of inconsistent spelling-to-sound correspondences with the letter
string <ough> ............................................................................................................ 39!Figure 3.1 “Chain of borrowing” leading to the Roman, Cyrillic, and Pinyin
alphabets .................................................................................................................... 52!Figure 3.2 Abecedary of the modern Roman alphabet ................................................... 59!Figure 3.3 Abecedary of the Cyrillic Alphabet ............................................................... 63!Figure 3.4 Abecedary of the Pinyin alphabet .................................................................. 65!Figure 3.5 English Consonant Inventory ......................................................................... 66!Figure 3.6 English Vowel Inventory ................................................................................ 67!Figure 3.7 English syllable structure ............................................................................... 68!Figure 3.8 Russian Consonant Inventory ........................................................................ 71!Figure 3.9 Russian Vowel Inventory ............................................................................... 72!Figure 3.10 Russian syllable structure ............................................................................ 73!Figure 3.11 Mandarin Consonant Inventory .................................................................. 77!Figure 3.12 Mandarin Vowel Inventory ......................................................................... 77!Figure 3.13 Mandarin syllable structure ......................................................................... 78!Figure 5.1 Mean MNL0 and RNL0 square root values of reflected accuracy rates for
the L1 matched and mismatched conditions ........................................................... 137!Figure 5.2 Mean MNL0 and RNL0 logged RTs for the L1 matched and mismatched
conditions ................................................................................................................ 139!Figure 5.3 Mean square root values of reflected accuracy rates for the L1 and L0
matched and mismatched nonhomophones ............................................................. 143!Figure 5.4 Mean logged RTs for the L1 and L0 matched and mismatched
nonhomophones ...................................................................................................... 145!Figure 5.5 Mean square root values of reflected accuracy rates comparing the L0
matched and mismatched cross-language homophones .......................................... 152!Figure 5.6 Mean logged RTs comparing the L0 matched and mismatched cross-
language homophones ............................................................................................. 153!

xiii
Figure 5.7 Mean square root values of reflected accuracy rates for MNL0 and RNL0 comparing the L0 nonhomophones with the cross-language homophones across the matched and mismatched conditions ................................................................ 156!
Figure 5.8 Mean MNL0 and RNL0 logged RTs comparing the L0 nonhomophones with the cross-language homophones across the matched and mismatched conditions ................................................................................................................ 160!
Figure 5.9 Mean square root values of reflected accuracy rates comparing the L2 matched and mismatched nonhomophones and homophones ................................. 171!
Figure 5.10 Mean RFL and MFL response times comparing the L2 matched and mismatched nonhomophones and homophones ...................................................... 175!
Figure 5.11 Mean square root values of the reflected accuracy rates comparing the match-mismatch differences between the L1, L2 and L0 nonhomophones for the RFL and MFL groups ............................................................................................. 180!
Figure 5.12 Mean logged RT comparing the match-mismatch differences between the L1, L2 and L0 nonhomophones for the RFL and MFL groups ......................... 182!
Figure 6.1 Bipartite Model of Orthographic Knowledge and Transfer ......................... 220!Figure 6.2 Mean accuracy of the English mismatched items ........................................ 243!Figure 6.3 Mean accuracy of the English mismatched items ........................................ 244!Figure 6.4 Original analyses of L1 and L2 H with the diphthongs phonemicised as 2
phonemes ................................................................................................................ 251!Figure 6.5 Reanalysed L1 and L0 H data with the diphthongs phonemicised as 1
phoneme .................................................................................................................. 253!Figure G.1 Boxplots identifying RT outliers for the overall data ................................ 303!Figure G.2 Boxplots identifying RT outliers for the subgroup data .............................. 303!Figure H.1 Mean proportion of responses for the English mismatched tokens ............. 304!

xiv
ACKNOWLEDGEMENTS
As with any major undertaking, this dissertation is not the work of one person alone. The
contributions of the many different people in their different ways have made this research
possible. I greatly appreciate the following people for their contributions.
I would like to extend my deepest gratitude to my supervisor, Dr. Sonya Bird, whose
enthusiasm, understanding, and patience have been instrumental in my academic
development and achievements as a graduate student. She was an extraordinary
supervisor and mentor; I would have been lost without her. I would also like to thank my
other committee members, Dr. John Archibald, Dr. Julia Rochtchina, and Dr. Patrick
Bolger, for their encouraging and constructive feedback through all the aspects of this
research project. Finally, thank you to Dr. Bruce Derwing for serving as the External
Examiner and dedicating considerable time and attention to my dissertation.
I also wish to extend my gratitude to all the people who helped me with the
experiment creation and data collection. Thank you Abbey Bell, Yulia Ekeltchik, Yanan
Fan, Maggie Hofman, Shu-min Huang, Rachel Laviriere, Xiaojuan Qian, Jordan Rivet,
Tusa Shea, and Siobhan Sintzel. A very special thank you goes out to all the participants
who generously gave up their free time to participate in this research. Their willingness
to participate and share their own language learning experiences truly helped shape this
research.
In addition, I’d like to thank the all people in the Department of Linguistics and
Writing Centre, who provided a collegial, stimulating, and fun environment in which to
learn and grow. I am especially grateful to Allison Benner, Marion Caldecott, Chris
Coey, Ewa Czaykowska-Higgins, Bridget Henley, Jenny Jessa, Maureen Kirby, Janet

xv
Leonard, Thomas Magnuson, Gretchen McCulloch, Dave McKercher, Akitsugu Nogita,
Judith Nylvek, Matthew Richards, Pauliina Saarinen, Leslie Saxon, Jun Tian, Nick
Travers, Su Ubranczyk, and Laurie Waye.
I am eternally thankful to my family and friends for helping me get through all the
difficult times and celebrate all the successes. Their emotional support, encouragement,
friendship, and distractions are what helped to keep me sane through the entire process.
Finally, I would like to acknowledge the various institutions that made this doctoral
research possible through their financial assistance: the University of Victoria
(President’s Research Scholarship), the Department of Linguistics (Teaching
Assistantships), the Provincial Government of British Columbia (Pacific Century
Scholarship), and the Social Sciences and Humanities Research Council (SSHRC
Doctoral Fellowship #752-2010-1157).

xvi
DEDICATION
For Mom, Dad, and Dragon

1
Chapter One
INTRODUCTION
“Writing changes the way we think about language and the way we use it.” (Coulmas, 2003, p. 17)
1.1 Background
Research generally agrees that orthographic knowledge (especially alphabetic
knowledge) plays a pivotal role in speech processing. In fact, so strong is the influence of
alphabetic knowledge that Frith (1998) likens the possession of an alphabetic
representation to a virus where the “virus infects all speech processing” and “language is
never the same again” (p. 1011). Olson (1996) claims “people familiar with an alphabet
come to hear [original emphasis] words as composed of the sounds represented by the
letters of the alphabet” (p. 93). Research has demonstrated that alphabetic knowledge
affects speech processing by influencing individuals’ abilities to 1) isolate phonemes, 2)
perceive phonemes, and 3) separate phonemes and letters (see Appendix B for definitions
of important terms.). First, research has demonstrated that learning to read creates a
virtually unbreakable bond between letters and sounds such that individuals cannot
completely separate sounds from letters (Treiman & Cassar, 1997) and cannot avoid
thinking of sounds in terms of their orthographic representations (Burnham, 2003;
Landerl, Frith, & Wimmer, 1996). Second, research has established that only individuals
with alphabetic experience are able to breakdown words into their component sounds
because alphabets “sensitise” individuals to the phonemic level (e.g., Bassetti, 2006;
Carroll, 2004; Cheung & Chen, 2004; Cook & Bassetti, 2005; Derwing, 1992; Gombert,

2
1996; Read, Zhang, Nie, & Ding, 1986). For example, Read et al. (1986) discovered that
only alphabetically literate individuals could successfully perform phoneme-monitoring
tasks. Finally, more recent research has shown that when a mismatch occurs between the
number of letters and the number of phonemes in a word, the orthographic representation
overrides the phonological representation thereby causing individuals to misperceive
sounds (Erdener & Burnham, 2005; Hallé, Chéreau, & Segui, 2000).
While an abundance of research exists regarding the effect of orthographic
knowledge on first language (L1) speech processing, there is a surprising lack of research
on how orthographic knowledge affects nonnative language speech processing. If the
influence of an orthographic representation on a phonological system is as strong as the
research suggests, it would have serious implications for how speakers perceive sounds
not only in their L1, but also in their second language (L2) and in an unfamiliar language
(L0). This research contributes to the sparse body of research on orthography’s
relationship to nonnative phoneme perception by shedding light on how much influence
orthographic representation exerts on listeners’ phoneme recognition and perception in an
L2 and in an L0.
1.2 The Current Study
This study expands our understanding of orthographic effects by examining the
relationship between orthographic knowledge and phonological knowledge via native
English speakers’ abilities to count phonemes in their L1, their L2, and an L0. This
project revolves around two key concepts: 1) orthographic representation and 2)
phonemic information. Orthographic representation refers to the visual representation of
words, i.e., how words are written and the symbols used to represent words in written

3
language. Phonemic information refers to the auditory input of words, i.e., how words
are pronounced and the sounds that make up words in spoken language.
This research seeks to discover whether orthographic representation influences how
individuals perceive phonemes in words, specifically with respect to native speakers of
Canadian English perceiving phonemes in a language unfamiliar to them—either Russian
or Mandarin Chinese (the overall data). In addition, this research is also interested in
determining how L1 and L2 orthographies interact (if at all) in influencing second
language learners’ perception of L2 phonemes (the subgroup data). The general question
is: in an auditory task, does the orthographic representation (i.e., alphabetic knowledge)
override the phonological representation and determine the number of phonemes
individuals “hear” in a word? That is, do literate native speakers of English rely on their
knowledge of how words are spelt in order to count phonemes, and if so, how does this
affect their perception of phonemes in other languages and the speed with which they
identify those phonemes?
1.2.1 Research Questions
To answer the general question raised above, a phoneme-awareness task—specifically a
phoneme counting task where English speakers make decisions on how many phonemes
are present in any given word—was employed to answer the following the four primary
research questions outlined below.
1. Does L1 orthographic knowledge affect how native English speakers count
phonemes in their first language (L1)? Specifically, do they count
phonemes more accurately in words with consistent letter-to-phoneme
correspondences (i.e., the numbers of letters and phonemes are the same)

4
than in words with inconsistent letter-phoneme correspondences (i.e., the
numbers of letters and phonemes is not the same)? Also, are native English
speakers faster at counting phonemes in consistent words than in inconsistent
words? A supplementary question here is: are native English speakers more
successful at counting phonemes in orthographically unfamiliar words with
inconsistent letter-phoneme correspondences than in orthographically
familiar words with inconsistent correspondences because they would not be
affected by orthographic interference in the L0?
2. Does L1 orthographic knowledge affect how native English speakers count
phonemes in an unfamiliar language (L0)? That is, when L0 words are
homophonous with L1 words, does L1 orthographic knowledge affect
participants’ abilities to accurately perceive the phonemes in L0 words.
Specifically, do native English speakers more accurately count phonemes in
L0 words that are homophonous with the L1 words with consistent letter-
phoneme correspondences than in L0 words that are homophonous with L1
words with inconsistent letter-phoneme correspondences?
3. The third primary research question is a two-part research question.
a. Does L2 orthographic knowledge affect how native English
speakers count phonemes in their L2? That is, as predicted with the
L1, do language learners count phonemes more accurately and faster
in L2 words with consistent letter-to-phoneme correspondences (i.e.,
the numbers of letters and phonemes are the same) than in L2 words

5
with inconsistent letter-phoneme correspondences (i.e., the numbers
of letters and phonemes is not the same)?
b. If so, how does L2 orthographic knowledge interact with L1
orthographic knowledge? That is, since “the nature of the L1
orthography influences the way L2 learners attend to the L2
orthographic units” (Wade-Woolley, 1999, p. 448), does L1
orthographic knowledge override L2 orthographic knowledge and
affect phoneme perception in the L2?
4. Does the strength of the orthographic effect vary depending on experience
with the language? Are listeners more likely to be negatively influenced by
inconsistent letter-phoneme correspondences when they have more
experience with the target language? In other words, is the difference
between the matched and mismatched L1 words greater than the difference
between the matched and mismatched L2 words, which in turn is greater
than the difference between the matched and mismatched L0 words?
1.2.2 Research Hypotheses
In answering the research questions, we can imagine two scenarios. If the orthographic
representation does not intrude on the phonological representation, native English
speakers should be able to transcend letter-phoneme associations. As a result, individuals
should be able to ignore how the words are spelt and successfully count phonemes in
their L1, their L2, and an L0. On the other hand, if, as the literature suggests, the
orthographic representation does exert a strong influence on the phonological

6
representation and interferes with speech processing, then, native English speakers will
have difficulty separating letter-phoneme associations. As a result, a mismatch between
the number of letters and phonemes in a word will cause listeners to miscount the
phonemes they hear. This, of course, is contingent on the individuals knowing how words
are spelt. Thus, the orthographic representation will only interfere with individuals’
performance in their L1 and L2 and with all cross-language (including the L0’s)
homophones (see §4.2 and Table 4.2 for a more detailed discussion of the experimental
stimuli.).
In light of previous findings, namely that individuals cannot completely separate
phonemes and letters (e.g., Burnham, 2003; Treiman & Cassar, 1997) and that the
orthographic representation overrides auditory information (e.g., Erdener & Burnham,
2005; Hallé at al., 2000), the second scenario seems more plausible. Therefore, I
hypothesise that native speakers of Canadian English will rely on their knowledge of how
words are spelt to help them count phonemes. The numbered predictions below parallel
the aforementioned research questions such that each research question has a
corresponding research prediction. For the purposes of this research, consistent words
refer to words where the number of letters equals the number of phonemes (e.g., cat,
/kœt/, hint /hInt/, and traps /t®œps/). In contrast, inconsistent words refer to words where
the number of letters does not equal the number of phonemes (e.g., house /haws/, peck
/p”k/, and tough /tØf/). In other words, consistent words have one-to-one letter-phoneme
correspondences and inconsistent words have either one-to-many or many-to-one letter-
phoneme correspondences.

7
1. Because L1 orthography facilitates L1 phoneme perception in consistent
words but hinders in inconsistent words, native English speakers will count
phonemes more accurately and faster in English words where a match
between number of phonemes and the number of letters occurs (i.e.,
consistent letter-phoneme correspondences) than in English words where a
mismatch between the number of phonemes and letter occurs (i.e.,
inconsistent correspondences).
2. L1 orthography facilitates L0 phoneme perception in consistent cross-
language homophones because the associated L1 spellings help parse L0
phonemes, but L1 orthography does not affect perception in consistent
nonhomophones because no spelling associations exist. In addition, L1
orthography hinders L0 phoneme perception in inconsistent cross-language
homophones because the associated L1 spellings interfere with perception,
but L1 orthography does not affect perception in inconsistent
nonhomophones because, as with the consistent nonhomophones, no L1
spelling associations exist.
3. As with L1, L2 orthography facilitates L2 phoneme perception in consistent
L2 nonhomophones but hinders in inconsistent L2 nonhomophones. In
contrast, for the cross-language L2 homophones, which have associated L1
spellings, L1 orthographic knowledge overrides L2 orthographic knowledge
and influences L2 phoneme perception such that L1 orthography facilitates
L2 phoneme perception in L2 words with consistent L1 associations but
hinders in L2 words with inconsistent L1 associations.

8
4. As native speakers, the listeners have many more years of experience with
English than they do with their L2 and thus the L1 orthography is more
entrenched and potentially exerts more influence on the L1 than the L2
orthography exerts on the L2. Therefore, the accuracy and response time
differences between the consistent and inconsistent L1 words would be
greater than the differences between the consistent and inconsistent L2
words, which in turn would be greater than the differences between the
consistent and inconsistent L0 words (i.e., L1 differences >> L2 differences
>> L0 differences).
In sum, with regards to the cross-language homophones, native speakers English
should rely on their knowledge of how similar sounding L2 and L0 words are spelt in the
L1 because of the ingrained L1 orthographic representations. Therefore, when the L1
associations have consistent correspondences, listeners should count phonemes more
accurately and faster than when the L1 associations have inconsistent correspondences.
With regards to the L1 and L2 nonhomophonous words, native English speakers should
be more successful (i.e., higher accuracy and faster response times) with consistent words
because orthographic knowledge helps in parsing phonemes than with inconsistent words
because orthographic knowledge interferes with parsing phonemes. Finally, listeners
should be as successful at counting phonemes in the L0 consistent nonhomophones as the
inconsistent L0 nonhomophones because the listeners do not know the words’ spellings
and the words have no L1 associations.
To test the hypotheses, an experiment was conducted in which L1 English speakers
counted phonemes in English, Russian, and Mandarin stimuli that were created and

9
organised according to two parameters: homophony and match. That is, each set of
language stimuli had four types of words: 1) nonhomophonous words with consistent
letter-phoneme correspondences (e.g., big /bIg/, !"# /duS/, and hu$ /xwa/), 2)
nonhomophonous words with inconsistent correspondences (e.g., fish /fIS/, %& /juk/, and
yòng /jON/), 3) cross-language homophonous words with consistent L1 associations (e.g.,
brat /b®œt/ – '()* /brat/ and bow /baw/ – bào /paw/), and 4) cross-language
homophonous words with inconsistent L1 associations (e.g., tree /t®i/ – *(+ /tri/ and rue
/®u/ – rú /!u/). The assumption here was that accuracy and speed differences between
matched and mismatched words – as well as homophones and nonhomophones—would
indicate an effect of orthographic knowledge on phoneme perception. Together, results
from these stimuli allow us to determine that orthographic knowledge influences the
perception of phonemes in our L1 and in other, less familiar languages.
1.3 Dissertation outline
This dissertation consists of seven chapters. Chapter One provides an introduction to the
research project by outlining the research questions and hypotheses. Chapter Two
discusses the relevant literature including theories of L1 influence on L2 learning, the
current models of speech processing, phoneme awareness, and orthographic depth.
Chapter Three discusses the orthographic representation of the Roman alphabet, the
Cyrillic alphabet, and the Pinyin alphabet. This chapter also outlines the important
language characteristics of English, Russian, and Mandarin Chinese with special attention
to each language’s phoneme inventory, syllable structure, and orthographic system used
to represent the phonemes in each language. Next, Chapter Four provides a
comprehensive description of the methodology employed in the research project.

10
Chapter Five presents the results and analyses of the data. Chapter Six provides an in-
depth discussion of the results by returning to the research questions and hypotheses,
discussing the major findings in terms of the current literature, and proposing the
Bipartite Model of Orthographic Knowledge and Transfer. Finally, Chapter Seven
concludes this dissertation by summarizing the main findings, outlining the limitations of
the project, highlighting the research contributions, and suggesting future research
endeavours.

11
Chapter Two
BACKGROUND RESEARCH
“Language and writing are two distinct systems of signs;
the second exists for the sole purpose of representing the first.” (Saussure as cited in Aronoff, 1992)
This chapter highlights the relevant background research regarding second language
speech perception and orthographic influence on first language (L1), second language
(L2), and unfamiliar language (L0) phoneme perception. To determine whether learners’
L1 alphabetic knowledge influences L2 and L0 sound perception, we must first
understand L1 transfer and the current theories of speech processing in second language
acquisition (§2.1). We must also understand how alphabetic knowledge promotes
phoneme awareness and influences word and sound recognition as well as how
orthographic depth influences and shapes speech processing (§2.2).
2.1 Second Language Acquisition
Since this study investigates the relationship between orthographic representation and L2
speech processing, a section on L2 learning is important. This section includes two
subsections. The first subsection (§2.1.1) discusses L1 influence (i.e., language transfer)
on second language acquisition (SLA), and the second subsection (§2.1.2) discusses the
theory that L2 learners/users perceive their L2 through the filter of their L1 and outlines
the three current models of speech processing, namely the Native Language Magnet
(NLM), the Perceptual Assimilation Model (PAM), and the Speech Learning Model
(SLM).

12
2.1.1 Early models: First language transfer
In an attempt to explain the effect of the L1 on an L2, Lado (1957) proposed one of the
first and most influential theories in second language acquisition (SLA), the Contrastive
Analysis Hypothesis (CAH). In this model, CAH claimed that interference from the
learner’s L1 was the major barrier to the acquisition of an L2. Specifically, CAH claimed
that learning (or the lack thereof) was contingent on the notion of transfer, which
Archibald (1998) defines as “the process whereby a feature or rule from a learner’s first
language is carried over to the IL [interlanguage] grammar” (p. 3)1. In SLA, L1 transfer
can be either positive or negative. Positive transfer occurs when an L1 feature is carried
over into the interlanguage and facilitates learning and/or performance in the L2 while
negative transfer occurs when an L1 feature is carried over into the interlanguage but
hinders learning and/or performance in the L2. According to CAH, negative transfer
from the L1 into the interlanguage grammar can explain ALL errors in the L2. Thus by
systematically comparing the differences between the L2 and the L1, CAH proposed that
researchers could predict where the learners would have difficulty and where they would
not (Major, 2001): acquiring similar2 L1 and L2 elements would be easy (positive
transfer), and acquiring different elements would be difficult (negative transfer).
While the promise of predicting all errors was certainly appealing, in the years
following its proposal, CAH encountered two major criticisms. First, contrary to its
1 The interlanguage, or IL, is the language system that an L2 learner uses. This is a system that is neither the L1 nor the L2 – it is a system that is somewhere between the two other systems. According to Major (2002), the IL is formed by three factors: 1) the L1, 2) the L2, and 3) universal principles. 2 While researchers often use the terms similar and dissimilar to characterise the degree of difference between L1 and L2 elements, they have yet to satisfactorally operationalize their definitions. That is, researchers currently do not have any clear parameters for what constitutes a similar element and what consistitutes a dissimilar elemet. Thus, the question still remains: at what point do elements become dissimilar from each other?

13
claim, CAH failed to predict all the errors that were made by language learners (what
future SLA theorists would call “developmental” errors), and it predicted some errors that
did not occur. Second, CAH also failed to account for why learners with different L1s
substitute different L1 elements for the same L2 element (Brown, 2000; Major, 2001).
Research has shown that learners with different L1s substitute different L1 phonemes for
the same L2 phoneme even though the L1s may have the same substitute options. For
example, CAH could not account for why Japanese English-as-a-second-language (ESL)
learners substitute /s/ for /T/ and Russian ESL learners substitute /t/ for the same fricative
when both Japanese and Russian have /s/ and /t/ (Hancin-Bhatt, 1994).
In light of serious criticisms against traditional CAH, Oller and Ziahosseiny (1970)
proposed a moderate version of CAH in an attempt to remedy its shortcomings. This
moderate version considered degrees of similarity the between L1 and L2 elements. In
fact, Oller and Ziahosseiny were the first to suggest that similar L1 and L2 elements
would cause more difficulty than dissimilar L1 and L2 elements. In their study of English
spelling errors, they discovered that those learners whose native language used a different
orthography from the Roman alphabet made fewer mistakes than those whose native
language used the Roman alphabet. Based on their results, they claimed that learning
similar “sounds, sequences and meanings” would cause more difficulty for language
learners than dissimilar ones because “whenever patterns are minimally distinct in form
in one or more systems, confusion may result” (p. 186). Since Oller and Ziahosseiny’s
work, subsequent researchers have come to agree that more dissimilar L2 elements are
easier than the similar ones. Why would dissimilar elements be easier than similar ones,
and why would transfer hinder rather than facilitate L2 learning? Because dissimilar

14
elements have no corresponding structure in the L1, they are less likely to be influenced
by negative transfer and are therefore more likely to be learnt (Major; 2001; Wode,
1983). Moreover, Major (2001) points out that the differences between similar L1 and
L2 elements are not perceptually salient enough to allow learners to perceive the minute
differences between the two languages. In other words, the greater the difference between
structures (i.e., the more dissimilar they are), the more easily the learner should be able to
perceive the difference and learn it.
2.1.2 Current models: The L1 filter
Since the 1970s, considerable research in SLA has investigated Oller and Ziahosseiny’s
(1970) claim that similar elements are more difficult to acquire than dissimilar ones. By
far, the most research has focused on the area of L2 phonology and attempted to
characterize the relationship and interaction between the L1 phonological system and the
target L2 phonology. SLA researchers agree that “L2 sounds are mapped on to L1
sounds” (Brown, 2000, p. 8), and recent perceptual models (e.g., Best, 1995, 2001; Flege,
1987, 1995; Kuhl, 1993, 2000) suggest that native sound experience gives learners an
“organizing perceptual framework” with which to discriminate and classify nonnative
phonemes (Best, 2001, p. 776). In other words, L2 learners perceive L2 language
elements (not just phonology but also prosody, syllable structure, and syntax as well)
through the filter of their L1, which, in turn, often leads to interference (i.e., negative
transfer) from the L1.
Kuhl’s (1993, 2000) Native Language Magnet (NLM) is one model that attempts to
account for L2 speech perception. NLM accounts for the perception of individual
phonemes and claims that both innate factors and linguistic experience influence speech

15
perception. This model accounts for 1) how native language categories are created and 2)
how L2 phonemes interact with L1 phonemes. According to NLM, a “general auditory
processing mechanism” allows infants to use the acoustic features of the sounds and
group those sounds into gross universal categories. However, NLM also claims linguistic
experience defines speech perception such that as infants gain experience and input from
their native language (L1), they reconfigure the gross category boundaries and create
language-specific mental maps of speech sounds. These language-specific maps then
“warp” the phonetic space and “ produc[e] a complex network, or filter, through which
language is perceived” (Kuhl, 2000, p. 11854). Moreover, the reconfiguration process of
phonetic boundaries establishes language specific prototypes, which act like “perceptual
magnets” that distort the phonetic space, reducing the perceptual distance between the
prototype and a given stimulus (Kuhl, 1993). These perceptual magnets attract nearby
sounds to make them more similar to the category prototype. Thus, foreign sounds are
more difficult to discriminate when they closely resemble native magnets because
magnets distort the space surrounding them. Also by attracting L2 sounds, those L2
sounds that are closer to the L1 magnets are more likely to be assimilated to and
indistinguishable from the L1 prototypes.
While Kuhl’s (1993, 2000) NLM considers perception of individual phonemes,
Best’s (1995, 2001) Perceptual Assimilation Model (PAM) is a model that aims to
account for the role that the L1 plays in the perception of nonnative contrasts. Like NLM,
PAM holds that learners are heavily influenced by their knowledge of their established
native phoneme categories. Because of this influence, PAM predicts that learners should
assimilate nonnative sounds to native phonemes “whenever possible based on detection

16
of commonalities in the articulators, constriction locations and/or constriction degrees
used” (Best, 2001). In this model, learners categorise nonnative sounds in one of three
ways: as either (1) part of a native category, (2) as an uncategorizable speech sound, or
(3) an unassimilatable non-speech sound. According to PAM, learners should more
accurately distinguish an L2 phoneme contrast if the two contrasting phonemes are
assimilated to two separate L1 phoneme categories rather than to one L1 phoneme
category.
Like PAM, a third speech perception model, Flege’s (1987, 1995) Speech Learning
Model (SLM), assumes that phonemes similar to L1 phonemes are more difficult for
learners because of learners’ tendencies to equate similar nonnative phonemes with
already existing native ones. SLM distinguishes two kinds of phonemes: new and similar.
New phonemes (i.e., dissimilar phonemes) are phonemes that have no counterpart in the
L1, while similar phonemes are phonemes with an L1 counterpart, though they differ
from it systematically. SLM maintains that the greater the difference between an L2
phoneme and the closest L1 phoneme, the easier it is for the learner to discern the
phonetic differences and produce as well as perceive the L2 phoneme (Flege, 1995). The
differences between similar phonemes and their L1 counterparts are relatively subtle, and
therefore, relatively difficult to discern. SLM attributes this difficulty to “equivalence
classification,” such that a “single phonetic category will be used to process perceptually
linked L1 and L2 sounds” (Flege, 1995, p. 239) and thus will hinder learners’ abilities to
create new phonetic categories for similar sounds.
Just as the learners tend to view the L2 through the L1 at the segmental level, they
also view the L2 through the L1 at the prosodic level. For example, research on

17
Mandarin learners of English and English learners of Mandarin found that both groups of
learners failed to produce the appropriate prosodic characteristics of interrogatives in
their L2 (Pytlyk, 2008; Visceglia & Fodor, 2006). Visceglia and Fodor (2006) discovered
that native Mandarin speakers tended to compress pitch excursions in English
declaratives and interrogatives to the final syllable rather than from the pitch accent to the
boundary. In contrast, native English speakers tend to use a final rise on the final syllable
in Mandarin ma particle questions, as they would in uttering an English question (Pytlyk,
2008; Visceglia & Fodor, 2006).
In sum, what the models have in common is that they capture the fact that L1 acts as
a filter for L2 speech perception such that learners’ L1 phonological system profoundly
(and irrevocably) influences L2 speech perception. The NLM, PAM, and SLM establish
that the L1 is a filter through which an L2 or L0 is perceived. More specifically, these
models agree that the L1 system constrains L2 learners’ abilities to perceive and produce
L2 structures. In other words, L2 learners/users perceive L2 elements (such as phonemes
and prosody) in relation to existing L1 elements. Therefore, given that elements constrain
perception of nonnative phonemes, the current research investigates whether L1
orthographic knowledge is among the L1 elements that affect nonnative speech
processing. The driving question here is: considering the inseparable connection between
phonology and orthography (See §2.2 below.), is L1 orthographic knowledge another
filter through which learners perceive nonnative speech?
2.2 Alphabetic Knowledge
This section highlights the research that demonstrates that alphabetic knowledge i)
creates phoneme awareness (§2.2.1), ii) affects sound and word recognition and is co-

18
activated with phonological representation (§2.2.2), iii) makes separating letter-phoneme
associations extremely difficult (§2.2.3), and iv) overrides phonetic information and
suggests sounds (§2.2.4). This section also highlights the research surrounding
orthographic depth and its effect on alphabetic knowledge (§2.2.5).
2.2.1 Acquisition and development of phoneme awareness
As this research is primarily concerned with phoneme awareness, we must first
differentiate phoneme awareness from phonological awareness. In short, phonological
awareness encompasses phoneme awareness. Cheung (1999) defines phonological
awareness as “an individual’s ability to analyse spoken language into smaller component
sound units and to manipulate them mentally” (p. 2). These smaller component sound
units (i.e., sublexical units) can be either: 1) syllables, 2) onsets and rimes, or 3)
phonemes (Bruck, Treiman, & Caravolas, 1995; Treiman & Zukowski, 1991). For
example, people demonstrate phonological awareness (but not phoneme awareness) in a
task where they can successfully identify and rearrange syllables (e.g., cil-pen from pen-
cil). Similarly, people demonstrate phonological awareness (but not phoneme awareness)
in a task where they can successfully identify and blend the onset of one syllable with the
rime of another syllable (e.g., map from mob and sap). Finally, people demonstrate
phoneme awareness (and thus phonological awareness) in a task where they can
successfully identify and delete phonemes (e.g., rack from track). (See Table 2.1 below
for a list of phoneme awareness assessment tasks.)
Figure 2.1 below visually represents the three aspects of phonological awareness and
illustrates those levels with the word neglect as an example.

19
Figure 2.1 Illustration of the levels of phonological awareness
In her analysis of phonemic awareness tasks, Yopp (1988) concludes that “phonemic
awareness can be defined as the ability to manipulate individual sounds in the speech
stream, or, more simply, as control over phonemic units of speech” (p. 173). In short,
while phonological awareness refers to the ability to manipulate any sublexical unit, (i.e.,
syllables, onsets and rimes, or phonemes), phoneme awareness strictly refers to the
ability to manipulate phonemes and as such phoneme awareness is the third level of
phonological awareness. Table 2.1 below lists and describes the various tasks employed
by researchers to determine phoneme awareness.
Word neglect
Syllables ne glect sub- lexical units Onsets/Rimes phonological / n E / /gl ”ct/ awareness
Phonemes phoneme / n E g l ” c t/ awareness

20
Tasks Description Previous Studies
phoneme counting
- count (or tap) the number of phonemes in a given syllable or word
- e.g., the word tough contains 3 phonemes /t/, /Ø/, and /f/
Arnqvist, 1992; Bassetti, 2006; Cheung, 1999; Cossu et al., 1988; Derwing, 1992; Ehri & Wilce, 1980; Gombert, 1996; Landerl et al., 1996; Lehtonen & Treiman, 2007; Liberman et al., 1974; Mann, 1986; Perin, 1983; Pytlyk, to appear; Spencer & Hanley, 2003; Treiman & Cassar, 1997; Yopp, 1988
phoneme deletion
- isolate the target phoneme, delete it from the given syllable/word and then say the syllable/word that is left once the target phoneme has been removed
- e.g., deleting the initial consonant from the word flag to create lag.
Ben-Dror et al., 1995; Bertelson et al., 1989; Caravolas & Bruck, 1993; Carroll, 2004; Carroll et al., 2003; Castles et al., 2003; Cheung, 1999; Hu, 2008; Mann, 1986; Morais et al., 1979; Read et al., 1986; Saiegh-Haddad et al., 2010; Russak & Saiegh-Haddad, 2011; Tyler & Burnham, 2006; Wade-Woolley, 1999; Yopp, 1988
phoneme segmentation
- identify the phonemes in a given word - e.g., the word big has the phonemes /b/, /I/, and /g/
Cossu et al., 1988; Russak & Saiegh-Haddad, 2011; Silva et al., 2010; Williams, 1980; Yopp, 1988
phoneme isolation
- identify a specific phoneme in a give word - e.g., /k/ is the first phoneme in the word cat
Burnham, 2003; Caravolas & Bruck, 1993; Castles et al., 2009; Russak & Saiegh-Haddad, 2011; Saiegh-Haddad, 2007; Yopp, 1988
phoneme reversal
- reverse two specific phonemes in a word - e.g., switch the first and last phonemes in the word
pit to create tip
Alegria et al., 1982; Castles et al., 2003; Yopp, 1988
phoneme blending
- combine given phonemes into a word - e.g., use the phonemes /g/, /”/, /s/, and /t/ to create
the word guest
Cheung, 1999; Williams, 1980; Yopp, 1988
word-to-word
matching
- identify if the given words share the same phoneme
- e.g., do pen and hit begin with the same phoneme?
Cheung & Chen, 2004; Silva et al., 2010; Treiman & Zukowski, 1991; Yopp, 1988
phoneme identity
- target phoneme illustrated in example word, then identify (from 2 words) which word starts (or ends) with the same phoneme as the target
- e.g., hop and hum start with the same sound as hit
Bowey, 1994; Fletcher-Flinn et al., 2011; Wallach et al., 1977
phoneme oddity
- identify the odd word out based on phoneme difference – either onset, medial, or final
- e.g., deck is the odd word out of fit, fan, deck
Bowey, 1994; Hu, 2008
phoneme monitoring
- push a button as soon as a the target phoneme is identified
- e.g., push the “space bar” when you hear /p/
Cutler et al., 2010; Dijkstra et al., 1995; Frauenfelder et al., 1995; Hallé et al., 2000; Morais et al., 1986
invented spellings
- spell the words heard - e.g., picture is spelt <piccher>
He & Wang, 2009; Morris, 1983; Silva et al., 2010
Table 2.1 Phoneme awareness assessment tasks (adapted from Yopp (1988))

21
Not only is phoneme awareness the most fine-grained level of phonological
awareness, but it is also much more difficult to acquire and develops much later than the
other two levels of phonological awareness (Cossu, Shankweiler, Liberman, Tola, &
Katz, 1988; Liberman, 1971; Liberman, Cooper, Shankweiler, & Studdert-Kennedy,
1967; Liberman, Shankweiler, Fischer, & Carter, 1974). According to Liberman and her
colleagues, syllables are easier to perceive and manipulate than phonemes because
syllables are temporally discrete units of sound; they have a peak of acoustic energy that
provides a direct auditory cue for identification and explicit segmentation. In contrast,
phonemes lack an independent existence; “the consonant segments of the phonemic
message are typically folded, at the acoustic level, into the vowel, with the result that
there is no acoustic criterion by which the phonemic segments are dependably marked”
(Liberman et al., 1974, p. 204). In other words, because all phonemes are affected by co-
articulation, individual phonemes often cannot be clearly delineated, and phoneme
segmentation becomes much more difficult than syllable segmentation.
With respect to phonological awareness, writing systems dictate the sub-word
language units literate speakers are aware of and thus can identify and manipulate (e.g.,
Bassetti, 2006; Cook & Bassetti, 2005; Derwing, 1992; Mann, 1986; Saiegh-Haddad,
Kogan, & Walters, 2010). For example, syllabaries, like the Japanese kana and hiragana,
make speakers aware of morae (Cook & Bassetti, 2005; Mann, 1986; Wade-Woolley,
1999), consonantal writing systems, like the Arabic and Hebrew systems, make speakers
aware of consonant-vowel (CV) units (Cook & Bassetti, 2005; Saiegh-Haddad et al.,
2010), and alphabets, like the Roman and Cyrillic systems, make English and Russian
speakers aware of phonemes (e.g., Gombert, 1996; Goswami, 1999; Goswami & Bryant,

22
1990; Mann, 1986; Treiman & Cassar, 1997; Wade-Woolley, 1999). That is, different
types of writing systems make different phonological units salient, and Derwing (1992)
thus suggests:
the segment (or phoneme) may not be the natural, universal unit of speech segmentation, after all, and that the orthographic norms of a given speech community may play a larger role in fixing what the appropriate scope is for those discrete repeated units into which the semi-continuous, infinitely varying physical speech wave is actually broken down (p. 200).
Thus, while children/people acquire the first two aspects of phonological awareness (i.e.,
the ability to manipulate syllables and onsets/rimes) naturally without reading instruction,
they can only acquire phoneme awareness (i.e., the ability to manipulate individual
phonemes) with instruction in a written code—specifically an alphabetic code (Morais,
1991). In other words, alphabetic experience allows listeners to abstract the phonemes
from the speech signal.
Indeed, a substantial body of research on children, dyslexics, illiterates, and
nonalphabetic literates suggests that phoneme awareness is a product of alphabetic
knowledge. In fact, the research indicates that alphabetic knowledge precedes phoneme
awareness. That means, for individuals to perform successfully on phoneme awareness
tasks (e.g., phoneme counting, phoneme deletion, blending, and so on), they must have
experience with an alphabetic script. Chueng and Chen (2004) argue “phoneme
awareness requires support from alphabetic reading […] because the identity of the
phoneme is made explicit only in alphabets” (p.3). Children learn how to isolate and/or
segment phonemes via learning letters and their threshold for phoneme awareness is
knowledge of a few letters and the phonemes those letters represent (Carroll, 2004). In

23
short, alphabetic knowledge allows listeners to parse words into their component
phonemes because alphabets sensitise listeners to the phonemic level.
For children, the research suggests that whereas knowledge of syllables and onsets
and rimes appears to develop spontaneously before children go to school, knowledge of
phonemes appears to develop when children go to school and begin to learn to read in an
alphabetic orthography (e.g., Chueng & Chen, 2004; Gombert, 1996; Goswami, 1999;
Goswami & Bryant, 1990; Morais, Cary, Alegria, & Bertelson, 1979; Treiman & Cassar,
1997). According to Goswami (1999), phonological awareness develops in young
children from the syllabic level via the onset/rime level (prior to learning to read) to the
phonemic level (after learning to read). This sequence of development has been observed
for child learners of alphabetic orthographies including English speaking children
(Liberman et al., 1974; Treiman & Zukowski, 1991), Italian children, (Cossu et al.,
1988), German children (Wimmer, Landerl, & Schneider, 1994), Czech children
(Caravolas & Bruck, 1993), Swedish children (Arnqvist, 1992), and Norwegian children
(Høien, Lundberg, Stanovich, & Bjaalid, 1995). The research suggests that the
development of phonological awareness—from awareness of syllables to awareness of
onsets/rimes to awareness of phonemes—is similar for all children and independent of
language background, provided that the language employs an alphabetic writing system.
Further support for the argument that alphabetic knowledge precedes phoneme
awareness comes from research with non-literates (Bertelson, de Gelder, Tfouni, &
Morais, 1989; Morais, Bertelson, Cary, & Alegria, 1986; Morais et al., 1979) and
nonalphabetic literates (Cheung, 1999; Cheung & Chen, 2004; Read et al., 1986). For
example, Morais et al. (1979) compared the segmentation skills of literate and non-

24
literate adults in Portugal to determine whether phoneme awareness can develop over
time without literacy. Morais et al. discovered that only the literate adults could add and
delete consonants at the beginning of non-words. In a follow up to Morais et al.’s study,
Read et al. (1986) argued that a comparison of alphabetic literates and non-alphabetic
literates would be a more direct test of whether phoneme awareness can develop over
time without alphabetic literacy. In this study, Read et al. compared Chinese speakers
who had learnt Pinyin—a romanized script used to teach Mandarin Chinese—in addition
to Chinese characters (the alphabetic group) and Chinese speakers who had only learnt
Chinese characters (the nonalphabetic group). They discovered that the alphabetic
literates were significantly more successful at adding and deleting consonants than
nonalphabetic literates, thereby concluding that differences in segmentation skills are a
result of alphabetic literacy.
Finally, research in SLA also indicates that phoneme awareness is contingent on
alphabetic experience. Alphabetic L1 orthographies facilitate L2 phoneme awareness
such that L2 learners who have an alphabetic L1 orthography perform better on phoneme
manipulation tasks than L2 learners who have a non-alphabetic L1 orthography. For
example, via a phoneme deletion task, Ben-Dror, Frost, and Bentin (1995) discovered
that the English speakers could accurately delete target phonemes in both English (L1)
and Hebrew (L2) while the Hebrew speakers tended to delete initial CV segments rather
than the single target phonemes in Hebrew (L1) and English (L2). Ben-Dror et al. suggest
that since the orthographic units in English generally correspond to single phonemes, the
L1 orthography enhances phoneme awareness. In contrast, they suggest that since the
orthographic units in Hebrew (a consonantal system) generally correspond to CV

25
segments, the L1 orthography inhibits Hebrew speakers’ abilities to accurately
manipulate individual phonemes. Similarly, Wade-Woolley (1999) also argues that L1
orthographic experience is a contributing factor for performance in phoneme awareness
tasks. In her study of Russian and Japanese ESL learners, Wade-Woolley (1999)
discovered that Russian ESL learners performed significantly better in a phoneme
deletion task than Japanese ESL learners. According to Wade-Woolley, the Russian
learners’ experience with an alphabetic orthography (i.e., Cyrillic) positively facilitated
their ability to manipulate sublexical speech units (positive L1 transfer), while the
Japanese learners’ experience with a syllabic orthography (i.e., Kana) sensitised them to
visual information but did not help them perform the phoneme deletion task (negative L1
transfer).
In sum, phoneme awareness is a type of phonological awareness that requires the
ability to perceive and manipulate individual phonemes, and phoneme detection tasks,
such as phoneme counting, phoneme deletion, and phoneme segmentation, measure
listeners’ degree of phoneme awareness. In the words of Castles, Holmes, Neath, and
Kinoshita (2003) while
a certain level of phonological awareness is necessary for understanding the rudiments of the alphabetic principle, […] as the learning of phoneme-grapheme correspondences progresses, this [alphabetic] knowledge in turn promotes the development and refinement of phonological awareness. (p. 447)
As we have seen from the above discussion, phoneme detection tasks in the research on
children, illiterates, non-alphabetic literates, and L2 learners strongly suggest that
phoneme awareness is contingent on learning to read an alphabetic orthography.

26
2.2.2 Word/phoneme recognition and automatic co-activation
Not only has research demonstrated that alphabetic knowledge creates phoneme
awareness, but research has also demonstrated that alphabetic knowledge influences word
pronunciation and recognition. For example, research into “consistency effects” has
shown that word pronunciation and recognition is affected by knowledge of similarly
spelt words. This means that spelling-to-sound or sound-to-spelling inconsistencies
increase processing times and error rates (Glushko, 1979; Lacruz & Folk, 2004; Jared,
McRae, & Seidenberg, 1990; Stone, Vanhoy, & Van Orden, 1997; Ziegler, Ferrand, &
Montant, 2004).
In his seminal work, Glushko (1979) was the first researcher to investigate
consistency effects. He investigated three types of pseudowords, which were generated
from real words (e.g., hean from dean and heaf from deaf). The first type were “regular
consistent” words where the rimes do not have any alternate pronunciations. For
example, the rime <eap> in a word like heap can only be pronounced in one way—/ip/ 3.
The second and third types of words were “regular inconsistent” words where the rimes
do have alternative pronunciations, and “exception” words where the rimes have irregular
pronunciations, respectively. For example, words like gave are regular inconsistent words
because their rimes have pronunciations that follow orthographic rules (/ejv/); however,
these rimes also occur in exception words like have, which have irregular pronunciations
that cannot be derived from any orthographic rule (/œv/). For both regular consistent and
regular inconsistent words, the pronunciations are predictable based on general 3 With regards to notation, slant lines // refer to phonemic categories, square brackets [] refer to phonetic realisations, and angle brackets <> refer to graphemic representations. For example, in English, the phoneme /k/ can be realised as [k] or [kÓ] and spelt as <k>, <c>, <ck>, <ch> or even <q> as in the words karma, tract, stack, anchor, and query, respectively.

27
orthographic rules. Conversely, exception words have irregular pronunciations that must
be memorized. The participants were asked to pronounce each target pseudoword, which
was presented on a display screen. Glushko discovered that when participants
pronounced regular inconsistent and exception words, they had higher error rates and
longer response times. That is, exception pseudowords like heaf /h”f/ had higher error
rates and longer response times than regular pseudowords like hean /hin/ because
according to Glushko, speakers’ knowledge of words with similar spellings influences
their pronunciation and recognition of target words.
Since Glushko (1979), a number of other researchers have examined consistency
effects. These researchers have discovered that the effects of spelling consistency are
contingent on other factors. First, low frequency words are more susceptible to
consistency effects than high frequency words, which are rarely affected by consistency
effects (Jared et al., 1990). Second, consistency effects influence words according to a
“bi-directional flow of activation” such that both spelling-to-sound (ex. <int> to /Int/ or
/ajnt/ as in hint and pint, respectively) and sound-to-spelling inconsistencies (ex. /ip/ to
<eep> or <eap> as in sleep and cheap, respectively) decrease accuracy and slow
processing times (Stone et al., 1997). Figure 2.2 below illustrates this bi-directional flow
of inconsistencies.

28
Figure 2.2 Illustration of “bi-directional flow of activation” (based on Stone et al., 1997)
In short, both frequency and direction contribute to speech processing difficulties.
As with word recognition, research has also investigated consistency effects on
“phoneme-related tasks”. In these studies, researchers have found evidence that
phonemes that can be spelt in more than one way have higher processing costs than those
that have only one possible spelling (e.g., Dijkstra, Roelofs, & Fieuws, 1995;
Frauenfelder, Segui, & Dijkstra, 1990). Frauenfelder et al. (1990) conclude that the
reason their French speakers took longer to detect /k/ than /p/ was because, while /p/ has
only one possible spelling, /k/ has multiple spellings. In a similar study on /k/ detection,
Dijkstra et al. (1995) found that Dutch speakers had more difficulty and took longer when
detecting the phoneme /k/ in words where /k/ was spelt with its subdominant spelling
<c>. Both consistency and letter-phoneme correspondence frequency appear to affect
speech processing at the sub-word level by increasing difficulty and response latencies.
The research into consistency effects and co-activation of orthographic and
phonological codes has led researchers to challenge the traditional assumption that
speech processing is independent of orthographic representation such that speech
sound-to-spelling spelling-to-sound inconsistencies inconsistencies /ip/ /Int/ /ajnt/
<eep> <eap> <int>
sleep cheap hint pint

29
processing is primary and orthographic representation is secondary (Derwing, 1992;
Ziegler & Ferrand, 1998). In fact, Landerl, Frith, and Wimmer (1996) claim that in adult
literates, orthography and phonology are very closely connected—so closely connected
that orthography “intrudes” on phoneme awareness and the two are automatically co-
activated.
A growing body of research has demonstrated that orthographic representation is
automatically activated during auditory processing tasks and affects spoken word
recognition (e.g., Blau, van Atteveldt, Formisano, Goebel, & Blomert, 2008; Perre &
Ziegler, 2008; Perreman, Dufour, & Burt, 2009; Taft, Castles, Davis, Lazendic, &
Nguyen-Hoan, 2008; Ventura, Kolinsky, Pattamadilok, & Morais, 2008; Ventura,
Morais, & Kolinsky, 2007; Ziegler & Ferrand, 1998; Ziegler et al., 2004; Ziegler,
Muneaux, & Grainger, 2003). Specifically, research has demonstrated that even in the
absence of visual information, orthographic knowledge influences the speech processing
of alphabetic literate speakers. Ziegler and Ferrand (1998) asked French speakers to
identify whether French words were real words or pseudowords in an auditory lexical
decision task. They discovered that their French-speaking participants had higher error
rates and longer response times when a phonological rime could be spelt in more than
one way. For example, consistent French words like stage where the phonological rime
can only be spelt as <age> as in stage, rage, cage were identified as real words more
accurately and faster than inconsistent French words like plomb where the phonological
rime can be spelt in different ways as in nom, prompt, ton, tronc, and long. Ziegler and
Ferrand conclude that since orthographic consistency affects auditory processing,

30
phonological representation and orthographic representation are co-activated with the
speech signal.
Additional evidence supporting the automatic activation of orthographic knowledge
in speech processing comes from priming research studies. Chéreau, Gaskell, and Dumay
(2007) examined the effect of orthographic overlap between a prime and the target in
English real words and pseudowords. The primes and targets in this study had the same
phonological rimes, but they differed in orthographic overlap. The orthographic overlap
stimuli had primes and targets that spell their rimes in the same way (e.g., winch–finch).
In contrast, the no orthographic overlap stimuli had primes and targets that spell their
rimes in different ways (e.g., lynch–finch). Chéreau et al. also included a control
condition where the prime and targets had unrelated rimes (e.g., lump–finch). They
discovered a “substantial extra facilitation” for targets with primes containing
orthographic overlap (e.g., winch–finch). That is, the primes with orthographic overlap
helped the participants make significantly faster lexical decisions on real and pseudo-
words than did the primes without orthographic overlap and the unrelated primes. From
their results in normal and speeded lexical decisions, Chéreau et al. conclude “spoken
word recognition involves swift and automatic access to orthographic representations” (p.
347).
Similarly, Taft et al. (2008) used masked priming of pseudohomographs to confirm
that orthographic representation is indeed automatically activated during auditory
processing. In this study, the pseudohomographs were spoken nonword primes embedded
in a stream of meaningless syllables that were presented before the targets. Taft and
colleagues discovered pseudohomographs that could potentially be spelt in the same way

31
as their targets would facilitate lexical decisions on the targets (as measured in response
times), whereas pseudohomographs that could not be spelt in the same way as their
targets would not help with lexical decisions. For example, the pseudohomograph /dri:d/
would facilitate the lexical decision of /dr”d/ because /dri:d/ could logically be spelt as
<dread>. In contrast, the pseudohomograph /Sri:d/ would not facilitate the lexical
decision of /Sr”d/ because /Sri:d/ could not possibly be spelt <shred>. These results, like
Chéreau et al.’s (2007), confirm that the orthographic information associated with a
speech utterance is automatically activated (Taft et al., 2008, p. 376).
The nature of the experimental tasks in the above studies has called into question the
processing locus of orthographic information. The above studies have demonstrated
orthographic information affects post-lexical and decisional language processing;
however, other researchers have examined whether orthographic information also affects
online pre-lexical language processing (Cutler, Treiman, & Van Ooijen, 1998, 2010;
Perre & Ziegler, 2008). For example, using event-related brain potentials (ERP), Perre
and Ziegler (2008) sought to “track the on-line time course of an orthographic effect on
spoken word recognition” (p. 133) for native French speakers. Perre and Ziegler
employed three types of stimuli: 1) consistent words, 2) early inconsistent words
(inconsistency in the onset), and 3) late inconsistent words (inconsistency in the coda).
Not only did they find ERP differences between consistent and inconsistent words, but
they also found ERP differences that were “time-locked to the ‘arrival’ of the
orthographic inconsistency” (p. 135). Specifically, the ERP differences occurred
approximately 200ms after the onset of the inconsistency—around 320ms for the early
inconsistent words and around 600ms for the late inconsistent words. From these results,

32
Perre and Ziegler claim that the “temporal synchronization” of ERP differences to the
orthographic inconsistency provides strong evidence that orthographic information is
activated during spoken word recognition and is processed on-line.
Researchers argue that co-activation of orthographic representations and
phonological representations occur because orthographic knowledge permanently alters
the way children and adults categorise and perceive spoken language (e.g., Burnham,
2003; Frith, 1998; Perre, Pattamadilok, Montant, & Ziegler, 2009; Ziegler et al., 2003).
The effect of orthographic knowledge on spoken language is so strong that Frith (1998)
likens the alphabetic code to a virus that “infects all speech processing” and concludes
“language is never the same again” (p. 1011). Once children start to acquire an alphabet,
the orthographic knowledge reorganises the L1 phonological system and the two systems
become interdependent (Burnham, 2003). Similarly, Ziegler et al. (2003) argue that
orthographic knowledge “provides an additional constraint in driving segmental
restructuring” (p. 790). As a result of this restructuring, orthographic knowledge affects
perception because this knowledge is automatically activated with print, which in turn
provides information to the phonological system. Moreover, after restructuring,
orthographic knowledge is so intimately linked to the phonological system that readers
cannot avoid thinking about the letters even when specifically instructed not to do so
(Landerl et al., 1996) and in the absence of visual stimulation (e.g., Ziegler & Ferrand,
1998; Ziegler et al., 2004; Ziegler et al., 2003). In short, by triggering phonological
restructuring and reorganization, orthographic representation and the phonological
system it has altered become irrevocably linked and are thus co-activated in spoken word
recognition.

33
2.2.3 Letter-phoneme associations
Because alphabetic knowledge restructures the L1 phonological system, it also makes
separating letter-phoneme associations almost impossible (e.g., Burnham, 2003; Treiman
& Cassar, 1997). In fact, research suggests that both literate children and adults cannot
completely ignore letter-phoneme associations and separate the phonemes from the letters
used to represent them. For example, Treiman and Cassar (1997) found that listeners—
both children and adults—are more likely to report a two-phoneme string (e.g., /"#/ and
/$m/) as one phoneme when that string was also a letter name (e.g., <r> and <m>,
respectively). Based on these results, Treiman and Cassar conclude that complete
separation of letters and phonemes is impossible once individuals begin to learn to read.
The impossibility of separating letter-phoneme associations is further supported by
other phoneme counting research. Generally speaking, research has demonstrated that,
when asked to count phonemes in a phoneme counting task, listeners often count more
phonemes in words with more letters and fewer phonemes in words with fewer letters
(Bassetti, 2006; Ehri & Wilce, 1980; Perin, 1983; Spencer & Hanley, 2003). In a classic
study, Ehri and Wilce (1980) discovered that when asked to count phonemes, fourth
graders report more phonemes in words like pitch and badge than in words like rich and
page. From these results, they conclude that orthography does affect how readers
conceptualize the sound structure of words.
Similarly, in L2 research, Bassetti (2006) discovered that native English learners of
Chinese (CFL) count one fewer vowel when the vowel is not represented in the Pinyin
spelling. Specifically, in Mandarin words like huí /xwej/ (“return, go back”) and xi,
/Çjow/ (“to stop, to rest, to pause”), CFL learners count only three phonemes rather than

34
four because the triphthong is represented by only two letters (<ui> and <iu>). In
contrast, in Mandarin words like wéi /wej/ (“do, act”) and y-u /jow/ (“have”), CFL
learners count three phonemes because each of those phonemes is represented by an
individual letter. In a second experiment, Bassetti confirmed that CLF learners segment
Mandarin vowels as they are spelt. Bassetti concludes that CFL learners interpret the L2
letters “as representing the same phonemes they represent in the L1” (p.110) and suggests
that CFL learners are strongly influenced by L1 letter-phoneme conversion rules. These
findings are particularly relevant here as the current research further investigates whether
or not L1 orthographic knowledge determines how listeners perceive phonemes in two
nonnative languages, Mandarin and Russian.
Evidence from other phoneme manipulation tasks also supports the virtual
impossibility of separating letter-phoneme associations once those associations are
cemented by learning letters. The research shows that listeners have more difficulty
manipulating phonemes that are not present in a word’s orthographic representation. In
an interesting study, Castles et al. (2003) discovered that their adult participants had
lower accuracy rates and longer response times when deleting or reversing phonemes in
“opaque” items (i.e., items without a straightforward correspondence between the target
phoneme and the letter(s) representing it) than in “transparent” items (i.e., items with a
direct one-to-one correspondence). For example, they found that their participants had
extreme difficulty in deleting the phoneme /s/ in words like fix where the /s/ is not
represented by the letter <s> but rather it is represented, along with /k/, by the single
letter <x>. That the letter <x> makes isolating /k/ or /s/ difficult is not surprising
considering that as children, in alphabetic orthographies like English at least, we are

35
taught that “one letter equals one sound.” Based on this alphabetic learning mantra, it is
easy to see why children/listeners assume that <x>, like most of the other letters of the
alphabet, also represents one phoneme, and as a result, they fail to perceive the two
phonemes represented by this letter.
Although the aforementioned research suggests that letter-phoneme associations are
extremely difficult to disregard once made, limited research has shown that in some
cases, orthography can help L2 listeners distinguish between nonnative contrasts. For
example, Escudero and Wanrooij (2010) found that different visual representations (i.e.,
<aa> and <a>, respectively) for the Dutch vowels /a/ and /"/ aided native Spanish
speakers in distinguishing between the two vowels. Specifically, Spanish-Dutch biliguals
were significantly more accurate at distinguishing between Dutch /a/ and /"/ (a contrast
that does not exist in Spanish) in a forced choice orthographic task (where listeners heard
a stimulus and identified which spelling option best matched the stimulus) than in a
forced choice XAB auditory task (where from a series of there stimuli, listeners had to
identify whether the first stimulus better matched the second or third stimulus).
According to Escudero and Wanrooij, the representations of <aa> and <a> led the
listeners to pay attention to the durational difference between /a/ and /"/ which ultimately
helped them distinguish between the two.
2.2.4 Misperception of phonemes
In addition to establishing that orthographic interference increases response latencies and
error rates and fosters processing difficulties, research has also shown that orthographic
spelling can “suggest” phonemes and override phonemic information. Hallé et al. (2000)
demonstrated that native French speakers misperceived the phonemes they heard in

36
French words like absurde /apsyrd/ and reported hearing /b/ instead of the actual /p/
produced because the letter <b> in these types of words suggested the phoneme /b/.
From their results, Hallé et al. conclude that orthographic representation affects the
perception of phonemic representation. Specifically, when the phonetic and orthographic
information do not match, the orthographic representation overrides the phonetic
representation thus causing the listeners to misperceive the phoneme produced.
As with L1 orthography’s effect on the perception of L1 phonemic representation,
research has also shown that L1 orthography affects the perception of nonnative
phonemes in SLA. In their research, Erdener and Burnham (2005) discovered
orthography interferes with native Turkish speakers’ production of Irish and Spanish
nonnative phonemes. While the letter <j> exists in both the Turkish and Spanish
alphabets, the letter represents the phoneme /Z/ in Turkish and the phoneme /x/ in
Spanish. In the experiment, when given only auditory information, the Turkish
participants had 0% error rates for reproduction of the nonnative Spanish phonemes.
However, when given both auditory and orthographic information, the Turkish
participants’ error rates increased to 46% (i.e., /x/ was pronounced as /Z/). Erdener and
Burnham conclude that these increased error rates result from the participants substituting
the L1 phoneme /Z/ associated with the letter <j> they saw, which, in turn, suggests that
orthographic representation overrides the auditory information.
As with Bassetti’s (2006) research, Erdener and Burnham’s (2003) L2 research
informs the present study by illustrating that listeners are affected by L1 orthographic
knowledge. It demonstrates that listeners find it almost impossible to avoid L1
orthography when performing phoneme-related tasks in a nonnative language, which in

37
turn, affects how they perceive and thus produce nonnative speech sounds. In fact,
according to Young-Scholten (1995), premature L2 orthographic exposure leads to
increased L1 transfer such that when learners encounter L2 letters, they are compelled to
search for phonological constituents that the L2 letters represent, and in the absence of
established L2 phonology, these learners are only able access the L1 phonology.
2.2.5 Orthographic depth
When attempting to account for their results, Erdener and Burnham (2005) suggest that
orthographic depth plays an important role in how orthographic representation influences
speech processing. For alphabetic orthographies, orthographic depth refers to the
consistency and predictability of letter-to-phoneme correspondences in a language (Ellis,
Natwume, Stavrolpoulou, Hoxhallari, van Daal, Polyzoe, Tsipa, & Petalas, 2004; Frost &
Katz, 1989; Katz & Frost, 1992; Liberman, Liberman, Mattingly, & Shankweiler, 1980).
According to Liberman et al. (1980), orthographic depth depends on two variables: 1) the
depth of the morphophonological representation (i.e., whether the system represents the
language at the phonemic, syllabic, or morphemic level), and 2) the degree to which the
orthography approximates the phonemic representation (i.e., the degree of letter
regularity).
Essentially, the regularity and consistency of letter-phoneme correspondences
determines the degree of orthographic transparency. Transparent (or shallow)
orthographies have a high degree of regularity between the letters and phonemes such
that one letter represents one phoneme. Spanish, German, Italian, Finnish, and Serbo-
Croatian are languages with shallow orthographies. Opaque (or deep) orthographies, in
contrast, have a high degree of irregularity in their letter-phoneme correspondences such

38
that letters often represent more than one phoneme (inconsistent sound-to-spelling
correspondences) and phonemes often have more than one way of spelling them
(inconsistent spelling-to-sound correspondences). English, Danish, Russian, French, and
Scots Gaelic are examples of languages with a high degree of irregularity and
inconsistency, and are thus categorised as deep orthographies, although some languages
may be considered deeper than others. See Figure 2.3 below.
Because of the varying degrees of transparency, languages can be viewed along a
continuum of orthographic depth (e.g., Danielsson, 2003; Ellis et al., 2004; Liberman et
al., 1980; Seymour, Aro, & Erskine, 2003). Figure 2.3 visually illustrates this
orthographic depth continuum.
Figure 2.3 Continuum of orthographic depth [based on Seymour et al.’s (2003) hypothetical classification of orthographic depth]4
This figure places languages along the continuum according to their varying degrees of
transparency. Highly transparent languages, like Finnish and Serbo-Croation, are at the
4 This continuum only approximates the degree of orthographic depth for alphabetic languages. In a larger picture, the continuum could be extended to include much deeper orthographies such as logographies (e.g., the Chinese character system).
orthographic depth shallow deep
Finnish Greek Portuguese French English Scots Gaelic Arabic Serbo-Croatian Italian Dutch Danish Irish Hebrew
Spanish Russian German Norwegian Welsh

39
left edge of the continuum and the languages increase in depth as we move from left to
right until we reach the deep orthographies like Arabic and Hebrew.
Notice that English exists at the deep end of the orthographic depth continuum due to
its irregularity and the high degree of sound-to-spelling and spelling-to-sound
inconsistencies. Figure 2.4 and Figure 2.5 below provide examples of these types of
inconsistencies in English. Figure 2.4 shows that the phoneme /i/ can be spelt in at least
seven different ways (i.e., sound-to-spelling inconsistency). Similarly, Figure 2.5 shows
that the letter string <ough> can be pronounced in at least eight different ways (i.e.,
spelling-to-sound inconsistency).
Figure 2.4 Example of inconsistent sound-to-spelling correspondences with the single phoneme /i/
*This pronunciation is characteristic of Canadian English speakers – also known as Canadian Raising. Non-Canadian raisers pronounce the <ough> in drought as /aÁ/ like in plough.
Figure 2.5 Example of inconsistent spelling-to-sound correspondences with the letter string <ough>
/i/
<e> <ee> <ea> <ei> <ie> <y> <i>
ether meet meat conceive siege city spaghetti
<ough>
/Øf/ /Af/ /u/ /ow/ /Øp/ /A/ /Øw/* /aw/
tough cough through though hiccough brought drought plough

40
Research has shown that reading abilities are directly linked to whether the children
learn to read in a transparent or deep orthography. The Orthographic Depth Hypothesis
(ODH) (Katz & Frost, 1992) predicts that orthographic depth leads to processing
differences in word recognition and lexical decisions. According to ODH, transparent
orthographies support word recognition processes based on a language’s phonology and
deep orthographies support word recognition based on accessing lexical information
through visual analysis of the orthographic structure (Danielsson, 2007; Ellis et al.,
2004). ODH also predicts that learners of transparent orthographies should be able to read
aloud and spell faster than those who learn a deep orthography. Research supports the
ODH by demonstrating that shallow orthographies are easier for children to learn than
deep orthographies (e.g., Goswami, Gombert, & De Barrera, 1999; Goswami, Porpodas,
& Wheelwright, 1997; Seymour et al., 2003). For instance, Seymour et al. (2003)
compared children’s acquisition of foundation literacy in 14 European orthographies
(including Scottish English) and found that the time needed to establish foundation
literacy (i.e., decoding and word recognition skills) varied according to the depth of the
orthography. In other words, children learning deep orthographies (Danish and English)
exhibit a delayed acquisition of foundation literacy compared to children learning
transparent orthographies. In fact, Seymour et al. (2003) estimate that after the first year
of literacy learning, readers of English require an additional 2 % years, at minimum, of
learning to gain mastery of word recognition—a mastery that most readers of transparent
orthographies gain by the end of the first year of learning.
Research also supports the ODH by demonstrating that learners of shallow
orthographies not only develop their reading and spelling skills more rapidly than

41
learners of deep orthographies (Ellis & Hooper, 2001; Juul & Sigurdsson, 2005; Landerl,
2000; Seymour et al., 2003; Spencer & Hanley, 2003, 2004; Wimmer & Hummer, 1990)
but learners of transparent orthographies also develop their phonological awareness skills
more rapidly than learners of deep orthographies (Cossu et al., 1988; Spencer & Hanley,
2003; Spencer & Hanley, 2004). Spencer and Hanley (2003, 2004) compared Welsh-
speaking (a transparent orthography) children with English-speaking (a deep
orthography) children in North Wales. They discovered the Welsh children outperformed
their English children counterparts in both reading of words and nonwords and phoneme
detection. Specifically, the Welsh children were much more likely to use letter-phoneme
correspondences to read aloud words with which they were unfamiliar (i.e., the nonwords
and English words). In addition, the Welsh children were significantly better than the
English children at counting phonemes in both the Welsh and English words, and they
performed equally as well counting phonemes in words that had the same number of
letters and phonemes as counting phonemes in words that had more letters than
phonemes. In contrast, the English children performed worse when the English words
contained more letters than phonemes. From these results, Spencer and Hanley (2003)
conclude “phonemic awareness test scores in an opaque orthography are much more
strongly mediated by knowledge of the spellings of words than is the case with
transparent orthographies” (p. 25). A follow up experiment also demonstrated that Welsh
children maintain the performance advantage after the first year of reading instruction
(i.e., one year later) for reading words and nonwords as well as for phoneme detection.
In sum, Spencer and Hanley argue that the degree of orthographic transparency is a
critical factor in reading and phoneme detection success.

42
In terms of the current research, we must consider orthographic depth since the depth
of the English orthographic system may affect the degree of orthographic influence. L1
orthographic transfer is more likely to affect speakers of more transparent languages
since there is a stronger correlation between letters and phonemes in transparent
languages. In contrast, since deep orthographies have more inconsistencies between
orthographic representations and phonetic information, speakers are less likely to rely on
the inconsistent relationships between letters and phonemes. Therefore, if native English
speakers do not rely on letters to aid them in counting phonemes, as predicted, then, a
possible explanation is that deep orthographies do not foster strong bonds between letters
and phonemes as transparent languages do.
2.3 Summary and relevance to the current research
As little research has investigated L1 orthographic influence on L2 speech perception (cf.
Bassetti, 2006; Erdener & Burnham, 2005; Wade-Woolley, 1999), we must look to non-
orthographic L1–L2 transfer effects (§2.1) and orthographic effects on L1 speech
perception (§2.2) to provide us with clues for the current project. Research (outlined in
§2.2) has shown that orthographic knowledge—specifically alphabetic knowledge—
affects speech perception in six ways.
1. Alphabetic knowledge precedes phoneme awareness such that the ability
to count phonemes is contingent on knowing an alphabet (e.g., Bertelson
et al., 1989; Carroll, 2004; Morais et al., 1986; Morais et al., 1979; Read et
al., 1986).

43
2. Orthographic knowledge influences response latencies and accuracy in
spoken word and sound recognition (e.g., Glushko, 1979; Jared et al.,
1990; Lacruz & Folk, 2004; Stone et al., 1997).
3. Even without visual stimuli, orthographic knowledge is automatically
activated with speech processing (e.g., Burnham, 2003; Chéreau et al.,
2007; Taft et al., 2008; Ziegler & Ferrand, 1998; Ziegler, et al., 2003).
4. Once children learn to read, the bonds between letters and phonemes are
so strong that learners cannot ignore letters when thinking about phonemes
(e.g., Bassetti, 2006; Castro-Caldas et al., 1998; Ehri & Wilce, 1980;
Perin, 1983; Pytlyk, to appear; Treiman & Cassar, 1997).
5. Orthographic information overrides phonologic information and
“suggests” phonemes (e.g., Erdener & Burnham, 2005; Hallé et al., 2000).
6. Orthographic consistency determines orthographic depth, which, in turn,
affects phonological skills, word recognition, and lexical decisions (e.g.,
Cossu et al., 1988; Danielsson, 2007; Ellis et al., 2004; Katz & Frost,
1992).
What is not currently clear is how these ways might interact with each other and to
what degree. If, as the above research (outlined in §2.1) suggests, an L2 is filtered
through the lens of the L1 phonemes, phonology, syllable structure, and so on, then, we
can reasonably hypothesise that an L2 (or an L0) will also be filtered through the lens of
the L1 orthography. As mentioned above, little research has investigated the effect of
orthography on nonnative speech perception; however, the pioneering works of Bassetti
(2006), Erdener and Burnham (2005), and Wade-Woolley (1999) suggest that L1
orthographic knowledge does indeed affect how listeners perceive nonnative phonemes.

44
The current research builds on their research and contributes to the sparse body of
literature surrounding the effect of orthography on nonnative language learning. By
investigating native English speakers’ abilities to perceive phonemes in their L1, their L2,
and an L0, this research strives to determine whether L1 orthographic representation
affects nonnative phoneme recognition.5
From the research outlined in this chapter, three key factors that shape L2 speech
processing and learning are apparent. First, an L2 phonological system interacts with the
L1 system whereby L2 phonemes are perceived and analysed with relation to the L1
phonological system. Second, the interaction between these two systems leads to transfer
from the learners’ L1 experiences such that negative transfer can interfere with L2
acquisition. Third, orthography and phonology are intimately connected. With these
factors in mind, by analogy, we can first posit that, for English L1 listeners, English
alphabetic knowledge should interfere with listeners’ phoneme awareness in L0 cross-
language homophones (i.e., words in an unfamiliar language that sound like English
words such as c*". /stul/ (chair) in Russian and ni# /ni/ (you) in Mandarin). We can also
posit that L1 and L2 orthographic systems may also interact with each other such that L1
orthography may interfere with learners’ perceptions of L2 speech. By investigating
English learners of Russian (which uses the Cyrillic alphabet) and Mandarin Chinese
(which uses the Pinyin alphabet), the current research can determine whether L1
orthographic knowledge interferes with both L2 orthographic knowledge and with L2 and
L0 speech processing.
5 Speech perception is distinct from phoneme recognition/awareness. Speech perception is a subconscious process that happens regardless of literacy while phoneme recognition is a conscious process that comes after the acquisition of alphabetic literacy (e.g., Burnham, 2003; Treiman & Cassar, 1997).

45
However, before we can investigate this important issue, we must first discuss and
understand the orthographic systems used by English, Russian, and Mandarin Chinese.
Therefore, the next chapter discusses writing systems in general, the phoneme inventories
and syllable structures of English, Russian, and Mandarin, and the orthographic systems
used to represent these phoneme inventories.

46
Chapter Three
ORTHOGRAPHIC REPRESENTATION
“Writing can never be considered an exact counterpart of the spoken language.
Such an ideal state of point-by-point equivalence in which one speech unit is expressed by one sign, and one sign expresses only one speech unit,
has never been attained in writing.” (Gelb, 1963, p. 15)
As the focus of this dissertation revolves around how orthographic representation affects
the perception of phonemes in English, Russian, and Mandarin Chinese, we must discuss
how each of these languages is represented alphabetically. The first section (§3.1)
discusses writing systems in general including the 1) creation of writing, 2) types of
writing systems, and 3) Roman, Cyrillic, and Pinyin alphabets. The second section (§3.2)
presents the phoneme inventories, syllable structures, and orthographic systems of
English, Russian, and Mandarin. Next, the third section (§3.3) compares the letter-
phoneme correspondences of the three target languages. The fourth section (§3.4)
discusses the impetus behind the current project, and finally, the fifth section (§3.5)
outlines the four major predictions surrounding the research.
3.1 Writing Systems
What is writing and what is its relationship to language? Writing represents language; it
is not language itself. Coulmas (1999), in The Blackwell Encyclopedia of Writing
Systems, defines a writing system as:

47
a set of visible or tactile signs used to represent units of language in a systematic way, with the purpose of recording messages which can be retrieved by everyone who knows the language in question and the rules by virtue of which its units are encoded in the writing system (p. 560).
Simply put, writing systems are (in general) visual means of expressing and recording
specific linguistic forms (Read, 1983). Writing is an important form of communication
that allows speakers “to record and convey information and stories beyond the immediate
moment” and “to communicate at a distance, either at a distant place or at a distant time”
(Rogers, 2005, p. 1). Writing systems are systematic in two ways. First, they have
systematic relationships to language, and second, they have systematic internal structures
(Rogers, 2005).
3.1.1 Important definitions
Table 3.1 provides all the important terms and definitions used in this dissertation
regarding writing systems and orthography (See also Appendix B for a glossary of all
relevant linguistic terms.).

48
Table 3.1 Definitions of important terms regarding writing and orthography
Term Definition Example(s) Abecedary An abecedary is an inventory of letters (in order) for an alphabet
(Rogers, 2005).
Allograph Allographs are the non-contrastive variants of a grapheme (Rogers, 2005).
<G> and <g> are allographs of <g>.
Alphabet
An alphabet is “a writing system characterized by a systematic mapping relation between its signs (graphemes) and the minimal units of speech (phonemes)” (Coulmas, 1999, p. 9).
Roman, Cyrillic, Greek, Hebrew, Arabic…
Grapheme
A grapheme is a “contrastive unit in a writing system, parallel to phoneme or morpheme” (Rogers, 2005, p. 10). Graphemes can be represented by letters, characters, numerals, and/or other symbols.
The grapheme <z> contrasts with other graphemes like <p t h>.
Homograph
Homographs are words where the “phonemic distinctions are neutralized graphemically” (Rogers, 2005, p. 16). Homographs are words that are spelt the same but pronounced differently.
Present tense read /®id/ and past tense read /®”d/
Homophone
Homophones are words where the “graphemic distinctions are neutralized phonemically” (Rogers, 2005, p. 16). That is, homophones are words that are spelt differently but pronounced the same way.
In English, one and won are pronounced the same /wØn/ but spelt differently.
Letter A letter is a shape that is “recognized as [an instance] of abstract graphic concepts which represent the basic units of an alphabetic writing system” (Coulmas, 1999, p. 291).
Logography
A logography is a writing system where words or morphemes are the units of representation such that a written symbol can represent a word or morpheme (Coulmas, 1999; Cheung & Chen, 2004; DeFrancis, 1990).
Chinese characters Japanese Kanji
Opaque
orthography
Opaque (or deep) orthographies have a high degree of irregular letter-to-phoneme correspondences. Some letters can have more than one phoneme attached to them, and some phonemes can have more than one graphemic representation.
English, Irish, French, Scots Gaelic, Hebrew, …
Orthographic depth
Orthographic depth refers to the regularity of grapheme-to-phoneme correspondences (Frost & Katz, 1989; Katz & Frost, 1992)- see Opaque orthography and Transparent orthography, also defined in this table.
Shallow (or transparent) Deep (or opaque)
Orthography
Orthography refers to the “set of rules for using a script in a particular language” (Cook & Bassetti, 2005, p.3).
Canadian English orthography, Finnish orthography, …
Script A script is “the graphic form of the units of a writing system” (Coulmas, 2003, p. 35).
Syllabary
A syllabary is a writing system where the syllable is the unit of representation such that graphemes represent syllables or morœ (Coulmas, 1999; Chueng & Chen, 2004; Rogers, 2005).
Taiwanese Zhùy/n zìm0 Japanese Kana Cherokee
Transparent orthography
Transparent (or shallow) orthographies have regular one-to-one grapheme-to-phoneme correspondences. That means, graphemes have only one phoneme, and phonemes have only one representation.
Spanish, Italian, Serbo-Croatian, Finnish, …
Writing
Writing is defined as “the use of graphic marks to represent specific linguistic utterance” where these marks “mak[e] an utterance visible” (Rogers, 2005, p. 2)
Writing system A writing system uses visual or tactile symbols to represent language. It has a systematic relationship to language and a systematic internal structure and organization (Coulmas, 1999; Rogers, 2005).

49
An important note here is that, in this research, the terms letter and grapheme are NOT
synonymous, although they have been used somewhat interchangeably in the literature.
On the surface, they may appear interchangeable as both letters and graphemes are
described as written symbols/characters that represent speech sounds. Here we must
make an important distinction between the two. A letter is defined as a shape/symbol that
is “recognized as [an instance] of abstract graphic concepts which represent the basic
units of an alphabetic writing system” (Coulmas, 1999, p. 291), and a grapheme is
defined as “a contrastive unit in a writing system” (Rogers, 2005, p. 10). While a single
letter often does represent a single phoneme, which makes it a grapheme, there are certain
instances where more than one letter is used to represent a single phoneme, which makes
the combination of letters a grapheme. Consider the letters <s> and <h> in the English
words mishap and reshape. In mishap, the letter <s> represents the phoneme /s/, and the
letter <h> represents the sound /h/; in this case, each letter is an independent grapheme.
Conversely, in reshape, both the letters <s> and <h> are used to represent the single
phoneme /S/, thus creating the grapheme (or digraph) <sh>. In this research, the
assumption is that one grapheme equals one phoneme, and that inconsistency most often
arises when a single grapheme (e.g., <sh>) representing a single phoneme (e.g., /S/)
contains more than one letter (e.g., <s> and <h>), or sometimes when a single letter or
grapheme (e.g., <x>) represents more than one phoneme (e.g., /k/ and /s/). Therefore,
letter-phoneme (in)consistency in this research refers to the relationship between the
number of letters and the number of phonemes in a word. Specifically, consistent letter-
phoneme correspondence refers to a match between the number of letters and the number

50
of phonemes in a word, and inconsistent letter-phoneme correspondence refers to a
mismatch between the number of letters and the number of phonemes in a word.
3.1.2 Creation of writing systems
A writing system can be created in one of three ways (Coulmas, 2003; Rogers, 2005).
First, a writing system may be created “from scratch”, i.e., with no prior model of
writing. The creation of a completely new and original system is extremely rare.
However, this phenomenon has happened at least three times (Daniels, 1996). The
earliest known system is Sumerian Cuneiform, which was created by the Sumerians
about 5500 years ago in Mesopotamia. Then, approximately 2000 years later the Chinese
invented writing in Asia. Finally, in Mesoamerica 2000 years ago, the Mayans also
invented writing. These three independently created systems are the three known
instances of new original writing systems. Some scholars also claim that Egyptian
Hieroglyphics was an original creation; however, there is debate about whether the
hieroglyphics developed independently or by “stimulus diffusion” (see below) (Rogers,
2005).
Second, a writing system may be a new script but not a new idea. This type of
creation is called stimulus diffusion. Unlike with new original creations, with stimulus
diffusion, the idea of writing is not new. That is, the creators are aware of the concept of
writing and create a new writing system based on the general idea of writing. This type
of system is also rather rare. Some examples of languages whose writing systems were
created in this way are Cree and Cherokee (Rogers, 2005).
Third, a writing system may be created by borrowing the system from another
culture and applying it to a new language. This type of creation is extremely common.

51
Indeed, most writing systems have resulted from the spread of other systems and the
majority of all systems can be traced back to one of the three original creations (Coulmas,
2003). Not surprisingly, the two major sources behind the spread of writing are religion
and commerce (Daniels, 1996). For example, the Roman alphabet was the writing system
of the Roman Empire and Holy See, and the Roman alphabet “has been adopted to write
so many languages as a direct result of the christianization of Europe” (Coulmas, 2003, p.
201). According to Rogers (2005), almost all of the world’s writing systems are
descendants of either the Chinese or Semitic writing system.
Interestingly, what Coulmas (2003) calls the “chain of borrowing” is reflected in the
rather static order of the letters. Coulmas declares that:
the great continuity of the alphabetic tradition is attested by a feature often disregarded as trivial, the order of the letters. Actually, it is a most remarkable fact that the letters of the Semitic alphabet have been handed down to us through roughly 140 generations in the form of the same canonical list, give or take a few additions and omissions along the way. (p. 207)
Figure 3.1 below traces the chain of borrowings that led to the Roman, Cyrillic, and
Pinyin alphabets. See §3.1.4 for a more detailed discussion of the development and
history of the Roman, Cyrillic, and Pinyin alphabets.
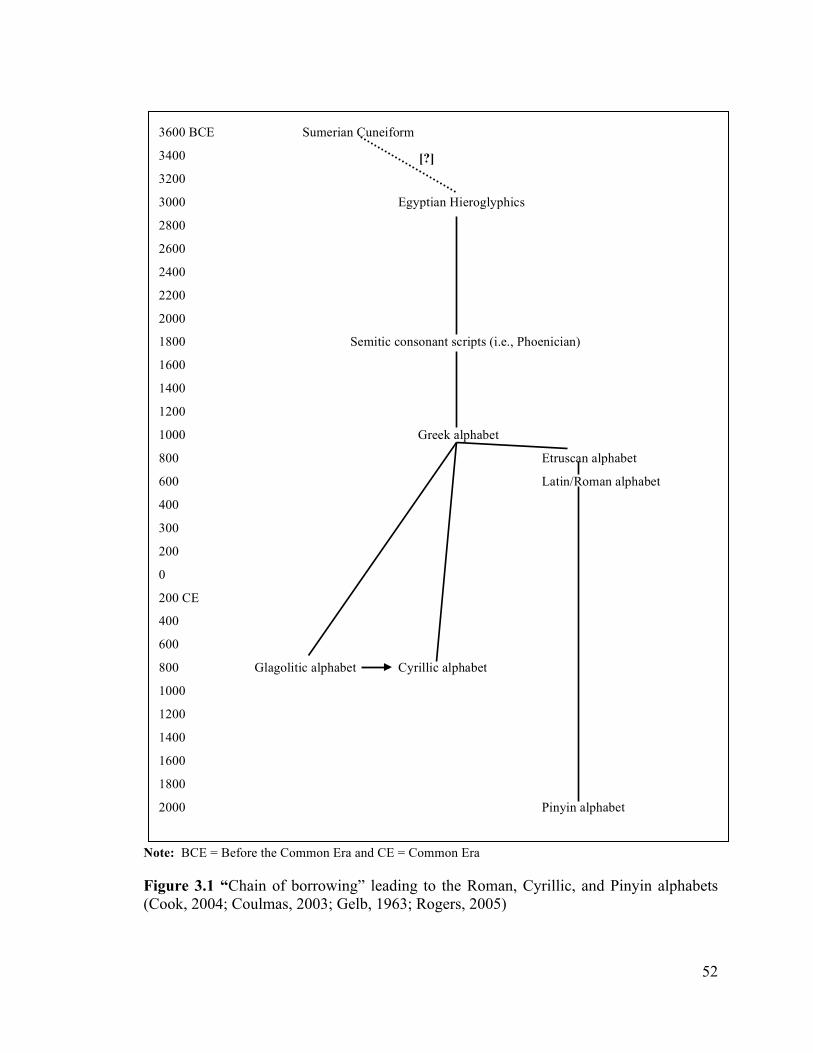
52
Note: BCE = Before the Common Era and CE = Common Era
Figure 3.1 “Chain of borrowing” leading to the Roman, Cyrillic, and Pinyin alphabets (Cook, 2004; Coulmas, 2003; Gelb, 1963; Rogers, 2005)
3600 BCE Sumerian Cuneiform
3400
3200
3000 Egyptian Hieroglyphics
2800
2600
2400
2200
2000
1800 Semitic consonant scripts (i.e., Phoenician)
1600
1400
1200
1000 Greek alphabet
800 Etruscan alphabet
600 Latin/Roman alphabet
400
300
200
0
200 CE
400
600
800 Glagolitic alphabet Cyrillic alphabet
1000
1200
1400
1600
1800
2000 Pinyin alphabet
[?]

53
As illustrated in Figure 3.1, the “alphabetic tradition” began with the Egyptian
hieroglyphics, which influenced the Semitic consonant scripts6. Although these two
scripts are not considered alphabetic, they created the foundation for the development of
an alphabetic script. Circa the tenth century BCE, the Greeks adapted the Semitic script
into the first phonetic system of writing (i.e., the first true alphabet) that represented not
only consonantal but also vocalic segments (Cook, 2004; Coulmas, 1999; Gelb, 1963;
Harris, 1986). Based on their need to represent vowels, the Greeks adapted the
Phoenician consonantal signs that were not needed for Greek phonology, and used them
to represent the necessary vowel sounds (Bloomfield, 1933; Daniels, 1996; Henderson,
1982; Rogers, 2005; Swiggers, 1996). That the Greek alphabet is derived from the
Phoenician alphabet is evident in the shapes, ordering, and names of the letters
(Swiggers, 1996; Threatte, 1996). Since the Greek adaption of the Phoenician alphabet,
“nothing new has happened in the inner structural development of writing” (Gelb, 1963,
p. 184). However, many cultures have borrowed the Greek alphabet. In fact, the letters
of the Greek alphabet form the basis of all the alphabets that developed in the West
(Swiggers, 1996). Most notably, the Etruscans in Italy borrowed the Greek alphabet for
their Etruscan alphabet, which, in turn, the Romans borrowed for their Roman (i.e.,
Latin) alphabet. This is the alphabet now used by the majority of Indo-European
languages and many indigenous languages around the world. The Chinese government
based its “romanization” of Chinese—the Pinyin alphabet—on the Roman alphabet. The
6 The broken line in Figure 3.1 between the Sumerian Cuneiform and the Egyptian Hieroglyphics represents a possible borrowing of symbols from the Sumerians (Fischer (1977) and Schekel (1984) as cited in Daniels, 1996). However, evidence that the Egyptians did borrow from the Sumerians is still scant and there is much debate surrounding this theory.

54
Greek missionary Saint Cyril also borrowed the Greek alphabet for the Glagolitic and
Cyrillic alphabets.
3.1.3 Types of writing systems
As mentioned above, writing systems are systems for graphically representing language
utterances. The written symbols either have a relationship with the spoken sounds or a
relationship with the meaning (Cook, 2004). For example, in English, the symbols
(letters) <c>, <a>, and <t> are related to the sounds (phonemes) /k/, /œ/, and /t/ in the
word cat. However, English also has some symbols that represent meanings rather than
phonemes. For example, we recognise the symbols <$>, <%>, <&>, and <7> as meaning
dollar, percent, and, and seven (respectively) without any indication of each word’s
pronunciation. Languages show a “preference for a particular way of writing rather than
to an absolute distinction” (Cook, 2004, p. 5); most writing systems use a mix of systems,
and represent language in more than one way (Cook, 2004; Read, 1983). In other words,
while no languages rely on writing systems that are strictly based on grapheme-phoneme
relationships or grapheme-mopheme relationships, some languages like Chinese and
Japanese (Kanji) use predominantly morpheme-based writing systems, and other
languages like English, Tamil, Russian, and Cherokee use predominantly sound-based
writing systems. The following subsections discuss morpheme-based (§3.1.3.1) and
sound-based (§3.1.3.2) writing systems.
3.1.3.1 Morpheme-based writing systems
Morpheme-based writing systems (also called logographies) employ written graphemes
to represent morpheme. That is, the graphemes are linked to the morphemes rather than

55
pronunciation of words. The graphemes in morpheme-based writing systems such as
Chinese characters, Sumerian cuneiform, and Egyptian hieroglyphics developed from
drawings of natural objects (Coulmas, 2003; Gelb, 1963). All of these logographic
systems appear to have developed independently from each other (Henderson, 1982).
Because of the relationship between graphemes and morphemes, morpheme-based
writing systems must have a separate grapheme for each morpheme. Consequently, these
systems have an extremely large number of graphemes. For instance, typical Chinese
dictionaries have up to 40,000 characters. However, functionally literate Chinese
speakers know between 2000–3000 characters (Coulmas, 2003; Smith as cited in Read,
1983), educated Chinese speakers know approximately 5000 characters (Cook, 2004),
and knowing between 4000–7000 characters is sufficient to read a newspaper (Wang,
1973).
The advantage of a morpheme-based writing system like the Chinese system is that
although China has many regional dialects that are not mutually intelligible, the writing
system transcends this barrier to communication. All literate Chinese, regardless of
dialect, can read Chinese characters; while each character may be pronounced differently
in each dialect, the meaning is the same across dialects. That is, although speakers of
different dialects may not be able to communicate verbally, over 500 million Chinese can
communicate visually via the writing system (Wang, 1973).
3.1.3.2 Sound-based writing systems
In contrast to morpheme-based writing systems, sound-based writing systems employ
graphemes to represent sound units. The advantage to such a system is that unlike
morpheme-based systems, which require many thousands of graphemes, sound-based

56
systems require a small number of graphemes, roughly corresponding to the number of
sound units in the language. For example, the Roman alphabet has 26 graphemes; the
Japanese Kana has 49 graphemes (Coulmas, 1999), and Arabic consonantal alphabet has
28 consonant graphemes (Cook, 2004). While all sound-based systems link graphemes
and sound units, the type of sound unit linked to the written graphemes varies among
languages. Specifically, three types of sound units are represented by written graphemes
in sound-based writing systems: 1) syllables, 2) consonants only, and 3) all phonemes –
both consonants and vowels (Cook, 2004).
Syllable-based writing systems (also called syllabaries) represent speech “by means
of graphemes each of which has a syllable as its value” (Coulmas, 1999, p. 483).
Usually, the grapheme represents a syllable that is comprised of a consonant and vowel
(Cook, 2004). This type of system works best with languages that have a limited numbers
of syllables (i.e., simple CV syllables). For example, with limited number of consonants
and vowels, in addition to its simple syllable structure (Japanese syllables are primarily of
the shape (C)V, with an extremely limited set of allowable coda consonants.), Japanese
has only about 75 possible syllables that need representation (Read. 1983). Some
languages that use syllabaries are Japanese Katakana and Hiragana, Tamil (Indian),
Cherokee (Iroquois language), and Cree (Algonquian language).
Consonant-based writing systems also use graphemes to represent sound units, but
instead of representing syllables, consonant-based writing systems – as the name suggests
– use graphemes to represent consonants. This type of system “operate[s] on the level of
segments but do[es] not indicate vowels” (Coulmas, 1999, p. 91). Because only
consonants are represented in the writing system, consonant-based systems require the

57
distribution of vowels within the language to be predictable; these usually indicate
grammatical or derivational changes (Cook, 2004; Coulmas, 1999). Semitic languages
like Arabic and Hebrew are examples of languages with consonant-based alphabetic
systems.
Like consonant-based writing systems, phoneme-based writing systems (called
alphabets) also represent phonemes. However, the alphabetic graphemes represent both
the consonants and vowels of a given language. Coulmas (1999) defines alphabets as
being “characterized by a systematic mapping relation between its signs (graphemes) and
the minimal units of speech (phonemes)” (p. 9). Among all types of writing systems,
alphabets are the most common writing system in use; they are used by approximately
49% of the world’s population (Cook, 2004; Rogers, 2005). Perhaps, the most familiar
alphabets in use today are the Roman, Greek, and Cyrillic alphabets, but other modern
alphabets include the Georgian, Armenian, Ethiopic, and Mongolian alphabets.
In theory, phoneme-based systems have a one-to-one relationship between single-
letter graphemes and phonemes. In practice, however, a high degree of variation exists in
the consistency of the letter-phoneme correspondences among languages such that no
system has exact correspondences between the individual phonemes of the language and
the individual letters used to represent those phonemes (Gelb, 1963). Some languages
like Finnish, Serbo-Croatian, and Spanish have highly consistent writing systems (i.e.,
transparent orthographies) that rely heavily on the one-to-one letter-phoneme connection.
Other languages like English and French have highly inconsistent writing systems (i.e.,
opaque orthographies) that contain a great deal of morphological information (Coulmas,
1999; Rogers, 2005). That is, in a deep orthography, some letter-phoneme inconsistency

58
arises because the system often spells different allomorphs the same way to preserve the
meaning of the morpheme (e.g., south-southern, child-children) (Rogers, 2005). See
§2.2.5 for a discussion of orthographic depth.
3.1.4 The Alphabets
Since this dissertation investigates the influence of alphabetic knowledge on phoneme
awareness for English speakers or English learners of Russian and English learners of
Mandarin, we must understand the three alphabets around which this research revolves:
the 1) Roman, 2) Cyrillic, and 3) Pinyin alphabets.
3.1.4.1 The Roman Alphabet
As mentioned above in subsection 3.1.2, in the seventh century BCE, the Roman alphabet
borrowed the Etruscan alphabet, which had itself been borrowed from the Greek
alphabet. In classical times, until the first century BCE, the Roman alphabet was
comprised of twenty-one letters: <A, B, C, D, E, F, G, H, I, K, L, M, N, O, P, Q, R, S, T,
V, and X>. At this time, the Romans used <I> to represent both /i/ and /j/, and they used
<V> to represent the three phonemes /v/, /u/, and /w/. The Romans originally also
discarded <Z> as they did not have a /z/ sound for it to represent (Rogers, 2005). In
addition, while the Greeks used <C> to represent /g/, the Etruscans had no voiced
consonants and used <C> to represent /k/ – along with <K> and <Q>. The Romans
retained the Etruscan system of using <C K Q> for the phoneme /k/. Therefore, because
Latin did have voiced consonants, the Romans needed a letter to represent /g/. They
added a stroke to <C> to create <G> and placed this new letter as the seventh letter in
their alphabet (Bonfante, 1996; Rogers, 2005).

59
Through the course of the Roman alphabet’s development, the Romans revised their
alphabet by adding some new letters. For example, to accommodate the increase in Greek
loan words into Latin, the Romans re-incorporated <Z>, but, instead of putting it back in
its original position as the seventh letter of the alphabet (as with the Greek alphabet), the
Romans placed <Z> at the end of their alphabet (Bonfante, 1996). Also, in mediœval
times, four new letters <J, U, W, and Y> were developed. These letters were developed
to differentiate /i/ from /j/ (previously both represented by <I>) and /v/, /u/, and /w/ from
each other (previously all represented by <V>) (Cook, 2004; Rogers, 2005). Today, the
modern Roman alphabet has a total of twenty-six letters: five vowel letters and twenty-
one consonant letters. Figure 3.2 below gives the complete abecedary of the modern
Roman alphabet.
Figure 3.2 Abecedary of the modern Roman alphabet
While the Romans adapted the Etruscan alphabet and kept the letter order relatively
intact, the Roman alphabet differed from the Etruscan alphabet in two significant ways.
First, the Romans did not borrow the letter names; rather, they created new letters based
on the sounds of the letters (Rogers, 2005). For these new names, each vowel sound was
a letter name; and the sounds /e/ and /$/ were added before and after consonants
respectively to create consonant names; for example, the letters for Latin were
pronounced as <B> /be/, <C> /se/, <F> /$f/, <L> /$l/. The letter name for <Z> came
Aa Bb Cc Dd Ee Ff Gg Hh Ii Jj Kk
Ll Mm Nn Oo Pp Qq Rr Ss Tt Uu Vv Ww Xx Yy Zz

60
from the Greek letter zeta and has since evolved in to the modern name zed.7 Second,
unlike the Etruscan alphabet, which was written from right-to-left, the Roman alphabet is
written from left-to-right. This reform effectively changed the orientation of the letters.
That is, with the right-to-left Etruscan alphabet, letters faced to the left while with the
left-to-right Roman alphabet, the letters face to the right (Rogers, 2005).
Other modifications have also occurred since the Roman alphabet was first created.
Originally, the Roman alphabet consisted only of what we know today as capital letters.
The lower case letters were developed by scribes to create a fast flowing writing style
(Cook, 2004; Knight, 1996). In addition, traditionally Latin was written without spaces
between words; however, in the eighth century CE, putting spaces between words
became a common practice (Cook, 2004).
According to Rogers (2005), languages that use the Roman alphabet rarely create
entirely new letters to add to the original 26 letters. Instead, languages use diacritics
(e.g., French: <è é ê ç> and German: <ä ö ü>) and/or diagraphs (e.g., English: <sh th ch
ng>) for sounds not represented by the standard 26 letters. The Roman alphabet has been
used for the majority of the world’s languages (Knight, 1996). Some examples of
languages that write with the Roman alphabet are English, French, Spanish, German,
Finnish, Italian, and Czech.
3.1.4.2 The Cyrillic Alphabet
Like the Etruscan alphabet, the Cyrillic alphabet was based on the Greek alphabet and
also the Glagolitic alphabet – an alphabet used for approximately 100 years prior to the 7 In the United States, the pronunciation norm for <Z> is /zi/ as advocated by the nineteenth century American lexicographer Noah Webster who wanted to regularise this grapheme so that it rhymed with the other graphemes like /bi ci di and so on/ (Rogers, 2005).

61
Cyrillic alphabet to represent the Old Slavonic languages. At the request of the prince of
Moravia, in 862 CE, the Byzantine Emperor sent the Greek missionaries Cyril and
Methodius to convert the Slavs to Christianity. Since no one had previously attempted to
write down any Slavic language, Cyril had to first create an alphabet that represented the
Slavic sounds (i.e., Old Bulgarian, also called Old Church Slavonic) so that he could then
translate the Bible for the Morovians (Dumbreck, 1964). While Cyril is commonly
believed to be the creator of the Cyrillic alphabet (from whom the alphabet gets its
name), scholars now believe that Cyril, in fact, created the older Glagolitic alphabet in
the mid-ninth century CE. The Glagolitic alphabet – adapted from cursive Greek – was
the first Slavic alphabet and was first used to translate the Bible into Old Bulgarian
(Coulmus, 1999). According to Cubberley (1996), Cyril’s disciples in Bulgaria in the
890s felt the Glagolitic alphabet was not suitable for church books and created a new
alphabet derived from the Glagolitic alphabet and the “more dignified” unial Greek.
While the Glagolitic and Cyrillic alphabets existed concurrently for some time, by the
twelfth century CE, the Cyrillic alphabet had replaced the Glagolitic—possibly because
the Glagolitic letters were very similar to each other and were very difficult to read
(Dumbreck, 1964).
As mentioned above, the Cyrillic alphabet was derived from the Greek and
Glagolitic alphabets. Evidence of this comes from the old Cyrillic alphabet—i.e., the
Cyrillic alphabet prior to Peter the Great’s and the 1918 reforms (discussed below)—
containing three letters <&>, <i>, and <!>, which all corresponded to the exact same
vowel sound (/i/) in Russian and ninth century Greek. Also, since ninth century Greeks
pronounced <'> as /v/, a new letter <(> was created in Cyrillic because Old Bulgarian

62
had both /v/ and /b/. Therefore, in the Cyrillic alphabet, <)> represents /v/ and <(>
represents /b/ (Dumbreck, 1964).
In the eighteenth century, Peter the Great initiated a reform of the Cyrillic spelling
system (Istrin, 1965). First, he simplified the characters, which since the alphabet’s
creation had become increasingly ornate. Second, he removed redundant letters. As
mentioned above, the letters <&>, <i>, and <!> all represented the same sound, /i/.
Therefore, <i> and <!> were removed, leaving <&> to represent /i/. Two other sounds in
Russian also had multiple letters representing them. Specifically, <"> and <*> both
represented /j”/, and <+> and <,> both represented /f/. In the Cyrillic alphabet reform,
<"> and <+> were removed and only <*> and <,> remain to represent /j”/ and /f/,
respectively. Finally, the spelling reform omitted <-> (the ‘hard sign’) from the end of
words since the absence of <.> (the ‘soft sign’) at the end of a word indicates that a
consonant is hard, i.e., non-palatalized (Dumbreck, 1964). However, because there was
no mechanism to enforce Peter’s reforms, it was not until the language reforms in 1918
that the redundant letters were removed entirely (Cubberley, 1996).
The modern Cyrillic Alphabet has a total of thirty-three letters. Of these 33 letters,
21 represent consonants, 10 represent vowels and 2 (<-> and <.>) do not have any
phonemic value themselves and serve only to indicate that the preceding consonant is
either hard (not palatalized) or soft (palatalised), respectively. Figure 3.3 provides the 33
upper and lower case letters in the Cyrillic alphabet.
The Cyrillic alphabet is used in the Eastern Orthodox Slavic areas such as Russia,
Ukraine, Bulgaria, and Macedonia. In addition to these Slavic areas, many non-Slavic

63
languages in Eastern Europe and Asia are written in Cyrillic. For example, Kazakh,
Uzbek, and Turkman are all written in Cyrillic.8
Figure 3.3 Abecedary of the Cyrillic Alphabet
3.1.4.3 The Pinyin Alphabet
Since the early seventeenth century CE, people have tried to “romanize” Chinese. In
other words, people have sought to create an alphabetic system to represent Chinese. The
first alphabetic system for Chinese was designed in 1605 by the Italian missionary
Matteo Ricci. Since the mid-nineteenth century, “proponents of language reform believed
that alphabetical writing was a key to the strength of a modern nation” (Duanmu, 2000, p.
6). As a result, between 1840 and 1930, reformers proposed over 30 different alphabetic
systems.
After the Communist Revolution, the new government proposed the Hanyu Pinyin
(“Chinese Spelling System”) as a standard writing system for Chinese (Coulmas, 1999).
They believed that a romanized writing system would further the government’s goal of
linguistic and ethnic assimilation where one standard language and one standard writing
system would make the assimilation process smoother (Zhou, 2001). In 1958, Pinyin was
adopted as the official spelling system by the Chinese government.
8 To my knowledge, there is no proven relationship between the number of phonemes in a language and the choice of alphabet employed to represent those phonemes.
/0 (1 )2 34 56 7* Ëë 89 :; <& => ?@ AB CD EF GH IJ KL MN OP QR S,
TU VW XY Z[ \] - ^_ . `a bc de

64
The government originally intended for Pinyin to supplant the use of Chinese
characters; however, the high level intellectual officials opposed the promotion of the
Pinyin system, and Pinyin currently plays a secondary role (DeFrancis, 2006). Still,
Pinyin has garnered widespread national and international popularity and acceptance, and
it has been recognized as the standard form of romanization of Mandarin (Mair, 1996).
For instance, Pinyin is the official transcription system in China. Chinese names have
been standardized on the basis of the Pinyin orthography. The educational system
requires the instruction of Pinyin to all children in grade one. Pinyin is used in
dictionaries, library catalogues, and other reference materials; it is also used on street
signs, building names, and product labels. Pinyin’s proponents “have succeeded in
consolidating Pinyin as THE [original emphasis] system of representing Chinese in an
alphabetic script” (DeFrancis, 1990, p. 10) which makes Pinyin “the most important
Chinese romanization system in modern usage” (Killingly, 1998, p. 5). Although not the
only motivation for its creation, Pinyin makes the orthographic representation of
Mandarin more similar to languages that also employ an alphabetic system of writing,
such as English.
As for the system itself, Pinyin is a phonemic orthography (Coulmas, 1999) and the
designers borrowed letters that had a basis in either western orthographies or linguistic
notation to represent the individual Mandarin phonemes (DeFrancis, 1990). Abecedaries
for this alphabet are usually organised according to the elements that form the syllable:
the onsets and rimes (Coulmas, 1999). In Pinyin, these elements are called the initials
and finals, and Mandarin syllables are created by combining one initial with one final (or
sometimes two finals). For example, Pinyin combines the initial <ch> and the final

65
<ang> to form the Mandarin word ch$ng /tßÓaf/ (“to sing”). Figure 3.4 below provides
the initial and final letters associated with the Pinyin alphabet.
Figure 3.4 Abecedary of the Pinyin alphabet
Unlike the Roman and Cyrillic alphabets, Pinyin is only used by one language, Mandarin.
3.2 Language backgrounds
In order to explore the relationships between letters and phonemes in English, Russian,
and Mandarin, we need to not only understand the how the phonemes are represented in
each language, but we must also familiarize ourselves with the phonemic inventories of
each language.
3.2.1 English
The following three subsections describe the North American English consonant and
vowel inventories, English syllable structure, and the English orthographic system.
Initials: Bb Pp Mm Ff Dd Tt Nn Ll Gg Kk Hh Jj Qq Xi Zhzh Chch Shsh Rr Zz Cc Ss Ww
Yy Finals: -a -o -i -u -ü -r -ai -ei -ao -ou -an -en -ang -eng -ong -ia
-ie -iao -iu -ian -in -iang -ing -iong -ua -uo -uai -ui -uan -un -ueng -uang - üe - üan - ün

66
3.2.1.1 English phoneme inventory
North American English consists of 24 consonants, 10 simple vowels (monothongs), and
5 diphthongs (Boberg, 2004; Ladefoged, 1999).9 As shown in Figure 3.5, English makes
a phonemic distinction between voiced and voiceless stops, fricatives, and affricates (but
not aspirated and unaspirated stops). English also has dental voiceless and voiced
fricatives.
Note: The sounds in brackets [] are not considered to be phonemic.
Figure 3.5 English Consonant Inventory (Boberg, 2004; Davenport & Hannahs, 2010; Ladefoged, 1999; Rogers, 2000)
In terms of vowels, North American English has 10 simple vowels (including schwa)
and 5 diphthongs. Of the 10 simple vowels, 4 are front unrounded vowels (/i/, /I/, /”/,
9 The simplifying assumption here is that there are very few differences between the consonants in the general American and Canadian dialects of English (Rogers, 2000). The vowels do differ substantially across American and Canadian dialects, but since this research does not focus on vowel quality, the differences between the dialects are not addressed further.
LABIAL DENTAL ALVEOLAR ALVEO-
PALATAL PALATAL VELAR GLOTTAL
STOPS
+asp [pÓ] [tÓ] [kÓ] [/] -v p t k +v b d g
AFFRI-CATES
+asp tS -v +v dZ
FRICA-TIVES
-v f T s S h +v v D z Z
NASALS m n N
LIQUIDS l [:]
® GLIDES w j

67
and /œ/); 2 are central vowels (/E/ and /Ø/); 4 are back vowels (/A/, /o/, /u/, and /Á/)10. In
addition to these simple vowels, standard North American English has 5 diphthongs
where the vowel starts as either a low or mid vowel and the glides rise to a high front or
high back position (/aj/, /ej/, /aw/, /ow/, and /Oj/) (Davenport & Hannahs, 2010;
Ladefoged, 1999). The diphthongs in Figure 3.6 are represented at their starting point and
the arrows indicate the direction and length of the off-glides. These diphthongs and
simple vowels occur in syllables with primary stress. In unstressed syllables, vowels are
most oftern reduced to either /I/ or /E/ and are usually very short (Rogers, 2000).
Front Central Back
High Mid Low
Figure 3.6 English Vowel Inventory (Boberg, 2004; Davenport & Hannahs, 2010; Ladefoged, 1999; Rogers, 2000)
3.2.1.2 English syllable structure
English syllable structure is highly variable. That is, English allows many different types
of syllables (Hammond, 1999; Rogers, 2000). (See Figure 3.7 below.). In short, English
syllables are comprised of a nucleus (usually as single vowel) with optional onset and
coda consonants. For example, English allows open syllables (i.e., syllables without
codas in words such as stew /stu/), closed syllables (i.e., syllables with codas in words
such as an /œn/ and rip /®Ip/). In addition, syllables can have up to three consonants in
onset position (e.g., sprint /sp®Int/) and four in coda position (e.g., worlds /wO®:ds/). With
10 An additional sound not included here is the rhoticised /„/ as in bird /b„d/ as I assume it to be /E/ plus /®/.
i u I Á
ej [E] ow g ” Ø OI œ aj aw A

68
the exception of /N/, all English consonants can appear in the onset position, and with the
exception of /h/, all consonants can occur in the coda position (Rogers, 2000).11 Figure
3.7 below visually illustrates English syllable structure.
Figure 3.7 English syllable structure
3.2.1.3 English orthographic system
English orthography employs the Roman alphabet, where 21 consonant and 5 vowel
letters represent over 40 phonemes (Ellis et al., 2004). The relationship between the
letters and phonemes is very complex. Not only does English have sound-to-spelling
inconsistencies, but also has spelling-to-sound inconsistencies. For example, the phoneme
/i/ can be written as <e, ee, ea, ie, ei, y, and i> as in the words ether, meet, meat, siege,
conceive, city, and spaghetti. Similarly, the letter sequence <ough> can be pronounced as
/Øf/, /Af/, /u/, and /ow/ as in the words tough, cough, through, and though (examples from
Rogers, 2005, p. 5). See also Figure 2.2 and Figure 2.3.
In addition to its original 26 letters, English also uses digraphs to represent
phonemes not accommodated by the single letter graphemes, namely the post-alveolar
11 The parentheses indicate optional segments.
!
onset rhyme
nucleus coda
(C) (C) (C) V (C) (C) (C) (C)

69
phonemes, the dental fricatives, and the velar nasal: <sh> represents /S/; <j> and <dg>
represent /dZ/; <ch> represents /tS/; <th> represents /T/ and /D/, and <ng> represents /N/.
According to Katz and Frost (1992),
English spelling represents a compromise between the attempt to maintain a consistent letter-phoneme relation and the attempt to represent morphological communality among words even at the cost of inconsistency in the letter-phoneme relation (p. 70).
Because of the complex relationship between graphemes and phonemes and the spelling-
to-sound and sound-to-spelling inconsistencies, English orthography is classified as an
opaque (or deep) orthography.
3.2.2 Russian
The following three subsections describe the Russian consonant and vowel inventories,
Russian syllable structure, and the Russian orthographic system.
3.2.2.1 Russian phoneme inventory
The Russian sound inventory contains forty phonemes, which are presented below in
Figure 3.8 and Figure 3.9. As illustrated in Figure 3.8, Russian consonants can be divided
along two major distinctions: voiced/voiceless and hard (non-palatalized)/soft
(palatalised) consonants (Press, 2000; Unbegaun, 1957; Wade, 2011). First, Russian has
six pairs of voiceless/voiced obstruents (/p b/12, /f v/, /t d/, /s z/, /S Z/, /k g/). Second,
Russian also has consonants that are paired for palatalization. In fact, with the exception
12 Unlike English, Russian voiceless stops /p t k/ do not have allophonic aspirated variants (Unbegaun, 1957).

70
of six Russian consonants (/S Z ts / only hard and /S":13 tS" j/ only soft), all the consonants
have hard and soft alternations (Wade, 2011). For the palatal consonants, the middle of
the tongue rises toward the hard palate. These soft and hard consonants in each
palatalized pair (except for the velars) are considered to be separate phonemes since the
palatal distinction between the two consonants can result in a meaning difference
between two words (Kerek & Niemi, 2009; Unbegaun, 1957). For example, the word
1)*14 /mat/ (with a non-palatalised <P>) means “checkmate” while 1)*2 /mat"/ (with a
palatalised <P>)15 means “mother.” In addition to these two distinctions, Russian dental
consonants (e.g., /t! d! /) are articulated further forward in the mouth than their English
counterparts, which are alveolar (e.g., /t d/) and Russian voiceless obstruents are not
articulated with aspiration as with English and Mandarin (Dumbreck, 1964).
13 While technically an alternation, /S/ and /S":/ differ in that only the shortened /S/ is ever non-palatalised and only the lengthened /S":/ is ever palatalized. In addition, each phoneme is represented by a different grapheme in the orthography. That is, /S/ is represented by <[>, and /S":/ is represented by <]>. 14 In Russian, the cursive version of the grapheme <P> is written as <*>. 15 The soft sign <.> has no phonemic value itself but serves to indicate that the previous consonant is palatalised.

71
LABIAL DENTAL ALVEOLAR POST-
ALVEOLAR PALATAL VELAR GLOTTAL
STOPS
+asp -v p p" t1 t1" k [k"] +v b b" d1 d1" g [g"]
AFFRI-CATES
+asp -v ts tS" +v
FRICA-TIVES
-v f f" s1 s1" S S": x [x"] +v v v" z1 z1" Z [V]
NASALS m m" n1 n1" LIQUIDS :1 l1"
TRILL r r" GLIDES j
Note: The sounds in brackets [] are not considered to be phonemic.
Figure 3.8 Russian Consonant Inventory (Kerek & Niemi, 2009; Robin et al., 2007; Press, 2000; Unbegaun, 1957; Wade, 2011)
In addition to the consonants, Russian has 6 vowel phonemes (Russian does not have
any diphthongs (see the discussion below) or long versus short vowels.). Also, when the
four vowels /i/, /e/, /a/, and /o/ are in unstressed syllables, they undergo different degrees
of vowel reduction, depending on the position of the vowel compared to the stressed
syllable (Dumbreck, 1964; Kerek & Niemi, 2009; Robin, Evans-Romaine, Shatalina, &
Robin, 2007; Unbegaun, 1957). For example, the vowel /o/ is realised as /o/ in a stressed
syllable, /a/ in the syllable before the stressed syllable, and /E/16 in a syllable more than
one syllable before the stressed syllable and anywhere after the stressed syllable. The
Russian word &!.!3á (“voices”) is pronounced /gElasa/. Unlike both English and
Mandarin, Russian does not have diphthongs. In fact, Reformatsky (1996) points out that
16 Schwa is not phonemic in Russian, and is, therefore, represented in square brackets in Table 3.9.

72
diphthongs are alien to the Russian language and when faced with borrowed words with
diphthongs, Russian speakers either break them into two syllabic monothongs, creating
an extra syllable, or turn the non-syllablic off-glide into a consonant, following licenced
Russian phonotactics. For example, the German one-syllable Faust can become either the
two-syllable 4)"3* /fa.ust/ (a literary character) or the one-syllable combination with
one vowel: 4)53* /favst/ (proper name).17 Also, like English, the glide /j/ in Russian is
part of the consonantal inventory. Therefore, Russian words such as 1)6 /maj/ are
considered CVC sequences—in contrast to the similar sounding English word my [maj],
which is considered to be a CV sequence where the V sequence is a diphthong consisting
of a V plus an offglide /j/ or /w/.
Front Central Back High Mid Low
Figure 3.9 Russian Vowel Inventory (Kerek & Niemi, 2009; Padgett & Tabain, 2005; Robin et al., 2007; Press, 2000; Unbegaun, 1957)
3.2.2.2 Russian syllable structure
Like English, Russian syllable structure is highly variable and allows many different
types of syllables. Russian syllables are comprised of a nucleus (i.e., a single vowel) with
optional onset and coda consonants (Kolni-balozky, 1938; Wade, 2011). Russian allows
open syllables (e.g., !a /da/ “yes” and 7+ /S":i/ “cabbage soup”), closed syllables (e.g., 89
/on/ “he/it” and .": /luk/ “onion”). In addition, although the most common syllables in
17 Thank you to Julia Rochtchina for helping translate Reformatsky (1996) into English.
i ˆ u
e o [E]
a

73
Russian are consonant plus vowel syllables (Kolni-balozky, 1938), the language allows
clusters of up to four consonants in both onset and coda position (e.g., 5;&.<! /vzgl"at/
“look, glance” and 3*(8+*=.23*5 /strait"Il"stf/ “of constructions”) (Kerek & Niemi,
2009). Figure 3.10 below visually illustrates Russian syllable structure.
Figure 3.10 Russian syllable structure
3.2.2.3 Russian orthographic system
Russian uses the Cyrillic alphabet. According to Kerek and Niemi (2009), “the phoneme-
grapheme correspondences are not always straightforward because many of the
graphemes in the Russian alphabet are not bound to representing only one phoneme” (p.
6). Dumbreck (1964) attributes the irregularities and discrepancies between written and
spoken Russian and the “illogicalities of orthography” (p. 5) to the fact that the Cyrillic
alphabet was not devised for Russian; rather it was devised for Old Bulgarian. The 33
letters of the Cyrillic alphabet can be divided into three groups of letters: 1) letters that do
not symbolize independent phonemes (<- .>), 2) letters that represent two phonemes (<*
h c e>), and 3) letters that represent one phoneme (all others) (Grigorenko, 2006).
Unlike the English and Mandarin Pinyin orthographies, the Russian orthography does not
traditionally have any digraphs (although Russian does use digraphs for loan words such
as "#); “jazz” /dZac/). For example, both English and Pinyin represent the frictive /!/
!
onset rhyme
nucleus coda
(C)(C)(C)(C) V (C)(C)(C)(C)

74
with the digraph <sh> (i.e., a grapheme consisting of two letters); Russian, in contrast,
uses a single letter grapheme <[> to represent the same phoneme.
While Russian letter correspondences contain four major irregularities, these
irregularities are highly predictable. First, many phonemes share the same letter. That is,
14 of the consonant letters <1 2 6 9 ; B D F J L N P ,> represent two phonemes: the hard
and soft phonemes. Palatalization (or lack thereof) is indicated by the following letter
rather than as part of the letter itself. For example, <,> can represent either /f/ or /f"/; the
softness of the consonant is indicated by the letter following it, either a soft sign <.> or a
vowel letter (see below), and is entirely predictable. Second, while there are only 6 vowel
phonemes, these phonemes are represented by 10 vowel letters <0 a H _ R & > represent
the simple vowel phonemes, and <e * h c> represent these vowels preceded by [j] in
word-initial position or after a vowel. For example, the word => (“her”) is pronounced as
/j”jO/. When these 4 vowels follow a consonant, they indicate that the preceding
consonant is soft (see above). Third, the soft sign <.> does not represent a phoneme;
rather it is used to indicate softness of a preceding consonant when the consonant is not
followed by a vowel. For example, the <.> indicates that the final consonant, /t/, in
'()*2 (“to take”) is palatalised (/brat"/) in contrast to the lack of <.> in '()* (“brother”)
where the /t/ is non-palatalised (/brat/). Finally, the Russian orthographic system does not
represent vowel reduction, and therefore, the vowel letters can represent different vowel
sounds depending on where the stressed syllable is. (In second language teaching
materials, stress is indicated by an accent over the vowel in the stressed syllable.) For
example, in the word 8:9ó (“window”), <o> is pronounced as /o/ in the second syllable
(stressed) but as /a/ in the first syllable (unstressed). In addition, Russian has a number of
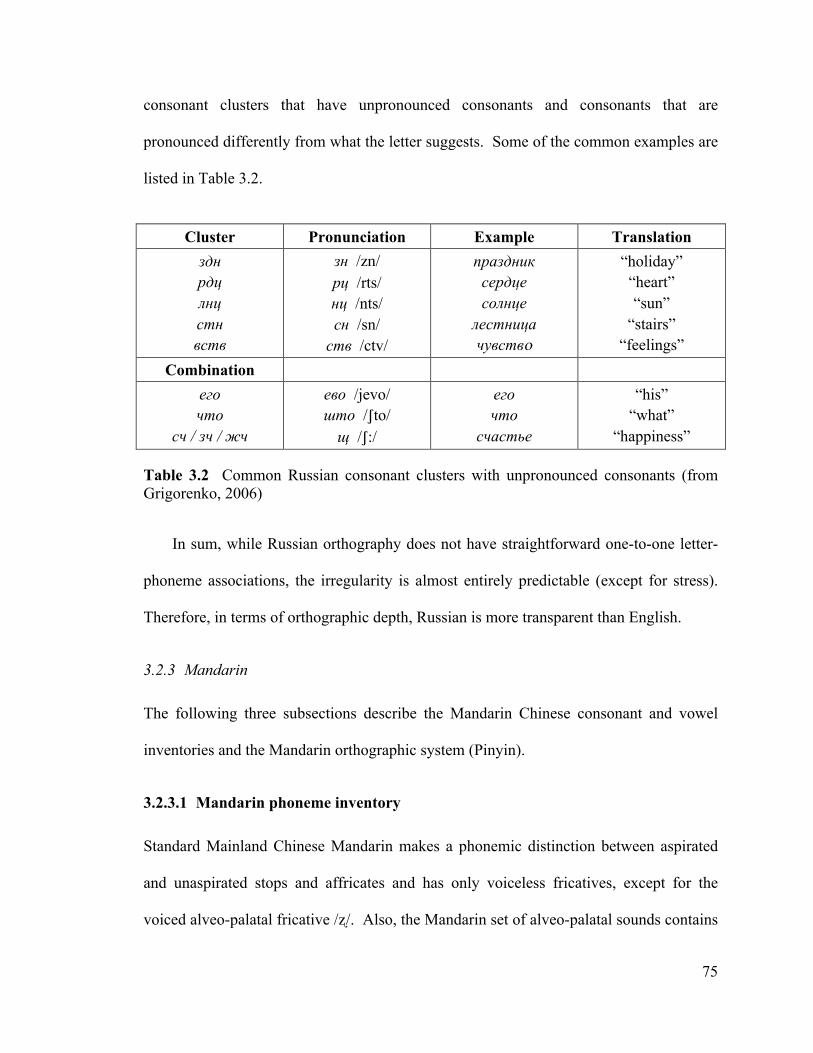
75
consonant clusters that have unpronounced consonants and consonants that are
pronounced differently from what the letter suggests. Some of the common examples are
listed in Table 3.2.
Cluster Pronunciation Example Translation ;!9 (!? .9? 3*9 53*5
;9 /zn/ (? /rts/ 9? /nts/ 39 /sn/ 3*5 /ctv/
@();!9+: 3=(!?= 38.9?= .=3*9+?) A"53*5o
“holiday” “heart” “sun”
“stairs” “feelings”
Combination =&8 A*8
3A / ;A / BA
=58 /jevo/ #*8 /Sto/ 7 /S:/
=&8 A*8
3A)3*2=
“his” “what”
“happiness”
Table 3.2 Common Russian consonant clusters with unpronounced consonants (from Grigorenko, 2006)
In sum, while Russian orthography does not have straightforward one-to-one letter-
phoneme associations, the irregularity is almost entirely predictable (except for stress).
Therefore, in terms of orthographic depth, Russian is more transparent than English.
3.2.3 Mandarin
The following three subsections describe the Mandarin Chinese consonant and vowel
inventories and the Mandarin orthographic system (Pinyin).
3.2.3.1 Mandarin phoneme inventory
Standard Mainland Chinese Mandarin makes a phonemic distinction between aspirated
and unaspirated stops and affricates and has only voiceless fricatives, except for the
voiced alveo-palatal fricative /!/. Also, the Mandarin set of alveo-palatal sounds contains

76
all retroflex sounds. Mandarin also has a set of dental affricates. The sounds [tÇÓ], [tÇ],
and [Ç] are considered to be allophones of the retroflex alveo-palatal consonants and only
occur in limited environments, namely, before the high front vowels /i/ and /y/ (Lin,
2001). In addition to the twenty consonantal phonemes, Mandarin has six vowel
phonemes: two high front vowels, one central low vowel, and three back vowels.18
Figure 3.11 and Figure 3.12 below provide complete phoneme inventories for the
Mandarin consonants and vowels, respectively. NOTE: Mandarin also employs tone
phonemically, which increases the number of distinctions made on the vowels: while
there are only 6 Mandarin tones, each one can take the 4 different tones, leading to 24
possible distinctions in the vowel system.
18 The non-high vowels /ø/ and /a/ each have allophonic variations. The vowel /ø/ has three variations; 1) [e] before the high-front-unrounded vowel [i], 2) [”] after [i] or [ü] and before the syllable boundary, and [E] before nasals. The vowel /a/ has two variations: 1) [”] between the high front vowels [i] and [ü], before [n], and before [i] and 2) [A] before [N] (Lin, 2001).

77
LABIAL DENTAL ALVEOLAR ALVEO-
PALATAL PALATAL VELAR GLOTTAL
STOPS
+asp pÓ tÓ kÓ -v p t k +v
AFFRI-CATES
+asp tsÓ tßÓ [tÇÓ] -v ts tß [tÇ] +v
FRICA-TIVES
-v f s1 ß [Ç] x +v !
NASALS m n N
LIQUIDS l
’ GLIDES [w] [j]
Note: The sounds in brackets [] are not considered to be phonemic.
Figure 3.11 Mandarin Consonant Inventory (Duanmu, 2000; Lin, 2001)
Front Central Back
High
Mid
Low
Figure 3.12 Mandarin Vowel Inventory (Duanmu, 2000; Lin, 2001)
3.2.3.2 Mandarin syllable structure
Compared with English and Russian syllable structure, Mandarin syllable structure is
much more restricted. In fact, there are only 405 possible syllable combinations (Lin,
2001). Specifically, Mandarin allows, at most, one consonant in onset position. This does
not include glides. These can follow an onset consonant but are considered to be part of
i y u [e] [E] ø o [”]
a [A]

78
the rhyme by native speakers (e.g., guài /kwaj/ “strange, odd”). Mandarin codas are even
more restricted than the onsets. Codas may contain either a glide (e.g., wèi /wej/ “place,
location”) or /n/ (e.g., fàn /fan/ “cooked rice”) or /N/ (e.g., míng /miN/ “bright, brilliant”).
Neither nasal /m/ nor obstruents are permitted in Mandarin codas. For clarity, Figure
3.13 below illustrates Mandarin syllable structure (Lin, 2001).
Figure 3.13 Mandarin syllable structure
3.2.3.3 Mandarin orthographic system
As mentioned above, in addition to Chinese characters, Mainland Chinese Mandarin uses
Pinyin. Compared with the English and Russian orthographic systems, Pinyin is a highly
systematic and transparent alphabetic system (see Table 3.3 for a comparison of the
systems). According to Coulmas (1999), Pinyin’s systematicity and transparency have
allowed it to replace other romanization systems in China. While the Pinyin orthography
is much more transparent than either the Russian or the English orthography, it is not
without its letter-phoneme inconsistencies. Pinyin contains two major spelling
irregularities. Although irregular, both are highly predictable. First, Pinyin has three
digraphs that represent single phonemes; <sh>, <zh>, and <ng> represent /ß/, /!/, and /N/,
respectively. Second, as well as diphthongs, Mandarin also has triphthongs (i.e., glide-
!
onset rhyme
nucleus coda
(C) (G) V (G) (n) (N)

79
vowel-glide sequences), which are represented differently depending on whether or not
they are preceded by a consonantal onset (Bassetti, 2006). Before the nucleus vowel, the
glides /w/ and /j/ are represented orthographically as <w> and <y> when they do not
follow a consonant onset. In contrast, they are represented as <u> and <i> when they do
follow a consonant onset. In addition, when not preceded by a consonant onset, the main
vowel in a triphthong is represented orthographically, but when preceded by a consonant,
the main vowel is not represented orthographically. For example, compare the following
Mandarin words duì /twej/ (“team/group”) and wèi /wej/ (“place/location”). In both
words, the triphthong is /wej/. However, in wèi, the first glide is spelt as <w> because
there is no preceding consonant, but in duì, the glide is spelt as <u> because it is
preceded by the consonant /t/. Moreover, when not preceded by a consonant, each
segment of the triphthong is represented orthographically: in wèi, /wej/=<wei>.
However, when preceded by a consonant, only the glides and NOT the main vowel are
represented orthgrophically: in duì, /wej/=<ui>.
3.3 Letter-Phoneme correspondences in English, Russian, and Mandarin
The following table compares the letter-phoneme correspondences in English, Russian,
and Mandarin. This table shows that the English and Russian letters (with a few
exceptions) represent more than one phoneme. As discussed in §3.2.2.2, although
Russian orthography contains four irregularities, these irregularities are almost entirely
predictable which makes Russian more transparent than English. The Mandarin Pinyin
letters, in contrast, have more consistent one-to-one relationships between letters and
phonemes.

80
English – Roman Alphabet Russian – Cyrillic Alphabet Mandarin – Pinyin Alphabet
letter(s) phoneme(s) letter(s) phoneme(s) letter(s) phoneme(s) Aa /œ/ /ej/19 /E/ !" /a/ /E/ Bb /p/ Bb /b/ /bÓ/ #$ /b/ /b"/ Pp /pÓ/ Cc /k/ /kÓ/ /s/ %& /v/ /v"/ Mm /m/ Dd /d/ /dÓ/ '( /g/ /g"/ Ff /f/ Ee /”/ /i/ /E/ )* /d 1/ /d 1"/ Dd /t/ Ff /f/ +, /j”/ /i/ Tt /tÓ/ Gg /g/ /dZ/ -ë /jO/ Nn /n/ Hh /h/ ./ /Z/ /Z"/ Ll /l/ Ii /I/ /aj/ /E/ 01 /z/ /z"/ Gg /k/ Jj /dZ/ 23 /i/ Kk /kÓ/
Kk /k/ /kÓ/ 45 /j/ Hh /x/ Ll /l/ /:/ 67 /k/ /k"/ Jj /tÇ/
Mm /m/ 89 /:/ /l"/ Qq /tÇÓ/ Nn /n/ :; /m/ /m"/ Xx /Ç/ Oo /a/ /O/ /ow/ /E/ <= /n 1/ /n" 1/ Zz /ts/ Pp /p/ /pÓ/ >? /o/ /a/ /E/ Cc /tsÓ/ Qq /kw/ @A /p/ /p"/ Ss /s1/ Rr /®/ BC /r/ /r"/ Zhzh /tß/ Ss /s/ DE /s 1/ /s 1"/ Chch /tßÓ/ Tt /t/ /tÓ/ FG /t/ /t"/ Shsh /ß/ Uu /Á/ /u/ /Ø/ /E/ HI /u/ Rr /!/ Vv /v/ JK /f/ /f"/ Yy /j/
Ww /w/ LM /x/ /x"/ Ww /w/ Xx /j/ NO /ts/ -ng /N/ Yy /j/ PQ /tS"/ Aa /a/ Zz /z/ RS /S/ o /o/
sh20 /S/ TU /S":/ e /”/ /E/ ch /tS/ V silent i /i/ ng /N/ WX /ˆ/ u /u/ th /T/ /D/ Y silent u · /y/ Z[ /”/ er /’/ \]
^_ /ju/
/ja/ /jE/ /I/
Table 3.3 English, Russian, and Mandarin letter-phoneme relationships
19 The offglides in each diphthong are transcribed with either a /j/ or /w/ since I assume that diphthongs are 2 segments comprised of a vowel plus offglide. See §4.2.2.1 for a discussion.
20 This bold line separates the letters listed in the Roman alphabet from the English digraphs that are not part of the alphabet. In contrast, the Mandarin digraphs <sh zh ch ng> are listed in the Pinyin alphabet, and are, therefore not separated from the other letters in this list.

81
3.4 Orthographic representation and the current project
Now that we have explored the relevant previous research (Chapter 2) and outlined the
language characteristics of English, Russian, and Mandarin (Chapter 3), we can discuss
how these two chapters inform the current research project. Chapter 2 established that
alphabetic experience shapes how individuals perceive phonemes. First, according to Ehri
(1985), “the visual forms of words acquired from reading experiences serve to shape
learner’s conceptualizations of the phoneme segments in those words” (p. 342). Second,
research has also demonstrated that the ability to count phonemes only surfaces once
children learn to read via and alphabet (e.g., Bertelson et al., 1989; Carroll, 2004; Morais
et al., 1979; Read et al., 1986) and that after they make letter-phoneme associations,
readers may have “difficulty focusing on phonemes and ignoring letters” (Gombert,
1996, p. 762). Finally, research has shown that learners interpret L2 orthographic input
according to the L1 letter-phoneme correspondences (Bassetti, 2006; Erdener &
Burnham, 2005). The research outlined in Chapters 2 suggests that at least four factors
may shape native speakers’ abilities to count phonemes in their L1, L2 and an L0. These
factors are: 1) L1 interference, 2) the strength of the connection between letter-phoneme
correspondences, 3) orthographic depth, and 4) phoneme awareness.
If alphabetic knowledge overrides auditory information (i.e., what is heard) (Erdener
& Burnham, 2005; Hallé et al., 2000), then a mismatch between the number of letters and
the number of phonemes in a word should affect participant responses. Therefore, I
predict that (reproduced from Chapter One):

82
1) L1 orthography facilitates L1 phoneme perception in consistent21 English
words where a match between number of phonemes and the number of
letters occurs (i.e., consistent letter-phoneme correspondences) but hinders
it in inconsistent English words where a mismatch between the number of
phonemes and letter occurs (i.e., inconsistent correspondences).
2) L1 orthography facilitates L0 phoneme perception in consistent cross-
language homophones because the associated L1 spellings help parse L0
phonemes, but L1 orthography does not affect perception in consistent
nonhomophones because no spelling associations exist. In addition, L1
orthography hinders L0 phoneme perception in inconsistent cross-language
homophones because the associated L1 spellings interfere with perception,
but L1 orthography does not affect perception in inconsistent
nonhomophones because, as with the consistent nonhomophones, no L1
spelling associations exist.
3) As with L1, L2 orthography facilitates L2 phoneme perception in consistent
L2 nonhomophones but hinders it in inconsistent L2 nonhomophones. In
contrast, for the cross-language L2 homophones, which have associated L1
spellings, L1 orthographic knowledge overrides L2 orthographic knowledge
(due to L1 transfer effects) and influences L2 phoneme perception such that
L1 orthography facilitates L2 phoneme perception in L2 words with
21 Recall that for the purposes of this research, consistent words are words where the number of letters equals the number of phonemes, and inconsistent words are words where the number of letters does not equal the number of phonemes.

83
consistent L1 associations but hinders it in L2 words with inconsistent L1
associations.
4) As native speakers, the listeners have many more years of experience with
English than they do with their L2 and thus the L1 orthography is more
entrenched and potentially exerts more influence on the L1 than the L2
orthography exerts on the L2. Therefore, the accuracy and response time
differences between the consistent and inconsistent L1 words would be
greater than the differences between the consistent and inconsistent L2
words, which in turn would be greater than the differences between the
consistent and inconsistent L0 words (i.e., L1 differences >> L2 differences
>> L0 differences).
Confirmation of these predictions will demonstrate that L1 alphabetic knowledge affects
L1 speech processing and nonnative language speech processing, thereby suggesting that
not only do learners perceive nonnative sounds (both L2 and L0 sounds) through the filter
of their L1 sound system (Best, 2001; Flege, 1995, Kuhl, 2000) but also through the filter
of their L1 writing system. Such results will identify another L1-related factor
contributing to L2 speech processing that, up to now, has remained relatively unexplored:
orthography. Indeed, the relationship between orthographic representation and phonemic
representation in nonnative speech processing has been largely ignored. This research
characterises and explores that relationship. Specifically, this research focuses on how
orthographic representation influences sound perception in L2 learning and whether
orthographic representation overrides phonemic information in L2 speech processing. It
sheds light on how much influence (if any) orthographic representation exerts on

84
learners’ perceptions of phonemes in their L1, their L2, and L0. Research of this kind
contributes to the sparse body of research on orthography’s relationship to nonnative
sound processing, which, in turn, informs pedagogical practices in second language
classrooms. That is, given that second languages are taught primarily through writing, it
is essential to understand how using a writing system common to L1 in teaching L2 may
affect learning correct L2 letter-phoneme correspondences and thus L2 phoneme
awareness.
3.5 Summary
In sum, this chapter has provided orthographic background on four areas that are essential
to understanding the current research. First, the chapter showed that writing systems can
be created in one of three ways: from 1) a brand new idea, 2) stimulus diffusion, or 3)
borrowing. Second, this chapter discussed the two broad types of writing systems: 1)
morpheme-based systems (logographies), and 2) sound-based writing systems
(syllabaries, consonantal scripts, or alphabets). Third, this chapter provided the necessary
phonemic, syllabic, and orthographic background for English, Russian, and Mandarin.
Finally, this chapter outlined the rationale behind and predictions of the current research
project.

85
Chapter Four
METHODOLOGY
“… to assume straightaway that an English spoken word such as bat consists of just three ‘individual sounds’ because its written form comprises just
three letters is simply to put the alphabetic cart before the phonetic horse.” (Harris, 1986, p. 38)
In order to determine how L1 orthography affects phoneme detection in not only a first
language but also nonnative languages, a study was designed in which L1 English
speakers counted phonemes in: 1) L1 words and 2) L0 (i.e., unfamiliar language) words.
In addition, a subgroup of those L1 English speakers also counted phonemes in L2 words.
The three languages under investigation are English, Russian, and Mandarin because they
each employ different alphabetic orthographies and the last two are both taught at the
University of Victoria as foreign languages. The following sections describes, in depth,
the methodology employed in the current research—including the pilot study (§4.1), the
primary data collection (§4.2), and the secondary data collection (§4.3). Both the primary
and secondary data collection sections include subsections describing the participants, the
experimental stimuli, the experimental materials, the experimental tasks, and the
experimental procedure.
4.1 The pilot study
As a step towards developing the experimental task for the current research, a pilot study
(Pytlyk, to appear) was designed to test the hypothesis that native English speakers have
more difficulty accurately perceiving phonemes in English words with inconsistent letter-
phoneme correspondences (i.e., no one-to-one relationship between letters and

86
phonemes) than in English words with consistent letter-phoneme correspondences (i.e.,
one-to-one relationship). Twenty-one native English listeners counted phonemes in 60
monosyllabic English words: 30 consistent words (e.g., <bed> and /b”d/) and 30
inconsistent words (e.g., <tax> and /tœks/). The results showed that participants were
significantly less accurate at counting phonemes in inconsistent words (70%) than in
consistent words (86%). Also, the analyses demonstrated that even when participants
accurately count phonemes in inconsistent words, they were significantly slower (3.68
seconds) than when they accurately count phonemes in consistent words (2.75 seconds).
The results confirm that, in the L1 at least, orthographic knowledge interferes with
phoneme awareness and affects speech processing (e.g., Burnham, 2003; Glushko, 1979;
Ziegler & Ferrand, 1998). In short, the pilot study results suggest that when letters equal
phonemes, listeners do not receive conflicting orthographic and phonetic information,
resulting in higher accuracy rates and faster processing times. In contrast, when letters do
not equal phonemes, listeners must spend extra cognitive resources to reconcile the
conflicting information, as reflected in their lower accuracy rates and slower processing
times.
4.2 The primary study
The primary study undertaken in this dissertation investigated the extent to which
orthographic knowledge influences native and nonnative speech processing, namely
phoneme perception. Via a phoneme counting task, data were collected and analysed to
determine the effect of orthographic knowledge. This section outlines the methodology
employed for this investigation, including the participants, stimuli, materials, tasks,
procedure, and data analyses.

87
4.2.1 Participants
Fifty-two participants who were all first language speakers of Canadian English
participated in the primary. Participants were split into two groups, one of which heard
Russian as the L0 (RNL0), and the other of which heard Mandarin as the L0 (MNL0).
Of these 52 participants, 12 participants were learning Mandarin-as-an-second-language
(MFL subgroup), and 13 participants were learning Russian-as-a-second-language (RFL
subgroup). These two subgroups made it possible to not only assess listeners’
perceptions of L1 and L0 phonemes but also their perceptions of L2 phonemes.
1) Russian L0 (RNL0) (26 participants) – All participants were
unfamiliar with Russian (L0), and a subset of this group (12
participants) were MFL learners (Mandarin L2).
2) Mandarin L0 (MNL0) (26 participants) – All participants were
unfamiliar with Mandarin (L0), and a subset of this group (13
participants) were RFL learners (Russian L2).
The Russian and Mandarin second language learners (i.e., the MFL and RFL subgroups)
were recruited from University of Victoria language classes—specifically, from PAAS
111 (formerly CHIN 150) and RUSS 200B language classes. 22 All of the other
participants were recruited from first year linguistics classes and posters placed around
the university. Only those volunteers who reported no auditory or visual impairments
were accepted for the study.
22 By the end of these classes, both groups of students had completed the equivalent of four semesters of language learning.

88
Table 4.1 below provides a summary of the participant characteristics within each
experimental group.
group number of
participants mean age other languages learned
primary data
Russian L0
overall
n = 26
21.0 years
! Japanese, French, Korean, Cantonese, German, Spanish, Italian, and Attic Greek
subgroup
(MFL)
n = 12
21.3 years
! Japanese, French, Korean, Cantonese, German, Spanish, Italian, and Attic Greek
Mandarin L0
overall
n = 26
20.7 years
! French, Italian, Japanese, Spanish, Polish, German, Java23, Ainu24, Gaelic, Arabic, and Farsi
subgroup (RFL) n = 13 20.8 years
! French, Italian, Japanese, Spanish, Polish, German, Java, Ainu, and Gaelic
n = total number, L0 = unfamiliar language, MFL = Mandarin-as-a-second-language, RFL = Russian-as-a-second-language
Table 4.1 Primary data participant demographics
In this table, the participant summaries are divided according to primary data groups (i.e.,
RNL0 and MNL0), and within each group, the participants are summarised according to
the overall population in that group as well as the number of participants in the subgroup.
For example, the RNL0 group had 26 overall participants, and a subgroup of 12
participants who were L2 learners of Mandarin. This table also contains information
about the mean age of each group and subgroup as well as the other languages these
participants had learnt. Henceforth, all primary data participants who belong to the
subgroup data are referred to as the RFL and MFL participants, and all the other primary
23 The participant considers Java, a programming language used for computer games and business applications, a language. 24 Ainu is an indigenous language spoken in North-East Asia.

89
data participants who are not in the subgroup data are referred to as the non-L2
participants.
4.2.2 Experimental stimuli
The following two subsections outline and describe the process and decisions made
regarding the selection and creation of the experimental stimuli—including the target
words (§4.2.1) and the stimuli creation process (§4.2.2).
4.2.2.1 Target words
In order to assess the effect of orthographic knowledge on listeners’ perception of L1, L2,
and L0 phonemes, the stimuli in this project were English, Russian, and Mandarin
Chinese words that contained between 1 and 5 letters and/or phonemes. These target
words were organised according to two variables: homophone, and match. (See §4.2.6
for a more detailed discussion of all the independent and dependent variables.) The
homophone variable refers to whether the nonnative words (Russian and Mandarin) had
homophonous L1 (i.e., English) counterparts. The homophone variable has two levels,
nonhomophone and homophone.
1. NONHOMOPHONE (NH) where the word does not have a
homophonous counterpart in another language. For example, neither
the Russian word @.)7 /plaSÜ/ (“raincoat”) nor the Mandarin hC25 /xø/
(“to drink”) sound like any English word.
25 For ease of reading, all Mandarin words are given using the Pinyin orthography. See §3.1.4.3 for a discussion of the Pinyin alphabet.

90
2. HOMOPHONE (H) where the word has a (nearly) homophonous
counterpart in another language. The homophone pairs were either L1–
L0 pairs or L1–L2 pairs. For example, the English word cart /kÓA®t/
and the Russian word :)(* /kart/ (“map” GEN PL) are homophonous
with each other. Similarly, the English word May /mej/ and the
Mandarin méi /mej/ (“did not/have not”) are also homophonous with
each other.
The match variable refers to whether the number of letters equalled the number of
phonemes in the words. The match variable has two levels, matched or mismatched.
1. MATCH (M) where the number of letters in the word equals the
number of phonemes. For example, the English word big /bIg/, the
Russian word 53> /fs"O/26 (“everything”), and the Mandarin word su$n
/swan/ (“sour”) all have the same number of letters as the number of
phonemes. The English word has 3 letters and 3 phonemes; the Russian
word has 3 letters and 3 phonemes, and the Mandarin word has 4 letters
and 4 phonemes.
2. MISMATCH (MM) where the number of letters in the word is either
more or less than the number of phonemes. For example, the English
word sock /sAk/, the Russian word ;5)*2 /zvat"/ (“to call”), and the
Mandarin word huáng /xwaN/ (“yellow”) do not have the same number
of letters as the number of phonemes. The English word has 4 letters
26 The assumption here is that palatalisation is a characteristic of the consonant and not a phoneme itself (Unbegaun, 1957; Wade, 2011).

91
and 3 phonemes; the Russian word has 5 letters and 4 phonemes, and
the Mandarin word has 5 letters and 4 phonemes.
Because this research also revolves around investigating whether L1 orthographic
knowledge interferes with L2 orthographic knowledge and L0/L2 phonetic information,
the MM-H conditions are of primary interest (highlighted bottom right quadrant in Table
4.2). It was impossible to find Russian and Mandarin words27 with letter-phoneme
mismatches that were homophonous with English words with letter-phoneme matches. In
other words, because of their relative transparency, finding Russian and Mandarin words
that had letter-phoneme mismatches and that were homophonous with English words that
had a 1-to-1 letter-phoneme correspondence was almost impossible. For this reason, the
mismatch was always in the L1. The homophone L0/L2 words therefore always had one-
to-one letter to phoneme correspondence. For example, in the English-Russian
homophone pair stool–c*". (“chair”) and the English-Mandarin homophone pair when–
wèn (“to ask”), the English words stool and when have mismatches (5 letters/4 phonemes
and 4 letters/3 phonemes, respectively) while the Russian word c*". and the Mandarin
word wèn each have the same number of letters and phonemes in them (4 letters/4
phonemes and 3 letters/3 phonemes, respectively).
With respect to the target words, two other important considerations guided their
selection. First, because the subgroup data analyses investigate a) the interaction between
the L1 orthography and the L2 orthography and b) the effect of the L2 orthography on L2
phonology, the L2 subgroup participants needed to be familiar with the words—both
27 The Russian and Mandarin words were chosen in consultation with native speakers – Julia Rochtchina (Russian), Shu-min Huang (Mandarin), Xiaojuan Qian (Mandarin), and Yanan Fan (Mandarin). These native speakers intuitions contributed to the phonemic analyses of the Russian and Mandarin words.

92
orthographically and phonologically. Therefore, based on the vocabulary both the RFL
and MFL learners learn in their language classes, there were a limited number of cross-
language homophones that fit all the parameters (including the parameters that these
target words be monosyllabic and contain between 1 to 5 phonemes). As a result, the
matched homophone (M-H) conditions for the English, Russian, and Mandarin words
only contained 10 target words as opposed to the 14 target words in the other conditions.
Second, due of the nature of Mandarin Chinese syllable structure (See §3.2.3.2.), it
was impossible to avoid having target words containing diphthongs (i.e., a CVG
syllable). Some examples of these types of Mandarin words include gòu /kow/ (enough),
maì /maj/ (to sell), tóu /tÓow/ (head), and nào /naw/ (noisy). A diphthong is defined as a
syllable nucleus that contains two target positions (Lehiste & Peterson, 1961) or as a
sequence of a simple vowel and a glide (Rogers, 2000). While researchers generally
agree that diphthongs are complex nuclei, there is still some debate surrounding the
question of whether diphthongs should be classified as two units (Berg, 1986; Lehiste &
Peterson, 1961) or one unit (Wiebe, 1998; Wiebe & Derwing, 1992, 1994). Based on the
definitions given by Lehiste and Peterson (1961) and Rogers (2000) (see above), this
research assumes all diphthongs in open syllables are two units—a vowel plus an offglide
/j/ or /w/. For example, the word go (an open syllable) is phonemicised as /gow/ with the
offglide /w/ while the word pole (a closed syllable) is phonemicised as /po:/.28 Thus,
accurate responses will be those responses where listeners count two phonemes for each
diphthong heard. The decision to count diphthongs as two units obviously has an impact
28 In the two English target words dome and pole, which both have closed syllables, I assume that the vowel does not have an offglide. In pole, the offglide is subsumed under the /:/, and in dome, there is no offglide to make the articulation of /m/ easier.

93
on the classification of the words into the match and mismatch categories. For example,
when the diphthongs are counted as two phonemes the words now /naw/, May /mej/, and
toe /tow/ are categoried as matched words (number of letters = the number of phonemes),
and my /maj/ and go /gow/ are categoried as mismatched words (number of letters "
number of phonemes). Consequently, this decision potentially affects the results. This
issue is discussed further in §6.4.
Comparing the phoneme counting data for target words containing diphthongs with
an orthographic mismatch (e.g., English my /maj/—has 2 letters but 3 phonemes) and
target words containing diphthongs with no mismatch (e.g., Mandarin maì /maj/—has 3
letters and 3 phonemes) may shed additional light on orthographic influence. For
example, if participants count 2 phonemes in English words like go and my, but 3
phonemes in words like now and how, this would suggest that listeners hear the
diphthong as 1 phoneme when it is represented by one letter, but they hear diphthongs as
2 phonemes when it is represented by 2 letters. Similarly, if the MFL participants count 2
phonemes in English go and my but 3 phonemes in Mandarin gòu and maì, it would also
suggest that the orthographic spelling of the diphthong dictates the number of phonemes
heard. Moreover, this would also suggest that that the influence of L2 orthography is
stronger on L2 phoneme perception than the influence of the L1 orthography.
Each L0/L229 language condition consisted of 52 tokens (14 M-NH + 14 MM-NH +
14 MM-H + 10 M-H). For example, in the M-H tokens, 10 were paired with English M-
29 Russian was the L2 for the subset of RFL learners, but the L0 for all other participants. Similarly, Mandarin was the L2 for the subset of MFL learners, but the L0 for all the other participants.

94
H words (like Russian .+D* /lift/ (“elevator”) [4/4]30 and English lift /lIft/ [4/4]), and in
the MM-H, 14 were paired with English MM-H words (like Mandarin wèn /wøn/ (“to
ask”) [3/3] and English when /w”n/[4/3]). The English consisted of 76 tokens (14 M-NH
+ 14 MM-NH + 20 M-H (10 paired with Russian / 10 paired with Mandarin) + 28 MM-H
(14 paired with Russian / 14 paired with Mandarin). See Table 4.3 and Table 4.4 for the
list of all the experimental words. In total, each participant was tested on 180 tokens (76
English + 52 Russian + 52 Mandarin). In Table 4.2, the words given in angled brackets
are the cross-language counterparts of the example words. EN refers to English words;
RN refers to Russian words, and MN refers to Mandarin words. For example, the English
matched words have 14 nonhomophone tokens (e.g., cup), 10 homophones paired with
Russian words (e.g., brat–'()* (“brother”)), and 10 homophones paired with Mandarin
words (e.g., bow–bào (“newspaper”)). Similarily, the English mismatched words have 14
nonhomphone tokens (e.g., month), 14 homophones paired with Russian words (e.g.,
stool–c*". (“chair”)), and 14 homophones paired with Mandarin words (e.g., my–maì
(“to buy”)). For clarity, Table 4.2 breaks down the types of stimuli according to the
homophone and match variables. The shaded cells (MM) are the crucial tokens in terms
of investigating cross-linguistic orthographic influence.
30 The pair of numbers in the square brackets outlines the number of letters and the number of phonemes for each word, respectively. For example, [4/4] indicates that the Russian word, .+D* /lift/ has 4 letters and 4 phonemes. In contrast, [4/3] indicates that the English word, when /w”n/ has 4 letters but only 3 phonemes.

95
HOMOPHONE no (NH) yes (H)
MATCH
yes (M) [letter-
phoneme correspond-
ence]
(i.e., letters = phonemes)
EN
14 tokens
e.g., cup /kØp/ (3 letters/3 phonemes)
10 tokens (paired with RN M-H) e.g., brat /b®œt/ (4 letters/4 phonemes) *homophonous with RN !"#$ /brat/ (brother) 10 tokens (paired with MN M-H) e.g., bow /baw/ (3 letters/3 phonemes) * homophonous with MN bào /paw/ (newspaper)
RN 14 tokens
e.g., %"&' /druk/ (friend) (4 letters/4 phonemes)
10 tokens (paired with EN M-H) e.g., !"#$/brat/ (brother) (4 letters/4 phonemes) *homophonous with EN brat /b®œt/
MN 14 tokens
e.g., hu(n /xwan/ (to like) (4 letters/4 phonemes)
10 tokens (paired with EN M-H) e.g., bào /paw/ (newspaper) (3 letters/3 phonemes) * homophonous with EN bow /baw/
no (MM)
[1 fewer or 1 more letter
than phonemes]
(i.e., letters ! phonemes)
EN
14 tokens
e.g., month /mØnT/ (5 letters/4 phonemes)
14 tokens (paired with RN MM-H) e.g., stool /stu:/ (5 letters/4 phonemes) * homophonous with RN c$&) /stul/ (chair) 14 tokens (paired with MN MM-H) e.g., my /maj/ (2 letters/3 phonemes) * homophonous with MN maì /maj/ (to buy)
RN 14 tokens
e.g., %*+, /d!”n!/ (day) (4 letters/3 phonemes)
14 tokens (paired with EN MM-H) e.g., c$&) /stul/ (chair) (4 letters/4 phonemes) * homophonous with EN stool /stu:/
MN 14 tokens
e.g., huáng /xwaN/ (yellow) (5 letters/4 phonemes)
14 tokens (paired with EN MM-H) e.g., maì /maj/ (to buy) (3 letters/3 phonemes) * homophonous with EN my /maj/
EN = English, RN = Russian, MN = Mandarin, NH = nonhomophone, H = homophone, M = match, MM = mismatch
Table 4.2 Breakdown of experimental stimuli for the primary study

96
The following two tables provide the complete word lists for all the experimental
stimuli. These tables list each target token for each language according to the word’s 1)
orthographic spelling, 2) phonemic representation, 3) English translation (where
necessary), and 4) letter-phoneme relationship. Table 4.3 gives the matched and
mismatched nonhomophonous words. In the first row of the table, the first Russian word
is spelt (in the Cyrillic alphabet) as !"#; it is pronounced as /dva/; its English translation
is “two”, and it contains 3 letters and 3 phonemes. Next, the English word is spelt (in the
Roman alphabet) as up; it is pronounced as /Øp/, and it has two letters and two phonemes.
Finally, the Mandarin word is spelt as ba@; it is pronounced as /pa/; its English translation
is “eight”, and it has 2 letters and 2 phonemes. This table also lists (bottom 4 rows) the
words used in the practice test—none of which were homophones.
Table 4.4 provides the homophonous word sets where the L0/L2 homophonous
words are listed adjacent to their EN counterparts. In the first row of the MM-H stimuli
in Table 4.4 (the lower section), the first Russian word is spelt as $#%; it is pronounced as
/maj/; its English translation is May, and it contains 3 letters and 3 phonemes. Next in
the row is the English word associated with the Russian word. This English word is spelt
as my; it is pronounced as /maj/, and it has 2 letters and 3 phonemes. After that English
word is a second English word; this word is homophonous with the following Mandarin
word. The shaded and crossed out tokens indicate those tokens that were later removed
from the data and were not analysed. See §4.2.6.3 for a more detailed discussion of the
discarded tokens. NOTE: The transcriptions given in the word lists are phonemic
transcriptions.

97
Russian [28 tokens] English [28 tokens] Mandarin [28 tokens] M-NH [14 per language]
!"# /dva/ (two) 3-3 $%& /l!”t/ (years GEN PL) 3-3 "#' /vaS/ (your) 3-3 (# /na/ (on) 2-2
)*(& /zont/ (umbrella) 4-4 +$#, /plaSÜ/ (raincoat) 4-4 -#- /kak/ (how) 3-3 ".! /vit/ (type) 3-3
!/' /duS/ (shower) 3-3 (%& /n!”t/ (no) 3-3
"01 /fs!O/ (everthing) 3-3 !2/3 /druk/ (friend) 4-4 4&* /StO/ (what) 3-3 .5 /ix/ (their) 2-2
up /Øp/ 2-2 big /bIg/ 3-3 set /s”t/ 3-3
cup /kØp/ 3-3 yes /j”s/ 3-3
best /b”st/ 4-4 risk /®Isk/ 4-4 help /h”lp/ 4-4 stop /stAp/ 4-4
hand /hœnd/ 4-4 if /If/ 2-2
print /p®Int/ 5-5 run /®Øn/ 3-3 cost /kAst/ 4-4
ba @ /pa/ (eight) 2-2 hu6 /xwa/ (flower) 3-3
du7 /twO/ (much . many) 3-3 nán /nan/ (difficult) 3-3
dà /ta/ (big) 2-2 hu6n /xwan/ (to like) 4-4
h8 /xø/ (to drink) 2-2 g6o /kaw/ (tall) 3-3
guàn /kwan/ (accustomed) 4-4 lü /ly/ (green) 2-2
du9n /twan/ (short) 4-4 fú /fu/ (clothes) 2-2 y9n /jan/ (eye) 3-3
kuài /kÓwaj/ (fast) 4-4 MM-NH [14 per language]
: /ja/ (I) 1-2 )"#&; /zvat!/ (to call) 5-4 #$;& /al!t/ (viola) 4-3 <3 /juk/ (south) 2-3 =.&; /Zit!/ (to live) 4-3 -2*"; /krof!/ (blood) 5-4 !*=!; /doSt!/ (rain) 5-4 +:&; /p!at!/ (five) 4-3 0%>; /s!”m!/ (seven) 4-3 "%0; /v!”!!/ (whole) 4-3 )!%0; /zd!”s!/ (here) 5-4 !#&; /dat!/ (to give) 4-3 '%0&; /S!”st!/ (six) 5-4 !%(; /d!”n!/ (day) 4-3
talk /tAk/ 4-3 box /bAks/ 3-4 long /lAN/ 4-3 fish /fIS/ 4-3
truth /truT/ 5-4 six /sIks/ 3-4
month /mØnT/ 5-4 quick /kwIk/ 5-4
king /kIN/ 4-3 shot /SAt/ 4-3 tax /tœks/ 3-4
speak /spik/ 5-4 whom /hum/ 4-3
give /gIv/ 4-3
wàng /waN/ (to forget) 4-3 y? /i/ (one) 2-1
sh6n /ßan/ (mountain) 4-3 w@ /u/ (five) 2-1
huáng /xwaN/ (yellow) 5-4 shAo /ßwO/ (to speak) 4-3
yuè /y”/ (month) 3-2 yòng /jON/ (to use) 4-3 y?n /in/ (reason) 3-2
péng /pÓøN/ (friend) 4-3 duì /twej/ (correct) 3-4 máng /maN/ (busy) 4-3
shéi /ßej/ (who) 4-3 t?ng /tÓiN/ (listen) 4-3
PRAC-TICE [4 per language]
+.&; /pit!/ (to drink) 4-3 0"*B /svOj/ (one’s self) 4-4 &C /tó/ (you-SG) 2-2
-&* /kto/ (who-NOM) 3-3
cat /kœt/ 3-3 in /In/ 2-2
tough /tØf/ 5-3 skin /skIn/ 4-4
sh8ng /ßøN/ (student) 5-3 shA /ßu/ (book) 3-2
wD /wO/ (I) 2-2 guài /kwaj/ (to blame) 4-4
Table 4.3 English, Russian, and Mandarin nonhomophone wordlists

98
Russian [24 tokens] English [48 tokens] Mandarin [24 tokens] M-H: 1-to-1 relation-ship in both L1 and L2 [10 per language]
*( /an/ (he) 2-2 -*& /kAt/ (cat) 3-3
$.E& /lift/ (elevator) 4-4 !#B /daj/ (to give) 3-3 F*! /got/ (city) 3-3
0#! /sat/ (garden) 3-3 2#! /rat/ (glad) 3-3
>#2& /mart/ (March) 4-4 -#2& /kart/ (map GEN.PL) 4-4
G2#& /brat/ (brother) 4-4
on /An/ 2-2 cot /kAt/ 3-3 lift /lIft/ 4-4 die /daj/ 3-3 got /gAt/ 3-3 sat /sœt/ 3-3 rat /®œt/ 3-3
mart /mA®t/ 4-4 cart /kA®t/ 4-4
brat /b®œt/ 4-4
May /mej/ 3-3 now /naw/ 3-3
do /du/ 2-2 toe /tÓow/ 3-3
swan /swAn/ 4-4 bow /baw/ 3-3 ban /bœn/ 3-3 how /haw/ 3-3
man /mœn/ 3-3 bun /bØn/ 3-3
méi /mej/ (did not have not) 3-3 nào /naw/ (noisy) 3-3
dú /tu/ (to read) 2-2 tóu /tÓow/ (head) 3-3
su6n /swan/ (sour) 4-4 bào /paw/ (newspaper) 3-3
bàn /pan/ (half) 3-3 hào /xaw/ (number) 3-3
màn /man/ (slow) 3-3 bèn /pøn/ (stupid) 3-3
MM-H: *mismatch in spelling for L1 *1-to-1 relation-ship in L2 [14 per language]
>#B /maj/ (May) 3-3 !*> /dom/ (house) 3-3
,. /S:i/ (cabbage soup) 2-2 &*2& /tOrt/ (cake) 4-4 0&/$ /stul/ (chair) 4-4 0&*$ /stol/ (table) 4-4 0/+ /sup/ (soup) 3-3 &/&31 /tut/ (here) 3-3 &2. /tri/ (three) 3-3 (/ /nu/ (well) 2-2
0*- /sok/ (juice) 3-3 +*$ /pol/ (floor) 3-3 3$a) /glas/ (eye) 4-4 5.& /xit/ (hit) 3-3
my /maj/ 2-3 dome /dom/ 4-3
she /Si/ 3-2 torte /tO®t/ 5-4 stool /stu:/ 5-4 stole /sto:/ 5-4 soup /sup/ 4-3
toot /tut/ 4-3 tree /t®i/ 4-3
(k)new /nu/ 4-3 sock /sAk/ 4-3 pole /po:/ 4-3
gloss /glAs/ 5-4 heat /hit/ 4-3
my /maj/ 2-3 when /w”n/ 4-3
coo /ku/ 3-2 lean /lin/ 4-3
sheen /Sin/ 5-4 pea/pee /pi/ 3-2
sue /su/ 3-2 tea/tee /ti/ 3-2
who /hu/ 3-2 knee /ni/ 4-2
she /Si/ 3-2 go /gow/ 2-3
high /haj/ 4-3 rue /®u/ 3-2
maì /maj/ (to sell) 3-3 wèn /wøn/ (to ask) 3-3
kA /kÓu/ (to cry) 2-2 lín /lin/ (forest) 3-3 x?n /Çin/ (heart) 3-3
pí /pÓi/ (skin) 2-2 sù /su/ (to tell) 2-2
tí /tÓi/ (to carry) 2-2 hA /xu/ (to call) 2-2
ni # /ni/ (you) 2-2 x? /Çi/ (west) 2-2
gòu /kow/ (enough) 3-3 hái /xaj/ (still / yet) 3-3
rú /"u/ (if / as if) 2-2
Table 4.4 English, Russian, and Mandarin homophone wordlists
In addition to the homophone and nonhomophone lists in the above tables, Table 4.5
below outlines the letter-phoneme pairings of interest in the project.
31 Unlike English, Russian voiceless stops (i.e., /p t k/) are not subject to aspiration (Unbegaun, 1957).

99
English Russian Mandarin letter(s) phonemes(s) letter(s) phonemes(s) letter(s) phonemes(s)
y e
igh o
oo ue ou ee kn ew ck ea l x
ng sh th wh
/aj/ silent /aj/ /o/ /u/ /u/ /u/ /i/ /n/ /u/ /k/ /i/
silent /ks/ /N/ /S/ /T/ /w/
" # $
/ja/ /ju/ silent
ng y sh w ue ui
/N/ /j/ /ß/ /w/ /”/
/wej/
18 3 6
Table 4.5 List of English, Russian, and Mandarin letters that create the mismatched target words
Two main observations are apparent from the above three tables. First, the English words
have a higher degree of letter-phoneme mismatch variability than either Russian or
Mandarin. That is, in English, a greater variety of letter-phoneme correspondences (18)
contribute to the mismatched tokens than in either Russian (3) or Mandarin (6). Indeed,
12 of the 14 Russian mismatched words result from the letter <$>. This letter has not
phonemic value itself; rather, its function is to indicate palatalisation of the preceding
consonant. As for Mandarin, most mismatches result from borrowed digraphs like <sh>
and <ng> as well as the reduced spelling of triphthongs like <ui>. (See §3.2.3.3 for a
discussion of how Mandarin represents triphthongs orthographically.) The differences in
the variety of mismatches across languages are a direct reflection of the depth (or

100
opacity) of their orthographies. The high number of mismatches in English reflects the
fact that English has a much deeper (or more opaque) orthography than either Russian or
Mandarin.
A second observation is that the letter-phoneme mismatches do not always come
from the same type of orthographic inconsistency, suggesting subcategories of
inconsistency. For example, inconsistency in words like fish, month, and wàng come
from two consonant letters representing one phoneme; inconsistency in speak, and stool
comes from two vowel letters representing one phoneme, inconsistency in box, six, and
!& comes from one letter representing two phonemes, and inconsistency in talk, '()*",
and w+ comes from a silent letter.
As discussed above, selecting stimuli for this experiment was restricted by a number
of considerations, such that creating mismatch categories that were more uniform within
and across languages was not possible. This limitation, while unavoidable, must be kept
in mind in understanding and interpreting the results. In terms of uniformity of the
mismatch categories across languages, differences in orthographic transparency may
affect participant responses. In particular for the L2 subgroups, listeners may have more
difficulty ignoring mismatches in Russian and Mandarin (more transparent) than in
English (less transparent)—resulting in larger accuracy and response time differences
between the matched and mismatched words in Russian and Mandarin than in English.
The increased difficulty would arise from readers/listeners of more transparent
orthographies (i.e., Russian and Mandarin) relying more heavily on letter-phoneme
correspondences than readers/listeners of less transparent languages (Frost & Katz, 1989;
Katz & Frost, 1992; Liberman et al., 1980; Seymour et al., 2003). In terms of uniformity

101
of the mismatch category within languages, it is likely that not all types of mismatched
tokens affect phoneme counting equally. This issue is taken up at length in Chapter 6
(§6.3.3).
4.2.2.2 Creation of stimuli
Three female native speakers (one from each language) recorded the target words for
their L1s, either English (EN), Russian (RN), or Mandarin (MN). The speakers recorded
the target words in the University of Victoria’s Department of Linguistics Speech
Research Lab. The words were presented to the speakers via Microsoft PowerPoint 2007.
The speakers repeated each target word five times with a short pause between each
repetition, and they took a short break every 25 words. The words were recorded in a
sound-treated booth with Audacity [version 1.2.6] using a Grove Tubes GT57 large
diaphragm microphone and a Mackie 1402-VLZ3 mixer. Each set of 25 words was
saved as a .wav file.
Using the EN, RN, and MN target word recordings from the three native speakers,
the stimuli tokens were created in the following four steps.
1. The third token in each series was segmented out to use as the
experimental token. In some cases, either the second or fourth token
were used when the third token was problematic.
2. Each token was saved as an individual .wav file.
3. The duration of each sound file was manually recorded to use for
calculating response times (RTs) in E-prime Pro (version 2.0.1.97).

102
4. All the individual sound files were normalised for loudness using the
software WavNormalizer (version 1.0).
Three native speakers for each language judged the nativeness of the chosen target
words. That is, three native speakers of English judged the English words, three native
speakers of Russian judged the Russian words, and three native speakers of Mandarin
judged the Mandarin words. The native judgements were essential to ensure that the
segmented words were indeed the chosen target words. Each native speaker listened to
the target words via Sony MDR-7506 headphones and wrote the words they heard using
the orthography of their particular language. The English speakers used the Roman
alphabet. The Russian speakers used the Cyrillic alphabet, and the Mandarin speakers
used the Pinyin alphabet. The Chinese educational system requires that teachers teach
Pinyin in Grade One (DeFrancis, 1990). Therefore, although adult Mandarin speakers
predominantly use Chinese characters, all three speakers stated that they were extremely
comfortable with Pinyin and would have no difficulty in writing out the words using this
alphabet. The speakers also indicated any tokens that were problematic (i.e., unclear,
mispronounced, unnatural, etc.). All problematic tokens were discarded, rerecorded, and
judged again. In addition, all three judges in each group of native speakers (i.e., English,
Russian, and Mandarin) agreed on the “correct” spelling of each word. That is, none of
the native speaker judges misspelled any of the target words in their languages.
4.2.3 Experimental materials
After all the stimuli were judged and confirmed to be good, natural representations of the
target words, the software E-prime Pro (version 2.0.1.97) was used to create the
perception test because E-prime records both accuracy and response times (RTs). As

103
mentioned above, the English language session consisted of 76 target words, and the
Russian and Mandarin language sessions had 52 target words each. This means that each
participant was tested on 180 target words. The perception test was organized into four
sessions: Practice > L1 (native language) > L2 (second language for the subgroup
participants but an L0 for the non-L2 participants) > L0 (unfamiliar language). For each
participant group, the order of the languages varied depending on the L2 language
learning experiences of the subgroup participants. For the MNL0 group, which contained
the RFL subgroup, their counting task was organized as: Practice session > English
session (L1) > Russian session (L2 for subgroup but L0 for others) > Mandarin session
(L0). Conversely, for the RNL0 group, which contained of the MFL subgroup, the task
was organised as: Practice > English (L1) > Mandarin (L2 for subgroup but L0 for
others) > Russian (L0).
4.2.4 Experimental tasks
This subsection outlines and discusses the experimental tasks employed for the primary
experiment. For the MNL0 and the RNL0 participants (including the RFL and MFL
subgroups), this research included two experimental tasks. First, the participants
completed a phoneme counting task (e.g., Arnqvist, 1992; Bassetti, 2006; Cheung,
1999; Derwing, 1992; Ehri & Wilce, 1980; Gombert, 1996; Landerl et al., 1996;
Lehtonen & Treiman, 2007; Liberman et al., 1974; Perin, 1983; Pytlyk, to appear;
Spencer & Hanley, 2003; Treiman & Cassar, 1997) where they indicated the number of
individual “sounds” they counted in a given auditorily presented word. Phoneme
counting was first employed by Liberman et al. (1974) to test children’s explicit analysis
of spoken utterances (i.e., metalinguistic analysis). The cognitive requirements for

104
phoneme counting include 1) perceiving separate phonemes, 2) holding the target in
memory, and 3) segmenting sound units (Yopp, 1988). Based on these cognitive
requirements, phoneme counting is commonly used as a measure of phoneme awareness.
While Liberman et al. (1974) developed the phoneme counting task for testing children’s
phoneme awareness, it has since been used as a measure of adult’s phoneme awareness
and the influence of orthographic factors (Treiman & Cassar, 1997). Thus, because the
current research seeks to determine the effects of L1 and L2 orthographic knowledge on
L1, L2, and L0 phoneme awareness, a phoneme counting task is an appropriate method
for measuring the L1 and L2 orthographic effects as it will provide evidence for how
listeners hear phonemes.
With respect to the second task, half way through the RFL and MFL data collection,
it became apparent that in order to strengthen any potential claims about L1 and L2
orthographic influence, I needed to first confirm that the participants did in fact know
how to spell the L1 and L2 words. Therefore, the last 34 of the 52 participants also
completed a spelling dictation. In this part of the experimental task, the participants
listened to the L1 (and L2 for the MFL and RFL subgroups) cross-language homophones
and wrote them out according to English (and Russian or Mandarin) spelling
conventions. (See Appendix D for a sample dictation response sheet.) Specifically, the
non-L2 participants (i.e., the participants not in an L2 subgroup) were tested on a total of
48 words in the dictation—all the English cross-language homophones (24 associated
with Russian and 24 associated with Mandarin). The RFL and MFL were not only tested
on the 48 English words but they were also tested on 52 words in their L2, i.e., all the L2
words (both nonhomophone and homophone). The spelling dictation task confirmed that

105
the speakers did, in fact, know how each word is spelt. Unfortunately, because this task
was only added midway through the data collection when most of the subgroup data had
already been collected, not all RFL and MFL participants completed this dictation task:
only two RFL and five MFL participants completed the spelling dictation.
Table 4.6 below presents total number of accurate spellings (i.e., total) and the mean
spelling accuracy (i.e., percentage) for each group across each language. The totals vary
as the number of participants in each group varies. This table also provides the total
number of participants who completed the spelling dictation in each group. For example,
this table shows that 19 participants in the RNL0 group completed the spelling dictation
for an overall total of 912 English words (19 participants x 48 tokens). The accurate total
(given in bold) indicates that of the 912 tokens, these participants spelt 879 of them
correctly for an accuracy of 96%. The high accuracy percentages confirm that the
participants do know how to spell the L1 (and L2) target words.
group # of
participants L1 (English) L2 (Mandarin or
Russian)
total* percentage total** percentage
RNL0 overall n = 19 879/912 96% n.a. n.a
subgroup (MFL) n = 5 232/240 97% 238/260 92%
MNL0 overall n = 15 702/720 98% n.a. n.a
subgroup (RFL) n = 2 94/96 98% 97/104 93%
* overall total = number of participants x 48 L1 words ** overall total = number of participants x 52 L2 words
Table 4.6 Overall results of the spelling dictation
After these mean accuracy rates were calculated, the incorrect spellings were analysed for
any common spelling errors. For example, of the total 51 incorrect spellings for both

106
overall groups [(912-879) + (720-702) = 51], 41 (80%) of those spellings were of the
words cot and torte (the incorrect spellings were caught and tort). While not technically
incorrect spellings, these spellings provided by the participants deviated from the
intended spellings/associations, which rendered their use in the data analyses impossible.
Therefore, the data from these items were discarded. (See §4.2.6.3 for a more detailed
discussion of discarded data.) The other 10 misspellings showed no similar pattern.
4.2.5 Procedure
Each participant in the primary study completed nine separate tasks (See Table 4.7 below
for a summary.) First, each participant read and signed a consent form (See Appendix
E.). Second, after signing their consent forms, the participants received verbal
instructions in their L1 (English) on how to complete their assigned tasks. Specifically,
the participants were told that while all the words were one-syllable words, these words
varied in the number of sounds (between 1 and 5 sounds) within each word. (Note that
all participants were non-linguistically trained; therefore, to avoid confusion, the term
sound (rather than the term phoneme) was used when explaining the tasks and speaking
to the participants about the research project in general.) The researcher demonstrated
that the words at and milk while both having only one syllable differed in the number of
sounds—2 and 4 sounds, respectively. The participants were asked to “count the
individual sounds that they heard in each particular word”.
The participants completed the “sound counting” task in 4 blocks:
1) a practice session (4 English words, 4 Mandarin words, and 4 Russian
words),
2) the L1 session (the English words),

107
3) the L2 session (the Russian words for the MNL0/RFL participants and
the Mandarin words for the RNL0/MFL participants.),32 and
4) the L0 session (Russian words for the RNL0/MFL participants and the
Mandarin words for the MNL0/RFL participants).
Participants indicated their responses by pressing the number on a keyboard (1, 2, 3, 4, or
5) that corresponded to the number of sounds they heard in each word. They were asked
to use their right hand and respond using the number pad on the keyboard. The
participants were warned that they would only hear each word once. To force the
participants to respond as quickly as possible, they only had 10 seconds within which to
respond, and if they did not respond in that time, the program would record a “non-
response” and move on to the next word. In cases where the participants were unsure,
they were encouraged to make their best guess. E-prime recorded the number responses
and response times (RTs) from each participant. The RTs were recorded as the time
between the onset of the stimuli and the point at which the participants pressed one of the
response keys.
The participants first completed the practice session. Then they had another
opportunity to ask questions about their participation. Once any questions were answered
and the participants felt they were comfortable with the task, the participants completed
the actual counting task. The participants took short breaks between the L1 and L2/L0
sessions and between the L2/L0 and L0 sessions. During the short break between the L1
and L2/L0 sessions, the subgroup participants (i.e., the RFL and MFL participants) read 32 These data were only used for the L2 subgroup analyses. However, the non-L2 learners also completed this session to maintain the continuity and length of the task so that the L0 results in the final session (4 above) from all participants could be compiled and analysed together. These non-L2 learners were told that they would complete two L0 sessions; however, their L0 data from the first L0 session were discarded.

108
aloud a short passage called “The North Wind and Sun” in their L2 (See Appendix B).
The participants’ readings of the “North Wind and the Sun” were not recorded and/or
evaluated in anyway. Rather, the participants were told that the purpose of reading this
fable aloud was to prepare the participants for thinking in their L2. The non-L2 did not
do any passage reading. During the short break between the L2/L0 and L0 sessions, all
participants completed a background questionnaire. The breaks were incorporated so that
the participants would not find the counting task too long and tedious.
Once the participants completed the phoneme counting task, they answered three
questions about their impressions of the task and its relative difficulty. These questions
were as follows:
1) Which of the three sessions (English, Russian, and Mandarin) did you
find the most difficult? Why?
2) What factors influenced you when counting sounds? Did any factors
hinder you?
3) How easy or hard were the L0 words? Do you think that you listened
to them differently?
Finally, after completing the counting task and answering the above questions, most (34
of 52) of the participants completed a spelling dictation task (See explanation on page
103.). The dictation task for the RFL and MFL participants involved listening to and
writing out the spelling of all the L1 and L2 words. The dictation task for the non-L2
participants involved listening to and writing out the spelling of only the L1 words.

109
Table 4.7 below summarizes the experimental procedure for primary data collection by
listing the order of tasks and briefly describing each task.
TASKS DESCRIPTION / RATIONALE
1) Consent forms ! Participants read and signed consent forms as per University of Victoria Ethics regulations.
2) Practice session
! Participants completed a practice session (with L1, L2 and L0) words.
! None of the practice session tokens were used in the data analyses. ! After the practice session, participants had an opportunity to ask
questions about the task. 3) L1 session ! Participants counted phonemes in 76 English words. 4) Passage
reading ! Only the L2 subgroups of participants did this activity. ! The subgroup participants read aloud either the Russian or Mandarin
translation of the “North Wind and the Sun.” 5) L2(L0) session ! The RFL and MFL participants counted phonemes in 52 words in
their L2. ! The L2 was Russian for the RFL learners and Mandarin for the MFL
learners ! The non-L2 participants also did this session (to maintain task
continuity), but their data were not used in the overall analyses. 6) Background
questionnaire ! Participants completed the background questionnaire about their
previous and current language learning 7) L0 session ! Participants counted phonemes in 52 words in an L0.
! The L0 was Mandarin for the RFL learners and Russian for the MFL learners
8) Interview ! The participants answered questions about the difficulty of the phoneme counting task.
9) L1 (and L2) dictation
! The participants completed a dictation task of the cross-language English homophones.
! The subgroup participants also completed a L2 word dictation task to determine that they did in fact know how to spell each L2 word they counted phonemes for.
Table 4.7 Experimental procedure summary
4.2.6 Data analyses
Now that the participants, stimuli, materials, task, and procedure, have been outlined,
§4.2 concludes the methodological discussion of the primary study by considering and

110
discussing the analyses of the primary data. First, §4.2.6.1 and §4.2.6.2 identify and
define both the independent and dependent factors in this research. Next, §4.2.6.3
discusses the discarded data, and §4.2.6.4 discusses the statistical analyses employed for
analysing the data.
4.2.6.1 Independent factors
As mentioned above, this research examines two sets of data: 1) the overall data from the
52 participants (i.e., the L1–L0 comparisons), and 2) the subgroup data from 25 English
L2 learners of Russian (12) and Mandarin (13) (i.e., the L1–L2–L0 comparisons).
The four independent factors (variables) for the overall data in this research are:
I. Group (2 levels)
1. Mandarin L0 (MNL0) – The participants in this experimental group
were native speakers of Canadian English, and Mandarin Chinese
was their unfamiliar language (L0).
2. Russian L0 (RNL0) – The participants in this experimental group
were native speakers of Canadian English, and Russian was their
unfamiliar language (L0).
II. Language (2 levels)
1. L1 – English for both experimental groups
2. L0 – Mandarin for the MNL0 group and Russian for the RNL0 group
III. Homophone (2 levels)
1. Nonhomophone (NH) – Words do not have a homophonous
counterpart in one of the other test languages.

111
2. Homophone (H) – Words have a homophonous (or near
homophonous) counterpart in one of the other test languages. The
homophone pairs were L1-L0 pairs.
IV. Match (2 levels)
1. Match (M) – The number of letters in each word equals the number of
phonemes.
2. Mismatch (MM) – The number of letters in each word is either more
or less than the number of phonemes.
Like the overall data, the subgroup data in this research also have four independent
factors. Here, the homophone and match factors were the same as for the overall data, but
the group and language factors are different. All four factors are as follows:
I. Group (2 levels)
1. Russian-as-a-second-language learners (RFL) – The participants in
this experimental group were native speakers of Canadian English;
Russian was their L2, and Mandarin was their L0.
2. Mandarin-as-a-second-language (MFL) – The participants in this
experimental group were native speakers of Canadian English,
Mandarin Chinese was their L2, and Russian was their L0.
II. Language (3 levels)
1. L1 – English for both experimental groups
2. L2 – The L2 for the RFL group was Russian, and the L2 for the MFL
group was Mandarin.

112
3. L0 – The L0 for the RFL group was Mandarin, and the L0 for the
MFL group was Russian.
III. Homophone (2 levels)
1. Nonhomophone (NH) – Words do not have a homophonous
counterpart in one of the other test languages.
2. Homophone (H) – Words have a homophonous (or near
homophonous) counterpart in one of the other test languages. The
homophone pairs were either L1-L2 pairs or L1-L0 pairs.
IV. Match (2 levels)
1. Match (M) – The number of letters equals the number of phonemes.
2. Mismatch (MM) – The number of letters is either more or less than
the number of phonemes.
4.2.6.2 Dependent factors
Using the four independent factors for each set of data, this research investigates native
English speakers’ phoneme awareness/perception in the three languages (English,
Russian, and Mandarin). Specifically, the role of four independent factors in determining
phoneme awareness was measured through two dependent factors (i.e., variables): 1)
accuracy rates (Acc) and 2) response times (RTs). To analyse the accuracy rates and
response times, the average accuracy and response times for each condition were first
calculated. Note that only group is a between-subjects factor, and because the other three
factors are within-subjects factors, there is a condition for each combination of the
within-subjects factors. Therefore, in the overall data, the levels of the three within-

113
factors, language, homophone, and match result in 8 conditions [2 x 2 x 2]. Specifically,
the 8 conditions for the overall groups’ data are outlined in Table 4.8.
HOMOPHONE
NH H M MM M MM33
LANGUAGE
L1 L1 matched
nonhomophone e.g., risk /®Isk/
L1 mismatched nonhomophone e.g., box /bAks/
L1 matched homophone
e.g., man /mœn/
L1 mismatched homophone e.g., knee /ni/
L0 L0 matched
nonhomophone e.g., MN du#n /twan/
or RN $%& /vaS/
L0 mismatched nonhomophone
e.g., MN yòng /jON/ or RN !' /juk/
L0 matched homophone
e.g., MN nào /naw/ or RN (%) /daj/
L0 mismatched homophone
e.g., MN k* /kÓu/ or RN +,- /sup/
Table 4.8 The 8 conditions for the overall data
Likewise, in the subgroup data, the levels of the three within-factors, language,
homophone, and match result in 12 conditions [2 x 3 x 2]. These 12 conditions for the
subgroups’ data are outlined in Table 4.9.
33 Recall that for the MM-H condition, the mismatch was always in the L1 (not the L0).

114
HOMOPHONE NH H
M MM M MM
LANGUAGE
L1 L1 matched
nonhomophone e.g., risk /®Isk/
L1 mismatched nonhomophone e.g., box /bAks/
L1 matched homophone
e.g., man /mœn/
L1 mismatched homophone e.g., knee /ni/
L2 L2 matched
nonhomophone e.g., MN du#n /twan/
L2 mismatched nonhomophone
e.g., MN yòng /jON/
L2 matched homophone
e.g., MN nào /naw/
L2 mismatched homophone
e.g., MN k* /kÓu/
L0 L0 matched
nonhomophone e.g., RN $%& /vaS/
L0 mismatched nonhomophone e.g., RN !' /juk/
L0 matched homophone
e.g., RN (%) /daj/
L0 mismatched homophone
e.g., RN +,- /sup/
Table 4.9 The 12 conditions for the subgroup data
The first dependent factor is accuracy rates. The accuracy rate of each condition for
each participant was calculated by adding the number of correct responses in that
condition (i.e., when the participant response equalled the number of phonemes in a
word) and dividing that number by the total number of tokens in that condition. Then,
the accuracy rates for each condition were averaged over all the participants to calculate
the overall mean accuracy rate for that condition.
The second dependent variable is response times (RTs). The RTs were calculated in
milliseconds (ms) as the time between the offset of the stimulus token and the point at
which the participants pressed one of the response keys. Because E-prime records RTs
from the onset of the stimulus, the RT for each target word was first re-calculated by
subtracting the duration of the sound file associated with the stimulus item from the RT
recorded by E-prime. The revised RTs34 were then used to calculate the mean RTs for
each condition by averaging the RTs of the accurate responses only. The RTs for all the
participants in each condition were then averaged for the overall mean RTs for that
34 All subsequent references to RTs refer to these revised RTs.

115
condition. In sum, based on the data, phoneme awareness/perception was measured for
the overall data (i.e., the L1–L0 comparisons) and the subgroup data (i.e., L1–L2–L0
comparisons) by using both accuracy rates and RTs.
4.2.6.3 Discarded data
Although the total number of tokens in the MM-H, M-NH, and MM-NH conditions was
14 tokens for each (See Table 4.3 and Table 4.4), information from the secondary data
(see §4.3 below) identified eight problematic tokens, namely the Mandarin tokens lín
(“forest”) and x,n (“heart”), the Russian tokens &-a. (“eye”), /#! (“glad”), and 01!
(“city”), and the English tokens torte and cot. The Mandarin and Russian tokens were
problematic because the secondary data participants did not identify these words as
homophonous with their intended English counterparts, lean, sheen, gloss, rat, and got,
respectively. As a result, it is relatively safe to assume that the primary data participants
also did not perceive them as homophonous with the English words, and therefore, these
tokens (and their English counterparts) were discarded from the data because they were
not likely to show any L1 interference effect. The Russian token )*1- (“table”) and its
English counterpart stole were also discarded because the secondary data indicated that
perhaps the final /l/ in )*1- was relatively difficult to perceive, and participants may
have heard /sto/ rather than /stol/. Additionally, over half of the secondary data
participants spelt the English target words torte as tort and cot as caught (as did the
primary data participants who completed the spelling dictation), effectively eliminating
the word torte’s categorisation as a MM-H word and the word cot’s categorisation as a
M-H word. Therefore, the English tokens torte and cot and their homophonous
counterparts, the Russian tokens *1/* (“cake”) and 21* (“cat”), were also discarded

116
from the data. While all these tokens were discarded from the data analyses, they remain
listed in the homophone (i.e., Table 4.4) wordlists. (In this table, the shading and
strikethrough for each indicate that they were later discarded and thus not used in the
final data analysis.)
Finally, data with negative RTs were also discarded. Recall that the final RTs were
calculated by subtracting the duration of the sound file from the overall RT value (since
E-prime records RTs from the onset of the token rather than the offset of the token).
Negative values were considered “accidental responses”: they resulted from participants
responding before hearing the entire word, implying that they had not counted the
phonemes in that word. All in all, for the overall data, 32 tokens with negative values
were discarded (out of a total of 4553 tokens), and for the subgroup data, 19 tokens were
discarded (out of a total of 3151 tokens).
In addition to the previously mentioned discarded data, the L2 session data and the
corresponding L1 homophone data from the non-RFL and non-MFL (i.e., the non-
subgroups) participants were discarded. That means, for the non-RFL participants in the
MNL0 group, the Russian data and their English homophonous counterparts were
removed. Similarly, for the non-MFL participants in the RNL0 group, the Mandarin data
and their English homophonous counterparts were not used. These data were only used
for the L2 subgroup analyses to compare the L1, L2, and L0. As mentioned previously,
the non-L2 learners also completed this session to maintain the continuity and length of
the task so that the L0 results from all participants could be compiled and analysed
together. Therefore, although each participant was tested on 180 tokens, only 100 tokens
from each MNL0 participant were analysed, and only 92 tokens from each RNL0

117
participant were analysed (because more Russian tokens than Mandarin tokens were
discarded). More specifically, the MNL0 token data came from i) 22 L1 homophones
(corresponding with the Mandarin L0), ii) 28 L1 nonhomophones, iii) 22 L0
homophones, and iv) 28 L0 nonhomophones while the RNL0 token data came from i) 18
L1 homophones (corresponding with the Russian L0), ii) 28 L1 nonhomophones, iii) 18
L0 homophones, and iv) 28 L0 nonhomophones. For the subgroup analyses, only 164
tokens from each participant were analysed. That is, the token data for the subgroup data
analyses came from i) 43 L1 homophones (corresponding to both Russian and Mandarin
homophones), ii), 28 L1 nonhomophones, iii) 21 L2 homophones, iv) 28 L2
nonhomophones, v) 21 L0 homophones, and vi) 28 L0 nonhomophones. For clarity,
Table 4.10 below breaks down the number of tokens analysed per participant in the
overall data analyses (i.e., L1–L0 data) and the subgroup data analyses (i.e., L1–L2–L0)
once the unusable data had been discarded. Notice that the L1 M-H and MM-H
conditions differ in the token numbers for the overall data and the subgroup data.

118
overall data subgroup data
MNL0 RNL0 RFL MFL L1 match-homophone 10 [with L0] 7 [with L0] 17 [with L2 & L0] 17 [with L2 & L0] L1 mismatch-homophone 12 [with L0] 11 [with L0] 23 [with L2 & L0] 23 [with L2 & L0] L1 match-nonhomophone 14 14 14 14 L1 mismatch-nonhomophone 14 14 14 14 L2 match-homophone – – 7 10 L2 mismatch-homophone – – 11 12 L2 match-nonhomophone – – 14 14 L2 mismatch-nonhomophone – – 14 14 L0 match-homophone 10 7 10 7 L0 mismatch-homophone 12 11 12 11 L0 match-nonhomophone 14 14 14 14 L0 mismatch-nonhomophone 14 14 14 14
Total tokens 100 92 164 164
Table 4.10 Breakdown of token numbers in each experimental condition after discarding data for the overall data and the subgroup data analyses
4.2.6.4 Statistical analyses
Since this experiment incorporates four independent variables (group, language,
homophone, and match) and two dependent variables (accuracy and response times), a
four-way factorial analysis of variance (ANOVA) with repeated measures was conducted
to calculate significance using the statistical package PASW 18.0 (formerly SPSS). The
significance level was set at 0.05 such that any p-value less than 0.05 was considered
statistically significant. By-subject analyses35 (where the data are averaged over items)
were conducted on the data. The following paragraphs outline the between- and within-
35 By-items analyses were not performed on the data as the groups did not count phonemes in all the experimental items: the RNL0 group counted phonemes in the English and Russian items while the MNL0 groups counted phonemes in the English and Mandarin items. Therefore, by-items analyses could not compare all the items across all four independent variables.

119
subjects factors for the by-subjects analyses of the overall data (§4.6.4.1) and the
subgroup data (§4.6.4.2).
To determine the effect of L1 orthography on the perception of phonemes in both L1
and L0 matched/mismatched words, the overall data were analysed using all four
independent variables in by-subjects analyses. Moreover, in this analysis, because each
listener participated in both language levels, both homophone levels, and both match
levels, these 3 factors were within-subjects factors. In contrast, because individual
listeners did not participate in both groups (only MNL0 or only RNL0), group was a
between-subjects factor. In sum, the data were analysed using a by-subjects 4-way mixed
factorial design ANOVA with one between-subjects factor, group (MNL0, RNL0) and 3
within-subjects factors: language36 (L1, L0), homophone (homophone, nonhomophone),
and match (match, mismatch). Table 4.11 below summarises these factors and their levels
where the shaded columns indicate the within-subjects factors.
GROUP
(between-subjects) LANGUAGE (within-subjects)
HOMOPHONE (within-subjects)
MATCH (within-subjects)
LEVELS
1 Mandarin L0 (MNL0)
first language (L1)
nonhomophone (NH)
match (M)
2 Russian L0 (RNL0)
unfamiliar language (L0)
homophone (H) mismatch (MM)
Table 4.11 Between-subjects and within-subjects factors for the by-subjects analysis of the overall data (L1–L0 comparisons)
Because of the two dependent variables (accuracy and response times), 4-way repeated
measures ANOVAs by-subjects were conducted for each dependent variable.
36 Recall that the L0 for each experimental group was not the same. Specifically, the L0 for the MNL0 group was Mandarin, and the L0 for the RNL0 group was Russian.

120
As mentioned previously, the data were analysed according to two separate focuses:
1) the overall data for the L1–L0 comparisons, and 2) the subgroup data for the L1–L2–
L0 comparisons. In addressing the second focus, we were only concerned with the L2
learners’ L1, L2, and L0 data (i.e., the subgroups). Still, as with the overall data, the
subgroup data were analysed using a 4-way by-subjects ANOVA with one between-
subjects factor, group (RFL, MFL) and three within-subjects factors: language (L1, L2,
L0), homophone (homophone, nonhomophone), and match (match, mismatch). The
between-subjects and within-subjects factors for the by-subjects analysis are identified
and summarised below in Table 4.12. The shaded columns represent the within-subjects
factors.
GROUP
(between-subjects) LANGUAGE (within-subjects)
HOMOPHONE (within-subjects)
MATCH (within-subjects)
LEVELS
1 RFL L1 nonhomophone match 2 MFL L2 homophone mismatch 3 -- L0 -- --
Table 4.12 Between-subjects and within-subjects factors for the by-subjects analysis of the subgroup data (L1–L2–L0 comparisons)
Again, as with the overall data, 4-way repeated measures ANOVAs by-subjects were
conducted on the dependent variables, accuracy rates and RTs, for the subgroup data.
4.3 The secondary study
In addition to the primary data, secondary data were also collected to potentially help
interpret the results from the primary experiment and, as it turned out, to discard
inappropriate tokens from the analyses. This section outlines this secondary study—

121
including the participants (§4.3.1), the experimental stimuli (§4.3.2), and the
experimental task and procedure (§4.3.3).
4.3.1 Participants
Fourteen participants were recruited for the secondary study. All participants were native
speakers of Canadian English, and all were unfamiliar with both Russian and Mandarin.
These participants were recruited from first year linguistics classes and posters around the
university. Only those volunteers who reported no auditory or visual impairments were
accepted for the secondary study. Table 4.13 below provides a summary of the
participants in this secondary data group. This table also contains information about mean
the age of the participants in this group as well as the other languages these participants
have learnt.
group number of participants
mean age other languages learned
secondary data
n = 14
26.8 years
! Japanese, French, Latin, German, Classical Greek, Icelandic, Italian, Cantonese, and Spanish
n = total number, L0 = unfamiliar language, MFL = Mandarin-as-a-second-language, RFL = Russian-as-a-second-language
Table 4.13 Secondary data participant demographics
4.3.2 Experimental stimuli
The stimuli for this secondary data collection were a subset of the stimuli used in the
primary data collection. Specifically, the stimuli used were the English, Russian, and
Mandarin homophones. The total number of stimuli was 96 stimuli: 24 English words
and 24 Russian words that were homophonous with each other (e.g., EN tree /tÓ®i/ and
RN */3 /tri/), and 24 English words and 24 Mandarin words that were homophonous

122
with each other (e.g., EN who /hu/ and MN h4 /xu/). See Table 4.4 for the complete list
of English, Russian, and Mandarin homophones.
4.3.3 Experimental task and procedure
For the secondary data group, the experimental task and procedure involved two
components: an English dictation task and a nonnative language judgment task. For both
these components, the researcher individually presented the target words via Windows
2007 Media Player to the participants who listened to these target words using Sony
MDR-7506 headphones.
First, after reading and signing the consent form (See Appendix E.), the participants
completed an English spelling dictation. The participants did this task to 1) confirm that
the words they heard were in fact the intended target words and 2) parallel the English
homophone priming reflected in the primary data collection. The participants listened to
48 words spoken by a native English speaker. They were told that they would hear each
word twice, and they should listen to these words carefully. Once they had heard the
word twice, they wrote down the word they heard in order to confirm that in fact, as
assumed, other listeners would all hear the same word. The participants were also
informed that the words might sound a bit strange since they were presented in isolation
(i.e., without any context) and some of the words were not common (e.g., toot and rue).
Finally, the participants were instructed that if more than one spelling was possible, then,
they should write the first spelling that came to mind.
Second, participants completed an accentedness judgment task on the L2 and L0
cross-language homophones. In this component, they listened to each Russian and
Mandarin homophone twice, wrote out the English homophonous word they heard (using

123
English orthography) and rated the “accentedness” of the non-L1 word on a scale from 1
to 9 where 1 equals native-like pronunciation and 9 equals highly accented pronunciation.
(See Appendix C for the response sheet used to collect the native speaker judgements.)
The goal of the cross-language judgements of accentedness was to confirm that native
English speaking listeners did associate the MN and RN words with their intended EN
counterparts and to help determine the degree of homophony between the English-
Russian homophones and the English-Mandarin homophones. At no point during the
instructions were the participants explicitly told that these words were English words nor
were they told that the words were not English words. The description of the words was
intentionally vague; the participants were led to assume the nonnative speakers’ words
were English so that they would feel comfortable using English spelling to write out the
words, which, in turn, would indicate whether those MN and RN words were associated
with the intended EN counterparts. Also, the belief here was that if the participants were
told that the words were not English words, then they would be likely to rate all the
words as more accented than if they thought the words were English words. They were
given the following instructions regarding the rating of accentedness:
1) If they felt a word was spoken like a native English speaker, then, they
should circle one of the lower numbers (i.e., 1 or 2).
2) If they felt a word was spoken with a heavy accent (not native-like at
all), then, they should circle one of the higher numbers (i.e., 8 or 9).
3) If they felt the word was spoken with an accent somewhere between a
native speaker and a heavily accented speaker, then, they should circle
a number in the middle.

124
Prior to rating the MN and RN cross-language homophones, the participants were also
informed that they were to provide their intuitions as native speakers of English about the
accentedness of the words and as such there were no right or wrong answers—only their
impressions.
As mentioned above, these secondary data were used for two purposes: 1) to help
determine how to analyse the primary study results, and 2) to identify any inappropriate
token stimuli (which were then subsequently discarded). Because these data are
secondary, they are not reported on (Chapter 5) nor discussed on their own (Chapter 6).
4.4 Summary
In the search to determine if and how orthographic knowledge influences L1 and L0/L2
phoneme perception, this chapter has laid out in detail not only the primary research
methodology (§4.2) but also the pilot study leading up to the primary research (§4.1) and
the secondary study used to evaluate the stimuli tokens used in the primary (§4.3). Since
the focus of this dissertation revolves around the orthographic effects, the following
chapter—Chapter 5—reports on the results and analyses of the primary data only.

125
Chapter Five
ANALYSES AND RESULTS
“In a phoneme counting task, a spelling strategy will back fire when the number of letters in a word’s spelling does not match the
number of phonemes in its pronunciation.” (Treiman & Cassar, 1997, p. 771)
Up to now, all the previous chapters (Chapters 1 through 4) of this dissertation have been
dedicated to outlining and discussing all the necessary research, background, and
methodology upon which the current research rests. The remainder of this dissertation
reports on (Chapter 5), discusses (Chapter 6), and summarises (Chapter 7) the research
findings. This chapter reports on the statistical analyses used to evaluate the primary
study data and the results from those statistical analyses. Prior to exploring the statistical
analyses, we must first briefly review the experimental groups and the four primary
research questions. Therefore, the first section of this chapter, §5.1, outlines the questions
and predictions driving this research and highlights the comparisons necessary for
answering those questions. The remaining sections address each of the following
questions.
5.1 Outline of research questions, comparisons, and predictions
Recall that this research employed a phoneme counting task and collected data from two
experimental groups to answer four primary research questions. The experimental task
was one in which participants carefully listened to and counted phonemes in
monosyllabic words from their native language (English) and 2 nonnative languages

126
(Russian and Mandarin). The experimental groups were comprised of native speakers of
Canadian English, who were divided into two L0 (unfamiliar language) groups. One
group counted phonemes in English and Mandarin (the MNL0 group) where English was
the L1 and Mandarin was the L0, and the other group counted phonemes in English and
Russian (the RNL0 group) where English was the L1 and Russian was the L0. In
addition, each group contained a subgroup of participants who were L2 learners of one of
the nonnative languages: the participant subgroup in the MNL0 group contained L2
learners of Russian, and the participant subgroup in the RNL0 group contained L2
learners of Mandarin.
The four primary questions stem from one general question: in an auditory task, does
the orthographic representation (i.e., alphabetic knowledge) override the phonological
representation and determine the number of phonemes individuals perceive in a word?
Specifically, do literate native speakers of English rely on their knowledge of how words
are spelt in order to count phonemes, and if so, how does this affect their perception of
phonemes in other languages and the speed with which they identify those phonemes?
The more specific questions investigated in this research were designed to not only
determine the effect of orthography on the L1 but also its effect on an L2 and an L0.
The first primary research question asks: does L1 orthographic knowledge affect
how native English speakers count phonemes in L1 (Q1)? Specifically, do they count
phonemes more accurately in words with consistent letter-to-phoneme correspondences
(i.e., the numbers of letters and phonemes are the same) than in words with inconsistent
letter-phoneme correspondences (i.e., the numbers of letters and phonemes is not the
same)? Also, are native English speakers faster at counting phonemes in consistent

127
words than in inconsistent words? An additional question here is: are native English
speakers more successful at counting phonemes in orthographically unfamiliar words
(from L0) with inconsistent letter-phoneme correspondences than in orthographically
familiar (from L1) words with inconsistent correspondences because they are not affected
by orthographic interference in the L0?
The second primary research question asks: does L1 orthographic knowledge affect
how native English speakers count phonemes in L0 (Q2)? That is, when L0 words are
homophonous with L1 words, does L1 orthographic knowledge affect participants’
abilities to accurately perceive the phonemes in the L0 words. Specifically, do native
English speakers more accurately count phonemes in L0 words that are homophonous
with L1 words with consistent letter-phoneme correspondences than in L0 words that are
homophonous with L1 words with inconsistent letter-phoneme correspondences?
With respect to the subgroup data, the third primary research question is a two-part
question. First, does L2 orthographic knowledge affect how native English speakers
count phonemes in L2? (Q3a) In parallel with L1, do language learners count phonemes
more accurately in L2 words with consistent letter-to-phoneme correspondences than in
L2 words with inconsistent letter-phoneme correspondences? Second, if so, how does L2
orthographic knowledge interact with L1 orthographic knowledge? (Q3b) Since “the
nature of the L1 orthography influences the way L2 learners attend to the L2 orthographic
units” (Wade-Woolley, 1999, p. 448), does L1 orthographic knowledge override L2
orthographic knowledge and affect phoneme perception in the L2? For example, when
counting the sounds in the Russian word )*5- (which sounds like English stool /stu:/), do

128
listeners default to the L1 spelling of the homophonous word even if they are RFL
learners?
Finally, the fourth primary research question asks: does the strength of the
orthographic effect vary depending on experience with the language (Q4)?
Specifically, is the difference between the L1 matched and mismatched words greater
than the L2 matched and mismatched difference because the listeners have more
experience with the L1 than the L2? Similarly, is the L2 difference greater than the L0
matched and mismatched difference because the listeners have some experience with the
L2 but no experience with the L0?
Table 5.1 below outlines the four primary research questions along with the specific
data comparisons necessary to answer the questions. This table also includes the
hypotheses for the accuracy rates and response times surrounding each comparison; these
will be explained further in the relevant sections. In this table (and henceforth), the “>>”
symbol indicates that one condition is either more accurate or faster than another
condition, the “<<” symbol indicates that one condition is either less accurate or slower
than another conditions, and the “=” symbol indicates that two conditions are equal. For
example, the table shows that in the L1 matched and mismatched comparison (§5.3.1),
L1 matched words are predicted to be more accurately and more quickly counted than the
L1 mismatched words. NOTE: For the purposes of the analyses and results in this
chapter, the MM tokens are analysed as a single group, because the research design does
not allow otherwise. However, see §6.3.3 in Chapter 6 for an indepth discussion of
mismatch subcategory effects.

129
§ research questions comparisons predictions
5.3
Q1: Does L1 orthographic knowledge affect how listeners count phonemes in their first language (L1)?
5.3.1
L1 matched vs. mismatched words (both NH and H)
1) L1 matched words >> L1 mismatched words
5.3.2
L1 vs. L0 matched NH 1) L1 matched NH >> L0 matched NH
L1 vs. L0 mismatched NH 2) L1 mismatched NH << L0 mismatched NH
L0 matched vs. mismatched NH 3) L0 matched = L0 mismatched NH
5.4
Q2: Does L1 orthographic knowledge affect how listeners count phonemes in an unfamiliar language (L0)?
5.4.1 L0 matched vs. mismatched H 1) L0 matched H >> L0 mismatched H
5.4.2
L0 matched NH vs. H 1) L0 matched NH << L0 matched H
L0 mismatched NH vs. H 2) L0 mismatched NH >> L0 mismatched H
5.6
Q3a: Does L2 orthographic knowledge affect how listeners count phonemes in the L2? 5.6.1 L2 matched vs. mismatched NH 1) L2 matched NH >> L2 mismatched NH
Q3b: If so, how does L2 orthographic knowledge interact with L1 orthographic knowledge?
5.6.1
L2 matched vs. mismatched H 1) L2 matched H >> L2 mismatched H
L2 matched NH vs. mismatched H 1) L2 matched NH >> L2 mismatched H
5.7 Q4: Does the strength of the orthographic effect vary depending on experience with the language?
match-mismatch differences between L1, L2, and L0 NH
1) L1 NH >> L2 NH >> L0 NH
L1 = first language, L0 = unfamiliar language, L2 = second language, NH = nonhomophone, H = homophone, RT = response time
Table 5.1 Outline of the primary research questions, the comparisons needed to answer the questions, and the hypotheses associated with the comparisons

130
The remainder of the chapter is divided into six sections. §5.2, §5.3, and §5.4 report
on and evaluate the overall data with respect to the first and second research questions
and their respective hypotheses: §5.2 provides the overall descriptive statistics for the
mean accuracy rates and response times; §5.3 reports on the results and statistical
analyses that answer the first primary research question, and §5.4 reports on the results
and statistical analyses that answer the second primary research question. §5.5, §5.6, and
§5.7 consider only the subgroup data with respect to the third and fourth research
questions. §5.5 provides the descriptive statistics for the accuracy rates and RTs. §5.6
reports on the results and statistical analyses that answer the third primary research
question, and §5.7 reports on the results and statistical analyses that answer the fourth
primary research question. Finally, this chapter concludes with a general summary—
outlining all the significant results discovered from the data comparisons (§5.8).
5.2 Descriptive statistics for the overall data
The overall data were analysed with the first two research questions in mind. As
mentioned previously, the overall data were organised and analysed using four
independent factors – group, language, homophone, and match – and two dependent
factors – accuracy rates and response times. Exploration of the raw ACC and RT data
showed that ACC data were negatively skewed (the frequent scores were clustered at the
higher end and the tail points towards the lower scores) and the RT data were positively
skewed (the frequent scores were clustered at the lower end and the tail points towards
the higher scores) (Field, 2005). Therefore, square root transformations (ACC) and
natural-log (RT) were applied to normalize the data. Via the transformation process, the
ACC values were reversed such that the transformed values (henceforth “reflected

131
accuracy”) are interpreted as "error" not "accuracy". For this reason, in the following
tables and figures, with respect to participant accuracy, higher numbers mean lower
accuracy (= higher error). With respect to the participant RTs (henceforth “logged
RTs”), logging the RTs brings extreme, long RT values in closer to the faster RT values.
In other words, it pulls in the positive skew. In these calculations, the natural log "e"
base is 2.718. As an additional manipulation, boxplots for each participant were used to
identify RT outliers, which were not factored into the mean logged RTs values. (See
Appendix I for the boxplots.)
Table 5.2 below provides the descriptive statistics for the MNL0 and RNL0
experimental groups. The table includes the mean reflected accuracy rates (RACC) and
logged response times (LRT) for each group according to each experimental condition.
In addition to the mean RACC and LRT, the table includes the standard deviations (given
in parentheses) of these mean numbers. Also included in this table are the mean
differences between the matched and mismatched words for each homophone type,
language, and group. The match-mismatch accuracy differences were calculated by
subtracting the mean matched values from the mean mismatched values. Simiarly, the
match-mismatch LRT differences were calculated by subtracting the mean matched
LRTvalues from the mean mismatched LRT values. These calculations were conducted
so that positive values would support the research predictions and negative values would
contradict the research predictions: positive values represent higher accuracy and faster
RTs for the matched words than the mismatched words (as predicted), and negative
values represent lower accuracy and slower RTs.

132
For example, this table indicates that for the MNL0 group’s L1 accuracy results, the
mean square root of the reflected accuracy for the matched NH is 0.18 with a standard
deviation of 0.23 and the mean for the mismatched NH is 0.54 with a standard deviation
of 0.23. The reflected accuracy difference between these NH matched and mismatched
words is +0.36, which demonstrates better accuracy with matched NH words than with
mismatched NH words (as predicted). Similarly, the MNL0 group’s L1 mean LRT value
for the matched NH is 7.81 with a standard deviation of 0.21 and the mean LRT value for
the mismatched NH is 8.10 with a standard deviation of 0.22. The LRT difference
between the matched and mismatched NH is +0.29, which demonstrates faster response
times for the matched NH words than the mismatched NH words (also as predicted).
Impressionistically, the numbers in Table 5.2 hint that by and large the predictions
surrounding the overall data are supported: the differences between the matched and
mismatched words for each homophone condition show that matched words were
generally counted more accurately and faster than mismatched words, as reflected by the
positive difference values, particularly in L1.

133
L1 L0
group condition RACC (SD) LRTs! (SD) RACC (SD) LRTs (SD)
MNL0
NH-M NH-MM
0.18 (0.23) 0.54 (0.23)
7.81 (0.21) 8.10 (0.22)
0.51 (0.15) 0.60 (0.18)
7.86 (0.25)
7.99 (0.23) difference +0.36 +0.29 +0.09 +0.13
H-M H-MM
0.43 (0.18) 0.51 (0.12)
7.83 (0.21) 7.88 (0.23)
0.36 (0.24) 0.53 (0.16)
7.83 (0.27)
7.81 (0.26) difference +0.08 +0.05 +0.17 -0.02
RNL0
NH-M NH-MM
0.17 (0.22) 0.52 (0.25)
7.83 (0.30) 8.15 (0.33)
0.52 (0.12) 0.54 (0.12)
8.00 (0.29) 8.06 (0.31)
difference +0.35 +0.32 +0.02 +0.06
H-M H-MM
0.44 (0.15) 0.47 (0.15)
7.86 (0.31) 7.91 (0.36)
0.23 (0.23) 0.31 (0.21)
7.98 (0.32) 7.92 (0.37)
difference +0.03 +0.05 +0.08 -0.06 ! response times are in milliseconds (SD) = standard deviation
Table 5.2 Mean nonhomophone (NH) and homophone (H) reflected accuracy (RACC) and logged response times (RTs) for the MNL0 and RNL0 experimental groups in the L1 and L0 across the matched (M) and mismatched conditions (MM)
Based on the experimental design outlined in Chapter 4, both the reflected accuracy
rate data and the logged RT data were analysed using a 4-factor repeated measures
ANOVA with a 2 x 2 x 2 x 2 design. In this design, group (MNL0, RNL0) was the
between-subjects factor and language (L1, L0) 37 , homophone (nonhomophone,
homophone), and match (match, mismatch) were the three within-subjects factors. For
the overall reflected accuracy data, three main effects, five 2-way interactions, and two 3-
way interaction were significant (language: F(1,50)=7.090, p<0.05; homophone:
F(1,50)=5.722, p<0.05; match: F(1,50)=56.807, p<0.001; homophone by group:
F(1,50)=5.557, p<0.05; language by homophone: F(1,50)=81.967, p<0.001; language by
match: F(1,50)=12.492, p<0.001; homophone by match: F(1,50)=21.829, p<0.001;
language by group: F(1,50)=6.829, p<0.05; language by homophone by match:
37 Recall that the L2 data are relevant only for the subgroup data, discussed in §5.5, §5.6, and §5.7 below.

134
F(1,50)=41.304, p<0.001; language by homophone by group: F(1,50)=5.743, p<0.05).
None of the other interactions—including the 4-way interaction—was significant (group:
F(1,50)=3.404 38 ; match by group: F(1,50)=1.965; language by match by group:
F(1,50)=1.297; homophone by match by group: F(1,50)=0.388; language by homophone
by match by group: F(1,50)=0.019; all effects not significant at p>0.05).
For the logged RT data, the main effects for homophone and match, three 2-way
interactions, and one 3-way interaction were significant (homophone: F(1,50)=94.016,
p<0.001; match: F(1,50)=66.409, p<0.001; language by match: F(1,50)=48.059,
p<0.001; homophone by match: F(1,50)=92.644, p<0.001; language by group:
F(1,50)=4.270, p<0.05; language by homophone by match: F(1,50)=19.194, p<0.001).
None of the other main effects or interactions—including the 4-way interaction—were
significant (language: F(1,50)=0.110; group: F(1,50)=1.048; match by group:
F(1,50)=0.780; homophone by group: F(1,50)=0.056, p<0.05; language by homophone
F(1,50)=0.282; language by homophone by group: F(1,50)=0.426; language by match by
group: F(1,50)=2.267; homophone by match by group: F(1,50)=0.007; language by
homophone by match by group: F(1,50)=1.154; all effects not significant at p>0.05). The
lack of a significant 4-way interaction tells us that the pattern of interaction of three
factors does not differ significantly for each level of the fourth factor. Therefore, this
allows us to divide and collapse the data to focus on and investigate the main effects and
interactions that answer each specific research question.
38 This p-value approached significance (p=0.071).

135
5.3 Research question 1: L1 orthographic effect on L1 phoneme counting
Regarding the first primary research question, the current research tested two hypotheses
using the accuracy rates and response times. The first hypothesis states the L1
orthography should a) positively affect how native English speakers perceive phonemes
in L1 words with consistent letter-phoneme correspondences (e.g., cup /kÓØp/ – 3 letters
and 3 phonemes) and b) negatively affect how they perceive phonemes in L1 words with
inconsistent letter-phoneme correspondences (e.g., box /bAks/ – 3 letters and 4
phonemes). Therefore, if the results support the hypothesis, native English listeners
should count matched words more accurately and faster because the L1 orthography
facilitates phoneme perception; in contrast, listeners should count mismatched words less
accurately and more slowly because the L1 orthography interferes with how many
phonemes listeners perceive.
In addition, when comparing the L1 data with the L0 data, a second hypothesis
predicts that native speakers of Canadian English should count phonemes in L1 matched
NH more accurately and faster than L0 matched NH because the L1 orthography
facilitates counting in the L1 but not in the L0. Conversely, the hypothesis predicts that
native speakers should count phonemes in L1 mismatched NH less accurately and more
slowly than L0 mismatched NH because the conflict between the orthography and
phonology hinders accurate phoneme perception in L1 but not L0. Finally, a third
hypothesis predicts that because participants do not have any orthographic associations
with either the L0 matched or mismatched NH, L1 orthographic knowledge will not
interfere; thus, there should be no accuracy or RT differences between L0 matched vs.
mismatched NH words.

136
5.3.1 Comparisons of L1 matched and mismatched words (both NH and H)
As mentioned previously, accuracy rates and response times are used as dependent
measures of orthographic interference. These values were calculated to determine
whether native speakers of Canadian English count phonemes more accurately and faster
in English words with consistent one-to-one letter-phoneme correspondences than in
words with inconsistent correspondences. Regarding the matched and mismatched L1
data comparisons, the predictions are as follows. (Recall that “>>” indicates higher
accuracy and faster response times.)
Prediction:
In addition to the descriptive statistics given above in Table 5.2, Figure 5.1 below
provides a visual representation of the MNL0 and RNL0 groups’ reflected accuracy rates
for the L1 matched and mismatched words. The height of the bars in this figure indicates
the square root of the reflected accuracy rates (i.e., lower bars = more accurate), and the
error bars indicate a 95% confidence interval. This figure illustrates that both groups
performed similarly on the matched and mismatched L1 NH and H although the RNL0
group appears to have performed slightly more accurately than the MNL0 group on all
the conditions except the matched H condition. In addition, both groups were much more
accurate at counting phonemes in the matched NH condition than the other three
conditions. This figure also shows that both groups more accurately counted phonemes
in matched NH and H than they did in mismatched NH and H.
L1 matched NH and H
>>
L1 mismatched NH and H

137
Figure 5.1 Mean MNL0 and RNL0 square root values of reflected accuracy rates for the L1 matched and mismatched conditions
The reflected accuracy rate data for the L1 words were analysed using a 3-factor
repeated measures ANOVA with group (MNL0, RNL0) as the one between-subjects
factor and homophone (nonhomophone, homophone) and match (match, mismatch) as the
two within-subjects factors. The main effects for homophone and match as well as the
interaction of homophone by match were significant (homophone: F(1,50)=28.983,
p<0.001; match: F(1,50)=50.035, p<0.001; homophone by match: F(1,50)=51.644,
p<0.001). All of the other main effects and interactions were not significant (group:
F(1,50)=0.251; match by group: F(1,50)=0.099; homophone by group: F(1,50)=0.016;
homophone by match by group: F(1,50)=0.344; all effects not significant at p>0.05).
Follow-up tests for the effects match, collapsed over group (since group did not
participate in any significant interactions), for each homophone type (i.e., the NH and the
H mismatchH matchNH mismatchNH match
Squ
are
root
of r
efle
cted
acc
urac
y ra
tes
0 .6000
0.4000
0.2000
0.0000
Error Bars: 95% CI
RNL0MNL0
group
Page 3

138
H) separately showed the main effect of match was significant for the NH
(F(1,50)=78.289, p<0.001), with participants more accurately counting phonemes in L1
matched NH than in L1 mismatched NH. The follow up tests also showed the main effect
of match was significant for the H (F(1,50)=5.648, p<0.05), with participants more
accurately counting phonemes in L1 matched H than in L1 mismatched H. While the
participants counted phonemes more accurately in both the matched NH and H than in
the mismatched NH and H, the difference between the matched and mismatched words
was greater for the NH than the H.
In sum, the statistical analyses indicate that the participants in both groups more
accurately counted phonemes in matched words than in mismatched words. These results
confirm previous findings that L1 orthography influences speech perception in the L1
such that it facilitates phoneme counting when there are consistent letter-phoneme
correspondences but hinders phoneme counting when there are inconsistent
correspondences. The analyses also show no significant difference in accuracy
performance between the two groups for both the NH and the H words.
RT data provided an additional opportunity to determine possible L1 interference
effects on performance differences between matched and mismatched L1 words. To
determine the effect of L1 orthography on the speed of response, only the RT data for the
accurate responses were analysed. In addition, the RTs were calculated from the offset of
the word and only positive RTs were used since negative RTs indicated participants had
answer before hearing the entire word (i.e., they had guessed). The prediction here was
that reconciling mismatched letter-phoneme correspondences would require greater
cognitive resources and processing, and thus would result in longer RTs. Therefore,

139
observing significant differences between matched and mismatched words would further
support the hypothesis that orthography is co-activated with the speech signal and
influences phoneme perception.
Figure 5.2 below presents the mean logged RTs for each group for each homophone
and match condition. This figure shows three patterns of results. First, both groups are
faster at counting phonemes in matched NH and H words than in the mismatched NH and
H words. Second, the MNL0 group appears to count phonemes in both L1 NH and H
words faster than the RNL0 group does. Finally, the RT difference appears greater
between the matched and mismatched NH words than between the matched and
mismatched H words for both groups.
Figure 5.2 Mean MNL0 and RNL0 logged RTs for the L1 matched and mismatched conditions
H mismatchH matchNH mismatchNH match
Logg
ed R
T
8 .50
8.25
8.00
7.75
7.50
7.25
7.00
Error Bars: 95% CI
RNL0MNL0
group
GLM L1NHm L1NHmm L1Hm L1Hmm BY group /WSFACTOR=HOM 2 Polynomial MAT 2 Polynomial /METHOD=SSTYPE(3) /CRITERIA=ALPHA(.05) /WSDESIGN=HOM MAT HOM*MAT /DESIGN=group.
General Linear Model
Page 9

140
Like the reflected accuracy data, the logged RT data for the L1 words were analysed
using a 3-factor repeated measures ANOVA with group (MNL0, RNL0) as the one
between-subjects factor and homophone (nonhomophone, homophone) and match
(match, mismatch) as the two within-subjects factors. The main effects of homophone
and match and the interaction of homophone by match were significant (homophone:
F(1,50)=60.764; p<0.001; match: F(1,50)=143.131; p<0.001; homophone by match:
F(1,50)=102.748; p<0.001). All other effects—including the 3-way interaction—were
not significant (group: F(1,50)=0.173; match by group: F(1,50)=0.122; homophone by
group: F(1,50)=0.090; homophone by match by group: F(1,50)=0.446; all effects not
significant at p>0.05). Follow-up tests for the effects match, collapsed over group, for
each homophone type separately showed the main effect of match was significant for the
NH (F(1,51)=255.599, p<0.001), with participants counting phonemes faster in L1
matched NH than in L1 mismatched NH. The follow up tests also showed that main
effect of match was significant for the H (F(1,51)=7.448, p>0.01), with participants
counting phonemes faster in L1 matched H than mismatched H. In other words, the both
the NH and H matched words were counted faster than their NH and H mismatched
counterparts, but the difference between the matched and mismatched words was greater
for the NH than the H.
In sum, the analyses show that the logged RT results parallel the reflected accuracy
data. That is, the statistical analyses show that both groups were significantly faster at
counting phonemes in matched NH and H words than in the mismatched NH and H
words although the matched-mismtached difference was greater for the NH than the H.

141
In addition, the analyses show no significant difference in speed between the two groups
for the both the NH and H words.
5.3.2 Comparisons of L1 and L0 matched and mismatched NH
To further investigate L1 orthography’s effect on phoneme perception in the L1, the
current research also compared 1) the L1 matched NH with the L0 matched NH, 2) the
L1 mismatched NH with the L0 mismatched NH, and 3) the L0 matched and mismatched
NH. If L1 orthography does affect phoneme perception in the L1, we should observe an
important difference in accuracy and RTs in the first two comparisons. First, in the L1
and L0 matched NH comparison, the prediction is that both the MNL0 and the RNL0
groups should count phonemes more accurately in the matched L1 NH than in matched
L0 NH because orthography facilitates the perception of sound in the L1 but not in the L0
since L0 spellings are not known, and therefore cannot facilitate perception. Second, in
the L1 and L0 mismatched comparison, the prediction is that both groups would count
phonemes less accurately in the L1 mismatched NH than in the L0 mismatched NH
because the orthography interferes with how many phonemes listeners perceive in the L1
but not in the L0 since these words have no orthographic association. Finally, in the
matched and mismatched L0 NH comparison, the prediction is that the accuracy and
speed for the matched and mismatched NH should be the same since the listeners do not
have any orthographic knowledge that will impede their success.

142
Predictions:
In addition to the descriptive statistics given above in Table 5.2, Figure 5.3 below
provides a visual representation of the MNL0 and RNL0 groups’ reflected accuracy rates
of the L1 and L0 matched and mismatched NHs. The height of the bars in this figure
indicates the mean reflected accuracy (higher bars = lower accuracy), and the error bars
indicate a 95% confidence interval. This figure illustrates that the MNL0 group and the
RNL0 group performed similarly with respect to accuracy for the L1 (i.e., English)
matched NHs and the L1 mismatched NHs, and that both groups performed more
accurately counted phonemes in L1 matched NHs (0.91 and 0.93, respectively) than in L1
mismatched NHs (0.66 for both groups) (as previously shown in Figure 5.1). With
respect to the L0 accuracy, Figure 5.3 shows that neither group was as accurate at
counting phonemes in the L0 matched NHs as it was at counting phonemes in the L1
matched NHs. In fact, for both groups, their L0 matched NH reflected accuracy rates
were about the same as their mean reflected accuracy for the L1 mismatched NHs and for
the L0 mismatched NHs.
L1 matched
>>
L0 matched, L0 mismatched
>>
L1 mismatched

143
Figure 5.3 Mean square root values of reflected accuracy rates for the L1 and L0 matched and mismatched nonhomophones
The reflected accuracy data for the L1 and L0 NH were analysed using a 3-factor
repeated measures ANOVA with group (MNL0, RNL0) as the one between-subjects
factor and language (L1, L0) and match (match, mismatch) as the two within-subjects
factors. The main effects of language and match as well as the interaction of language
and match were significant (language: F(1,50)=60.169, p<0.001; match: F(1,50)=72.513,
p<0.001; language by match: F(1,50)=39.779, p<0.001). All other effects were not
significant (group: F(1,50)=0.433; language by group: F(1,50)=0.002; match by group:
F(1,50)=0.702; language by match by group: F(1,50)=0.736; all effects not significant at
p>0.05). Tests for the effects of language for each match, collapsed over group, show
that participants more accurately count phonemes in L1 matched NH than in L0 matched
L0 mismatchL1 mismatchL0 matchL1 match
Squ
are
root
of r
efle
cted
acc
urac
y ra
tes
0 .6000
0.4000
0.2000
0.0000
Error Bars: 95% CI
RNL0MNL0
group
GLM L1NHm L1NHmm L0NHm L0NHmm BY group /WSFACTOR=LANG 2 Polynomial MAT 2 Polynomial /METHOD=SSTYPE(3) /CRITERIA=ALPHA(.05) /WSDESIGN=LANG MAT LANG*MAT /DESIGN=group.
General Linear Model
Page 21

144
NH (F(1,51)=111.459, p<0.001); however, the effect of language was not significant for
the mismatched NH (F(1,51)=1.256, p>0.05). Finally, the effects of match, collapsed
over group, were tested for the L0 NH words. In this test, the main effect of match was
significant (F(1,51)=4.378, p<0.05), with participants counting phonemes more
accurately in L0 matched NH than in L0 mismatched NH.
In short, the statistical analyses show no significant accuracy difference between
groups. They also show that both groups are significantly more accurate at counting
phonemes in the L1 matched NHs than in the L0 matched NHs (as predicted). This result
suggests that L1 orthographic knowledge facilitates phoneme counting in L1 words with
consistent letter-phoneme correspondences. However, the analyses also show that no
difference exists between the L1 and L0 mismatched NHs (not predicted). Also, contrary
to the prediction, the analyses also show that listeners were significantly more accurate at
counting phonemes in L0 matched NH than in L0 mismatched NH, suggesting perhaps an
effect of the words themselves within the matched and mismatched NH (However, as
illustrated later in §5.4.2, word effect cannot possibly be the only factor influencing
performance.).
With respect to the RTs, the hypotheses predict that both groups of participants will
a) count phonemes faster in the L1 matched NH than in the L0 matched NH, b) count
phonemes slower in the L1 mismatched NH than in the L0 mismatched NH, and c) count
equally as fast in the L0 matched NH words as in the L0 mismatched NH words. Figure
5.4 below indicates that the participants were faster at counting phonemes in the L1
matched NH than in the L0 matched phonemes. This figure also indicates that
participants were slower at counting phonemes in the L1 mismatched NH than in the L0

145
mismatched NH. Finally, both groups appear to count phonemes in the L0 matched NH
slightly faster than in the L0 mismatched NH.
Figure 5.4 Mean logged RTs for the L1 and L0 matched and mismatched nonhomophones
The logged RT data for the L1 and L0 NH were also analysed using a 3-factor
repeated measures ANOVA with group (MNL0, RNL0) as the one between-subjects
factor and language (L1, L0) and match (match, mismatch) as the two within-subjects
factors. The main effects for match and the interaction of language and match were
significant (match: F(1,50)=172.148, p<0.001; language by match: F(1,50)=61.398,
p<0.001). All other effects were not significant (group: F(1,50)=1.057; language:
F(1,50)=0.006; language by group: F(1,50)=2.736; match by group: F(1,50)=0.467;
L0 mismatchL1 mismatchL0 matchL1 match
Logg
ed R
T
9 .00
8.75
8.50
8.25
8.00
7.75
7.50
7.25
7.00
Error Bars: 95% CI
RNL0MNL0
group
GLM L1NHm L1NHmm L0NHm L0NHmm BY group /WSFACTOR=LANG 2 Polynomial MAT 2 Polynomial /METHOD=SSTYPE(3) /CRITERIA=ALPHA(.05) /WSDESIGN=LANG MAT LANG*MAT /DESIGN=group.
General Linear Model
Page 19

146
language by match by group: F(1,50)=0.3.11439; all effects not significant at p>0.05).
Tests of the effect of language on each match type, collapsed over group, show that
participants counted phonemes in L1 matched NH significantly faster than in L0 matched
NH (F(1,51)=16.193, p<0.001). In contrast, participants counted phonemes in L1
mismatched NH significantly slower than in L0 mismatched NH (F(1,51)=16.693,
p<0.01). Finally, the effects of match, collapsed over group, were tested for the L0 NH
words. The main effect of match was significant (F(1,51)=18.255, p<0.001), with
participants counting phonemes faster in L0 matched NH than in L0 mismatched NH.
In sum, the statistical analyses on LRT support and even go beyond the RACC
results, showing that participants counted phonemes in the L1 matched NH faster than in
the L0 matched NH, but they counted phonemes in the L1 mismatched NH slower than in
the L0 mismatched NH. As with accuracy results, LRT results show that participants
also counted phonemes faster in L0 matched NH than in L0 mismatched NH, which is
contrary to the predictions surrounding the L0 NH words. Again, this suggests an effect
of the words in each match type.
5.3.3 Summary for primary research question 1
The previous subsections have reported on the results and statistical analyses of the
overall data regarding the first primary research question (Q1). Three-way repeated
measures ANOVAs and subsequent tests for effects were conducted to analyse the effect
of L1 orthography on phoneme perception in listeners’ first language (L1) and an
unfamiliar language (L0) in terms of two dependent measures – accuracy and RTs. Table
5.3 summarises the accuracy and RT results below according to the matched and 39 This p-value approached significance, p=0.084.

147
mismatched L1 NH comparison as well as the L1 and L0 comparisons. This table also
indicates whether each result confirms the research hypotheses (!) or not ("). All
differences indicated in the table are significant.
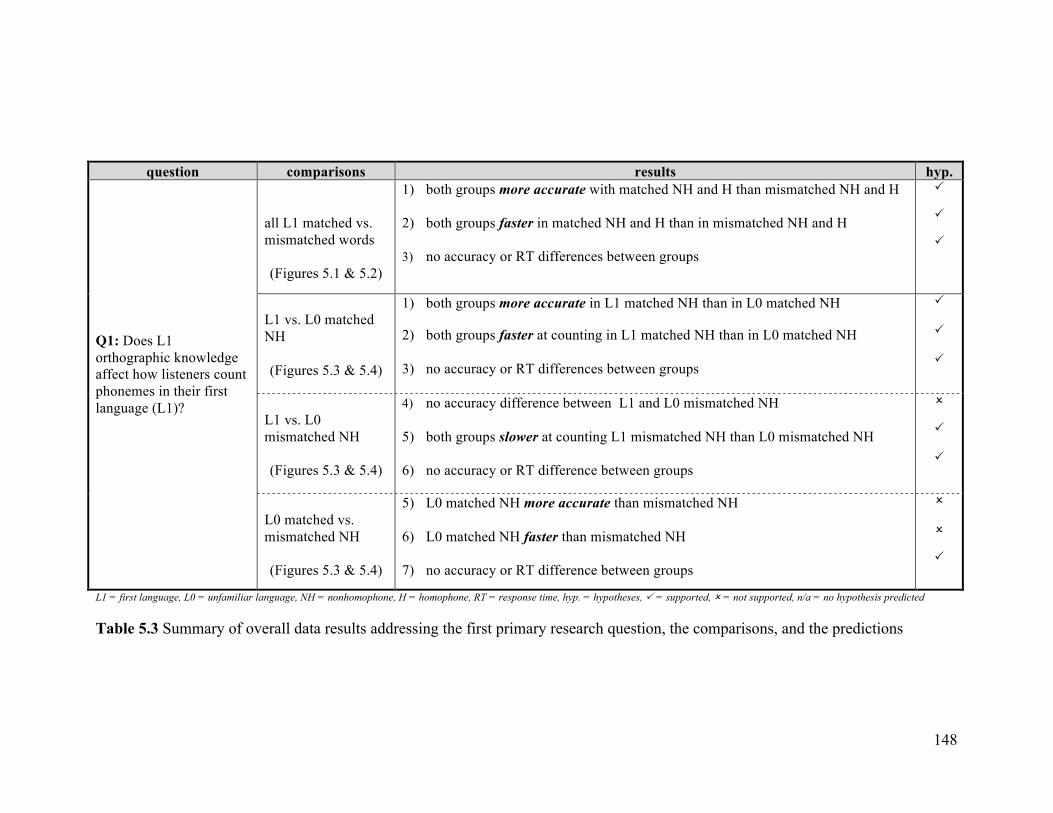
148
question comparisons results hyp.
Q1: Does L1 orthographic knowledge affect how listeners count phonemes in their first language (L1)?
all L1 matched vs. mismatched words
(Figures 5.1 & 5.2)
1) both groups more accurate with matched NH and H than mismatched NH and H
2) both groups faster in matched NH and H than in mismatched NH and H 3) no accuracy or RT differences between groups
! !
!
L1 vs. L0 matched NH
(Figures 5.3 & 5.4)
1) both groups more accurate in L1 matched NH than in L0 matched NH
2) both groups faster at counting in L1 matched NH than in L0 matched NH 3) no accuracy or RT differences between groups
! ! !
L1 vs. L0 mismatched NH
(Figures 5.3 & 5.4)
4) no accuracy difference between L1 and L0 mismatched NH
5) both groups slower at counting L1 mismatched NH than L0 mismatched NH 6) no accuracy or RT difference between groups
" !
!
L0 matched vs. mismatched NH
(Figures 5.3 & 5.4)
5) L0 matched NH more accurate than mismatched NH
6) L0 matched NH faster than mismatched NH 7) no accuracy or RT difference between groups
" " !
L1 = first language, L0 = unfamiliar language, NH = nonhomophone, H = homophone, RT = response time, hyp. = hypotheses, ! = supported, " = not supported, n/a = no hypothesis predicted
Table 5.3 Summary of overall data results addressing the first primary research question, the comparisons, and the predictions

149
These results suggest that for accuracy, L1 orthography has a facilitative effect but
not an inhibitory one: the matched L1 NH words were counted more accurately than the
mismatched L1 NH, the matched L0 NH, and the mismatched L0 NH. In contrast, the
mismatched L1 NH were not counted less accurately than the matched and mismatched
L0 NH, suggesting that L1 orthography does not hinder counting any more than not
knowing the language does. Conversely, the results suggest that L1 orthography has both
a facilitative and inhibitory effect with respect to counting speed: L1 NH were counted
faster than the matched and mismatched L0 NH (facilitation), but the mismatched L1 NH
were counted more slowly than the L0 NH words (inhibition). Finally, the analyses show
one unexpected result: contrary to the hypothesis, both groups of listeners counted
phonemes in matched L0 NH more accurately and faster than they did in mismatched L0
NH, suggesting that something about the words themselves (i.e., a word effect) may also
have influenced how listeners perceived and counted L0 phonemes.
Given that L1 orthography appears to facilitate phoneme counting in L1 words with
consistent correspondences and, to a lesser extent, hinder phoneme counting in L1 words
with inconsistent correspondences, the next important question here is: does L1
orthography affect perception of L0 phonemes? If so, does it affect L0 phoneme
perception in the same way as it affects L1 phoneme perception? The following
subsection addresses the second primary research question to investigate L1
orthography’s effect on the L0.
5.4 Research question 2: L1 orthographic effect on L0 phoneme counting
As mentioned above in §5.1, the second primary research question asks: does L1
orthographic knowledge affect how native English speakers count phonemes in an

150
unfamiliar language (L0)? Specifically, when L0 words are homophonous with L1
words, does L1 orthographic knowledge intrude on L0 perception and affect participants’
abilities to accurately perceive the phonemes in the L0 words. In concrete terms: do
native English speakers more accurately count phonemes in L0 words that are
homophonous with L1 words with consistent letter-phoneme correspondences (e.g.,
Mandarin méi /mej/ and English May /mej/) than in L0 words that are homophonous with
L1 words with inconsistent letter-phoneme correspondences (e.g., Mandarin h! /xu/ and
English who /hu/)?
Regarding these questions, the first hypothesis predicts that listeners should tap into
their L1 orthographic knowledge to help them count phonemes in the L0. This strategy
should facilitate phoneme counting (both in accuracy and speed) when the L0 words are
homophonous with L1 words that have consistent letter-phoneme correspondences, but it
should hinder counting when the L0 words are homophonous with L1 words that have
inconsistent correspondences. This should be reflected in significantly higher accuracy
rates and faster RTs for the L0 matched H than for L0 mismatched H. Also, a second
hypothesis predicts that if L1 orthographic knowledge intrudes on L0 phoneme
perception, we should observe significant differences in accuracy and speed between the
L0 NH and H words. First, listeners should more accurately count phonemes and respond
faster for L0 matched H than L0 matched NH because listeners tap into their L1
orthographic knowledge to help them with matched H, but they have no orthographic
associations for the matched NH, and therefore, receive no such boost from the L1. In
contrast, listeners should less accurately count phonemes and respond slower for L0
mismatched H words than L0 mismatched NH because again they tap into their L1

151
orthographic knowledge, but the inconsistent correspondences prevent the same degree of
success for the mismatched H words.
5.4.1 Comparison of L0 matched and mismatched H
To test the hypothesis that the L1 orthography would facilitate counting in L0 words with
consistent L1 letter-phoneme associations and hinder counting in the L0 words with
inconsistent L1 letter-phoneme associations, this subsection analyses and compares the
L0 matched and mismatched H data. As mentioned above, the hypothesis predicts that
listeners should count phonemes more accurately and faster in the L0 matched H than
mismatched H because when they use their L1 orthographic knowledge to help them with
the matched H words, there is no conflict between the number of letters and phonemes.
Prediction:
Figure 5.5 below indicates two major trends in the L0 H words. First, the RNL0
group appears to count phonemes in both the matched H and mismatched H conditions
more accurately than the MNL0 group does. Second, regardless of the group differences,
L0 matched H words appear to be counted more accurately than the L0 mismatched H.
L0 matched H
>>
L0 mismatched H

152
Figure 5.5 Mean square root values of reflected accuracy rates comparing the L0 matched and mismatched cross-language homophones
These data were analysed with a 2-way repeated measures ANOVA with group (MNL0,
RNL0) as a between-subjects factor and match (match, mismatch) as a within-subjects
factor. The main effects for match and group were significant (match: F(1,50)=14.179,
p<0.001; group: F(1,50)=13.085, p<0.05); however, the interaction of match and group
was not significant (F(1,50)=2.3, p>0.05). In other words, both groups were significantly
more accurate at counting phonemes in L0 matched H than in mismatched H. Also, the
RNL0 group was significantly more accurate at counting phonemes in the L0 matched
and mismatched H than the MNL0 group was.
With respect to the RT data, the hypothesis predicts that listeners should count
phonemes faster in the L0 matched H because when they tap into their L1 orthographic
mismatchmatch
Squ
are
root
of r
efle
cted
acc
urac
y ra
tes
0 .6000
0.4000
0.2000
0.0000
Error Bars: 95% CI
RNL0MNL0
group
GLM L0Hm L0Hmm BY group /WSFACTOR=MAT 2 Polynomial /METHOD=SSTYPE(3) /CRITERIA=ALPHA(.05) /WSDESIGN=MAT /DESIGN=group.
General Linear Model
Page 3

153
knowledge for help, they do not need extra time to reconcile a conflict between the
number of letters and phonemes. Figure 5.6 below indicates two trends with the data.
First, the MNL0 group appears to count phonemes in the matched and mismatched
conditions faster than the RNL0 group does. Second, both groups appear to count L0
mismatched H slightly faster than L0 matched H.
Figure 5.6 Mean logged RTs comparing the L0 matched and mismatched cross-language homophones
These RT data were also analysed using the 2-way repeated measures ANOVA with
group (MNL0, RNL0) as the between-subjects factor and match (match, mismatch) as the
within-subjects factor. Contrary to the trends observed above in Figure 5.6 all of the
effects—including the interaction of group and match—were not significant (match:
F(1,50)=2.856; group: F(1,50)=2.290; match by group: F(1,50)=0.903; all effects not
mismatchmatch
Logg
ed R
T
9 .00
8.75
8.50
8.25
8.00
7.75
7.50
7.25
7.00
Error Bars: 95% CI
RNL0MNL0
group
GLM L0Hm L0Hmm BY group /WSFACTOR=MAT 2 Polynomial /METHOD=SSTYPE(3) /CRITERIA=ALPHA(.05) /WSDESIGN=MAT /DESIGN=group.
General Linear Model
Page 3

154
significant at p>0.05). That means neither group was faster than the other in counting
phonemes. Also, the listeners did not count phonemes in one condition (either the
matched or mismatched) faster than the other condition.
In sum, the statistical analyses of the reflected accuracy rates indicate that overall the
RNL0 group was more accurate than the MNL0 group at counting phonemes (not
predicted). As predicted, the analyses also indicate that both groups were significantly
more accurate with the L0 matched H words than with the mismatched H words. The
reflected accuracy results suggest that L1 orthographic knowledge is also a factor in L0
phoneme perception. Specifically, the L1 orthography facilitates phoneme perception in
L0 words when they are homophonous with L1 words that have consistent
correspondences but hinders perception when the L0 are homophonous with L1 words
that have inconsistent correspondences. In short, participants appear to employ the L1
orthography to help them count phonemes in the L0, but that strategy is not as successful
when the number of letters does not match the number of phonemes in the associated L1
cross-language H words. However, the RT data here do not show the same facilitative
effect of L1 orthography. In fact, the analyses show no significant differences exist not
only between the two groups but also between the L0 matched and mismatched H words.
5.4.2 Comparison of L0 NH and H
This subsection reports on the results and statistical analyses of the accuracy rates for the
L0 NH and H comparison. While reading the following, keep in mind that the phoneme
counting task was a purely auditory task and that neither group knew the L0 words, and
thus by extention nor did they know how to spell the L0 words in the L0 orthography.
However, the groups were familiar with the L1 spellings of the cross-language H;

155
therefore, differences in performance between the L0 NH and L0 H would suggest an
effect of L1 orthography. While the previous section focuses exclusively on comparing
L0 matched and mismatched homophones, we must also compare the NH and H data to
confirm that the H effects found in the previous section are due to L1 interference. If L1
orthographic knowledge intrudes on L0 phoneme perception, listeners should count
phonemes more accurately for L0 matched H than for L0 matched NH because listeners
tap into their L1 orthographic knowledge to help them with the Hs. In contrast, they have
no orthographic associations for the matched NH and, therefore, receive no such boost
from the L1. In addition, listeners should count phonemes less accurately for L0
mismatched H words than L0 mismatched NH because again they tap into their L1
orthographic knowledge for the Hs, but in this case, the inconsistent correspondences
prevent them from counting phonemes as accurately in the mismatched H words.
Finally, listeners should count phonemes as accurately for the L0 matched NH as for the
L0 mismatched NH (already reported in §5.3.2) because they have no orthographic
knowledge for these words.
Predictions:
Figure 5.7 shows three patterns of behaviour. (Note that this figure is the same as
Table 5.5 but with the addition of the matched and mismatched NH data.) First, both the
MNL0 and the RNL0 groups count phonemes more accurately in L0 matched NH and H
L0 matched H
>>
L0 matched NH, L0 mismatched NH
>>
L0 mismatched H

156
words than in L0 mismatched NH and H words. Second, the RNL0 group is generally
more accurate than the MNL0 group—with the exception of the matched NH condition
(mentioned previously in §5.3.2). Finally, both groups are more accurate at counting
phonemes with matched H than with matched NH, and they are more accurate with
mismatched H than with mismatched NH.
Figure 5.7 Mean square root values of reflected accuracy rates for MNL0 and RNL0 comparing the L0 nonhomophones with the cross-language homophones across the matched and mismatched conditions
The overall reflected accuracy rates data for the L0 NH and H were analysed using
group (MNL0, RNL0) as the one between-subjects factor and homophone
(nonhomophone, homophone) and match (match, mismatch) as the two within-subjects
factors. All main effects and the interactions of match and group and homophone and
H mismatchNH mismatchH matchNH match
Squ
are
root
of r
efle
cted
acc
urac
y ra
tes
0 .6000
0.4000
0.2000
0.0000
Error Bars: 95% CI
RNL0MNL0
group
GLM L0NHm L0NHmm L0Hm L0Hmm BY group /WSFACTOR=HOM 2 Polynomial MAT 2 Polynomial /METHOD=SSTYPE(3) /CRITERIA=ALPHA(.05) /WSDESIGN=HOM MAT HOM*MAT /DESIGN=group.
General Linear Model
Page 8

157
group were significant (group: F(1,50)=8.970, p<0.01; homophone: F(1,50)=57.883,
p<0.001; match: F(1,50)=18.211, p<0.001; homophone by group: F(1,50)=9.694,
p<0.01; match by group: F(1,50)=4.658, p<0.05); however, all the other interactions were
not significant (homophone by match: F(1,50)=3.05440; homophone by match by group:
F(1,50)=0.068; all effects not significant at p>0.05). Follow up analyses of the effects of
homophone and group were conducted for match and mismatch separately. For the
matched words, the main effects of homophone and group as well as the interaction of
homophone by group were all significant (homophone: F(1,50)=46.432, p<0.001; group:
F(1,50)=4.661, p<0.05; homophone by group: F(1,50)=4.661, p< 0.05). Subsequent tests
of the effects of homophone for each group separately showed a significant main effect of
homophone for both the MNL0 group (F(1,50)=10.417, p<0.01) and the RNL0 group
(F(1,50)=41.943, p<0.001), with both groups of participants counting matched H more
accurately than matched NH. However, the difference between the matched NH and H
was greater for the RNL0 group than the MNL0 group. Similarly, the follow up tests for
the mismatched words showed the main effects of homophone and group as well as the
interaction of homophone by group were all significant (homophone: F(1,50)=21.853, p<
0.001; group: F(1,50)=6.547, p<0.05; homophone by group: F(1,50)=6.547, p< 0.05).
Subsequent tests of the effects of homophone for each group separately showed a
significant main effect of homophone for both the MNL0 group (F(1,50)=4.024, p=0.05)
and the RNL0 group (F(1,50)=18.123, p<0.001), with both groups of participants
counting mismatched H more accurately than mismatched NH. However, the difference
40 The p-value approached significance, p=0.087.

158
between the mismatched NH and H was greater for the RNL0 group than the MNL0
group.
In addition to the analyses of the effects of match and group on the L0 homophone
data (reported above in §5.4.1), follow-up analyses of the effects of match and group
were also conducted on the L0 nonhomophone data. These analyses showed a significant
main effect of match (F(1,50)=4.510, p<0.05), but the main effect of group and the
interaction of match and group were not significant (group: F(1,50)=0.547; match by
group: F(1,50)=2.534; both effects not significant at p>0.05). In other words, neither
group was more accurate at counting phonemes than the other group, and both groups
were more accurate at counting phonemes in matched NH than they were at counting
phonemes in mismatched NH.
In sum, the statistical analyses show that both groups of participants more accurately
count phonemes in homophones than in nonhomophones, with the RNL0 group showing
a greater difference between H and NH words than the MNL0 group for both matched
and mismatched words. In addition, both groups of participants more accurately count
phonemes in matched words than in mismatched words with the RNL0 group
demonstrating a greater accuracy difference between matched and mismatched words
than the MNL0 group. These two results suggest that two effects are at play: 1) a
familiarity effect and 2) L1 an orthographic knowledge effect. First, performing better on
both sets of homophonous words (i.e., the matched and mismatched) than
nonhomophonous words suggests that homophony with English words make L0 words
more familiar to participants thus making them more successful regardless of whether the
words have consistent letter-phoneme correspondences or not. Second, performing better

159
on matched words than mismatched words suggests that while familiarity helps them
count phonemes in general, the inconsistent letter-phoneme correspondences in the L0
mismatched words do interfere with their abilities to count the phonemes accurately.
In addition to the previous comparisons made with the L0 data, comparing the L0
NH and H response times further provide insight into L1 orthography’s influence on
phoneme perception in L0 words. Here, the hypotheses predict 1) participants should be
faster at counting phonemes in matched H than in matched NH because the associated L1
orthography facilitates counting, and 2) participants should be slower at counting
phonemes in the mismatched H than in the mismatched NH because the associated L1
orthography hinders phoneme perception in the mismatched H. Figure 5.8 presents three
observations about the L0 data comparisons. First, the MNL0 group appears to be faster
at counting phonemes in all the L0 words than the RNL0 group is (as reported previously
in §5.3.2). Second, both groups appear to be faster at counting phonemes in matched H
than in matched NH. Finally, both groups appear to be faster at counting phonemes in
mismatched H than in mismatched NH.

160
Figure 5.8 Mean MNL0 and RNL0 logged RTs comparing the L0 nonhomophones with the cross-language homophones across the matched and mismatched conditions
The overall logged RT data for the L0 NH and H were analysed using group (MNL0,
RNL0) as the between-subjects factor and homophone (nonhomophone, homophone) and
match (match, mismatch) as the within-subjects factors. The main effect for homophone
and the interaction between homophone and match were significant (homophone:
F(1,50)=39.374, p<0.001; homophone by match: F(1,50)=30.644, p<0.001). All of the
other main effects and interactions were not significant (match: F(1,50)=2.280; group:
F(1,50)=2.328; homophone by group: F(1,50)=0.350; match by group: F(1,50)=2.273;
homophone by match by group: F(1,50)=0.313; all effects not significant at p>0.05). The
simple effect of homophone was tested for each match type separately, collapsed over
group (since group did not participate in any significant interactions). These tests show
H mismatchNH mismatchH matchNH match
Logg
ed R
T
9 .00
8.75
8.50
8.25
8.00
7.75
7.50
7.25
7.00
Error Bars: 95% CI
RNL0MNL0
group
GLM L0NHm L0NHmm L0Hm L0Hmm BY group /WSFACTOR=HOM 2 Polynomial MAT 2 Polynomial /METHOD=SSTYPE(3) /CRITERIA=ALPHA(.05) /WSDESIGN=HOM MAT HOM*MAT /DESIGN=group.
General Linear Model
Page 8

161
that participants were significantly faster at counting L0 mismatched H than L0
mismatched NH (F(1,51)=57.450, p<0.001); however they were not significantly faster at
counting matched H than matched NH (F(1,51)=2.722, p>0.05).
Like the accuracy data, follow up analyses of match and group were conducted on
the RT data for each homophone type separately. The results for the H data are reported
in §5.4.1. For the NH data, the analyses showed a significant main effect of match
(F(1,50)=18.813, p<0.001), but neither the main effect of group nor the interaction of
match and group was significant (group: F(1,50)=2.557; match by group F(1,50)=2.557;
both effects not significant at p>0.05). That is, both groups were as equally as fast at
counting phonemes in both matched and mismatched NH; however, both groups were
significantly faster at counting phonemes in matched NH than they were at counting
phonemes in mismatched NH.
In sum, although Figure 5.8 suggests that the MNL0 group is faster than the RNL0
group at counting phonemes, the statistical analyses show that there was no significant
difference between the two groups. In addition, the analyses show that participants are
faster at counting the L0 matched and mismatched H than they are at counting in the L0
matched and mismatched NH, again suggesting a familiarity effect of L1 orthography. In
addition, the RT difference was significant between the mismatched Hs and NHs but not
significant between the matched Hs and NHs. Also, unlike the L1 RT results (§5.3.2), L1
orthographic knowledge does not appear to exert the same inhibitory effect for the L0
mismatched H. Rather, the results suggest that the familiarity effect outweighs any
inhibitory effect such that familiarity allows listeners to respond faster with mismatched

162
H than mismatched NH even though they must still reconcile the letter-phoneme conflict
associated with the mismatched H.
5.4.3 Summary for primary research question 2
The previous subsections have reported on the results and statistical analyses of the
overall data regarding the second primary research question (Q2). Three-way repeated
measures ANOVAs were conducted to analyse the effect of L1 orthography on phoneme
perception in listeners’ unfamiliar language (L0) in terms of accuracy rates and response
times. Table 5.4 below summarises the accuracy and RT results according to the L0
matched and mismatched comparisons and the L0 NH and H comparisons. This table
also indicates whether each result confirms the research hypotheses (!) or not ("). All
differences indicated in the table are significant. The analyses of the L0 data thus far
suggest three effects are potentially at play in this phoneme monitoring task. First, an L1
orthographic effect can account for why the L0 matched Hs are more accurate than the
L0 mismatched Hs. Second, a familiarity effect accounts for why the L0 Hs are more
accurate and faster than the NHs, regardless of match or mismatch. Finally, a word effect
can account for why the L0 matched NHs are more accurate than the L0 mismatched
NHs (as reported in §5.3.2). Therefore, while the results do suggest an effect of L1
orthographic knowledge, the effect of L1 orthographic knowledge interacts with the other
two effects (i.e., the familiarity effect and the word effect) and this interaction mitigates
the effects of L1 orthography alone such that its influence is not as strong in the L0 as it
is in the L1.

163
questions comparisons results hyp.
Q2: Does L1 orthographic knowledge affect how listeners count phonemes in an unfamiliar language (L0)?
L0 matched vs. mismatched H (Figures 5.5 & 5.6)
1) RNL0 group demonstrates a greater accuracy difference between the matched and mismatched words than MNL0 group
2) both groups more accurate in L0 matched H than in mismatched H
3) no RT difference between groups
4) no RT difference between L0 matched and mismatched H
! "
" !
L0 matched NH vs. H (Figures 5.7 & 5.8)
1) RNL0 group demonstrates a greater accuracy difference between the matched and mismatched words than RNL0 group
2) matched H more accurate than matched NH
3) no RT difference between groups
4) no RT difference between matched H and NH
! "
" !
L0 mismatched NH vs. H (Figures 5.7 & 5.8)
5) RNL0 group demonstrates a greater accuracy difference between the matched and mismatched words than RNL0 group
6) No RT difference between groups
7) mismatched H more accurate than mismatched NH 8) mismatched H faster the mismatched NH
! "
! !
L1 = first language, L0 = unfamiliar language, NH = nonhomophone, H = homophone, RT = response time, hyp. = hypotheses, ! = supported, " = not supported
Table 5.4 Summary of overall data results addressing the second primary research question, the comparisons, and the predictions

164
Given that the previous two sections (§5.3 and §5.4) have established that
orthographic knowledge affects phoneme perception in both the native language and the
unfamiliar language, albeit to a lesser extent in the L0, the next logical question is: how
does orthographic knowledge affect phoneme perception in an L2 (i.e., a language that
the listeners are already familiar with)? Does the strength of its influence fall somewhere
between its effect on the L1 and its effect on the L0? Therefore, to investigate
orthography’s effect on L2 phoneme perception, the following sections report on and
analyse the L2 subgroup data.
5.5 Descriptive statistics for the subgroup data
The subgroup41 data were analysed to answer the third primary research question and test
the research hypotheses surrounding that question. (See the subsections below for a
reminder of these hypotheses.) Like the overall data, the subgroup data were also
organised and analysed using 4 independent factors – group, language, homophone, and
match – and 2 dependent factors – accuracy rates and response times. Table 5.5 provides
the descriptive statistics for the Russian-as-a-second-language (RFL) and Mandarin-as-a-
second-language (MFL) experimental subgroups’ data. The table contains the mean
reflected accuracy rates (RACC) and logged response times (LRT) for each group
according to each experimental condition as well as the standard deviations of these mean
numbers, which are given in parentheses (See §5.2 for the rationale behind the reflected
accuracy and logged RTs.).
41 Recall that the RFL subgroup was part of the MNL0 overall group, and the MFL subgroup was part of the MFL overall group.

165
Also included in this table are the mean differences between the matched and
mismatched words for each of homophone type, language, and group. Again, as with the
overall data, the match-mismatch accuracy and RT differences were calculated by
subtracting the mean matched values from the mean mismatched values. These
calculations were conducted so that positive values would support for the research
predictions and negative values would contradict the research predictions. Therefore,
positive values represent higher accuracy and faster RTs for the matched words than the
mismatched words, and negative values represent lower accuracy and slower RTs.
L1 L2 L0
group condition RACC (SD)
LRTs!
(SD) RACC
(SD) LRTs
(SD) RACC
(SD) LRTs
(SD)
RFL
NH-M NH-MM
0.23 (0.27) 0.54 (0.26)
7.54 (0.30) 7.93 (0.25)
0.23 (0.21) 0.38 (0.17)
7.57 (0.29) 7.79 (0.19)
0.47 (0.16) 0.61 (0.22)
7.60 (0.39) 7.72 (0.32)
difference +0.31 +0.39 +0.15 +0.22 +0.14 +0.12
H-M H-MM
0.39 (0.22) 0.50 (0.14)
7.59 (0.28) 7.69 (0.32)
0.23 (0.30) 0.18 (0.21)
7.56 (0.38) 7.58 (0.29)
0.30 (0.23) 0.49 (0.19)
7.51 (0.42) 7.42 (0.39)
difference +0.11 +0.10 -0.05 +0.02 +0.19 -0.09
MFL
NH-M NH-MM
0.13 (0.258) 0.53 (0.31)
7.59 (0.45) 8.01 (0.49)
0.40 (0.28) 0.63 (0.17)
7.56 (0.42) 7.86 (0.50)
0.57 (0.14) 0.60 (0.08)
7.81 (0.43) 7.89 (0.46)
difference +0.40 +0.42 +0.13 +0.30 +0.03 +0.08
H-M H-MM
0.42 (0.16) 0.50 (0.15)
7.61 (0.49) 7.72 (0.54)
0.41 (0.32) 0.42 (0.23)
7.46 (0.61) 7.54 (0.66)
0.31 (0.23) 0.36 (0.20)
7.78 (0.49) 7.77 (0.57)
difference +0.08 +0.11 +0.01 +0.08 +0.05 -0.01
! response times are in milliseconds (SD) = standard deviation
Table 5.5 Mean nonhomophone (NH) and homophone (H) reflected accuracy (RACC) and logged response times (LRTs) for the RFL and MFL experimental groups in the L1, L2, and L0 across the matched (M) and mismatched conditions (MM)
For example, this table indicates that for the RFL’s L1 accuracy results, the mean
reflected accuracy for the matched NH is 0.23 with a standard deviation of 0.27 and the
mean reflected accuracy for the mismatched NH is 0.54 with a standard deviation of 0.26.

166
The accuracy difference between these NH matched and mismatched words is +0.31,
which demonstrates higher accuracy in the matched NHs than in the mismatched NHs.
Similarly, the RFL’s L1 RT results are a mean logged RT for the matched NH of 7.54
with a standard deviation of 0.30 and a mean logged RT for the mismatched NH of 7.93
with a standard deviation of 0.25. The RT difference between the matched and
mismatched NH is +0.39, which demonstrates faster response time in the matched NHs
than in the mismatched NHs. Overall, the numbers in Table 5.5 suggest that the
predictions surrounding the subgroup data are supported. The positive differences
between the matched and mismatched words for the L1, L2, and L0 homophones and
nonhomophones show that matched words were generally counted more accurately and
faster than mismatched words (as reflected by more positive values).
As outlined in Chapter 4, both the reflected accuracy data and the logged RT data for
the subgroups were analysed using a 4-factor repeated measures ANOVA with a 2 x 3 x 2
x 2 design. In this design, group (RFL, MFL) was the one between-subjects factor and
language (L1, L2, L0), homophone (nonhomophone, homophone), and match (match,
mismatch) were the three within-subjects factors. For the subgroup reflected accuracy
data, Mauchly’s test indicated the assumption of sphericity had been violated for the main
effect of language (!2(2)=9.355, p<0.01); therefore, the degrees of freedom were
corrected using Greenhouse-Geisser estimates of sphericity ("=0.748). The main effects
for language, homophone and match as well as the 2-way interactions for language by
group, language by homophone, language by match, and homophone by match, and the
3-way interaction of language by homophone by match were all significant (language:
F(1.485,34.166)=6.077, p=0.01; homophone: F(1,23)=11.028, p<0.01; match:

167
F(1,23)=24.078, p<0.001; language by group: F(2,46)=9.293, p<0.001; language by
homophone: F(2,46)=15,902, p<0.001; language by match: F(2,46)=4.310, p<0.05;
homophone by match: F(1,23)=22.159, p<0.001; language by homophone by match
F(2,46)=8.617, p<0.001). All other main effects and interactions, including the 4-way
interaction, were not significant (group: F(1,23)=1.231; homophone by group:
F(1,23)=0.085; match by group: F(1,23)=0.024; language by homophone by group:
F(2,46)=0.1.395; homophone by match by group: F(1,23)=0.833; language by
homophone by match by group: F(2,46)=0.373; all effects not significant at p>0.05).
For the subgroup RT data, Mauchly’s test indicated no violations of sphericity. The
main effects for language, homophone and match, the 2-way interactions of language by
group, language by match, and homophone by match, and the 3-way interactions of
language by homophone by match and language by homophone by group were all
significant (language; F(2,46)=4.003, p<0.05; homophone: F(1,23)=27.715, p<0.001;
match: F(1,23)=40.179, p<0.001; language by group: F(2,36.732)=7.957, p<0.001;
language by match: F(2,46)=21.028, p<0.001; homophone by match: F(1,23)=29.587,
p<0.001; language by homophone by match: F(2,46)=3.026, p=0.05; language by
homophone by group: F(2,46)=4.774, p<0.05). All other main effects and interactions,
including the 3-way interactions and the 4-way interaction, were not significant (group:
F(1,23)=0.361; homophone by group: F(1,23)=0.001; match by group: F(1,23)=0.635;
language by homophone: F(2,46)=0.662; language by match by group: F(1,23)=0.227;
homophone by match by group: F(1,23)=0.119; language by homophone by match by
group: F(2,46)=0.664; all effects not significant at p>0.05).

168
5.6 Primary research question 3: Orthographic effect on L2 phoneme counting
As mentioned above in §5.1, with respect to the L1–L2–L0 subgroup data, the third
primary research question asks: does L2 orthographic knowledge affect how native
English speakers count phonemes in their second language (L2)? That is, as predicted
with the L1, do language learners count phonemes more accurately in L2 words with
consistent L2 letter-to-phoneme correspondences than in L2 words with inconsistent L2
letter-phoneme correspondences? Subsequently, if L2 orthography does affect L2
phoneme perception, how does L2 orthographic information interact with L1
orthographic information? In other words, do L1 orthographic representations of L2
cross-language H also influence native speakers? Specifically, does L1 orthographic
knowledge override L2 orthographic knowledge and affect phoneme perception in the
L2?
With respect to the first question, specifically concerned with L2, the prediction is
that listeners should employ their L2 orthographic knowledge to help them count
phonemes in the nonhomophonous L2 words. (Recall that these subgroup participants
were intermidate learners of either Russian or Mandarin, and they were familiar with the
spelling of the L2 target words.) As with the L1 words in the overall data, this strategy
should facilitate phoneme counting—both in accuracy and speed—when the L2 NH
words contain consistent letter-phoneme correspondences (ex. Russian !"#$ /zont/—4
letters and 4 phonemes), but it should hinder counting when the L2 NH words have
inconsistent correspondences (ex. Russian %& /juk/—2 letters and 3 phonemes).
Therefore, significantly higher accuracy and faster RTs for the L2 matched NH than for

169
L2 mismatched NH would suggest that L2 orthography impacts phoneme counting in the
L2.
With respect to the second question above, concerning the interaction between L1
and L2 orthographies, the prediction is not as clear. Since the research suggests that L1
orthographic knowledge is co-activated with L1 phonology (e.g., Perreman et al., 2009;
Castles et al., 2008; Ziegler & Ferrand, 1998) and that the L1 affects L2 learning in a
general sense (e.g., Archibald, 1998; Brown, 2000; Major, 2001, 2002), then logically,
we can propose that L1 orthographic knowledge will affect L2 phoneme perception. The
question is whether L1 orthographic knowledge will override L2 orthographic knowledge
and affect L2 phoneme perception? Remember that in the L2 mismatched H words, the
L2 spellings have consistent letter-phoneme correspondences; the mismatches are in the
associated L1 homophones. If L1 orthography intrudes, listeners should count phonemes
relatively accuractely and quickly for L2 matched Hs because listeners tap into their L1
orthographic knowledge to help them. In contrast, listeners should count phonemes
relatively inaccurately and slowly for L2 mismatched H words because again they tap
into their L1 orthographic knowledge, but the inconsistent correspondences prevent the
same degree of success for the mismatched H words. In addition, if L1 orthography
overrides L2 orthography, L2 matched NH words (where no L1 orthographic associations
exist) should be counted more accurately and faster than L2 mismatched H words (where
the L1 associations contain inconsistent correspondences).
As mentioned above, the subgroup data were collected to investigate the effect of L2
orthography and the L1-L2 interaction of orthographic effects on L2 phoneme perception.
Three comparisons for both the accuracy rates and the response times were conducted to

170
1) determine the effect of L2 orthography on L2 phoneme perception (the matched and
mismatched NH word comparison), 2) determine the effect of L1 orthography on L2
phoneme perception (the matched and mismatched H word comparison), and 3) tease
apart the effects of the L1 orthography and the L2 orthography on L2 phoneme
perception (the matched NH and mismatched H comparison). The predictions relating to
these comparisons are
Prediction 1:
Prediction 2:
Prediction 3:
When comparing the L2 matched and mismatched NH and H words, Figure 5.9
below shows four trends in the L2 data. First, overall, the RFL group was more accurate
at counting L2 phonemes than the MFL group. Second, both groups more accurately
counted phonemes in L2 matched NH words than in L2 mismatched NH words. Third,
while the MFL group more accurately counted phonemes in matched H than in
L2 matched H >>
L2 mismatched H
L2 matched NH >>
L2 mismatched H
L2 matched NH
>>
L2 mismatched NH

171
mismatched H, the RFL group is more accurate at counting phonemes in the mismatched
H than in the matched H. Finally, both the MFL and RFL learners count L2 phonemes in
the matched NH words roughly to the same degree that they count phonemes in the
mismatched H words.
Figure 5.9 Mean square root values of reflected accuracy rates comparing the L2 matched and mismatched nonhomophones and homophones
To determine the effects L2 orthography on L2 phoneme perception and the
interaction of the L1 and the L2 orthography, the accuracy rates of the subgroup L2 NH
and H data were analysed using a 3-factor repeated measures ANOVA with group (RFL,
MFL) as the one between-subjects factor and homophone (nonhomophone, homophone)
and match (match, mismatch) as the within-subjects factors. The main effects of
homophone, match and group, and the 2-way interaction of homophone and match were
H mismatchH matchNH mismatchNH match
Squ
are
root
of r
efle
cted
acc
urac
y ra
tes
0 .80
0.60
0.40
0.20
0.00
Error Bars: 95% CI
MFLRFL
group
GLM L2NHm L2NHmm L2Hm L2Hmm BY group /WSFACTOR=HOM 2 Polynomial MAT 2 Polynomial /METHOD=SSTYPE(3) /CRITERIA=ALPHA(.05) /WSDESIGN=HOM MAT HOM*MAT /DESIGN=group.
General Linear Model
Page 10

172
significant (homophone: F(1,23)=5.269, p<0.05; match: F(1,23)=4.814, p<0.05; group:
F(1,23)=8.395, p<0.01; homophone by match: F(1,23)=14.348, p<0.001). All other
effects were not significant (homophone by group: F(1,23)=0.001; match by group:
F(1,23)=0.767; homophone by match by group: F(1,23)=0.007; not significant at
p>0.05). The effects of match and group were tested separately for each homophone
type. For the NH words, the tests indicate significant main effects of match and group
(match: F(1,23)=17.977, p<0.001; group: F(1,23)=8.211, p<0.01), but no significant
interaction of match and group (F(1,23)=0.677, p>0.05). Thus, as Figure 5.9 suggests,
the RFL group is significantly more accurate at counting phonemes than the MFL group
in the NH words and both groups are significantly more accurate at counting phonemes in
matched words than in mismatched words. For the H words, the follow-up tests indicate
a significant main effect for group (F(1,23)=2.812, p<0.05), with the RFL group more
accurately counting phonemes than the MFL group. Neither the main effect of match nor
the interaction of match by group were significant (match: F(1,23)=0.097; match by
group: F(1,23)=0.402; all effects not significant at p>0.05), which means that the groups
show the same degree of accuracy on the L2 matched and mismatched H words,
suggesting L1 orthographic knowledge has no effect on phoneme counting in L2.
Finally, to confirm the lack of L1 effect and further test for any L1 and L2
interaction effects, an additional analysis was conducted comparing the L2 matched NH
and the L2 mismatched H word data. This analysis tested the effects of match and group
for the L2 matched NH words and the L2 mismatched H words. This test indicated a
significant main effect of group (F(1,23)=7.089, p<0.05) such that the RFL group
counted phonemes more accurately than the MFL group. However, the test indicated no

173
main effect for match or interaction of match and group (match: F(1,23)=0.030; match by
group: F(1,23)=0.454; both effects not significant at p>0.05) such that there was no
accuracy difference between the matched NH words and the mismatched H words for
either group, again suggesting that L1 orthography does not have an effect on L2
phoneme perception.
In sum, the subgroup L2 data were compared and analysed in three ways. First, the
statistical analyses of the L2 matched and mismatched NH show that the RFL group is
significantly more accurate at counting phonemes in Russian NH than the MFL group is
at counting phonemes in Mandarin NH. This is possibly due to the linguistic nature of
Russian versus Mandarin (See §6.3.2 for a discussion.). Also, the analyses show that both
groups more accurately counted phonemes in L2 matched NH than in L2 mismatched
NH, suggesting that L2 orthographic knowledge was present in the auditory phoneme
counting task and influenced L2 phoneme perception and counting. Second, the statistical
analyses of the L2 matched and mismatched H comparisons show that while the RFL
learners counted phonemes more accurately overall than the MFL learners, neither group
was more accurate at counting phonemes in the matched H than in the mismatched H.
Since the mismatches in the mismatched H were always in the L1 associations and the L2
orthographic spellings of the mismatched H were always consistent, these results suggest
that the L1 orthography does NOT negatively impact L2 phoneme perception (as
previously predicted). These results are supported by the third and final comparison,
which show no significant difference between the matched NH words and the
mismatched H words. These results further suggest that L1 orthography does not
negatively affect L2 phoneme perception. The combination of a) the matched and

174
mismatched NH results, b) the matched and mismatched H results, and c) the matched
NH and mismatched H results suggest that L1 orthography does not have as strong an
impact on L2 phoneme perception as L2 orthography does at the intermediate stage of L2
learning. In fact, L2 orthographic knowledge appears to override entrenched L1
orthographic knowledge for both RFL and MFL learners. On the other hand, the fact that
participants counted mismatched H as accurately as matched NH suggest that familiarity
has a positive impact on L2 phoneme perception, so L1 DOES have an effect, just not an
orthographic one.
As with first two research questions, RTs provide an additional opportunity to
investigate the effects of L1 and L2 orthography on L2 phoneme perception. Figure 5.10
shows four trends in the L2 logged RT data. First, the RFL group appears faster at
counting phonemes in NH words than the MFL group. Second, for both groups, the
matched NH words were counted faster than the mismatched NH words. Third, there are
no apparent RT differences between the RFL and MFL groups or between the L2
matched and mismatched H words. Finally, the figure shows no apparent RT difference
between the matched NH words and the mismatched H for either group.

175
Figure 5.10 Mean RFL and MFL response times comparing the L2 matched and mismatched nonhomophones and homophones
To further determine the effects of L1 and/or L2 orthography on L2 phoneme
perception, the logged RTs of the subgroup L2 NH data were analysed using a 3-factor
repeated measures ANOVA with group (RFL, MFL) as the one between-subjects factor
and homophone (nonhomophone, homophone) and match (match, mismatch) as the
within-subjects factors. The main effects of homophone and match as well as the
interaction of homophone and match were significant (homophone: F(1,23)=15.054,
p<0.001; match: F(1,23)=18.929, p<0.001; homophone by match: F(1,23)=8.736,
p<0.01). All other effects were not significant (group: F(1,23)=0.010; homophone by
group: F(1,23)=1.362; match by group: F(1,23)=0.838; homophone by match by group:
F(1,23)=0.003; effects not significant at p>0.05). Tests for the effects of match for each
H mismatchH matchNH mismatchNH match
Logg
ed R
T
9 .00
8.75
8.50
8.25
8.00
7.75
7.50
7.25
7.00
Error Bars: 95% CI
MFLRFL
group
GLM L2NHm L2NHmm L2Hm L2Hmm BY group /WSFACTOR=HOM 2 Polynomial MAT 2 Polynomial /METHOD=SSTYPE(3) /CRITERIA=ALPHA(.05) /WSDESIGN=HOM MAT HOM*MAT /DESIGN=group.
General Linear Model
Page 10

176
homophone type separately, collapsed over group, indicate a significant effect of match
for NH words, with participants counting phonemes faster in matched NH than in
mismatched NH (F(1,23)=34.613, p<0.001), but the effect was not significant for the H
words (F(1,23)=0.755, p>0.05). Like the accuracy data, the effects of match, collapsed
over group, on the matched NH data and mismatched H data were conducted to tease
apart the effects of the L1 and L2 orthographies. This analysis indicates no significant
effect of match (F(1,23)=0.016, p>0.05) such that neither match type was significantly
faster than the other.
In sum, these RT analyses indicate that neither group counted phonemes faster in
their L2 than the other group. The analyses also indicate that both groups count
phonemes faster in L2 matched NH than in L2 mismatched NH. In contrast, the analyses
show 1) no significant RT difference between the matched H and the mismatched H
words, and 2) no significant RT difference between the matched NH and mismatched H
words. These results parallel and support the accuracy rate results. They suggest that L2
orthographic knowledge is present in an auditory phoneme counting task and influences
L2 phoneme perception and counting more so than L1 orthographic knowledge does.
However, unlike the accuracy results, there was no group effect. In other words, the RFL
group was neither faster nor slower than the MFL group at counting L2 phonemes.
This section has reported on the results and statistical analyses of the subgroup data
regarding the third primary research question (Q3). Three-way repeated measures
ANOVAs were conducted to analyse the effect of both the L2 and L1 orthography on
phoneme perception in listeners’ second language (L2) in terms of accuracy and RT.
Table 5.6 summarises the accuracy and RT results according to the L2 matched and

177
mismatched NH comparisons, and L2 matched and mismatched H comparisons. This
table also indicates whether each result confirms the research hypotheses (!) or not (").
All differences indicated in the table are significant. In short, the results from the three
L2 comparisons suggest that not only does L2 orthographic knowledge influence L2
phoneme perception (L2 matched > mismatched NH) but it also overrides any potential
L1 orthographic effect (L2 matched H = L2 mismatched H and L2 matched NH = L2
mismatched NH).

178
question comparisons results hyp.
Q3a: Does L2 orthographic knowledge affect how listeners count phonemes in their second language (L2)?
L2 matched vs. mismatched NH (Figures. 5.9 & 5.10)
1) RFL group more accurate than MFL group
2) L2 matched NH counted more accurately than L2 mismatched NH 3) no RT difference between the RFL and MFL groups 4) L2 matched NH counted faster then L2 mismatched NH
! " " "
Q3b: If so, how does L2 orthographic knowledge interact with L1 orthographic knowledge?
L2 matched vs. mismatched H (Figures. 5.9 & 5.10)
1) RFL group more accurate than MFL group
2) no accuracy difference between matched and mismatched H
3) no RT difference between groups
4) no RT difference between matched and mismatched H
!
! "
!
L2 matched NH vs. L2 mismatched H (Figures. 5.9 & 5.10)
1) RFL group more accurate than MFL group 2) no accuracy difference between matched NH and mismatched H 3) no RT difference between groups 4) no RT difference between matched NH and mismatched H
!
! "
!
L1 = first language, L2 = second language, L0 = unfamiliar language, NH = nonhomophone, H = homophone, RT = response time, hyp. = hypotheses, ! = supported, " = not supported, n/a = no hypothesis predicted
Table 5.6 Summary of subgroup data results addressing the third primary research question, the comparisons, and the predictions

179
5.7 Primary research question 4: strength of orthographic effect
Considering the previous results suggest that L1 orthography affects L1 phoneme
perception (§5.3) and L2 orthography affects L2 phoneme perception (§5.6), the next
logical question is: does the strength of the orthographic effect vary depending on
experience with the language? The hypothesis here predicts that the difference between
the matched and mismatched L1 NH would be greater than the difference between the
matched and mismatched L2 NH, which in turn would be greater than the difference
between the matched and mismatched L0 NH. That is,
Prediction:
As native English speakers, the participants have many more years of experience
with English than they do with their L2. Thus, the L1 orthography is more entrenched
and should exert more influence on L1 perception than the L2 orthography does on L2
perception. The mean reflected accuracy and logged RT differences were calculated by
subtracting the matched value from the mismatched value for each condition. Positive
values indicate higher accuracy rates and faster RTs in the matched conditions than in the
mismatched conditions, and negative values indicate lower accuracy and faster RTs in
the matched conditions than in the mismatched conditions. (See Table 5.5 for a summary
of the mean reflected accuracy and logged RT differences for each homophone type and
across each language.)

180
Figure 5.11 represents the match-mismatch accuracy differences for the RFL and MFL
groups across each language (i.e., L1, L2, and L0). In this figure, all mean reflected
accuracy differences have positive values, indicating higher accuracy in the matched NHs
than in the mismatched NHs. This figure also shows that the degree and pattern of the
RFL group’s differences appear to diverge from the MFL group’s differences. That is,
while both groups exhibit a greater difference between the matched and mismatched NH
in the L1 than in the L2 and L0, the RFL group appears to exhibit the same degree of
difference in the L2 and L0. In contrast, the MFL group appears to exhibit the predicted
pattern of L1 difference > L2 difference > L0 difference.
Figure 5.11 Mean square root values of the reflected accuracy rates comparing the match-mismatch differences between the L1, L2 and L0 nonhomophones for the RFL and MFL groups
L0L2 L1
Squ
are
root
of
refle
cted
acc
urac
y ra
tes
0 .6000
0.4000
0.2000
0.0000
Error Bars: 95% CI
MFLRFL
group
GLM L1diff L2diff L0diff BY group /WSFACTOR=LANG 3 Polynomial /METHOD=SSTYPE(3) /CRITERIA=ALPHA(.05) /WSDESIGN=LANG /DESIGN=group.
General Linear Model
Page 3

181
The reflected accuracy differences between the matched and mismatched NH were
analysed using a 2-factor repeated measures ANOVA with group (RFL, MFL) as a
between-subjects factor and language (L1, L2, L0) as a within-subjects factor.
Mauchly’s test indicated no violations of the assumption of sphericity. The main effect
of language was significant (F(2,46)=11.552, p<0.005), but neither the effect of group
nor the interaction of language and group was significant (group: F(1,23)=0.085;
language by group: F(2,46)=1.841; all effects not significant at p>0.05). Subsequent
analyses, collapsed over group, indicated that the L1 difference was significantly greater
than both the L2 difference (F(1,24)=6.433, p<0.05) and the L0 difference
(F(1,24)=10.825, p<0.005), but the L2 difference was not significantly greater than the
L0 difference (F(1,24)=2.924, p>0.05).
With respect to the match-mismatch RT differences, Figure 5.12 reflects the pattern
predicted by the hypothesis, namely that the L1 differences would be greater than the L2
differences, which in turn, would be greater than the L0 differences. In this figure, the
positive values indicate that participants responded faster for the matched NHs than for
the mismatched NHs. This figure also shows that the MFL group appears to have greater
match-mismatch differences for each language than the RFL group does. These RT
differences between the matched and mismatched NH were analysed using a 2-factor
repeated measures ANOVA with group (RFL, MFL) as a between-subjects factor and
language (L1, L2, L0) as a within-subjects factor. The main effect of language was
significant (F(2,46)=46.144, p<0.001), but neither the effect for group nor the interaction
of language and group was significant (group: F(1,23)=0.215; language and group:
F(2,46)=0.586; not significant at p>0.05). Follow up tests, collapsed over group, indicate
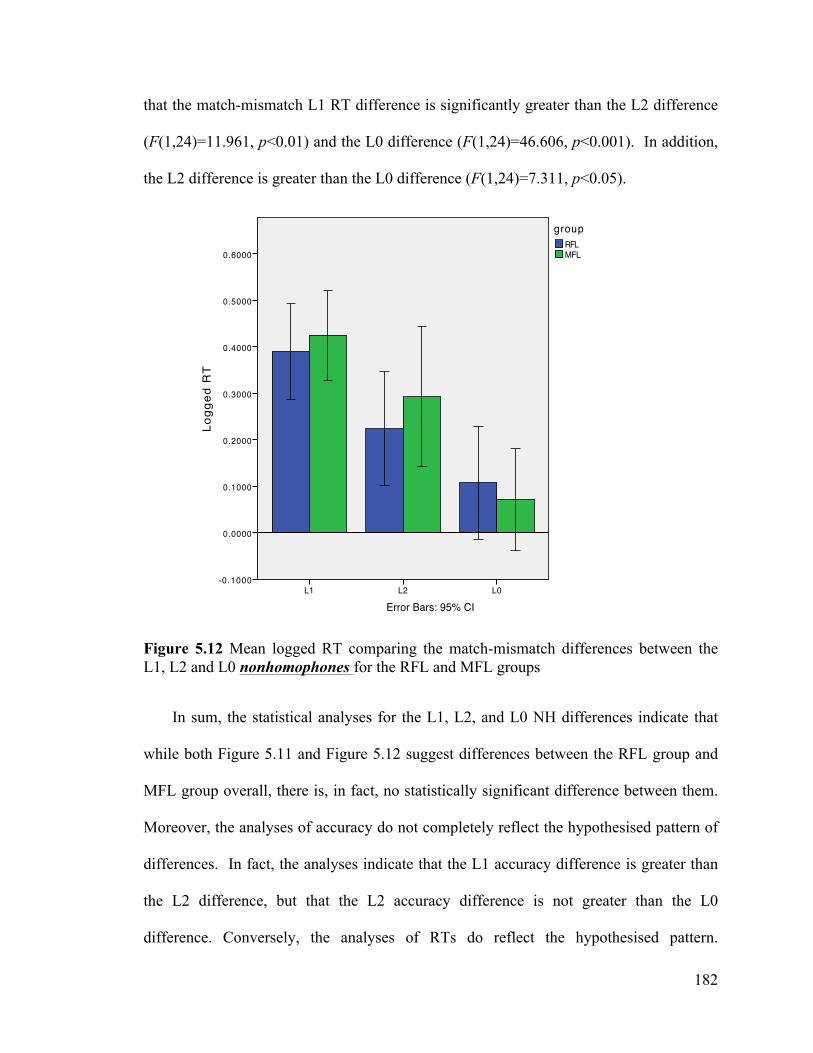
182
that the match-mismatch L1 RT difference is significantly greater than the L2 difference
(F(1,24)=11.961, p<0.01) and the L0 difference (F(1,24)=46.606, p<0.001). In addition,
the L2 difference is greater than the L0 difference (F(1,24)=7.311, p<0.05).
Figure 5.12 Mean logged RT comparing the match-mismatch differences between the L1, L2 and L0 nonhomophones for the RFL and MFL groups
In sum, the statistical analyses for the L1, L2, and L0 NH differences indicate that
while both Figure 5.11 and Figure 5.12 suggest differences between the RFL group and
MFL group overall, there is, in fact, no statistically significant difference between them.
Moreover, the analyses of accuracy do not completely reflect the hypothesised pattern of
differences. In fact, the analyses indicate that the L1 accuracy difference is greater than
the L2 difference, but that the L2 accuracy difference is not greater than the L0
difference. Conversely, the analyses of RTs do reflect the hypothesised pattern.
L0L2L1
Logg
ed R
T
0 .6000
0.5000
0.4000
0.3000
0.2000
0.1000
0.0000
-0.1000
Error Bars: 95% CI
MFLRFL
group
GLM L1diff L2diff L0diff BY group /WSFACTOR=LANG 3 Polynomial /METHOD=SSTYPE(3) /CRITERIA=ALPHA(.05) /WSDESIGN=LANG /DESIGN=group.
General Linear Model
Page 14

183
Specifically, the RT analyses indicate that the L1 RT difference is greater than the L2
difference, and the L2 RT difference is greater the L0 difference. These results and
analyses suggest that the L1 orthographic effect is stronger in the L1 than the L2
orthographic effect is in the L2. In fact, the L2 orthography appears weaker than the L1
orthography at this stage of L2 learning as evidenced by the lack of a significant
difference between the L2 and L0 in accuracy rates, but the presence of a significant
difference between the L2 and the L0 in RTs.

184
question comparisons results hyp.
Q4: Does the strength of the orthographic effect vary depending on experience with the language?
match-mismatch differences for the L1, L2, and L0 NH (Figures 5.11 & 5.12)
1) L1 accuracy difference greater than both L2 and L0
2) L2 accuracy difference not greater than L0
3) L1 RT difference greater than L2, which is greater than L0
!
"
!
L1 = first language, L2 = second language, L0 = unfamiliar language, NH = nonhomophone, H = homophone, RT = response time, hyp. = hypotheses, ! = supported, " = not supported, n/a = no hypothesis predicted
Table 5.7 Summary of subgroup data results addressing the third primary research question, the comparisons, and the predictions

185
5.8 General summary
This chapter has presented and analysed the primary data collected in this research. The
data were analysed according to reflected accuracy rates and logged RTs in order to
investigate the effects of orthographic knowledge on phoneme perception in listeners’
first language, second language, and unfamiliar language. To determine this effect, 4-way
repeated measures ANOVAs analysed the data along four independent factors (group,
language, homophone, and match) to answer four primary research questions:
1. Does L1 orthographic knowledge affect how native English speakers
count phonemes in their first language (L1)?
2. Does L1 orthographic knowledge affect how native English speakers
count phonemes in an unfamiliar language (L0)?
3. Does L2 orthographic knowledge affect how native English speakers
count phonemes in their second language (L2), and if so how does
L2 orthography interact with L1 orthography?
4. Does the strength of the orthographic effect vary depending on
language experience?
The results of the analyses overall confirm the hypotheses that L1 orthographic
knowledge influences both L1 and L0 phoneme perception and that L2 orthographic
knowledge influences L2 phoneme perception. Specifically, for L1 phoneme perception,
L1 orthography has a facilitative effect on accuracy such that L1 orthographic knowledge
helps listeners count phonemes when the words have consistent (one-to-one) letter-
phoneme correspondences. In addition, L1 orthography has both a facilitative and
inhibitory effect on RTs such that the L1 orthography allows participants to count

186
consistent L1 words faster than inconsistent L1 words and prevents them from counting
phonemes in inconsistent L1 words as fast as they count phonemes in unknown L0
words. For L2 phoneme perception, the results show that not only does L2 orthographic
knowledge influence L2 phoneme perception, but it also overrides any potential L1
orthographic effect.
However, the analyses also indicated that the picture is much more complex than
simple orthographic interference. In fact, and perhaps not so surprisingly, the results
show that the orthographic effect interacts with at least three other effects – 1) familiarity,
2) word, and 3) experience – to influence phoneme perception. First, familiarity allows
listeners to count phonemes in L0 words that are homophonous with L1 words more
accurately and faster than in L0 words that are not homophonous with L1 words even if
the H words are mismatched. Second, a word effect (i.e., an unanticipated difference
between the L0 matched and mismatched NH) makes counting L0 matched NHs more
accurate than the L0 mismatched NHs. These first two effects attenuate the effects of L1
orthography such that its influence does not appear as strong in the L0 as it is in the L1.
Third, L1, L2, and L0 differences between the matched and mismatched conditions
suggest that the orthographic effect is directly related to the amount of experience the
listeners have with the target language. That is, the orthographic effect is the strongest
for the L1 (the most experience), followed by the L2, and then the L0 (the least
experience).
Finally, the results and analyses reported on in this chapter point towards two major
findings surrounding the effect of orthographic knowledge.

187
1. Orthographic knowledge facilitates and hinders phoneme
perception in both native and nonnative languages, which
explains why the matched words were counted more accurately
and faster than the mismatched words, and
2. The effect of orthographic knowledge appears to be language
specific, which explains why L2 orthography has a greater
influence over L2 perception than L1 orthography has over L2
perception.
These two effects and findings (as well as the other interesting findings) are explored and
discussed at length in the next chapter, Chapter 6.

188
Chapter Six
DISCUSSION
“The visual forms of words acquired from reading experiences serve to shape learners’ conceptualizations of the phoneme segments in those words.”
(Ehri, 1985, p. 342) The previous chapter has reported on and analysed the overall and subgroup data
according to the four primary research questions, which were designed to ascertain the
effect of orthographic knowledge on phoneme perception. Many interesting findings and
subsequent questions have come to the fore in light of the data analyses. This chapter
discusses each of these findings and questions in depth. To facilitate the discussion, this
chapter is divided into three major sections. The first section (§6.1) provides an overview
of the research project itself and the results—including the experimental groups, the
experimental task, research questions, hypotheses, rationales supporting the hypotheses,
and the results. The second section is the General Discussion of orthographic effects with
reference to phoneme awareness (§6.2.1), language-specificity (§6.2.2), the Bipartite
Model of Orthographic Knowledge and Transfer (§6.2.3), and experience-dependency
(§6.2.4). The third section (§6.3) discusses three unanticipated (albeit very interesting)
results stemming from the research, including familiarity and word effects (§6.3.1),
phonological effects (§6.3.2), and mismatch subcategory effects (§6.3.3). The fourth
section (§6.4) explores the phonemicisation of the diphthongs. Finally, the fifth section
(§6.5) concludes the chapter by summarising the main findings and discussions.

189
6.1 Research overview
As outlined and discussed in Chapter 2, previous research suggests that alphabetic
literacy is the foundation upon which phoneme awareness rests (e.g., Carroll, 2004;
Cheung, 2004; Cheung & Chen, 1999; Ehri, 1985) and speech processing is not
independent of written language (Ziegler & Ferrand, 1998). Therefore, this project
contributes to the body of research on orthographic influence by determining and
investigating how orthographic knowledge affects phoneme detection not only in a first
language (L1) but also in a second language (L2) and an unfamiliar language (L0). For
this project, each set of stimuli was created and organised according to two parameters:
match and homophony. That is, within each language, the stimuli set had four types of
words:
1) M-NH – nonhomophonous words with consistent letter-phoneme
correspondences (e.g., big /bIg/, !"# /duS/, and hu$ /xwa/),
2) MM-NH – nonhomophonous words with inconsistent correspondences
(e.g., fish /fIS/, %& /juk/, and yòng /jON/)
3) M-H – cross-language homophonous words with consistent L1 and
L2/L0 associations (e.g., brat /b®œt/–'()* /brat/ and bow /baw/–bào
/paw/), and
4) MM-H – cross-language homophonous words with inconsistent L1
(but not L2/L0) associations (e.g., tree /t®i/–*(+ /tri/ and rue /®u/–rú
/!u/).

190
The assumption here was that accuracy and response time differences between matched
and mismatched words, as well as between homophones and nonhomophones, would
indicate an effect of orthographic knowledge on phoneme perception.
In this research, 52 native speakers of Canadian English counted phonemes in words
from their L1 (English) and an L0 (either Russian or Mandarin). The MNL0 group
counted phonemes in English (L1) and Mandarin (L0) words while the RNL0 group
counted phonemes in English (L1) and Russian (L0) words. In addition, two subgroups of
participants also counted phonemes in their L2. The L2 for the subgroup within the
MNL0 was Russian (the RFL subgroup), and the L2 for the subgroup within the RNL0
was Mandarin (the MFL subgroup). Via a phoneme counting task, which assesses the
influence of orthographic factors and measures phoneme awareness (Treiman & Cassar,
1997), the participants listened to the target stimuli and counted the number of “sounds”
they heard in the each word.
The data were analysed according to accuracy rates and response times in order to
investigate the effects of orthographic knowledge on L1, L2, and L0 phoneme perception.
Four-factor repeated measures ANOVAs analysed the data along four independent
factors (group, language, homophone, and match) to answer four primary research
questions designed to investigate the orthographic effects (See Table 6.1 for a review.).
Overall, the results of the analyses show that L1 orthographic knowledge influences both
L1 and L0 phoneme perception and that L2 orthographic knowledge influences L2
phoneme perception. Specifically, L1 orthography has a facilitative effect on accuracy in
L1 phoneme perception and both a facilitative and inhibitory effect on response times in
L1 phoneme perception. For L2 phoneme perception, the results show that L2

191
orthographic knowledge influences L2 phoneme perception, and it overrides any
potential L1 orthographic effect. These L2 results suggest that orthographic effects are
language-specific and experience-dependent. In terms of L0 phoneme perception, the
results suggest that orthographic knowledge interacts with familiarity, the words
themselves, and language experience. The interaction of these effects reduces the effects
of L1 orthography such that its influence is not as strong in the L0 as it is in the L1.
As a reminder, Table 6.1 summarises the four primary research questions, their
predictions, the rationales behind the predictions, and the results (! indicates results that
support the predictions, and where the predictions are not supported, the results are
provided.). For example, with respect to the L1 consistent and inconsistent42 words
(column 2, row 1), the hypothesis predicts that matched words should be counted more
accurately and faster than the mismatched words because L1 orthography helps listeners
perceive and segment phonemes in consistent words but misdirects listeners in
inconsistent words. As indicated by the “!”, both the accuracy rates and response times
support the L1 predictions. In contrast, with respect to the L2 matched and mismatched
H, the hypothesis predicts that L2 matched H should be counted more accurately and
faster than mismatched H (column 2, row 9) because L1 orthography would interfere and
affect how many phonemes are perceived. The table indicates that this prediction is not
supported; the results, in fact, show no difference between the L2 matched and
mismatched H words. The subsequent sections address and discuss the effects of
orthography and other observed effects in more depth.
42 Recall that consistent words (i.e., matched) words refer to words with one-to-one letter-phoneme correspondences while inconsistent words (i.e., mismatched) words refer to words without one-to-one letter-phoneme correspondences.

192
questions rationale predictions results Q1: Does L1 orthographic knowledge affect how listeners count phonemes in their first language (L1)?
- L1 orthography facilitates L1 phoneme perception in matched words but hinders in mismatched words
2) L1 matched words more accurate than L1 mismatched words
3) L1 matched words faster than L1mismatched words
! !
- L1 orthography facilitates L1 phoneme perception in L1 matched NH and does not affect L0 phoneme perception in L0 matched NH because spelling is unknown
- L1 orthography hinders L1 phoneme perception in L1 mismatched NH and does not affect L0 phoneme perception in L0 mismatched NH because spelling is unknown
- L1 orthography does not affect L1 phoneme perception when spelling is NOT known
4) matched L1 NH more accurate than matched L0 NH
5) matched L1 NH faster than matched L0 NH
! !
6) L1 mismatched NH less accurate than L0 mismatched NH
7) L1 mismatched NH slower than L0 mismatched NH
L1 NH = L0 NH !
8) no accuracy difference between L0 matched and mismatched NH
9) no RT difference between L0 matched and mismatched NH
M-NH >> MM-NH
M-NH >> MM-NH
Q2: Does L1 orthographic knowledge affect how listeners count phonemes in an unfamiliar language (L0)?
- L1 orthography facilitates L0 phoneme perception in matched H but hinders in mismatched H
2) L0 matched H more accurate than L0 mismatched H
3) L0 matched H faster than L0 mismatched H
!
M-H = MM-H
- L1 orthography facilitates L0 phoneme perception in matched H but does not affect matched NH because spelling is unknown
- L1 orthography hinders L0 phoneme perception in mismatched H but does not affect mismatched NH because spelling is unknown
3) L0 matched H more accurate than matched L0 NH
4) L0 matched H faster than matched L0 NH
!
MM-H = M-NH
5) L0 mismatched H less accurate than mismatched NH
6) L0 mismatched H slower than mismatched NH
MM-H >> MM-NH
MM-H >> MM-NH
Table 6.1 Primary research questions, predictions, and results revisited

193
Q3a: Does L2 orthographic knowledge affect how listeners count phonemes in their second language (L2)?
- L2 orthography facilitates L2 phoneme perception in matched NH but hinders in mismatched NH
2) L2 matched NH more accurate than L2 mismatched NH
3) L2 matched NH faster than mismatched NH
! !
Q3b: If so, how does L2 orthographic knowledge interact with L1 orthographic knowledge?
- L1 orthographic knowledge hinders L2 phoneme perception because it overrides L2 orthographic knowledge
- L1 orthography facilitates L2 phoneme perception in L2 words with matched L1 associations but hinders in L2 words with mismatched L1 associations
1) matched H more accurate than mismatched H
2) matched H faster than mismatched H
M-H = MM-NH
M-H = MM-NH
3) L2 matched NH more accurate than L2 mismatched H
4) L2 matched NH faster than L2 mismatched H
M-NH = MM-H
M-NH = MM-H
Q4: Does the strength of the orthographic effect vary depending on the language experience?
- greater language experience results in greater differences between matched and mismatched words
1) L1 NH greater accuracy and RT differences than L2 NH, and L2 NH greater accuracy and RT differences than L0 NH
A: L1 > L2 = L0
RT: !
L1 = first language, L0 = unfamiliar language, L2 = second language, NH = nonhomophone, H = homophone, M = match, MM = mismatch, RT = response time, A = accuracy
Table 6.1 Continued …

194
6.2 General Discussion
The following subsections discuss indepth the effects of orthography as suggested by the
results. The first section discusses the overall orthographic effects on phoneme perception
in all three languages, the L1, L2, and L0 (§6.2.1); the second section focuses on the
language-specific aspect of orthographic effects (§6.2.2). Next, to account for the
language-specific effect and other previous findings, the third subsection proposes the
Bipartite Model of Orthographic Knowledge and Transfer (§6.2.3). Finally, the fourth
section (§6.2.4) discusses how language experience affects the influence of orthographic
knowledge.
6.2.1 Orthographic knowledge’s influences on phoneme perception
The first step of this research project was to confirm—as claimed by previous research
(e.g., Burnham, 2003; Castles et al., 2003; Ehri & Wilce, 1980; Perin, 1983; Pytlyk, to
appear; Treiman & Cassar, 1997)—that L1 orthography influences listeners’ abilities to
perceive L1 phonemes. This part of the research analysed the overall data from native
Canadian English-speaking participants who counted phonemes in English words with
consistent letter-phoneme correspondences (e.g., run /®Øn/ has 3 letters and 3 phonemes)
and with inconsistent letter-phoneme correspondences (e.g., truth /truT/ has 5 letters and
only 4 phonemes). Indeed, the results confirm that participants’ orthographic knowledge
interferes with their phoneme awareness of words: the statistical analyses indicate that the
participants were significantly more accurate and faster at counting phonemes with
consistent words than with inconsistent words (given in (1) below):43
43 Henceforth, all discussed comparisons and differences are statistically significant unless otherwise indicated.

195
(1) L1 M-NH and M-H >> L1 MM-NH and MM-H.
In general, these L1 findings suggest that L1 orthography influences speech perception in
L1 such that it facilitates phoneme counting when the words contain consistent letter-
phoneme correspondences but hinders phoneme counting when the words contain
inconsistent correspondences, although see the discussion below for further details. In
other words, because listeners receive conflicting orthographic and phonetic information,
inconsistent letter-phoneme correspondences inhibit speech processing, which results in
lower accuracy rates and longer processing times (e.g., Glushko, 1979; Jared et al., 1990;
Lacruz & Folk, 2004; Stone et al., 1997; Ziegler et al., 2004).
When comparing the L1 NH (i.e., nonhomophone) data with the L0 NH data, we
gain even more insight into the effects of L1 orthography on phoneme perception. First,
in terms of accuracy, recall the L1 matched NH words were counted more accurately than
not only the L1 mismatched NH but also the L0 matched and mismatched NH (as
expected). However, the L1 mismatched NH words were counted as accurately as the L0
mismatched NH (not as expected). In short, we can represent the results as:
(2) L1 M-NH >> L0 M-NH >> L1 MM-NH = L0 MM-NH.
This suggests that, in terms of accuracy, L1 orthography actually has a facilitative effect
but not an inhibitory one on accuracy. That is, the lack of accuracy differences between
the L1 mismatched NHs and the L0 NHs suggest that L1 orthography does not hinder
counting any more than not knowing the language does. If orthography did hinder
counting, we would expect listeners to more accurately count phonemes in the L0 NHs
that in the L1 mismatched NHs.

196
In addition, the analyses comparing L0 H data indicate that both groups were
significantly more accurate with the L0 matched H words than with the mismatched H
words, as given below in (3).
(3) L0 M-H >> L0 MM-H
The accuracy rates results suggest that L1 orthographic knowledge is also a factor in L0
phoneme perception. Specifically, the L1 orthography facilitates phoneme perception in
L0 words when they are homophonous with L1 words that have consistent
correspondences but hinders perception when the L0 are homophonous with L1 words
that have inconsistent correspondences. In short, participants appear to employ the L1
orthography to help them count phonemes in the L0, a strategy that helps with counting
phonemes in matched words but not with mismatched words.
In terms of speed, while the phonemes in the L1 matched NH were counted faster
than the L1 mismatched NH and all the L0 NH (as with the accuracy rates), the L1
mismatched NH were counted slower than the L0 NH. Compare the representation in (2)
with the following one in (4).
(4) L1 M-NH >> L0 M-NH = L0 MM-NH >> L1 MM-NH.
These RT results suggest that L1 orthography has both a facilitative and inhibitory effect
with respect to counting speed as the L1 orthography allowed participants to count
matched L1 NH faster than the matched and mismatched L0 NH but made them count the
mismatched L1 NH slower than the L0 NH words. The response time data here do not
show the same facilitative effect of L1 orthography as with accuracy (given in (2) above).
In fact, the analyses show no significant differences exist either between the MNL0 and
RNL0 groups or between the L0 matched and mismatched H words.

197
While previous research has established—rather convincingly—that L1 orthographic
knowledge exerts an unavoidable influence on L1 phonology, little research has
investigated the effect of orthography on nonnative language phoneme awareness—both
unfamiliar (L0) and familiar (L2) nonnative languages. After investigating the effects of
orthographic knowledge on L0, this research also investigated what effect orthography
exerts on phoneme awareness in the listeners’ second language. Does L2 orthography
affect L2 phoneme awareness? This part of the research analysed L2 nonhomophone
word data (i.e., the L2 words without L1 orthographic associations) from two subgroups
of participants. One subgroup contained L2 learners of Russian (RFL) who counted
phonemes in Russian words with consistent letter-phoneme correspondences (e.g., !"#$
/druk/ has 4 letters and 4 phonemes) and with inconsistent letter-phoneme
correspondences (e.g., %"&'( /krof!/ has 5 letters but only 4 phonemes). The other
subgroup contained L2 learners of Mandarin (MFL) who counted phonemes in Mandarin
words with consistent letter-phoneme correspondences (e.g., hu)n /xwan/ has 4 letters
and 4 phonemes) and with inconsistent letter-phoneme correspondences (e.g., sh*o /ßwO/
has 4 letters but only 3 phonemes).
The analyses of the subgroup data suggest that L2 orthographic knowledge does
influence L2 phoneme perception. That is, the analyses show that both groups more
accurately count phonemes in L2 matched NH than in L2 mismatched NH. In addition,
the analyses indicate that both groups count phonemes faster in L2 matched NH than in
L2 mismatched NH. That is, for both accuracy and RTs,
(5) L2 M-NH >> L2 MM-NH.

198
These results suggest that L2 orthographic knowledge is a contributing factor for
performance in an auditory phoneme counting task: as with the effect of L1 orthography
on L1 words, L2 orthography facilitates L2 phoneme perception and counting in L2
words with consistent letter-phoneme correspondences and hinders L2 phoneme
perception and counting in L2 words with inconsistent correspondences.
As this research employed a strictly auditory task, these L1 and L2 results support
other findings on letter-phoneme inconsistencies. Previous research has shown that even
in absence of visual stimulation, orthographic knowledge influences auditory processing
(Ziegler & Ferrand, 1998; Ziegler et al., 2003; Ziegler et al., 2004). The current findings
support the theory that orthographic knowledge is co-activated with auditory information,
and once it is activated, orthographic knowledge influences how and what phonemes are
perceived even when visual stimulation is absent (Blau et al., 2008; Chéreau et al., 2007;
Taft et al., 2008). Because “the orthographic code cannot be suppressed even when it
hinders performance” (Perin, 1983, p. 138), orthographic interference is unavoidable
(e.g., Burnham, 2003; Treiman & Cassar, 1997). Dijkstra et al. (1995) propose that when
completing phoneme-monitoring tasks such as phoneme detection, listeners may keep
both the orthographic representation and the phonological representation in mind even if
it is detrimental to performance. In fact, the automatic co-activation makes separating
orthographic knowledge and phonological representation virtually impossible (Treiman
& Cassar, 1997), and as a result, individuals are more “susceptible to unwanted
interference” from the orthographic code (Landerl et al., 1996, p.12), and have “difficulty
focusing on phonemes and ignoring the letters” (Gombert, 1996, p. 262). The L1 results
in this current research confirm that individuals are susceptible to interference from their

199
L1 orthographic code, and more importantly, the L2 results demonstrate that individuals
are also susceptible to interference from their L2 orthographic code.
This research has demonstrated that due to pervasiveness of orthographic
interference, orthographic knowledge facilitates phoneme perception in words with
consistent letter-phoneme correspondences but hinders phoneme perception in words
with inconsistent correspondences. One possible explanation for why L1 and L2
orthographic knowledge both facilitates and hinders phoneme perception may lie in the
assumptions listeners make about the relationship between letters and phonemes. Recall
that two or more single letters that are used to represent individual phonemes (e.g., <s>
and <h>) are sometimes combined (e.g., <sh>) to represent a different phoneme (e.g., /!/).
In general, speakers of languages with alphabetic representations function under the
assumption that one letter represents one phoneme and “take for granted that letters
correspond to individual phonemes” (Cook, 2004; p. 8). Therefore, in situations where
the number of letters does not match the number of phonemes in a word, listeners are
faced with conflicting information (orthographic and phonetic), and they must reconcile
their underlying assumption about the relationship between letters and phonemes with the
phonetic information they hear. To do this, listeners must spend extra cognitive resources
reconciling the letter-phoneme contradictions, and trying to reconcile these contradictions
results in processing difficulties which, in turn, results in lower accuracy rates and longer
processing times. In contrast, when the number of letters equals the number of phonemes,
listeners do not receive any conflicting information and as such are extremely accurate at
counting phonemes. In fact, the orthographic information supports the phonetic
information and the listeners do not experience processing difficulties.

200
In short, the results from the current project further corroborate that, as predicted,
orthographic knowledge affects how listeners perceive phonemes. The L1 results here
are consistent with previous findings on L1 phoneme perception and awareness (e.g.,
Ehri & Wilce, 1980; Perin, 1983; Pytlyk, to appear), namely that L1 orthographic
knowledge plays a pivotal role in L1 speech perception. In addition, this research
expands on the previous research by also demonstrating that L2 orthographic knowledge
is factor in L2 phoneme perception. However, additional questions remain about the
interaction between L1 and L2 orthographic knowledge. Does L1 orthographic
knowledge 1) transfer into L2 speech perception, 2) override the influence of L2
orthographic knowledge, and 3) affect L2 phoneme awareness? These questions are
addressed in the following subsection.
6.2.2 The language-specific nature of orthographic effects
The statistical analyses of the L2 matched and mismatched homophone (i.e., the H data)
comparisons—as well as the L0 matched and mismatched homophone comparisons—
further demonstrate the effects of orthography and provide answers for those questions
asked in the paragraph above. Indeed, the results from this research suggest that for
alphabetic languages in which listeners are literate (i.e., L1 and L2), the effect of
orthographic knowledge is language-specific. In other words, the results suggest that
once an L2 orthography is learnt, it exerts its own effect on L2 speech perception and in
fact replaces the effect of L1 orthography.
The analyses show that while the RFL learners counted phonemes more accurately
overall than the MFL learners (discussed below in §6.3.3), neither the RFL nor the MFL

201
group was more accurate or faster at counting phonemes in L2 matched H words than in
the mismatched H words. We can represent these L2 H accuracy and RT results as
(6) L2 M-H = L2 MM-H.
In contrast, the L1 matched and mismatched H accuracy and RT results are
(7) L1 M-H >> L1 MM-H.
Recall that for the L2 mismatched H, the mismatches were always in the L1 homophones
and the L2 orthographic spellings of the mismatched H were always consistent. For
example, the Russian mismatched H word +, /!:i/ has 2 letters and 2 phonemes while its
associated English counterpart she /!i/ has 3 letters but only 2 phonemes. Similarly, the
Mandarin mismatched H word ni# /ni/ has 2 letters and 2 phonemes while the associated
English word knee /ni/ has 4 letters but only 2 phonemes. Thus, the finding that L2 MM-
H = L2 M-H suggests (contrary to the prediction) that the L1 orthography does not
intrude on L2 phoneme perception. If L1 orthographic information did override L2
orthographic information, the results would have shown the same kind of difference in
accuracy and RTs between the matched and mismatched H as was observed with the L1
matched and mismatched H (i.e., L2 M-H >> L2 MM-H). When we consider these
results in conjunction with the L2 NH results (See (4) above.), L2 listeners do not appear
to fall back on their L1 orthographic knowledge to help them count phonemes in their L2.
Rather, the difference between the L2 matched and mismatched NH (i.e., L2 words with
no L1 associations) and the lack of difference between the matched and mismatched H
(i.e., L2 words with L1 associations where the mismatch was in the L1) indicate that the
L2 listeners rely more heavily on their L2 orthographic knowledge than they do on their
L1 orthography knowledge.

202
To be certain that the L2 orthographic information overrides the L1 orthographic
information, L2 words without L1 associations were also compared to L2 words with L1
associations in one additional test: the L2 matched NH word data were compared with the
L2 mismatched H word data. This comparison teases apart the potential orthographic
effects of L1 (mismatched H) and L2 (matched NH). If L1 orthography did intrude, we
would expect the L2 M-NH to be more accurately counted than the L2 MM-H since the
listeners would have been positively influenced by the consistent L2 letter-phoneme
correspondences of the L2 matched nonhomophones, and they would have been
negatively influenced by the inconsistent L1 letter-phoneme correspondences of the L2
mismatched homophones. However, this comparison yielded no significant accuracy or
RT differences between the L2 matched NH words (no L1 association) and the L2
mismatched H words (L1 association):
(8) L2 M-NH = L2 MM-H
This final comparison supports the above results suggesting that L2 orthographic
knowledge is paramount in L2 speech processing, and further suggesting that L1
orthography does not negatively affect L2 phoneme perception.
In sum, the combination of a) the matched and mismatched NH results, b) the
matched and mismatched H results, and c) the matched NH and mismatched H results
suggest that L1 orthography does not have as strong an impact on L2 phoneme perception
as L2 orthography does, at least at an intermediate stage of L2 learning. In fact, L2
orthographic knowledge appears to override the more established L1 orthographic
knowledge for both RFL and MFL learners. These language-specific findings raise two
very important questions. First, how do the L2 orthographic and phonological systems

203
become so closely connected? In other words, how does L2 phonology become linked
with L2 orthography? Second, what promotes (or prevents) the formulation of the
orthography-phonology link?
Regarding the first question, researchers have suggested that orthography and
phonology are co-activated in the native language because learning orthographic
representations of phonemes serves to reorganise and restructure the L1 phonological
system (e.g., Burnham, 2003; Frith, 1998; Perre et al., 2009; Ziegler & Muneaux, 2007;
Ziegler et al., 2003). Burnham (2003) claims that once children start to acquire an
alphabet, the orthographic knowledge reorganises the L1 phonological system and the
two systems become interdependent. Ziegler et al. (2003) suggest that orthographic
knowledge “provides an additional constraint in driving segmental restructuring” (p.
790). In addition to research on offline metalinguistic phonological processing, research
using event-related potentials (ERPs) has measured online activation of phonological
codes. This research too supports the restructuring hypothesis by demonstrating that
orthographic knowledge influences the functional organization of the temporal-parietal
junction (Perre et al., 2009). After reorganising and restructuring the phonological
system, orthographic knowledge is so intimately linked to the phonological system that
readers cannot avoid thinking about the letters even when specifically instructed not to do
so (Landerl et al., 1996) and in the absence of visual stimulation (e.g., Ziegler & Ferrand,
1998; Ziegler et al., 2004; Ziegler et al., 2003).
Can we extrapolate from the L1 orthographic and phonological co-activation to L2
orthographic and phonological co-activation? If L1 orthographic learning does indeed
force a reorganisation of L1 phonology, can we posit that L2 orthography forces an

204
organisation of L2 phonology? In L1, native speakers learn phonology before
orthography, but in L2, learners generally learn phonology and orthography concurrently.
Therefore, learning L2 phonology cannot “reorganise” the L2 phonology. However, does
learning L2 orthography help to organize L2 phonology? The L2 results suggest that
perhaps learning L2 orthography dictates the organisation of the L2 phonology thus
making these two systems interconnected, which in turn, means that they are co-activated
in L2 speech processing. This reduces the influence and impact L1 orthography has on
the L2. Indeed, Coutsougera (2007) maintains that “beginner learners are forced [original
emphasis] into reaching some kind of phonological awareness [in L2] so that they are
able to start reading and writing” and that “learners urgently need to establish letter-
phoneme correspondences in order to decode writing” (pp. 3–4). As a result of this
urgency, L2 learners build the L2 letter-phoneme correspondences upon the foundation of
L1 orthographic assumptions and principles. The question then becomes how (or at what
point) does L2 orthography organise L2 phonology?
Other avenues of first language acquisition may provide answers to the questions
surrounding the acquisition of L2 orthography and the organisation of L2 phonology. In
general, previous research indicates that L1 phonology is sharpened and reorganised at
two important junctures of L1 acquisition: 1) in infancy with exposure to the ambient/oral
language (Kuhl, 2000; Werker & Tees, 1987) and 2) in childhood with the onset of
learning to read (e.g., Burnham, 1986, 2003; Burnham, Earnshaw, & Clark, 1991;
Carroll, 2004; Castro-Caldas et al., 1998; Flege, 1991; Olson, 1996; Treiman & Cassar,
1997; Ziegler et al., 2004). With respect to the second juncture, Olson argues that
learning to read results in “learning to hear speech in a new way” (p. 95) because it

205
provides an abstract conceptual model that creates speech categories and brings those
categories into consciousness. Similarly, Castro-Caldas et al. (1998) propose that learning
to read modifies the phonological system by adding a “visuographic” dimension and
opens the door for new language-processing possibilities such that different and more
areas of the brain are activated in literates than in non-literates. Furthermore, Burnham
(2003) maintains that children’s heightened language-specific speech perception is
related to the onset of reading. For these researchers, the onset of reading is a critical
developmental step in L1 phonological acquisition because (as mentioned above)
learning to read forces a reorganisation of the L1 phonology, which in turn, creates a co-
dependency between the two systems whereby they are co-activated, and they
reciprocally influence each other. More importantly, orthographic effects are not limited
to skilled readers; in fact, orthographic knowledge affects speech perception and
awareness as soon as children begin to learn how speech is represented in print (Treiman
& Cassar, 1997).
If learning to read is a critical juncture in L1 phonological development (e.g.,
Burnham, 2003; Carroll, 2004; Castro-Caldas et al., 1998; Flege, 1991; Olson, 1996;
Treiman & Cassar, 1997; Ziegler & Muneaux, 2007; Ziegler et al., 2004), then, we can
reasonably speculate that learning to read in the L2 is also a critical juncture in L2
phonological development. Recall that the current research found L2 orthographic
knowledge exerts a greater influence on L2 phoneme perception than L1 orthographic
knowledge does, at least for intermediate learners of Russian and Mandarin Chinese.
According to Burnham (2003), language-specific speech perception is heightened
following and significantly related to the onset of reading instruction. Therefore, one

206
possible explanation is that as in L1, learning to read in L2 may organise the L2
phonology and lead learners to develop a similar co-dependency between the L2
orthography and L2 phonology. As a result of the new co-dependency, L2 learners are
able to disassociate themselves from L1 orthographic knowledge and use L2 orthographic
information as a new crutch when performing L2 phoneme awareness tasks. Moreover, if
learning to read in L2 parallels learning to read in L1, then, orthographic effects will not
be limited to advanced learners but will also affect L2 learners as soon as they begin to
learn to read in the L2 orthography (Treiman & Cassar, 1997).
Regarding the second question—what promotes the link between orthography and
phonology—orthographic transparency and active engagement appear to dictate the
formulation and strength of the link. The new L2 co-dependency may be strengthened by
the degree of orthographic transparency of the L2 orthographic system. Again, we need
to turn to L1 acquisition research to provide us with some insight. In L1 acquisition
research, the general consensus is that children who learn more transparent orthographies
(like Greek, Spanish, and Welsh) acquire orthography-phonology relations rapidly in the
first year of reading instruction, while children who learn less transparent orthographies
(like English and French) acquire these relations slowly over the course of many years
(e.g., Goswami et al., 1998; Goswami, et al., 1997; Landerl, 2000; Seymour et al., 2003;
Spencer & Hanley, 2003, 2004). In addition, Goswami and colleagues (Goswami et al.,
1998; Goswami et al., 1997) found that children who learn transparent orthographies like
Spanish and Welsh develop orthographic representations that encode individual letter-
phoneme correspondences; in contrast, children who learn opaque orthographies like

207
English and French develop orthographic representations that encode sequences of letter-
phoneme correspondences (i.e., rimes).
In other studies investigating orthographic transparency, Spencer and Hanley (2003,
2004) discovered Welsh children consistently outperformed their English counterparts in
both reading and phoneme detection skills. Interestingly, not only did the Welsh children
perform better on Welsh words than English children performed on English words, but
the Welsh children also performed better on the English words than the English children
performed on the English words. Spencer and Hanley (2003) conclude that “the critical
factor at play here is the transparent nature of the alphabetical orthography” (p. 24). In
other words, learning a transparent orthography allowed the Welsh children to
successfully perform tasks in Welsh and generalize from Welsh to English, and learning
an opaque orthography created difficulty for the English children in English and
prevented them from generalizing from English to Welsh. Orthographic transparency
does indeed appear to be the critical factor in dictating the development of orthographic-
phonological associations in L1.
Could orthographic transparency have also been the factor in the relatively rapid
development and strength of L2 orthographic and phonological associations observed in
the current research? As discussed in §3.2, both the Russian and Mandarin orthographies
are more transparent than the English orthography. If learning transparent orthographies
facilitates rapid development of letter-phoneme correspondences, this would explain the
current results, which suggest that L2 learners gathered enough experience in their
language classes to create and foster L2 orthographic and phonological associations that

208
were strong enough to withstand any potential interference from L1 orthographic
knowledge.
The second aspect that appears to promote the formulation of the orthography-
phonology link is active engagement. Research in the area of nonnative language speech
perception indirectly suggests that not only learning to read but also actively engaging in
reading activities are necessary for orthographic knowledge to have an impact on L2
speech processing. Two very recent studies (Pytlyk, 2011; Simon, Chambless, & Alves,
2010) sought to improve nonnative phoneme perception via orthographic training. Both
studies posited that using novel letter-to-phoneme correspondences may aid nonnative
speakers in distinguishing between difficult non-phonemic sounds. Non-phonemic
sounds refer to sounds that do not participate in a phonemic distinction in the L1 and as
such do not have their own phonemic category at the outset of L2 acquisition/exposure.
These sounds may be involved in an L2 contrast where only one phoneme belongs to L1
phoneme inventory (e.g., /u/–/y/ contrast in French; /u/ is an English phoneme but /y/ is
not), or individual L2 phonemes sound similar to L1 phonemes but are not contrastive
with the L1 (e.g., /x/ in Mandarin is similar to /h/ in English). As a result, nonnative
speakers often fail to distinguish between these non-phonemic sounds and similar
sounding phonemes. Interestingly, neither study found evidence that novel orthographic
representations promote L2 phoneme distinctions (at the outset of L2 learning at least).
In their study of America English listeners, Simon et al. (2010) investigated whether
orthographic training would help the listeners distinguish between two similar sounding
contrastive French vowels, /u/–/y/—a contrast that does not exist in American English.
The question asked was whether or not representing each vowel with a different novel

209
letter in a pre-test training phase facilitated establishment of separate phoneme categories
for these vowels. Specifically, the participants were divided into two groups and were
told they would learn words from an unfamiliar language. Half the participants learnt
nonsense words in the “sound only” group where they were saw pictures and heard the
words, and half learnt nonsense words in the “sound-spelling” group where they were not
only saw pictures and heard the words, but they also saw the spelling of the words. For
the spelling, the researchers used <ou> to represent /u/ (e.g., douge /duZ/) and <û> to
represent /y/ (e.g., dûge /dyZ/). Then, Simon et al. used an AXB discrimination task to
determine if orthographic support assisted in the creation of distinct phonological
categories for the two sounds. They discovered (contrary to the predictions) that those
participants trained on new words with orthographic support did not outperform those
participants trained on new words without orthographic support. In other words, we could
interpret Simon et al.’s results as indicating that initial orthographic training in the L2
does not promote separate category creation. Most likely, the participants did not have
enough exposure and experience with the orthography at this point for it to have a
positive impact on their /u/–/y/ distinction.
Similarly, Pytlyk (2011) sought to determine if learners’ abilities to distinguish new
L2 sounds from similar sounding L1 sounds could be enhanced by training in an
unfamiliar orthography. Specifically, the research investigated whether English speakers
who learn Mandarin Chinese via a familiar orthography (i.e., the alphabetic system
Pinyin) differ from those who learn via a non-familiar orthography (i.e., the syllabic
system Zhuyin) in their perception of English–Mandarin sound pairs. Pytlyk found no
significant perceptual differences between the two groups and concluded that Mandarin

210
instruction via the non-familiar orthography did not appear to provide an advantage over
instruction via the familiar orthography (at the very beginning stages of learning at least).
Pytlyk suggested that 1) conflict between the L1 orthographic system and the unfamiliar
L2 orthographic system (i.e., Zhuyin) may neutralize any potential benefits of learning
novel letter associations, and 2) lack of orthographic engagement (i.e., active reading)
does not allow listeners to develop strong L2 letter-phoneme associations.
What these previous two studies show is that a short orthographic training period is
insufficient for creating strong reciprocal relationships between L2 orthography and
phonology. In fact, these findings suggest that before L2 orthography exerts any
measurable influence, the listeners/learners may have to possess some experience reading
in the target language’s orthography—much like when children learn to read in their first
language. However, as the current results suggest, the L2 learners are sophisticated
enough to realise that the L1 correspondences do not apply to the L2 correspondences
once they do have experience with an L2 orthography.
Finally, another possible explanation for the language-specificness of the
orthographic effects may come from the nature of the experimental design itself
(Dijkstra, Grainger, & van Heuven, 1999; Dijkstra, van Jaarsveld, & ten Brinke, 1998;
Schulpen, Dijkstra, Schriefers, & Hasper, 2003). That is, L1 interference is dependent on
whether participants are presented with stimuli from both languages or just one. When
homophonous stimuli from both languages are presented, the homophone representations
from both languages are activated and suppress each other thereby creating phonological
inhibition effects—competition between two phonological representations of
homophones. However, when presented with stimuli from only one language, only

211
representations from the target language are activated and non-target language
interference is reduced. While the current research did present both stimuli in both
languages, the L1 and L2 stimuli were presented in separate blocks (not intermingled
with each other) and the blocks were separated by a short break and a L2 reading activity.
Thus, when counting phonemes in the L2 block, the participants were presented with
stimuli from only the L2, which may have limited the amount of L1 interference.
In addition, the L2 listeners may have been more susceptible to L2 orthographic
knowledge than L1 orthographic knowledge because they were primed with the L2
orthography prior to completing the phoneme counting task (Jared & Kroll, 2001; Jared
& Szucs, 2002; Lukatela, Turvy, & Todorovi", 1991). Recall that the participants read
aloud a short passage called “The North Wind and the Sun” in their L2 to prepare them
for thinking in their L2. Other work has found that orthographic priming strongly affects
accuracy and RT performances in adult speakers. In a very interesting study, Lukatela et
al. (1991) investigated native Serbo-Croatian speakers’ identification of phonologically
ambiguous words. Serbo-Croatian is a bi-alphabetic language: it uses both the Roman
and Cyrillic alphabets. These alphabets share a number of letters that represent different
phonemes (e.g., <B> represents the phoneme /v/ in the Cyrillic alphabet and /b/ in the
Roman alphabet). Some words in Serbo-Croatian are made entirely up of shared letters—
hence the ambiguity. For example, the letter string <BETAP> can be pronounced as
either /vetar/ (Cyrillic), /betap/ (Roman), /vetap/ (mixed), or /betar/ (mixed). Using
masked and unmasked orthographic priming, Lukatela et al. discovered that their
participants pronounced and identified the target words more accurately and faster when
the phonologically ambiguous target was preceded by a same-alphabet context than when

212
it was preceded by an other-alphabet context. Based on these results, they concluded that
the alphabet specific context “adjust[s] temporarily the states of the letter-phoneme
connections, biasing processing in favor of the letter-phoneme correspondencies of one
alphabet rathar than those of another” (p. 660).
Similarly, Jared and collegues (Jared & Kroll, 2001; Jared & Szucs, 2002) also
discovered an effect of orthographic priming. In their studies of English–French and
French–English bilinguals in Canada, they found that bilinguals are significantly faster at
naming target words after reading in the target language than after reading in the non-
target language. For example, for the French word grand, bilinguals are more likely to
encounter conflicting pronunciations (i.e., /grã/ vs. /g®œnd/) after reading in English than
after reading in French, and vice versa. With these previous findings in mind, it is
possible that in the current project, the L2 passage reading biased the listeners towards L2
orthography, thus helping L2 orthographic knowledge override L1 orthographic
knowledge and emphasizing the language-specific effect of orthography.
6.2.3 Bipartite Model of Orthographic Knowledge and Transfer
Taking the view that L2 orthography exerts its own influence on L2 phoneme perception
once it is learnt, the next question is how—if at all—does L1 orthographic knowledge
affect L2 orthographic knowledge’s influence on L2? Currently, researchers are debating
the issue of L1 orthographic transfer. On one hand, some researchers provide evidence
that L1 orthographic knowledge does transfer into and affect nonnative speech processing
(Bassetti, 2006; Ben-Dror et al., 1995; Holm & Dodd, 1996; Sun-Alperin & Wang, 2011,
Vokic, 2011; Wade-Woolley, 1999). On the other hand, other researchers provide
evidence that L1 orthographic knowledge does not, in fact, transfer into and affect

213
nonnative speech processing (Wang, Park, & Lee, 2006; Wang, Perfetti, & Liu, 2005).
The findings in the current study appear to support both sides of the debate. The L0
results suggest that L1 orthographic knowledge is transferred into and affects the
nonnative language. However, the L2 results suggest the contrary: L2 orthographic
knowledge appears to supersede L1 orthographic knowledge and affects L2 processing.
How can we account for these conflicting results (not only within the current findings but
between previous findings)?
On the side of the debate advocating L1 orthographic transfer, previous researchers
have argued that L1 orthographic knowledge shapes L2 orthographic knowledge, which,
in turn, shapes L2 phoneme perception (Bassetti, 2006; Erdener & Burnham, 2005; Holm
& Dodd, 1996; Vokic, 2011). Holm and Dodd (1996) claim that L2 learners draw on
their L1 literacy skills and strategies and apply them to their L2 orthography. In other
words, once literate in their L1 alphabet and when learning an L2 alphabet, L2 learners
transfer their L1 knowledge of the orthographic mapping principle44 and assumptions
about the function of the orthography and its relationship to phonology. These
assumptions are learnt via the L1 orthography acquisition, and they are transferred and
applied to the L2 orthographic relationships. That is, the abstract ideas about the function
of orthographic representation are acquired when people/children become literate in their
first language, and the mapping principle and its assumptions are then transferred into
their L2 learning and applied to the L2 orthographic-phonological associations.
44 A mapping principle refers to what sound units (i.e., morphemes, syllables, or phonemes) graphemes map onto (e.g., Perfetti, 2003; Wang et al., 2005). For example, alphabetic orthographies like English or Korean map graphemes onto phonemes while logographic orthographies like Chinese map graphemes onto syllabic morphemes (DeFrancis, 1989).

214
In a study to determine the effect of orthographic transfer, Bassetti (2006) used a
phoneme counting task and a phoneme segmentation task to investigate learners’ mental
representations of Mandarin Chinese rimes. Here, Bassetti studied beginning English
learners of Chinese-as-a-foreign-language (CFL). Via the phoneme counting task, she
discovered that the CFL learners counted one fewer vowel in Mandarin rimes that do not
represent the main vowel orthographically than they did in Mandarin rimes that do
represent the main vowel orthographically. In Mandarin consonant-glide-vowel-glide
(CGVG) syllables, the main vowel is not represented in the orthography. For example, in
the word tui /dwej/, the main vowel is /e/, but there is no graphemic representation of this
sound in the Pinyin spelling; only the pre-vocalic glide /w/ and post-vocalic glide /j/ are
encapsulated in the spelling, the <u> and <i>, respectively. In contrast, in Mandarin GVG
syllables, the main vowel is represented in the orthography. For example, in wei /wej/, the
main vowel is also /e/, which is represented in the spelling by the letter <e> (along with
the pre- and post-vocalic glides). Via a phoneme segmentation task (where learners
pronounced all the phonemes in a Mandarin syllable one by one), Bassetti discovered that
the CFL learners failed to pronounce the main vowel as a separate segment when the
spelling did not include a letter for it. In short, Mandarin rimes were most often counted
and segmented as they are spelt. Based on these results, Bassetti argues that English CFL
learners interpret Pinyin orthography in terms of English letter-phoneme conversion rules
rather than the L2 orthographic conventions. She concludes then that L1 orthographic
knowledge transfers into L2 and shapes the mental representations of Mandarin Chinese
rimes.

215
Vokic (2011) agrees with Bassetti (2006) in that she too argues that learners interpret
their L2 orthography through the “prism” of their L1 orthography. Studying native
Spanish speakers producing the English flap /|/, Vokic investigated how much difficulty
these speakers had recovering phonological information from the graphemic
representation. She found that Spanish speakers’ access to the English flapping rule was
blocked by their reliance on Spanish orthographic rules. The native Spanish speakers
failed to produce /|/ when faced with words like city and lady where the <t> and <d>
orthographically represent the flap. Rather, these speakers produced /t1/ and /D/ for <t>
and <d>, respectively—based on the Spanish letter-phoneme associations. From these
results, Vokic concludes that because Spanish has highly regular orthographic-
phonological mappings, native Spanish speakers cannot easily recover the English
phonology from the highly irregular orthographic-phonological mappings in English
despite the fact that /|/ is also part of the Spanish consonant inventory. Therefore,
according to Vokic, L2 learners interpret L2 graphs “through the prism of L1 graphs,
much like L2 phonemes are interpreted in light of L1 phonemic categories” (p. 412).
In addition, Erdener and Burnham’s (2005) research also supports the argument that
the nonnative language is interpreted through L1 orthographic knowledge. Specifically,
they discovered L1 orthography impacts native Turkish speakers’ production of Spanish
(L0) phonemes. Although the letter <j> exists in both the Turkish and Spanish alphabets,
it represents entirely different phonemes in Turkish and Spanish, /Z/ and /x/ respectively.
They found that when given only auditory information, the Turkish participants had 0%
error rates for reproduction of the L0 Spanish phonemes. However, when given both
auditory and orthographic information, the Turkish participants’ error rates increased to

216
46%. Erdener and Burnham conclude that these increased error rates result from the
participants substituting the L1 phoneme /Z/ associated with the letter <j> they saw.
These results provide additional evidence that in the absense of nonnative orthographic
knowledge, listeners transfer their L1 orthographic operational knowledge into their
speech processing of a nonnative language.
As mentioned above, the current L0 finding provides support for Bassetti (2006),
Erdener and Burnham (2005), and Vokic’s (2011) side of the L1 orthographic transfer
debate. These results suggest that without any experience in a nonnative language,
learners do transfer their L1 orthographic knowledge to help them parse nonnative
phonemes. However, the L2 finding (i.e., L2 orthographic knowledge overrides L1
orthographic knowledge to influence L2 phoneme perception) appears to contradict their
claims of L1 orthographic transfer. In fact, the current finding suggests that L1
orthographic knowledge does not transfer into L2 phoneme perception.
Researchers on the other side of the debate have found that orthographic skills do not
transfer from L1 to L2. In a series of experiments involving biliteracy, Wang and
colleagues (Sun-Alperin & Wang, 2011; Wang et al., 2006; Wang et al., 2005) sought to
determine whether orthographic skills transfer from L1 to L2 in learning to read. In the
first study, Wang et al. (2005) investigated Chinese (L1)–English (L2) bilingual children.
Using combined phonological and orthographic tasks and regression analyses, Wang et
al. found that while phonological skills transfer from L1 to L2, orthographic skills do not.
Specifically, Chinese orthographic skills (with characters) could not predict reading skills
in English. From this, they concluded that orthographic skills “may be language-specific
with little facilitation from one to the other” (p. 83). One possible explanation they offer

217
for this lack of facilitation is that the Chinese and English orthography do not share the
same mapping principle: Chinese maps graphemes to morphemes while English maps
graphemes (i.e., letters) to phonemes. Therefore, Wang et al. speculate that this disparity
in mapping principles does not lend itself to L1–L2 transfer.
A subsequent study by Wang et al. (2006) asked the same question—do orthographic
skills transfer from the L1 to L2 in learning to read? However, in this study, they
investigated Korean (L1)–English (L2) bilingual children. Unlike the different mapping
principles between the Chinese and English orthographies, Korean and English
orthographies share the same mapping principle, even though the systems are different:
both are alphabetic systems that map letters onto phonemes. Through similar tasks and
analyses as in Wang et al. (2005), Wang et al. (2006) again found that phonological skills
transfered from L1 to L2, but orthographic skills did not; Korean L1 orthographic skills
did not predict English L2 word reading. Again, Wang and colleagues concluded that in
learning to read, there is little facilitation of orthographic skills from L1 to L2, and thus,
orthographic skills appear to be language-specific, even when the two languages share
the same mapping principle (i.e., an alphabetic principle).
From these two studies, Wang et al. (2005, 2006) suggest that the visual orientations
of graphemes may contribute to the language-specificness of their respective
orthographies. That is, while the Korean writing system, Hangul, is alphabetic, its
representation is non-linear (similar to Chinese characters) and creates a “square-like
syllable block” (Wang et al., 2006, p. 149). As a result, the non-linear Korean Hangul
representations visually resemble Chinese characters more than the linear Roman
alphabet letter representations. Because of the drastically different visual orientations of

218
their respective L1 orthographies, learners did not transfer their L1 orthographic
knowledge.
More recently, Sun-Alperin and Wang (2011) sought to investigate orthographic
transfer in two languages where the orthographic representation not only shares the same
mapping principle but also resembles each other, Spanish (L1) and English (L2). They
hypothesised since the two orthographies were closely related, the Spanish orthography
(L1) may facilitate English reading and spelling. The results here showed that when
closely related, the orthographic skills are transferred into and facilitate L2 reading but
not L2 spelling, indicating “an independence of orthographic processing as it relates to
spelling” (p. 612). Like Wang and colleagues, the L2 NH and H results and L1 NH and
H results imply that orthographic effects are language-specific (as discussed above)
thereby suggesting that L2 orthographic knowledge overrides L1 orthographic
knowledge.
How can we reconcile the findings from Bassetti (2006) and Vokic (2011) with those
from Wang and collegues (Wang et al., 2006; Wang et al., 2005; Sun-Alperin & Wang,
2011)? The current results suggest that L1 orthographic knowledge is comprised of at
least two types of knowledge: abstract and operational. When we consider the notion of
orthographic knowledge not as a single entity but rather as a combination of
components—the abstract and operational—the findings from this and previous research
no longer contradict each other. The following paragraphs outline the proposal; further
details and validation await future research.
Abstract orthographic knowledge refers to the assumptions literates have about the
function of orthographic representation and its relationship to the phonological

219
representation. Children/learners acquire abstract knowledge through the process of
becoming literate in their L1, which creates a set of assumptions upon which all other
orthographic effects rest. The general assumption surrounding alphabets (like the Roman
and Cyrillic alphabets) is that individual letters represent individual phonemes (Cook,
2004; Coutsougera, 2007). In contrast, the general assumption surrounding logographies
(like the Chinese characters) is that individual letters represent individual morphemes
(Cook, 2004; Coulmas, 2003). That is, alphabetic literates generally assume that
graphemes (i.e., letters) map onto phonemes while logographic literates generally assume
that graphemes (i.e., characters) map onto morphemes.
In the case of alphabetic systems, literates use their abstract knowledge about the
function of orthographic representation to interpret the operational letter-phoneme
correspondences. Operational orthographic knowledge refers to the actual letter-
phoneme correspondences in any given language. For example, English literates know
that the letter <t> corresponds to the phoneme /t/, <x> corresponds to the phonemes /ks/,
<c> corresponds to either /k/ or /s/, and so on. Similarly, Russian literates know that the
letter <#> corresponds to the phoneme /u/, <$> corresponds to the phonemes /g/ or /g!/,
<%> corresponds to the phonemes /ju/, and so on. In L1, operational orthographic
knowledge is also acquired as children become literate in their L1 orthography.
The abstract and operational components of orthographic knowledge proposed here
can be unified as in Figure 6.1, in what is termed here the are Bipartite Model of
Orthographic Knowledge and Transfer (henceforth the Bipartite Model). Included in
Figure 6.1 are the current findings (found in the lettered boxes) that provide support for

220
the predictions of the Bipartite Model. Also included (in the box with dashed lines) is an
additional prediction made by the model for which no data exists yet (See §7.4.).
45
L1 = native language, L0 = unfamiliar language, L2 = second language
Figure 6.1 Bipartite Model of Orthographic Knowledge and Transfer
While both abstract and operational knowledge are acquired concurrently in L1
acquisition, the proposal is that this is not always the case for L2 orthographic
45 The current model represents literacy as a pre-literate-literate dichotomy. However, one alternative (as suggested by Dr. Patrick Bolger) is to represent literacy along a continuum from pre-literate to literate, which may also allow us to include orthographic depth and time course in the model. I leave the questions of how to expand the model to include orthographic depth and time for future research.
(a) (b) (c) (d) (e)
L1 ORTHOGRAPHIC KNOWLEDGE
ABSTRACT (mapping principle)
OPERATIONAL (actual letter-phoneme
correspondences)
TRANSFER TRANSFER NO TRANSFER
L0 L2 L0 L2
L0 M-H >>
L0 MM-H
L2 M-NH >>
L2 MM-NH
L0 M-H >>
L0 MM-H
L2 M-H =
L2 MM-H
pre-literate in L0/L2 literate in L2
L2
L2 M-H >>
L2 MM-H

221
knowledge. For example, in L2 learning, when both L1 and L2 orthographies share visual
orientation (i.e., a linear alphabetic orientation), abstract L1 orthographic knowledge
transfers into L2 and contributes to a perceived relationship between L2 orthography and
phonology. Specifically, the L1 assumptions about the function of orthography transfer
into L2 letter-phoneme associations such that learners assume that the L2 orthography
functions in relation to the L2 phonology in much the same way that the L1 orthography
functions in relation to the L1 phonology. Then, through this perceived relationship
(whether accurate or not), learners acquire new operational orthographic knowledge
about L2 letter-phoneme correspondences. Once this new L2-specific operational
knowledge is acquired, it supercedes L1 operational knowledge.
The Bipartite Model makes a number of predictions regarding the transfer of
orthographic knowledge. First, in this model, abstract knowledge transfers into both L2
and L0 (assuming the same broad type of alphabetic system) such that the L1
assumptions about the function of orthographic representations are applied to the
nonnative language regardless of whether L0/L2 literacy exists. This is shown on the
previous page in Figure 6.1. In the current study, the L1 results showed that native
English speakers are strongly influenced by orthographic representation such that they
were significantly more accurate at counting phonemes in matched L1 words than they
were in mismatched L1 words. This finding is interpreted as evidence that native English
speakers assume individual letters represent individual phonemes in English, which is the
key characteristic in abstract knowledge. The model proposes that this assumption is
then transferred (regardless of literacy) into nonnative speech processing and is reflected

222
in both the higher accuracy of L0 matched H (given above in (a)) and L2 matched NH
(given in (b)) than of the L0 mismatched H and L2 mismatched NH.
Second, the model proposes that transfer of operational knowledge depends on the
existence of literacy in the nonnative language. Although literate L2 learners/listeners do
transfer L1 abstract knowledge, this knowledge facilitates the formation of L2-specific
operational knowledge, which overrides L1 operational knowledge. Recall that in the
MM-H tokens, the mismatch was always in the L1 not the L2; therefore, any difference
between the L0/L2 matched-mismatched words would indicate an L1 transfer effect. The
lack of difference between the L2 matched and mismatched H (given in (e)) suggest the
L2 listeners employ L2 letter-phoneme associations rather than L1 associations. In
contrast, without any L0 orthographic knowledge, L0 listeners transfer their L1
operational orthography into L0 phoneme processing, which is reflected in the difference
between the L0 matched and mismatched H (given in (c)). This model also proposes that
non-literate L2 learners would also experience L1 operational transfer. That is, using a
similar research methodology, the model predicts that non-literate L2 listeners would
more accurately count phonemes in L2 matched H than they would in L2 mismatched H
(given in (d)).
Third, operational transfer entails abstract transfer because operational knowledge is
built on the foundation of abstract knowledge; however, abstract transfer does not entail
operational transfer. Therefore, it is possible to transfer abstract knowledge without
transferring operational knowledge (as is the case for L2 learners), but it is not possible to
transfer operational knowledge without also transferring abstract knowledge (as is the
case for L0 in the current study).

223
By means of the Bipartite Model, the current research adds insight into L1
orthographic transfer and facilitation, namely with respect to L2 speech perception. It
provides evidence that abstract orthographic knowledge behaves differently from
operational orthographic knowledge. First, the L2 NH data parallel the L1 NH data.
Specifically, for both L1 NH and L2 NH, the matched words (i.e., the consistent words)
were counted more accurately and faster than the mismatched words (i.e., the inconsistent
words). These differences suggest that learners apply their assumptions about the
function of orthography and its relationship to phonology (i.e., abstract knowledge) that
they learn in L1 orthographic acquisition to their L2. Second, the L2 H data indicates
that once learners become literate in their L2, they do not transfer L1 operational
knowledge; rather, they employ their L2 operational knowledge to aid them in phoneme
awareness tasks. As with L2 reading (Sun-Alperin & Wang, 2011; Wang et al., 2006;
Wang et al., 2005) and L2 spelling (Sun-Alperin & Wang, 2011), the L2 findings here
suggest that abstract orthographic knowledge transfers when L1 and L2 share same
visual orientations (i.e., alphabetic letters). That is, listeners rely on their L1 assumptions
about how letters are mapped onto phonemes and apply those assumptions to the
relationship between L2 letters and phonemes (e.g., Ben-Dror et al., 1995; Wade-
Woolley, 1999). In addition, operational orthographic knowledge appears to be
language-specific for L2 speech perception; once L2 learners are literate in their L2, they
rely on actual L2 letter-phoneme associations. In other words, the results here provide
little evidence for operational L1 orthographic transfer in L2 speech perception once
learners have learnt an L2 orthography; in fact, the results suggest that L2 orthographic
knowledge takes over and influences L2 phoneme perception. Finally, the L0 H data

224
indicate that listeners do transfer their L1 operational knowledge (in addition to abstract
knowledge) to the unfamiliar language because they have no other orthographic
associations (i.e., other operational knowledge) to aid them (Erdener & Burnham, 2005).
In support of the non-transfer of operational knowledge, listeners in the current
research appeared to use a language-specific spelling strategy in the phoneme counting
task. As mentioned above, Sun-Alperin and Wang (2011) have suggested that L1
orthographic processing is independent from L2 spelling. In the current study, of the 52
participants, 39 participants mentioned spelling in their debrief interviews. Many
participants commented that spelling was a strategy for counting (whether helpful or not)
and that they often “saw” the words in their heads before counting. For example, some
general comments about the task include
… visualized English spelling
… saw the spelling
… automatically saw the word
… started seeing letters not sounds…
… I could see the words
… you could see the word in your head
… heard letters
… knowing words and spelling helped recognize sounds
Indeed, many participants recognised that spelling was a distraction and hindered their
counting, but they also found it difficult to put aside. They had to remind themselves that
spelling was not the focus. For example, some of the participants’ responses included
… letters did not help counting … had to put them aside
… danger of going by the letter rather than the sound
… could visualize spelling although sometimes misleading
… spelling was a distraction, especially in English
… I had to remind myself not to spell
… spelling got in the way

225
… had to remind myself not to count letters
Therefore, even when spelling was not explicitly mentioned at any time during the
perception task, it appears that listeners could not help but think of spelling, suggesting
that, as previous research has also suggested (discussed above in §6.2.1), orthography and
phonology are co-activated in an auditory task (e.g., Blau et al., 2008; Chéreau et al.,
2007; Perreman et al., 2009; Taft et al., 2008; Ventura et al., 2008; Ventura et al., 2007;
Ziegler & Ferrand, 1998; Ziegler et al., 2004; Ziegler, Muneaux, & Grainger, 2003).
In addition to the general comments about spelling, listeners’ debrief comments
suggest that in the absence of nonnative orthographic knowledge (i.e., the L0), listeners
ascribe English orthographic knowledge to nonnative phoneme awareness. For example,
… pictured how the word would be spelt in English and transliterate into
Mandarin and Russian
… tried not to spell L0[words] in English terms
… I spelt out the words how they would be in English
In contrast, in the presence of nonnative orthographic knowledge (i.e., L2 orthographic
knowledge), listeners no longer rely on L1 orthography, but rather, fall back on the L2
orthography to aid their L2 phoneme perception.
… pictured Russian and English letters
…when I heard a sound, immediately thought about how to spell it in Pinyin
The results and listeners’ comments in this research add further support to the idea that
once an L2 orthography is learnt in conjunction with an L2 phonology, L2 orthographic
knowledge appears to be co-activated with L2 phonology—much like the L1 orthography
is co-activated with L1 phonology.
While this new Bipartite Model is still in its infancy and has yet to be thoroughly
tested, it does provide us with a new way of thinking about orthographic knowledge and

226
allows us to unify the seemingly conflicting accounts of L1 orthographic transfer into L2
and/or L0. For example, the model accounts for Bassetti’s (2006) findings nicely.
Bassetti herself states “the orthographic representation is interpreted in terms of the first
language letter-phoneme conversion rules” (p. 107)—abstract transfer. (I interpret
conversion rules here to refer to the general rules governing letter-phoneme mapping, not
the actual letter-phoneme correspondences.) The CFL results also contain evidence of
lack of L1 operational transfer. When participants were asked to segment (by
pronouncing each segment) the sounds in a word, Bassetti reports that words were
segmented as they are spelt (abstract transfer again), but they were segmented with
Mandarin pronunciations of each individual letter, suggesting operational knowledge of
Mandarin Pinyin letter-phoneme associations (i.e., no L1 operational transfer). If L1
operational transfer had occurred as well as abstract transfer, Bassetti would have
observed English pronunciations of Pinyin spelt words; however, the Pinyin spellings
were pronounced with Mandarin phonemes, i.e., you was segmented with a Mandarin
pronunciation as /jow/ rather than with an English pronunciation as /ju/.
While the model can account for Bassetti’s (2006) findings rather nicely, Vokic’s
(2011) findings are a little trickier to account for. Recall that Vokic discovered native
Spanish speakers failed to produce the English flap when represented by the letters <t>
and <d> in words like city and lady. She attributes this failure to L1 transfer of actual
Spanish letter-phoneme associations (what the Bipartite Model would call L1 operational
transfer). However, the model proposes that once learners acquire an L2 orthography, the
L2 operational knowledge overrides L1 operational knowledge. So why would L1
operational knowledge still transfer Vokic’s research? Vokic’s findings indicate that

227
orthographic knowledge and transfer effects involve more complexity than has been
considered here. In particular, for example, Vokic’s findings suggest that L1 operational
transfer may be mediated by orthographic transparency. Perhaps L2 operational
knowledge of less transparent languages (i.e., English) takes longer to acquire because of
its inconsistency than L2 operational knowledge of more transparent languages (i.e.,
Russian and Mandarin Pinyin). In fact, Seymour et al. (2003) have shown that L1 English
children take at least twice as much time to develop decoding skills as L1 children with a
transparent orthography. (See also Spencer & Hanley, 2003, 2004). The delayed mastery
of decoding skills has also been observed in Danish—another less transparent
orthography (Juul & Sigurdsson, 2005). This delay for less transparent languages
possibly explains why the current results show L2 operational effects but Vokic’s (2011)
results show L1 operational effects: the current study went from a deep L1 to a shallow
L2 while Vokic’s study went from a shallow L1 to a deep L2. Maybe the English
operational knowledge had yet to take hold of the native Spanish speakers’ English letter-
phoneme associations. Thus, future research needs to establish if transparency is a factor
affecting operational knowledge and, if so, what its role is in determining at what point
L2 operational knowledge takes over from L1 operational knowledge.
6.2.4 The experience-dependency of orthographic effects
In light of the previous discussion, the additional finding that orthographic effects are
experience-dependent is perhaps not so surprising. These results were determined by
analysing the accuracy and RT differences between the matched and mismatched NH for
the L1, L2, and L0 subgroup data. For this analysis, the mean mismatch NH accuracy
and RT values were subtracted from the mean NH accuracy and RT values for each

228
language condition. Positive values indicated higher accuracy rates and shorter RTs from
the matched to mismatched NH conditions (See §5.7.). In general, the accuracy and RT
difference results can be summarised as
(9) L1 >> L2 >> L0.
In other words, the effects are the largest for L1, the smallest for L0 and between the L1
and L0 for L2. However, the accuracy results do not directly reflect this pattern. In fact,
the analyses indicate that the L1 accuracy difference is greater than the L2 difference, but
that the L2 accuracy difference is not significantly greater than the L0 difference.
Conversely, the analyses of RTs do reflect the pattern: the RT analyses indicate that the
L1 RT difference is greater than the L2 difference, and the L2 RT difference is greater
the L0 difference. These results and analyses suggest that the L1 orthographic effect is
stronger in the L1 than the L2 orthographic effect is in the L2. In fact, the strength of the
L2 orthography appears tenuous at this stage of learning as evidenced by the lack of a
significant difference between the L2 and L0 in accuracy rates, but the presence of a
significant difference between the L2 and the L0 in RTs. Still while not entirely cut and
dried, the results do suggest an experience-dependent trend whereby the more experience
listeners have with the target language’s orthography and phonology, the greater the
effects of the orthography. To be clear, while orthographic knowledge affects phoneme
perception from the beginning of learning to read, these effects get stronger as the
readers/learners gain more and more experience with the language.
These results run parallel to other linguistic research that has demonstrated the effect
of language experience influences speech processing. According to Burnham (2003), as
a component of language-specific speech perception, linguistic experience facilitates the

229
perception of speech sounds. In addition, age-related differences in performance and
perception have been interpreted as evidence of language experience-dependency. For
example, in a classic study, McGurk and MacDonald (1976) investigated the “McGurk
effect”46 in children and adults. They demonstrated that children aged 3–5 and 7–8 were
influenced to a lesser extent by visual cues than adults were. Subsequent research also
showed similar age-related effects (i.e., experience effects) of visual influence (e.g., Chen
& Hazan, 2009; Massaro, Thompson, Barron, & Laren, 1986; Sekiyama, Burnham, Tam,
& Erdener, 2003). Research has even reported a developmental increase of visual
influence across ages—from age 5 to adulthood (Hockley & Polka, 1994; Sekiyama et al.
2003). In short, the previous research has shown that the use of visual information
increases as age increases (i.e., as experience with the language increases).
The results here suggest that reliance on orthographic information also increases as
experience increases. While the current study used only an auditory task, many
participants commented that they “saw” the words in their heads. Thus, even though they
did not receive any direct visual information from orthography, the listeners appear to
rely on their existing mental visualisations of the words’ spellings. In this research, the
different target languages (i.e., L1, L2, and L0) represent different levels of language
experience: listeners had the most experience with their L1, less experience in their L2,
and no experience with the L0. Therefore, the listeners experienced the largest influence
from visual information (i.e., the orthographic knowledge) in their L1, the second largest
influence from their L2, and the smallest visual influence from the L0. Extending the
language experience parallel, we can liken the L0 language perception with the very 46 The “McGurk effect” refers to a phenomenon observed by McGurk and MacDonald (1976) whereby when a visual /ga/ syllable is presented concurrently with an auditory /ba/ syllable, listeners typically report hearing a /da/ syllable.

230
beginning stages of nonnative language learning where learners have little to no
experience with the nonnative language, and we can liken L2 language perception with
more advanced stages of nonnative language learning where the learners do have some
experience in the nonnative language but not as much as the native language.
6.3 Unanticipated Effects
In addition to the findings discussed above, other effects also surfaced during the course
of this research. These effects are 1) familiarity and word effects (§6.3.1), 2)
phonological effects (§6.3.2), and 3) MM subcategory effects (§6.3.3).
6.3.1 Familiarity and word effects
The analyses of the L0 data suggest two other effects—familiarity and word effects—
influence the perception of phonemes in words from an unfamiliar language. While an
L1 orthographic effect can account for why the L0 matched Hs were counted more
accurately and faster than the L0 mismatched Hs, a familiarity effect accounts for why
the L0 matched Hs were counted more accurately and faster than the matched NHs. That
is, performing better on both sets of H (i.e., the matched and mismatched) suggests that
homophony with English words make L0 H words more familiar to participants, and that
this familiarity facilitated performance, regardless of whether the familiar words had
consistent letter-phoneme correspondences. Related to the facilitative effect of
familiarity, Russak and Saigh-Haddad (2011) discovered that native Hebrew speakers
exhibited higher levels of phoneme awareness in their L1 (Hebrew) than in their L2
(English). They argue that higher levels of language proficiency as well as the degree of
experience with the language facilitate phoneme awareness and that awareness is

231
enhanced by language familiarity (This also accounts for the experience-dependency of
orthographic effects discussed above in (§6.2.4.). Thus, although the participants had no
previous knowledge of the L0s in the current research, the very nature of the L0 cross-
language homophones made them familiar to a certain degree thereby increasing the
participants’ phonemic awareness in the L0 homophones.
Other research on cross-language homophones has also shown a phonological
facilitation effect such that both L1 and L2 phonological codes are activated
simultaneously when reading in the L2, and phonological information from both codes
contribute to word recognition (Brysbaert, Van Dyck, & Van de Poel, 1999; Carrasco-
Ortiz, Midgley, & Frenck-Mestre, 2012; Haigh & Jared, 2007; Lemhöfer & Dijkstra,
2004). In other words, L2 cross-language homophones benefit from the co-activation of
their nonpresented L1 cross-language counterparts. For example, Lemhöfer and Dijkstra
(2004) found phonological overlap facilitates lexical decisions such that Dutch-English
bilinguals identified cross-language homophones more accurately and faster than the
control words, which did not share a phonological overlap. Similarly, Haigh and Jared
(2007) found that French-English bilinguals made more accurate and faster lexical
decisions on cross-language homophones than control words. Haigh and Jared also
discovered that the phonological facilitation effect was greater when participants were
reading in their L2 than when they were reading in their L1.
In addition to research involving metalinguistic awareness, other research—
specifically research involving ERPs—provide further evidence for the facilitatory effect
of phonological overlap. For example, Carrasco-Ortiz et al. (2012) compared the cortical
responses to cross-language homophones and control words of English monolignuals

232
with French-English biliguals. The monolinguals showed no variation in N400 amplitude
between the cross-language homophones and control words, suggesting no advantage of
one stimulus type over another. In contrast, the bilinguals showed a significant reduction
in N400 amplitude in response to the homophones compared with the control words,
which Carrasco-Ortiz et al. interpret as a processing advantage for the homophones.
Taken together, these studies all suggest that familiarity (via the phonological overlap
inherent in cross-language homophones) facilitates speakers’ abilities to process a
nonnative language.
Conversely, it is likely that with the nonhomophones, the listeners were more
distracted by the “strangeness” of the unfamiliar words thereby resulting in lower
accuracy rates and longer response times. In fact, when asked which language was the
most difficult to count, most participants identified the L0 as the most difficult. They
claimed the “unfamiliarity” with the words and the L0 language was a barrier to
successful phoneme parsing. For example, some comments include
… not familiar with the sound combinations
… wasn’t sure about what is an individual sound
… not used to some sounds
… sounds were really different
… less familiar sound combinations
… couldn’t recognise most sounds and sound combinations
… Russian sounds were weird … difficult to pick out sounds
… Russian sound combinations were hard to separate
… a lot of unfamiliar sounds—hard to determine whether 1 or 2 sounds
…very foreign
… not sure about some sounds—were they sounds?
… sounds so much more different—not recognisable

233
If many of the L0 words sounded strange or foreign, then these comments suggest that
participants may have found the H easier than NH because they were not so foreign or
“weird” sounding. Thus, the homophony allowed listeners to more easily hear the words.
Therefore, the L0 results strongly suggest that familiarity with phonemes and phoneme
sequences play a large role in listeners’ abilities to distinguish individual phonemes.
An interesting question worth asking is whether the familiarity effect is due to whole
words sounding familiar or to their internal phonotactics sounding familiar. Previous
research has shown that listeners’ knowledge/familiarity with “legal” L1 phonotactic
patterns affects auditory L2 speech processing (Dupoux, Kakehi, Hirose, Pallier, &
Mehler, 1999; Kabak & Idsardi, 2007). For example, Dupoux et al. (1999) discovered
that Japanese listeners hear illusory epenthetic vowels in French consonantal sequences
that violate the legal phonotactic patterns of Japanese. Dupoux et al. interpret these
findings as evidence that L1 listeners “may invent or distort [L2] segments so as to
conform to the typical phonotactics of their language (p. 1577). In the Carrasco-Ortiz et
al. (2012), Lemhöfer and Dijkstra (2004) and Haigh and Jared (2007) studies outlined
above, the L1 representations were real (homophonous) words. Would they have found
the same results if the L1 representations were nonsense words with similar and familiar
phonotactic structures as the L2 target representations? The participant comments above
clarify to some extent what “‘counts”’ as familiar. Specifically, they indicate that it is not
necessarily familiarity with the homophonous words themselves that matters, but rather
familiarity with the phonetic quality of their component sounds and their phonotactic
rules. Indeed, comparing the accuracy rates of the Russian L0 and Russian L2 listeners
(See Table 6.4 on page 241.) further suggests that phonotactic familiarity plays an

234
important role in listeners’ abilities to parse nonnative phonemes. Russian MM-NHs
containing the consonant combinations of /zv/ and /zd/, which are not licenced
combinations in either English or Mandarin, were more difficult to parse for speakers
with Russian as the L0 (no experience with Russian phonotactics) than for speakers with
Russian as the L2 (experience with Russian phonotactics). The Russian L2 listeners had
0.85 accuracy for both -!./( /zd!”s!/ and -'01( /zvat!/ compared with the Russian L0
listeners’ accuracy of 0.50 for both. In other words, the Russian L2 listeners were highly
successful at parsing these combinations because although these combinations do not
exist in English, they are familiar with them from learning of Russian. Conversely, the
Russian L0 listeners were relatively unsuccessful at parsing /zv/ and /zd/ because neither
their L1 nor their L2 (Mandarin) provide any phonotactic familiarity with the
combinations.
In addition to orthographic and familiarity effects, the results suggest a word effect
also influenced L0 phoneme perception. A word effect can account for why the L0
matched NHs were counted more accurately and faster than the L0 mismatched NHs (as
reported in §5.3.2). The hypothesis predicted that participants would count phonemes in
the matched and mismatched NH equally accurately because the listeners had neither
orthographic knowledge nor any L1 orthographic associations with these words. The
results, however, did not support this prediction: participants were better at counting the
matched NH than the mismatched NH. While the reasons for the accuracy difference
between the matched and mismatched NH are not clear, most likely something about the
words themselves in the mismatched condition made them more difficult to count.

235
Thus, although the results do suggest an effect of L1 orthographic knowledge on L0
phoneme counting, it interacts with the other two effects, the familiarity effect and the
word effect, and this interaction mitigates the effects of L1 orthography alone such that
its influence is not as strong in the L0 as it is in the L1. While both effects interact with
L1 orthographic knowledge, the familiarity effect is likely a “real” effect, whereas the
word effect is likely an artifact of the stimuli selection (See §7.2 for a discussion of
research limitations.).
6.3.2 Phonological Effects
The second unanticipated effect discovered in this research project is a phonological
effect. Here, the phonological effect refers to phonological characteristics of a particular
language that make it easier or harder to process. The analyses showed that in four
comparisons, listeners counted phonemes in the Russian words more accurately than in
the Mandarin words. Specifically,
1. The RNL0 group counted Russian H, regardless of match, more
accurately than the MNL0 group counted Mandarin H (§5.4.1).
2. The RNL0 group counted Russian L0 matched H and NH more
accurately than the MNL0 group counted Mandarin L0 matched H and
NH (§5.4.2).
3. The RFL subgroup counted Russian NH more accurately than the MFL
subgroup counted Mandarin NH (§5.6).
4. The RFL subgroup counted Russian matched NH and mismatched H
more accurately than the MFL subgroup counted Mandarin matched NH
and mismatched H (§5.6).

236
This raises a very interesting question: in what ways do the Russian and Mandarin words
differ such that the phonemes in Russian words are easier to perceive (and therefore
count) than the phonemes in the Mandarin words?
One reasonable explanation for the asymmetry in Russian and Mandarin
performance has to do with the different phonological structure of the Russian and
Mandarin words. According to Saiegh-Haddad et al. (2010), the phonological structure of
a word affects the ease with which listeners can access phonemes in different positions
(i.e., onset and coda positions) and in different linguistic contexts. As discussed in (§3.2),
the Russian and the Mandarin syllable structures differ significantly. Russian syllable
structure (§3.2.2.2) allows many different syllable types—(C)(C)(C)(C)V(C)(C)(C)(C)—
which results in many closed syllables (i.e vowel–obstruent sequences). In contrast,
Mandarin syllable structure (§3.2.3.2) is much more limited—(C)(G)V(G) or (n) or (N)—
which results in many open syllables ending in a diphthong (i.e vowel–glide sequences).
In taking a closer look at the word stimuli, we see that no Russian words contained
diphthongs while 12 Mandarin words containing diphthongs. (See Table 4.4.) When we
consider the raw accuracy rates of words containing diphthongs in comparison to words
without diphthongs, we see a dramatic difference in accuracy—44% versus 80%
(regardless of letter-phoneme consistency). This difference suggests that the phonological
ambiguity of diphthongs, which were particularly common in the Mandarin stimuli (12
Mandarin words had diphthongs compared with zero Russian words with diphthongs),
creates confusion and makes these sequences harder to count. In fact, some listeners
commented on the difficulty of separating the vowel sounds. For example,
… sounds blended together … not sure if 1 or 2 sounds
… unsure about what constitutes a sound … not sure if 1 sound or 2

237
… Mandarin vowel combinations were hard to distinguish
… hard to separate vowel sounds
Section 6.4 provides a more detailed discussion on the debate surrounding diphthongs
and how they are counted.
Another possible explanation for the differences in accuracy between the RFL and
MFL groups may lie in the differences between the Cyrillic and Pinyin alphabets.
Specifically, the Pinyin orthography is based on the Roman alphabet, which makes it
very similar to the English orthography. Conversely, the Russian orthography uses the
Cyrillic alphabet, which makes it less similar to the English orthography than the Pinyin
alphabet. Therefore, a greater difference between the L1 and L2 (i.e., Russian)
orthographies may encourage greater disassociation between the L1 and L2, which may
in turn lead to greater success (or less interference from the L1 orthography) and/or
greater reliance on the L2 rather than the L1.
6.3.3 Subcategory effects
The most important unanticipated effect, and one that deserves a relatively lengthy
discussion here, involves internal inconsistency within the MM category. The question
is: do different words within the MM category exert different effects on the perception of
phonemes, depending on nature of the MM? That is, does a continuum of difficulty exist
for different types of inconsistent words? The present study was not designed to answer
this question; however, it has become apparent that some of the overall differences
between M and MM categories may be due to a subset (or subsets) of words in the MM
category47. Therefore, some preliminary analyses are included here in an attempt to shed
47 Thank you to Dr. Bruce Derwing for pointing this out and encouraging me to explore the issue further.

238
light on the issue and provide us with some direction for future research. The following
three tables provide the raw accuracy rates by item of the mismatched nonhomophones
(Table 6.2) and mismatched homophones (Table 6.3) for the overall data as well as the
mismatched nonhomophones (Table 6.4) for the subgroup data.
Russian (L0) English (L1) Mandarin (L0)
word mean word mean word mean
MM-NH
!"#$ /al!t/ 0.96 fish /fIS/ 0.88 sh%n /ßan/ 0.88 &!$# /dat!/ 0.92 shot /SAt/ 0.88 y' /i/ 0.85 () /juk/ 0.92 give /gIv/ 0.85 máng /maN/ 0.69 * /ja/ 0.88 whom /hum/ 0.83 huáng /xwaN/ 0.62 &+,&# /doSt!/ 0.85 speak /spik/ 0.81 wàng /waN/ 0.62 ,-$# /Zit!/ 0.73 month /mØnT/ 0.79 yòng /jON/ 0.62 &./# /d!”n!/ 0.73 truth /truT/ 0.75 yuè /y”/ 0.62 0&.1# /zd!”s!/ 0.69 talk /tAk/ 0.67 t'ng /tÓiN/ 0.58 2.1$# /S!”st!/ 0.58 quick /kwIk/ 0.65 sh3o /ßwO/ 0.58 04!$# /zvat!/ 0.58 king /kIN/ 0.65 w5 /u/ 0.58 67+4# /krof!/ 0.54 long /lAN/ 0.62 y'n /in/ 0.58 1.8# /s!”m!/ 0.50 six /sIks/ 0.33 péng /pÓøN/ 0.54 9*$# /p!at!/ 0.42 tax /tœks/ 0.29 shéi /ßej/ 0.42 4.1# /v!”&!/ 0.42 box /bAks/ 0.25 duì /twej/ 0.31
Table 6.2 Mean accuracy rates by mismatched item for English (L1), Russian (L0), and Mandarin (L0) nonhomophones

239
Table 6.3 Mean item accuracy rates for English (L1), Russian (L0), and Mandarin (L0) homophones
From the raw data in Table 6.2 and Table 6.3, five observations are apparent. First,
not all types of mismatched tokens exhibit the same level of difficulty. Specifically, with
respect to English (the only language in the overall data where spelling is known), the
stimuli with <sh>, <wh>, silent <e>, and multiple vowel letters (e.g., <oo> and <ea>)
pose little difficulty, stimuli with <ng>, <th>, and silent <l> pose moderate difficulty, and
stimuli with <x> and diphthongs pose great difficulty. Second, for the Russian MM-NH
the 3 most difficult tokens contained 2 palatalized consonants each. Third, for the L0
MM-H, 9 of the 11 Russian tokens and 9 of the 12 Mandarin tokens had the same
accuracy as or greater accuracy than their English counterparts.48 Fourth, in the Russian
MM-NH, stimuli with unfamiliar phoneme combinations (e.g., /zd/ and /zv/) appear to be
harder than familiar phoneme combinations, suggesting that phonotactic familiarity may
48 Recall that for the L0 and L2 MM-H, the mismatch was only in their English counterparts.
Russian (L0) English (L1) Mandarin (L0) word mean mean word mean mean word
MM-H
$7- /tri/ 0.88 0.96 tree /t®i/ when /w”n/ 0.92 0.92 wèn /wøn/ &+8 /dom/ 0.92 0.92 dome /dom/ coo /ku/ 0.88 0.88 k3 /kÓu/ 1:9 /sup/ 0.92 0.92 soup /sup/ she /Si/ 0.88 0.81 x' /Çi/ 9+" /pol/ 0.81 0.92 pole /po:/ sue /su/ 0.85 0.81 sù /su/ ;- /S:i/ 0.88 0.88 she /Si/ tea/tee /ti/ 0.81 0.92 tí /tÓi/ $:$ /tut/ 0.96 0.85 toot /tut/ who /hu/ 0.81 0.88 h3 /xu/ 1$:" /stul/ 0.88 0.85 stool /stu:/ knee /ni/ 0.81 0.54 ni # /ni/ <-$ /xit/ 0.88 0.85 heat /hit/ rue /®u/ 0.81 0.85 rú /"u/ 1+6 /sok/ 0.88 0.73 sock /sAk/ pea/pee /pi/ 0.77 0.85 pí /pÓi/ /: /nu/ 1.00 0.50 (k)new /nu/ my /maj/ 0.21 0.46 maì /maj/ 8!= /maj/ 0.42 0.21 my /maj/ high /haj/ 0.19 0.31 hái /xaj/
go /gow/ 0.00 0.04 gòu /kow/

240
be a factor (See §6.2.1 above.). Finally, diphthongs have lowest accuracy in all conditions
(regardless of whether spelling is known or not).
Like the mismatched tokens for the overall data, Table 6.4 below reports the raw
accuracy rates of the mismatched nonhomophones for the subgroup data, and these data
suggest that the aforementioned observations for the overall data also hold for the
subgroup data. In addition, the raw subgroup data here provide even more support for
and insight into two of the observations made in Tables 6.2 and 6.3. First, as with <x> in
English, words containing single letters (i.e., <%> and <'> in Russian) that represent 2
phonemes have low accuracy when the listeners possess orthographic knowledge of the
language (the L2) but have high accuracy when the listeners do not possess orthographic
knowledge of the language (L0). Notice that listeners for whom Russian was the L2 had
accuracies of 0.62 and 0.54 for the Russian words 2$ /juk/ and 3 /ja/, respectively; in
contrast, listeners for whom Russian was the L0 had much higher accuarcies of 0.92 and
0.83 for 2$ /juk/ and 3 /ja/, respectively. These differing results suggest that L2 listeners
experience more difficulty in parsing phonemes when those phonemes are represented
together via one letter (Castles et al., 2003).

241
L1 L2 L0
word mean word mean word mean
RFL
whom /hum/ 0.92 &!$# /dat!/ 1.00 yuè /y”/ 0.85 shot /SAt/ 0.85 &+,&# /doSt!/ 0.92 sh%n /ßan/ 0.77 fish /fIS/ 0.77 ,-$# /Zit!/ 0.92 y' /i/ 0.77 give /gIv/ 0.77 !"#$ /al!t/ 0.92 máng /maN/ 0.77 speak /spik/ 0.77 2.1$# /S!”st!/ 0.92 yòng /jON/ 0.77 month /mØnT/ 0.77 67+4# /krof!/ 0.92 w5 /u/ 0.54 truth /truT/ 0.77 &./# /d!”n!/ 0.85 y'n /in/ 0.54 talk /tAk/ 0.69 0&.1# /zd!”s!/ 0.85 wàng /waN/ 0.54 quick /kwIk/ 0.69 04!$# /zvat!/ 0.85 péng /pÓøN/ 0.54 long /lAN/ 0.69 1.8# /s!”m!/ 0.85 sh3o /ßwO/ 0.54 king /kIN/ 0.46 4.1# /v!”&!/ 0.85 huáng /xwaN/ 0.46 tax /tœks/ 0.38 () /juk/ 0.62 t'ng /tÓiN/ 0.46 six /sIks/ 0.31 9*$# /p!at!/ 0.54 shéi /ßej/ 0.38 box /bAks/ 0.23 * /ja/ 0.54 duì /twej/ 0.23
MFL
fish /fIS/ 0.92 sh%n /ßan/ 0.92 !"#$ /al!t/ 0.92 shot /SAt/ 0.83 yòng /jON/ 0.83 () /juk/ 0.92 give /gIv/ 0.75 péng /pÓøN/ 0.75 &!$# /dat!/ 0.83 whom /hum/ 0.75 wàng /waN/ 0.75 * /ja/ 0.83 speak /spik/ 0.75 máng /maN/ 0.67 &+,&# /doSt!/ 0.83 quick /kwIk/ 0.67 sh3o /ßwO/ 0.67 &./# /d!”n!/ 0.58 king /kIN/ 0.67 t'ng /tÓiN/ 0.58 4.1# /v!”&!/ 0.50 month /mØnT/ 0.67 shéi /ßej/ 0.58 ,-$# /Zit!/ 0.50 truth /truT/ 0.67 y' /i/ 0.58 0&.1# /zd!”s!/ 0.50 long /lAN/ 0.58 yuè /y”/ 0.50 2.1$# /S!”st!/ 0.50 talk /tAk/ 0.50 w5 /u/ 0.42 04!$# /zvat!/ 0.50 six /sIks/ 0.33 huáng /xwaN/ 0.33 67+4# /krof!/ 0.50 tax /tœks/ 0.25 y'n /in/ 0.25 1.8# /s!”m!/ 0.50 box /bAks/ 0.25 duì /twej/ 0.17 9*$# /p!at!/ 0.42
Table 6.4 RFL and MFL subgroups item accuracy for L1, L2, and L0 mismatched nonhomophones
Second, while not a factor related to letter-phoneme inconsistency, these accuracy
data further demonstrate that phonotactic unfamiliarity results in lower accuracy rates (as
discussed above in §6.2.1.). Consider the L2 and L0 accuracy rates for the Russian words
-!./( /zd!”s!/ and -'01( /zvat!/. With Russian as the L2, listeners are relatively accurate
at counting the phonemes—0.85 accuracy for both. In contrast, with Russian as the L0,

242
listeners’ abilities to accuracy count the phonemes greatly decrease to 0.50 for both
words. In short, similar to the overall data (Table 6.2), Russian MM-NH words
containing the consonant combinations of /zv/ and /zd/, which are not licenced in English
(or Mandarin), were more difficult to parse for speakers with Russian as the L0 than for
speakers with Russian as the L2.
When further exploring different possible subcategories of inconsistent words and
their potential varying degrees of difficulty, the question becomes: what are the different
subcategories? Figure 6.2 visually presents the raw accuracy for each of the English
mismatched items, arranged from the most accurately counted word, tree, to the least
accurately counted word, go. This figure suggests at least four subcategories of
inconsistent words: words containing 1) multiple consonant letters <sh> and <wh>, 2)
multiple vowel letters (including silent <e>), 3) multiple consonant letters <th> and
<ng>, and 4) <x> and diphthongs. (Note: The subcategories are partly based on the
characteristics of the inconsistent representation, i.e., whether the inconsistency
represents consonants or vowels, thus the separate categorization of subcategory 1 and
subcategory 2, although the data suggest they pose the same level of ease.)

243
Figure 6.2 Mean accuracy of the English mismatched items
To further explore subcategory differences in accuracy, the word items in Figure 6.2
were grouped into the four subcategories outlined above. Six items (talk, go, knew, sock,
quick, and knee) were not included in the analysis because either they a) were single
instances of an inconsistency (e.g., talk was the only token with a silent <l>), b) were
ambiguous tokens (both knee and knew contained two inconsistencies—a silent <k> and
multiple vowel letters), or c) did not pattern together even though they contained the
same inconsistency (sock patterned with the multiple vowel letter items, and quick
patterned with the <th> and <ng> items.). Each subcategory was analysed using a one-
factor ANOVA with item as the between-subjects factor to determine whether there were
any significant differences between the items in that subcategory. There were no
statistically significant differences between the items in any of the subcategories
(subcat1: F(5,358)=0.464; subcat2: F(14,765)=0.677; subcat3: F(3,204)=1.631; subcat4:
word
gomy
highbox
taxsix
newlong
kingquick
talktruth
monthspeak
stoolwhom
peagive
sockwho
heattea
ruecoo
domefish
shotsue
poleshe
soupknee
whentoot
tree
Mea
n ac
cura
cy b
y m
ism
atch
ed it
em
1 .00
0.75
0.50
0.25
0.00
Error Bars: 95% CI
UNIANOVA accuracy BY word /METHOD=SSTYPE(3) /INTERCEPT=INCLUDE /POSTHOC=word(TUKEY) /CRITERIA=ALPHA(0.05) /DESIGN=word.
Univariate Analysis of Variance
Page 3

244
F(4,307)=0.936; all effects not significant at p>0.05). In other words, the accuracy
performance of each item within a subcategory was not significantly different from any
of the other items in that subcategory.
Figure 6.3 below represents the mean accuracy for each of the four subcategories.
From this figure, we can see that subcategory 1 (i.e., sh/wh) and subcategory 2 (i.e.,
multiple vowel letters) exhibit roughly the same high level of accuracy followed by
subcategory 3 (i.e., th/ng) with a moderate level of accuracy followed by subcategory 4
(i.e., x/diphthongs) with a low level of accuracy.
Figure 6.3 Mean accuracy of the English mismatched items
Once internal consistency within each subcategory was confirmed (see above),
differences between the four subcategories were analysed using one-factor ANOVA with
subcatgory as the between-items factor. The main effect of subcategory was significant
subcategoryx/diphthongsth/ng2V letterssh/wh
Mea
n ac
cura
cy
1 .00
0.80
0.60
0.40
0.20
0.00
Error Bars: 95% CI
UNIANOVA accuracy BY subcategory /METHOD=SSTYPE(3) /INTERCEPT=INCLUDE /POSTHOC=subcategory(TUKEY) /CRITERIA=ALPHA(0.05) /DESIGN=subcategory.
Univariate Analysis of Variance
Page 3

245
(F(3, 25)=246.232, p<0.001), which indicates a significant difference between at least
two of the subcategories. Post hoc comparisons using the Tukey test indicate that the
mean accuracy of subcategory 1 (M=0.87, SD=0.03) was not significantly different from
the mean accuracy of subcategory 2 (M=0.87, SD=0.04). However, mean accuracy of
subcategories 1 and 2 did differ significantly from the mean accuracies of both
subcatgory 3 (M=0.70, SD=0.08) and subcategory 4 (M=0.26, SD=0.05), and the mean
accuracy of subcategory 3 differed significantly from mean accuracy of subcategory 4.
In other words, while the words in subcategories 1 and 2 were not different from each
other, both of these groups of words were significantly more accurate than the words in
subcategory 3, which, in turn, were significantly more accuracte than the words in
subcategory 4. Taken together, these results indicate that not all inconsistent words
exhibit the same degree of difficulty for listeners. Specifically, when counting phonemes,
listeners find inconsistent words containing <sh>, <wh>, and multiple vowel letters
relatively unproblematic, inconsistent words containing <th> and <ng> moderately
problematic, and inconsistent words containing <x> and diphthongs highly problematic.
The findings here are, for the most part, in line with other previous research. With
respect to multiple letters representing single phonemes, listeners usually ignore “silent
letters” (e.g., the <h> in when and the <e> in home) and interpret the digraphs <th>,
<sh>, and <ch> as single units (Derwing, 1992; Derwing, Nearey, & Dow, 1986). Using
an eye-tracking paradigm, Hayes-Harb, Nicol, and Barker (2010) too discovered that
silent letters did not negatively impact listeners’ judgements. Lehtonen and Treiman
(2007) discovered that <ng> is more often counted as two phonemes than <th> and <sh>,
possibly because (other than at the end of a word) /(/ can only appear before a velar stop

246
as in tank /tæ(k/ and finger /f)(*+,/ where only the <n> represents /(/. Lehtonen and
Treiman suggest that listeners analogize this pattern to other <ng> words like hang and
come to believe that the <n> spells /(/ and the <g> spells /*/. With respect to single
letters representing multiple phonemes, other research has shown that both children and
adults are more likely to say a two-sound sequence such as /-m/ and /.,/ consists of only
one sound when that sequence is a letter name—<m> and <r>, respectively (Treiman &
Cassar, 1997). Castles et al. (2003) also found that multiple phonemes associated with a
single letter are very difficult for native speakers to parse; specifically, their participants
had great difficulty deleting the phoneme /s/ in words like fix because it is represented
along with /k/ by the single phoneme <x>.
In sum, the analysis of the MM subcategories suggest that not all types of letter-
phoneme inconsistency hinder phoneme monitoring, and that the overall differences
observed between M and MM categories were possibly due to a subset of the MM tokens
rather than the MM tokens as a whole. Given that the current experiment was not meant
to tease apart different types of letter-phoneme inconsistencies, the methodological
design did not allow us to compare each MM subcategory condition against the matched
condition. Indeed, this would have entailed 5 levels of the match variable (i.e., matched,
subcategory 1, subcategory 2, subcategory 3, and subcategory 4), which would have
required many more tokens per subcategory than were available for analysis (and equal
numbers across subcategories). In light of the findings of the preliminary analyses
presented above, further investigation of this issue is clearly warranted, using an
experiment specifically designed to compare different types of letter-phoneme
inconsistencies.

247
6.4 Phonemicisation of diphthongs
As mentioned previously, researchers are still debating whether diphthongs should be
considered two separate units (Berg, 1986; Lehiste & Peterson, 1961; Rogers, 2000) or
one cohesive unit (Wiebe, 1998; Wiebe & Derwing, 1992, 1994). On the 2 unit-side of
the debate, Lehiste and Peterson (1961) argue that diphthongs should be classified as two
segments because they contain two target positions. In contrast, on the 1 unit-side of the
debate, Wiebe and Derwing (1992, 1994) and Wiebe (1998) argue that diphthongs form a
cohesive unit because they are most often counted and perceived as one unit rather than
two.49 Why would listeners tend to perceive diphthongs as one unit? One possible
explanation is that vowel-obstruent sequences might very well be more perceptible and
easier to parse than vowel-glide sequences as the sonority distance between a vowel and
an obstruent is greater than between a vowel and a glide. This speculation is not
unreasonable given the multitude of research surrounding sonority sequencing (e.g.,
Clements, 1990; Selkirk, 1984) and perceptibility (e.g., Blevins, 2003; Steriade, 1999). If
the hypothesis that the sonority distance between a vowel and its following consonant
determines the perceptibility of that consonant as an individual segment is in fact correct,
this might explain why the listeners more accurately counted phonemes in Russian words
than in Mandarin words: fewer Russian words had vowels followed by glides (only 2
words) than Mandarin words (12 words). However, the limited and uneven number of
tokens prevents us from arriving at any firm accounts of the performance differences
between the Russian and Mandarin tokens at this stage. No doubt, future research must
49 Interestingly, as the literature suggests, the 1-unit side is primarily based on acoustic evidence whereas the 2-unit side is based on psycho-linguistic evidence.

248
explore the connection between the sonority of segments and their effects on phoneme
counting tasks, and more generally on phoneme perception.
Given the controversy surrounding the number of segments in diphthongs, some
questions have arisen about the proper phonemicisation of the diphthong stimuli in the
current project. Should the English and Mandarin diphthongs have been coded as one unit
rather than two? If so, would that coding effectively change the results? To shed light on
these questions, I investigated the raw accuracy rates of the diphthongs and reanalysed
the data with the reverse phonemecisation of the diphthongs.
Table 6.5 below lists the raw accuracy rates for the English and Mandarin
diphthongs and orders them from the most accurately counted to the least accurately
counted (when the diphthongs are counted as 2 phonemes). This table also includes the
accuracy rates for each of the diphthongs if they were re-phonemecised as 1 phoneme.
The raw accuracy rates suggest that coding diphthongs as one unit is not necessarily the
answer. Rather, the accuracy suggests that the cohesiveness of diphthongs depends on the
diphthong and that not all diphthongs are the same. For example, /aw/ diphthongs appear
to be more often counted as two units (e.g. how=0.81, hào=0.85), while /ow/ and /aj/
diphthongs appear to be more often counted as one unit (my=0.21, toe=0.19, hái=0.31).
The question then is: do speakers parse diphthongs as one or two units depending on the
compatibility of their component sounds? According to Reetz and Jongman (2009), /aw/
and /Oj/ as in plow and toy are true diphthongs with much more substantial articulatory
movement from the vowel to the glide than in diphthongised vowels such as /ej/ and /ow/
as in way and grow. This substantial difference in articulatory movement and

249
consequently in acoustic movement may explain why /aw/ was counted as two segments
while /ej/ and /ow/ were counted as one.
word language 2 phonemes 1 phoneme50
hào /xaw/ Mandarin 0.85 0.12 how /haw/ English 0.81 0.19 bào /paw/ Mandarin 0.81 0.19 nào /naw/ Mandarin 0.77 0.23 now /naw/ English 0.69 0.31 g%o /kaw/ Mandarin 0.69 0.31 bow /baw/ English 0.62 0.31 méi /mej/ Mandarin 0.62 0.35 maì /maj/ Mandarin 0.46 0.54 May /mej/ English 0.46 0.48 shéi /ßej/ Mandarin 0.42 0.54 tóu /tÓow/ Mandarin 0.42 0.58
kuài /kÓwaj/ Mandarin 0.31 0.62 duì /twej/ Mandarin 0.31 0.54 hái /xaj/ Mandarin 0.31 0.65 my /maj/ English 0.21 0.78 high /haj/ English 0.19 0.75 toe /tow/ English 0.19 0.73 die /daj/ English 0.15 0.81
gòu /kow/ Mandarin 0.04 0.96 go /gow/ English 0.00 0.96
Table 6.5 Raw accuracy rates for English and Mandarin diphthongs
In addition to investigating the raw accuracy rates, I also reanalysed the L1 and L0
homophone data51 with the diphthongs re-phonemecised as 1 phoneme and re-categoried
into the appropriate M and MM categories to determine whether the choice of
50 In the cases where the 2 phoneme accuracy and 1 phoneme accuracy do not add up to 100%, the missing percentages result from instances where participants counted the words with diphthongs as neither 2 phonemes nor 1 phoneme.
51 I could not reanalyse the L2 data because the diphthongs could not be re-phonemecised in a way that did not also introduce other confounding factors. That is, the L2 MM-H condition would have contained both matched and mismatched tokens rather than matched tokens. The match-mismatch mix, however, is not problematic for the L0 data as the participants had no knowledge of the spellings of the L0 words.

250
phonemicisation had a bearing on the results. Table 6.6 and Figure 6.4 reproduce the
categorisation of the diphthongs (highlighted in grey) and the results from the original
analysis, respectively.
Russian [24 tokens] English [48 tokens] Mandarin [24 tokens] M-H: 1-to-1 relation-ship in both L1 and L2 [10 per language]
+/ /an/ (he) 2-2 "->$ /lift/ (elevator) 4-4 &!= /daj/ (to give) 3-3 1!& /sat/ (garden) 3-3
8!7$ /mart/ (March) 4-4 6!7$ /kart/ (map GEN.PL) 4-4
?7!$ /brat/ (brother) 4-4
on /An/ 2-2 lift /lIft/ 4-4 die /daj/ 3-3 sat /sœt/ 3-3
mart /mA®t/ 4-4 cart /kA®t/ 4-4
brat /b®œt/ 4-4
May /mej/ 3-3 now /naw/ 3-3
do /du/ 2-2 toe /tow/ 3-3
swan /swAn/ 4-4 bow /baw/ 3-3 ban /bœn/ 3-3 how /haw/ 3-3
man /mœn/ 3-3 bun /bØn/ 3-3
méi /mej/ (did not have not) 3-3 nào /naw/ (noisy) 3-3
dú /tu/ (to read) 2-2 tóu /tÓow/ (head) 3-3
su%n /swan/ (sour) 4-4 bào /paw/ (newspaper) 3-3
bàn /pan/ (half) 3-3 hào /xaw/ (number) 3-3
màn /man/ (slow) 3-3 bèn /pøn/ (stupid) 3-3
MM-H: *mismatch in spelling for L1 *1-to-1 relation-ship in L2 [14 per language]
8!= /maj/ (May) 3-3 &+8 /dom/ (house) 3-3
;- /S:i/ (cabbage soup) 2-2 1$:" /stul/ (chair) 4-4 1:9 /sup/ (soup) 3-3 $:$ /tut/ (here) 3-3 $7- /tri/ (three) 3-3 /: /nu/ (well) 2-2
1+6 /sok/ (juice) 3-3 9+" /pol/ (floor) 3-3 <-$ /xit/ (hit) 3-3
my /maj/ 2-3 dome /dom/ 4-3
she /Si/ 3-2 stool /stu:/ 5-4 soup /sup/ 4-3
toot /tut/ 4-3 tree /t®i/ 4-3
(k)new /nu/ 4-3 sock /sAk/ 4-3 pole /po:/ 4-3 heat /hit/ 4-3
my /maj/ 2-3 when /w”n/ 4-3
coo /ku/ 3-2 pea/pee /pi/ 3-2
sue /su/ 3-2 tea/tee /ti/ 3-2
who /hu/ 3-2 knee /ni/ 4-2
she /Si/ 3-2 go /gow/ 2-3
high /haj/ 4-3 rue /®u/ 3-2
maì /maj/ (to sell) 3-3 wèn /wøn/ (to ask) 3-3
k3 /ku/ (to cry) 2-2 pí /pÓi/ (skin) 2-2
sù /su/ (to tell) 2-2 tí /tÓi/ (to carry) 2-2 h3 /xu/ (to call) 2-2
ni /ni/ (you) 2-2 x' /Çi/ (west) 2-2
gòu /kow/ (enough) 3-3 hái /xaj/ (still / yet) 3-3
rú /"u/ (if / as if) 2-2
Table 6.6 Original categorisation of target words with diphthongs phonemicised as 2 segments

251
Figure 6.4 Original analyses of L1 and L0 H with the diphthongs phonemicised as 2 phonemes
The data here show that for the L1 data, the matched Hs were more accurately counted
than the mismatched Hs but that there was no difference between the RNL0 and MNL0
groups. In contrast, for the L0 data, the results suggest that while both groups counted
matched L0 Hs more accurately than mismatched L0 Hs, the RNL0 was more accurate
than the MNL0 overall. (See §5.3 for the complete statistical analyses of these original
data.)
L0 mismatchL0 matchL1 mismatchL1 match
squa
re r
oot o
f ref
lect
ed a
ccur
acy
rate
s
0 .6000
0.4000
0.2000
0.0000
Error Bars: 95% CI
RNL0MNL0
group
GLM L1Hm L1Hmm L0Hm L0Hmm BY group /WSFACTOR=LANG 2 Polynomial MAT 2 Polynomial /METHOD=SSTYPE(3) /CRITERIA=ALPHA(.05) /WSDESIGN=LANG MAT LANG*MAT /DESIGN=group.
General Linear Model
Page 3

252
Table 6.7 and Figure 6.5 below present the re-categorised and re-analysed data
results for the diphthongs phonemicised as 1 phoneme (rather than 2 as in the original
analysis).
Russian [24 tokens] English [48 tokens] Mandarin [24 tokens] M-H: 1-to-1 relation-ship in both L1 and L2 [10 per language]
+/ /an/ (he) 2-2 "->$ /lift/ (elevator) 4-4 &!= /daj/ (to give) 3-3 1!& /sat/ (garden) 3-3
8!7$ /mart/ (March) 4-4 6!7$ /kart/ (map GEN.PL) 4-4
?7!$ /brat/ (brother) 4-4
on /An/ 2-2 lift /lIft/ 4-4 die /daj/ 3-2 sat /sœt/ 3-3
mart /mA®t/ 4-4 cart /kA®t/ 4-4
brat /b®œt/ 4-4
my /maj/ 2-252 go /gow/ 2-2 do /du/ 2-2
swan /swAn/ 4-4 ban /bœn/ 3-3
man /mœn/ 3-3 bun /bØn/ 3-3
maì /maj/ (to sell) 3-2 gòu /kow/ (enough) 3-2
dú /tu/ (to read) 2-2 su%n /swan/ (sour) 4-4
bàn /pan/ (half) 3-3 màn /man/ (slow) 3-3 bèn /pøn/ (stupid) 3-3
MM-H: *mismatch in spelling for L1 *1-to-1 relation-ship in L2 [14 per language]
8!= /maj/ (May) 3-3 &+8 /dom/ (house) 3-3
;- /S:i/ (cabbage soup) 2-2 1$:" /stul/ (chair) 4-4 1:9 /sup/ (soup) 3-3 $:$ /tut/ (here) 3-3 $7- /tri/ (three) 3-3 /: /nu/ (well) 2-2
1+6 /sok/ (juice) 3-3 9+" /pol/ (floor) 3-3 <-$ /xit/ (hit) 3-3
my /maj/ 2-2 dome /dom/ 4-3
she /Si/ 3-2 stool /stu:/ 5-4 soup /sup/ 4-3
toot /tut/ 4-3 tree /t®i/ 4-3
(k)new /nu/ 4-3 sock /sAk/ 4-3 pole /po:/ 4-3 heat /hit/ 4-3
May /mej/ 3-2 now /naw/ 3-2
toe /tow/ 3-2 bow /baw/ 3-2 how /haw/ 3-2
when /w”n/ 4-3 coo /ku/ 3-2
pea/pee /pi/ 3-2 sue /su/ 3-2
tea/tee /ti/ 3-2 who /hu/ 3-2 knee /ni/ 4-2
she /Si/ 3-2 high /haj/ 4-2
rue /®u/ 3-2
méi /mej/ (did not/have not) 3-2 nào /naw/ (noisy) 3-2 tóu /tÓow/ (head) 3-2
bào /paw/ (newspaper) 3-2 hào /xaw/ (number) 3-2 wèn /wøn/ (to ask) 3-3
k3 /ku/ (to cry) 2-2 pí /pÓi/ (skin) 2-2
sù /su/ (to tell) 2-2 tí /tÓi/ (to carry) 2-2 h3 /xu/ (to call) 2-2
ni /ni/ (you) 2-2 x' /Çi/ (west) 2-2
hái /xaj/ (still / yet) 3-2 rú /"u/ (if/as if) 2-22
Table 6.7 Re-categorised L1 and L0 H data with the diphthongs phonemicised as 1 phoneme
Interestingly, in Figure 6.5 below, we can see a very similar pattern of results to the
original analyses, except the accuracy difference between the matched and mismatched
L1 H appears to be much greater than in the original analyses.
52 When phonemecised as 2 phonemes the diphthongs are represented as VG sequences as in /aw/, /ej/, /aj/ and /ow/. In contrast, when phonemecised as 1 phoneme the diphthongs are represented as VG sequences as in /aw/, /ej/, /aj/ and /ow/

253
Figure 6.5 Re-analysed L1 and L0 H data with the diphthongs phonemicised as 1 phoneme
The reflected accuracy data for the L1 and L0 H were analysed using a 3-factor
repeated measures ANOVA with group (MNL0, RNL0) as the between-subjects factor
and language (L1, L0) and match (match, mismatch) as the two within-subjects factors.
The main effects of match and group, the 2-way interactions of language and group, and
match and group, and the 3-way interaction of language and match and group were
significant (match: F(1,50)=102.212, p<0.001; group: F(1,50)=16.873, p<0.001; match
by group: F(1,50)=5.687, p<0.05; language by group: F(1,50)=41.480, p<0.001;
language by match by group: F(1,50)=4.049, p-=0.05). All other effects were not
significant (language: F(1,50)=2.208; language by match: F(1,50)=2.133; all effects not
L0 mismatchL0 matchL1 mismatchL1 match
squa
re r
oot
of r
efle
cted
acc
urac
y ra
tes
0 .6000
0.4000
0.2000
0.0000
Error Bars: 95% CI
RNL0MNL0
group
SAVE OUTFILE='C:\Documents and Settings\Sonya\Desktop\DIPH1all.sav' /COMPRESSED.GLM L1Hm L1Hmm L0Hm L0Hmm BY group /WSFACTOR=LANG 2 Polynomial MAT 2 Polynomial /METHOD=SSTYPE(3) /CRITERIA=ALPHA(.05) /WSDESIGN=LANG MAT LANG*MAT /DESIGN=group.
General Linear Model
Page 3

254
significant at p>0.05). Tests for the effects of match and group for each language show a
significant main effect of match for the L1 H (F(1,50)=66.936, p<0.001) such that all
participants more accurately counted phonemes in L1 matched H than mismatched H.
In addition, the effects of match and group were tested separately for each language.
For the L1 H words, the tests indicate a significant main effect of match (F(1,50)=66.936,
p<0.001), but no significant main effect for group (F(1,50)=0.021, p>0.05) or interaction
of match and group (F(1,50)=0.099, p>0.05). Thus, both groups are significantly more
accurate at counting phonemes in matched L1 H than in mismatched L1 H. For the L0 H
words, the follow-up tests indicate significant main effects of match and group as well as
the interaction of match and group (match: F(1,50)=40.246, p<0.001; group:
F(1,50)=238.289, p<0.001; match by group: F(1,50)=9.955, p<0.01). Subsequent tests
for the effects of match for each group separately indicate a significant effect of match
for the RNL0 (F(1,50)=4.894, p<0.05) and MNL0 (F(1,50)=46.943, p<0.001) groups.
That is, both groups more accurately counted phonemes in the matched L0 Hs than the
mismatched L0 Hs, but the difference was greater for the MNL0 group than the RNL0
group.
Re-phonemicising the diphthongs did not bring all the diphthongs into one inclusive
category. Rather, by changing the phonemicisation from 2 phonemes to 1 phoneme, the
originally matched words and mismatched words swapped categories so that the matched
words became mismatched words and vice versa. By swapping categories, there were still
diphthongs in each reorganised category, except that now the /ej/ and /ow/ diphthongs
were accurately counted while the /aw/ diphthongs were not. In other words, the
diphthongs still may have balanced each other out—just in the opposite way from the

255
original data—thus possibly explaining why the pattern of results remained the same.
Also, the greater difference between the reanalysed L1 M and MM might be explained by
the /aw/ words (phonemicised as 1 phoneme /aw/) moving into the MM condition. These
/aw/ words were accurately counted as 2 phonemes in the original analysis, so they would
have been counted inaccurately in the re-analysis, adding to the inaccuracy of the MM
category and widening the gap between the L1 M and MM conditions and the Mandarin
L0 M and MM conditions (The Russian L0 conditions had no diphthongs.). In short,
simply categorising diphthongs as either 1 or 2 phonemes across the board is not the
answer; instead, when phonemicsing diphthongs, it appears that each diphthong must be
analysed individually on its own terms.
6.5 Summary
This chapter has discussed the two major findings regarding orthographic effects. The
first major finding here supports previous research findings that participants’
orthographic knowledge influences their phoneme awareness of words (e.g., Bassetti,
2006; Burnham, 2003; Castles et al., 2003; Ehri & Wilce, 1980; Perin, 1983; Pytlyk, to
appear; Treiman & Cassar, 1997). In short, listeners count phonemes more accurately in
words with consistent letter-phoneme correspondences than in words with inconsistent
letter-phoneme correspondences. The results demonstrate that L1 orthographic
knowledge influences phoneme awareness in the first language and an unfamiliar
language and that L2 orthographic knowledge influences phoneme perception in a second
language. We can conclude from the results that when a match exists between the number
of letters and the number of phonemes in a word, the orthography aids listeners in
perceiving the correct number of phonemes in a word. In contrast, when a mismatch

256
exists between the number of letters and the number of phonemes, the orthography
prevents listeners from perceiving the correct number of phonemes because they receive
conflicting orthographic and phonological information. These results provide further
evidence that orthographic and phonological information are co-activated in L1 and L2
speech processing even in the absence of visual stimuli (Blau et al., 2008; Chéreau et al.,
2007; Taft et al., 2008; Ziegler & Ferrand, 1998; Ziegler et al., 2003; Ziegler et al., 2004).
Moreover, these results provide evidence that listeners are sensitive to orthographic
information, which can trigger unwanted interference when the two systems provide
conflicting information (Burnham, 2003; Landerl et al., 1996; Perin, 1983; Treiman &
Cassar, 1997). Most importantly, the results from this current project reveal that not only
are listeners susceptible to L1 orthographic interference, but they are also susceptible to
L2 orthographic interference.
The second major finding stemming from this research is that orthographic effects
appear to be language-specific. Comparisons of subgroups’ homophone data show that
the listeners were equally accurate and as fast at counting phonemes in L2 matched H
words (i.e., L2 words with consistent L1 associations) as they were in counting the
mismatched H words (i.e., L2 words with inconsistent L1 associations). The lack of any
significant performance differences between these two types of L2 words suggest that L2
listeners rely on the L2 orthographic information rather than the L1 orthographic
information when counting phonemes in their L2. These results suggest that L2
orthographic effects override L1 orthographic effects by the intermediate stages of
second language learning, at least for Russian and Mandarin. Apparently, by the time L2
learners become intermediate learners, they are able to transcend L1 orthographic

257
influence, but they do have to contend with L2 orthographic influence as evidenced by
the significant differences in performance between the L2 NH matched and mismatched
words. As with L2 reading and spelling (Sun-Alperin & Wang, 2011; Wang et al., 2006;
Wang et al., 2005), these results indicate that L1 orthographic effects may not transfer
into L2 speech perception when the L2 orthography is known. Rather, L2 listeners appear
to dissociate themselves from L1 orthographic knowledge and employ their L2
orthographic knowledge to aid them in speech perception. While the reasons why L2
orthographic knowledge overrides the more entrenched L1 orthographic knowledge are
not entirely clear at this point, it is possible that—as has been suggested for L1
orthography and phonology (e.g., Burnham, 1986, 2003; Burnham et al., 1991; Carroll,
2004; Castro-Caldas et al., 1998; Flege, 1991; Olson, 1996; Treiman & Cassar, 1997;
Ziegler et al., 2004)—learning to read forces the organisation of L2 phonology such that
the two systems become inseparably linked and thus are co-activated in L2 speech
processing. In addition to the language-specific nature of orthographic effects, the degree
of orthographic influence also appears to be directly correlated to the degree of
experience listeners have in the target language. The more experience listeners have with
the language the greater the orthographic effects are.
This chapter has also proposed the Bipartite Model, which accounts for the
seemingly contradictory findings discovered in this and previous research. The model
identifies two types of L1 orthographic knowledge: abstract and operational. Abstract
knowledge refers to the assumptions and principles children/learners have about the
function of orthography and its relationship to phonology. Based on the current and
previous findings, the model proposes that this aspect of L1 orthographic knowledge

258
appears to transfer into nonnative language processing regardless of whether the
listeners/speakers are familiar with the nonnatiave language (e.g., Bassetti, 2006; Vokic,
2011). In contrast, operational knowledge in this model refers the actual letter-phoneme
correspondences created in any given language. Here, the model predicts that this aspect
of L1 orthographic knowledge transfers into the nonnative language processing in the
absence of nonnative orthographic knowledge (i.e., the L0), but does not transfer in the
presence of nonnative orthographic knowledge (i.e., the L2).
In addition to the major findings, this chapter outlined and discussed three
unanticipated findings from the data analyses. First, listeners also demonstrate familiarity
and word effects, which interact with orthographic knowledge and attenuate orthographic
effects. Second, a phonological effect accounts for the performance asymmetry between
the Russian and Mandarin words. This phonological effect is likely due to the differing
phonological structures of Russian and Mandarin. Third, preliminary analyses of the
mismatched stimuli suggest at least four different subcategories of inconsistency that
vary in terms of their influence on L1 and L2 speech perception. Finally, this chapter
addresses the question of the proper phonemicisation of the diphthongs and reanalysed
the data to determin whether rephonemicising the diphthongs as 1 phoneme would impact
the results. Interestingly, the pattern of results remained the same; likely due to the fact
that the diphthongs varied in accuracy from 85% to 0% and re-phonemicising them
simply swapped their categories but maintained the balance.

259
Chapter Seven
CONCLUSION
“The nature of the L1 orthography influences the way L2 learners attend to the L2 orthographic units”
(Wade-Woolley, 1999, p. 448)
This final chapter completes this dissertation with four closing sections. The first section
summarises the entire project from the research questions and hypotheses to the
conclusions stemming from the major findings (§7.1). The second section (§7.2)
discusses the limitations of the research. The third section (§7.3) suggests some potential
future research endeavours. The final section (§7.4) completes this dissertation by
outlining the contributions this research makes to the growing body of literature
surrounding the effects of orthographic knowledge on speech processing not only in
native languages but also in nonnative languages.
7.1 Summary of research
This research investigated how orthographic knowledge affects phoneme detection in
listeners’ first language (L1), second language (L2) and an unfamiliar language (L0).
This study sought to
1. confirm that L1 orthographic knowledge influences L1 phoneme
perception,
2. determine if L1 orthographic knowledge affects L0 phoneme pereception,
3. discover whether L2 orthographic knowledge influences L2 phoneme
perception and if so how it interacts with L1 orthographic knowledge, and

260
4. ascertain whether amount of language experience dictates the strength of
orthographic effects.
The project studied the effect of orthographic knowledge on phoneme awareness in
English (L1), Russian (L2 or L0), and Mandarin (L2 or L0). The stimuli for each
language were created and organised according to two parameters: match and
homophony. The assumption here was that accuracy and response time differences
between the different types of target words would indicate an effect of orthographic
knowledge on phoneme perception.
In the research project, participants listened to the target stimuli and counted the
number of “sounds” they heard in each word via a phoneme counting task, which
assesses the influence of orthographic factors and measures phoneme awareness
(Treiman & Cassar, 1997). Fifty-two native speakers of Canadian English participated
and counted phonemes in words from their L1 (English) and L0 (either Russian or
Mandarin). The MNL0 group counted phonemes in English (L1) and Mandarin (L0)
words while the RNL0 group counted phonemes in English (L1) and Russian (L0) words.
In addition, two subgroups of participants also counted phonemes in their L2. The L2 for
the subgroup within the MNL0 was Russian (the RFL subgroup), and the L2 for the
subgroup within the RNL0 was Mandarin (the MFL subgroup).
Once collected from the participants, the data were analysed according to accuracy
rates and response times in order to investigate the effects of orthographic knowledge on
L1, L2, and L0 phoneme perception. Four-way repeated measures ANOVAs analysed the
data along four independent factors (group, language, homophone, and match) to answer
the four primary research questions outlined above. Overall, the results of the analyses

261
confirm the hypotheses that L1 orthographic knowledge influences both L1 and L0
phoneme perception (Questions 1 and 2), that L2 orthographic knowledge influences L2
phoneme perception (Question 3), and that the degree of language experience determines
the strength of orthographic effects such that orthographic effects are strongest in L1
followed by L2 and are the weakest in L0 (Question 4). Specifically, L1 orthographic
knowledge facilitates L1 and L0 phoneme perception when the number of letters equals
the number of phonemes in a word, and conversely, L1 orthographic knowledge hinders
L1 and L0 phoneme perception when the number of letters does not equal the number of
phonemes. The results also show a parallel pattern of influence with L2 orthographic
knowledge facilitating L2 phoneme perception in consistent words but hindering L2
perception in inconsistent words. These L1, L0, and L2 results provide further evidence
that orthographic and phonological information are co-activated in speech processing
even in the absence of visual stimuli (Blau et al., 2008; Chéreau et al., 2007; Taft et al.,
2008; Ziegler & Ferrand 1998; Ziegler et al. 2003; Ziegler et al. 2004). In addition, these
results provide evidence that listeners are sensitive to orthographic information, which
may trigger unwanted interference when the orthographic and phonological systems
provide conflicting information (Burnham, 2003; Landerl et al., 1996; Perin, 1983;
Treiman & Cassar, 1997). Finally and most interestingly, the results reveal that listeners
are susceptible to L2 orthographic interference as well as L1 orthographic interference.
Not only does L2 orthographic knowledge appear to influence L2 phoneme
perception, but it also appears to override any potential L1 orthographic effects thereby
suggesting that orthographic effects are language-specific. Comparisons of subgroups’
homophone data show that the listeners were as accurate and as fast at counting

262
phonemes in L2 matched homophones words (i.e., L2 words with consistent L1
associations) as they were in counting the mismatched homophones (i.e., L2 words with
inconsistent L1 associations). The lack of any significant performance differences
between these two types of L2 words suggest that L2 listeners rely on the L2
orthographic information rather than the L1 orthographic information when counting
phonemes in their L2. These results imply that by the intermediate stage of learning, L2
listeners appear to dissociate themselves from L1 orthographic knowledge and employ
their L2 orthographic knowledge to aid them in speech perception. The reasons why L2
orthographic knowledge overrides the more entrenched L1 orthographic knowledge are
not entirely clear at this point. However, it is possible that—as with L1 acquisition—
learning to read forces the organisation of L2 phonology such that the two systems
become inseparably linked and thus are co-activated in L2 speech processing.
As a way of synthesising the findings here and the findings from previous research,
this dissertation proposes two components of orthographic knowledge: abstract and
operational. Abstract knowledge refers to the general assumptions and principles children
and/or learners have about the function of orthography and its relationship to phonology
(e.g., letters map onto phonemes or letters map onto morphemes). It predicts that this
aspect of L1 orthographic knowledge transfers into nonnative language processing
regardless of whether the listeners/speakers are familiar with the nonnatiave language
(e.g., Bassetti, 2006; Vokic, 2011). In contrast, operational knowledge refers to the actual
letter-phoneme correspondences created in any given language (i.e., what letters map to
what phonemes). Here, the proposal predicts that this aspect of L1 orthographic
knowledge transfers into the nonnative language processing in the absence nonnative

263
orthographic knowledge (i.e., the L0), but does not transfer in the presence of nonnative
orthographic knowledge (i.e., the L2). Rather, L2-specific operational knowledge is
created based partly on the transferred abstract knowledge. These two aspects of
orthographic knowledge are encapsulated in what is termed the Bipartite Model of
Orthographic Knowledge and Transfer.
In addition to the major findings regarding the effects of orthographic knowledge,
the results suggest a number of other effects and interactions. First, the results indicate
that orthographic knowledge interacts with familiarity and with the nature of the words
themselves to influence L0 phoneme perception. The interaction of these effects reduces
the effects of L1 orthography on L0 phoneme counting, such that its influence is not as
strong in the L0 as it is in the L1. Second, the phonological structure of the target
languages appears to influence the ease of phoneme perception. Finally, investigation
into the internal consistency of the mismatched tokens suggest that not all mismatched
words pose the same level of difficulty for listeners, and that the observed difference
between the M and MM words may be due to a subset of MM words rather than the MM
words as a whole.
7.2 Limitations
While every aspect and decision was carefully considered, this research is not without its
limitations. This research contains two types of limitations. The first type includes the
limitations that were unavoidable due to the differences between the target languages. As
mentioned in Chapter 4, because the L2 subgroup participants needed to be
orthographically and phonologically familiar with the target words, there were a limited
number of cross-language homophones available that fit all the parameters. This resulted

264
in certain unavoidable limitations with respect to stimuli selection. First, only 10 target
words could be found for the matched homophone conditions, in contrast to the 14 target
words of each of the other conditions. Second, not all the Russian nonhomophone words
followed English phonotactic rules, although particularly difficult consonant clusters in
Russian were avoided. Third, the relatively simple syllable structure of Mandarin (See
§3.2.3.2.) meant that diphthongs (and tone) were impossible to avoid. Some of the L0
listeners commented on the “strange” or “weird” sound combinations in the L0 words.
The unlicensed combinations (Russian) and the contour pitch (Mandarin) may have
thrown off the participants from the task at hand, especially with the nonhomophone
targets where they did not have any orthographic support in parsing phonemes. In
addition, cross-linguistic differences in syllable structure and phonotactics may have
contributed the word effects discussed in §6.3.2 above. Finally, the limited stimuli
available prevented controlling for the internal consistency of the mismatched words.
That is, to have enough tokens in the MM conditions, these conditions were populated
with different types of inconsistency, which, as it turned out, were not all equal in terms
of their effect on phoneme counting. Potential solutions to these limitations might include
1) choosing target languages that are more phonotactically similar and with fewer
restrictions on phonological structure, 2) investigating potential differences between
subcategories of mismatched tokens and comparing them with the matched tokens, and 3)
studying more advanced learners so that it is possible to draw the homophones from a
more extensive L2 vocabulary.
The second type of limitations includes the unforeseen and unanticipated limitations
with the methodological design. First, half way through the L2 data collection, it became

265
apparent that knowing whether the participants knew how to spell the L1 words (and the
L2 words in case of the RFL and MFL subgroups) was extremely important.
Unfortunately, 18 of the 52 participants did not complete a spelling dictation.
Fortunately, those participants whose spelling was tested indicated that they could spell
the vast majority of the words. While we may assume that the first 18 participants would
have been equally adept at spelling, still we cannot be absolutely certain that those whose
spelling was not tested also knew how to spell the L1 (and L2 words). Second, the order
of the data collection (i.e., primary data then secondary data) was a methodological
limitation. The secondary data should have been collected and analysed before the
primary data so that the problematic tokens (which were discarded) would have been
identified prior to the primary data collection, and other stimuli could have been chosen
in their places thereby equalising the number of tokens in each condition. The secondary
data collection came after the primary data because it was envisioned to help interpret the
primary results not to evaluate the stimuli. While this is not an exhaustive list, these
limitations outlined here are the major limitations discovered within the research.
7.3 Future research
The Bipartite Model proposed in Chapter 6 is clearly still in its infancy; much research is
required to support and refine its claims and predictions. For example, future research
needs to determine to what extent orthographic transparency affects L2 orthographic
learning, and if transparency does exert a strong influence, the model needs to be adapted
to reflect this influence. Also, future research needs to test the model’s prediction that
non-literate L2 learners would transfer L1 operational knowledge as well as L1 abstract
knowledge into their L2 speech processing. Indeed, the model predicts that non-literate

266
L2 learners would behave like the L0 listeners in this research because they do not have
any L2 orthographic knowledge. These non-literates should therefore rely on both their
abstract and operational L1 orthographic knowledge. In addition, other interesting
research possibilities would test and help refine the Bipartite Model. These include
investigating and comparing:
1. L2 groups that vary according to proficiency/experience (i.e., beginner,
intermediate, and advanced) to determine/confirm that the degree of
language experience is, indeed, a factor in the strength of orthographic
effects and to see when L2 specific operational knowledge takes hold,
2. L2 learners from a transparent L1 orthography learning an opaque L2
orthography (e.g., Spanish L1 and English L2) and L2 learners from a
opaque L1 orthography learning a transparent L2 orthography (e.g., English
L1 and Spanish L2) to determine whether learning an opaque L2
orthography requires more time and exposure in order to develop L2
decoding skills and operational knowledge than learning a transperent L2
orthography does,
3. the strength of orthography-phonology connections between L2s with
differing transparency to determine whether the connections are stronger
between orthography and phonology when the L2 is more transparent than
when the L2 is less transparent.
4. “Good” vs. “bad” spellers to determine whether “good” spellers rely more
on L2 operational knowledge than “bad” spellers do, to determine if degree
of literacy is also a factor in the model, and

267
One of the most interesting and important issues raised here involves internal
inconsistency within the MM words. Future research must delve into the question of
whether different types of MM exert different effects on the perception of phonemes.
That is, does a continuum of difficulty exist for subcategories of inconsistent words?
While the present study was not designed to answer this question, the preliminary
analysis of the MM words suggests that not all MM words influence listeners’ abilities to
parse phonemes to the same degree. Thus, future research is required to test these
preliminary findings and determine how many subcategories of inconsistency exist and
which subcategories hinder phoneme perception.
The suggestions listed here are only a few of the possibilities for future research.
Because the effect of orthographic knowledge on L2 and L0 phoneme awareness remains
relatively unexplored, the research possibilities are seemingly endless.
7.4 Contributions
This project contributes to the body of literature on orthographic knowledge by
investigating and determining how orthographic knowledge affects phoneme perception
not only in an L1 but also in an L2 and an L0. Specifically, the research here contributes
to the body of literature in three ways. First, the current research supports previous
findings and claims regarding orthographic knowledge and native language speech
processing. Second, the L2 findings provide insight into the relatively sparse—but
growing—understanding of the relationship between L1 and L2 orthography and
nonnative speech perception. In fact, the research suggests that L2 learners can transcend
L1 transfer effects, at least for operational orthographic knowledge. Finally, this research
proposes an alternative view of orthographic knowledge, one that views orthographic

268
knowledge not as a single homogeneous entity but rather an entity comprised of at least
two components, abstract knowledge and operational knowledge. If true, this division of
orthographic knowledge will redefine and shape our future understanding of how
orthography influences speech processing in native and nonnative languages, specifically
as it relates to perception, orthographic depth, and literacy.
Pedagogically, this research is valuable for language instructors in that it identifies
orthographic knowledge as a potential barrier to L2 speech perception, a barrier they may
not have previously considered. Although language instructors may not always view
orthographic knowledge as an obvious barrier to nonnative speech processing, this
research demonstrates that L1 and L2 orthographic knowledge exert very real effects on
L0 and L2 phoneme perception. First, the L0 results suggest that at the initial stages of
learning (=L0), L1 orthographic knowledge may provide a visual crutch with which
beginners use to help them parse nonnative phonemes. Second, while the L2 results
suggest that L2 learners can overcome the effects of L1 operational knowledge after they
gain more experience in the language, the results also caution language instructors that
L2 orthographic knowledge too can influence how learners hear and parse L2 phonemes.
That is, these findings can raise instructors’ awareness about how firmly learners rely on
their orthographic knowledge to aid them in L2 speech processing. More specifically, the
current findings suggest that instructors may find it worthwhile to explicitly discuss with
their students the relationship between orthography and phonology in the L2. Such a
discussion would be the most beneficial for learners who are accustomed to a vastly
different orthography-phonology relationship in their L1. For example, knowing that
learners transfer abstract knowledge into L2, English language instructors would be wise

269
at the outset to draw attention to the high degree of inconsistency in letter-phoneme
correspondences, especially for their students whose L1 employs a more transparent
orthography than English, such as Spanish and Greek.

270
REFERENCES
Alegria, J., Pignot, E., & Morais, J. (1982). Phonetic analysis of speech and memory codes in beginning readers. Memory & Cognition, 10 (5), 451–456. http:// www. springerlink.com/content/0090-502x/10/5/
Archibald, J. (1998). Second Language Phonology. Amsterdam: John Benjamins Publishing Company.
Arnqvist, A. (1992). The impact of consonant clusters on preschool children’s phonemic awareness: A comparison between readers and nonreaders. Scandinavian Journal of Psychology, 33 (1), 29–35. doi: 10.1111/j.1467-9450.1992.tb00810.x
Aronoff, M. (1992). Segmentalism in linguistics: The alphabetic basis of phonological theory. In P. Downing, S. D. Lima, & M. Noonan (Eds.), The Linguistics of Literacy (pp. 71–82). Amsterdam: John Benjamins.
Bassetti, B. (2005). Effects of writing systems on second language awareness: Word awareness in English learners of Chinese as a foreign language. In V. Cook & B. Bassetti (Eds), Second Language Writing Systems (pp. 335–356). North York, ON: Multilingual Matters Ltd.
Bassetti, B. (2006). Orthographic input and phonological representations in learners of Chinese as a foreign language. Written Language and Literacy, 9 (1), 95–114. Print
Ben-Dror, I., Frost, R., & Bentin, S. (1995). Orthographic representation and phonemic segmentation in skilled readers: A cross-language comparison. Psychological Science, 6 (3), 176–181. Retrieved from http://www.jstor.org/stable/40063011
Berg, T. (1986). The monophonematic status of diphthongs revisited. Phonetica, 43, 198–205. Print
Bertelson, P., & de Gelder, B. (1991). The emergence of phonological awareness: Comparative approaches. In I. G. Mattingly & M. Studdert-Kennedy (Eds.), Modularity and the Motor Theory of Speech Perception (pp. 393–412). Hillsdale, NJ: Erlbaum.
Bertelson, P., de Gelder, B., Tfouni, L. V. Morais, J. (1989). Metaphonological abilities of adult illiterates: New evidence of heterogeneity. European Journal of Cognitive Psychology, 1 (3), 239–250. doi: 10.1080/09541448908403083
Best, C. (1995). A direct realist view of cross-language speech perception. In W. Strange (Ed.), Speech Perception and Linguistic Experience: Issues in Cross Language Research (p. 171–204). Baltimore, MD: York Press.

271
Best, C. (2001). Discrimination of non-native consonant contrasts varying in perceptual assimilation to the listener’s native phonological system. Journal of the Acoustical Society of America, 109 (2), 775–794. doi: 10.1121/1.1332378
Blau, V., van Atteveldt, N., Formisamo, E., Goebel, R., & Blomert, L. (2008). Task-irrelevant visual letters interact with the processing of speech sounds in heteromodal and unimodal cortex. European Journal of Neuroscience, 28, 500–509. doi: 10.1111/j.1460-9568.2008.06350.x
Blevins, J. (2003). The independent nature of phonotactic constraints. In Féry, C. and R. van de Vijver (eds.) The Syllable in Optimality Theory. Cambridge, UK: University Press. 375–403.
Bloomfield, L. (1933). Language. New York, NY: Holt.
Boberg, C. (2004). English in Canada: Phonology. In E. W. Schneider, K. Burridge, B. Kortmann, R. Mesthrie, & C. Upton, A Handbook of Varieties of English: Volume 1 Phonology, (pp. 351–365). New York, NY: Mouton de Gruyter.
Bohn, O. S., & Flege, J. E. (1992). The production of new and similar vowels by adult German learners of English. Studies in Second Language Acquisition, 14 (2), 131–158. Print
Bonfante, L. (1996). The scripts of Italy. In P. T. Daniels and W. Bright (eds.) The World’s Writing Systems (pp. 297–311). New York, NY: Oxford University Press.
Bowey, J. A. (1994). Phonological sensitivity in novice readers and nonreaders. Journal of Experimental Child Psychology, 58, 134–159. doi: 10.1006/jecp.1994.1029
Brown, C. (2000). The interrelation between speech perception and phonological acquisition from infant to adult. In J. Archibald (Ed.), Second Language Acquisition and Linguistic Theory (pp. 4–63). Malden, MA: Blackwell Publishers Ltd.
Bruck, M., Treiman, R., & Caravolas, M. (1995). Role of the syllable in the processing of spoken English: Evidence from a nonword comparison task. Journal of Experimental Psychology: Human Perception and Performance, 21 (4), 469–479. doi: 10.1037/0096-1523.21.3.469
Brysbaert, M., Van Dyck, G., & Van de Poel, M. (1999). Visual word recognition in bilinguals: Evidence from masked phonological priming. Journal of Experimental Psychology: Human Perception and Performance, 25 (1), 137–148. doi: 10.1037/ 0096-1523.25.1.137
Burnham, D. K. (1986). Developmental loss of speech perception: Exposure to and experience with a first language. Applied Psycholinguistics, 7, 207–240. doi: 10. 1017/S0142716400007554

272
Burnham, D. K., Earnshaw, L. J., & Clark, J. E. (1991). Development of categorical identification of native and non-native bilabial stops: Infants, children and adults. Journal of Child Language, 18 (2), 231–260. doi: 10.1017/S0305000900011041
Burnham, D. K. (2003). Language specific speech perception and the onset of reading. Reading and Writing, 16 (6), 573–609. doi: 10.1023/A:1025593911070
Caravolas, M., & Bruck, M. (1993). The effect of oral and written language input on children’s phonological awareness: a cross-linguistic study. Journal of Experimental Child Psychology, 55 (1), 1–30. doi: 10.1006/jecp.1993.1001
Carrasco-Ortiz, H., Midgley, K. J., & Frenck-Mestre, C. (2012). Are phonological representations in bilinguals language-specific? An ERP study on interlingual homophones. Psychophysiology, 49, 531–543. doi: 10.1111/j.1469-8986.2011. 01333.x
Carroll, J. M. (2004). Letter knowledge precipitates phoneme segmentation, but not phoneme invariance. Journal of Research in Reading, 27 (3), 212–225. doi: 10.1111/j.1467-9817.2004.00228.x
Carroll, J. M., Snowling, M., Hulme, C., & Stevenson, J. (2003). The development of phonological awareness in preschool children. Developmental Psychology, 39 (5), 913–923. doi: 10.1037/0012-1649.39.5.913
Castles, A., Coltheart, M., Wilson, K., Valpied, J., & Wedgwood, J. (2009). The genesis of reading ability: What helps children learn letter-sound correspondences? Journal of Experimental Child Psychology, 104, 68–88. doi: 10.1016/ j.jecp.2008.12.003
Castles, A., Holmes, V. M., Neath, J., & Kinoshita, S. (2003) How does orthographic knowledge influence performance on phonological awareness tasks? The Quarterly Journal of Experimental Psychology: Section A, 56 (3), 445–467. doi: 10.1080/02724980244000486
Castro-Caldas, A., Petersson, K. M., Reis, A., Stone-Elander, S., & Ingvar, M. (1998). The illiterate brain: Learning to read and write during childhood influences the functional organization of the adult brain. Brain, 121, 1053–1063. doi: 10.1093/brain/121.6.1053
Chen, Y., & Hazan, V. (2009). Developmental factors and the non-native speaker effect in auditory-visual speech perception. Journal of the Acoustical Society of America, 126 (2), 858–865. doi: 10.1121/1.3158823
Ch’en, T. T., Link, P., Tai, Y. J., & Tang, H. T. (1994). Chinese Primer: Lessons. Princeton, NJ: Princeton University Press.

273
Ch’en, T. T., Link, P., Tai, Y. J., & Tang, H. T. (1994). Chinese Primer: Notes and Exercises. Princeton, NJ: Princeton University Press.
Chéreau, C., Gaskell, M. G., & Dumay, N. (2007). Reading spoken words: Orthographic effects in auditory priming. Cognition, 102, 341–360. doi: 10.1016/j.cognition. 2006.01.001
Cheung, H. (1999). Improving phonological awareness and word reading in a later learned alphabetic script. Cognition, 70 (1), 1–26. doi: 10.1016/S0010-0277(98)00074-2
Cheung, H., & Chen, H. C. (2004). Early orthographic experience modifies both phonological awareness and on-line speech processing. Language and Cognitive Processes, 19 (1), 1– 28. doi: 10.1080/01690960344000071
Clements, G. N. (1990). The role of the sonority cycle in core syllabification. In J. Kingston and M. E. Beckman (eds.) Papers in Laboratory Phonology I: Between the grammar and the physics of speech. Cambridge, UK: Cambridge University Press. 283–333.
Cook, V. (2002). Background to the L2 user. In V. Cook (Ed.), Portraits of the L2 User (pp. 1–28). North York, ON: Multilingual Matters.
Cook, V. (2004). The English Writing System. London, UK: Hodder Education.
Cook, V., & Bassetti, B. (2005). An introduction to researching second language writing systems. In V. Cook & B. Bassetti (Eds.), Second Language Writing Systems (pp. 1–67). Toronto, ON: Multilingual Matters Ltd.
Cossu, G., Shankweiler, D., Liberman, I. Y., & Gugliotta, M. (1995) Visual and phonological determinants of misreading in a transparent orthography. Reading and Writing, 7 (3), 237–256. doi: 10.1007/BF02539523
Cossu, G., Shankweiler, D., Liberman, I. Y., Tola, G., & Katz, L. (1988). Awareness of phonological segments and reading ability in Italian children. Applied Psycholinguistics, 9, 1–16. doi: 10.1017/S0142716400000424
Coulmas, F. (1989). The Writing Systems of the World. New York, NY: Basil Blackwell Ltd.
Coulmas, F. (1999). The Blackwell Encyclopedia of Writing Systems. Hoboken, NJ: John Wiley & Sons.
Coulmas, F. (2003). Writing Systems: An Introduction to their Linguistic Analysis. Cambridge, UK: Cambridge University Press.
Coutsougera, P. (2007). The impact of orthography on the acquisition of L2 phonology: Inferring the wrong phonology form print. In the Proceedings of the Phonetics

274
Teaching and Learning Conference 2007 (pp. 1–5). London, UK: University College London.
Cubberley, P. (1996). The Slavic alphabets. In P. T. Daniels and W. Bright (eds.) The World’s Writing Systems (pp. 346–355). New York, NY: Oxford University Press.
Cutler, A., Treiman, R., & van Ooijen, B. (1998). Orthogra/k inkoncistensy ephekts in foneme detektion? In R. Mannell, & J. Robert-Ribes (Eds.), Proceedings of the Fifth International Conference on Spoken Language Processing: Vol. 6 (pp. 2783–2786). Sydney: ICSLP.
Cutler, A., Treiman, R., & van Ooijen, B. (2010). Strategic deployment of orthographic knowledge in phoneme detection. Language and Speech, 53 (3), 307–320. doi: 10.1177/0023830910371445
Daniels, P. T. (1996). The first civilizations. In P. T. Daniels and W. Bright (eds.) The World’s Writing Systems (pp. 21–32). New York, NY: Oxford University Press.
Danielsson, K. (2003). The relationship between grapheme-phoneme correspondences and reading errors in Swedish beginners’ oral reading. Scandinavian Journal of Educational Research, 47 (5), 511–528. doi: 10.1080/0031383032000122435
Davenport, M., & Hannahs, S. J. (2010). Introducing Phonetics and Phonology Third Edition. New York, NY: Oxford University Press.
DeFrancis, J. (1989). Visible speech: The diverse oneness of writing systems. Honolulu, HI: University of Hawaii Press.
DeFrancis, J. (1990). The why of Pinyin grapheme selection. The Journal of the Chinese Language Teachers Association, 25 (3), 1–14. Print
DeFrancis, J. (2006). The prospects for Chinese writing reform. Sino-Platonic Papers, 171 (June), 1–24. Print
Derwing, B. L. (1992). Orthographic aspects of linguistic competence. In P. Downing, S. D. Lima, & M. Noonan (Eds.), The Linguistics of Literacy (pp. 193–210). Amsterdam: Benjamins.
Derwing, B. L., Nearey, T. M., & Dow, M. L. (1986). On the phoneme as the unit of the ‘second articulation’. Phonology Yearbook, 3, 45–69. http://www.jstor.org/stable /4615392
Detey, S., & Nespoulous, J. L. (2008). Can orthography influence second language syllabic segmentation? Japanese epenthetic vowels and French consonantal clusters. Lingua, 118, 66–81. doi: 10.1016/j.lingua.2007.04.003

275
Dijkstra, T., Grainger, J., & van Heuven, W. (1999). Recognition of cognates and interlingual homographs: The neglected role of phonology. Journal of Memory and Language, 41 (4), 496–518. doi: 10.1006/jmla.1999.2654
Dijkstra, T., Roelofs, A., & Fieuws, S. (1995). Orthographic effects on phonemic monitoring. Canadian Journal of Experimental Psychology, 49 (2), 264–271. doi: 10.1037/1196-1961.49.2.264
Dijkstra, T., van Jaarsveld, H., & ten Brinke, S. (1998). Interlingual homograph recognition: Effects of task demands and language intermixing. Bilingualism: Language and Cognition, 1 (1), 51–66. doi: 10.1017/S1366728998000121
Duanmu, S. (2000). The Phonology of Standard Chinese. Oxford, UK: Oxford University Press.
Dumbreck, J. C. (1964). Forbes’ Russian Grammar (3rd ed). Oxford, UK: Oxford University Press.
Dupoux, E., Kakehi, K., Hirose, Y., Pallier, C., & Mehler, J. (1999). Epenthetic vowels in Japanese: A perceptual illusion? Journal of Experimental Psychology: Human Perception and Performance, 25 (6), 1568–1578. doi: 10.1037/0096-1523.25.6.1568
Ehri, L. C. (1984). How orthography alters spoken language competencies in children learning to read and spell. In J. Downing & R. Valtin (Eds.), Language Awareness and Learning to Read (pp. 119–147). New York, NY: Springer.
Ehri, L. C. (1985). Effects of printed language acquisition on speech. In D. Olsen, N. Torrence, & A. Hildyard (Eds.), Literacy, Language, and Learning: The Nature and Consequences of Reading and Writing (pp. 333–367). New York, NY: Cambridge University Press.
Ehri, L. C., & Wilce, L. S. (1980). The influence of orthography on readers’ conceptualization of the phonemic structure of words. Applied Psycholinguistics, 1 (4), 371–385. doi: 10.1017/S0142716400009802
Ellis, N. (2002). Frequency effects in language processing. Studies in Second Language Acquisition, 24 (2), 143–188. doi: 10.1017/S0272263102002024
Ellis, N., & Hooper, A. M. (2001). It is easier to learn to read in Welsh than in English: Effects of orthographic transparency demonstrated using frequency-matched cross-linguistic reading tests. Applied Psycholinguistics, 22 (4), 571–590. doi: 10.1017/S014271640 1004052
Ellis, N., Natsume, M., Stavropoulou, K., Hoxhallari, L., Van Daal, V. H. P., Polyzoe, N., Tsipa, M., & Petalas, M. (2004). The effects of orthographic depth on learning to read alphabetic, syllabic, and logographic scripts. Reading Research Quarterly, 39 (4), 438–468. doi: 10.1598/RRQ.39.4.5

276
Erdener, V. D., & Burnham, D. K. (2005). The role of audiovisual speech and orthographic information in nonnative speech production. Language Learning, 55 (2) June, 191–228. doi: 10.1111/j.0023-8333.2005.00303.x
Escudero, P., & Wanrooij, K. (2010). The effect of L1 orthography on non-native vowel perception. Language and Speech, 53 (3), 343–365. doi: 10.1177/002383 0910371447
Everson, M. E. (1998). Word recognition among learners of Chinese as a foreign language: Investigating the relationship between naming and knowing. Modern Language Journal, 82 (ii), 194–203. Retrieved from http://www.jstor.org/stable/ 329208
Field, A. (2005). Discovering Statistics Using SPSS 2nd Edition. London, UK: Sage Publications.
Flege, J. E. (1987). The production of new and similar phones in a foreign language: evidence for the effect of equivalence classification. Journal of Phonetics, 15, 47–65. Print
Flege, J. E. (1991). Interlingual identification of Spanish and English vowels: Orthographic evidence. Quarterly Journal of Experimental Psychology Section A: Human Experimental Psychology, 43(3), 701–731. Print.
Flege, J. E. (1995). Second language speech learning theory, findings and problems. In W. Strange (Ed.), Speech Perception and Linguistic Experience: Issues in Cross Language Research (p. 233–277). Baltimore, MD: York Press.
Fletcher-Flinn, C. M., Thompson, G. B., Yamada, M., & Naka, Makiko. (2011). The acquisition of phoneme awareness in children learning the hiragana syllabary. Reading and Writing, 24 (6), 623–633. doi: 10.1007/s11145-010-9257-8
Frauenfelder, U. H., Segui, J., & Dijkstra, T. (1990). Lexical effects in phonemic processing: Facilitatory or inhibitory? Journal of Experimental Psychology: Human Perception and Performance, 16 (1), 77–91. doi: 10.1037/0096-1523.16.1.77
Frith, U. (1998). Editorial: Literally changing the brain. Brain, 121, 1011–1012. doi: 10.1093/brain/121.6.1011
Frost, R. (1998). Toward a strong phonological theory of visual word recognition: True issues and false trails. Psychological Bulletin, 123 (1), 71–99. doi: 10.1037/0033-2909.123.1.71
Frost, R., & Katz, L. (1989). Orthographic depth and the interaction of visual and auditory processing in word recognition. Memory & Cognition, 17 (3), 302–310. doi: 10.3758/BF03198468

277
Gelb, I. J. (1963). A Study of Writing (2nd Edition). Chicago, IL: The University of Chicago Press.
Glushko, R. (1979). The organization and activation of orthographic knowledge in reading aloud. The Journal of Experimental Psychology: Human Perception and Performance, 5 (4), 674–691. doi: 10.1037/0096-1523.5.4.674
Gombert, J. E. (1996). What do children do when they fail to count phonemes? International Journal of Behavioral Development, 19 (4), 757–772. Print
Goswami, U. (1999). The relationship between phonological awareness and orthographic representation in different orthographies. In M. Harris & G. Hatano (Eds.), Learning to Read and Writing: A Cross-Linguistic Perspective (pp. 134–156). New York, NY: Cambridge University Press.
Goswami, U., & Bryant, P. E. (1990). Phonological Skills and Learning to Read. Hove, East Sussex, UK: Psychology Press.
Goswami, U., Gombert, J. E., & De Barrera, L. F. (1998). Children’s orthographic representations and linguistic transparency: Nonsense word reading in English, French, and Spanish. Applied Psycholinguistics, 19 (1), 19–52. doi: 10.1017 /S01427164000 10560
Goswami, U., Porpodas, C., & Wheelwright, S. (1997). Children’s orthographic representations in English and Greek. European Journal of Psychology of Education, 12 (3), 273–292. doi: 0.1007/BF03172876
Grigorenko, E. L. (2006). If John were Ivan, would he fail in reading? In M. Malatesha Joshi & P. G. Aaron (Eds.), Handbook of Orthography and Literacy (pp. 303–320). Mahwah, NJ: Lawrence Erlbaum Associates.
Haigh, C., & Jared, D. (2007). The activation of phonological representations by bilinguals while reading silently: Evidence from interlingual homophones. Journal of Experimental Psychology: Learning, Memory, and Cognition, 33 (4), 623–644. doi: 10.1037/0278-7393.33.4.623
Hallé, P. A., Chéreau, C., & Segui, J. (2000). Where is the /b/ in “absurde” [apsyrd]? It is in French listeners’ minds. Journal of Memory and Language, 43 (4), 618–639. doi: 10.1006/jmla.2000.2718
Hammond, M. (1999). The Phonology of English: A Prosodic Optimality-Theoretic Approach. New York, NY: Oxford University Press.
Hancin-Bhatt, B. (1994). Segment transfer: A consequence of a dynamic system. Sound Language Research, 10 (3), 241-269. Print
Harris, R. (1986). The Origin of Writing. London, UK: Gerald Duckworth & CO. Ltd.

278
Hayes-Harb, R., Nicol, J., & Barker, J. (2010). Learning the phonological forms of new words: Effect of orthographic and auditory input. Language and Speech, 53 (3), 367–381. doi: 10.1177 /0023830910371460
He, T., & Wang, W. (2009). Invented spelling of EFL young beginning writers and its relation with phonological awareness and grapheme-phoneme principles. Journal of Second Language Writing, 18, 44–56. doi: 10.1016/jslw.2008.06.001
Henderson, L. (1982). Orthography and Word Recognition in Reading. Toronto, ON: Academic Press.
Høien, T., Lundberg, L., Stanovich, K. E., & Bjaalid, I. K. (1995). Components of phonological awareness. Reading and Writing, 7 (2), 171–188. doi: 10.1007/BF 01027184
Hockley, N., & Polka, L. (1994). A developmental study of audiovisual speech perception using the McGurk paradigm. Journal of the Acoustical Society of America, 96, 3309. doi: 10.1121/1.410782
Holm, A., & Dodd, B. (1996). The effect of first written language on the acquisition of English literacy. Cognition, 59 (2), 119–147. doi: 10.1016/0010-0277(95)00691-5
Hu, C-F. (2008). Use orthography in L2 auditory word learning: Who benefits? Reading and Writing, 21 (8), 823–841. doi: 10.1007/s11145-007-9094-6
Istrin, V. A. (1965). 4&-5,%5&'.5,. , "0-',1,. 6,/(7.55&/1, [The Origin and Development of Writing]. Moscow, Russia: Academy of Science Publishing.
Jared, D., McRae, K., & Seidenberg, M. S. (1990). The basis of consistency effects in word naming. The Journal of Memory and Language, 29 (6), 687–715. doi: 10. 1016/0749-596X(90)90044-Z
Jared, D., & Kroll, J. F. (2001). Do bilinguals activate phonological representations in one or both of their languages when naming words? Journal of Memory and Language, 44 (1), 2–31. doi: 10.1006/jmla.2000.2747
Jared, D., & Szucs, C. (2002). Phonological activation in bilinguals: Evidence from interlingual homograph naming. Bilingualism: Language and Cognition, 5 (3), 225–239. doi: 10.1017/S1366728902003024
Juul, H., & Sigurdsson, B. (2005). Orthography as a handicap? A direct comparison of spelling acquisition in Danish and Icelandic. Scandinavian Journal of Psychology, 46 (3), 263–272. doi: 10.1111/j.1467-9450.2005.00456.x
Kabak, B., & Idsardi, W. J. (2007). Perceptual distortions in the adaption of English consonant clusters: Syllable structure or consonantal contact constraints? Language and Speech, 50 (1), 23–52. doi: 10.1177/00238309070500010201

279
Katz, L., & Frost, R. (1992). The reading process is different for different orthographies. In R. Frost & L. Katz (Eds.), Orthography, Phonology, Morphology, and Meaning. Advances in Psychology, 94, 67–84.
Kerek, E., & Niemi, P. (2009). Russian orthography and learning to read. Reading in a Foreign Language, 21 (1), 1–21. Retrieved from http://nflrc.hawaii.edu.ezproxy. library.uvic.ca/rfl/April2009/
Killingley, S. Y. (1998). Learning to Read Pinyin Romanization and its Equivalent in Wade-Giles: A Practical Course for Students of Chinese. Newcastle, UK: LINCOM Europa.
Knight, S. (1996). The Roman alphabet. In P. T. Daniels and W. Bright (eds.) The World’s Writing Systems (pp. 312–332). New York, NY: Oxford University Press.
Koda, K. (1989). Effects of L1 orthographic representation on L2 phonological coding strategies. Journal of Psycholinguistic Research, 18 (2), 201–222. doi: 10.1007 /BF01067782
Kolni-balozky, J. (1938). A Progressive Russian Grammar. London, UK: Sir Isaac Pitman & Sons, Ltd.
Kuhl, P. K. (1993). Early linguistic experience and phonetic perception: implications for theories of developmental speech perception. Journal of Phonetics, 21, 125–139. Print
Kuhl, P. K. (2000). A new view of language acquisition. Proceedings of the National Academy of Sciences of the United States of America, 97 (22) October, 11850–11857. Retrieved from http://www.pnas.org/content/97/22/11850.full
Lacruz, I., & Folk, J. R. (2004). Feedforward and feedback consistency effects for high- and low-frequency words in lexical decision and naming. The Quarterly Journal of Experimental Psychology, 57A (7), 1261–1284. doi: 10.1080/02724980 34300 0756
Ladefoged, P. (1999). American English. In Handbook of the International Phonetic Association: A Guide to the Use of the International Phonetic Alphabet (pp. 41–44). New York, NY: Cambridge University Press.
Lado, R. (1957). Linguistics Across Cultures. Ann Arbor, MI: University of Michigan Press.
Landerl, K. (2000). Influences of orthographic consistency and reading instruction on the development of nonword reading skills. European Journal of Psychology of Education, 15 (3), 239–257. doi: 10.1007/BF03173177

280
Landerl, K., Frith, U., & Wimmer, H. (1996). Intrusion of orthographic knowledge on phoneme awareness: Strong in normal readers, weak in dyslexic readers. Applied Psycholinguistics, 17 (1), 1–14. doi: 10.1017/S0142716400009437
Lehiste, I., & Peterson, G. E. (1961). Transitions, glides, and diphthongs. The Journal of the Acoustical Society of America, 33 (3), 268–277.
Lehtonen, A., & Treiman, R. (2007). Adults’ knowledge of phoneme-letter relationships is phonology based and flexible. Applied Psycholinguistics, 28 (1), 95–114. doi: 10.1017/S0142716406070056
Lemhöfer, K., & Dijkstra, T. (2004). Recognizing cognates and interlingual homographs: Effects of code similarity in language-specific and generalized lexical decision. Memory & Cognition, 32 (4), 533–550. doi: 10.3758/BF03195845
Liberman, A. (1980). Orthography and phonemics in present-day Russia. In J. Kavanagh & R. Venezky (Eds.), Orthography, Reading and dyslexia (pp. 51–55). Baltimore, MD: University Park Press.
Liberman, I. Y. (1971). Basic research in speech lateralization of language: Some implications for reading disability. Bulletin of the Orton Society, 21, 71–87.
Liberman, I. Y., Cooper, F. S., Shankweiler, D., & Studdert-Kennedy, M. (1967). Perception of the speech code. Psychological Review, 74 (5), 431–461. doi: 10. 1037/h0020279
Liberman, I. Y., Liberman, A. M., Mattingly, I. G., & Shankweiler, D. L. (1980). Orthography and the beginning reader. In J. Kavanagh & R. Venezky (Eds.), Orthography, Reading and dyslexia (pp. 137–153). Baltimore, MD: University Park Press.
Liberman, I. Y., Shankweiler, D., Fischer, F, F. W., & Carter, B. (1974). Explicit syllable and phoneme segmentation in the young child. Journal of Experimental Child Psychology, 18, 201–212. doi: 10.1016/0022-0965(74)90101-5
Lin, H. (2001). A Grammar of Mandarin Chinese. Munich: LINCOM Europa.
Lukatela, G., & Turvey, M. T. (1994). Visual lexical access is initially phonological: 1. Evidence form associative priming by words, homophones, and pseudo-homophones. Journal of Experimental Psychology: General, 123 (2), 107–128. doi: 10.1037/0096-3445.123.2.107
Lukatela, G., Turvey, M. T., & Todorovi", D. (1991). Is alphabet biasing in bialphabetical word perception automatic and prelexical. Journal of Experimental Psychology: Learning, Memory, and Cognition, 17 (4), 653–663. doi: 10.1037/0278-7393.17.4.653

281
Mair, V. H. (1996). Modern Chinese Writing. In P. T. Daniels and W. Bright (eds.) The World’s Writing Systems (pp. 200–208). New York, NY: Oxford University Press.
Major, R. (2001). Foreign Accent: The Ontogeny and Phylogeny of Second Language Phonology. Mahwah, NJ: Lawrence Erlbaum Associates, Inc.
Major, R. (2002). The phonology of the L2 user. In V. Cook (Ed.), Portraits of the L2 User (pp. 7–92). Clevedon, UK: Multilingual Matters Ltd.
Mann, V. A. (1986). Phonological awareness: The role of reading experience. Cognition, 24 (1–2), 65–92. doi: 10.1016/0010-0277(86)90005-3
Massaro, D. W., Thompson, L. A., Barron, B., & Laren, E. (1986). Developmental changes in visual and auditory contribution to speech perception. Journal of Experimental Child Psychology, 41 (1), 93–113. doi: 10.1016/0022-0965(86) 90053-6
McMahon, A. (2002). An Introduction to English Phonology. New York, NY: Oxford University Press.
McGurk, H., & MacDonald, J. (1976). Hearing lips and seeing voices. Nature, 264, 746–748. Print
Morais, J. (1991). Constraints on the development of phonemic awareness. In S. A. Brady & D. P. Shankweiler (Eds.), Phonological Processes in Literacy: A Tribute to Isabelle Y. Liberman (pp. 5–27). Hillsdale, NJ: Lawrence Erlbaum Associates.
Morais, J., Bertelson, P., Cary, L., Alegria, J. (1986). Literacy training and speech segmentation. Cognition, 24 (1), 45–64. Print
Morais, J., Cary, L., Alegria, J., & Bertelson, P. (1979). Does awareness of speech as a sequence of phones arise spontaneously? Cognition, 7 (4), 323–331. Print
Morris, D. (1983). Concept of word and phoneme awareness in the beginning reader. Research in the Teaching of English, 17 (4), 359–373. http://www.jstor.org /stable /40170971
Muneaux, M., & Zeigler, J. C. (2004). Locus of orthographic effects in spoken word recognition: Novel insights for the neighbour generation task. Language and Cognitive Processes, 19 (5), 641–660. doi: 10.1080/01690960444000052
Oller, J. W., & Ziahosseiny, S. M. (1970). The contrastive analysis hypothesis and spelling errors. Language Learning, 20 (2), 183–189. doi: 10.1111/j.1467-1770. 1970.tb00475.x
Olson, D. R. (1993). How writing represents speech. Language & Communication, 13 (1), 1–17. doi: 10.1016/0271-5309(93)90017-H

282
Olson, D. R. (1996). Towards a psychology of literacy: On the relations between speech and writing. Cognition, 60 (1), 83–104. doi: 10.1016/0010-0277(96)00705-6
Padgett, J., & Tabain, M. (2005). Adaptive dispersion theory and phonological vowel reduction in Russian. Phonetica, 62, 14–54. doi: 10.1159/000087223
Peereman, R., Dufour, S., & Burt, J. S. (2009). Orthographic influences in spoken word recognition: The consistency effect in semantic and gender categorization tasks. Psychonomic Bulletin & Review, 16 (2), 363–368. doi: 10.3758/PBR.16.2.363
Peng, T. H. (1984). Hanyu Pinyin. Singapore: Times Books International.
Perfetti, C. (2003). The universal grammar of reading. Scientific Studies of Reading, 7 (10), 3–24. doi: 10.1207/S1532799XSSR0701_02
Perin, D. (1983). Phonemic segmentation and spelling. British Journal of Psychology, 74 (1), 129–144. Retrieved from http://ezproxy.library.uvic.ca/login?url= http:// search.ebscohost.com/login.aspx?direct=true&db=byh&jid=BJP&site=ehost-live
Perre, L., Pattamadilok, C., Montant, M., & Ziegler, J. C. (2009). Orthographic effects in spoken language: On-line activation phonological restructuring? Brain Research, 1275, 73–80. doi: 10.1016/j.brainres.2009.04.018
Perre, L., & Ziegler, J. C. (2008). On-line activation of orthography in spoken word recognition. Brain Research, 1188, 132–138. doi: 10.1016/j.brainres.2007.10.084
Press, I. (2000). What’s in a Russian Word? From Sounds to Structures. London: Bristol Classical Press.
Pytlyk, C. (2008). Interlanguage prosody: Native English speakers’ production of Mandarin yes-no questions. In The Proceedings of the 2008 Annual Conference of the Canadian Linguistics Association, ed. Susie Jones. Canadian Linguistics Association.
Pytlyk, C. (2011). Shared orthography: Do shared written symbols influence the perception of L2 sounds? Modern Language Journal, 95 (4), 541–557.
Pytlyk, C. (to appear). Orthographic representation and phoneme awareness: Does alphabetic knowledge affect how individuals perceive phoneme in English words? Toronto Working Papers in Linguistics.
Randal, M. (2005). Orthographic knowledge and first language reading: Evidence form single work dictation from Chinese and Malaysian users of English as a foreign language. In V. Cook & B. Bassetti (Eds), Second Language Writing Systems (pp. 122–146). North York, ON: Multilingual Matters Ltd.

283
Read. C. (1983). Orthography. In M. Martlew (Ed.), The Psychology of Written Language Development and Educational Perspectives (pp. 143–162). Toronto, ON: John Wiley & Sons.
Read, C., Zhang, Y. F., Nie, H. Y., Ding, B. Q. (1986). The ability to manipulate speech sounds depends on knowing alphabetic writing. Cognition, 24, 31–44. doi: 10.1016/0010-0277(86)90003-X
Reetz, H., & Jongman, A. (2009). Phonetics: Transcription, Production, Acoustics, and Perception. Malden, MA: Wiley-Blackwell.
Reformatsky, A. A. (1996). 4'.!.5,. ' 3-8%&'.!.5,. [Introduction to Linguistics]. Moscow, Russia: Accent Press.
Robin, R., Evans-Romaine, K., Shatalina, G., & Robin, J. (2007). 9&:&/0: A Basic Course in Russian Book 1 (4th Edition). Upper Saddle River, NJ: Pearson Education, Inc.
Rogers, H. (2000). The Sounds of Language: An Introduction to Phonetics. Essex, UK: Pearson Education Limited.
Rogers, H. (2005). Writing Systems: A Linguistic Approach. Malden, MA: Blackwell Publishing.
Russak, S., & Saiegh-Haddad, E. (2011). Phonological awareness in Hebrew (L1) and English (L2) in normal and disabled readers. Reading and Writing, 24 (4), 427–442. doi: 10.1007/s11145-010-9235-1
Saiegh-Haddad, E. (2007). Linguistic constraints on children’s ability to isolate phonemes in Arabic. Applied Psycholinguistics, 28 (4), 605–625. doi: 10.1017/ S0142716407070336
Saiegh-Haddad, E., Kogan, N., & Walters, J. (2010). Universal and language-specific constraints on phonemic awareness: Evidence from Russian-Hebrew bilingual children. Reading and Writing, 23, 359–384. doi: 10.1007/s11145-009-9204-8
Schulpen, B., Dijkstra, T., Schriefers, H. J., & Hasper, M. (2003). Recognition of interlingual homophones in bilingual auditory word recognition. Journal of Experimental Psychology: Human Perception and Performance, 29 (6), 1155–1178. doi: 10.1037/0096-1523.29.6.1155
Seidenberg, M. S., Waters, G. S., Barnes, M. A., & Tanenhaus, M. K. (1984). When does irregular spelling of pronunciation influence word recognition? The Journal of Verbal Learning and Verbal Behavior, 23, 383–440. Print
Sekiyama, K., Burnham, D. K., Tam, H., & Erdener, D. (2003). Auditory-visual speech perception development in Japanese and English speakers. In J.-L Schwartz, F.

284
Berthommier, M.-A. Cathiard, & D. Sodoyer (Eds.), Proceedings of AVSP [Audio Visual Speech Processing] 2003 (pp. 43–47). Grenoble, France: Université Stendhal, Institute de la Communication Parlée.
Selinker, L. (1972). Interlangauge. International Review of Applied Linguistics, 10, 209–231. Print
Selkirk, E. (1984). The major class features and syllable theory. In Aronoff, M. et al. (eds.) Language Sound Structure (pp. 107–136). Cambridge, MA: MIT Press.
Seymour, P. H. K., Aro, M., & Erskine, J. M. (2003). Foundation literacy acquisition in European orthographies. British Journal of Psychology, 94 (2), 143–174. doi: 10.1348/000712 603321661859
Silva, C., Almeida, T., Martins, M. A. (2010). Letter names and sounds: Their implication for the phonetisation process. Reading and Writing, 23, 147–172. doi: 10.1007/s11145-008-9157-3
Simon, E., Chambless, D., & Alves, U. K. (2010). Understanding the role of orthography in the acquisition of a non-native vowel contrast. Language Sciences, 32, 380–394. doi: 10.1016/j.langsci.2009.07.001
Spencer, L. H., & Hanley, J. R. (2003). Effects of orthographic transparency on reading and phoneme awareness in children learning to read in Wales. British Journal of Psychology, 94 (1), 1–28. doi: 10.1348/000712603762842075
Spencer, L. H., & Hanley, J. R. (2004). Learning a transparent orthography at five years old: Reading development of children during their first year of formal reading instruction in Wales. Journal of Research in Reading, 27 (1), 1–14. doi: 10.1111/j.1467-9817.2004.00210.x
Steriade, D. (1999). Alternatives to syllable-based accounts of consonantal phonotactics. Proceedings of the 1998 Linguistics and Phonetics Conference. The Karolinum Press. 205–242.
Stone, G. O., Vanhoy, M., & Van Orden, G. (1997). Perception is a two-way street: Feedforward and feedback phonology in visual word recognition. The Journal of Memory and Language, 36 (3), 337–359. doi: 10.1006/jmla.1996.2487
Sun-Alperin, M. K., & Wang, M. (2011). Cross-language transfer of phonological and orthographic processing skills from Spanish L1 to English L2. Reading and Writing, 24 (5), 591–614. doi: 10.1007/s11145-009-9221-7
Swiggers, P. (1996). Transmission of the Phoenician scrip to the West. In P. T. Daniels and W. Bright (eds.) The World’s Writing Systems (pp. 261–270). New York, NY: Oxford University Press.

285
Taft, M., Castles, A., Davis, C., Lazendic, G., & Nguyen-Hoan, M. (2008). Automatic activation of orthography in spoken word recognition: Pseudohomograph priming. Journal of Memory and Language, 58, 366–379. doi: 10.1016/j.jml. 2007.11.002
Threatte, L. (1996). The Greek alphabet. In P. T. Daniels and W. Bright (eds.) The World’s Writing Systems (pp. 271–280). New York, NY: Oxford University Press.
Treiman, R., & Cassar, M. (1997). Can children and adults focus on sound as opposed to spelling in a phoneme counting task? Developmental Psychology, 33 (5), 771–780. doi: 10.1037/0012-1649.33.5.771
Treiman, R., & Zukowski, A. (1991). Levels of phonological awareness. In S. A. Brady & D. P. Shankweiler (Eds.), Phonological Processes in Literacy: A Tribute to Isabelle Y. Liberman (pp. 67–83). Hillsdale, NJ: Lawrence Erlbaum Associates.
Tyler, M. D., & Burnham, D. K. (2006). Orthographic influences on phoneme deletion response times. The Quarterly Journal of Experimental Psychology, 59 (11), 2010–2031. doi: 10.1080/174702 10500521828
Unbegaun, B. O. (1957). Russian Grammar. Oxford, UK: Claredon Press.
Venezky, R. L. (1970). The Structure of English Orthography. The Hague, The Netherlands: Mouton.
Ventura, P., Kolinsky, R., Pattamadilok, C., & Morais, J. (2008). The developmental turnpoint of orthographic consistency effects in speech recognition. Journal of Experimental Child Psychology, 100, 135–145. doi: 10.1016/j.jecp.2008.01.003
Ventura, P., Morais, J., & Kolinsky, R. (2007). The development of the orthographic consistency effect in speech recognition: From sublexical to lexical involvement. Cognition, 105 (3), 547–576. doi:10.1016/j.cognition.2006.12.005
Visceglia, T., & Fodor, J. D. (2006). Fundamental frequency in Mandarin and English: Comparing first- and second-language speakers. In C. Lleoa (Ed.), Interfaces in Multilingualism: Acquisition and Representation, (pp. 27–59). Amsterdam: John Benjamins.
Vokic, G. (2011). When alphabets collide: Alphabetic first-language speakers’ approach to speech production in an alphabetic second language. Second Language Research, 27 (3), 391–417. doi: 10.1177/0267658310396627
Wade, T. (2011). A Comprehensive Russian Grammar (3rd Edition). West Sussex, UK: Wiley-Blackwell.

286
Wade-Woolley, L. (1999). First language influences on second language word reading: All roads lead to Rome. Language Learning, 49 (3), 447–471. doi: 10.1111/0023 -8333.00096
Wallach, L., Wallach, M. A., Dozier, M. G., & Kaplan, N. E. (1997). Poor children learning to read do not have trouble with auditory discrimination but do have trouble with phoneme recognition. Journal of Educational Psychology, 69 (1), 36–39. doi: 10.1037/0022-0663.69.1.36
Wang, M., Park, Y., & Lee, K. (2006). Korean-English biliteracy acquisition: Cross language and orthographic transfer. Journal of Educational Psychology, 98 (1), 148–158. doi: 10.1037/0022-0663.98.1.148
Wang, M., Perfetti, C. A., & Liu, Y. (2005). Chinese-English biliteracy acquisition: Cross language writing system transfer. Cognition, 97 (1), 67–88. doi: 10.1016/j. cognition.2004.10.001
Wang, W. S-Y. (1973). The Chinese language. Scientific American, 228 (2), 53–62.
Werker, J., & Tees, R. (1984). Phonemic and phonetic factors in adult cross-language speech perception. Journal of the Acoustical Society of America, 75, 1866–1878. Print.
Werker, J., & Tees, R. (1987). Speech perception in severely disabled and average reading children. Canadian Journal of Psychology, 41, 48–61. doi: 10.1037/ h0084150
Widmann, A., Kujala, T., Tervaniemi, M., Kujala, A., & Schroger, E. (2004). From symbols to sounds: Visual symbolic information activates sound representations. Psychophysiology, 41 (5), 709–715. doi: 10.1111/j.1469-8986.2004.00208.x
Wiebe, G. E. (1998). The syllabic status of postvocalic resonants: Evidence from global sound similarity judgements. In S. Embleton (Ed.), LACUS Forum XXIV (pp. 66–76). Chapel Hill, NC: Linguistic Association of Canada and the United States.
Wiebe, G. E., & Derwing, B. (1992). The syllabic status of postvocalic resonants in an unwritten Low German dialect. In J. J. Ohala, T. M. Nearey, B. L. Derwing, M. M. Hodge, & G.E. Wiebe, (eds.) ICSLP 1992, 1, 293–296.
Wiebe, G. E., & Derwing, B. (1994). Rime embeddedness in an unwritten language. In S. Hargus, G.R. McMenamin & V. Samiian (eds.) Proceedings of the 23rd WECOL (pp. 490–502). Fresno, CA: CSU Fresno, Department of Linguistics.
Williams, J. P. (1980). Teaching decoding with an emphasis on phoneme analysis and phoneme blending. Journal of Educational Psychology, 72 (1), 1–15. PsycARTICLES

287
Wimmer, H., & Hummer, P. (1990). How German speaking first graders read and spell: Doubts on the importance of the logographic stage. Applied Psycholinguistics, 11 (4), 349–368. doi: 10.1017/S0142716400009620
Wimmer, H., Landerl, K., & Schneider, W. (1994). The role of rhyme awareness in learning to read a regular orthography. British Journal of Developmental Psychology, 12, 469–484. Print
Wode, H. (1983). Phonology in L2 acquisition. In H. Wode (Ed.), Papers on Language Acquisition, Language Learning and Language Teaching (p. 175–187). Heidelberg, Germany: Groos.
Yopp, H. K. (1988). The validity and reliability of phonemic awareness tests. Reading Research Quarterly, 23 (2), 159–177. http://www.jstor.org/stable/747800
Young-Scholten, M. (1995). The negative effects of ‘positive’ evidence on L2 phonology. In L. Eubank, L. Selinker, & M. Sharwood Smith (Eds.), The Current State of Interlangauge: Studies in Honor of William E. Rutherford (pp. 107–121). Philadelphia, PA: John Benjamins Publishing Company.
Zhou, M. (2001). Language policy and reforms of writing systems for minority languages in China. Written Language & Literacy, 4 (1), 31–65. Print
Ziegler, J. C., & Ferrand, L. (1998). Orthography shapes the perception of speech: The consistency effect in auditory word recognition. Psychonomic Bulletin & Review, 5 (4), 683–689. doi: 10.3758/BF03208845
Ziegler, J. C., Ferrand, L, & Montant, M. (2004). Visual phonology: The effects of orthographic consistency on different auditory word recognition tasks. Memory & Cognition, 32 (5), 732–741. doi: 10.3758/BF03195863
Ziegler, J. C., & Muneaux, M. (2007). Orthographic facilitation and phonological inhibition in spoken word recognition: A developmental study. Psychonomic Bulletin & Review, 14 (1), 75–80. doi: 10.3758/BF03194031
Ziegler, J. C., Muneaux, M., & Grainger, J. (2003). Neighborhood effects in auditory word recognition: Phonological competition and orthographic facilitation. Journal of Memory and Language, 48 (4), 779–793. doi: 10.1016/S0749-596X(03)00006-8

288
APPENDIX A: Glossary
Abecedary: An abecedary is an inventory of letters for an alphabet (Rogers, 2005).
Accessibility: Accessibility refers to the availability of a unit (e.g., a word, syllable, or phoneme) such that speakers/listeners are aware of and can manipulate that unit (Read, 1983).
Allograph: Allographs are “non-contrastive variants of a grapheme” (Rogers, 2005, p. 10). For example, a cursive <g>, an upper case <G>, and a lower case <g> are all allographs.
Alphabet: An alphabet is “a writing system characterized by a systematic mapping relation between its signs (graphemes) and the minimal units of speech (phonemes)” (Coulmas, 1999). Letters of an alphabet are used to represent consonants (Hebrew and Arabic) or consonants and vowels (Greek and Cyrillic). Alphabets represent speech segments that are unpredictable.
Character: Character is the term for a single symbol in logographic writing systems like Chinese and Japanese (Cook, 2004). For example, the Chinese graphemes <人> (‘person’), < > (‘sleep’), and <國> (‘country’) are all individual characters.
Coda: The coda is the part of the syllable that follows the nucleus (Rogers, 2000). For example, in the word /post/, the consonants /s/ and /t/ – which come after the nucleus /o/ – form the coda /st/.
Correspondence rules: Correspondence rules are the means by which we relate written letters and sounds (Cook, 2004). For example, in the word hand, each letter – <h>, <a>, <n>, and <d> – corresponds with a single phoneme /h/, /œ/, /n/, and /d/, respectively.
Diagraph: “A sequence of two graphemes which represents a linguistic unit normally represented by one grapheme” (Rogers, 2005, p. 292). For example, in English, the diagraph <th> represents both the voiced /D/ and voiceless /T/ dental fricatives.
Deep orthography (opaque): Deep orthographies have a high degree of irregular letter-to-sound correspondences. That means, that some letters can have more than one sound attached to it, and some phonemes can have more than one graphemic representation. English and Hebrew are examples of languages with deep orthographies. (Katz & Frost, 1992; Liberman et al., 1980)
Dual-route model: “A dual-route model of reading aloud has two processes or ‘routes’: the phonological route, which converts letters into sounds through rules, and the lexical route, which matches words as wholes in the mental lexicon” (Cook, 2004, p. 16).

289
First language (L1): An L1 refers to a speaker’s native language (Archibald, 1998; Cook, 2002; Major, 2001).
Grapheme: A grapheme is a “contrastive unit in a writing system, parallel to phoneme or morpheme” (Rogers, 2005, p. 10). Graphemes can be represented by letters, characters, numerals, and/or other symbols. For example, in English, the grapheme <z> is a letter that contrasts with other letter graphemes like <p t h g l>.
Homography: Homographs are words where the “phonemic distinctions are neutralized graphemically” (Rogers, 2005, p. 16). For example, in English, the words read /®id/ and read /®”d/ are spelt the same way but pronounced differently.
Homophony: Homophonous words are words where the “graphemic distinctions are neutralized phonemically” (Rogers, 2005, p. 16). For example, in English, the words one and won are pronounced the same /wØn/ but spelt differently.
Interlanguage: The linguistic system of an adult second language user is called an interlanguage as it has influences from both the first and second languages as well as language universals (Archibald, 1998; Major, 2001; Selinker, 1972).
Letter: A letter is a shape that is “recognized as [an instance] of abstract graphic concepts which represent the basic units of an alphabetic writing system” (Coulmas, 1999, p. 291).
Ligature: A ligature refers to two graphemes that are fused together and written as one unit. For example, <œ> is a ligature for <ae>, and <w> is a ligature for <uu>. (Coulmas, 2003)
Literacy: According to Coulmas (1999), literacy is a “mastery of writing and reading skills” (p. 302).
Logograph: A logography is a writing system where words or morphemes are the units of representation such that a written grapheme can represent a word or morpheme (Coulmas, 1999; Cheung & Chen, 2004; DeFrancis, 1990).
Mapping Principle: A mapping principle refers to what sound units (i.e., morphemes, syllables, or phonemes) graphemes map onto (e.g., Perfetti, 2003; Wang et al., 2005). For example, alphabetic orthographies like English or Korean map graphemes onto phonemes while logographic orthographies like Chinese map graphemes onto syllabic morphemes (DeFrancis, 1989).
Markedness: Markedness refers to the relative commonality and complexity of linguistic elements. Those elements that are simple or common are considered unmarked and those that are complex and uncommon are considered marked. (Archibald, 1998; Major, 2001)

290
Mental Lexicon: Each speaker of a language stores all the words they know in a mental dictionary (lexicon). The mental lexicon contains many thousands of items. (Cook, 2004)
Morpheme: The smallest meaningful unit in a language.
Morphophonemic orthography: In morphophonemic orthographies, graphemes (or strings of graphemes) represent morphologically related forms often at the expense of pronunciation consistency. That is, the morpheme has the same visual representation even though the pronunciation may differ (Coutsougera, 2007). For example, the spelling of the words insane /)nsejn/ and insanity /InsœnIti/ indicate that the words are morphologically related, and the spelling does not reflect pronunciation difference between the vowels represented by the grapheme <a>.
Negative Transfer: This type of transfer refers to when an L1 feature is transferred into a learner’s interlanguage and hinders the learning of the L2 (Archibald, 1998; Major, 2001).
Nucleus: The nucleus is the most sonorous part of a syllable and is usually a vowel (Rogers, 2000). For example, in the word /bÁk/, the vowel /Á/ is the nucleus.
Onset: The onset is the part of the syllable that precedes the nucleus (Gombert, 1996; Rogers, 2000). For example, in the word /sniz/, the consonants /s/ and /n/ – which come before the nucleus /i/ – form the onset /sn/.
Orthographic depth: Orthographic depth refers to the consistency and predictability of letter-to-sound correspondences in a language (Frost & Katz, 1989; Katz & Frost, 1992; Liberman et al., 1980).
Orthographic depth hypothesis (ODH): The ODH states that in shallow orthographies, the word recognition process involves the language’s phonology and that, in deep orthographies, readers must process printed words by their morphology through the word’s visual-orthographic structure. (Katz & Frost, 1992, p. 71)
Orthographic neighbourhood: An orthographic neighbourhood refers to “the range of strings that can be made by changing one letter or character at a time (Ellis et al., 2004, p. 457). Neighbourhoods can be either dense (where many new words can be generated) or sparse (where very few new words can be generated).
Orthography: Orthography refers to the rules or principles by which a script is used for a particular language (Cook & Bassetti, 2005; Read, 1983).

291
Phoneme: A phoneme is a contrastive segment in a language (Rogers, 2000). For example, in English, the phoneme /p/ contrasts with the phoneme /b/ as indicated by the meaning difference between the words /pIt/ and /bIt/.
Phoneme awareness: Phoneme awareness refers to the ability to analyse and mentally manipulate spoken language at the phonemic level (e.g., Cheung, 1999; Goswami, 1999: Read et al., 1986; Yopp, 1988). Phoneme awareness is one of the three sub-levels of phonological awareness. (See also Phonological Awareness.)
Phoneme blending: In a blending task, participants are presented with two syllables. They are asked to take the initial phoneme from the first syllable and the vowel from the second syllable and combine these phonemes to form a new syllable (Cheung, 1999).
Phoneme completion task: Participants must supply the final phoneme in a single syllable word (Carroll, 2004).
Phoneme counting task: Participants must count the number of phoneme (‘sounds’) in words (e.g., Lehtonen & Treiman, 2007; Treiman & Cassar, 1997).
Phoneme deletion task: Participants must remove either the beginning or final phoneme from a single syllable word and produce the word without that removed phoneme (Carroll, 2004; Cheung, 1999).
Phoneme identity task: Participants are given a target sound illustrated in an example word; then, they must identify (from 2 words) which word starts (or ends) with the same sound as the target. (e.g., Bowey, 1994; Fletcher-Flinn et al., 2011; Wallach et al., 1977)
Phoneme isolation task: Participants identify a specific sound in a give word. For instance, the participants would have to identify /k/ as the first phoneme in the word cat. (e.g., Caravolas & Bruck, 1993; Castles et al., 2009; Yopp, 1988)
Phoneme monitoring task: Participants must push a button as soon as they here the target. (e.g., Dijkstra et al., 1995; Frauenfelder et al., 1995; Hallé et al., 2000; Morais et al., 1986)
Phoneme oddity task: Participants must identify the odd word out based on phoneme difference – either onset, medial, or final phonemes. For instance, participants must identify that deck is the odd word out from the following words fit, fan, deck because the other two words begin with the phoneme /f/. (e.g., Bowey, 1994)
Phoneme reversal task: Participants must reverse two specific phonemes in a word. For example, participants have to switch the- first and last sounds in the word pit to create the word tip. (e.g., Alegria et al., 1982; Castles et al., 2003; Yopp, 1988)

292
Phoneme segmentation task: Participants identify the phonemes in a given word. For example, the participants must identify that the word big has the phonemes /b/, /I/, and /g/. (e.g., Cossu et al., 1988; Williams, 1980; Yopp, 1988)
Phonemic orthography: The only function of graphemes in a phonemic orthography is to represent phonemes (Coutsougera, 2007). The Greek and Spanish orthographies are examples of phonemic orthographies.
Phonological awareness (PA): Cheung (1999) defines phonological awareness as “an individual’s ability to analyse spoken language into smaller component sound units and to manipulate them mentally” (p. 2). PA has three levels: the syllable, onsets and rimes, and the phoneme.
Phonological Recoverability: Phoneme recoverability “refers to how systematically the graphemic representation can be converted inot the phonological representation” (Vokic, 2011, p. 395)
Pinyin: Pinyin is a phonemic alphabet that is the standard Romanization system in China. This orthography uses Roman letters to represent Chinese sounds. (Coulmas, 1999; DeFrancis, 1990; Killingly, 1998)
Positive Transfer: This type of transfer refers to when an L1 feature is transferred into a learner’s interlanguage and facilitates the learning of the L2 (Archibald, 1998; Major, 2001).
Regularity: Regularity refers to “the consistency with which representations correspond to the linguistic units within a writing system” (Read, 1983, p.157).
Rime (also rhyme): The rime is the part of the syllable that contains the nucleus and the coda. (Gombert, 1996; Rogers, 2000) For example, in the word /kœt/, the vowel /œ/ and the coda /t/ form the rime /œt/.
Rime judgement: Participants must match syllables that share the same rime (Cheung, 1999).
Script: A script is “the graphic form of the units of a writing system” (Coulmas, 2003, p. 35)
Second language (L2): An L2 is a language other than a speaker’s native language (Cook, 2002; Major, 2001).
Segment: A segment is a consonant or vowel in any given language (Rogers, 2000).
Shallow orthography (transparent): Shallow orthographies have more regular one-to-one letter-to-sound correspondences. That means, letters have only one sound, and

293
phonemes have only one representation. Serbo-Croatian and Spanish are examples of languages with shallow orthographies. (Katz & Frost, 1992; Liberman et al., 1980; Rogers, 2005)
Syllabary: A syllabary is a writing system where the syllable is the unit of representation such that graphemes represent syllables or morœ (Coulmas, 1999; Chueng & Chen, 2004; Rogers, 2005).
Syllable: A syllable is a “phonological unit of organisation” that is “typically larger than a segment and smaller than a word” (Rogers, 2000, p. 314). All syllables contain a nucleus (i.e., a vowel or syllabic consonant) and may also contain an onset and/or coda.
Transfer: Transfer refers to“the process whereby a feature or rule from a learner’s first language is carried over to the IL [interlanguage] grammar” (Archibald, 1998, p. 3). Transfer can be either positive or negative.
Word-to-word matching task: Participants must identify if the given words share the same phoneme. For example, participants would have to decide whether pen and hit begin with the same phoneme. (e.g., Cheung & Chen, 2004; Treiman & Zukowski, 1991; Yopp, 1988)
Writing: Writing is defined as “the use of graphic marks to represent specific linguistic utterance” where these marks “mak[e] an utterance visible” (Rogers, 2005, p. 2)
Writing system: A writing system uses visual or tactile graphemes to represent language. It has a systematic relationship to language and a systematic internal structure and organization (Coulmas, 1999; Rogers, 2005).

294
APPENDIX B: Translated versions of “The North Wind and the Sun”
English Translation
The north wind and the sun were disputing which was stronger, when a traveler came
along wrapped in a warm cloak. They agreed that the one who first succeeded in making
the traveler take his cloak off should be considered stronger than the other. Then the
north wind blew as hard as he could. But the more he blew the more closely did the
traveler fold his cloak around him; and at last the north wind gave up the attempt. Then
the sun shone out warmly, and immediately the traveler took off his cloak. And so the
north wind was obliged to confess that the sun was the stronger of the two.
Russian Translation
01213456 21713 8 &9:4;1 &<938:8, =79 &8:>411. ? @79 231A' A8A9 48B <39B9C8:
<#748= 2 7D<:9A <:EF1. G48 31H8:8, I79 797 J#C17 &8:>411, =79 <1325A KE&7E287
<#748=E &4'7> <:EF. L9$CE &1213456 21713 &7E: C#7> 8K9 2&1B &8:. M9 I1A J9:>H1
94 C#:, 71A <:97411 <#748= KE=#752E:&' 2 <:EF. ? =94;1 =94;92, &1213456 21713
<31=3E78: &298 #&8:8'. L9$CE 25$:'4#:9 NE3=91 &9:4;1, 8 <#748= &3EK# &4': <:EF.
O &1213456 21713 254#NC14 J5: <38K4E7>, I79 &9:4;1 &8:>411 41$9.
Mandarin Translation
yPu yQ cì,bRi fSng hé tài yáng zhèng zài zhSng lùn shéi bT jiào qiáng。tU men zhèng hVo
kàn dào yPu gè lù rén zPu guò,nà gè rén chuUn zhù yQ jiàn dPu péng。tU men jiù jué
dìng,shéi kR yT ràng lù rén tuW diào nà jiàn dPu péng,jiù suàn shéi bT jiào lì hài。yú
shì bRi fSng jiù pQn mìng dì chuQ。méi xiVng dào,tU chuQ dé yù lì hài,lù rén jiù yù shì
yòng dPu péng bUo jTn zì jT。zuì hòu, bRi fSng méi bàn fV le,zhT hVo fàng qì。jiS zhe,
tài yáng chX lái wSn nuVn di zhào yào le yQ xià,lù rén jiù lì kè bV dPu péng tuW diào le。
yú shì,bRi fSng zhT hVo rèn shX,chéng rèn tài yáng bT jiào lì hài。

295
APPENDIX C: Secondary data collect response sheet
NATIVE ENGLISH SPEAKER
1. ______________
2. ______________
3. ______________
4. ______________
5. ______________
6. ______________
7. ______________
8. ______________
9. ______________
10. ______________
11. ______________
12. ______________
13. ______________
14. ______________
15. ______________
16. ______________
17. ______________
18. ______________
19. ______________
20. ______________
21. ______________
22. ______________
23. ______________
24. ______________
25. ______________
26. ______________
27. ______________
28. ______________
29. ______________
30. ______________
31. ______________
32. ______________
33. ______________
34. ______________
35. ______________
36. ______________
37. ______________
38. ______________
39. ______________
40. ______________
41. ______________
42. ______________
43. ______________
44. ______________
45. ______________
46. ______________
47. ______________
48. ______________

296
NONNATIVE SPEAKERS OF ENGLISH 1. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
2. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
3. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
4. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
5. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
6. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
7. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
8. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
9. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
10. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
11. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
12. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
13. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
14. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
15. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
16. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
17. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
18. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
19. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
20. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
21. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
22. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
23. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
24. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
25. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
26. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
27. word ____________ 1 2 3 4 5 6 7 8 9 native non-native

297
28. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
29. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
30. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
31. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
32. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
33. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
34. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
35. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
36. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
37. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
38. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
39. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
40. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
41. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
42. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
43. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
44. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
45. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
46. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
47. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
48. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
49. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
50. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
51. word ____________ 1 2 3 4 5 6 7 8 9 native non-native
52. word ____________ 1 2 3 4 5 6 7 8 9 native non-native

298
APPENDIX D: Dictation response sheet
ENGLISH WORDS 1. ________________
2. ________________ 3. ________________
4. ________________ 5. ________________
6. ________________ 7. ________________
8. ________________ 9. ________________
10. ________________ 11. ________________
12. ________________ 13. ________________
14. ________________ 15. ________________
16. ________________ 17. ________________
18. ________________ 19. ________________
20. ________________ 21. ________________
22. ________________ 23. ________________
24. ________________ 25. ________________
26. ________________
27. ________________
28. ________________ 29. ________________
30. ________________ 31. ________________
32. ________________ 33. ________________
34. ________________ 35. ________________
36. ________________ 37. ________________
38. ________________ 39. ________________
40. ________________ 41. ________________
42. ________________ 43. ________________
44. ________________ 45. ________________
46. ________________ 47. ________________
48. ________________ 49. ________________
50. ________________ 51. ________________
52. ________________
53. ________________
54. ________________ 55. ________________
56. ________________ 57. ________________
58. ________________ 59. ________________
60. ________________ 61. ________________
62. ________________ 63. ________________
64. ________________ 65. ________________
66. ________________ 67. ________________
68. ________________ 69. ________________
70. ________________ 71. ________________
72. ________________ 73. ________________
74. ________________ 75. ________________
76. ________________

299
SECOND LANGUAGE WORDS [RUSSIAN / MANDARIN]
1. ________________ 2. ________________
3. ________________ 4. ________________
5. ________________ 6. ________________
7. ________________ 8. ________________
9. ________________ 10. ________________
11. ________________ 12. ________________
13. ________________ 14. ________________
15. ________________ 16. ________________
17. ________________ 18. ________________
19. ________________ 20. ________________
21. ________________ 22. ________________
23. ________________ 24. ________________
25. ________________ 26. ________________
27. ________________ 28. ________________
29. ________________ 30. ________________
31. ________________ 32. ________________
33. ________________ 34. ________________
35. ________________ 36. ________________
37. ________________ 38. ________________
39. ________________ 40. ________________
41. ________________ 42. ________________
43. ________________ 44. ________________
45. ________________ 46. ________________
47. ________________ 48. ________________
49. ________________ 50. ________________
51. ________________ 52. ________________

300
APPENDIX E: Participant Consent Form
Participant Consent Form
Perceptual Illusions:
How do Native English speakers hear sounds in English, Russian, and Mandarin words?
You are being invited to participate in a study that is being conducted by Carolyn Pytlyk, who is a PhD student in the Department of Linguistics. As a doctoral student, Carolyn is required to conduct research as part of the requirements for her PhD. The research is being conducted under the supervision, Dr Sonya Bird. You may contact Dr Bird at [email protected]. Purpose and Objectives This research investigates how individuals hear the sounds that make up words in languages they are more vs. less familiar with. This research aims to identify and understand the difficulties native English speakers encounter when trying to isolate the component sounds of English, Russian, and Mandarin words and to discuss possible reasons for and solutions to such problems and/or difficulties. Importance of this Research Research of this type contributes to the growing body of knowledge on second language (L2) phoneme awareness. Specifically, the research will contribute to our understanding of what factors affect our perception of sounds in language with which are familiar and those we are not familiar. Participant Selection You are being asked to participate in this study because you are either 1) a native English speaker who is learning either Russian or Mandarin as an L2, OR 2) a native English speaker who has not learnt either Russian or Mandarin. What is involved? If you agree to voluntarily participate in this research, and you are a Russian or Mandarin learner, your participation will include a 30 minute identification task where you will count the sounds in English, Russian, and Mandarin words and a 20 minute dictation task where you will write the words that you hear. You will also complete a questionnaire to ascertain your language learning background. If you are not a learner of Mandarin or Russian, your participation will include judging the nativeness of English, Russian, and Mandarin words as well as the background questionnaire. Inconvenience Participation in this study may cause some inconvenience to you as you will have to allot approximately 60 minutes for participation. Risks There are no known or anticipated risks to you by participating in this research.

301
Benefits The potential benefits of your participation in this research include learning more about how L2 speech perception works which may, in turn, help with your second language learning. If you want a more detailed report about the study, we can send it to you when a report is available. Voluntary Participation Your participation in this research must be completely voluntary. Any relationship with the researcher (i.e., as a fellow classmate) must not affect your decision to participate. If you would not participate if you did not know the researcher, then you should decline. If you do decide to participate, you may withdraw at any time without any consequences or any explanation. If you do withdraw from the study, your data will not be used for the analysis and will be destroyed. Anonymity In terms of protecting your anonymity, all data collected will be kept completely anonymous. All information and the data collected will be arranged and stored according to your identification numbers. Any analysis and mentioning of the testing processes will be anonymous; no names or other defining characteristics will be revealed. Confidentiality The confidentiality of your data will be protected by ensuring that all your data and information is stored in password protected files and/or in a locked research lab. Dissemination of Results The results of this study may be shared with others in the following ways;
(1) presentations at scholarly meetings (i.e., conferences), (2) a published article, and (3) a dissertation.
(Please check the boxes to which you consent.) Disposal of Data
I agree to let this data be saved for the purposes of future research by either these or other researchers.
I would like my data to be destroyed after their use for these projects. Contacts Individuals that may be contacted regarding this research include Dr Sonya Bird ([email protected]) and Carolyn Pytlyk ([email protected]). In addition, you may verify the ethical approval of this study, or raise any concerns you might have, by contacting the Human Research Ethics Office at the University of Victoria (250-472-4545 or [email protected]). Your signature below indicates that you understand the above conditions of participation in this study and that you have had the opportunity to have your questions answered by the researchers. Name of Participant Signature Date
A copy of this consent will be left with you, and a copy will be taken by the researchers.

302
APPENDIX F: Background Questionnaire
Participant Questionnaire
BACKGROUND INFORMATION
Age _____________________________ Gender _______________________
What dialect of English do you speak (ex. Canadian English, British English …)?
________________________________________________________________________
LANGUAGE LEARNING INFORMATION What is your second language? RUSSIAN MANDARIN OTHER
Have you studied any languages other than English and Russian/ Mandarin? YES NO If so, what language(s)?
_________________________________________________ How long?
___________________________________________________________ Do you consider yourself
! MONOLINGUAL ! BILINGUAL ! MULTILINGUAL
Do you have any known speech and/or hearing difficulties? YES NO
Dear Participant,
Please be advised that this is not a test. This is a questionnaire designed to identify your language background. The information provided by you below will be used in conjunction with your data collected from the study. In order to ensure your anonymity, no names will be elicited. Instead, you will be assigned an identification code. All data will be stored according to these identification numbers. If at any time you decide to withdraw from this study, all the data collected (including the information provided here) will not be used for the analysis and will be destroyed. If you have any questions or concerns, Carolyn Pytlyk ([email protected]) will be happy to discuss them with you. Thank you for your participation.

303
APPENDIX G: Boxplots identifying RT outliers
All circles in the following boxplots indicate RT outliers; these outlier values were not used in the analyses of the RT data.
Figure G.1 Boxplots identifying RT outliers for the overall data
Figure G.2 Boxplots identifying RT outliers for the subgroup data
lnRT
subject52515049484746454443424140393837363534333231302928272625242322212019181716151413121110987654321
lnRT
9 .50
9.00
8.50
8.00
7.50
7.00
6.50
6,004
5,9725,961 5,955
5,938
6,003
5,920
238
137
6,011
7
67
400333
327
5,4805,338
5,315
5,952
5,9345,933
1,051
70
4,801
22
5,977
361
215170
5,113
5,847
224
SAVE OUTFILE='/Users/cara/Desktop/revisedSTATS/overall.ALL.data.RTsav.sav' /COMPRESSED.SORT CASES BY subject(A).SAVE OUTFILE='/Users/cara/Desktop/revisedSTATS/overall.ALL.data.RTsav.sav' /COMPRESSED.SAVE OUTFILE='/Users/cara/Desktop/revisedSTATS/overall.ALL.data.RTsav.sav' /COMPRESSED.
Page 42
ValueCase
Number1234512345
Highest
Lowest
38.00lnRT
6.873596.641606.631486.621456.365 08.8040088.8540508.8940709.0241109.104129
subjectsubject
Extreme Values
lnRT
subject
38.00
37.00
36.00
35.00
34.00
33.00
32.00
31.00
30.00
29.00
28.00
27.00
13.00
12.00
11.00
10.00
9.00
8.00
7.00
6.00
5.00
4.00
3.00
2.00
1.00
lnR
T
10.00
9.00
8.00
7.00
6.00
5.00
1481455 0
275
257 254190
3,6204,0644,039
4,035
840
153
4 0179
158154
268128
SORT CASES BY subject(A).SAVE OUTFILE='/Users/cara/Desktop/revisedSTATS/subgroup.ALL.sav' /COMPRESSED.
Page 21

304
APPENDIX H: Response summaries
Response summaries by phoneme, letter, and other
Figure H.1 Mean proportion of responses for the English mismatched tokens
These data were analysed with a 1-way repeated measures ANOVA with response type (phoneme, letter, other) as a within-subjects factor. The main effect for response type was significant (F(1,68)=53.721, p<0.001), indicating that a significant difference between at least two levels of response type factor. Subsequent analyses showed a significant difference between phoneme response and letter response (F(1,34)=38.546, p<0.001), with participants more often providing a response consistent with the number of phonemes in the word than with the number of letters in the word. Similarly, the analyses also showed a significant difference between phoneme response and other response (F(1,34)=143.117, p<0.001), with participants more often providing a response consistent with the number of phonemes than with a number other than the number of phonemes or letters in the word. Finally, the analyses showed a significant difference between letter response and other response (F(1,34)=4.468, p<0.05), with participants more often providing a response consistent with the number of letters in a word than with a number other than the number of phonemes or letters in a word.
otherlettersphonemes
prop
orti
on o
f re
spon
ses
1 .00
0.80
0.60
0.40
0.20
0.00
Error Bars: 95% CI
GLM Pavg Lavg Oavg /WSFACTOR=response 3 Polynomial /METHOD=SSTYPE(3) /CRITERIA=ALPHA(.05) /WSDESIGN=response.
General Linear Model
Page 3

305
Word Transcription Response 1 2 3 4 5 n.r.
tree /t®i/ 1 2 49 0 0 0 toot /tut/ 0 2 48 2 0 0 when /w”n/ 0 3 47 2 0 0 knee /ni/ 1 47 4 0 0 0 soup /sup/ 0 1 47 4 0 0 she * /Si/ 2 93 8 0 0 1 pole /po:/ 0 2 46 4 0 0 sue /su/ 0 46 6 0 0 0 shot /SAt/ 0 1 46 5 0 0 fish /fIS/ 0 1 46 5 0 0 dome /dom/ 0 3 46 2 1 0 coo /ku/ 3 46 2 1 0 0 rue /®u/ 2 45 5 0 0 0 tea/tee /ti/ 7 45 0 0 0 0 heat /hit/ 1 3 45 3 0 1 who /hu/ 4 44 4 0 0 0 sock /sAk/ 0 1 44 7 0 0 give /gIv/ 0 1 44 7 0 0 pea/pee /pi/ 6 44 3 0 0 0 whom /hum/ 1 3 42 6 0 0 stool /stu:/ 0 0 7 43 2 0 speak /spik/ 0 0 6 43 3 0 month /mØnT/ 0 0 4 41 7 0 truth /truT/ 0 0 7 39 5 1 talk /tAk/ 0 3 35 13 0 1 quick /kwIk/ 0 0 15 35 2 0 king /kIN/ 1 2 34 14 0 2 long /lAN/ 0 0 32 20 0 0 new /nu/ 0 25 26 1 0 0 six /sIks/ 1 2 34 17 0 0 tax /tœks/ 0 2 35 15 0 0 box /bAks/ 0 1 38 13 0 0 high /haj/ 1 39 11 1 0 0 my * /maj/ 2 81 21 0 0 0 go /gow/ 1 50 1 0 0 0 * Both my and she have twice the number of data (i.e., 104) because there was a counterpart for each target stimuli in each language.
BOLD: response = number of phonemes (i.e., correct response) SHADED: response = number of letters n.r. = no response
Table H.1 Response summaries by item of the English mismatched words for the overall data (total = 52)

306
word transcription &
translation Response
1 2 3 4 5 n.r. * /ja/ (I) 6 7 0 0 0 0 04!$# /zvat!/ (to call) 0 0 1 11 1 0 !"#$ /al!t/ (viola) 0 1 12 0 0 0 () /juk/ (south) 0 5 8 0 0 0 ,-$# /Zit!/ (to live) 1 2 11 0 0 0 67+4# /krof!/ (blood) 0 0 1 12 0 0 &+,&# /doSt!/ (rain) 0 0 1 12 0 0 9*$# /p!at!/ (five) 0 0 7 6 0 0 1.8# /s!”m!/ (seven) 0 1 11 1 0 0 4.1# /v!”&!/ (whole) 0 0 11 2 0 0 0&.1# /zd!”s!/ (here) 0 0 0 11 2 0 &!$# /dat!/ (to give) 0 0 13 0 0 0 2.1$# /S!”st!/ (six) 0 0 1 12 0 0 &./# /d!”n!/ (day) 0 0 11 2 0 0
Table H.2 Response summaries by item of the Russian mismatched words for the subgroup data (total = 13)
Word transcription &
translation Response
1 2 3 4 5 n.r. wàng /waN/ (to forget) 0 1 9 2 0 0 y' /i/ (one) 7 5 0 0 0 0 sh%n /ßan/ (mountain) 0 1 11 0 0 0 w5 /u/ (five) 5 5 2 0 0 0 huáng /xwaN/ (yellow) 0 1 4 4 3 0 sh3o /ßwO/ (to speak) 1 2 8 1 0 1 yuè /y”/ (month) 0 6 6 0 0 0 yòng /jON/ (to use) 0 0 10 2 0 0 y'n /in/ (reason) 1 3 7 1 0 0 péng /pÓøN/ (friend) 0 1 9 2 0 0 duì /twej/ (correct) 0 3 7 2 0 0 máng /maN/ (busy) 0 1 8 3 0 0 shéi /ßej/ (who) 0 4 7 1 0 0 t'ng /tÓiN/ (listen) 1 1 7 3 0 0
Table H.3 Response summaries by item of the Mandarin mismatched words for the subgroup data (total = 12)